201 E 24th St, Austin, TX 78712, 22email: lkaiser@utexas.edu 33institutetext: Richard Tsai 44institutetext: Oden Institute for Computational Engineering and Science, University of Texas at Austin;
201 E 24th St, Austin, TX 78712, 44email: ytsai@math.utexas.edu 55institutetext: Christian Klingenberg 66institutetext: Department of Mathematics, University of Wuerzburg; Emil-Fischer-Straße 40, 97074 Wuerzburg, Germany, 66email: klingen@mathematik.uni-wuerzburg.de
Efficient Numerical Wave Propagation Enhanced By An End-to-End Deep Learning Model
Abstract
In a variety of scientific and engineering domains, the need for high-fidelity and efficient solutions for high-frequency wave propagation holds great significance. Recent advances in wave modeling use sufficiently accurate fine solver outputs to train a neural network that enhances the accuracy of a fast but inaccurate coarse solver. In this paper we build upon the work of Nguyen and Tsai (2023) and present a novel unified system that integrates a numerical solver with a deep learning component into an end-to-end framework. In the proposed setting, we investigate refinements to the network architecture and data generation algorithm. A stable and fast solver further allows the use of Parareal, a parallel-in-time algorithm to correct high-frequency wave components. Our results show that the cohesive structure improves performance without sacrificing speed, and demonstrate the importance of temporal dynamics, as well as Parareal, for accurate wave propagation.
1 Introduction
Wave propagation computations form the forward part of a numerical method for solving the inverse problem of geophysical inversion. This involves solving the wave equation with highly varying sound speed many times in a most efficient way. For instance, by accurately analyzing the reflections and transmissions generated by complex media discontinuities, it becomes possible to characterize underground formations when searching for natural gas. However, traditional numerical computations often demand a computationally expensive fine grid to guarantee stability.
Aside from physics-informed neural networks (PINNs) moseley2020solving ; MENG2020113250 and neural operators kovachki2023neural ; li2020fourier , convolutional neural network (CNN) approaches yield remarkable results nguyen2022numerical ; rizzhelm ; mlfluid to improve the efficiency of wave simulations, but demand preceding media analysis and tuning of inputs. Furthermore, numerical solvers are avoided to prioritize speed RAISSI2019686 ; especially for extended periods, these methods can diverge.
Therefore, combining a classical numerical solver with a neural network to solve the second-order linear wave equation efficiently across a variety of wave speed profiles is a central point of our research. We take a first step by expanding the method of Nguyen and Tsai nguyen2022numerical and build an end-to-end model that enhances a fast numerical solver through deep learning. Thus, component interplay is optimized, and training methods can involve multiple steps to account for temporal wave dynamics. Similarly, while other Parareal-based datasets nguyen2022numerical ; ibrahim2023parareal are limited to single time-steps to add back missing high-frequency components, a cohesive system can handle Parareal for sequential time intervals.
Approach and Contribution.
An efficient numerical solver is used to propagate a wave for a time step on a medium described by the piecewise smooth wave speed for . This method is computationally cheap since the advancements are computed on a coarse grid using a large time step within the limitation of numerical stability; however, it is consistently less accurate than an expensive fine solver . Consequently, the solutions exhibit numerical dispersion errors and miss high-fidelity details. In a supervised learning framework, we aim to reduce this discrepancy using the outputs from as the examples.
We define a restriction operator which transforms functions from a fine grid to a coarse grid. Additionally, for mapping coarse grid functions to a fine grid, we integrate a neural network to augment the under-resolved wave field. We can now define a neural propagator that takes a wave field defined on the fine grid, propagates it on a coarser grid, and returns the enhanced wave field on the fine grid,
| (1) |
The models are parameterized by the family of initial wave fields and wave speeds .
2 Finite-Difference-Based Wave Propagators
We consider smooth initial conditions and absorbing or periodic boundary conditions that lead to well-posed initial boundary value problems. Since we are interested in seismic exploration applications, both boundary conditions can be used to simulate the propagation of wave fields with initial energy distributed inside a compact domain. Following the setup in nguyen2022numerical , let denote a numerical approximation of with discretized spatial and temporal domains, i.e.,
| (2) |
For the spatial () and temporal spacing () on uniform Cartesian grids, the approximation can be solved by a time integrator:
-
•
Coarse solver with , which operates on the lower resolution grid, . is characterized by the velocity Verlet algorithm with absorbing boundary conditions enq .
-
•
Fine solver with , which operates on the higher resolution grid, , and is sufficiently accurate for the wave speed. We shall use the explicit Runge-Kutta of forth-order (RK4) pseudo-spectral method runge-kutta . Since this approach is only suitable for PDEs with periodic boundary conditions, we first apply to a larger domain and then crop the result.
Model Components.
As the two solvers operate on different Cartesian grids, with and , we define the restriction operator , which transforms functions from a fine to a coarse grid, and the prolongation operator , which maps the inverse relation. The enhanced variants consist of (a) bilinear interpolations denoted as and , while , and (b) neural network components denoted as , while the lower index indicates that the neural networks are trained when the step size is used. For improved neural network inference, we use the transition operator to transform physical wave fields to energy component representations , with as the pseudo-inverse (see also nguyen2022numerical ; energy1 ). Figure 1 provides a schema visualizing the wave argument transitions.
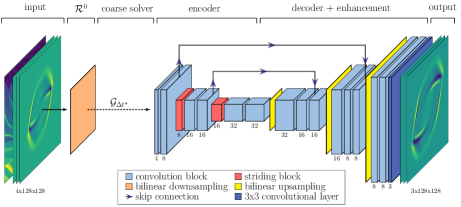
Variants of the neural propagators.
A simple model with bilinear interpolation (E2E-V, ) is used as a baseline. Each variant changes the baseline by exactly one aspect. This allows us to isolate the effect of each architecture modification. The four investigated end-to-end models are:
- E2E-JNet3:
-
E2E 3-level JNet (Figure 1)
- E2E-JNet5:
-
E2E 5-level JNet
- E2E-Tira:
-
Tiramisu JNet tiramisu
- E2E-Trans:
-
Transformer JNet petit2021unet
The second baseline is taken from nguyen2022numerical and denoted as the modular, not end-to-end 3-level JNet (NE2E-JNet3), ), while results of are used to separately train the E2E-JNet3 upsampling component.
3 Data Generation Approaches
For optimal results, the training horizon must be long enough to contain sufficiently representative wave patterns that develop in the propagation from the chosen distribution of initial wave fields. Yet the number of iterations must remain small to maintain similarities across different wave speeds. Similar to nguyen2022numerical , we chose to generate the dataset in the following way:
-
1.
An initial wave field is sampled from a Gaussian pulse,
(3) with , and the initial velocity field . is the displacement of the Gaussian pulse’s location from the center.
-
2.
Every is then propagated eight time steps by . We adopt the fine grid settings for the spatial () and temporal resolution () from nguyen2022numerical .
The wave trajectories provide the input and output data for the supervised learning algorithm, which aims to learn the solution map :
| (4) |
where with , . is modified to create , (Subsection 3.1), and (Subsection 3.2). For brevity, the dataset is only specified if the model is trained on a modified version; e.g., E2E-JNet3 () is the E2E-JNet3 model trained on .
Wave Speeds
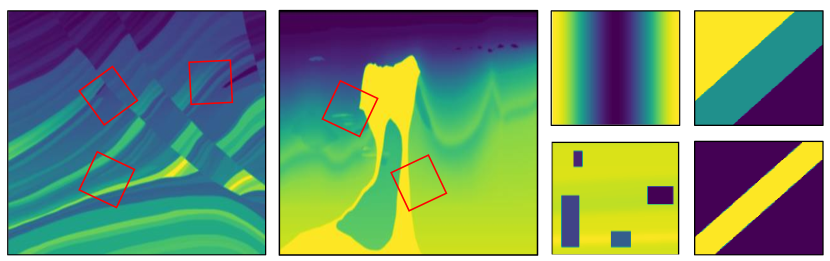
are sampled from randomly chosen subregions of two synthetic geological structures, Marmousi marmousi and BP bp , that are mapped onto the spatial grid (see Figure 2). Four manually modified media (cf. nguyen2022numerical ) are added during testing to examine rapid variations in wave speed.
3.1 Multi-Step Training
During evaluation, the end-to-end model is applied multiple times to itself to iteratively advance waves over the duration . It comes naturally to include longer-term dependencies also in our training dataset. For time steps, we therefore introduce a multi-step training strategy that modifies Eq. 1:
| (5) |
By computing the gradient with respect to the sum of consecutive losses, the gradient flows through the entire computation graph across multiple time steps.
For each initial condition , is applied times with solutions denoted as . In random order, is applied to every for a random amount of steps . Formally, the optimization problem can therefore be described as:
| (6) |
The norm is the discretized energy semi-norm MSE as detailed in nguyen2022numerical . We draw both and from the uniform random distributions, i.e., and , respectively. The novel dataset is denoted as .
Weighted Approach.
Since in the model’s initial, untrained phase, feature variations can be extreme and may lead to imprecise gradient estimations, we aim to accelerate convergence by weighting individual losses. Therefore, rather than drawing from a uniform distribution, we select values according to a truncated normal distribution TN from the sample space represented as . This focuses on minimizing the impact of errors in the early training stage. After every third epoch, the mean is increased by one to account for long-term dependencies. We refer to this dataset as .
3.2 Parareal Algorithm
Identical to nguyen2022numerical , our implemented scheme iteratively refines the solution using the difference between and for each subinterval . In particular, missing high-frequency components occur due to the transition to a lower grid resolution, or a too simple numerical algorithm. Therefore, a more elaborate model is required for convergence. Formally, we rearrange Eq. 1 for the time stepping of , and replace by the computationally cheaper strategy end-to-end:
| (7) | |||
| (8) |
We observe that the computationally expensive on the right-hand side of Eq. 7 can be performed in parallel for each iteration in .
Parareal iterations alter a given initial sequence of wave fields to for . This means that neural operators should be trained to map to . Therefore, appropriate training patterns for this setup would naturally differ from those found in , and the dataset for use with Parareal should be sampled from a different distribution, denoted as .
4 Evaluation Setup
The parameters for are set to and , with a bilinear interpolation scale factor of two.
Experiment 1: Architecture Preselection.
The average training time of each variant is approximately CPU core hours. Due to resource constraints, we therefore limit our main analysis to one end-to-end variant. Here, we selected the most promising approach from four deep learning architectures trained on .
Experiment 2: Multi-Step Training.
We train the chosen end-to-end variant from experiment 1 on using an equal number of training points as in . The test set is consistent with to enable comparison with other experiments.
Experiment 3: Weighted Multi-Step Training.
The setup follows experiment 2, while the models are trained on .
Experiment 4: Parareal Optimization.
We explore improvements to our variants using the Parareal scheme in two datasets:
A. Comprehensive Training ():
The models are trained according to the Parareal scheme in Eq. 7 and Eq. 8 with
using a random sample that constitutes a quarter of the original dataset for fair comparisons.
The gradients are determined by summing the losses of a Parareal iteration.
B. Fine-tuning ():
Rather than employing an un-trained model,
we deploy variants that were pre-trained on a random subset containing half of .
Then, for another subset that constitutes an eighth of , is applied with Parareal.
5 Discussion
Each of the total runs required an average of GPU core hours on one NVIDIA A100 Tensor Core GPU to complete, while the E2E-JNet3 was trained almost faster and the E2E-Tira three times slower than the average. This sums up to a total runtime on a single GPU of just over hours.
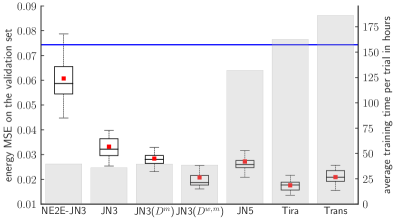
The best trial on the test set was achieved by E2E-Tira with an energy MSE of , which is well below the from the previously published model, NE2E-JNet3. Our most efficient variant is E2E-JNet3 trained on with an energy MSE of , which is close to the results of more extensive models such as E2E-Tira and E2E-Trans, but is more than five times faster.
End-to-end Structure.
The first important observation based on Figure 3 is that integrating NE2E-JNet3 into a single, end-to-end system (E2E-JNet3) improved the average accuracy on the validation set by more than , and on the test set by ca. . The ability to include the loss of both the coarse solver and downsampling layer also caused a lower standard deviation and fewer outliers, since the mean is well above the median for NE2E-JNet3 compared to E2E-JNet3.
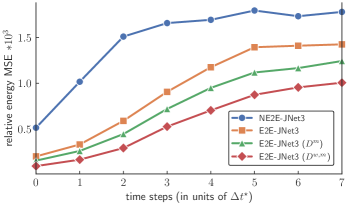
Multi-Step Training.
Introducing a multi-step training loss enhanced the benefits of an end-to-end architecture even further (cf. E2E-JNet3 () in Figure 3) without increasing the number of model parameters. Figure 4 depicts how all end-to-end models had a much lower relative energy MSE (cf. nguyen2022numerical ) increase particularly for the first three time steps on the test set. Hence, we conclude that connecting wave states to incorporate temporal propagation dynamics in the training data appears to be especially important for the early stages of wave advancements. Additionally, by taking fewer steps through sampling from a normal distribution that is being shifted along the x-axis (cf. E2E-JNet3 ()), we successfully avoid high performance fluctuations when the model is only partially trained. Figure 5 visualizes the correction of the low-fidelity solution of by E2E-JNet3 ().

Upsampling Architecture.
An overview of the upsampling architecture performances can be found in Table 1. As expected, the larger networks (E2E-Tira and E2E-Trans) performed slightly better compared to the 3-level JNet architecture, but for the ResNet architecture (E2E-JNet5), more weights did not increase accuracy by much. Consequently, we theorize that the ResNet design may be insufficient for capturing high-fidelity wave patterns, while especially highly-connected layers with an optimized feature and gradient flow (E2E-Tira) are better suited. Given that E2E-JNet3 () had only a slightly worse average energy MSE on the test set, we generally advise against using the expensive models in our setup.
| variant | number of parameters | GPU time (sec) | test energy MSE |
|---|---|---|---|
| - | 57.96749 | - | |
| E2E-V | - | 2.40421 | 0.07437 |
| E2E-JNet3 | 40,008 | 2.88331 | 0.02496 |
| E2E-JNet5 | 640,776 | 10.84893 | 0.02379 |
| E2E-Tira | 123,427 | 13.57449 | 0.01274 |
| E2E-Trans | 936,816 | 15.67633 | 0.01743 |
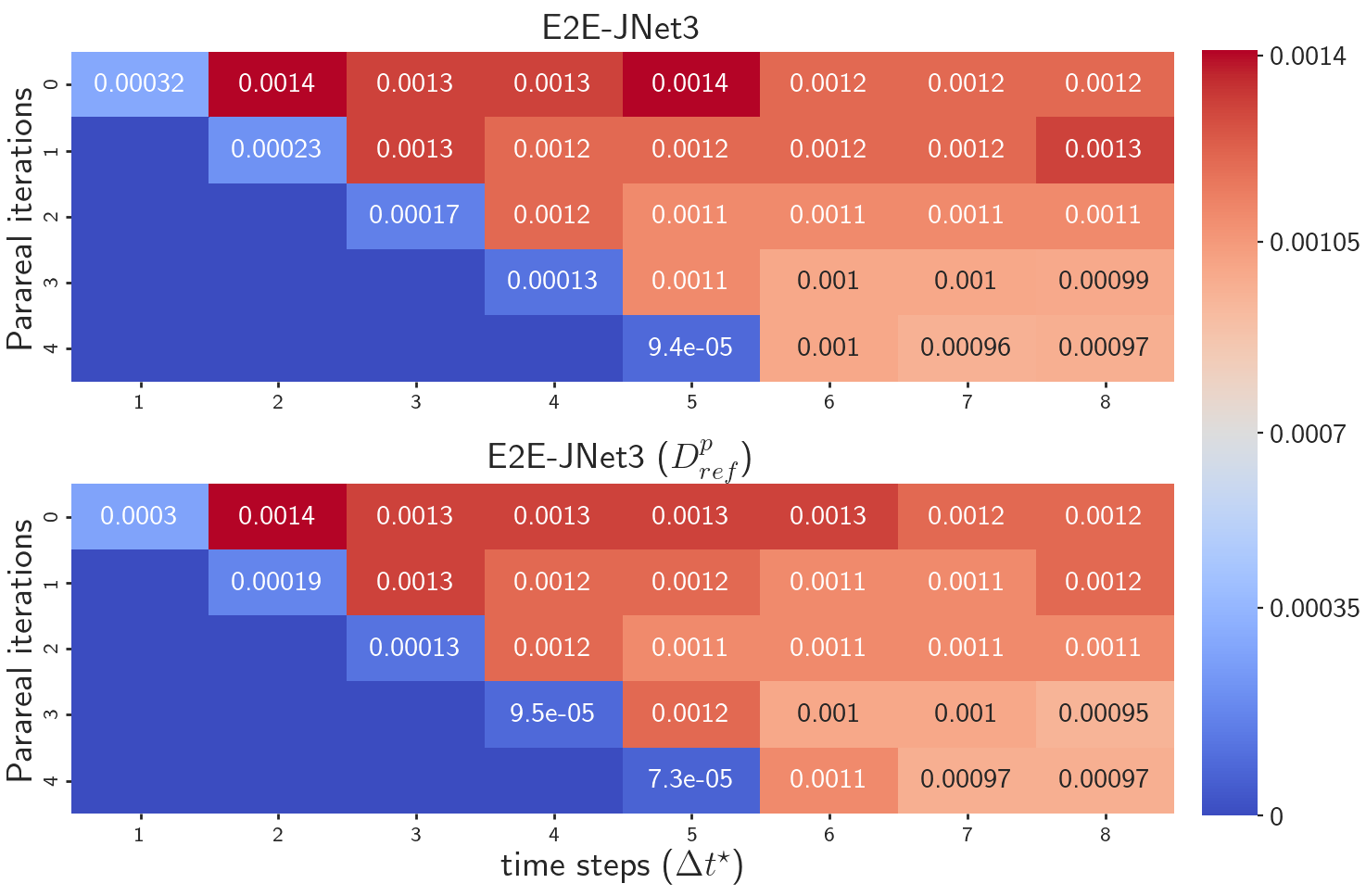
Parareal.
While models trained with have an unstable training progress and diverging loss, applying E2E-JNet3 () within the Parareal scheme showed better accuracy than E2E-JNet3 with Parareal (cf. Figure 6). As this training method improved the stability of Parareal, sampling the causality of concurrently solving multiple time intervals is an efficient enhancement to our end-to-end structure.
6 Conclusion
In this paper we enhanced the method proposed by Nguyen and Tsai nguyen2022numerical , and reported the results of a large-scale study on different variants that investigate the efficacy of these enhancements.
All end-to-end variants, including the variants with training modifications, outperformed the modular framework of nguyen2022numerical . In particular, the lightweight end-to-end 3-level JNet (E2E-JNet3) performed reasonably well given its low computation cost, and was further improved through a weighted, multi-step training scheme () to feature time-dependent wave dynamics without adding complexity to the model or substantially extending the training duration. Similarly, the Parareal iterations using the neural propagator trained by the Parareal-based data showed significant performance improvements over E2E-JNet3 without extensive additional computational cost due to parallelization.
As expected, certain expensive upsampling architectures, such as intensify the interconnections between feature and gradient flows (Tiramisu JNet), significantly increased the accuracy. However, the high computational demand makes its application mostly impractical in modern engineering workflows.
Acknowledgements.
Tsai is partially supported by National Science Foundation Grants DMS-2110895 and DMS-2208504. The authors also thank Texas Advanced Computing Center (TACC) for the computing resources.References
- (1) Moseley, B., Markham, A., Nissen-Meyer, T.: Solving the Wave Equation with Physics-Informed Deep Learning. ArXiv eprint:2006.11894 (2020)
- (2) Meng, X., Li, Z., Zhang, D., Karniadakis, G. E.: PPINN: Parareal Physics-Informed Neural Network for Time-Dependent PDEs. CMAME 370, (2020)
- (3) Kovachki, N., Li, Z., Liu, B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A., Anandkumar, A.: Neural Operator: Learning Maps between Function Spaces with Applications to PDEs. Journal of Machine Learning Research 24(89), pp. 1–97 (2023)
- (4) Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., Anandkumar, A.: Fourier Neural Operator for Parametric PDEs. ArXiv preprint:2010.08895 (2020)
- (5) Nguyen, H., Tsai, R.: Numerical Wave Propagation Aided by Deep Learning. Journal of Computational Physics 475, (2023)
- (6) Rizzuti, G., Siahkoohi, A., Herrmann, F. J: Learned Iterative Solvers for the Helmholtz Equation. 81st EAGE Conference and Exhibition, pp. 1–5 (2019)
- (7) Kochkov, D., Smith, J., Alieva, A., Wang, Q., Brenner, M., Hoyer, S.: Machine Learning–Accelerated Computational Fluid Dynamics.PNAS 118(21), pp. 89–97 (2021)
- (8) Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations. Journal of Computational Physics 378, pp. 686–707 (2019)
- (9) Ibrahim, A. Q., Götschel, S., Ruprecht, D.: Parareal with a Physics-Informed Neural Network as Coarse Propagator. ISBN: 978-3-031-39698-4, pp. 649–66 (2023)
- (10) Engquist, B., Majda, A.: Absorbing Boundary Conditions for Numerical Simulation of Waves. PNAS 74(5), pp. 1765–1766 (1977)
- (11) Runge, C.: Ueber die Numerische Aufloesung von Differentialgleichungen. Mathematische Annalen 46, pp. 167–-178 (1895)
- (12) Rocha, D., Sava, P.: Elastic Least-Squares Reverse Time Migration Using the Energy Norm. Geophysics 83(3), pp. 5MJ–Z13 (2018)
- (13) Jégou, S., Drozdzal, M., Vazquez, D., Romero, A., Bengio, Y.: The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1175–1183 (2017)
- (14) Petit, O., Thome, N., Rambour, C., Soler, L.: U-Net Transformer: Self and Cross Attention for Medical Image Segmentation. Machine Learning in Medical Imaging, Springer International Publishing, pp. 267–276 (2021)
- (15) Brougois, A., Bourget, M., Lailly, P., Poulet, M., Ricarte, P., Versteeg, R.: Marmousi, model and data. Conference: EAEG Workshop - Practical Aspects of Seismic Data Inversion (1990)
- (16) Billette, F., Brandsberg-Dahl, S.: The 2004 BP Velocity Benchmark. European Association of Geoscientists & Engineers (67th EAGE Conference & Exhibition) (2005)