Dual T: Reducing Estimation Error for Transition Matrix in Label-noise Learning
Abstract
The transition matrix, denoting the transition relationship from clean labels to noisy labels, is essential to build statistically consistent classifiers in label-noise learning. Existing methods for estimating the transition matrix rely heavily on estimating the noisy class posterior. However, the estimation error for noisy class posterior could be large due to the randomness of label noise, which would lead the transition matrix to be poorly estimated. Therefore, in this paper, we aim to solve this problem by exploiting the divide-and-conquer paradigm. Specifically, we introduce an intermediate class to avoid directly estimating the noisy class posterior. By this intermediate class, the original transition matrix can then be factorized into the product of two easy-to-estimate transition matrices. We term the proposed method the dual- estimator. Both theoretical analyses and empirical results illustrate the effectiveness of the dual- estimator for estimating transition matrices, leading to better classification performances.
1 Introduction
Deep learning algorithms rely heavily on large annotated training samples [6]. However, it is often expensive and sometimes infeasible to annotate large datasets accurately [11]. Therefore, cheap datasets with label noise have been widely employed to train deep learning models [41]. Recent results show that label noise significantly degenerates the performance of deep learning models, as deep neural networks can easily memorize and eventually fit label noise [47, 1].
Existing methods for learning with noisy labels can be divided into two categories: algorithms with statistically inconsistent or consistent classifiers. Methods in the first category usually employ heuristics to reduce the side-effects of label noise, such as extracting reliable examples [12, 43, 44, 11, 24, 30, 14], correcting labels [23, 15, 33, 29], and adding regularization [10, 9, 36, 35, 19, 18, 37]. Although those methods empirically work well, the classifiers learned from noisy data are not guaranteed to be statistically consistent. To address this limitation, algorithms in the second category have been proposed. They aim to design classifier-consistent algorithms [45, 49, 15, 20, 26, 31, 25, 8, 27, 34, 46, 21, 42, 39], where classifiers learned by exploiting noisy data will asymptotically converge to the optimal classifiers defined on the clean domain. Intuitively, when facing large-scale noisy data, models trained via classifier-consistent algorithms will approximate to the optimal models trained with clean data.
The transition matrix plays an essential role in designing statistically consistent algorithms, where and we set as the probability of the event , as the random variable of instances/features, as the variable for the noisy label, and as the variable for the clean label. The basic idea is that the clean class posterior can be inferred by using the transition matrix and noisy class posterior (which can be estimated by using noisy data). In general, the transition matrix is unidentifiable and thus hard to learn [4, 38]. Current state-of-the-art methods [11, 10, 27, 26, 25] assume that the transition matrix is class-dependent and instance-independent, i.e., . Given anchor points (the data points that belong to a specific class almost surely), the class-dependent and instance-independent transition matrix is identifiable [20, 31], and it could be estimated by exploiting the noisy class posterior of anchor points [20, 27, 46] (more details can be found in Section 2). In this paper, we will focus on learning the class-dependent and instance-independent transition matrix which can be used to improve the classification accuracy of the current methods if the matrix is learned more accurately.
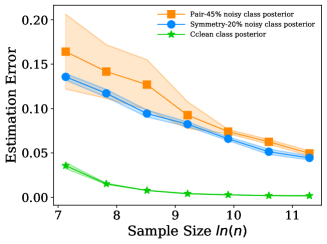
The estimation error for the noisy class posterior is usually much larger than that of the clean class posterior, especially when the sample size is limited. An illustrative example is in Fig. 1. The rationale is that label noise are randomly generated according to a class-dependent transition matrix. Specifically, to learn the noisy class posterior, we need to fit the mapping from instances to (latent) clean labels, as well as the mapping from clean labels to noisy labels. Since the latter mapping is much more random and independent of instances, the learned mapping that fits label noise is prone to overfitting and thus will lead to a large estimation error for the noisy class posterior [47]. The error will also lead to a large estimation error for the transition matrix. As estimating the transition matrix is a bottleneck for designing consistent algorithms, the large estimation error will significantly degenerate the classification performance [38].
Motivated by this phenomenon, in this paper, to reduce the estimation error of the transition matrix, we propose the dual transition estimator (dual- estimator) to effectively estimate transition matrices. In a high level, by properly introducing an intermediate class, the dual- estimator avoids directly estimating the noisy class posterior, via factorizing the original transition matrix into two new transition matrices, which we denote as and . represents the transition from the clean labels to the intermediate class labels and the transition from the clean and intermediate class labels to the noisy labels. Note that although we are going to estimate two transition matrices rather than one, we are not transforming the original problem to a harder one. In philosophy, our idea belongs to the divide and conquer paradigm, i.e., decomposing a hard problem into simple sub-problems and composing the solutions of the sub-problems to solve the original problem. The two new transition matrices are easier to estimate than the original transition matrix, because we will show that (1) there is no estimation error for the transition matrix , (2) the estimation error for the transition matrix relies on predicting noisy class labels, which is much easier than learning a class posterior, as predicting labels require much less information than estimating noisy posteriors111 Because the noisy labels come from taking the argmax of the noisy posteriors, where the argmax compresses information. Thus, the noisy labels contain much less information than the noisy posterior, and predicting the noisy labels require much less information than estimating the noisy posteriors., and (3) the estimators for the two new transition matrices are easy to implement in practice. We will also theoretically prove that the two new transition matrices are easier to predict than the original transition matrix. Empirical results on several datasets and label-noise settings consistently justify the effectiveness of the dual- estimator on reducing the estimation error of transition matrices and boosting the classification performance.
The rest of the paper is organized as follows. In Section 2, we review the current transition matrix estimator that exploits anchor points. In Section 3, we introduce our method and analyze how it reduces the estimation error. Experimental results on both synthetic and real-world datasets are provided in Section 4. Finally, we conclude the paper in Section 5.
2 Estimating Transition Matrix for Label-noise Learning
Problem setup. Let be the distribution of a pair of random variables , where denotes the variable of instances, the variable of labels, the feature space, the label space, and the size of classes. In many real-world classification problems, examples independently drawn from are unavailable. Before being observed, their clean labels are randomly flipped into noisy labels because of, e.g., contamination [32]. Let be the distribution of the noisy pair , where denotes the variable of noisy labels. In label-noise learning, we only have a sample set independently drawn from . The aim is to learn a robust classifier from the noisy sample that can assign clean labels for test instances.
Transition matrix. To build statistically consistent classifiers, which will converge to the optimal classifiers defined by using clean data, we need to introduce the concept of transition matrix [25, 20, 29]. Specifically, the -th entry of the transition matrix, i.e., , represents the probability that the instance with the clean label will have a noisy label . The transition matrix has been widely studied to build statistically consistent classifiers, because the clean class posterior can be inferred by using the transition matrix and the noisy class posterior , i.e., we have . Specifically, the transition matrix has been used to modify loss functions to build risk-consistent estimators, e.g., [8, 27, 46, 38], and has been used to correct hypotheses to build classifier-consistent algorithms, e.g., [25, 31, 27]. Moreover, the state-of-the-art statically inconsistent algorithms [14, 11] also use diagonal entries of the transition matrix to help select reliable examples used for training.
As the noisy class posterior can be estimated by exploiting the noisy training data, the key step remains how to effectively estimate the transition matrix. Given only noisy data, the transition matrix is unidentifiable without any knowledge on the clean label [38]. Specifically, the transition matrix can be decomposed to product of two new transition matrices, i.e., , and a different clean class posterior can be obtained by composing with , i.e., . Therefore, are both valid decompositions. The current state-of-the-art methods [11, 10, 27, 26, 25] then studied a special case by assuming that the transition matrix is class-dependent and instance-independent, i.e., . Note that there are specific settings [7, 22, 2] where noise is independent of instances. A series of assumptions [20, 31, 28] were further proposed to identify or efficiently estimate the transition matrix by only exploiting noisy data. In this paper, we focus on estimating the class-dependent and instance-independent transition matrix which is focused by vast majority of current state-of-the-art label-noise learning algorithms [11, 10, 27, 26, 25, 14, 11]. The estimated matrix by using our method then can be seamlessly embedded into these algorithms, and the classification accuracy of the algorithms can be improved, if the transition matrix is estimated more accurate.
Transition matrix estimation. The anchor point assumption [20, 31, 38] is a widely adopted assumption to estimate the transition matrix. Anchor points are defined in the clean data domain. Formally, an instance is an anchor point of the -th clean class if [20, 38]. Suppose we can assess to the the noisy class posterior and anchor points, the transition matrix can be obtained via , where the second equation holds because when and otherwise. The last equation holds because the transition matrix is independent of the instance. According to the Equation, to estimate the transition matrix, we need to find anchor points and estimate the noisy class posterior, then the transition matrix can be estimated as follows,
| (1) |
This estimation method has been widely used [20, 27, 38] in label-noise learning and we term it the transition estimator ( estimator).
Note that some methods assume anchor points have already been given [46]. However, this assumption could be strong for applications, where anchor points are hard to identify. It has been proven that anchor points can be learned from noisy data [20], i.e., , which only holds for binary classification. The same estimator has also been employed for multi-class classification [27]. It empirically performs well but lacks theoretical guarantee. How to identify anchor points in the multi-class classification problem with theoretical guarantee remains an unsolved problem.
Eq. (1) and the above discussions on learning anchor points show that the estimator relies heavily on the estimation of the noisy class posterior. Unfortunately, due to the randomness of label noise, the estimation error of the noisy class posterior is usually large. As the example illustrated in Fig. 1, with the same number of training examples, the estimation error of the noisy class posterior is significantly larger than that of the clean class posterior. This motivates us to seek for an alternative estimator that avoids directly using the estimated noisy class posterior to approximate the transition matrix.
3 Reducing Estimation Error for Transition Matrix
To avoid directly using the estimated noisy class posterior to approximate the transition matrix, we propose a new estimator in this section.
3.1 dual- estimator
By introducing an intermediate class, the transition matrix can be factorized in the following way:
| (2) |
where represent the random variable for the introduced intermediate class, , and . Note that and are two transition matrices representing the transition from the clean and intermediate class labels to the noisy class labels and transition from the clean labels to the intermediate class labels, respectively.
By looking at Eq. (2), it seems we have changed an easy problem into a hard one. However, this is totally not true. Actually, we break down a problem into simple sub-problems. Combining the solutions to the sub-problems gives a solution to the original problem. Thus, in philosophy, our idea belongs to the divide and conquer paradigm. In the rest of this subsection, we will explain why it is easy to estimate the transition matrices and . Moreover, in the next subsection, we will theoretically compare the estimation error of the dual- estimator with that of the estimator.
It can be found that has a similar form to . We can employ the same method that is developed for , i.e., the estimator, to estimate . However, there seems to have two challenges: (1) it looks as if difficult to access ; (2) we may also have an error for estimating . Fortunately, these two challenges can be well addressed by properly introducing the intermediate class. Specifically, we design the intermediate class in such a way that , where represents an estimated noisy class posterior. Note that can be obtained by exploiting the noisy data at hand. As we have discussed, due to the randomness of label noise, estimating directly will have a large estimation error especially when the noisy training sample size is limited. However, as we have access to directly, according to Eq. (1), the estimation error for is zero if anchor points are given222If the anchor points are to learn, the estimation error remains unchanged for the estimator and dual- estimator by employing ..
Although the transition matrix contains three variables, i.e., the clean class, intermediate class, and noisy class, we have class labels available for two of them, i.e., the intermediate class and noisy class. Note that the intermediate class labels can be assigned by using . Usually, the clean class labels are not available. This motivates us to find a way to eliminate the dependence on clean class for . From an information-theoretic point of view [5], if the clean class is less informative for the noisy class than the intermediate class , in other words, given , contains no more information for predicting , then is independent of conditioned on , i.e.,
| (3) |
A sufficient condition for holding the above equalities is to let the intermediate class labels be identical to noisy labels. Note that it is hard to find an intermediate class whose labels are identical to noisy labels. The mismatch will be the main factor that contributes to the estimation error for . Note also that since we have labels for the noisy class and intermediate class, in Eq. (3) is easy to estimate by just counting the discrete labels, and it will have a small estimation error which converges to zero exponentially fast [3].
Based on the above discussion, by factorizing the transition matrix into and , we can change the problem of estimating the noisy class posterior into the problem of fitting the noisy labels. Note that the noisy class posterior is in the range of while the noisy class labels are in the set . Intuitively, learning the class labels are much easier than learning the class posteriors. In Section 4, our empirical experiments on synthetic and real-world datasets further justify this by showing a significant error gap between the estimation error of the estimator and dual- estimator.
Implementation of the dual- estimator. The dual- estimator is described in Algorithm 1. Specifically, the transition matrix can be easily estimated by letting and then employing the estimator (see Section 2). By generating intermediate class labels, e.g., letting be the label for the instance , the transition matrix can be estimating via counting, i.e.,
| (4) |
where is an indicator function which equals one when holds true and zero otherwise, are examples from the training sample , and represents the AND operation.
Many statistically consistent algorithms [8, 27, 46, 38] consist of a two-step training procedure. The first step estimates the transition matrix and the second step builds statistically consistent algorithms, for example, via modifying loss functions. Our proposed dual- estimator can be seamlessly embedded into their frameworks. More details can be found in Section 4.
3.2 Theoretical Analysis
In this subsection, we will justify that the estimation error could be greatly reduced if we estimate and rather than estimating directly.
As we have discussed before, the estimation error of the estimator is caused by estimating the noisy class posterior; the estimation error of the dual- estimator comes from the estimation error of , i.e., fitting the noisy class labels and estimating by counting discrete labels. Note that to eliminate the dependence on the clean label for , we need to achieve . Let the estimation error for the noisy class posterior be , i.e., . Let the estimation error for by counting discrete labels is , i.e., . Let the estimation error for fitting the noisy class labels is , i.e., . We will show that under the following assumption, the estimation error of the dual- estimator is smaller than the estimation error the estimator.
Assumption 1.
For all , .
Assumption 1 is easy to hold. Theoretically, the error involves no predefined hypothesis space, and the probability that is larger than any positive number will converge to zero exponentially fast [3]. Thus, is usually much smaller than and . We therefore focus on comparing with by ignoring . Note that when , we have ; when , we have . Intuitively, the error is smaller than because it is easy to obtain a small estimation error for fitting noisy class labels than that for estimating noisy class posteriors. We note that the noisy class posterior is in the continuous range of while the noisy class labels are in the discrete set . For example, suppose we have an instance , then, as long as the empirical posterior probability is greater than , the noisy label will be accurately learned. However, the estimated error of the noisy class posterior probability can be up to . We also empirically verify the relation among these errors in Appendix 2.
Theorem 1.
Under Assumption 1, the estimation error of the dual- estimator is smaller than the estimation error the estimator.
4 Experiments
We compare the transition matrix estimator error produced by the proposed dual- estimator and the estimator on both synthetic and real-world datasets. We also compare the classification accuracy of state-of-the-art label-noise learning algorithms [20, 27, 14, 11, 38, 48, 24] obtained by using the estimator and the dual- estimator, respectively. The MNIST [17], Fashion-MINIST (or F-MINIST) [40], CIFAR10, CIFAR100 [16], and Clothing1M [41] are used in the experiments. Note that as there is no estimation error for , we do not need to do ablation study to show how the two new transition matrices contribute to the estimation error for transition matrix estimation.

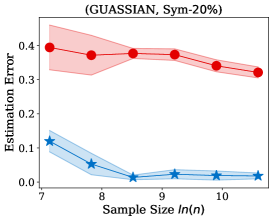
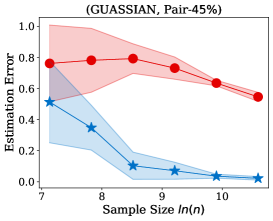
4.1 Transition Matrix Estimation
We compare the estimation error between our estimator and the estimator on both synthetic and real-world datasets with different sample size and different noise types. The synthetic dataset is created by sampling from 2 different 10-dimensional Gaussian distributions. One of the distribution has unit variance and zero mean among all dimension. Another one has unit variance and mean of two among all dimensions. The real-world image datasets used to evaluate transition matrices estimation error are MNIST [17], F-MINIST [40], CIFAR10, and CIFAR100 [16].
We conduct experiments on the commonly used noise types [11, 38]. Specifically, two representative structures of the transition matrix will be investigated: Symmetry flipping (Sym-) [27]; (2) Pair flipping (Pair-) [11]. To generate noisy datasets, we corrupt the training and validation set of each dataset according to the transition matrix .
Neural network classifiers are used to estimate transition matrices. For fair comparison, the same network structure is used for both estimators. Specifically, on the synthetic dataset, a two-hidden-layer network is used, and the hidden unit size is ; on the real-world datasets, we follow the network structures used by the state-of-the-art method [27], i.e., using a LeNet network with dropout rate for MNIST, a ResNet- network for F-MINIST and CIFAR10, a ResNet- network for CIFAR100, and a ResNet- pre-trained on ImageNet for Clothing1M. The network is trained for 100 epochs, and stochastic gradient descent (SGD) optimizer is used. The initial learning rate is , and it is decayed by a factor after -th epoch. The estimation error is calculated by measuring the -distance between the estimated transition matrix and the ground truth . The average estimation error and the standard deviation over repeated experiments for the both estimators is illustrated in Fig. 2 and 3.
It is worth mention that our methodology of anchor points estimation are different from the original paper of estimator [27]. Specifically, the original paper [27] includes a hyper-parameter to estimate anchor points for different datsets, e.g., selecting the points with and largest estimated noisy class posteriors to be anchor points on CIFAR-10 and CIFAR-100, respectively. However, clean data or prior information is needed to estimate the value of the hyper-parameter. By contrast, we assume that we only have noisy data, then it remains unclear to select the value of the hyper-parameter. In this case, from a theoretical point of view, we discard the hyper-parameter and select the points with the largest estimated intermediate class posteriors to be the anchor points for all datasets. This estimation method has been proven to be a consistent estimation of anchor points in binary case, and it also holds for multi-class classification when the noise rate is upper bounded by a constant [4]. Note that estimator [27] also selects the points with the largest estimated class posteriors to be anchor points on some datasets, which is the same as ours. Comparison on those datasets could directly justify the superiority of the proposed method. In addition, to estimate the anchor points, we need to estimate the noisy class posterior. However, deep networks are likely to overfit label noise [47, 1]. To prevent overfitting, we use training examples for validation, and the model with the best validation accuracy is selected for estimating anchor points. The anchor points are estimated on training sets.
Fig. 2 illustrates the estimation error of the estimator and the dual- estimator on the synthetic dataset. For two different noise types and sample sizes, the estimation error of the both estimation methods tend to decrease with the increasing of the training sample size. However, the estimation error of the dual- estimator is continuously smaller than that of the estimator. Moreover, the estimation error of the dual- estimator is less sensitive to different noise types compared to the estimator. Specifically, even the estimator is trained with all the training examples, its estimation error on Pair- noise is approximately doubled than that on Sym- noise, which is observed by looking at the right-hand side of the estimation error curves. In contrast, when training the dual estimator

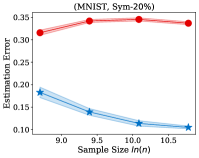
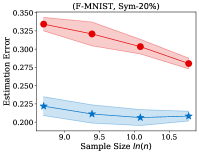
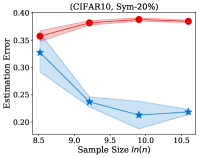
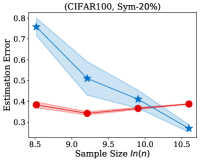
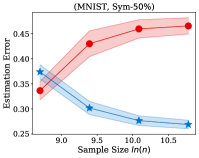
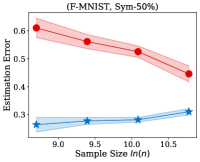
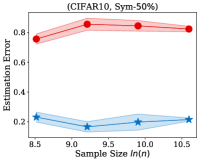
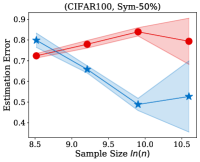
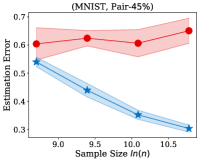
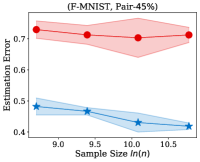
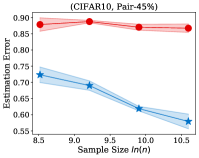
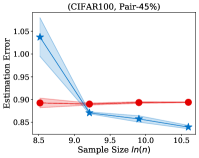
with all the training examples, its estimation error on the different noise types does not significantly different, which all less than . Similar to the results on the synthetic dataset, the experiments on the real-world image datasets illustrated in Fig. 3 also shows that the estimation error of the dual- estimator is continuously smaller than that of the estimator except CIFAR100, which illustrates the effectiveness of the proposed dual- estimator. On CIFAR100, both estimators have a larger estimation error compared to the results on MNIST, F-MINIST, and CIFAR10. The dual- estimator outperforms the estimator with the large sample size. However, when the training sample size is small, the estimation error of the dual- estimator can be larger than that of the estimator. Because the numbers of images per class are too small to estimate the transition matrix , leading to a large estimation error.
4.2 Classification Accuracy Evaluation
| MNIST | F-MNIST | |||||
| Sym-20% | Sym-50% | Pair-45% | Sym-20% | Sym-50% | Pair-45% | |
| CE | ||||||
| Mixup | ||||||
| Decoupling | ||||||
| MentorNet | ||||||
| MentorNet | ||||||
| Coteaching | ||||||
| Coteaching | ||||||
| Forward | ||||||
| Forward | ||||||
| Reweighting | ||||||
| Reweighting | ||||||
| Revision | ||||||
| Revision |
| CIFAR10 | CIAR100 | |||||
| Sym-20% | Sym-50% | Pair-45% | Sym-20% | Sym-50% | Pair-45% | |
| CE | ||||||
| Mixup | ||||||
| Decoupling | ||||||
| MentorNet | ||||||
| MentorNet | ||||||
| Coteaching | ||||||
| Coteaching | ||||||
| Forward | ||||||
| Forward | ||||||
| Reweighting | ||||||
| Reweighting | ||||||
| Revision | ||||||
| Revision |
| CE | Mixup | Decoupling | MentorNet | Coteaching | Forward | Reweighting | Revision |
|---|---|---|---|---|---|---|---|
| () | () | () | () |
We investigate how the estimation of the estimator and the dual- estimator will affect the classification accuracy in label-noise learning. The experiments are conducted on MNIST, F-MINIST, CIFAR10, CIFAR100, and Clothing1M. The classification accuracy are reported in Table 1 and Table 2. Eight popular baselines are selected for comparison, i.e., Coteaching [11], and MentorNet [14] which use diagonal entries of the transition matrix to help selecting reliable examples used for training; Forward [27], and Revision [38], which use the transition matrix to correct hypotheses; Reweighting [20], which uses the transition matrix to build risk-consistent algorithms. There are three baselines without requiring any knowledge of the transition matrix, i.e., CE, which trains a network on the noisy sample directly by using cross entropy loss; Decoupling [24], which trains two networks and updates the parameters only using the examples which have different prediction from two classifiers; Mixup [48] which reduces the memorization of corrupt labels by using linear interpolation to feature-target pairs. The estimation of the estimator and the dual- estimator are both applied to the baselines which rely on the transition matrix. The baselines using the estimation of estimator are called Coteaching, MentorNet, Forward, Revision, and Reweighting. The baselines using estimation of dual- estimator are called Coteaching, MentorNet, Forward, Revision, and Reweighting.
The settings of our experiments may be different from the original paper, thus the reported accuracy can be different. For instance, in the original paper of Coteaching [11], the noise rate is given, and all data are used for training. In contrast, we assume the noise rate is unknown and needed to be estimated. We only use data for training, since data are leaved out as the validation set for transition matrix estimation. In the original paper of revision [38], the experiments on Clothing1M use clean data for validation. In contrast, we only use noisy data for validation.
In Table 1 and Table 2, we bold the better classification accuracy produced by the baseline methods integrated with the estimator or the dual- estimator. The best classification accuracy among all the methods in each column is highlighted with . The tables show the classification accuracy of all the methods by using our estimation is better than using that of the estimator for most of the experiments. It is because that the dual- estimator leads to a smaller estimation error than the estimator when training with large sample size, which can be observed at the right-hand side of the estimation error curves in Fig. 3. The baselines with the most significant improvement by using our estimation are Coteaching and MentorNet. Coteaching outperforms all the other methods under Sym- noise. On Clothing1M dataset, revision has the best classification accuracy. The experiments on the real-world datasets not only show the effectiveness of the dual- estimator for improving the classification accuracy of the current noisy learning algorithms, but also reflect the importance of the transition matrix estimation in label-noise learning.
5 Conclusion
The transition matrix plays an important role in label-noise learning. In this paper, to avoid the large estimation error of the noisy class posterior leading to the poorly estimated transition matrix, we have proposed a new transition matrix estimator named dual- estimator. The new estimator estimates the transition matrix by exploiting the divide-and-conquer paradigm, i.e., factorizes the original transition matrix into the product of two easy-to-estimate transition matrices by introducing an intermediate class state. Both theoretical analysis and experiments on both synthetic and real-world label noise data show that our estimator reduces the estimation error of the transition matrix, which leads to a better classification accuracy for the current label-noise learning algorithms.
Broader Impact
In the era of big data, it is expensive to expert-labeling each instance on a large scale. To reduce the annotation cost of the large datasets, non-expert labelers or automated annotation methods are widely used to annotate the datasets especially for startups and non-profit organizations which need to be thrifty. However, these cheap annotation methods are likely to introduce label-noise to the datasets, which put threats to the traditional supervised learning algorithm, and label-noise learning algorithms, therefore, become more and more popular.
The transition matrix which contains knowledge of the noise rates is essential to building the classifier-consistent label-noise learning algorithms. The classification accuracy of the state-of-the-art label-noise learning applications are usually positively correlated to the estimation accuracy of the transition matrix. The proposed method is to estimate the transition matrix of noisy datasets. We have shown that our method usually leads to a better estimation compared to the current estimator and improves the classification accuracy of current label-noise learning applications. Therefore, outcomes of this research including improving the accuracy, robustness, accountability of the current label-noise learning applications, which should benefit science, society, and economy internationally. Potentially, our method may have a negative impact on the job of annotators.
Because the classification accuracy of the label-noise learning applications is usually positively correlated to the estimation accuracy of the transition matrix. Therefore, the failure of our method may lead to a degenerating of the performance of the label-noise learning applications.
The proposed method does not leverage biases in the data.
Acknowledgments
TL was supported by Australian Research Council Project DE-190101473. BH was supported by the RGC Early Career Scheme No. 22200720, NSFC Young Scientists Fund No. 62006202, HKBU Tier-1 Start-up Grant and HKBU CSD Start-up Grant. GN and MS were supported by JST AIP Acceleration Research Grant Number JPMJCR20U3, Japan. The authors thank the reviewers and the meta-reviewer for their helpful and constructive comments on this work.
References
- Arpit et al. [2017] Devansh Arpit, Stanisław Jastrzębski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, et al. A closer look at memorization in deep networks. In ICML, pages 233–242. JMLR. org, 2017.
- Bao et al. [2018] Han Bao, Gang Niu, and Masashi Sugiyama. Classification from pairwise similarity and unlabeled data. In ICML, pages 452–461, 2018.
- Boucheron et al. [2013] Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. Concentration inequalities: A nonasymptotic theory of independence. Oxford university press, 2013.
- Cheng et al. [2020] Jiacheng Cheng, Tongliang Liu, Kotagiri Ramamohanarao, and Dacheng Tao. Learning with bounded instance-and label-dependent label noise. In ICML, 2020.
- Csiszár et al. [2004] Imre Csiszár, Paul C Shields, et al. Information theory and statistics: A tutorial. Foundations and Trends® in Communications and Information Theory, 1(4):417–528, 2004.
- Daniely and Granot [2019] Amit Daniely and Elad Granot. Generalization bounds for neural networks via approximate description length. In NeurIPS, pages 12988–12996, 2019.
- Elkan and Noto [2008] Charles Elkan and Keith Noto. Learning classifiers from only positive and unlabeled data. In SIGKDD, pages 213–220, 2008.
- Goldberger and Ben-Reuven [2017] Jacob Goldberger and Ehud Ben-Reuven. Training deep neural-networks using a noise adaptation layer. In ICLR, 2017.
- Guo et al. [2018] Sheng Guo, Weilin Huang, Haozhi Zhang, Chenfan Zhuang, Dengke Dong, Matthew R Scott, and Dinglong Huang. Curriculumnet: Weakly supervised learning from large-scale web images. In ECCV, pages 135–150, 2018.
- Han et al. [2018a] Bo Han, Jiangchao Yao, Gang Niu, Mingyuan Zhou, Ivor Tsang, Ya Zhang, and Masashi Sugiyama. Masking: A new perspective of noisy supervision. In NeurIPS, pages 5836–5846, 2018a.
- Han et al. [2018b] Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In NeurIPS, pages 8527–8537, 2018b.
- Han et al. [2020] Bo Han, Gang Niu, Xingrui Yu, Quanming Yao, Miao Xu, Ivor W Tsang, and Masashi Sugiyama. Sigua: Forgetting may make learning with noisy labels more robust. ICML, 2020.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- Jiang et al. [2018] Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. MentorNet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In ICML, pages 2309–2318, 2018.
- Kremer et al. [2018] Jan Kremer, Fei Sha, and Christian Igel. Robust active label correction. In AISTATS, pages 308–316, 2018.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- LeCun et al. [2010] Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. Available: http://yann. lecun. com/exdb/mnist, 2, 2010.
- Li et al. [2020] Mingchen Li, Mahdi Soltanolkotabi, and Samet Oymak. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In AISTATS, 2020.
- Li et al. [2017] Yuncheng Li, Jianchao Yang, Yale Song, Liangliang Cao, Jiebo Luo, and Li-Jia Li. Learning from noisy labels with distillation. In ICCV, pages 1910–1918, 2017.
- Liu and Tao [2016] Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting. IEEE Transactions on pattern analysis and machine intelligence, 38(3):447–461, 2016.
- Liu and Guo [2019] Yang Liu and Hongyi Guo. Peer loss functions: Learning from noisy labels without knowing noise rates. arXiv preprint arXiv:1910.03231, 2019.
- Lu et al. [2018] Nan Lu, Gang Niu, Aditya Krishna Menon, and Masashi Sugiyama. On the minimal supervision for training any binary classifier from only unlabeled data. In ICLR, 2018.
- Ma et al. [2018] Xingjun Ma, Yisen Wang, Michael E Houle, Shuo Zhou, Sarah M Erfani, Shu-Tao Xia, Sudanthi Wijewickrema, and James Bailey. Dimensionality-driven learning with noisy labels. In ICML, pages 3361–3370, 2018.
- Malach and Shalev-Shwartz [2017] Eran Malach and Shai Shalev-Shwartz. Decoupling" when to update" from" how to update". In NeurIPS, pages 960–970, 2017.
- Natarajan et al. [2013] Nagarajan Natarajan, Inderjit S Dhillon, Pradeep K Ravikumar, and Ambuj Tewari. Learning with noisy labels. In NeurIPS, pages 1196–1204, 2013.
- Northcutt et al. [2017] Curtis G Northcutt, Tailin Wu, and Isaac L Chuang. Learning with confident examples: Rank pruning for robust classification with noisy labels. In UAI, 2017.
- Patrini et al. [2017] Giorgio Patrini, Alessandro Rozza, Aditya Krishna Menon, Richard Nock, and Lizhen Qu. Making deep neural networks robust to label noise: A loss correction approach. In CVPR, pages 1944–1952, 2017.
- Ramaswamy et al. [2016] Harish Ramaswamy, Clayton Scott, and Ambuj Tewari. Mixture proportion estimation via kernel embeddings of distributions. In ICML, pages 2052–2060, 2016.
- Reed et al. [2014] Scott E Reed, Honglak Lee, Dragomir Anguelov, Christian Szegedy, Dumitru Erhan, and Andrew Rabinovich. Training deep neural networks on noisy labels with bootstrapping. CoRR, 2014.
- Ren et al. [2018] Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In ICML, pages 4331–4340, 2018.
- Scott [2015] Clayton Scott. A rate of convergence for mixture proportion estimation, with application to learning from noisy labels. In Artificial Intelligence and Statistics, pages 838–846, 2015.
- Scott et al. [2013] Clayton Scott, Gilles Blanchard, and Gregory Handy. Classification with asymmetric label noise: Consistency and maximal denoising. In Conference On Learning Theory, pages 489–511, 2013.
- Tanaka et al. [2018] Daiki Tanaka, Daiki Ikami, Toshihiko Yamasaki, and Kiyoharu Aizawa. Joint optimization framework for learning with noisy labels. In CVPR, pages 5552–5560, 2018.
- Thekumparampil et al. [2018] Kiran K Thekumparampil, Ashish Khetan, Zinan Lin, and Sewoong Oh. Robustness of conditional gans to noisy labels. In NeurIPS, pages 10271–10282, 2018.
- Vahdat [2017] Arash Vahdat. Toward robustness against label noise in training deep discriminative neural networks. In NeurIPS, pages 5596–5605, 2017.
- Veit et al. [2017] Andreas Veit, Neil Alldrin, Gal Chechik, Ivan Krasin, Abhinav Gupta, and Serge Belongie. Learning from noisy large-scale datasets with minimal supervision. In CVPR, pages 839–847, 2017.
- Wu et al. [2020] Songhua Wu, Xiaobo Xia, Tongliang Liu, Bo Han, Mingming Gong, Nannan Wang, Haifeng Liu, and Gang Niu. Class2simi: A new perspective on learning with label noise. arXiv preprint arXiv:2006.07831, 2020.
- Xia et al. [2019] Xiaobo Xia, Tongliang Liu, Nannan Wang, Bo Han, Chen Gong, Gang Niu, and Masashi Sugiyama. Are anchor points really indispensable in label-noise learning? In NeurIPS, pages 6835–6846, 2019.
- Xia et al. [2020] Xiaobo Xia, Tongliang Liu, Bo Han, Nannan Wang, Mingming Gong, Haifeng Liu, Gang Niu, Dacheng Tao, and Masashi Sugiyama. Parts-dependent label noise: Towards instance-dependent label noise. In NeurIPS, 2020.
- Xiao et al. [2017] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- Xiao et al. [2015] Tong Xiao, Tian Xia, Yi Yang, Chang Huang, and Xiaogang Wang. Learning from massive noisy labeled data for image classification. In CVPR, pages 2691–2699, 2015.
- Xu et al. [2019] Yilun Xu, Peng Cao, Yuqing Kong, and Yizhou Wang. L_dmi: A novel information-theoretic loss function for training deep nets robust to label noise. In NeurIPS, pages 6222–6233, 2019.
- Yao et al. [2020] Quanming Yao, Hansi Yang, Bo Han, Gang Niu, and J Kwok. Searching to exploit memorization effect in learning with noisy labels. In Proceedings of the 37th International Conference on Machine Learning, ICML, volume 20, 2020.
- Yu et al. [2019] Xingrui Yu, Bo Han, Jiangchao Yao, Gang Niu, Ivor W Tsang, and Masashi Sugiyama. How does disagreement help generalization against label corruption? ICML, 2019.
- Yu et al. [2017] Xiyu Yu, Tongliang Liu, Mingming Gong, Kun Zhang, Kayhan Batmanghelich, and Dacheng Tao. Transfer learning with label noise. arXiv preprint arXiv:1707.09724, 2017.
- Yu et al. [2018] Xiyu Yu, Tongliang Liu, Mingming Gong, and Dacheng Tao. Learning with biased complementary labels. In ECCV, pages 68–83, 2018.
- Zhang et al. [2017] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. In ICLR, 2017.
- Zhang et al. [2018] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. In ICLR, 2018.
- Zhang and Sabuncu [2018] Zhilu Zhang and Mert Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In NeurIPS, pages 8778–8788, 2018.
Appendix
Proof of Theorem 1
Proof.
According to Eq. (1) in the main paper, the estimation error for the estimator is
| (5) |
As we have assumed, for all instance , for all ,
| (6) |
Then, we have
| (7) |
The estimation error for the -the entry of the dual- estimator is
| (8) | |||
where the first equation holds because there is no estimation error for the transition matrix denoting the transition from the clean class to the intermediate class (as we have discussed in Section 3.1). The estimation error for the dual- estimator comes from the estimation error for fitting the noisy class labels (to eliminate the dependence on the clean label) and the estimation error for by counting discrete labels.
We have assumed that the estimation error for is , i.e., . Note that, to eliminate the dependence on the clean label for , a sufficient condition is to let the intermediate class labels and the noisy labels be identical. If they are not identical, an error might be introduced, i.e., . We have
Hence, the estimation error of is
| (9) |
Therefore, under Assumption 1 in the main paper, the estimation error of the dual- estimator is smaller than the estimation error the estimator. ∎
Empirical Validation of Assumption 1
We empirically verify the relations among the three different errors in Assumption 1 on different type of classifiers. Note that is the estimation error for the noisy class posterior, i.e., ; is the estimation error for counting discrete labels, i.e., ; is the estimation error for fitting the noisy class labels, i.e., .
The experiments are conducted on the synthetic dataset, and setting is same as those of the synthetic experiments in Section . The three errors are calculated on the training set, since both the estimator and the dual- estimator estimates the transition matrix on the training set. We employ a -layer neural network with short cut connection [13] for feature extraction. Then the extracted features are passed to a linear classifier by employing cross entropy loss and a logistic regression classifier by employing logistics loss, respectively.
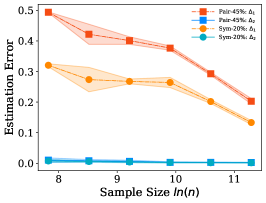
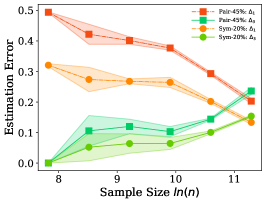
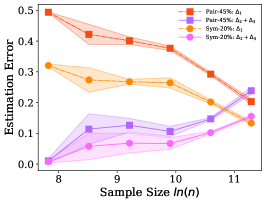
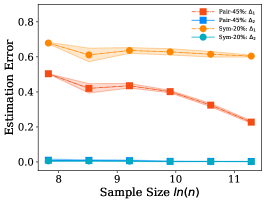
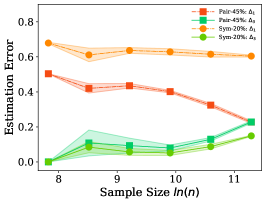
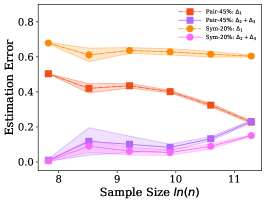
Both Figure 4 and Figure 5 show that the error is very small and can be ignored. is continuously smaller than when the sample size is small. The recent work [6] shows that the sample complex of the network is linear in the number of parameters, which means that, usually, we may not have enough training examples to learn the noisy class posterior well (e.g., CIFAR10, CIFAR100, and Fashion-MNIST), and Assumption 1 can be easily satisfied. It is also worth to mention that, even Assumption 1 does not hold, the estimation error of the dual- estimator may also be smaller than the estimator. Specifically, the error of the proposed estimator is upper bounded by . Generally, the increasing of the upper bound does not imply the increasing of the error . Figure 4 and Figure 5 also show that different types of the classifiers have different capabilities to fit the noisy labels. Specifically, the linear classifier has smaller error on pair flipping compared to that on symmetry flipping , by contrast, the logistic regression classifier has larger error on pair flipping compared to that on symmetry flipping .