Dynamics–Decoupling Control for Strings
of Heterogenous Nonlinear Autonomous Agents
Abstract
We introduce a distributed control architecture for a class of heterogeneous, nonlinear dynamical agents moving in the “string” formation, while guaranteeing trajectory tracking, collision avoidance and the preservation of the formation’s topology. Each autonomous agent uses information and relative measurements only with respect to its predecessor in the string. The performance of the scheme is independent of the number of agents in the network and also on the agent’s relative position in the network. The scalability is a consequence of the “decoupling” of a certain bounded approximation of the closed–loop equations, which allows the regulation and controller design (at each agent) to be done individually, in a completely decentralized manner. A practical method for compensating communication induced delays is also presented. Numerical examples illustrate the effectiveness and the main features of the proposed approach.
I Introduction
Practical algorithms for distributed control of dynamically coupled systems are needed in many diverse applications raging from formation control of autonomous mobile agents [1, 2], synchronization of local clocks offsets or phase differences between (neighboring) coupled oscillators [3] or synchronous generators in power networks, sensor networks, load balancing [4], distributed agreement algorithms, cooperative control of multi-robot systems [5], opinion dynamics etc. In the specific setting of autonomous agents, the intricacies of dynamical coupling are not caused by the structure of the plant but rather by: (i) the structure of the cost functional resulting from the definition of the regulated measurements (e.g. in formation control - the inter-agent spacing distances defining the topology of the formation) and (ii) the coupling induced in the entailing feedback loop (with the distributed controller). The subsequent controller design problem is further complicated by the constraints to be imposed on the sensing and communications radii111By communications radius we mean the number of hops associated to an agent in the communications graph. The communications graph designates for each agent the neighbors with which it is able to communicate. of each agent.
The goal of the distributed control scheme is for all the agents to attain certain types of global collaborative behavior, such as their outputs/states reaching agreement in a precisely defined metric. In modern control parlance this class of objectives have been dubbed consensus [6, 7] and synchronization [8, 9, 10, 11, 12] problems. In the existing literature there is no clear demarcation line for this terminology (consensus versus synchronization), therefore we refer to [13, Section 1], [14, Section 1] for a useful discussion. It is worth mentioning that synchronization is a far more ambitious objective than classical reference tracking [15, Chapter 5.4], not only due to the distributed nature of the problem but also because the reference signals are never explicitly available to all agents, while in certain scenarios the synchronization trajectory is not even assigned beforehand and therefore there is no explicit reference to be tracked [14].
In this paper we deal with a group of heterogenous, nonlinear dynamical agents that solve a conventional agreement task (velocities matching in our case) but to which we append a specific set of constraints linking the individual states of two adjacent agents (in our case their positions in space). It turns out that the inclusion of such constraints render existing methods in distributed synchronization (e.g. distributed output regulation) inapplicable directly. The constraints relate to the inter-spacing distance between two agents, defined as the difference of their individual positions in space. In distance-based formation control222When referring to the position in space of an autonomous agent within a group of agents, the position must be defined with respect to an inertial system of reference common to all agents, e.g. a Global Positioning System. Note that the methods described here do not employ positioning systems, relying exclusively on measurements of relative distances between agents (acquired using for example onboard lidars). such constraints on the inter-spacing distances between neighboring agents arise naturally when: (i) defining the formation’s steady-state topology and (ii) when framing the collision avoidance requirement, via restrictions on inter-agent distances in the transitory regime. For illustrative simplicity we will only look at the string graph, while our method handles the heterogeneity of the formation and the inter-agent communications time delays, overlooking applications in the automotive industry. For consistency, we will refer to this setting as a synchronization problem.
Existing results in distributed synchronization (or distributed agreement) for Linear and Time Invariant (LTI) dynamics rely on observer-based distributed controllers [13, 16, 17], while the results from [18, 19, 20] remove the necessity of communicating the internal states of the local observers/sub-controllers and rely solely on the communication of the agents’ outputs. The results [21, 22, 23] for the heterogenous case, rely on the existence of a (virtual) exo-system generating the reference trajectory, while [24] outlines the intrinsic connections between the set of possible agreement trajectories and the sharing of all agents of certain “common dynamics”. The authors’ recent results in [25] provide a solution in the more ambitious setting of a distributed disturbances attenuation problem for the string graph, encompassing heterogenous agents and communications induced time delays. In this context, the current paper can be looked at as an extension to nonlinear control of the novel ideas for LTI dynamics from [25].
Theoretical advancements for nonlinear agents are in an incipient phase and have only been available more recently. The Lyapunov function approach in [26] is based on differential inequalities. The results in [27] pertaining to weakly minimum phase nonlinear agents are viable only under a passivity hypothesis, while those in [28, 29] pertain to globally Lipshitz-like conditions on the nonlinearities and leader-following networks. The reference [30] brings forward a necessary condition but no controller synthesis procedure while in [31] the agreement objective can only be set to a constant. Very recent results applicable to more complicated nonlinear dynamics include feedforward schemes [32] or are set up as cooperative output regulation problems e.g. [33, 34, 35, 36] and the references within, among which [33, 34] deal with leader-following networks. A notable feature of [35, 36] and especially [14] is that the sub-controller corresponding to an agent can be designed independently to all other sub-controllers. The downside of [35, 36] is the requirement of full state information exchange among agents, requirement entirely circumvented in [14] in a generic setting.
I-A Motivation and Scope of Work
The references above deal with the standard setup in which agents must achieve agreement of certain, pre-specified variables from each agent’s own state-space. For the class of problems treated in this paper, this takes the form of guaranteeing velocity matching in the steady-state, irrespective of the velocity profile of the leader (whose trajectory represents the reference for the entire formation) and which is seen as an adversarial player. However, the problem statement is further complicated by the inclusion of constraints that impose a substantial “coupling” between individual state variables of distinct agents, where these states represent the positions of agents333See also footnote 2 on page one.. These constraints cast on the relative distances between two neighboring agents render the existing methods referred above inapplicable directly444Existing results [37, 38, 39] on graph rigidity show how easy it is for these types of constraints to cause certain variations of this formulation of the distance-based formation control problem to become not well-posed. That happens when in an effort to preserve the topology of the formation, the controller encounters simultaneously conflicting constraints.. However, the constraints are needed in order to frame sufficient conditions for: (i) collision avoidance in the transitory regimes and (ii) topology preservation of the formation in steady-state (i.e. the interspacing distances between agents must converge asymptotically to certain pre-specified, constant values).
For high performance displacement-based formation control [40, Section 6], global positioning systems are not viable due to their relative large latencies and problematic reliability. The absence of a global coordinate system (combined with the fact that we avoid the use of accelerometers555Longitudinal accelerometers are notoriously unreliable for applications in the automotive industry.) requires that the agents must rely only on real time measurements of relative variables with respect to their neighbors, with all the difficulties such schemes entail, including the fact that collision avoidance and topology preservation cannot be reduced to a cooperative, output regulation problem (as those referred above).
I-B Contributions of the Paper
Our controller’s architecture is borrowed from platoon control literature666The conceptual architecture behind such distributed control schemes have been dubbed Cooperative Adaptive Cruise Control in the platooning control parlance [41, 25]. and is conceptually different from the aforementioned methods (e.g. [33, 34, 14] and the references within). Unlike [33, 34] it doesn’t require exchange of internal states (plant internal states or controller states) among agents. In turn, each agent needs to transmit its control action only to its immediate follower in the string. Furthermore, the design of each sub-controller, (“local” to an agent ) can be done in a completely independent manner - feature which is known to be especially challenging in distributed synchronization (see [14] and the references within for a comprehensive discussion in a related setting). Indeed, solely the knowledge of the dynamical model of the immediate predecessor is required for the local sub-controller at each agent, but once this is made available the regulation and controller design (at each agent) is done individually, in a completely decentralized manner.
Perhaps the most appealing feature of the proposed scheme is a particular dynamic “decoupling” of a certain bounded approximation of the closed–loop equations, entailing that individual, local analyses of the closed–loop stability at each agent will in turn guarantee the aggregated stability of the entire formation. This entails a complete scalability with respect to: (i) the number of agents in the string and (ii) the same performance irrespective of the relative position in formation (front or back of the string).
By comparison to our method, the main result in [42] is restricted to an undirected topology of the distributed controller, with stringent requirements involving: (i) the transmission of the exact state of the leader to many agents in the formation (virtual leaders) and (ii) the necessity of high control gains (see the last paragraph in [43, page 1] for a more detailed discussion).
Overall, our scheme improves on existing results in the following essential aspects:
-
1.
The agent dynamics are permitted to be heterogenous as long as they are nonlinear, globally Lipschitz.
-
2.
The agents achieve the synchronization of their velocities in the steady-state, while guaranteeing collision avoidance.
-
3.
The scheme guarantees steady-state topology preservation. Very recent results [44] are able to achieve this but only for identical single-integrators, exploiting an adaptation of the Cucker-Smale type nonlinear controllers [45]. Collision avoidance is obtained in [46] for single-integrators but without topology preservation.
-
4.
The distributed controller determines a “dynamic decoupling” of the closed loop, rendering the same performance independent of the number of agents or the relative position in formation. (The Lyapunov function guaranteeing the closed-loop stability of the entire formation is actually the sum of “local” Lyapunov functions, proper to each agent. This decoupling is also the root cause of the feature stated at the next point.)
-
5.
Completely independent regulation and controller design at each agent, under the sole requirement that each agent knows the dynamical model of its predecessor777This aspect is essential when dealing with merging/exiting of agents, since it allows only local reconfigurations (at the merging agent or at the follower of the exiting agent) without the need to reconfigure the control scheme for the entire formation..
-
6.
We provide a simple, practical method for the efficient compensation of the notoriously detrimental (communications induced) time-delays [47], at the expense of a negligible loss in performance.
I-C Paper Organization
The paper is organized as follows: in Section II we introduce the general framework and problem formulations. Section III provides a preliminary description of the novel distributed control architecture introduced in this work along with a first glimpse at the closed-loop dynamics “decoupling” featured by the control scheme. Section IV contains the main result as it delineates the guarantees for stability, velocity matching, collision avoidance and topology preservation. Finally, Section V outlines a practical delays compensation mechanism while Section VI provides an illustrative numerical example, worked out on an actual dynamical model for road vehicles.
II General Framework and Problem Statement
The notation being used is fairly standard throughout the literature, for example the derivatives with respect to the time variable are sometimes denoted by . Also, throughout the paper it will become apparent from the context when the time argument is being omitted for the sake of brevity. The notation means that the left hand side quantity is defined to be the right hand side quantity .
Definition II.1
The –norm of a vector is defined as
| (1) |
where is a strictly positive constant. Note that (1) is a class function of and is differentiable everywhere.
Definition II.2
A set is said to be forward invariant with respect to an equation, if any solution of the equation satisfies:
Definition II.3
Artificial Potential Function (APF). The function is a class , nonnegative, radially unbounded function of satisfying the following properties:
(i) as ,
(ii) has a unique minimum, which is attained at , with being a positive constant.
II-A Distributed Trajectory Tracking in the String Formation
We consider a heterogeneous group of agents (e.g. autonomous road vehicles) moving along the same (positive) direction of a roadway, with the origin at the starting point of the leader. The dynamical model for the agents, relating the control signal of the –th vehicle to its position is given by
| (2a) | |||
| (2b) |
where is the instantaneous speed of the –th agent, is its command signal and is the initial interspacing distance between the –th agent and its predecessor in the string. Throughout the sequel we will use the notation
| (3) |
to denote (especially for the graphical representations) the input–output operator of the dynamical system from (2a), with the initial conditions (2b).
Assumption II.4
The index “” is reserved for the leader agent, the first agent in the string. This situation leads to exactly inter-agent distances, which are part of the regulated measurements.
In the rest of the paper it will become apparent from the context that we often omit the time argument , for the sake of brevity. Let us further define
| (4) |
to be the interspacing and relative velocity error signals respectively (with respect to the predecessor in the string). By differentiating the first equation in (4) it follows that , therefore implying that constant interspacing errors (in steady state) are equivalent with zero relative velocity errors and also allowing to write the following time evolution for the relative velocity error of the –th vehicle
| (5) |
III A Practical Distributed Control Architecture
After five decades of consistent academic efforts and hundreds of references on the subject, it turned out that control of a string of mere double integrators might well be the epitome of the difficulties typical to distributed control, since it suffers from all pitfalls one might have expected from more general and complex dynamical networks, e.g. performance is in general dependant on the number of agents in the string and on their relative position in formation and is highly sensitive to communications delays.
We introduce a novel control architecture featuring a highly beneficial “decoupling” property of the closed–loop dynamics, that resolves the troubling nested interdependencies of the regulated measurements. We consider non–linear controllers built on the so-called Artificial Potential Functions (APF), in particular we will look at control laws of the type
| (6) |
with , where each of the functions is an Artificial Potential Function [42, Definition 7], with being a proportional gain to be designed for supplemental performance requirements. With the notation from (4), the control policy (6) for the –th agent becomes
| (7) |
Note that the distributed control laws rely only on information locally available to each agent, since it can further be written as the sum of the following two components: firstly, the control signal of the preceding agent, which is received onboard the –th agent via wireless communications (e.g. digital radio) along with the function characterizing the predecessor’s dynamical model. Secondly, the local component, which we denote with
| (8) |
and which is based solely on a high accuracy speedometer for measuring 888For automotive applications, high accuracy speedometers are affordable and widely available. On the contrary, longitudinal accelerometers are notoriously unreliable and only used for purposes extraneous to navigation, such as the triggering of airbags in a collision event. and on the measurements (4), locally available to the –th agent (acquirable for instance via onboard LIDAR sensors999For automotive applications, commercially available affordable and high accuracy “dot” LIDARs have latencies well under 1s. Given the typical speeds of road vehicles, this implies that a numerical differentiation of the interspacing distance in order to obtain the relative speed is feasible via a high sampling frequency.). Thus, the control law at the –th agent reads:
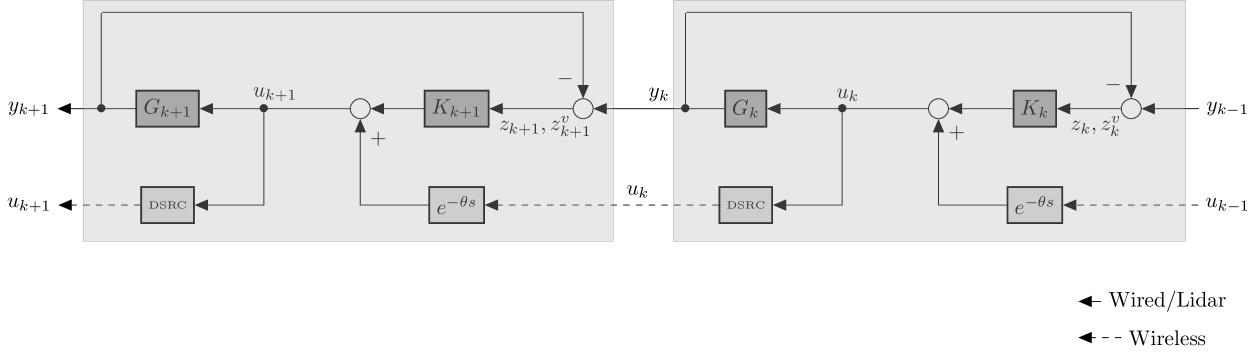
In Figure 1, we denoted with the input–output operator from and respectively to of the -th sub-controller from (8), namely
| (9) |
The resulted control architecture for any two consecutive agents () can be pictured as in Figure 1. For all practical purposes, the existence of a time delay on each of the feedforward links , with must be taken into account. For readability, these time delays are figuratively denoted by in Figure 1 (the Laplace transform of a delay of seconds), representative to the situation in which the delayed version version of the signal is received on board of the agent. In applications, these delays are caused by the physical limitations of the wireless communications system used for the implementation of the feedforward link , entailing a time delay at the receiver. For automotive applications the standard digital radio communications systems (included in Figure 1) are DSRC101010 IEEE 802.11p - Dedicated Short Range Communications.
Remark III.1
Without the assumption of inter-agent communications delays, one might argue that information from the leader propagates instantaneously to all the agents in formation, via a relay mechanism (from each agent to its successor) and consequently the resulted distributed scheme doesn’t employ local, but rather global information from the leader. It is known that precisely this type of time delays can drastically alter the performance control architectures based on such relay schemes [48].
Remark III.2
For the illustrative simplicity of the exposition, we look first at the scenario in which there are no time–delays induce by the inter-agent (wireless) communication of information, such as the predecessor’s control signal . A “synchronization” mechanism that can cope with the time-varying communications induced time–delays will be addressed in Section V.
III-A A First Glance at the Closed–Loop Dynamics Decoupling
The control policy (7) entails a highly beneficial “decoupling” feature of the closed–loop dynamics at each agent, as illustrated next. Firstly, note that by plugging (7) into (5) we obtain the following closed–loop error equations at the –th agent:
| (10) |
The following result will be instrumental in the sequel. Consider the following Lyapunov candidate functions:
| (11) |
IV Decoupling control design
The following result is the main result of this Section, as it delineates a “decoupling” property of the closed–loop dynamics, achieved by the type (7) control policy along with: (i) closed-loop stability, (ii) velocity matching, (iii) collision avoidance and (iv) formation topology preservation. Specifically, assuming that the acceleration of the leader vehicle becomes zero after a finite period of time (i.e. reaches a steady-state) then the following theorem holds:
Theorem IV.1
| (15) |
then for any of the type (7) control laws, such that , the following hold:
(A) Given the Lyapunov function from (11), local to the -th agent,
then for any real constant the sub–level sets of are compact and they represent forward invariant sets for the local closed–loop dynamics (10) of the –th agent.
(B) The control laws (7) guarantee velocity matching in the steady-state i.e. and collision avoidance in the transient regime, i.e. there exists such that
(C) The controller (6) guarantees the formation’s topology preservation in the steady-state, i.e.
where is a pre-specified real, positive value.
Proof:
(A) We show that for any real the local sub–level sets of are compact. Note that implies that and . Since is radially unbounded this implies that is bounded and consequently is bounded. Therefore is a bounded set111111Here denotes the dimension of the vector valued function of time, which in general may be greater than one.. Moreover due to the continuity of and of , one obtains that is a closed set. Precisely is the pre-image of a closed set through a continuous function. In the Banach space it therefore holds that is closed and bounded thus is compact. Furthermore, Lemma III.3 and the Lipschitz–like assumption (15) on all implies that
along the trajectories of (10). Therefore it suffices to choose the controller gain in order to guarantee that along the trajectories of (10) it holds that and also that is a forward invariant set for the “decoupled” closed–loop system (10), local to the -th agent.
(B) From the properties of the APF (Definition II.3) it follows that as , i.e. such that
| (16) |
Let . It follows from (16) that for any positive one has that
| (17) |
Note that an increase of is correlated with a corresponding decrease of . Next, let us fix . From point (A) above it follows that for it holds that is a forward invariant set with respect to (10) and consequently . This implies via (11) that which in turn yields and so from (16) we conclude that
It is noteworthy that is implicitly defined by which in turn depends on the initial conditions .
(C) Given as introduced in (11), it is claimed that the string formation’s steady–state configuration is attained at the minimum of the following formation-level Lyapunov function, defined as
| (18) |
where are the aggregated vectors of the regulated measurements for the entire formation, obtained by adequately stacking the local measurements of the agents:
| (19) |
| (20) |
The minimum of (18) therefore coincides (component–wise) with the minima of the Lyapunov functions (11) local to the -th agent.
In order to prove the claim, first note that the level sets of given by are compact, since is a finite cartesian product of the sets, whose compactness was proved at point (B) above. By a similar argument, it follows that represents a forward invariant set for the closed–loop dynamics of the entire formation, along the trajectories of (10), where .
Note that from the definition of (18) and Lemma III.3 that along the trajectories of (2) and (7) one has that
| (21) |
Therefore, by employing LaSalle’s invariance principle we conclude that the Lyapunov function converges asymptotically to its minimum i.e. , which is attained at velocity matching as (or equivalently when ) . Denote with the point at which such minimum is attained and note that by the collision avoidance attribute from point (B). Consequently, in the steady-state converges to , while converges to and the formation’s topology preservation
is guaranteed. ∎
Remark IV.2
The pre-specified positive constants (with ) representing the desired steady-state inter-agent distances, can be integrated in the Lyapunov functions at the controller design stage, as exemplified in Section VI.
IV-A Communicating the Control Signals of the sub-Controllers
When looking at the problem of agents moving in the string formation, the intuition behind the type (7) control law is that it essentially includes an implementation of the common “break lamp bulb” regulated in all road traffic. This is the conceptual difference of the proposed distributed architecture: instead of choosing to communicate the regulated measurements between sub-controllers (as done in the cooperative output regulation setup such as [33, 34, 35, 36]) the sub-controllers choose to transmit their control actions. This feature turns out to be essential in achieving the synchronization objective along with all the other standard performance requirements (e.g. collision avoidance, topology preservation) from displacement-based formation control [40, Section 6], as outlined by the following result.
Proposition IV.3
If the predecessor’s control action is not made available at the -th agent in the controller equation (7) then velocity matching cannot be attained.
Proof:
We prove the result by contradiction. Let us assume that velocity matching is achieved. Consequently, in the steady-state converges to zero and converges to some constant . Since is a class function, all its partial derivatives are continuous and so converges to a vector
Whenever converges to zero, it follows that
| (22) |
In order to show that (22) is violated, let be fixed and . Therefore, we should have .
Since converges to one has that such that
Employing (15) (while noting that is implicitly present in the closed-loop equations (10)), one obtains:
Therefore, while
| (23) |
it follows that which in turn implies that (22) doesn’t hold. It is important to note here that no increase in the control effort by choosing a larger gain can help in achieving velocity matching, since for arbitrarily large but finite values of , under the assumption that converges to zero, one gets that the term becomes arbitrarily small. Nevertheless, once this term becomes small, there always exists a bounded contro input of the form (23) that precludes from converging to zero. ∎
IV-B Some Considerations and Future Work
For illustrative simplicity, we provide below an informal outlook of our approach leading to the proposed distributed controller architecture for the string network. We look at how the aggregated variables for the entire formation relate to the agents’ individual variables (the states - including the absolute coordinates and the speeds , the sub-controller’s outputs and the measurements local to the -th agent) . Let us define:
| (24) |
| (25) |
| (26) |
while the vectors of the aggregated measurements have been introduced in (19), (20). The aggregated equations (2a) for the entire formation become
| (27) |
The objective of the control scheme is related to the regulated measurements (in our case ), which (in general) are functions of the agent’s states (in our case ). Let us describe this dependence by
| (28) |
In many situations of practical interest the operator may be linear. For the situation studied here, it follows from (4) that is an real matrix having entries equal to “” on its diagonal and “” on its supra-diagonal. In displacement-based formation control the type (28) definition of the regulated variables (e.g. relative distances or relative speeds) encapsulates the topology of the multi-agent formation. In related formulations (e.g. the optimal control formulation for LTI agents from [25]) the operator may also enclose norm based costs.
Let us assume next that commutes with the differentiating operator and apply to both sides of (27), while taking into account its linearity and the definition of the regulated variables (28) in order to get
| (29) |
The merit of the type (29) formulation is that it is expressed directly in terms of the regulated measurements (on the left-hand side) and not of the original states from (27), while the dynamics of “the plant” have changed from to . The morale is that the distributed controller design may now be performed on (29) in order to obtain the control laws . This is exactly the approach taken for the string formation, where for the regulated measurements we have essentially performed a decentralized controller synthesis (6) for the control signals . The relation from (29) also suggests that the sub-controller communications topology should “borrow” the formation’s topology. This entails the “dynamic decoupling” attained by the string formation, the existence of “local” forward invariant sets and Lyapunov functions and the possibility of performing independent regulation and sub-controller design at each agent.
Finding suitable distributed controllers for more general types of operators is the objective of future investigations. Assuming that the distributed controller design for (29) successfully yields the control laws , there still remains the problem of finding a causal implementation of such a controller121212This aspect will appear even more more clearly in those formulations of these type of problems involving dynamical systems with discrete-time. in terms of the signals of the original formulation (27). This may require certain invertibility assumptions on the mapping. Furthermore, looking at any practical implementation of the proposed law from (7), the local control should only depend on the delayed version of (or on its history). These important issues will be discussed in Section V below.
IV-C Platooning Control
Platooning control has been a longstanding problem in control engineering, encompassing a vast literature. For a series of recent, interesting results also providing a good outline of existing literature we refer to [49, 50]. To the best of the authors’s knowledge, the current results are the only ones guaranteeing collision avoidance and topology preservation for heterogenous, nonlinear dynamical agents in the presence of communication induced time-delays, as outlinen in Section V below. In this context, the current paper can be looked at as an extension to nonlinear control of the novel ideas for control of LTI agents in [25].
V A Practical Time-Delays Compensation Mechanism
The difficulties caused for networked systems by the communications induced delays and time jittering have been a topic of intensive study for decades. In formation control practical applications it has been argued in [48] that the (relatively low latency) time delays induced by the wireless communications of the control signals from one agent to its successor in the string (even if assumed time-invariant and homogeneous131313For digital radio wireless systems such as WiFi, Bluetooth or Zigbee, the corresponding time-delays have low latencies but they are time-varying, taking values around a nominal delay of about 20 ms.) irremediably alter the performance of the control scheme. What happens is that the delays propagate through the closed-loops towards the back of the platoon where they “accumulate” in a manner depending on the number of vehicles in formation [48].
For the case of LTI dynamical agents, the very recent results from [25] provide a functional solution for compensating the effect of the communications delays by introducing (with high accuracy) supplemental delays at key points in the closed loop. However, the aforementioned method [25, Section VI] of essentially “moving” the synchronization delay through the loop and ultimately incorporating it in the model of the “plant” cannot be directly adapted to nonlinear dynamical systems. In this section we show how an adaptation of the distributed controller of Section IV is able to compensate the communications delays, while essentially preserving all the performance features from the delay free case. The approach taken here is based on: (i) the tailored use of the so-called time-headways without sacrificing the tightness of the formation and (ii) changing the definition of regulated measurements to a meaningful approximation. The main challenge here is for the re-defined regulated measurements to remain measurable (on board of each agent) in a distributed manner.
V-A Adapting Time-Headways for Delays Compensation
Classical results in platooning control [51, 52, 53] proved that a considerable improvement of performance can be obtained by adequately modifying the regulated interspacing distance (for each vehicle ) such as to include a factor proportional with the speed of the current vehicle. The resulted interspacing policies (dubbed time-headways) become (where , the so called time-headway, is a real, positive constant) and provide a spacing in time rather than distance (between two consecutive vehicles). Up until the recent distributed scheme introduced in [25] - in the case of LTI dynamical agents - good attenuation at all frequencies could only be achieved via the use of time headways policies [54]. The generally adopted value for highway platooning (which became the standard at some point) is second. The main drawback of such large time headways is that they destroy the tightness of the formation, drastically reducing the highway traffic throughput or any potential fuel savings achievable by the air drag reduction.
We introduce next a novel method for delays compensation that combines the synchronized-clocks mechanism from [25, Section VI] with an adequate adaptation of the time headways. Firstly, let us revamp as follows the definitions (4) of the interspacing distances and of the regulated relative speeds respectively at the -th vehicle:
| (30) |
where the positive constant , i.e. the time-headway, will be taken to be equal with the communications delay and will be considered (without any loss of generality) to be the same for all vehicles in formation141414See also Remark V.1 below. It can be seen that the signals defined in (30) are merely delayed version of (4) with a time-headway.
If at the current moment in time , we would choose to regulate instead the measurements taken at moment according to (30), that would be a limitation imposed by the communications delay (which are relatively very small, though) and it would entail some loss in performance which was to be expected. The inclusion of the time headway results in a slightly more conservative policy, since it induces slightly larger interspacing distances as the speed increases. The same conservative effect (of the time headway) occurs with respect to the regulated relative speeds during the transient regime when the acceleration is sizable.
Remark V.1
For all practical applications related to platooning, the value of will be taken to be equal to a worst case scenario value of the latency of the wireless communication systems, which is about seconds for digital radio systems such as DSRC, WiFi, Bluetooth or Zigbee. Furthermore, the “synchronized clocks” mechanism introduced in [25, Section VI] used in conjunction with time stamping protocols (at the transmission of the predecessor’s control signal ) is able to emulate and implement time invariant and heterogeneous communications time delays throughout the entire formation, by introducing with high accuracy supplemental delays in the closed-loop.
Remark V.2
The effect of the time-headway on the behavior of the formation is directly proportional with the numerical value of , which is very small in practice151515See Remark V.1 above.. In fact, for formation control practical applications the effect is almost negligible given the order of magnitude of compared to the time constants of the dynamics of road or aerial agents.
V-B Changing the Regulated Measurements
In the next proposition we re-define the regulated measurements and make the express remark that the definition included below will be enforced onward, throughout the contents of the current Section V.
Proposition V.3
Proof:
Remark V.4
One essential practical issue is to establish if the new regulated signals (31) remain measurable on board of the -th agent (in a distributed manner). Writing in (31) the Taylor series expansion with an integral rest for and respectively, we obtain the following equivalent expressions:
| (33) |
or equivalently
| (34) |
and so it becomes apparent that the signals introduced in (31) can be measured on board the -th vehicle via (34), using only onboard ranging sensors161616Preferably very low latency LIDAR sensors, which are already affordable and widely available commercially and high accuracy longitudinal speedometers in conjunction with a mere integrator. Specifically, the first term in (34) consists of the -delayed measurement of the interspacing distance minus the integration of the absolute speed (measurable on board) over a -length interval. The second term in (34) consists of the -delayed measurement of the relative speed171717The relative speed with respect to the preceding vehicle, which is also measurable onboard, see also footnote number 9 on page four. minus the term, comprised of absolute speeds measurable onboard the agent. Finally, the entire history on the interval of the ranging sensors (34) must be stored in a memory buffer, in order to be used by the distributed controller we will introduce next.
The following remark represents the conclusion of the current Subsection V-B:
Remark V.5
Given the values of that appear in practice (see Remark V.1) and given the worst case scenario of breaking decelerations that could occur during highway traffic, it follows via Proposition V.3 that the signals from (31) are such an accurate approximation of (34), that the order of the approximation falls way below the tolerated measurement errors of the most performant ranging sensors. That is to say that choosing between two controllers that regulate either the (30) signals or the (34) signals respectively, has considerably less influence on the resulted scheme than the measurement noise of an highly accurate LIDAR. Consequently, in the scheme proposed next, we choose to regulate (34).
V-C A Controller to Cope with Time Delays
Considering the definition of and as in (31), we will prove that the distributed control policies given next are able to entirely compensate the communication induced delays:
| (35) |
Remark V.6
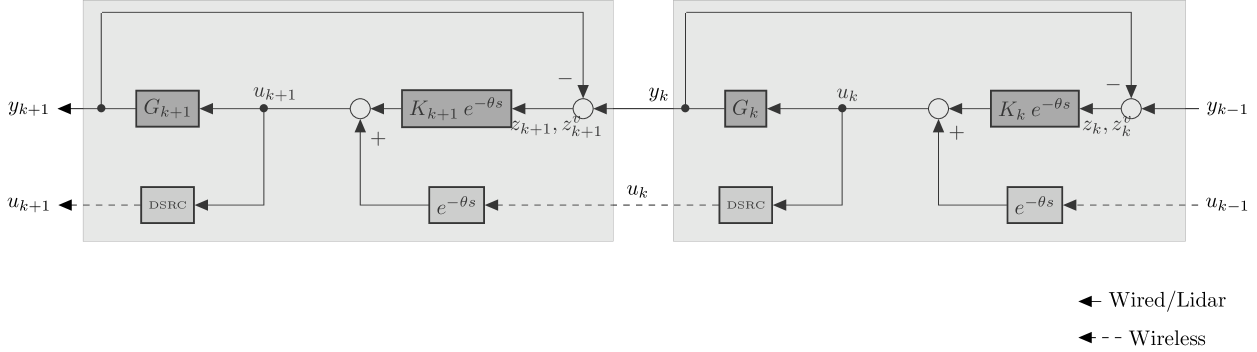
Note that for the real time, practical implementation of type (35) control policies onboard the -th vehicle, two pieces of information are needed: (i) the command signal of the predecessor, received on board via (DRSC) wireless communications with a -delay and (ii) the (34) sensor measurements , which are measurable on board the -th agent, as per the considerations from Remark V.4. Note that in order for the scheme to be effective, the communications delay from must be replicated with high accuracy in the in measurements from (34). This resembles the (GPS time-base) synchronization mechanism in [25, Section VI]) for the LTI case and it can be implemented using time-stamping protocols of the involved signals and . In Figure 2, such “synchronization” delays to be imposed on the signals from (34) have been figuratively incorporated in the controller, via the term. The aforementioned synchronization will ensure time invariant, point-wise delays of value exactly , homogeneously throughout the entire formation as per the considerations from Remark V.1.
We employ the Lyapunov function from (11) keeping in mind that the definitions of are in accordance to (31). Specifically, assuming that the acceleration of the leader vehicle becomes zero after a finite period of time (i.e. reaches a steady-state), the time delays adaptation for the main result of Section IV reads:
Theorem V.7
If the function from (2a) satisfies the global Lipshitz–like condition (15) then for any of the type (35) control laws, such that the following hold:
(A) The derivative of the Lyapunov candidate function from (11), local to the -th agent, along the trajectories of (5) and (35) is given by
| (36) |
and does not depend on the choice of the APFs .
(B)
Given the Lyapunov function from (11),
local to the -th agent, the sub–level sets of are compact and they represent forward invariant sets for the local closed–loop dynamics of the –th vehicle.
(C) The control laws (35) guarantee velocity matching in the steady-state i.e. and collision avoidance in the transient regime, i.e. there exists such that
The controller (35) also guarantees the formation’s topology preservation in the steady-state, i.e.
where is a pre-specified real, positive value.
Proof:
(A) With the controller (35) at hand we obtain the following closed–loop equations at the –th agent:
| (37) |
Let us notice that we deal with one fixed delay. Therefore, its derivative is 0 and consequently no complexity is added to the computations with respect to the proof of Lemma III.3. One straightforwardly gets that
with as defined in (31). Since it follows that
(B) Notice that since satisfies (15) it follows that
Consequently, along the trajectories of the closed-loop system (37) one has
Choosing we guarantee that along the trajectory of (37). Moreover, it follows along the lines of the proof of Theorem IV.1 that is compact and forward invariant.
(C) Along the lines of the proofs of points (B) and (C) of Theorem IV.1 we can show that there exists such that
and the steady state value is given by
In order to obtain the desired results we have just to notice that for all the function is non-decreasing in time. Consequently,
and
∎
Remark V.8
The scheme proposed above is able to regulate in the presence of communications delays. Therefore, as far as the leader’s velocity profile is slowly varying relatively to the order of magnitude of the communications delays, the scheme does regulate an accurate approximation of . Nevertheless, oscillations of the leader’s velocity at a frequency that is of the same order of magnitude with , cannot be efficiently compensated and the accordion effect will appear. These assumptions are very well satisfied in the platooning setting, but they may not be valid for other applications. The conclusion is in line with the well known fact that for the validity of the control scheme it is always necessary that the time delays that propagate through the controller are smaller than those propagating through the given plant.
VI A Numerical Example and Further Considerations
In this section we illustrate the distributed controllers introduced above for dynamical agents (2) where the function has a quadratic form , in accordance with the dynamical model of road vehicles from [55, (1)/pp. 1]. Here, is the gravitational acceleration, is the tyre rolling resistance coefficient and the air drag constant of vehicle . The dynamics (2) are
| (38a) | |||
| (38b) |
with the gear ratio and the wheel radius. The command signal is the engine’s torque, and its linear transformation corresponds to the input in (2). We take the same values for and across all the vehicles, to preserve the same meaning of the input . Note that for bounded velocities , in (38) satisfies the Lipschitz–like condition [42, Assumption 1] , with . We take m/s (i.e. 216 km/h) in our experiments.
| (39) |
and a gain is chosen, which will be greater than for all vehicle parameters below. The reference signal for the entire formation is imposed by the control of the leader vehicle, namely , which consists of three smoothed rectangular pulses between the levels 15 and 30 Nm. There are six vehicles in total including the leader, and they start at relatively small separations of about m, with an initial velocity of m/s.
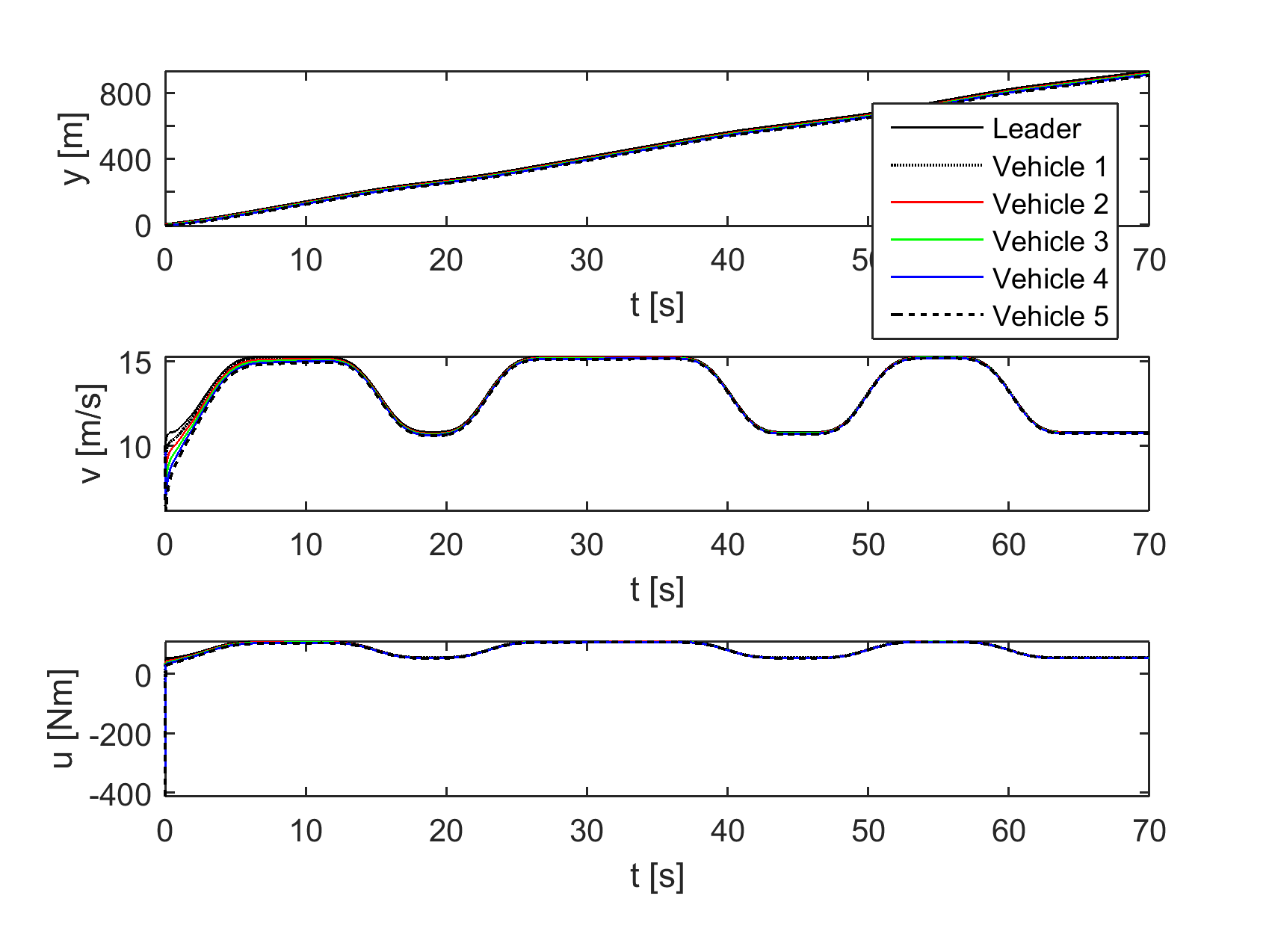
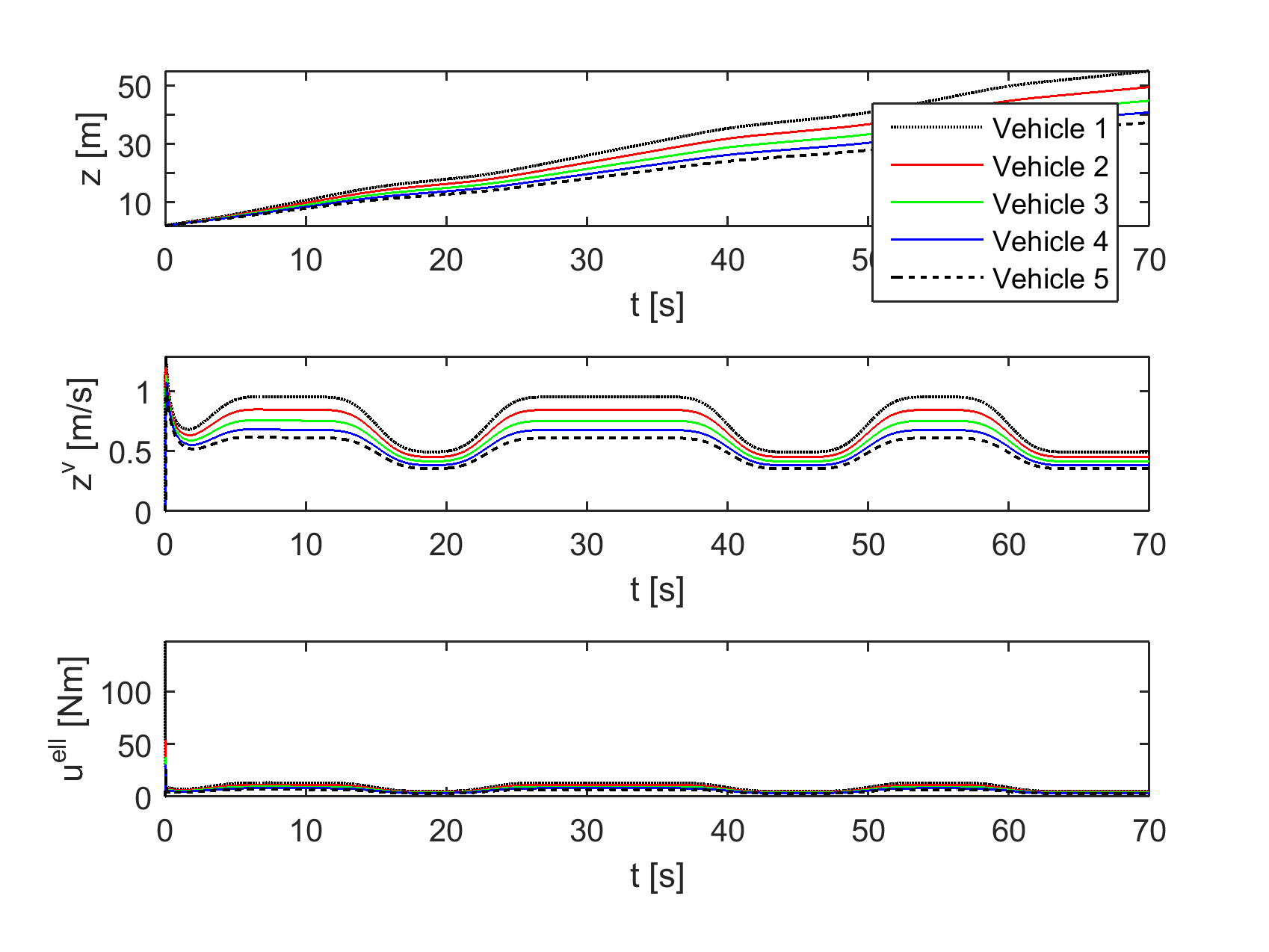
For our baseline experiment, we take homogeneous vehicle dynamics with and kg/m for all vehicles , and no delay. Note that in this case the term from (7) disappears. Figure 3, top shows the states and controls of the vehicles using absolute values to give an idea of their true trajectories; in Figure 3, bottom the corresponding interspacing distances , velocity differences , and relative controls are reported. All subsequent figures will use such relative values. The baseline results show how the controllers initially prioritize increasing interspacing distances, after which the velocities are brought together. Note that on the timeline of this experiment the interspacings have not yet converged; by allowing the experiment to run longer we have confirmed that the steady-state interspacings are 10.95 m, equal to the minimum of the potential function chosen (the trajectories are not shown here since they are not much more informative than Figure 3).
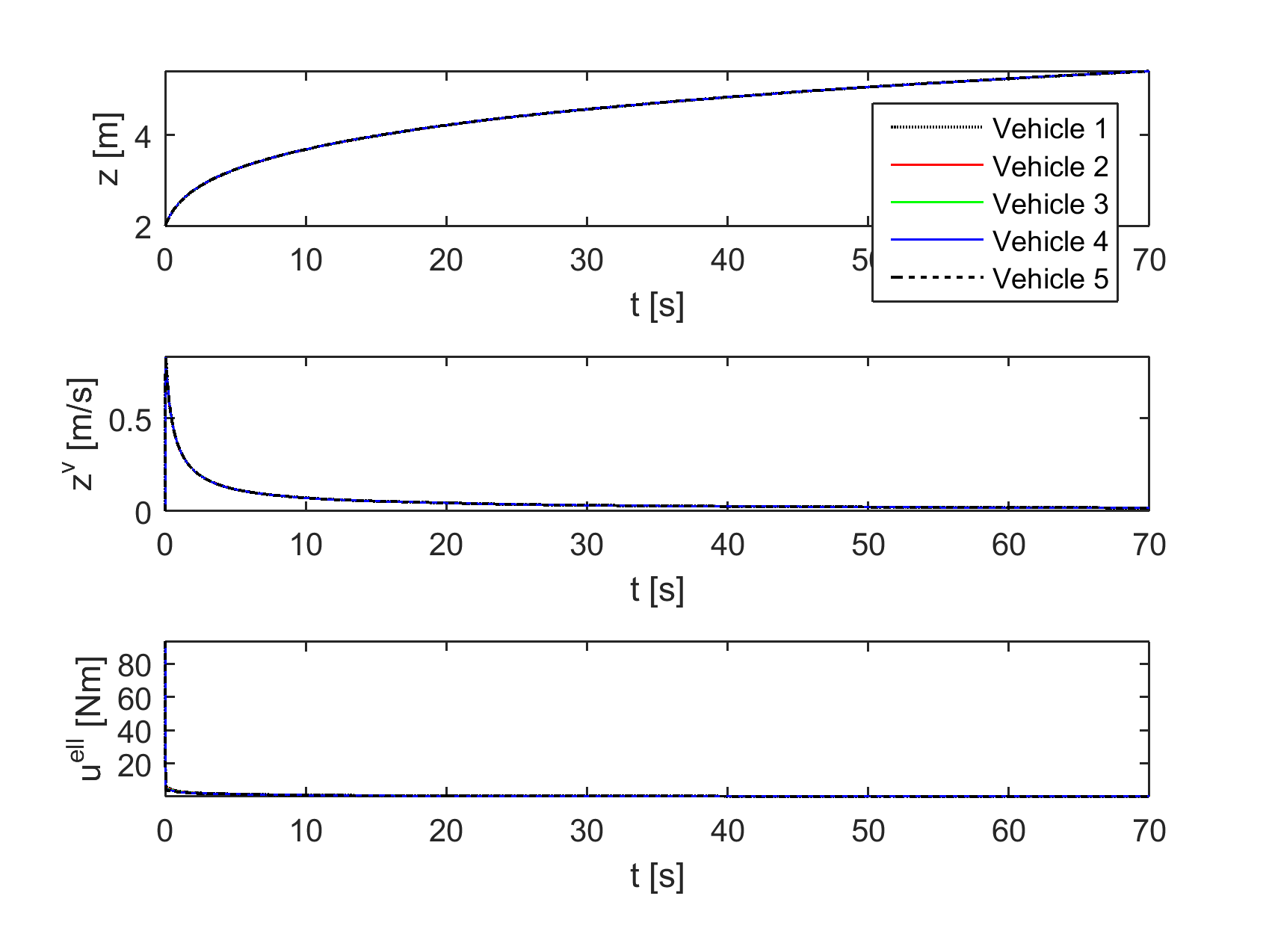
To verify Proposition IV.3, the previous vehicle’s input is removed from the control law of vehicle . Figure 4 shows that, indeed, velocity agreement cannot be achieved, leading to divergence of the positions.
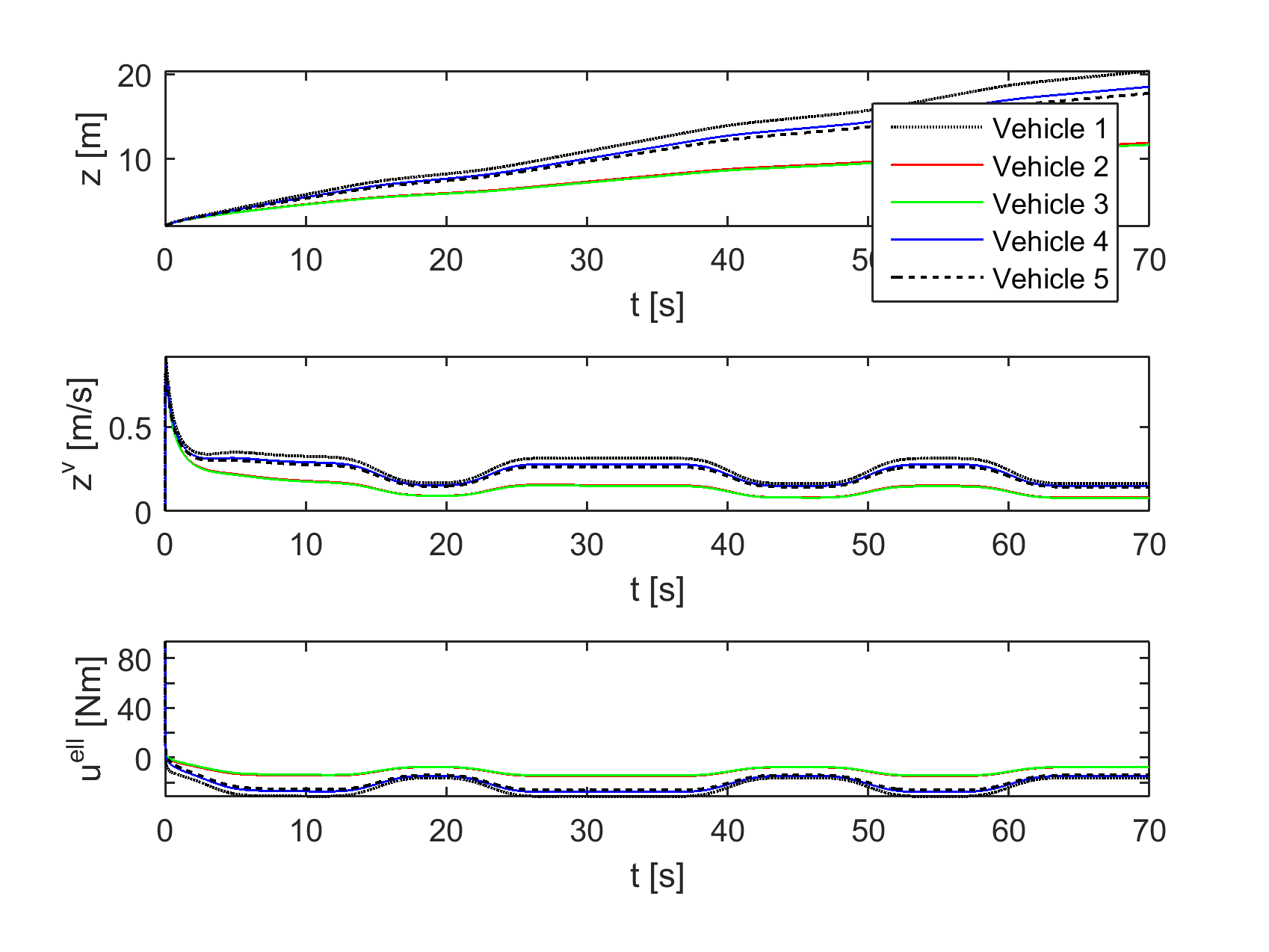
Next, we take heterogeneous vehicle dynamics: in order from the leader to vehicle , and . First we keep the control form of the baseline experiment, without the term , to illustrate the need of compensating for vehicle heterogeneity. The results are shown in Figure 5, top, where it is clearly seen that velocity agreement is lost in this case. If we then introduce the appropriate compensation term, the trajectories are those from Figure 5, bottom, with nearly the same performance as in Figure 3. Therefore, the controller efficiently compensates the heterogeneity. Note also the need to apply different control inputs to the vehicles due to their different dynamics.
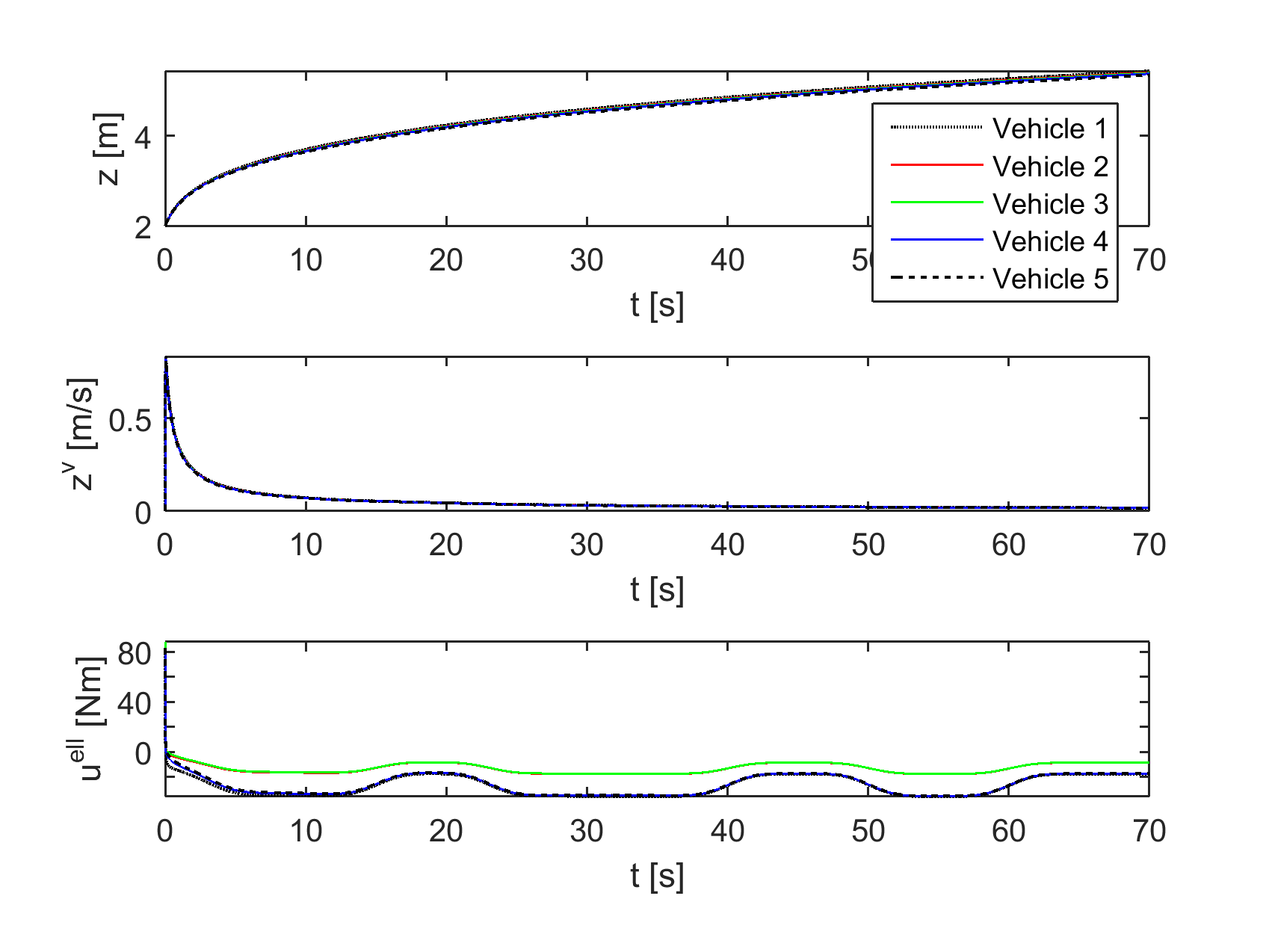
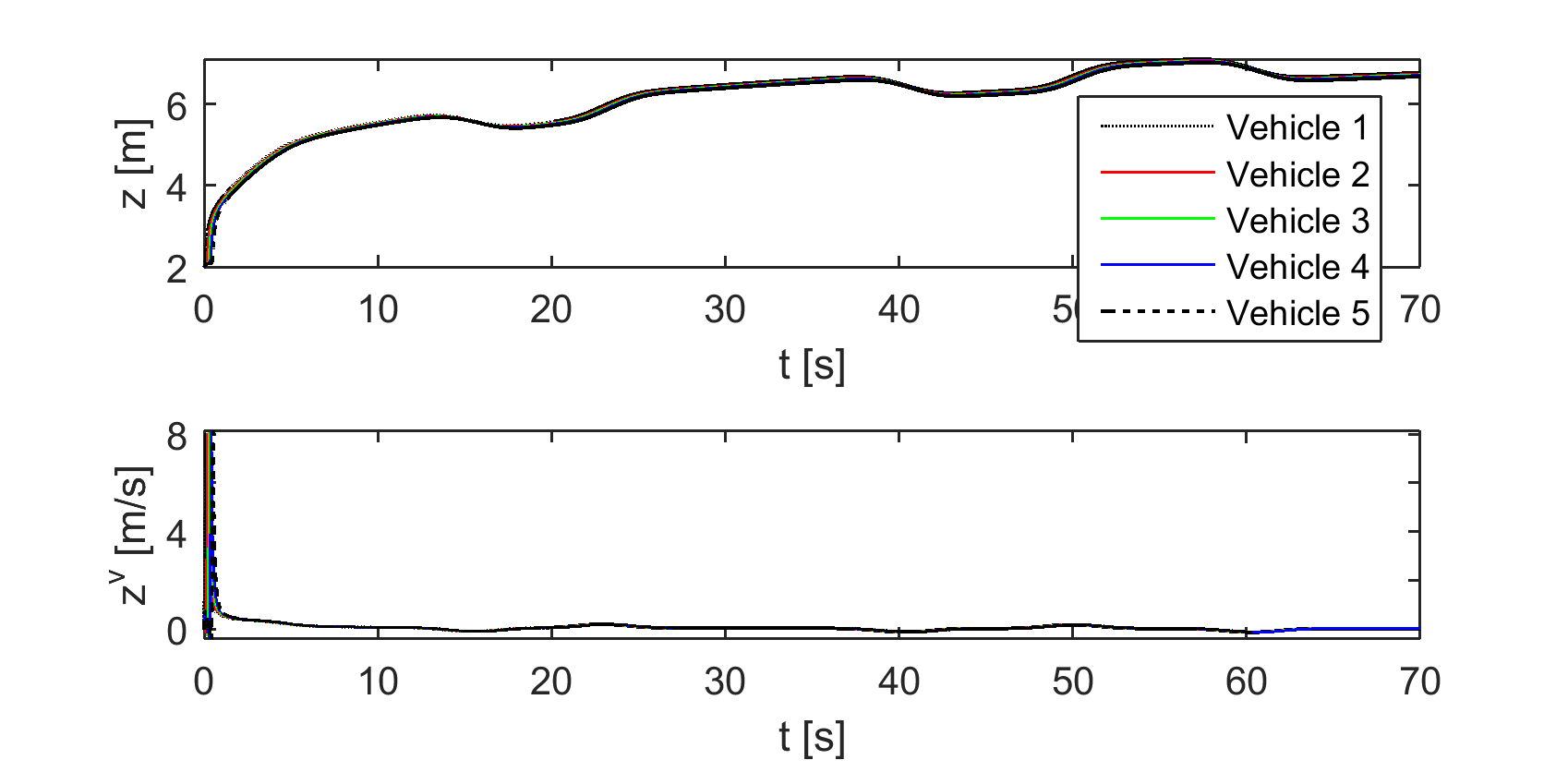
On top of heterogeneity we now introduce a time delay of s, which is quite conservative (about ten times the actual values) for digital radio communications and we apply the delay compensation mechanism from Section V. The trajectories are those from Figure 6. Note that the quantities reported are the actual instantaneous differences , , and not the actual regulated measurement (31) from Section V.
VI-A A Heuristic for Optimal Control
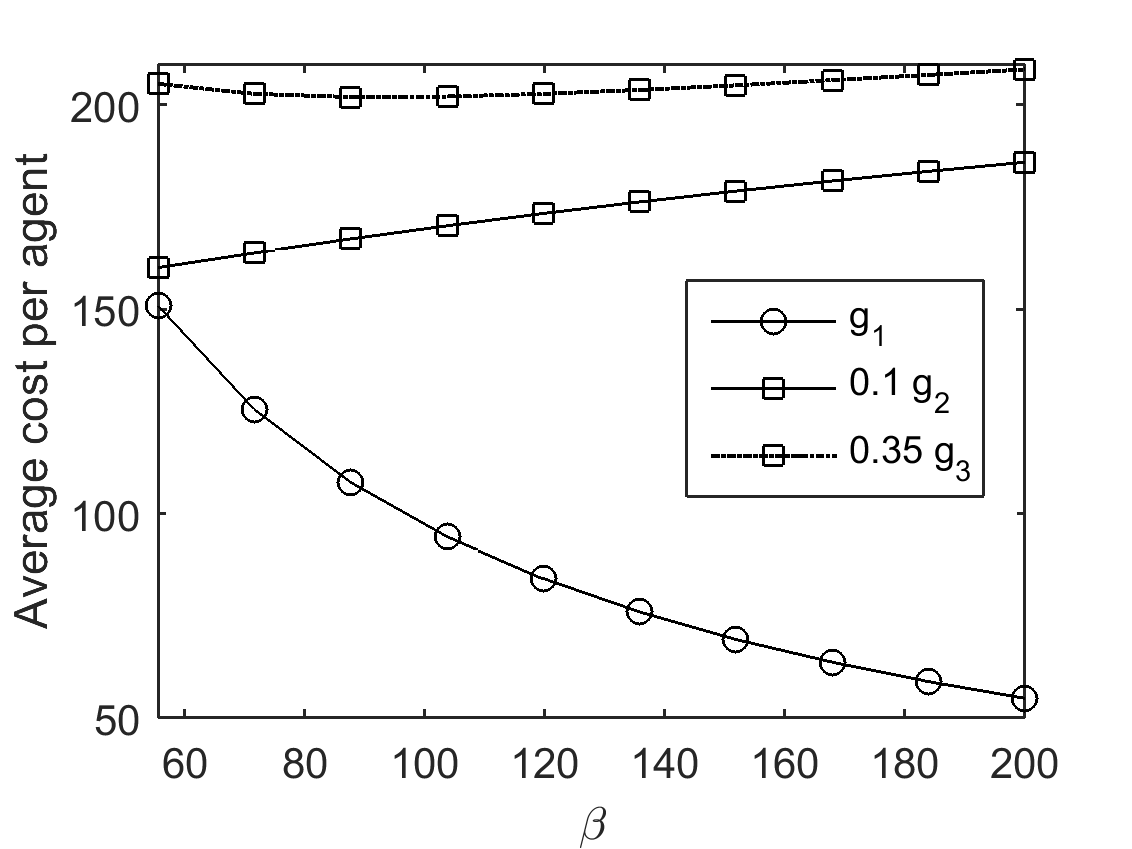
Since the stability analysis holds for any gain , a relevant practical problem is finding a good value for this gain. It turns out that this value depends on the particular objectives of the user. To illustrate, we choose several cost functions and optimize in the baseline experiment, for which . Optimization is done by gridding the interval into values, setting all the follower gains to each value of in turn, and experimentally measuring the cost across all follower vehicles, integrated over time and averaged over the followers. The maximum of the range (here, ), is related to the maximum inputs that the vehicles can apply. The results are shown in Figure 7. The first cost function penalizes velocity disagreements and the control effort: (we skip vehicle indices since the cost function is the same for al the vehicles). In this case, larger values are better, so we suggest taking the largest value that is achievable given the physical limits of the vehicles’ drive train. However, if we introduce a “safety” premium and add a ‘barrier’ term to penalize relatively small interspacing distances, obtaining cost function , the situation is reversed: the larger values focus too much on reducing velocity disagreements to the detriment of the interspacing distances, so in this case works best. Depending on the particular weights, the optimal value may also be inside the interval, e.g. for , works best (keeping in mind the resolution of our grid is limited; to find a better approximation of the true optimum, a simple sample-based optimization method could be used, such as golden section rule or even binary search).
VII Conclusions
We have presented a novel method for the distributed control of a string of heterogenous, nonlinear agents guaranteeing collision avoidance and topology preservation in the presence of communication induced time-delays. Numerical experiments seem to suggest that the proposed scheme also benefits from a remarkable robustness to time-varying delays. The study of the root cause of this robustness is the scope of future investigations along with the study of more complicated cost functionals , introduced in Subsection IV-B and also the study of more general formation topologies, including those containing self-loops.
References
- [1] A. Jadbabaie, J. Lin, and A. Morse, “Coordination of groups of mobile autonomous agents using nearest neighbors rules,” Automatic Control, IEEE Transactions on, vol. 48, no. 6, pp. 988–1001, 2003.
- [2] J. Fax and R. Murray, “Information flow and cooperative control of vehicle formations,” IEEE Transactions on Automatic Control, vol. 49, no. 9, pp. 1465–1476, September 2004.
- [3] E. Mallada and A. Tan, “Synchronization of weakly coupled oscillators: coupling, delay and topology,” Journal of Physics A: Mathematical and Theoretical, vol. 46, no. 50, p. p. 505101, 2013.
- [4] H.Sayyaadi and M. Moarref, “A distributed algorithm for proportional task allocation in networks of monile agents,” IEEE Transactions on Automatic Control, vol. 56, no. 2, pp. 405–410, February 2011.
- [5] H.Zhang, Z.Chen, L.Yan, and Y.Wu, “Applications of collective circular motion control to multirobot systems,” IEEE Transactions on Control Syst. Tech, vol. 21, no. 4, pp. 1416–1422, 2013.
- [6] R. Olfati-Saber and R. Murray, “Consensus problems in networks of agents with switching topologies and time delays,” IEEE Transactions on Automatic Control, vol. 49, no. 9, pp. 1520–1533, September 2004.
- [7] W. Ren and E. Atkins, “Second order consensus protocols in multiple vehicle systems with local interactions,” in AIAA Guidance, Navigation Control Conf. Exhib. San Francisco, CA, USA, 2005.
- [8] L. Pecora and T. Caroll, “Synchronization in chaotic systems,” Phys. Rev. Letters, vol. 64, no. 8, p. 821, 1990.
- [9] H.Su, X. Wang, and Z. Lin, “Synchronization of coupled harmonic oscillators in a dynamic proximity network,” Automatica, vol. 45, no. 10, pp. 2286–2291, 2009.
- [10] N. Chopra and M.Spong, “On exponential synchronization of kuramoto oscillators,” IEEE Transactions on Automatic Control, vol. 54, no. 2, pp. 353–357, February 2009.
- [11] L. Pecorra and T. Caroll, “Master stability functions for synchronized coupled systems,” Phys. Rev. Letters, vol. 80, no. 10, p. 2109, 1998.
- [12] J. Lu, J. Cao, and D. Ho, “Adaptive stabilization and synchronization for chaotic lur’e systems with time-varying delay,” IEEE Transactions on Circuits Syst. I, vol. 55, no. 5, pp. 1347–1356, May 2008.
- [13] L.Scardoci and R. Sepulchre, “Synchronization in networks of identical linear systems,” Automatica, vol. 45, no. 11, pp. 2557–2562, 2009.
- [14] l. Zhu, Z. Chen, and R. Middleton, “A general framework for robust output synchronization of heterogenous nonlinear networked systems,” IEEE Transactions on Automatic Control, vol. 61, no. 8, 2016.
- [15] H. Kwakernaak and R. Sivan, Linear Optimal Control Systems, J. W. . Sons, Ed. Wiley-Interscience, 1972.
- [16] Z. Li, Z. Duan, G. Chen, and L. Huang, “Consensus of multiagent systems and synchronization of complex networks: A unified viewpoint,” IEEE Transactions on Circuits Syst. I, vol. 57, no. 1, pp. 213–224, January 2010.
- [17] Z. D. Z. Li and G. Chen, “Dynamic consensus of linear multiagent systems,” ControlTheory Applic. IET, vol. 5, no. 1, pp. 19–28, 2011.
- [18] S. Tuna, “Consitions for synchronizability in arrays of coupled linear systems,” IEEE Transactions on Automatic Control, vol. 54, no. 10, pp. 2416–2410, October 2009.
- [19] C. Ma and J. Zhang, “Necessary and sufficient conditions for consensuability of linear multiagent systems,” IEEE Transactions on Automatic Control, vol. 55, no. 5, pp. 1263–1268, May 2010.
- [20] J. Seo, H. Shim, and J. Back, “Consensus of high order linear systems using dynamic output feedback compensator,” Automatica, vol. 45, no. 11, pp. 2659–2664, 2009.
- [21] P.Weiland, R. Sepulchre, and F. Allgower, “An internal model principle is necessary and sufficient for linear output synchronization,” Automatica, vol. 47, no. 5, pp. 1068–1074, 2011.
- [22] H. Kim, H. Shim, and J. Seo, “Output consensus of heterogenous uncertain linear multiagent systems,” IEEE Transactions on Automatic Control, vol. 56, no. 1, pp. 200–206, 2011.
- [23] H. Grip, A. Saberi, and A. Stoorvogel, “On the existence of virtual exosystems for synchronized linear networks,” Automatica, vol. 49, no. 10, pp. 3145–3148, 2013.
- [24] J. Lunze, “Synchronization of heterogenous agents,” IEEE Transactions on Automatic Control, vol. 57, no. 11, pp. 2885–2890, November 2012.
- [25] Ş. Sabău, C. Oară, S. Warnick, and A. Jadbabaie, “Optimal distributed control for platooning via sparse coprime factorizations,” IEEE Transactions on Automatic Control, vol. 62, no. 1, pp. 305–320, 2017.
- [26] Z. Qu, J. Chunyu, and J. Wang, “Nonlinear cooperative control for consensus of nonlinear and heterogenous systems,” in Proceedings of 46th IEEE Conference on Decision and Control, 2007, pp. 2301–2308.
- [27] N. Chopra and M. Spong, Output synchronization of nonlinear systems with relative degree one, ser. Recent Advances in Learning and Control. New York, NY, USA: Springer Verlag, 2008.
- [28] W. Yu, G. Chen, and M. Cao, “Consensus in directed networks of agents with nonlinear dynamics,” IEEE Transactions on Automatic Control, vol. 56, no. 6, pp. 1436–1441, June 2011.
- [29] H. Su, G. Chen, X. Wang, and Z. Lin, “Adaptive second order consensus of networked mobile agents with nonlinear dynamics,” Automatica, vol. 47, no. 2, pp. 368–375, 2011.
- [30] P. W. andF. Allgower, “An internal model principle for synchronization,” in Proc. 7th IEEE Int. Conf. Control Autom, 2009, pp. 285–190.
- [31] L. Zhu and Z. Chen, “Robust homogenization and consensus of nonlinear multiagent systems,” Systems & Control Letters, vol. 65, pp. 50–55, 2014.
- [32] Z. Chen, “Pattern synchronization of nonlinear heterogenous multiagent networks with jointly connected toplogies,” IEEE Transactions on Networked Systems, vol. 1, no. 4, pp. 349–359, 2014.
- [33] Y. Su and J. Huang, “Cooperative global output regulation of heterogenous second-order nonlinear uncertain multiagent systems,” Automatica, vol. 49, no. 11, pp. 2245–3350, 2013.
- [34] J. Huang and Y. Su, “Cooperative global robust output regulation for nonlinear uncertain multi-agent systems in lower triangular form,” Automatica, vol. 60, no. 9, pp. 2378–2389, 2015.
- [35] A. Isisdori, L. Marconi, and G. Casadei, “Robust output synchronization of a network of heterogenous nonlinear agents via nonlinear regulation theory,” IEEE Transactions on Automatic Control, vol. 59, no. 10, pp. 2680–2691, October 2014.
- [36] X. Chen and Z. Chen, “Robust perturbed output regulation and synchronization of nonlinear heterogenous multiagents,” IEEE Tarsn. on Cybernetics.
- [37] J.Baillieul and A. Suri, “Information patterns and hedging brockett’s theorem in controlling vehicle formations,” in Decision and Control, 2003. Proceedings. 42nd IEEE Conference on, December 2003, pp. 556–563.
- [38] B. Anderson, C. Yu, B. Fidan, and J. Hendrickx, “Rigid graph control architectures for autonomous formations,” IEEE Control Systems Magazine, no. 1, pp. 48–63, December 2008.
- [39] S. Mou, A. Morse, M. Belabbas, and B. Anderson, “Undirected rigid formations are problematic,” Preprint on arxiv.org, pp. 1–42, March 2015.
- [40] K.-K. O. M.-C. P. H.-S. Ahn, “A survey of multi–agent formation control,” Automatica, vol. 53, pp. 424–440, March 2015.
- [41] J. Ploeg, D. Shukla, N. Wouw, and H. Nijmeier, “Controller synthesis for string stability of vehicle platoons,” Intelliogent Transportation Systems, IEEE Transactions on, vol. 15, no. 2, pp. 854–865, 2014.
- [42] J. Zhou, X. Wu, W. Yu, M. Small, and J. Lu, “Flocking of multi–agent dynamical systems based on pseudo–leader mechanism,” Systems & Control Letters, vol. 61, pp. 195 – 202, 2012.
- [43] Ş. Sabău, I.-C. Morărescu, L. Buşoniu, and A. Jadbabaie, “Decoupled–dynamics distributed control for strings of nonlinear autonomous agents,” in Proceedings of IEEE American Control Conference, 2017.
- [44] C. Somarakis and N. Motee, “Nonlinear flocking with fixed distances,” vol. 49-18, IFAC - Papers Online. Elsevier Ltd., 2016, pp. 576–581.
- [45] F. Cucker and S. Smale, “Emergent behavior in flocks,” IEEE Transactions on Automatic Control, vol. 52, no. 5, pp. 852–862, 2007.
- [46] F. Cucker and J. Dong, “A general collision-avoiding flocking framework,” IEEE Transactions on Automatic Control, vol. 56, no. 5, pp. 1124–1129, 2011.
- [47] A. P. R. M. O. Mason, “Leader tracking in homogeneous vehicle platoons with broadcast delays,” Automatica, vol. 50, pp. 64–75, 2014.
- [48] A. Peters, R. Middleton, and O. Mason, “Leader tracking in homogeneous vehicle platoons with broadcast delays,” Automatica, vol. 50, pp. 64–74, 2014.
- [49] J. I. Ge and G. Orosz, “Optimal control of connected vehicle systems with communicatio delay and driver reaction time,” IEEE Trans. Intelligent Transp. Systems, vol. 18, no. 8, pp. 2056–2070, August 2017.
- [50] L. Zhang and G. Orosz, “Consensus and disturbance attenuation in multi-agent chains with nonlinear control and time delays,” Int. Journal of Robust and Nonlinear Control, vol. 27, pp. 781–803, August 2017.
- [51] C. Chien and P. Ioannou, “Automatic vehicle following,” in Proceedings of IEEE American Control Conference, 1992, pp. 1748–1752.
- [52] S. Klinge and R. Middleton, “Time headway requirements for string stability of homogeneous linear unidirectionally connected systems,” in Proceedings of 48th IEEE Conference on Decision and Control, 2009, pp. 1992–1997.
- [53] D. Swaroop, J. Hedrick, C. Chien, and P. Ioannou, “A comparison of spacing and headway control laws for automatically controlled vehicles,” Vehicle System Dynamics, vol. 23, no. 1, pp. 597 – 625, 1994.
- [54] R. H. Middleton and J. Braslavsky, “String stability in classes of linear time invariant formation control with limited communication range,” IEEE Transactions on Automatic Control, vol. 55, no. 7, pp. 1519–1530, 2010.
- [55] G. Orosz and S. Shah, “A nonlinear framework for autonomous cruise control,” in ASME 5–th Annual Dynamic Systems and Control Conference joint with JSME 11–th Motion and Vibration Conference, 2012.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/718944de-5074-426f-b2ec-b8ca660780db/sserban2.jpg) |
Şerban Sabău Şerban Sabău received the M.S. degree in electrical engineering from “Politehnica” University Bucharest, Romania in 2002 and the Ph.D. degree in Electrical and Computer Engineering from the University of Maryland at College Park, in 2011. Before joining Stevens Institute of Technology in 2013 as an Assistant Professor, he was a postdoctoral researcher at the University of Pennsylvania. His research interests are in numerical algorithms for distributed control and distributed optimization. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/718944de-5074-426f-b2ec-b8ca660780db/Morarescu.png) |
Irinel-Constantin Morărescu is currently Associate Professor at Université de Lorraine and researcher at the Research Centre of Automatic Control (CRAN UMR 7039 CNRS) in Nancy, France. He received the B.S. and the M.S. degrees in Mathematics from University of Bucharest, Romania, in 1997 and 1999, respectively. In 2006 he received the Ph.D. degree in Mathematics and in Technology of Information and Systems from University of Bucharest and University of Technology of Compiègne, respectively. In November 2016 he received the "Habilitation à Diriger des Recherche" from Université de Lorraine. From March 2007 to December 2008 he was postdoctoral researcher at INRIA Grenoble, from January 2009 to December 2009 he was postdoctoral researcher at Jean Kuntzmann Laboratory and from January 2010 to October 2010 he was postdoctoral researcher at GipsaLab grenoble. His works concern stability and control of time-delay systems, stability and tracking for different classes of hybrid systems, consensus and synchronization problems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/718944de-5074-426f-b2ec-b8ca660780db/biophoto_lucianbusoniu.jpg) |
Lucian Buşoniu received the M.Sc. degree (valedictorian) from the Technical University of Cluj-Napoca, Romania, in 2003, and the Ph.D. degree (cum laude) from the Delft University of Technology, the Netherlands, in 2009. He is an associate professor with the Department of Automation at the Technical University of Cluj-Napoca, and has previously held research positions in the Netherlands and France. His research interests include planning, reinforcement learning, and aproximate dynamic programming for nonlinear optimal control; as well as multiagent systems and robotics. He received the 2009 Andrew P. Sage Award for the best paper in the IEEE Transactions on Systems, Man, and Cybernetics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/718944de-5074-426f-b2ec-b8ca660780db/Ali.jpg) |
Ali Jadbabaie Ali Jadbabaie is the JR East Professor of Engineering and Associate Director of the Institute for Data, Systems and Society at MIT, where he is also on the faculty of the department of civil and environmental engineering and is a principal investigator in the Laboratory for Information and Decision Systems (LIDS). He is the director of the Sociotechnical Systems Research Center, one of MIT’s 13 research laboratories and serves as the director of the Social and Engineering systems PhD Program. He received his Bachelors (with high honors) from Sharif University of Technology in Tehran, Iran, a Masters degree in electrical and computer engineering from the University of New Mexico, and his PhD in control and dynamical systems from the California Institute of Technology. He was a postdoctoral scholar at Yale University before joining the faculty at Penn in July 2002. Prior to joining MIT faculty, he was the Alfred Fitler Moore a Professor of Network Science and held secondary appointments in computer and information science and operations, information and decisions in the Wharton School. He was the inaugural editor-in-chief of IEEE Transactions on Network Science and Engineering, a new interdisciplinary journal sponsored by several IEEE societies. He is a recipient of a National Science Foundation Career Award, an Office of Naval Research Young Investigator Award, the O. Hugo Schuck Best Paper Award from the American Automatic Control Council, and the George S. Axelby Best Paper Award from the IEEE Control Systems Society. His students have been winners and finalists of student best paper awards at various ACC and CDC conferences. He is an IEEE fellow and a recipient of the 2016 Vannevar Bush Fellowship from the office of Secretary of Defense, and a member of the national Academic of Science, Engineering, and Medicine’s Intelligence Science and Technology Expert Group (ISTEG). His current research interests are in distributed decision making, social learning, multi-agent coordination and control, distributed optimization, network science, and network economics. |