Efficient Postprocessing Procedure for Evaluating Hamiltonian Expectation Values in Variational Quantum Eigensolver.
Abstract
We proposed a simple strategy to improve the postprocessing overhead of evaluating Hamiltonian expectation values in Variational quantum eigensolvers (VQEs). Observing the fact that for a mutually commuting observable group G in a given Hamiltonian, is fixed for a measurement outcome bit string in the corresponding basis, we create a measurement memory (MM) dictionary for every commuting operator group G in a Hamiltonian. Once a measurement outcome bit string appears, we store and as key and value, and the next time the same bit string appears, we can find from the memory, rather than evaluate it once again. We further analyze the complexity of MM and compare it with commonly employed post-processing procedure, finding that MM is always more efficient in terms of time complexity. We implement this procedure on the task of minimizing a fully connected Ising Hamiltonians up to 20 qubits, and H2, H4, LiH, and H2O molecular Hamiltonians with different grouping methods. For Ising Hamiltonian, where all terms commute, our method offers an speedup in terms of the percentage of time saved. In the case of molecular Hamiltonians, we achieved over percentage time saved, depending on the grouping method.
Index Terms:
Quantum computing, Variational quantum eigensolver, VQE, Measurement memoryI INTRODUCTION
Variational quantum eigensolvers (VQEs)[1, 2, 3] have been considered one of the main applications of quantum computers in the noisy intermediate-scale quantum (NISQ) era[4]. VQEs can be applied to a broad type of tasks, such as chemistry, optimization, and machine learning. A common goal of most of these applications is to minimize an objective function, which usually is represented by a Hamiltonian that can be decomposed into a sum of tensor products of Pauli operators, i.e.
| (1) |
where , and is the number of qubits. In VQE, the goal is to minimize the Hamiltonian expectation value, obtained from a statistical average over a large number of measurements. The general process of VQEs can be summarized as follows:
-
1.
Design the parameterized ansatz .
-
2.
Choose the initial parameter vector .
-
3.
Calculate the gradient of , where is the initial state.
-
4.
Update according to the gradient, and check if has decreased.
-
5.
Go back to step 3 until cannot be minimized anymore or has reached the maximum iterations.
Assuming choosing a gradient-based classical optimizer, the gradient can be calculated analytically with the parameter shift rule [5] for a quantum circuit. However, this process also requires evaluating the expectation value times at and for each dimension in . This results in times of evaluations of Hamiltonian expectation value for step 3, where is the dimension of . Then we evaluate once again with the updated in step 4, making it a total of times of evaluation in every optimization step, and thus evaluations are required for a whole VQE process with iterations. This number increases as the problem size grows since the number of parameters should grow, and the number of iterations may also grow. It is well known that evaluating a Hamiltonian expectation value once already requires a large number of circuit repetitions [6]. However, as stated above, we even need to repeat this task over and over again to complete the whole VQE process.
There have been many elaborated methods proposed to reduce the circuit repetition for evaluating the Hamiltonian expectation value, such as efficient state tomography [7, 8, 9], measurement distribution [6, 10, 11], and Hamiltonian partitioning [1, 12, 13, 14, 15, 11]…etc. However, the measurement needed to reach a specific error is still very large. For example, it still requires hundreds of millions of circuit repetitions to evaluate even small molecules [11] (e.g., H2O, NH3) to chemical accuracy. Moreover, with such a large number of measurements, the classical overhead of postprocessing becomes nontrivial.
First, we started from a Hamiltonian that is partitioned into commuting groups, i.e.,
| (2) |
Since commuting operators share common eigenstates, the Pauli operators in the same group can be evaluated with the same set of measurement outcomes in the corresponding measurement basis. The classical cost of evaluating a bit string depends on the number of terms in the group. For example, a fully connected Ising Hamiltonian has all of its operators in the same group, since they are all composed of Pauli Z, and thus requires scaling of cost. A molecular Hamiltonian is known to have operators, and a grouping strategy with groups will thus result in linear scaling of operators in each group, which requires cost to evaluate. Observing the fact that is fixed and needs to be calculated every time occurs, a straightforward strategy is to memorize it. Since looking up a bit string with length in a dictionary requires only on average. This is the main idea of measurement memory (MM).
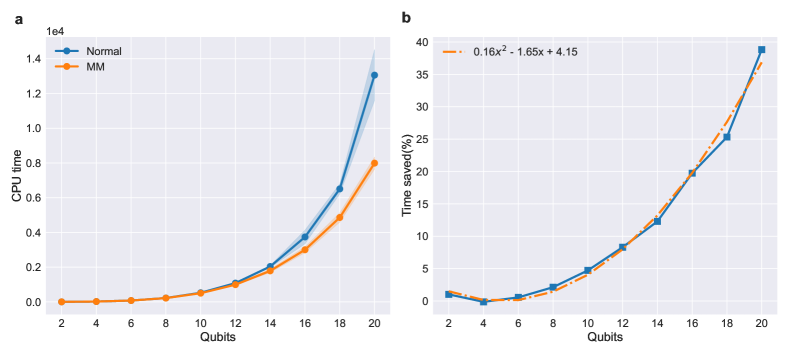
We implemented MM on fully connected Ising Hamiltonians up to 20 qubits, finding an speedup in terms of the percentage of time saved. MM is also tested on Molecular Hamiltonian of H2, H4, LiH, and H2O, each with 3 different grouping strategies: qubit-wise commuting (QWC) grouping [1, 13], general commuting (GC) grouping [14], and Fermion grouping (FG) [16]. Each grouping method has different scaling of groups and operators in each group, thus leading to a different degree of improvement.
II Measurement Memory
For a Hamiltonian that has been divided into commuting operator groups, i.e.,
| (3) | ||||
where , and
| (4) |
The operators in the same commuting groups are simultaneously diagonalizable and can be evaluated with the same set of measurements in the corresponding basis. Measurement Memory (MM) creates an independent dictionary for each group at the beginning. During the future process, every time we evaluate the Hamiltonian expectation value via quantum computer measurement results (including calculating the gradient with the parameter shift rule), we try to find the value in the corresponding dictionary for each group with key . If it doesn’t exist, we evaluate it as the normal process and store and in the dictionary as key and value.
The pseudocode shown in Algorithm 1 represents the process of evaluating once. For each measurement we evaluate, accumulates and starts to develop potential to reduce more and more computational cost.
Note that one does not have to sort the measured bit string into probability or count dictionaries in advance, as we usually do in regular procedures when applying MM. We will discuss the complexity of sorting and MM further in the next chapter. We also analyzed the time complexity in the appendix, showing that the potential performance improvement of MM is mainly determined by the scaling of the number of operators in each group. Thus, the improvement will be very limited for an MM created for a sublinear scaling operator group. On the other hand, we should expect fruitful performance improvement for superlinear scaling operator groups.
III Comparison with Regular Procedure
For every commuting group in a Hamiltonian, we set up the circuit in the corresponding measurement basis and repeat the circuit, say times, to obtain a collection of measured bit strings . Typically, one would sort the set into distinct terms with corresponding counts or probabilities, such as , where . For simplicity, we refer to the process of evaluating from as the ”sort-and-evaluate” procedure and the process of directly evaluating every bit string in as the ”naive evaluation”. The sort-and-evaluate procedure reduces the evaluation of by times. However, the sorting process is not free and might waste a lot of time in the worst case (i.e., ). Nevertheless, we showed in the Appendix that in general and practical cases, one will still prefer the sort-and-evaluate procedure over naive evaluation.
One thing to mention here is that the MM procedure has already incorporated the process of sorting raw measurement results into probability dictionaries. Thus, we do not have to sort the measured result in advance when applying MM. The main difference is that we are now storing their eigenvalues () instead of probabilities. While a probability dictionary is useless except for one specific evaluation of the expectation value, the information of MM is able to sustain through the whole VQE and develop the potential to save more and more cost as the iteration goes on. We further proved that the computational cost of the worst-case scenario of MM, which is the case that no eigenvalue of measured bit strings is stored in memory, is identical to the sort-and-evaluate procedure. This indicates that there are no downside trade-offs for adopting MM in terms of time complexity.
IV Neumerical Simulation
IV-A Ising Hamiltonian
Here we implement MM on fully connected Ising Hamiltonians up to 20 qubits. A random fully connected Ising Hamiltonian can be written as
| (5) |
where is the qubit number and . These types of Hamiltonians are commonly seen for solving quadratic unconstrained binary optimization (QUBO) problems [17]. The operators all consist of Pauli , thus we have local operator terms in the same commuting group and require only a single measurement basis .
We observed a special property of the Ising Hamiltonian, given the measured bit string set ,
| (6) | ||||
This implies that the cost of post-measurement classical computation per measurement is equivalent to searching one eigenstate. Due to the large number of circuit repetitions for evaluating the Hamiltonian expectation value, it would be very likely that the circuit repetition exceeds the search space of the problem () for problem sizes that are not large enough. It is thus difficult to justify the usage of VQE for Ising Hamiltonian on intermediate-scale quantum computers today and in the near future. MM here provides a simple strategy to bypass this limitation.
The measurement is done after a one CNOT layer ansatz, with parameters. We adopted circuit repetition scaling with problem size for each evaluation of Hamiltonian expectation value, proportional to the scaling of operator terms. We take 10 initial parameter guesses, and run VQE for 200 iterations. The final result is an average over 10 incidents. Note that the Hamiltonian is fixed for both normal procedure and MM procedure at every qubit size, and so are those 10 initial guesses.
The results are shown in Fig 1, MM achieved quadratic speed up in terms of percentage compared with the normal evaluation procedure. There is an additional benefit from using MM for optimization problems. Since the whole Ising Hamiltonian is one commuting group, , where is the measured bit string and also an eigenstate of . Thus, we are able to store every eigenvalue of every eigenstate that ever measured during the whole VQE process. This largely increases the probability of finding a good solution (i.e. low energy eigenstate) due to the large number of measurements.
| Mol | QWC | GC | FG | |||
| total | groups | total | groups | total | groups | |
| H2 | 15 | 5 | 15 | 2 | 34 | 4 |
| H4 | 185 | 67 | 185 | 9 | 317 | 11 |
| LiH | 631 | 151 | 631 | 34 | 877 | 22 |
| H2O | 1086 | 556 | 1086 | 90 | 1611 | 29 |
IV-B Molecular Hamiltonian
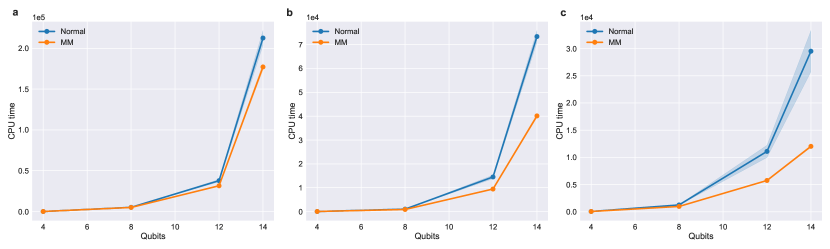
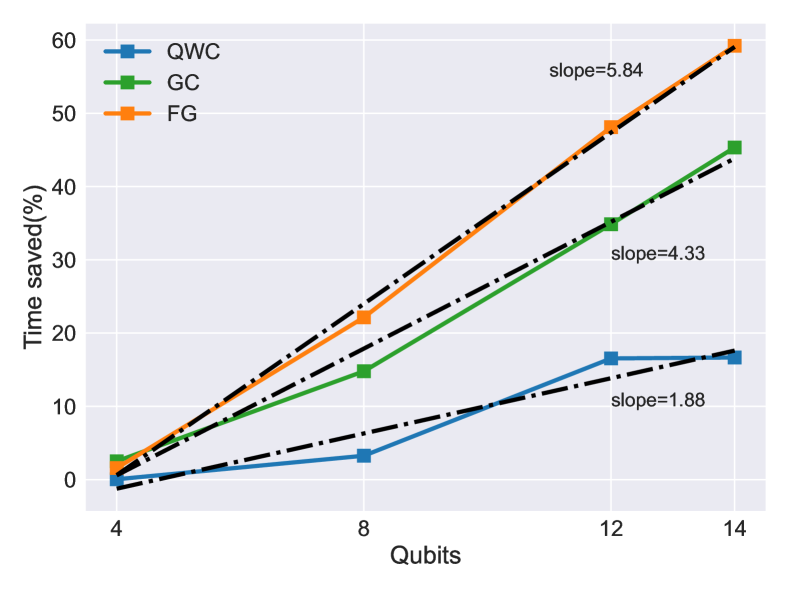
It is well known that the Pauli operator terms scales with system size for molecular Hamiltonian. Fortunately, several method have been proposed to partition those operators into commuting groups[13, 14, 16]. Although it may not directly reduce the circuit repetition without gingerly selection of grouping terms[16], MM is able to reduce more classical overhead of postprocessing the more terms are grouped together. We test MM on three grouping strategies, qubit-wise commuting (QWC) grouping[1, 13], general commuting (GC) grouping[14], and Fermion grouping (FG)[16]. QWC results in scaling with constant scaling terms in each group, while GC results in scaling and linear scaling group members. FG is a more special case since it permits reasonable discarding of small eigenvalues in second quantization Hamiltonian, resulting in scaling groups, where each group contains terms for small size molecules and reaching as the system size become large[18].
Here we demonstrated the improvement of MM on H2 (4 qubit), H4 (8 qubit), LiH (12 qubit), and H2O (14 qubit) molecules with sto-3g basis set, transformed via Jordan–Wigner (J-W) transformation. The comparison of MM with normal evaluation procedure is shown in Fig 2. As expected, the order of improvement is FG ¿ GC ¿ QWC, since the improvement of MM is more significant if there are more terms in the same group, and also because FG results in more terms of Pauli operators in total (TABLE I). The time saved in terms of percentage is also shown in Fig 3. All three grouping methods (i.e. QWC , GC, and FG grouping) are able to achieve linear to superlinear improvement in percentage time saved. However, for FG case, the qubit sizes we are able to demonstrate here are at the transition point of the term scaling, i.e. to , making it more difficult to estimate the scaling of improvement of MM for larger qubit systems.
V CONCLUSIONS and OUTLOOK
In this article, we introduced a Measurement Memory (MM) dictionary designed to store a measured bit string and its eigenvalue of a commuting group in a Hamiltonian. Throughout the VQE process, MM accumulates records, reducing the computational cost of evaluating over all terms in each time occurs after the first instance. We achieved percentage time savings for a fully connected Ising Hamiltonian, providing an additional benefit of increasing the probability of finding a low-energy solution. MM also provides over time savings for molecular Hamiltonian depending on the grouping method. With careful selection of grouping elements, one may be able to reduce both circuit repetition and postprocessing classical overhead. We further compare the time complexity of regular sort-and-evaluate procedure with MM, finding that that MM is a more efficient way of storing useful information for evaluating Hamiltonian expectation values in VQE, which sustains through the whole process. Moreover, the worst case scenario of MM is identical to the regular procedure. Thus, MM is a more efficient procedure of doing post-processing for evaluating Hamiltonian expectation value in VQE, and employing MM has no down side trade offs. For future applications, MM can also be applied to other deterministic measurement schemes, such as other grouping methods, and derandomized shadow[9] as long as the measurement basis are fixed.
References
- [1] J. R. McClean, J. Romero, R. Babbush, and A. Aspuru-Guzik, “The theory of variational hybrid quantum-classical algorithms,” New Journal of Physics, vol. 18, no. 2, p. 023023, 2016.
- [2] A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, “Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,” Nature, vol. 549, no. 7671, pp. 242–246, 2017.
- [3] M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, et al., “Variational quantum algorithms,” Nature Reviews Physics, vol. 3, no. 9, pp. 625–644, 2021.
- [4] J. Preskill, “Quantum computing in the nisq era and beyond,” Quantum, vol. 2, p. 79, 2018.
- [5] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, “Quantum circuit learning,” Physical Review A, vol. 98, no. 3, p. 032309, 2018.
- [6] D. Wecker, M. B. Hastings, and M. Troyer, “Progress towards practical quantum variational algorithms,” Physical Review A, vol. 92, no. 4, p. 042303, 2015.
- [7] S. Aaronson, “Shadow tomography of quantum states,” SIAM Journal on Computing, vol. 49, no. 5, pp. STOC18–368, 2019.
- [8] H.-Y. Huang, R. Kueng, and J. Preskill, “Predicting many properties of a quantum system from very few measurements,” Nature Physics, vol. 16, no. 10, pp. 1050–1057, 2020.
- [9] H.-Y. Huang, R. Kueng, and J. Preskill, “Efficient estimation of pauli observables by derandomization,” Physical review letters, vol. 127, no. 3, p. 030503, 2021.
- [10] N. C. Rubin, R. Babbush, and J. McClean, “Application of fermionic marginal constraints to hybrid quantum algorithms,” New Journal of Physics, vol. 20, no. 5, p. 053020, 2018.
- [11] T.-C. Yen, A. Ganeshram, and A. F. Izmaylov, “Deterministic improvements of quantum measurements with grouping of compatible operators, non-local transformations, and covariance estimates,” npj Quantum Information, vol. 9, no. 1, p. 14, 2023.
- [12] A. Jena, S. Genin, and M. Mosca, “Pauli partitioning with respect to gate sets,” arXiv preprint arXiv:1907.07859, 2019.
- [13] V. Verteletskyi, T.-C. Yen, and A. F. Izmaylov, “Measurement optimization in the variational quantum eigensolver using a minimum clique cover,” The Journal of chemical physics, vol. 152, no. 12, p. 124114, 2020.
- [14] T.-C. Yen, V. Verteletskyi, and A. F. Izmaylov, “Measuring all compatible operators in one series of single-qubit measurements using unitary transformations,” Journal of chemical theory and computation, vol. 16, no. 4, pp. 2400–2409, 2020.
- [15] P. Gokhale, O. Angiuli, Y. Ding, K. Gui, T. Tomesh, M. Suchara, M. Martonosi, and F. T. Chong, “ measurement cost for variational quantum eigensolver on molecular hamiltonians,” IEEE Transactions on Quantum Engineering, vol. 1, pp. 1–24, 2020.
- [16] W. J. Huggins, J. R. McClean, N. C. Rubin, Z. Jiang, N. Wiebe, K. B. Whaley, and R. Babbush, “Efficient and noise resilient measurements for quantum chemistry on near-term quantum computers,” npj Quantum Information, vol. 7, no. 1, p. 23, 2021.
- [17] F. Glover, G. Kochenberger, and Y. Du, “A tutorial on formulating and using qubo models,” arXiv preprint arXiv:1811.11538, 2018.
- [18] M. Motta, E. Ye, J. R. McClean, Z. Li, A. J. Minnich, R. Babbush, and G. K.-L. Chan, “Low rank representations for quantum simulation of electronic structure,” npj Quantum Information, vol. 7, no. 1, p. 83, 2021.
Time Complexity of sort-and-evaluate
Given with m total terms and distinct term, which can be sorted into dictionary , where . The sorting process is
First we analyze the complexity for sort-and-evaluate method. Dictionaries in python are implemented with hash table, checking if a new key is in requires calculating the hash function, which has cost since each has length . If hash function points to an empty memory, we know is not in , then we add it to with . If hash function points to an occupied memory, we need to check if is the same bit string as the occupied one to prevent from hash collision, costing additional . With the bit string set given above, we would result in ”no”s and ”yes”s (whether the memory is occupied). Since we only have to evaluate for distinct s, making the complexity for sort-and-evaluate
| (7) |
where is the complexity of evaluating for one bit string.
On the other hand, naive evaluation simply evaluates for every in , making the complexity
| (8) |
The condition for choosing sort-and-evaluate over naive evaluation is
| (9) |
and thus
| (10) |
Now we consider two extreme cases, first is an ansatz with same probability distribution over all eigenstates. Sampling from this ansatz is equivalent to a random sample. In this case, we can estimate by calculating the expectation value of distinct values of drawing times randomly from the binary string space,
| (11) |
and as . Thus, substituting for in condition 10, we end up with , which implies that one should conduct naive evaluation in this case. However, despite the fact that naive evaluation is always better in this case, the degree of improvement may not be significant. By comparing the complexity of two schemes with , the improvement, although may be large if scales badly, is not the bottleneck if . Since evaluating requires looping through every Pauli word on each qubit for every operator in the group,
| (12) |
where is the scaling of operator terms in group . This shows that is always true and thus the additional cost of adapting sort-and-evaluate scheme will not be the bottleneck. The second case is a highly concentrated ansatz, i.e. . In this case, condition 10 becomes
| (13) |
suggesting that if the complexity of evaluating is worse than linear, which, as mentioned above, is true for general cases, one should conduct the sort-and-evaluate scheme.
This discussion thus conclude that one can always conduct the sort-and-evaluate scheme with advantage in most case, and with acceptable disadvantage in some cases.
Time Complexity of MM
As shown in algorithm 1, for every bit string in , we check if is in . It also takes to calculate the hash function to see if the corresponding memory is occupied. A ”no” requires evaluating , and a ”yes” requires checking if it is exact the same string.
Assuming the same set of bit string mentioned in the first part of Appendix, where we have total bit strings with distinct ones. We also have bit strings in distinct bit strings stored in with its corresponding eigenvalue .
We will thus get ”no”s and ”yes”s, and the complexity for naive evaluation of given is
| (14) |
Now, if one sort the bit string into probability dictionary before feeding into MM, i.e. the in the step in algorithm 1 becomes , and all following becomes . The complexity is thus
| (15) |
The first two terms represent the cost for sorting, and the last two terms represent the cost of finding the sorted bit strings in . By comparing equation 14 and equation 15, we see that sorting before MM introduced additional computational cost. Although it is also not the bottleneck in most cases, it is totally unnecessary to sort in advance when applying MM.
In equation 14, we can see that in the worst case, for example, the first step, , the complexity is equal to sort-and-evaluate scheme, i.e. equation 7. For every extra state we store (i.e. ), we are trading cost for . Since in general (one will have to evaluate through the pauli word on every qubit, including ”I”), we explicitly proofed that MM is more efficient than the original sort-and-evaluate procedure (without MM). Furthermore, if given enough iteration, as accumulates, we expect asymptotic behavior of to zero, making the complexity
| (16) |