Dynamical Persistent Homology via Wasserstein Gradient Flow
Abstract
In this study, we introduce novel methodologies designed to adapt original data in response to the dynamics of persistence diagrams along Wasserstein gradient flows. Our research focuses on the development of algorithms that translate variations in persistence diagrams back into the data space. This advancement enables direct manipulation of the data, guided by observed changes in persistence diagrams, offering a powerful tool for data analysis and interpretation in the context of topological data analysis.
Keywords: persistent homology, optimal transport, Wasserstein gradient flow
1 Introduction
Persistent homology (Edelsbrunner et al., 2000) analyzes the multi-scale topological features of data, and a persistence diagram summarizes these features by keeping their birth and death across a filtration. Persistence diagram is also the most common topological feature that applied in topological data analyais (TDA) machine learning whose typical extraction can be presented as:
Here, we begin with input data, which can be point clouds, graphs, images, or manifolds, and use these to construct abstract simplicial complexes. A filtration, denoted by , creates a sequence of nested simplicial complexes from the data. With this structure, we use a matrix reduction algorithm (Edelsbrunner and Harer, 2022) to compute the persistence diagram, , for the -th homology group. The persistence diagram is a collection of points, each representing the birth and death of a topological feature.
Traditionally, the pipeline flows in one direction: from data to persistence diagrams. However, recent research highlights the need to reverse this process, allowing for filtration or even data adjustments through manipulation of persistence diagrams (Gameiro et al., 2016; Hofer et al., 2020; Oudot and Solomon, 2020; Ballester and Rieck, 2024).
This paper focuses on adapting data based on the dynamics of persistence diagrams along Wasserstein gradient flows. This builds on prior work by using Wasserstein gradient flows to guide the process of modifying data to achieve desired topological characteristics. By developing algorithms that translate changes in persistence diagrams back to the data space, this research enables data analysis and interpretation through TDA.
2 Related Work
As mentioned in Introduction 1, persistence diagrams are a powerful tool for summarizing topological information (Edelsbrunner et al., 2000; Edelsbrunner and Harer, 2022; Chazal and Divol, 2018). They have found applications in diverse fields including shape analysis (Poulenard et al., 2018), image analysis (Li et al., 2014; Singh et al., 2007), graph classification (Li et al., 2012; Rieck et al., 2019; Carrière et al., 2020; Wang et al., ), link prediction (Yan et al., 2021; Aktas et al., 2019), and various machine learning tasks (Chen et al., 2021a, b, 2024; Wang et al., 2024).
One key aspect of persistence diagrams is their stability with respect to perturbations in the data they are built upon. The most common metric used to compare persistence diagrams is the bottleneck distance, which corresponds to the -Wasserstein distance. The stability of persistence diagrams under the bottleneck distance has been well studied (Cohen-Steiner et al., 2005; Edelsbrunner et al., 2006; Chazal et al., 2009). However, the bottleneck distance can be sensitive to outliers and often provides overly pessimistic bounds, especially in high-dimensional settings. Recent work has shifted focus to the use of -Wasserstein distances, A central challenge in this area has been establishing the stability of persistence diagrams with respect to the -Wasserstein distance(Skraba and Turner, 2020).
The differentiability of persistence diagrams is another important consideration for optimization problems. Early work relied on explicitly computing the derivatives of persistence diagrams with respect to function values, often requiring combinatorial updates (Poulenard et al., 2018). More recently, researchers have leveraged tools from real analytic geometry and o-minimal theory to establish the differentiability of persistence-based functions. Carriere et al. (2021) demonstrated that the persistence map can be viewed as a semi-algebraic map between Euclidean spaces, enabling the definition and computation of gradients for a wide range of persistence-based functions. Moreover, Leygonie (2022); Leygonie et al. (2022) not only provide a theoretical foundation for the application of gradient-based optimization techniques to persistence-based problems, but also establish a framework for understanding how changes in data parameters impact persistence diagrams.
Several previous studies have explored methods for manipulating data through modifications to persistence diagrams. Gameiro et al. (2016) developed a method for point cloud continuation by using the Newton-Raphson method to move a persistence diagram towards a target diagram, iteratively updating the point cloud to achieve the desired topological features. Poulenard et al. (2018) presented an approach for optimizing real-valued functions based on topological criteria, using derivatives of persistence diagrams to guide the modification of the function and achieve desired topological properties. Corcoran and Deng (2020) focused on regularizing the computation of persistence diagram gradients to improve the optimization process in data science applications.
These works demonstrate the potential of using persistence diagrams as a tool for manipulating data to achieve desired topological characteristics. The current work aims to build upon these efforts by developing novel algorithms that translate variations in persistence diagrams back into the data space, with a focus on the -Wasserstein distance and gradient-based optimization techniques.
3 Preliminaries
This study’s theoretical foundation rests on two key areas: Wasserstein gradient flows (WGFs) and differentiable persistence diagrams. In this Preliminaries section, we first introduce the concept of gradient flows in Hilbert spaces, providing the necessary mathematical background. We then extend this to gradient flows in Wasserstein spaces, a crucial framework for our analysis. Finally, we present the fundamentals of differentiable persistent homology, an essential tool in topological data analysis that connects persistent homology with differentiable optimization techniques. These concepts form the basis for the methodologies and analyses presented in subsequent chapters.
3.1 Gradient Flow in Hilbert Space
Gradient flow in Hilbert space (Ambrosio et al., 2008) is a fundamental concept in the analysis of variational problems and partial differential equations. It describes the evolution of a function in a Hilbert space under the influence of its gradient, leading to a minimization of the associated energy functional.
Let be a Hilbert space with inner product and norm . Consider an energy functional , which is typically assumed to be Fréchet differentiable. The gradient flow of is the solution to the differential equation
| (1) |
where represents the state of the system at time , and denotes the gradient of at .
The gradient is defined by the property that for all ,
| (2) |
This ensures that the direction of the gradient is the direction of the steepest ascent of the functional . Consequently, the negative gradient points in the direction of the steepest descent, which is why it appears in Equation (1).
One of the key properties of gradient flow is that it decreases the energy functional over time. Specifically, if is a solution to Equation (1), then
| (3) |
This implies that is non-increasing along the curve . Moreover, since , if has a unique stationary point , converges to it as under appropriate conditions.
3.2 Proximal Map in Hilbert Space
From a computational perspective, discretization schemes are essential for approximating gradient flows in Hilbert spaces. The implicit Euler scheme, also known as the minimizing movement scheme or proximal map (Bubeck et al., 2015), is particularly effective for this purpose. This scheme approximates the continuous-time gradient flow by a sequence of discrete minimization problems:
| (4) |
where is the time step, represents the approximation at the -th time step, is the energy functional, and is the Hilbert space. This scheme not only provides a practical method for numerical computations but also offers insights into the theoretical properties of gradient flows, such as their connection to proximal operators and convex analysis.
3.3 Gradient Flow in Wasserstein Space
Gradient flow in Wasserstein space extends the concept of gradient flow from Hilbert spaces to the space of probability measures. This framework is particularly valuable for studying partial differential equations and variational problems involving mass transport. While this subsection provides a brief introduction, readers are encouraged to consult Ambrosio et al. (2008) for a more comprehensive treatment.
The Wasserstein space is defined as the space of probability measures with finite second moments, equipped with the Wasserstein distance. More formally, let be a metric space. The Wasserstein space of order over , denoted by , is the set of all probability measures on with finite -th moment:
| (5) |
where is a fixed reference point in . This definition ensures that the measures in have well-behaved moments, which is crucial for various analytical properties.
The Wasserstein distance of order between two probability measures is defined as:
where represents the set of all joint probability measures on with marginals and . This distance metric quantifies the optimal cost of transporting mass from one probability distribution to another, providing a natural way to compare and analyze probability measures in the context of gradient flows.
With a series of works by Benamou and Brenier (2000); Otto (2001); Ambrosio et al. (2008), the concept of gradient flow in Wasserstein space has been rigorously established.
Consider an energy functional defined on a Wasserstein space, where denotes the space of probability measures with finite second moments as in Equation (5). A curve of probability measures is called a Wasserstein gradient flow for the functional if it satisfies the following continuity equation in a weak sense:
| (6) |
Here, represents the first variation of at , defined by
This first variation can be interpreted as the “functional derivative” of with respect to , extending the concept of derivatives to measure spaces. Consequently, for represents a time-dependent family of vector fields. Chewi et al. (2020) refer to this as the Wasserstein gradient, denoted as . This term draws an analogy with the standard gradient in Euclidean spaces due to its similar role in describing the flow of probability measures. Additionally, some literature defines the Wasserstein gradient as to maintain consistency with Equation (1).
3.4 JKO Scheme
The JKO scheme, named after Jordan, Kinderlehrer, and Otto, is a time-discretization method for approximating the Wasserstein gradient flow (Jordan et al., 1998), It involves solving a sequence of minimization problems:
where is the time step. The transition from the continuous Wasserstein gradient flow to the discrete JKO scheme can be understood through the concept of minimizing movement which approximates the continuous flow by discrete steps. The convergence of the JKO scheme to the continuous Wasserstein gradient flow as is established through -convergence (Ambrosio et al., 2008). The functional often represents the internal energy or potential energy of the system, and its gradient with respect to the Wasserstein metric drives the evolution of the distribution (Villani et al., 2009; Villani, 2021). The JKO scheme is particularly useful in numerical simulations of diffusion processes and other phenomena described by partial differential equations (PDEs) in the Wasserstein space (Santambrogio, 2015). Applications of the JKO scheme include image processing, machine learning, and fluid dynamics, where the evolution of distributions is of interest (Peyré et al., 2019).
3.5 Differentiability on Persistence Diagrams
Nigmetov and Morozov (2024) introduces a novel method that directly uses the cycles and chains involved in the persistence computation to define gradients for larger subsets of the data. This contrasts with prior methods that focused solely on individual PD points. The authors also demonstrate that this approach can significantly reduce the number of steps required for optimization. Our work builds upon this idea, allowing it to adapt data based on variations in PDs along Wasserstein gradient flows.
4 Methodology
We introduce our basic settings as follows. Let a function , where denotes a simplicial complex, induce a filtration. This function assigns a real value to each simplex in the complex, thereby defining a sequence of subcomplexes for . Let be the algorithm to compute -th persistence homology based on Nigmetov and Morozov (2024, Algorithm 1). In this study, we don’t take essential features into account. To construct the dynamical persistence diagram, we consider two situations: with or without a target persistence diagram.
4.1 Dynamical Persistent Homology via McCann Interpolation
In this subsection, we assume that the target persistence diagram is known a priori. Our objective is to develop a learnable process for generating persistence diagrams guided by a dynamical system. To approach this problem, we draw upon two fundamental theorems from optimal transport theory: the Benamou-Brenier Theorem and the McCann Interpolation Theorem. The Benamou-Brenier Theorem provides a dynamic formulation of optimal transport, allowing us to view the transport problem as a fluid flow minimizing a kinetic energy functional. Meanwhile, the McCann Interpolation Theorem offers a way to construct geodesics in the space of probability measures, which is crucial for understanding the geometry of persistence diagrams. By leveraging these theorems, we can formulate a continuous evolution of persistence diagrams that converges to the target diagram while respecting the underlying topological structure of the data.
The Benamou-Brenier theorem shows that the optimal transport cost can be expressed as the infimum of the action integral over all possible time-dependent probability measures and velocity fields that transport to .
Theorem 1 (Benamou-Brenier (Benamou and Brenier, 2000))
Let and be two probability measures on with finite second moments. The squared Wasserstein distance between and can be expressed as:
| (7) |
subject to the continuity constraints:
| (8) |
On the other hand, McCann’s interpolation theorem describes the displacement interpolation between two probability measures in the context of optimal transport, showing that the interpolation is a geodesic in the Wasserstein space.
Theorem 2 (McCann Interpolation (Villani, 2021))
Let and be two probability measures on with finite second moments, and let be the optimal transport map pushing forward to . Define the displacement interpolation for by:
| (9) |
where denotes the push-forward operation, is the identity map and is the interpolation map. Then:
-
1.
is a probability measure for each ,
-
2.
The curve is a geodesic in the Wasserstein space ,
-
3.
The Wasserstein distance between and can be expressed as:
(10)
Therefore, we have the following remark.
Remark 3 (McCann Interpolation is a WGF (Ambrosio et al., 2008))
The McCann interpolation can be viewed as a specific instance of a dynamical process. Based on this insight, we have developed an algorithm that leverages McCann interpolation to guide the optimization within the context of persistence diagrams.
In the Algorithm 1, the can be efficiently computed using the Sinkhorn algorithm (Cuturi, 2013), known for its rapid convergence and computational efficiency. Alternatively, conventional linear programming methods can also be employed. The optimal transportation plan is represented as an matrix, where and denote the cardinalities of the source persistence diagram and the target persistence diagram , respectively. Each entry in the matrix indicates the amount of mass to be transported from to . The mass associated with each point and is and , respectively.
In cases where and are not equal, the function computes an appropriate target persistence diagram. This is achieved by using the barycenter to determine the target locations, calculated as follows:
| (15) |
The Algorithm 1 demonstrates the use of McCann interpolation to guide optimization on persistence diagrams. The core idea is to obtain the next persistence diagram through McCann interpolation and employ a learnable scheme, specifically the critical set method (Nigmetov and Morozov, 2024), to determine the subsequent filtration. This approach allows for the construction of the entire dynamical process of the persistence diagram.
The results represent the persistence diagram, the next target persistence diagram, and the filtration at step , respectively. We explicitly store to maintain the next step’s persistence diagram because the learnable scheme cannot guarantee that the persistence diagram is always achievable (Nigmetov and Morozov, 2024). This is also why we do not compute the full trajectories before learning the filtration. Instead, we compute the McCann interpolation at each step to ensure that the persistence diagram progresses towards the target persistence diagram. In other words, this algorithm optimizes the filtration towards the final target rather than intermediate states.
The proposed algorithm is particularly well-suited for applications where a target persistence diagram is explicitly defined. Additionally, in the context of McCann interpolation, our algorithm guarantees that the measure evolves along the geodesic in Wasserstein space, provided that the target persistence diagram is achievable at each step. This property ensures that the topological features of the data, as captured by persistence diagrams, change towards the target diagram in the best possible manner.
4.2 Dynamical Persistent Homology via Energy Functional
The previous subsection demonstrated the dynamical persistence diagrams along McCann interpolation trajectories, given a target persistence diagram. In this subsection, we extend our methodology to scenarios without a predefined target diagram. As introduced in Subsection 3.3, a dynamical system describes the temporal evolution of a state according to a set of rules or equations. In the context of Wasserstein gradient flow, the probability measure evolves following the gradient flow of an energy functional in the Wasserstein space. This evolution follows a path that locally minimizes most efficiently with respect to the Wasserstein distance. The choice of functional determines the system’s ultimate configuration, allowing for diverse outcomes depending on the specific energy landscape.
To perform the dynamical persistence diagram through Wasserstein gradient flows, we propose the following Algorithm 2.
Algorithm 2, akin to Algorithm 1, outputs , , and , which represent the current persistence diagram, the target persistence diagram, and the filtration at step , respectively. The key distinction lies in Algorithm 2’s utilization of the JKO scheme to compute the target persistence diagram at each iteration. Importantly, we initialize the target persistence diagram with the current persistence diagram, ensuring equal cardinalities. This approach enables us to leverage the energy functional to guide the optimization process without prior knowledge of the final target persistence diagram.
5 Case Illustrations
The most beneficial aspect of the proposed methodology is its ability to capture the dynamic evolution of topological features in complex data. To demonstrate the effectiveness of our approach, inspired by the examples in Carriere et al. (2021), we present two case illustrations: circle denoising and circle emerging. These examples showcase the power of dynamical persistence diagrams in uncovering the underlying topological structures of noisy data and emerging patterns. In both cases, we use Rips filtration.
5.1 Circle Denoising
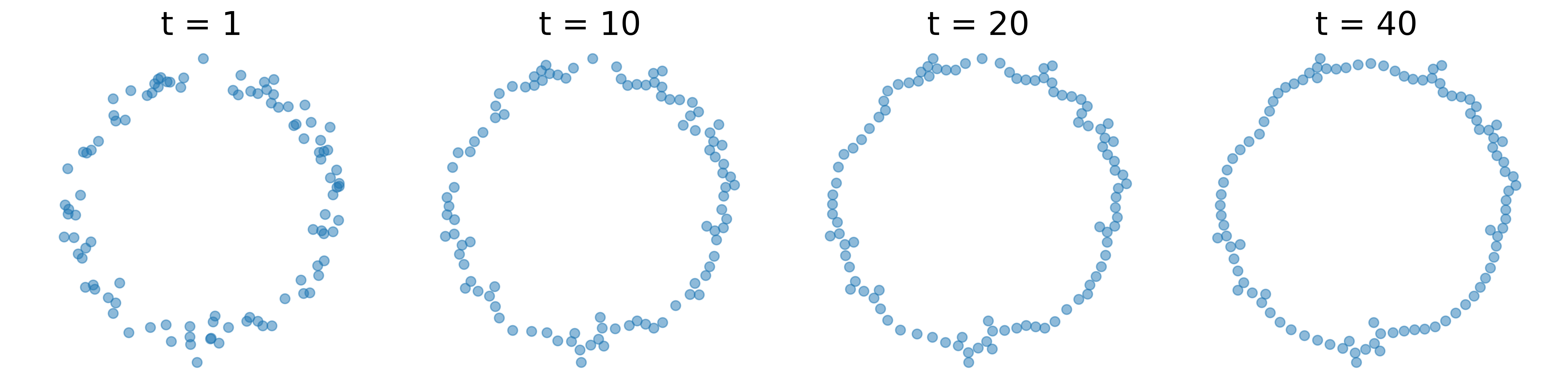
Our first illustration concerns the denoising of a circle. The input data consists of a set of points in a 2D plane, sampled from a circle with added Gaussian noise. This noisy data forms a perturbed circle, as depicted in Figure 1. The objective is to remove the noise and highlight the primary 1-dimensional topological feature, namely the circle itself.
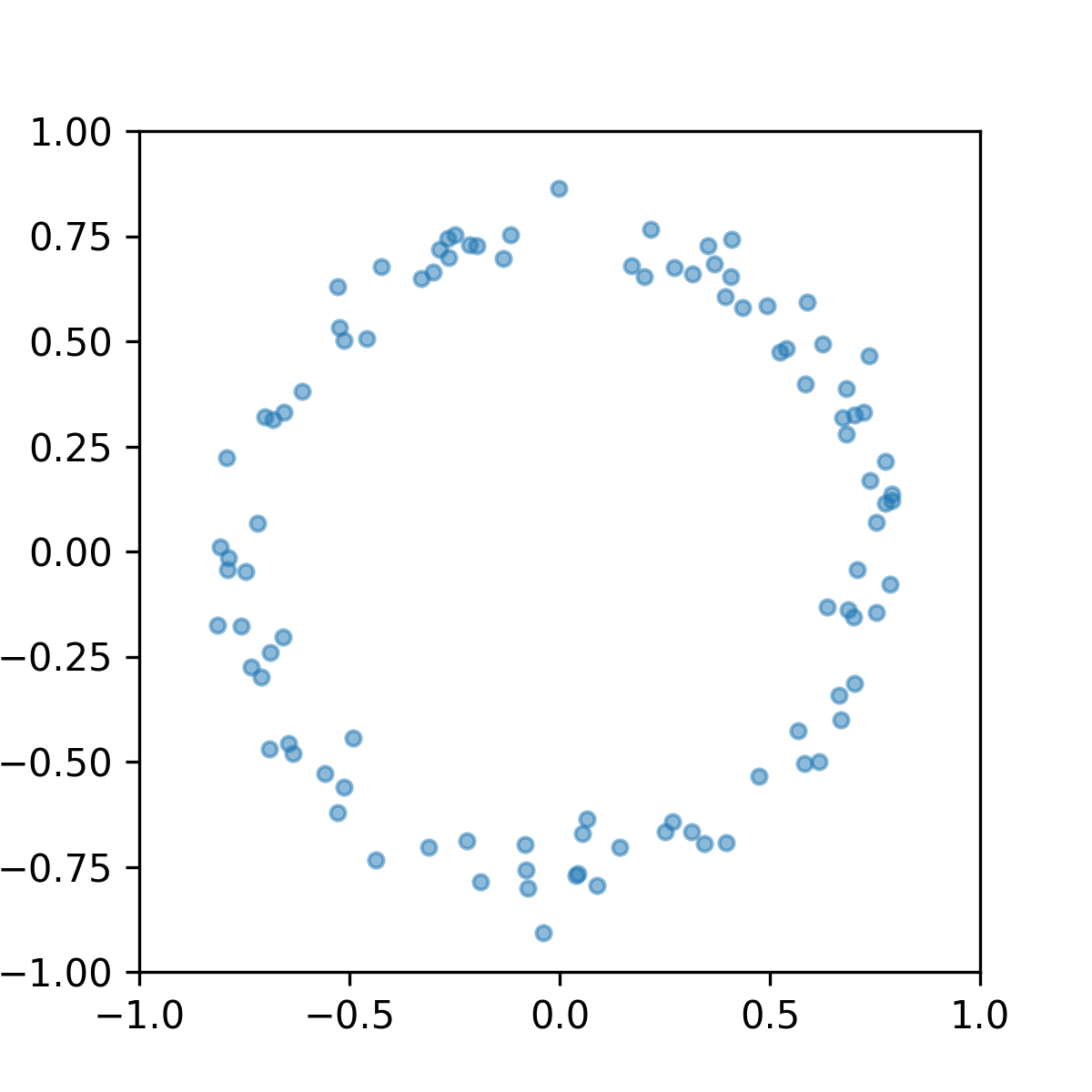
5.1.1 Repulsion Loss
In this experiment, we need to prevent the points from clustering together. To achieve this, we introduce an auxiliary loss function designed to enforce point separation. Specifically, given the point set , where each , the repulsion loss is defined as follows:
This formula calculates the repulsion loss for the point set . The parameter is a small positive constant that ensures the denominator does not become zero, thereby avoiding numerical instability.
5.1.2 Circle Denoising via McCann Interpolation on 0th Persistence Diagram
The target persistence diagram represents a 1-dimensional circle, which is the primary topological feature of interest. We apply Algorithm 1 to denoise the 0th persistence diagram, using the target persistence diagram as a reference. More specifically, we set the target of the 0th persistence diagram to in the experiment, aiming to give these points a reasonable distance from nearby points. For the 1st persistence diagram, we employ a built-in denoising method. The evolution of the denoising process is illustrated in Figure 2, where the denoised circle becomes clearly visible.
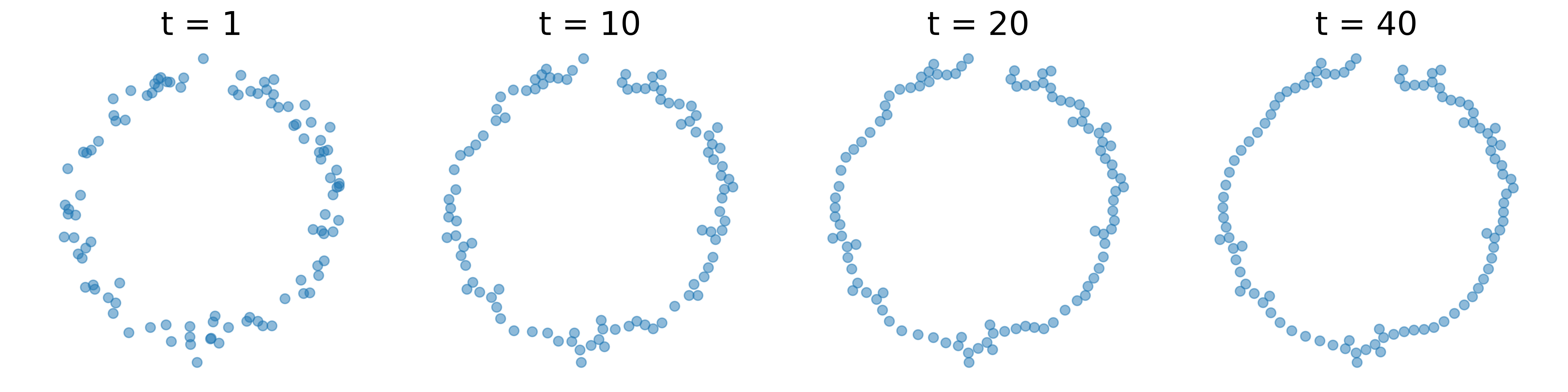
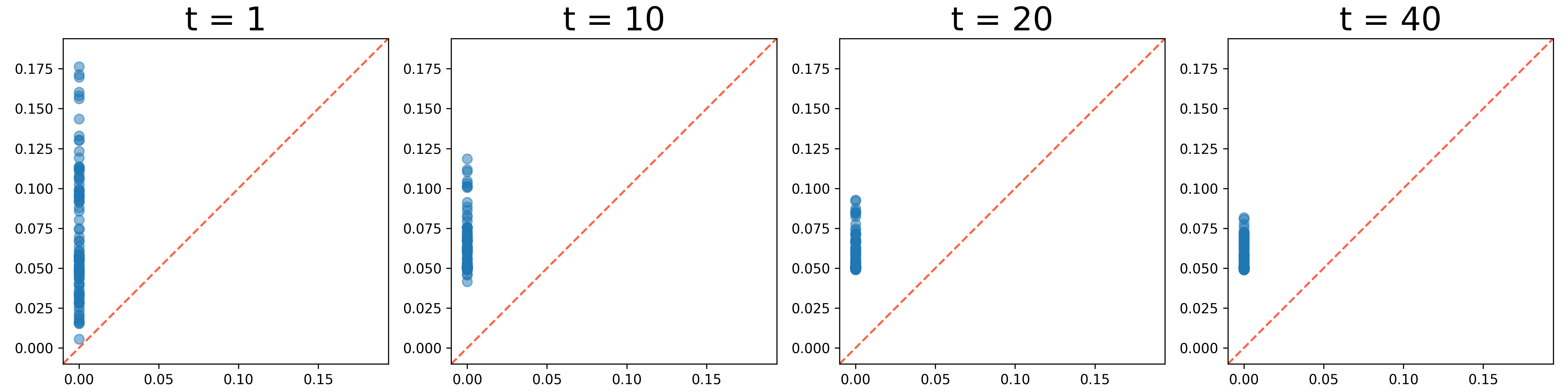
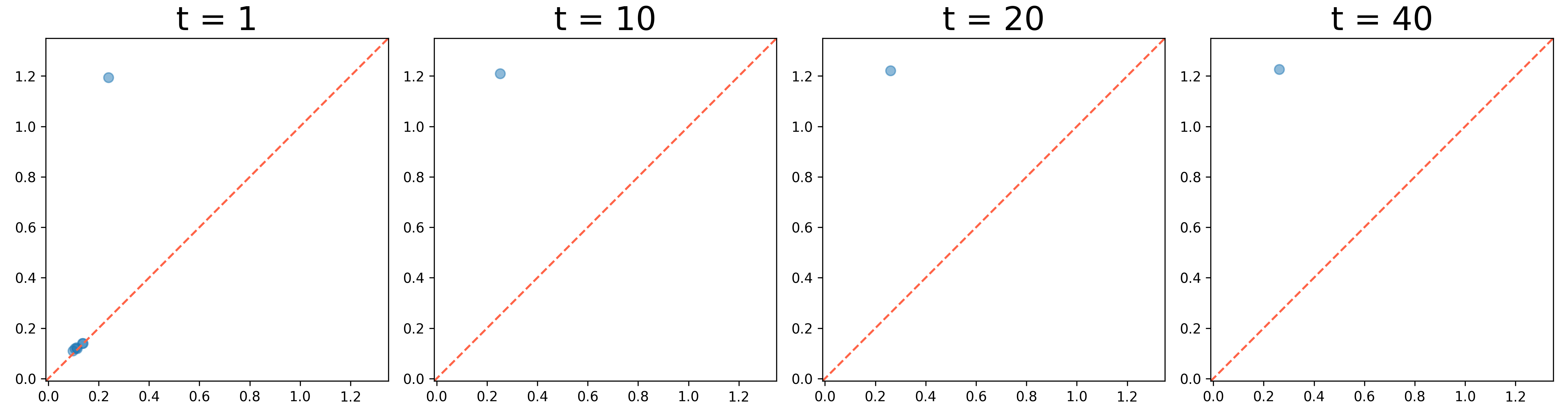
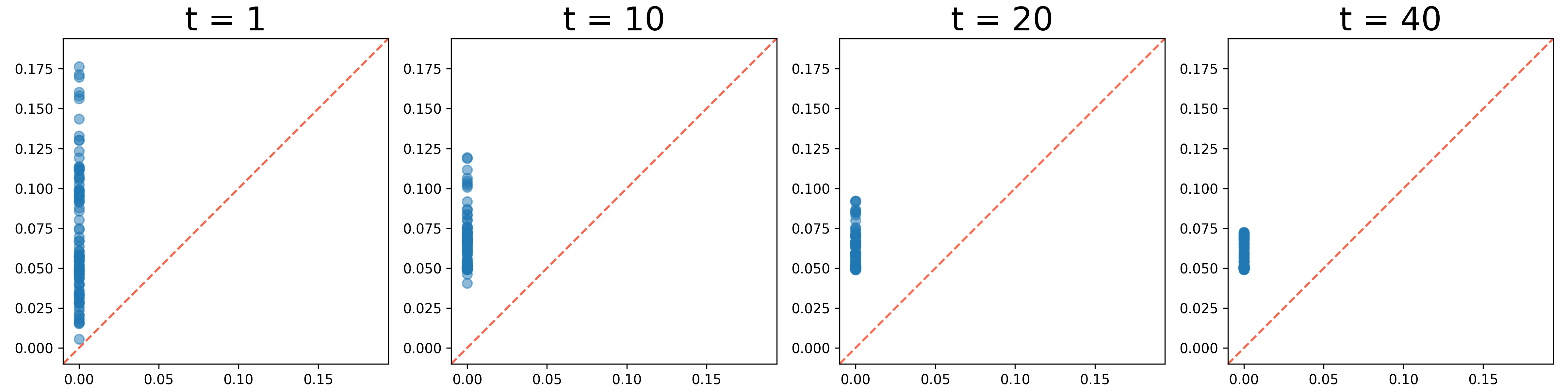
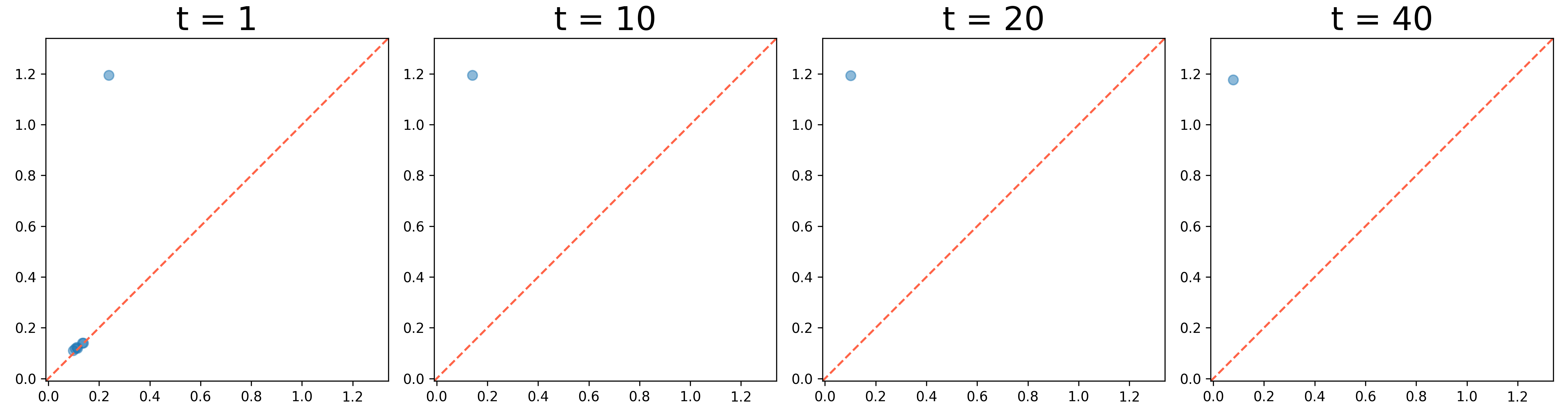
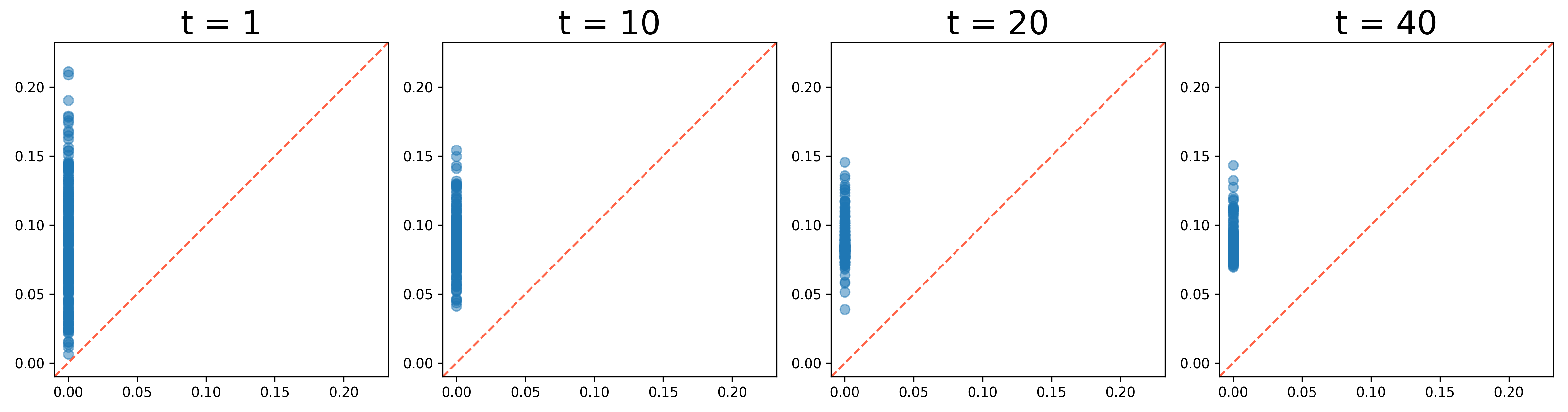
We present the evolution of the 0th and 1st persistence diagrams in Figure 3 and Figure 4, respectively. The denoising process effectively eliminates noise from the data, thereby revealing the underlying circular structure. As shown in the figures, the persistence diagrams progressively converge to the target diagram, illustrating the successful denoising of the circle data.
However, we observe a gap at the top of the circle in the results. This occurs because the McCann interpolation is applied solely to the 0th persistence diagram, neglecting the 1st persistence diagram. The built-in denoising process lacks control over the upper left 1st persistence pair, which represents the circle. To address this issue, we apply Algorithm 2 to denoise the 1st persistence diagram and let the persistence pair move towards the left.
5.1.3 Circle Denoising via Energy Functional on 1st Persistence Diagram
To achieve the goal we mentioned above, we apply Algorithm 2 with the energy functional
It makes the points near to the diagonal move towards the diagonal, while points far from the diagonal move towards . The results of this process are illustrated in Figure 5, Figure 6, and Figure 7. In JKO, we use the sliced Wasserstein implementation from Bonet et al. (2022) for efficiency purposes. As shown, the algorithm not only effectively removes noise from the data but also fills gaps at the top of the circle successfully.
5.2 Circle Emerging
Given a set of random 2D points on a plane, we observe that the first persistence diagram is not always empty. In this case, the objective is to enhance the circles represented by the first persistence diagram. In the experiment, we independently and identically sample 250 points from the uniform distribution on the square . Similar to the previous case, we apply the McCann algorithm with a target of on the 0th persistence diagrams. Additionally, we apply Algorithm 2 with the functional
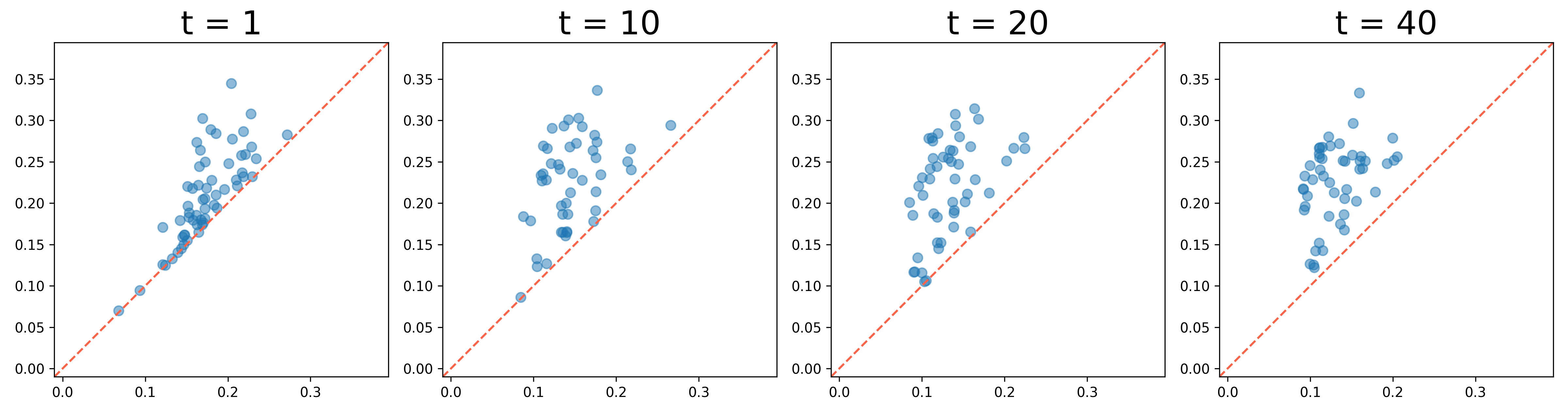
to encourage the first persistence pairs above a certain threshold to evolve away from the diagonal line and drift to the left. The results of this process are illustrated in Figure 8. We also present 0th and 1st persistence diagrams in Figure 9 and Figure 10, respectively. The results demonstrate how the persistence diagrams evolve over time, highlighting the emergence of the circle from the random 2D points.
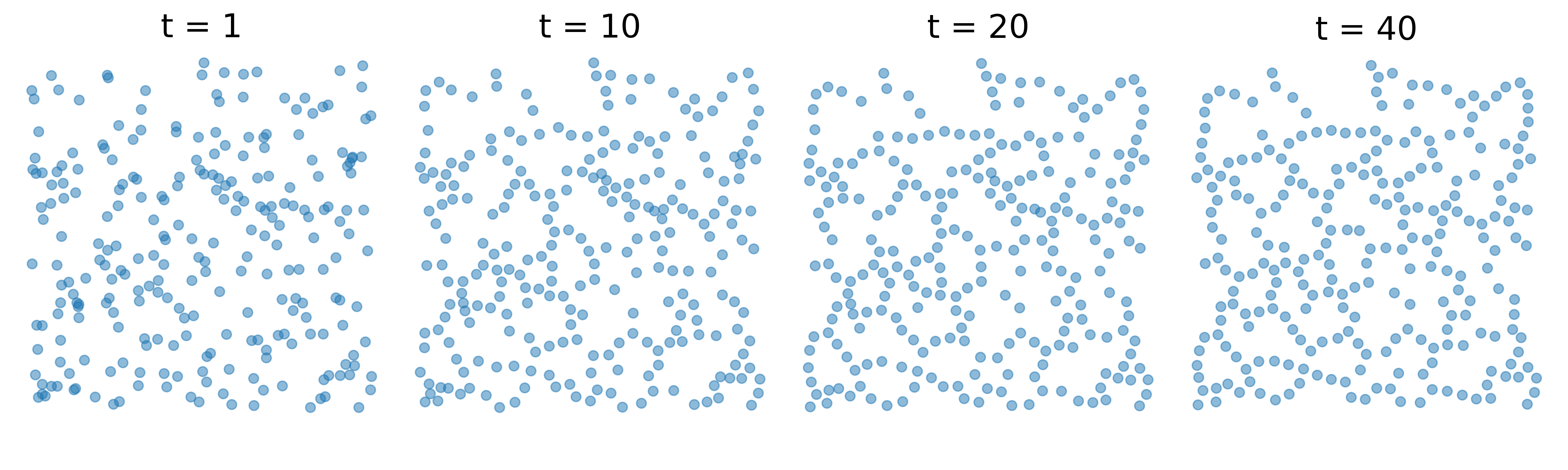
6 Limitations and Further Works
First, the current learnable persistence diagram scheme cannot be executed on a GPU, which hinders the scalability of the proposed algorithms when applied to large datasets. This limitation restricts the practical application of these methods in real-world scenarios where computational efficiency is crucial. Second, the proposed methods exclusively consider persistence diagrams. It is worth exploring whether other topological features, such as Zigzag persistence or multiparameter persistence, can be integrated into the proposed framework to enhance its versatility. Third, there is a need to establish statistical theories for the proposed methods when utilizing different energy functionals. For instance, when deriving dynamical persistence diagrams from a time series of real-world data, it is essential to determine the statistical properties of these diagrams. Additionally, identifying an appropriate energy functional that governs the generation of dynamical persistence diagrams from the time series is crucial. Furthermore, guidelines for selecting suitable energy functionals for various tasks should be developed to ensure optimal performance. Finally, a more effective approach is required to address the conflicts arising from singleton losses (Nigmetov and Morozov, 2024) in the proposed methods, as these conflicts can significantly impact the accuracy and reliability of the results.
7 Conclusion
In this study, we propose two methods to integrate Wasserstein gradient flow into the learning process for persistence diagrams. First, by leveraging McCann interpolation, we develop an algorithm that optimizes persistence diagrams along the geodesic in the Wasserstein space. This approach ensures that the optimization path respects the intrinsic geometry of the space, leading to more accurate and meaningful results. Second, we introduce an energy functional-based approach that guides the optimization process without requiring a predefined target persistence diagram. This method allows for greater flexibility and adaptability in various applications. We demonstrate the effectiveness of our methods through case studies, including the denoising of a circle and the emergence of a circle from noisy data. These examples illustrate how our techniques can enhance the temporal evolution of topological features, highlighting the potential of dynamical persistence diagrams in topological data analysis.
Acknowledgments
We are grateful for the insightful discussion with Dr. Ziyun Huang at the outset of this paper, which played a crucial role in shaping its development.
References
- Aktas et al. (2019) M. E. Aktas, E. Akbas, and A. E. Fatmaoui. Persistence homology of networks: methods and applications. Applied Network Science, 4(1):1–28, 2019.
- Ambrosio et al. (2008) L. Ambrosio, N. Gigli, and G. Savaré. Gradient flows: in metric spaces and in the space of probability measures. Springer Science & Business Media, 2008.
- Ballester and Rieck (2024) R. Ballester and B. Rieck. On the expressivity of persistent homology in graph learning. In The Third Learning on Graphs Conference, 2024.
- Benamou and Brenier (2000) J.-D. Benamou and Y. Brenier. A computational fluid mechanics solution to the monge-kantorovich mass transfer problem. Numerische Mathematik, 84(3):375–393, 2000.
- Bonet et al. (2022) C. Bonet, N. Courty, F. Septier, and L. Drumetz. Efficient gradient flows in sliced-wasserstein space. Transactions on Machine Learning Research, 2022.
- Bubeck et al. (2015) S. Bubeck et al. Convex optimization: Algorithms and complexity. Foundations and Trends® in Machine Learning, 8(3-4):231–357, 2015.
- Carrière et al. (2020) M. Carrière, F. Chazal, Y. Ike, T. Lacombe, M. Royer, and Y. Umeda. Perslay: A neural network layer for persistence diagrams and new graph topological signatures. In International Conference on Artificial Intelligence and Statistics, pages 2786–2796. PMLR, 2020.
- Carriere et al. (2021) M. Carriere, F. Chazal, M. Glisse, Y. Ike, H. Kannan, and Y. Umeda. Optimizing persistent homology based functions. In International conference on machine learning, pages 1294–1303. PMLR, 2021.
- Chazal and Divol (2018) F. Chazal and V. Divol. The density of expected persistence diagrams and its kernel based estimation. arXiv preprint arXiv:1802.10457, 2018.
- Chazal et al. (2009) F. Chazal, D. Cohen-Steiner, M. Glisse, L. J. Guibas, and S. Y. Oudot. Proximity of persistence modules and their diagrams. In Proceedings of the twenty-fifth annual symposium on Computational geometry, pages 237–246, 2009.
- Chen et al. (2021a) Y. Chen, B. Coskunuzer, and Y. Gel. Topological relational learning on graphs. Advances in neural information processing systems, 34:27029–27042, 2021a.
- Chen et al. (2021b) Y. Chen, I. Segovia, and Y. R. Gel. Z-gcnets: Time zigzags at graph convolutional networks for time series forecasting. In International Conference on Machine Learning, pages 1684–1694. PMLR, 2021b.
- Chen et al. (2024) Y. Chen, J. Frias, and Y. R. Gel. Topogcl: Topological graph contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11453–11461, 2024.
- Chewi et al. (2020) S. Chewi, T. Le Gouic, C. Lu, T. Maunu, and P. Rigollet. Svgd as a kernelized wasserstein gradient flow of the chi-squared divergence. Advances in Neural Information Processing Systems, 33:2098–2109, 2020.
- Cohen-Steiner et al. (2005) D. Cohen-Steiner, H. Edelsbrunner, and J. Harer. Stability of persistence diagrams. In Proceedings of the twenty-first annual symposium on Computational geometry, pages 263–271, 2005.
- Corcoran and Deng (2020) P. Corcoran and B. Deng. Regularization of persistent homology gradient computation. arXiv preprint arXiv:2011.05804, 2020.
- Cuturi (2013) M. Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26, 2013.
- Edelsbrunner and Harer (2022) H. Edelsbrunner and J. L. Harer. Computational topology: an introduction. American Mathematical Society, 2022.
- Edelsbrunner et al. (2000) H. Edelsbrunner, D. Letscher, and A. Zomorodian. Topological persistence and simplification. In Proceedings 41st annual symposium on foundations of computer science, pages 454–463. IEEE, 2000.
- Edelsbrunner et al. (2006) H. Edelsbrunner, D. Morozov, and V. Pascucci. Persistence-sensitive simplification functions on 2-manifolds. In Proceedings of the twenty-second annual symposium on Computational geometry, pages 127–134, 2006.
- Gameiro et al. (2016) M. Gameiro, Y. Hiraoka, and I. Obayashi. Continuation of point clouds via persistence diagrams. Physica D: Nonlinear Phenomena, 334:118–132, 2016.
- Hofer et al. (2020) C. Hofer, F. Graf, B. Rieck, M. Niethammer, and R. Kwitt. Graph filtration learning. In International Conference on Machine Learning, pages 4314–4323. PMLR, 2020.
- Jordan et al. (1998) R. Jordan, D. Kinderlehrer, and F. Otto. The variational formulation of the fokker–planck equation. SIAM journal on mathematical analysis, 29(1):1–17, 1998.
- Leygonie (2022) J. Leygonie. Differential and fiber of persistent homology. PhD thesis, University of Oxford, 2022.
- Leygonie et al. (2022) J. Leygonie, S. Oudot, and U. Tillmann. A framework for differential calculus on persistence barcodes. Foundations of Computational Mathematics, pages 1–63, 2022.
- Li et al. (2014) C. Li, M. Ovsjanikov, and F. Chazal. Persistence-based structural recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1995–2002, 2014.
- Li et al. (2012) G. Li, M. Semerci, B. Yener, and M. J. Zaki. Effective graph classification based on topological and label attributes. Statistical Analysis and Data Mining: The ASA Data Science Journal, 5(4):265–283, 2012.
- Nigmetov and Morozov (2024) A. Nigmetov and D. Morozov. Topological optimization with big steps. Discrete & Computational Geometry, 72(1):310–344, 2024.
- Otto (2001) F. Otto. The geometry of dissipative evolution equations: the porous medium equation. 2001.
- Oudot and Solomon (2020) S. Oudot and E. Solomon. Inverse problems in topological persistence. In Topological Data Analysis: The Abel Symposium 2018, pages 405–433. Springer, 2020.
- Peyré et al. (2019) G. Peyré, M. Cuturi, et al. Computational optimal transport: With applications to data science. Foundations and Trends® in Machine Learning, 11(5-6):355–607, 2019.
- Poulenard et al. (2018) A. Poulenard, P. Skraba, and M. Ovsjanikov. Topological function optimization for continuous shape matching. In Computer Graphics Forum, volume 37, pages 13–25. Wiley Online Library, 2018.
- Rieck et al. (2019) B. Rieck, C. Bock, and K. Borgwardt. A persistent weisfeiler-lehman procedure for graph classification. In International Conference on Machine Learning, pages 5448–5458. PMLR, 2019.
- Santambrogio (2015) F. Santambrogio. Optimal transport for applied mathematicians. Birkäuser, NY, 55(58-63):94, 2015.
- Singh et al. (2007) G. Singh, F. Mémoli, G. E. Carlsson, et al. Topological methods for the analysis of high dimensional data sets and 3d object recognition. PBG@ Eurographics, 2:091–100, 2007.
- Skraba and Turner (2020) P. Skraba and K. Turner. Wasserstein stability for persistence diagrams. arXiv preprint arXiv:2006.16824, 2020.
- Villani (2021) C. Villani. Topics in optimal transportation, volume 58. American Mathematical Soc., 2021.
- Villani et al. (2009) C. Villani et al. Optimal transport: old and new, volume 338. Springer, 2009.
- (39) M. Wang, H. Yan, Z. Huang, D. Wang, and J. Xu. Persistent local homology in graph learning. Transactions on Machine Learning Research.
- Wang et al. (2024) M. Wang, Z. Huang, and J. Xu. Multiset transformer: Advancing representation learning in persistence diagrams. arXiv preprint arXiv:2411.14662, 2024.
- Yan et al. (2021) Z. Yan, T. Ma, L. Gao, Z. Tang, and C. Chen. Link prediction with persistent homology: An interactive view. In International conference on machine learning, pages 11659–11669. PMLR, 2021.