Dynamic Structure Estimation from Bandit Feedback using Nonvanishing Exponential Sums
Abstract
This work tackles the dynamic structure estimation problems for periodically behaved discrete dynamical system in the Euclidean space. We assume the observations become sequentially available in a form of bandit feedback contaminated by a sub-Gaussian noise. Under such fairly general assumptions on the noise distribution, we carefully identify a set of recoverable information of periodic structures. Our main results are the (computation and sample) efficient algorithms that exploit asymptotic behaviors of exponential sums to effectively average out the noise effect while preventing the information to be estimated from vanishing. In particular, the novel use of the Weyl sum, a variant of exponential sums, allows us to extract spectrum information for linear systems. We provide sample complexity bounds for our algorithms, and we experimentally validate our theoretical claims on simulations of toy examples, including Cellular Automata.
1 Introduction
System identification has been of great interest in controls, economics, and statistical machine learning (cf. Tsiamis & Pappas (2019); Tsiamis et al. (2020); Lale et al. (2020); Lee (2022); Kakade et al. (2020); Ohnishi et al. (2024); Mania et al. (2022); Simchowitz & Foster (2020); Curi et al. (2020); Hazan et al. (2018); Simchowitz et al. (2019); Lee & Zhang (2020)). In particular, estimations of periodic information, including eigenstructures for linear systems, under noisy and partially observable environments, are essential to a variety of applications such as biological data analysis (e.g., Hughes et al. (2017); Sokolove & Bushell (1978); Zielinski et al. (2014); also see Furusawa & Kaneko (2012) for how gene oscillation affects differentiation of cells), earthquake analysis (e.g., Rathje et al. (1998); Sabetta & Pugliese (1996); Wolfe (2006); see Allen & Kanamori (2003) for the connections of the frequencies and magnitude of earthquakes), chemical/asteroseismic analysis (e.g., Aerts et al. (2018)), and communication and information systems (e.g., Couillet & Debbah (2011); Derevyanko et al. (2016)), just to name a few.
In this paper, we focus on the periodic structure estimation problem for nearly periodically behaved discrete dynamical systems (cf. Arnold (1998); specifically, we mainly study theoretical aspects of recovering structural information under a novel set of model assumptions. We allow systems that are not exactly periodic with sequentially available bandit feedback. Due to the presence of noise and partial observability, our problem setups do not permit the recovery of the full set of period/eigenvalues information in general; as such we particularly ask the following question: what subset of information on dynamic structures can be statistically efficiently estimated? This work successfully answers this question by identifying and mathematically defining recoverable information, and proposes algorithms for efficiently extracting such information.
The technical novelty of our approach is highlighted by the careful adoption of the asymptotic bounds on the exponential sums that effectively cancel out noise effects while preserving the information to be estimated. When the dynamics is driven by a linear system, the use of the Weyl sum Weyl (1916), a variant of exponential sums, enables us to extract more detailed information. To our knowledge, this is the first attempt of employing asymptotic results of the Weyl sum for statistical estimation problems, and further studies on the relations between statistical estimation theory and exponential sums (or even other number theoretical results) are of independent interests.
With this summary of our work in place, we present our dynamical system model below followed by a brief introduction of the properties of the exponential sums used in this work.
Dynamic structure in bandit feedback. We define as a (finite or infinite) collection of arms to be pulled. Let be a noise sequence. Let be a set of latent parameters. We assume that there exists a dynamical system on , equivalently, a map . At each time step , a learner pulls an arm and observes a reward
for some .
In other words, the hidden parameters for the rewards may vary over time but follow only a rule with initial value . The function could be viewed as the specific instance of partial observation (cf. Ljung (2010)).
Brief overview of the properties of the exponential sums used in this work. Exponential sums, also known as trigonometric sums, have developed as a significant area of study in number theory, employing various methods from analytical and algebraic number theory (see Arkhipov et al. (2004) for an overview). An exponential sum consists of a finite sum of complex numbers, each with an absolute value of one, and its absolute value can trivially be bounded by the number of terms in the sum. However, due to the cancellation among terms, nontrivial upper and lower bounds can sometimes be established. Several classes of exponential sums with such nontrivial bounds are known, and in this study, we apply bounds from a class known as Weyl sums to extract information from dynamical systems using bandit feedback. In the mathematical community, these bounds are valuable not only in themselves but also for applications in fields like analysis within mathematics (Katz, 1990). This research represents an application of these bounds in the context of machine learning (statistical learning/estimation problem) and is cast as one of the first attempts to open the applications of number theoretic results to learning theory.
In fact, even the standard results utilized in discrete Fourier transform can be leveraged, with their (non)asymptotic properties, to provably handle noisy observations to extract (nearly) periodic information. This process is illustrated in Figure 1 (the one for period estimation); where we show that one can effectively average out the noise through the exponential sum (which is denoted by in Figure 1) while preventing the correct period estimation from vanishing. By multiplying the (scalar) observations by certain exponential value, the bounds of the Weyl sum (which is denoted by in Figure 1) can be applied to guarantee the survival of desirable target eigenvalue information; this is illustrated in Figure 1 (the one for eigenstructure estimation).

Our contributions. The contributions of this work are three folds: First, we mathematically identify and define a recoverable set of periodic/eigenvalues information when the observations are available in a form of bandit feedback. The feedback is contaminated by a sub-Gaussian noise, which is more general than those usually considered in system identification work. Second, we present provably correct algorithms for efficiently estimating such information; this constitutes the first attempt of adopting asymptotic results on the Weyl sum. Lastly, we implemented our algorithms for toy and simulated examples to experimentally validate our claims.
Summary of technical contributions and challenges. Here, we showcase a summary of technical contributions and challenges to be overcome:
-
•
Exploiting the exponential sum techniques (including the discrete Fourier transform) studied in number theory community as a filtering within the context of statistical estimation problems.
-
•
Adapt the Weyl sum technique to deal with eigenvalues by extending it to matrix sum.
-
•
Defining novel mathematical concepts: (aliquot) nearly period and -distinct eigenvalues.
-
•
Concurrently applying a set of filterings to statistically identify correct periodic structure (we call this as concurrent application of filterings in Algorithm 1).
-
•
System recovery through maintenance of isomorphic structure in observation (we call it as isomorphicity maintenance lemma; see Lemma C.1).
Notations. Throughout this paper, , , , , , , and denote the set of the real numbers, the nonnegative real numbers, the natural numbers (), the positive integers, the rational numbers, the positive rational numbers, and the complex numbers, respectively. Also, for . The Euclidean norm is given by for , where stands for transposition. and are the spectral norm and Frobenius norm of a matrix respectively, and and are the image space and the null space of , respectively. If is a divisor of , it is denoted by . The floor and the ceiling of a real number is denoted by and , respectively. Finally, the least common multiple and the greatest common divisor of a set of positive integers are denoted by and , respectively.
2 Motivations
As our main body of the work is largely theoretical with a new problem formulation, this section is intended to articulate the motivations behind this work from scientific (theoretical) and practical perspectives followed by the combined aspects for our formulation.
2.1 Scientific (theoretical) motivation
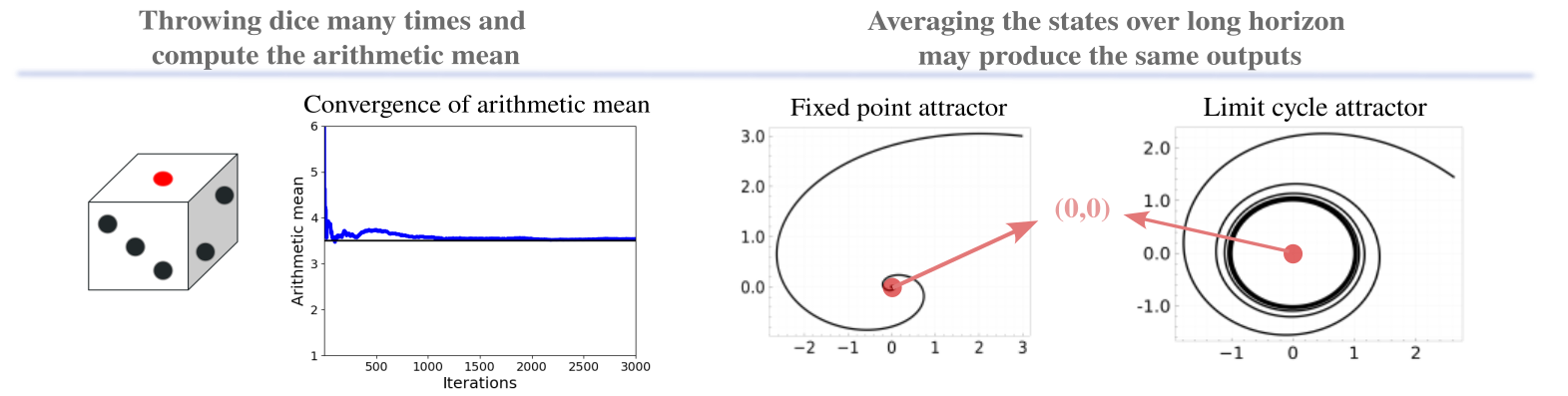
When dealing with noisy observation, it is advised to use concentrations of measure to extract the true target value by averaging out the noise effect over sufficiently many samples. On the other hand, when the samples are generated by a dynamical system, averaging over the samples will have an effect of averaging over time, which could lose some information on the evolution of dynamics.
Dynamic information recovery from noisy observation.
Consider for example a fixed point attractor and a limit cycle attractor dynamics as depicted in Figure 2; when averaging over samples generated by sufficiently long time horizon, both cases would output values that are close to which ambiguates the dynamical properties. In particular, properties of long-time average of the dynamics have been studied in ergodic theory (cf. Walters (2000)), and studying dynamical systems from both time and measure is of independent interest.
Dynamic information recovery from scalar observations.
Also, linear bandit feedback system is a special case of partially observable systems, and specifically considers scalar (noisy) observations.
For reconstruction of attractor dynamics from noiseless scalar observations, as will be mentioned in Section 3, Takens’ theorem (or delay embedding theorem; Takens (1981)) is famous, where an observation function is used to construct the embedding. It identifies the dynamical system properties that are preserved through the reconstruction as well.
If the noise is also present, the problems become extensively complicated and some attempts on the analysis have been made (Casdagli et al., 1991); which discusses the trade-off between the distortion and estimation errors.
2.2 Practical motivation
Practically, periodic information estimation is of great interest as we have mentioned in Section 1; in addition, eigenvalue estimation problems are particularly important for analyzing linear systems.
Physical constant estimation.
Some of the important linear systems include electric circuits and vibration (or oscillating) systems which are typically used to model an effect of earthquakes over buildings. Eigenvalue estimation problems in such cases reduce to the estimation of physical constants. Also, they have been studied for channel estimation (Van De Beek et al., 1995) as well.
Dynamic mode decomposition.
Attractor reconstruction.
With Takens’ theorem, obtaining dynamic structure information of attractors in a finite-dimensional space from a finite number of scalar observations is useful in practice as well; see (Bakarji et al., 2022) for an application in deep autoencoder. Our problems are not dealing with general nonlinear attractor dynamics; however, the use of exponential sums in the estimation process would become a foundation for the future applications for modeling target dynamics.
Communication capacity.
There has been an interest of studying novel paradigms for coding, transmitting, and processing information sent through optical communication systems (Turitsyn et al., 2017); when encoding information in (nearly) periodic signals to transmit, computing communication capacity that properly takes communication errors into account is of fundamental interest. If the observation is made as a mix of the outputs of multiple communication channels, the problem becomes relevant to bandit feedback as well.
Bandit feedback – single-pixel camera.
As widely studied in a context of compressed sensing (cf. Donoho (2006); Eldar & Kutyniok (2012); Candes et al. (2006)), reconstruction of the target image from the single-pixel camera (e.g., Duarte et al. (2008)) observations relies on a random observation matrix (or vector) to obtain a single pixel value for each observation. It is advantageous to concentrate light to one pixel for the cases where the light intensity is very low. Bandit feedback naturally coincides with a random observation matrix that the user can design. The observation through a random matrix coupled with compressed sensing has been studied for channel estimation, magnetic resonance imaging, visualization of black holes, and vibration analysis as well.
Bandit feedback – recommendation system.
Reward maximization problems from bandit feedback have been applied to recommendation system (e.g., Li et al. (2010)) for example, where the observations are in scalar form. Other applications of bandit problems include healthcare, dynamic pricing, dialogue systems and telecommunications. Although our problem formulation is not meant to maximize any reward, it is seamlessly connected to the bandit problems as described below.
Connection to reward maximization problems.
As we will briefly describe in Appendix E, thanks to the problem formulations in this work, one could use our estimation algorithms for downstream bandit problems (i.e., reward maximization problem with bandit feedback). A naive approach is an explore-then-commit type algorithm (cf. Robbins (1952); Anscombe (1963)) where the “explore” stage utilizes our estimation mechanism to identify the dynamics structure behind the system parameter. Devising efficient dynamic structure estimation algorithms for other types of information than the periodicity and eigenstructure under bandit feedback scenarios may also be an interesting direction of research.
2.3 Combined aspects
In our work, we essentially consider periodic (and eigenstructure) information recovery from observation data, which as mentioned is crucial in some application domains. In particular, our formulation cares about the situation where the observation is made by a bandit feedback which produces a sequence of scalar observations. We mention that the bandit feedback is essentially just a (noisy) scalar observation where (possibly random) observation vectors are selected by users.
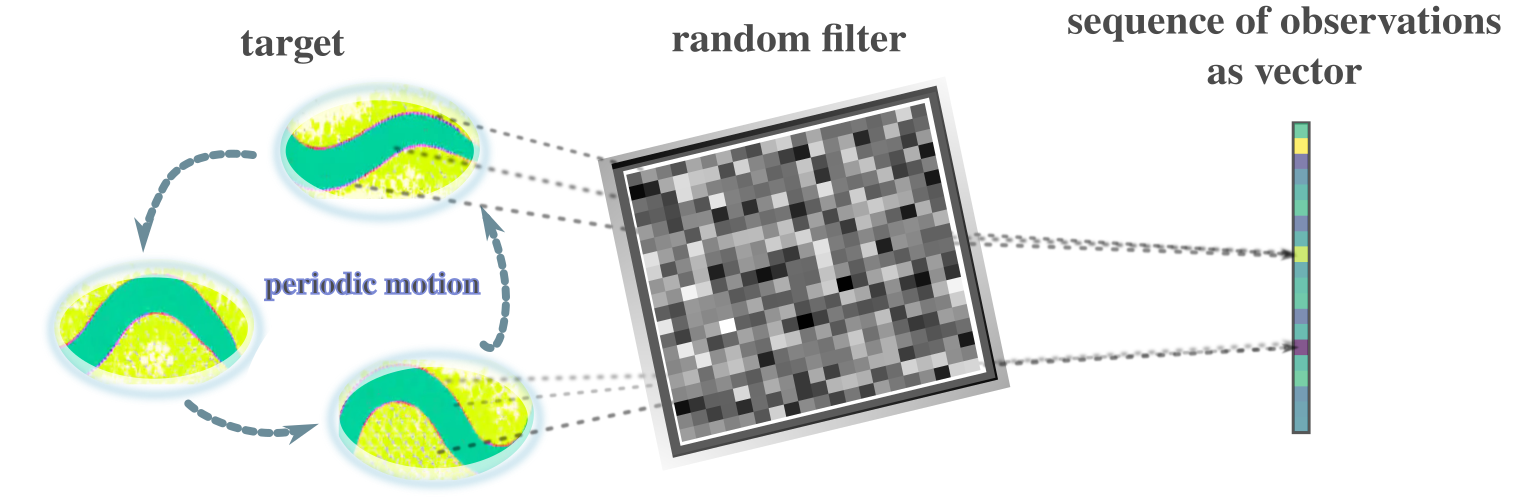
One possible example scenario in which bandit feedback and dynamic structure estimation meet is illustrated in Figure 3 where the target system has some periodicity and the noisy observation is made through a single-pixel camera equipped with a random filter to be used to determine the periodic structure of the target system.
Also, as mentioned, we emphasize again that reconstruction of dynamical systems characteristics such as their attractor dynamics through (noisy, user-selected) scalar observation is an important area of research; we believe the use of exponential sums in the reconstruction of dynamics opens up further research directions and applications in a similar manner to Takens’ theorem (see Section 3 as well).
3 Related work
As we have seen in Section 2, our broad motivation stems from the reconstruction of dynamical system information from noisy and partial observations. The most relevant lines of work to this problem are (1) that of Takens (Takens, 1981) and its extensions, and (2) system identifications for partially observed dynamical systems.
While the former studies more general nonlinear attractor dynamics from a sequence of scalar observations made by certain observation function having desirable properties, it is originally for the noiseless case. Although there exist some attempts on extending it to noisy situations (e.g., Casdagli et al. (1991)), provable estimation of some dynamic structure information with sample complexity guarantees (or nonasymptotic result) under fairly general noise case is not elaborated. On the other hand, our work may be viewed as a special instance of system identifications for partially observed dynamical systems. Existing works for sample complexity analysis of partially observed linear systems (e.g., Menda et al. (2020); Hazan et al. (2018); Simchowitz et al. (2019); Lee & Zhang (2020); Tsiamis & Pappas (2019); Tsiamis et al. (2020); Lale et al. (2020); Lee (2022); Adams et al. (2021); Bhouri & Perdikaris (2021); Ouala et al. (2020); Uy & Peherstorfer (2021); Subramanian et al. (2022); Bennett & Kallus (2021); Lee et al. (2020)) typically consider additive Gaussian noise and make controllability and/or observability assumptions (for autonomous case, transition with Gaussian noise with positive definite covariance is required). While (Mhammedi et al., 2020) considers nonlinear observation, it still assumes Gaussian noise and controllability. The work (Hazan et al., 2018) considers adversarial noise but with limited budget; we mention its wave-filtering approach is interesting and our use of exponential sums could also be viewed as filtering. Also, the work (Simchowitz et al., 2019) considers control inputs and bounded semi-adversarial noise, which is another set of strong assumptions.
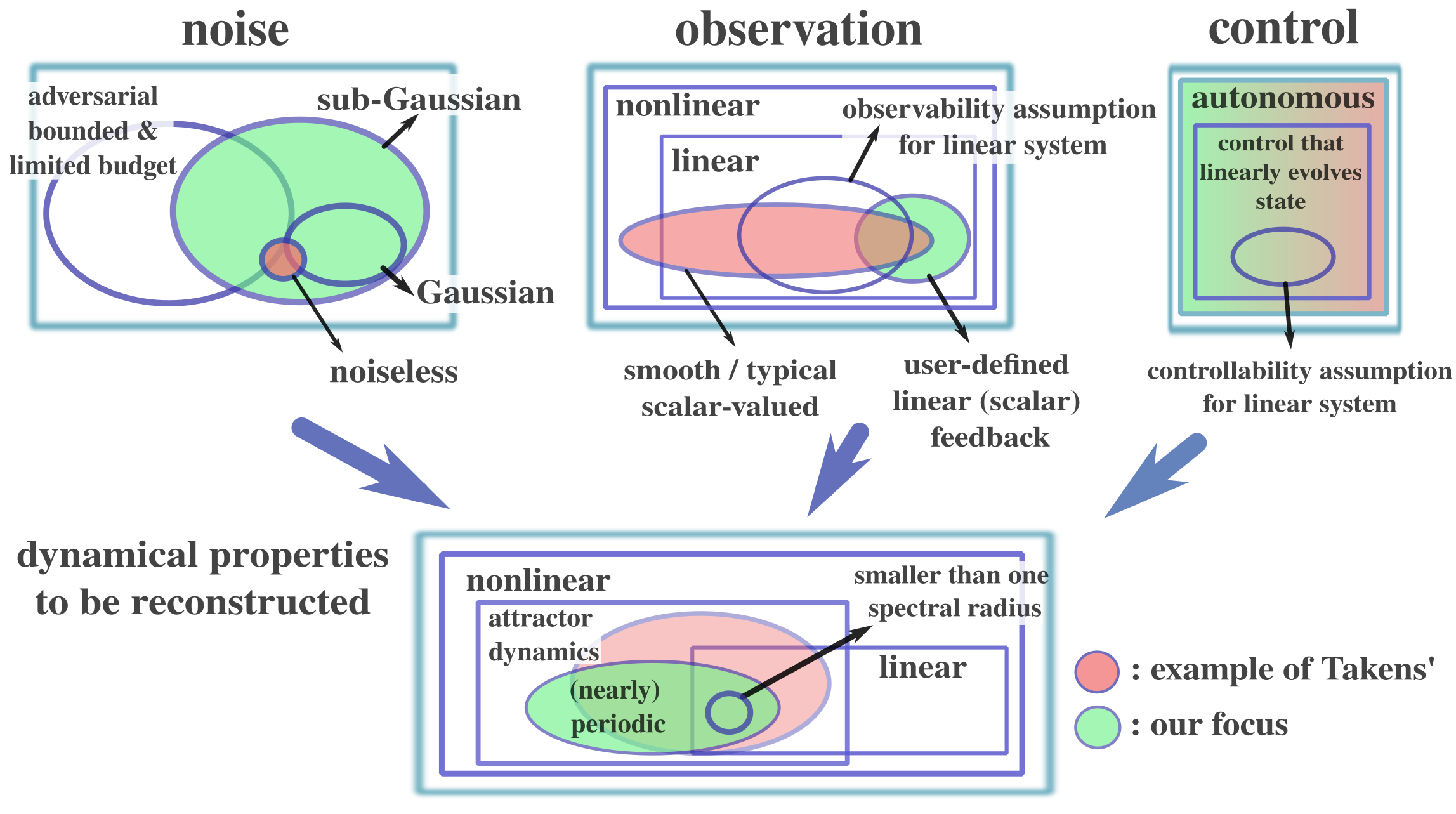
Our work is based on the different set of assumptions and aims at estimating a specific set of information; i.e., while we restrict ourselves to the case of (nearly) periodic systems and allow observations in the form of bandit feedback, our goal is to estimate (nearly) periodic structure of the target system. In this regard, we are not proposing “better” algorithms than the existing lines of work but are considering different problem setups that we believe are well motivated from both theoretical and practical perspectives (see Section 2). We mention that there exist many period estimation methods (e.g., Moore et al. (2014); Tenneti & Vaidyanathan (2015)), and in the case of zero noise, this becomes a trivial problem. For intuitive understandings of how our work may be placed in the literature, we show the illustration in Figure 4.
We also mention that our model of bandit feedback is commonly studied within stochastic linear bandit literature (cf. Abe & Long (1999); Auer (2003); Dani et al. (2008); Abbasi-Yadkori et al. (2011)). Also, as we consider the dynamically changing system states (or reward vectors), it is closely related to adversarial bandit problems (e.g., Bubeck & Cesa-Bianchi (2012); Hazan (2016)). Recently, some studies on non-stationary rewards have been made (cf. Auer et al. (2019); Besbes et al. (2014); Chen et al. (2019); Cheung et al. (2022); Luo et al. (2018); Russac et al. (2019); Trovo et al. (2020); Wu et al. (2018)) although they do not deal with periodically behaved dynamical system properly (see discussions in (Cai et al., 2021) as well). For discrete action settings, (Oh et al., 2019) proposed the periodic bandit, which aims at minimizing the total regret. Also, if the period is known, Gaussian process bandit for periodic reward functions was proposed (Cai et al., 2021) under Gaussian noise assumption. While our results could be extended to the regret minimization problems by employing our algorithms for estimating the periodic information before committing to arms in a certain way, we emphasize that our primary goal is to estimate such periodic information in provably efficient ways. We thus mention that our work is orthogonal to the recent studies on regret minimization problems for non-stationary environments (or in particular, periodic/seasonal environments). Refer to (Lattimore & Szepesvári, 2020) for bandit algorithms that are not covered here.
4 Problem definition
In this section, we describe our problem setting. In particular, we introduce some definitions on the properties of dynamical system.
4.1 Nearly periodic sequence
First, we define a general notion of nearly periodic sequence:
Definition 4.1 (Nearly periodic sequence).
Let be a metric space. Let and let . We say a sequence is -nearly periodic of length if for any . We also call the length of the -nearly period.
Intuitively, there exist balls of diameter in and the sequence moves in the balls in order if is -nearly periodic of length . Obviously, nearly periodic sequence of length is also nearly periodic sequence of length for any . We say a sequence is periodic if it is -nearly periodic. We introduce a notion of aliquot nearly period to treat estimation problems of period:
Definition 4.2 (Aliquot nearly period).
Let be a metric space. Let and . Assume a sequence is -nearly periodic of length for some and . A positive integer is a -aliquot nearly period (-anp) of if and the sequence is -nearly periodic.
We may identify the -anp with a -nearly period under an error margin . When we estimate the length of the nearly period of unknown sequence , we sometimes cannot determine the itself, but an aliquot nearly period.
Example 4.1.
A trajectory of finite dynamical system is always periodic and it is the most simple but important example of (nearly) periodic sequence. We also emphasize that if we know the upper bound of the number of underlying space, the period is bounded above by the upper bound as well. These facts are summarized in Proposition 4.1. The cellular automata on finite cells is a specific example of finite dynamical systems. We will treat LifeGame Conway et al. (1970), a special cellular automata, in our simulation experiment (see Section 6).
Proposition 4.1.
Let be a map on a set . If , then for any and , for some .
Proof.
Since , there exist such that by the pigeon hole principal. Thus, for all . ∎
If a linear dynamical system generates a nearly periodic sequence, we can show the linear system has a specific structure as follows:
Proposition 4.2.
Let be a linear map. Let be the decomposition via generalized eigenspaces of , where runs over the eigenvalues of and . Assume that there exists , for any , is -nearly periodic for some . Let . Then, each eigenvalue such that satisfies , in addition, if and , .
Proof.
We note that is bounded for any by the assumption on . Thus, cannot have an eigenvalue of magnitude greater than . We show that is in the form of for some if . Suppose that for an irrational number . Then, for an eigenvector for with , cannot become a -periodic sequence. Thus, we conclude for some . Next, we show if and . Suppose . Since , there exists such that but . Let . Then, we see that but . By direct computation, we see that
Thus, we have as , which contradicts the fact that is a bounded sequence. The last statement is obvious. ∎
Let be a linear subspace of generated by the trajectory and denote by . Note that restriction of to induces a linear map from to . We denote by the induced linear map from to . Let be the decomposition via the generalized eigenspaces of , where is the set of eigenvalues of and . We define
Then, we have the following statement as a corollary of Proposition 4.2:
Corollary 4.3.
There exist linear maps such that
-
1.
,
-
2.
,
-
3.
is diagonalizable and any eigenvalue of is of magnitude , and
-
4.
any eigenvalue of is of magnitude smaller than .
Proof.
Let be the projection and let be the inclusion map. We define . We can construct in the similar manner and these matrices are desired ones. ∎
Example 4.2.
Let be a finite group and let be a finite dimensional representation of , namely, a group homomorphism , where is the set of complex regular matrices of size . Fix . Let be a matrix whose eigenvalues have magnitudes smaller than . We define a matrix of size by
Then, is a -nearly periodic sequence for any , , and sufficiently large . Moreover, we know that the length of the nearly period is . We treat the permutation of variables in in the simulation experiment (see Section 6), namely the case where is the symmetric group and is a homomorphism from to defined by , which is the permutation of variable via .
4.2 Problem setting
Here, we state our problem settings. We use the notation introduced in the previous sections. First, we summarize our technical assumptions as follows:
Assumption 1 (Conditions on arms).
The set of arms contains the unit hypersphere.
Assumption 2 (Assumptions on noise).
The noise sequence is conditionally -sub-Gaussian (), i.e., given ,
and , , where is an ascending family and we assume that are measurable with respect to .
Assumption 3 (Assumptions on dynamical systems).
There exists such that for any , the sequence is -nearly periodic of length for some . We denote by the radius of the smallest ball containing .
Remark 4.4.
Assumption 1 excludes the lower bound arguments of the minimally required samples for our work since taking sufficiently large vector (arm) makes the noise effect negligible. Considering more restrictive conditions for discussing lower bounds is out of scope of this work.
Then, our questions are described as follows:
-
•
Can we estimate the length from the collection of rewards efficiently ?
-
•
If we assume the dynamical system is linear, can we further obtain the eigenvalues of from a collection of rewards ?
-
•
How many samples do we need to provably estimate the length or eigenvalues of ?
We will answer these questions in the following sections and via simulation experiments.
5 Algorithms and theory
With the above settings in place, we present a (computationally efficient) algorithm for each presented problem, and show its sample complexity for estimating certain information.
5.1 Period estimation
Here, we describe an algorithm for period estimation followed by its theoretical analysis. The overall procedure is summarized in Algorithm 1. Line 8 executes concurrent application of filterings.
Input: Current time ; ; ; ; orthogonal basis of
Output: Estimated length
To analyze the sample complexity of this estimation algorithm, we first introduce an exponential sum that plays a key role:
Definition 5.1.
For a positive rational number and complex numbers , we define
For a -nearly periodic sequence of length , we define the supremum of the standard deviations of the sequential data of :
The exponential sum can extract a divisor of the nearly period of a -nearly periodic sequence if is “sufficiently smaller” than the variance of the sequence even when the sequence is contaminated by noise; more precisely, we have the following lemma:
Lemma 5.1.
Let be a -nearly periodic sequence of length . Then, we have the following statements:
-
1.
if , then there exists with such that
(5.1) -
2.
if is not a divisor of , then for any ,
(5.2) where .
Proof.
As is -almost periodic, there exist of period and with such that .
First, we prove (5.1). Let
We claim that
| (5.3) |
In fact, the first inequality is obvious. The equality follows from the Plancherel formula for a finite abelian group (see, for example, (Serre, 1977, Excercise 6.2)). As for the last inequality, take arbitrary and define and . Then, we have
Here, we used the Cauchy-Schwartz inequality in the second inequality. Since is arbitrary, we have (5.3). Let and let . Let for some with . Then, we have
Then, we obtain the explicit lower bound of the samples for period estimation:
Proposition 5.2.
Let be a -nearly periodic sequence of length . Fix a positive integer with , , , and . Let be a noise sequence satisfying Assumption 2. Put and . We define
If , then, for any
the set of rational numbers
is non-empty with probability at least .
If we apply several collections of rewards for sufficiently large indicated in Proposition 5.2, we obtain various divisors of . Finally, we provide the precise inputs and output of Algorithm 1 in the following Theorem:
Theorem 5.3.
If is sufficiently small, we may set as a small positive number, in particular if the system is periodic.
Remark 5.4.
If random arm selection is adopted rather than the orthogonal basis, it may underestimate an error margin on some dimensions, which could lead to the nearly period with much larger error margin than expected; considering failure probability of such a case may potentially produce a variant of our algorithm.
5.2 Eigenvalue estimation
If the underlying system has certain structures, more detailed information about the system is expected to be obtained. In this section, we assume the following condition, linearity of the underlying dynamical system on , in addition to Assumption 1, 2, and 3:
Assumption 4 (Linear dynamical systems).
The dynamical system is linear and is represented by a matrix .
Let be the decomposition via generalized eigenspaces of , where runs over the eigenvalues of and . We describe with . We remark that an eigenvalue of such that is in the form of unless by Proposition 4.2.
Our objective is to estimate some of, if not all of, the eigenvalues of with high probability within some error that decreases by the sample size. To this end, we define the meaningful subset of eigenvalues of .
Definition 5.2 (-distinct eigenvalues).
For a vector and , we define a -distinct eigenvalue by an eigenvalue of such that and .
In our case, starting from a vector , the effect of the eigenvalues that are not of -distinct eigenvalues of may not be observable. Basically, once being able to ignore the effects of eigenvalues of magnitudes less than , the system becomes nearly periodic and we aim at estimating -distinct eigenvalues as we obtain more samples.
Input: Effective sample size ; threshold
Output: Matrix
Our eigenvalue estimation algorithm is summarized in Algorithm 2; it maintains the following matrices. For , random unit vectors , and , we define the matrix so that its element is given by
| (5.6) |
That is, after steps, the reward multiplied by is placed from the top row of and then the top row of , followed by the second rows of them, and so on. Then, those values are summed up for every steps or every th cycle. Here, after throwing away samples, the effects of eigenvalues of magnitude less than become negligible, and the trajectory becomes nearly periodically behaved under Assumption 4. The rest of the samples is used to average out the observation noise while maintaining some meaningful information about .
The aforementioned exponential sum can be characterized by the Weyl-type sum of matrices, a key machinery for our algorithm, which we define below:
Definition 5.3.
Let be a linear space and let for be linear maps on . For , we define
Remark 5.5.
Let be a noise matrix for . Let
Then, has an alternative description as follows:
| (5.7) |
As in Proposition 5.7 below, the Weyl-type sum has a crucial property. Define by
where is a Jordan normal form of . Also, we define to be a value such that, for any eigenvalue of satisfying , (define if no such eigenvalue exists). Note by Proposition 4.2, the existence of such spectral gap is guaranteed without any further assumptions.
Roughly speaking, Algorithm 2 estimates “”. Of course, the formula in “…” is not valid as , , and the Weyl-type sum are not necessarily invertible and we cannot recover full information of in general. However, we can still reconstruct information of restricted on the eigenspaces for -distinct eigenvalues.
To see this, we introduce the Weyl sum and its lower bound:
Lemma 5.6 (Lower bound on the Weyl sum Bourgain (1993); Oh ).
Define the Weyl sum by
for some and . Then, for , it holds that
Proof.
It is immediate from Proposition 3.1 in Oh because , , and is even. ∎
We define by
Then, we have the following proposition:
Proposition 5.7.
Let and be matrices as in Corollary 4.3. We define linear maps on by
Then, we have the following statements:
-
1.
,
-
2.
for any , is invertible on ,
-
3.
for any and for any , ,
-
4.
for any , we have
Proof.
We prove 1. By the properties 1 and 2 in Corollary 4.3, we have . Next, we prove 2. When we regard as a linear map on , it is represented as a diagonal matrix , where . Therefore, by Lemma 5.6, is a bijective linear map on . Next, we prove 3. We estimate . Let be the orthogonal projection and let be the inclusion map. Let . Then, we have
Next, we estimate . Let . Then, and . Let be a regular matrix such that
where is the Jordan normal form. Then, for , we see that
The second last inequality is proved as follows: for , and ,
where, the last inequality follows from
Thus, we have
∎
Proposition 5.7 plays an essential role in our analysis and guarantees that the information in about -distinct eigenvalues does not vanish while noise effects are canceled out. Now, we state our main theoretical result for the eigenvalue estimation algorithm. Before stating the theorem, we introduce lower rank approximation via the singular value threshold.
Definition 5.4.
Let be a matrix. Let be a singular valued decomposition of where and are unitary matrices and is a diagonal matrix with nonnegative components. Let . We define a low rank approximation of via the singular value threshold by the matrix defined by , where, and is defined to be the characteristic function supported on .
Given this definition, we are ready to present the following main result:
Theorem 5.8.
Suppose Assumptions 1, 2, 3, and 4 hold. Given , let the effective sample size
| (5.8) |
and . Then, there exists a matrix whose eigenvalues are zeros except for -distinct eigenvalues of , such that the output of Algorithm 2, i.e. , satisfies, with probability at least , that
| (5.9) |
Here, is the Moore-Penrose pseudo inverse of a lower rank approximation of via the singular value threshold . The constant depends on , , , , and .
We mention that by using the results shown in Song (2002), the bound on spectral norm (5.9) can be translated to the bounds on eigenvalues, where the constant depends on the form of . As described in Theorem 5.8, the constant is not the absolute constant for any problem instance but depends on several factors; however, for the same execution, this rate is useful to judge how many samples one collects to estimate eigenvalues.
Remark 5.9.
We note that we can reconstruct the -distinct eigenvalues of via Algorithm 2 using the following trick: Fix non-negative integer . Take random unit vectors . Then, for , we may define a matrix so that its element is given by
Then, we see that Algorithm 2 outputs a matrix that well approximates the -distinct eigenvalues of since the matrix coincides with in the case when we replace and with and defined by
Let be an integer such that is prime to and fix a positive integer such that . Then, the eigenvalues of is close to those of -distinct eigenvalues if we take sufficiently large .
6 Simulated experiments
In this section, we present simulated experiments that complement the theoretical claims. In particular, we conducted period estimations for an instance of LifeGame Conway et al. (1970), which is a special case of cellular automata Von Neumann et al. (1966), and for a nearly periodic toy system, and an eigenvalue estimation for a linear system, where some dimensions are for permutations and the rest is for shrinking.
Period estimation: LifeGame.
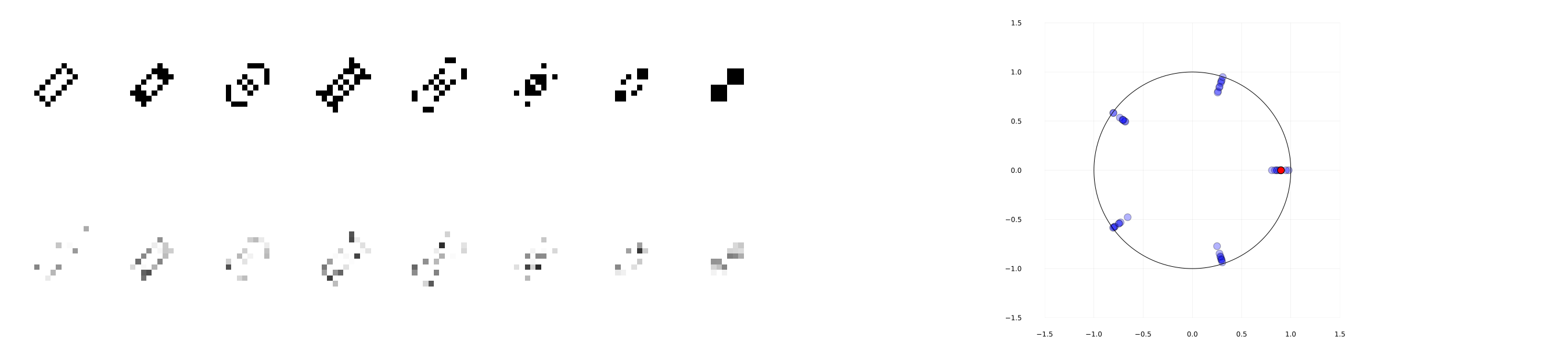
We use a specific instance of LifeGame which is illustrated in Figure 5. As shown on the top eight pictures, starting from certain configuration of cells, it shows transitions of period eight. The sample size is computed as the smallest integer satisfying (5.5), and the threshold is given by (5.4). To prevent the dimension from becoming too large, we used five cells that correctly display period eight; that is . Noise is given by i.i.d. Gaussian with proxy , and the down eight pictures of Figure 5 are some instances of noisy observations. We tested 50 different random seeds (i.e., 1, 51, 101, 151, … , 2451), and computed the error rate (the number of runs producing a wrong estimate other than the fundamental period eight, which is divided by 50); and it was zero.
Period estimation: Simple -nearly periodic system. We consider the following -nearly periodic system that circulates over a circle with small variations:
| (6.1) |
where and are the radius and angle, and . We use , , and . Noise is drawn i.i.d. from the uniform distribution within for . We tested 50 different random seeds (i.e., 1, 51, 101, 151, … , 2451), and computed the error rate; and it was zero.
Eigenvalue estimation: Permutation and shrink. We use , and is made such that 1) the first four dimensions are for permutation (i.e., each of row and column of sub-matrix has only one nonzero element that is one.), and 2) the last dimension is simply shrinking; we gave for -element of . Initial vector and each arm are uniformly sampled from the unit sphere in . The value is computed by . We used the smallest integer that satisfies (5.8), multiplied by . The results are shown in Table 1; it is observed that the more samples we use the more accurate the estimates become to -distinct eigenvalues of . Noise is drawn i.i.d. from the uniform distribution within for , and the Table 1 is of the random seed 1234. We also tested 50 different random seeds (i.e., 1, 51, 101, 151, … , 2451) for , and computed the mean absolute error between the true -distinct eigenvalues and their nearest estimated values; it was , which is sufficiently small.
| eigenvalues of | |||||
|---|---|---|---|---|---|
| when | |||||
| when | |||||
| when | |||||
| when |
Attempt on applications to more realistic data: Worm simulation. Finally, we present an attempt on applications to more realistic situation, which will demonstrate some of the important aspects that need to be taken into account when naively applying our algorithms to the real world problems. In particular, we use OpenWorm (https://openworm.org/) (Szigeti et al., 2014) to simulate a worm motion (we ran more than around hours for simulations); example images from this simulation is shown in Figure 6 (left). It is known that the behavior of worm has some periodicity (e.g., Ahamed et al. (2021)). We resized the images to (i.e., ), and downsampled the video by extracting one per eight images. Also, we repeat the same video in the way that the entire video still shows smooth flow (i.e., cut the video so that the end image is similar to the image in the beginning, and concatenate the same videos) so that we can sample a large number of data.
First, we assume we have no access to reasonable values for the hyperparameters, and show what happens when we use hyperparameters that do not reflect the target system. With such a choice of parameters (see Appendix F.4), the algorithm outputs an estimate that contradicts to the hyperparemters; with the value , it outputs the estimate . In particular, there exist dimensions that output the estimates and , from which the final estimate becomes . Note that, in this experiment, we use a fixed number of samples since we have no access to the reasonable hyperparameters. On the other hand, we increased the margin significantly, and then the output becomes where each dimension shows or in this case. In fact, one segment of our video data (recall we concatenate the same video to create a sequence of an indefinite number of images) consists of images and contains periods of sequence.
We mention that the aforementioned fact implies that the choice of hyperparameters may be practically validated by confirming that the outputs are consistent to the parameters.
Next, we assume that the system is linear and run the DMD over this canonical basis of the state space. Let be the solution to the exact DMD over the video data, and we compute the eigenvalues of and of the output of Algorithm 2. We tested the algorithm with the fixed hyperparameters given in Appendix F.4 and with varying number of , namely, , , and . For the cases of and , we only obtained one eigenvalue which is close to and the others were almost zero. For , we obtained three nonzero eigenvalues which are plotted in Figure 7 against the top four eigenvalues of . The actual nonzero eigenvalues and the estimated errors for all three cases are given in Table 2.
From the results, we argue that, for some real applications where the system is not exactly linear, the eigenvalue estimation algorithm may not work well although it does not output insane values.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f5cb6e10-7909-47c9-9311-ade4bf11d3c6/dmd_eigen.png)
| Nonzero eigenvalues | Errors | |
7 Discussion and conclusion
This work proposed novel algorithms for estimating periodic information about the dynamical systems from bandit feedback contaminated by a sub-Gaussian noise. Since we consider a rather novel problem setup, the setting itself would be seen as a limitation of our work, and we present a potentially important list of future works below.
Choice of hyperparameters such as : If those hyperparameters are correctly chosen for nearly periodic systems, the outputs of our algorithms are consistent and reasonable across runs, which follows the theoretical insights; therefore, practically, one can check if the hyperparameters are properly chosen by running the algorithms. Refer to Section 6 for related discussions; in short, inappropriate choice of hyperparameters leads to contradicting outputs (e.g., period estimate larger than the assumed maximum value). On the other hand, studying if it is possible to theoretically ensure correctness of hyperparameters (e.g., by standard doubling trick (Cesa-Bianchi et al., 1997) for efficient guessing) or to identify non-periodic systems is an important future work.
Extension to general spectrum information estimation problems: We only impose nearly periodicity on the dynamical systems on top of the linearity for the eigenvalue estimation problem. Nevertheless, additional studies are needed to allow other forms of observations (not limited to bandit feedback) and non-periodic systems to consider eigenvalues with arguments of times irrational numbers. Actually, the asymptotic bounds of the Weyl sum themselves are still valid when it is sufficiently well approximated by a rational number (Bourgain, 1993; Oh, ). Moreover, allowing control inputs would make eigenvalues of magnitudes smaller than one efficiently recoverable.
Extensions to random dynamical systems: This work studied deterministic dynamical systems; however, we conjecture that, under the condition that the variance of trajectories generated by a random dynamical system (RDS) (cf. Arnold (1998)) is sufficiently small, the similar estimation procedure is adopted for such RDSs. It is important to study if the estimation problem becomes easier when the system is driven by a particular noise as it could be treated as a random control input. Also, studying other dynamic structures such as the Lyapunov exponents for nonlinear systems is an interesting future work.
Study of statistical estimation leveraged by other number theoretical results: The proper use of exponential sums enables us to average out the noise while preserving particular information. Studying when this separation is feasible for different sets of information, noise, and class of problems should be important.
Optimality of the results: Although we gave a sufficient number of samples for provably guaranteeing (approximate) correctness of the estimates, it is unclear if our sample complexity is what one can best achieve under particular problem settings. Recall that the current problem settings without an assumption on boundedness of the set of arms exclude the lower bound arguments of the minimally required samples as mentioned in Remark 4.4.
As such, instead of arguing the tightness, to justify the complexity of our algorithms, we hence mention that the very naive approach for (nearly) period estimation would cost the order of sample complexity. To see this, suppose we know the maximum possible (nearly) period then it follows that is a true (nearly) period as a multiple of the fundamental (nearly) period. As such, one could employ the concentration of measures to average out the sample. With sufficiently many sequences of length depending on the rate of concentration, one could approximately reconstruct the original (noiseless) sequence of length from which one could estimate a desired which is an (aliquot) nearly period.
Lower bound of the minimally required samples may be discussed by using similar arguments to the best arm identification problems (cf. Kaufmann et al. (2016)); however, our problems consider dynamical systems, and we have no clue on potential technical tools to deal with the arguments at this point.
Acknowledgments
We thank the constructive comments by anonymous reviewers for improving this work. Motoya Ohnishi thanks Sham Kakade, Yoshinobu Kawahara, Emanuel Todorov, Jacob Sacks, Tomoharu Iwata, and Hiroya Nakao for valuable discussions and thanks Sham Kakade for computational supports. This work of Motoya Ohnishi, Isao Ishikawa, and Masahiro Ikeda was supported by JST CREST Grant, Number JPMJCR1913, including AIP challenge program, Japan. Also, Motoya Ohnishi is supported in part by Funai Overseas Fellowship. Isao Ishikawa is supported by JST ACT-X Grant, Number JPMJAX2004, Japan. This work of Yuko Kuroki was supported by Microsoft Research Asia and JST ACT-X JPMJAX200E.
References
- Abbasi-Yadkori et al. (2011) Y. Abbasi-Yadkori, D. Pál, and C. Szepesvári. Improved algorithms for linear stochastic bandits. Advances in neural information processing systems, 24, 2011.
- Abe & Long (1999) N. Abe and P. M. Long. Associative reinforcement learning using linear probabilistic concepts. In ICML, pp. 3–11, 1999.
- Adams et al. (2021) J. Adams, N. Hansen, and K. Zhang. Identification of partially observed linear causal models: Graphical conditions for the non-Gaussian and heterogeneous cases. Advances in Neural Information Processing Systems, 34, 2021.
- Aerts et al. (2018) C. Aerts, G. Molenberghs, M. Michielsen, MG. Pedersen, R. Björklund, C. Johnston, JSG. Mombarg, DM. Bowman, B. Buysschaert, PI. Pápics, et al. Forward asteroseismic modeling of stars with a convective core from gravity-mode oscillations: parameter estimation and stellar model selection. The Astrophysical Journal Supplement Series, 237(1):15, 2018.
- Ahamed et al. (2021) T. Ahamed, A. C. Costa, and G. J. Stephens. Capturing the continuous complexity of behaviour in Caenorhabditis elegans. Nature Physics, 17(2):275–283, 2021.
- Allen & Kanamori (2003) R. M. Allen and H. Kanamori. The potential for earthquake early warning in southern California. Science, 300(5620):786–789, 2003.
- Anscombe (1963) F. J. Anscombe. Sequential medical trials. Journal of the American Statistical Association, 58(302):365–383, 1963.
- Arkhipov et al. (2004) G. I. Arkhipov, V. N. Chubarikov, and A. A. Karatsuba. Trigonometric Sums in Number Theory and Analysis. De Gruyter, Berlin, New York, 2004.
- Arnold (1998) L. Arnold. Random dynamical systems. Springer-Verlag, 1998.
- Auer (2003) P. Auer. Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3:397–422, 2003.
- Auer et al. (2019) P. Auer, Y. Chen, P. Gajane, C. Lee, H. Luo, R. Ortner, and C. Wei. Achieving optimal dynamic regret for non-stationary bandits without prior information. In Conference on Learning Theory, pp. 159–163. PMLR, 2019.
- Bakarji et al. (2022) J. Bakarji, K. Champion, J. N. Kutz, and S. L. Brunton. Discovering governing equations from partial measurements with deep delay autoencoders. arXiv preprint arXiv:2201.05136, 2022.
- Bennett & Kallus (2021) A. Bennett and N. Kallus. Proximal reinforcement learning: Efficient off-policy evaluation in partially observed Markov decision processes. arXiv preprint arXiv:2110.15332, 2021.
- Besbes et al. (2014) O. Besbes, Y. Gur, and A. Zeevi. Stochastic multi-armed-bandit problem with non-stationary rewards. Advances in neural information processing systems, 27, 2014.
- Bezanson et al. (2017) J. Bezanson, A. Edelman, S. Karpinski, and V. B. Shah. Julia: A fresh approach to numerical computing. SIAM review, 59(1):65–98, 2017.
- Bhouri & Perdikaris (2021) M. A. Bhouri and P. Perdikaris. Gaussian processes meet NeuralODEs: A Bayesian framework for learning the dynamics of partially observed systems from scarce and noisy data. arXiv preprint arXiv:2103.03385, 2021.
- Bourgain (1993) J. Bourgain. Fourier transform restriction phenomena for certain lattice subsets and applications to nonlinear evolution equations. Geometric & Functional Analysis GAFA, 3(3):209–262, 1993.
- Bubeck & Cesa-Bianchi (2012) S. Bubeck and N. Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Foundations and Trends® in Machine Learning, 5:1–122, 2012.
- Cai et al. (2021) H. Cai, Z. Cen, L. Leng, and R. Song. Periodic-GP: Learning periodic world with Gaussian process bandits. arXiv preprint arXiv:2105.14422, 2021.
- Candes et al. (2006) E. J. Candes, J. K. Romberg, and T. Tao. Stable signal recovery from incomplete and inaccurate measurements. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 59(8):1207–1223, 2006.
- Casdagli et al. (1991) M. Casdagli, S. Eubank, J. D. Farmer, and J. Gibson. State space reconstruction in the presence of noise. Physica D: Nonlinear Phenomena, 51(1-3):52–98, 1991.
- Cesa-Bianchi et al. (1997) N. Cesa-Bianchi, Y. Freund, D. Haussler, D. P. Helmbold, R. E. Schapire, and M. K. Warmuth. How to use expert advice. Journal of the ACM, 44(3):427–485, 1997.
- Chen et al. (2019) Y. Chen, C. Lee, H. Luo, and C. Wei. A new algorithm for non-stationary contextual bandits: Efficient, optimal and parameter-free. In Conference on Learning Theory, pp. 696–726. PMLR, 2019.
- Chesneau & Bagul (2020) C. Chesneau and Y. J. Bagul. A note on some new bounds for trigonometric functions using infinite products. Malaysian Journal of Mathematical Sciences, 14:273–283, 07 2020.
- Cheung et al. (2022) W. Cheung, D. Simchi-Levi, and R. Zhu. Hedging the drift: Learning to optimize under nonstationarity. Management Science, 68(3):1696–1713, 2022.
- Conway et al. (1970) J. Conway et al. The game of life. Scientific American, 223(4):4, 1970.
- Couillet & Debbah (2011) R. Couillet and M. Debbah. Random matrix methods for wireless communications. Cambridge University Press, 2011.
- Curi et al. (2020) S. Curi, F. Berkenkamp, and A. Krause. Efficient model-based reinforcement learning through optimistic policy search and planning. Advances in Neural Information Processing Systems, 33:14156–14170, 2020.
- Dani et al. (2008) V. Dani, T. P. Hayes, and S. M. Kakade. Stochastic linear optimization under bandit feedback. In 21st Annual Conference on Learning Theory, pp. 355–366, 2008.
- Derevyanko et al. (2016) S. A. Derevyanko, J. E. Prilepsky, and S. K. Turitsyn. Capacity estimates for optical transmission based on the nonlinear Fourier transform. Nature communications, 7(1):12710, 2016.
- Donoho (2006) D. L. Donoho. Compressed sensing. IEEE Trans. Information Theory, 52(4):1289–1306, 2006.
- Duarte et al. (2008) M. F. Duarte, M. A. Davenport, D. Takhar, J. N. Laska, T. Sun, K. F. Kelly, and R. G. Baraniuk. Single-pixel imaging via compressive sampling. IEEE Signal Processing Magazine, 25(2):83–91, 2008.
- Eldar & Kutyniok (2012) Y. C. Eldar and G. Kutyniok. Compressed sensing: theory and applications. Cambridge university press, 2012.
- Furusawa & Kaneko (2012) C. Furusawa and K. Kaneko. A dynamical-systems view of stem cell biology. Science, 338(6104):215–217, 2012.
- Hazan (2016) E. Hazan. Introduction to online convex optimization. Foundations and Trends® in Optimization, 2(3-4):157–325, 2016.
- Hazan et al. (2018) E. Hazan, H. Lee, K. Singh, C. Zhang, and Y. Zhang. Spectral filtering for general linear dynamical systems. Advances in Neural Information Processing Systems, 31, 2018.
- Hughes et al. (2017) M. E. Hughes, K. C. Abruzzi, R. Allada, R. Anafi, A. B. Arpat, G. Asher, P. Baldi, C. De Bekker, D. Bell-Pedersen, J. Blau, et al. Guidelines for genome-scale analysis of biological rhythms. Journal of Biological Rhythms, 32(5):380–393, 2017.
- Kakade et al. (2020) S. Kakade, A. Krishnamurthy, K. Lowrey, M. Ohnishi, and W. Sun. Information theoretic regret bounds for online nonlinear control. Advances in Neural Information Processing Systems, 33:15312–15325, 2020.
- Katz (1990) N. M. Katz. Exponential Sums and Differential Equations. (AM-124). Princeton University Press, 1990.
- Kaufmann et al. (2016) E. Kaufmann, O. Cappé, and A. Garivier. On the complexity of best-arm identification in multi-armed bandit models. The Journal of Machine Learning Research, 17(1):1–42, 2016.
- Kutz et al. (2016) J. N. Kutz, S. L. Brunton, B. W. Brunton, and J. L. Proctor. Dynamic mode decomposition: data-driven modeling of complex systems. SIAM, 2016.
- Lale et al. (2020) S. Lale, K. Azizzadenesheli, B. Hassibi, and A. Anandkumar. Logarithmic regret bound in partially observable linear dynamical systems. Advances in Neural Information Processing Systems, 33:20876–20888, 2020.
- Lattimore & Szepesvári (2020) T. Lattimore and C. Szepesvári. Bandit algorithms. Cambridge University Press, 2020.
- Lee et al. (2020) A. X. Lee, A. Nagabandi, P. Abbeel, and S. Levine. Stochastic latent actor-critic: Deep reinforcement learning with a latent variable model. Advances in Neural Information Processing Systems, 33:741–752, 2020.
- Lee (2022) H. Lee. Improved rates for prediction and identification of partially observed linear dynamical systems. In International Conference on Algorithmic Learning Theory, pp. 668–698. PMLR, 2022.
- Lee & Zhang (2020) H. Lee and C. Zhang. Robust guarantees for learning an autoregressive filter. In Algorithmic Learning Theory, pp. 490–517. PMLR, 2020.
- Li et al. (2010) L. Li, W. Chu, J. Langford, and R. E. Schapire. A contextual-bandit approach to personalized news article recommendation. In Proc. International Conference on World Wide Web, pp. 661–670, 2010.
- Ljung (2010) L. Ljung. Perspectives on system identification. Annual Reviews in Control, 34(1):1–12, 2010.
- Luo et al. (2018) H. Luo, C. Wei, A. Agarwal, and J. Langford. Efficient contextual bandits in non-stationary worlds. In Conference on Learning Theory, pp. 1739–1776. PMLR, 2018.
- Mania et al. (2022) H. Mania, M. I. Jordan, and B. Recht. Active learning for nonlinear system identification with guarantees. Journal of Machine Learning Research, 23(32):1–30, 2022.
- Menda et al. (2020) K. Menda, J. De B., J. Gupta, I. Kroo, M. Kochenderfer, and Z. Manchester. Scalable identification of partially observed systems with certainty-equivalent EM. In ICML, pp. 6830–6840, 2020.
- Meng & Zheng (2010) L. Meng and B. Zheng. The optimal perturbation bounds of the Moore-Penrose inverse under the Frobenius norm. Linear algebra and its applications, 432(4):956–963, 2010.
- Mhammedi et al. (2020) Z. Mhammedi, D. J. Foster, M. Simchowitz, D. Misra, W. Sun, A. Krishnamurthy, A. Rakhlin, and J. Langford. Learning the linear quadratic regulator from nonlinear observations. Advances in Neural Information Processing Systems, 33:14532–14543, 2020.
- Moore et al. (2014) A. Moore, T. Zielinski, and A. J. Millar. Online period estimation and determination of rhythmicity in circadian data, using the BioDare data infrastructure. In Plant Circadian Networks, pp. 13–44. Springer, 2014.
- Oh et al. (2019) S. Oh, A. M. Appavoo, and S. Gilbert. Periodic bandits and wireless network selection. In 46th International Colloquium on Automata, Languages, and Programming (ICALP 2019), pp. 149:1–149:15, 2019.
- (56) T. Oh. Note on a lower bound of the Weyl sum in Bourgain’s NLS paper (GAFA’93).
- Ohnishi et al. (2024) M. Ohnishi, I. Ishikawa, K. Lowrey, M. Ikeda, S. M. Kakade, and Y. Kawahara. Koopman spectrum nonlinear regulators and efficient online learning. Transactions on Machine Learning Research, 2024.
- Ouala et al. (2020) S. Ouala, D. Nguyen, L. Drumetz, B. Chapron, A. Pascual, F. Collard, L. Gaultier, and R. Fablet. Learning latent dynamics for partially observed chaotic systems. Chaos: An Interdisciplinary Journal of Nonlinear Science, 30, 2020.
- Rathje et al. (1998) E. M. Rathje, N. A. Abrahamson, and J. D. Bray. Simplified frequency content estimates of earthquake ground motions. Journal of Geotechnical and Geoenvironmental Engineering, 124(2):150–159, 1998.
- Robbins (1952) H. Robbins. Some aspects of the sequential design of experiments. Bulletin of the American Mathematical Society, 58(5):527–535, 1952.
- Russac et al. (2019) Y. Russac, C. Vernade, and O. Cappé. Weighted linear bandits for non-stationary environments. Advances in Neural Information Processing Systems, 32, 2019.
- Sabetta & Pugliese (1996) F. Sabetta and A. Pugliese. Estimation of response spectra and simulation of nonstationary earthquake ground motions. Bulletin of the Seismological Society of America, 86(2):337–352, 1996.
- Serre (1977) J.-P. Serre. Linear Representations of Finite Groups. Springer New York, NY, 1977. doi: https://doi.org/10.1007/978-1-4684-9458-7.
- Simchowitz & Foster (2020) M. Simchowitz and D. Foster. Naive exploration is optimal for online LQR. In ICML, pp. 8937–8948. PMLR, 2020.
- Simchowitz et al. (2019) M. Simchowitz, R. Boczar, and B. Recht. Learning linear dynamical systems with semi-parametric least squares. In Conference on Learning Theory, pp. 2714–2802. PMLR, 2019.
- Sokolove & Bushell (1978) P. G. Sokolove and W. N. Bushell. The Chi square periodogram: its utility for analysis of circadian rhythms. Journal of Theoretical Biology, 72(1):131–160, 1978.
- Song (2002) Y. Song. A note on the variation of the spectrum of an arbitrary matrix. Linear algebra and its applications, 342(1-3):41–46, 2002.
- Subramanian et al. (2022) J. Subramanian, A. Sinha, R. Seraj, and A. Mahajan. Approximate information state for approximate planning and reinforcement learning in partially observed systems. Journal of Machine Learning Research, 23(12):1–83, 2022.
- Summers et al. (2020) C. Summers, K. Lowrey, A. Rajeswaran, S. Srinivasa, and E. Todorov. Lyceum: An efficient and scalable ecosystem for robot learning. In Learning for Dynamics and Control, pp. 793–803. PMLR, 2020.
- Szigeti et al. (2014) B. Szigeti, P. Gleeson, M. Vella, S. Khayrulin, A. Palyanov, J. Hokanson, M. Currie, M. Cantarelli, G. Idili, and S. Larson. OpenWorm: an open-science approach to modeling Caenorhabditis elegans. Frontiers in Computational Neuroscience, 8:137, 2014.
- Takens (1981) F. Takens. Detecting strange attractors in turbulence. In Dynamical systems and turbulence, pp. 366–381. Springer, 1981.
- Tenneti & Vaidyanathan (2015) S. V. Tenneti and P. Vaidyanathan. Nested periodic matrices and dictionaries: New signal representations for period estimation. IEEE Transactions on Signal Processing, 63(14):3736–3750, 2015.
- Trovo et al. (2020) F. Trovo, S. Paladino, M. Restelli, and N. Gatti. Sliding-window Thompson sampling for non-stationary settings. Journal of Artificial Intelligence Research, 68:311–364, 2020.
- Tsiamis & Pappas (2019) A. Tsiamis and G. J. Pappas. Finite sample analysis of stochastic system identification. In IEEE CDC, pp. 3648–3654, 2019.
- Tsiamis et al. (2020) A. Tsiamis, N. Matni, and G. Pappas. Sample complexity of Kalman filtering for unknown systems. In Learning for Dynamics and Control, pp. 435–444. PMLR, 2020.
- Tu (2013) J. H. Tu. Dynamic mode decomposition: Theory and applications. PhD thesis, Princeton University, 2013.
- Turitsyn et al. (2017) S. K. Turitsyn, J. E. Prilepsky, S. T. Le, S. Wahls, L. L. Frumin, M. Kamalian, and S. A. Derevyanko. Nonlinear Fourier transform for optical data processing and transmission: advances and perspectives. Optica, 4(3):307–322, 2017.
- Uy & Peherstorfer (2021) W. I. T. Uy and B. Peherstorfer. Operator inference of non-Markovian terms for learning reduced models from partially observed state trajectories. Journal of Scientific Computing, 88(3):1–31, 2021.
- Van De Beek et al. (1995) J. Van De Beek, O. Edfors, M. Sandell, S. K. Wilson, and P. O. Borjesson. On channel estimation in ofdm systems. In IEEE 45th Vehicular Technology Conference. Countdown to the Wireless Twenty-First Century, volume 2, pp. 815–819, 1995.
- Von Neumann et al. (1966) J. Von Neumann, A. W. Burks, et al. Theory of self-reproducing automata. IEEE Transactions on Neural Networks, 5(1):3–14, 1966.
- Walters (2000) P. Walters. An introduction to ergodic theory, volume 79. Springer Science & Business Media, 2000.
- Wedin (1973) P. Wedin. Perturbation theory for pseudo-inverses. BIT Numerical Mathematics, 13(2):217–232, 1973.
- Weyl (1916) H. Weyl. Über die gleichverteilung von zahlen mod eins. Math. Ann., 77:31–352, 1916.
- Williams et al. (2015) M. O. Williams, I. G. Kevrekidis, and C. W. Rowley. A data–driven approximation of the Koopman operator: Extending dynamic mode decomposition. Journal of Nonlinear Science, 25:1307–1346, 2015.
- Wolfe (2006) C. J. Wolfe. On the properties of predominant-period estimators for earthquake early warning. Bulletin of the Seismological Society of America, 96(5):1961–1965, 2006.
- Wu et al. (2018) Q. Wu, N. Iyer, and H. Wang. Learning contextual bandits in a non-stationary environment. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 495–504, 2018.
- Zielinski et al. (2014) T. Zielinski, A. M. Moore, E. Troup, K. J. Halliday, and A. J. Millar. Strengths and limitations of period estimation methods for circadian data. PloS one, 9(5):e96462, 2014.
Appendix A Proof of Proposition 5.2
Proof.
Then, satisfies the following inequality
if and only if
Since , , , , and
where we used . Since , the statement follows from Lemma 5.1. ∎
Appendix B Proof of Theorem 5.3
Proof.
Let be the set of all combinations such that , , and . We remark that
Also, let be the event such that, for the combination ,
Because the error sequence satisfies conditionally -sub-Gaussian, using Lemma D.1 and from the fact that any subsequence of the filtration is again a filtration, we obtain, for each ,
Define . Then, it follows from the Fréchet inequality that
Let be the output of Algorithm 1. We show that, with probability , is -anp of . In fact, suppose is not -anp. We note that . There exists and ,
Let . Put . Then, for any , we have
Thus, by definition, we have
Let and . Then, , and
The last inequality follows from . Thus, by Proposition 5.2, the algorithm finds in -th loop, and the output becomes an integer larger than , which is contradiction. ∎
Appendix C Proof of Theorem 5.8
Here, we provide the proof of Theorem 5.8.
C.1 Proof
Let
For a linear map , we define linear maps:
For , we define linear maps on by
We note that is identical to defined in (5.7). We impose the following assumption on :
Assumption 5.
The kernel of the linear map is the same as .
Note that this assumption holds with probability 1 if we randomly choose (see Lemma C.7).
The following isomorphicity maintenance lemma provides an explicit description of .
Lemma C.1 (Isomorphicity maintenance lemma).
Suppose Assumption 5 holds. Assume . Let
Let be the inclusion map and the orthogonal projection. Then, restriction of (resp. ) to (resp. ) induces an isomorphism onto (resp. ). If we denote the isomorphism by (resp, ). Then, is given by
Proof.
Since we have for all and Assumption 5, surjectivity of by Proposition C.5, and bijectivity of on by Proposition 5.7, we have
Thus, the restriction of (resp. ) to (resp. ) induces an isomorphism onto (resp. ). Let us denote the isomorphism by (resp. ). Then, the last statement follows from Proposition C.4. ∎
Lemma C.2.
Assume . Let
Then, is independent of and its eigenvalues are zeros except for -distinct eigenvalues of .
Proof.
The following result will be used in the proof of Theorem 5.8 (but not essential).
Lemma C.3.
We have
Proof.
Considering the Jordan normal form, the first inequality is obvious. As for the second inequality, we define by the nilpotent matrix
Then, we have
∎
Proof of Theorem 5.8.
Let be the matrix introduced in Lemma C.2. Let
Let and be matrices as in Corollary 4.3. Then, by Proposition 4.2, we see that
We denote by (resp, ) the low rank approximation via the singular value threshold (see Definition 5.4). By direct computations, we have
By Proposition 5.7, for and for , we have
where we used (Assumption 3), and (Lemma C.3), and . By Lemma C.1 with Proposition 5.7, we see that
By using Lemma D.1 and union bounds, we obtain
with probability at least . Assume that
Then, we see that . Thus, by Lemma C.6, with probability at least , we have
Therefore, there exists depending on , , , , , , and such that
with probability at least . ∎
C.2 Miscellaneous
We provide an expression of Moore-Penrose pseudo inverse:
Proposition C.4.
Let be a linear map. Let be the inclusion map and let be the orthogonal projection. Let be an isomorphism. Then, the Moore-Penrose pseudo inverse coincides with .
Proof.
Let . We remark that , , we see that , , , and . By the uniqueness of Moore-Penrose pseudo inverse, . ∎
Proposition C.5.
Let be a matrix and let be a vector. Let be a linear subspace generated by . Then, .
Proof.
Put . The inclusion is obvious, we prove the opposite inclusion. It suffices to show that for any positive integer . By the Cayley-Hamilton theorem, for some . Thus, by induction is a linear combination of , namely, . ∎
We give several lemmas here.
Lemma C.6 (Perturbation bounds of the Moore-Penrose inverse).
Suppose is a matrix. Let be a matrix satisfying
and let be the low rank approximation of via SVD with the singular value threshold . Then, we obtain
Proof.
Let be the minimal singular value of . From (Meng & Zheng, 2010, Theorem 1.1) (or originally Wedin (1973)) and from the fact
we obtain
For such that , we have . Suppose singular values , of , and , of are sorted in descending order. Then, it holds that
Therefore, for , the minimum singular value is greater than . In this case, , and it follows that . Hence, for all , we obtain
from which, it follows that
∎
Lemma C.7 (Null space of random matrix).
Suppose , have the same null space. Then, the null space of
| (C.5) |
where , are unit vectors independently drawn from the uniform distribution over the unit hypersphere, is the same as those of with probability one.
Proof.
Given any dimensional linear subspace in for any , it holds that the probability that lies on that space is zero. Therefore, by union bound, and by the fact that the row space is the orthogonal complement of the null space, we obtain the result. ∎
Appendix D Azuma-Hoeffding inequality for exponential sum
Lemma D.1.
Let for be sub-Gaussian martingale difference with variance proxy and a filtration . Also, let be a sequence of complex numbers satisfying for all . Then, the followings hold, where stands for or .
Proof.
For a filtration , we have
where the first inequality follows from the assumption of filtration, and the second inequality follows from
By induction, we obtain
By using Markov inequality and the union bound, it follows that
Similarly, we have
Therefore, we obtain
where the first inequality follows from the Fréchet inequality. ∎
Appendix E Applications to bandit problems
We briefly cover the applicability of our proposed algorithms to bandit problems (e.g., regret minimization) which is mentioned in the introduction.
A naive approach is an explore-then-commit type algorithm (cf. Robbins (1952); Anscombe (1963)). One employs our algorithm to estimate a nearly period, followed by a certain periodic bandit algorithm such as the work in Cai et al. (2021) to obtain an asymptotic order of regret. Caveat here is, because our estimate is only an aliquot nearly period, one may need to take into account the regret caused by this misspecification when running bandit algorithms (e.g., and may lead to (small) linear regret). Avoiding this small linear regret would require the system to be -nearly periodic and that there exists a sufficiently large gap ensuring -nearly period with sufficiently small implies -nearly period.
If one aims at designing an anytime algorithm, the straightforward application of our algorithms may not give near optimal asymptotic rate of expected regret because the failure probability of periodic structure estimations cannot be adjusted later. To remedy this, one can employ our algorithm repetitively, and gradually increase the span of such procedure. Importantly, samples from separated spans can contribute to the estimate together when the surplus beyond a multiple of period is properly dealt with. Since failure probability decreases exponentially with respect to sample size, we conjecture that increasing the span for bandit algorithm by a certain order will lead to the same rate (up to logarithm) of expected regret of the adopted bandit algorithm.
Appendix F Simulation setups and results
Throughout, we used the following version of Julia Bezanson et al. (2017); for each experiment, the running time was less than a few minutes.
Julia Version 1.6.3 Platform Info: OS: Linux (x86_64-pc-linux-gnu) CPU: Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz WORD_SIZE: 64 LIBM: libopenlibm LLVM: libLLVM-11.0.1 (ORCJIT, broadwell) Environment: JULIA_NUM_THREADS = 12
We also used some tools and functionalities of Lyceum Summers et al. (2020). The licenses of Julia and Lyceum are [The MIT License; Copyright (c) 2009-2021: Jeff Bezanson, Stefan Karpinski, Viral B. Shah, and other contributors: https://github.com/JuliaLang/julia/contributors], and [The MIT License; Copyright (c) 2019 Colin Summers, The Contributors of Lyceum], respectively.
In this section, we provide simulation setups, including the details of parameter settings.
F.1 Period estimation: LifeGame
The hyperparameters of LifeGame environment and the algorithm are summarized in Table 3. Note because it is a periodic transition. Here, we used blocks of cells and we focused on the five blocks surrounded by the red rectangle in Figure 8. The transition rule is given by
-
1.
If the cell is alive and two or three of its surrounding eight cells are alive, then the cell remains alive.
-
2.
If the cell is alive and more than three or less than two of its surrounding eight cells are alive, then the cell dies.
-
3.
If the cell is dead and exactly three of its surrounding eight cells are alive, then the cell is revived.
| LifeGame hyperparameter | Value | Algorithm hyperparameter | Value |
|---|---|---|---|
| height | accuracy for estimation | ||
| width | failure probability bound | ||
| observed dimension | maximum possible period | ||
| observation noise proxy | |||
| ball radius |
F.2 Period estimation: Simple -nearly periodic system
The dynamical system
is -nearly periodic. See Figure 9 for the illustrations when . It is observed that there are five clusters. We mention that this system is not exactly periodic. The hyperparameters of this system and the algorithm are summarized in Table 4.
| System hyperparameter | Value | Algorithm hyperparameter | Value |
|---|---|---|---|
| dimension | accuracy for estimation | ||
| failure probability bound | |||
| maximum possible nearly period | |||
| observation noise proxy | |||
| ball radius |
F.3 Eigenvalue estimation
We used the matrix given by
| (F.6) |
The first block matrix is for permutation. After steps, it is expected that the last dimension shrinks so that the system becomes nearly periodic. It follows that is a multiple of the length . Eigenvalues of are given by , and the -distinct eigenvalues are .
The hyperparameters of the environment and the algorithm are summarized in Table 5. Note we don’t necessarily need , , and to run the algorithm as long as the effective sample size is sufficiently large; we used the values (satisfying the conditions) in Table 5 for simplicity.
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| a nearly period | |||
| failure probability bound | |||
| dimension | observation noise proxy | ||
| ball radius |
F.4 Realistic simulation
The hyperparameters used for period estimation that outputs an invalid estimate are summarized in Table 6 while those for a reasonable output are summarized in Table 7. Also, the hyperparameters used for the eigenvalue estimation are summarized in Table 8. Note for all of them, we used the fixed number of sample sizes.
| System hyperparameter | Value | Algorithm hyperparameter | Value |
|---|---|---|---|
| dimension | accuracy for estimation | ||
| sample number | maximum possible nearly period | ||
| observation noise proxy |
| System hyperparameter | Value | Algorithm hyperparameter | Value |
|---|---|---|---|
| dimension | accuracy for estimation | ||
| sample number | maximum possible nearly period | ||
| observation noise proxy |
| Hyperparameter | Value | Hyperparameter | Value |
|---|---|---|---|
| sample number | failure probability bound | ||
| dimension | observation noise proxy | ||
| a nearly period |