Efficient Second Order Online Learning by Sketching
Abstract
We propose Sketched Online Newton (SON), an online second order learning algorithm that enjoys substantially improved regret guarantees for ill-conditioned data. SON is an enhanced version of the Online Newton Step, which, via sketching techniques enjoys a running time linear in the dimension and sketch size. We further develop sparse forms of the sketching methods (such as Oja’s rule), making the computation linear in the sparsity of features. Together, the algorithm eliminates all computational obstacles in previous second order online learning approaches.
1 Introduction
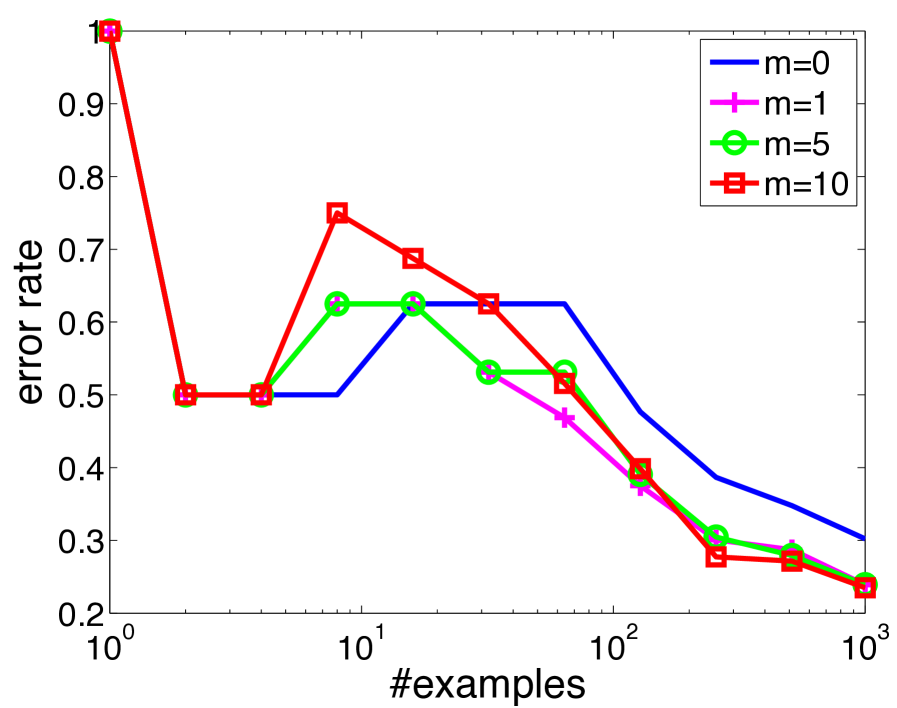
Online learning methods are highly successful at rapidly reducing the test error on large, high-dimensional datasets. First order methods are particularly attractive in such problems as they typically enjoy computational complexity linear in the input size. However, the convergence of these methods crucially depends on the geometry of the data; for instance, running the same algorithm on a rotated set of examples can return vastly inferior results. See Fig. 1 for an illustration.
Second order algorithms such as Online Newton Step (Hazan et al., 2007) have the attractive property of being invariant to linear transformations of the data, but typically require space and update time quadratic in the number of dimensions. Furthermore, the dependence on dimension is not improved even if the examples are sparse. These issues lead to the key question in our work: Can we develop (approximately) second order online learning algorithms with efficient updates? We show that the answer is “yes” by developing efficient sketched second order methods with regret guarantees. Specifically, the three main contributions of this work are:
1. Invariant learning setting and optimal algorithms (Section 2).
The typical online regret minimization setting evaluates against a benchmark that is bounded in some fixed norm (such as the -norm), implicitly putting the problem in a nice geometry. However, if all the features are scaled down, it is desirable to compare with accordingly larger weights, which is precluded by an apriori fixed norm bound. We study an invariant learning setting similar to the paper (Ross et al., 2013) which compares the learner to a benchmark only constrained to generate bounded predictions on the sequence of examples. We show that a variant of the Online Newton Step (Hazan et al., 2007), while quadratic in computation, stays regret-optimal with a nearly matching lower bound in this more general setting.
2. Improved efficiency via sketching (Section 3).
To overcome the quadratic running time, we next develop sketched variants of the Newton update, approximating the second order information using a small number of carefully chosen directions, called a sketch. While the idea of data sketching is widely studied (Woodruff, 2014), as far as we know our work is the first one to apply it to a general adversarial online learning setting and provide rigorous regret guarantees. Two different sketching methods are considered: Frequent Directions (Ghashami et al., 2015; Liberty, 2013) and Oja’s algorithm (Oja, 1982; Oja and Karhunen, 1985), both of which allow linear running time per round. For the first method, we prove regret bounds similar to the full second order update whenever the sketch-size is large enough. Our analysis makes it easy to plug in other sketching and online PCA methods (e.g. (Garber et al., 2015)).
3. Sparse updates (Section 4).
For practical implementation, we further develop sparse versions of these updates with a running time linear in the sparsity of the examples. The main challenge here is that even if examples are sparse, the sketch matrix still quickly becomes dense. These are the first known sparse implementations of the Frequent Directions111Recent work by (Ghashami et al., 2016) also studies sparse updates for a more complicated variant of Frequent Directions which is randomized and incurs extra approximation error. and Oja’s algorithm, and require new sparse eigen computation routines that may be of independent interest.
Empirically, we evaluate our algorithm using the sparse Oja sketch (called Oja-SON) against first order methods such as diagonalized AdaGrad (Duchi et al., 2011; McMahan and Streeter, 2010) on both ill-conditioned synthetic and a suite of real-world datasets. As Fig. 1 shows for a synthetic problem, we observe substantial performance gains as data conditioning worsens. On the real-world datasets, we find improvements in some instances, while observing no substantial second-order signal in the others.
Related work
Our online learning setting is closest to the one proposed in (Ross et al., 2013), which studies scale-invariant algorithms, a special case of the invariance property considered here (see also (Orabona et al., 2015, Section 5)). Computational efficiency, a main concern in this work, is not a problem there since each coordinate is scaled independently. Orabona and Pál (2015) study unrelated notions of invariance. Gao et al. (2013) study a specific randomized sketching method for a special online learning setting.
The L-BFGS algorithm (Liu and Nocedal, 1989) has recently been studied in the stochastic setting222Stochastic setting assumes that the examples are drawn i.i.d. from a distribution. (Byrd et al., 2016; Mokhtari and Ribeiro, 2015; Moritz et al., 2016; Schraudolph et al., 2007; Sohl-Dickstein et al., 2014), but has strong assumptions with pessimistic rates in theory and reliance on the use of large mini-batches empirically. Recent works (Erdogdu and Montanari, 2015; Gonen et al., 2016; Gonen and Shalev-Shwartz, 2015; Pilanci and Wainwright, 2015) employ sketching in stochastic optimization, but do not provide sparse implementations or extend in an obvious manner to the online setting. The Frank-Wolfe algorithm (Frank and Wolfe, 1956; Jaggi, 2013) is also invariant to linear transformations, but with worse regret bounds (Hazan and Kale, 2012) without further assumptions and modifications (Garber and Hazan, 2016).
Notation
Vectors are represented by bold letters (e.g., , , …) and matrices by capital letters (e.g., , , …). denotes the entry of matrix . represents the identity matrix, represents the matrix of zeroes, and represents a diagonal matrix with on the diagonal. denotes the -th largest eigenvalue of , denotes , is the determinant of , is the trace of , denotes , and means that is positive semidefinite. The sign function is if and otherwise.
2 Setup and an Optimal Algorithm
We consider the following setting. On each round : (1) the adversary first presents an example , (2) the learner chooses and predicts , (3) the adversary reveals a loss function for some convex, differentiable , and (4) the learner suffers loss for this round.
The learner’s regret to a comparator is defined as . Typical results study against all with a bounded norm in some geometry. For an invariant update, we relax this requirement and only put bounds on the predictions . Specifically, for some pre-chosen constant we define We seek to minimize regret to all comparators that generate bounded predictions on every data point, that is:
Under this setup, if the data are transformed to for all and some invertible matrix , the optimal simply moves to , which still has bounded predictions but might have significantly larger norm. This relaxation is similar to the comparator set considered in (Ross et al., 2013).
We make two structural assumptions on the loss functions.
Assumption 1.
(Scalar Lipschitz) The loss function satisfies whenever .
Assumption 2.
(Curvature) There exists such that for all , is lower bounded by
Note that when , Assumption 2 merely imposes convexity. More generally, it is satisfied by squared loss with whenever and are bounded by , as well as for all exp-concave functions (see (Hazan et al., 2007, Lemma 3)).
Enlarging the comparator set might result in worse regret. We next show matching upper and lower bounds qualitatively similar to the standard setting, but with an extra unavoidable factor. 333In the standard setting where and are restricted such that and , the minimax regret is . This is clearly a special case of our setting with .
Theorem 1.
We now give an algorithm that matches the lower bound up to logarithmic constants in the worst case but enjoys much smaller regret when . At round with some invertible matrix specified later and gradient , the algorithm performs the following update before making the prediction on the example :
| (1) |
The projection onto the set differs from typical norm-based projections as it only enforces boundedness on at round . Moreover, this projection step can be performed in closed form.
Lemma 1.
For any and positive definite matrix , we have
If is a diagonal matrix, updates similar to those of Ross et al. (2013) are recovered. We study a choice of that is similar to the Online Newton Step (ONS) (Hazan et al., 2007) (though with different projections):
| (2) |
for some parameters and . The regret guarantee of this algorithm is shown below:
Theorem 2.
The dependence on implies that the method is not completely invariant to transformations of the data. This is due to the part in . However, this is not critical since is fixed and small while the other part of the bound grows to eventually become the dominating term. Moreover, we can even set and replace the inverse with the Moore-Penrose pseudoinverse to obtain a truly invariant algorithm, as discussed in Appendix D. We use in the remainder for simplicity.
The implication of this regret bound is the following: in the worst case where , we set and the bound simplifies to
essentially only losing a logarithmic factor compared to the lower bound in Theorem 1. On the other hand, if for all , then we set and the regret simplifies to
| (3) |
extending the results in (Hazan et al., 2007) to the weaker Assumption 2 and a larger comparator set .
3 Efficiency via Sketching
Our algorithm so far requires time and space just as ONS. In this section we show how to achieve regret guarantees nearly as good as the above bounds, while keeping computation within a constant factor of first order methods.
Let be a matrix such that the -th row is where we define to be the to-sketch vector. Our previous choice of (Eq. (2)) can be written as . The idea of sketching is to maintain an approximation of , denoted by where is a small constant called the sketch size. If is chosen so that approximates well, we can redefine as for the algorithm.
To see why this admits an efficient algorithm, notice that by the Woodbury formula one has With the notation and , update (1) becomes:
The operations involving or require only time, while matrix vector products with require only . Altogether, these updates are at most times more expensive than first order algorithms as long as and can be maintained efficiently. We call this algorithm Sketched Online Newton (SON) and summarize it in Algorithm 1.
We now discuss two sketching techniques to maintain the matrices and efficiently, each requiring storage and time linear in .
Frequent Directions (FD).
| Algorithm 2 FD-Sketch for FD-SON 1: and . 2: 3:Set and . 4:Return . 1: 2:Insert into the last row of . 3:Compute eigendecomposition: and set . 4:Set . 5:Return . | Algorithm 3 Oja’s Sketch for Oja-SON 1:, , and . 2: 3:Set and to any matrix with orthonormal rows. 4:Return (, ). 1: 2:Update , and as Eqn. 4. 3:Set . 4:Set . 5:Return . |
Frequent Directions sketch (Ghashami et al., 2015; Liberty, 2013) is a deterministic sketching method. It maintains the invariant that the last row of is always . On each round, the vector is inserted into the last row of , then the covariance of the resulting matrix is eigendecomposed into and is set to where is the smallest eigenvalue. Since the rows of are orthogonal to each other, is a diagonal matrix and can be maintained efficiently (see Algorithm 2). The sketch update works in time (see (Ghashami et al., 2015) and Appendix F) so the total running time is per round. We call this combination FD-SON and prove the following regret bound with notation for any .
Theorem 3.
The bound depends on the spectral decay , which essentially is the only extra term compared to the bound in Theorem 2. Similarly to previous discussion, if , we get the bound With tuned well, we pay logarithmic regret for the top eigenvectors, but a square root regret for remaining directions not controlled by our sketch. This is expected for deterministic sketching which focuses on the dominant part of the spectrum. When is not tuned we still get sublinear regret as long as is sublinear.
Oja’s Algorithm.
Oja’s algorithm (Oja, 1982; Oja and Karhunen, 1985) is not usually considered as a sketching algorithm but seems very natural here. This algorithm uses online gradient descent to find eigenvectors and eigenvalues of data in a streaming fashion, with the to-sketch vector ’s as the input. Specifically, let denote the estimated eigenvectors and the diagonal matrix contain the estimated eigenvalues at the end of round . Oja’s algorithm updates as:
| (4) |
where is a diagonal matrix with (possibly different) learning rates of order on the diagonal, and the “” operator represents an orthonormalizing step.444For simplicity, we assume that is always of full rank so that the orthonormalizing step does not reduce the dimension of . The sketch is then . The rows of are orthogonal and thus is an efficiently maintainable diagonal matrix (see Algorithm 3). We call this combination Oja-SON.
The time complexity of Oja’s algorithm is per round due to the orthonormalizing step. To improve the running time to , one can only update the sketch every rounds (similar to the block power method (Hardt and Price, 2014; Li et al., 2015)). The regret guarantee of this algorithm is unclear since existing analysis for Oja’s algorithm is only for the stochastic setting (see e.g. (Balsubramani et al., 2013; Li et al., 2015)). However, Oja-SON provides good performance experimentally.
4 Sparse Implementation
In many applications, examples (and hence gradients) are sparse in the sense that for all and some small constant . Most online first order methods enjoy a per-example running time depending on instead of in such settings. Achieving the same for second order methods is more difficult since (or sketched versions) are typically dense even if is sparse.
We show how to implement our algorithms in sparsity-dependent time, specifically, in for FD-SON and in for Oja-SON. We emphasize that since the sketch would still quickly become a dense matrix even if the examples are sparse, achieving purely sparsity-dependent time is highly non-trivial and may be of independent interest. Due to space limit, below we only briefly mention how to do it for Oja-SON. Similar discussion for the FD sketch can be found in Appendix F. Note that mathematically these updates are equivalent to the non-sparse counterparts and regret guarantees are thus unchanged.
There are two ingredients to doing this for Oja-SON: (1) The eigenvectors are represented as , where is a sparsely updatable direction (Step 3 in Algorithm 5) and is a matrix such that is orthonormal. (2) The weights are split as , where maintains the weights on the subspace captured by (same as ), and captures the weights on the complementary subspace which are again updated sparsely.
We describe the sparse updates for and below with the details for and deferred to Appendix G. Since and , we know is
| (5) |
Since is sparse by construction and the matrix operations defining scale with , overall the update can be done in . Using the update for in terms of , is equal to
| (6) |
Again, it is clear that all the computations scale with and not , so both and require only time to maintain. Furthermore, the prediction can also be computed in time. The in the overall complexity comes from a Gram-Schmidt step in maintaining (details in Appendix G).
The pseudocode is presented in Algorithms 4 and 5 with some details deferred to Appendix G. This is the first sparse implementation of online eigenvector computation to the best of our knowledge.
5 Experiments
Preliminary experiments revealed that out of our two sketching options, Oja’s sketch generally has better performance (see Appendix H). For more thorough evaluation, we implemented the sparse version of Oja-SON in Vowpal Wabbit.555An open source machine learning toolkit available at http://hunch.net/ṽw We compare it with AdaGrad (Duchi et al., 2011; McMahan and Streeter, 2010) on both synthetic and real-world datasets. Each algorithm takes a stepsize parameter: serves as a stepsize for Oja-SON and a scaling constant on the gradient matrix for AdaGrad. We try both methods with the parameter set to for and report the best results. We keep the stepsize matrix in Oja-SON fixed as throughout. All methods make one online pass over data minimizing square loss.
5.1 Synthetic Datasets
To investigate Oja-SON’s performance in the setting it is really designed for, we generated a range of synthetic ill-conditioned datasets as follows. We picked a random Gaussian matrix ( and ) and a random orthonormal basis . We chose a specific spectrum where the first coordinates are 1 and the rest increase linearly to some fixed condition number parameter . We let be our example matrix, and created a binary classification problem with labels , where is a random vector. We generated 20 such datasets with the same and labels but different values of }. Note that if the algorithm is truly invariant, it would have the same behavior on these 20 datasets.
Fig. 1 (in Section 1) shows the final progressive error (i.e. fraction of misclassified examples after one pass over data) for AdaGrad and Oja-SON (with sketch size ) as the condition number increases. As expected, the plot confirms the performance of first order methods such as AdaGrad degrades when the data is ill-conditioned. The plot also shows that as the sketch size increases, Oja-SON becomes more accurate: when (no sketch at all), Oja-SON is vanilla gradient descent and is worse than AdaGrad as expected; when , the accuracy greatly improves; and finally when , the accuracy of Oja-SON is substantially better and hardly worsens with .
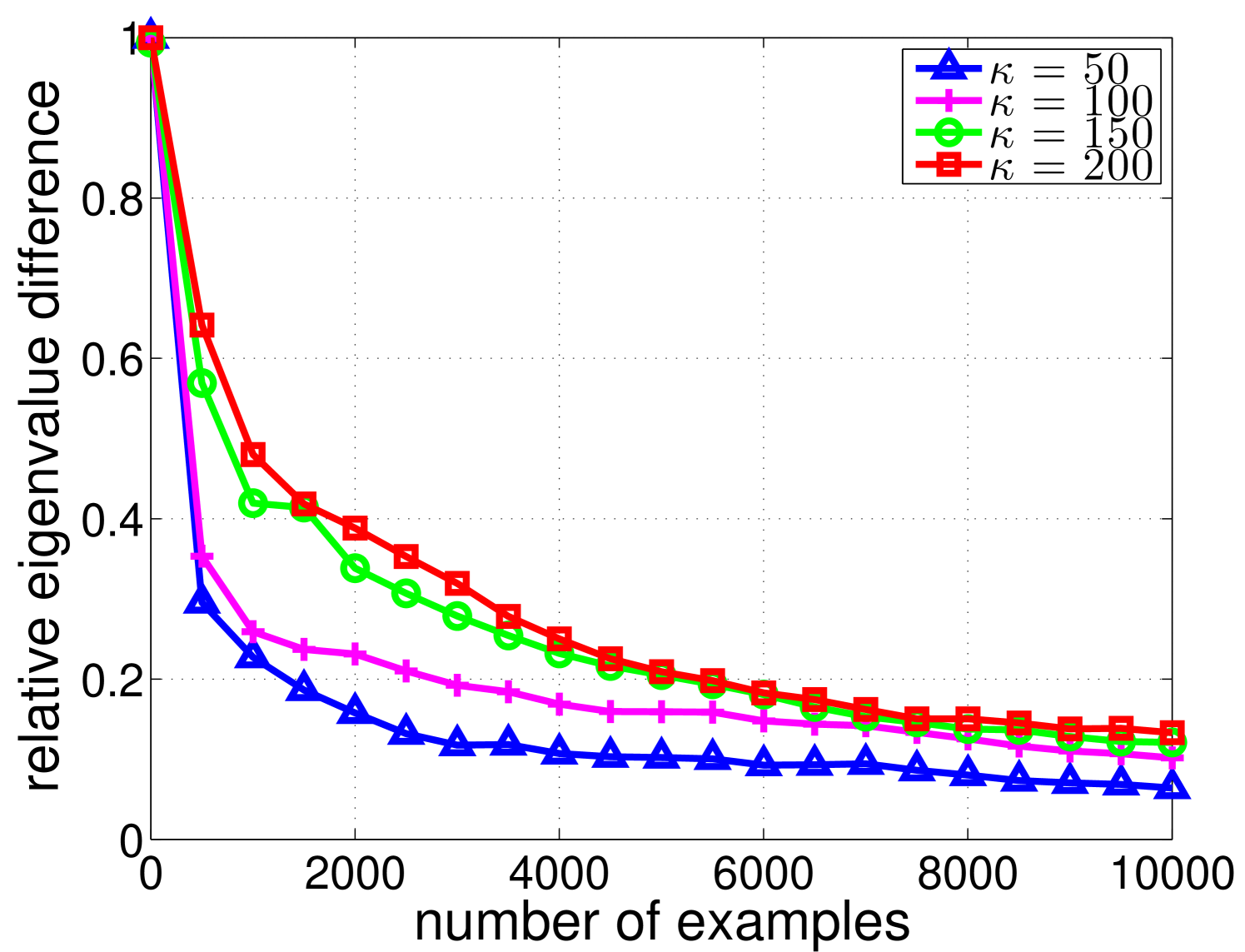
To further explain the effectiveness of Oja’s algorithm in identifying top eigenvalues and eigenvectors, the plot in Fig. 2 shows the largest relative difference between the true and estimated top 10 eigenvalues as Oja’s algorithm sees more data. This gap drops quickly after seeing just 500 examples.
5.2 Real-world Datasets
Next we evaluated Oja-SON on 23 benchmark datasets from the UCI and LIBSVM repository (see Appendix H for description of these datasets). Note that some datasets are very high dimensional but very sparse (e.g. for 20news, and ), and consequently methods with running time quadratic (such as ONS) or even linear in dimension rather than sparsity are prohibitive.
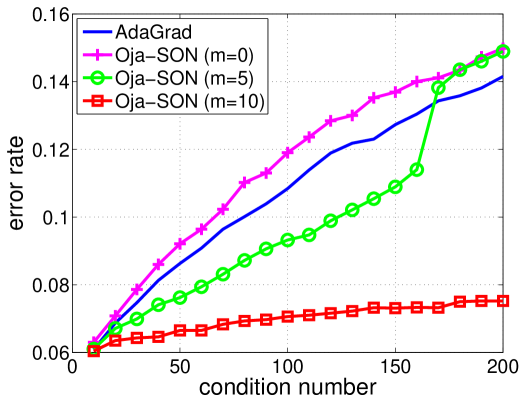
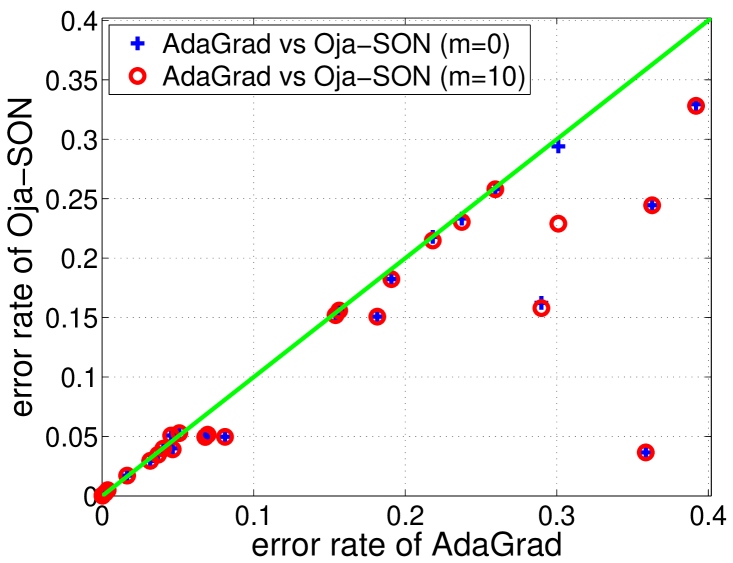
In Fig. 3, we show the effect of using sketched second order information, by comparing sketch size and for Oja-SON (concrete error rates in Appendix H). We observe significant improvements in 5 datasets (acoustic, census, heart, ionosphere, letter), demonstrating the advantage of using second order information. However, we found that Oja-SON was outperformed by AdaGrad on most datasets, mostly because the diagonal adaptation of AdaGrad greatly reduces the condition number on these datasets. Moreover, one disadvantage of SON is that for the directions not in the sketch, it is essentially doing vanilla gradient descent. We expect better results using diagonal adaptation as in AdaGrad in off-sketch directions.
To incorporate this high level idea, we performed a simple modification to Oja-SON: upon seeing example , we feed to our algorithm instead of , where is the diagonal part of the matrix .666 is defined as to avoid division by zero. The intuition is that this diagonal rescaling first homogenizes the scales of all dimensions. Any remaining ill-conditioning is further addressed by the sketching to some degree, while the complementary subspace is no worse-off than with AdaGrad. We believe this flexibility in picking the right vectors to sketch is an attractive aspect of our sketching-based approach.
With this modification, Oja-SON outperforms AdaGrad on most of the datasets even for , as shown in Fig. 3 (concrete error rates in Appendix H). The improvement on AdaGrad at is surprising but not impossible as the updates are not identical–our update is scale invariant like Ross et al. (2013). However, the diagonal adaptation already greatly reduces the condition number on all datasets except splice (see Fig. 4 in Appendix H for detailed results on this dataset), so little improvement is seen for sketch size over . For several datasets, we verified the accuracy of Oja’s method in computing the top-few eigenvalues (Appendix H), so the lack of difference between sketch sizes is due to the lack of second order information after the diagonal correction.
The average running time of our algorithm when is about 11 times slower than AdaGrad, matching expectations. Overall, SON can significantly outperform baselines on ill-conditioned data, while maintaining a practical computational complexity.
Acknowledgements
This work was done when Haipeng Luo and Nicolò Cesa-Bianchi were at Microsoft Research, New York. We thank Lijun Zhang for pointing out our mistake in the regret proof of another sketching method that appeared in an earlier version.
References
- Balsubramani et al. [2013] A. Balsubramani, S. Dasgupta, and Y. Freund. The fast convergence of incremental pca. In NIPS, 2013.
- Byrd et al. [2016] R. H. Byrd, S. Hansen, J. Nocedal, and Y. Singer. A stochastic quasi-newton method for large-scale optimization. SIAM Journal on Optimization, 26:1008–1031, 2016.
- Cesa-Bianchi and Lugosi [2006] N. Cesa-Bianchi and G. Lugosi. Prediction, Learning, and Games. Cambridge University Press, 2006.
- Cesa-Bianchi et al. [2005] N. Cesa-Bianchi, A. Conconi, and C. Gentile. A second-order perceptron algorithm. SIAM Journal on Computing, 34(3):640–668, 2005.
- Duchi et al. [2011] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. JMLR, 12:2121–2159, 2011.
- Erdogdu and Montanari [2015] M. A. Erdogdu and A. Montanari. Convergence rates of sub-sampled newton methods. In NIPS, 2015.
- Frank and Wolfe [1956] M. Frank and P. Wolfe. An algorithm for quadratic programming. Naval research logistics quarterly, 3(1-2):95–110, 1956.
- Gao et al. [2013] W. Gao, R. Jin, S. Zhu, and Z.-H. Zhou. One-pass auc optimization. In ICML, 2013.
- Garber and Hazan [2016] D. Garber and E. Hazan. A linearly convergent conditional gradient algorithm with applications to online and stochastic optimization. SIAM Journal on Optimization, 26:1493–1528, 2016.
- Garber et al. [2015] D. Garber, E. Hazan, and T. Ma. Online learning of eigenvectors. In ICML, 2015.
- Ghashami et al. [2015] M. Ghashami, E. Liberty, J. M. Phillips, and D. P. Woodruff. Frequent directions: Simple and deterministic matrix sketching. SIAM Journal on Computing, 45:1762–1792, 2015.
- Ghashami et al. [2016] M. Ghashami, E. Liberty, and J. M. Phillips. Efficient frequent directions algorithm for sparse matrices. In KDD, 2016.
- Gonen and Shalev-Shwartz [2015] A. Gonen and S. Shalev-Shwartz. Faster sgd using sketched conditioning. arXiv:1506.02649, 2015.
- Gonen et al. [2016] A. Gonen, F. Orabona, and S. Shalev-Shwartz. Solving ridge regression using sketched preconditioned svrg. In ICML, 2016.
- Hardt and Price [2014] M. Hardt and E. Price. The noisy power method: A meta algorithm with applications. In NIPS, 2014.
- Hazan and Kale [2012] E. Hazan and S. Kale. Projection-free online learning. In ICML, 2012.
- Hazan et al. [2007] E. Hazan, A. Agarwal, and S. Kale. Logarithmic regret algorithms for online convex optimization. Machine Learning, 69(2-3):169–192, 2007.
- Jaggi [2013] M. Jaggi. Revisiting frank-wolfe: Projection-free sparse convex optimization. In ICML, 2013.
- Li et al. [2015] C.-L. Li, H.-T. Lin, and C.-J. Lu. Rivalry of two families of algorithms for memory-restricted streaming pca. arXiv:1506.01490, 2015.
- Liberty [2013] E. Liberty. Simple and deterministic matrix sketching. In KDD, 2013.
- Liu and Nocedal [1989] D. C. Liu and J. Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45(1-3):503–528, 1989.
- McMahan and Streeter [2010] H. B. McMahan and M. Streeter. Adaptive bound optimization for online convex optimization. In COLT, 2010.
- Mokhtari and Ribeiro [2015] A. Mokhtari and A. Ribeiro. Global convergence of online limited memory bfgs. JMLR, 16:3151–3181, 2015.
- Moritz et al. [2016] P. Moritz, R. Nishihara, and M. I. Jordan. A linearly-convergent stochastic l-bfgs algorithm. In AISTATS, 2016.
- Oja [1982] E. Oja. Simplified neuron model as a principal component analyzer. Journal of mathematical biology, 15(3):267–273, 1982.
- Oja and Karhunen [1985] E. Oja and J. Karhunen. On stochastic approximation of the eigenvectors and eigenvalues of the expectation of a random matrix. Journal of mathematical analysis and applications, 106(1):69–84, 1985.
- Orabona and Pál [2015] F. Orabona and D. Pál. Scale-free algorithms for online linear optimization. In ALT, 2015.
- Orabona et al. [2015] F. Orabona, K. Crammer, and N. Cesa-Bianchi. A generalized online mirror descent with applications to classification and regression. Machine Learning, 99(3):411–435, 2015.
- Pilanci and Wainwright [2015] M. Pilanci and M. J. Wainwright. Newton sketch: A linear-time optimization algorithm with linear-quadratic convergence. arXiv:1505.02250, 2015.
- Ross et al. [2013] S. Ross, P. Mineiro, and J. Langford. Normalized online learning. In UAI, 2013.
- Schraudolph et al. [2007] N. N. Schraudolph, J. Yu, and S. Günter. A stochastic quasi-newton method for online convex optimization. In AISTATS, 2007.
- Sohl-Dickstein et al. [2014] J. Sohl-Dickstein, B. Poole, and S. Ganguli. Fast large-scale optimization by unifying stochastic gradient and quasi-newton methods. In ICML, 2014.
- Woodruff [2014] D. P. Woodruff. Sketching as a tool for numerical linear algebra. Foundations and Trends in Machine Learning, 10(1-2):1–157, 2014.
Supplementary material for
“Efficient Second Order Online Learning by Sketching”
Appendix A Proof of Theorem 1
Proof.
Assuming is a multiple of without loss of generality, we pick from the basis vectors so that each appears times (in an arbitrary order). Note that now is just a hypercube:
Let be independent Rademacher random variables such that . For a scalar , we define loss function777By adding a suitable constant, these losses can always be made nonnegative while leaving the regret unchanged. , so that Assumptions 1 and 2 are clearly satisfied with . We show that, for any online algorithm,
which implies the statement of the theorem.
First of all, note that for any . Hence we have
which, by the construction of , is
where the final bound is due to the Khintchine inequality (see e.g. Lemma 8.2 in Cesa-Bianchi and Lugosi [2006]). This concludes the proof. ∎
Appendix B Projection
We prove a more general version of Lemma 1 which does not require invertibility of the matrix here.
Lemma 2.
For any and positive semidefinite matrix , we have
where and is the Moore-Penrose pseudoinverse of . (Note that when is rank deficient, this is one of the many possible solutions.)
Proof.
First consider the case when . If , then it is trivial that . We thus assume below (the last case is similar). The Lagrangian of the problem is
where and are Lagrangian multipliers. Since cannot be and at the same time, The complementary slackness condition implies that either or . Suppose the latter case is true, then setting the derivative with respect to to , we get where can be arbitrary. However, since , this part does not affect the objective value at all and we can simply pick so that has a consistent form regardless of whether is full rank or not. Now plugging back, we have
which is maximized when . Plugging this optimal into gives the stated solution. On the other hand, if instead, we can proceed similarly and verify that it gives a smaller dual value ( in fact), proving the previous solution is indeed optimal.
We now move on to the case when . First of all the stated solution is well defined since is nonzero in this case. Moreover, direct calculation shows that is in the valid space: , and also it gives the minimal possible distance value , proving the lemma. ∎
Appendix C Proof of Theorem 2
We first prove a general regret bound that holds for any choice of in update 1:
This bound will also be useful in proving regret guarantees for the sketched versions.
Proposition 1.
Proof.
Proof of Theorem 2.
We apply Proposition 1 with the choice: and , which gives and
where the last equality uses the Lipschitz property in Assumption 1 and the boundedness of and .
For the term , define . Since and is non-increasing, we have , and therefore:
where the second inequality is by the concavity of the function (see [Hazan et al., 2007, Lemma 12] for an alternative proof), and the last one is by Jensen’s inequality. This concludes the proof. ∎
Appendix D A Truly Invariant Algorithm
In this section we discuss how to make our adaptive online Newton algorithm truly invariant to invertible linear transformations. To achieve this, we set and replace with the Moore-Penrose pseudoinverse : 888See Appendix B for the closed form of the projection step.
| (7) |
When written in this form, it is not immediately clear that the algorithm has the invariant property. However, one can rewrite the algorithm in a mirror descent form:
where we use the fact that is in the range of in the last step. Now suppose all the data are transformed to for some unknown and invertible matrix , then one can verify that all the weights will be transformed to accordingly, ensuring the prediction to remain the same.
Moreover, the regret bound of this algorithm can be bounded as below. First notice that even when is rank deficient, the projection step still ensures the following: , which is proven in [Hazan et al., 2007, Lemma 8]. Therefore, the entire proof of Theorem 2 still holds after replacing with , giving the regret bound:
| (8) |
The key now is to bound the term where we define . In order to do this, we proceed similarly to the proof of [Cesa-Bianchi et al., 2005, Theorem 4.2] to show that this term is of order in the worst case.
Theorem 4.
Let be the minimum among the smallest nonzero eigenvalues of and be the rank of . We have
Proof.
First by Cesa-Bianchi et al. [2005, Lemma D.1], we have
where denotes the product of the nonzero eigenvalues of matrix . We thus separate the steps such that from those where . For each let be the first time step in which the rank of is (so that ). Also let for convenience. With this notation, we have
Fix any and let be the nonzero eigenvalues of and be the nonzero eigenvalues of . Then
Hence, we arrive at
To further bound the latter quantity, we use and Jensen’s inequality :
Finally noticing that
completes the proof. ∎
Taken together, Eq. (8) and Theorem 4 lead to the following regret bounds (recall the definitions of and from Theorem 4).
Corollary 1.
If for all and is set to be , then the regret of the algorithm defined by Eq. (7) is at most
On the other hand, if for all and is set to be , then the regret is at most
Appendix E Proof of Theorem 3
Proof.
We again first apply Proposition 1 (recall the notation and stated in the proposition). By the construction of the sketch, we have
It follows immediately that is again at most . For the term , we will apply the following guarantee of Frequent Directions (see the proof of Theorem 1.1 of [Ghashami et al., 2015]): Specifically, since we have
Finally for the term , we proceed similarly to the proof of Theorem 2:
where the first inequality is by the concavity of the function , the second one is by Jensen’s inequality, and the last equality is by the fact that is of rank and thus for any . This concludes the proof. ∎
Appendix F Sparse updates for FD sketch
The sparse version of our algorithm with the Frequent Directions option is much more involved. We begin by taking a detour and introducing a fast and epoch-based variant of the Frequent Directions algorithm proposed in [Ghashami et al., 2015]. The idea is the following: instead of doing an eigendecomposition immediately after inserting a new every round, we double the size of the sketch (to ), keep up to recent ’s, do the decomposition only at the end of every rounds and finally keep the top eigenvectors with shrunk eigenvalues. The advantage of this variant is that it can be implemented straightforwardly in time on average without doing a complicated rank-one SVD update, while still ensuring the exact same guarantee with the only price of doubling the sketch size.
Algorithm 6 shows the details of this variant and how we maintain . The sketch is always represented by two parts: the top part () comes from the last eigendecomposition, and the bottom part () collects the recent to-sketch vector ’s. Note that within each epoch, the update of is a rank-two update and thus can be updated efficiently using Woodbury formula (Lines 4 and 5 of Algorithm 6).
Although we can use any available algorithm that runs in time to do the eigendecomposition (Line 8 in Algorithm 6), we explicitly write down the procedure of reducing this problem to eigendecomposing a small square matrix in Algorithm 7, which will be important for deriving the sparse version of the algorithm. Lemma 3 proves that Algorithm 7 works correctly for finding the top eigenvector and eigenvalues.
Lemma 3.
The outputs of Algorithm 7 are such that the -th row of and the -th entry of the diagonal of are the -th eigenvector and eigenvalue of respectively.
Proof.
Let be an orthonormal basis of the null space of . By Line 4, we know that and forms an orthonormal basis of . Therefore, we have
where in the last step we use the fact . Now it is clear that the eigenvalue of will be the eigenvalue of and the eigenvector of will be the eigenvector of after left multiplied by matrix , completing the proof. ∎
We are now ready to present the sparse version of SON with Frequent Direction sketch (Algorithm 8). The key point is that we represent as for some and , and the weight vector as and ensure that the update of and will always be sparse. To see this, denote the sketch by and let and be the top and bottom half of . Now the update rule of can be rewritten as
We will show that for some shortly, and thus the above update is efficient due to the fact that the rows of are collections of previous sparse vectors .
Similarly, the update of can be written as
It is clear that can be computed efficiently, and thus the update of is also efficient. These updates correspond to Line 7 and 11 of Algorithm 8.
It remains to perform the sketch update efficiently. Algorithm 9 is the sparse version of Algorithm 6. The challenging part is to compute eigenvectors and eigenvalues efficiently. Fortunately, in light of Algorithm 7, using the new representation one can directly translate the process to Algorithm 10 and find that the eigenvectors can be expressed in the form . To see this, first note that Line 1 of both algorithms compute the same matrix . Then Line 4 decomposes the matrix
using Gram-Schmidt into the form such that the rows of are orthonormal (that is, corresponds to in Algorithm 7). While directly applying Gram-Schmidt to would take time, this step can in fact be efficiently implemented by performing Gram-Schmidt to (instead of ) in a Banach space where inner product is defined as with
being the Gram matrix of . Since we can efficiently maintain the Gram matrix of (see Line 11 of Algorithm 9) and and can be computed sparsely, this decomposing step can be done efficiently too. This modified Gram-Schmidt algorithm is presented in Algorithm 11 (which will also be used in sparse Oja’s sketch), where Line 6 is the key difference compared to standard Gram-Schmidt (see Lemma 4 below for a formal proof of correctness).
Line 3 of Algorithms 7 and 10 are exactly the same. Finally the eigenvectors in Algorithm 7 now becomes (with defined in Line 4 of Algorithm 10)
Therefore, having the eigenvectors in the form , we can simply update as and as so that the invariant still holds (see Line 12 of Algorithm 9). The update of is sparse since is sparse.
We finally summarize the results of this section in the following theorem.
Theorem 5.
Lemma 4.
The output of Algorithm 11 ensures that and the rows of are orthonormal.
Proof.
It suffices to prove that Algorithm 11 is exactly the same as using the standard Gram-Schmidt to decompose the matrix into and an orthonormal matrix which can be written as . First note that when , Algorithm 11 is simply the standard Gram-Schmidt algorithm applied to . We will thus go through Line 1-10 of Algorithm 11 with replaced by and by and show that it leads to the exact same calculations as running Algorithm 11 directly. For clarity, we add “” to symbols to distinguish the two cases (so and ). We will inductively prove the invariance and . The base case and is trivial. Now assume it holds for iteration and consider iteration . We have
which clearly implies that after execution of Line 5-9, we again have and , finishing the induction. ∎
Appendix G Details for sparse Oja’s algorithm
We finally provide the missing details for the sparse version of the Oja’s algorithm. Since we already discussed the updates for and in Section 4, we just need to describe how the updates for and work. Recall that the dense Oja’s updates can be written in terms of and as
| (9) |
Here, the update for the eigenvalues is straightforward. For the update of eigenvectors, first we let where (note that under the assumption of Footnote 4, is always invertible). Now it is clear that is a sparse rank-one matrix and the update of is efficient. Finally it remains to update so that is the same as orthonormalizing , which can in fact be achieved by applying the Gram-Schmidt algorithm to in a Banach space where inner product is defined as where is the Gram matrix (see Algorithm 11). Since we can maintain efficiently based on the update of :
the update of can therefore be implemented in time.
Appendix H Experiment Details
This section reports some detailed experimental results omitted from Section 5.2. Table 1 includes the description of benchmark datasets; Table 2 reports error rates on relatively small datasets to show that Oja-SON generally has better performance; Table 3 reports concrete error rates for the experiments described in Section 5.2; finally Table 4 shows that Oja’s algorithm estimates the eigenvalues accurately.
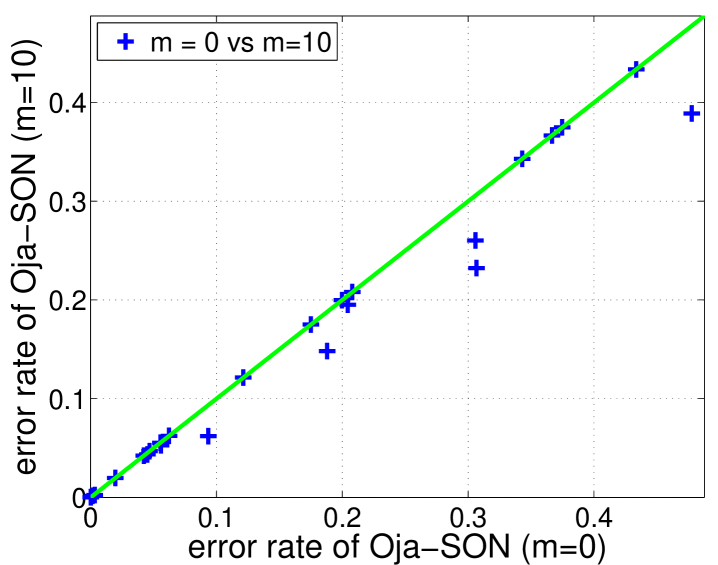
As mentioned in Section 5.2, we see substantial improvement for the splice dataset when using Oja’s sketch even after the diagonal adaptation. We verify that the condition number for this dataset before and after the diagonal adaptation are very close (682 and 668 respectively), explaining why a large improvement is seen using Oja’s sketch. Fig. 4 shows the decrease of error rates as Oja-SON with different sketch sizes sees more examples. One can see that even with Oja-SON already performs very well. This also matches our expectation since there is a huge gap between the top and second eigenvalues of this dataset ( and respectively).
| Dataset | #examples | avg. sparsity | #features |
|---|---|---|---|
| 20news | 18845 | 93.89 | 101631 |
| a9a | 48841 | 13.87 | 123 |
| acoustic | 78823 | 50.00 | 50 |
| adult | 48842 | 12.00 | 105 |
| australian | 690 | 11.19 | 14 |
| breast-cancer | 683 | 10.00 | 10 |
| census | 299284 | 32.01 | 401 |
| cod-rna | 271617 | 8.00 | 8 |
| covtype | 581011 | 11.88 | 54 |
| diabetes | 768 | 7.01 | 8 |
| gisette | 1000 | 4971.00 | 5000 |
| heart | 270 | 9.76 | 13 |
| ijcnn1 | 91701 | 13.00 | 22 |
| ionosphere | 351 | 30.06 | 34 |
| letter | 20000 | 15.58 | 16 |
| magic04 | 19020 | 9.99 | 10 |
| mnist | 11791 | 142.43 | 780 |
| mushrooms | 8124 | 21.00 | 112 |
| rcv1 | 781265 | 75.72 | 43001 |
| real-sim | 72309 | 51.30 | 20958 |
| splice | 1000 | 60.00 | 60 |
| w1a | 2477 | 11.47 | 300 |
| w8a | 49749 | 11.65 | 300 |
| Dataset | FD-SON | Oja-SON |
|---|---|---|
| australian | 16.0 | 15.8 |
| breast-cancer | 5.3 | 3.7 |
| diabetes | 35.4 | 32.8 |
| mushrooms | 0.5 | 0.2 |
| splice | 22.6 | 22.9 |
| Dataset | Oja-SON | AdaGrad | |||
|---|---|---|---|---|---|
| Without Diagonal Adaptation | With Diagonal Adaptation | ||||
| 20news | 0.121338 | 0.121338 | 0.049590 | 0.049590 | 0.068020 |
| a9a | 0.204447 | 0.195203 | 0.155953 | 0.155953 | 0.156414 |
| acoustic | 0.305824 | 0.260241 | 0.257894 | 0.257894 | 0.259493 |
| adult | 0.199763 | 0.199803 | 0.150830 | 0.150830 | 0.181582 |
| australian | 0.366667 | 0.366667 | 0.162319 | 0.157971 | 0.289855 |
| breast-cancer | 0.374817 | 0.374817 | 0.036603 | 0.036603 | 0.358712 |
| census | 0.093610 | 0.062038 | 0.051479 | 0.051439 | 0.069629 |
| cod-rna | 0.175107 | 0.175107 | 0.049710 | 0.049643 | 0.081066 |
| covtype | 0.042304 | 0.042312 | 0.050827 | 0.050818 | 0.045507 |
| diabetes | 0.433594 | 0.433594 | 0.329427 | 0.328125 | 0.391927 |
| gisette | 0.208000 | 0.208000 | 0.152000 | 0.152000 | 0.154000 |
| heart | 0.477778 | 0.388889 | 0.244444 | 0.244444 | 0.362963 |
| ijcnn1 | 0.046826 | 0.046826 | 0.034536 | 0.034645 | 0.036913 |
| ionosphere | 0.188034 | 0.148148 | 0.182336 | 0.182336 | 0.190883 |
| letter | 0.306650 | 0.232300 | 0.233250 | 0.230450 | 0.237350 |
| magic04 | 0.000263 | 0.000263 | 0.000158 | 0.000158 | 0.000210 |
| mnist | 0.062336 | 0.062336 | 0.040031 | 0.039182 | 0.046561 |
| mushrooms | 0.003323 | 0.002339 | 0.002462 | 0.002462 | 0.001969 |
| rcv1 | 0.055976 | 0.052694 | 0.052764 | 0.052766 | 0.050938 |
| real-sim | 0.045140 | 0.043577 | 0.029498 | 0.029498 | 0.031670 |
| splice | 0.343000 | 0.343000 | 0.294000 | 0.229000 | 0.301000 |
| w1a | 0.001615 | 0.001615 | 0.004845 | 0.004845 | 0.003633 |
| w8a | 0.000101 | 0.000101 | 0.000422 | 0.000422 | 0.000221 |
| Dataset |
|
||
|---|---|---|---|
| a9a | 0.90 | ||
| australian | 0.85 | ||
| breast-cancer | 5.38 | ||
| diabetes | 5.13 | ||
| heart | 4.36 | ||
| ijcnn1 | 0.57 | ||
| magic04 | 11.48 | ||
| mushrooms | 0.91 | ||
| splice | 8.23 | ||
| w8a | 0.95 |