\ul
DPR: An Algorithm Mitigate Bias Accumulation in Recommendation feedback loops
Abstract.
Recommendation models trained on the user feedback collected from deployed recommendation systems are commonly biased. User feedback is considerably affected by the exposure mechanism, as users only provide feedback on the items exposed to them and passively ignore the unexposed items, thus producing numerous false negative samples. Inevitably, biases caused by such user feedback are inherited by new models and amplified via feedback loops. Moreover, the presence of false negative samples makes negative sampling difficult and introduces spurious information in the user preference modeling process of the model. Recent work has investigated the negative impact of feedback loops and unknown exposure mechanisms on recommendation quality and user experience, essentially treating them as independent factors and ignoring their cross-effects. To address these issues, we deeply analyze the data exposure mechanism from the perspective of data iteration and feedback loops with the Missing Not At Random (MNAR) assumption, theoretically demonstrating the existence of an available stabilization factor in the transformation of the exposure mechanism under the feedback loops. We further propose Dynamic Personalized Ranking (DPR), an unbiased algorithm that uses dynamic re-weighting to mitigate the cross-effects of exposure mechanisms and feedback loops without additional information. Furthermore, we design a plugin named Universal Anti-False Negative (UFN) to mitigate the negative impact of the false negative problem. We demonstrate theoretically that our approach mitigates the negative effects of feedback loops and unknown exposure mechanisms. Experimental results on real-world datasets demonstrate that models using DPR can better handle bias accumulation and the universality of UFN in mainstream loss methods.
1. Introduction
Recommendation systems facilitate people’s lives (Imran et al., 2023; Zheng et al., 2023). They change the way of retrieving information through precise personalization and enhance the user experience. Existing models are dedicated to extracting user preferences from data collected from user feedback on previous system recommendations (Liu et al., 2023; Fei et al., 2022; Cai et al., 2023; Wang et al., 2023b) and generating new recommendations in the next stage. The interaction processes contained there induce a feedback loop: the recommendation model affects the user behavior data it observes, and the data affects the model trained on these data. As the model iterates, increasing bias accumulates in the data, hiding the performance of the trained model. (Chen et al., 2023; Wang et al., 2023a).
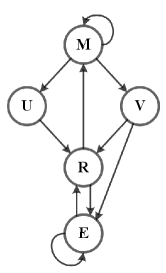
(a)
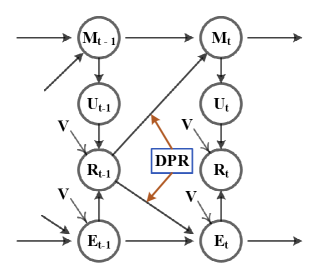
(b)
Furthermore, recent work (Chen et al., 2021; Saito, 2020; Saito et al., 2020a; Damak et al., 2021) shows that most systems rely on the assumption that user feedback is Missing At Random (MAR), which means that items are equally possible to be observed by users. However, in most scenarios, users cannot be exposed to all items, especially for e-commerce, there is a significant imbalance in the ratio of users to items. Thus, real-world data generally obeys the Missing Not At Random (MNAR) assumption. This means that missing interactions in the user feedback data cannot simply be considered negative, since items may be preferred by users but are not exposed to them. In this case, previous researchers directly treat unobserved items as negative samples, creating the false-negative sample problem and preventing the model from properly modeling user preferences. In recommendation systems, the MNAR assumption can be translated into the exposure mechanism, which determines the possibility of the item being exposed to users.
The impact of the feedback loops and the exposure mechanism on the recommendation system is not independent. The model (M) calculates the relevance score (R) of user-item pairs for ranking and recommends high-rankers to the user, thus changing the initial exposure mechanism (E) that items have the same possibility to be exposed to the user in the user-item interaction phase, the presence of the feedback loops makes the bias accumulate and get serious. A typical graph is displayed in Figure 1. For example, early popular items are more likely to be recommended to users than cold start items, because the recommendation system passively observes more interaction data for popular items, which causes the “rich-get-richer” problem.
In this work, we study the exposure mechanism under the feedback loops with the MNAR assumption and propose Dynamic Personal Ranking (DPR), an algorithm that can provably mitigate the cross-effects of feedback loops and exposure mechanisms in recommendation systems. We have a key observation: the recommendation system does have an impact on the exposure mechanism and keeps accumulating in the feedback loops, and an available stabilization factor in the transformation of the exposure mechanism under the feedback loops. Bias in feedback data collected from recommendation systems increases and is inherited by the new model as the length of the feedback loops increase. Breaking the chain of influence of feedback data collected in the feedback loops on the model and the exposure mechanism is a possible solution to free recommendations from bias accumulation. To achieve this goal, we design an unbiased algorithm, DPR, a pairwise loss function that uses dynamic re-weighting to eliminate accumulation bias in the data, as shown in Figure 1 (b). DPR employs the stabilization factor in the above-mentioned exposure mechanism transition process as the weight, enabling the model to be free from accumulated bias in data and modeling true user preference without additional information, no matter how long the feedback loops. In addition, we introduce the Universal Anti-False Negative (UFN), a removable plug-in to solve the common problem of false negatives in pairwise ranking methods. UFN enables the model to combat false negative samples and reduce the impact of the false information they carry.
The main contributions of our work are summarized as follows:
-
•
We use theoretical and empirical analysis to reveal the cross-effects of feedback loops and exposure mechanisms on recommendation systems. We find an available stabilization factor in the transformation of the exposure mechanism under the feedback loops.
-
•
We propose a pairwise loss function named Dynamic Personalized Ranking (DPR) to eliminate accumulation bias in real-world datasets and achieves unbiased recommendation with theoretical accuracy guarantees.
-
•
We introduce a plug-in named Universal Anti-False Negative (UFN) to mitigate the false negative sample problem to improve training quality, help the model combat false negative samples and reduce the impact of the false information they carry.
-
•
We conduct empirical studies on the simulation dataset and six real-world datasets to demonstrate DPR can mitigate bias accumulation in recommendation feedback loops and the universality of UFN in mainstream loss methods.
-
•
We conduct experiments on widely used models such as MLPs, and DIN to demonstrate the ease of use and effectiveness of DPR.
| MANR Assumption | Exposure Mechanism | Negative Sample | Debias | Backbone | |
| BPR | MF | ||||
| UBPR | ✓ | ✓ | ✓ | MF | |
| EBPR | ✓ | MF | |||
| CPR | ✓ | ✓ | MF | ||
| PDA | ✓ | MF | |||
| UPL | ✓ | ✓ | ✓ | MF | |
| DPR | ✓ | ✓ | ✓ | ✓ | MF |
2. Background
In this section, we briefly review previous work from three perspectives: feedback loops, MNAR problems, and pairwise ranking.
Feedback loops
Recent research has shown that ignoring feedback effects will negatively impact recommendation system performance (Schmit and Riquelme, 2018; Krauth et al., 2020; Chaney et al., 2018; Mansoury et al., 2020). Feedback loops can introduce bias in the collected user feedback data, such as popularity bias, selection bias, and homogenization (Cañamares and Castells, 2018; Chaney et al., 2018). With the growth of loops, the bias is amplified and accumulates (Kalimeris et al., 2021). Therefore, breaking the loop to correct feedback effects is a direct way to solve the problem. A common solution is to use the causal mechanism to break the loop (Bonner and Vasile, 2018; Zheng et al., 2021; Wang et al., 2020) so that the model does not suffer from feedback loops in muti-step recommendations or combine inverse propensity weighting (IPW) with active learning to correct for feedback effects (Sun et al., 2019; Liang et al., 2016; Xu et al., 2022a). However, they focus on the feedback loops without considering the exposure mechanism, which is equally important.
MNAR problem
The missing–not-at-random (MNAR) problem has been extensively studied in recommendation systems: recommendation systems aim to infer missing ratings over a static dataset (Marlin and Zemel, 2009; Sinha et al., 2017; Hernández-Lobato et al., 2014). One prevalent solution is Inverse Propensity Scoring (IPS) (Schnabel et al., 2016), where popular items are down-weighted and unpopular items are up-weighted, but if the model cannot accurately estimate the propensity score of each sample, it can not reach the theoretically unbiased. Simply using the inverse propensity score as a substitute for the exposure mechanism ignores the dynamic nature of the exposure mechanism under feedback loops. Hence, IPS-based methods do not properly deal with the effect of unknown exposure mechanisms.
Pairwise ranking
There are two types of loss functions that are generally used to optimize models: pointwise loss and pairwise loss. Pairwise loss received more praise due to its high accuracy compared to the pointwise loss. Pairwise loss learns user preferences over two items by maximizing the prediction of positive items over negative ones. Bayesian Personalized Ranking (BPR) (Rendle et al., 2009) is the first loss function that uses a pairwise ranking setting. Since it does not consider the bias in data, there are many improved versions of it, such as Unbiased Bayesian Personalized Ranking (UBPR) (Saito, 2020), Cross Pairwise Ranking (CPR) (Wan et al., 2022) and Explainable Bayesian Personalized Ranking (EBPR) (Damak et al., 2021). Although they achieve unbiased recommendations, they ignore the feedback loops that affect the performance of the recommendation system and suffer from false negative problems. Here, we briefly summarized the common pairwise ranking methods in Table 1 with respect to four dimensions.
3. Problem Formulation
In this section, we first show how the feedback loops affect the exposure mechanism, and provide an in-depth analysis of the exposure mechanism, identify the key factors that cause bias. Then, we demonstrate existing pairwise ranking methods are biased in the presence of feedback loops. We give the notation in Table 2.
| Symbol | Description |
|---|---|
| The number of users. | |
| The number of items. | |
| rating matrix. | |
| recommendation matrix. | |
| The relevance between user u and item i. | |
| The probability of the item i exposed to the users. | |
| Low dimensional user factors. | |
| Low dimensional item factors. | |
| The feedback loops length, larger T, implies longer feedback loops. |
3.1. Feedback loops in Recommendation system
Recommendation systems make recommendations and collect user feedback, and then train the next model based on collected feedback, a process that induces a feedback loop (Figure 1). The recommendation system forces the exposure mechanism to change the probability of an item being exposed to the user. For example, a personalized recommendation system aims to recommend items that the user prefers as much as possible. Such items will have a higher probability of being exposed to users than others. As a result, we can observe more interactions of such items in the collected feedback, and the next model trained on such feedback might infer that the user likes it and continue to recommend it. However, the recommendation system cannot know all user preferences perfectly which leads to biased feedback data. The new model optimizes its parameter can be seen as a maximum likelihood estimator under the feedback data:
| (1) | ||||
where indicates the user preference we can learn from the feedback data, and is the inference of user preference by the new model. It is obvious from Equation 1 that models try to fit the feedback data, which means that models will inherit the biased user preferences in the collected feedback data and make sub-optimal recommendations. From this, we make the assumption that the original recommendation system does affect the exposure mechanism, which is reflected in the feedback data and will be inherited by the new model in the feedback loops.
To validate our assumption, we choose two datasets for analysis: Coat111https://www.cs.cornell.edu/ schnabts/mnar/ and KuaiRec222https://chongminggao.github.io/KuaiRec/ (Gao et al., 2022). Both have full-observed and partial-observed data, which better reflect the difference in exposure mechanisms under and out of the feedback loops. Coat obtains fully observed data from questionnaires under randomized control and thus does not suffer from feedback loops, while KuaiRec does the opposite and obtains data from an online recommendation system without randomized control where impact of the recommendation system and feedback loops cannot be ignored. We choose the positive interaction counts of items in feedback data as the dominant indicator of the exposure mechanism, treating the full observed data as Missing At Random (MAR) data and the partial-observed data as Missing Not At Random (MNAR) data for Coat, and both the full observed data and the partial-observed data in Kuairec are Missing Not At Random (MNAR) data. The MNAR and MAR data are representative of the biased and unbiased exposure mechanisms, respectively. We process both datasets into implicit feedback without loss of generality, the results are shown in Figure 2.
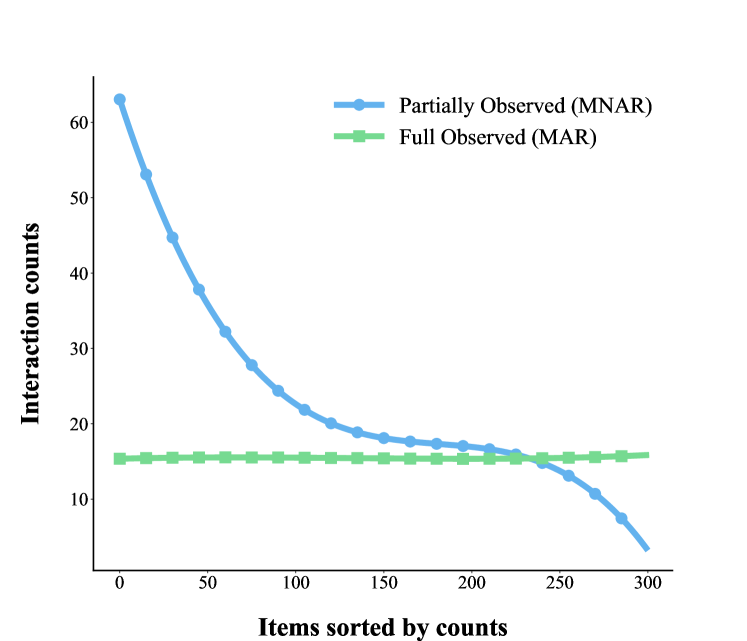
(a) Coat
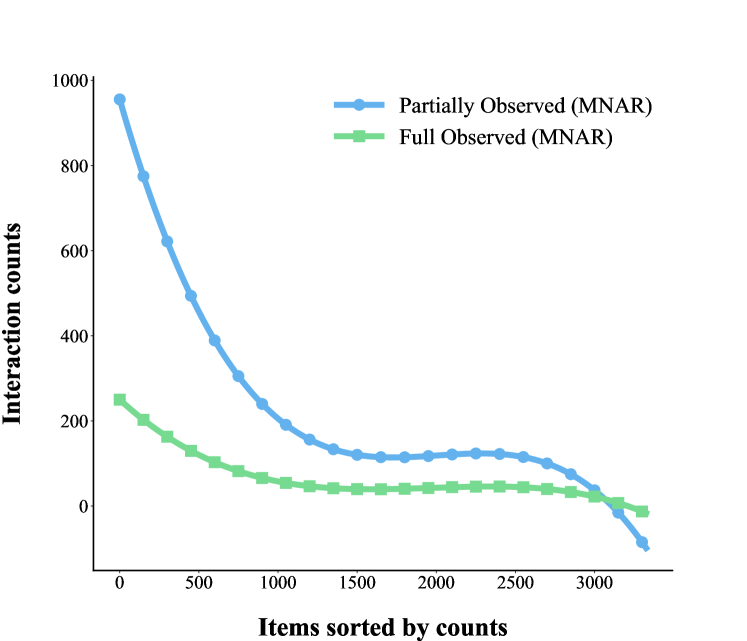
(b) KuaiRec
The results show clear differences between the full observed data and the partial-observed data in Coat and Kuairec. The difference between the full observed data and the partial-observed data in Figure 2 indicates that the exposure mechanism does have an impact on the user-item interaction, thus most of the datasets in real scenario are long-tailed distributions. Otherwise, MAR data is not affected by feedback loops, and items in MAR data have nearly the same ratio, meaning that items have the same probability of being exposed to users, as shown in Figure 2 (a). The MNAR data is affected by both feedback loops and exposure mechanisms, so the items have different exposure probabilities and show significantly different trends with respect to the MAR data. However, the KuaiRec dataset, which suffers more from feedback loops, shows a high similarity between the full observed data and the partial-observed data, with a significantly higher ratio of head-to-tail items in partial-observed data compared to Coat. The results between the two types of datasets justify the above assumption, the exposure mechanism suffers from feedback loops.
3.2. Exposure mechanism
The exposure mechanism plays an indispensable role in the user-item interaction process by determining the exposure probability of the item to the user, which we can describe as . Interaction occurs when the user is interested in the item and observes it:
| (2) |
indicates that the user rates the item, which means that an interaction has occurred. If the exposure mechanism is not affected by recommendation systems, such as the system makes random recommendations, which means feedback data obey MAR assumption, and items have the same opportunity to be exposed to users, leading to:
| (3) |
However, most recommendation systems make personal recommendations to improve the quality of recommendations and the user experience, which inevitably affects the exposure mechanism. To measure the change in the exposure mechanism, we can derive the exposure probability from the feedback data because we theoretically have access to all the data. That is:
| (4) | ||||
Since our problem is focused on the exposure mechanism under the feedback loops, we further transform Equation 4 into a more general formulation of the pattern. The current exposure mechanism at T = is mostly depend on the relevance score predicted by the current model and the past exposure mechanism at T = .
| (5) |
Based on Equation 5, we can calculate the difference of the exposure mechanisms after one feedback loop.
| (6) | ||||
From Equation 6, we can learn that items with high popularity can have low , which means that the exposure probability will be higher compared to unpopular items. This can better explain why mainstream models suffer from the ”rich-get-richer” problem. For ease of calculation, we extract the relationship between variation in exposure mechanism and static data.
| (7) |
If the data is collected from a recommendation system that makes random recommendations or through other methods such as surveys, we can regard it as free from the feedback loops, which means . Then we can have an iterative computation between and :
| (8) | ||||
By Equation 8, we can calculate the at with no known exact exposure mechanism in the current timestamp, which can be formulated as:
| (9) |
where is the frequency weight of the exposure mechanism that suffers from feedback loops. However, direct computation of relevance score between user-item pairs is time-consuming and the accuracy of the computed results is difficult to guarantee, so we need to find a replacement. From Equation 2, we can obtain an inequality between the relevance score and the observed ratings:
| (10) |
Then the lower bound on can be directly computed from the observed ratings without external information:
| (11) |
The calculation method of the lower bound is understandable, existing methods such as UBPR and Rel-MF typically exploit the interaction counts of items as the main source of propensity scores and achieve better performance, but they focus on the current timestamp and ignore the variability of exposure mechanisms. Otherwise, Eq. 11 tells us that it is fallacious to simply use the interaction counts of the items, and therefore it is suboptimal to compute the propensity score based on the interaction counts.
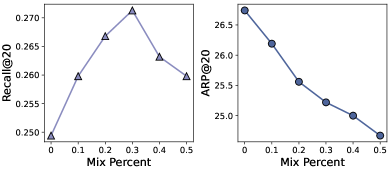
This finding makes us aware that the exposure mechanism suffers from feedback loops, which will harm the new model. So the key to unbiased recommendation is to free the model from the loops. We conduct an experiment on Coat to prove that the change in the exposure mechanism does improve the quality of the recommendation. The performance of the backbone model MF in different exposure mechanisms is presented in Figure 3. We mix various percentages of MAR data into the training set (MNAR data) to represent different exposure mechanisms. Increasing the percentage of mixing implies a closer fit to the original exposure mechanism.
As shown in Figure 3, the performance of the model does improve at the beginning, which proves that the change in the exposure mechanism does improve the performance of the model. However, the performance of the model deteriorates as the exposure mechanism closes to the original exposure mechanism up to a point since the change in the exposure mechanism is not always negative. For example, the fashion of clothes changes over time, and the corresponding styles of clothes that are popular at a certain time are bound to be popular with the public, therefore the exposure mechanism that gives preferential attention to such clothes will improve the performance of the recommendation system and user satisfaction, which is clearly different from the original exposure mechanism. Moreover, the average popularity of the final recommended items keeps decreasing as the similarity between the exposure mechanism and the original exposure mechanism increases, which indicates that the original exposure mechanism benefits the recommendation of cold items.
In summary, the effects of unknown exposure mechanisms on model performance under feedback loops are confounded, and the key to solving the problem is to maintain its beneficial effects while eliminating its negative ones.
3.3. Bias of pairwise ranking algorithm
Pairwise ranking-based methods, which learn a user’s preference for two items by maximizing the predicted score of a positive item, are always biased. Since the choice of positive and negative items depends on the observed interactions instead of the relevance of user-item. Previous studies (Saito, 2020; Saito et al., 2020a; Schnabel et al., 2016) have defined unbiasedness in terms of expectation, making the expectation of the loss equal to the ideal loss, which suffers from practical limitations, such as the high variance of the reweighted loss. Therefore, we propose a more universal definition of unbiasedness similar to (Wan et al., 2022):
Definition 3.1.
A loss function is unbiased if it optimizes the ranking of the predicted score of user-item pairs to that of the true relevance score:
| (12) |
where is the predicted score of the user-item pair, and the is the true relevance score.
Most of the paired ranking methods derive from Bayesian Personalized Ranking (BPR) (Rendle et al., 2009):
| (13) |
where is the set of all possible triplets for pairwise ranking. Then with Equation 13 we prove that BPR is biased.
Proposition 3.2.
Pairwise ranking methods are biased.
Proof.
Pairwise ranking encourages the predicted scores of positive pairs for every user to be higher than negative ones, which can be represented as:
| (14) |
According to the Equation 2, we have:
| (15) |
By combining these two equations, we can rewrite the ranking:
| (16) |
In contrast to the definition, Equation 13 does not serve the purpose of reflecting the true relevance score. This is because if the item i is more popular, as shown in Equation 7, may be much higher than . Therefore, the pairwise wanking methods are biased, models optimized with them will produce biased recommendations. ∎
4. Proposed Method: DPR and UFN
In this section, we propose a new pairwise ranking method called DPR and theoretically demonstrate its unbiasedness. Then we introduce a plugin named Universal Anti-False Negative, called UFN, to alleviate the false negative problem in pairwise ranking.
4.1. Dynamic personalized ranking
We begin by presenting the construction of DPR:
| (17) | ||||
where is the exposure probability of item i, which can be used as a proxy for the probability of exposure according to Equation 11; is a hyper-parameter that reflects the length of the feedback loops suffered by the data, a higher value of means longer loops. When , DPR is equivalent to BPR because there are no feedback loops on the data, and the presence of the exposure mechanism does not contribute to bias. The value of the depends on the training data.
4.2. Variance control of DPR
Unbiased pairwise methods commonly use inverse propensity scores of items as weights, such as UBPR and PDA, and lower accuracy in computing the propensity scores might lead to higher variance and sub-optimal recommendations, especially for the tail items with low exposure probability. To alleviate this problem, existing methods (Lee et al., 2021; Saito, 2020) apply non-negative estimators that clip large negative values for practical variance control but introduce additional bias.
Unlike existing methods, DPR uses the lower bound of the exposure mechanism as the weight, and once is determined, the accuracy of the lower bound is guaranteed. Equation 16 shows that is bounded at and is therefore bounded at . Due to the large number of items, the final value will tilt towards the left side of the range, so that the variance of DPR is acceptable even for the least popular items. In summary, the variance of DPR is much lower than the existing re-weighting methods without any additional operations.
4.3. Unbias of DPR
Similar to BPR, DPR also encourages the score of positive pairs to be higher than negative ones. DPR can also be reformulated as:
| (18) |
Proposition 4.1.
DPR is unbiased under the assumption of Equation 5.
Proof.
According to the assumption Equation 5 and Equation 12, given the pairs , we have:
| (19) |
Substitution for Equation 15 gives:
| (20) | ||||
If a proper parameter is chosen, the negative impact of the exposure mechanism is canceled by and . Model prediction scores for user-item pairs are ranked in the same order as the true relevance scores. Thus, the DPR is unbiased.
∎
4.4. False negative samples approach
The pairwise ranking method usually assumes that unobserved interactions are all negative, which is unrealistic because an item may not be exposed to the user, rather than the user does not prefer it, thus introducing false negative samples into the training process. The existence of false negative samples hurts the performance of the model because it prevents the model from fully tapping into user preferences. Previous studies (Ding et al., 2020a; Wang et al., 2021) have shown that both false negative samples and hard negative samples have large scores, but false negative samples have comparatively lower prediction variance. This means that false negative samples maintain a high prediction score in the training process. On the basis of these findings, we introduce a plugin named Universal Anti-False Negative (UFN) to alleviate the false negative problem:
| (21) |
where is the predicted score of negative items, and is the hyper-parameter to control the strength, with a higher implying a stronger effort to alleviate false negative samples. is a mapping function like , for the convenience of the proof, we use . The DPR with UFN can be written as:
| (22) |
Proposition 4.2.
UFN can alleviate the false negative problem
Proof.
For obvious results, the next proof procedure will be based on matrix factorization, which is common in recommendation systems. It is common to use the regularization algorithm in the training process, so DPR with regularization can be rewritten as:
The gain after a single batch is obtained by SGD is:
| (23) |
where and is the latent factor of the model parameters . As we can see from Equation 20 when a higher prediction score of false negative sample j contributes less to the user u, which means that false negative samples do not damage the model construction of user preferences. In addition, the plugin helps false negative samples to stable their preferences, which proves its effectiveness and improves the quality of recommendations. ∎
4.5. Comparison with IPS-based methods
IPS and DPR both focus on exposure mechanisms to achieve unbiased recommendations, but with different views of the exposure mechanism and thus provide different solutions. Here we briefly explain the difference between DPR and IPS in modeling the exposure mechanism and the superiority of our novel design. UBPR is the application of IPS in pairwise ranking:
The problems of IPS can be summarized as follows:
-
•
IPS believes that the exposure mechanism is constant, but the fact is that it changes over loops.
-
•
IPS substitutes propensity score for the exposure mechanism, which is an oversimplification of the exposure mechanism. In addition, whether the re-weight loss is equal to the ideal expectation as the condition for unbiased or not will suffer from high variance if the propensity score is incorrect.
Our DPR alleviates the following problems:
-
•
We conduct an in-depth analysis of the exposure mechanism to find its key factors over time, which are used in the DPR to counteract the effects of the exposure mechanism.
-
•
DPR considers changes in the exposure mechanism over time and uses a parameter to improve its generalization across different datasets.
-
•
Compared to using the ideal expectation to achieve unbias in IPS, DPR focuses on discovering the true performance of users and theoretical proof of its validity.
-
•
IPS-based methods need to compute the propensity score of items and thus suffer from high variance problems. DPR uses a lower bound on the exposure probability and thus has a stable performance compared to IPS-based methods.
5. Experiments
In this section, we first describe the experimental setup and then demonstrate the effectiveness of the proposed DPR and UFN.
5.1. Experimental setup
5.1.1. Datasets.
Our experiments are conducted on six real-world datasets from three datasets have full observed data Yahoo! R3333https://webscope.sandbox.yahoo.com/, Coat444https://www.cs.cornell.edu/ schnabts/mnar/ and KuaiRec555https://chongminggao.github.io/KuaiRec/ (Gao et al., 2022), and three common dataset Movielens 100K666https://grouplens.org/datasets/movielens/ (Harper and Konstan, 2016), Movielens 1M and Lastfm777https://grouplens.org/datasets/hetrec-2011/ (Cantador et al., 2011). Following prior works, ratings in Yahoo! R3, Coat, Movielens 100K, Movielens 1M and Lastfm are binarized by setting ratings under 4 to 0 and the rest to 1. For KuaiRec, We define the interest of a user-item interaction as the watching ratio, which is the ratio of watching time length to the total length, and also binarize it by setting the ratio under 2 to 0, and the rest to 1. Meanwhile, we apply leave-one-out to split training, validation, and test data for all datasets. The properties of datasets are summarized in Table 3.
| Dataset | #Users | #Items | #Interactions | Sparsity |
|---|---|---|---|---|
| Coat | 290 | 300 | 6,960 | 92.0% |
| Yahoo! R3 | 15,400 | 1,000 | 311,704 | 97.9% |
| KuaiRec | 7,176 | 10,729 | 12,530,806 | 83.7% |
| Movielens 100K | 943 | 1,682 | 100,000 | 93.6% |
| Lastfm | 1,891 | 12,522 | 149,959 | 99.2% |
| Movielens 1M | 6,039 | 3,705 | 802,553 | 95.9% |
5.1.2. Simulation dataset
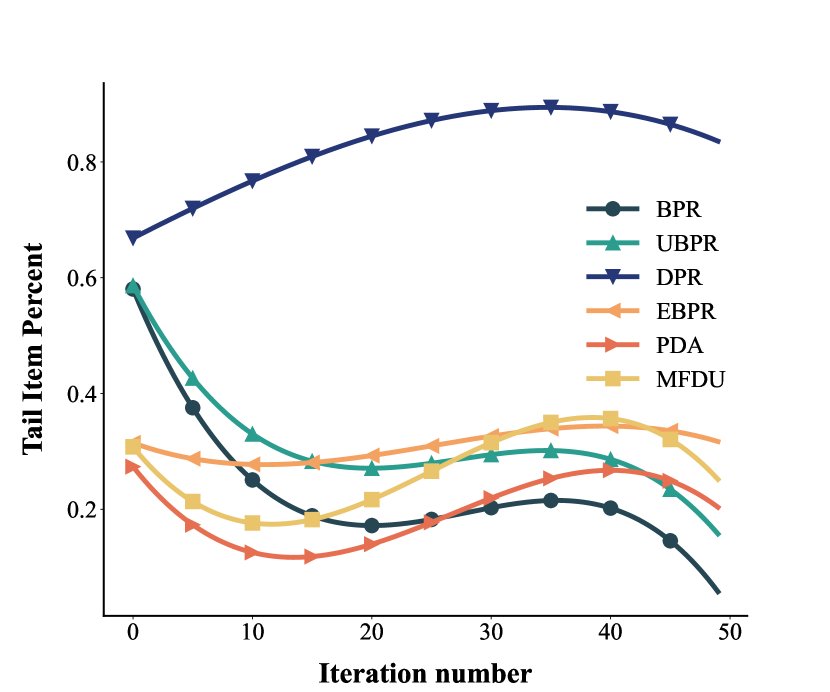
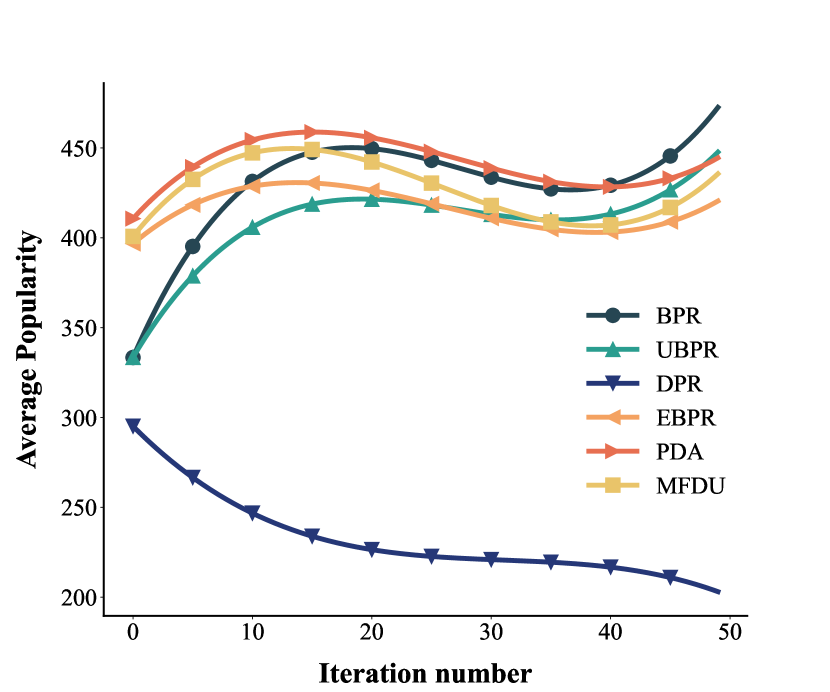
To evaluate whether the effect of the feedback loops is indeed present, we conduct experiments on simulated datasets. The simulation dataset contains 200 users and 500 items, and we generate the initial dataset by randomly exposing 20 items per user and 20 users per item. After initialization, we randomly select k = 2 of the top 10 items recommended by the model in the current loop as the new user-item interaction. We run a total of 50 loops for each method and then summarize the results. The initial data static are shown in Figure 4.
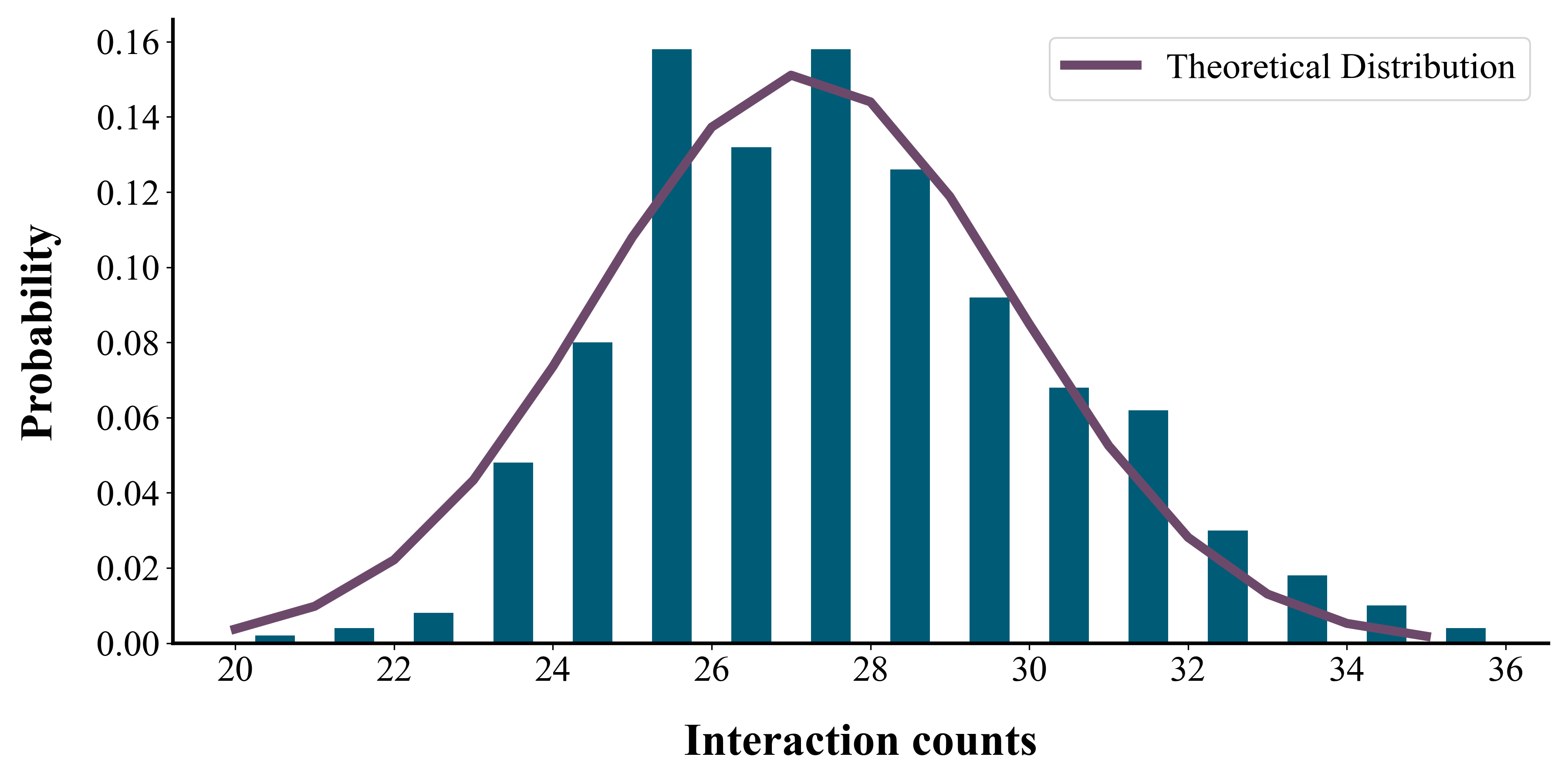
(a)
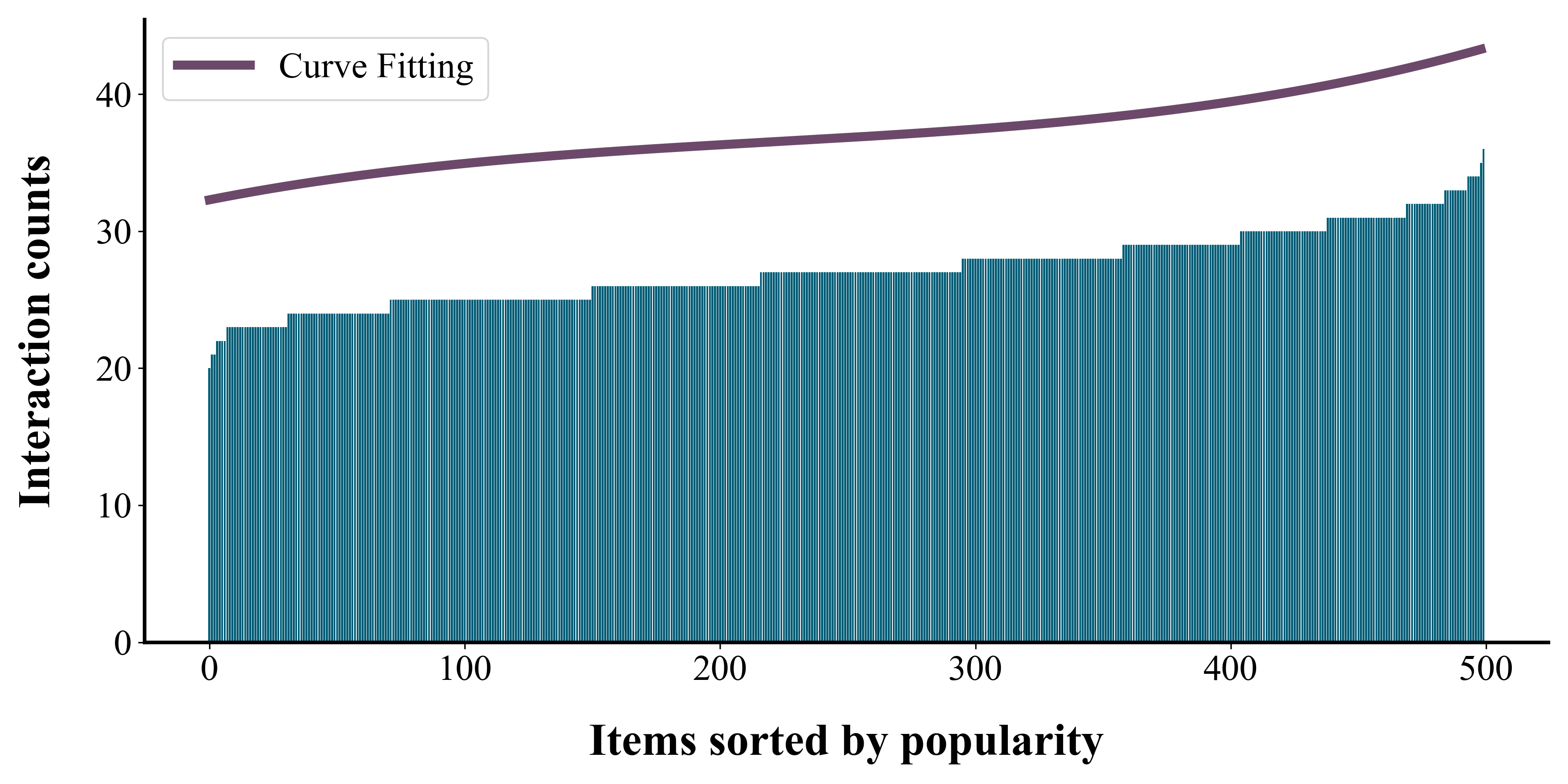
(b)
5.1.3. Evaluation.
Note that the sampling-based evaluation approach does not truly reflect the ability of the model to capture the true preferences of users, simply fitting the data may also have better performance. To this end, we report the all-ranking performance w.r.t. two widely used metrics: Recall, and NDCG cut at K = 5. In order to measure the popularity of recommended items, we use average popularity rank (ARP) and tail percentage (TAP) as the other two indicators, and the formula is:
where is the ranking of times item i has been rated in the training set, is the tail item set, we set the last 80% of the total rank of the popularity of all items as the tail item. is the recommended list of items for user . We apply sampling-based evaluation on hyperparameter experiments, which can better reflect the performance of the model in terms of modeling accuracy. Specifically, we sample 99 negative samples for each user-item interaction in the test set.
5.1.4. Baselines
We also use BPR and six other debiasing methods for comparison, including four pairwise methods and two pointwise methods.
-
•
BPR (Rendle et al., 2009) is the basic pairwise ranking algorithm that is widely used in training.
-
•
UBPR (Saito, 2020) is an IPS-based method that modifies pairwise loss.
-
•
EBPR (Damak et al., 2021) uses item-based explanations to enhance the interpretability of the pairwise loss.
-
•
PDA (Zhang et al., 2021) is an method focus on eliminate popularity problem.
-
•
UPL (Ren et al., 2023) is an unbiased method that focused on the high-variance problem of IPS-based methods.
-
•
Rel-MF (Saito et al., 2020b) is an unbiased method of binary cross-entropy loss for solving missing-not-at-random problems.
-
•
CPR (Wan et al., 2022) constructs special training samples to achieve debiasing.
-
•
MFDU (Lee et al., 2021) simultaneously eliminates the bias of clicked and unclicked data.
For a fair comparison, we apply the above methods to the widely used model, Matrix Factorization (MF) (Koren et al., 2009) and LightGCN (He et al., 2020).
5.1.5. Implementation details
We implement DPR and baselines in PyTorch. We take the embedding dimension as 64, and all models are trained with the Adam optimizer via early stopping. We set the learning rate to 1e-3 and the -regularization weight to 1e-6. We randomly sample 10 negative items for each positive item for pairwise ranking methods. For DPR, we tune the hyper-parameter in the range of for different data sets, with the default setting . We implement DPR- as DPR without the use of the UFN to measure the effectiveness of the proposed plugin. To detect significant differences in DPR and the best baseline on each data set, we repeat their experiments five times by varying the random seeds, we choose the average performance to report. All ranking metrics are computed at a cutoff K = 5 for the Top-5 recommendation(Xu et al., 2022b).
(a)
 (b)
(b)
 (c)
(c)
Following (Lee et al., 2021; Ren et al., 2023), for MFDU, we separately computed the propensity scores for positive and negative items respectively as:
where means the number of interactions to the item i by all users. While for RelMF, UBPR, UPL, and PDA, we used as the propensity scores for all of the items. For DPR, we calculate for all items as follows:
5.2. Simulation experiments
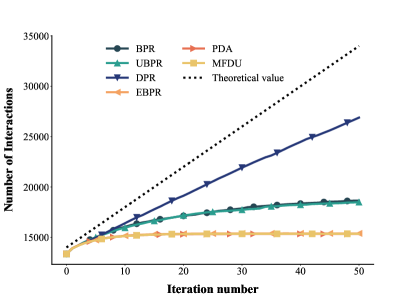
We conduct experiments with all baselines and the proposed method DPR on simulated datasets, and the results are shown in Figure 5. As can be seen from Figure 5 (a), as the feedback loops progress, there are almost no new user-item interactions in baselines after 30 loops. This means that users are surrounded by popular items and have no opportunity to come into contact with unpopular items, a phenomenon often referred to as filter bubbles. The user-item interaction growth rate of baselines is significantly below the theoretical value, and the baseline with better performance on debiasing may even be lower than the BPR, largely due to they seek to eliminate the bias in the current timestamp and ignore the impact of the feedback loops. DPR achieves a significant rate increase compared to other baselines, the existence of a gap between the growth curve of DPR and the theoretical value is justified by the fact that items cannot be preferred by all users and thus we cannot achieve a perfect curve like the theoretical value. The performance of DPR on the growth rate of user-item interactions validates that DPR can help the model break feedback loops and delay the arrival of filter bubbles.
DPR helps the model escape the feedback loop and perform better than the baselines in terms of debiasing. As can be seen from Figure 5 (b) and (a), DPR has a significantly high value in the percentage of tail items, while the baseline reaches a lower value. As the model iterates, the baselines fail to capture the variability of exposure mechanisms, such that items with high popularity have high exposure probabilities and deteriorate as the iteration progresses, thus achieving lower performance in terms of tail items. Debiasing loss functions such as UBPR, MFDU and EBPR perform better than BPR, demonstrating that debiasing methods can alleviate the bias accumulation in feedback loops, but the performance is not measurable in the long term as they formulate the problem in a single time step.
| Coat | Yahoo | Kuairec | |||||||||
| Recall@5 | NDCG@5 | ARP@5 | Recall@5 | NDCG@5 | ARP@5 | Recall@5 | NDCG@5 | ARP@5 | |||
| MF | Pairwise | BPR | 0.01702 | 0.05498 | 210.40965 | 0.02313 | 0.01691 | 993.31318 | 0.05655 | 0.66579 | 10607.80000 |
| UBPR | 0.01681 | 0.05493 | \ul189.01965 | \ul0.02637 | 0.01733 | 970.32435 | 0.05653 | 0.66455 | 10607.49270 | ||
| EBPR | 0.01681 | 0.05422 | 255.27896 | 0.02527 | 0.01680 | 994.95318 | 0.05655 | 0.66374 | 10607.80000 | ||
| PDA | 0.01735 | 0.05651 | 255.15689 | 0.02215 | 0.01580 | 995.07494 | 0.05655 | 0.66579 | 10607.80000 | ||
| UPL | 0.01757 | 0.05690 | 265.37344 | 0.02533 | 0.01741 | 993.93612 | 0.05129 | 0.62390 | 10607.50000 | ||
| Pointwise | RelMF | 0.01832 | \ul0.05944 | 194.67310 | 0.02512 | \ul0.01861 | 987.01681 | 0.05655 | 0.66571 | \ul10607.49135 | |
| MFDU | \ul0.01843 | 0.05867 | 284.49655 | 0.02256 | 0.01546 | \ul993.05911 | \ul0.05655 | \ul0.66579 | 10607.80000 | ||
| Ours | 0.01921 | 0.06132 | 174.64896 | 0.02760 | 0.01872 | 980.11035 | 0.05695 | 0.66628 | 10504.79300 | ||
| DPR | 0.02035 | 0.06199 | 178.32158 | 0.02831 | 0.01901 | 972.92581 | 0.05732 | 0.67028 | 10454.62584 | ||
| LightGCN | Pairwise | BPR | 0.01713 | 0.05421 | 201.79896 | 0.02158 | 0.01450 | 902.34749 | 0.00291 | 0.02619 | 10288.08072 |
| UBPR | 0.01713 | 0.05369 | 198.06517 | 0.01535 | 0.01005 | \ul798.96615 | 0.00282 | 0.04705 | 9607.58150 | ||
| EBPR | \ul0.01767 | \ul0.05610 | 201.18551 | \ul0.02470 | \ul0.01896 | 958.38517 | 0.01089 | 0.10802 | 10530.25301 | ||
| PDA | 0.01670 | 0.05366 | 195.31827 | 0.01892 | 0.01400 | 936.49770 | 0.00768 | 0.05380 | 10507.58242 | ||
| UPL | 0.01670 | 0.05256 | 203.44310 | 0.02156 | 0.01455 | 853.06432 | 0.00599 | 0.10106 | 9840.43940 | ||
| Pointwise | RelMF | 0.01627 | 0.05211 | 209.18172 | 0.02021 | 0.01470 | 854.45460 | 0.00379 | 0.05228 | \ul9342.29305 | |
| MFDU | 0.01573 | 0.05122 | \ul196.58034 | 0.02232 | 0.01583 | 956.23090 | \ul0.01152 | \ul0.14999 | 10564.60496 | ||
| Ours | 0.018642 | 0.060286 | 194.172414 | 0.02880 | 0.01981 | 764.64297 | 0.01275 | 0.14256 | 9352.88490 | ||
| DPR | 0.018725 | 0.060328 | 183.25149 | 0.02931 | 0.01995 | 779.15264 | 0.01284 | 0.14334 | 9345.51632 | ||
| Movielens 100K | Lastfm | Movielens 1M | |||||||||
| Recall@5 | NDCG@5 | ARP@5 | Recall@5 | NDCG@5 | ARP@5 | Recall@5 | NDCG@5 | ARP@5 | |||
| MF | Pairwise | BPR | 0.05987 | 0.07313 | 1660.67730 | 0.04200 | 0.06496 | 11976.18810 | 0.03276 | 0.08673 | 3674.39914 |
| UBPR | 0.05857 | 0.06926 | \ul1616.57269 | 0.05609 | 0.05694 | 10507.83587 | 0.03272 | 0.08740 | \ul3665.27997 | ||
| EBPR | 0.04670 | 0.05991 | 1671.57558 | 0.04351 | 0.06931 | 11946.89653 | 0.03333 | 0.08543 | 3673.60000 | ||
| PDA | 0.05542 | 0.06912 | 1669.68297 | 0.04110 | 0.06466 | 12148.00000 | 0.03276 | 0.08672 | 3674.39990 | ||
| UPL | 0.05723 | 0.06784 | 1670.44657 | \ul0.06393 | \ul0.07097 | \ul12083.15468 | \ul0.03424 | \ul0.08853 | 3674.32333 | ||
| Pointwise | RelMF | \ul0.06826 | 0.07714 | 1633.62087 | 0.05395 | 0.05476 | 10165.80245 | 0.03316 | 0.08724 | 3672.15789 | |
| MFDU | 0.06382 | \ul0.07768 | 1674.16167 | 0.04171 | 0.06502 | 12146.58093 | 0.03431 | 0.08807 | 3674.80000 | ||
| Ours | 0.06941 | 0.07825 | 1601.21017 | 0.07363 | 0.07407 | 980.11035 | 0.03533 | 0.08932 | 3662.80000 | ||
| DPR | 0.07057 | 0.07883 | 1599.21017 | 0.07421 | 0.07487 | 983.11035 | 0.03594 | 0.09017 | 3659.7259 | ||
| LightGCN | Pairwise | BPR | 0.05471 | 0.06306 | 1590.23019 | 0.16280 | 0.16939 | 11876.99043 | 0.02577 | 0.05364 | 3404.32303 |
| UBPR | 0.04600 | 0.05211 | \ul1555.11584 | 0.17884 | 0.17780 | 11682.94342 | 0.02582 | 0.05397 | 3407.13363 | ||
| EBPR | \ul0.05875 | 0.06715 | 1618.03265 | 0.10616 | 0.13413 | 11852.51579 | 0.01761 | 0.03615 | 3199.43516 | ||
| PDA | 0.05753 | \ul0.06742 | 1611.92944 | 0.14669 | 0.15424 | 11996.39314 | \ul0.04023 | \ul0.08204 | 3600.08885 | ||
| UPL | 0.04331 | 0.05042 | 1568.27109 | 0.12003 | 0.11568 | \ul11482.49704 | 0.03383 | 0.07373 | 3537.03534 | ||
| Pointwise | RelMF | 0.03492 | 0.04136 | 1525.22344 | \ul0.17973 | \ul0.18246 | 11668.15456 | 0.01350 | 0.02676 | \ul3015.77742 | |
| MFDU | 0.04548 | 0.05341 | 1625.08715 | 0.10001 | 0.10457 | 11941.92372 | 0.02055 | 0.04108 | 3245.67513 | ||
| Ours | 0.06137 | 0.06835 | 1490.20107 | 0.18087 | 0.18774 | 11277.13549 | 0.04194 | 0.08666 | 3106.81232 | ||
| DPR | 0.06213 | 0.06901 | 1485.33579 | 0.18521 | 0.18795 | 11263.15942 | 0.04259 | 0.08713 | 3099.25963 | ||
5.3. Overall performance comparison
In Table 4 and 5, we present the overall performance of applying baseline methods and our method over six datasets on two recommendation backbones. The baseline models include five pairwise ranking methods and two pointwise methods. For all datasets, the ranking performance of our DPR method outperforms the alternative baseline methods.
-
•
The performance of the IPS-based methods is not stable and even worse than BPR on some datasets. In a major part, because this type of approach requires relatively accurate inference prior, Ref-MF, for example, is an IPS-based method, and a better estimate of the property score might make it closer to the theoretical maximum. EPR adds additional user-item information to enhance explainability, but introducing additional information does not fully exploit the model and thus performs poorly on three common datasets. The IPS-based methods UPR and Rel-MF show worse performance in KuaiRec, as the IPS-based methods cannot well mitigate the effects of exposure mechanisms in lengthy feedback loops.
-
•
The baseline model fails to achieve the best performance in both debiasing and ranking performance. Baselines forcing the model to include de-biasing as an additional requirement in the optimization options come at the cost of model performance. Instead of adding a forcing requirement in the training process, DPR increases the adaptability of the model and shows the expected performance of the model as much as possible. Thus DPR has shown promising results on different backbones. Although the de-biasing effect of DPR on the Kuairec dataset is poor compared to RelMF, the accuracy of DPR is significantly higher than that of RelMF. The goal of DPR is to achieve the best possible debiasing performance while maintaining accuracy.
-
•
The proposed plug-in UFN further improves the performance of DPR. UFN reduces spurious information from false negative samples, which helps the model to avoid falling into sub-optimal traps. Further, DPR equipped with UFN can achieve better performance on most datasets, it is possible that unpopular items have a higher probability of being false negative samples, and UFN can help DPR to be more sensitive to unpopular items, thus achieving lower ARP scores.
In summary, DPR achieves better performance than other baseline methods in mitigating the negative effects of the feedback loops and unknown exposure mechanisms without sacrificing recommendation performance in most cases.
| Methods | BPR | BPR | DPR- | DPR | |
|---|---|---|---|---|---|
| Coat | Recall@20 | 0.2408 | 0.2474 | 0.2558 | 0.2595 |
| ARP@20 | 27.21 | 26.37 | 25.75 | 25.55 | |
| %Improv. | - | 2.74% | 6.23% | 7.77% | |
| Movielens 100K | Recall@20 | 0.7125 | 0.7233 | 0.7861 | 0.797 |
| ARP@20 | 138.21 | 115.38 | 99.57 | 95.22 | |
| %Improv. | - | 1.52% | 10.33% | 11.92% | |
5.4. Effectiveness of the proposed plugin UFN
We conduct experiments on two datasets to show the effectiveness of the proposed plugin for model performance improvement. As shown in Table 6, deploying UFN on BPR alone can make a certain improvement in the model performance and decreases the weight of popular items in the final recommended items. This proves that UFN can mitigate the problem of false negative samples and improve the performance of the model. Moreover, the DPR also shows better performance than the baseline methods without UFN. This demonstrates that the two modules proposed in this paper are useful for model performance improvement and that the effects can be superimposed. UFN can further improve the performance of the loss function on both BPR and DPR, indicating that it can be widely used in the pairwise loss function to mitigate the interference caused by false negative samples.
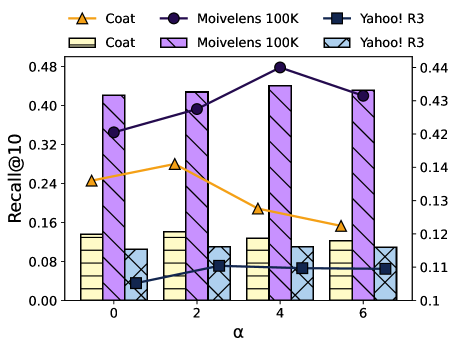
5.5. Variants of DPR loss.
We compare the performance of DPR with different levels of feedback loop parameter on different datasets. As shown in Figure 6, DPR performs best with on Coat, which is a dataset with short feedback loops. In addition, DPR performs best with on Movielens 100K, which is a dataset that suffers from more feedback loops. An increase in the starting improves the performance of the model on Yahoo! R3, but the model is not as sensitive to an increase in as it is on Movielens 100K. We speculate that this may be due to the higher sparsity of the data. The different levels of optimal in the three datasets demonstrate the ability of to mitigate the different lengths of feedback loops suffered by datasets.
Moreover, the performance of DPR deteriorates when the level of alpha continues to increase. The results match our previous analysis of exposure mechanisms, where having the same exposure for all items is not necessarily beneficial for personalized recommendations. Compared to a fully fair exposure mechanism, a personalized user-oriented exposure mechanism is the ideal exposure mechanism. This means that full debiasing does not achieve the best recommendation performance.
| Methods | BPR | DPR | %Improv. | ||
|---|---|---|---|---|---|
| Recall@20 | ARP@20 | Recall@20 | ARP@20 | ||
| MF | 0.7125 | 97.02 | 0.7974 | 95.22 | 11.92% |
| LightGCN | 0.7910 | 108.41 | 0.8176 | 88.76 | 3.36% |
| DIN | 0.7688 | 125.32 | 0.8057 | 96.42 | 5.07% |
| Wide&Deep | 0.8021 | 113.44 | 0.8245 | 85.71 | 2.79% |
5.6. Diversity backbone experiments
To demonstrate the generalizability of DPR, we conduct comparison experiments on multiple types of backbone. Here, MF is representative of DNN-based models, LightGCN is representative of graph-based models, DIN(Zhou et al., 2018) is representative of self-attention-based models, and Wide&Deep(Cheng et al., 2016) is representative of MLP-based models. As shown in Table 7, DPR demonstrated superior performance with an average improvement of 5.79 % over BPR on four different backbones. The final results using DPR on MF can compete with and even outperform complex algorithms such as LightGCN using BPR, and complex models such as DIN can be further improved by using DPR, thus demonstrating that DPR can further develop the potential of the model itself and achieve better performance.
The outstanding performance of DPR on different classes of baselines highlights that DPR is an effective algorithm that can be widely used in mainstream recommendation models today. We believe that DPR has the potential to replace BPR as a commonly used loss function because of its ability to achieve high accuracy and powerful debiasing effects.
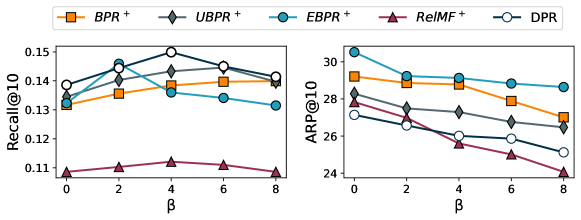
5.7. Universal applicability of UFN and comparison of different levels of
We deploy UFN on multiple baseline methods to demonstrate its universality. Figure 5 shows that the baseline methods all show a certain improvement after the deployment of UFN. Among them, pairwise-based methods have a more obvious improvement, while the improvement of the pointwise method is smaller. Probably because they have different objectives, pointwise methods place more importance on the accuracy of prediction scores than pairwise methods, and the deployment of UFN may affect the accuracy of model prediction scores. For pairwise-based methods, UFN can help to widen the score gap between positive and negative items, leading to better performance.
We compare the performance of DPR and baseline methods with different levels of parameter . As shown in Figure 7, Initially, the model performs better with increasing since a larger beta means that the model focuses more on false negative samples, which improves the model performance. However, the high attention to false negative samples means that the effect of some strongly negative samples is equally compromised so that the model becomes worse when grows beyond a certain point and continues to increase. To our knowledge, items as false negative examples are more likely to be cold items, gaining low exposure due to their low initial popularity and deteriorating as the feedback loop proceeds, transforming into false negative examples because they have no opportunity to interact with users. Thus, the average popularity of the final recommendation keeps decreasing as the beta increases.
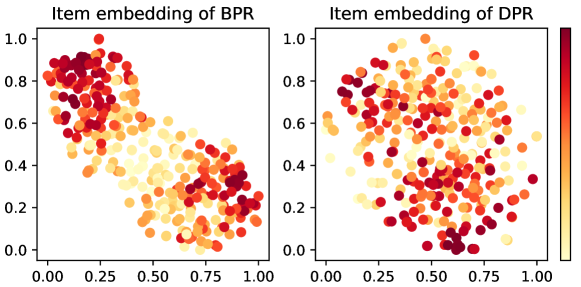
5.8. Interpretability based on model embeddings
As previously introduced, DPR can help the model mitigate accumulated bias in feedback loops and model the true preferences of users. We investigate whether DPR has such advantages by visualizing the learned item embeddings using t-SNE (van der Maaten and Hinton, 2008).
Figure 8 shows the learned item embeddings of BPR and DPR on MF, where the items with different popularity are painted in different colors. We observe that the embeddings of BPR are significantly separated according to item popularity, with popular items distributed at both ends, meaning that popular items receive more attention from the model. Items with higher popularity are considered high-quality items by the model and thus receive higher exposure. At this point, the dominant factor in the recommendation of the model is not the properties of the item itself, but other external factors such as popularity. The accumulated bias in the feedback data is inherited by the trained model and will be amplified via feedback loops.
On the other hand, there is no significant difference between popular and unpopular items in the embeddings of DPR, which means that explicit properties in the dataset, such as item popularity, do not play an influential role in the modeling process, but the true identity of items does. DPR can help reduce the influence of irrelevant factors in the training process and establish more reliable user and item embedding, so as to achieve unbiased recommendations. Visualization of the learned item embeddings illustrates the advantages of DPR and makes reasonable interpretations.
6. Conclusion and Future Work
In this work, we show that exposure mechanisms and feedback loops have a cross-effect on the recommendation model and find the key factor for the transformation of the exposure mechanism under feedback loops. Moreover, we revisit the commonly used pairwise ranking methods and point out that they are biased in modeling the true preferences of users. As a result, we propose DPR, an unbiased pairwise ranking method where the cross-effects of exposure mechanisms and feedback loops are mitigated by simply setting an optimal without knowing the exact exposure mechanism and the feedback loop length. We conduct experiments on widely used models such as MLPs, and DIN to demonstrate the ease of use and effectiveness of DPR. DPR achieves better performance than other baseline methods in mitigating the negative effects of the feedback loops and unknown exposure mechanisms without sacrificing recommendation performance in most cases.
To mitigate the effect of false negative samples, we propose UFN, a removable plug-in with generality. UFN can further improve the performance of the loss function on pairwise-based methods, indicating that it can be widely used in the pairwise loss function to mitigate the interference caused by false negative samples. However, because the pointwise-based methods do not achieve positive versus negative comparison, it does not work well with UFN and therefore fail to achieve the same performance as the pairwise-based methods.
However, DPR is not able to exploit the favorable side of the exposure mechanism to improve the performance of personalized recommendations. In the future, we will conduct a deeper analysis of the exposure mechanism to explore and exploit its role in the recommendation system and further explore the identity of false negative samples and propose a more general approach. Moreover, personalized hyperparameters for datasets are demanding for the practical effectiveness of the proposed method, and further research on hyperparameter learnability will be conducted in the future to improve the ease of use of the proposed method.
Acknowledgements.
This work was supported by the National Natural Science Foundation of Authority Youth Fund under Grant 62002123, the Key Project of Science and technology development Plan of Jilin Province under Grant 20210201082GX, the Science and Technology project of Education Department of Jilin Province under Grand JJKH20221010KJ, and Science and Technology Department project of Jilin Province under Grant 20230101067JC.References
- (1)
- Abdollahpouri et al. (2019) Himan Abdollahpouri, Robin Burke, and Bamshad Mobasher. 2019. Managing Popularity Bias in Recommender Systems with Personalized Re-Ranking. , 413–418 pages. https://aaai.org/ocs/index.php/FLAIRS/FLAIRS19/paper/view/18199
- Bonner and Vasile (2018) Stephen Bonner and Flavian Vasile. 2018. Causal Embeddings for Recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems (Vancouver, British Columbia, Canada) (RecSys ’18). Association for Computing Machinery, New York, NY, USA, 104–112. https://doi.org/10.1145/3240323.3240360
- Cañamares and Castells (2018) Rocío Cañamares and Pablo Castells. 2018. Should I Follow the Crowd? A Probabilistic Analysis of the Effectiveness of Popularity in Recommender Systems. In The 41st International ACM SIGIR Conference on Research amp; Development in Information Retrieval (Ann Arbor, MI, USA) (SIGIR ’18). Association for Computing Machinery, New York, NY, USA, 415–424. https://doi.org/10.1145/3209978.3210014
- Cai et al. (2023) Desheng Cai, Shengsheng Qian, Quan Fang, Jun Hu, and Changsheng Xu. 2023. User Cold-Start Recommendation via Inductive Heterogeneous Graph Neural Network. ACM Trans. Inf. Syst. 41, 3, Article 64 (feb 2023), 27 pages. https://doi.org/10.1145/3560487
- Cantador et al. (2011) Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. 2nd Workshop on Information Heterogeneity and Fusion in Recommender Systems (HetRec 2011). In Proceedings of the 5th ACM conference on Recommender systems (Chicago, IL, USA) (RecSys 2011). ACM, New York, NY, USA.
- Chaney et al. (2018) Allison J. B. Chaney, Brandon M. Stewart, and Barbara E. Engelhardt. 2018. How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. , 224–232 pages. https://doi.org/10.1145/3240323.3240370
- Chen et al. (2023) Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and Debias in Recommender System: A Survey and Future Directions. ACM Trans. Inf. Syst. 41, 3, Article 67 (feb 2023), 39 pages. https://doi.org/10.1145/3564284
- Chen et al. (2021) Jiawei Chen, Chengquan Jiang, Can Wang, Sheng Zhou, Yan Feng, Chun Chen, Martin Ester, and Xiangnan He. 2021. CoSam: An Efficient Collaborative Adaptive Sampler for Recommendation. ACM Trans. Inf. Syst. 39, 3, Article 34 (may 2021), 24 pages. https://doi.org/10.1145/3450289
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah. 2016. Wide& Deep Learning for Recommender Systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems (Boston, MA, USA) (DLRS 2016). Association for Computing Machinery, New York, NY, USA, 7–10. https://doi.org/10.1145/2988450.2988454
- Damak et al. (2021) Khalil Damak, Sami Khenissi, and Olfa Nasraoui. 2021. Debiased Explainable Pairwise Ranking from Implicit Feedback. In Fifteenth ACM Conference on Recommender Systems (Amsterdam, Netherlands) (RecSys ’21). Association for Computing Machinery, New York, NY, USA, 321–331. https://doi.org/10.1145/3460231.3474274
- Ding et al. (2020a) Jingtao Ding, Yuhan Quan, Quanming Yao, Yong Li, and Depeng Jin. 2020a. Simplify and Robustify Negative Sampling for Implicit Collaborative Filtering. https://proceedings.neurips.cc/paper/2020/hash/0c7119e3a6a2209da6a5b90e5b5b75bd-Abstract.html
- Ding et al. (2020b) Jingtao Ding, Guanghui Yu, Yong Li, Xiangnan He, and Depeng Jin. 2020b. Improving Implicit Recommender Systems with Auxiliary Data. ACM Trans. Inf. Syst. 38, 1, Article 11 (feb 2020), 27 pages. https://doi.org/10.1145/3372338
- Fei et al. (2022) Hao Fei, Tat-Seng Chua, Chenliang Li, Donghong Ji, Meishan Zhang, and Yafeng Ren. 2022. On the Robustness of Aspect-Based Sentiment Analysis: Rethinking Model, Data, and Training. ACM Trans. Inf. Syst. 41, 2, Article 50 (dec 2022), 32 pages. https://doi.org/10.1145/3564281
- Gao et al. (2022) Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A Fully-Observed Dataset and Insights for Evaluating Recommender Systems (CIKM ’22). Association for Computing Machinery, New York, NY, USA, 540–550. https://doi.org/10.1145/3511808.3557220
- Gao et al. (2023) Chongming Gao, Shiqi Wang, Shijun Li, Jiawei Chen, Xiangnan He, Wenqiang Lei, Biao Li, Yuan Zhang, and Peng Jiang. 2023. CIRS: Bursting Filter Bubbles by Counterfactual Interactive Recommender System. ACM Trans. Inf. Syst. (apr 2023). https://doi.org/10.1145/3594871
- Harper and Konstan (2016) F. Maxwell Harper and Joseph A. Konstan. 2016. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 5, 4 (2016), 19:1–19:19. https://doi.org/10.1145/2827872
- He et al. (2020) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, YongDong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 639–648. https://doi.org/10.1145/3397271.3401063
- Hernández-Lobato et al. (2014) José Miguel Hernández-Lobato, Neil Houlsby, and Zoubin Ghahramani. 2014. Probabilistic Matrix Factorization with Non-random Missing Data. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014 (JMLR Workshop and Conference Proceedings, Vol. 32). JMLR.org, 1512–1520. http://proceedings.mlr.press/v32/hernandez-lobatob14.html
- Imran et al. (2023) Mubashir Imran, Hongzhi Yin, Tong Chen, Quoc Viet Hung Nguyen, Alexander Zhou, and Kai Zheng. 2023. ReFRS: Resource-Efficient Federated Recommender System for Dynamic and Diversified User Preferences. ACM Trans. Inf. Syst. 41, 3, Article 65 (feb 2023), 30 pages. https://doi.org/10.1145/3560486
- Kalimeris et al. (2021) Dimitris Kalimeris, Smriti Bhagat, Shankar Kalyanaraman, and Udi Weinsberg. 2021. Preference Amplification in Recommender Systems. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery amp; Data Mining (Virtual Event, Singapore) (KDD ’21). Association for Computing Machinery, New York, NY, USA, 805–815. https://doi.org/10.1145/3447548.3467298
- Koren et al. (2009) Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix Factorization Techniques for Recommender Systems. Computer 42, 8 (2009), 30–37. https://doi.org/10.1109/MC.2009.263
- Krauth et al. (2020) Karl Krauth, Sarah Dean, Alex Zhao, Wenshuo Guo, Mihaela Curmei, Benjamin Recht, and Michael I. Jordan. 2020. Do Offline Metrics Predict Online Performance in Recommender Systems? arXiv:arXiv:2011.07931
- Krauth et al. (2022) Karl Krauth, Yixin Wang, and Michael I. Jordan. 2022. Breaking Feedback Loops in Recommender Systems with Causal Inference. arXiv:arXiv:2207.01616
- Lee et al. (2021) Jae-woong Lee, Seongmin Park, and Jongwuk Lee. 2021. Dual Unbiased Recommender Learning for Implicit Feedback (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 1647–1651. https://doi.org/10.1145/3404835.3463118
- Liang et al. (2016) Dawen Liang, Laurent Charlin, James McInerney, and David M. Blei. 2016. Modeling User Exposure in Recommendation. In Proceedings of the 25th International Conference on World Wide Web (Montréal, Québec, Canada) (WWW ’16). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 951–961. https://doi.org/10.1145/2872427.2883090
- Liu et al. (2023) Dugang Liu, Pengxiang Cheng, Zinan Lin, Xiaolian Zhang, Zhenhua Dong, Rui Zhang, Xiuqiang He, Weike Pan, and Zhong Ming. 2023. Bounding System-Induced Biases in Recommender Systems with a Randomized Dataset. ACM Trans. Inf. Syst. 41, 4, Article 108 (apr 2023), 26 pages. https://doi.org/10.1145/3582002
- Mansoury et al. (2020) Masoud Mansoury, Himan Abdollahpouri, Mykola Pechenizkiy, Bamshad Mobasher, and Robin Burke. 2020. Feedback Loop and Bias Amplification in Recommender Systems. In Proceedings of the 29th ACM International Conference on Information amp; Knowledge Management (Virtual Event, Ireland) (CIKM ’20). Association for Computing Machinery, New York, NY, USA, 2145–2148. https://doi.org/10.1145/3340531.3412152
- Marlin and Zemel (2009) Benjamin M. Marlin and Richard S. Zemel. 2009. Collaborative prediction and ranking with non-random missing data. In Proceedings of the 2009 ACM Conference on Recommender Systems, RecSys 2009, New York, NY, USA, October 23-25, 2009, Lawrence D. Bergman, Alexander Tuzhilin, Robin D. Burke, Alexander Felfernig, and Lars Schmidt-Thieme (Eds.). ACM, 5–12. https://doi.org/10.1145/1639714.1639717
- Ren et al. (2023) Yi Ren, Hongyan Tang, Jiangpeng Rong, and Siwen Zhu. 2023. Unbiased Pairwise Learning from Implicit Feedback for Recommender Systems without Biased Variance Control. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023. (2023). https://doi.org/10.1145/3539618.3592077 arXiv:arXiv:2304.05066
- Rendle et al. (2009) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian Personalized Ranking from Implicit Feedback. In UAI 2009, Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, June 18-21, 2009, Jeff A. Bilmes and Andrew Y. Ng (Eds.). AUAI Press, 452–461. https://dslpitt.org/uai/displayArticleDetails.jsp?mmnu=1&smnu=2&article_id=1630&proceeding_id=25
- Saito (2020) Yuta Saito. 2020. Unbiased Pairwise Learning from Biased Implicit Feedback (ICTIR ’20). Association for Computing Machinery, New York, NY, USA, 5–12. https://doi.org/10.1145/3409256.3409812
- Saito et al. (2020a) Yuta Saito, Suguru Yaginuma, Yuta Nishino, Hayato Sakata, and Kazuhide Nakata. 2020a. Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback. In Proceedings of the 13th International Conference on Web Search and Data Mining (Houston, TX, USA) (WSDM ’20). Association for Computing Machinery, New York, NY, USA, 501–509. https://doi.org/10.1145/3336191.3371783
- Saito et al. (2020b) Yuta Saito, Suguru Yaginuma, Yuta Nishino, Hayato Sakata, and Kazuhide Nakata. 2020b. Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback. In WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, February 3-7, 2020, James Caverlee, Xia (Ben) Hu, Mounia Lalmas, and Wei Wang (Eds.). ACM, 501–509. https://doi.org/10.1145/3336191.3371783
- Schmit and Riquelme (2018) Sven Schmit and Carlos Riquelme. 2018. Human Interaction with Recommendation Systems. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 84), Amos Storkey and Fernando Perez-Cruz (Eds.). PMLR, 862–870.
- Schnabel et al. (2016) Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. 2016. Recommendations as Treatments: Debiasing Learning and Evaluation. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016 (JMLR Workshop and Conference Proceedings, Vol. 48), Maria-Florina Balcan and Kilian Q. Weinberger (Eds.). JMLR.org, 1670–1679. http://proceedings.mlr.press/v48/schnabel16.html
- Sinha et al. (2017) Ayan Sinha, David F. Gleich, and Karthik Ramani. 2017. Deconvolving Feedback Loops in Recommender Systems. CoRR abs/1703.01049 (2017). arXiv:1703.01049 http://arxiv.org/abs/1703.01049
- Sun et al. (2019) Wenlong Sun, Sami Khenissi, Olfa Nasraoui, and Patrick Shafto. 2019. Debiasing the Human-Recommender System Feedback Loop in Collaborative Filtering. In Companion Proceedings of The 2019 World Wide Web Conference (San Francisco, USA) (WWW ’19). Association for Computing Machinery, New York, NY, USA, 645–651. https://doi.org/10.1145/3308560.3317303
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing Data using t-SNE. Journal of Machine Learning Research 9, 86 (2008), 2579–2605. http://jmlr.org/papers/v9/vandermaaten08a.html
- Wan et al. (2022) Qi Wan, Xiangnan He, Xiang Wang, Jiancan Wu, Wei Guo, and Ruiming Tang. 2022. Cross Pairwise Ranking for Unbiased Item Recommendation. In WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, Frédérique Laforest, Raphaël Troncy, Elena Simperl, Deepak Agarwal, Aristides Gionis, Ivan Herman, and Lionel Médini (Eds.). ACM, 2370–2378. https://doi.org/10.1145/3485447.3512010
- Wang et al. (2021) Jinpeng Wang, Jieming Zhu, and Xiuqiang He. 2021. Cross-Batch Negative Sampling for Training Two-Tower Recommenders. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 1632–1636. https://doi.org/10.1145/3404835.3463032
- Wang et al. (2023a) Wenjie Wang, Xinyu Lin, Liuhui Wang, Fuli Feng, Yunshan Ma, and Tat-Seng Chua. 2023a. Causal Disentangled Recommendation Against User Preference Shifts. ACM Trans. Inf. Syst. (apr 2023). https://doi.org/10.1145/3593022 Just Accepted.
- Wang et al. (2020) Yixin Wang, Dawen Liang, Laurent Charlin, and David M. Blei. 2020. Causal Inference for Recommender Systems. In RecSys 2020: Fourteenth ACM Conference on Recommender Systems, Virtual Event, Brazil, September 22-26, 2020, Rodrygo L. T. Santos, Leandro Balby Marinho, Elizabeth M. Daly, Li Chen, Kim Falk, Noam Koenigstein, and Edleno Silva de Moura (Eds.). ACM, 426–431. https://doi.org/10.1145/3383313.3412225
- Wang et al. (2023b) Yifan Wang, Weizhi Ma, Min Zhang, Yiqun Liu, and Shaoping Ma. 2023b. A Survey on the Fairness of Recommender Systems. ACM Trans. Inf. Syst. 41, 3, Article 52 (feb 2023), 43 pages. https://doi.org/10.1145/3547333
- Xu et al. (2022a) Yuanbo Xu, En Wang, Yongjian Yang, and Yi Chang. 2022a. A Unified Collaborative Representation Learning for Neural-Network Based Recommender Systems. IEEE Transactions on Knowledge and Data Engineering 34, 11 (2022), 5126–5139. https://doi.org/10.1109/TKDE.2021.3054782
- Xu et al. (2022b) Yuanbo Xu, Yongjian Yang, En Wang, Fuzhen Zhuang, and Hui Xiong. 2022b. Detect Professional Malicious User With Metric Learning in Recommender Systems. IEEE Transactions on Knowledge and Data Engineering 34, 9 (2022), 4133–4146. https://doi.org/10.1109/TKDE.2020.3040618
- Zhang et al. (2021) Yang Zhang, Fuli Feng, Xiangnan He, Tianxin Wei, Chonggang Song, Guohui Ling, and Yongdong Zhang. 2021. Causal Intervention for Leveraging Popularity Bias in Recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, Canada) (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 11–20. https://doi.org/10.1145/3404835.3462875
- Zheng et al. (2023) Ruiqi Zheng, Liang Qu, Bin Cui, Yuhui Shi, and Hongzhi Yin. 2023. AutoML for Deep Recommender Systems: A Survey. ACM Trans. Inf. Syst. 41, 4, Article 101 (mar 2023), 38 pages. https://doi.org/10.1145/3579355
- Zheng et al. (2021) Yu Zheng, Chen Gao, Xiang Li, Xiangnan He, Yong Li, and Depeng Jin. 2021. Disentangling User Interest and Conformity for Recommendation with Causal Embedding. In Proceedings of the Web Conference 2021 (Ljubljana, Slovenia) (WWW ’21). Association for Computing Machinery, New York, NY, USA, 2980–2991. https://doi.org/10.1145/3442381.3449788
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (London, United Kingdom) (KDD ’18). Association for Computing Machinery, New York, NY, USA, 1059–1068. https://doi.org/10.1145/3219819.3219823