Efficient Off-Policy Safe Reinforcement Learning
Using Trust Region Conditional Value at Risk
Abstract
This paper aims to solve a safe reinforcement learning (RL) problem with risk measure-based constraints. As risk measures, such as conditional value at risk (CVaR), focus on the tail distribution of cost signals, constraining risk measures can effectively prevent a failure in the worst case. An on-policy safe RL method, called TRC, deals with a CVaR-constrained RL problem using a trust region method and can generate policies with almost zero constraint violations with high returns. However, to achieve outstanding performance in complex environments and satisfy safety constraints quickly, RL methods are required to be sample efficient. To this end, we propose an off-policy safe RL method with CVaR constraints, called off-policy TRC. If off-policy data from replay buffers is directly used to train TRC, the estimation error caused by the distributional shift results in performance degradation. To resolve this issue, we propose novel surrogate functions, in which the effect of the distributional shift can be reduced, and introduce an adaptive trust-region constraint to ensure a policy not to deviate far from replay buffers. The proposed method has been evaluated in simulation and real-world environments and satisfied safety constraints within a few steps while achieving high returns even in complex robotic tasks.
Index Terms:
Reinforcement learning, robot safety, collision avoidance.I Introduction
Safe reinforcement learning (RL) addresses the problem of maximizing returns while satisfying safety constraints, so it has shown attractive results in a number of safety-critical robotic applications, such as locomotion for legged robots [1, 2] and safe robot navigation [3]. Traditional RL methods prevent agents from acting undesirably through reward shaping, which is known as a time-consuming and laborious task. In addition, the reward shaping can enlarge the optimality gap since reward shaping can be considered as fixing Lagrange multipliers in constrained optimization problems [4]. In contrast, safe RL methods [3, 5, 6, 7] can achieve better safety performance than traditional RL methods because they directly solve optimization problems with explicitly defined safety constraints.
Safety constraints can be defined by various types of measures about safety signals, and several literatures [8, 3, 7] have shown that risk measures such as conditional value at risk (CVaR) can effectively reduce the likelihood of constraint violations. Yang et al. [7] have proposed a CVaR-constrained RL method using a soft actor-critic (SAC) [9], called worst-case SAC (WCSAC). WCSAC utilizes aplenty of data from replay buffers to update a policy and deals with the constraint using the Lagrangian method. However, WCSAC generates an overly conservative policy if constraints are excessively violated during the early training phase due to Lagrange multipliers (see the experiment section in [3]). As several studies claim that the Lagrangian method makes training unstable [6, 10, 11], Kim and Oh [3] have proposed a trust region-based safe RL method for CVaR constraints called TRC, which shows the state-of-the-art performance in both simulations and sim-to-real experiments. However, since TRC can only use on-policy trajectories for policy improvements, it has low sample efficiency. Hence, there is a need for an efficient safe RL method which can take the advantage of the sample efficiency of off-policy algorithms.
In this paper, we propose a TRC-based off-policy safe RL method, called off-policy TRC. To update a policy using a trust-region method, including TRC, it is required to predict the constraint value of a random policy using collected data. However, if using off-policy data for on-policy algorithms, prediction errors can be increased due to the distributional shift, and trained policies can breach constraints as demonstrated in Section V-D. To leverage off-policy trajectories for TRC without the distributional shift, we formulate novel surrogate functions motivated by a TRPO-based method in [12]. Then, we show how the upper bound of CVaR with off-policy data from a replay buffer can be estimated using the proposed surrogate functions under the assumption that the cumulative safety signals follow the Gaussian distribution. Additionally, an adaptive trust-region constraint is derived, which indirectly lowers the estimation error by ensuring that the state distribution of the current policy does not deviate from the state distribution in the replay buffer. By iteratively maximizing the lower bound of the objective while constraining the upper bound of CVaR in the trust region, it is possible to ensure a monotonic improvement of the objective while satisfying the constraint. With various experiments in MuJoCo [13], Safety Gym [14], and real-robot environments, off-policy TRC shows excellent sample efficiency with high returns compared to previous methods.
Our main contributions are threefold. First, we formulate the surrogate functions which leverage off-policy trajectories, and derive the upper bound of CVaR using the surrogate functions under the Gaussian assumption. Second, we propose a practical algorithm for CVaR-constrained RL in off-policy manners with adaptive trust region, called off-policy TRC. Finally, off-policy TRC is evaluated in a number of experiments both in simulations and real environments and shows outstanding performance as well as the lowest total number of constraint violations while significantly improving sample efficiency.
II RELATED WORK
II-A Risk Measure-Constrained RL
Safe RL methods generally set safety constraints using the expectation of the cumulative costs. If expectation-based constraints are used, the Bellman operator for the traditional Markov decision process (MDP) can be applied to the safety critic, giving mathematical simplicity. However, since these constraints focus only on the average case, it is challenging to prevent failures which occurred in the worst case. For this reason, research on risk measure-based constraints is increasing to concentrate on the worst case. Kim and Oh [3] and Yang et al. [7] proposed methods constraining CVaR, which is a risk measure widely used in financial investment [15], and estimated the CVaR using distributional safety critics. Both methods resulted in fewer constraint violations than the expectation-constrained RL methods, and used the trust-region and Lagrangian methods to deal with constraints, respectively. Methods proposed by Ying et al. [16] and Chow et al. [8] also use the CVaR-based constraints but estimate CVaR using the sampling method proposed by Rockafellar et al. [15]. However, the estimation error can increase when the state space is high-dimensional because of the nature of sampling methods. Instead of CVaR, methods proposed by Thananjeyan et al. [17] and Bharadhwaj et al. [2] use chance constraints restricting the likelihood that the cumulative costs become above a specific value. These methods calculate the violation likelihood and correct the action to lower the likelihood at every environmental interaction, which can cause a longer action execution time.
II-B Off-Policy Safe RL
The usage of off-policy data not only improves the sample efficiency, but also reduces the optimality gap to reach higher final performance.111Since the MuJoCo tasks [13] are dominated by off-policy algorithms as shown in the benchmarks of the Spinning-Up from OpenAI [18], using off-policy data can reduce the optimality gap. Therefore, it is crucial to use off-policy data in safe RL to rapidly satisfy the constraints and maximize the return. Wang et al. [19] and Ha et al. [20] proposed safe RL methods based on the SAC method. These methods use off-policy data to estimate the safety critic and utilize the Lagrangian approach to reflect the expectation-based constraints. There is another method based on the Q-learning approach proposed by Huang et al. [21], which deals with the safe RL problem with multiple objectives. Liu et al. [10] transform the safe RL problem into a variational inference problem and proposes a new safe RL approach based on the expectation-maximization (EM) algorithm. This method uses off-policy data in the E-step to fit a non-parametric distribution, and updates a policy in the M-step by minimizing the distance between the policy and the non-parametric distribution.
II-C Other Safe RL
In addition to the methods mentioned above, there are various approaches to safe RL. First, there are Lyapunov-based methods to train a safe policy [22, 23]. They learn the Lyapunov function using auxiliary costs and update policies to satisfy the Lyapunov property. In [24, 25], control barrier functions are used to prevent agents from entering unsafe regions, and the control barrier functions can be constructed using trained transition models or prior knowledge of systems. Also, there are projection-based methods that handle constraints through a primal approach [6, 26]. They update policies to maximize the sum of reward and project the update direction to a safe policy set.
III BACKGROUND
III-A Safe Reinforcement Learning
We use constrained Markov decision processes (CMDPs) to define a safe reinforcement learning (RL) problem. A CMDP is defined with a state space , an action space , a transition model , an initial state distribution , a discount factor , a reward function , a cost function , and a safety measure . Given a policy , value and advantage functions are defined as follows:
| (1) | ||||
The cost value and advantage can be defined by replacing the reward with the cost in (1). Additionally, a discounted state distribution is defined as . For safety constraints, we introduce a notion called the cost return, which is used in [3, 7]:
| (2) |
where , , and . Then, we can define a safe RL problem as follows:
| (3) |
where is a limit value, and the objective function is denoted by .
III-B Conditional Value at Risk for Trust Region Method
Kim and Oh [3] proposed a trust region-base safe RL method for conditional value at risk (CVaR) constraints, called TRC. CVaR is one of the commonly used risk measures in financial risk management and formulated as follows [15]:
| (4) |
where is a clipping function that truncates values below zero. Because CVaR is calculated by conditional expectations above a certain level, it focuses on the worst case rather than the average case. Therefore, constraining CVaR is a compelling way to prevent a worst-case failure. By using CVaR for safety measures, TRC outperforms other expectation-constrained RL methods. To formulate CVaR constraints, the followings are defined in [3].
| (5) | ||||
where and are called cost square value and advantage, and expectations of the cost value and cost square value are denoted as and , respectively. Also, a doubly discounted state distribution is defined as . With state distributions, the expectations of the cost and cost square value can be expressed as follows [3]:
| (6) | ||||
Assuming that the cost return follows the Gaussian distribution as in [3, 7], CVaR can be expressed as follows:
| (7) |
where is a risk level for CVaR, and and are probability and cumulative density functions of the standard normal distribution, respectively.
III-C Off-Policy Trust Region Policy Optimization
Meng et al. [12] improved trust region policy optimization (TRPO) [27] using replay buffers and shown that monotonic improvement is guaranteed. The method proposed in [12], called off-policy TRPO, estimates an objective of a new policy using a surrogate function which can utilize a large number of data from replay buffers. The surrogate function is expressed as follows:
| (8) |
where is a behavioral policy and is a policy before being updated. The objective function of has a lower bound, which is derived using the surrogate function as follows:
| (9) |
where , is the total variation (TV) distance, and . By iteratively maximizing the lower bound of , off-policy TRPO can guarantee that the objective is monotonically improved [12]. However, the surrogate function (8) is only valid for expectation-based objectives, so there is a need to develop new surrogate functions for objectives and constraints if a different safety measure is considered.
IV PROPOSED METHOD
We aim to develop a CVaR-constrained RL method with high sample efficiency. Therefore, we propose a trust region-based method in an off-policy manner which optimizes the following problem:
| (10) |
where is a limit value. Since (10) is maximizing the reward return while limiting the CVaR of the cost return for the policy , it is necessary to estimate and using trajectories collected by a behavioral policy . Thus, we introduce surrogate functions for the constraint in (10) and approximate CVaR using the surrogate functions. In the rest of this section, we show that the approximation is bounded and finally describe the proposed algorithm.
IV-A Surrogate Functions
Calculating CVaR of a random policy using (7) requires trajectories sampled by , which is computationally expensive. Therefore, it is desirable to estimate CVaR using trajectories sampled from a behavioral policy and the current policy rather than calculate it directly. To estimate the CVaR constraint, two surrogate functions are proposed as follows:
| (11) | ||||
In (11), and can be calculated using (6) with trajectories sampled from , and the other terms can be calculated using trajectories from . Using the proposed surrogate functions and (7), CVaR of a random policy can be approximated as follows:
| (12) |
The next section shows that the difference between the above approximation and the true value of CVaR is bounded.
IV-B Upper Bound
Before showing the upper bound of CVaR, the following notations are introduced for brevity:
| (13) | ||||
Then, the upper bound of can be derived as follows.
Theorem 1.
For any polices , , and , define
.
Then, the following inequality holds:
| (14) | ||||
where the equality holds when .
The proof is given in Appendix -B. Theorem 1 shows that approximates well enough when and are close to each other since becomes sufficiently small. In addition, as shown in the definition, is highly correlated to and , and they become larger when the state change according to actions is huge. Therefore, it is possible to decrease by designing an RL environment with a shorter time interval.
IV-C Off-Policy TRC
Directly calculating the objective and constraints of a random policy through sampling is computationally expensive, so we utilize their bounds to get the policy gradient efficiently. Using the upper bound of CVaR derived in Theorem 1 and the lower bound of the objective in (9), we can build a subproblem to obtain a new policy given an old policy and a behavioral policy as follows:
| (15) | ||||
However, the TV distances in the subproblem hinder training policies with large update steps, which is an issue raised in several trust region-related literature [12, 5, 27]. Thus, we remove the TV distances from (15) and add a trust region constraint as done in [12, 3, 27] to enlarge update steps. For the trust region constraint, we convert the TV distances into KL divergences using the Pinsker’s inequality and formulate the constraint as follows:
| (16) |
where , , and is a constant for the trust region size. The derivation is presented in Appendix -C. When the KL divergence between and is large enough, becomes nearly zero, so the trust region constraint ensures that the policy is updated not far from the replay buffer. Hence, the subproblem (15) can be reformulated as follows:
| (17) | ||||
The subproblem (17) is nonconvex, so we approximate the objective and the CVaR constraint as linear and the trust region as quadratic, and obtain using linear and quadratic constrained linear programming (LQCLP) as in [3, 5]. If the feasibility set of (17) is empty, we solely minimize the approximated CVaR under the trust region constraint.
To update the value and cost value networks, we use the following retrace estimators as target values [12, 28].
| (18) | ||||
where , , , and is a trace-decay value. The retrace estimator for the cost square value can also be defined as follows.
| (19) | ||||
Then, the value, cost value, and cost square networks are updated by minimizing the mean squared error between the target values. The overall process of off-policy TRC is summarized in Algorithm 1.
V EXPERIMENTS
We aim to answer the following questions through experiments: 1) Does off-policy TRC provide better performance and higher sample efficiency than other safe RL methods? 2) Can it be applied to robots with different dynamics? 3) Are the newly defined surrogate functions valid for off-policy data? To answer these questions, we set up simulations and sim-to-real experiments with various types of robots and use several safe RL baseline methods. Next, the effectiveness of the surrogate function is evaluated by comparing off-policy TRC with a variant of TRC, which considers off-policy data as on-policy data. In addition, experiments are also performed on different settings of the replay buffer-related hyperparameters to examine the effect of off-policy data on training.
V-A Simulation Setup
V-A1 MuJoCo
For robotic locomotion tasks, we use HalfCheetah-v2 and Walker2d-v2 provided by the MuJoCo simulator [13]. For stable movement in HalfCheetah-v2, the following cost function, which penalizes the agent if the angle of the torso is above a specific value, is defined.
| (20) |
where is the angle of the torso, and () and () are constants. In Walker2d-v2, to make the height of the center of mass away from the ground, the following cost function is defined.
| (21) |
where is the height of the center of mass, and , and . In the both tasks, agents are trained without early termination.
V-A2 Safety Gym
The Safety Gym [14] provides multiple robots and tasks for safe RL, and we use the following tasks: Safexp-PointGoal1-v0, Safexp-CarGoal1-v0, and Safexp-DoggoGoal1-v0 with two modifications. The goal information is provided in a LIDAR form in the original state, which is not a realistic setting, so we modify the state to include the goal position. Additionally, instead of providing a binary cost signal indicating whether the robot is in a hazard area or not, we use a soft cost signal which is defined by replacing in (21) with the minimum distance to obstacles (, ). The other settings including the reward function are the same as the original.

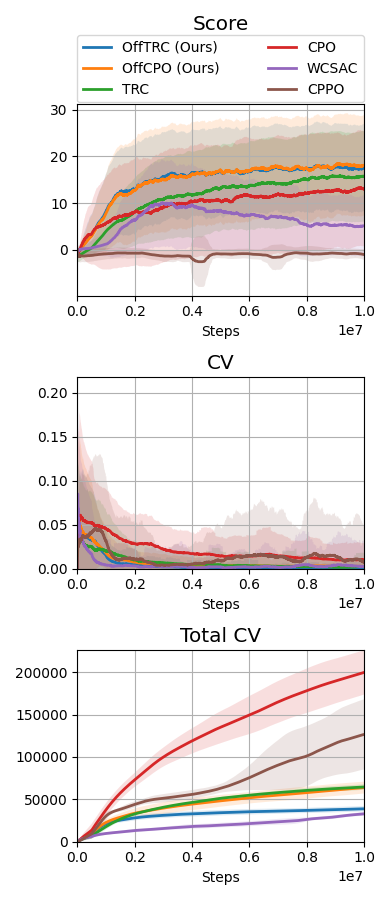
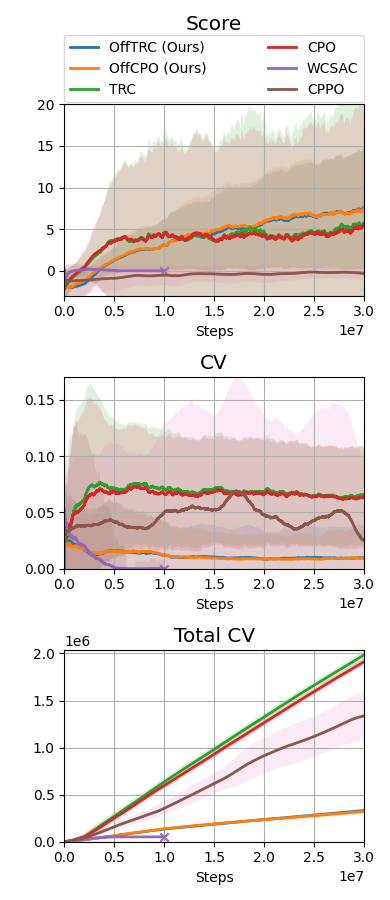
V-B Sim-to-Real Experiment Setup
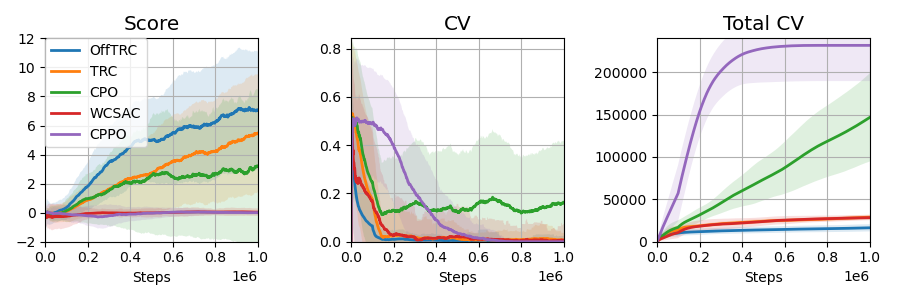
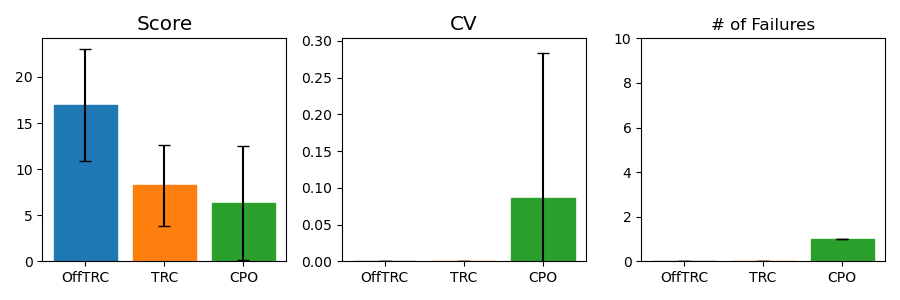
To verify that off-policy TRC is applicable to real robots, we conduct a sim-to-real experiment on a UGV robot, Jackal from Clearpath [29], shown in Fig. 1a. Agents are first trained in a MuJoCo simulator, where the state space is a 32-dimensional space consisting of LIDAR values, linear and angular velocities of the robot, and the goal position, and the action space is a two-dimensional space consisting of the linear acceleration and angular velocity. Eight obstacles are spawned at random positions in the beginning of each episode, and the reward and cost function are the same as the Safety Gym. Once trained in simulation, agents are evaluated in the real world without additional training on a task shown in Fig. 1b, where goals are spawned sequentially. If the agent gets closer than to obstacles, a failure occurs and the episode ends.
In all tasks, the number of constraint violations (CVs) is counted when , and the following score metric is used as in [3].222The score metric is defined by reward sum divided by the number of CVs. Since the reward sum increases as safety is ignored, this metric is used for fair comparisons.
| (22) |
The policy and all value functions are modeled by neural networks with two hidden layers of 512 nodes, and the activation functions are ReLU. The learning rate for all value networks is and for the trust region is . We update networks at every collect steps () using trajectories of length () sampled from the replay buffer of length (). Exceptionally, we set and for the MuJoCo and doggo goal tasks. For constraints, we use for CVaR as or and as .333 To give a tip for how to set and , if you want the agent to violate safety less than times out of interaction steps with probability, set as and as , where .
V-C Comparison with Baselines
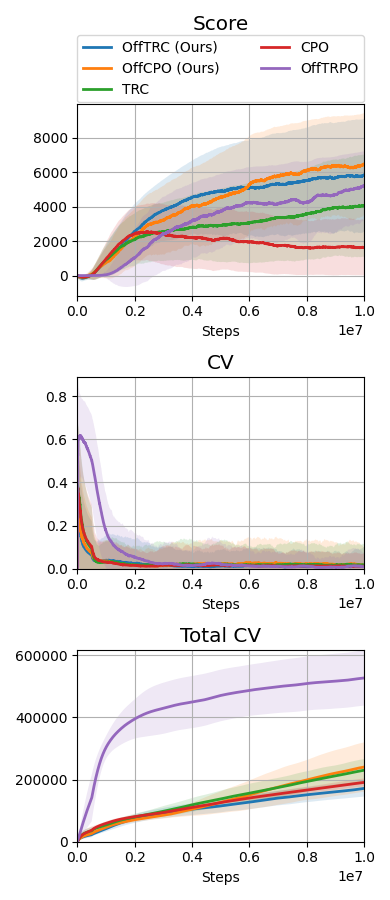
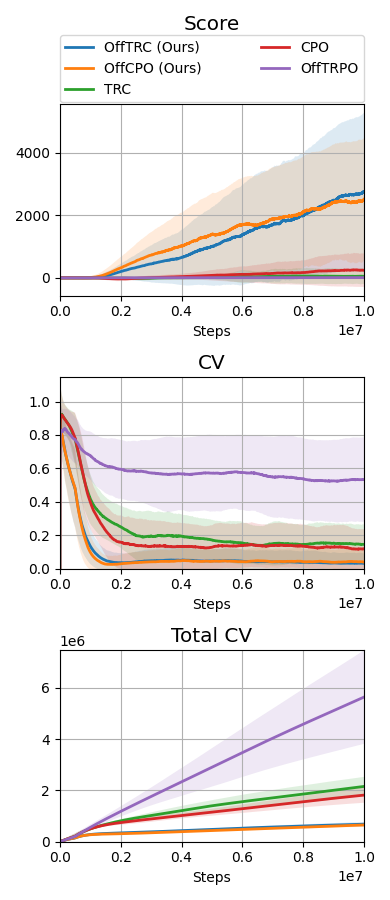
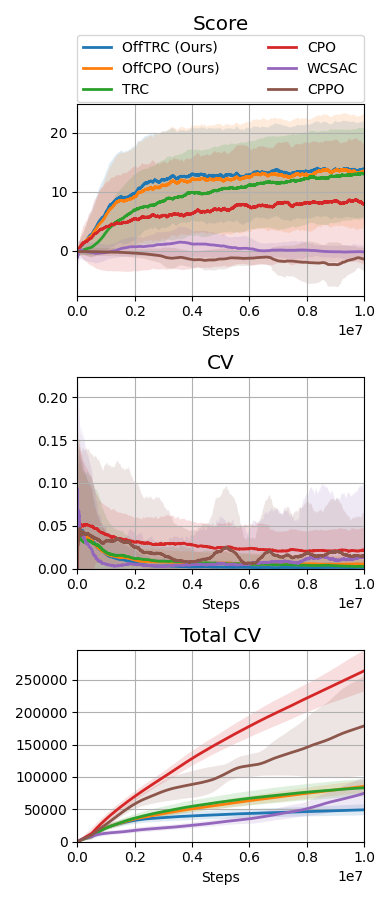
Throughout the experiments, we evaluate the proposed method, off-policy TRC, with , indicated as OffTRC, and with , indicated as OffCPO. If , off-policy TRC becomes the off-policy version of constrained policy optimization (CPO) [5], as the CVaR becomes an expectation if . In the MuJoCo experiment, to show the sample efficiency, the off-policy TRC is compared to other trust region-based methods: CPO [5] and TRC [3]. In addition, to check how the constraints defined in (20) and (21) have an effect on the locomotion tasks, the traditional RL method, off-policy trust region policy optimization (OffTRPO) [12] is also used. For the Safety Gym and the sim-to-real experiments, we use the following risk measure-constrained RL methods as baselines: CVaR-proximal policy optimization (CPPO) [16], WCSAC [7], and TRC [3]. CPPO estimates CVaR from sampling, while WCSAC and TRC estimate CVaR using distributional safety critics. To compare with expectation-based safe RL methods, CPO is also used as a baseline.
The MuJoCo and Safety Gym simulation results are shown in Fig. 2, and the Jackal simulation and real-world evaluation results are shown in Fig. 3. WCSAC and CPPO are excluded from the real-world evaluation because the agents trained by them do not move but freeze at initial positions in the Jackal simulation. In all tasks, including the real-world experiment, the proposed methods, which are OffTRC and OffCPO, show the highest scores and the lowest total number of CVs. OffTRC and OffCPO show the similar level in scores, but OffTRC shows lower total numbers of CVs than OffCPO in half-cheetah, point goal, and car goal tasks. In the walker and doggo tasks, it is difficult to satisfy the constraints due to the unstable dynamics, so the number of CVs of OffTRC and OffCPO are similar. However, OffCPO scores higher than OffTRC in the half-cheetah task, which means that the CVaR constraints make it difficult to learn tasks with stable dynamics. Observing that the scores increase the fastest and the total number of CVs are significantly low, the proposed methods show excellent sample efficiency by simultaneously increasing the return while satisfying the safety constraints. OffTRPO results in the third highest score in the half-cheetah task, showing that the number of CVs converges to zero. As the dynamics model of the half-cheetah is stable, OffTRPO can train policies well without any constraints. Nevertheless, OffTRPO shows the worst performance in the walker-2d task, inferring that restricting the height of CoM helps training. CPO shows the third-highest score in the walker-2d, but there is a significant score gap between off-policy TRC and CPO, which indicates that sample efficiency is essential to achieve outstanding performance. Additionally, CPO shows excessive numbers of CVs in all other tasks and records a failure in the real-world evaluation, as shown in Fig. 3b. It means that risk measure-constrained RL methods rather than expectation-constrained RL methods are required to prevent failures. TRC shows the third-best performance for all tasks except the MuJoCo tasks. Because TRC is an on-policy RL algorithm, it is difficult to train complex robots such as multi-joint robots, since these robotic tasks require large quantities of training data. Still, as TRC is a trust-region-based safe RL method, it shows monotonic performance improvement and low CVs. WCSAC uses the Lagrangian method to handle the CVaR constraint and is one of the off-policy RL methods, so it can be expected to show high sample efficiency. However, WCSAC shows low scores in all tasks and synthesizes immobile policies in the doggo and Jackal tasks because the Lagrangian method makes training unstable. CPPO is also one of the CVaR-constrained RL method and estimate CVaR using a sampling method. However, CPPO suffers performance degradation because it uses a sampling-based estimation for CVaR with large variances and the Lagrangian approach to handle the constraints.
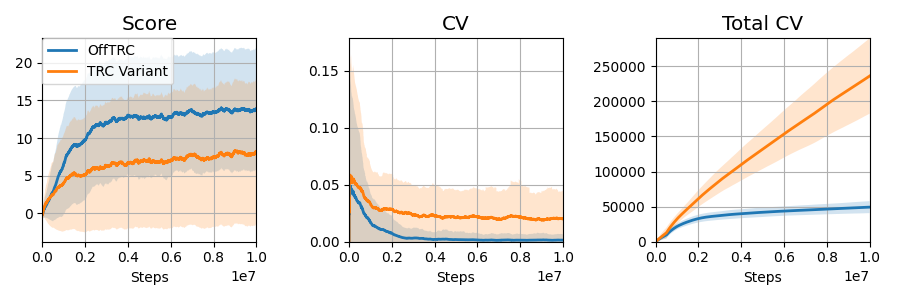
V-D Effectiveness of Surrogate Functions
To show that the proposed surrogate functions (11) are effective for off-policy data, we perform an experiment comparing a variant of TRC against off-policy TRC. The TRC variant treats off-policy data as on-policy data and updates the policy via the TRC method. The result is presented in Fig. 4. In the training curve, the CVs of the variant are high relative to the off-policy TRC, which can be considered estimation errors due to the distributional shift in the training data. Hence, we can conclude that the CVaR estimation through the proposed surrogate functions (11) is critical for utilizing off-policy data.
V-E Ablation Study
Since the off-policy TRC uses off-policy data from a replay buffer, it is required to analyze how the parameters related to the replay buffer affect learning. The replay buffer-related parameters are the batch size (the length of sampled trajectories for policy update), the length of the replay buffer, and the collect steps (the policy is updated for each collect step). We train the off-policy TRC on the point goal task for each parameter with three different values, and the results are shown in Table I. The parameter with the greatest influence on training is the batch size. The larger the batch size, the lower the total number of CVs. As the batch size increases, the search direction for policy update becomes accurate, so the agent can effectively lower the constraint value at the early training phase. Next, the collect steps affect the length of on-policy data and the number of policy updates. Since on-policy data is used to calculate and , constituting the approximated CVaR , the approximation error increases as the amount of on-policy data decreases. Thus, the larger the collect steps, the lower the total number of CVs, but also the lower the reward sum, as shown in Table I. Lastly, while the length of the replay buffer has a little effect on performance, if it is too short, the total number of CVs can increase slightly.
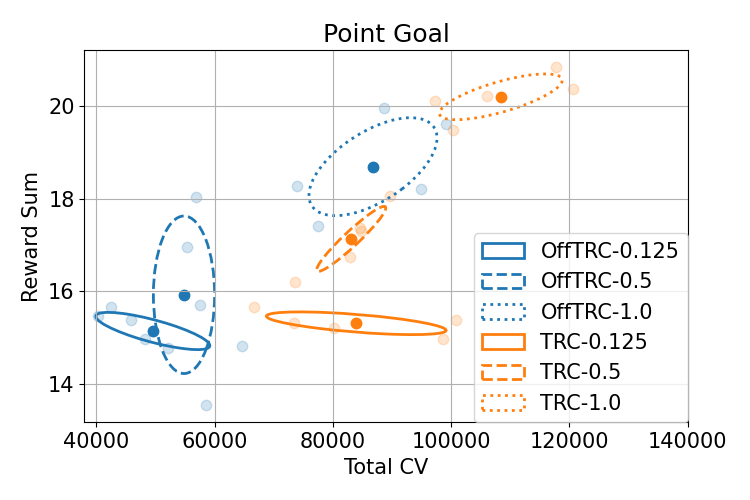
To give an intuition for the risk level , experiments with different risk levels for TRC and off-policy TRC are also conducted, and the result is shown in Fig. 5. Observing that policies with high-risk levels are located in the upper right corner of the figure, a high return but risky policy can be obtained with a high-risk level.
| Reward Sum | CV (mean, std) | Total CV | ||
|---|---|---|---|---|
| Batch size | 2e3 | 17.073 | 0.0024, 0.0067 | 85211 |
| 5e3 | 14.616 | 0.0007, 0.0035 | 45238 | |
| 1e4 | 14.550 | 0.0007, 0.0037 | 27951 | |
| Collect steps | 5e2 | 15.270 | 0.0016, 0.0058 | 42945 |
| 1e3 | 14.616 | 0.0007, 0.0035 | 45238 | |
| 2e3 | 13.872 | 0.0006, 0.0041 | 39407 | |
| Replay length | 2e4 | 14.934 | 0.0017, 0.0061 | 52788 |
| 5e4 | 14.616 | 0.0007, 0.0035 | 45238 | |
| 1e5 | 15.072 | 0.0008, 0.0047 | 45731 | |
VI CONCLUSIONS
In this paper, a sample efficient off-policy safe RL algorithm using trust region CVaR, called off-policy TRC, is presented. We have proposed novel surrogate functions such that the CVaR constraint can be estimated using off-policy data without the distributional shift, as shown in Section V-D. In simulation and real-world experiments, the proposed off-policy TRC has achieved the highest returns with the lowest number of constraint violations in all tasks, showing its high sample efficiency.
In this section, we assume that the state space and action space are finite spaces. Thus, , , and are treated as vectors in .
-A Preliminary
Lemma 1.
Given stochastic policies , and a behavior policy , the following inequality holds:
| (23) |
where .
Proof.
For any function , let define the following variable:
Then, the following equation holds by Corollary 1 in [3]:
By substituting with ,
∎
-B Proof of Theorem 1
-C Trust Region Constraint
By Pinsker’s inequality, the following inequality holds:
From Appendix B in [12], the following inequality also holds:
Then, the trust region constraint can be expressed as:
| (27) | ||||
As the maximum operation is difficult to implement in continuous state space settings, we replace it with expectation on trajectories sampled by as follows:
| (28) |
The square root operation on can lead to infinite value and increase nonlinearity while computing gradients. Thus, by rearranging (28), we remove the square root on .
| (29) | ||||
References
- [1] S. Gangapurwala, A. Mitchell, and I. Havoutis, “Guided constrained policy optimization for dynamic quadrupedal robot locomotion,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3642–3649, 2020.
- [2] H. Bharadhwaj, A. Kumar, N. Rhinehart, S. Levine, F. Shkurti, and A. Garg, “Conservative safety critics for exploration,” in International Conference on Learning Representations, 2021.
- [3] D. Kim and S. Oh, “TRC: Trust region conditional value at risk for safe reinforcement learning,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2621–2628, Apr. 2022.
- [4] C. Tessler, D. J. Mankowitz, and S. Mannor, “Reward constrained policy optimization,” in International Conference on Learning Representations, 2019.
- [5] J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” in International Conference on Machine Learning. PMLR, 2017, pp. 22–31.
- [6] T. Xu, Y. Liang, and G. Lan, “CRPO: A new approach for safe reinforcement learning with convergence guarantee,” in International Conference on Machine Learning. PMLR, 18–24 Jul 2021, pp. 11 480–11 491.
- [7] Q. Yang, T. D. Simão, S. H. Tindemans, and M. T. Spaan, “WCSAC: Worst-case soft actor critic for safety-constrained reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 10 639–10 646.
- [8] L. Janson, M. Pavone, M. Ghavamzadeh, and Y. Chow, “Risk-constrained reinforcement learning with percentile risk criteria,” JMLR, vol. 18, pp. 1–51, 2017.
- [9] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft Actor-Critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in Proc. of the 35th International Conference on Machine Learning, vol. 80. PMLR, 10–15 Jul 2018, pp. 1861–1870.
- [10] Z. Liu, Z. Cen, V. Isenbaev, W. Liu, Z. S. Wu, B. Li, and D. Zhao, “Constrained variational policy optimization for safe reinforcement learning,” CoRR, vol. abs/2201.11927, 2022.
- [11] Y. Zhang, Q. Vuong, and K. Ross, “First order constrained optimization in policy space,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 15 338–15 349.
- [12] W. Meng, Q. Zheng, Y. Shi, and G. Pan, “An off-policy trust region policy optimization method with monotonic improvement guarantee for deep reinforcement learning,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2021.
- [13] E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012, pp. 5026–5033.
- [14] S. Fujimoto, E. Conti, M. Ghavamzadeh, and J. Pineau, “Benchmarking batch deep reinforcement learning algorithms,” CoRR, vol. abs/1910.01708, 2019.
- [15] R. T. Rockafellar, S. Uryasev et al., “Optimization of conditional value-at-risk,” Journal of risk, vol. 2, pp. 21–42, 2000.
- [16] C. Ying, X. Zhou, D. Yan, and J. Zhu, “Towards safe reinforcement learning via constraining conditional value at risk,” in ICML 2021 Workshop on Adversarial Machine Learning, 2021.
- [17] B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, and K. Goldberg, “Recovery rl: Safe reinforcement learning with learned recovery zones,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4915–4922, 2021.
- [18] J. Achiam, “Spinning up in deep rl,” https://openai.com/blog/spinning-up-in-deep-rl/, November 2018.
- [19] W. Wang, N. Yu, Y. Gao, and J. Shi, “Safe off-policy deep reinforcement learning algorithm for volt-var control in power distribution systems,” IEEE Transactions on Smart Grid, vol. 11, no. 4, pp. 3008–3018, 2020.
- [20] S. Ha, P. Xu, Z. Tan, S. Levine, and J. Tan, “Learning to walk in the real world with minimal human effort,” in Proceedings of the 2020 Conference on Robot Learning, ser. Proceedings of Machine Learning Research, vol. 155. PMLR, 16–18 Nov 2021, pp. 1110–1120.
- [21] S. Huang, A. Abdolmaleki, G. Vezzani, P. Brakel, D. J. Mankowitz, M. Neunert, S. Bohez, Y. Tassa, N. Heess, M. Riedmiller, and R. Hadsell, “A constrained multi-objective reinforcement learning framework,” in Proc. of the 5th Conference on Robot Learning, vol. 164. PMLR, 08–11 Nov 2022, pp. 883–893.
- [22] Y. Chow, O. Nachum, E. A. Duéñez-Guzmán, and M. Ghavamzadeh, “A lyapunov-based approach to safe reinforcement learning,” in NeurIPS, 2018, pp. 8103–8112.
- [23] H. Sikchi, W. Zhou, and D. Held, “Lyapunov barrier policy optimization,” CoRR, vol. abs/2103.09230, 2021.
- [24] W. Zhao, T. He, and C. Liu, “Model-free safe control for zero-violation reinforcement learning,” in 5th Annual Conference on Robot Learning, 2021.
- [25] Y. Luo and T. Ma, “Learning barrier certificates: Towards safe reinforcement learning with zero training-time violations,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 25 621–25 632.
- [26] T.-Y. Yang, J. Rosca, K. Narasimhan, and P. J. Ramadge, “Projection-based constrained policy optimization,” in International Conference on Learning Representations, 2020.
- [27] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” in International conference on machine learning. PMLR, 2015, pp. 1889–1897.
- [28] Z. Wang, V. Bapst, N. Heess, V. Mnih, R. Munos, K. Kavukcuoglu, and N. de Freitas, “Sample efficient actor-critic with experience replay,” in 5th International Conference on Learning Representations, 2017.
- [29] C. R. Inc., “Jackal ugv - small weatherproof robot,” https://clearpathrobotics.com/jackal-small-unmanned-ground-vehicle/, September 2015.