DyNaVLM: Zero-Shot Vision-Language Navigation System with Dynamic Viewpoints and Self-Refining Graph Memory
Abstract
We present DyNaVLM, an end-to-end vision-language navigation framework using Vision-Language Models (VLM). In contrast to prior methods constrained by fixed angular or distance intervals, our system empowers agents to freely select navigation targets via visual-language reasoning. At its core lies a self-refining graph memory that 1) stores object locations as executable topological relations, 2) enables cross-robot memory sharing through distributed graph updates, and 3) enhances VLM’s decision-making via retrieval augmentation. Operating without task-specific training or fine-tuning, DyNaVLM demonstrates high performance on GOAT and ObjectNav benchmarks. Real-world tests further validate its robustness and generalization. The system’s three innovations—dynamic action space formulation, collaborative graph memory, and training-free deployment—establish a new paradigm for scalable embodied robot, bridging the gap between discrete VLN tasks and continuous real-world navigation.
I Introduction
Navigation is a foundational capability for autonomous agents, requiring the integration of spatial reasoning, real-time decision-making, and adaptability to dynamic environments. While humans navigate seemingly effortlessly through complex spaces, replicating this ability in artificial systems remains a formidable challenge. Traditional approaches often decompose the problem into modular components—such as perception, reflection, planning, and control—to leverage specialized algorithms for each subtask.[1][2] However, such systems struggle with generalization, scalability, and real-world deployment due to their reliance on task-specific engineering and rigid pipelines. Recent advances in VLM [3][4] offer promising alternatives by unifying perception and reasoning within a single framework, yet their application to embodied navigation remains constrained by limitations in spatial granularity and contextual reasoning.
In this work, we demonstrate that VLM can function as a zero-shot, end-to-end navigation policy without requiring fine-tuning or prior exposure to navigation-specific data. Our approach is built on three key innovations. First, we introduce a dynamic action space formulation that replaces fixed motion primitives with free-form target selection through visual-language reasoning. Second, we develop a collaborative graph memory mechanism, inspired by retrieval-augmented generation (RAG), which enables persistent spatial knowledge representation and cross-robot memory sharing. Third, our method allows for training-free deployment, achieving high performance without task-specific fine-tuning.
At the core of our system is a self-refining graph memory architecture that encodes object relationships as executable topological maps, supports distributed memory updates across robots, and enhances VLM decision-making through context-aware memory retrieval. This architecture bridges the sim-to-real gap by allowing agents to dynamically adjust navigation targets based on safety constraints, such as obstacle avoidance and adherence to warning signs, while maintaining human-interpretable spatial representations. Fig. 1
Our contributions are threefold. First, we introduce a novel graph memory architecture that encodes environments as executable topological maps, enabling persistent spatial reasoning and facilitating distributed knowledge sharing across robotic agents. Second, we present DyNaVLM, a novel VLM-based navigation framework capable of achieving human-level target selection flexibility, effectively eliminating the constraints of fixed action spaces. Third, it provides comprehensive validation demonstrating high-performance in both simulated benchmarks and real-world deployment, showcasing the framework’s robustness for practical applications without requiring task-specific training.

II Related work
II-A Vision-Language Models for Navigation
One of the most common vision-language navigation (VLN) policies is training end-to-end models from scratch using offline datasets[5][6][7][8][9], but face fundamental limitations in generalization due to the prohibitive costs of collecting large-scale navigation data. These methods struggle to adapt to novel object configurations or unseen environments.An alternative line of work fine-tunes pre-trained vision-language models with robot-specific data [10][11][12][13], aiming to preserve semantic understanding while adapting to navigation tasks. However, this risks catastrophic forgetting of the original model’s capabilities, revealing the fragility of such approaches. The cost of fine-tuning is also non-negligible, requiring extensive data collection and annotation efforts.
Recent efforts have shifted toward zero-shot prompting of VLMs without fine-tuning, but these methods impose restrictive action spaces such as fixed angular increments and cardinal directions [7][14][15] or directions (”north,” ”south”, ”east,” ”west”) [2] that limit motion flexibility. This fixed-distance and fixed-direction action space either oversimplifies the situation or relies on extremely small distances or angles, causing the robot to make repeated small steps, which leads to an unacceptable time cost. In any case, such action spaces remain merely an idealized abstraction.
Visual prompting methods have emerged to enhance spatial reasoning in VLMs. Building on annotation techniques like Set-of-Mark [16], navigation-specific approaches overlay markers on input images to ground language instructions in visual features [17]. PIVOT [18] and VLMnav [19] represent this category, generating action proposals through arrow prompts. While these methods improve navigation performance, they still rely on fixed action spaces and lack consideration for hard constraints (walkable areas) and soft constraints (such as warning signs or task requirements).
II-B Memory for Navigation
Effective navigation in mobile robotics requires robust environmental memory systems that integrate sensory perception with spatial modeling. Traditional approaches build upon Simultaneous Localization and Mapping (SLAM) [20], which constructs geometric maps through sensor fusion and localization. While SLAM enables basic obstacle avoidance and path planning, its purely geometric representations lack semantic context, limiting applicability in human-centric environments and cannot be directly used for VLM.
This semantic gap has spurred development of augmented memory systems that layer object-level understanding onto spatial maps. Current solutions incorporate semantic information through two primary modalities: direct human interaction via dialogue systems [21], or automated annotation using machine learning models. The latter encompasses hierarchical 3D scene graphs encoding room connectivity[22], vision-language models generating textual scene descriptions [23], and region classifiers labeling navigable spaces in RGB-D streams [24]. Despite these advances, implementation barriers persist—particularly dependence on specialized sensors and compute-intensive hardware—which restrict real-world deployment scalability, especially unable to annotate the environment for a robot in real time. Existing methods thus face a fundamental tradeoff: geometric precision and semantic richness remain inversely correlated with practical feasibility across diverse robotic platforms.
Recent works like SayPlan [21] and Text2Map [25] demonstrate graph-based mapping approaches that encode spatial relationships through hierarchical structures. While we similarly adopt graph representations for location encoding, these methods rely on specialized prior knowledge—SayPlan requires pre-constructed 3D scene graphs (3DSG) of large environments, while Text2Map depends on human-provided navigation instructions for graph initialization. In contrast, our framework integrates memory construction as an inherent component of exploration, enabling VLMs to dynamically build graph-structured memory without prior environmental knowledge. This dual approach ensures robustness through self-supervised map generation while eliminating dependence on human annotations.
III Method
III-A Problem Formulation
We introduce DyNaVLM, a navigation system that processes a goal (expressed in either natural language or an image), an RGB-D observation at every step, and the robot’s pose to determine an appropriate action . The agent maintains a memory function that extracts spatio features from historical observations. The action space is parameterized in polar coordinates , comprising a yaw-axis rotation and a forward displacement in the robot’s local frame. In summary, at every step , our policy computes an action , where .
III-B Memory manager

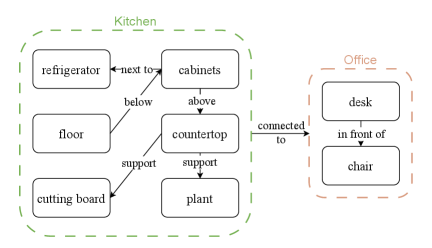
The Memory manager serves as the central middleware coordinating the interaction between the VLM and our graph-structured memory system. As illustrated in Fig. 2, this component maintains a dynamic knowledge graph (Memory Bank) that captures spatial relationships and semantic object information within the environment.
The graph structure of memory implements a hybrid representation where vertices encode object instances with attributes {name, location, visual_features}, while edges model spatial adjacency and navigation accessibility. Upon receiving real-time perceptual input from RGB-D sensors, the manager performs two critical functions: (1) node embedding updates using VLM-generated object descriptors, (2) edge addition, where the VLM determines spatial relationships between nodes. The VLM can update the memory through functions
-
•
add_node(name, attributes): Create or update a node in the memory.
-
•
add_edge(start, target, relation): Add a directed edge between two nodes.
The manager exposes a structured query interface to the LLM controller through function templates including:
-
•
spatial_query(semantic_filter): Retrieves neighborhood subgraphs based on semantic constraints.
-
•
path_inference(start, target): Generates potential navigation trajectories.
This architecture facilitates efficient context propagation between the VLM’s visual grounding capabilities and the LLM’s symbolic reasoning, which is particularly crucial for handling ambiguous object references (e.g., ”find the charging station near seating areas”). Additionally, this structured memory can be easily converted back into natural language to describe objects and spatial relationships within the memory, serving as input for the VLM. Moreover, it enables seamless memory transfer and preservation.




III-C Action Proposer
Enabling a VLM to directly output navigation coordinates from an image is inherently challenging, as spatial reasoning is not explicitly encoded in standard language model training objectives. To bridge this gap without introducing task-specific training, we propose a candidate-based discretization strategy that simplifies the continuous search space into a finite set of uniformly sampled points. These candidate points are generated without prior environmental assumptions, ensuring minimal human bias and maximizing adaptability to novel scenes. The action proposal process involves two stages:
III-C1 Spatial Sampling
Given RGB-D data , we define the navigable boundary as a continuous set of maximum reachable ground points in polar coordinates:
| (1) |
where represents the depth measurement at angular coordinate .
With uniform angular sampling, we generate a set of candidate points along the navigable boundary. To ensure the visual spacing between actions is enough for the VLM to discern, the points are filted by a minimum angular distance . To encourage exploration, the near points are removed in priority to the far points. A coefficient is multiplied to the distance to ensure a safe margin.
| (2) |
III-C2 Safety-Aware Filtering
VLM is used to further filter and sdjust the candidate points. The coordinates of the candidate points are concatenated with the natural language constraints to form the input to the VLM, and points are also annoted on the image . To ensure real-world applicability, candidate points undergo rigorous safety checks. Our framework dynamically eliminates infeasible waypoints (e.g., near obstacles, on non-traversable surfaces) caused by ground recognition errors (see Fig. 3). Natural language-defined constraints (e.g., ”stay away from the oven”) can also be involved.
Moreover, for surviving candidates, the VLM performs geometric adjustments based on visual context. By analyzing scene semantics (e.g., objects, signage), the model fine-tunes point positions or rotating headings to better align with task objectives. This refinement process leverages the VLM’s commonsense understanding of objects, enabling precise navigation without relying on domain-specific object detectors or geometric priors.
| (3) |
This dual-stage approach exemplifies our framework’s generalizability: it avoids hardcoding environmental assumptions while maintaining robustness through the VLM’s inherent world knowledge. By decoupling spatial sampling from semantic reasoning, we preserve the model’s zero-shot capabilities while ensuring safety-critical constraints are systematically enforced.
III-D Action Selector
The Action Selector synthesizes geometric candidates, perceptual context, and retrieved memory to produce the final navigation action.
III-D1 Multimodal Prompt Engineering
III-D2 Confidence-Based Execution
Using chain-of-thought reasoning, the VLM evaluates candidate actions based on the multimodal prompt to generate a confidence score for each action. To determine whether terminate the navigation, a stop action is checked . The original image is used to verify the stop action. The final action is selected:
| (5) |
This architecture enables zero-shot adaptation to novel environments while maintaining safety constraints through the memory-guided verification process.
IV Simulation Evaluation

To assess and compare our approach with the prior ones, performances are compared on two embodied navigation benchmarks, ObjectNav [26] and GOAT-Bench [27], with the HM3D dataset [28]. Further, ablation studies are conducted to evaluate the effectiveness of memory in our framework.
IV-A Experiment Setups
We adopt the same setup as VLMnav [19]. The agent has a cylindrical body with a radius of 0.17m and a height of 1.5m. It is equipped with an egocentric RGB-D sensor with a resolution of and a horizontal field-of-view of . We use Gemini 2.0 Flash-Lite as the vision-language model.
IV-B Metrics
Following [2, 19, 27], we evaluate performance using:
-
•
Success Rate (SR): The fraction of episodes completed successfully.
(6) where is the number of successfully completed episodes, and is the total number of episodes.
-
•
Success weighted by Path Length (SPL): A path efficiency measure penalizing unnecessary movement.
(7) where is a binary success indicator for episode , is the shortest path length from start to goal in episode , and is the actual path length taken by the agent.
IV-C Results
IV-C1 ObjectNav
The Object-Goal Navigation (ObjectNav) benchmark, which evaluates an agent’s ability to navigate to an object specified by its category label (Sofa, Toilet, TV, Plant, Chair, Bed) in an unexplored environment. The agent starts at a random location and must explore efficiently to approach the target. The threshold of success is 0.3m.
We compare our approach against PIVOT [5] and VLMnav [19] , the most relevant baselines using VLM. We also evaluate an ablated variant, Ours w/o Memory, which removes the Memory Manager modules.
| Method | SR (%) | SPL |
|---|---|---|
| Ours | 45.0 | 0.232 |
| w/o Memory | 43.1 | 0.187 |
| VLMnav [19] | 42.8 | 0.218 |
| PIVOT [5] | 22.7 | 0.108 |
Table I shows that our approach achieves the best performance on ObjectNav, with a 45.0% success rate (SR) and an SPL of 0.232, outperforming the previous VLM frameworks. The ablated variant Ours w/o Memory, which removes the memory module, sees a performance drop on the SPL, demonstrating the effectiveness of our memory design in improving both success rate and path efficiency. Moreover, both Ours and Ours w/o Memory outperform PIVOT [5]. This suggests that restricting the sampling of navigation points to the ground plane is a crucial strategy, allowing for more efficient exploration and goal localization.
IV-C2 GOAT-Bench
GO to AnyThing (GOAT) benchmark [27] is a challenging benchmark for embodied AI navigation, requiring agents to follow targets specified through three modalities: (i) object names, (ii) object images, and (iii) detailed text descriptions (as shown in Fig. 4). Each episode consists of 5–10 sub-tasks, testing the agent’s adaptability to different goal representations. GOAT-Bench evaluates methods on multimodal navigation, robustness to noisy goals, and memory usage in lifelong scenarios.
Besides comparing to VLMnav and PIVOT, We also evaluate our method against two state-of-the-art specialized approaches: (i) SenseAct-NN [17], a reinforcement learning-based policy that employs learned submodules for different navigation skills, and (ii) Modular GOAT [20], a system that constructs a semantic memory map and utilizes a low-level policy for object navigation.
Unlike SenseAct-NN and Modular GOAT, our approach is zero-shot and requires no task-specific training. We do not depend on low-level policies or external object detection/segmentation modules. Instead, our method leverages a generalizable memory module, allowing it to achieve competitive performance with these specialized approaches while maintaining flexibility across different goal modalities.
| Method | SR (%) | SPL |
|---|---|---|
| SenseAct-NN Skill Chain [27] | 29.5 | 0.113 |
| Ours | 25.5 | 0.102 |
| Modular GOAT [29] | 24.9 | 0.172 |
| VLMnav [19] | 20.1 | 0.096 |
| PIVOT [5] | 10.2 | 0.055 |
As shown in Table II, our method achieves strong performance on the GOAT-Bench benchmark. Among all VLM-based approaches, our method achieves the best performance, demonstrating that a well-designed memory module can significantly enhance the generalization capability of VLMs for embodied navigation. While SenseAct-NN [27] attains a 15% higher performance, our method achieves 25.5% SR and 0.102 SPL, demonstrating competitive results despite being a zero-shot approach without task-specific training.
Compared to Modular GOAT [29], our method achieves a higher SR, while Modular GOAT attains a higher SPL (0.172 vs. 0.102). This suggests that the object recognition model, which provides precise object locations for navigation, allows the agent to take more direct and efficient paths to the target, improving its SPL. In contrast, our approach relies solely on a vision-language model (VLM) with memory to reason about spatial relationships, achieving competitive success rates without explicit object localization.
Moreover, our method outperforms VLMnav [19] by 27% in SR, demonstrating the substantial benefit of our memory module in longer and more complex navigation tasks. Since GOAT-Bench includes multiple sub-tasks in navigation episodes and noisy goal specifications, memory plays a crucial role in helping the VLM track previously visited locations, recognize partially observed objects, and efficiently plan future movements. This further supports our hypothesis that memory is especially valuable in lifelong learning settings and real-world embodied AI scenarios, where agents must retain and utilize past knowledge over extended durations.
V Real-world Evaluation
We condected experiments under various real-world tasks to verify the effectiveness of the proposed method.


V-A Experiment Setups
The proposed method was deployed on a Unitree Go2 quadrupedal robot. A RealSense D435 camera is used to acquire aligned RGB-D images, which is mounted at a downward angle of 10 degrees and a height of 85cm (related to the ground). A Unitree L1 LiDAR located beneath the robot’s head is used to provide local odometry for controlling the robot’s movement towards the target point. The experiments are deployed on a large flat floor containing open-plan offices of different sizes, meeting rooms, lecture hall and laboratory space. The overview of the scenarios are shown in Fig. 5.
In each task, the agent is prompted to find 1 or 2 nearest objects. We employed FastSAM [30] for the segmentation of the ground in the RGB image. For the determined target point, we project its position into the robot’s base frame using the aligned depth image. Coordinate transformation between the robot and the target position is updated from the local odometry to command the robot’s movement using the default motion controller of Go2. To reserve space for the movement, the L1 LiDAR is also used to detect surrounding obstacles. When an obstacle is detected within a cylindrical area whose diameter exceeds the length of robot by 15cm, the robot will first move a certain distance in the opposite direction of the obstacle, and then proceed towards the target.
V-B Metrics
The performance in real-world tasks are evaluated using the Success Rate (SR) metric mentioned in Sec. IV-B and the average cumulative distance (ACD) traversed across all succeeded tasks.
The success of real-world tasks is defined as the distance between the target object and the robot being less than 5m, with the target appearing within the last frame of camera. For the first target, the robot is allowed a maximum travel distance of 200m, which is approximately twice the distance required to traverse the entire experimental scenario. For the second target (if given), the robot is permitted an additional maximum travel distance of 100m.
V-C Results
We conducted five tasks in total, with three tasks requiring the agent to locate single targets: a water dispenser, a printer, and a trash can. In the remaining two tasks the agent were sequentially required to find two targets, specifically first the printer and then the trash can, and first the water dispenser and then the printer. To enhance the diversity of the tasks, we conducted three separate experiments for each task, initiating from distinct locations.
We compared the proposed method with the VLMnav baseline [19], ensuring fairness by starting from the same location and direction for the same experiment. The experimental results are shown in Table III. The superscript “1” denotes the target as the first instructional objective, while the superscript “2” signifies the target as the second instructional objective. The result indicates that our method notably outperforms the baseline in terms of both success rate and travel distance, with an particularly pronounced improvement in tasks requiring the identification of the second target.
| Printer1 | Water dispenser1 | Trash can1 | ||||
| SR. | ACD. | SR. | ACD. | SR. | ACD. | |
| Ours | 2/6 | 89m | 3/6 | 65m | 2/3 | 29m |
| VLMnav | 1/6 | 23m | 1/6 | 44m | 2/3 | 41m |
| Printer2 | Trash can2 | |||||
| SR. | ACD. | SR. | ACD. | |||
| Ours | 1/3 | 76m | 2/3 | 17m | ||
| VLMnav | 0/3 | – | 1/3 | 35m | ||
Fig. 6 illustrates key frames from one of the tasks, where the agent starts from the laboratory space and gradually searches for the water dispenser. In the 4th frame, the proposed method chooses to walk towards the door because, through the memory manager, the agent determines that the current site is a laboratory space and therefore suggests leaving the site to find the water dispenser. Conversely, the baseline method demonstrates a propensity to navigate towards the faucet, which leads it into a loop and ultimately results in a failure to locate the target successfully.
VI Conclusion
In this work, we propose DyNaVLM, a vision-language navigation framework that leverages self-refining graph memory to enhance VLM-based decision-making. By dynamically encoding topological spatial relations, our approach enables agents to navigate flexibly without relying on fixed action spaces or task-specific training. Our experiments on ObjectNav and GOAT-Bench demonstrate that DyNaVLM surpasses prior VLM-based methods while achieving competitive performance with specialized navigation systems. The results highlight the advantages of memory-augmented reasoning, particularly in long-horizon tasks with complex goal specifications.
To further validate DyNaVLM’s effectiveness, we conducted real-world evaluations where the agent was tasked with locating objects in diverse environments. The experimental results confirm that DyNaVLM significantly outperforms the baseline in both success rate and efficiency, particularly in multi-target tasks requiring sequential goal identification. The agent demonstrated robust generalization across different starting locations and maintained reliable performance under real-world constraints such as dynamic obstacles and environmental variations. These findings underscore the practical viability of our approach for embodied AI applications beyond simulation-based benchmarks.
Despite these advancements, there are areas for future improvement. The performance gap with specialized methods indicates that integrating additional spatial priors or structured representations may further enhance navigation efficiency. Additionally, while DyNaVLM operates effectively in zero-shot settings, incorporating few-shot adaptation techniques could refine its decision-making over time. As VLMs continue to evolve, we anticipate that frameworks like DyNaVLM will play a pivotal role in bridging the gap between discrete VLN tasks and real-world embodied navigation. Future research should explore real-time learning mechanisms and multi-agent collaboration to further enhance the robustness of these systems, paving the way for more intelligent, interactive, and autonomous robotic assistants.
References
- [1] ZHOU, Gengze, HONG, Yicong, et WU, Qi. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In : Proceedings of the AAAI Conference on Artificial Intelligence. 2024. p. 7641-7649.
- [2] ZENG, Qingbin, YANG, Qinglong, DONG, Shunan, et al. Perceive, reflect, and plan: Designing llm agent for goal-directed city navigation without instructions. arXiv preprint arXiv:2408.04168, 2024.
- [3] ACHIAM, Josh, ADLER, Steven, AGARWAL, Sandhini, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [4] TEAM, Gemini, GEORGIEV, Petko, LEI, Ving Ian, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- [5] SHAH, Dhruv, EYSENBACH, Benjamin, KAHN, Gregory, et al. Ving: Learning open-world navigation with visual goals. In : 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021. p. 13215-13222.
- [6] SHAH, Dhruv, EYSENBACH, Benjamin, KAHN, Gregory, et al. Rapid exploration for open-world navigation with latent goal models. arXiv preprint arXiv:2104.05859, 2021.
- [7] MOUDGIL, Abhinav, MAJUMDAR, Arjun, AGRAWAL, Harsh, et al. Soat: A scene-and object-aware transformer for vision-and-language navigation. Advances in Neural Information Processing Systems, 2021, vol. 34, p. 7357-7367.
- [8] SHAH, Dhruv, SRIDHAR, Ajay, DASHORA, Nitish, et al. ViNT: A foundation model for visual navigation. arXiv preprint arXiv:2306.14846, 2023.
- [9] SHAH, Dhruv, SRIDHAR, Ajay, BHORKAR, Arjun, et al. Gnm: A general navigation model to drive any robot. In : 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023. p. 7226-7233.
- [10] KIM, Moo Jin, PERTSCH, Karl, KARAMCHETI, Siddharth, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
- [11] BROHAN, Anthony, BROWN, Noah, CARBAJAL, Justice, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022.
- [12] ZHANG, Jiazhao, WANG, Kunyu, XU, Rongtao, et al. Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852, 2024.
- [13] ZHEN, Haoyu, QIU, Xiaowen, CHEN, Peihao, et al. 3d-vla: A 3d vision-language-action generative world model. arXiv preprint arXiv:2403.09631, 2024.
- [14] LONG, Yuxing, LI, Xiaoqi, CAI, Wenzhe, et al. Discuss before moving: Visual language navigation via multi-expert discussions. In : 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024. p. 17380-17387.
- [15] YU, Bangguo, KASAEI, Hamidreza, et CAO, Ming. L3mvn: Leveraging large language models for visual target navigation. In : 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023. p. 3554-3560.
- [16] YANG, Jianwei, ZHANG, Hao, LI, Feng, et al. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023.
- [17] SHTEDRITSKI, Aleksandar, RUPPRECHT, Christian, et VEDALDI, Andrea. What does clip know about a red circle? visual prompt engineering for vlms. In : Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. p. 11987-11997.
- [18] NASIRIANY, Soroush, XIA, Fei, YU, Wenhao, et al. Pivot: Iterative visual prompting elicits actionable knowledge for vlms. arXiv preprint arXiv:2402.07872, 2024.
- [19] GOETTING, Dylan, SINGH, Himanshu Gaurav, et LOQUERCIO, Antonio. End-to-End Navigation with Vision Language Models: Transforming Spatial Reasoning into Question-Answering. arXiv preprint arXiv:2411.05755, 2024.
- [20] DURRANT-WHYTE, Hugh et BAILEY, Tim. Simultaneous localization and mapping: part I. IEEE robotics & automation magazine, 2006, vol. 13, no 2, p. 99-110.
- [21] BASTIANELLI, Emanuele, BLOISI, Domenico Daniele, CAPOBIANCO, Roberto, et al. On-line semantic mapping. In : 2013 16th International Conference on Advanced Robotics (ICAR). IEEE, 2013. p. 1-6.
- [22] RANA, Krishan, HAVILAND, Jesse, GARG, Sourav, et al. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning. arXiv preprint arXiv:2307.06135, 2023.
- [23] BIGAZZI, Roberto, BARALDI, Lorenzo, KOUSIK, Shreyas, et al. Mapping high-level semantic regions in indoor environments without object recognition. In : 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024. p. 7686-7693.
- [24] SÜNDERHAUF, Niko, DAYOUB, Feras, MCMAHON, Sean, et al. Place categorization and semantic mapping on a mobile robot. In : 2016 IEEE international conference on robotics and automation (ICRA). IEEE, 2016. p. 5729-5736.
- [25] KARKOUR, Ammar, HARRAS, Khaled A., et FEO-FLUSHING, Eduardo. Text2Map: From navigational instructions to graph-based indoor map representations using LLMs. In : 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024. p. 1153-1160.
- [26] BATRA, Dhruv, GOKASLAN, Aaron, KEMBHAVI, Aniruddha, et al. Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171, 2020.
- [27] KHANNA, Mukul, RAMRAKHYA, Ram, CHHABLANI, Gunjan, et al. Goat-bench: A benchmark for multi-modal lifelong navigation. In : Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. p. 16373-16383.
- [28] YADAV, Karmesh, RAMRAKHYA, Ram, RAMAKRISHNAN, Santhosh Kumar, et al. Habitat-matterport 3d semantics dataset. In : Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. p. 4927-4936.
- [29] M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y. Min, K. Shah, C. Paxton, S. Gupta, D. Batra, R. Mottaghi, J. Malik, and D. S. Chaplot, “Goat: Go to any thing,” 2023.
- [30] X. Zhao, W. Ding, Y. An, Y. Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,” arXiv preprint arXiv:2306.12156, 2023.