Efficiently and Effectively: A Two-stage Approach to Balance Plaintext and Encrypted Text for Traffic Classification
Abstract.
Encrypted traffic classification is the task of identifying the application or service associated with encrypted network traffic. One effective approach for this task is to use deep learning methods to encode the raw traffic bytes directly and automatically extract features for classification (byte-based models). However, current byte-based models input raw traffic bytes, whether plaintext or encrypted text, for automated feature extraction, neglecting the distinct impacts of plaintext and encrypted text on downstream tasks. Additionally, these models primarily focus on improving classification accuracy, with little emphasis on the efficiency of models. In this paper, for the first time, we analyze the impact of plaintext and encrypted text on the model’s effectiveness and efficiency. Based on our observations and findings, we propose an efficient and effective two-stage approach to balance the trade-off between plaintext and encrypted text in traffic classification. Specifically, stage one proposes a DPC selector to Determine whether the Plaintext information is sufficient to perform subsequent Classification (DPC). This stage quickly identifies samples that can be classified using plaintext, leveraging explicit byte features in plaintext to enhance model’s efficiency. Stage two aims to adaptively make a classification with the result from stage one. This stage could incorporate encrypted text information for samples that cannot be classified using plaintext alone, ensuring the model’s effectiveness on traffic classification tasks. Experiments on two public datasets and one real-world collected dataset demonstrate that our proposed model achieves state-of-the-art results in both effectiveness and efficiency. The model code will be released in https://github/after/review.
1. Introduction
Encrypted traffic classification is a critical task in the field of cybersecurity, focusing on identifying and categorizing network traffic data that has been encrypted (Bujlow et al., 2015; Aceto et al., 2020). This process is essential for maintaining network security, managing bandwidth, detecting malicious activities, and ensuring regulatory compliance (Akbari et al., 2021; Cui et al., 2023). Applications of encrypted traffic classification span various domains, including intrusion detection systems, quality of service (QoS) management, and network forensics. As illustrated in Figure 1, some common applications include encrypted application classification (Lin et al., 2022), attack detection (Meng et al., 2021), VPN classification (Draper-Gil et al., 2016; Oh et al., 2023), etc.
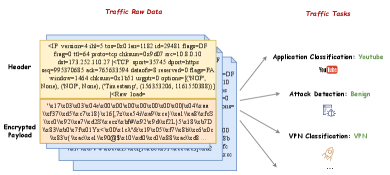
Network traffic is composed of packets, as shown in Figure 1, each consisting of two main components: the header (plaintext) and the payload (usually encrypted text). The header contains metadata about the packet, such as source and destination IP addresses, protocol information, and so on. The payload, on the other hand, contains the actual data being transmitted and is often encrypted in the form of hexadecimal to ensure confidentiality and integrity. Current byte-based encrypted traffic classification researches (Liu et al., 2019; Jemal et al., 2021; Meng et al., 2022; Zhao et al., 2023) typically use both the header and the payload as inputs to the models. A fixed number of bytes, like 128, 256, 512, etc., is utilized for the classification task. These bytes often include a mix of plaintext information from the header and encrypted data from the payload. At the same time, some studies (Akbari et al., 2022; Zhang et al., 2023) have shown that plaintext information significantly contributes to the effectiveness of classification. For example, the paper (Akbari et al., 2022) mentions that the availability of some obvious feature of the server (e.g., plain-text SNI field) in-the-clear is crucial for the utility of deep-learning-based (DL) approaches. Another research (Zhang et al., 2023) proves through ablation experiments that plaintext information is more helpful for the effectiveness of classification than encrypted text information. This leads to a fascinating hypothesis: Can we achieve satisfactory traffic classification performance using only the plaintext information present in the header?
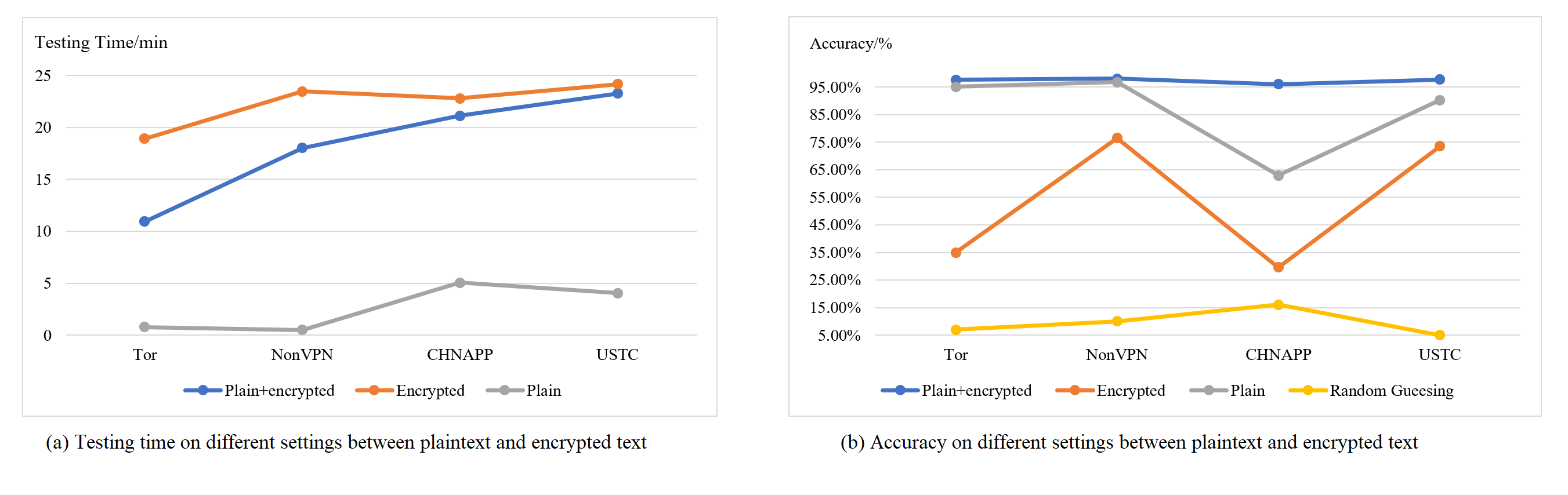
To further validate the roles of plaintext, encrypted text, and their combination in traffic classification, we compare the one of the state-of-the-art (SOTA) models (Meng et al., 2022) performance and time overhead across four datasets (Draper-Gil et al., 2016; Lashkari et al., 2017; Wang et al., 2017). For the combined plaintext-encrypted text setting, as shown in Figure 2(b), the current prevalent methods that utilize both plaintext and encrypted text achieve the highest accuracy (indicated by the blue line). However, this setting results in high time overhead, as depicted in Figure 2(a) blue line.
Some studies (Akbari et al., 2022; Zhang et al., 2023) have demonstrate that the effectiveness of DL-based methods largely rely on plaintext information. This suggests that satisfactory classification performance can be achieved by leveraging only plaintext data. Notably, for the plaintext-only setting, as indicated by the gray line in Figure 2(b), the model achieves around 90% accuracy on certain datasets, further substantiating the crucial role of plaintext in classification. Surprisingly, this setting also enhances time efficiency by approximately 4 to 10 times (indicated by the gray line in Figure 2(a)). However, relying solely on plaintext data obtains lower accuracy on some situations, like result on USTC and CHNAPP datasets (Wang et al., 2017) in Figure 2(b).
For the encrypted text setting, the results in Figure 2(b) indicate that using purely encrypted text for classification performs better than random guessing, implying that encrypted data can also aid in improving classification accuracy alongside plaintext.
In conclusion, the time overhead for the combined plaintext-encrypted text setting is considerably high, although the accuracy is the best in these settings. Therefore, balancing the utilization of plaintext and encrypted text to ensure accurate classification while optimizing time efficiency remains a key research challenge. Our study aims to explore this trade-off to achieve both high accuracy and low time overhead in traffic classification.
To address the above issues, we propose a simple but Efficient and Effective Two-Stage approach (EETS) to balance plaintext and encrypted text for traffic classification. In the first stage, we introduce a new traffic classification task: Determining whether the Plaintext is sufficient to perform subsequent Classification (DPC) and propose a DPC selector. The purpose of this stage is to fully leverage plaintext information to quickly determine if the traffic can be classified using only plaintext (plaintext classifiable). This allows us to enhance the time efficiency by avoiding unnecessary processing of encrypted data when plaintext alone suffices. In the second stage, we proceed with the plaintext classification model for a efficient classification if the traffic can be classified only using plaintext. Otherwise (plaintext non-classifiable), a combination of plaintext and encrypted text is considered to further improve the model’s accuracy. The two-stage design ensures a balance between effectiveness and efficiency. By attempting to classify with plaintext, DL-based models can significantly reduce processing time for a large portion of the traffic. For cases where plaintext is insufficient, incorporating encrypted text ensures that models still achieve high accuracy, while maintaining high time efficiency.
The contributions can be summarized as follows:
-
•
For the first time, we analyze the impact of plaintext and encrypted text on model performance and time overhead. Based on this, we introduce an interesting idea of categorizing data packets into two types: plaintext classifiable and plaintext non-classifiable. Then, a simple but efficient and effective approach is designed to significantly reduce time overhead while maintaining high classification accuracy.
-
•
We propose a two-stage approach to balance the trade-off between plaintext and encrypted text in traffic classification. Stage one proposes a DPC selector to determine whether the plaintext information is sufficient to perform subsequent classification. Stage two is to adaptively make a classification with the result from stage one.
-
•
Experimental results on two public datasets and one real-world dataset collected by ourselves demonstrate the efficiency and effectiveness of our approach.
2. Related Work
2.1. Plaintext Classification
In the early days of network traffic classification, methods (Cheng and Wang, 2011; Yoon et al., 2009; Zhang et al., 2014; Shbair et al., 2015, 2016) mainly rely on plaintext information to analyze traffic data. This includes using transport layer protocol port numbers, such as UDP or TCP, or leveraging plaintext information like the Server Name Indication (SNI). Port-based methods (Cheng and Wang, 2011; Yoon et al., 2009; Zhang et al., 2014) are straightforward to implement and have low time complexity, making them a popular choice when only specific port applications needed to be classified. However, as applications and protocols diversified and techniques such as port hopping and port masquerading emerge, the accuracy of port-based classification methods decrease, rendering them unreliable. SNI-based methods (Shbair et al., 2015, 2016) use the hostname information requested during the TLS handshake to determine the traffic category. These methods boast high accuracy and are easy to implement. Nevertheless, not all clients support SNI, particularly older browsers or operating systems. When such clients attempt to access SNI-enabled websites, SNI-based methods fail.
Rencently, with the continuous evolution of encryption protocols (Han et al., 2020; Thakur et al., 2023), plaintext classification models have become increasingly limited. Early plaintext classification approaches heavily relied on manually crafted feature engineering, and solely using plaintext information may not suffice for certain scenarios. As a result, researchers have shifted towards DL-based models, which allow for automatic feature extraction without the need to restrict the data to plaintext or encrypted text. This approach enhances the adaptability and robustness of network traffic classification methods.
2.2. Encrypted Traffic Classification
From a methodological perspective, encrypted traffic classification techniques can be broadly categorized into feature-based methods and byte-based models. Given that this paper directly uses both the header and payload content as inputs, the focus will be on byte-based models (Sirinam et al., 2018; Liu et al., 2019; Jemal et al., 2021; Meng et al., 2022; Zhao et al., 2023). The details are as follows.
Byte-based models leverage raw bytes sequences of network traffic for classification. These models do not rely on manually crafted features but utilize the inherent information present in the raw bytes. This approach allows the models to automatically learn the relevant patterns and features necessary for accurate classification, making them highly suitable for handling encrypted traffic where traditional feature extraction methods fall short.
Byte-based models (Sirinam et al., 2018; Liu et al., 2019; Jemal et al., 2021; Meng et al., 2022; Zhao et al., 2023) work directly on raw traffic bytes and learn representations using techniques like Convolutional Neural Networks (CNNs) and Long Short-Term Memory Networks (LSTMs). They can capture complex patterns in encrypted data packets without manual feature engineering. These approaches can be categorized as image-based or text-based depending on how they interpret the input traffic. Specifically, image-based models (Sirinam et al., 2018; Jemal et al., 2021; Zhao et al., 2023) treat the traffic data as 2D images by transforming the raw bytes into grayscale intensity values or RGB colors. They then apply well-known image classification CNN architectures like ResNet and Inception that have shown excellent performance in computer vision. These models can identify visual patterns in the transformed input matrix based on learned convolutional filters. Text-based models such as Recurrent Neural Networks (RNN) and LSTMs process the input sequentially as text sequences (Lotfollahi et al., 2020; Meng et al., 2022). They can analyze long-range dependencies in the raw traffic bytes. Self-attention models like transformer are also popular for learning contextual relationships in encrypted traffic data. For example, Meng et al. (2022) utilize contrastive loss with a sample selector and attention mechanism to optimize the learned representations with various traffic classification tasks.
3. Models
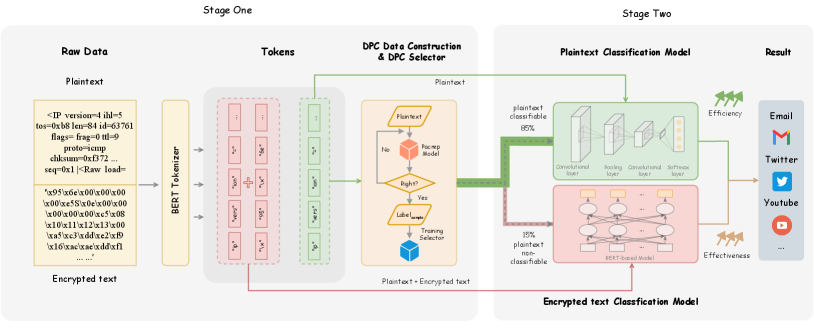
The proposed approach EETS is presented in Figure 3, which efficiently and effectively to balance plaintext and encrypted text for traffic classification. The core modules consist of a DPC selector (in stage one) and plaintext or encrypted text classification models (in stage two). Specifically, the DPC selector is able to determine whether the plaintext information is sufficient to perform subsequent classification. The purpose of this module is to fully leverage plaintext information to quickly determine if the traffic can be classified using only plaintext. Then, plaintext or encrypted text classification models can make an adaptively classification with the result from stage one. In the following, we first describe the problem formulation. Then, the detail of the EETS is introduced.
3.1. Problem Formulation
Given a pcap file, the scapy toolkit parses the file and extracts the network packets. Each packet includes header portion (plaintext) and payload data (usually encrypted text) in the form of string that consists of traffic words, with a category label , e.g. YouTube, Facebook, etc., where indicates plaintext, indicates encrypted text, means the number of plaintext traffic words. Our task can be divided into two subtasks. The first subtask involves determining, based on plaintext information, whether the data is sufficient for subsequent classification. The second subtask depends on the result of the first subtask, selecting different branches to output the corresponding packet category label, which is a multi-class classification task.
3.2. Training Stage One
3.2.1. DPC Data Construction
In the first stage of training, the proposed new DPC task involves assessing whether the plaintext information is sufficient for subsequent classification. However, existing datasets do not contain labels for this specific purpose, making the construction of the DPC data a crucial step.
Considering that the DPC task is a traffic classification problem and relatively straightforward, many SOTA traffic classification models (Lin et al., 2022; Meng et al., 2022) can be leveraged for data labeling. Specifically, we use only plaintext information as input and employ the Pacrep model to perform standard traffic classification training. Once the model is trained, we predict the labels for all data samples. A data sample is labeled as “1” (plaintext classifiable) only if the predicted label matches the original sample’s label. Otherwise, the sample is labeled as “0” (plaintext non-classifiable). The formulation can be defined as follows:
| (1) |
where is the predicted label by the traffic classification model.
After obtaining all the labels, we can then train the DPC selector, which will enable us to distinguish between plaintext classifiable and non-classifiable effectively. This process ensures accurate and efficient traffic classification in subsequent stage.
3.2.2. DPC Selector
After obtaining the training data, we proceed to train the DPC selector. This module aims to filter traffic data, directing plaintext classifiable samples to the plaintext classification model and plaintext non-classifiable samples to the encrypted classification model. This adaptive approach enhances the effectiveness of classification for different types of data, as well as playing a crucial role in optimizing the efficiency of traffic classification. Specifically, existing off-the-shelf traffic classification model 111https://github.com/ict-net/PacRep is utilized as the DPC selector to ensure robust and effective performance. The cross-entropy loss function is used for training. Then, we test the model to selectively separate the samples in the test set into two categories. As illustrated in Figure 3, our experiments show that the majority of data (represented by the green portion) is directed towards the plaintext classification model, while a smaller portion is directed towards the encrypted text classification model. This demonstrates the superiority of our proposed framework, effectively and efficiently achieving traffic classification.
3.3. Training Stage Two
In the second phase, the proposed EETS aims to adaptively select different branches for traffic classification, ensuring both effectiveness and efficiency. To further enhance the model’s efficiency, the plaintext classification model will employ a simple CNN-based deep learning approach, which allows for faster predictions. On the other hand, the encrypted classification model will utilize more complicated DL-based techniques, like attention mechanism or Pre-trained Language Model (PLM), to ensure high accuracy. Below, we provide a detailed introduction to these two modules.
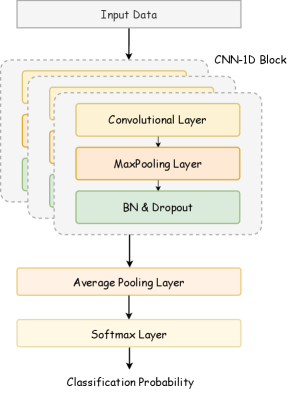
3.3.1. Plaintext Classification Model
The plaintext classification model leverages CNNs to enhance the model’s efficiency, which are well-suited to quickly process and classify a large number of data. CNNs are advantageous in this context due to their efficiency in feature extraction and their ability to capture contextual relationships in the data. This allows the model to make fast and accurate predictions, making it ideal for scenarios where rapid decision-making is critical. Specifically, the model begins by tokenizing the input plaintext to obtain a sequence of strings. These words are then converted into corresponding numerical values using the one-hot encoding layer, resulting in a sequence :
| (2) |
where , is the dimension of one-hot layer, is the index, is the total number of plaintext words.
This numerical representation enables the model to perform subsequent computations. Next, a 1D-convolution layer with a dimension of (1, ) is employed to capture local dependencies within the sequence and extract essential features. The advantage of using a 1D-convolution layer lies in its ability to efficiently process sequential data by sliding a filter across the input, thus detecting patterns and relationships within a localized context. The encoded hidden vectors are as follows:
| (3) |
where , is the dimension of 1D-convolution layer.
Following this, max-pooling is applied to reduce the dimensionality of the hidden vectors and highlight the most significant features, enhancing computational efficiency and robustness to variations in the input. Batch normalization and dropout are then utilized to normalize the activations and prevent overfitting, respectively. Finally, average pooling is performed before passing the features through a softmax layer to output the probability distribution over the classes, where is the total number of applications in the dataset. This distribution indicates the likelihood of the input belonging to each classes.
3.3.2. Encrypted Text Classification Model
For the encrypted classification model, a more intricate DL-based method is employed to handle the additional complexity of encrypted data. Techniques such as attention mechanism or Transformer-based models, e.g.BERT (Devlin et al., 2019), can be considered for their superior ability to manage sequential and highly structured data. These models, though computationally intensive, provide the necessary accuracy to classify encrypted traffic effectively. At the same time, after the first selecting stage, only a smaller portion of the data is towards this branch. Specifically, given the complexity of encrypted text, we utilize pre-trained language models such as BERT (Devlin et al., 2019; Lin et al., 2022) as the encoder in our encrypted classification model. The BERT is employed to encode network traffic data, resulting in rich hidden representations. The choice of BERT leverages its capability to understand and process complex traffic patterns, which is crucial for effectively handling encrypted traffic data, the equation is defined as:
| (4) |
where , is the dimension of BERT layer, is the index, is the total number of traffic words.
Subsequently, we apply an attention mechanism to model the interactions between different parts of the encoded traffic data. The attention mechanism allows the model to focus on the most relevant portions of the data, enhancing the model’s ability to capture intricate dependencies within the traffic sequences. The updated hidden representation can be expressed in the following:
| (5) |
where , and denotes the refined hidden representations post-attention.
Finally, these refined hidden representations are passed through a classifier, e.g. multilayer perceptron, which outputs the probability distribution over the possible traffic classes, as:
| (6) |
| Dataset | Total Packets | Train | Valid | Test |
|---|---|---|---|---|
| ISCXTor | 614,575 | 450,001 | 82,287 | 82,287 |
| ISCXVPN | 492,598 | 443,337 | 24,631 | 24,630 |
| CHNAPP | 1,287,303 | 1,158,520 | 64,391 | 64,392 |
| Methods | ISCXVPN | ISCXTor | CHNAPP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Ma-F1 | Mi-F1 | Effi. | Ma-F1 | Mi-F1 | Effi. | Ma-F1 | Mi-F1 | Effi. | |
| APPS (Taylor et al., 2018) | 81.68 | 81.33 | - | - | 49.68 | - | - | - | - |
| SMT (Shen et al., 2019) | 76.31 | 76.00 | - | - | 31.54 | - | 34.77 | 45.62 | - |
| Deep Packet (Lotfollahi et al., 2020) | 65.06 | 66.70 | - | - | 26.81 | 31.28 | 41.07 | - | |
| TR-IDS (Min et al., 2018) | 54.98 | 57.66 | - | - | 20.75 | - | - | - | - |
| HEDGE (Casino et al., 2019) | 29.67 | 34.00 | - | - | 15.08 | - | 25.67 | 36.35 | - |
| 3D-CNN (Zhang et al., 2020) | 54.34 | 57.00 | - | - | 33.96 | - | 38.74 | 51.12 | - |
| BERT (Devlin et al., 2019)† | 88.45 | 88.73 | 41.04 | 61.84 | 92.25 | 58.33 | 56.94 | 84.08 | 32.88 |
| ET-BERT (Lin et al., 2022)† | 94.25 | 96.05 | 10.83 | 95.12 | 97.86 | 18.99 | 94.08 | 96.09 | 20.14 |
| YaTC (Zhao et al., 2023)† | 96.67 | 98.04 | 23.68 | 96.30 | 98.15 | 23.07 | 90.44 | 93.50 | 29.41 |
| PacRep (Meng et al., 2022) † | 99.32 | 99.13 | 22.75 | 95.02 | 96.38 | 36.76 | 95.10 | 98.75 | 44.46 |
| EETS (Ours) | 99.89 | 99.88 | 124.01 | 97.56 | 98.87 | 171.43 | 94.95 | 99.14 | 82.11 |
4. Experiments
4.1. Public Dataset
First of all, the proposed EETS and comparison methods are evaluated using two public traffic datasets (Draper-Gil et al., 2016; Lashkari et al., 2017). Specifically, the ISCXVPN (Draper-Gil et al., 2016) dataset predominantly consists of network traffic data using Virtual Private Networks (VPNs), with each packet labeled by application, such as Gmail, Facebook, and others. The ISCXTor (Lashkari et al., 2017) dataset utilizes The Onion Router (Tor) to enhance communication privacy and includes 13 categories of application classification, like Bittorent, Netflix, Youtube and so on. Detailed statistical information on the number of packets used for training, validation, and testing is provided in Table 1.
4.2. Collected Dataset
To further conduct an effective and efficient comparison between the SOTA models and EETS, we conduct a real-world dataset collection manually, named CHNAPP. This dataset comprises network traffic data from six widely-used Internet applications: Weibo, WeChat, QQMail, TaoBao, Youku, and QQMusic. By incorporating these popular applications, CHNAPP provides a robust basis for evaluating and contrasting the performance of EETS with leading models in real-world scenarios. This comprehensive collection ensures that the comparison is both realistic and relevant. The dataset will be released in the future, and the statistical dataset information can be seen in Table 1.
4.3. Evaluation Metrics
Evaluation metrics are designed from two perspective. For effectiveness, the category distribution in these tasks varies, with some being balanced and others imbalanced. To accurately assess performance, both Macro F1 (Ma-F1) and Micro F1 (Mi-F1) scores are utilized. The Macro F1 score calculates the F1 score independently for each class and then takes the average, treating each class equally regardless of its size. This approach is particularly effective for evaluating model performance in scenarios with imbalanced class distributions, as it ensures that smaller classes are given the same consideration as larger ones. Conversely, the Micro F1 score aggregates the contributions from all classes to compute a global F1 score. This method places more emphasis on the performance of larger classes, providing a measure of overall accuracy. By considering both Macro F1 and Micro F1 scores, we can provide a more comprehensive evaluation. For the efficiency calculation, Effi. (Efficiency) metric means that the number of samples that the model predicts per second. The above evaluation metrics are the higher the value, the better.
4.4. Experimental Setting
For the experimental settings, the model parameters are detailed in three aspects. Firstly, for the DPC selector, the training data comprises approximately 100,000 samples, while the testing data consists of 10,000 samples. The training process runs for 3 epochs with a learning rate of 1e-5 and a batch size of 64. Next, for the plaintext classification model, the one-hot layer dimension is set to 100, and the dimension of the 1D-convolution layer is set to (1, 10). This model is trained for 1 epoch with a learning rate of 1e-5 and a batch size of 64. Finally, for the encrypted text classification model, the BERT layer dimension is set to 768. All other parameters remain consistent with the Pacrep model (Meng et al., 2022). Epoch is set to 5 , with a learning rate of 5e-6 and a batch size of 64. The Adam (Kingma and Ba, 2014) optimizer with the initial learning rate of e- is utilized for training, and the Pytorch framework (Paszke et al., 2017) is adapted. The experiments are implemented on the Tesla A100-80G GPU.
4.5. Baselines
The baselines can be divided into three categories for comparison: (1) feature-based methods (i.e., APPS (Taylor et al., 2018), SMT (Shen et al., 2019)); (2) byte-based methods (i.e., Deep Packet (Lotfollahi et al., 2020), TR-IDS (Min et al., 2018), HEDGE (Casino et al., 2019), 3D-CNN (Zhang et al., 2020)); and (3) PLMs-based methods (i.e., BERT (Devlin et al., 2019), PacRep (Meng et al., 2022), ET-BERT (Lin et al., 2022), YaTC (Zhao et al., 2023)). In this paper, PLMs-based methods are main comparison points due to their competitive performance. More details of these compared baselines can be seen in Appendix A.1 because of the space limitation.
 |
 |
| (a) Confusion matrix on plaintext classifiable setting. | (b) Confusion matrix on plaintext non-classifiable setting. |
| Methods | ISCXVPN | ISCXTor | CHNAPP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Ma-F1 | Mi-F1 | Effi. | Ma-F1 | Mi-F1 | Effi. | Ma-F1 | Mi-F1 | Effi. | |
| PacRep (Meng et al., 2022) † | 99.32 | 99.13 | 22.75 | 95.02 | 96.38 | 36.76 | 95.10 | 98.75 | 44.46 |
| Plaintext Classifiable | 99.98 | 99.97 | 304.41 | 97.16 | 99.97 | 314.40 | 79.85 | 99.89 | 103.40 |
| Plaintext non-Classifiable | 77.62 | 94.22 | 19.78 | 86.48 | 92.75 | 48.03 | 79.58 | 86.18 | 18.27 |
| Overall | 99.89 | 99.88 | 124.01 | 97.56 | 98.87 | 171.43 | 94.95 | 99.14 | 82.11 |
4.6. Main Results
Considering the different techniques employed by feature-based methods, byte-based models, and PLMs-based methods, we focus our reproduction only on PLMs-based methods to ensure a fair comparison of time overheads and provide time efficiency metric (Effi.) for these methods. In addition, to highlight the effectiveness of PLMs-based methods, we compare their Macro-F1 and Micro-F1 scores with those of feature-based methods and byte-based models. Due to the relatively poor accuracy of feature-based methods and byte-based models, we do not compare their time overheads with our approach. Instead, we focus on comparing the time efficiency of our method with the current SOTA models, i.e. PLMs-based methods, to ensure both effectiveness and efficiency.
As shown in Table 2, the conclusions drawn from this comparison are as follows: (1) In terms of effectiveness , feature-based methods and byte-based models perform comparably, while PLMs-based methods demonstrate further improvement. Notably, our proposed EETS model achieves SOTA results across almost all evaluation metrics, illustrating the superiority of the two-stage framework, which adaptively makes a balance between the plaintext and encrypted text. It is noteworthy that although EETS may obtain slightly lower performance in certain metrics, such as a 0.15% reduction in the Macro-F1 score on the CHNAPP dataset, the model achieves approximately a 2 to 4 times improvement in efficiency. This significant enhancement in time efficiency validates that the proposed method not only maintains robust effectiveness but also substantially improves the prediction time efficiency of the model.
(2) From a efficiency perspective, EETS exhibits a notable improvement across three datasets. Specifically, when compared to the PacRep model, a BERT-based model fine-tuned directly under supervised learning, the EETS model shows clear advantages (about 2 to 5 times improvement). On the other hand, ET-BERT and YaTC incorporate an additional pre-training phase before fine-tuning, resulting in greater overhead compared to directly fine-tuning BERT.
Overall, the analysis of both effectiveness and efficiency demonstrates the superiority of the EETS framework and underscores the necessity of analyzing both plaintext and encrypted text.
4.7. Results on Different Settings
To perform a fine-grained analysis of our model’s final performance (i.e., to understand why the model performs well), we conduct a detailed comparison in plaintext classifiable and non-classifiable settings. The backbone of our model is Pacrep. As shown in Table 3, our model achieves overall optimal performance across three datasets, excelling in both effectiveness and efficiency metrics.
Specifically, in the plaintext classifiable setting, our model EETS demonstrates superior prediction efficiency, outperforming baseline models by approximately 3 to 15 times while maintaining decent accuracy. This significant improvement underscores the model’s capability to handle classifiable plaintext data efficiently. In addition, in the plaintext non-classifiable setting, the model’s accuracy is relatively lower. This phenomenon is likely due to the inherent difficulty of classifying these difficult samples. Despite this, our model still achieves almost SOTA results in terms of overall performance. For further analysis of the Macro-F1 scores, refer to Section 5.1 Confusion Matrix Visualization.
| Methods | ISCXTor | ISCXVPN | CHNAPP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Ma-F1 | Mi-F1 | Num. | Ma-F1 | Mi-F1 | Num. | Ma-F1 | Mi-F1 | Num. | |
| DPC Selector (ours) | 97.56 | 97.56 | 82,287 | 89.65 | 99.61 | 24,630 | 92.45 | 98.60 | 64,392 |
 |
 |
| (a) Testing sample size analysis on setting one. | (b) Testing sample size analysis on setting two. |
5. Analysis
5.1. Confusion Matrix Visualization
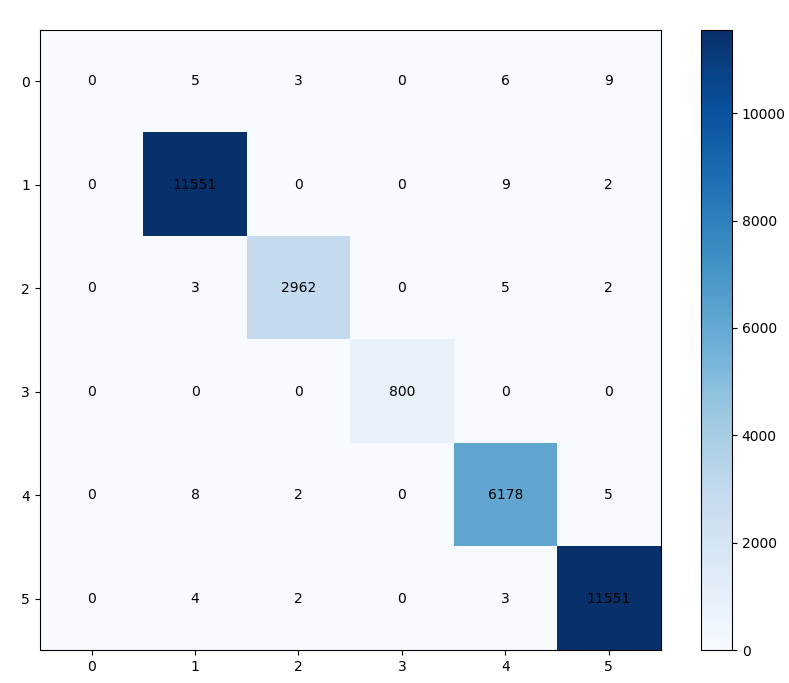
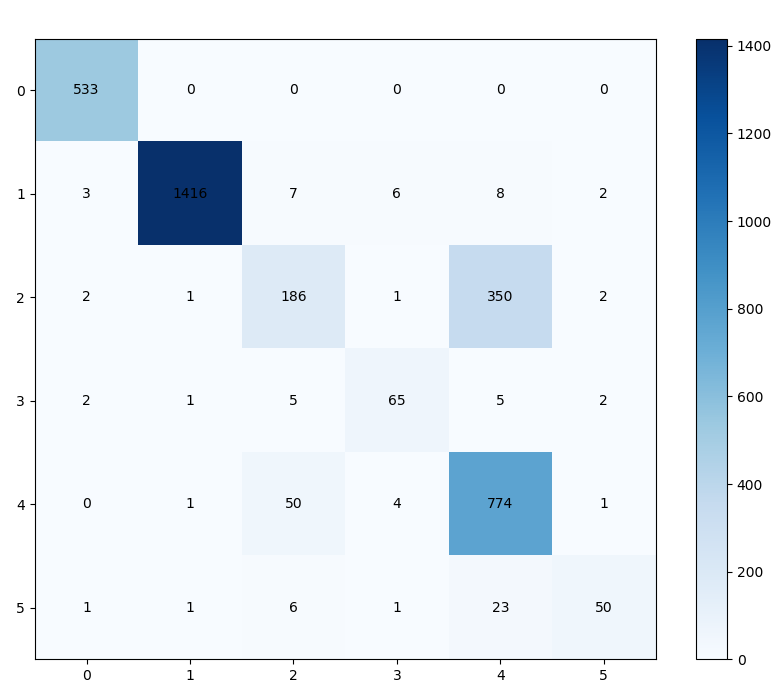
In Table 3, we have made a new discovery. Horizontally examining the three datasets, particularly CHNAPP, we observe that the Macro-F1 scores under both settings are relatively low. However, the final Macro-F1 score reaches an impressive 94.95%. To analyze this phenomenon, we conduct a detailed statistical analysis of the results for different classes within CHNAPP and visualize the confusion matrix in Figure 5. Figures 5 (a) and (b) represent the plaintext classifiable and non-classifiable settings, respectively. From Figure 5 (a), it is evident that most samples are accurately classified. Specifically, the accuracy for the last four classes is nearly 99%, although there is some misclassification in the QQmail class, which leads to a lower Macro-F1 score (79.85%), while the Micro-F1 score reaches an outstanding 99.89%. Additionally, in Figure 5 (b), we observe: (1) The classification difficulty in setting two is higher compared to the plaintext classifiable setting. Specificially, there exists lower performance on the Youku class samples, while other categories still achieve good levels of accuracy. (2) The QQmail class samples are all correctly classified, further proving that the introduction of encrypted text effectively helps the model in classification. This makes up for the misclassification issue of the QQmail class samples observed in setting one.
All in all, the proposed model’s performance metrics on the CHNAPP dataset are decent, with a Macro-F1 of 94.95% and a Micro-F1 of 99.14%. This observation holds true for other datasets as well, indicating consistent performance improvements across different scenarios.
5.2. DPC Selector Analysis
The proposed method is a two-stage approach where the outcome of the first stage serves as the input for the second stage. Consequently, the performance of the model in the first stage significantly impacts the results of the second stage. To further analyze the model’s performance and demonstrate the effectiveness of the two-stage approach, this section presents the DPC selector analysis. Specifically, we examine the performance of the DPC selector in the first stage. As shown in the Table 4, the Micro-F1 scores exceed 97% across all three datasets, indicating that almost all data can be correctly selected, thereby ensuring robust performance in the second stage.
Regarding the Macro-F1 metric, the score for the ISCXTor dataset is slightly lower at 89.65%, likely due to data imbalance. However, the Micro-F1 score for ISCXTor reaches 99.61%, making the impact on the final classification results negligible. Additionally, the Macro-F1 scores remain high for the other two datasets. All in all, this experimental analysis confirms the effectiveness of the proposed DPC selector, therefore guaranteeing the accurate traffic classification in the second stage.
5.3. Testing Sample Size Analysis
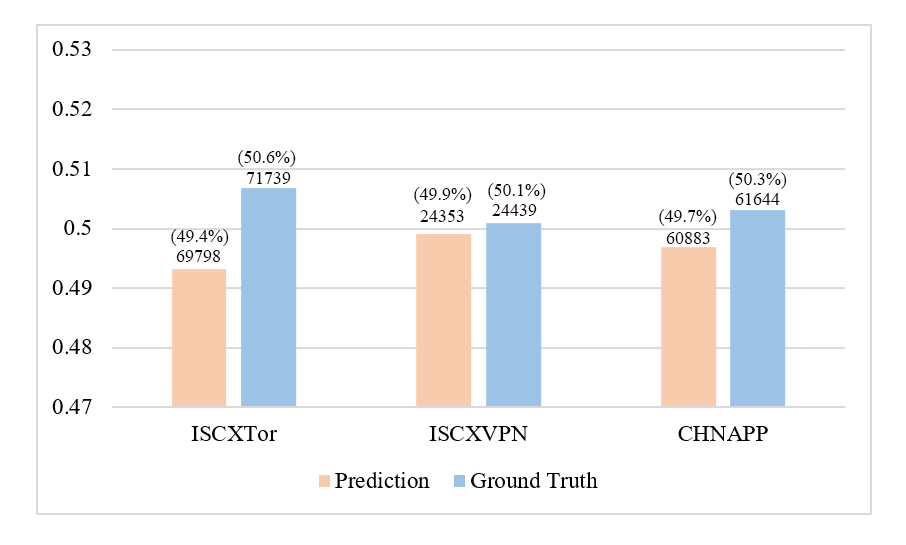
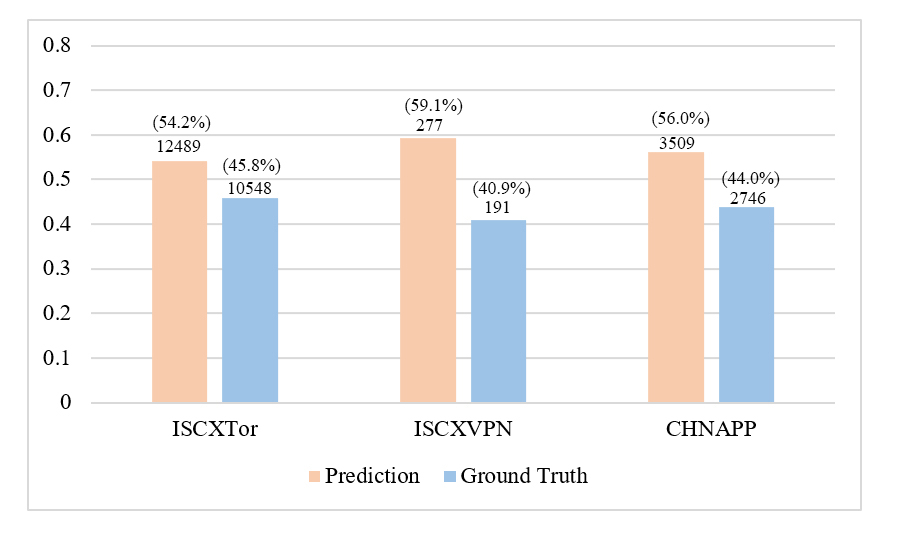
To further validate the performance of the DPC selector and the reliability of plaintext classification, we conduct a sample size analysis under both plaintext classification and non-classification settings. As shown in Figure 6 (a), in setting one, the ratio of samples predicted to be plaintext-classifiable closely matches the actual samples, with both ratios covering around 50%. Similarly, in setting two, the ratio is maintained between 45% and 55%, with a slightly larger variance observed in the ISCXVPN dataset. These results further demonstrate the effectiveness of the DPC selector.
In a cross-comparison, as illustrated in Figures 6 (a) and (b), the number of samples predicted to be plaintext-classifiable accounts for a large proportion. Specifically, in the ISCXVPN dataset, the results reach nearly 100 times (24,439/191), while in the other two datasets, the results range from 7 to 30 times. This strongly indicates that relying on plaintext information can address the majority of traffic classification scenarios. And encrypted data can also aid in improving classification accuracy alongside plaintext. Moreover, the simplicity and readability of plaintext further enhance the model’s prediction efficiency, providing that the motivation behind this paper is both effective and necessary.
6. Conclusion
In this paper, we propose a simple but Efficient and Effective Two-Stage approach (EETS) to balance plaintext and encrypted text for traffic classification. Moreover, we make the first attempt to analyze the impact of plaintext and encrypted text on model performance and time efficiency, which provides a new insight to make an analysis on the plaintext and encrypted text in network traffic field. For experiments, EETS is very effective and efficient, which outperforms the previous methods on two public datasets and one real-world dataset collected by ourselves. The analyses also demonstrate the necessity and interpretability. For future work, the design of modules in the EETS could be considered for further research.
Appendix A Appendix
A.1. Details of Baselines
The details of utilized baselines can be seen in the following.
-
•
APPS (Taylor et al., 2018), which selects statistical features, and uses a random tree classifier for application classification.
-
•
SMT (Shen et al., 2019), which fuses features of different dimensions by a kernel function for decentralized applications fingerprinting.
-
•
Deep Packet (Lotfollahi et al., 2020), which integrates both feature extraction and classification phases to train the stacked autoencoder and CNN for application classification.
-
•
3D-CNN (Zhang et al., 2020), which leverages the byte data as input for 3D-CNN and can classify packets from both known and unknown patterns.
-
•
BERT (Devlin et al., 2019), which is based on Transformer architecture and has achieved noticeable performance on various NLP tasks.
-
•
PacRep (Meng et al., 2022), which utilizes the BERT as an encoder and uses contrastive loss to optimize the learned packet representations with multi-task learning.
-
•
ET-BERT (Lin et al., 2022), which pre-trains deep contextualized datagram-level representation from large-scale raw traffic bytes.
-
•
YaTC (Zhao et al., 2023), which introduces a masked autoencoder based traffic transformer with multi-level flow representation and then performs pre-training process for traffic classification.
References
- (1)
- Aceto et al. (2020) Giuseppe Aceto, Domenico Ciuonzo, Antonio Montieri, and Antonio Pescapè. 2020. Toward effective mobile encrypted traffic classification through deep learning. Neurocomputing 409 (2020), 306–315. https://doi.org/10.1016/J.NEUCOM.2020.05.036
- Akbari et al. (2021) Iman Akbari, Mohammad A. Salahuddin, Leni Ven, Noura Limam, Raouf Boutaba, Bertrand Mathieu, Stephanie Moteau, and Stéphane Tuffin. 2021. A Look Behind the Curtain: Traffic Classification in an Increasingly Encrypted Web. Proc. ACM Meas. Anal. Comput. Syst. 5, 1 (2021), 04:1–04:26. https://doi.org/10.1145/3447382
- Akbari et al. (2022) Iman Akbari, Mohammad A. Salahuddin, Leni Ven, Noura Limam, Raouf Boutaba, Bertrand Mathieu, Stephanie Moteau, and Stéphane Tuffin. 2022. Traffic classification in an increasingly encrypted web. Commun. ACM 65, 10 (2022), 75–83. https://doi.org/10.1145/3559439
- Bujlow et al. (2015) Tomasz Bujlow, Valentín Carela-Español, and Pere Barlet-Ros. 2015. Independent comparison of popular DPI tools for traffic classification. Comput. Networks 76 (2015), 75–89. https://doi.org/10.1016/J.COMNET.2014.11.001
- Casino et al. (2019) Fran Casino, Kim-Kwang Raymond Choo, and Constantinos Patsakis. 2019. HEDGE: Efficient Traffic Classification of Encrypted and Compressed Packets. IEEE Trans. Inf. Forensics Secur. 14, 11 (2019), 2916–2926. https://doi.org/10.1109/TIFS.2019.2911156
- Cheng and Wang (2011) Guang Cheng and Song Wang. 2011. Traffic classification based on port connection pattern. In 2011 International Conference on Computer Science and Service System (CSSS). IEEE, 914–917.
- Cui et al. (2023) Lei Cui, Jiancong Cui, Yuede Ji, Zhiyu Hao, Lun Li, and Zhenquan Ding. 2023. API2Vec: Learning Representations of API Sequences for Malware Detection. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, WA, USA, July 17-21, 2023, René Just and Gordon Fraser (Eds.). ACM, 261–273. https://doi.org/10.1145/3597926.3598054
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, 4171–4186. https://doi.org/10.18653/V1/N19-1423
- Draper-Gil et al. (2016) Gerard Draper-Gil, Arash Habibi Lashkari, Mohammad Saiful Islam Mamun, and Ali A. Ghorbani. 2016. Characterization of Encrypted and VPN Traffic using Time-related Features. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy, ICISSP 2016, Rome, Italy, February 19-21, 2016, Olivier Camp, Steven Furnell, and Paolo Mori (Eds.). SciTePress, 407–414. https://doi.org/10.5220/0005740704070414
- Han et al. (2020) Juhyeng Han, Seong Min Kim, Daeyang Cho, Byungkwon Choi, Jaehyeong Ha, and Dongsu Han. 2020. A Secure Middlebox Framework for Enabling Visibility Over Multiple Encryption Protocols. IEEE/ACM Trans. Netw. 28, 6 (2020), 2727–2740. https://doi.org/10.1109/TNET.2020.3016785
- Jemal et al. (2021) Ines Jemal, Mohamed Amine Haddar, Omar Cheikhrouhou, and Adel Mahfoudhi. 2021. Performance evaluation of Convolutional Neural Network for web security. Comput. Commun. 175 (2021), 58–67. https://doi.org/10.1016/J.COMCOM.2021.04.029
- Kingma and Ba (2014) Diederik P. Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Optimization. CoRR abs/1412.6980 (2014). https://api.semanticscholar.org/CorpusID:6628106
- Lashkari et al. (2017) Arash Habibi Lashkari, Gerard Draper-Gil, Mohammad Saiful Islam Mamun, and Ali A. Ghorbani. 2017. Characterization of Tor Traffic using Time based Features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy, ICISSP 2017, Porto, Portugal, February 19-21, 2017, Paolo Mori, Steven Furnell, and Olivier Camp (Eds.). SciTePress, 253–262. https://doi.org/10.5220/0006105602530262
- Lin et al. (2022) Xinjie Lin, Gang Xiong, Gaopeng Gou, Zhen Li, Junzheng Shi, and Jing Yu. 2022. ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification. In WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, Frédérique Laforest, Raphaël Troncy, Elena Simperl, Deepak Agarwal, Aristides Gionis, Ivan Herman, and Lionel Médini (Eds.). ACM, 633–642. https://doi.org/10.1145/3485447.3512217
- Liu et al. (2019) Chang Liu, Longtao He, Gang Xiong, Zigang Cao, and Zhen Li. 2019. FS-Net: A Flow Sequence Network For Encrypted Traffic Classification. In 2019 IEEE Conference on Computer Communications, INFOCOM 2019, Paris, France, April 29 - May 2, 2019. IEEE, 1171–1179. https://doi.org/10.1109/INFOCOM.2019.8737507
- Lotfollahi et al. (2020) Mohammad Lotfollahi, Mahdi Jafari Siavoshani, Ramin Shirali Hossein Zade, and Mohammdsadegh Saberian. 2020. Deep packet: a novel approach for encrypted traffic classification using deep learning. Soft Comput. 24, 3 (2020), 1999–2012. https://doi.org/10.1007/S00500-019-04030-2
- Meng et al. (2022) Xuying Meng, Yequan Wang, Runxin Ma, Haitong Luo, Xiang Li, and Yujun Zhang. 2022. Packet Representation Learning for Traffic Classification. In KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, Aidong Zhang and Huzefa Rangwala (Eds.). ACM, 3546–3554. https://doi.org/10.1145/3534678.3539085
- Meng et al. (2021) Xuying Meng, Yequan Wang, Suhang Wang, Di Yao, and Yujun Zhang. 2021. Interactive Anomaly Detection in Dynamic Communication Networks. IEEE/ACM Trans. Netw. 29, 6 (2021), 2602–2615. https://doi.org/10.1109/TNET.2021.3097137
- Min et al. (2018) Erxue Min, Jun Long, Qiang Liu, Jianjing Cui, and Wei Chen. 2018. TR-IDS: Anomaly-Based Intrusion Detection through Text-Convolutional Neural Network and Random Forest. Secur. Commun. Networks 2018 (2018), 4943509:1–4943509:9. https://doi.org/10.1155/2018/4943509
- Oh et al. (2023) Sanghak Oh, Minwook Lee, Hyunwoo Lee, Elisa Bertino, and Hyoungshick Kim. 2023. AppSniffer: Towards Robust Mobile App Fingerprinting Against VPN. In Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, Ying Ding, Jie Tang, Juan F. Sequeda, Lora Aroyo, Carlos Castillo, and Geert-Jan Houben (Eds.). ACM, 2318–2328. https://doi.org/10.1145/3543507.3583473
- Paszke et al. (2017) Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zach DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. Automatic differentiation in PyTorch. https://api.semanticscholar.org/CorpusID:40027675
- Shbair et al. (2016) Wazen M. Shbair, Thibault Cholez, Jérôme François, and Isabelle Chrisment. 2016. Improving SNI-Based HTTPS Security Monitoring. In 36th IEEE International Conference on Distributed Computing Systems Workshops, ICDCS Workshops, Nara, Japan, June 27-30, 2016. IEEE Computer Society, 72–77. https://doi.org/10.1109/ICDCSW.2016.21
- Shbair et al. (2015) Wazen M. Shbair, Thibault Cholez, Antoine Goichot, and Isabelle Chrisment. 2015. Efficiently bypassing SNI-based HTTPS filtering. In IFIP/IEEE International Symposium on Integrated Network Management, IM 2015, Ottawa, ON, Canada, 11-15 May, 2015, Remi Badonnel, Jin Xiao, Shingo Ata, Filip De Turck, Voicu Groza, and Carlos Raniery Paula dos Santos (Eds.). IEEE, 990–995. https://doi.org/10.1109/INM.2015.7140423
- Shen et al. (2019) Meng Shen, Jinpeng Zhang, Liehuang Zhu, Ke Xu, Xiaojiang Du, and Yiting Liu. 2019. Encrypted traffic classification of decentralized applications on ethereum using feature fusion. In Proceedings of the International Symposium on Quality of Service, IWQoS 2019, Phoenix, AZ, USA, June 24-25, 2019. ACM, 18:1–18:10. https://doi.org/10.1145/3326285.3329053
- Sirinam et al. (2018) Payap Sirinam, Mohsen Imani, Marc Juarez, and Matthew Wright. 2018. Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS 2018, Toronto, ON, Canada, October 15-19, 2018, David Lie, Mohammad Mannan, Michael Backes, and XiaoFeng Wang (Eds.). ACM, 1928–1943. https://doi.org/10.1145/3243734.3243768
- Taylor et al. (2018) Vincent F. Taylor, Riccardo Spolaor, Mauro Conti, and Ivan Martinovic. 2018. Robust Smartphone App Identification via Encrypted Network Traffic Analysis. IEEE Trans. Inf. Forensics Secur. 13, 1 (2018), 63–78. https://doi.org/10.1109/TIFS.2017.2737970
- Thakur et al. (2023) Hasnain Nizam Thakur, Abdullah Al Hayajneh, Kutub Thakur, Abu Kamruzzaman, and Md Liakat Ali. 2023. A Comprehensive Review of Wireless Security Protocols and Encryption Applications. In 2023 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, June 7-10, 2023. IEEE, 373–379. https://doi.org/10.1109/AIIOT58121.2023.10174571
- Wang et al. (2017) Wei Wang, Ming Zhu, Xuewen Zeng, Xiaozhou Ye, and Yiqiang Sheng. 2017. Malware traffic classification using convolutional neural network for representation learning. In 2017 International Conference on Information Networking, ICOIN 2017, Da Nang, Vietnam, January 11-13, 2017. IEEE, 712–717. https://doi.org/10.1109/ICOIN.2017.7899588
- Yoon et al. (2009) Sung-Ho Yoon, Jin-Wan Park, Jun-Sang Park, Young-Seok Oh, and Myung-Sup Kim. 2009. Internet Application Traffic Classification Using Fixed IP-Port. In Management Enabling the Future Internet for Changing Business and New Computing Services, 12th Asia-Pacific Network Operations and Management Symposium, APNOMS 2009, Jeju, South Korea, September 23-25, 2009, Proceedings (Lecture Notes in Computer Science, Vol. 5787), Choong Seon Hong, Toshio Tonouchi, Yan Ma, and Chi-Shih Chao (Eds.). Springer, 21–30. https://doi.org/10.1007/978-3-642-04492-2_3
- Zhang et al. (2023) Haozhen Zhang, Le Yu, Xi Xiao, Qing Li, Francesco Mercaldo, Xiapu Luo, and Qixu Liu. 2023. TFE-GNN: A Temporal Fusion Encoder Using Graph Neural Networks for Fine-grained Encrypted Traffic Classification. In Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, Ying Ding, Jie Tang, Juan F. Sequeda, Lora Aroyo, Carlos Castillo, and Geert-Jan Houben (Eds.). ACM, 2066–2075. https://doi.org/10.1145/3543507.3583227
- Zhang et al. (2020) Jielun Zhang, Fuhao Li, Feng Ye, and Hongyu Wu. 2020. Autonomous Unknown-Application Filtering and Labeling for DL-based Traffic Classifier Update. In 39th IEEE Conference on Computer Communications, INFOCOM 2020, Toronto, ON, Canada, July 6-9, 2020. IEEE, 397–405. https://doi.org/10.1109/INFOCOM41043.2020.9155292
- Zhang et al. (2014) Qianli Zhang, Yunlong Ma, Jilong Wang, and Xing Li. 2014. UDP traffic classification using most distinguished port. In The 16th Asia-Pacific Network Operations and Management Symposium, APNOMS 2014, Hsinchu, Taiwan, September 17-19, 2014. IEEE, 1–4. https://doi.org/10.1109/APNOMS.2014.6996569
- Zhao et al. (2023) Ruijie Zhao, Mingwei Zhan, Xianwen Deng, Yanhao Wang, Yijun Wang, Guan Gui, and Zhi Xue. 2023. Yet another traffic classifier: a masked autoencoder based traffic transformer with multi-level flow representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 5420–5427.