Dreaming: Model-based Reinforcement Learning
by Latent Imagination without Reconstruction
Abstract
In the present paper, we propose a decoder-free extension of Dreamer, a leading model-based reinforcement learning (MBRL) method from pixels. Dreamer is a sample- and cost-efficient solution to robot learning, as it is used to train latent state-space models based on a variational autoencoder and to conduct policy optimization by latent trajectory imagination. However, this autoencoding based approach often causes object vanishing, in which the autoencoder fails to perceives key objects for solving control tasks, and thus significantly limiting Dreamer’s potential. This work aims to relieve this Dreamer’s bottleneck and enhance its performance by means of removing the decoder. For this purpose, we firstly derive a likelihood-free and InfoMax objective of contrastive learning from the evidence lower bound of Dreamer. Secondly, we incorporate two components, (i) independent linear dynamics and (ii) the random crop data augmentation, to the learning scheme so as to improve the training performance. In comparison to Dreamer and other recent model-free reinforcement learning methods, our newly devised Dreamer with InfoMax and without generative decoder (Dreaming) achieves the best scores on 5 difficult simulated robotics tasks, in which Dreamer suffers from object vanishing.
I Introduction
In the present paper, we focus on model-based reinforcement learning (MBRL) from pixels without complex reconstruction. MBRL is a promising technique to build controllers in a sample efficient manner, which trains forward dynamics models to predict future states and rewards for the purpose of planning and/or policy optimization. The recent study of MBRL in fully-observable environments [1, 2, 3, 4] have achieved both sample efficiency and competitive performance with the state-of-the-art model-free reinforcement learning (MFRL) methods like soft-actor-critic (SAC) [5]. Although real-robot learning has been achieved with fully-observable MBRL [6, 7, 8, 9, 10, 11], there has been an increasing demand for robot learning in partially observable environments in which only incomplete information (especially vision) is available. MBRL from pixels can be realized by introducing deep generative models based on autoencoding variational Bayes [12].
Object vanishing is a critical problem of the autoencoding based MBRL from pixels. Previous studies in this field [13, 14, 15, 16, 17, 18, 19] train autoencoding models along with latent dynamics models that generate imagined trajectories that are used for planning or policy optimization. However, the autoencoder often fails to perceive small objects in pixel space. The top part of Fig. 1 exemplifies this kind of failures where small (or thin) and important objects are not reconstructed in their correct positions. This shows the failure to successfully embed their information into the latent space, which significantly limits the training performance. This problem is a result of a log-likelihood objective (reconstruction loss) defined in the pixel space. Since the reconstruction errors of small objects in the pixel space are insignificant compared to the errors of other objects and uninformative textures that occupy most parts of the image region, it is hard to train the encoder to perceive the small objects from the weak error signals. Also, we have to train the decoder which requires a high model capacity with massive parameters from the convolutional neural networks (CNN), although the trained models are not exploited both in the planning and policy optimization.
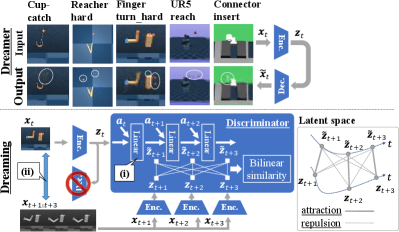
To avoid this complex reconstruction, some previous MBRL studies have proposed decoder-free representation learning [16, 21] based on contrastive learning [22, 23], which trains a discriminator instead of the decoder. The discriminator is trained by categorical cross-entropy optimization, which encourages latent embeddings to be sufficiently distinguishable among different embeddings. Nevertheless, to the best of our knowledge, no MBRL methods have achieved the state-of-the-art results on the difficult benchmark tasks of DeepMind Control Suite (DMC) [20] without reconstruction.
Motivated by these observations, this paper aims to achieve the state-of-the-art results with MBRL from pixels without reconstruction. This paper mainly focuses on the latest autoencoding-based MBRL method Dreamer, considering the success of a variety of control tasks (i.e., DMC and Atari Games [24]), and tries to extend this method to be a decoder-free fashion. We adopt Dreamer’s policy optimization without any form of modification. We call our extended Dreamer as Dreamer with InfoMax and without generative decoder (Dreaming). The concept of this proposed method is illustrated in the bottom part of Fig. 1. Our primary contributions are summarized as follows.
-
•
We derive a likelihood-free (decoder-free) and InfoMax objective for contrastive learning by reformulating the variational evidence lower bound (ELBO) of the graphical model of the partially observable Markov decision process.
-
•
We show that two key components, (i) an independent and linear forward dynamics, which is only utilized for contrastive learning, and (ii) appropriate data augmentation (i.e., random crop), are indispensable to achieve the state-of-the-art results.
In comparison to Dreamer and the recent cutting edge MFRL methods, Dreaming can achieve the state-of-the-art results on difficult simulated robotics tasks exhibited in Fig. 1 in which Dreamer suffers from object vanishing. The remainder of this paper is organized as follows. In Sec. II, key differences from related work are discussed. In Sec. III, we provide a brief review of Dreamer and contrastive learning. In Sec. IV, we first describe the proposed contrastive learning scheme in detail, and then introduce Dreaming. In Sec. V, the effectiveness of Dreaming is demonstrated through simulated evaluations. Finally, Sec. VI concludes this paper.
II Related Work
Some of the most related work are contrastive predictive coding (CPC) [22] and contrastive forward model (CFM) [21]. Our work is highly inspired by CPC, and our contrastive learning scheme has similar components with CPC; e.g., a recurrent neural network and a bilinear similarity function. However, CPC has no action-conditioned dynamics models. Since CPC alone cannot generate imagined trajectories from arbitrary actions, CPC is only used as an auxiliary objective of MFRL. CFM heuristically introduces a similar decoder-free objective function like ours. A primary difference between ours and CFM is that CFM exploits a shared and non-linear forward model for both contrastive and behavior learning. In addition, the relation between the ELBO of time-series variational inference is not discussed in the above two literature. Meanwhile, the original Dreamer paper [16] has also derived a contrastive objective from the ELBO. However, dynamics models and temporal correlation of observations are not involved in the contrastive objective. Furthermore, CPC, CFM, and Dreamer do not introduce data augmentation.
MFRL methods with representation learning: A state-of-the-art MFRL method, contrastive unsupervised representation for reinforcement learning (CURL) [25], also makes use of contrastive learning with the random crop data augmentation. Deep bisimulation for control (DBC) [26] and discriminative particle filter reinforcement learning (DPFRL) [27] are other types of cutting edge MFRL methods, which utilize different concepts of representation learning without reconstruction.
MFRL methods without representation learning: Recently proposed MFRL methods, which include reinforcement learning with augmented data (RAD) [28], data-regularized Q (DrQ) [29], and simple unified framework for reinforcement learning using ensembles (SUNRISE) [30], have achieved state-of-the-art result without representation learning. All these work employ the random crop data augmentation as an important component of their method.
III Preliminary
III-A Autoencoding Variational Bayes for Time-series
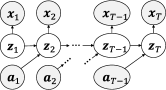
Let us begin by considering the graphical model illustrated in Fig. 2, whose joint distribution is defined as follows:
| (1) |
where , , and denote latent state, observation, and action, respectively. As in the case of well-known variational autoencoders (VAEs) [12], generative models , and inference model can be trained by maximizing the evidence lower bound [15]:
| (2) | |||
If the models are defined to be differentiable and trainable, this objective can be maximized by the stochastic gradient ascent via backpropagation.
Multi-step variational inference is proposed in [15] to improve long-term predictions. This inference, named latent overshooting, involves the multi-step objective defined as:
| (3) |
where
is the multi-step prediction model.
For the purpose of planning or policy optimization, not only for the dynamics model but also the reward function is also required. To do this, we can simply regard the rewards as observations and learn the reward function along with the decoder . For readability, we omit the specifications of the reward function in the following discussion. Although we remove the decoder later, the reward function and its likelihood objective are kept untouched.
III-B Recurrent State Space Model and Dreamer
The recurrent state space model (RSSM) is a latent dynamics model equipped with an expressive recurrent neural network, realizing accurate long-term prediction. RSSM is used as an essential component of various MBRL methods from pixels [15, 16, 17, 19, 31] including Dreamer. RSSM assumes the latent comprises where , are the probabilistic and deterministic variables, respectively. RSSM’s generative and inference models are defined as:
| (4) | ||||
where deterministic is considered to be the hidden state of the gated recurrent unit (GRU) [32] so that historical information can be embedded into .
Dreamer [16] makes use of RSSM as a differentiable dynamics and efficiently learns the behaviors via backpropagation of Bellman errors estimated from imagined trajectories. Dreamer’s training procedure is simply summarized as follows: (1) Train RSSM with a given dataset by optimizing Eq. (2). (2) Train a policy from the latent imaginations. (3) Execute the trained policy in a real environment and augment the dataset with the observed results. The above steps are iteratively executed until the policy performs as expected.
III-C Contrastive Learning of RSSM
The original Dreamer paper [16] also introduced a likelihood-free objective by reformulating of Eq. (2). By adding a constant and applying Bayes’ theorem, we get a decoder-free objective:
| (5) |
where denotes the mini-batch and the lower bound in the second line was from the Info-NCE (noise-contrastive estimator) mini-batch bound [33]. Let be the batch size of , is considered as a -class categorical cross entropy objective to discriminate the positive pair among the other negative pairs . In this interpretation, can be considered as a discriminator to discern the positive pairs. Representation learning with this type of objective is known as contrastive learning [22, 23] that encourages the embeddings to be sufficiently seperated from each other in the latent space. However, the experiment in [16] has demonstrated that this objective significantly degrades the performance compared to the original objective .
IV Proposed Contrastive Learning
and MBRL Method
IV-A Deriving Another Contrastive Objective
We propose to further reformulate of Eq. (5) by introducing a multi-step prediction model: The accent of implies that an independent dynamics model from in Eq. (2) can be employed here. By multiplying a constant , we obtain an importance sampling form of as:
| (6) |
For computational simplicity, we approximate the likelihood ratio as a constant and assume that the summation of across batch and time dimension is approximated as: where
| (7) | |||
We further import the concept of overshooting and optimize along with on multi-step prediction of varying s. Finally, the objective we use to train RSSM is:
| (8) |
Note that and have different dynamics model (i.e., and , respectively).
IV-B Relation among the Objectives
As shown in Appx. A, is a lower bound of the mutual information , while is a bound of . Since the latent state sequence is Markovian, we have the data processing inequality as . In other words, and approximately derived share the same InfoMax upper bound metrics. An intuitive motivation to introduce instead of is so that we can incorporate temporal correlation between and . Another motivation is that we can increase the model capacity of the discriminator by incorporating the independent dynamics model .
IV-C Model Definitions
This section discusses how we define the discriminator components: and . Ref. [34] has empirically shown that the inductive bias from model architectures is a significant factor for contrastive learning. As experimentally recommended in the literature, we define as an exponentiated bilinear similarity function parameterized with :
| (9) |
where and denotes feature extraction by a CNN unit. With this definition, is simply a softmax cross-entropy objective with logits . Contrary to the previous contrastive learning literature [22, 34], the definition of newly introduced is required. Here, we propose to apply linear modeling to define the model deterministically as:
| (10) |
is the Dirac delta function, and are linear parameters.
This linear modeling of successfully regularizes and contributes to construct smooth latent space. We can alternatively define , where is generally defined as an expressive model aiming at precise prediction. However, the high model capacity allows to embed temporally consecutive samples too distant from each other to sufficiently optimize , thus yielding unsmooth latent space.
IV-D Instantiation with RSSM
Figure 3 illustrates the architecture to compute . We describe the two paramount components which characterize our proposed contrastive learning scheme as follows:
(i) Independent linear forward dynamics: As previously proposed in Sec. IV-C, we employ a simple linear forward dynamics , which is used only for contrastive learning. During the policy optimization phase, the expressive model with GRU is alternatively utilized to make the most out of its long-term prediction accuracy.
(ii) Data augmentation: We append two independent image preprocessors which process two sets of input images (i.e., and ). Considering the empirical success of the previous literature [23, 25, 28, 30, 29], we adopt the random crop of images. In our implementation, the original image shaped is cropped to be . The origin of the crop rectangle is determined at each preprocessor randomly and indenpendently. This makes it difficult for the contrastive learner to discriminate correct positive pairs, encouraging only informative features for control to be extracted.
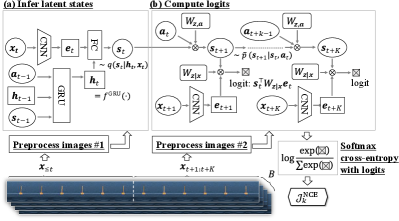
We propose a decoder-free variant of Dreamer, which we call Dreamer with InfoMax and without generative decoder (Dreaming). Dreaming trains a policy as almost same way with the original Dreamer. The only difference between the methods is that we alternatively use the contrastive learning scheme introduced in the previous section to train RSSM. We implement Dreaming in TensorFlow [35] by modifying the official source code of Dreamer111https://github.com/google-research/dreamer. We keep all hyperparameters and experimental conditions similar to the original ones. A newly introduced hyperparameter in Eq. (8) (overshooting distance) is set to be based on the ablation study in Appx. C.
V Experiments
V-A Comparison to State-of-the-art Methods
| Dreaming (ours) | Dreamer w/ | Dreamer w/ | CURL [25] | DrQ [29] | RAD [28] | |||||||
| [16] | [16] | |||||||||||
| (A) Manipulation tasks where object vanishing is critical | ||||||||||||
| Cup-catch (100K) |
|
|
|
|
|
|
||||||
| Reacher-hard |
|
|
|
|
|
|
||||||
| Finger-turn-hard |
|
|
|
|
|
|
||||||
| UR5-reach |
|
|
|
|
|
|
||||||
| Connector-insert |
|
|
|
|
|
|
||||||
| (B) Manipulation tasks where object vanishing is NOT critical | ||||||||||||
| Reacher-easy |
|
|
|
|
- | - | ||||||
| Finger-turn-easy |
|
|
|
|
- | - | ||||||
| Finger-spin |
|
|
|
|
- | - | ||||||
| (C) Pole-swingup tasks | ||||||||||||
| Pendulum-swingup |
|
|
|
|
- | - | ||||||
| Acrobot-swingup |
|
|
|
|
- | - | ||||||
| Cartpole-swingup-sparse |
|
|
|
|
- | - | ||||||
| (D) Locomotion tasks | ||||||||||||
| Quadrupled-walk |
|
|
|
|
- | - | ||||||
| Walker-walk |
|
|
|
|
- | - | ||||||
| Cheetah-run |
|
|
|
|
- | - | ||||||
| Hopper-hop |
|
|
|
|
- | - | ||||||
The main objective of this experiment is to demonstrate that Dreaming has advantages over the baseline method Dreamer [16] on difficult 5 manipulation tasks exhibited in Fig. 1, in which Dreamer suffers from object vanishing. We also prepare a likelihood-free variant of Dreamer introduced in Sec. III-C, which utilizes the vanilla contrastive objective instead of and . The specifications of the two original tasks, UR5-reach and Connector-insert, are described in Appx. B. For the difficult 5 tasks, we also compare the performance with the latest cutting edge MFRL methods, which are CURL [25], DrQ [29] and RAD [28]. In addition, another variety of 10 DMC tasks are evaluated, which are categorized into three classes namely; manipulation, pole-swingup, and locomotion. For the additional 10 tasks, only CURL is selected as an MFRL representative.
Table I summarizes the training results benchmarked at certain environment steps. The results show the mean and standard deviation averaged 4 seeds and 10 consecutive trajectories. This table shows a similar result as in [16] that decoder-free Dreamer with the vanilla contrastive objective degrades the performances on most of tasks than decoder-based Dreamer with . In the following discussions, we use the decoder-based Dreamer as a primary baseline. (A) We put much focus on these difficult tasks and it can be seen that Dreaming consistently achieves better performance than Dreamer. Hence, this indicates that the decoder-free nature of the proposed method successfully surmounts the object vanishing problem. In addition, Dreaming achieves outperforming performance than the leading MFRL methods. (B) On other manipulation tasks, there are no significant difference between Dreaming and Dreamer because the key objects are large enough. (C) Since the pole-swingup tasks also cause vanishing of thin poles, Dreaming takes better performance than Dreamer. (D) Dreaming lags behind the Dreamer on 3 of 4 locomotion tasks, i.e., planar locomotion tasks (Walker-walk, Cheetah-run and Hopper-hop). On these tasks, the cameras always track the center of locomotive robots, and this causes the key control information (i.e., velocity) to be extracted from the background texture. We suppose that this robot-centric nature makes it difficult for the contrastive learner to extract such information because only robots’ attitudes provide enough information to discriminate different samples.
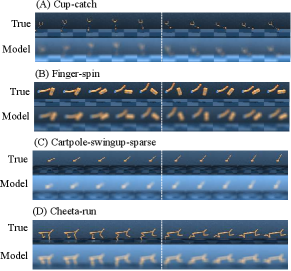
Figure 4 shows video prediction by Dreaming, in which principal features for control (e.g., positions and orientations) are successfully reconstructed from the embeddings learned without likelihood objective. However on Cheeta-run, another kind of object vanishing arises; the checkered floor pattern, which is required to extract the velocity information, is vanished.
V-B Ablation Study
This experiment is conducted to analyze how the major components of the proposed representation learning, introduced in Sec. IV-D, contribute to the overall performance. For this purpose, some variants of the proposed method have been prepared: (i) the effect of independent linear dynamics is demonstrated with a variant that has shared dynamics 222 The prepared variant can be considered as a special case of the contrastive forward model (CFM) [21] as discussed in Sec. II. , (ii) the effect of data augmentation is demonstrated by removing the image preprocessors shown in Fig. 3. We also prepare another data augmentation called color jittering [23, 29, 28], for reference. Only three tasks, which are Cup-catch, Reacher-hard, and Finger-turn-hard, are taken into this experiment. Tables II summarize the results from the performed ablation study, which reveals that both of the proposed components are essential to achieve state-of-the-art results.
VI Conclusion
In the present paper, we proposed Dreaming, a decoder-free extension of the state-of-the-art MBRL method from pixels, Dreamer. A likelihood-free contrastive objective was derived by reformulating the original ELBO of Dreamer. We incorporated the two indispensable components below to the contrastive learning: (i) independent and linear forward dynamics, (ii) the random crop data augmentation. By making the most of the decoder-free nature and the two components, Dreaming was able to outperform the baseline methods on difficult tasks especially where Dreamer suffers from object vanishing.
An disadvantage we observed in the experiments was that Dreaming degraded the training performance on planar locomotion tasks (e.g., Walker-walk), where the contrastive learner has to focus on not only robots but also the background texture. This weak point should be resolved in future work as it may affect industrial manipulation tasks where first-person-view from robots dynamically changes. Another future research direction is to incorporate the uncertainty-aware concepts proposed in recent MBRL studies [1, 2, 19, 30]. Although we have achieved state-of-the-art results on some difficult tasks, we have often observed overfitted behaviors during the early training phase. We believe that this model-bias problem [36] can be successfully solved by the above state-of-the-art strategy.
Appendix A Derivation
In this section, we clarify that is a lower bound of . can be rewriten as:
| (11) |
where includes deterministic multi-step prediction with and computation of the bilinear similarity by Eq. (9). For ease of notation, actions in the conditioning set are omitted from . As already shown in [22], the optimal value of is given by:
| (12) |
By applying Bayes’ theorem and inserting this to Eq. (11), we get:
| (13) |
By marginalizing Eq. (13) with respect to the data distribution, we finally obtain: Note that setting derives
Appendix B Specifications of the Original Tasks
Figure 5 exhibits the specifications of newly introduced robotics tasks.

Appendix C Ablation Study of Overshooting Distance
Table III summarizes the ablation study of the overshooting distance , which demonstrates that incorporating temporal correlation of appropriate multi-steps () is effective.
| Cup-catch (100K) | 280 437 | 925 48 | 734 378 | 736 378 |
|---|---|---|---|---|
| Reacher-hard | 234 364 | 868 272 | 561 447 | 471 433 |
| Finger-turn-hard | 354 438 | 752 325 | 468 432 | 715 375 |
References
- [1] K. Chua, R. Calandra, R. McAllister, and S. Levine, “Deep reinforcement learning in a handful of trials using probabilistic dynamics models,” in NeurIPS, 2018.
- [2] M. Okada and T. Taniguchi, “Variational inference MPC for Bayesian model-based reinforcement learning,” in CoRL, 2019.
- [3] E. Langlois, S. Zhang, G. Zhang, P. Abbeel, and J. Ba, “Benchmarking model-based reinforcement learning,” arXiv:1907.02057, 2019.
- [4] L. Kaiser, M. Babaeizadeh, P. Milos, B. Osinski, et al., “Model-based reinforcement learning for Atari,” in ICLR, 2020.
- [5] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in ICML, 2018.
- [6] S. Bechtle, Y. Lin, A. Rai, L. Righetti, and F. Meier, “Curious iLQR: Resolving uncertainty in model-based RL,” in CoRL, 2019.
- [7] A. Nagabandi, K. Konolige, S. Levine, and V. Kumar, “Deep dynamics models for learning dexterous manipulation,” in CoRL, 2019.
- [8] Y. Yang, K. Caluwaerts, A. Iscen, T. Zhang, J. Tan, and V. Sindhwani, “Data efficient reinforcement learning for legged robots,” in CoRL, 2019.
- [9] Y. Zhang, I. Clavera, B. Tsai, and P. Abbeel, “Asynchronous methods for model-based reinforcement learning,” in CoRL, 2019.
- [10] G. R. Williams, B. Goldfain, K. Lee, J. Gibson, J. M. Rehg, and E. A. Theodorou, “Locally weighted regression pseudo-rehearsal for adaptive model predictive control,” in CoRL, 2019.
- [11] K. Fang, Y. Zhu, A. Garg, S. Savarese, and L. Fei-Fei, “Dynamics learning with cascaded variational inference for multi-step manipulation,” in CoRL, 2019.
- [12] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in ICLR, 2014.
- [13] D. Ha and J. Schmidhuber, “Recurrent world models facilitate policy evolution,” in NeurIPS, 2018.
- [14] A. X. Lee, A. Nagabandi, P. Abbeel, and S. Levine, “Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model,” arXiv:1907.00953, 2019.
- [15] D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning latent dynamics for planning from pixels,” in ICML, 2019.
- [16] D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” ICLR, 2020.
- [17] D. Han, K. Doya, and J. Tani, “Variational recurrent models for solving partially observable control tasks,” in ICLR, 2020.
- [18] D. Yarats, A. Zhang, I. Kostrikov, B. Amos, J. Pineau, and R. Fergus, “Improving sample efficiency in model-free reinforcement learning from images,” arXiv:1910.01741, 2019.
- [19] M. Okada, N. Kosaka, and T. Taniguchi, “PlaNet of the Bayesians: Reconsidering and improving deep planning network by incorporating Bayesian inference,” in IROS, 2020.
- [20] Y. Tassa, Y. Doron, A. Muldal, T. Erez, Y. Li, et al., “DeepMind control suite,” arXiv:1801.00690, 2018.
- [21] W. Yan, A. Vangipuram, P. Abbeel, and L. Pinto, “Learning predictive representations for deformable objects using contrastive estimation,” arXiv:2003.05436, 2020.
- [22] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv:1807.03748, 2018.
- [23] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in ICLR, 2020.
- [24] M. G. Bellemare, Y. Naddaf, J. Veness, and M. Bowling, “The arcade learning environment: An evaluation platform for general agents,” Journal of Artificial Intelligence Research, vol. 47, pp. 253–279, 2013.
- [25] A. Srinivas, M. Laskin, and P. Abbeel, “CURL: Contrastive unsupervised representations for reinforcement learning,” in ICML, 2020.
- [26] A. Zhang, R. McAllister, R. Calandra, Y. Gal, and S. Levine, “Learning invariant representations for reinforcement learning without reconstruction,” arXiv:2006.10742, 2020.
- [27] X. Ma, P. Karkus, D. Hsu, W. S. Lee, and N. Ye, “Discriminative particle filter reinforcement learning for complex partial observations,” in ICLR, 2020.
- [28] M. Laskin, K. Lee, A. Stooke, L. Pinto, P. Abbeel, and A. Srinivas, “Reinforcement learning with augmented data,” arXiv:2004.14990, 2020.
- [29] I. Kostrikov, D. Yarats, and R. Fergus, “Image augmentation is all you need: Regularizing deep reinforcement learning from pixels,” arXiv:2004.13649, 2020.
- [30] K. Lee, M. Laskin, A. Srinivas, and P. Abbeel, “SUNRISE: A simple unified framework for ensemble learning in deep reinforcement learning,” arXiv:2007.04938, 2020.
- [31] R. Sekar, O. Rybkin, K. Daniilidis, P. Abbeel, D. Hafner, and D. Pathak, “Planning to explore via self-supervised world models,” arXiv:2005.05960, 2020.
- [32] K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, et al., “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” arXiv:1406.1078, 2014.
- [33] B. Poole, S. Ozair, A. v. d. Oord, A. A. Alemi, and G. Tucker, “On variational bounds of mutual information,” in ICML, 2019.
- [34] M. Tschannen, J. Djolonga, P. K. Rubenstein, S. Gelly, and M. Lucic, “On mutual information maximization for representation learning,” ICLR, 2020.
- [35] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, et al., “TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015.
- [36] M. Deisenroth and C. E. Rasmussen, “PILCO: A model-based and data-efficient approach to policy search,” in ICML, 2011.
- [37] R. Okumura, M. Okada, and T. Taniguchi, “Domain-adversarial and -conditional state space model for imitation learning,” in IROS, 2020.