Efficient and Model-Agnostic Parameter Estimation Under Privacy-Preserving Post-randomization Data
Abstract
Protecting individual privacy is crucial when releasing sensitive data for public use. While data de-identification helps, it is not enough. This paper addresses parameter estimation in scenarios where data are perturbed using the Post-Randomization Method (PRAM) to enhance privacy. Existing methods for parameter estimation under PRAM data suffer from limitations like being parameter-specific, model-dependent, and lacking efficiency guarantees. We propose a novel, efficient method that overcomes these limitations. Our method is applicable to general parameters defined through estimating equations and makes no assumptions about the underlying data model. We further prove that the proposed estimator achieves the semiparametric efficiency bound, making it optimal in terms of asymptotic variance.
1 Introduction
1.1 Background
To make data accessible to the public, agencies like the Census Bureau, medical institutes, and law enforcement often release statistical databases. However, when statistical databases are released publicly, attackers can use them to identify individuals or uncover sensitive information by combining them with other available databases. For example, Sweeney, (2001) was able to reidentify some cancer patients in an anonymous medical database by matching some information (e.g., gender or zip code) in some named external databases (e.g., voter registration database). Thus, data de-identification alone is not enough to protect individuals’ private information. In addition to data de-identification, where information like name is removed, statistical disclosure control (SDC) methods aim to prevent the sensitive information from being re-identified in inference attacks. One can find a general introduction to SDC methodology in Hundepool et al., (2012) and Willenborg and De Waal, (2012).
Data perturbation is a type of commonly used SDC methods. It involves intentionally modifying data before publication to safeguard individual privacy. The core concept is straightforward: sensitive information (e.g., gender, zip code, and date of birth) needs to be altered in a way that prevents linking it to external datasets; thus making inference attacks difficult to implement. Common approaches include adding simple additive Gaussian noise or utilizing the Laplacian noise mechanism within the differential privacy framework. We refer to Mivule, (2012) and Okkalioglu et al., (2015) for more details.
This paper considers the problem where we need to perturb categorical variables. The post-randomization method (PRAM), which is firstly proposed by Gouweleeuw et al., (1998), is a natural way to adding noise to categorical variables: Suppose there is a sensitive binary variable that we wish to perturb, the PRAM method performs the perturbation using a known transition matrix, denoted by . In this example, suppose the transition matrix is defined as
where is the original unperturbed sensitive variable, and is the perturbed one. We can see that the PRAM method performs data perturbation probabilistically: There is a probability ( or ) that the variable can keep its original value after perturbations; otherwise, its value will be flipped to the opposite category. Similarly, we can extend the PRAM method to variables with categories with a transition matrix.
The transition matrix is crucial in balancing data privacy with data utility. While all columns in must sum to 1, with each entry between 0 and 1, the value along the diagonal (i.e., for ) is typically set to be greater than 0.5. Such a requirement prioritizes preserving the original data up to a certain extent, as overly emphasizing privacy would significantly reduce the usefulness of the published data. For example, in an extreme case, all entries in are set to 0.5 in the binary example, the resulting perturbed variable would contain no usable information.
1.2 Existing Work and Motivations
PRAM’s probabilistic nature inherently protects against inference attacks. However, for users who do not have access to the original data, how to use the perturbed data for faithful statistical analysis poses significant challenges. Consider a simple example: Suppose we have a logistic regression task with the “PRAM-ed” response variable (from the original variable ) and the original covariate , and we are interested in estimating a parameter defined as the solution to an estimating equation for some known function (e.g., can be the coefficient of in logistic regression by choosing accordingly, see Section 2.1 for more details). The estimation of is generally biased if we treat the perturbed as if it is the original response without making any adjustment. This is because (which is the solution to the equation ) is generally different from . So, even if the estimation method is unbiased given the original data, it becomes biased with PRAM data because we estimate a totally different parameter .
There is some existing work on parameter estimation with PRAM-ed data. In their seminal works, Gouweleeuw et al., (1998) proposed an unbiased moment estimator for frequency counts, whereas van den Hout and van der Heijden, (2002) studied a general framework to estimate odds ratios. Provided that a suitable parametric model is available, the EM algorithm (Dempster et al.,, 1977) appeared to be a popular choice to adjust for PRAM data. van den Hout and Kooiman, (2006) estimated the parameters in a linear regression model when covariates are subject to randomized response. Woo and Slavković, (2012) developed and implemented EM-type algorithms to obtain maximum likelihood estimates in logistic regression models, and Woo and Slavković, (2015) further extended the framework to generalized linear models. In both Woo and Slavković, (2012) and Woo and Slavković, (2015), the variables subject to PRAM could be either response, covariate, or both. However, existing methods have the following major limitations:
-
1.
Parameter-specificity: These methods are often designed for specific parameters and may not apply to more general ones.
-
2.
Parametric model dependence: Many methods rely on specific assumptions about the underlying data model, such as assuming a logistic regression relationship between . This dependence can make them vulnerable to model misspecification.
-
3.
Limited Optimality: Existing methods may not offer a guaranteed optimal solution for all situations. Specific data characteristics and analysis goals can heavily influence their performance.
1.3 Related Work
The PRAM problem is closely related to the label noise problem in the machine learning literature (e.g., Lawrence and Schölkopf, 2001; Scott, 2015; Li et al., 2021; Liu et al., 2023; Guo et al., 2024), as well as the misclassification problem in the statistical literature (e.g., Carroll et al., 2006; Buonaccorsi, 2010; Yi, 2017, 2021). The label noise problem is usually considered in a supervised learning setting, and the goal is to train a classifier using labeled data. However, we can only observe contaminated label instead of clean label . Such a problem is common in real-world applications. In a medical context, obtaining an accurate gold standard for diagnosis can be challenging due to factors such as cost, time limitations, and ethical considerations. This often necessitates the use of less reliable, “imperfect” diagnostic procedures, leading to potential misdiagnoses. Consequently, the labels assigned (healthy or diseased) based on these imperfect methods can introduce noise into the data.
In the context of label noise or misclassification, a common assumption known as class-dependent noise (Lawrence and Schölkopf, 2001) states that the probability of a noisy label given the true label and the features is equal to the probability of the noisy label given only the true label : . Under the class-dependent noise assumption, the label noise and PRAM problems share similar settings. However, a crucial distinction lies in the intentionality of the noise. In label noise scenarios, misclassification occurs unintentionally, arising from various factors such as human error, measurement limitations, or imperfect diagnostic procedures. Conversely, the noise is deliberately introduced through the known transition matrix (representing ) in the PRAM setting. Unlike the label noise setting, where the transition matrix is typically unknown, the PRAM setting assumes the transition matrix is readily available for the general public because itself is not sensitive. This access to the transition matrix allows for different approaches and analyses compared to the unintentional noise encountered in typical label noise problems.
1.4 Overview
We propose a novel method for parameter estimation with PRAM data, and we allow the PRAM-ed variables to be either the response or covariate. We address the aforementioned limitations of existing methods accordingly.
-
1.
General Parameters: we consider a parameter defined through an estimating equation , which is general and covers many commonly used parameters.
-
2.
Model-Agnostic Method: we do not impose any parametric assumptions on the data model, and our proposed method is free of the problem of model misspecifications.
-
3.
Estimation Efficiency: We answer the optimality question by proving that our proposed method achieves the semiparametric efficiency bound (Bickel et al., 1993; Tsiatis, 2006). In other words, the proposed estimator has the smallest possible asymptotic variance among all the regular asymptotic linear estimators.
The rest of the paper is organized as follows. Section 2 first formally introduces the problem setup and then explains why existing methods rely on parametric assumptions. Section 3 utilizes the findings in Section 2 and proposes an efficient and model-agnostic estimator. Section 4 conducts comprehensive numerical studies to evaluate and compare the proposed method and existing methods. Section 5 concludes the paper with discussions on potential future research.
2 Understanding Model Dependence in Existing Methods
2.1 Problem Setting
We start this section by formally introducing the notation used throughout the paper. We consider a random vector , where
-
•
: Represents the original sensitive categorical variable .
-
•
: Represents the PRAM-ed variable, which is the sensitive variable after applying the privacy-preserving transformation.
-
•
: Represents a vector of covariates associated with the variable of interest.
Furthermore, we assume that the perturbed variable is independent of conditional on (e.g., ) due to the PRAM mechanism. However, the original is unobservable; users can only access data from and the transition matrix , whose th entry is the probability of transforming to : . Though we present the method by transforming the response variable , it is crucial to note that the following discussions and the proposed method also apply seamlessly to transforming sensitive covariates. We transform here solely for illustrative purposes.
We are interested in estimating a parameter , which is defined as the solution to the estimating equation for a known function . This general form of parameter definition encompasses various quantities of interest. For example, by letting , the parameter of interest becomes the mean of the response . For binary if we let
where . Then corresponds to the intercept and coefficient of in a logistic regression model. For continuous (suppose is a categorical sensitive variable), if we let
then corresponds to the intercept and coefficient of in a simple linear regression model. Importantly, we do not make any model assumptions on when defining these parameters. The definition of the parameter is independent of the model, making it well-defined even if the model (e.g., ) is misspecified or unknown. Lastly, the goal is to estimate and perform statistical inference on the parameter given PRAM data .
2.2 Why Existing Methods Are Model-Dependent?
This section examines the key limitation of existing methods (e.g., van den Hout and Kooiman, 2006, Woo and Slavković, 2012, Woo and Slavković, 2015): their reliance on parametric assumptions. By analyzing this limitation, we aim to pave the way for introducing our proposed model-agnostic method, which offers greater flexibility and robustness. The rest of this section provides a high-level examination of existing model-dependent methods.
Due to the absence of the original label , we cannot use the estimating equation directly to solve for . However, we can rewrite the estimating equation as
| (1) |
where the conditional expectation in (1) is a function observable variables and . Therefore, the conditional expectation is crucial for estimating because once we can derive (or at least estimate) , we can estimate by solving from the empirical version of (1), which is given by
| (2) |
By the definition of conditional expectation, we have
where we can see that is determined by . Using the Bayes rule, we can be further write as
| (3) |
Equation (3) shows that , or equivalently, , is determined by , , and . The first one, , is known, so we only need to focus on the latter two: and . These two conditional distributions are closely connected, as we can show that
| (4) |
Namely, if we specify , then is determined by (4). On the contrary, under mild conditions, one can also solve from the integral equation (4) when given . To summarize, once we put a parametric assumption on or , we can estimate as well as . Then by replacing with the estimated in (2), we can estimate the parameter by solving the equation. This explain why existing methods hinge on imposing model assumption on or .
So far, our analysis highlights the fundamental limitation of existing methods: their dependence on parametric assumptions for estimating . The question is: how to bypass the parametric assumption? We provide our answer in the next section.
3 Towards Efficient Estimation: A Model-Agnostic Approach
3.1 All Roads Lead to Rome (But Some Are Better)
We consider a simple example where the sensitive variable is binary . We try to answer the following question: Given the distribution of the perturbed variable and the transition matrix , how to recover the distribution of the latent ?
From a probabilistic point of view, the marginal distributions of and are connected through a reversion matrix as follows.
| (5) |
where
The problem with this approach is that the reversion matrix is not readily available. But we can compute the reversion matrix using the Bayes rule:
| (6) |
where is the th entry of the transition matrix and for .
Another way to reach the same goal is simply inverting the transition matrix. By the definition of the transition matrix, we have
Therefore, we can recover the marginal distribution of in the following way, as long as is nonsingular.
| (7) |
where the reversion matrix is given by .
While both reversion matrices and can achieve the same goal, comparing and reveals their key difference: the first reversion matrix depends on the data model (i.e., and ) while the second reversion matrix does not. After all, contains and while is purely an inverse of a known matrix and non-probabilistic. Calling a model may sound strange, but that is because we consider a simple example.
To further illustrate the distinction between these approaches and lay the groundwork for our proposed method, we consider a general scenario by introducing a covariate vector . The task now becomes recovering the joint distribution using the noisy and the transition matrix P. Similarly to the previous case in (5), we can derive p(y,x) as follows:
where the reversion matrix
depends on the data model , which is similar to the issue encountered in Section 2.2. This dependence on the data model underscores the reason why existing methods are model-dependent: they need to estimate .
In contrast, the second approach only requires the known matrix , which is the inverse of the transition matrix. It can be verified that
| (8) |
Our discussion above highlights the key advantage of using the reversion matrix : It enables us to bypass the need for parametric assumptions. Therefore, to answer the question posed at the end of Section 2.2 (“how to bypass the parametric assumption?”), our solution is simple: use the inverse of the transition matrix .
3.2 A Model-Agnostic Estimator
To enhance understanding, in this section, we present our method using a simple example: the parameter of interest is a scalar and the sensitive variable is binary. We will explain the core concept using intuitive language in this section before delving into the formal details in Section 3.3.
The parameter of interest is defined as the solution to the estimation equation . Suppose we have a sample for , then we can rewrite the expectation as
| (9) |
One can understand the third equation in (9) by treating as if it is a discrete variable with support . By the relationship in (8), we can further write (9) as
| (10) |
Equation (10) implies that , which is originally an expectation with respect to , can be transformed into an expectation with respect to with the help of . Therefore, we can estimate the expectation in (10) using the Monte Carlo method with the sample for , and estimate the parameter by solving the following equation:
| (11) |
where the indicator function satisfies if ; otherwise, . The empirical estimating equation (11) does not contain any models, thus making our proposed estimator model-agnostic.
3.3 Theoretical Results
Influence Function
Firstly, we extend our discussion in Section 3.2 to a general setting where we have a vector of parameters and a multi-class variable . The parameter of interest is defined by the solution of for some known function . Using similar arguments as in Section 3.2, for , the influence function of our proposed estimator is given by
where is the th entry of , is a matrix with its th column being such that
and is a basis vector whose th entry is 1 while other entries are all 0 for . Based on the influence function in (3.3), our proposed estimator given a sample , , is the solution to
| (13) |
Semiparametric Efficiency
Using the theories of the M-estimator (e.g., van der Vaart, 2000), the proposed estimator in (13) is readily consistent and has an asymptotic normal distribution. Moreover, we will prove in Theorem 1 that there are no better alternative estimators regarding estimation efficiency because our proposed has the smallest possible asymptotic variance (i.e., achieves the semiparametric efficiency bound).
Notably, the proposed estimator achieves the semiparametric efficiency bound without relying on any additional assumptions. This is because it operates independent of any models, both parametric and nonparametric. This is a significant advantage, as achieving semiparametric efficiency in other methods often requires some challenging conditions. For example, literature on double machine learning usually requires that the nonparametric nuisance functions (functions whose specific form is unknown but belongs to a certain class) need to be estimated precisely, typically requiring a convergence rate of . Additionally, for most semiparametric estimator, the parametric part of the model needs to be specified correctly. We establish the efficiency results in the following theorem. The proofs are given in the supplementary materials.
Theorem 1.
The efficient influence function for estimating is given by
where is a constant matrix and is defined as evaluated at the true value and is given in (3.3).
Proposition 1.
The proposed efficient has the asymptotic representation
The proposed estimator achieves the semiparametric efficiency bound (i.e., ), and is semiparametrically efficient.
Remark 1 (Efficiency Loss of Compared to Oracle Estimator ).
We define the oracle estimator as the solution of
We say is an oracle estimator because it needs the unobservable original label . The asymptotic representation of the oracle estimator is given as
Noticing that , one can write
Therefore, is the efficiency loss of compared to the oracle estimator . It is also the price to pay for preserving privacy. Considering a special case where does not contain , then from (3.3), we have , and there is no efficiency loss because is not involved.
Statistical Inference
Finally, to preserve the model-agnostic feature of when conducting statistical inference, we propose to use the resampling method by Jin et al., (2001) to estimate the asymptotic variance of . The details of this method have been carefully studied in Jin et al., (2001), so we only briefly describe the procedure here. Note that is the solution of , where the randomness of comes from different realizations of the data sample for . Now, conditional on one observed sample for , we denote the observed estimate of as (which is fixed now). Let , be independent and identically distributed copies of a nonnegative, completely known random variable with mean one and variance one (e.g., ). Then, we denote as the solution of where only ’s are random in the above estimating equation. It can be shown that (when conditional on the sample) shares the same asymptotic distribution as . In practice, conditional on , and , the distribution of can be estimated by generating a large number, say, , of random samples . Denote the solution in the th replication as , then the asymptotic variance of can be estimated by the sample covariance matrix constructed from .
4 Numerical Studies
4.1 Simulation Studies
We conduct comprehensive simulation studies to investigate the proposed method’s finite sample performance and its comparison to some existing methods. In Simulation A1, we consider a binary and use the logistic regression model with and . The marginal distribution of is chosen as . The response variable is subject to PRAM. We choose three different transition matrices in PRAM as and we vary the sample size . The parameters of interest are defined through the solution of the following estimating equation:
Such a choice of is equivalent to estimating the coefficients from a logistic regression model so that, immediately, we have and ; however, the estimating equation itself does not imply any model assumptions. Using the same way for generating as in Simulation A1, we conduct Simulation A2, where we fix the sample size at . However, we do not require for the transition matrix; we vary and between and with increment of .
In Simulation B, we consider the situation that the sensitive variable is a covariate, rather than the response variable. The data-generating mechanism is given by and for binary . We set and . The parameters of interest are the coefficients of a simple linear regression model
Again, the definition of parameters does not depend on parametric model assumptions, but we align the parameter definition with the data-generating mechanism so that we can obtain the true parameter values and . Similar to Simulations A1 and A2, in Simulation B1, we let the sample size vary and use as the transition probabilities; while in Simulation B2, we fix at and allow and to vary freely between and with increment of . We run Monte Carlo replicates for the following methods in all the aforementioned simulations.
-
1.
The proposed estimator in (13).
-
2.
The oracle estimator : using the un-perturbed original sensitive variable.
-
3.
The naive estimator : treat the perturbed variable as the original one; this estimator is generally biased.
-
4.
Model-dependent estimator (Model 1): We model (3) using a parametric model.
-
5.
Model-dependent estimator (Model 2): We model (3) using a parametric model, but the model used is relatively worse than the one used in .
The purpose of introducing and is to investigate the effects of the degree of model misspecification on the estimations. In Simulations A (resp., B), we model (resp., ) using a logistic regression for while we force the intercept of the logistic regression to be in . The motivations for such a setting are:
-
•
Neither the model in or is correct; but the parametric model used in provides a better fit than that used in . In other words, the degree of model misspecification is worse in
-
•
By comparing and as well as and , we can investigate the benefits brought by our model-agnostic method.
-
•
By comparing and , we can investigate the severity of model misspecification on the estimation. It is worth noting that does not have any practical meanings, nor do we want to establish the superiority of our proposed method by comparing it with .
-
•
We do not include the estimator where (or ) is correctly specified. This is because using the correct model needs oracle information, and we consider the semiparametric setting where the model is unknown (which mimics the real-world application scenario).
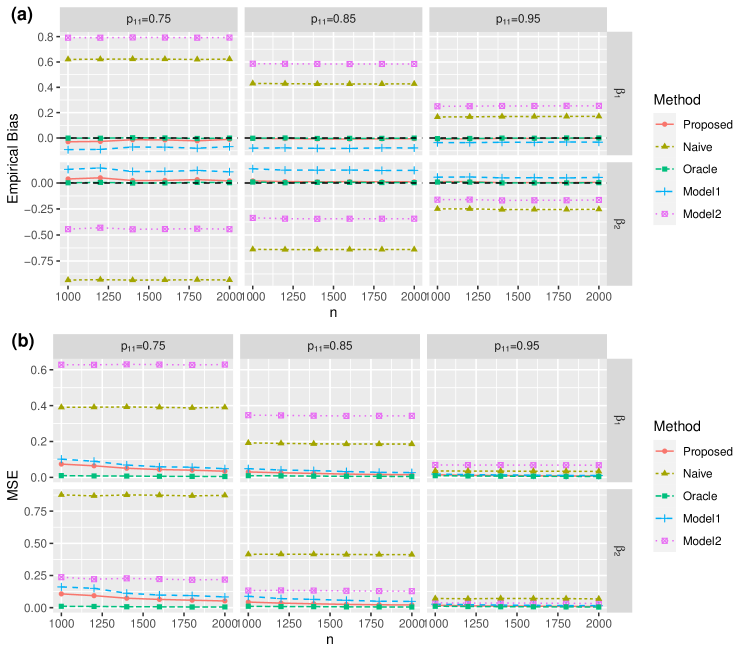
Firstly, Figure 1(a) summarizes the empirical bias results in Simulation A1. In general, the oracle and proposed estimators and almost always have no bias, whereas has a small bias; however, estimators and have huge biases. These noticeable biases reduce when increase from to but do not diminish when the sample size increases. The empirical bias results in Simulation B1 are very similar, so they are omitted here (contained in the supplementary materials).
We then compare the mean squared error (MSE) across these estimators and report the results in Simulation A1 in Figure 1(b). The results in Simulation B1 are similar and omitted here (can be found in the supplementary materials). Similarly, the naive and Model 2 estimators and perform badly. Among the three estimators , , and , the oracle estimator has the smallest MSE while has the largest, with our proposed estimator in between, which matches our theoretical results. The efficiency loss of over has been demonstrated in Remark 1, which is the price to pay for protecting private information.
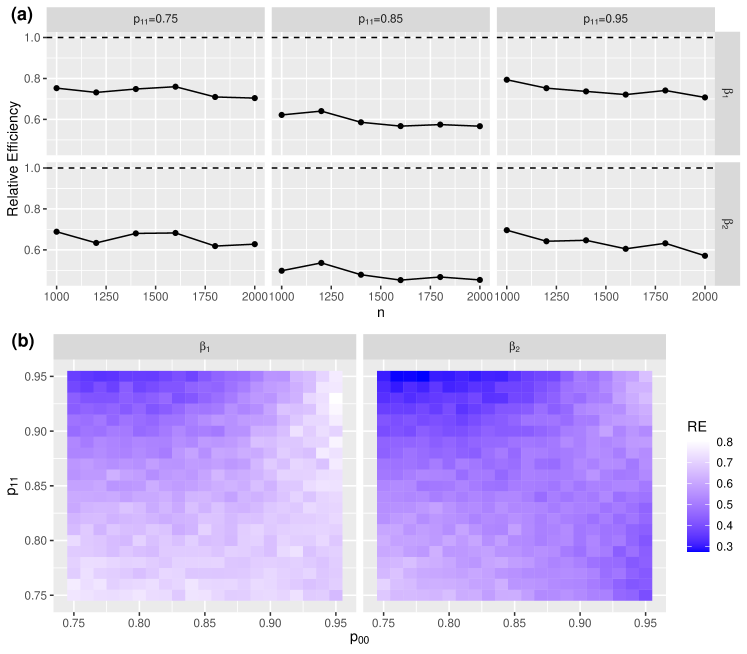
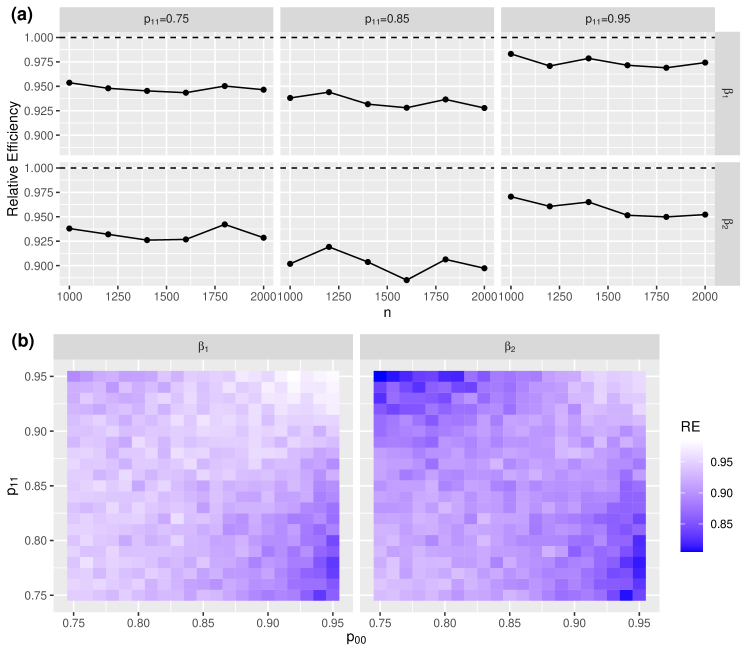
Next, we compare the estimation efficiency of and by assessing the relative efficiency (RE) of to , which is defined as
If , then is preferable than , and the smaller is, the more efficient is. Our results in Figure 2 show that the proposed estimator is always more efficient than the estimator in every situation we consider. The RE in simulation A1 is about 50% to 80% (see Figure 2(a)) while the RE in simulation B1 is about 90% to 97.5% (see Figure 3(a)). When we vary and in a wider interval , the RE in simulation A2 may range from 30% to 80% (see Figure 2(b)) and the RE in simulation B2 can be as small as 80% (see Figure 3(b)). Interestingly, in simulations A2 and B2, the area where is more efficient is in either the top-left or bottom-right corners.
Lastly, we thoroughly report our proposed estimator ’s estimation and inference results. Table 1 is for simulation A1, and a similar table for simulation B1 is in the supplementary materials. In Table 1, we summarize the empirical bias (Bias) (sample bias across 2000 replicates), the empirical standard deviation (SD) (sample standard deviation across 2000 replicates), the estimated standard error (SE) (average across 2000 estimated standard deviations, with each computed using 500 perturbed samples), and the coverage probability (CP) of the equal-sided confidence interval. Apparently, the estimated standard error matches the empirical standard deviation closely, and the coverage probability is close to the nominal level .
| Bias | SD | SE | CP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1000 | -0.030 | 0.038 | 0.270 | 0.325 | 0.283 | 0.351 | 0.968 | 0.960 | |
| 1200 | -0.027 | 0.049 | 0.252 | 0.302 | 0.258 | 0.320 | 0.962 | 0.960 | |
| 1400 | -0.013 | 0.023 | 0.224 | 0.270 | 0.233 | 0.287 | 0.959 | 0.960 | |
| 1600 | -0.015 | 0.024 | 0.208 | 0.252 | 0.217 | 0.268 | 0.960 | 0.957 | |
| 1800 | -0.022 | 0.032 | 0.199 | 0.239 | 0.205 | 0.252 | 0.958 | 0.960 | |
| 2000 | -0.010 | 0.020 | 0.184 | 0.228 | 0.192 | 0.235 | 0.967 | 0.959 | |
| 1000 | -0.003 | 0.019 | 0.173 | 0.208 | 0.177 | 0.213 | 0.957 | 0.958 | |
| 1200 | -0.005 | 0.013 | 0.159 | 0.188 | 0.161 | 0.193 | 0.960 | 0.962 | |
| 1400 | -0.007 | 0.011 | 0.148 | 0.174 | 0.149 | 0.178 | 0.957 | 0.955 | |
| 1600 | -0.008 | 0.013 | 0.134 | 0.160 | 0.139 | 0.166 | 0.963 | 0.967 | |
| 1800 | -0.006 | 0.011 | 0.126 | 0.150 | 0.130 | 0.156 | 0.960 | 0.965 | |
| 2000 | -0.005 | 0.011 | 0.121 | 0.146 | 0.123 | 0.147 | 0.954 | 0.954 | |
| 1000 | -0.008 | 0.012 | 0.119 | 0.136 | 0.119 | 0.135 | 0.953 | 0.953 | |
| 1200 | -0.006 | 0.013 | 0.107 | 0.122 | 0.108 | 0.123 | 0.958 | 0.955 | |
| 1400 | -0.003 | 0.002 | 0.100 | 0.112 | 0.100 | 0.113 | 0.951 | 0.955 | |
| 1600 | -0.003 | 0.003 | 0.093 | 0.106 | 0.094 | 0.106 | 0.947 | 0.946 | |
| 1800 | -0.001 | 0.003 | 0.088 | 0.101 | 0.088 | 0.099 | 0.949 | 0.952 | |
| 2000 | -0.001 | 0.006 | 0.084 | 0.094 | 0.083 | 0.095 | 0.954 | 0.949 | |
4.2 Real Data Application
To evaluate our method’s performance in a practical setting, we applied it to a real dataset from the Korean Labor & Income Panel Study (dataset provided in the supplementary materials). This dataset includes information on regular wage earners for the year 2005. We focused on modeling the average monthly income (denoted by Y as a continuous variable) as a function of three demographic covariates: age (, also continuous), education level ( as a binary variable, where 1 indicates education beyond high school and 0 otherwise), and gender ( as a binary variable, where 1 indicates female and 0 indicates male). Both income and age were standardized before analysis.
We focus on modeling the average monthly income () as a linear function of the three demographic covariates: age (), education level (), and gender ().
The parameters of interest are denoted by the vector in our data analysis. These parameters are defined as the solution to the following estimating equation.
In other words, the parameters are the minimizers of the mean least square error
However, the true value of is unknown as we only have a limited sample of data. To assess estimators’ performance, we compare them to an oracle estimator (denoted by ) obtained using the ordinary least squares method, assuming access to all the original variables.
We perform the PRAM procedure on the education level variable to generate a perturbed version . The transition probabilities controlling the amount of noise introduced during perturbation were set to . For each transition probability value, we compare the performance of four estimators
-
1.
Proposed Estimator .
-
2.
Naive Estimator : This estimator treats the perturbed variable as the original , ignoring the impact of PRAM.
-
3.
Model-Dependent Estimator (Model 1): This method uses logistic regression to model .
-
4.
Model-Dependent Estimator (Model 2): This method uses probit regression for the same purpose as Model 1.
We estimate the standard errors for each method using the resampling approach described in Section 3.3. To evaluate estimator performance, we calculate two metrics:
-
•
Bias: The difference between the estimated value and the oracle estimator.
-
•
Root Mean Square Error (rMSE):This combines the bias and standard error to provide a more comprehensive measure of estimation accuracy: .
A lower bias and/or rMSE indicate a better estimator.
The results are summarized in Table 2. Our proposed estimator consistently achieves the smallest bias and rMSE across all perturbation levels, demonstrating its superiority when compared to the other methods. This implies that the proposed estimator provides estimates closest to the true values, even when data is perturbed for privacy preservation. The performance of the other three estimators varies. While model-dependent methods generally outperform the naive estimator, they can also perform worse in some cases (particularly with low perturbation levels).
| Parameter | Method | Measure | |||
|---|---|---|---|---|---|
| Intercept | Oracle | Estimate (SE) | 0.410 (0.043) | ||
| Proposed | Estimate (SE) | 0.370 (0.062) | 0.411 (0.051) | 0.388 (0.041) | |
| “Bias” | -0.040 | 0.001 | -0.022 | ||
| “rMSE” | 0.074 | 0.051 | 0.047 | ||
| Model1 | Estimate (SE) | 0.317 (0.034) | 0.332 (0.034) | 0.281 (0.031) | |
| “Bias” | -0.093 | -0.078 | -0.129 | ||
| “rMSE” | 0.099 | 0.085 | 0.133 | ||
| Model2 | Estimate (SE) | 0.235 (0.038) | 0.267 (0.041) | 0.293 (0.030) | |
| “Bias” | -0.175 | -0.143 | -0.117 | ||
| “rMSE” | 0.179 | 0.149 | 0.121 | ||
| Naive | Estimate (SE) | 0.651 (0.042) | 0.583 (0.043) | 0.454 (0.043) | |
| “Bias” | 0.242 | 0.173 | 0.044 | ||
| “rMSE” | 0.246 | 0.178 | 0.062 | ||
| Age | Oracle | Estimate (SE) | 0.396 (0.038) | ||
| Proposed | Estimate (SE) | 0.423 (0.049) | 0.404 (0.045) | 0.411 (0.039) | |
| “Bias” | 0.027 | 0.008 | 0.015 | ||
| “rMSE” | 0.056 | 0.046 | 0.042 | ||
| Model1 | Estimate (SE) | 0.544 (0.034) | 0.524 (0.036) | 0.538 (0.032) | |
| “Bias” | 0.148 | 0.128 | 0.142 | ||
| “rMSE” | 0.152 | 0.133 | 0.146 | ||
| Model2 | Estimate (SE) | 0.609 (0.038) | 0.584 (0.041) | 0.519 (0.032) | |
| “Bias” | 0.213 | 0.188 | 0.123 | ||
| “rMSE” | 0.216 | 0.192 | 0.127 | ||
| Naive | Estimate (SE) | 0.242 (0.038) | 0.287 (0.038) | 0.366 (0.038) | |
| “Bias” | -0.154 | -0.109 | -0.030 | ||
| “rMSE” | 0.159 | 0.115 | 0.048 | ||
| Edu (PRAM-ed) | Oracle | Estimate (SE) | 0.342 (0.019) | ||
| Proposed | Estimate (SE) | 0.371 (0.042) | 0.335 (0.032) | 0.363 (0.021) | |
| “Bias” | 0.029 | -0.007 | 0.021 | ||
| “rMSE” | 0.051 | 0.032 | 0.030 | ||
| Model1 | Estimate (SE) | 0.258 (0.010) | 0.274 (0.014) | 0.339 (0.013) | |
| “Bias” | -0.084 | -0.068 | -0.003 | ||
| “rMSE” | 0.085 | 0.069 | 0.013 | ||
| Model2 | Estimate (SE) | 0.277 (0.011) | 0.296 (0.013) | 0.349 (0.014) | |
| “Bias” | -0.065 | -0.046 | 0.007 | ||
| “rMSE” | 0.066 | 0.048 | 0.016 | ||
| Naive | Estimate (SE) | 0.170 (0.019) | 0.220 (0.020) | 0.320 (0.019) | |
| “Bias” | -0.172 | -0.122 | -0.020 | ||
| “rMSE” | 0.173 | 0.124 | 0.028 | ||
| Gender | Oracle | Estimate (SE) | -0.290 (0.019) | ||
| Proposed | Estimate (SE) | -0.282 (0.022) | -0.296 (0.018) | -0.288 (0.017) | |
| “Bias” | 0.008 | -0.006 | 0.002 | ||
| “rMSE” | 0.023 | 0.019 | 0.017 | ||
| Model1 | Estimate (SE) | -0.275 (0.015) | -0.293 (0.015) | -0.281 (0.014) | |
| “Bias” | 0.015 | -0.003 | 0.009 | ||
| “rMSE” | 0.021 | 0.015 | 0.017 | ||
| Model2 | Estimate (SE) | -0.261 (0.014) | -0.289 (0.016) | -0.285 (0.015) | |
| “Bias” | 0.029 | 0.001 | 0.005 | ||
| “rMSE” | 0.032 | 0.016 | 0.016 | ||
| Naive | Estimate (SE) | -0.316 (0.020) | -0.312 (0.020) | -0.296 (0.020) | |
| “Bias” | -0.026 | -0.022 | -0.006 | ||
| “rMSE” | 0.033 | 0.030 | 0.021 |
5 Conluding Remarks
This paper proposes a novel method for efficient and model-agnostic parameter estimation with data perturbed using the PRAM method for privacy preservation. Our estimator offers significant advantages over existing methods by overcoming their limitations of parameter-specificity and model dependence. Notably, we prove that the proposed estimator achieves the semiparametric efficiency bound. In simpler terms, this implies that our method offers the best possible accuracy among all estimators when the true data distribution is unknown, which is almost always true in real-world applications. Looking towards future research, several interesting questions emerge. First, extending the framework to handle continuous sensitive variables presents a natural challenge. While categorical variables allow for a simple matrix inversion during reversion, continuous variables might require solving integral equations. Second, the method can be further generalized to address cases where multiple variables have undergone privacy-preserving transformations. Combining multiple covariates into a single variable offers a straightforward solution for certain scenarios (e.g., combining binary variables and into a new variable with four levels). However, the problem becomes significantly more complex when dealing with a mix of categorical and continuous variables.
References
- Bickel et al., (1993) Bickel, P. J., Klaassen, J., Ritov, Y., and Wellner, J. A. (1993). Efficient and Adaptive Estimation for Semiparametric Models. Johns Hopkins University Press.
- Buonaccorsi, (2010) Buonaccorsi, J. P. (2010). Measurement Error: Models, Methods, and Applications. Chapman and Hall/CRC.
- Carroll et al., (2006) Carroll, R. J., Ruppert, D., Stefanski, L. A., and Crainiceanu, C. M. (2006). Measurement Error in Nonlinear Models: A Modern Perspective. Chapman and Hall/CRC.
- Dempster et al., (1977) Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39:1–22.
- Gouweleeuw et al., (1998) Gouweleeuw, J. M., Kooiman, P., and De Wolf, P. (1998). Post randomisation for statistical disclosure control: Theory and implementation. Journal of Official Statistics, 14:463–478.
- Guo et al., (2024) Guo, H., Wang, B., and Yi, G. (2024). Label correction of crowdsourced noisy annotations with an instance-dependent noise transition model. In Advances in Neural Information Processing Systems.
- Hundepool et al., (2012) Hundepool, A., Domingo-Ferrer, J., Franconi, L., Giessing, S., Nordholt, E. S., Spicer, K., and De Wolf, P.-P. (2012). Statistical Disclosure Control, volume 2. Wiley.
- Jin et al., (2001) Jin, Z., Ying, Z., and Wei, L. (2001). A simple resampling method by perturbing the minimand. Biometrika, 88:381–390.
- Lawrence and Schölkopf, (2001) Lawrence, N. and Schölkopf, B. (2001). Estimating a kernel Fisher discriminant in the presence of label noise. In International Conference on Machine Learning.
- Li et al., (2021) Li, X., Liu, T., Han, B., Niu, G., and Sugiyama, M. (2021). Provably end-to-end label-noise learning without anchor points. In International Conference on Machine Learning.
- Liu et al., (2023) Liu, Y., Cheng, H., and Zhang, K. (2023). Identifiability of label noise transition matrix. In International Conference on Machine Learning.
- Mivule, (2012) Mivule, K. (2012). Utilizing noise addition for data privacy, an overview. In International Conference on Information and Knowledge Engineering.
- Okkalioglu et al., (2015) Okkalioglu, B. D., Okkalioglu, M., Koc, M., and Polat, H. (2015). A survey: deriving private information from perturbed data. Artificial Intelligence Review, 44:547–569.
- Scott, (2015) Scott, C. (2015). A rate of convergence for mixture proportion estimation, with application to learning from noisy labels. In International Conference on Artificial Intelligence and Statistics.
- Sweeney, (2001) Sweeney, L. (2001). Computational Disclosure Control: A Primer on Data Privacy Protection. PhD thesis, Massachusetts Institute of Technology.
- Tsiatis, (2006) Tsiatis, A. A. (2006). Semiparametric Theory and Missing Data. Springer.
- van den Hout and Kooiman, (2006) van den Hout, A. and Kooiman, P. (2006). Estimating the linear regression model with categorical covariates subject to randomized response. Computational Statistics & Data Analysis, 50:3311–3323.
- van den Hout and van der Heijden, (2002) van den Hout, A. and van der Heijden, P. G. (2002). Randomized response, statistical disclosure control and misclassification: a review. International Statistical Review, 70:269–288.
- van der Vaart, (2000) van der Vaart, A. W. (2000). Asymptotic Statistics. Cambridge University Press.
- Willenborg and De Waal, (2012) Willenborg, L. and De Waal, T. (2012). Elements of Statistical Disclosure Control. Springer.
- Woo and Slavković, (2012) Woo, Y. M. J. and Slavković, A. B. (2012). Logistic regression with variables subject to post randomization method. In International Conference on Privacy in Statistical Databases.
- Woo and Slavković, (2015) Woo, Y. M. J. and Slavković, A. B. (2015). Generalised linear models with variables subject to post randomization method. Statistica Applicata-Italian Journal of Applied Statistics, 24:29–56.
- Yi, (2017) Yi, G. Y. (2017). Statistical Analysis with Measurement Error or Misclassification: Strategy, Method and Application. Springer.
- Yi, (2021) Yi, G. Y. (2021). Likelihood methods with measurement error and misclassification. In Handbook of measurement error models, pages 99–126. Chapman and Hall/CRC.