Dynamic Multi-Person Mesh Recovery From Uncalibrated Multi-View Cameras
Abstract
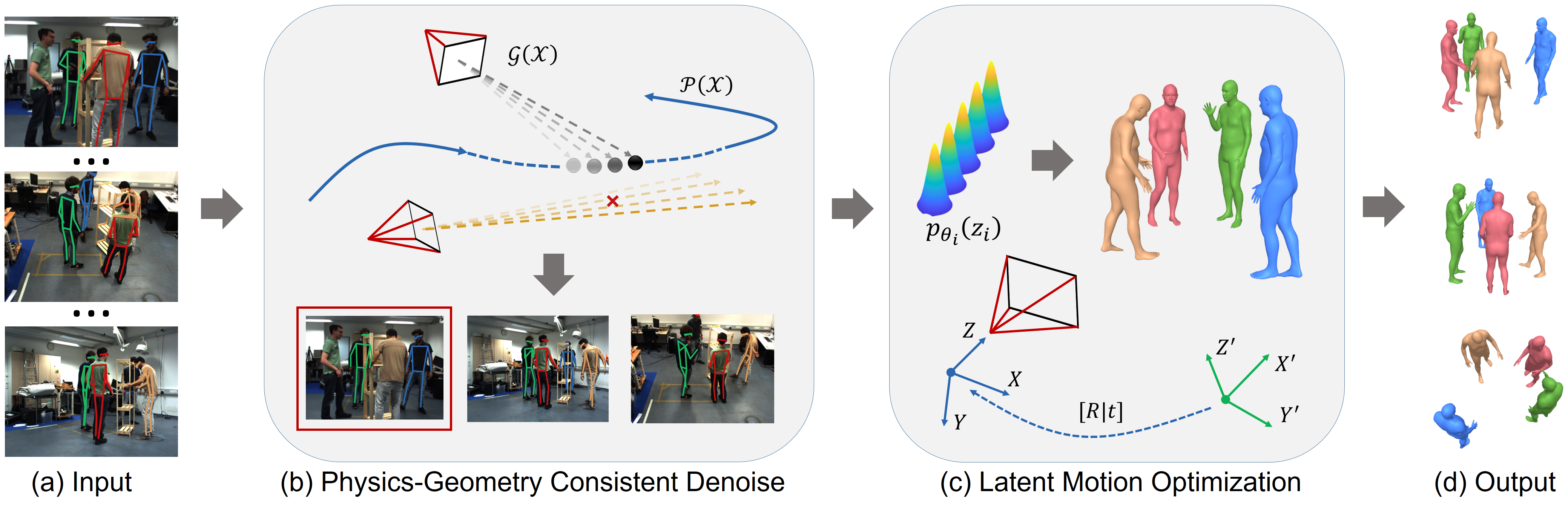
Dynamic multi-person mesh recovery has been a hot topic in 3D vision recently. However, few works focus on the multi-person motion capture from uncalibrated cameras, which mainly faces two challenges: the one is that inter-person interactions and occlusions introduce inherent ambiguities for both camera calibration and motion capture; The other is that a lack of dense correspondences can be used to constrain sparse camera geometries in a dynamic multi-person scene. Our key idea is incorporating motion prior knowledge into simultaneous optimization of extrinsic camera parameters and human meshes from noisy human semantics. First, we introduce a physics-geometry consistency to reduce the low and high frequency noises of the detected human semantics. Then a novel latent motion prior is proposed to simultaneously optimize extrinsic camera parameters and coherent human motions from slightly noisy inputs. Experimental results show that accurate camera parameters and human motions can be obtained through one-stage optimization. The codes will be publicly available at https://www.yangangwang.com.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f86f2d3e-0610-4363-91cb-e6c5a1ce4958/x1.png)
1 Introduction
Recovering multiple human motions from video is essential for many applications, such as social behavior understanding, sports broadcasting, virtual reality applications, etc. Numerous previous works have been aimed at capturing multi-person motions from multi-view input via geometry constraints [2, 16, 9, 38, 62, 29] or optimization-based model fitting [61, 35, 40, 34, 59]. While these works have made remarkable advances in multi-person motion capture, they all rely on accurate calibrated cameras to build view-view and model-view consistency. Few works focus on multi-person motion capture from uncalibrated cameras. [47] constructs a two-stage framework that first calibrates the camera using the static geometry from the background and then generates 3D human models from dynamic object reconstruction and segmentations. [17] utilizes the similarity of the estimated 3D poses in each view to find pose pairs and refines them in the global coordinate system. However, these methods require a large space distance among the target people and can not capture interactive human bodies.
In this paper, we address the problem of directly recovering multiple human bodies with unknown extrinsic camera parameters. There are two main challenges. The first one is that inter-person interactions and occlusions introduce inherent ambiguities for both camera calibration and motion reconstruction. The ambiguous low-level visual features lead to severe low and high frequency noises in detected human semantics (e.g., 2D pose [3], appearance [35]), which causes extreme difficulty in establishing view-view and model-view consistency. The other is that a lack of sufficient local image features (e.g., SIFT [43]) can be used to constrain sparse camera geometries in a dynamic multi-person scene.
To tackle the obstacles, our key-idea is to use motion prior knowledge to assist the simultaneous recovery of camera parameters and dynamic human meshes from noisy human semantics. We introduce a physics-geometry consistency to reduce the low and high-frequency noises of the detected multi-person semantics. Then a latent motion prior is proposed to recover multiple human motions with extrinsic camera parameters from partial and slightly noisy multi-person 2D poses. As shown in Fig.2, the multi-view 2D poses from off-the-shelf 2D pose detection [18, 7] and tracking [66] contain high-frequency 2D joint jitter and low-frequency identity error. Without proper camera parameters, we can not filter out the noises by epipolar constraint [2, 9]. However, we found that the triangulated skeleton joint trajectories are continuous, even though the camera parameters are inaccurate. Based on this observation, we propose a physics-geometry consistency and construct a convex optimization to combine kinetic energy prior and epipolar constraint to reduce the high and low frequency noises.
Simultaneously optimizing extrinsic camera parameters and multi-person motions from the filtered and slightly noisy 2D poses is a highly non-convex problem. We then introduce a compact latent motion prior to jointly recover temporal coherent human motions and accurate camera parameters. We adopt a variational autoencoder [30] (VAE) architecture for our motion prior. Different from existing VAE-based motion models [41, 44, 39], we use bidirectional GRU [10] as backbone and design a latent space both considering local kinematics and global dynamics. Therefore, our latent prior can be trained on a limited amount of short motion clips [45] and be used to optimize long sequences. While the motion prior can generate diverse and temporal coherent motions, it is not robust to noises in motion optimization. We found that linearly interpolating the latent code of VPoser [48] will produce consecutive poses. Inspired by this, we propose a local linear constraint on motion latent code in model training and optimization. This constraint ensures motion prior to produce coherent motions from noisy input. In addition, to keep local kinematics, a skip-connection between explicit human motion and latent motion code is incorporated in the model. Using the noisy 2D poses as constraints, we can recover human motions and camera parameters by simultaneously optimizing the latent code and cameras.
The main contributions of this work are summarized as follows.
-
•
We propose a framework that directly recovers multi-person human motions with accurate extrinsic camera parameters from sparse multi-view cameras.
-
•
We propose a physics-geometry consistency to reduce the notorious low and high frequency noises in detected human semantics.
-
•
We propose a human motion prior that contains both local kinematics and global dynamics, which can be trained on limited short motion clips and be used to optimize temporal coherent long sequences.
2 Related Work
Multi-view Human pose and shape estimation. Reconstructing human pose and shape from multi-view inputs has been a long-standing problem in 3D vision. [40] reconstructs interactive multi-person with manually specified masks. To avoid manual operations, the color [46, 59], appearance [35], location [34] and other cues of human are utilized to build the spatio-temporal correspondences, thus realizing optimization-based model fitting. In contrast, [2, 3, 38, 62, 6, 29] firstly establish view-view correspondences via detected 2D poses and geometric constraints and then reconstruct through triangulation or optimization. [16] considers geometric and appearance constraints simultaneously. However, these methods all rely on accurate camera parameters. Besides, 2D poses and appearance can be easily affected by partial occlusion, which is very common in multi-person interaction sceneries.
To recover multiple human meshes from uncalibrated cameras, [47] first calibrates the camera using the static geometry from the background and then generates 3D human models from dynamic object reconstruction. [17] realizes reconstruction via the similarity of the detected 3D poses from different views. However, these methods require a large space distance among the target people and can not capture interactive human bodies.
Extrinsic camera calibration. Conventional camera calibration methods rely on specific tools (e.g., checkerboard[63] and one-dimensional objects[64]). Except for the complex calibration process, it leads to two separate stages for calibration and reconstruction. [26, 47, 69] propose more convenient methods that directly use image features from static background (e.g., SIFT [43]) to calibrate the camera. However, the dynamic human bodies occupy the most proportion of the image pixels in multi-person scenarios. To handle this obstacle, [50, 12, 8, 50, 13] obtain structure cues and estimate camera parameters from the semantics of the scene (e.g., lines of the basketball court). [24, 55] estimate the extrinsic camera parameters from the tracked human trajectories in more general multi-person scenes. [52, 4, 5] extract frontier points of the silhouette and recover epipolar geometry by using points between different perspectives. Nevertheless, getting accurate human segmentations from in-the-wild images itself is a challenging problem. [15] realizes camera calibration by using the depth camera in an indoor scene to extract the skeleton. [49, 20, 54] and [21] use detected human 2D joints and mesh respectively to calibrate the camera, further simplifying the calibration device. State-of-the-art 2D/3D pose estimation frameworks [18, 7, 32] can hardly get accurate 2D/3D keypoints in multi-person scenes, and such methods cannot be directly applied to multi-person cases. To reduce the ambiguities generated by human interactions and occlusions, we propose a physics-geometry consistent denoising framework and a robust latent motion prior to remove the noises, realizing multi-person reconstruction and extrinsic camera calibration in an end-to-end way.
Motion prior. Traditional marker-less motion capture relies on massive views to provide sufficient visual cues [29, 57, 14]. To reconstruct from sparse cameras, [67, 35] employ the euclidean distance of poses in adjacent frames as the regularization term, which may limit the dynamics of the reconstructed motions. Thus, applying strong and compact motion prior in motion capture has attracted wide attention. The simple and feasible motion priors (e.g., Principal Component Analysis [51], Low-dimensional Non-linear Manifolds [27, 19]) lack expressiveness and are not robust to noises. Historically, Gaussian Process Latent Variable Model (GPLVM) [33, 60, 37, 36] succeed in modeling human motions [58, 56] since it takes uncertainties into account, but is difficult to make a smooth transition among mixture models. [25] uses low-dimensional Discrete Cosine Transform (DCT) basis [1] as the temporal prior to capture human motions. With the development of deep learning, VIBE [31] trains a discriminator to determine the quality of motion, but one-dimensional variables can hardly describe dynamics. [41] and [44, 65] train VAEs based on Temporal Convolutional Networks(TCN) and Recurrent Neural Network(RNN) respectively and represent motion with latent code. However, both of these two methods use latent code in a fixed dimension, which is not suitable for dealing with sequences of varying lengths. [39] constructs a conditional variational autoencoder (cVAE) to represent motions of the two adjacent frames. Although this structure solves the problem of sequence length variation, it can only model sequence information of the past, which is not suitable for optimizing the whole sequence.
In this paper, we propose a motion prior that contains local kinematics and global dynamics of the motion. The structure of the model makes it is suitable for large-scale variable-length sequence optimization.
3 Method
Our goal is to recover both multi-person motions and extrinsic camera parameters simultaneously from multi-view videos. Firstly, we propose a physics-geometry consistency to reduce the high and low frequency noises in the detected human semantics (Sec.3.2). Then, we introduce a robust latent motion prior (Sec.3.3), which contains human dynamics and kinematics, to assist estimation from noisy inputs. Finally, with the trained motion prior, we design an optimization framework to recover accurate extrinsic camera parameters and human motions from multi-view uncalibrated videos (Sec.3.4).
3.1 Preliminaries
Human motion representation. We adopt SMPL [42] to represent human motion, which consists of the shape , pose and translation . To generally learn human dynamics and kinematics from training data, we separate global rotation , translation and human shape when constructing the motion prior. Moreover, we use the more appropriate continuous 6D rotation representation [68] for the prior. Finally, a motion that contains frames is represented as .
2D pose detection and camera initialization. We first use off-the-shelf 2D pose estimation [18] and tracking framework [66] to get tracked 2D poses for each person. Then, we estimate initial camera extrinsic parameters for the denoising framework Sec.3.2. We obtain the fundamental matrix from multi-view 2D poses in the first frame using epipolar geometry with known intrinsic parameters. Then the initial extrinsic parameters can be decomposed from it. Since the 2D poses are noisy, a result selection is used to ensure robustness. The details can be found in the Sup. Mat.
3.2 Physics-geometry Consistent Denoising
Due to the inherent ambiguities in inter-person interactions and occlusions, state-of-the-art pose detection and tracking methods [18, 7, 53, 66] can hardly get the precise 2D poses with accurate identity from in-the-wild videos. The drift and jitter generated by pose detection are often high-frequency, while identity error generated by pose tracking is low-frequency. The mixture of the two types of noises is notorious in multi-person mesh recovery. To solve this obstacle, we propose a physics-geometry consistency to reduce both high and low frequency noises in 2D poses from each view.
Supposing the target person is detected in views, our goal is to remove the noisy detections that do not satisfy the physics-geometry consistency. Theoretically, despite that the camera parameters are not accurate, the triangulated skeleton joint trajectories from 2D poses with accurate identity are continuous. So we first utilize a set of optical rays, which come from the optical center of the camera and pass through corresponding 2D joint coordinates, to construct a physical constraint. For view , the ray in the plücker coordinates is represented as . Given the skeleton joint positions of the previous frame , the optical rays should be close to . We represent the distance between and the rays as:
| (1) |
The rays generated by the wrong detection will produce an out-of-range physical cost . However, with only the above physical constraint, the system may get the wrong results in inter-person occlusion cases. Consequently, we further propose an additional geometric constraint. We enforce the rays from view and view to be coplanar precisely:
| (2) |
We combine these two constraints as the physics-geometry consistency. We then follow [23] to filter out incorrect detections with the physics-geometry consistency. The physical cost and geometric cost of different views are represented in matrices and .
| (3) |
where and are physical cost and geometric cost of view and view . We use a positive semidefinite matrix to represent the correctness of correspondences among different views. Our goal is to solve , which minimizes the physics-geometry consistency cost:
| (4) |
where , are 0.7 and 0.3 in our experiment. denotes the hadamard product. Finally, we use the estimated to extract accurate detections.
The skeleton joint position of the start frame is triangulated with the queries of pose tracking [66]. We triangulate with filtered results and use it to calculate the physical consistency cost in the next frame. The filtered 2D poses will be used in Eqn.(13) to find optimal motions. More details can be found in Sup. Mat.
3.3 Latent Motion Prior
Simultaneous optimization of multi-person motions and camera parameters from slightly noisy 2D poses is a highly non-convex problem and is likely to fall into the local minima. To address this challenge, we design a compact VAE-based latent motion prior to obtain accurate and temporal coherent motions. The prior has three strengths. 1) It contains compact dynamics and kinematics to reduce computational complexity. 2) It can be trained on short motion clips and applied to long sequence fitting. 3) The latent local linear constraint ensures robustness to noisy input. The details are described as following.
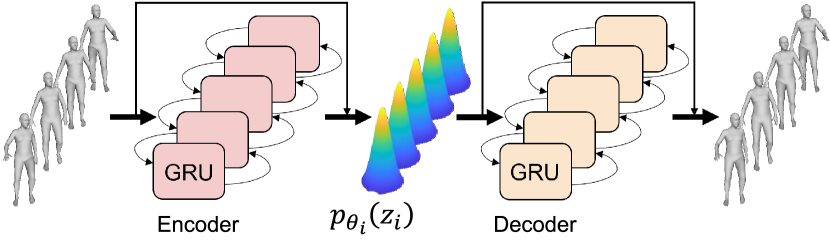
Model architecture. Our network is based on VAE [30], which shows great power in modeling motions [39, 44]. As shown in Fig.3, the encoder consists of a bidirectional GRU, a mean and variance encoding network with a skip-connection. The decoder has a symmetric network structure. Different from previous work [39], the bidirectional GRU ensures that the prior is able to see all the information from the entire sequence and that the latent code can represent global dynamics. However, the latent prior encoded only by features extracted from GRU is difficult to reconstruct accurate local fine-grained poses when used for large-scale sequence optimization. Thus, we construct a skip-connection for the encoder and decoder, respectively, allowing the latent prior to accurately capture the refined kinematic poses and the global correlation between them. Besides, we design the latent code whose frame length is corresponding to the input sequence. Thus, our prior can be trained on a limited amount of short motion clips [45] and be applied to long sequence fitting.
Training. In the training phase, a motion is fed into the encoder to generate mean and variance . The sampled latent code is then decoded to get the reconstructed motion . The reparameterization trick [30] is adopted to achieve gradient backpropagation. We train the network through maximizing the Evidence Lower Bound (ELBO):
| (5) |
The specific loss function is:
| (6) |
where and are:
| (7) |
| (8) |
where is the deformed SMPL vertices of frame . This term guarantees that the prior learns high fidelity local details.
| (9) |
which enforces its output to be near the Gaussian distribution. The regularization term, which ensures the network will not be easily overfitted:
| (10) |
Although applying the above constraints can produce diverse and temporal coherent motions, it is not robust to noisy 2D poses. The jitter and drift of 2D poses and identity error will result in an unsmooth motion. Inspired by the interpolation of VPoser [48], we add a local linear constraint to enforce a smooth transition on latent code:
| (11) |
When the motion prior is applied in long sequence fitting, the parameters of the decoder are fixed. The latent code is decoded to get the motion .
3.4 Joint Optimization of Motions and Cameras
Optimization variables. Different from traditional structure-from-motion (SFM), which lacks structural constraints between 3D points and is not robust to noisy input. We directly optimize the motion prior, so that the entire motions are under inherent kinematic and dynamic constraints. The optimization variables of views videos that contain people are . The is camera extrinsic parameter that contains rotation and translation.
Objective. We formulate the objective function as following:
| (12) |
where the data term is:
| (13) |
where is the robust Geman-McClure function [22]. , are the filtered 2D poses and its corresponding confidence. is the skeleton joint position generated by model parameters.
Besides, the regularization term is:
| (14) |
is the same as Eqn.(11). We further apply a collision term based on differentiable Signed Distance Field (SDF) [28] to prevent artifacts generated from multi-person interactions.
| (15) |
where is the distance from sampled vertex to the human mesh surface.

4 Experiments
In this section, we conduct several evaluations to demonstrate the effectiveness of our method. The comparisons in Sec.4.1 show that our method can recover multiple human bodies from uncalibrated cameras and achieves state-of-the-art. Then, we prove that the accurate extrinsic camera parameters can be obtained from joint optimization. Finally, several ablations in Sec.4.3 are conducted to evaluate key components. The details of the datasets that are used for training and testing can be found in the Sup. Mat.

|
Campus | Shelf | |||||
|---|---|---|---|---|---|---|---|
| A1 | A2 | A3 | A1 | A2 | A3 | ||
| Belagiannis et al. [2] | 82.0 | 72.4 | 73.7 | 66.1 | 65.0 | 83.2 | |
| Belagiannis et al. [3] | 93.5 | 75.7 | 85.4 | 75.3 | 69.7 | 87.6 | |
| Bridgeman et al. [6] | 91.8 | 92.7 | 93.2 | 99.7 | 92.8 | 97.7 | |
| Dong et al. [16] | 97.6 | 93.3 | 98.0 | 98.9 | 94.1 | 97.8 | |
| Chen et al. [9] | 97.1 | 94.1 | 98.6 | 99.6 | 93.2 | 97.5 | |
| Zhang et al. [62] | – | – | – | 99.0 | 96.2 | 97.6 | |
| Chu et al. [11] | 98.4 | 93.8 | 98.3 | 99.1 | 95.4 | 97.6 | |
| VPoser-t [48] | 97.3 | 93.5 | 98.4 | 99.8 | 94.1 | 97.5 | |
| Ours | 97.6 | 93.7 | 98.7 | 99.8 | 96.5 | 97.6 | |
4.1 Multi-person Motion Capture
We first conducted qualitative and quantitative comparisons on Campus and Shelf datasets. To the best of our knowledge, no method has ever recovered human meshes on these datasets. We compared several baseline methods that regress 3D poses. [2] and [3] introduce 3D pictorial structure for multi-person 3D pose estimation from multi-view images and videos respectively. [6, 16, 9, 62, 11] are recent works based on calibrated cameras. The quantitative results shown in Tab.1 demonstrate that our method achieves state-of-the-art on Campus and Shelf datasets in terms of PCP. Since only a few works target to multi-person mesh recovery task from multi-view input, we compared with EasyMocap ***https://github.com/zju3dv/EasyMocap which fits SMPL model to the 3D pose estimated by [16]. Row 2 and row 4 of Fig.4 show that [16] produces the wrong result due to partial occlusion, while our method generates accurate poses with physics-geometry consistency. Besides, our method obtains more natural and temporal coherent results even for challenging poses since the proposed motion prior provides local kinematics and global dynamics.
We then evaluated our method on MHHI dataset. [40, 34, 35] can reconstruct closely interacting multi-person meshes from multi-view input, but all these works rely on accurate calibrated camera parameters. We conducted quantitative comparisons with these methods in Tab.2. The numbers are the mean distance with standard deviation between the tracked 38 markers and its paired 3D vertices in mm. In the single-view case, since the motion prior provides additional prior knowledge, our method generates far more accurate results than [34]. In addition, the proposed approach achieves competitive results with the least views.
To further demonstrate the effectiveness of the proposed method in single-view occluded situations, we show the qualitative results on 3DOH in Fig.5. Our method can recover complete and reasonable human bodies from partial observation with the local kinematics and global dynamics in the motion prior. More qualitative and quantitative results on single-person datasets can be found in Sup. Mat.
|
1 view | 2 views | 4 views | 8 views | 12 views | |
|---|---|---|---|---|---|---|
| Liu et al. [40] | - | - | - | - | 51.67 | |
| Li et al. [34] | 1549.88 | 242.27 | 58.42 | 48.57 | 43.30 | |
| Li et al. [35] | - | 63.93 | 37.88 | 32.73 | 30.35 | |
| VPoser-t [48] | 158.33 | 60.02 | 38.46 | 32.11 | 31.48 | |
| Ours | 140.96 | 58.04 | 37.86 | 30.92 | 29.83 | |
|
Panoptic Dataset | Shelf Dataset | |||||
|---|---|---|---|---|---|---|---|
|
Ang. | Reproj. | Pos. | Ang. | Reproj. | ||
| PhotoScan | 505.02 | 35.29 | 188.18 | - | - | - | |
| initial | 3358.51 | 44.30 | 637.21 | 1532.42 | 26.86 | 79.34 | |
| w/o P-G consis. + opt cam. | 178.78 | 1.10 | 23.00 | 29.09 | 0.68 | 18.88 | |
| VPoser-t [48] + opt cam. | 118.88 | 0.64 | 22.76 | 34.30 | 0.59 | 18.83 | |
| MotionPrior + opt cam. | 101.25 | 0.59 | 22.69 | 23.18 | 0.52 | 18.70 | |

|
MHHI | Shelf | ||||
| Mean | Std | A1 | A2 | A3 | ||
| VPoser-t [48] | 31.48 | 11.54 | 99.8 | 94.1 | 97.5 | |
| w/o P-G consis. | 32.31 | 12.17 | 92.4 | 89.8 | 91.6 | |
| w/o local linear | 30.25 | 11.07 | 99.8 | 95.4 | 97.3 | |
| MotionPrior | 29.83 | 9.87 | 99.8 | 96.5 | 97.6 | |
| VPoser-t [48] + opt cam. | 43.72 | 19.57 | 97.4 | 89.7 | 89.7 | |
| w/o P-G consis.+ opt cam. | 49.34 | 24.37 | 91.5 | 86.7 | 88.6 | |
| w/o local linear + opt cam. | 35.25 | 17.07 | 97.5 | 90.4 | 93.3 | |
| MotionPrior + opt cam. | 34.44 | 10.57 | 98.4 | 91.5 | 94.4 | |

4.2 Camera Calibration Evaluation
We then qualitatively and quantitatively evaluate the estimated camera parameters. Since there exists a rigid transformation between the predicted camera parameters and the ground-truth provided in the datasets, we follow [12] to apply rigid alignment to the estimated cameras. We first compared with PhotoScan †††https://www.agisoft.com/, which is a commercial software that reconstructs 3D point clouds and cameras. As shown in Tab.3, PhotoScan fails to work for sparse inputs (Shelf dataset) since it relies on the dense correspondences between each view. We evaluate the results with position error, angle error, and re-projection error. Under relatively massive views, our method outperforms PhotoScan in all metrics. Fig.7 shows the results on Panoptic dataset with 31 views. The cameras in red and blue colors are the ground-truth and the predictions, respectively. PhotoScan only captures part of the cameras with low accuracy. On the contrary, our method successfully estimates all the cameras with complete human meshes. We then compared with the initial extrinsic parameters estimated in Sec.3.1. After joint optimization, the final results gain significant improvement. Our method achieves better performance both from massive and sparse inputs with the physics-geometry consistency and the motion prior.
4.3 Ablation Study
Physics-geometry consistency. We conducted ablation on the physics-geometry consistency to reveal its importance of removing the noises in the human semantics. Fig.6 illustrates that without the consistency, the reconstruction is unnatural due to the noisy detections. As shown in Tab.4, without the proposed consistency, the mean distance error of joint optimization increases 12.42, demonstrating its significance.
Motion prior. VPoser-t is a combination of [48] which lacks global dynamics. We first compared it to illustrate the superiority of the proposed motion prior. Tab.4 shows that the standard variance of our method on MHHI is smaller since the motion prior models the temporal information. Tab.3, Tab.4 and Fig.6 demonstrate that due to the lack of temporal constraints, VPoser-t is more sensitive to the noisy detections. The local linear constraint ensures a smooth transition between each frame of the latent code. We then removed the local linear constraint when training the motion prior. In Tab.4, without local linear constraint, although the mean distance error of joint optimization on MHHI dataset is small, the standard variance of which is large. Thus, the results prove that the constraint is effective in modeling temporal coherent motions.
5 Conclusion
This paper proposes a framework that directly recovers human motions and extrinsic camera parameters from sparse multi-view video cameras. Unlike previous work, which fails to establish view-view and model-view corresponds, we introduce a physics-geometry consistency to reduce the low and high frequency noises of the detected human semantics. In addition, we also propose a novel latent motion prior to jointly optimize camera parameters and coherent human motions from slightly noisy inputs. The proposed method simplifies the conventional multi-person mesh recovery by incorporating the calibration and reconstruction into a one-stage optimization framework.
Acknowledgments. The authors would like to thank Professor Yebin Liu and Professor Kun Li for sharing the data. This work was supported in part by National Key RD Program of China (No. 2018YFB1403900), in part by National Natural Science Foundation of China (No. 61806054), in part by Natural Science Foundation of Jiangsu Province (No. BK20180355), Young Elite Scientist Sponsorship Program by the China Association for Science and Technology and ”Zhishan Young Scholar” Program of Southeast University.
References
- [1] I. Akhter, T. Simon, S. Khan, I. Matthews, and Y. Sheikh. Bilinear spatiotemporal basis models. ACM Transactions on Graphics (TOG), 31(2):1–12, 2012.
- [2] V. Belagiannis, S. Amin, M. Andriluka, B. Schiele, N. Navab, and S. Ilic. 3d pictorial structures for multiple human pose estimation. In CVPR, 2014.
- [3] V. Belagiannis, S. Amin, M. Andriluka, B. Schiele, N. Navab, and S. Ilic. 3d pictorial structures revisited: Multiple human pose estimation. IEEE transactions on pattern analysis and machine intelligence, 38(10):1929–1942, 2015.
- [4] G. Ben-Artzi, Y. Kasten, S. Peleg, and M. Werman. Camera calibration from dynamic silhouettes using motion barcodes. In CVPR, 2016.
- [5] E. Boyer. On using silhouettes for camera calibration. In ACCV, 2006.
- [6] L. Bridgeman, M. Volino, J.-Y. Guillemaut, and A. Hilton. Multi-person 3d pose estimation and tracking in sports. In CVPR Workshops, 2019.
- [7] Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh. Openpose: realtime multi-person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence, 43(1):172–186, 2019.
- [8] J. Chen and J. J. Little. Sports camera calibration via synthetic data. In CVPR Workshops, 2019.
- [9] L. Chen, H. Ai, R. Chen, Z. Zhuang, and S. Liu. Cross-view tracking for multi-human 3d pose estimation at over 100 fps. In CVPR, 2020.
- [10] K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In EMNLP, 2014.
- [11] H. Chu, J.-H. Lee, Y.-C. Lee, C.-H. Hsu, J.-D. Li, and C.-S. Chen. Part-aware measurement for robust multi-view multi-human 3d pose estimation and tracking. In CVPR, 2021.
- [12] A. Cioppa, A. Deliège, F. Magera, S. Giancola, O. Barnich, B. Ghanem, and M. Van Droogenbroeck. Camera calibration and player localization in soccernet-v2 and investigation of their representations for action spotting. arXiv preprint arXiv:2104.09333, 2021.
- [13] L. Citraro, P. Márquez-Neila, S. Savarè, V. Jayaram, C. Dubout, F. Renaut, A. Hasfura, H. B. Shitrit, and P. Fua. Real-time camera pose estimation for sports fields. Machine Vision and Applications, 31(3):1–13, 2020.
- [14] A. Collet, M. Chuang, P. Sweeney, D. Gillett, D. Evseev, D. Calabrese, H. Hoppe, A. Kirk, and S. Sullivan. High-quality streamable free-viewpoint video. ACM Transactions on Graphics (ToG), 34(4):1–13, 2015.
- [15] K. Desai, B. Prabhakaran, and S. Raghuraman. Skeleton-based continuous extrinsic calibration of multiple rgb-d kinect cameras. In Proceedings of the 9th ACM Multimedia Systems Conference, 2018.
- [16] J. Dong, W. Jiang, Q. Huang, H. Bao, and X. Zhou. Fast and robust multi-person 3d pose estimation from multiple views. In CVPR, 2019.
- [17] S. Ershadi-Nasab, S. Kasaei, and E. Sanaei. Uncalibrated multi-view multiple humans association and 3d pose estimation by adversarial learning. Multimedia Tools and Applications, 80(2):2461–2488, 2021.
- [18] H.-S. Fang, S. Xie, Y.-W. Tai, and C. Lu. Rmpe: Regional multi-person pose estimation. In ICCV, 2017.
- [19] J. Gall, A. Yao, and L. Van Gool. 2d action recognition serves 3d human pose estimation. In ECCV, 2010.
- [20] N. Garau and N. Conci. Unsupervised continuous camera network pose estimation through human mesh recovery. In Proceedings of the 13th International Conference on Distributed Smart Cameras, 2019.
- [21] N. Garau, F. G. De Natale, and N. Conci. Fast automatic camera network calibration through human mesh recovery. Journal of Real-Time Image Processing, 17(6):1757–1768, 2020.
- [22] S. Geman. Statistical methods for tomographic image reconstruction. Bull. Int. Stat. Inst, 4:5–21, 1987.
- [23] Q.-X. Huang and L. Guibas. Consistent shape maps via semidefinite programming. In Computer Graphics Forum, volume 32, pages 177–186. Wiley Online Library, 2013.
- [24] S. Huang, X. Ying, J. Rong, Z. Shang, and H. Zha. Camera calibration from periodic motion of a pedestrian. In CVPR, 2016.
- [25] Y. Huang, F. Bogo, C. Lassner, A. Kanazawa, P. V. Gehler, J. Romero, I. Akhter, and M. J. Black. Towards accurate marker-less human shape and pose estimation over time. In 3DV, 2017.
- [26] R. Inomata, K. Terabayashi, K. Umeda, and G. Godin. Registration of 3d geometric model and color images using sift and range intensity images. In International Symposium on Visual Computing, 2011.
- [27] T. Jaeggli, E. Koller-Meier, and L. Van Gool. Learning generative models for multi-activity body pose estimation. International Journal of Computer Vision, 83(2):121–134, 2009.
- [28] W. Jiang, N. Kolotouros, G. Pavlakos, X. Zhou, and K. Daniilidis. Coherent reconstruction of multiple humans from a single image. In CVPR, 2020.
- [29] H. Joo, T. Simon, X. Li, H. Liu, L. Tan, L. Gui, S. Banerjee, T. Godisart, B. Nabbe, I. Matthews, et al. Panoptic studio: A massively multiview system for social interaction capture. IEEE transactions on pattern analysis and machine intelligence, 41(1):190–204, 2017.
- [30] D. P. Kingma and M. Welling. Auto-encoding variational bayes. In ICLR, 2014.
- [31] M. Kocabas, N. Athanasiou, and M. J. Black. Vibe: Video inference for human body pose and shape estimation. In CVPR, 2020.
- [32] N. Kolotouros, G. Pavlakos, M. J. Black, and K. Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. In ICCV, 2019.
- [33] N. Lawrence and A. Hyvärinen. Probabilistic non-linear principal component analysis with gaussian process latent variable models. Journal of machine learning research, 6(11), 2005.
- [34] K. Li, N. Jiao, Y. Liu, Y. Wang, and J. Yang. Shape and pose estimation for closely interacting persons using multi-view images. In Computer Graphics Forum, 2018.
- [35] K. Li, Y. Mao, Y. Liu, R. Shao, and Y. Liu. Full-body motion capture for multiple closely interacting persons. Graphical Models, 110:101072, 2020.
- [36] R. Li, T.-P. Tian, and S. Sclaroff. Simultaneous learning of nonlinear manifold and dynamical models for high-dimensional time series. In ICCV, 2007.
- [37] R. Li, T.-P. Tian, S. Sclaroff, and M.-H. Yang. 3d human motion tracking with a coordinated mixture of factor analyzers. International Journal of Computer Vision, 87(1-2):170, 2010.
- [38] J. Lin and G. H. Lee. Multi-view multi-person 3d pose estimation with plane sweep stereo. In CVPR, 2021.
- [39] H. Y. Ling, F. Zinno, G. Cheng, and M. Van De Panne. Character controllers using motion vaes. ACM Transactions on Graphics (TOG), 39(4):40–1, 2020.
- [40] Y. Liu, J. Gall, C. Stoll, Q. Dai, H.-P. Seidel, and C. Theobalt. Markerless motion capture of multiple characters using multiview image segmentation. IEEE transactions on pattern analysis and machine intelligence, 35(11):2720–2735, 2013.
- [41] S. Lohit, R. Anirudh, and P. Turaga. Recovering trajectories of unmarked joints in 3d human actions using latent space optimization. In WACV, 2021.
- [42] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. Smpl: A skinned multi-person linear model. ACM transactions on graphics (TOG), 34(6):1–16, 2015.
- [43] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2):91–110, 2004.
- [44] Z. Luo, S. A. Golestaneh, and K. M. Kitani. 3d human motion estimation via motion compression and refinement. In ACCV, 2020.
- [45] N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. Amass: Archive of motion capture as surface shapes. In ICCV, 2019.
- [46] J. R. Mitchelson and A. Hilton. Simultaneous pose estimation of multiple people using multiple-view cues with hierarchical sampling. In BMVC, 2003.
- [47] A. Mustafa, H. Kim, J.-Y. Guillemaut, and A. Hilton. General dynamic scene reconstruction from multiple view video. In ICCV, 2015.
- [48] G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, and M. J. Black. Expressive body capture: 3d hands, face, and body from a single image. In CVPR, 2019.
- [49] J. Puwein, L. Ballan, R. Ziegler, and M. Pollefeys. Joint camera pose estimation and 3d human pose estimation in a multi-camera setup. In ACCV, 2014.
- [50] L. Sha, J. Hobbs, P. Felsen, X. Wei, P. Lucey, and S. Ganguly. End-to-end camera calibration for broadcast videos. In CVPR, 2020.
- [51] H. Sidenbladh, M. J. Black, and D. J. Fleet. Stochastic tracking of 3d human figures using 2d image motion. In ECCV, 2000.
- [52] S. N. Sinha and M. Pollefeys. Camera network calibration and synchronization from silhouettes in archived video. International journal of computer vision, 87(3):266–283, 2010.
- [53] K. Sun, B. Xiao, D. Liu, and J. Wang. Deep high-resolution representation learning for human pose estimation. In CVPR, 2019.
- [54] K. Takahashi, D. Mikami, M. Isogawa, and H. Kimata. Human pose as calibration pattern; 3d human pose estimation with multiple unsynchronized and uncalibrated cameras. In CVPR Workshops, 2018.
- [55] Z. Tang, Y.-S. Lin, K.-H. Lee, J.-N. Hwang, and J.-H. Chuang. Esther: Joint camera self-calibration and automatic radial distortion correction from tracking of walking humans. IEEE Access, 7:10754–10766, 2019.
- [56] R. Urtasun, D. J. Fleet, and P. Fua. 3d people tracking with gaussian process dynamical models. In CVPR, 2006.
- [57] D. Vlasic, P. Peers, I. Baran, P. Debevec, J. Popović, S. Rusinkiewicz, and W. Matusik. Dynamic shape capture using multi-view photometric stereo. In SIGGRAPH Asia, 2009.
- [58] J. M. Wang, D. J. Fleet, and A. Hertzmann. Gaussian process dynamical models for human motion. IEEE transactions on pattern analysis and machine intelligence, 30(2):283–298, 2007.
- [59] C. Wu, C. Stoll, L. Valgaerts, and C. Theobalt. On-set performance capture of multiple actors with a stereo camera. ACM Transactions on Graphics (TOG), 32(6):1–11, 2013.
- [60] A. Yao, J. Gall, L. V. Gool, and R. Urtasun. Learning probabilistic non-linear latent variable models for tracking complex activities. Advances in Neural Information Processing Systems, 24:1359–1367, 2011.
- [61] G. Ye, Y. Liu, N. Hasler, X. Ji, Q. Dai, and C. Theobalt. Performance capture of interacting characters with handheld kinects. In ECCV, 2012.
- [62] Y. Zhang, L. An, T. Yu, X. Li, K. Li, and Y. Liu. 4d association graph for realtime multi-person motion capture using multiple video cameras. In CVPR, 2020.
- [63] Z. Zhang. A flexible new technique for camera calibration. IEEE Transactions on pattern analysis and machine intelligence, 22(11):1330–1334, 2000.
- [64] Z. Zhang. Camera calibration with one-dimensional objects. IEEE transactions on pattern analysis and machine intelligence, 26(7):892–899, 2004.
- [65] Z. Zhao, X. Zhao, and Y. Wang. Travelnet: Self-supervised physically plausible hand motion learning from monocular color images. In ICCV, 2021.
- [66] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang. Omni-scale feature learning for person re-identification. In ICCV, 2019.
- [67] X. Zhou, M. Zhu, G. Pavlakos, S. Leonardos, K. G. Derpanis, and K. Daniilidis. Monocap: Monocular human motion capture using a cnn coupled with a geometric prior. IEEE transactions on pattern analysis and machine intelligence, 41(4):901–914, 2018.
- [68] Y. Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. In CVPR, 2019.
- [69] D. Zou and P. Tan. Coslam: Collaborative visual slam in dynamic environments. IEEE transactions on pattern analysis and machine intelligence, 35(2):354–366, 2012.