Double-Hard Debias:
Tailoring Word Embeddings for Gender Bias Mitigation
Abstract
Word embeddings derived from human-generated corpora inherit strong gender bias which can be further amplified by downstream models. Some commonly adopted debiasing approaches, including the seminal Hard Debias algorithm Bolukbasi et al. (2016), apply post-processing procedures that project pre-trained word embeddings into a subspace orthogonal to an inferred gender subspace. We discover that semantic-agnostic corpus regularities such as word frequency captured by the word embeddings negatively impact the performance of these algorithms. We propose a simple but effective technique, Double-Hard Debias, which purifies the word embeddings against such corpus regularities prior to inferring and removing the gender subspace. Experiments on three bias mitigation benchmarks show that our approach preserves the distributional semantics of the pre-trained word embeddings while reducing gender bias to a significantly larger degree than prior approaches.
1 Introduction
Despite widespread use in natural language processing (NLP) tasks, word embeddings have been criticized for inheriting unintended gender bias from training corpora. Bolukbasi et al. (2016) highlights that in word2vec embeddings trained on the Google News dataset (Mikolov et al., 2013a), “programmer” is more closely associated with “man” and “homemaker” is more closely associated with “woman”. Such gender bias also propagates to downstream tasks. Studies have shown that coreference resolution systems exhibit gender bias in predictions due to the use of biased word embeddings (Zhao et al., 2018a; Rudinger et al., 2018). Given the fact that pre-trained word embeddings have been integrated into a vast number of NLP models, it is important to debias word embeddings to prevent discrimination in NLP systems.
To mitigate gender bias, prior work have proposed to remove the gender component from pre-trained word embeddings through post-processing (Bolukbasi et al., 2016), or to compress the gender information into a few dimensions of the embedding space using a modified training scheme (Zhao et al., 2018b; Kaneko and Bollegala, 2019). We focus on post-hoc gender bias mitigation for two reasons: 1) debiasing via a new training approach is more computationally expensive; and 2) pre-trained biased word embeddings have already been extensively adopted in downstream NLP products and post-hoc bias mitigation presumably leads to less changes in the model pipeline since it keeps the core components of the original embeddings.
Existing post-processing algorithms, including the seminal Hard Debias Bolukbasi et al. (2016), debias embeddings by removing the component that corresponds to a gender direction as defined by a list of gendered words. While Bolukbasi et al. (2016) demonstrate that such methods alleviate gender bias in word analogy tasks, Gonen and Goldberg (2019) argue that the effectiveness of these efforts is limited, as the gender bias can still be recovered from the geomrtry of the debiased embeddings.
We hypothesize that it is difficult to isolate the gender component of word embeddings in the manner employed by existing post-processing methods. For example, Gong et al. (2018); Mu and Viswanath (2018) show that word frequency significantly impact the geometry of word embeddings. Consequently, popular words and rare words cluster in different subregions of the embedding space, despite the fact that words in these clusters are not semantically similar. This can degrade the ability of component-based methods for debiasing gender.
Specifically, recall that Hard Debias seeks to remove the component of the embeddings corresponding to the gender direction. The important assumption made by Hard Debias is that we can effectively identify and isolate this gender direction. However, we posit that word frequency in the training corpora can twist the gender direction and limit the effectiveness of Hard Debias.
To this end, we propose a novel debiasing algorithm called Double-Hard Debias that builds upon the existing Hard Debias technique. It consists of two steps. First, we project word embeddings into an intermediate subspace by subtracting component(s) related to word frequency. This mitigates the impact of frequency on the gender direction. Then we apply Hard Debias to these purified embeddings to mitigate gender bias. Mu and Viswanath (2018) showed that typically more than one dominant directions in the embedding space encode frequency features. We test the effect of each dominant direction on the debiasing performance and only remove the one(s) that demonstrated the most impact.
We evaluate our proposed debiasing method using a wide range of evaluation techniques. According to both representation level evaluation (WEAT test (Caliskan et al., 2017), the neighborhood metric (Gonen and Goldberg, 2019)) and downstream task evaluation (coreference resolution (Zhao et al., 2018a)), Double-Hard Debias outperforms all previous debiasing methods. We also evaluate the functionality of debiased embeddings on several benchmark datasets to demonstrate that Double-Hard Debias effectively mitigates gender bias without sacrificing the quality of word embeddings111Code and data are available at https://github.com/uvavision/Double-Hard-Debias.git.
2 Motivation
Current post-hoc debiasing methods attempt to reduce gender bias in word embeddings by subtracting the component associated with gender from them. Identifying the gender direction in the word embedding space requires a set of gender word pairs, , which consists of “she & he”, “daughter & son”, etc. For every pair, for example “boy & girl”, the difference vector of the two embeddings is expected to approximately capture the gender direction:
| (1) |
Bolukbasi et al. (2016) computes the first principal component of ten such difference vectors and use that to define the gender direction.222The complete definition of is: “woman & man”, “girl & boy”, “she & he”, “mother & father”, “daughter & son”, “gal & guy”, “female & male”, “her & his”, “herself & himself”, and “Mary & John” (Bolukbasi et al., 2016).
Recent works (Mu and Viswanath, 2018; Gong et al., 2018) show that word frequency in a training corpus can degrade the quality of word embeddings. By carefully removing such frequency features, existing word embeddings can achieve higher performance on several benchmarks after fine-tuning. We hypothesize that such word frequency statistics also interferes with the components of the word embeddings associated with gender. In other words, frequency-based features learned by word embedding algorithms act as harmful noise in the previously proposed debiasing techniques.
To verify this, we first retrain GloVe Pennington et al. (2014) embeddings on the one billion English word benchmark (Chelba et al., 2013) following previous work Zhao et al. (2018b); Kaneko and Bollegala (2019). We obtain ten difference vectors for the gendered pairs in and compute pairwise cosine similarity. This gives a similarity matrix in which denotes the cosine similarity between difference vectors and .
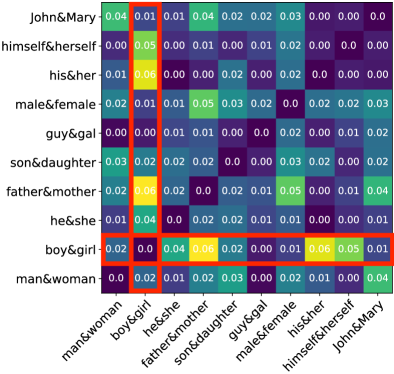
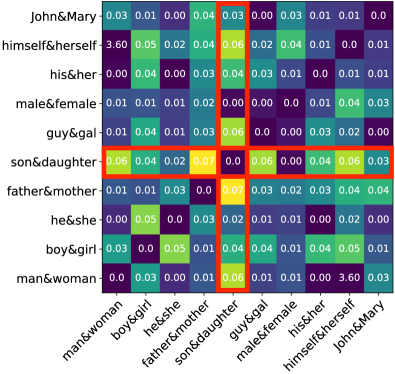
We then select a specific word pair, e.g. “boy” & “girl”, and augment the corpus by sampling sentences containing the word “boy” twice. In this way, we produce a new training corpus with altered word frequency statistics for “boy”. The context around the token remains the same so that changes to the other components are negligible. We retrain GloVe with this augmented corpus and get a set of new offset vectors for the gendered pairs . We also compute a second similarity matrix where denotes the cosine similarity between difference vectors and .
By comparing these two similarity matrices, we analyze the effect of changing word frequency statistics on gender direction. Note that the offset vectors are designed for approximating the gender direction, thus we focus on the changes in offset vectors. Because statistics were altered for “boy”, we focus on the difference vector and make two observations. First, the norm of has a relative change while the norms of other difference vectors show much smaller changes. For example, the norm of only changes by . Second, the cosine similarities between and other difference vectors also show more significant change, as highlighted by the red bounding box in Figure 1(a). As we can see, the frequency change of “boy” leads to deviation of the gender direction captured by . We observe similar phenomenon when we change the frequency of the word “daughter” and present these results in Figure 1(b).
Based on these observations, we conclude that word frequency plays an important role in gender debiasing despite being overlooked by previous works.
3 Method
In this section, we first summarize the terminology that will be used throughout the rest of the paper, briefly review the Hard Debias method, and provide background on the neighborhood evaluation metric. Then we introduce our proposed method: Double-Hard Debias.
3.1 Preliminary Definitions
Let be the vocabulary of the word embeddings we aim to debias. The set of word embeddings contains a vector for each word . A subspace is defined by orthogonal unit vectors . We denote the projection of vector on by
| (2) |
Following Bolukbasi et al. (2016), we assume there is a set of gender neutral words , such as “doctor” and “teacher”, which by definition are not specific to any gender. We also assume a pre-defined set of male-female word pairs , where the main difference between each pair of words captures gender.
Hard Debias. The Hard Debias algorithm first identifies a subspace that captures gender bias. Let
| (3) |
The bias subspace is the first () rows of SVD(), where
| (4) |
Following the original implementation of Bolukbasi et al. (2016), we set . As a result the subspace is simply a gender direction.333Bolukbasi et al. (2016) normalize all embeddings. However, we found it is unnecessary in our experiments. This is also mentioned in Ethayarajh et al. (2019)
Hard Debias then neutralizes the word embeddings by transforming each such that every word has zero projection in the gender subspace. For each word , we re-embed :
| (5) |
Neighborhood Metric. The Neighborhood Metric proposed by Gonen and Goldberg (2019) is a bias measurement that does not rely on any specific gender direction. To do so it looks into similarities between words. The bias of a word is the proportion of words with the same gender bias polarity among its nearest neighboring words.
We selected of the most biased male and females words according to the cosine similarity of their embedding and the gender direction computed using the word embeddings prior to bias mitigation. We use and to denote the male and female biased words, respectively. For , we assign a ground truth gender label . For , . Then we run KMeans () to cluster the embeddings of selected words , and compute the alignment score with respect to the assigned ground truth gender labels:
| (6) |
We set . Thus, a value of in this metric indicates perfectly unbiased word embeddings (i.e. the words are randomly clustered), and a value closer to indicates stronger gender bias.
3.2 Double-Hard Debiasing
According to Mu and Viswanath (2018), the most statistically dominant directions of word embeddings encode word frequency to a significant extent. Mu and Viswanath (2018) removes these frequency features by centralizing and subtracting components along the top dominant directions from the original word embeddings. These post-processed embedddings achieve better performance on several benchmark tasks, including word similarity, concept categorization, and word analogy. It is also suggested that setting near provides maximum benefit, where is the dimension of a word embedding.
We speculate that most the dominant directions also affect the geometry of the gender space. To address this, we use the aforementioned clustering experiment to identify whether a direction contains frequency features that alter the gender direction.
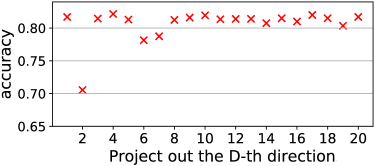
More specifically, we first pick the top biased words ( male and female) identified using the original GloVe embeddings. We then apply PCA to all their word embeddings and take the top principal components as candidate directions to drop. For every candidate direction , we project the embeddings into a space that is orthogonal to . In this intermediate subspace, we apply Hard Debias and get debiased embeddings. Next, we cluster the debiased embeddings of these words and compute the gender alignment accuracy (Eq. 6). This indicates whether projecting away direction improves the debiasing performance. Algorithm 1 shows the details of our method in full.
We found that for GloVe embeddings pre-trained on Wikipedia dataset, elimination of the projection along the second principal component significantly decreases the clustering accuracy. This translates to better debiasing results, as shown in Figure 2. We further demonstrate the effectiveness of our method for debaising using other evaluation metrics in Section 4.
4 Experiments
In this section, we compare our proposed method with other debiasing algorithms and test the functionality of these debiased embeddings on word analogy and concept categorization task. Experimental results demonstrate that our method effectively reduces bias to a larger extent without degrading the quality of word embeddings.
4.1 Dataset
We use 300-dimensional GloVe Pennington et al. (2014) 444Experiments on Word2Vec are included in the appendix. embeddings pre-trained on the 2017 January dump of English Wikipedia555https://github.com/uclanlp/gn_glove, containing unique words. To identify the gender direction, we use pairs of definitional gender words compiled by Bolukbasi et al. (2016)666https://github.com/tolga-b/debiaswe.
4.2 Baselines
We compare our proposed method against the following baselines:
GloVe: the pre-trained GloVe embeddings on Wikipedia dataset described in 4.1. GloVe is widely used in various NLP applications. This is a non-debiased baseline for comparision.
GN-GloVe: We use debiased Gender-Neutral GN-GloVe embeddings released by the original authors Zhao et al. (2018b). GN-GloVe restricts gender information in certain dimensions while neutralizing the rest dimensions.
GN-GloVe(): We exclude the gender dimensions from GN-GloVe. This baseline tries to completely remove gender.
GP-GloVe: We use debiased embeddings released by the original authors Kaneko and Bollegala (2019). Gender-preserving Debiasing attempts to preserve non-discriminative gender information, while removing stereotypical gender bias.
GP-GN-GloVe:: This baseline applies Gender-preserving Debiasing on already debaised GN-GloVe embeddings. We also use debiased embeddings provided by authors.
Hard-GloVe: We apply Hard Debias introduced in Bolukbasi et al. (2016) on GloVe embeddings. Following the implementation provided by original authors, we debias netural words and preserve the gender specific words.
Strong Hard-GloVe: A variant of Hard Debias where we debias all words instead of avoiding gender specific words. This seeks to entirely remove gender from GloVe embeddings.
Double-Hard GloVe: We debias the pre-trained GloVe embeddings by our proposed Double-Hard Debias method.
| Embeddings | OntoNotes | PRO-1 | ANTI-1 | Avg-1 | Diff-1 | PRO-2 | ANTI-2 | Avg-2 | Diff-2 |
| GloVe | |||||||||
| GN-GloVe | |||||||||
| GN-GloVe() | |||||||||
| GP-GloVe | |||||||||
| GP-GN-GloVe | |||||||||
| Hard-GloVe | |||||||||
| Strong Hard-GloVe | |||||||||
| Double-Hard GloVe |
4.3 Evaluation of Debiasing Performance
We demonstrate the effectiveness of our debiasing method for downstream applications and according to general embedding level evaluations.
4.3.1 Debiasing in Downstream Applications
Coreference Resolution. Coreference resolution aims at identifying noun phrases referring to the same entity. Zhao et al. (2018a) identified gender bias in modern coreference systems, e.g. “doctor” is prone to be linked to “he”. They also introduce a new benchmark dataset WinoBias, to study gender bias in coreference systems.
WinoBias provides sentences following two prototypical templates. Each type of sentences can be divided into a pro-stereotype (PRO) subset and a antistereotype (ANTI) subset. In the PRO subset, gender pronouns refer to professions dominated by the same gender. For example, in sentence “The physician hired the secretary because he was overwhelmed with clients.”, “he” refers to “physician”, which is consistent with societal stereotype. On the other hand, the ANTI subset consists of same sentences, but the opposite gender pronouns. As such, “he” is replaced by “she” in the aforementioned example. The hypothesis is that gender cues may distract a coreference model. We consider a system to be gender biased if it performs better in pro-stereotypical scenarios than in anti-stereotypical scenarios.
We train an end-to-end coreference resolution model (Lee et al., 2017) with different word embeddings on OntoNotes 5.0 training set and report the performance on WinoBias dataset. Results are presented in Table1. Note that absolute performance difference (Diff) between the PRO set and ANTI set connects with gender bias. A smaller Diff value indicates a less biased coreference system. We can see that on both types of sentences in WinoBias, Double-Hard GloVe achieves the smallest Diff compared to other baselines. This demonstrates the efficacy of our method. Meanwhile, Double-Hard GloVe maintains comparable performance as GloVe on OntoNotes test set, showing that our method preserves the utility of word embeddings. It is also worth noting that by reducing gender bias, Double-Hard GloVe can significantly improve the average performance on type-2 sentences, from (GloVe) to .
4.3.2 Debiasing at Embedding Level
The Word Embeddings Association Test (WEAT). WEAT is a permutation test used to measure the bias in word embeddins. We consider male names and females names as attribute sets and compute the differential association of two sets of target words777All word lists are from Caliskan et al. (2017). Because GloVeembeddings are uncased, we use lower cased people names and replace “bill” with “tom” to avoid ambiguity. and the gender attribute sets. We report effect sizes () and p-values () in Table2. The effect size is a normalized measure of how separated the two distributions are. A higher value of effect size indicates larger bias between target words with regard to gender. p-values denote if the bias is significant. A high p-value (larger than ) indicates the bias is insignificant. We refer readers to Caliskan et al. (2017) for more details.
As shown in Table 2, across different target words sets, Double-Hard GloVe consistently outperforms other debiased embeddings. For Career & Family and Science & Arts, Double-Hard GloVe reaches the lowest effect size, for the latter one, Double-Hard GloVe successfully makes the bias insignificant (p-value ). Note that in WEAT test, some debiasing methods run the risk of amplifying gender bias, e.g. for Math & Arts words, the bias is significant in GN-GloVe while it is insignificant in original GloVe embeddings. Such concern does not occur in Double-Hard GloVe.
| Embeddings | Career & Family | Math & Arts | Science & Arts | |||
| GloVe | ||||||
| GN-GloVe | ||||||
| GN-GloVe() | ||||||
| GP-GloVe | ||||||
| GP-GN-GloVe | ||||||
| Hard-GloVe | ||||||
| Strong Hard-GloVe | ||||||
| Double-Hard GloVe | ||||||
Neighborhood Metric. Gonen and Goldberg (2019) introduces a neighborhood metric based on clustering. As described in Sec 3.1, We take the top most biased words according to their cosine similarity with gender direction in the original GloVe embedding space888To be fair, we exclude all gender specific words used in debiasing, so Hard-GloVe and Strong Hard-GloVe have same acurracy performance in Table 3. We then run k-Means to cluster them into two clusters and compute the alignment accuracy with respect to gender, results are presented in Table 3. We recall that in this metric, a accuracy value closer to indicates less biased word embeddings.
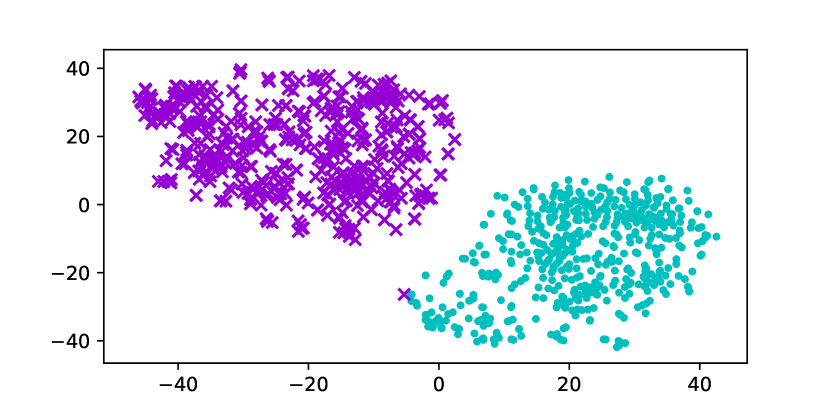
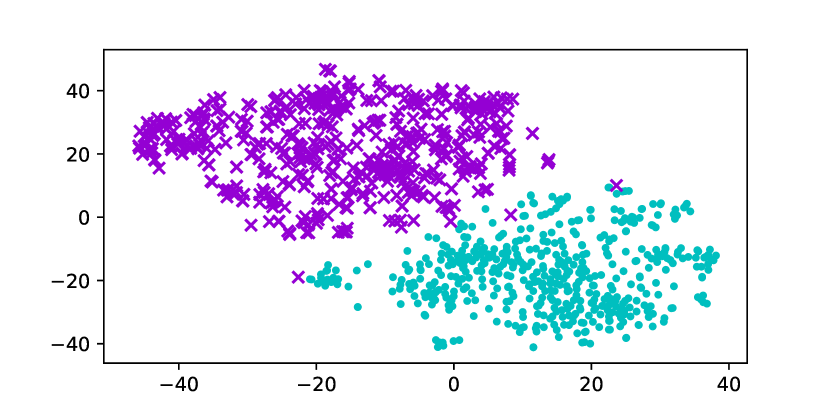
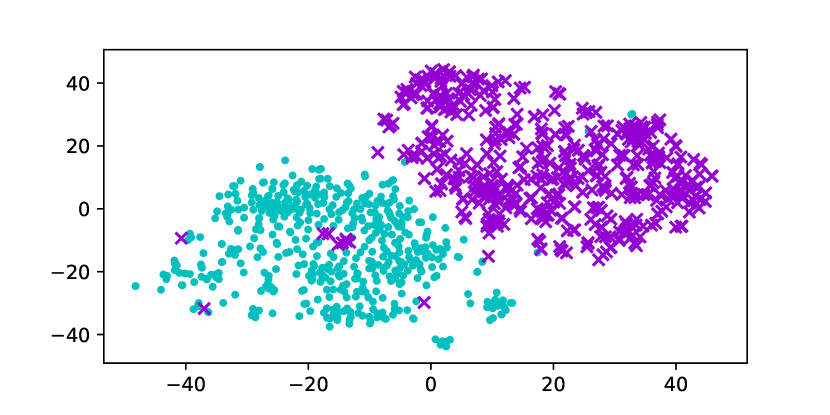
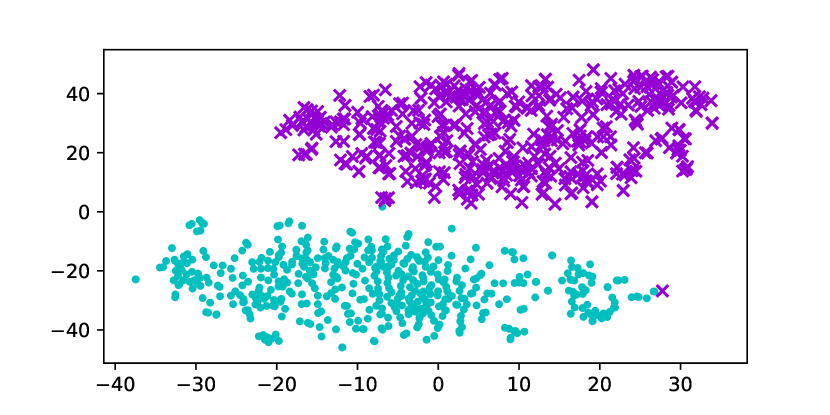
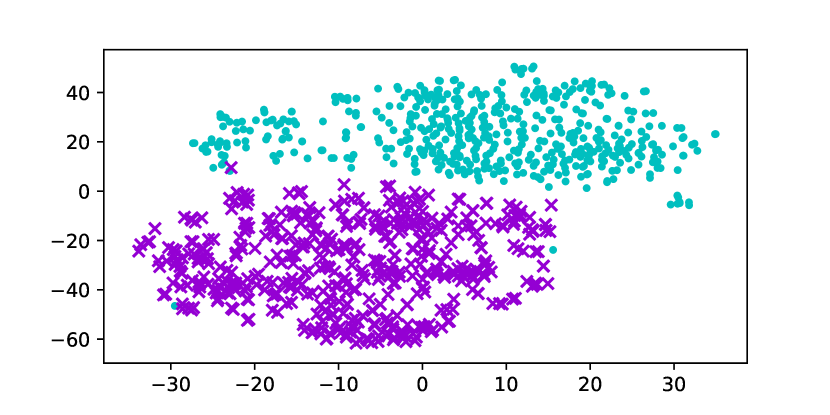
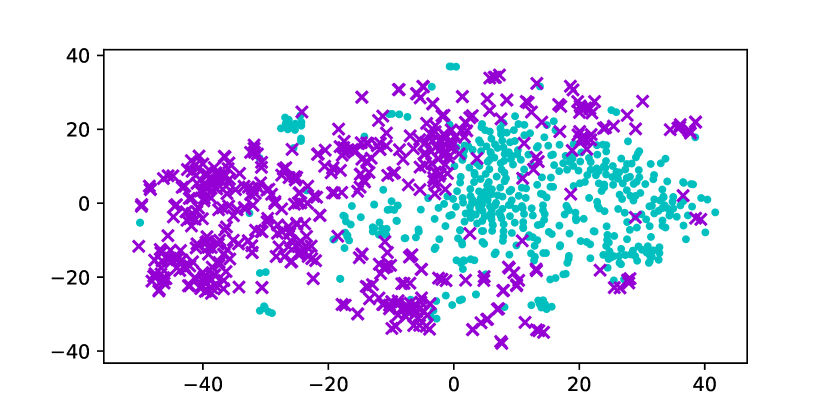
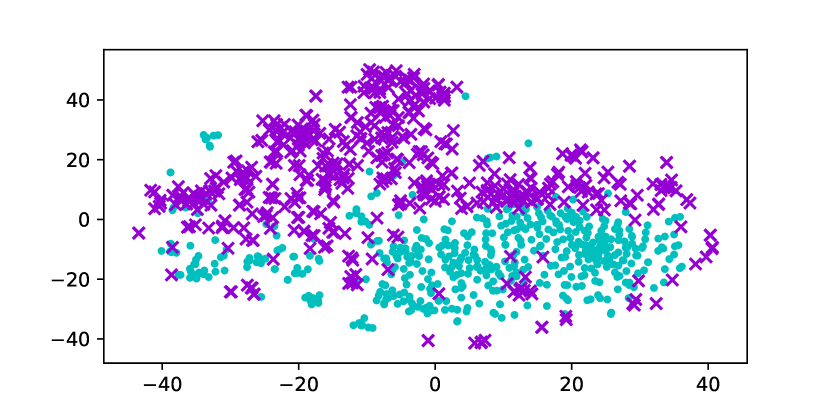
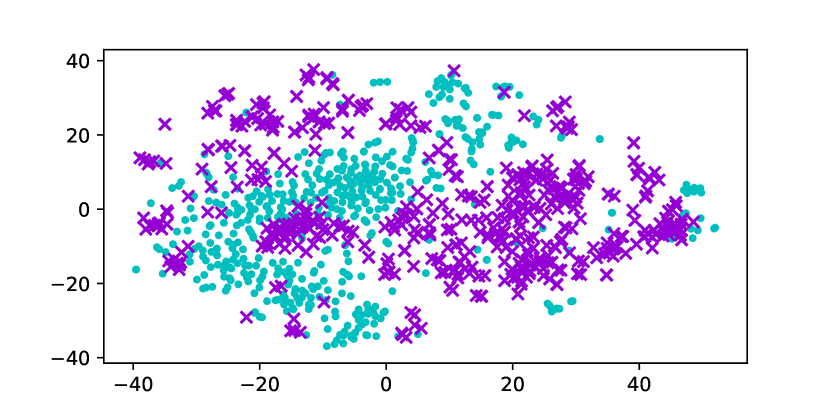
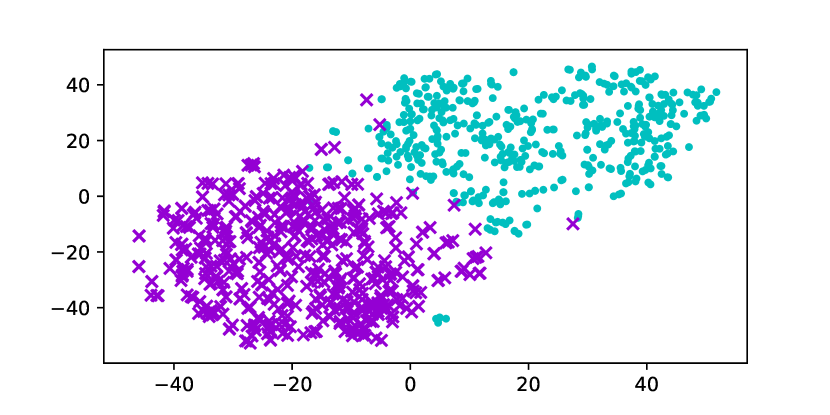
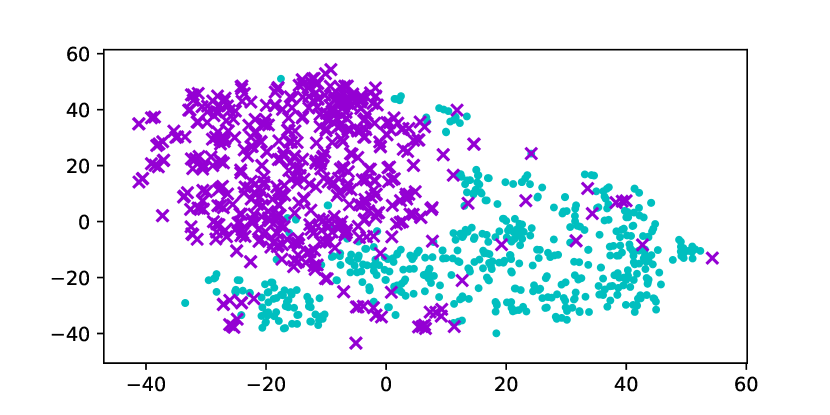
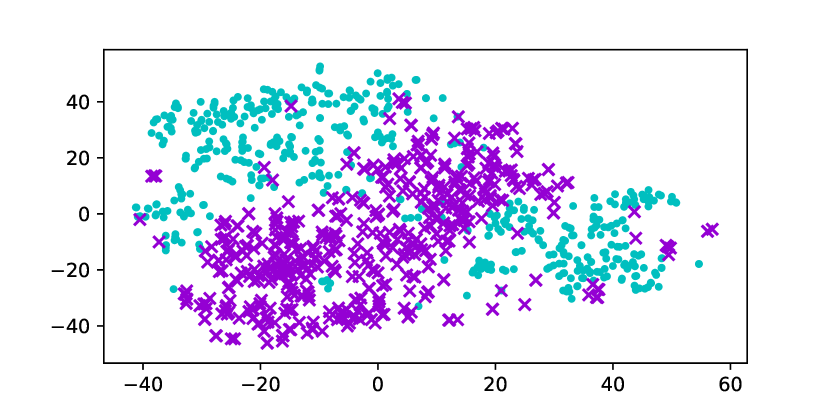
Using the original GloVe embeddings, k-Means can accurately cluster selected words into a male group and a female group, suggesting the presence of a strong bias. Hard Debias is able to reduce bias in some degree while other baselines appear to be less effective. Double-Hard GloVe achieves the lowest accuracy across experiments clustering top 100/500/1000 biased words, demonstrating that the proposed technique effectively reduce gender bias. We also conduct tSNE (van der Maaten and Hinton, 2008) projection for all baseline embeddings. As shown in Figure 3, original non-debiased GloVe embeddings are clearly projected to different regions. Double-Hard GloVe mixes up male and female embeddings to the maximum extent compared to other baselines, showing less gender information can be captured after debiasing.
| Embeddings | Top 100 | Top 500 | Top 1000 |
| GloVe | |||
| GN-GloVe | |||
| GN-GloVe() | |||
| GP-GloVe | |||
| GP-GN-GloVe | |||
| (Strong) Hard GloVe | |||
| Double-Hard GloVe |
4.4 Analysis of Retaining Word Semantics
| Embeddings | Analogy | Concept Categorization | ||||||
| Sem | Syn | Total | MSR | AP | ESSLI | Battig | BLESS | |
| GloVe | ||||||||
| GN-GloVe | ||||||||
| GN-GloVe() | ||||||||
| GP-GloVe | ||||||||
| GP-GN-GloVe | ||||||||
| Hard-GloVe | ||||||||
| Strong Hard-GloVe | ||||||||
| Double-Hard GloVe | ||||||||
Word Analogy. Given three words , and , the analogy task is to find word such that “ is to as is to ”. In our experiments, is the word that maximize the cosine similarity between and . We evaluate all non-debiased and debiased embeddings on the MSR (Mikolov et al., 2013c) word analogy task, which contains syntactic questions, and on a second Google word analogy (Mikolov et al., 2013a) dataset that contains (Total) questions, including semantic (Sem) and syntactic (Syn) questions. The evaluation metric is the percentage of questions for which the correct answer is assigned the maximum score by the algorithm. Results are shown in Table4. Double-Hard GloVe achieves comparable good results as GloVe and slightly outperforms some other debiased embeddings. This proves that Double-Hard Debias is capable of preserving proximity among words.
Concept Categorization. The goal of concept categorization is to cluster a set of words into different categorical subsets. For example, “sandwich” and “hotdog” are both food and “dog” and “cat” are animals. The clustering performance is evaluated in terms of purity (Manning et al., 2008) - the fraction of the total number of the words that are correctly classified. Experiments are conducted on four benchmark datasets: the Almuhareb-Poesio (AP) dataset (Almuhareb, 2006); the ESSLLI 2008 (Baroni et al., 2008); the Battig 1969 set (Battig and Montague, 1969) and the BLESS dataset (Baroni and Lenci, 2011). We run classical Kmeans algorithm with fixed . Across four datasets, the performance of Double-Hard GloVe is on a par with GloVe embeddings, showing that the proposed debiasing method preserves useful semantic information in word embeddings. Full results can be found in Table4.
5 Related Work
Gender Bias in Word Embeddings. Word embeddings have been criticized for carrying gender bias. Bolukbasi et al. (2016) show that word2vec (Mikolov et al., 2013b) embeddings trained on the Google News dataset exhibit occupational stereotypes, e.g. “programmer” is closer to “man” and “homemaker” is closer to “woman”. More recent works (Zhao et al., 2019; Kurita et al., 2019; Basta et al., 2019) demonstrate that contextualized word embeddings also inherit gender bias.
Gender bias in word embeddings also propagate to downstream tasks, which substantially affects predictions. Zhao et al. (2018a) show that coreference systems tend to link occupations to their stereotypical gender, e.g. linking “doctor” to “he” and “nurse” to “she”. Stanovsky et al. (2019) observe that popular industrial and academic machine translation systems are prone to gender biased translation errors.
Recently, Vig et al. (2020) proposed causal mediation analysis as a way to interpret and analyze gender bias in neural models.
Debiasing Word Embeddings. For contextualized embeddings, existing works propose task-specific debiasing methods, while in this paper we focus on more generic ones. To mitigate gender bias, Zhao et al. (2018a) propose a new training approach which explicitly restricts gender information in certain dimensions during training. While this method separates gender information from embeddings, retraining word embeddings on massive corpus requires an undesirably large amount of resources. Kaneko and Bollegala (2019) tackles this problem by adopting an encoder-decoder model to re-embed word embeddings. This can be applied to existing pre-trained embeddings, but it still requires train different encoder-decoders for different embeddings.
Bolukbasi et al. (2016) introduce a more simple and direct post-processing method which zeros out the component along the gender direction. This method reduces gender bias to some degree, however, Gonen and Goldberg (2019) present a series of experiments to show that they are far from delivering gender-neutral embeddings. Our work builds on top of Bolukbasi et al. (2016). We discover the important factor – word frequency – that limits the effectiveness of existing methods. By carefully eliminating the effect of word frequency, our method is able to significantly improve debiasing performance.
6 Conclusion
We have discovered that simple changes in word frequency statistics can have an undesirable impact on the debiasing methods used to remove gender bias from word embeddings. Though word frequency statistics have until now been neglected in previous gender bias reduction work, we propose Double-Hard Debias, which mitigates the negative effects that word frequency features can have on debiasing algorithms. We experiment on several benchmarks and demonstrate that our Double-Hard Debias is more effective on gender bias reduction than other methods while also preserving the quality of word embeddings suitable for the downstream applications and embedding-based word analogy tasks. While we have shown that this method significantly reduces gender bias while preserving quality, we hope that this work encourages further research into debiasing along other dimensions of word embeddings in the future.
References
- Almuhareb (2006) Abdulrahman Almuhareb. 2006. Attributes in lexical acquisition. Ph.D. thesis, University of Essex, Colchester, UK.
- Baroni et al. (2008) Marco Baroni, Stefan Evert, and Alessandro Lenci. 2008. Bridging the gap between semantic theory and computational simulations: Proceedings of the esslli workshop on distributional lexical semantics.
- Baroni and Lenci (2011) Marco Baroni and Alessandro Lenci. 2011. How we blessed distributional semantic evaluation. In Proceedings of the GEMS 2011 Workshop on GEometrical Models of Natural Language Semantics, GEMS ’11, pages 1–10, Stroudsburg, PA, USA. Association for Computational Linguistics.
- Basta et al. (2019) Christine Basta, Marta Ruiz Costa-jussà, and Noe Casas. 2019. Evaluating the underlying gender bias in contextualized word embeddings. CoRR, abs/1904.08783.
- Battig and Montague (1969) William F. Battig and William E. Montague. 1969. Category norms of verbal items in 56 categories a replication and extension of the connecticut category norms. Journal of Experimental Psychology, 80(3p2):1.
- Bolukbasi et al. (2016) Tolga Bolukbasi, Kai-Wei Chang, James Y. Zou, Venkatesh Saligrama, and Adam Tauman Kalai. 2016. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. In NIPS.
- Caliskan et al. (2017) Aylin Caliskan, Joanna J. Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183–186.
- Chelba et al. (2013) Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. 2013. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005.
- Ethayarajh et al. (2019) Kawin Ethayarajh, David Duvenaud, and Graeme Hirst. 2019. Understanding undesirable word embedding associations. arXiv preprint arXiv:1908.06361.
- Gonen and Goldberg (2019) Hila Gonen and Yoav Goldberg. 2019. Lipstick on a pig: Debiasing methods cover up systematic gender biases in word embeddings but do not remove them. In NAACL-HLT.
- Gong et al. (2018) Chengyue Gong, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. 2018. Frage: Frequency-agnostic word representation. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 1334–1345. Curran Associates, Inc.
- Kaneko and Bollegala (2019) Masahiro Kaneko and Danushka Bollegala. 2019. Gender-preserving debiasing for pre-trained word embeddings. CoRR, abs/1906.00742.
- Kurita et al. (2019) Keita Kurita, Nidhi Vyas, Ayush Pareek, Alan W. Black, and Yulia Tsvetkov. 2019. Measuring bias in contextualized word representations. CoRR, abs/1906.07337.
- Lee et al. (2017) Kenton Lee, Luheng He, Mike Lewis, and Luke Zettlemoyer. 2017. End-to-end neural coreference resolution. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, September 9-11, 2017, pages 188–197. Association for Computational Linguistics.
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of Machine Learning Research, 9:2579–2605.
- Manning et al. (2008) Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. 2008. Introduction to Information Retrieval. Cambridge University Press, Cambridge, UK.
- Mikolov et al. (2013a) Tomas Mikolov, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013a. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781.
- Mikolov et al. (2013b) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013b. Distributed representations of words and phrases and their compositionality. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 26, pages 3111–3119. Curran Associates, Inc.
- Mikolov et al. (2013c) Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. 2013c. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia. Association for Computational Linguistics.
- Mu and Viswanath (2018) Jiaqi Mu and Pramod Viswanath. 2018. All-but-the-top: Simple and effective postprocessing for word representations. In International Conference on Learning Representations.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar. Association for Computational Linguistics.
- Rudinger et al. (2018) Rachel Rudinger, Jason Naradowsky, Brian Leonard, and Benjamin Van Durme. 2018. Gender bias in coreference resolution. arXiv preprint arXiv:1804.09301.
- Stanovsky et al. (2019) Gabriel Stanovsky, Noah A Smith, and Luke Zettlemoyer. 2019. Evaluating gender bias in machine translation. arXiv preprint arXiv:1906.00591.
- Vig et al. (2020) Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Causal mediation analysis for interpreting neural nlp: The case of gender bias.
- Zhao et al. (2019) Jieyu Zhao, Tianlu Wang, Mark Yatskar, Ryan Cotterell, Vicente Ordonez, and Kai-Wei Chang. 2019. Gender bias in contextualized word embeddings. In North American Chapter of the Association for Computational Linguistics (NAACL).
- Zhao et al. (2018a) Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. 2018a. Gender bias in coreference resolution: Evaluation and debiasing methods. In North American Chapter of the Association for Computational Linguistics (NAACL).
- Zhao et al. (2018b) Jieyu Zhao, Yichao Zhou, Zeyu Li, Wei Wang, and Kai-Wei Chang. 2018b. Learning gender-neutral word embeddings. In EMNLP.
Appendix A Appendices
| Embeddings | Top 100 | Top 500 | Top 1000 |
| Word2Vec | |||
| Hard-Word2Vec | |||
| Double-Hard Word2Vec |
| Embeddings | Career & Family | Math & Arts | Science & Arts | |||
| Word2Vec | ||||||
| Hard-Word2Vec | ||||||
| Double-Hard Word2Vec | ||||||
| Embeddings | Analogy | Concept Categorization | ||||||
| Sem | Syn | Total | MSR | AP | ESSLI | Battig | BLESS | |
| Word2Vec | ||||||||
| Hard-Word2Vec | ||||||||
| Double-Hard Word2Vec | ||||||||
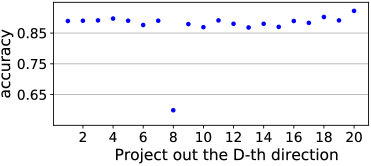
We also apply Double-Hard Debias on Word2Vec embeddings Mikolov et al. (2013b) which have been widely used by many NLP applications. As shown in Figure 4, our algorithm is able to identify that the eighth principal component significantly affects the debiasing performance.
Similarly, we first project away the identified direction from the original Word2Vec embeddings and then apply Hard Debias algorithm. We compare embeddings debiased by our method with the original Word2Vec embeddings and Hard-Word2Vec embeddings.
Table 5 reports the experimental result using the neighborhood metric. Across three experiments where we cluster top // male and female words, Double-Hard Word2Vec consistently achieves the lowest accuracy . Note that neighborhood metric reflects gender information that can be captured by the clustering algorithm. Experimental result validates that our method can further improve Hard Debias algorithm. This is also verified in Figure 5 where we conduct tSNE visualization of top male and female embeddings. While the original Word2Vec embeddings clearly locate separately into two groups corresponding to different genders, this phenomenon becomes less obvious after applying our debiasing method.
We further evaluate the debiasing outcome with WEAT test. Similar to experiments on GloVe embeddings, we use male names and female names as attribute sets and analyze the association between attribute sets and three target sets. We report effective size and p-value in Table 6. Across three target sets, Double-Hard Word2Vec is able to consistently reduce the effect size. More importantly, the bias related to Science & Arts words becomes insignificant after applying our debiasing method.
To test the functionality of debiased embeddings, we again conduct experiments on word analogy and concept categorization tasks. Results are included in Table 7. We demonstrate that our proposed debiasing method brings no significant performance degradation in these two tasks.
To summarize, experiments on Word2Vec embeddings also support our conclusion that the proposed Double-Hard Debiasing reduces gender bias to a larger degree while is able to maintain the semantic information in word embeddings.