Edema Estimation from Facial Images Taken
Before and After Dialysis via Contrastive
Multi-Patient Pre-Training
Abstract
Edema is a common symptom of kidney disease, and quantitative measurement of edema is desired. This paper presents a method to estimate the degree of edema from facial images taken before and after dialysis of renal failure patients. As tasks to estimate the degree of edema, we perform pre- and post-dialysis classification and body weight prediction. We develop a multi-patient pre-training framework for acquiring knowledge of edema and transfer the pre-trained model to a model for each patient. For effective pre-training, we propose a novel contrastive representation learning, called weight-aware supervised momentum contrast (WeightSupMoCo). WeightSupMoCo aims to make feature representations of facial images closer in similarity of patient weight when the pre- and post-dialysis labels are the same. Experimental results show that our pre-training approach improves the accuracy of pre- and post-dialysis classification by 15.1% and reduces the mean absolute error of weight prediction by 0.243 kg compared with training from scratch. The proposed method accurately estimate the degree of edema from facial images; our edema estimation system could thus be beneficial to dialysis patients.
Index Terms:
Edema, Kidney disease, Renal failure, Dialysis, Facial image, Convolutional neural network, Contrastive learning, Pre-Training, Transfer learning.I Introduction
Edema is the accumulation of excess fluid in tissues beyond the limits of physiological drainage [1]. Edema can arise from a variety of causes, including kidney, central, circulatory, orthopedic, and metabolic diseases. Chronic accumulation, or more generalized edema, is due to the onset of chronic systemic conditions such as heart failure and kidney disease [2]. When the kidney is unable to remove water and waste products from the body due to renal failure, dialysis is performed to remove excess water from the blood. At the end of 2018, there were approximately 550,000 dialysis patients in the United States [3] and 340,000 in Japan [4]. It is crucial for dialysis patients to control weight gain from the appropriate body weight after dialysis [5, 6], which is called dry weight [7]. Many studies have reported that large weight gain is associated with a higher risk of death [8, 9, 10, 11, 12]. To control weight gain, dialysis patients need to limit fluid and salt intake in their daily lives. It is expected that excessive water intake is associated with the presence of edema. If the degree of edema can be estimated from the appearance of dialysis patients and the amount of fluid in the body can be predicted, it will assist in self-management of fluid intake on a daily basis.
A few studies have attempted to estimate the degree of edema by using images of edema areas [13, 14]. With the aim of estimating the degree of peripheral edema, Chen et al. [13] captured images during a pitting test using a physical simulator that reproduced edema. In the pitting test, the characteristics of peripheral edema are classified into four levels according to the degree of indentation when the edema area is compressed with a finger. Subsequently, they estimated the edema level from the images by using a support vector machine (SVM) [15] or convolutional neural network (CNN) [16]. Whereas Chen et al. [13] attempted a camera-based edema level estimation by using a simulator, it is necessary to acquire those images during the pitting test. Since the pitting test is usually performed by medical staff, it is difficult for patients to obtain images themselves for self-management of their fluid intake. Also, they did not conduct a validation with actual patient images. Smith et al. [14] estimated edema levels of peripheral edema by using images of arms and limbs of healthy subjects and heart failure patients captured with short-wave infrared molecular chemical imaging (SWIR MCI). By utilizing the large absorption coefficient of water in certain spectral regions of the SWIR MCI, a regression model was constructed to estimate the edema level from the spectra. Unlike Chen et al. [13], Smith et al. [14] used data from actual heart failure patients, but required a special SWIR camera. In daily fluid volume management for dialysis patients, it is difficult to use a special camera at home or outside the home. Therefore, a simpler method to estimate the degree of edema is desired.
This study attempts to estimate the degree of edema by using facial images of dialysis patients captured with a tablet device, which is relatively easy for patients to use. Compared with images of arms and legs used in previous studies, facial images can be taken more easily by patients themselves. Also, diagnosis using facial images could be easily incorporated in video-based telemedicine. Furthermore, by combining facial recognition systems, it becomes possible to acquire facial images as soon as the patient arrives at the hospital. To the best of our knowledge, this is the first study to estimate edema from facial images of dialysis patients captured with a common visible-light camera.
We use facial images taken before and after dialysis of renal failure patients to estimate the degree of edema in two ways: i) pre- and post-dialysis classification and ii) weight prediction. In the pre- and post-dialysis classification, we classify the facial images into two categories: pre-dialysis, when edema is present, and post-dialysis, when edema is alleviated. In the weight prediction, we estimate the degree of edema by predicting the body weight, which reflects the fluid volume in the dialysis patient’s body. Although body weight changes may be due to alterations in activity, diet, and medication use [17], body weight is usually recommended as a proxy measurement of edema [18]. In particular, the interdialytic weight gain is a function of oral fluid intake, which includes routine food ingestion [19]. Since fluid overload usually implies the degree of edema [20], we can assume that the degree of edema is correlated with body weight in dialysis patients. The pre- and post-dialysis classification is a straightforward evaluation to identify facial changes before and after dialysis, and the weight prediction is a more practical task to evaluate our method. By using pre- and post-dialysis labels and body weight as ground-truth, it becomes unnecessary to perform labeling tasks such as like having medical staff subjectively annotate edema levels, as was done in the previous study [14].
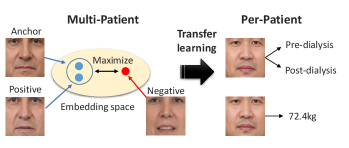
As a first attempt, we trained a single CNN-based model across all patients for the pre- and post-dialysis classification. However, the classification accuracy for new patients not in the training data reached only 59.7% (see Results section IV-C). This low level of performance may have been because the changes in the face before and after dialysis are subtle and also because the faces vary widely from patient to patient. Therefore, this study focuses on training a model for each patient to identify subtle changes in the face before and after dialysis. In this situation, the training data for the model is limited to a small dataset obtained from individual patients. To overcome this limitation, we pre-train the model using multi-patient data. Specifically, we first pre-train the model to acquire knowledge about edema from multi-patient data and then perform transfer learning using per-patient data.
In this paper, we propose a novel contrastive learning method for pre-training, called weight-aware supervised momentum contrast (WeightSupMoCo). Contrastive learning is self-supervised or supervised representation learning that differentiates between similar example pairs and dissimilar example pairs [21, 22, 23, 24]. WeightSupMoCo is a supervised representation learning that leverages pre- and post-dialysis labels and patient weight. The aim of the WeightSupMoCo loss is to make feature representations of facial images closer in similarity of patient weight when the pre- and post-dialysis labels are the same. First, contrastive multi-patient pre-training is performed based on WeightSupMoCo and then pre- and post-dialysis classification and weight prediction are performed by transfer learning on per-patient data (see Fig. 1 111For illustrative purposes, this paper does not use facial images obtained from actual patients, but rather facial images from Generated Photos (https://generated.photos/).). Experiments using data from 39 dialysis patients demonstrate that the contrastive multi-patient pre-training based on WeightSupMoCo significantly improves edema estimation performance. Our main contributions are summarized as follows:
-
•
This is the first work to estimate the degree of edema from facial images taken before and after dialysis. The main purpose of this study is to verify the feasibility of the estimation and to develop a deep learning model suitable for this purpose.
-
•
We construct an edema estimation model for each patient after the pre-training on multi-patient data. We propose a novel contrastive multi-patient pre-training method to acquire knowledge about edema.
-
•
We validate the edema estimation by using facial images collected from 39 patients on a total of 210 dialysis days. Our edema estimation system has the potential to become a health management tool for dialysis patients.
The rest of this paper is organized as follows: Section II reviews the related work, and section III explains the proposed method. Section IV reports experimental results, and section V discusses our edema estimation system. Section VI provides the conclusions of this paper.
II Related Work
This section reviews recent work in three key areas related to this paper: edema measurement methods (II-A), disease identification from facial images (II-B), and contrastive representation learning (II-C).
II-A Edema Measurement Methods
Traditional methods for measuring peripheral edema use a pitting test [25] or a medical tape to measure ankle circumference [26]. Both of these methods have significant intra- and inter-measurer variability [27] and require a medical staff to take the measurements. Another traditional method is measuring limb volume using water displacement [28], which can measure the total foot volume and thus edema. Although water displacement volumetry is accurate and sensitive [27], it takes a lot of time (25 minutes per foot [18]) and labor for the patient. Some recent work [18, 29, 30, 31] has utilized 3D imaging to measure foot volume as alternative technologies to water displacement. However, they require expensive scanners [29], a 3D camera installed on the wall [18], and scanning around the feet with a hand-held depth camera [30, 31], which are still difficult for self-management of fluid intake.
To address these issues, we aim to develop a method that helps dialysis patients easily self-manage their fluid intake. We focus on facial images taken before and after dialysis and attempt to estimate the degree of edema from the facial images. Facial images can be captured more easily by patients themselves than foot images. They can also use a tablet or smartphone to capture facial images without introducing additional special equipment. Furthermore, our image-based method can be incorporated into telemedicine, which is becoming more widespread these days.
II-B Disease Identification from Facial Images
In recent years, several studies have identified developmental disorders [32], genetic disorders [33], acute illness [34], and Alzheimer’s disease [35] from facial images. They employed deep learning approaches to identify diseases from facial images. Gurovich et al. [33] predicted hundreds of genetic syndromes from facial images by fine-tuning the CNN model pre-trained on a large-scale face identity database [36]. Forte et al. [34] trained a CNN model to classify facial images into healthy or acutely ill by using sets of simulated sick faces and synthetically generated data. These disease identifications recognize facial features such as facial dysmorphism [32, 33], specific symptoms appearing on a part of the face [34], or a specific complexion [35]. A common CNN model across all patients was constructed in these studies.
On the other hand, edema appears and decreases subtly on each patient’s face. Therefore, it is difficult for a common model across all patients to capture such subtle changes in each patient. Here, we construct a CNN model for each individual patient, rather than a common model across all patients. We pre-train a model to acquire feature representations of edema from multi-patient data before fine-tuning it to each patient.
II-C Contrastive Representation Learning
Contrastive learning has recently become the mainstream of self-supervised [37, 38, 39, 40, 41] or supervised [42, 43] representation learning. In order to reduce manual annotations, self-supervised learning approaches produce pseudo-labels by applying specific augmentations or transformations to the input data. Subsequently, the model pre-trained or trained with the augmented/transformed data and associated pseudo-labels can be used in downstream tasks, e.g., classification and regression. A simple framework for contrastive learning of visual representations (SimCLR) [38] is one of the most popular self-supervised contrastive learning approaches. SimCLR first creates a pair of positively correlated views by applying augmentations including cropping, flipping, and color distortion to the input image. Then, both views are passed into a pair of convolutional encoders (e.g., ResNet50 [44]) and projection heads (e.g., two dense layers with ReLU activation [45]) to obtain their embedding vectors. SimCLR optimizes the whole architecture by maximizing the agreement between the positive pair of embedding vectors (i.e., augmented views of the same image) while minimizing the negative pairs (i.e., different images) in the same mini-batch. Finally, the projection heads are discarded while the convolutional encoders are kept to be utilized in downstream tasks. Momentum contrast (MoCo) [39] is another popular self-supervised contrastive learning approach. Instead of a pair of encoders as in SimCLR, MoCo uses an encoder and momentum encoder pair. The momentum encoder generates a dictionary as a queue of encoded keys by enqueuing the current mini-batch and dequeuing the oldest mini-batch. The advantage of using the momentum encoder is that the dictionary size is not restricted to the mini-batch size and can be larger. Whereas the number of negative samples available in SimCLR is limited to the mini-batch size, MoCo can cover a rich set of negative samples and learn better feature representations. Contrastive learning has been extended to supervised learning that makes use of the output labels [42, 43]. In supervised contrastive (SupCon) learning [42], the positive samples are generated not only from augmentations of the same input, but also from augmented views of other samples in the same class. While SupCon assumes the use of discrete labels as the output labels, contrastive learning utilizing continuous labels has also been proposed [43]. Dufumier et al. [43] introduced the y-Aware InfoNCE loss for 3D brain MRI classification to make feature representations of MRI images closer in similarity of patient age. The utilization of continuous labels (e.g., patient age) helps the model to learn a more generalizable representation of the data.
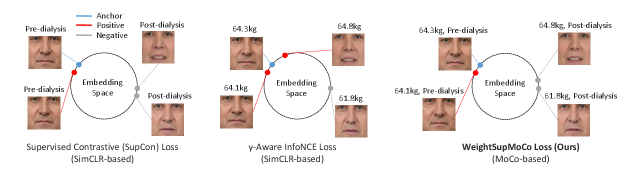
Our WeightSupMoCo loss leverages both discrete and continuous labels, i.e., pre- and post-dialysis labels and patient weight. Both of these two label types have important information about edema. Specifically, the pre- and post-dialysis labels provide coarse-grained information about edema while patient weight provides fine-grained information. Therefore, these two label types lead to better representation learning in the multi-patient pre-training step. Furthermore, we employ MoCo-based contrastive learning, which allows us to cover a richer set of positive and negative samples compared with the SimCLR-based SupCon [42] and y-Aware InfoNCE [43] losses. Figure 2 illustrates the differences between the SupCon, y-Aware InfoNCE, and WeightSupMoCo losses in our pre-training setting.
III Method
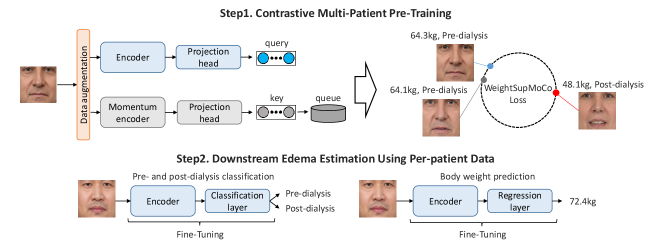
All procedures in this study were approved by the Ethical Review Board at University of Tsukuba (the protocol number: 1663, the date of approval: August 16, 2021). Figure 3 shows an overview of the proposed method. First, we perform contrastive multi-patient pre-training based on WeightSupMoCo. Then, we perform pre- and post-dialysis classification and weight prediction by transfer learning on per-patient data. In III-A, we describe the main components of our contrastive multi-patient pre-training framework. The WeightSupMoCo loss is detailed in III-B and the downstream edema estimation using per-patient data is presented in III-C.
III-A Contrastive Multi-patient Pre-training Components
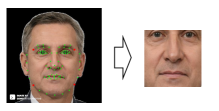
First, we obtain facial images of renal failure patients taken before and after dialysis. Then, we apply a facial detection method [46] to the obtained facial images and extract the centers of the facial images. Specifically, as shown in Fig. 4, we detect facial landmarks (green points) and extract the center part of the face by using four red points. By detecting facial landmarks for each patient and extracting the center part based on these landmarks, we compensate for rotation due to head or body tilt. Also, to compensate for the facial size, all extracted images are scaled to the same size. The center of the face includes the eyes and nose, where edema may appear and does not include areas unrelated to edema such as hair or clothes. Subsequently, the facial images are used in our MoCo-based contrastive learning framework (see Fig. 3. Step1). MoCo generates a query and key from the input images via the encoder and momentum encoder, respectively. Then, the encoder is trained by matching an encoded query to a dictionary of encoded keys (called a queue) by using the WeightSupMoCo loss (see III-B). The main components of our framework are the following data augmentation module, encoder network, and projection head:
Data Augmentation Module, . Various combinations of data augmentations are randomly applied to each input image , as . The input images are resized to 224224. The data augmentations consist of random horizontal flip (), random color jitter (, brightness , contrast , saturation , hue ), and random grayscale conversion (), where denotes a probability. These data augmentation settings are derived from the previous work[39, 47]. We generate two augmented views of each input image .
Encoder Network, , is used for both the encoder and the momentum encoder. The encoder network maps to a representation vector, . The augmented images are separately input to the encoder and the momentum encoder, resulting in a pair of representation vectors. In our experiment, we use ResNet18 [44] as the encoder network; the dimension of representation vectors is 512. Previous studies [38, 39, 42, 43] have shown that encoder pre-trained in contrastive learning can be used for several related downstream tasks. As in the previous studies, we perform transfer learning by adding a linear layer for each downstream task to the same encoder.
Projection Head, , maps the representation vector onto an embedding vector, . As in the previous work [38, 42], we instantiate as two dense layers with ReLU activation. The output dimension of the first layer is 512 and that of the second layer is 128. We normalize the output of the second layer to lie on the unit hypersphere, so that inner products can be used to measure cosine similarities in the embedding space. Although the projection head is an important component to project feature representations onto the embedding space, it is not required for the downstream edema estimation tasks. Therefore, we discard the projection head after the contrastive multi-patient pre-training and use only the encoder for the downstream tasks.
III-B WeightSupMoCo Loss
The embedding vector is used to optimize the encoder and projection head. The common loss function for self-supervised contrastive learning in SimCLR and MoCo is the following InfoNCE loss [37]:
| (1) |
where index is called the anchor and index is called the positive (i.e., the augmented view of the anchor). Here, denotes the indices of all augmented samples except anchor , consisting of one positive and all other negatives (i.e., different images from the anchor). The symbol denotes the inner product and is a temperature parameter.
The WeightSupMoCo loss aims to make the embedding vectors closer in similarity of patient weight when the pre- and post-dialysis labels are the same. This idea is based on two assumptions: (i) the pre- and post-dialysis labels indicate the presence or absence of edema, and (ii) patient weight indicates the degree of edema. These two label types thus provide coarse- and fine-grained information about edema. Let denote the pre- or post-dialysis label and denote the patient weight; the WeightSupMoCo loss is defined as follows:
| (2) |
where is a function representing the similarity of patient weights, in which we use the radial basis function (RBF) kernel, as in the y-Aware InfoNCE loss [43]. is an indicator function, which outputs 1 when , and 0 otherwise. The hyperparameter of the RBF kernel is set to 3.0 in our case, and the temperature parameter is set to 0.1 as in [38, 43]. In Eq. (2), when the pre- and post-dialysis label is the same and the similarity of weights is large, the value of increases and thus the embedding vectors are trained to be closer. On the other hand, when the pre- and post-dialysis label is different, becomes 0 and thus the distance of the embedding vectors is maximized. In our MoCo-based framework, the anchor is the set of all query and queue samples, and is the set of query samples except anchor in the same mini-batch and queue samples. The dictionary size of the queue (1024 in our case) can be much larger than the mini-batch size of the query and key (16 in our case). In the queue, the encoded key samples of the current mini-batch are enqueued and those of the oldest mini-batch are dequeued. Hence, the queue can hold newer keys and remove older ones.
Although the use of queues enables the dictionary to be large, updating the momentum encoder by back-propagation is intractable because the gradient should propagate to all samples in the queue. This issue can be addressed by using the following momentum update [39]:
| (3) |
where and respectively denote the parameters of the encoder and momentum encoder, and is the momentum coefficient. Only the is updated by back-propagation, while the evolves more smoothly than through the momentum update. Following the suggestion in [39], the momentum coefficient is set relatively large (0.9999 in our case) so that the will evolve slowly.
III-C Downstream Edema Estimation
After the contrastive multi-patient pre-training based on WeightSupMoCo, we perform the downstream edema estimation tasks by transfer learning on per-patient data (see Fig. 3. Step2). The downstream edema estimation tasks comprise pre- and post-dialysis classification and weight prediction. In these tasks, we discard the projection head and add a linear layer to the pre-trained encoder. The projection head is used to project the embedding vector in contrastive learning, while the linear layer is used for the pre- and post-dialysis classification and weight prediction in downstream tasks, as in [42, 43]. As the linear layer, we use the classification layer with two output dimensions for the pre- and post-dialysis classification. We also use the regression layer with one output dimension for the weight prediction. Finally, the entire model including the encoder and linear layer is fine-tuned with per-patient data. As the loss functions for the fine-tuning, we use the cross-entropy loss for the pre- and post-dialysis classification and the mean squared error (MSE) loss for the weight prediction.
| Number of patients | 39 |
|---|---|
| Total dialysis days | 210 |
| Number of pre-dialysis data | 210 |
| Number of post-dialysis data | 182 |
| Total number of data | 392 |
| Total number of facial images | 39,200 |
| Average number of images per patient | 1,005 |
| Age (years) | 73.5 9.4 |
| Gender (male/female) | 25 / 14 |
| Length of time on dialysis (months) | 81.0 54.8 |
| Weight before dialysis (kg) | 59.9 11.6 |
| Weight after dialysis (kg) | 57.8 11.5 |
| Water removal (ml) | 2214.0 639.7 |
IV Experiments
IV-A Dataset
To collect facial images from patients before and after dialysis, University of Tsukuba recruited dialysis patients in the Takemura Medical Nephro Clinic, Japan. We explained the purpose, methods, and freedoms in participating in the study to each patient and obtained consent from all patients.
A total of 40 patients participated in the data collection, and data ranging from 1 to 10 dialysis days were obtained for each patient. The number of participation days depended on the patient’s freedom. These dialysis patients have renal failures such as diabetic nephropathy and chronic glomerulonephritis. On each dialysis day, we acquired data twice, before and after dialysis. Data were not obtained for several days after dialysis due to the patient’s physical condition. Facial videos and medical records including age, body weight (before and after dialysis), and water removal were collected from each patient. One patient was excluded from the dataset because a valid medical record could not be obtained; hence, data from 39 patients were used in the experiment. The characteristics of the dataset and dialysis patients are listed in Table I. The relationship between the number of days and the number of patients is shown in Appendix A.
Facial videos were recorded using the built-in camera of a Surface Pro 7 222https://www.microsoft.com/en-us/surface/, a popular tablet device. Three minutes of video was captured, including frontal face and side views from the left and right while the patient was performing several tasks (e.g., rest, opening mouth, raising hands). In this experiment, we used only the facial videos from the frontal view at rest. Then, we randomly selected arbitrary frames from the video and obtained 100 images from each video, resulting in a total of 39,200 facial images. We excluded facial images when looking left or right based on the distance between the eye and nose landmarks (see Fig 4). We also excluded facial images when opening the mouth (e.g., while talking) based on the distance between the mouth landmarks (see Fig 4). We recorded the facial videos indoors with no direct sunlight. However, since lighting conditions could still vary from day to day, we apply data augmentation that changes the color of the image (i.e., color jitter and grayscale conversion). By changing the color of the image, we can mitigate over-fitting to lighting conditions and improve the performance of edema estimation (see Appendix C). The data of the 39 patients were divided into a contrastive multi-patient pre-training set (see Fig. 3, Step1) and downstream edema estimation set (see Fig. 3, Step2). In this experiment, data from 24 patients with less than 7 days of pre- and post-dialysis were used for the pre-training, and data from 15 patients with 7 or more days were used for the downstream edema estimation (see Appendix A).
IV-B Experimental Settings
For the multi-patient pre-training, 80% of the images were randomly selected as training data and the remaining 20% were used as validation data. For the downstream edema estimation, we performed a leave-one-day-out cross-validation, where the data from one day were used as the test data and the data from the other days were used as the training and validation data. The training and validation data ratios in this cross-validation were 80% and 20%, respectively. The method of splitting training and validation data in the multi-patient pre-training is discussed in Appendix B.
The framework was implemented with PyTorch [48] on an NVIDIA GeForce RTX 3060 GPU. During training, we used the Adam optimizer [49] with a learning rate of 1e-4 and weight decay of 5e-5 for the pre-training and a learning rate of 1e-3 for the downstream tasks. We trained for 100 epochs in the pre-training and 20 epochs in the downstream tasks. The best models using the validation data were used in the pre-training and downstream tasks. As in the data augmentation module in the pre-training (see III-A), data augmentations of random horizontal flip, random color jitter, and random grayscale conversion were used in the downstream tasks to mitigate the overfitting problem. An ablation study on data augmentation is shown in Appendix C. All images were resized to 224224, and the RGB channels were normalized using the mean and standard deviation of ImageNet [50]. In addition, for the weight prediction in the downstream task (not pre-training), each patient’s weight was normalized to mean 0 and variance 1. The predicted weights were then transformed back to the original scale using the mean and variance of the training data.
To verify the effectiveness of our WeightSupMoCo, we compared it to several methods (see Table II). In all comparative methods, we used the same CNN model (i.e., ResNet18) and data augmentation module as the proposed method. Performance comparisons using commonly used CNN networks other than ResNet18 are shown in Appendix D. To verify the effectiveness of the contrastive multi-patient pre-training, we compared our method with a model trained from scratch using only per-patient data (i.e., without multi-patient pre-training). To verify the effectiveness of using supervised labels (i.e., pre- and post-dialysis labels and patient weight), we compared our representation learning with the self-supervised learning methods, SimCLR [38], MoCo [39], and SimSiam [51]. SimSiam is one of the state-of-the-art self-supervised learning methods in computer vision. We also compared it with standard supervised pre-training methods, classification using pre- and post-dialysis labels based on the cross-entropy loss and weight prediction based on the MSE loss. In the weight prediction-based pre-training method, all patients’ weights were normalized. Furthermore, we compared our WeightSupMoCo loss with the SupCon loss [42] using pre- and post-dialysis labels and the y-Aware InfoNCE loss [43] using patient weight. In addition, to verify the effectiveness of using MoCo-based contrastive learning in our framework, we compared WeightSupMoCo loss with a SimCLR-based WeightSupCon loss (i.e., a SimCLR-based version of WeightSupMoCo). For a fair comparison, the downstream task settings were the same for all methods. In the pre-training, the learning rates of cross-entropy and MSE losses were set to 1e-3, while the other learning rates and epoch numbers were the same as in our method. The batch size was set to 16 for all methods. The temperature parameter in contrastive learning SimCLR, MoCo, SupCon, y-Aware InfoNCE, WeightSupCon, and WeightSupMoCo was set to 0.1. The dictionary size and momentum coefficient of MoCo and WeightSupMoCo were set to 1024 and 0.9999. The hyperparameter of the RBF kernel in y-Aware InfoNCE, WeightSupCon, and WeightSupMoCo was set to 3.0.
As evaluation metrics for the pre- and post-dialysis classification, we used accuracy, area under the receiver operating characteristic curve (ROC-AUC), and area under the precision-recall curve (PR-AUC). As evaluation metrics for the weight prediction, we used mean absolute error (MAE), root mean squared error (RMSE), and correlation coefficient (CorrCoef) between the predicted and ground-truth data.
| Pre- and post-dialysis classification | Body weight prediction | |||||
| Method | Accuracy | ROC-AUC | PR-AUC | MAE | RMSE | CorrCoef |
| Scratch | 69.8 9.7 | 77.3 11.9 | 78.3 11.1 | 0.798 0.194 | 0.934 0.233 | 0.406 0.234 |
| Self-supervised pre-training: | ||||||
| SimCLR [38] | 75.3 8.8 | 84.5 9.4 | 84.7 8.8 | 0.698 0.204 | 0.835 0.234 | 0.554 0.179 |
| MoCo [39] | 77.2 9.2 | 86.3 10.0 | 87.5 9.0 | 0.648 0.183 | 0.772 0.211 | 0.612 0.165 |
| SimSiam [51] | 73.3 8.5 | 81.6 10.3 | 82.5 9.4 | 0.760 0.183 | 0.899 0.216 | 0.487 0.185 |
| Supervised pre-training: | ||||||
| Classification (cross-entropy) | 80.2 7.8 | 88.1 7.5 | 88.7 6.5 | 0.621 0.161 | 0.737 0.181 | 0.662 0.124 |
| Weight prediction (MSE) | 82.4 6.2 | 90.8 7.4 | 91.9 6.3 | 0.577 0.186 | 0.706 0.208 | 0.675 0.139 |
| SupCon [42] | 77.7 9.4 | 86.6 10.4 | 87.5 9.6 | 0.665 0.166 | 0.779 0.186 | 0.599 0.154 |
| y-Aware InfoNCE [43] | 82.7 7.2 | 91.7 7.0 | 92.2 7.0 | 0.575 0.186 | 0.682 0.200 | 0.699 0.138 |
| WeightSupCon (SimCLR-based) | 84.7 7.5 | 92.5 7.6 | 92.9 7.2 | 0.569 0.182 | 0.676 0.199 | 0.707 0.135 |
| WeightSupMoCo (Ours) | 84.9 7.1 | 92.5 7.6 | 93.0 7.2 | 0.555 0.184 | 0.626 0.137 | 0.718 0.136 |
| Pre- and post-dialysis classification | Body weight prediction | |||||
| Method | Accuracy | ROC-AUC | PR-AUC | MAE | RMSE | CorrCoef |
| Patient-common model | 80.5 6.4 | 88.5 6.7 | 88.7 6.2 | 0.986 0.200 | 1.299 0.294 | 0.394 0.109 |
IV-C Results
IV-C1 Generalizability to new patients not in training data
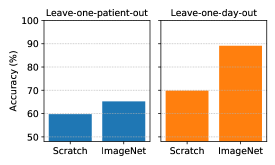
First, we investigate the generalizability to new patients not in the training data when training a single model for all patients (i.e., patient-common model), as discussed in I. To evaluate the generalizability, we performed the pre- and post-dialysis classification with a leave-one-patient-out cross-validation using 39 patients, where the data from one patient were used as test data and the data from the other patients were used as training and validation data (the ratios of the training and validation data were 80% and 20%). To get an upper bound on the classification accuracy, we also show the averaged results when training models for each patient (i.e., patient-specific model) with a leave-one-day-out cross-validation (see IV-B) using 15 patients in the downstream task. Note that this experiment tests the generalizability of the patient-common model to new patients, and a fair comparison between the patient-common model and the patient-specific model is provided in IV-C2. Figure 5 shows the accuracy of the pre- and post-dialysis classification with leave-one-patient-out and leave-one-day-out cross-validations. As pre-training setups, we compare ResNet18 trained from scratch (i.e., without pre-training) and ResNet18 initialized from ImageNet-supervised pre-training. From the results of the leave-one-patient-out cross-validation, the classification accuracy reaches only 59.7% for training from scratch and 65.2% with ImageNet pre-training. This low level of performance is because the changes in patients’ faces before and after dialysis are subtle compared with the differences in faces between patients. As a result, it is difficult to classify new patient faces into pre- and post-dialysis. On the other hand, from the results of the leave-one-day-out cross-validation, the classification accuracy reaches 69.8% for training from scratch and 89.1% with ImageNet pre-training. These results suggest that training models for each patient successfully identifies subtle changes in the face before and after dialysis. We can thus classify facial images on a new day into pre- and post-dialysis relatively well.
IV-C2 Effectiveness of WeightSupMoCo-based pre-training
Table II shows the estimation performances of the pre- and post-dialysis classification and body weight prediction of the proposed and comparative methods with the leave-one-day-out cross-validation. Note that the models were not initialized with ImageNet pre-training in order to fairly evaluate the effectiveness of the representation learning of each pre-training method (comparisons with ImageNet pre-training are provided in IV-C3). From the table, it is clear that our WeightSupMoCo outperforms all of the comparative methods. We investigated the statistical significance of WeightSupMoCo with a t-test using accuracy for pre- and post-dialysis classification and MAE for weight prediction. For the t-test, the results of all cross-validations were used. The significance was confirmed () with all methods except WeightSupCon in the pre- and post-dialysis classification, and with all methods except Weight prediction (MSE) in the weight prediction.
In the following, we evaluate the effectiveness of each component from the pre-training methods. First, a comparison between training from scratch and the other methods indicates the remarkable effectiveness of multi-patient pre-training. Hence, pre-training with a larger dataset obtained from multiple patients can boost the estimation performance and thereby overcome the problem of the limited dataset obtainable from individual patients. Next, a comparison of the results for the self-supervised pre-training methods (i.e., SimCLR, MoCo, and SimSiam) with supervised pre-training methods shows the effectiveness of utilizing supervised labels about edema, i.e., pre- and post-dialysis labels and patient weight. Thus, we can successfully acquire knowledge about edema by using supervised labels in the multi-patient pre-training. Specifically, by comparing Weight prediction (MSE) and y-Aware Info NCE with Classification (cross-entropy) and SupCon, we can see that patient weight is more effective than the pre- and post-dialysis labels. This result suggests that the fine-grained label on edema may provide more meaningful information than the coarse-grained label. Furthermore, by comparing WeightSupCon and WeightSupMoCo with Classification (cross-entropy), Weight prediction (MSE), SupCon, and y-Aware Info NCE, we can see that the use of both the pre- and post-dialysis labels and patient weight further enhances the estimation performance. From this result, we also find that the use of both coarse- and fine-grained labels improves the feature representation. Finally, by comparing WeightSupMoCo with WeightSupCon, we find that MoCo-based contrastive learning improves performance. This is because our MoCo-based approach makes the dictionary size larger, and enables contrastive learning with a larger number of samples.
We also show the estimation performance of the patient-common model with the leave-one-day-out cross-validation in Table III. The model is not trained in two steps (i.e., multi-patient pre-training and transfer learning for per-patient), but is trained with all patient data in a single step. The pre- and post-dialysis classification accuracy of the patient-common model is similar to its two-step version, cross-entropy. On the other hand, since the patient-common model is trained on multiple patients’ weight data, the performance of weight prediction is much lower than our two-step training. WeightSupMoCo still outperforms the patient-common model. Also, the training time of our model (transfer learning) is considerably shorter than that of the patient-common model, which is trained on all patients data. This is an important advantage because our method requires training before the patient can use it.
IV-C3 Estimation performance vs. number of training days in downstream tasks
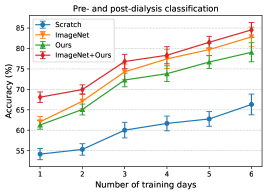
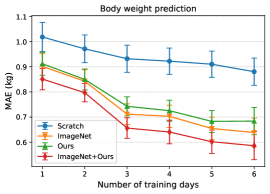
Since the number of dialysis days in the training data (i.e., training days) of each patient is limited, we aim to achieve more accurate estimation in the downstream tasks with fewer training days. Figure 6 shows the relationship between the number of training days for transfer learning and the estimation performance of pre- and post-dialysis classification and weight prediction. When reducing the number of training days, dialysis days were selected randomly but these sets were identical for all methods. For each training day, we randomly selected dialysis days five times for the training data and then averaged the performances across all trials. As pre-training setups, we compare a model trained from scratch, ImageNet-supervised pre-training, WeightSupMoCo-based pre-training (Ours), and WeightSupMoCo-based pre-training initialized from ImageNet pre-training (ImageNet+Ours) models. Also, when there are only a few training days, the model may be overfitted because of the small amount of training data. Therefore, when there were only one or two training days, most of the layers were frozen and only part of them (the last conv5_2 block [44] and the linear layer of ResNet18 were set after several trials) were trainable in ImageNet, Ours, and ImageNet+Ours. When there were three to six training days, all layers of ResNet18 were trainable. The estimation performances of all of the methods tend to improve as the number of training days are increased. We also find that there are large performance differences between the scratch and the pre-training methods. Among the pre-training methods, ImageNet is better than Ours, but this result may have heavily depended on the amount of pre-training data. That is, ImageNet was pre-trained on 1.28 million images [44], whereas Ours was pre-trained on only about 10,000 images, a difference in the number of images of more than 100 times. Therefore, as the number of patients used in the pre-training increases in the future, Ours will likely show a performance improvement. Furthermore, ImageNet+Ours boosts the estimation performance of ImageNet. This is means that employing ImageNet-based and WeightSupMoCo-based pre-training together is effective. Pre-training with ImageNet+Ours enables a relatively highly accurate estimation to be made with a small number of training days; e.g., the accuracy is 76.8% for the pre- and post-dialysis classification and MAE is 0.656 kg for the body weight prediction in the case of 3 training days.
V Discussion
We have demonstrated that the patient-specific model built using our pre-training strategy successfully performs pre- and post-dialysis classification and weight prediction from facial images. In this section, we further validate the estimation results, and discuss how an edema estimation system based on the proposed method can be used in the future. In the following, ImageNet+Ours refers to the proposed method that achieved the highest estimation performance in IV-C.
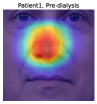
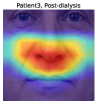
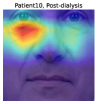
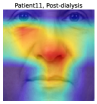
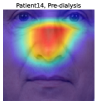
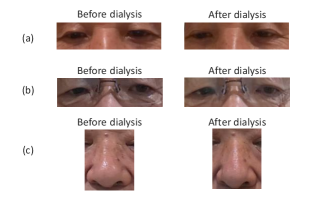
To understand the facial parts our model captures, we examine the visualization results of Grad-CAM [52]. Figure 7 shows 333Although the saliency maps are estimated from actual patients’ facial images, the background facial images are not of the patients’ faces but are Generated Photos (https://generated.photos/) to protect personal information. the saliency maps estimated by Grad-CAM when the proposed method classifies test facial images into pre- and post-dialysis. Here, we can see that our model uses mainly the eyes and nose for classification. Figure 8 shows the actual facial images of patients when our model focused on the eyes and nose for classification. As shown in Fig. 8 (a) and (b), the appearance of the eyelids changed before and after dialysis (e.g., edema-induced swelling was reduced, changing from a single eyelid to a double eyelid) due to the decrease in body fluid volume caused by dialysis. As shown in Fig. 8 (c), we also observed that the shape of the nose changed before and after dialysis (e.g., the edema-induced rounded shape disappears). Fig. 7 and Fig. 8 suggest that our model captures these changes in the eyes and nose before and after dialysis.

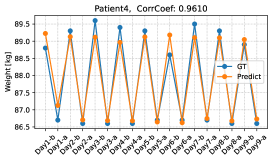
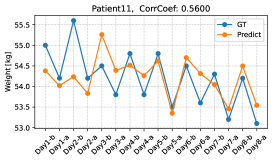
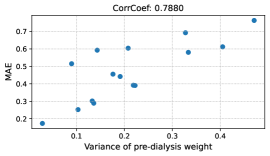
We further verify the body weights predicted by the proposed method by conducting a leave-one-day-out cross-validation. Figure 9 shows the changes in the predicted and ground-truth weights over all dialysis days. The top figure is for the patient with the highest estimation performance, and the bottom figure is for the patient with the lowest estimation performance. From the top figure, we see that our model can accurately predict weight changes throughout all dialysis days. On the other hand, the bottom figure shows that our model may perform poorly on some dialysis days. Although the performance of weight prediction in day 2 and day 3 of patient 11 is low, the pre- and post-dialysis classification accuracy in these days is relatively high (82.4% and 98.4%, respectively). Therefore, our model can predict weight gain or loss before and after dialysis even though the performance of weight prediction is low. The reason for the poor performance of weight prediction can be due to day-to-day variation in weight. Figure 10 shows the relationship between the variance of pre-dialysis weight and MAE of weight prediction in 15 patients. Note that the variance is calculated only from pre-dialysis weights, since post-dialysis weights are determined approximately by pre-dialysis weights. The correlation coefficient is 0.7880, indicating a positive correlation between the variance of pre-dialysis weights and MAE. Thus, when the day-to-day variation in weight is large (e.g., weight decreases from day 1 to day 8, as in patient 11), weight prediction becomes more difficult. From the above results, even when we can classify facial images into pre- and post-dialysis, estimation of body weight, which is a proxy for the degree of edema, may be difficult in some cases.
A system using our edema estimation method could have several practical applications in the future. First, since our edema estimation system can easily estimate body weight from facial images, it has the potential to be a very powerful tool for dialysis patients who require strict weight control. While an accurate weight can be measured indoors on a weight meter, our system allows patients to obtain a reference weight anytime and anywhere by simply using the camera on their smartphone. For example, in a restaurant, patients can easily know how much fluid they should intake. Also, if our estimation performance becomes very accurate in the future, we may be able to solve the problem of weight errors due to clothing on weight meters. In addition, the pre- and post-dialysis classification scores that our model predicts can allow patients to understand which of their conditions are similar to those before or after dialysis. On the basis of the estimated weight and classification scores, dialysis patients can determine their food and fluid intake, meal menus, and amount of medicine (e.g., diuretic). The strength of this system is that users’ existing tablets and smartphones can be used without any additional special equipment.
Although experimental results are promising, the proposed method still has some limitations. First, in order to construct a patient-specific model, it requires training data from a patient who uses our system. While our multi-patient pre-training strategy can reduce the number of training days needed to achieve high estimation performance (see Fig. 6), a further reduction in training days is desired. Second, this study examined only 39 Japanese patients, and our findings may not be generalizable to other racial groups. In future work, we should increase the number of patients and validate our findings in other racial groups. Third, this study used only facial images taken before and after dialysis and was not validated using facial images taken on non-dialysis days. Considering that our edema estimation system will be used in the daily lives of dialysis patients, we should evaluate its estimation performance using facial images taken on non-dialysis days.
VI Conclusions
This study aimed to estimate the degree of edema from facial images taken before and after dialysis. To estimate the degree of edema, we performed pre- and post-dialysis classification and weight prediction. We developed a multi-patient pre-training strategy and transferred the pre-trained model to a patient-specific model. To effectively pre-train the model with knowledge about edema from multiple patients, we have proposed a novel contrastive representation learning, called WeightSupMoCo. Experiments conducted on facial images taken from 39 patients over a total of 210 dialysis days demonstrated the effectiveness of our approach. The informative results of this study suggest that our edema estimation system could make a significant contribution to health monitoring of dialysis patients.
Acknowledgments
The authors would like to thank Dr. Katsumi Takemura, director of the Takemura Medical Nephro Clinic, and the clinic’s medical staff for their cooperation in patient recruitment and data collection. The authors also would like to thank all patients who participated in this study.
Appendix A
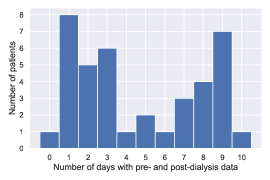
In our experiment, each patient participated in data collection for a different number of days. Figure 11 shows the relationship between the number of days and the number of patients. Note that the horizontal axis is the number of days including both pre- and post-dialysis data (0 days means that only pre-dialysis data are included).
Appendix B
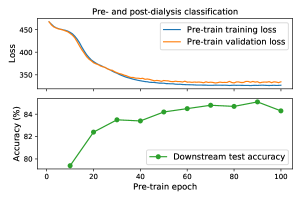
In our multi-patient pre-training setting, the same patients were used for training and validation data to use as many patients as possible in the training data. However, the training and validation data are not split by patient, that can cause overfitting. Therefore, we monitor training and validation losses in the pre-training and downstream test accuracy in the pre- and post-dialysis classification. Figure 12 shows the training and validation losses in WeightSupMoCo pre-training from 1 to 100 epochs and the downstream test accuracy for every 10 epochs. We find that the test accuracy improves at the epochs where the validation loss converges. Therefore, monitoring the validation loss is sufficient for achieving good test performance in the downstream task.
Appendix C
We use random horizontal flip, random color jitter, and random grayscale conversion as the data augmentation module in the multi-patient pre-training and downstream edema estimation. Here, we investigate the effectiveness of each data augmentation module in the WeightSupMoCo-based pre-training method. Table IV shows accuracy for the pre- and post-dialysis classification without data augmentation (w/o Aug), with each augmentation, and with a combination of all augmentation (Flip+Gray+Color Jitter) in the pre-training and downstream task. By comparing with w/o Aug, we confirm that any data augmentation is effective and combining all data augmentations further improves estimation performance. Among each data augmentation, changing the color of the image, such as color jitter and grayscale conversion, is particularly effective. This may be because the dataset size is small, causing overfitting to the lighting conditions of the original image. The data augmentation of changing colors can mitigate the overfitting and allow the model to focus on capturing edema features.
| w/o Aug | Flip | Gray | Color Jitter | Flip+Gray+Color Jitter | |
|---|---|---|---|---|---|
| Accuracy | 72.1 | 75.1 | 76.9 | 80.5 | 84.9 |
Appendix D
In all our experiments, we use ResNet18 as the backbone. Here, we show the estimation performance of other commonly used networks. Figure 13 shows the pre- and post-dialysis classification accuracy of several networks initialized with ImageNet-supervised pre-training. We find that ResNet18 achieves the highest accuracy compared with other networks. ResNet18 is better than ResNet34 and ResNet50, which have a larger number of parameters. This could be because our dataset size is small and a small-scale network performs better.

References
- [1] K. P. Trayes, J. Studdiford, S. Pickle, and A. S. Tully, “Edema: diagnosis and management,” American family physician, vol. 88, no. 2, pp. 102–110, 2013.
- [2] J. W. Ely, J. A. Osheroff, M. L. Chambliss, and M. H. Ebell, “Approach to leg edema of unclear etiology,” The Journal of the American Board of Family Medicine, vol. 19, no. 2, pp. 148–160, 2006.
- [3] K. L. Johansen, G. M. Chertow, R. N. Foley, D. T. Gilbertson, et al., “US renal data system 2020 annual data report: epidemiology of kidney disease in the united states,” American journal of kidney diseases, vol. 77, no. 4, pp. A7–A8, 2021.
- [4] K. Nitta, S. Nakai, I. Masakane, N. Hanafusa, et al., “2018 annual dialysis data report of the JSDT renal data registry: patients with hepatitis,” Renal Replacement Therapy, vol. 7, no. 1, pp. 1–17, 2021.
- [5] J. M Newmann and W. E. Litchfield, “Adequacy of dialysis: the patient’s role and patient concerns,” in Seminars in nephrology. Elsevier, 2005, vol. 25, pp. 112–119.
- [6] M. Lindberg, B. Wikström, and P. Lindberg, “Fluid intake appraisal inventory: Development and psychometric evaluation of a situation-specific measure for haemodialysis patients’ self-efficacy to low fluid intake,” Journal of psychosomatic research, vol. 63, no. 2, pp. 167–173, 2007.
- [7] G. E. Thomson, K. Waterhouse, H. P. McDonald, and E. A. Friedman, “Hemodialysis for chronic renal failure: clinical observations,” Archives of internal medicine, vol. 120, no. 2, pp. 153–167, 1967.
- [8] J. Leggat, S. M. Orzol, T. E. Hulbert-Shearon, T. A. Golper, et al., “Noncompliance in hemodialysis: predictors and survival analysis,” American Journal of Kidney Diseases, vol. 32, no. 1, pp. 139–145, 1998.
- [9] Robert N Foley, Charles A Herzog, and Allan J Collins, “Blood pressure and long-term mortality in united states hemodialysis patients: Usrds waves 3 and 4 study,” Kidney international, vol. 62, no. 5, pp. 1784–1790, 2002.
- [10] R. Saran, J. L. Bragg-Gresham, H. C. Rayner, D. A. Goodkin, et al., “Nonadherence in hemodialysis: associations with mortality, hospitalization, and practice patterns in the DOPPS,” Kidney international, vol. 64, no. 1, pp. 254–262, 2003.
- [11] BG. Stegmayr, M. Brannstrom, S. Bucht, E. Dimeny, et al., “Minimized weight gain between hemodialysis contributes to a reduced risk of death,” The International journal of artificial organs, vol. 29, no. 7, pp. 675–680, 2006.
- [12] E. Movilli, P. Gaggia, R. Zubani, C. Camerini, et al., “Association between high ultrafiltration rates and mortality in uraemic patients on regular haemodialysis. a 5-year prospective observational multicentre study,” Nephrology Dialysis Transplantation, vol. 22, no. 12, pp. 3547–3552, 2007.
- [13] J. Chen, T. Mao, Y. Qiu, D. Zhou, et al., “Camera-based peripheral edema measurement using machine learning,” in Proc. IEEE Int. Conf. Healthcare Informatics (ICHI), 2018, pp. 115–122.
- [14] A. G. Smith, R. Perez, A. Thomas, S. Stewart, et al., “Objective determination of peripheral edema in heart failure patients using short-wave infrared molecular chemical imaging,” Journal of Biomedical Optics, vol. 26, no. 10, pp. 105002, 2021.
- [15] C. Cortes and V. Vapnik, “Support-vector networks,” Machine Learning, vol. 20, no. 3, pp. 273–297, 1995.
- [16] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2012, vol. 25.
- [17] A. R. Webel, S. K. Frazier, D. K. Moser, and T. A. Lennie, “Daily variability in dyspnea, edema and body weight in heart failure patients,” European Journal of Cardiovascular Nursing, vol. 6, no. 1, pp. 60–65, 2007.
- [18] O. Chausiaux, G. Williams, M. Nieznański, A. Bagdu, et al., “Evaluation of the accuracy of a video and AI solution to measure lower leg and foot volume,” Medical Devices, vol. 14, pp. 105–118, 2021.
- [19] K. Kalantar-Zadeh, D. L. Regidor, C. P. Kovesdy, D. Van Wyck, et al., “Fluid retention is associated with cardiovascular mortality in patients undergoing long-term hemodialysis,” Circulation, vol. 119, no. 5, pp. 671–679, 2009.
- [20] C. Granado, R. L. Mehta, et al., “Fluid overload in the ICU: evaluation and management,” BMC nephrology, vol. 17, no. 1, pp. 1–9, 2016.
- [21] P. H. Le-Khac, G. Healy, and A. F. Smeaton, “Contrastive representation learning: A framework and review,” IEEE Access, vol. 8, pp. 193907–193934, 2020.
- [22] X. Liu, F. Zhang, Z. Hou, L. Mian, et al., “Self-supervised learning: Generative or contrastive,” IEEE Transactions on Knowledge and Data Engineering, 2021.
- [23] A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, et al., “A survey on contrastive self-supervised learning,” Technologies, vol. 9, no. 1, pp. 2, 2020.
- [24] S. Shurrab and R. Duwairi, “Self-supervised learning methods and applications in medical imaging analysis: A survey,” PeerJ Computer Science, vol. 8, pp. e1045, 2022.
- [25] S. Raju, S. Owen Jr, and P. Neglen, “The clinical impact of iliac venous stents in the management of chronic venous insufficiency,” Journal of vascular surgery, vol. 35, no. 1, pp. 8–15, 2002.
- [26] H. N. Mayrovitz, “Limb volume estimates based on limb elliptical vs. circular cross section models,” Lymphology, vol. 36, no. 3, pp. 140–143, 2003.
- [27] K. G. Brodovicz, K. McNaughton, N. Uemura, G. Meininger, et al., “Reliability and feasibility of methods to quantitatively assess peripheral edema,” Clinical medicine & research, vol. 7, no. 1-2, pp. 21–31, 2009.
- [28] JR Casley-Smith, “Measuring and representing peripheral oedema and its alterations.,” Lymphology, vol. 27, no. 2, pp. 56–70, 1994.
- [29] S. Mestre, F. Veye, A. Perez-Martin, T. Behar, et al., “Validation of lower limb segmental volumetry with hand-held, self-positioning three-dimensional laser scanner against water displacement,” Journal of Vascular Surgery: Venous and Lymphatic Disorders, vol. 2, no. 1, pp. 39–45, 2014.
- [30] K. Kiyomitsu, A. Kakinuma, H. Takahashi, N. Kamijo, et al., “Volume measurement of the leg by using kinect fusion for quantitative evaluation of edemas,” Bulletin of the Society of Photography and Imaging of Japan, vol. 27, no. 1, pp. 7–12, 2017.
- [31] K. Masui, K. Kiyomitsu, K. Ogawa, and N. Tsumura, “Visualization technique for change of edema condition by volume measurement using depth camera,” in Proc. Int. Conf. Image and Signal Processing (ICISP), 2018, pp. 526–533.
- [32] P. Shukla, T. Gupta, A. Saini, P. Singh, et al., “A deep learning frame-work for recognizing developmental disorders,” in Proc. IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2017, pp. 705–714.
- [33] Y. Gurovich, Y. Hanani, O. Bar, G. Nadav, et al., “Identifying facial phenotypes of genetic disorders using deep learning,” Nature medicine, vol. 25, no. 1, pp. 60–64, 2019.
- [34] C. Forte, A. Voinea, M. Chichirau, G. Yeshmagambetova, et al., “Deep learning for identification of acute illness and facial cues of illness,” Frontiers in medicine, vol. 8, no. 661309, 2021.
- [35] Y. Umeda-Kameyama, M. Kameyama, T. Tanaka, B. Son, et al., “Screening of alzheimer’s disease by facial complexion using artificial intelligence,” Aging (Albany NY), vol. 13, no. 2, pp. 1765–1772, 2021.
- [36] D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Learning face representation from scratch,” arXiv preprint arXiv:1411.7923, 2014.
- [37] A. Van den Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- [38] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in Proc. Int. conf. machine learning (ICML), 2020, pp. 1597–1607.
- [39] K. He, H. Fan, Y. Wu, S. Xie, et al., “Momentum contrast for unsupervised visual representation learning,” in Proc. IEEE/CVF conf. computer vision and pattern recognition (CVPR), 2020, pp. 9729–9738.
- [40] J. Grill, F. Strub, F. Altché, C. Tallec, et al., “Bootstrap your own latent-a new approach to self-supervised learning,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2020, vol. 33, pp. 21271–21284.
- [41] M. Caron, I. Misra, J. Mairal, P. Goyal, et al., “Unsupervised learning of visual features by contrasting cluster assignments,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2020, vol. 33, pp. 9912–9924.
- [42] P. Khosla, P. Teterwak, C. Wang, A. Sarna, et al., “Supervised contrastive learning,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2020, vol. 33, pp. 18661–18673.
- [43] B. Dufumier, P. Gori, J. Victor, A. Grigis, et al., “Contrastive learning with continuous proxy meta-data for 3d mri classification,” in Proc. Int. Conf. Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2021, pp. 58–68.
- [44] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE/CVF conf. computer vision and pattern recognition (CVPR), 2016, pp. 770–778.
- [45] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Proc. Int. conf. machine learning (ICML), 2010, pp. 807–814.
- [46] H. Imaoka, H. Hashimoto, K. Takahashi, A. F. Ebihara, et al., “The future of biometrics technology: from face recognition to related applications,” APSIPA Transactions on Signal and Information Processing, vol. 10, pp. 1–13, 2021.
- [47] Z. Wu, Y. Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” in Proc. IEEE/CVF conf. computer vision and pattern recognition (CVPR), 2018, pp. 3733–3742.
- [48] A. Paszke, S. Gross, F. Massa, A. Lerer, et al., “Pytorch: An imperative style, high-performance deep learning library,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2019, vol. 32, pp. 8024–8035.
- [49] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. Int. conf. learning representations (ICLR), 2015, pp. 1–13.
- [50] J. Deng, W. Dong, R. Socher, L. Li, et al., “Imagenet: A large-scale hierarchical image database,” in Proc. IEEE/CVF conf. computer vision and pattern recognition (CVPR), 2009, pp. 248–255.
- [51] X. Chen and K. He, “Exploring simple siamese representation learning,” in Proc. IEEE/CVF conf. computer vision and pattern recognition (CVPR), 2021, pp. 15750–15758.
- [52] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, et al., “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proc. IEEE/CVF conf. computer vision and pattern recognition (CVPR), 2017, pp. 618–626.