Efficient Personalized Text-to-image Generation by Leveraging Textual Subspace
Abstract
Personalized text-to-image generation has attracted unprecedented attention in the recent few years due to its unique capability of generating highly-personalized images via using the input concept dataset and novel textual prompt. However, previous methods solely focus on the performance of the reconstruction task, degrading its ability to combine with different textual prompt. Besides, optimizing in the high-dimensional embedding space usually leads to unnecessary time-consuming training process and slow convergence. To address these issues, we propose an efficient method to explore the target embedding in a textual subspace, drawing inspiration from the self-expressiveness property. Additionally, we propose an efficient selection strategy for determining the basis vectors of the textual subspace. The experimental evaluations demonstrate that the learned embedding can not only faithfully reconstruct input image, but also significantly improves its alignment with novel input textual prompt. Furthermore, we observe that optimizing in the textual subspace leads to an significant improvement of the robustness to the initial word, relaxing the constraint that requires users to input the most relevant initial word. Our method opens the door to more efficient representation learning for personalized text-to-image generation.
1 Introduction
An important human ability is to abstract multiple visible concepts and naturally integrate them with known visual content using a powerful imagination (Ding et al., 2022; Li et al., 2022; Zhou et al., 2022; Gao et al., 2021; Skantze & Willemsen, 2022; Kumar et al., 2022; Cohen et al., 2022). Recently, a method for rapid personalized generation using pre-trained text-to-image model has been attracting public attention (Gal et al., 2022; Ruiz et al., 2022; Kumari et al., 2022). It allows users to represent the input image as a “concept” by parameterizing a word embedding or fine-tuning the parameters of the pre-trained model and combining it with other texts. The idea of parameterizing a “concept” not only allows the model to reconstruct the training data faithfully, but also facilitates a large number of applications of personalized generation, such as text-guided synthesis (Rombach et al., 2022b), style transfer (Zhang et al., 2022), object composition (Liu et al., 2022), etc.
As the use of personalized generation becomes more widespread, a number of issues have arisen that need to be addressed. The problems are two-fold: first, previous methods such as Textual Inversion (Gal et al., 2022) choose to optimize directly in high-dimensional embedding space, which leads to inefficient and time-consuming optimization process. Second, previous methods only target the reconstruction of input images, degrading the ability to combine the learned embedding with different textual prompt, which makes it difficult for users to use the input prompt to guide the pre-trained model for controllable generation. A natural idea is to optimize in a subspace with high text similarity111As stated in (Gal et al., 2022), high text similarity indicates that encoding the embedding into the pre-trained model is more likely to generate the corresponding images (e.g., input the embedding of the word “cat” will output a photo of cat), which is usually measured by the cosine similarity between the image and text features transformed by the CLIP model (Hessel et al., 2021)., so as to ensure that the learned embedding can be flexibly combined with textual prompt. Meanwhile, optimizing in the low-dimensional space can also improve training efficiency and speed up convergence. However, existing methods directly used gradient backpropagation to optimize the embedding (Gal et al., 2022), making it difficult to explicitly constrain the embedding to a specific subspace for each dataset.
In order to bypass this difficulty, we drew inspiration from the self-expressiveness property222Each data point in a union of subspaces can be efficiently reconstructed by a combination of other points in the dataset. (Elhamifar & Vidal, 2013), which led us to the realization that any target embedding can be reconstructed by the combination of other pre-trained embeddings in the vocabulary provided by text-to-image models, where and is the number of elements in . Once such embeddings are obtained, we can construct a subspace by spanning them, i.e., . Subsequently, we can conduct an efficient optimization in a low-dimensional space . Specifically, we explicitly select a number of semantically relevant embeddings from the vocabulary as , and then we form a semantically meaningful subspace . To achieve semantically relevant embeddings, we introduce a rank-based selection strategy that uses the nearest neighbour algorithm. This strategy efficiently selects that are semantically close to the input concept, which allows the embeddings learned by our method to be naturally combined with other texts.
To this end, we proposed a method BaTex, which can efficiently learn arbitrary embedding in a textual subspace333Subspace with high text similarity.. Comparing with existing methods like such as Textual Inversion (Gal et al., 2022), the proposed BaTex do not require to search solutions in the entire high-dimensional embedding space, and thus it can improve training efficiency and speed up convergence. The schematic diagram is shown in Figure 1, where BaTex optimizes in a low-dimensional space (shown in red dashed area), which requires fewer training steps and achieves higher text similarity.
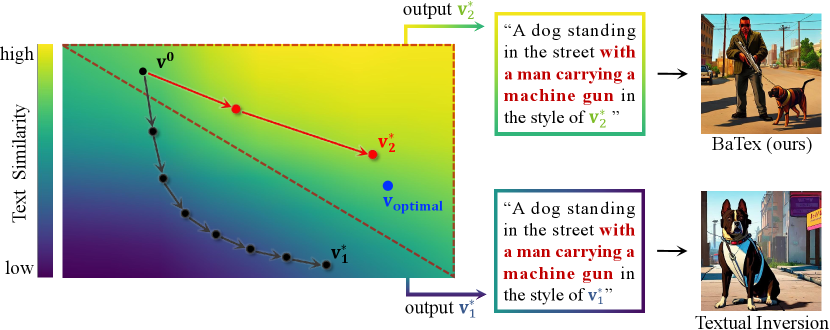
We have experimentally demonstrated the expressiveness and efficiency of the proposed BaTex across multiple object and style concepts. BaTex completely avoids the overfitting issues observed in some previous methods (Ruiz et al., 2022; Kumari et al., 2022). In addition, it has the potential to integrate with more advanced and expressive large-scale text-to-image models such as Stable-Diffusion-2444https://huggingface.co/stabilityai/stable-diffusion-2. By efficiently exploring the embedding in a textual subspace, our method opens the door to further advancements in efficient personalized text-to-image generation. We summarize the main contributions as follows:
-
•
We propose a novel method BaTex for learning arbitrary embedding in a low-dimentional textual subspace, which is time-efficient and better preserves the text similarity of the learned embedding.
-
•
On the theoretical side, we demonstrate that the selected basis embedding can be combined to produce arbitrary embedding. Also, we derive that the proposed method is equivalent to applying a projection matrix to the update of embedding of Textual Inversion.
-
•
We experimentally demonstrate that the learned embeddings can not only faithfully reconstruct the input image, but also significantly improve its alignment with different textual prompt. In addition, the robustness against initial word has been improved, relaxing the constraint that requires users to input the most relevant word as initialization.
2 Background and Related Work
In this section, we give the background and related work about deep generative models and its extensions. We first introduce the diffusion models, a class of deep generative models, then we briefly discuss text-to-image synthesis and personalized generation.
2.1 Diffusion Models
The goal of deep generative models, such as Flow-based Models (Dinh et al., 2016; Du et al., 2022), VAE (Burgess et al., 2018), GAN (Goodfellow et al., 2020) and Diffusion Models (Dhariwal & Nichol, 2021), is to approximate an unknown data distribution by explicitly or implicitly parameterizing a model distribution using the training data.
As a class of deep generative models which has been shown to produce high-quality images, Diffusion Models (Dhariwal & Nichol, 2021; Ho et al., 2020; Nichol & Dhariwal, 2021; Song et al., 2020) synthesize data via an iterative denoising process. As suggested in (Ho et al., 2020), a reweighted variational bound can be utilized as a simplified training objective and the sampling process aims to predict the corresponding noise added in forward process. The denoising objective is finally realized as a mean squared error:
| (1) |
where are training data with conditions , , is the gaussian noise sampled in the forward process, are pre-defined scalar functions of time step , is the parameterized reverse process with trainable parameter .
Recently, an introduced class of Diffusion Models named Latent Diffusion Models (Rombach et al., 2022a) raises the interest of the community, which leverages a pre-trained autoencoder to map the images from pixel space to a more efficient latent space that significantly accelerates training and reduces the memory. Latent Diffusion Models consist of two core models. Firstly, a pre-trained autoencoder is extracted, which consists of an encoder and a decoder . The encoder maps the images into a latent code in a low-dimensional latent space. The decoder learns to map it back to the pixel space, such that . Secondly, a diffusion model is trained on this latent space. The denoising objective now becomes
| (2) |
where is the latent code encoded by the pre-trained encoder .
For conditional synthesis, in order to improve sample quality while reducing diversity, classifier guidance (Dhariwal & Nichol, 2021) is proposed to use gradients from a pre-trained model , where . Classifier-free guidance (Ho & Salimans, 2022) is an alternative approach that avoids this pre-trained model by instead jointly training a single diffusion model on conditional and unconditional objectives via randomly dropping during training with probability , where is the guidance scale offering a tradeoff between sample quality and diversity. The modified predictive model is shown as follows: , where “ ” is the embedding of a null text and is the pre-trained text encoder such as BERT (Devlin et al., 2018) and CLIP (Radford et al., 2021).
2.2 Text-to-Image Synthesis
Recent large-scale text-to-image models such as Stable-Diffusion (Rombach et al., 2022a), GLIDE (Nichol et al., 2021) and Imagen (Saharia et al., 2022) have demonstrated unprecedented semantic generation. We implement our method based on Stable-Diffusion, which is a publicly available 1.4 billion parameters text-to-image diffusion model pre-trained on the LAION-400M dataset (Schuhmann et al., 2021). Here is the processed text condition.
Typical text encoder models include three steps to process the input text. Firstly, a textual prompt is input by the users and split by a tokenizer to transform each word or sub-word into a token, which is an index in a pre-defined language vocabulary. Secondly, each token is mapped to a unique text embedding vector, which can be retrieved through an index-based lookup (Gal et al., 2022). The embedding vector is then concatenated and transformed by the CLIP text encoder to obtain the text condition .
2.3 Personalized Generation
As the demand for personalized generation continues to grow, personalized generation has become a prominent factor in the field of machine learning, such as recommendation systems (Amat et al., 2018) and language models (Cattiau, 2022). Within the vision community, adapting models to a specific object or style is gradually becoming a target of interest. Users often wish to input personalized real images to parameterize a “concept” from them and combine it with large amounts of textual prompt to create new combination of images.
A recent proposed method Textual Inversion (Gal et al., 2022) choose the text embedding space as the location of the “concept”. It intervenes in the embedding process and uses a learned embedding to represent the concept, in essence “injecting” the concept into the language vocabulary. Specifically, it defines a placeholder string (such as “A photo of ”) as the textual prompt, where “” is the pseudo-word corresponding to the target embedding it wishes to learn. The embedding matrix can be obtained by concatenating with other frozen embeddings (such as the corresponding embeddings of “a”, “photo” and “of” in the example), where is the number of words in the placeholder string555In practice, the embedding matrix where is the pre-defined maximum number of words in a sentence and other words are filled with terminator. For clarity of expression, we only consider the words with practical meaning in the main text. and is the dimension of the embedding space. The above process is defined as (Gal et al., 2022): .
The optimization goal is defined as: , where , and are defined in Equation (1) and (2). Please note that is a function of . Although Textual Inversion can extract a single concept formed by images and reconstruct it faithfully, it can not be combined with textual prompt flexibly since it solely considers the performance of the reconstruction task during optimization. Also, it searches the target embedding in the high-dimensional embedding space, which is time-consuming and difficult to converge.
To address the issues above, we observe that the pre-trained embeddings in the vocabulary is expressive enough to represent any introduced concept. Therefore, we explicitly define a projection matrix to efficiently optimize the target embedding in a low-dimensional tetxual subspace, which speeds up convergence and better preserves the text similarity of the learned embedding.
3 The Proposed BaTex Method
In this section, we introduce the proposed BaTex method. Following the definition of Stable Diffusion (Rombach et al., 2022a), is the word embedding space with dimension and is the word vocabulary defined by the CLIP text model (Radford et al., 2021). The words in vocabulary corresponds to a set of pre-trained vectors , where is the cardinality of set .
3.1 Optimization Problem
We first state that any vector in the embedding space can be represented by the embeddings in the vocabulary , as shown in the following theorem whose proof can be found in Appendix B.
Theorem 1
Any vector in word embedding space can be represented by a linear combination of the embeddings in vocabulary .
As stated in Theorem 1, any vector in can be represented by a linear combination of the embeddings in the vocabulary . Now we define the weight vector with each component corresponding to a embedding in , and the embedding . Since the users input an initial embedding , we wish the start point in to be the same as in our algorithm. Thus, we initialize the weights as:
| (3) |
where denotes the index corresponding to . Then the embedding to be learned can now be initialized as:
| (4) |
Subsequently, it can be combined with the placeholder string to form the embedding matrix as stated in Section 2.3. The reconstruction task can be formulated as the following optimization problem:
| (5) |
where , , , and are detailed in Equation (1) and (2), is the text encoder defined in Section 2.1, is a function of . To solve problem (5), we iteratively update the weight vector by using gradient descent with initial point , so that the embedding is also updated.
While it is expressive enough to represent any concept in the embedding space , most weights and vectors are unnecessary since the rank as stated in Theorem 1, where . Thus, we only need at most vectors to optimize with included, which corresponds to selecting linearly-independent vectors from vocabulary .
3.2 Textual Subspace
As detailed in Section 3.1, any vector in the embedding space can be obtained using vectors . However, optimizing the embedding by solving problem (5) solely target the reconstruction of input images, leading to low text similarity (Gal et al., 2022). Besides, solving problem (5) requires to search in the whole high-dimensional embedding space , which results in time-consuming training process and slow convergence.
It is natural to construct a textual subspace with high text similarity, in which the searched embedding is able to capture the details of the input image. To this end, vectors with high semantic relevance to should be included. As suggested in (Mikolov et al., 2013a; b; Le & Mikolov, 2014; Goldberg & Levy, 2014; Rong, 2014), the vector distance (denoted by ) between the word embeddings in , such as dot product, cosine similarity and norm, can be employed as the semantic similarity of the corresponding words. Now, we are ready to give the distance vector to calculate the distance between and any embedding in , which is given by
| (6) |
Next, we re-order and the top vectors are selected as the basis vectors, where at most vectors are linearly-independent among them and is the dimension of the textual subspace. The choice of and are further discussed in Section 5 and Appendix F. The details of selection strategy are presented in Algorithm 1.
3.3 Concept Generation
Given the chosen embeddings , once the corresponding learned weights are obtained by with , the learned embedding can be formed as:
| (7) |
Then it can be combined with any input textual prompt as:
| (8) |
where the operator is defined in Section 2.3. Subsequently, the target images are generated using the pre-trained diffusion network :
| (9) |
Details of BaTex are shown in Algorithm 2.
Finally, we derive that for single-step optimization scenario, the difference of the embedding update between Textual Inversion and BaTex corresponds to a matrix transformation with rank , which is the dimension of the textual subspace. The formal theorem is presented as follows, and its proof is included in Appendix C.
Theorem 2
For single-step optimization, let and be the updated embedding of Textual Inversion and BaTex respectively, where is the initial embedding. Then there exists a matrix with rank , such that
where is the dimension of the textual subspace ().
It can be seen from Theorem 2 that BaTex actually defines a transformation from to using the selection strategy stated in Algorithm 1, which intuitively benefits for optimization process since is formed by the pre-trained embeddings, showing that BaTex explicitly extracts more information from the vocabulary .
4 Experiments
4.1 Experimental Settings
In this subsection, we present the experimental settings, and more details can be found in Appendix E.
We compare the proposed BaTex with Textual Inversion (TI) (Gal et al., 2022), the original method for personalized generation which lies in the category of “Embedding Optimization”. To analyze the quality of learned embeddings, we follow the most commonly used metrics in TI and measure the performance by computing the CLIP-space scores (Hessel et al., 2021).
We also compare with two “Model Optimization” methods, DreamBooth (DB) (Ruiz et al., 2022) and Custom Diffusion (CD) (Kumari et al., 2022). DB finetunes all the parameters in Diffusion Models, resulting in the ability of mimicing the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. However, it finetunes a large amount of model parameters, which leads to overfitting (Ramasesh et al., 2022). CD compares the effect of model parameters and chooses to optimize the parameters in the cross-attention layers. While it provides an efficient method to finetune the model parameters, it requires to prepare a regularized dataset (extracted from LAION-400M dataset (Schuhmann et al., 2021)) to mitigate overfitting, which is time-consuming and hinders its scalability to on-site application. A detailed comparison of method ability can be seen in Table 1.
| Category | Method | Param | Training | Training | High Image- | High Text- | Avoid |
|---|---|---|---|---|---|---|---|
| Size | Steps | Time | Alignment | Alignment | Overfitting | ||
| Model | Dreambooth | 860M | 800 | 12min | ✓ | ✗ | ✗ |
| Optimization | Custom-Diffusion | 57.1M | 250 | 10min | ✗ | ✓ | ✗ |
| Embedding | Textual Inversion | 768 | 3000 | 1h | ✓ | ✗ | ✓ |
| Optimization | BaTex (Ours) | < 768 | 500 | 10min | ✓ | ✓ | ✓ |
4.2 Qualitative Comparison

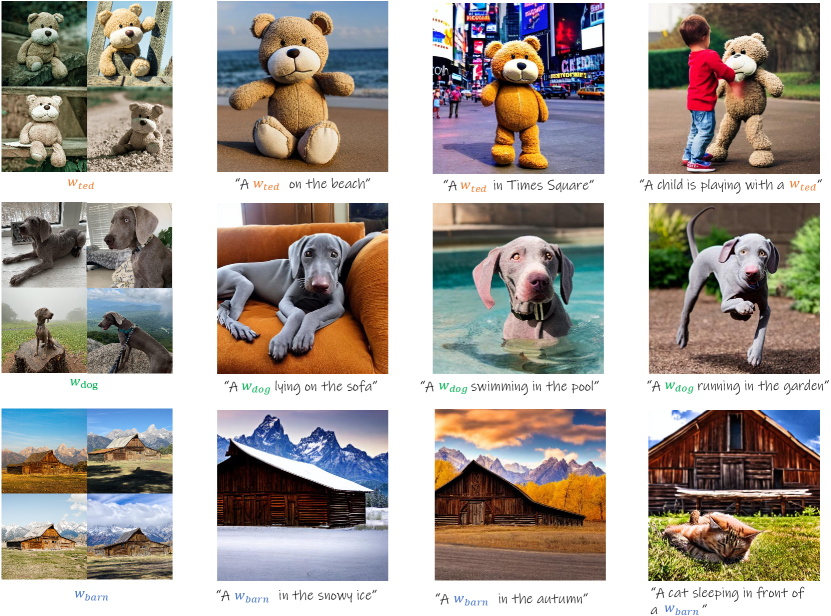
We first show that learning in a textual subspace significantly improves the text similarity of learned embedding while retaining the ability to reconstruct the input image. The results of text-guided synthesis are shown in Figure 2. As can be seen, for complex input textual prompt with additional text conditions, our method completely captures the input concept and naturally combines it with known concepts.
Additionally, We show the effectiveness of our method by composing two concepts together and introducing additional text conditions (shown in bolded text). The results are shown in Figure 3. It can be seen that BaTex not only allows for the lossless combination of two distinct concepts, but also faithfully generates the additional text conditions.
4.3 Quantitative Comparison
| Category | Method | Metric | Cat | Wooden-pot | Gta5-artwork | Anders-zorn | Cute-game | Mean |
|---|---|---|---|---|---|---|---|---|
| [5] | [4] | [14] | [12] | [8] | ||||
| DB | Text | 0.74 (0.00) | 0.63 (0.01) | 0.72 (0.01) | 0.72 (0.01) | 0.62 (0.00) | 0.69 | |
| Model | Image | 0.91 (0.01) | 0.88 (0.01) | 0.61 (0.01) | 0.74 (0.00) | 0.61 (0.01) | 0.75 | |
| Optimization | CD | Text | 0.79 (0.00) | 0.71 (0.00) | 0.74 (0.01) | 0.74 (0.01) | 0.74 (0.00) | 0.74 |
| Image | 0.87 (0.00) | 0.75 (0.00) | 0.59 (0.01) | 0.60 (0.02) | 0.56 (0.00) | 0.68 | ||
| TI | Text | 0.62 (0.00) | 0.66 (0.01) | 0.78 (0.01) | 0.72 (0.01) | 0.72 (0.00) | 0.70 | |
| Embedding | Image | 0.89 (0.01) | 0.81 (0.00) | 0.67 (0.01) | 0.67 (0.01) | 0.68 (0.01) | 0.74 | |
| Optimization | BaTex | Text | 0.76 (0.00) | 0.72 (0.01) | 0.80 (0.00) | 0.77 (0.00) | 0.77 (0.01) | 0.76 |
| Image | 0.88 (0.01) | 0.81 (0.01) | 0.66 (0.01) | 0.72 (0.00) | 0.66 (0.01) | 0.74 |
The results of image-image and text-image alignment scores compared with previous works are shown in Table 2. As can be seen, when compared with TI by text-image alignment score, BaTex substantially outperforms it (0.76 to 0.70) while maintaining non-degrading image reconstruction effect (0.74 to 0.74). For “Model Optimization” category, BaTex is competitive in both metrics, while their methods perform poorly in one of them due to overfitting. Additional results can be found in Appendix F.

4.4 User Study
Following Textual Inversion, we have conducted a human evaluation with two test phases of image-image and text-image alignments. We collected a total of 160 responses to each phase. The results are presented in Table 3, showing that the human evaluation results align with the CLIP scores.
| Metric | DB | CD | TI | Ours |
|---|---|---|---|---|
| Image-to-image alignment | 63.8 | 48.1 | 57.5 | 67.5 |
| Text-to-image alignment | 77.5 | 58.1 | 27.5 | 71.9 |
5 Discussion
In this section, we discuss the effects of proposed BaTex. Since the dimension of the textual subspace highly affects the search space of the target embedding, we perform an ablation study on the dimension and training steps. We also analyze the robustness and flexibility of BaTex by replacing the initial word. The results can be found in Appendix F. The limitations and societal impact of BaTex are discussed in Appendix A and D respectively. The reproducibility statement is presented in Appendix G.
Dimension of textual subspace
| Metric | M=96 | ||||
| Text-image alignment score | 0.77 | 0.78 | 0.80 | 0.80 | 0.79 |
| Image-image alignment score | 0.59 | 0.61 | 0.64 | 0.66 | 0.66 |
| Convergence steps | 150 | 100 | 400 | 500 | 1000 |
The choice of is significant to our method since it affects the solution space of target embedding. Specifically, we compare the text-alignment and image-alignment scores by the following numbers: (Since , we only compare values less than 768). We show the results of dataset Gta5-artwork with respect to the dimension in Table 4. As can be seen, choosing leads to relatively better results. The reasons are two-fold. First, for textual subspace with excessive dimension, optimizing is inefficient and requires more convergence steps as shown in the column of “”. Second, For low-dimensional textual subspace, although it generally converges faster, it is difficult to reconstruct the input image as can be seen in the row “Image-image alignment score”. We also observe a slight decrease in the value of text-image alignment score as the dimension decreases, which can be explained by the fact that it might not include enough semantic-related embeddings as its basis vectors. Thus, we choose to set although it is possible to finetune for each dataset.
Training steps
The convergence steps of dataset Gta5-artwork with respect to the dimension are shown in Table 4. We observe that when lowering the dimension, it significantly improves the convergence speed. We also notice an outlier for “”, which can be explained by its low image-image alignment score, making it difficult to converge. Thus, We recommend to train BaTex with for 500 steps.
6 Conclusion
We have proposed BaTex, a novel method for efficiently learning arbitrary concept in a textual subspace. Through a rank-based selection strategy, BaTex determines the textual subspace using the information from the vocabulary, which is time-efficient and better preserves the text similarity of the learned embedding. On the theoretical side, we demonstrate that the selected embeddings can be combined to produce arbitrary vectors in the embedding space and the proposed method is equivalent to applying a projection matrix to the update of embedding. We experimentally demonstrate the efficiency and robustness of the proposed BaTex. Future improvements include introducing sparse optimization algorithm to automatically choose the dimension of textual subspace, and combining with “Model Optimization” methods to improve its image-image alignment score.
References
- Alaluf et al. (2023) Yuval Alaluf, Elad Richardson, Gal Metzer, and Daniel Cohen-Or. A neural space-time representation for text-to-image personalization. arXiv preprint arXiv:2305.15391, 2023.
- Amat et al. (2018) Fernando Amat, Ashok Chandrashekar, Tony Jebara, and Justin Basilico. Artwork personalization at netflix. In Proceedings of the 12th ACM conference on recommender systems, pp. 487–488, 2018.
- Bengio & LeCun (2007) Yoshua Bengio and Yann LeCun. Scaling learning algorithms towards AI. In Large Scale Kernel Machines. MIT Press, 2007.
- Burgess et al. (2018) Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in -vae. arXiv preprint arXiv:1804.03599, 2018.
- Cattiau (2022) Julie Cattiau. A communication tool for people with speech impairments, 2022.
- Cohen et al. (2022) Niv Cohen, Rinon Gal, Eli A Meirom, Gal Chechik, and Yuval Atzmon. “this is my unicorn, fluffy”: Personalizing frozen vision-language representations. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XX, pp. 558–577. Springer, 2022.
- Corvi et al. (2022) Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. On the detection of synthetic images generated by diffusion models. arXiv preprint arXiv:2211.00680, 2022.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dhariwal & Nichol (2021) Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- Ding et al. (2022) Yuxuan Ding, Lingqiao Liu, Chunna Tian, Jingyuan Yang, and Haoxuan Ding. Don’t stop learning: Towards continual learning for the clip model. arXiv preprint arXiv:2207.09248, 2022.
- Dinh et al. (2016) Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016.
- Du et al. (2022) Shian Du, Yihong Luo, Wei Chen, Jian Xu, and Delu Zeng. To-flow: Efficient continuous normalizing flows with temporal optimization adjoint with moving speed. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12570–12580, 2022.
- Elhamifar & Vidal (2013) Ehsan Elhamifar and René Vidal. Sparse subspace clustering: Algorithm, theory, and applications. IEEE transactions on pattern analysis and machine intelligence, 35(11):2765–2781, 2013.
- Gal et al. (2022) Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022.
- Gal et al. (2023) Rinon Gal, Moab Arar, Yuval Atzmon, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. Encoder-based domain tuning for fast personalization of text-to-image models. ACM Transactions on Graphics (TOG), 42(4):1–13, 2023.
- Gao et al. (2021) Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters. arXiv preprint arXiv:2110.04544, 2021.
- Goldberg & Levy (2014) Yoav Goldberg and Omer Levy. word2vec explained: deriving mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722, 2014.
- Goodfellow et al. (2016) Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. Deep learning, volume 1. MIT Press, 2016.
- Goodfellow et al. (2020) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 63(11):139–144, 2020.
- Han et al. (2023) Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact parameter space for diffusion fine-tuning. arXiv preprint arXiv:2303.11305, 2023.
- Hessel et al. (2021) Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718, 2021.
- Hinton et al. (2006) Geoffrey E. Hinton, Simon Osindero, and Yee Whye Teh. A fast learning algorithm for deep belief nets. Neural Computation, 18:1527–1554, 2006.
- Ho & Salimans (2022) Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Kumar et al. (2022) Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. arXiv preprint arXiv:2202.10054, 2022.
- Kumari et al. (2022) Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. arXiv preprint arXiv:2212.04488, 2022.
- Le & Mikolov (2014) Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. In International conference on machine learning, pp. 1188–1196. PMLR, 2014.
- Li et al. (2022) Dingcheng Li, Zheng Chen, Eunah Cho, Jie Hao, Xiaohu Liu, Fan Xing, Chenlei Guo, and Yang Liu. Overcoming catastrophic forgetting during domain adaptation of seq2seq language generation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5441–5454, 2022.
- Liu et al. (2022) Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. Compositional visual generation with composable diffusion models. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVII, pp. 423–439. Springer, 2022.
- Loshchilov & Hutter (2017) Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Mikolov et al. (2013a) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013a.
- Mikolov et al. (2013b) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26, 2013b.
- Nichol et al. (2021) Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Nichol & Dhariwal (2021) Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pp. 8162–8171. PMLR, 2021.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Ramasesh et al. (2022) Vinay Venkatesh Ramasesh, Aitor Lewkowycz, and Ethan Dyer. Effect of scale on catastrophic forgetting in neural networks. In International Conference on Learning Representations, 2022.
- Rombach et al. (2022a) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695, 2022a.
- Rombach et al. (2022b) Robin Rombach, Andreas Blattmann, and Björn Ommer. Text-guided synthesis of artistic images with retrieval-augmented diffusion models. arXiv preprint arXiv:2207.13038, 2022b.
- Rong (2014) Xin Rong. word2vec parameter learning explained. arXiv preprint arXiv:1411.2738, 2014.
- Ruiz et al. (2022) Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv preprint arXiv:2208.12242, 2022.
- Saharia et al. (2022) Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022.
- Sauer et al. (2022) Axel Sauer, Katja Schwarz, and Andreas Geiger. Stylegan-xl: Scaling stylegan to large diverse datasets. In ACM SIGGRAPH 2022 conference proceedings, pp. 1–10, 2022.
- Schuhmann et al. (2021) Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Skantze & Willemsen (2022) Gabriel Skantze and Bram Willemsen. Collie: Continual learning of language grounding from language-image embeddings. Journal of Artificial Intelligence Research, 74:1201–1223, 2022.
- Song et al. (2020) Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- Voynov et al. (2023) Andrey Voynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. : Extended textual conditioning in text-to-image generation. arXiv preprint arXiv:2303.09522, 2023.
- Wei et al. (2023) Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. arXiv preprint arXiv:2302.13848, 2023.
- Zhang et al. (2022) Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based creativity transfer with diffusion models. arXiv preprint arXiv:2211.13203, 2022.
- Zheng et al. (2023) Guangcong Zheng, Xianpan Zhou, Xuewei Li, Zhongang Qi, Ying Shan, and Xi Li. Layoutdiffusion: Controllable diffusion model for layout-to-image generation. arXiv preprint arXiv:2303.17189, 2023.
- Zhou et al. (2022) Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9):2337–2348, 2022.
Supplementary Materials
Appendix A Limitations
Since BaTex requires to form a textual subspace to search the target embedding, the dimension has to be defined. In BaTex , has been treated as a hyperparameter and we have performed a detailed comparison in Section 5 to choose an appropriate value. However, in practice, should be determined automatically to avoid artificially tuning. In Section 6, we have given some directions for improvement to address this issue.
Appendix B Proof of Theorem 1
Theorem 3
Any vector in word embedding space can be represented by a linear combination of the embeddings in vocabulary .
Proof 1
For all embeddings in , it forms a matrix . It can be numerically computed that the rank of is , demonstrating that any linearly-independent vectors in can be formed as a basis of the word embedding space . Since , we can derive that if we select a subset of linearly-independent vectors from , it forms a basis of . Then any vector can be expressed as a linear combination of the subset as: , where are the weights of the basis vectors.
Appendix C Proof of Theorem 2
Theorem 4
For single-step optimization, let and be the updated embedding of Textual Inversion and BaTex respectively, where is the initial embedding. Then there exists a matrix with rank , such that , where is the dimension of the textual subspace ().
Proof 2
For BaTex , we have , where and are the selected embedding matrix and initialized weights respectively, is the number of embeddings selected. We also have . For single-step optimization, let be the updated weights, then , where is the objective of the reconstruction task. Now we have . So . Using the chain rule, we know that , which draws a conclusion that . Also, we know that for single-step optimization, (Here we omit the learning rate and other hyperparameters). Now we have . Set , we have .
Appendix D Societal Impact
With the gradual increase in the capacity of multimodal models in recent years, training a large model from scratch is no longer possible for most people. Our method allows users to combine private images with arbitrary text for customized generation. Our method is time and parameter efficient, allowing users to take advantage of a large number of pre-trained parameters, promising to increase social productivity in image generation. While being expressive and efficient, it might increase the potential danger in misusing it to generate fake or illegal data. Possible solutions include enhancing the detection ability of diffusion model (Corvi et al., 2022) and constructing safer vocabulary of Text model (Devlin et al., 2018).
Appendix E Additional Experimental Settings
Datasets
Following the existing experimental settings, we conduct experiments on several concept datasets, including datasets from Textual Inversion (Gal et al., 2022) and Custom Diffusion (Kumari et al., 2022). The datasets are all publicly available by the authors, as can seen in the website of Textual Inversion666https://github.com/rinongal/textualinversion and Custom-Diffusion777https://github.com/adobe-research/custom-diffusion. Besides, we collect several complex concept datasets from HuggingFace Library888https://huggingface.co/sd-concepts-library and perform detailed comparisons on them. It is worth noting that none of the datasets we have used contain personally identifiable information or offensive content.
Baselines
We compare our method with Textual Inversion (Gal et al., 2022), the original method for concept generation which lies in the category of “Embedding Optimization”. We also compare with two “Model Optimization” methods, DreamBooth (Ruiz et al., 2022) and Custom Diffusion (Kumari et al., 2022). DreamBooth finetunes all the parameters in Diffusion Models, resulting in the ability of mimicing the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. However, it finetunes a large amount of model parameters, which leads to overfitting (Ramasesh et al., 2022). Custom-Diffusion compares the effect of model parameters and chooses to optimize the parameters in the cross-attention layers. While it provides an efficient method to finetune the model parameters, it requires to prepare a regularized dataset (extracted from LAION-400M dataset (Schuhmann et al., 2021)) to mitigate overfitting, which is time-consuming and hinders its scalability to on-site application. A detailed comparison of method ability can be seen in Table 1 in the main text.
Implementation
We implement all three baseline methods by Diffusers999https://github.com/huggingface/diffusers, a third-party implementation compatible with Stable Diffusion (Rombach et al., 2022a), which is more expressive than the original Latent Diffusion Model. All four models are used with Stable-Diffusion-v1-5101010https://huggingface.co/runwayml/stable-diffusion-v1-5.
Evaluation Metrics
To analyze the quality of learned embeddings, we follow the most commonly used metrics in Textual Inversion and measure the performance by computing the clip-space scores (Hessel et al., 2021). We use the original implementation of CLIPScore111111https://github.com/jmhessel/clipscore.
We first evaluate our proposed method on image alignment, as we wish our learned embeddings still retain the ability to reconstruct the target concept. For each concept, we generate 64 examples using the learned embeddings with the prompt “A photo of ”. We then compute the average pair-wise CLIP-space cosine similarity between the generated images and the images in the training dataset.
Secondly, we want to measure the alignment of the generated images with the input textual prompt. We have set up a series of prompts and included as many variations as possible. These include background modifications (“A photo of on the beach”) and style transfer (“a waterfall in the style of ”).
Hardware
Our method and all previous works are trained on three NVIDIA A100 GPUs. For inference, BaTex uses a single NVIDIA A100 GPU.
Hyperparameter settings
We optimize the weights using AdamW (Loshchilov & Hutter, 2017), the same optimizer as Textual Inversion. The choice of other important hyperparameters are all discussed in Section 5.
Appendix F Additional Results
F.1 Quantitative comparison
| Category | Method | Metric | Low-poly | Midjourney-style | Chair | Dog | Elephant | Mean |
|---|---|---|---|---|---|---|---|---|
| [9] | [4] | [4] | [8] | [5] | ||||
| DB | Text | 0.74 (0.00) | 0.68 (0.01) | 0.63 (0.01) | 0.74 (0.01) | 0.64 (0.01) | 0.69 | |
| Model | Image | 0.69 (0.01) | 0.66 (0.01) | 0.91 (0.01) | 0.79 (0.00) | 0.89 (0.01) | 0.79 | |
| Optimization | CD | Text | 0.75 (0.00) | 0.74 (0.01) | 0.75 (0.01) | 0.73 (0.01) | 0.68 (0.00) | 0.73 |
| Image | 0.66 (0.01) | 0.60 (0.01) | 0.82 (0.00) | 0.73 (0.01) | 0.80 (0.00) | 0.72 | ||
| TI | Text | 0.73 (0.01) | 0.68 (0.00) | 0.58 (0.00) | 0.65 (0.00) | 0.68 (0.01) | 0.66 | |
| Embedding | Image | 0.70 (0.01) | 0.66 (0.01) | 0.88 (0.00) | 0.76 (0.00) | 0.84 (0.01) | 0.76 | |
| Optimization | BaTex | Text | 0.77 (0.00) | 0.74 (0.00) | 0.70 (0.01) | 0.74 (0.01) | 0.79 (0.00) | 0.75 |
| Image | 0.70 (0.01) | 0.70 (0.00) | 0.88 (0.01) | 0.76 (0.01) | 0.80 (0.00) | 0.76 |
We perform quantitative comparison on five additional datasets. Results are shown in Table 5. As can be seen, when compared with TI by text-image alignment score, BaTex substantially outperforms it (0.75 to 0.66) while maintaining non-degrading image reconstruction effect (0.76 to 0.76). For “Model Optimization” category, BaTex is competitive in both metrics, while their methods perform poorly in one of them due to overfitting.
F.2 Robustness against initial word
In practice, it is often difficult for users to give the most suitable initial word for complex concepts at once, posing a great challenge to the training of previous models. We show in Table 6 that when initializing by a less semantic-related word, BaTex outperforms all three previous models by a huge margin in terms of text-image alignment score. The robustness comes from the fact that BaTex selects embeddings by the initial word, which contains almost all synonyms or semantically similar words of the initial word.
| Method | Text Alignment | Image Alignment | ||
| “cat” | “animal” | “cat” | “animal” | |
| Dreambooth | 0.74 | 0.63 | 0.91 | 0.91 |
| Custom-Diffusion | 0.79 | 0.69 | 0.87 | 0.82 |
| Textual Inversion | 0.62 | 0.62 | 0.89 | 0.86 |
| BaTex (ours) | 0.76 | 0.75 | 0.88 | 0.88 |
We additionally test the robustness against initial word on Dog dataset and replace the initial word “dog” by “animal”. Results are shown in Table 7. It can be seen that when the text similarity of other three previous methods significantly decreases, BaTex obtains a much higher score.
| Method | Text Alignment | Image Alignment | ||
| “dog” | “animal” | “dog” | “animal” | |
| Dreambooth | 0.73 | 0.65 | 0.79 | 0.78 |
| Custom-Diffusion | 0.74 | 0.65 | 0.74 | 0.77 |
| Textual Inversion | 0.65 | 0.60 | 0.76 | 0.76 |
| BaTex (ours) | 0.73 | 0.73 | 0.75 | 0.74 |
F.3 Text-guided synthesis
We show additional text-guided synthesis results on Figure 4 and 5. As can be seen, for complex input textual prompt with additional text conditions, our method completely captures the input concept and naturally combines it with known concepts.


Also, qualitative results of more object concepts are shown in Figure 6. The results match the conclusion in Section 4.2.
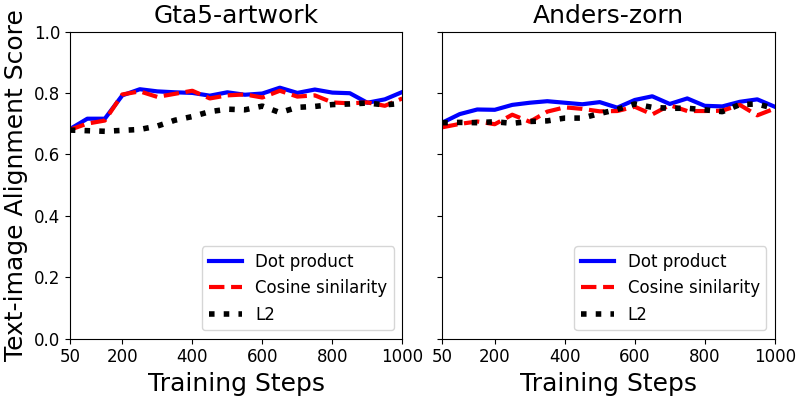
F.4 Vector Distance
We compare the text-image alignment score of three type of vector distance: dot product, cosine similarity and distance in Figure 7. As can be seen, dot product and cosine similarity both outperform in text-image alignment score and convergence speed. Compared with cosine similarity, the results of dot product are slightly better. We conjecture that the reason is dot product taking into account the modal length of the embedding when computing the distance between and other embeddings, which is meaningful in the textual subspace.
F.5 Top One Vector
Simply using the top one vector would lead to worse reconstruction results since only a scalar cannot fully store the details of the reference images. We have also added qualitative results using the top one vector in Figure 8, showing that using only one vector results in unsatisfying results.

F.6 Two Similar Objects
We have performed additional multi-concept generation for similar objects and the results are shown in Figure 9. The results show the appearance of object neglect (in the right-most column). We also find that BaTex can generate reasonable images for most cases of two similar objects (see the results of other three columns).

F.7 Two different Objects
In addition, we have provided additional experiments about composition of different objects in Figure 10, showing that BaTex successfully composites different objects.

F.8 Number Comparison
A comparison about different numbers (N = 1, 2, 4, 6, 8) of reference images over dataset Dog (the maximum number of reference images is 8) is shown in Figure 11. The experiments show that using only 2 images can obtain satisfying results. Although the performance of N = 1 is slightly deteriorating, BaTex mainly focuses on improving the training efficiency and text alignment over Textual Inversion.

F.9 Additional Comparison
| Method | Metric | Cat | Wooden-pot | Gta5-artwork | Anders-zorn | Cute-game | Mean |
|---|---|---|---|---|---|---|---|
| [5] | [4] | [14] | [12] | [8] | |||
| XTI | Text | 0.78 (0.01) | 0.73 (0.01) | 0.67 (0.01) | 0.73 (0.00) | 0.67 (0.00) | 0.72 |
| Image | 0.85 (0.00) | 0.74 (0.01) | 0.54 (0.01) | 0.63 (0.01) | 0.56 (0.01) | 0.66 | |
| NeTI | Text | 0.76 (0.00) | 0.72 (0.01) | 0.74 (0.00) | 0.71 (0.01) | 0.72 (0.00) | 0.73 |
| Image | 0.87 (0.01) | 0.76 (0.00) | 0.64 (0.01) | 0.69 (0.00) | 0.64 (0.01) | 0.72 | |
| SVDiff | Text | 0.79 (0.00) | 0.71 (0.00) | 0.76 (0.01) | 0.74 (0.01) | 0.76 (0.01) | 0.75 |
| Image | 0.85 (0.01) | 0.75 (0.00) | 0.58 (0.01) | 0.56 (0.01) | 0.59 (0.01) | 0.67 | |
| BaTex | Text | 0.76 (0.00) | 0.72 (0.01) | 0.80 (0.00) | 0.77 (0.00) | 0.77 (0.01) | 0.76 |
| Image | 0.88 (0.01) | 0.81 (0.01) | 0.66 (0.01) | 0.72 (0.00) | 0.66 (0.01) | 0.74 |
We have also compared BaTex with three concurrent works: SVDiff121212https://github.com/mkshing/svdiff-pytorch (Han et al., 2023), XTI131313https://github.com/mkshing/prompt-plus-pytorch (Voynov et al., 2023) and NeTI141414https://github.com/NeuralTextualInversion/NeTI (Alaluf et al., 2023). Quantitative results are shown in Table 8. It can be seen that BaTex achieves superior results over all three concurrent works. Also, we have shown qualitative comparison results in Figure 12, which demonstrates the effectiveness of our method over state-of-the-art methods.

Also, We perform qualitative comparison with encoder-based method (Wei et al., 2023) using example “cat”. Results have been shown in Figure 13. It can be seen that although encoder-based method finetunes much faster (it only needs one forward step), it lacks text-to-image alignment ability in some cases (e.g., miss “sleeping” in the second case).

F.10 Weight Visualization

To clarify the usage of basis vectors, we have shown the visualization of both learned weights and corresponding basis vectors for example “cat” in Figure 14. Due to page limit, we only showcase the first 10 basis vectors. As can be seen, starting from the initial word “cat”, BaTex learns a reasonable combination to obtain the target vector while TI tends to search around the initial embedding using only the reconstruction loss, which results in low text-to-image alignment.
F.11 Human Face Results

Human face domain is very challenging for personalization of image diffusion models, which contains more perceptible details than other domains. Therefore, we have performed test on “lecun” example used in (Gal et al., 2023). Results have been shown in Figure 15. It can be seen that BaTex generates results following the textual prompt, while successfully reconstructing the input human face image.
Appendix G Reproducibility Statement
We have provided main part of our code in the supplementary material. Please refer there for details of our method.