Elucidating Flow Matching ODE Dynamics with Respect to Data Geometries
Abstract
Diffusion-based generative models have become the standard for image generation. ODE-based samplers and flow matching models improve efficiency, in comparison to diffusion models, by reducing sampling steps through learned vector fields. However, the theoretical foundations of flow matching models remain limited, particularly regarding the convergence of individual sample trajectories at terminal time—a critical property that impacts sample quality and being critical assumption for models like the consistency model. In this paper, we advance the theory of flow matching models through a comprehensive analysis of sample trajectories, centered on the denoiser that drives ODE dynamics. We establish the existence, uniqueness and convergence of ODE trajectories at terminal time, ensuring stable sampling outcomes under minimal assumptions. Our analysis reveals how trajectories evolve from capturing global data features to local structures, providing the geometric characterization of per-sample behavior in flow matching models. We also explain the memorization phenomenon in diffusion-based training through our terminal time analysis. These findings bridge critical gaps in understanding flow matching models, with practical implications for sampling stability and model design.
1 Introduction
Diffusion-based generative models have become the de facto standard for the task of image generation [SDWMG15, HJA20, SE19]. Compared to previous generative models (e.g., GANs [GPAM+14]), diffusion models are easier to train but suffer from long sampling times due to the sequential nature of the sampling process. To address this limitation, (deterministic) ODE-based samplers were introduced, where the sampling process is done by integrating an ODE trajectory. This approach has been shown to be more efficient than traditional sampling with a significantly reduced number of sampling steps needed [SME21, LZB+22, KAAL22]. Recently, a new class of models, known as flow matching models [LCBH+22, LGL23] has been developed to use an ODE flow map to interpolate between a prior and a target data distribution—generalizing diffusion models with ODE samplers. By learning a vector field a new sample can be generated by integrating over the ODE below from some initial random sample :
Various versions of the flow matching model have gained popularity, such as the rectified flow model [LGL23], which is used in recent commercial image generation software [EKB+24]. Furthermore, the succinct and deterministic formulation of the flow matching model also makes theoretical analysis potentially easier.
However, despite their empirical success, the theoretical understanding of flow models remains incomplete, even for the well-posedness of the ODE trajectories, i.e., existence, uniqueness, as well as convergence as of the ODE trajectories. These are not thoroughly addressed in the pioneering papers [LCBH+22, LGL23], and only partially tackled in recent studies [GHJ24, LHH+24]. Specifically, in [LHH+24], well-posedness is established only on the open interval . Recent work [GHJ24] extend well-posedness to but under restrictive assumptions on the data distribution, excluding cases where data is supported on low-dimensional manifolds—an arguably crucial scenario in generative modeling [LGRH+24]. In both works, the challenge arises from the singularity in the vector field as the terminal time is approached, influenced by both the ODE formulation and the data geometry. The convergence of the ODE trajectories lies in a broader context of sample trajectory analysis, which is less explored in the literature as most work focuses on distribution level analysis [BDD23, LC24].
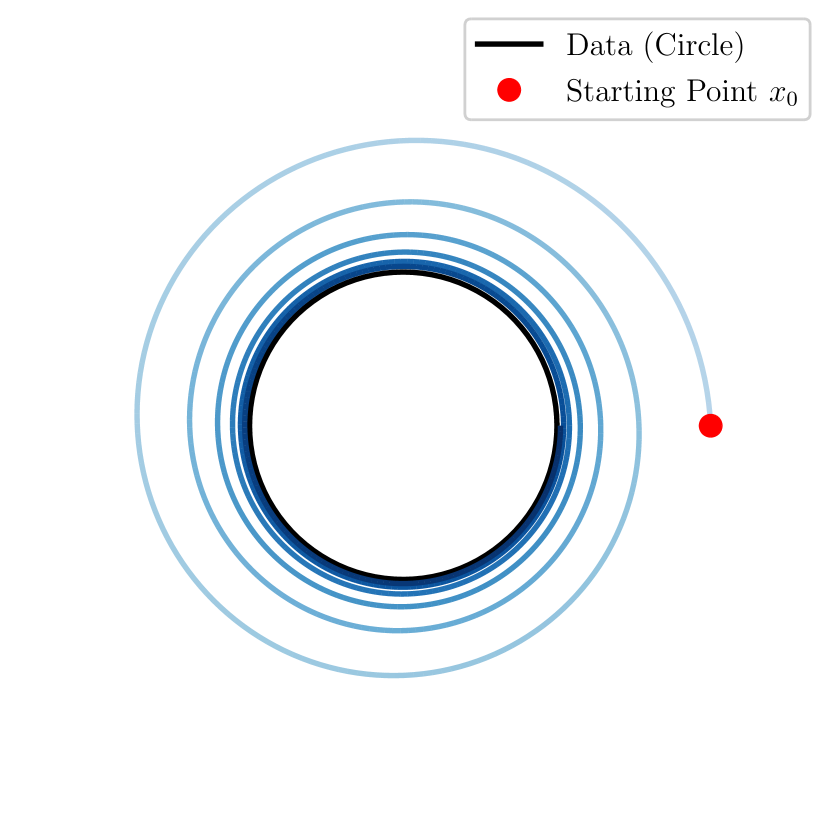

We also highlight that pushing the well-posedness to and performing sample trajectory analysis is not only theoretically interesting but also of practical importance. Suppose we know that the ODE trajectory exists in , and the intermediate distribution following the ODE flow is getting closer to the data distribution as increases. However, if the ODE trajectory does not converge at , the final sampling following a single ODE trajectory can be very sensitive to the chosen ODE discretization scheme, i.e., a slight change in sampling schedule will result in a drastically different outcome. This could happen if the individual ODE trajectories are winding towards the data distribution but never converge at as shown in Figure 1(a). A more desirable behavior is as in Figure 1(b), where the ODE trajectory converges to the data distribution as . Empirical studies find the ODE trajectories tend to stabilize as and hence be more aligned with that of Figure 1(b), and this observation is utilized to guide the choice of the ODE discretization scheme [KAAL22, EKB+24]. Furthermore, the convergence of the ODE trajectories at is a critical assumption for the consistency model [SDCS23], which utilizes the limit of the ODE trajectory to design a one-step diffusion model. These considerations motivate us to investigate the convergence of the ODE trajectories at and per sample trajectory analysis.
In this paper, our approach focuses on the denoiser, a key component of flow matching models. The denoiser, defined as the mean of the posterior distribution of the data given a noisy observation, governs the evolution of ODE trajectories. Initially, the posterior distribution is broad, and the denoiser approximates the global mean of the data. As time progresses, the posterior measure becomes more concentrated around nearby data points, and the denoiser captures finer details of the data distribution.
We show that when approaching the terminal time, the posterior distribution concentrates on the nearest data, and the denoiser converges to the projection of the current sample onto the data support. This extends previous partial results [PY24, SBDS24] to a general setting beyond a small neighborhood of the data support. By carefully leveraging this denoiser convergence and integrating it with the analysis of the ODE dynamics, we find that near the terminal time, the ODE trajectories will stay in a region away from the singularity and converge to the data support. As a result, we establish the convergence of the entire sampling process with minimal assumptions and validate that the ODE trajectories in flow matching models are well-behaved (as in Figure 1(b)).
Notably, the terminal time analysis of the denoiser provides a new perspective on the memorization phenomenon observed in diffusion-based training where models only repeat the training samples [CHN+23, WLCL24], rather than generate new unseen data points. We identify that the denoiser’s terminal time convergence to the data support precisely leads to this memorization behavior. In particular, if a neural network trained denoiser is asymptotically trained optimally with empirical data, it can only sample memorized training data.
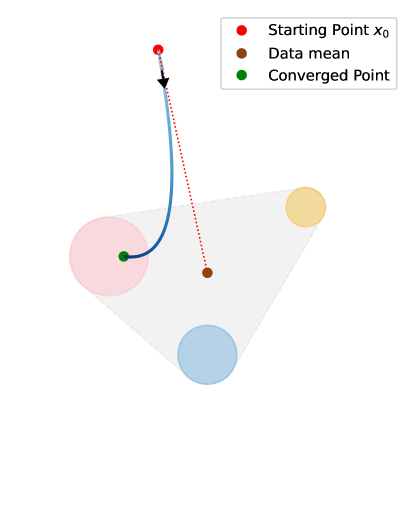
Finally, our analysis significantly strengthens the understanding of flow matching ODE dynamics, extending beyond the terminal time. By carefully examining the progressive concentration of the posterior distribution, we derive comprehensive insights into the behavior of ODE trajectories. Specifically, we establish a unified result demonstrating that trajectories are systematically attracted to, and ultimately absorbed by, sets associated with the data distribution. Initially, sample trajectories move towards the mean of the data distribution and will be absorbed into the convex hull of overall data distribution, capturing the global structure. As the process evolves, they are increasingly drawn towards local clusters within the data, reflecting a transition from global to local convergence. Ultimately, the trajectories converge to the data support at the terminal time, providing a geometric characterization of how samples naturally focus on local features; see Figure 2 for an illustration. In this way, we provide per sample trajectory analysis that complements the empirical, or distribution level discussion regarding the flow matching/diffusion model dynamics [BBDBM24, LC24].
Contributions and Organization.
In summary, we provide a comprehensive theoretical analysis of flow matching models by examining the behavior of denoisers and posterior distributions. We establish the convergence of ODE trajectories and characterize their geometric evolution, bridging key gaps in the theoretical understanding of these models. Our results address critical challenges related to terminal time singularities and offer new insights into the memorization phenomenon in diffusion-based training. The geometric perspective we develop—showing how trajectories evolve from global to local features—provides a unified framework for understanding flow matching dynamics, laying a foundation for future theoretical developments. The paper is structured as follows, and Figure 3 provides an illustration of the main theoretical results and their inter-dependencies.
-
•
In Section 2, we introduce the background on flow matching models, their training objectives, and the unification of different scheduling functions via the noise-to-signal ratio .
-
•
In Section 3, we discuss key properties of the denoiser and highlight its role as the guiding component in the flow matching model ODE dynamics, illustrating terminal time singularity and general attracting and absorbing properties. These will be fundamental tools for our theoretical analysis.
-
•
In Section 4, we study the concentration and convergence of the posterior distribution, establishing its initial closeness to the data distribution and its convergence to the data support at the terminal time. We also derive specific convergence rates under different data geometries.
-
•
In Section 5, we present the well-posedness of ODE trajectories fisrt in and then extend to with minimal assumptions on the data distribution. We then obtain refined convergence results based on data geometry. Lastly, with the existence of flow maps, we analyze its equivariance property under data transformation.
-
•
In Section 6, we analyze the ODE trajectories across different stages, demonstrating their initial attraction to the data mean and eventual absorption into the convex hull of the data distribution. Later, these trajectories are attracted to local clusters. We also provides quantitative results on the terminal time behavior for discrete data distributions and showcase the importance of terminal time behavior on the memorization phenomenon.
All technical proofs are deferred to the appendix.
2 Background on Flow Matching Models
In this section, we provide a brief overview of flow matching models and their training objectives and how the noise-to-signal ratio can be used to unify different scheduling functions.
2.1 Preliminaries and notations
We use to denote the -dimensional Euclidean space, and to denote the Euclidean norm. We use to denote a general closed subset and usually use to denote a manifold in . We let denote the distance function to , i.e.,
The medial axis of is defined as
The reach of is defined as . For any , the nearest point on is unique and we denote it by . We let denote the diameter of , i.e., . A set is said to be convex if for any and , we have . For any set , we let denote the convex hull of which is the smallest convex set containing .
For any and , we use to denote the open ball centered at with radius , i.e., . More generally, for any set , we use to denote the open -neighborhood of , i.e., .
We let denote the target data distribution in , denote the prior, which is often chosen to be the standard Gaussian . We say has a finite 2-moment, denoted by , if . We use a capitalized bold letter to denote a random variable with representing its law.
For any two probability measures and , the -Wasserstein distance for as
where denotes the set of all couplings of and , i.e. the set of all probability measures on with marginals and . The distance will be finite if and have finite -moments, i.e. and .
For any probability measures and on , we use to denote their convolution.
2.2 Conditional flow matching
Conditional flow matching models [LCBH+22, LGL23] are a class of generative models whose training process consists of learning a vector field that generates a probability path interpolating a prior and a target data distribution and whose sampling process consists of integrating an ODE trajectory from an initial point to a terminal point . For simplicity, we will call these models flow models.
More specifically, the flow model assumes a probability path interpolating and , and aims at finding a time-dependent vector field whose corresponding ODE
| (1) |
has an integration flow map that sends any initial point to along the ODE trajectory, satisfying . Within the framework, the probability path is constructed conditionally as
where the conditional distribution satisfies and , the Dirac delta measure at . When the prior is the standard Gaussian , the conditional distribution are often specified as , where and are scheduling functions satisfying and and often being monotonic. Common choices include linear scheduling and used in the rectified flow model [LGL23, EKB+24], as well as those arising from the original diffusion model, like DDPM [HJA20].
It turns out that the vector field satisfying the above properties can be explicitly expressed as follows using the data distribution . We first define the conditional vector field which enjoys a closed-form
where the dot represents the derivative with respect to . Then the desired vector field satisfies the following equation for any
| (2) |
where (we will use similar notation later) and denotes the posterior distribution (which is different from the conditional distribution defined earlier):
The guarantee that the vector field generates the probability path is stated in [LGL23, Theorem 3.3] and [LCBH+22, Theorem 1] under the explicit or implicit assumption that the ODE trajectory exists on . This result was further rigorously proved in [GHJ24] under some specific assumptions. We point out that the assumptions are very restrictive and cannot include the case when is supported on a low-dimensional manifold. See our results in Section 5 for a more general statement.
Ultimately, specifying the conditional distribution as Gaussian distributions allows one to train a neural network to learn the vector field by minimizing the following loss function whose unique minimizer is [LCBH+22]:
| (3) |
2.3 Unifying scheduling functions through noise-to-signal ratio
In this section, we describe a formulation that can unify different scheduling functions and . This is done by introducing the noise-to-signal ratio, which has been discussed in [SPC+24, CZW+24, KG24]. We find it useful in our analysis as it simplifies the ODE dynamics and allows us to present our results more cleanly.
When the scheduling functions and are assumed to be strictly monotonic, then the noise-to-signal ratio is defined as
By monotonicity, as a function of is invertible and we let denote the inverse function of . As goes from to , the noise-to-signal ratio goes from to . For any , we define as the convolution of and a Gaussian kernel with variance :
| (4) |
We also let . Then, we have the following result.
Proposition 2.1.
For any , define by sending to . Then, .
Under the map , the probability path satisfies an ODE with respect to .
Proposition 2.2.
For any , let denote an ODE trajectory of Equation 1. Then, satisfies the following ODE:
| (5) |
where denotes the probability density of .
During sampling, the ODE with respect to integrates backwards, that is, for any and any , the corresponding ODE trajectory is the solution of Equation 5 from with that satisfies . So now, we have an ODE model depicted in Equation 5 generating a probability path for . This way of parametrizing the ODE and its variants have been studied extensively in the literature of diffusion models [SME21, KAAL22].
The above transition from the parameter to the parameter works for any (monotonic) scheduling functions and . As a consequence, different choices of scheduling functions are equivalent up to a reparametrization. This is also discussed to some extent in [SPC+24] for creating a sampling schedule different from the ones used in the training process.
Remark 2.3 (Subtlety at the endpoints).
When , and there is an issue of division by zero which prevents the above transition from being valid. Furthermore, as goes to , the corresponding probability measure does not have a well-defined limit. Hence, one often uses a large instead of as the starting time of Equation 5, i.e., one samples with as the initial point for the backward ODE. This may introduce an extra error term in the sampling process since at , one should have sampled from which may deviate from . Indeed, it is empirically observed in [ZYLX24b] that this error is related to the average brightness issue in the generated images. The validity of the above transition property suggests an easy correction though: first sample and then perform an ODE step in to obtain , scale it by and then continue the noise-to-signal ratio backward ODE using . This is termed as SingDiffusion in [ZYLX24b].
In this paper, it is much cleaner and easier to state / prove most theoretical results using the noise-to-signal ratio rather than . Therefore, we will present these results in terms of (or alternatively ). However, note the equivalence between the two models and hence the results stated in terms of can be translated to the flow matching model in a straightforward manner. For results regarding flow maps , we will use parameter due to the inherent obstacles of defining a flow map as discussed in Remark 2.3 as well as the reverse process from to in Equation 5.
3 Denoiser: the Guiding Component in Flow Matching Models
At the core of the flow matching model is the vector field that generates the probability path . It turns out that the vector field is fully determined by the denoiser, i.e. the mean of the posterior distribution [KAAL22]. In this section, we will first talk about some basic properties of the denoiser, then mention certain difficulties in handling the denoiser and will eventually showcase how the ODE dynamics are guided by the denoiser and its implications in the flow model.
3.1 Basics of the denoiser
Recall that the vector field is given by , and by plugging in the explicit formula of , we have that
| (6) |
a formulation that is also given in [GHJ24, Equation (3.7)]. Here can be explicitly written as follows:
| (7) |
Remark 3.1 (Well-definedness of the denoiser).
In order for the above integral to converge, one only needs a mild condition that has a finite 1-moment. In this case, it follows that for any , the posterior distribution has a finite 1-moment and hence the denoiser is well-defined. The same conclusion holds for defined later.
Notice that the denoiser is the only part of dependent on the data distribution and hence fully determines the vector field . For simplicity, we use the notation to emphasize that it is the mean of the posterior distribution .
Noise-to-signal ratio formulation.
Likewise, the ODE in can also be expressed in terms of the denoiser as follows from Tweedie’s formula:
| (8) |
Notably, the ODE in can be simply interpreted as moving towards the denoiser at a speed inversely proportional to . Similarly, one can explicitly write as follows.
| (9) |
An alternative parametrization for .
This backward integration in might be cumbersome in analysis and we alternatively use the parameter . We similarly let define the inverse function. Then, when changes from to , changes from to . For an ODE trajectory , we define . For any , we define . Then, the ODE in has a concise form:
| (10) |
Jacobians of the denoiser and data covariance.
We point out that the denoiser, under some mild condition on the data distribution , is differentiable and its Jacobian is inherently connected with the covariance matrix of the posterior distribution (or ). Similar formulas for computing the Jacobian have been utilized before for various purposes; see, for example, [ZYLX24a, Lemma B.2.1] and [GHJ24, Lemma 4.1]. Moreover, the covariance formula in Proposition 3.2 is a direct consequence of higher order generalization of Tweedie’s formula, which has been studied in previous works (see, e.g., [Efr11], [MSLE21]).
Proposition 3.2.
Assume that has a finite 2-moment. For any , we have that is differentiable. In particular, the Jacobian can be explicitly expressed as follows for any :
Furthermore, if we let , then
A note on the training process.
As is the only part in dependent on , instead of training the vector field directly, one can train a neural network to learn the denoiser directly. By plugging Equation 6 into Section 2.2, we obtain the following training loss for which turns out to be equivalent to the training loss for the vector field Section 2.2:
| (11) |
The mean will always be bounded, which is opposite to the fact that the vector field can blow up when as discussed in Proposition 3.4. This makes the denoiser much easier to train than the vector field . Meanwhile, training of the denoiser, an alternative to the vector field, is also utilized in the diffusion model literature [KAAL22] (with ) and shows promising results.
Remark 3.3.
In the literature on diffusion models, the main object is the score function, which is the gradient of the log density of the probability distribution . The score function view or the denoiser view are equivalent to each other by applying Tweedie’s formula [Efr11], see e.g., [GHJ24][Remark 3.5]. As the mean of the posterior distribution, the denoiser is more interpretable and we will show its importance in the remainder of the paper.
3.2 Denoiser and ODE dynamics: terminal time singularity
The terminal time is referred to as the time (or , ) in the flow model. The convergence of the ODE trajectory at the terminal time relies on the terminal time regularity of the vector field. We now elucidate two types of singularities of the vector field that arise at the terminal time in the flow model, one due to the ODE formulation and the other due to the data geometry.
Singularity due to the ODE formulation.
Recall that the vector field is given by . Since the denominator approaches as , the vector field faces an issue of division by zero when approaching the terminal time. This singularity is intrinsic to the flow matching ODE formulation. In the following proposition, we show that when the data distribution is not fully supported, the limit goes to infinity for almost all while it is bounded when the data distribution is fully supported.
Proposition 3.4.
Assume that are smooth, and exist and are non zero. Let and let denote its medial axis. Then, we have the following properties:
-
•
If is fully supported, i.e., , and has a Lipschitz density, then for any , the vector field is uniformly bounded for all .
-
•
If is not fully supported, i.e., , then for any , .
The deciding factor on whether the vector field blows up for a given is if or not. We will show in Corollary 4.4 that for any , and thus when , and hence the vector field blows up. Another way to interpret the singularity of the ODE formulation is by considering the transformation of the ODE in in Equation 10 where the singularity corresponds to the term. This singularity can be addressed by using the parameter as in Equation 10 which results in the ODE:
with the trade-off of turning a finite-time ODE into an infinite-time ODE.
Singularity due to the data geometry.
When the data is not fully supported, the medial axis of the data support plays a crucial role in the singularity of the denoiser which may result in discontinuity of the limit . In this case, when the ODE is transformed into the , the vector field does not have a uniform Lipschitz bound for all and hence the typical ODE theory such as Picard-Lindelöf theorem can not be directly applied to analyze the flow matching ODEs.
The discontinuity behavior can be illustrated by the following simple example of a two-point data distribution which can be easily extended to higher dimensions. We specifically use the and consider for illustration as the sampling process is often done in , e.g., as in [SME21, KAAL22] and the values are more interpretable.
Example 3.5.
Let be a probability measure on . Then, the support is just a two-point set. The medial axis is the singleton whose distance to either point is . Now, we can explicitly write down the denoiser as follows:
| (12) |
Notice that when approaches ,
-
•
The denoiser is converging to a function with for , for and .
-
•
Certain singularity of is emerging at : the derivative (Jacobian if in high dimensions) is blowing up when .
A full characterization of the limit for discrete data distribution will be given in Corollary 4.12 where the discontinuity often arises at the medial axis of the data support. All these singularities pose challenges in theoretical analysis of the flow matching ODEs and particularly in the convergence of the ODE trajectory when approaching the terminal time. The data geometry singularity is more challenging to handle, especially the discontinuity behavior of the limit of the denoiser near the medial axis.
We will address these challenges in the convergence analysis of the flow matching ODEs in Section 5 by showing that even if the geometric singularities exist, the ODE trajectory will avoid the singularities and converge to the data support. This is done by identifying an absorbing and attracting property of the ODE dynamics, which will be discussed in the next section.
3.3 Denoiser and ODE dynamics: attracting and absorbing
Assume that the ODE trajectory exists and unique up to the terminal time—on for , and on (resp. ) for (resp. ). In Section 5.1, we rigorously establish this well-posedness for any data distribution with finite second moments. The Equation 8 suggests that the sample simply moves towards the denoiser from its current position . However, the main challenge is that the denoiser itself evolves along the trajectory.
Nevertheless, when certain coarse geometric information is available, one can provide preliminary insights into the ODE dynamics. Intuitively, as discussed in the introduction, the flow matching ODE initially points towards the data mean and later towards local clusters. These concepts can be described in terms of distance to certain set. Specifically, the flow matching ODE exhibits two key properties when the denoiser meets certain conditions that we will elaborate later.
-
•
Attracting Property: Trajectories are drawn towards specific closed set, i.e, the distance to the set decreases along the trajectory.
-
•
Absorbing Property: Trajectories remain confined within neighborhoods of certain closed set.
The closed sets that we work with can be a point (e.g. the data mean or a single training data), a convex set (e.g. certain convex hull of data), or a more general set (e.g. the data support). These properties are formalized in the following two meta-theorems. We describe them with respect to , but they can be translated to or in a straightforward manner.
Attracting towards sets.
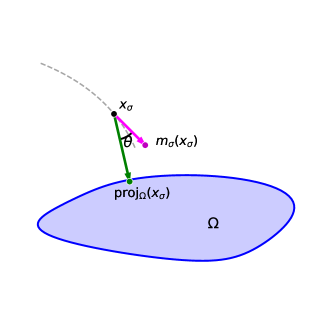
Let be a closed set in . We want to examine the distance to along the ODE trajectory with some . Assume that the trajectory avoids the medial axis of then the distance of to will decrease as decreases if the trajectory direction forms an acute angle with the direction pointing towards , that is
see Figure 5 for an illustration.
Notice that whenever , one has
| (13) |
Hence, as long as the term is small enough, one would guarantee that the acute angle condition is satisfied and then the distance to will decrease along the trajectory. This intuition is formalized in the following theorem.
Theorem 3.6 (Attracting towards sets).
Let be an ODE trajectory of Equation 8 starting from some . Assume that the trajectory avoids the medial axis of a closed then we have the following results.
-
1.
If for some along the trajectory, then decreases along the trajectory with rate:
In particular, if , then decreases to zero as .
-
2.
If and for some function along the trajectory with , then
Remark 3.7.
In fact, when considering the parameter and the trajectory , we obtain the following convergence rate for Item 2 in the above theorem:
The above theorems require the trajectory to avoid the medial axis of . We will find two situations that this condition is satisfied: (1) when is a convex set as its medial axis is empty. It turns out one can identify specific convex sets in different stages of the flow matching ODE dynamics where the denoiser satisfies the above estimates and hence the ODE trajectory is attracted towards these convex sets. We will discuss these in Sections 6.1 and 6.2. (2) when we can show that the trajectory will confined in a region outside the medial axis of . This is in particular related to the terminal behavior of the flow model sampling process which includes the convergence of the flow matching ODE to the data support which will be discussed in Section 5.2 and Section 6.3. Furthermore, the estimates in the conditions of the above theorem is related with the concentration properties of the posterior distribution which we will discuss in Section 4.
We now describe a general absorbing property in the next paragraph.
Absorbing by sets.
Let be any set in . For any , we say is absorbing for the flow matching ODE in , if for any , the ODE trajectory for Equation 8 starting at will remain in for all .
Now, we assume that is closed. It turns out that the acute angel condition
will also guarantee that the trajectory will remain confined within a neighborhood of . This is formalized in the following theorem.
Theorem 3.8 (Absorbing by sets).
For any closed set and , we consider the open neighborhood .
-
1.
If and for any and any , one has
then is absorbing in .
-
2.
If there exists some such that is absorbing in for all , then is absorbing in as well.
Note that the absorbing property only requires the denoiser information in some fixed region rather than a priori knowledge of how the denoiser evolves along the trajectory. This versatility makes the absorbing property to be utilized as a first step of controlling the ODE dynamics in many of our analysis.
We now describe how will we use the above absorbing property for convex sets which will be used often in Section 6, and how its generalization will be used to analyze the convergence of the flow matching ODEs in Section 5.2.
For a convex set , its the medial axis is empty and if we assume that the denoiser lies in for any then any neighborhood of will be absorbing for the ODE trajectory. We also obtain an stronger result regarding when the set itself is absorbing.
Proposition 3.9 (Absorbing of convex sets).
Let be a closed convex set in . Let be an ODE trajectory of Equation 8. Then, we have the following results.
-
1.
For any , if for any and any , then is absorbing for .
-
2.
If the interior of is not empty and for any and any , then is absorbing for .
Remark 3.10.
When is not convex, a typical way to show the acute angle condition is by requiring to be small enough on for all . This can be seen by the following computation:
Furthermore, once the absorbing property is established, it guarantees that to be bounded for a trajectory in consideration. In this case, the condition in Item 2 of the attracting theorem Theorem 3.6 can be derived from the decay of as
These type of arguments will be utilize in Section 6.2 and Section 6.3 when discussing the ODE dynamics of the flow matching ODEs.
When is unbounded, e.g the support of a general distribution, it would require much more assumptions for us to control the term uniformly on the boundary. As one way to circumvent this issue, we consider the intersection of with a bounded set and establish the absorbing property of the bounded subset. This is formalized in the following result.
Theorem 3.11 (Absorbing of data support).
Fix any small and any . Assume that there exists a constant such that for any and for any , one has that
where is a constant depending only on and and .
Then, there exists dependent on and satisfying the following property for any : The trajectory starting at any initial point of the ODE in Equation 8 will be absorbed in a slightly larger space: for any : .
Note that this absorbing result is slightly different from Theorem 3.8, where the neighborhood of the data support must be enlarged from to (and to ) to guarantee the absorbing property. This subtle difference arises from the additional treatment in the proof to account for the bounded ball in the above theorem.
We will then be able to show in Section 5.2 that near the terminal time, an ODE trajectory that starts from a point near the data support will never leave a neighborhood of the , which avoids the geometric singularities (cf. Section 3.2), and will eventually be attracted to the .
4 Concentration and Convergence of the Posterior Distribution
In the previous section, we established how the properties of denoisers influence the behavior of flow matching ODEs. Since denoisers are defined as expectations of posterior distributions, this section provides a detailed analysis of the concentration and convergence of the posterior distribution for a general data distribution . Such an analysis not only validates the assumptions on denoisers made in the meta-theorems on attraction (Theorem 3.6) and absorption (Theorem 3.8) but also forms the foundation for the ODE analysis in Section 5 and Section 6. Additionally, we discuss the cases when is supported either on a low-dimensional manifold or on a discrete set to explore the impact of different data geometries. As a natural consequence of the convergence of the posterior distribution, we also establish the convergence of the denoisers.
4.1 Concentration and convergence of the posterior distribution
Intuitively, for the posterior distribution , as goes to , the noise level goes to and hence the posterior distribution should concentrate around data points near . We will establish this rigorously utilizing the parameter .
Initially, the posterior distribution for large is close to the data distribution and hence the ODE trajectory will move towards the mean of the data distribution. The following proposition quantifies the initial stability of the posterior distribution.
Proposition 4.1 (Initial stability of posterior measure).
Let be a probability measure on with bounded support which is denoted as . Let be a point and consider the posterior measure . We then have the following Wasserstein distance bound:
Note that the bound above will only be meaningful when is large and will blow up to infinity as decreases to . This makes sense as the posterior distribution will gradually depart from and concentrate around the data points near and eventually converge to the delta distribution located at the nearest data point. The following theorem quantifies the concentration and convergence of the posterior distribution.
Theorem 4.2.
Let . Assume that has finite 2-moment, i.e., . For all , we let . Then, we have that
Remark 4.3.
The proof strategy of Theorem 4.2 is similar to that used in [SBDS24, Theorem 4.1], where the integral under consideration is split into two parts to analyze the concentration. However, it is important to note that our result is more general than that in [SBDS24] in two aspects. First, we do not require the data distribution to be supported on a manifold. Second, we do not require the points to be sufficiently close to the data support.
As a direct consequence of the convergence of the posterior distribution, we have the following convergence of the denoiser.
Corollary 4.4.
Under the same assumptions as in Theorem 4.2, we have that for any , we have that
When we turn back to the parameter , we have the following corollary. The proof turns out to be rather technical instead of being a direct consequence of the above theorem. The main difficulty lies in the scaling within the exponential term. This is another example that the parameter is more convenient for theoretical analysis.
Corollary 4.5.
Let . Assume that has finite 2-moment. For all , we let . Then, we have that
Finally, we establish the following convergence rate for the posterior distribution when more assumptions are made on the data distribution .
Theorem 4.6.
Assume that the reach is positive. Consider any . We assume that and that there exists such that there exist constants so that for any small radius , one has . Then, for any we have the following convergence rate for any :
where is a constant depending only on and .
This convergence rate result plays a central role in the subsequent analysis of the convergence of flow matching ODE trajectories (cf. Theorem 5.3). The assumptions underlying this theorem serve as a primary basis for the assumptions outlined in 1, which are critical for our analysis of ODEs. Consequently, any refinement or improvement of this theorem could potentially enhance the subsequent analysis of ODEs.
4.2 Distinct behaviors for posterior convergence rates under data geometry
In this subsection, we will revisit Theorem 4.2 under different data geometries. In particular, we focus on two cases: (1) is supported on a low-dimensional manifold with smooth density with respect to the Hausdorff measure (note that we do not exclude the case when ); (2) is a discrete distribution supported on a finite set.
The first case is motivated by the fact that many real-world data distributions are supported on low-dimensional manifolds. However, in practice, one usually has no access to the manifold but only to some samples drawn from . Let denote independent samples drawn from , and let denote the corresponding empirical probability measure. When training the objective function in Section 2.2 with the empirical , one unfortunately will obtain the unique empirical optimal solution with closed form:
| (14) |
Solving the ODE with will almost surely result in . This is an extremely undesired effect as no new samples can be generated from the model. To avoid this issue, we believe certain modification of the training objective must be made. In order to achieve this goal, we first need to theoretically contrast the solution with the empirical solution under the manifold hypothesis mentioned above. This is why we focus on the convergence rates of the posterior distribution in these two geometries in this section. We also point out that the comparison of posterior distributions is necessary as one can hardly tell the difference between the empirical solution and the ground truth solution at the level of the overall distributions.
Proposition 4.7.
Assume that is a good sample of such that . Then, for any , one has that .
This result follows trivially from the fact that convolution will decrease the Wasserstein distance. We point out that, however, there is no simple way of bounding the difference between the posterior distributions using . See Theorem 4.3 and Remark 4.4 in [MSW19] for some relevant results along this line.
In this section, we first tackle the convergence rates for the posterior distributions and will complete the convergence analysis for ODEs in Section 5.3.
An intuitive observation regarding the convergence rates.
We start with an observation regarding the Jacobian of the denoisers and . By Corollary 4.4 we have that and . Now, we consider the Jacobians of the two projection maps.
Proposition 4.8.
For almost everywhere , we have that
-
1.
where and is the orthogonal projection onto the tangent space ;
-
2.
.
Then, Proposition 3.2 and Proposition 4.8 imply the following results: if we assume that the convergence of to (resp. to ) holds up to the 1st order derivatives as (this assumption is made for illustrative purposes only and is not rigorously justified here, serving instead to motivate the later results), then one has the following convergence as :
-
•
-
•
.
Note the term in front of the integrals above. That the limits above exist immediately implies the following rate estimates (otherwise, the term will result in a blowup behaviour instead of the convergence above):
-
•
-
•
.
From this, we see that the convergence rate of the posterior must be significantly different when is supported on a manifold or on discrete points. The illustrative calculation above suggests that (1) the convergence rate for the manifold case should be , (2) whereas the discrete case should be . These can be seen by roughly taking a square root for the integrals above as one can vaguely think of the above integrals as certain squares of the posteriors. Now, we establish our final rigorous results below.
Convergence rates for the manifold case.
We first consider the case when is supported on a submanifold . Note that this does not exclude the case when . Under some mild conditions, we have the following convergence rate for the posterior distribution.
Theorem 4.9.
Let be a dimensional closed submanifold (without self-intersection) with a positive reach . Assume that has a smooth non-vanishing density . For any and , we let . If satisfies that , then we have that
Note that the first-order convergence rate depends solely on the dimension of the submanifold, while higher-order information, such as the second fundamental form, is encapsulated within the big O notation. Specifying these higher-order contributions in detail would be an interesting direction for future work.
As a direct consequence of the convergence of the posterior distribution, we have the following convergence of the denoiser.
Corollary 4.10.
Under the same assumptions as in Theorem 4.9, for any satisfying , we have that
Convergence rates for the discrete case.
Let the data distribution be a general discrete distribution with and . We use to denote the support of . We study the concentration and convergence of the posterior measure for each , including those on , the medial axis of . To this end, we introduce the following notations.
For each point , we denote the set of distance values from to each point in as follows:
| (15) |
We use to denote the -th smallest distance value in . A useful geometric notion will be the gap between the squares of the two smallest distances which we denote by
| (16) |
We further let
We use the notation to denote the normalized measure restricted to the points in that are closest to :
| (17) |
Whenever is not on , we have and . With the above notation, we have the following convergence result for the posterior measure as .
Theorem 4.11.
Let be a discrete distribution. For any , we have the following convergence of the posterior measure towards :
As a corollary, we have the following convergence of the denoiser.
Corollary 4.12.
Let be a discrete distribution. For any , we have the following convergence of the denoiser towards the mean of :
In particular, when , assume that we have that
Compared to the linear convergence rate in Corollary 4.10, the discrete setting exhibits an exponential convergence rate. Interestingly, this significant difference does not lead to any notable variation in the flow map convergence rate described in Theorem 5.4. Nevertheless, this discrepancy remains intriguing and could provide valuable insights into understanding the interplay between memorization and generalization in the future. Later in Section 6.3, we will utilize the above results to analyze memorization behavior.
5 Well-Posedness of Flow Matching ODEs
With the concentration and convergence of the posterior distribution established, we now establish the well-posedness of the flow matching ODEs within the interval as well as the convergence property when , in a general setting, including when the target data distribution is not fully supported such as those concentrated on a submanifold. This is the first theoretical guarantee for such cases, addressing gaps in prior works [LHH+24, GHJ24] that impose restrictive assumptions excluding manifold-supported data.
5.1 Well-posedness of flow matching ODEs at
First of all, we establish the existence of the flow map for , i.e., the uniqueness and existence of the solution of Equation 1 for . The following result was stated in the original flow matching paper [LCBH+22] under unspecified conditions and later on was proved in [GHJ24] in the case when satisfies many regularity assumptions such as absolute continuity w.r.t. the Lebesgue measure. In our case, we only require that has finite 2-moment, which significantly expands the applicability of the flow model.
Theorem 5.1.
As long as has finite 2-moment, for any initial point , there exists a unique solution for the ODE Equation 1. Furthermore, the corresponding flow map is continuous and satisfies that for all .
This proof involves carefully analyzing to establish the locally Lipschitz property of the vector field as well as establishing the integrability of the vector field so that we can apply the classic mass concentration result (see [Vil09]).
5.2 Well-posedness of flow matching ODEs at
Now, we establish the convergence of flow map as under mild assumptions and hence rule out the potential risk of divergence which can be a disaster for the flow model as shown in Figure 1(a).
Assumption 1 (Regularity assumptions for the data distribution).
Let be a probability measure on . We assume that satisfies the following properties:
-
1.
has a finite 2-moment, i.e., ;
-
2.
The support has a positive reach 111The support can be the whole space and in this case the reach .;
-
3.
There exists and such that for any radius , there exist constants so that for any small radius and any , one has for any .
Many common data distributions satisfy the above assumptions and we list some of them below:
Example 5.2.
-
1.
Any data distribution fully supported on with finite 2 moment and non-vanishing density, e.g., normal distribution, satisfies all the assumptions with .
-
2.
Any data distribution supported on a -dimensional linear subspace with finite 2 moment and non-vanishing density, e.g., projected normal distribution, satisfies all the assumptions with .
-
3.
Any data distribution supported on a -dimensional compact submanifold with positive reach with a non-vanishing density with respect to the volume measure on satisfies all the assumptions with (cf. Lemma B.8).
-
4.
Any empirical data distribution with a finite number of samples satisfies all the assumptions with .
Now, we establish the main result of this section below. The major reason that we require the reach to be positive is to handle the geometric singularity mentioned in Section 3.2 through the absorbing result in Theorem 3.11. In this way, we are able to ensure that an ODE trajectory will stay away from the medial axis and hence avoid the potential singularity issue. We need item 3 in 1 to ensure that at least locally, we can apply the posterior convergence rate result in Theorem 4.6 in a uniform way.
Theorem 5.3.
Let be a probability measure on satisfying the regularity assumptions in 1. Then,
-
1.
The limit exists almost everywhere with respect to the Lebesgue measure.
-
2.
is a measurable map and .
Furthermore, we have the following estimate of the convergence rate of the flow map. Recall that , then, we have that for any fixed ,
The in the theorem above is inherited from Theorem 4.6. As such, we chose to retain the original formulation, avoiding the simplification of to , which would have required redefining .
Notice that the convergence rate is for very general data distribution . In fact, if we further assume that is supported on a compact manifold or a discrete set, then the convergence rate can be improved. See Section 5.3 below for more details.
5.3 Refined convergence rates for manifolds and discrete cases
Now, we go back to the manifold hypothesis and give a detailed convergence analysis for the manifold case and the sampling case. Based on the convergence rates we established in Section 4.2, we develop the following ODE convergence result which is a refined version of Theorem 5.3. Unlike the vast difference in posterior convergence and in denoiser convergence, the ODE convergence rates of the manifold case and the discrete case are rather similar. This is a bit surprising but we will explain intuitively why this should be the case at the end.
Theorem 5.4.
When is supported on a submanifold or a discrete set, we have the following convergence rates for the flow map as .
-
•
Let be a dimensional closed submanifold (without self-intersection). Assume that has finite 2-moment, and has a smooth nonvanishing density and a positive reach . We further assume that the second fundamental form and its covariant derivative are bounded on . Then, for almost everywhere , we have that
-
•
If denotes a discrete probability measure, then for almost everywhere , we have that
Note that the geometric conditions for manifolds in the theorem are mild. These conditions only guarantee that the submanifold will not have “sharp turns” in the ambient space . For example, it includes the case when and is any low dimensional subspace or any compact submanifold, such as a sphere, torus, etc.
The rate for the discrete case is optimal as shown in the example below.
Example 5.5.
Consider the one point set with . Then, when choosing and , one has that starting with any , its ODE trajectory is given by . Therefore, . Hence, the flow map has a linear convergence rate.
However, we do not know whether the rate for the manifold case is optimal or not. In fact, we conjecture that the rate can be improved to the linear rate for the manifold case as well and hence the ODE convergence rate does not differ between the manifold case and the discrete case. This conjecture is motivated from the fact that the distribution with linear rate (see the proposition below) and hence its associated ODE should intuitively converge with the same rate.
Proposition 5.6.
For any probability measure with finite 2-moment, we have that
We note that the above proposition is relatively straightforward compared to the posterior convergence established in Theorem 4.2. This provides further evidence (in addition to Proposition 4.7 and the subsequent discussion) for the importance of focusing on analyzing the posterior rather than the entire data distribution.
5.4 Equivariance of the flow maps under data transformations
We have established in Theorem 5.3 the existence of the flow map sending directly any sampled point to a point following the target data distribution under 1. In this regard, it is of interest to establish theoretical properties of the flow map. In this subsection, we examine how the flow map behaves under certain transformations of the data distribution . More precisely, after certain transformation, one obtains a new data distribution . We then consider applying the flow model to the new data distribution and examine the corresponding flow map. In this paper, we assume that satisfies 1 and focus on rigid transformations and scaling (which will preserve the assumptions), leaving the investigation of other transformations for future work.
Rigid transformations
Consider the rigid transformation where is an orthogonal matrix and is any vector. It turns out that if we apply the flow model to such a transformed data distribution with the same scheduling functions and , the flow map is also a rigid transformation of the original flow map , i.e.,
In fact, if we let denote the corresponding denoiser, vector field, and flow map associated with , we establish the following result.
Theorem 5.7 (Equivariance under rigid transformations).
For any and , if we let , then
where represents the derivative of with respect to . Then, we have that
in particular, by convergence of as , we have that .
Scaling
We now consider the effect on the flow map when the data is scaled by a factor , i.e., . This case is more intricate than the previous two cases, as one needs to change the scheduling functions to obtain the invariance property of the flow map.
Assume that an initial flow model is applied to with scheduling functions and . Let denote any positive smooth function so that and . Then, consider
These are still legitimate scheduling functions satisfying and . We let denote the corresponding denoiser, vector field, and flow map associated with the flow matching model with the scaled data distribution and the new scheduling functions and . We establish the following result.
Theorem 5.8 (Equivariance under scaling transformations).
For any and , if we let , then
Therefore,
and in particular, by convergence of as , we have that .
6 Attraction Dynamics of Flow Matching ODEs
In this section, we utilize the concentration and convergence results of the posterior distribution to analyze the attraction dynamics of the flow matching ODEs.
Following the flow matching ODE, when using , the ODE trajectory can be simply interpreted as moving towards the denoiser at each time step. Intuitively, denoiser initially is close to the data mean and then progressively being close to nearby data points as the ODE trajectory evolves. Eventually, as goes to zero, the denoisers will converge to the nearest data point almost surely. We will instantiate this intuition and provide rigorous results. We will first analyze the initial stage of the sampling process and then discuss the attraction dynamics towards a local cluster of data points in the intermediate stage. Finally, we will discuss the terminal behavior of the ODE trajectory under the discrete measure along with its connection with memorization.
6.1 Initial stage of the sampling process
We will first work with a data distribution with bounded support and then later extend to a more general setting where is a convolution of a bounded support distribution and a Gaussian distribution. We assume the data distribution has finite -moment and hence the ODE trajectories of the flow model are well-defined (cf. Section 5.1). We now analyze the initial stage of the sampling process in the flow model.
The initial stage of the sampling process corresponds with being with a large value with which the initial sample is transformed from . As is large, is close to , and hence has an very large norm. In this case, is likely outside the support of . Therefore, the above corollary describes the initial stage of the sampling process.
Attracting toward data mean
By the initial stability of the posterior distribution, the denoiser will be close to the mean of the data distribution which can be summarized in the following proposition.
Proposition 6.1.
Let be a probability measure on with finite 2-moment and bounded support . Fix any . Then, for any with initial distance where , there exists a constant
such that for all , the denoiser will be close to the mean of the data distribution with the following estimate:
With the above proposition, we can then apply the meta absorbing result in Section 3.3 to show that the ODE trajectory will be absorbed in a ball centered at the mean of the data distribution.
Proposition 6.2.
Under the same assumptions as in Proposition 6.1, the closed neighborhood is an absorbing set for the ODE trajectory .
The abosorbing property guarantees the trajectory will remain in and hence the estimate in Proposition 6.1 holds for the trajectory as well. We can then apply the meta attracting result to show the ODE trajectory moves toward the mean of the data distribution in the initial stage.
Proposition 6.3 (Initial stage: Moving towards the data mean).
With the same assumptions as in Proposition 6.1, the ODE trajectory starting from will move towards the mean of the data distribution as shown in the following estimate:
where .
Note that an close to will make smaller and hence better convergence of the entire sampling process. However, the decay guarantee will be weaker as approaches 1.
Attracting and abosorbing to the convex hull of data support
How close the trajectory will be to the mean of the data distribution depends on the initial distance and how fast the posterior distribution concentrates. However, the trajectory will necessarily reach the convex hull of the support of as goes to zero as shown in the following proposition which is obtained by applying meta theorems of attracting and absorbing in Section 3.3 to the convex hull of the support of .
Proposition 6.4.
Given the data distribution defined above, for any , let be a flow matching ODE trajectory follows Equation 8. Then we have the following results.
-
1.
If , then for any ;
-
2.
If , then moves towards with the following decay guarantee:
for any .
The above propositions requires the data distribution to have a bounded support. We now extend the above results to a more general setting where the data distribution is , i.e., a convolution of a bounded support distribution and a Gaussian distribution. This is done by noting that the ODE trajectory with data distribution can be derived from the ODE trajectory with data distribution by a simple transformation.
Lemma 6.5.
Let be a distribution and let . Let be an ODE trajectory of Equation 5 with data distribution . We define . Then, is an ODE trajectory of Equation 5 with data distribution .
Corollary 6.6.
Let be a probability measure on with having a bounded support which is denoted as . Let be a point and denote , where . Let be a parameter such that . Then there exist a constant
such that for all , a trajectory starting from will move towards the mean of the data distribution . Additionally, we have the following decay result:
Corollary 6.7.
Given the data distribution defined above, for any , let be an ODE trajectory of Equation 8 from to . Then, we have that
-
1.
If , then for any ;
-
2.
If , then moves towards with the following decay guarantee:
for any .
6.2 Intermediate stage of the sampling process
Now we have described the flow matching ODE dynamics at initial stage. In this subsection, we shed light on the intermediate stage by showing that the ODE trajectory will be attracted towards the convex hull of local clusters of data under some assumptions.
We start by assuming that the data distribution contains a “local cluster” or “local mode”. More precisely, we consider the following assumptions.
Assumption 2.
Let be a probability measure on . We assume that that has a well separated local cluster , specifically, we assume that satisfies the following properties:
-
1.
, where is a closed bounded set with diameter .
-
2.
satisfies for all .
Then, it turns out that for any point that is close to the convex hull of , the denoiser will be attracted to the convex hull of as goes to zero.
Proposition 6.8.
Following the strategy illustrated in Remark 3.10, the above proposition can be used to show that the ODE trajectory will be absorbed in certain neighborhood of the convex hull of and eventually be attracted to the convex hull of .
Proposition 6.9.
Assume that satisfies 2. Let , and define
Then, the set is an absorbing set for the ODE trajectory with . Additionally, an ODE trajectory starting from will converge to the convex hull of as .
Remark 6.10.
A well separated local cluster can be regarded as a local mode of the data distribution. The above proposition give a quantitative measure when the ODE trajectory will be attracted to the local mode.
6.3 Terminal stage of the sampling process and memorization behavior
The local cluster dynamics described in the previous subsection can be manifested in the terminal stage of a discrete data distribution where each data point can eventually be regarded as a local cluster. In this subsection, we will show that the ODE trajectory will be attracted to the nearest data point as goes to zero and discuss the memorization behavior of the flow model. The results in this subsection complement those in Section 5.3 by specifying a precise range of parameters for terminal convergence, rather than focusing solely on the convergence rate as in Section 5.3.
We will first introduce some necessary notations and definitions. Throughout this subsection, denotes a discrete distribution . We let denote its support. The Voronoi diagram of gives a partition of into regions ’s based on the closeness to the data points:
In particular, each is a connected closed convex region and the union of all ’s covers the whole space . The boundary of the region consists of exactly the points on , the medial axis of . We will also consider a family of regions that lies inside and covers all interior points of as goes to zero. Specifically, let be a small positive number, we use to denote the region
| (18) |
Similar to the condition for , each is intersection of finitely many half-spaces and hence is a convex region.
For each , is the unique nearest data point to and the posterior measure will be fully concentrated at as goes to zero as shown in Theorem 4.11. As a consequence, we can identify a time as follows such that the ODE trajectory will never leave the region for . We use to denote the minimum distance from to other data points in and introduce a constant that depends on the data support , specific point , and the parameter . Then the time is defined as
We have the following proposition.
Proposition 6.11 (Terminal absorbing behavior under discrete distribution).
Fix an arbitrary . Then, for any , the ODE trajectory starting from will stay inside , i.e., .
With the above propositions, we can show that the ODE trajectory inside will be attracted to as goes to zero.
Proposition 6.12.
Fix an arbitrary . Then, for any , the ODE trajectory starting from will converge to as goes to zero.
Note that this result is complementary to the discrete part of Theorem 5.4 in the sense that we can identify a fairly explicit time such that the current nearest data point is what the ODE trajectory will converge to. This is in contrast to the general convergence rate of the flow map as in Theorem 5.4.
Discussion on Memorization
The constant in Proposition 6.12 can be regarded as a time under which a trajectory near the data point will eventually converge to under the flow matching ODE for the empirical data distribution. In particularly, the empirical optimal solution will only be able to repeat the training data points in the terminal stage of the sampling process—a phenomenon known as memorization. The constant can then be used as a measure of the memorization time for the empirical optimal solution. When considering the CIFAR-10 dataset and choose , the averaged value of over all data points is around which covers the last one fourth of the sampling process in the popular sampling schedule used in [KAAL22].
Furthermore, we want to emphasize that the memorization for the flow model is particularly depends on the denoiser near terminal time. In particular, if the denoiser is asymptotically close to the empirical denoiser, the flow model will only memorize the empirical data. This is formalized in the following proposition.
For the following, we will consider a neural network trained denoiser and its corresponding ODE trajectory following the flow matching ODE with replaced by , that is,
| (19) |
Proposition 6.13 (Memorization of trained denoiser).
Let denote a discrete probability measure and let denote its denoiser. Let be any smooth map (which should be regarded as any neural network trained denoiser). Assume that there exists a function such that and
Then, there exists a parameter such that for all , and for any , the ODE trajectory for Equation 8 (with replaced by ) starting from will converge to as .
Note that the above proposition do not necessarily specifying the convergence of and can be applied in general. In the case where we do have convergence of and the the limit of the denoiser , the two limits will coincide. This is formalized in the following proposition.
Proposition 6.14.
Let be any smooth map (which should be regarded as any neural network trained denoiser). Assume that the ODE trajectory for Equation 8 has a limit as and the limit also exist. Then, we must have that
This proposition shows that the final output of the flow model is fully determined by the behavior of the denoiser near the terminal time unlike a generic ODE where the near terminal time behavior only partially influence the final output. Therefore, for a flow model to have good generalization ability, it is crucial to ensure that the trained denoiser is diverse near terminal time and covers the entire data distribution—where the empirical optimal solution fails.
7 Discussion
Our study lays a steady theoretical foundation for the flow-matching model, especially in the case when data distribution is supported on a low dimensional manifold. Our analysis of the ODE dynamics, as well as the contrast between the manifold and sampling scenarios, will help shed light on designing better variants of the flow matching model that are memorization-free and with better generalization ability.
In particular, we point out the following two possible future directions. Suppose the submanifold has intrinsic dimension . Then, whereas (cf. Proposition 4.8). From this perspective, one can already see a huge difference between the empirical solution and the ground truth solution. This motivates us to consider incorporating the Jacobian of the denoiser into the training of the flow matching model to minimize memorization. Our analysis of the attraction region of the flow matching ODE in the discrete case also suggests that one should be careful on training the denoiser near the terminal time to avoid memorization.
Our general convergence result contains a coefficient that depends on the reach of the data support which is not stable under perturbations. However, some of our results can potentially be refined by using local variants of the reach, such as the local feature size, which could yield more robust and stronger theoretical guarantees.
Acknowledgements.
This work is partially supported by NSF grants CCF-2112665, CCF-2217058, CCF-2310411 and CCF-2403452.
References
- [AB98] Nina Amenta and Marshall Bern. Surface reconstruction by voronoi filtering. In Proceedings of the fourteenth annual symposium on Computational geometry, pages 39–48, 1998.
- [AB06] Stephanie B Alexander and Richard L Bishop. Gauss equation and injectivity radii for subspaces in spaces of curvature bounded above. Geometriae Dedicata, 117:65–84, 2006.
- [AL19] Eddie Aamari and Clément Levrard. Nonasymptotic rates for manifold, tangent space and curvature estimation. 2019.
- [BBDBM24] Giulio Biroli, Tony Bonnaire, Valentin De Bortoli, and Marc Mézard. Dynamical regimes of diffusion models. Nature Communications, 15(1):9957, 2024.
- [BDD23] Joe Benton, George Deligiannidis, and Arnaud Doucet. Error bounds for flow matching methods. arXiv preprint arXiv:2305.16860, 2023.
- [BHHS22] Clément Berenfeld, John Harvey, Marc Hoffmann, and Krishnan Shankar. Estimating the reach of a manifold via its convexity defect function. Discrete & Computational Geometry, 67(2):403–438, 2022.
- [Bia23] Adam Białożyt. The tangent cone, the dimension and the frontier of the medial axis. Nonlinear Differential Equations and Applications NoDEA, 30(2):27, 2023.
- [CHN+23] Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pages 5253–5270, 2023.
- [CLN23] Bennett Chow, Peng Lu, and Lei Ni. Hamilton’s Ricci flow, volume 77. American Mathematical Society, Science Press, 2023.
- [CZW+24] Defang Chen, Zhenyu Zhou, Can Wang, Chunhua Shen, and Siwei Lyu. On the trajectory regularity of ode-based diffusion sampling. In Forty-first International Conference on Machine Learning, 2024.
- [dM37] MR de Mises. La base géométrique du théoreme de m. mandelbrojt sur les points singuliers d’une fonction analytique. CR Acad. Sci. Paris Sér. I Math, 205:1353–1355, 1937.
- [DZ11] Michel C Delfour and J-P Zolésio. Shapes and geometries: metrics, analysis, differential calculus, and optimization. SIAM, 2011.
- [Efr11] Bradley Efron. Tweedie’s formula and selection bias. Journal of the American Statistical Association, 106(496):1602–1614, 2011.
- [EKB+24] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Dominik Lorenz Yam Levi, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024.
- [Fed59] Herbert Federer. Curvature measures. Transactions of the American Mathematical Society, 93(3):418–491, 1959.
- [GHJ24] Yuan Gao, Jian Huang, and Yuling Jiao. Gaussian interpolation flows. Journal of Machine Learning Research, 25(253):1–52, 2024.
- [GHL90] Sylvestre Gallot, Dominique Hulin, and Jacques Lafontaine. Riemannian geometry, volume 2. Springer, 1990.
- [GPAM+14] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- [HJA20] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- [HW20] Daniel Hug and Wolfgang Weil. Lectures on convex geometry, volume 286. Springer, 2020.
- [KAAL22] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems, 35:26565–26577, 2022.
- [KG24] Diederik Kingma and Ruiqi Gao. Understanding diffusion objectives as the elbo with simple data augmentation. Advances in Neural Information Processing Systems, 36, 2024.
- [LC24] Marvin Li and Sitan Chen. Critical windows: non-asymptotic theory for feature emergence in diffusion models. arXiv preprint arXiv:2403.01633, 2024.
- [LCBH+22] Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations, 2022.
- [LGL23] Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. In International conference on learning representations (ICLR), 2023.
- [LGRH+24] Gabriel Loaiza-Ganem, Brendan Leigh Ross, Rasa Hosseinzadeh, Anthony L Caterini, and Jesse C Cresswell. Deep generative models through the lens of the manifold hypothesis: A survey and new connections. arXiv preprint arXiv:2404.02954, 2024.
- [LHH+24] Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code. arXiv preprint arXiv:2412.06264, 2024.
- [LZB+22] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Systems, 35:5775–5787, 2022.
- [MMASC14] Maria G Monera, A Montesinos-Amilibia, and Esther Sanabria-Codesal. The taylor expansion of the exponential map and geometric applications. Revista de la Real Academia de Ciencias Exactas, Fisicas y Naturales. Serie A. Matematicas, 108:881–906, 2014.
- [MMWW23] Facundo Mémoli, Axel Munk, Zhengchao Wan, and Christoph Weitkamp. The ultrametric Gromov–Wasserstein distance. Discrete & Computational Geometry, 70(4):1378–1450, 2023.
- [MSLE21] Chenlin Meng, Yang Song, Wenzhe Li, and Stefano Ermon. Estimating high order gradients of the data distribution by denoising. Advances in Neural Information Processing Systems, 34:25359–25369, 2021.
- [MSW19] Facundo Memoli, Zane Smith, and Zhengchao Wan. The Wasserstein transform. In International Conference on Machine Learning, pages 4496–4504. PMLR, 2019.
- [PY24] Frank Permenter and Chenyang Yuan. Interpreting and improving diffusion models from an optimization perspective. In Forty-first International Conference on Machine Learning, 2024.
- [RTG98] Yossi Rubner, Carlo Tomasi, and Leonidas J Guibas. A metric for distributions with applications to image databases. In Sixth international conference on computer vision (IEEE Cat. No. 98CH36271), pages 59–66. IEEE, 1998.
- [SBDS24] Jan Pawel Stanczuk, Georgios Batzolis, Teo Deveney, and Carola-Bibiane Schönlieb. Diffusion models encode the intrinsic dimension of data manifolds. In Forty-first International Conference on Machine Learning, 2024.
- [SDCS23] Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, pages 32211–32252. PMLR, 2023.
- [SDWMG15] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. PMLR, 2015.
- [SE19] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
- [SME21] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- [SPC+24] Neta Shaul, Juan Perez, Ricky TQ Chen, Ali Thabet, Albert Pumarola, and Yaron Lipman. Bespoke solvers for generative flow models. In The Twelfth International Conference on Learning Representations, 2024.
- [Vil03] Cédric Villani. Topics in Optimal Transportation. Number 58. American Mathematical Soc., 2003.
- [Vil09] Cédric Villani. Optimal transport: old and new, volume 338. Springer, 2009.
- [WLCL24] Yuxin Wen, Yuchen Liu, Chen Chen, and Lingjuan Lyu. Detecting, explaining, and mitigating memorization in diffusion models. In The Twelfth International Conference on Learning Representations, 2024.
- [ZYLX24a] Pengze Zhang, Hubery Yin, Chen Li, and Xiaohua Xie. Formulating discrete probability flow through optimal transport. Advances in Neural Information Processing Systems, 36, 2024.
- [ZYLX24b] Pengze Zhang, Hubery Yin, Chen Li, and Xiaohua Xie. Tackling the singularities at the endpoints of time intervals in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6945–6954, 2024.
Appendix A Geometric Notions and Results
In this section, we recall some basic geometric notions and establish some results that are used in the proofs. The geometric results are of independent interest and can be used in other contexts as well.
A.1 Convex geometry notions and results
In this subsection, we collect some basic notions and results in convex geometry that are used in the proofs. Our main reference is the book [HW20].
We first introduce the definition of a convex set and convex function.
Definition 1 (Convex set).
A set is called a convex set if for any and such that , we have that .
Definition 2 (Convex function).
A function is called a convex function if for any and , we have that .
An intermediate result that the sublevel sets or of a convex function are convex sets; see [HW20, Remark 2.6].
We now introduce the definition of the convex hull of a set.
Definition 3 (Convex hull [HW20, Definition 1.3, Theorem 1.2]).
The convex hull of a set is the smallest convex set that contains and is denoted by . Additionally, we have that
Let be a set, and . We say a hyperplane give by a linear function is a supporting hyperplane of at if the following holds:
-
1.
.
-
2.
for all .
For a closed convex set , every boundary point of has a supporting hyperplane.
Proposition A.1 (Supporting hyperplane [HW20, Theorem 1.16]).
Let be a closed convex set in and . Then, there exists a supporting hyperplane of at .
We collect some basic properties regarding the convex set the distance function.
Proposition A.2.
Let be a convex set in and be a set in . Then, we have that
-
1.
For each , there exists a unique point such that .
-
2.
The distance function is a convex function.
-
3.
The thickening of by a distance is a convex set, that is is a convex set.
-
4.
The diameter of is the same as the diameter of its convex hull, that is .
-
5.
Let , then a set is convex if and only if is convex.
A.2 Metric geometry notions and results
Let be a closed subset and be the medial axis of . We let by defined by . In this section, we consider certain properties of the projection function .
We first recall the definition of the local feature size in [AB98] with a slight generalization that we consider all points in instead of only points in .
Definition 4 ([AB98]).
For any , we define the local feature size of as the distance from to the medial axis of .
Let be a point in such that it has a unique projection to , denoted by . We first consider the following set for any :
Lemma A.3.
we have the following characterizations of .
-
•
is an interval.
-
•
For any , we have that .
-
•
We let . If , we have that .
-
•
.
Proof of Lemma A.3.
The first three items follow from the pioneering work [Fed59, Theorem 4.8]; see also [DZ11, Theorem 6.2] for more details. We provide a proof for the last item. For the last item, first of all, it is straightforward to see that . Now, we assume that This implies that
and hence
This is a contradiction and hence . This concludes the proof. ∎
Next, for any point , we analyze the angle for any . The following lemma is a slight variant of [Fed59, Theorem 4.8 (7)].
Lemma A.4.
For any and any such that , the following holds for any :
Proof.
By definition of , we have that . Therefore, we have that
∎
When is convex, then . In this way, we have the following corollary.
Corollary A.5.
If is convex, then for any and any we have that .
This control of the angle allows us to derive the following result that bounds the distance between and the projection in terms of the distance between and .
Lemma A.6.
For any and any such that , we have that for any ,
Proof.
The case when trivially holds. Below we consider the case when . In this case, as is a closed set.
By the law of cosines, we have that
Suppose , then we have that
By applying Lemma A.4 to and , we have that
This implies the following estimate for the cosine of the angle :
This contradicts the inequality above and hence we must have that
We then have the following corollary which will be used in the proof of Theorem 4.2.
Corollary A.7.
Fix any , any and any . Then, we have that
Proof.
For any , we have that
By Lemma A.6, we have that
Combining the two inequalities, we have that and hence . ∎
Finally, we derive the local Lipschitz continuity of the projection function.
Lemma A.8 (Local Lipschitz continuity of the projection).
For any and for any such that and , we have that
Proof.
By applying Lemma A.4 to and separately to , we have that
By adding the two inequalities about the inner products, we have that
Let , then we have that
Therefore, by Cauchy-Schwarz inequality, we have that
This implies . ∎
Differentiability of the distance function
Let be any closed subset. We let denote the set of points in that achieve the infimum. When is not in the medial axis of , the set is a singleton and we denote it by .
Interestingly, there is the following result result showing the existence of one sided directional derivatives for by [dM37] (see also [Bia23] for a more recent English treatment).
Lemma A.9 ([dM37]).
For any vector , the one-sided directional derivative of at in the direction exists and is given by
Motivated by the this result, we mimick the proof and establish the following result for the squared distance function . Notice that, we can remove the constraint for .
Lemma A.10.
For any , the directional derivative of at exists and is given by
Proof.
Without loss of generality, we assume that is the origin and for some (one can achieve these by applying rigid transformations).
We let , and . Since , we have that
where denotes the first coordinate of . Note that . So we have that
Now we have that by the cosine rule of the triangle formed by , and , we have that
Therefore, we have that
As discussed above, we have that
By continuity of outside , we have that as . Therefore, we have that
Corollary A.11.
Let be a differentiable curve in , then we have that is differentiable with respect to and we have that
Appendix B Proofs
B.1 Proofs in Section 2
Proof of Proposition 2.1.
For any and , and the map is well-defined.
| ∎ |
Proof of Proposition 2.2.
We first write down the density of explicitly as follows:
Then, we have that
Note that . Therefore with the reparametrization , we have that
| ∎ |
B.2 Proofs in Section 3
Proof of Remark 3.1.
For the normalizing factor , we note that . Hence, the factor must be positive and bounded.
Now, we consider the following integral
The last inequality follows from the fact that has a finite 1-moment. Hence, the posterior distribution has a finite 1-moment and the denoiser is well-defined. ∎
Proof of Proposition 3.2.
Recall that
We let . Then,
The second equation follows from standard calculations. ∎
Proof of Proposition 3.4.
Let . Recall that
Then, we have that
By Lemma A.8, there exists a positive constant such that for any close to . Therefore,
Now, when , by Corollary 4.10, we have that
In this case, . This implies that for close to 1, we have that
The right hand side is bounded since exists. Therefore, the vector field is uniformly bounded for all .
If and , then . By Corollary 4.5, we have that as . This implies that . Then, as the denominator , we have that . ∎
The following result on the convergence of ODE under asymptotically vanishing perturbation will be used often in the proofs of this section.
Lemma B.1.
Let be a differentiable trajectory of non-negative real numbers satisfying the following differential inequality
where and . Then, we have:
-
1.
For any we have that
-
2.
If , then ;
Proof of Lemma B.1.
By multiplying the integrating factor , we have that
Then for all , we have
This proves Item 1.
For Item 2, we will first show that is bounded. As decays to zero as goes to infinity, so will be , and hence there exists some constant such that for all . Then, we have that
Hence, is bounded for all , and we denote by any bound for .
Next, we show that converges to zero as goes to infinity. For any , there is a sufficient large such that
-
1.
.
-
2.
for all .
Then for all , by integrating the inequality from to , we have that
This implies that converges to zero as goes to infinity. ∎
Proof of Theorem 3.6 and Remark 3.7.
We consider the change of variable . We let for all . Then, satisfies the nice ODE as in Equation 10. By assumption we have that is outside the convex set . For any , by Corollary A.11 we have that
For the first item, we have that . Multiplying with the exponential integrator , we have that
Then for any , we have that
Using the change of variable, we have that
For the second item, we have that
Then we can apply Item 2 of Lemma B.1 to obtain . This implies that .
We then apply Item 1 of Lemma B.1 to obtain that for any :
Using the fact that for any , we have that
This proves Remark 3.7 ∎
Proof of Theorem 3.8.
We will utilize the parameter for this proof with which we consider the ODE trajectory of Equation 10 with and .
For Item 1, we will show that the trajectory must stay inside for all whenever . Suppose otherwise then there exists some first time such that . By the assumption that , we can apply Lemma A.10 to obtain the derivative of the squared distance function along the trajectory for any :
This implies that . By the continuity of the derivative above, we have that for all for some . Note that and . Then by the mean value theorem, there exists some such that . This leads to a contradiction and hence the trajectory must stay inside for all , which concludes the proof.
The second part of the theorem follows straightforwardly from the fact that is a closed set. If a trajectory starts from but leaves at some point, it must also leave a neighborhood of , which would contradict the given assumption. This completes the proof. ∎
Proof of Proposition 3.9.
For the first item, for any , since lies in the convex set , we apply Corollary A.5 to conclude
Then there is
We then apply Theorem 3.8 to conclude that is absorbing for .
For the second item, the distance function does not distinguish between the interior and the boundary of and we utilize the supporting hyperplane function instead. Assume the trajectory leaves at some first time . Then, in particular, for all and . In terms of the parameter , we have and . Since is a closed convex set, there exist a supporting hyperplane at such that and for all . In particular, we can write , where is the unit normal vector of the hyperplane. Since for all and for all , we must have that . Therefore, we have that
Since lies in the interior of , we must have that . This leads to a contradiction and hence the trajectory must stay inside for all . ∎
Proof of Theorem 3.11.
Similarly as in the proofs of other theorems in this section, we consider the change of variable and .
We let and define (one can see how the definition is motivated from the following proof)
Then, .
By continuity of the ODE path, there exists a maximal interval so that for any , where the overline indicates the closure of the underlying set. Now, we show that must be infinity by showing that otherwise lies in the interior, i.e., and hence the trajectory will be able to extend within to for some small . In this way, we can extend the interval to which contradicts the maximality of .
Now, assume that . Then, by Corollary A.11, we have that for any ,
By our assumption on , we have that and for any , . Then, by Remark 3.7, we have that
where the inequality under the brace bracket follows from the definition of . Hence, .
Now we examine along the integral path. We have that
Now, for the integral of , we have that
Therefore,
| (20) |
where we used the definition of again to control all the exponential terms. This implies that for all (recall that we assumed that ) and hence . This concludes the proof. ∎
B.3 Proofs in Section 4
Proof of Proposition 4.1.
Let . Consider the function . By the fact that for any , we have that:
for all . Then for any Borel measurable set , we can bound the ratio of the posterior and prior measures as:
Similarly, we can bound the ratio from below:
Since , we have . Therefore, we have:
In particularly, there is for all which by definition bounds the total variation distance between and by . Then the Wasserstein distance can be bounded by ; see e.g [Vil03, Proposition 7.10]. ∎
Proof of Theorem 4.2.
We let and . We let . According to Corollary A.7, for any , if we define the radius
then we have the following inclusion
For the other direction, we have that
where
Here satisfies that as , . So can be thought of as an approximation of .
Then, we estimate the two terms below separately:
For , we have the following estimate:
For the second term , we have the following estimate:
Since is the support of , we have that . Hence, for any , we have
By letting , we have that . Therefore, we have that
Proof of Corollary 4.4.
This is a direct consequence of the following property of the Wasserstein distance where the case was proved in [RTG98] and the other cases follow from the fact that is increasing with respect to [Vil09].
Lemma B.2.
For any probability measures on and any , we have that
∎
Proof of Corollary 4.5.
By Lemma A.8, there exists a small and a constant such that for any , one has . As both and are continuous in a local neighborhood of , there exists a small such that for any with , one has
-
•
-
•
-
•
Now, take . Then, it is easy to check that for any such that , one has
This implies that for any such that , one has
Hence, when is small enough (dependent on ), we have that for any such that .
Now, we have that
As , there exists such that when , one has that and . By the analysis above, we can enlarge so that is small enough so that . Therefore, for any , we have that . Since is arbitrary, we have that . ∎
Proof of Theorem 4.6.
Recall from the proof of Theorem 4.2 that for any , we have that
Then, we have that . So
| (21) | ||||
| (22) | ||||
| (23) | ||||
| (24) |
On the other hand, we have that
Therefore, if one let , when we have that and then
Notice that , we have that eventually
The rightmost inequality in the theorem follows from the fact that the right most summand in the above equation has an exponential decay which is way faster than any polynomial decay. ∎
Proof of Proposition 4.7.
The case when is trivial. When , the statement follows from the following two results and from the fact that where .
Lemma B.3 ([MMWW23, Lemma B.11]).
Let be a measurable map. Then, for any probability measures with finite 2-moment, we have that
Lemma B.4 ([Vil03, Proposition 7.17]).
Let be two probability measures on . We let and as well as . Then, for any , one has that
∎
Proof of Theorem 4.11.
When , and and then the Wasserstein distance becomes 0 which proves the statement.
Now, we will focus on the case when . The posterior measure is given by
For the ease of notation, we use to denote the normalization constant in , to denote the -th term in . We use to denote the normalization constant in .
Observe that for any , one has
This motivates the following construction of a coupling between and :
Then, we bound the Wasserstein distance between and as follows:
By taking the square roots on both sides, we conclude the proof. ∎
Proof of Corollary 4.12.
The result follows from Theorem 4.11 and the stability of the mean operation under the Wasserstein distance Lemma B.2. ∎
B.3.1 Proof of Theorem 4.9
We still let . Then, we let and hence,
As , is concentrated around . For any , we have that
We first consider the term .
As we have shown already in the proof of Theorem 4.2, we have that . So, we have that
| (25) | ||||
| (26) |
Now, we consider the term . Since is a submanifold of , its tangent space can be identified as a subspace of . We use to denote the inclusion map. In particular, for any , we have that . Let denote the injective radius of . Note that, by [AB06, Corollary 1.4], . So, the exponential map will be an diffeomorphism in a small ball . Furthermore, we have the following inclusion relation between geodesic balls and Euclidean balls.
Lemma B.5.
For any , we have that
Proof of Lemma B.5.
The proof of the left hand side follows from Lemma A.1 and Lemma A.2 (ii) of [AL19]. Although Lemma A.2 (ii) stated compactness for the manifold , this assumption is not needed in the proof. The right hand side follows from the fact that for any , where denotes the geodesic distance. ∎
Now, we fix some . Then, there exists an open neighborhood around so that we have the following diffeomorphism (which gives rise to the normal coordinates):
In particular, and each can be written as for some .
Let denote the second fundamental form of at . Then, the exponential map in has the following Taylor expansion [MMASC14]:
| (27) |
where for some constant only dependent on and its derivatives .
For any , we let denote the metric tensor, then is the identity matrix. The volume form is given by and it admits the following Taylor expansion around :
where is the Ricci curvature tensor of at ; see e.g. [CLN23, Exercise 1.83].
We can write
| (28) |
where depends on Ricci curvature tensor and the gradient .
Now, we define
Let . Then, we have that
Using the same argument as the one used for controlling in the proof of Theorem 4.2, we have
| (29) |
So,
| (30) |
Next, we derive a Taylor expansion of the squared distance from to for around :
Lemma B.6.
Let . Then, we have that
where and for some positive constant , and is the identity matrix.
Proof of Lemma B.6.
We first note that
By equation (27), we have that
where we used the fact that belongs the normal space of at so that and . ∎
By Lemma B.6 and Equation 30, we have that
and
We will establish the following claims:
Claim 1.
| (31) | |||
Claim 2.
| (32) | |||
With the above two claims, there is
where in the last equality we used the fact that for a Gaussian random variable .
Therefore, we have that
and concludes the proof.
Now we prove the two claims. For the first claim, note that by , we can use [BHHS22, Theorem 2.1] to conclude
So the matrix is positive definite. We let be the smallest eigenvalues of . Note that . So, we can choose small enough at the beginning so that there exists some constant for all , we have that
Consider the transformation . Then, we let which goes to as and for sufficiently small , we have that hence there is
Then, we have that
Now, for , recall that . Hence, for any , we have that and hence
This implies that there is expansion . Therefore, we have that
where in the last part we used the fact that the the decay rate of such an integral as goes to is exponential.
For , we similarly have that
Therefore,
| (33) | |||
Similarly, we have that
| (34) | |||
Additionally, by , we have that
| (35) |
Then Claim 1 follows from Equation 33 and Equation 35 and Claim 2 follows from Equation 34.
B.4 Proofs in Section 5
Proof of Theorem 5.1.
We prove that the vector field is locally Lipschitz for any fixed and that the integral . Then, by the mass conservation formula (see for example [Vil09]), we conclude the proof.
To prove the local Lipschitz property, by Proposition 3.2, it suffices to show that the covariance matrix of the posterior distribution is locally (w.r.t. ) uniformly bounded (w.r.t. ). We establish the following lemma for this purpose.
Lemma B.7.
Let be a probability measure on with a finite 2-moment . For any , consider the posterior distribution:
We let . Then, the covariance matrix of satisfies:
Proof of Lemma B.7.
Fix a unit vector . Then, we have that
For , we have that
Therefore, one has that
Since is arbitrary, this concludes the proof. ∎
By dominated convergence theorem, it is straightforward to check that is continuous. Hence, for any and any local compact neighborhood of , is uniformly bounded below by some positive constant. Furthermore, as is differentiable (cf. Proposition 3.2), we have that is locally uniformly bounded as well. These together with Proposition 3.2 and Equation 6 imply that the vector field is locally Lipschitz for any . This concludes the proof of the well-posedness of the flow map.
Now we verify the integrality of .
We split the integral by the two terms according to the summation . For the first term, we use and the fact about the expected norm of a Gaussian random variable with variance is .
where we use the assumption that is a non-increasing function of and hence .
For the second term, we have that
The last step follows from the fact that has finite second moment and hence finite first moment. We also use the assumption that is a non-decreasing function of and hence . ∎
Proof of Proposition 5.6.
For any independent random variables and any , we have that . Hence,
The result follows. ∎
Proof of Theorem 5.7.
| (36) | ||||
where in the second equality we used the change of variable and the fact that .
Then, we have that
Now, let be an integral path w.r.t. . Consider the path . Notice that , then we have that for any ,
Therefore, . ∎
Proof of Theorem 5.8.
Consider . The transformed denoiser w.r.t. and is given by
| (37) | ||||
where we used the change of variable in the second equation.
Let denote an ODE path for . Then we consider the path . We need to check that .
Note that , hence we conclude the proof. ∎
B.4.1 Proof of Theorem 5.3
We utilize the change of variable for . We also let denote the inverse function of .
Next, we consider . Then, we have that satisfies ODE Equation 10: . Recall the transformation sending to . Then, we define .
By Theorem 4.6, we have the following convergence rate for :
Claim 3.
Fix . Then, there exists such that for any radius and all , one has
where is a constant depending only on and and .
Proof of 3.
We let . Note that . Since satisfies 1, we have that for small . Now, we let . By Theorem 4.6, we conclude the proof. ∎
The following Claim establishes an absorbing property for points in .
Claim 4.
Consider small such that . Fix any such that . Then, there exists satisfying the following property: the trajectory starting at any initial point of the ODE in Equation 10 satisfies that for any : .
Proof of 4.
This follows from 3 and Theorem 3.11 (by letting ). ∎
Next we establish a concentration result for when is large.
Claim 5.
For any small , there are large enough such that for any and , we have that
Proof of 5.
Consider the random variable where and are independent but from the same probability space . Then, has as its law. We have that . For any , we have that
Since follows the standard Gaussian, for any , there exists such that for all , we have that
Now, since has finite 2-moment and hence finite 1-moment, there exists such that .
Therefore, for all , we have that
| ∎ |
Now, we establish the desired convergence results for the scale of .
Claim 6.
For any small , there exist large enough , such that with probability at least , we have that satisfies the following properties:
-
1.
converges along the ODE trajectory starting from as ;
-
2.
the convergence rate is given by .
Proof of 6.
For any , by 4 and 5, there exist large enough and , such that
-
•
with probability at least , we have that lies in ;
-
•
the ODE trajectory starting at satisfies that for all , lies in and .
This implies that one can apply the convergence rate of denoiser in 3 to the entire trajectory with where . Then, for any in the interval , we have that
| (38) | ||||
where the bound is obtained in a way similar to how we obtain Section B.4.1.
This implies that the solution becomes a Cauchy sequence and hence converges to a limit .
Now, we let approach in the above inequality and and replace with to obtain the following convergence rate:
| (39) |
∎
Now, we change the coordinate back to to obtain the following result. Since is arbitrary so one can let approach 0 in the result below to conclude the proof of Theorem 5.3.
Claim 7.
For any small , one can sample with probability at least , such that the flow map converges to a limit as .
Proof of 7.
Let be the one given in 6. Then, we let . Consider the map sending to . Then, we have that
| (40) |
Both maps and (whose existence follows from Theorem 5.1) are continuous bijections. It is then easy to see that if an ODE trajectory of Equation 10 converges starting with some and has convergence rate , then the corresponding trajectory of the ODE Equation 1 starting with also converges to a limit as with the same convergence rate up to the change of variable . Finally, by Equation 40 we also have that
which concludes the proof. ∎
Item 2 in the theorem is a direct consequence of item 1. As is the pointwise limit of continuous maps (cf. Theorem 5.1), it is also measurable. We know that weakly converges to as . Now, we just verify that is also a weak limit of to show that .
For any continuous and bounded function , we have that
where we used the bounded convergence theorem in the last step. Therefore, we have that and hence is the flow map associated with the ODE .
B.4.2 Proof of Theorem 5.4
Part 1.
We first establish the following volume growth condition for the manifold satisfying assumptions in the theorem. Notice that by [AB06, Corollary 1.4], .
Lemma B.8.
There exists sufficiently small, where denotes the injective radius, such that the following holds. For any , there exists a constant so that for any radius , and for any , one has .
Proof.
Notice that within the compact region , the density is lower bounded by a positive constant . Additionally, the sectional curvature of is upper bounded by some constant due to the boundedness of the second fundamental form. Then by Gunther’s volume comparison theorem [GHL90, 3.101 Theorem] for , there exists constant such that
where , denotes the geodesic distance, and denotes the -dimensional sphere with sectional curvature .
We then choose to be small enough such that
for some constant and all .
Since for any , we have that . Hence, we have that for all and ,
By letting , we conclude the proof. ∎
Then, we can replicate the proof of Theorem 5.3 with only small changes of 3 as follows using :
Claim 8.
Under assumptions as in Theorem 5.4, there exsits such that for any radius , all , we have that
where is a constant depending only on and the geometry of .
Proof of 8.
This can be proved by carefully examining all bounds involved in the proof of Theorem 4.9.
-
•
Equation 25: Since , we have that and hence in the numerator can be bounded by . The denominator is lower bounded by some polynomial of by Equation 24 and the volume growth condition of established in Lemma B.8. We also notice that can be chosen uniformly for all as it is completely dependent on the reach. Therefore, the big O function is bounded above by some function of .
-
•
Equation 28: can be bounded by and the bounds on the local Lipschitz constant of the density and the second fundamental form (which bounds the Ricci tensor).
-
•
Equation 29: this one is bounded similarly as the one in Equation 25 by some function of .
-
•
Lemma B.6: the bound is bounded by the bounds on the second fundamental form and its covariant derivatives.
In conclusion,
where for all and depends only on and geometry bounds of such as reach and second fundamental form bounds. Then, by combining the two exponential terms, one concludes the proof. ∎
Part 2.
In the discrete case, we let . We can improve the convergence rate in Theorem 5.3 to be exponential by considering a direct consequence of Corollary 4.12:
Claim 9.
For all such that , we have that
where only depends on is the minimal separation between the points in .
Therefore, when is large enough, we have that for any
where is a constant dependent on and the properties of the exponential function.
Then, in particular, there is
where the we use the fact that is bounded by the absorbing result in Theorem 3.11 and hence the integral is bounded by a constant .
This implies that for some constant depending on . Now, following the rest of the estimations in the proof of Theorem 5.3, we can replace the rate in 6 with after the change above and conclude the proof.
B.5 Proofs in Section 6
Proof of Proposition 6.1.
By the estimate in Proposition 4.1 and the fact that is increasing for , one can check that for any , and for all with where there is
where . Then the result follows from Lemma B.2. ∎
Proof of Proposition 6.2.
The estimate in Proposition 6.1 shows that for all and for all , the denoiser lies in the ball and hence the interior of . The closed ball is clearly convex and we can then apply Item 2 of Proposition 3.9 to obtain the desired result. ∎
Proof of Proposition 6.3.
According to Propositions 6.1 and 6.2, the estimate
holds for the entire trajectory . We then obtain the result by Item 1 of the meta attracting result Theorem 3.6. ∎
Proof of Proposition 6.4.
The key observation comes from that, the posterior distribution is also supported on and hence its expectation, the denoiser must lie in the convex hull .
For the first part, the first Item in Proposition 3.9 applies to and hence any neighborhood of is absorbing . We then obtain the desired result by Item 2 in Theorem 3.8.
For the second part, we use Corollary A.5 to obtain
for all and all . Then we can apply Item 1 of the meta attracting result Theorem 3.6 with to conclude the proof. ∎
Proof of Lemma 6.5.
Let be the probability path with data distribution . Then, we have that satisfies
With the change of variable , we have that
One has that
where denotes the density of . Therefore, the trajectory satisfies
| ∎ |
Proof of Corollary 6.6.
This is a direct consequence of Proposition 6.3 and Lemma 6.5 ∎
Proof of Corollary 6.7.
This is a direct consequence of Proposition 6.4 and Lemma 6.5 ∎
Proof of Proposition 6.8.
For simplicity, we use to denote the posterior measure at . We restrict on to obtain the following probability measure
It is easy to see that lies in the convex hull of . We can then bound the distance from the denoiser to the convex hull of by the Wasserstein distance between and .
Similarly to the proof of Theorem 4.11, we construct the following coupling between and :
where is the diagonal map sending to .
We then have the following estimate:
By the assumption that , we have that for all
and for all
We then have that
Then by applying Lemma B.2 and the fact that , we have that
Proof of Proposition 6.9.
Note that, the set is convex itself as the distance function to a convex set if a function. For the first part, according to Item 2 of Proposition 3.9, it suffices to show that for all , the denoiser lies in the interior of for all . By Proposition 6.8, we need to show
That is to verify, when , the following inequality holds.
where . Then, when , the above inequality holds for all and when , it is straightforward to verify the above inequality holds for all . This concludes the proof of the first part.
For the second part, we use as the reparametrization and the corresponding trajectory . We want to show that the distance goes to zero as goes to infinity. By taking the derivative of , and use the notation
we have
where in the second to last inequality we use the fact that and hence
Note that is exactly the quantity used in the Proof of Proposition 6.8 which by the absorbing property in the first part of the proof, we can apply (in terms of ) to and obtain
Then by Lemma B.1, we have that as and hence converges to the convex hull of as . ∎
Proof of Proposition 6.11.
Since each is a convex set and in fact, a closure of an open convex set, by item 2 of Proposition 3.9, it suffices to prove that for all and all , which is the boundary of , one has that which is the interior of .
First of all, we define
It is straightforward to check that . In fact, .
Hence, by Corollary 4.12, for any we have that
Therefore, we need to identify when the above inequality is less than , that is,
Recall that . Then, it is direct to check that when , the above inequality holds for all and when , the above inequality holds for all . In summary, this implies that when . ∎
Proofs of Proposition 6.12.
We will first prove in the parameter and then the translation to the parameter is straightforward. We consider the trajectory for . We first show that as .
Along the trajectory , by Corollary A.11 we have
Applying Corollary 4.12 to points in , we have the following uniform bound for all ,
By Proposition 6.11 we have that . Therefore,
Then by Lemma B.1, we have that as . By the the fact that is discrete and is the nearest point to for all large , we must have as . ∎
Proof of Proposition 6.13.
The proof idea follows the same line as the proofs of Proposition 6.11 and Proposition 6.12. Similarly as in the case of denoisers, we can also consider the change of variable for handling . We let and let for any . Then, it is straightforward to check that
| (41) |
and converting everything back to is straightforward.
We first identify the parameter such that the denoiser is will always lie in the interior of for all and all .
By the triangle inequality, we have that
Since goes to zero as goes to infinity, there exists a parameter such that for all , . Then, with the same argument as in the proof of Proposition 6.11, we can prove that the trajectory will never leave for all .
Since the trajectory never leaves for all , we can then apply the uniform decay of to the differential inequality of as follows:
Now, we apply Lemma B.1 again as in the proof of Proposition 6.12, we have that goes to zero as goes to infinity and hence converges to . ∎
Proof of Proposition 6.14.
Similarly as in the proof of Proposition 6.13, we consider the parameter and the corresponding trajectory for . Then by assumptions, the limits and exist. In particular, the limit of the derivative exists and we will show that it has to be zero.
Suppose , then there must exist a coordinate with nonzero limit. Assume that the limit for the -th coordinate of is . Then, there exist a such that the -th coordinate of is bounded away from zero by for all . However, due to the convergence , we can find two numbers such that . This contradicts with the lower bound for the -th coordinate of the derivative by mean value theorem. Therefore, the limit of the derivative has to be zero which implies that