Earthquake Magnitude and b value prediction model using Extreme Learning Machine
University of British Columbia
Vancouver, BC V6T 1Z4
gbaveja@student.ubc.ca
&
Department of Computer Science and Engineering
GD Goenka University
Sohna Rural, India
jaspreet.singh@ggdu.org
Abstract
Earthquake Prediction has been a challenging research area for many decades, where the future occurrence of this highly uncertain calamity is predicted. In this paper, several parametric and non-parametric features were calculated, where the non-parametric features were calculated using the parametric features. 8 seismic features were calculated using Gutenberg-Richter law, total recurrence time, seismic energy release. Additionally, criterions such as Maximum Relevance and Maximum Redundancy were applied to choose the pertinent features. These features along with others were used as input for an Extreme Learning Machine (ELM) Regression Model. Magnitude and Time data of 5 decades from the Assam-Guwahati region were used to create this model for magnitude prediction. The Testing Accuracy and Testing Speed were computed taking Root Mean Squared Error (RMSE) as the parameter for evaluating the model. As confirmed by the results, ELM shows better scalability with much faster Training and Testing Speed (up to thousand times faster) than traditional Support Vector Machines. The Testing RMSE (Root Mean Squared Error) came out to be. To further test the model’s robustness, magnitude-time data from California was used to- calculate the seismic indicators, fed into neural network (ELM) and tested on the Assam-Guwahati region. The model proves to be successful and can be implemented in early warning systems as it continues to be a major part of Disaster Response and Management.
Keywords Earthquake Prediction Machine Learning Extreme Learning Machine Seismological Features
1 Introduction
Earthquake is one of the most destructive and the deadliest natural disaster that has caused thousands of deaths, and millions if not billions of dollars in property loss. No part of the world is immune to earthquakes. The developing countries, in particular, are the most affected because emergency response services may not be available even in stressful times. A reliable early warning system may potentially be able to save lives and land. Since the biggest and deadly earthquakes started occurring near the 1950s, primitive prediction methods were thought as necessities. But by the 1990s, continuing failure led to many questions whether it was even possible to foretell the Time-Location of Earthquakes.
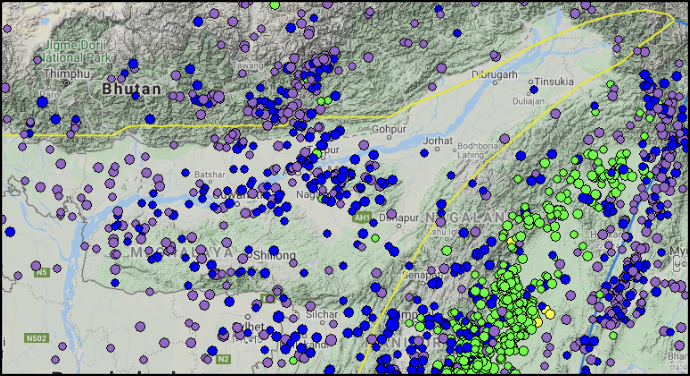
Fortunately, with the emergence of modern computer science based intelligent algorithms, it is relatively easy to predict or classify data which has a definite pattern. Significant results have been attained in different fields of study such as Flood Forecasting (Anupam and Pani, 2019), Weather Analysis and Forecasting (Mishra et al., 2013), and disease diagnosis (Cosma et al., 2016). Machine Learning and seismology can be linked together to produce considerable results.
Assam-Guwahati region is the most earthquake prone region of India due to subducting Indian plate under the Eurasian plate. This region has been experiencing earthquakes of significant magnitude at moderate depth. A polygon shaped Assam region was selected for calculation of seismic features. Machine Learning and Computational Intelligence has led to paradigm shift in the methods of predictions and determination of earthquakes. An ideal earthquake predictor must yield the Magnitude, Time, Energy release and Location of the earthquake. Although our prediction model isn’t perfect, it is indeed a huge step forward in Earthquake research.
The core idea of this work is to predict earthquakes with magnitude and also predict the number of days in between successive earthquakes. The mathematically calculated seismic features were used as an input to the SLFN (Single Layer Feed-Forward Network). The prediction results of the neural network and SVM were compared and discussed in this paper.
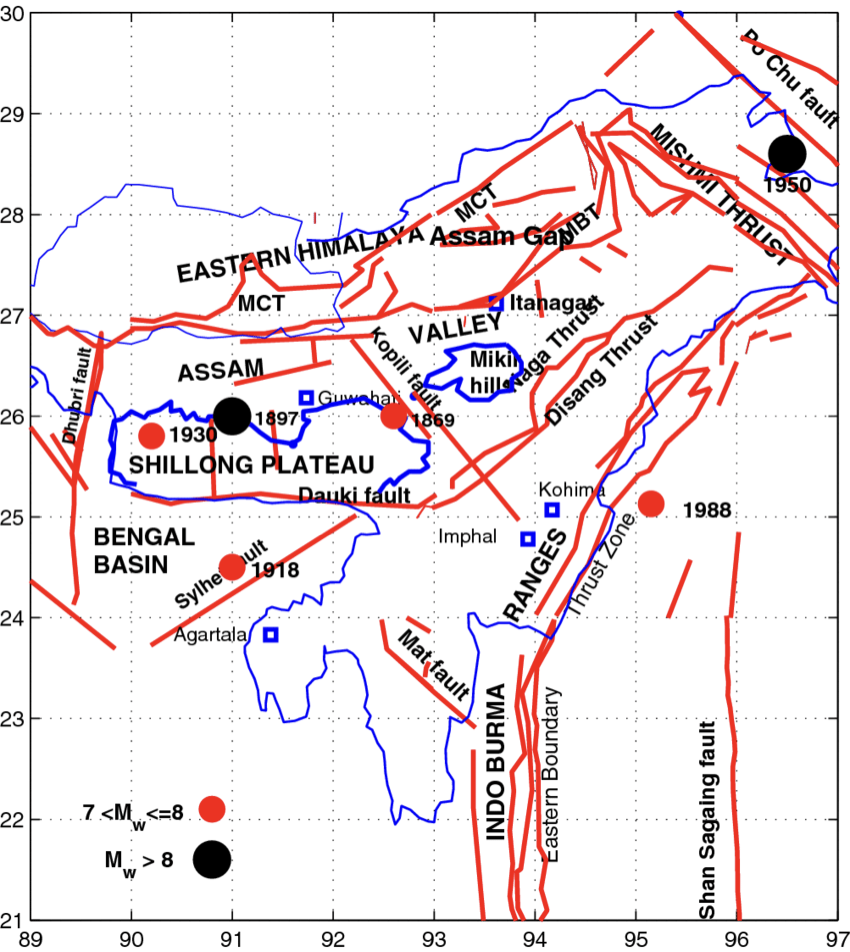
1.1 Tectonics of Assam region
Assam is one of the most seismically active regions in India with events occurring at shallow depth (0-70km). The region was geologically formed due to collision of Eurasian and Indian Plate during Eocene. The seismic parameters are mathematically calculated from a catalogue, so the catalogue should be complete above the cut- off magnitude. Here, the cut-off magnitude refers to the earthquake magnitude, below which seismic events are not considered for parameter calculations ( in our case). See Section 3.
2 Literature Review
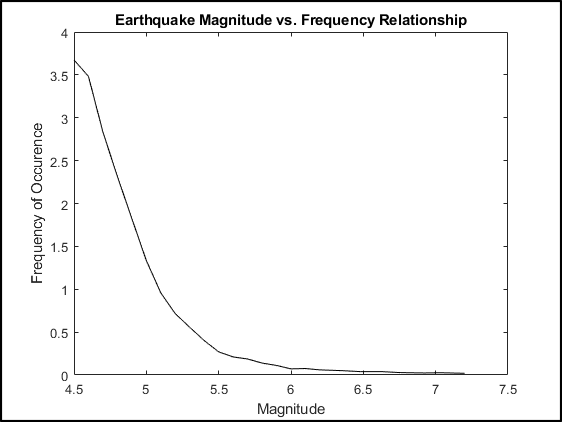
Various studies have been carried out by researchers over earthquake occurrences and predictions leading to various conclusions. The Gutenberg-Richter mathematical model is one such example where the relationship between earthquake magnitude and frequency was calculated; the relationship is analysed and used to predict distribution over time. (Petersen et al., 2019) carried out research under the umbrella of California Geological Survey (CGS) and proposed a time-independent model showing that probability of earthquake occurrence follows poisson’s distribution model.
Several approaches have been proposed in the literature for using artificial neural networks (ANNs) to predict earthquakes based on various seismic precursors. For example, (Negarestani et al., 2002) used a backpropagation neural network (BPNN) to identify abnormal changes in soil radon concentration, which can be induced by earthquakes, by differentiating them from normal environmental variations. (Liu et al., 2004) employed an ensemble of radial basis function (RBF) neural networks to forecast earthquakes in China using historical magnitude data as input. (Hossain et al., 2018) presented an expert system-based method for earthquake prediction that involves dividing the globe into four quadrants, using historic earthquake data as input and applying predicate logic and association rules to make predictions for each quadrant over a 24-hour period.
In their paper, (Asim et al., 2017) used four machine learning techniques, including a pattern recognition neural network, a recurrent neural network, a random forest, and a linear programming boost ensemble classifier, to predict earthquake magnitudes in the Hindukush region using a temporal sequence of past seismic activity. Earthquake precursors are phenomena that occur before a main shock and are causally linked to it, rather than simply occurring before it in time (Habermann, 1988). These precursors can be based on continuous observations of various physical parameters such as seismic wave velocity, gravity, resistivity, and electricity (Nuannin, 2006). For example, (Lu et al., 2002) found that drops in underground water levels and changes in resistivity recorded by geoelectric stations within km of the epicenter preceded the Tangshan earthquake.
Other proposed precursors include changes in seismicity rates, source parameters of earthquakes, and frequency-magnitude distributions (FMD) ((Nuannin, 2006); (Enescu and Ito, 2003); (Nagao et al., 2002); (Monterroso and Kulhánek, 2003); (Nuannin, 2006); (Schorlemmer et al., 2003); (Schorlemmer et al., 2005); (Wyss and Habermann, 1979); (Wyss and Martirosyan, 1998)). Seismic quiescence, or periods of significantly reduced seismicity, has also been suggested as a potential precursor (Katsumata and Kasahara, 1999).
3 Seismic Parameters
This study is carried out by using the eight seismic indicators, which are basically meant to represent the seismic state and potential of the ground. This section contains the overview of all the parameters and their calculation. One of the parameters is the Time T, which is the time span over the last n number of events and n in our case is 100 and t represents the time of earthquake occurrence.
| (1) |
3.1 Mean Magnitude
Time T represents the frequency of foreshocks before the month under consideration. The second seismic indicator considered is the mean magnitude of the last n events. It relates to the magnitudes of foreshocks, since the magnitude M of seismic activity increases before a larger earthquake.
| (2) |
3.2 Seismic Energy
The rate of square root of seismic energy release dE is another seismic indicator that can be related to seismic activity through the phenomenon of seismic quiescence. Seismic energy releases gradually from fault lines through low-magnitude seismic events but if this phenomenon gets disturbed, it may lead to a major seismic event. The equation for square root of seismic energy released is given below:
| (3) |
3.3 and value
The Frequency-Magnitude Distribution describes the number of earthquakes occurring in a given region as a function of their magnitude M as:
| (4) |
where is the cumulative number of earthquakes with magnitude equal to or larger than , and and are real constants that may vary in space and time.
The parameter characterizes the general level of seismicity in a given area during the study period, i.e., the higher the value, the higher the seismicity (Nuannin, 2006). The parameter is believed to depend on the stress regime and tectonic character of the region (Bhatt et al., 2009).
The and values are calculated numerically through two different methods. In earthquake prediction study for North-Eastern India, linear least square regression analysis based method is proposed.
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
5 and 7 represent the linear least square regression while 6 and 8 show the maximum likelihood method for calculation of and values.
In earthquake prediction study for North-Eastern India, linear least square regression analysis based method is proposed along with real time calculation of and values in this study.
3.4 Deviation from Gutenberg-Richter Law
Deviation of actual data from Gutenberg-Richter inverse power law (4) is also considered as a seismic indicator (Serra and Corral, 2017). We calculate it using the general variance model, where a greater value corresponds to a greater conformance and therefore– more likely to be predicted by the inverse power law:
| (9) |
3.5 Expected Magnitude
The difference between the maximum observed and the maximum occurred earthquake magnitude is also considered as a seismic indicator (refer to figure 9 and 9). The maximum observed event is listed in the catalog, while maximum expected event is obtained using the equation
| (10) |
where is the -intercept in the inverse power law obtained from 4.
3.6 Maximum magnitude in last seven days
3.7 Total recurrence time
It is also known as probabilistic recurrence time () and is defined as the time between two earthquakes of magnitude greater than or equal to and is calculated using 12. This parameter is another interpretation of Gutenberg-Richter’s law. As evident from the statement of inverse law, there will be different value of for every different value of , which would increase with increasing magnitude.
| (12) |
Available literature does not focus on which value of to be selected in such a scenario therefore is calculated for every from to magnitudes following the principle of retaining maximum available information. So for two sets of and values along with varying adds seismic features to the dataset.
3.8 Probability of earthquake occurrence
The probability of earthquake occurrence of magnitude greater than or equal to is also taken as an important seismic feature. It is represented by and calculated through 13. The inclusion of this feature supports the inclusion of Gutenberg-Richter law in an indirect way. The value of is dependent upon the corresponding value:
| (13) |
Therefore, and are separately used to calculate , thus giving two different values for this seismic feature.
4 Earthquake Magnitude Prediction model
Unlike previous other earthquake magnitude prediction models proposed, in this paper a new learning algorithm was used which consists of Single Layer Feed-forward Neural network (SLFN). This algorithm along with minimum Redundancy Maximum Relevance (mRMR) added to the hardiness of the model. The layout of the final prediction is given below. The dataset of the region was divided into Training and Testing sets. of the data for training and testing was performed on the rest of the data. All the parameters were taken into consideration while training and their variance within time.
The proposed procedure includes the two step feature selection. The features are selected after performing relevancy and redundancy checks, to make sure that only useful features are employed for earthquake prediction. The selected set of features was then passed on to Extreme Learning Machine (ELM).
4.1 Extreme Learning Machine (ELM)
ELM consists of a Single Layer Feed-Forward Neural Network where the parameters of the hidden nodes may not be tuned(Ding et al., 2015). This is an excellent feature which avoids the use of other Optimization Algorithms like Particle Swarm Optimization (PSO)(Kennedy and Eberhart, 1995), Salp Swarm Optimization (SSA)(Mirjalili et al., 2017). Here is a brief explanation of ELM (Nagao et al., 2002).
Given distinct training samples , where and , the output of a SLFN with hidden nodes (additive or RBF nodes) can be represented by:
| (14) |
where represents the weight vector that connects the hidden node and th output. represents the weight vector that connects the hidden node and the th output nodes.
is the output vector of the SLFN with respect to the input sample . and are learning parameters generated randomly of the th hidden node, respectively.
The standard of SLFNs and L hidden nodes in the activation function can be taken as samples of N without error. In other words,
| (15) |
From the equations given for , it can then be presented as
| (16) |
where
| (17) |
To minimise the cost function , ELM theories claim that the hidden nodes’ learning parameters and can be assigned randomly without considering the input data. Then, 16 becomes a linear system and the output weights can be analytically determined by finding a least-square solution as follows,
| (18) |
Where represents the Moore-Penrose generalized inverse of . Hence, by mathematical transformation the output weights are calculated. This avoids the lengthy training phase where adjustment of the parameters takes place iteratively along with some learning parameters (such as learning rate and iterations).
(Huang et al., 2006) listed the variables, where represents the output matrix of the hidden layer of the neural network. In , the th column is used to describe the th hidden layer nodes in terms of the input nodes. If represents the desired number of hidden nodes, the activation function g becomes infinitely differentiable.
5 Results
The data in this study came from United States Geological Survey. The model was run on a Lenovo G-80 laptop with Intel® Core™ iU CPU @ GHz and GB RAM. The results can be concluded into the following table: The ELM Model got an RMSE of which indicates over-fitting in the model. The average relative error percentage in other papers came out to be around 3%. The SVR had an RMSE of with a heavy training time of seconds. A significant drop in the testing time is observed in the ELM.
Using this model along with the CTS-M (Continuous Time Serious Markov) model which makes it possible to predict the location region of the next earthquake. This can improve the efficiency of the Early Warning Systems by a mile and also improve time efficacy of disaster response teams. As ELM proved to be better than SVR, it was used to predict earthquake magnitude trained on California Earthquake Data and tested on the Assam-Guwahati Region.
All models were tested on the Assam-Guwahati region with ratio of with the training data. for the California dataset, it had data points and was tested on data points.
6 Conclusion
Two Machine Learning techniques have been used to predict earthquakes in the subducting Assam-Guwahati Region, one of the most seismically active regions in India. Both Magnitude Predictors shows significant results when compared to one another.
Further, the better Machine Learning Model (Extreme Learning Machine) was trained on California Dataset and tested on the same Assam-Guwahati Data. This can be improved by using an M-ELM model which reduces the chances of over-fitting. In the end, it can drastically improve the retro-traditional machine learning models. The parameter (commonly referred to as the "-value") is commonly close to 1.0 in seismically active regions. This means that for a given frequency of magnitude or larger events there will be times as many magnitude or larger quakes and times as many magnitude or larger quakes. There is some variation of -values in the approximate range of to depending on the source environment of the region. In a notable portion of the data, the value seems to less than and gradually decreases.
The study used real time value change across time (), change recorded after every earthquake occurrence, instead of taking the value to be constant throughout one year time. The study shows, although earthquake occurrence is supposed to be decidedly nonlinear and appears to be a random phenomenon, yet it can be modeled on the basis of geophysical facts of the seismic region along with highly sophisticated modeling and learning approaches of machine learning.
| Assam-ELM | SVR | Cali-ELM | |
|---|---|---|---|
| Testing Time | s | s | s |
| RMSE | |||
| Training Time | s | s | s |
| Min -value | Max -value | Mean -value |
|---|---|---|
| Min -value | Max -value | Mean -value |
|---|---|---|
-
•
ELM model- trained and tested on Assam region proves to be better.
-
•
A Significant Drop ( in , ) in the Testing and Training Time can be observed in the California (ELM) and Assam (ELM) models
-
•
There exists a trade-off between and RMSE of ELM in Assam Data and California, indicating that the model is more sensitive to training data samples.
A smaller value likely suggests that the stress is high in the examined region. Decreasing value within the seismogenic volume under consideration has been found to correlate with increasing effective stress levels prior to major shocks.
Normal faulting is associated with the highest values, strike-slip events show mean values and thrust events the lowest values. This observation means that acts as a stress meter, depending inversely on the differential stress.
References
- Anupam and Pani [2019] Sagnik Anupam and Padmini Pani. Flood forecasting using a hybrid extreme learning machine-particle swarm optimization algorithm (ELM-PSO) model. Modeling Earth Systems and Environment, 6(1):341–347, November 2019. doi:10.1007/s40808-019-00682-z. URL https://doi.org/10.1007/s40808-019-00682-z.
- Mishra et al. [2013] Ashok Mishra, Christian Siderius, Kenny Aberson, Martine van der Ploeg, and Jochen Froebrich. Short-term rainfall forecasts as a soft adaptation to climate change in irrigation management in north-east india. Agricultural Water Management, 127:97–106, September 2013. doi:10.1016/j.agwat.2013.06.001. URL https://doi.org/10.1016/j.agwat.2013.06.001.
- Cosma et al. [2016] Georgina Cosma, David Brown, Matthew Archer, Masood Khan, and Alan Pockley. A survey on computational intelligence approaches for predictive modeling in prostate cancer. Expert Systems with Applications, 70, 11 2016. doi:10.1016/j.eswa.2016.11.006.
- Petersen et al. [2019] Mark Petersen, Allison Shumway, Peter Powers, Charles Mueller, Morgan Moschetti, Arthur Frankel, Sanaz Rezaeian, Daniel Mcnamara, Nico Luco, Oliver Boyd, Kenneth Rukstales, Kishor Jaiswal, Eric Thompson, Susan Hoover, Brandon Clayton, Edward Field, and Yuehua Zeng. The 2018 update of the us national seismic hazard model: Overview of model and implications. Earthquake Spectra, 36:875529301987819, 11 2019. doi:10.1177/8755293019878199.
- Negarestani et al. [2002] Ali Negarestani, Saeed Setayeshi, M Ghannadi-Maragheh, and B Akashe. Layered neural networks based analysis of radon concentration and environmental parameters in earthquake prediction. Journal of environmental radioactivity, 62:225–33, 02 2002. doi:10.1016/S0265-931X(01)00165-5.
- Liu et al. [2004] yu Liu, Qin Zheng, Zhewen Shi, and Junying Chen. Training radial basis function networks with particle swarms. In Advances in Neural Networks, volume 3173, pages 317–322, 08 2004. ISBN 978-3-540-22841-7. doi:10.1007/978-3-540-28647-9_54.
- Hossain et al. [2018] Mohammad Hossain, Abdullah Hasan, Sunanda Guha, and Karl Andersson. A belief rule based expert system to predict earthquake under uncertainty. Journal of Seismology, 9, 07 2018. doi:10.22667/JOWUA.2018.06.30.026.
- Asim et al. [2017] Khawaja Asim, Francisco Martínez-Álvarez, Abdul Basit, and Talat Iqbal. Earthquake magnitude prediction in hindukush region using machine learning techniques. Natural Hazards, 85:471–486, 01 2017. doi:10.1007/s11069-016-2579-3.
- Habermann [1988] R. E. Habermann. Precursory seismic quiescence: Past, present, and future. pure and applied geophysics, 126(2):279–318, 1988. doi:10.1007/BF00879000. URL https://doi.org/10.1007/BF00879000.
- Nuannin [2006] Paiboon Nuannin. The potential of b-value variations as earthquake precursors for small and large events. In Journal of Geology, 05 2006.
- Lu et al. [2002] Chia-Yu Lu, Hao-tsu Chu, Jian-Cheng Lee, YU-CHANG CHAN, KUO-JIAN CHANG, and Frederic Mouthereau. The 1999 chi-chi taiwan earthquake and basement impact thrust kinematics. Open House, 01 2002.
- Enescu and Ito [2003] Bogdan Enescu and Kiyoshi Ito. Values of b and p: their variations and relation to physical processes for earthquakes in japan. Ann. Disas. Prev. Res. Inst. Kyoto Univ., 46B, 01 2003.
- Nagao et al. [2002] T. Nagao, Y. Enomoto, Y. Fujinawa, M. Hata, M. Hayakawa, Q. Huang, J. Izutsu, Y. Kushida, K. Maeda, K. Oike, S. Uyeda, and T. Yoshino. Electromagnetic anomalies associated with 1995 kobe earthquake. Journal of Geodynamics, 33(4):401–411, 2002. ISSN 0264-3707. doi:https://doi.org/10.1016/S0264-3707(02)00004-2. URL https://www.sciencedirect.com/science/article/pii/S0264370702000042.
- Monterroso and Kulhánek [2003] David A. Monterroso and Ota Kulhánek. Spatial variations of b-values in the subduction zone of central america. Geofisica Internacional, 42:575–587, 2003.
- Schorlemmer et al. [2003] D. Schorlemmer, G. Neri, S. Wiemer, and A. Mostaccio. Stability and significance tests for b-value anomalies: Example from the tyrrhenian sea. Geophysical Research Letters, 30(16), 2003. doi:https://doi.org/10.1029/2003GL017335. URL https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2003GL017335.
- Schorlemmer et al. [2005] Danijel Schorlemmer, Stefan Wiemer, and Max Wyss. Variations in earthquake-size distribution across different stress regimes. Nature, 437:539–42, 10 2005. doi:10.1038/nature04094.
- Wyss and Habermann [1979] M. Wyss and R. E. Habermann. Seismic quiescence precursory to a past and a future kurile island earthquake. pure and applied geophysics, 117(6):1195–1211, 1979. doi:10.1007/BF00876215. URL https://doi.org/10.1007/BF00876215.
- Wyss and Martirosyan [1998] Max Wyss and Artak H. Martirosyan. Seismic quiescence before the m7, 1988, spitak earthquake, armenia. Geophysical Journal International, 134(2):329–340, 1998. doi:https://doi.org/10.1046/j.1365-246x.1998.00543.x. URL https://onlinelibrary.wiley.com/doi/abs/10.1046/j.1365-246x.1998.00543.x.
- Katsumata and Kasahara [1999] K. Katsumata and M. Kasahara. Precursory seismic quiescence before the 1994 kurile earthquake (mw = 8.3) revealed by three independent seismic catalogs. pure and applied geophysics, 155(2):443–470, 1999. doi:10.1007/s000240050274. URL https://doi.org/10.1007/s000240050274.
- Bhatt et al. [2009] Kaushalendra Mangal Bhatt, Andreas Hördt, and Santosh Kumar. Seismicity analysis of the kachchh aftershock zone and tectonic implication for 26 jan 2001 bhuj earthquake. Tectonophysics, 465(1):75–83, 2009. ISSN 0040-1951. doi:https://doi.org/10.1016/j.tecto.2008.11.011. URL https://www.sciencedirect.com/science/article/pii/S004019510800574X.
- Serra and Corral [2017] Isabel Serra and Álvaro Corral. Deviation from power law of the global seismic moment distribution. Scientific Reports, 7(1), January 2017. doi:10.1038/srep40045. URL https://doi.org/10.1038/srep40045.
- Wang [2015] Zhenming Wang. Predicting or forecasting earthquakes and the resulting ground-motion hazards: A dilemma for earth scientists. Seismological Research Letters, 86:1–5, 01 2015. doi:10.1785/0220140211.
- Alarifi et al. [2012] Abdulrahman S.N. Alarifi, Nassir S.N. Alarifi, and Saad Al-Humidan. Earthquakes magnitude predication using artificial neural network in northern red sea area. Journal of King Saud University - Science, 24(4):301–313, October 2012. doi:10.1016/j.jksus.2011.05.002. URL https://doi.org/10.1016/j.jksus.2011.05.002.
- Ding et al. [2015] Shifei Ding, Han Zhao, Yanan Zhang, Xinzheng Xu, and Ru Nie. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev., 44(1):103–115, jun 2015. ISSN 0269-2821. doi:10.1007/s10462-013-9405-z. URL https://doi.org/10.1007/s10462-013-9405-z.
- Kennedy and Eberhart [1995] J. Kennedy and R. Eberhart. Particle swarm optimization. In Proceedings of ICNN'95 - International Conference on Neural Networks. IEEE, 1995. doi:10.1109/icnn.1995.488968. URL https://doi.org/10.1109/icnn.1995.488968.
- Mirjalili et al. [2017] Seyedali Mirjalili, Amir H. Gandomi, Seyedeh Zahra Mirjalili, Shahrzad Saremi, Hossam Faris, and Seyed Mohammad Mirjalili. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Advances in Engineering Software, 114:163–191, December 2017. doi:10.1016/j.advengsoft.2017.07.002. URL https://doi.org/10.1016/j.advengsoft.2017.07.002.
- Huang et al. [2006] Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: Theory and applications. Neurocomputing, 70(1-3):489–501, December 2006. doi:10.1016/j.neucom.2005.12.126. URL https://doi.org/10.1016/j.neucom.2005.12.126.