Emergence of Globally Attracting Fixed Points in
Deep Neural Networks With Nonlinear Activations
Abstract
Understanding how neural networks transform input data across layers is fundamental to unraveling their learning and generalization capabilities. Although prior work has used insights from kernel methods to study neural networks, a global analysis of how the similarity between hidden representations evolves across layers remains underexplored. In this paper, we introduce a theoretical framework for the evolution of the kernel sequence, which measures the similarity between the hidden representation for two different inputs. Operating under the mean-field regime, we show that the kernel sequence evolves deterministically via a kernel map, which only depends on the activation function. By expanding activation using Hermite polynomials and using their algebraic properties, we derive an explicit form for kernel map and fully characterize its fixed points. Our analysis reveals that for nonlinear activations, the kernel sequence converges globally to a unique fixed point, which can correspond to orthogonal or similar representations depending on the activation and network architecture. We further extend our results to networks with residual connections and normalization layers, demonstrating similar convergence behaviors. This work provides new insights into the implicit biases of deep neural networks and how architectural choices influence the evolution of representations across layers.
1 Introduction
Deep neural networks have revolutionized various fields, from computer vision to natural language processing, due to their remarkable ability to learn complex patterns from data. Understanding the internal mechanisms that govern their learning and generalization capabilities remains a fundamental challenge.
One approach to studying these transformations is through the lens of kernel methods. Kernel methods have a long history in machine learning for analyzing relationships between data points in high-dimensional spaces (Schölkopf and Smola, 2002; Smola and Schölkopf, 2004). They provide a framework for understanding the similarity measures that underpin many learning algorithms. Recent theoretical studies have increasingly focused on analyzing neural networks from the perspective of kernels. The Neural Tangent Kernel (NTK) (Jacot et al., 2018) is a seminal work that provided a way to analyze the training dynamics of infinitely wide neural networks using kernel methods. This perspective has been further explored in various contexts, leading to significant advances in our understanding of neural networks (Lee et al., 2019; Arora et al., 2019; Yang, 2019).
Despite these advances, an important question remains unexplored: How does the similarity between hidden layer representations evolve across layers, and how is that affected by particular choices of nonlinear functions? Previous work has mainly focused on local behaviors or specific initialization conditions (Saxe et al., 2013; Schoenholz et al., 2017; Pennington et al., 2017). A comprehensive global analysis of neural kernel sequence fixed points and convergence properties, particularly in the presence of nonlinear activations, is still incomplete.
This paper addresses this gap by introducing and analyzing the evolution of kernel sequences in deep neural networks. Specifically, we consider the kernel sequence , where denotes a similarity measure, and and are representations of the inputs and at layer . Understanding whether and how this sequence converges to a fixed point as the depth of the network increases is crucial for uncovering the inherent implicit biases of deep networks.
Our analysis builds upon foundational work in neural network theory and leverages mean-field theory to simplify the analysis. By considering the infinite-width limit, stochastic sequences become deterministic, allowing us to focus on the underlying dynamics without the interference of random fluctuations (Poole et al., 2016; Yang et al., 2019; Mei et al., 2019).
Contributions:
-
•
By employing algebraic properties Hermite polynomials, we derive explicit forms of the neural kernel and identify its fixed points, leading to many elegant results.
-
•
We demonstrate that the kernel sequence converges globally to a unique fixed point for a wide class of functions that cover all practically used activations, revealing inherent biases in deep representations.
-
•
We extend our analysis to networks with normalization layers and residual connections, highlighting their impact on the convergence behavior.
Understanding these dynamics contributes to a deeper understanding of how depth and nonlinearity interact with one another at initialization.
2 Related works
The study of deep neural networks through the lens of kernel methods and mean-field theory has garnered significant interest in recent years. The Neural Tangent Kernel (NTK) introduced by Jacot et al. (2018) provided a framework to analyze the training dynamics of infinitely wide neural networks using kernel methods. This perspective was further expanded by Lee et al. (2019) and Arora et al. (2019), who explored the connections between neural networks and Gaussian processes.
The propagation of signals in deep networks has been studied in the works of Schoenholz et al. (2017) and Pennington et al. (2017). Previous studies have also explored the critical role of activation functions in maintaining signal propagation and stable gradient behavior in deep networks (Hayou et al., 2019). These studies focused on understanding the conditions required for the stable propagation of information and the avoidance of signal amplification or attenuation. However, these analyses often concentrated on local behaviors or specific conditions, leaving a gap in understanding the global evolution of representations across layers.
Hermite polynomials have been used in probability theory and statistics, particularly in the context of Gaussian processes (Williams and Rasmussen, 2006). Although Poole et al. (2016) and Daniely et al. (2016) have utilized polynomial expansions to analyze neural networks, they do not study global dynamics in neural networks, as presented in this paper. To the best of our knowledge, the only existing work that uses Hermite polynomials in the mean-field regime to study the global dynamics of the kernel is by Joudaki et al. (2023b). However, this study only covers centered activations, which fail to capture several striking global dynamics covered in this study.
Our work extends these foundational studies by providing an explicit algebraic framework to analyze the global convergence of kernel sequences in deep networks with nonlinear activations. Using Hermite polynomial expansions, we offer a precise characterization of the kernel map and its fixed points, contributing new insights into the implicit biases of nonlinear activations.
3 Preliminaries
This section introduces the fundamental concepts, notations, and definitions used throughout this paper. If and are vectors in , we use the inner product notation to denote their average inner product We consider a feedforward neural network with layers and constant layer width . The network takes an input vector and maps it to an output vector through a series of transformations. The hidden representations in each layer are denoted by . The transformation in each layer is composed of a linear transformation followed by a nonlinear activation function . We consider the multilayer perceptron (MLP), the hidden representation at layer is given by:
| (1) |
where is identified with the input. We can assume that elements of are drawn i.i.d. from a zero mean distribution, unit variance distribution. Two prominent choices for weight distributions, Gaussian and uniform distribution satisfy these conditions. In some variations of the MLP, we will use normalization layers and residual connections. Finally, the neural kernel between two inputs and at layer is defined as:
| (2) |
The main goal of this paper is to analyze the sequence at random initialization. The motivation for this analysis is to understand if architectural choices, specifically the activation function and the model depth, lead to specific biases of the kernel towards a certain fixed point. Namely, if there is a bias towards zero, it would imply that at initialization, the representations become more orthogonal. In contrast, a positive fixed point would mean the representations become more similar.
In the current setup, the sequence is a stochastic sequence or a Markov chain due to the random weights at each layer. However, we will show that under the mean-field regime, the sequence converges to a deterministic sequence, and we will analyze its properties.
4 The mean-field regime
In this section, we conduct a mean-field analysis of MLP to explore the neural kernel’s fixed point behavior as the network depth increases. This approach allows us to gain insight into the global dynamics of neural networks, mainly how the similarity between two input samples evolves as they pass through successive network layers. Now, we can state the mean-field regime for the kernel sequence, stating that in this regime, the sequence becomes deterministic.
As will be proven later, this sequence’s deterministic transition follows a scalar function defined below.
Definition 1.
Given two random variables with covariance and activation define the kernel map as the mapping between the covariance of preactivation and the covariance of post-activations:
| (3) |
This definition has appeared in previous studies, namely the definition of dual kernel by Daniely et al. (2016), and has been adopted by Joudaki et al. (2023b) to study the effects of nonlinearity in neural networks.
The following proposition formally states that in the mean-field regime, the kernel sequence follows iterative applications of the kernel map.
Proposition 1.
In the mean-field regime with , let denote the kernel sequence of an MLP with activation function obeying for . If each element of the weights drawn i.i.d. from a distribution with zero mean and unit variance, the kernel sequence evolves deterministically according to the kernel map
where the initial value corresponds to the input, and is defined in Definition 1.
Historically, conditions similar to have been used to prevent quantities on the forward pass from vanishing or exploding. For example, in a ReLU, half of the activations will be zeroed out, which will lead to a vanishing norm of forward representations. The initialization of (He et al., 2016) addresses that by scaling weights to maintain consistent forward pass norms across layers. This principle is further refined by Klambauer et al. (2017), proposing the idea of self-normalizing activation functions, which ensure consistent mean and variances between pre- and post-activations.
An interesting observation is that kernel dynamics is governed by kernel map defined on the basis of Gaussian preactivation, even if the weights are not Gaussian matrices. The main insight for this equivalence is that as long as elements are drawn i.i.d. from a zero mean unit variance distribution, we can apply the Central Limit Theorem (CLT) to conclude that preactivations follow the Gaussian distribution. This simple yet elegant observation gives us a powerful analytic tool to study kernel dynamics by leveraging algebraic properties for Gaussian preactivations; we will automatically get the same results for a wide class of distributions.
The proposition 1 tells us that the kernel sequence is precisely given by Thus, we can analyze its convergence by studying the fixed points of the kernel map which are the values of that satisfy With the assumption that the kernel map is a mapping between to itself. Thus, Brower’s fixed point theorem implies that the kernel map has at least one fixed point However, as we will show, there is potentially more than one fixed point, and it will be interesting to understand which ones are locally or globally attractive.
5 Hermite expansion of activation functions
Hermite polynomials possess completeness and orthogonality under the Gaussian measure. Therefore, any function that is square-integrable with respect to a Gaussian measure can be expressed as a linear combination of Hermite polynomials (see below). The square integrability rules out the possibility of having heavy-tailed postactivations without second moments. This holds for all activations that are used in practice. We use normalized Hermite polynomials and their coefficients.
Definition 2.
Normalized Hermite polynomials are defined as follows
Although Hermite polynomials have been used in probability theory and statistics, particularly in the context of Gaussian processes (Williams and Rasmussen, 2006), their application in analyzing neural network dynamics provides a novel methodological tool. Previous works, such as Daniely et al. (2016), have utilized polynomial expansions to study neural networks, but our explicit use of Hermite polynomial expansions to derive the kernel map and analyze convergence is a new contribution.
The crucial property of Hermite polynomials is their orthogonality:
| (4) |
Scaling by ensures that polynomials form a orthonormal basis. Based on this property, we can define:
Definition 3.
Given a function , square-integrable with respect to the Gaussian measure. Its Hermite expansion is given by:
Here, are called the Hermite coefficients of .
In addition to orthogonality, Hermite polynomials have another “magical” property that is crucial for our later analysis.
Lemma 1 (Mehler’s lemma).
For standard-normal random variables with covariance it holds
This lemma states that given two Gaussian random variables with covariance , the expectation of the product of Hermite polynomials is zero unless the indices are equal (see explanations in Section A for proof). The lemma 1 is crucial for our theory. Based on this lemma, we can express the kernel map in terms of the Hermite coefficients, showing a particular structure of the kernel map.
Corollary 1.
We have the following explicit form for the kernel map:
The proof follows directly from the definition of kernel map, expanding in the Hermite basis and then applying Lemma 1.
Daniely et al. (2016) show a similar analytic form for dual activation, which aligns with our definition of kernel map. However, they did not use this to study global dynamics. To our knowledge, the only study that uses Hermite polynomials to study global dynamics is (Joudaki et al., 2023b), which is limited to centered activations. i.e., those that satisfy or equivalently
6 Convergence of the kernel with general activations
In this section, we will show that for any nonlinear activation function, there is a unique fixed point that is globally attractive.
Theorem 1.
Given a nonlinear activation function with kernel map such that . Define the kernel sequence , with . Then there is a unique globally contracting fixed point , which is necessarily non-negative . The only other fixed points distinct from could be neither of which is stable. Furthermore, we have the following contraction rate towards :
-
1.
If then is an attracting with rate
-
2.
If and , then is attracting, with rate
-
3.
If , and then is attracting with rate
-
4.
If , and then the attracting fixed point is necessarily in the range , satisfying for which we have
where .
Implications.
Let us take a step back and review the main takeaway of Theorem 1. Omitting the constants and for sufficiently large depth we have
where denotes the input similarly.
Broadly speaking, we can think of three categories of bias:
-
•
Orthogonality bias : Implies that as the network becomes deeper, representations are pushed towards orthogonality exponentially fast. We can think of this case as a bias towards independence.
-
•
Weak similarity bias : Implies that as the network becomes deeper, the representations form angles between and . Thus, in this case, the representations are neither completely aligned nor completely independent.
-
•
Strong similarity : Implies that as the network becomes deeper, representations become more similar or aligned, as indicated by inner products converging to one, exponentially fast in case 2, polynomially in case 3.
The bias of activation and normalization layers has been extensively studied in the literature. For example, Daneshmand et al. (2021) show that batch normalization with linear activations makes representations more orthogonal, relying on a technical assumption that is left unproven (see assumption ). Similarly, Joudaki et al. (2023a) extend this to odd activations yet introduce another technical assumption about the ergodicity of the chain, which is hard to verify or prove (see Assumption 1). In a similar vein, Meterez et al. (2024) show the global convergence towards orthogonality in a network with batch normalization and orthogonal random weights, but do not theoretically analyze nonlinear activations. Yang et al. (2019) prove the global convergence of the Gram matrix of a network with linear activation and batch normalization (see Corollary F.3) toward a fixed point. However, the authors explain that because they cannot establish such a global convergence for general activations (see page 20, under the paragraph titled Main Technical Results), they resort to finding locally stable fixed points, meaning that if preactivations have such a Gram matrix structure and they are perturbed infinitesimally. Recent studies have also examined the evolution of covariance structures in deep and wide networks using stochastic differential equations (Li et al., 2022), which is similar to kernel dynamics and kernel ODE introduced here. However, the covariance SDE approach does not theoretically show the global convergence towards these solutions. Finally, Joudaki et al. (2023b) establish a global bias towards orthogonality for centered activations (see Theorem A2), which aligns with case 1 of Theorem 1, and to extend to other activations, they add layer normalization after the activation to make it centered. In contrast, Theorem 1 covers all existing activations.
One alternative way of interpreting the results of Theorem 1 is that as we pass two inputs through nonlinear activations, it ‘forgets’ the similarity between inputs and converges to a fixed point value that is independent of the inputs and only depends on the activation. Taking the view that the network ought to remember some similarity of the input for training, we can leverage Theorem 1 to strike a balance between depth and nonlinearity of the activations, as argued in the following.
Corollary 2.
Let be the some numerical precision, and let be an activation function such that , with its kernel map obeying . Then, for any initial pair of inputs and after layers, the representations of and will become numerically indistinguishable.
Approximately, represents the number of bits of numerical precision available in floating-point representations. For example for float32 numbers, is approximately . Therefore, when the network depth exceeds threshold , the representations of any two inputs will become numerically indistinguishable from one another. This effect propagates through subsequent layers, potentially making training ineffective or impossible. Notably, ReLU and sigmoid satisfy the conditions of this corollary, implying that this phenomenon can occur in networks utilizing these activations. Previous works on rank collapse (Daneshmand et al., 2020; Noci et al., 2022) and covariance degeneracy (Li et al., 2022) have observed and studied this phenomenon in various settings. However, the explicit and closed-form relationship presented in Corollary 2 provides a novel and precise quantification of this effect.
One of the most striking results of this theorem is that for any nonlinear activation, there is exactly one fixed point that is globally attractive, while other fixed points are not stable. Furthermore, the fixed point is necessarily non-negative. This implies that for any MLP with nonlinear activations, the covariance of preactivations will converge towards a fixed point, which is always non-negative. It turns out that there is a geometric reason why no globally attracting negative fixed point could exist (See remark S.2)
Theorem 1 has several aspects that may seem counterintuitive. For instance, case 1 demonstrates that a quantity decays exponentially as depth increases. To gain a better understanding of the theories behind Theorem 1, we can cast our layer-wise kernel dynamics as a continuous-time dynamical system, which is discussed next. For a detailed proof of Theorem 1, please refer to Section A.
6.1 A continuous time differential equation view to the kernel dynamics
One of the most helpful ways to find insights into discrete fixed point iterations is to cast them as a continuous problem. More specifically, consider our fixed point iteration:
We can replace this discrete iteration with a continuous time differential equation, which we will refer to as the kernel ODE:
| (kernel ODE) |
Recent studies have introduced stochastic models such as the Neural Covariance SDE by Li et al. (2022), which can be viewed as the stochastic analog of kernel ODE. However, kernel ODE will capture the most important parts of the discrete kernel dynamics for our main purpose of characterizing the attracting fixed points. The continuous analog of fixed points is a that satisfies Furthermore, the fixed point is globally attracting if we have become negative for and positive for We can say that the fixed point is locally attractive if this property only holds in some small neighborhood of
While the kernel ODE presents an interesting transformation of the problem, it does not necessarily have a closed-form solution in its general form. However, our main strategy is to find worst-case (slowest) scenarios for convergence that correspond to tractable ODEs. In many cases, however, the worst-case scenario depends on some boundary conditions. Thus, we can design worst-case ODEs for different cases and combine them in a joint bound. Let us use our centered activation equation as a case study.
6.2 Kernel ODE for centered activations
For the case of centered activation corresponding to case 1 of Theorem 1, the kernel ODE is given by
where the first term is canceled due to the assumption
Observe that when and when This implies that for sufficiently large Intuitively, the terms in that have the opposite sign of contribute to a faster convergence, while terms with a similar sign contribute to a slower convergence. Thus, we can ask what distribution of Hermite coefficients corresponds to the worst case, slowest convergence. If this is a tractable ODE, we can use its solution to bound the convergence of the original ODE. It turns out that the worst case depends on the positivity of which is why we study them separately.
Positive range. Let us first consider the dynamics when In this case, the term corresponding to contributes positively to a faster convergence, while terms make convergence slower. In light of this observation, a worst-case (slowest possible) convergence rate happens when the positive terms are maximized, which occurs when the weight of all is concentrated on the term, leading to kernel ODE
where we used the fact that Finally, we can solve this ODE
where corresponds to the initial values.
Negative range. Now, let us assume In this case, only the odd terms in contribute to a slowdown in convergence. Thus, the worst case occurs when all the weight of coefficients is concentrated in leading to the kernel ODE:
where corresponds to the initial values.
To summarize, we have obtained:
Now, we can use a numerical inequality valid for all and by solving for the constant, we can construct a joint bound for both cases:
where we have also replaced
Key insights.
The kernel ODE perspective reveals two important insights. First, the appearance of formula in our bound is due to the fact that is a fundamental solution of the differential equation Second, it reveals the importance of the positivity of coefficients in which allowed us to arrive at a worst-case pattern for the coefficients. This further highlights the value of algebraic properties of Hermite polynomials that canceled out the cross terms in
We can observe that the kernel ODE rate derived by analysis of kernel ODE is largely aligned with the exponential convergence of this term in Theorem 1. The slight discrepancy between the exponential rates between Theorem 1 and the kernel ODE rate is due to the discrete-continuous approximation. Despite this small discrepancy, the solution to kernel ODE can help us arrive at the right form for the solution. We can leverage the solution to kernel ODE to arrive at a bound for the discrete problem, namely using induction over steps.
Since Theorem 1 only provides an upper bound and not a lower bound for convergence, one natural question is: how big is the gap between this worst case and the exact ODE convergence rates? We can construct activations where the convergence is substantially faster, such as doubly exponential convergence (see Corollary S.1). However, for all practically used activations, the gap between our bound and the real convergence is enough (See section B).
7 Extension to normalization layers and residual connections
In this section, we extend our analysis to MLPs that incorporate normalization layers and residual (skip) connections and examine how they affect convergence.
7.1 Residual connections
Residual connections, inspired by ResNets (He et al., 2016), help mitigate the vanishing gradient problem in deep networks by allowing gradients to flow directly through skip connections. We consider the MLP with residual strength given by
where and are independent weight matrices of dimension with entries drawn i.i.d. from a zero-mean, unit-variance distribution, and modulates the strength of the residual connections (the bigger , the stronger residuals will be).
Proposition 2.
For an MLP with activation satisfying and residual parameter we have the residual kernel map
| (5) |
where denotes kernel map of
Furthermore, we have: 1) fixed points of are the same as those of 2) is a globally attracting fixed point of is a globally attracting fixed point of 3) the convergence of residual kernel map is monotonically decreasing in (the stronger residuals, the slower convergence).
Implications.
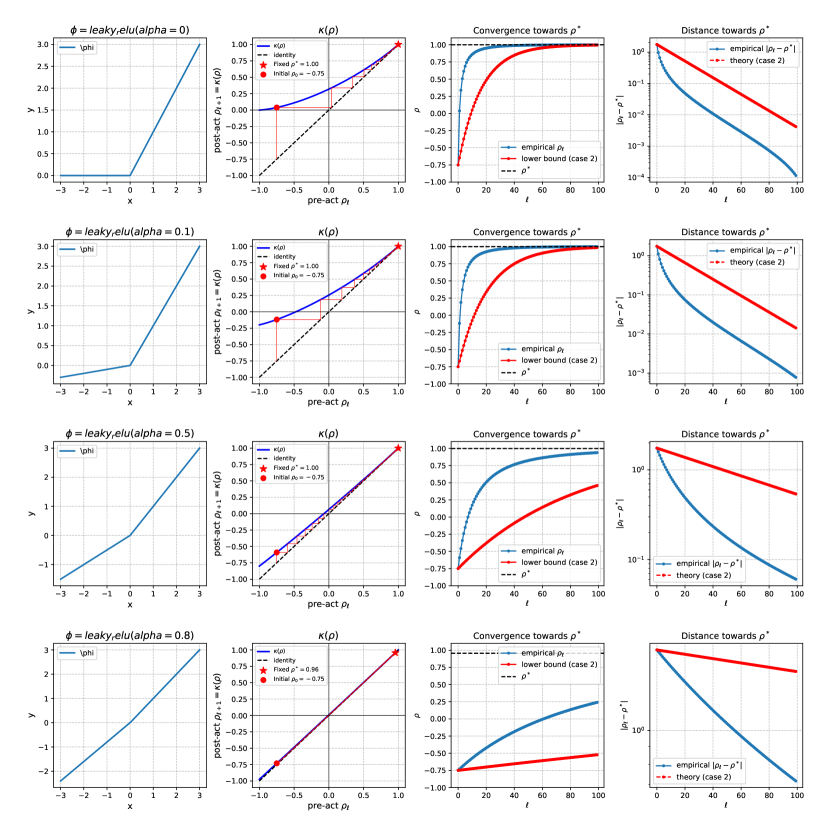
Proposition 2 reveals that residual connections modify the kernel map by blending the original kernel map with the identity function, weighted by the residual . This adjustment has several interesting implications. Our analysis here gives a quantitative way of balancing depth with the nonlinearity of activations. For example, Li et al. (2022) show as we ‘shape’ the negative slope of a leaky ReLU towards identity, it will prevent degenerate covariance in depth. In light of proposition 2 and corollary 2, we can write leaky ReLU as a linear combination of ReLU and identity and conclude that as residual strength increases (), the convergence rate becomes slower and thus degeneracy happens at deeper layers, which aligns with the prior study. Another interesting byproduct of proposition 2 is that it shows that when (highly strong residuals), the kernel ODE becomes an exact model for kernel dynamics (See remark S.1).
7.2 Normalization layers
Normalization layers are widely used in deep learning to stabilize and accelerate training. In this section, we focus on two common normalization layers:
-
•
Layer Normalization (LN) (Ba et al., 2016):
(6) where is the mean, and is the standard deviation of the vector .
-
•
Root Mean Square (RMS) Normalization:
(7)
The following theorem characterizes the joint activation and normalization kernel.
Proposition 3.
Let us assume satisfies where Consider an MLP layers
where denotes the joint activation and normalization layers. We have the following joint normalization and activation kernel:
where denotes the kernel map of .
Implications.
Proposition 3 implies that normalization layers adjust the kernel map by scaling and, in some cases, shifting it. When layer normalization is applied after activation, the activation and kernel map become centered. This means that for activations such as ReLU or sigmoid, the fixed point of the kernel sequence changes from to , indicating a shift from a bias towards the orthogonality of representations to aligning them. This result supports previous findings by Joudaki et al. (2023b) regarding the effect of layer normalization in centering, and extends it to other configurations (order of normalization and activation) for different orders of layers, as well as using root mean normalization. Furthermore, our findings align with studies showing that batch normalization induces orthogonal representations in deep networks (Yang et al., 2019; Daneshmand et al., 2021).
8 Discussion
The power of deep neural networks fundamentally arises from their depth and nonlinearity. Despite substantial empirical evidence demonstrating the importance of deep, nonlinear models, a rigorous theoretical understanding of how they operate and learn remains a significant theoretical challenge. Much of classical mathematical and statistical machinery was developed for linear systems or shallow models (Hastie et al., 2009), and extending these tools to deep, nonlinear architectures poses substantial difficulties. Our work takes a natural first step into this theoretical mystery by providing a rigorous analysis of feedforward networks with nonlinear activations.
We showed that viewing activations in the Hermite basis uncovers several strikingly elegant properties of activations. Many architectural choices, such as normalization layers, initialization techniques, and CLT-type convergences, make Gaussian preactivations central to understanding the role of activations. Hermite expansion can be viewed as the Fourier analog for the Gaussian kernel. These facts and our theoretical results, suggest that viewing activations in the Hermite basis is more natural than in the raw signal, analogous to viewing convolutions in the Fourier basis. For example, the fact that the kernel map is analytic and has a positive power series expansion, i.e., is infinitely smooth, does not require the activation to be smooth or even continuous. Thus, as opposed to many existing analyses that consider smooth and non-smooth cases separately, our theoretical framework gives a unified perspective. As an interesting example, smoothness, which has been observed to facilitate better training dynamics 3(Hayou et al., 2019), appears as a faster decay in Hermite coefficients. Thus, similar to leveraging the Fourier transform for understanding and designing filters, one can aspire to use Hermite analysis for designing and analyzing activation functions.
One of the key contributions of our work is the global perspective in analyzing neural networks. Traditional analyses often focus on local structure, such as Jacobian eigenspectrum by Pennington et al. (2018). While these local studies provide valuable insights, they do not capture the global kernel dynamics. More concretely, real-world inputs to neural networks, such as images of a dog and a cat, are not close enough to each other to be captured in the local changes. Our global approach allows us to study the evolution of representations across layers for any pair of inputs, providing further insights into how deep networks transform inputs with varying degrees of similarity.
One of the central assumptions for our approach is operating in the mean-field, i.e., infinite-width regime. While this approach led us to establish numerous elegant properties, it would be worth exploring the differences between finite-width and infinite-width results. This remains an important avenue for future work. Similarly, in the CLT application of Proposition 1, the exact discrepancies between the limited width and the infinite width would deepen our understanding of practical neural networks. Another intriguing endeavor is the potential to extend our framework to develop a theory for self-normalizing activation functions in a vein similar to (Klambauer et al., 2017). Finally, building on the mathematical foundations laid here to study first- and second-order gradients and their impact on training dynamics remains a highly interesting topic for future research.
References
- Arora et al. [2019] Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, Russ R Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. Advances in neural information processing systems, 32, 2019.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Daneshmand et al. [2020] Hadi Daneshmand, Jonas Kohler, Francis Bach, Thomas Hofmann, and Aurelien Lucchi. Batch normalization provably avoids ranks collapse for randomly initialised deep networks. Advances in Neural Information Processing Systems, 33:18387–18398, 2020.
- Daneshmand et al. [2021] Hadi Daneshmand, Amir Joudaki, and Francis Bach. Batch normalization orthogonalizes representations in deep random networks. Advances in Neural Information Processing Systems, 34:4896–4906, 2021.
- Daniely et al. [2016] Amit Daniely, Roy Frostig, and Yoram Singer. Toward deeper understanding of neural networks: The power of initialization and a dual view on expressivity. Advances in Neural Information Processing Systems, 29, 2016.
- Hastie et al. [2009] Trevor Hastie, Robert Tibshirani, Jerome H Friedman, and Jerome H Friedman. The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer, 2009.
- Hayou et al. [2019] Soufiane Hayou, Arnaud Doucet, and Judith Rousseau. On the impact of the activation function on deep neural networks training. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2672–2680. PMLR, 2019.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Jacot et al. [2018] Arthur Jacot, Franck Gabriel, and Clement Hongler. Neural tangent kernel: Convergence and generalization in neural networks. Advances in Neural Information Processing Systems, 31, 2018.
- Joudaki et al. [2023a] Amir Joudaki, Hadi Daneshmand, and Francis Bach. On bridging the gap between mean field and finite width in deep random neural networks with batch normalization. International Conference on Machine Learning, 2023a.
- Joudaki et al. [2023b] Amir Joudaki, Hadi Daneshmand, and Francis Bach. On the impact of activation and normalization in obtaining isometric embeddings at initialization. Advances in Neural Information Processing Systems, 36:39855–39875, 2023b.
- Klambauer et al. [2017] Günter Klambauer, Thomas Unterthiner, Andreas Mayr, and Sepp Hochreiter. Self-normalizing neural networks. Advances in Neural Information Processing Systems, 30, 2017.
- Lee et al. [2019] Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. Advances in Neural Information Processing Systems, 32, 2019.
- Li et al. [2022] Mufan Bill Li, Mihai Nica, and Daniel M. Roy. The neural covariance sde: Shaped infinite depth-and-width networks at initialization. Advances in Neural Information Processing Systems, 2022.
- Mei et al. [2019] Song Mei, Theodor Misiakiewicz, and Andrea Montanari. Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit. In Conference on learning theory, pages 2388–2464. PMLR, 2019.
- Meterez et al. [2024] Alexandru Meterez, Amir Joudaki, Francesco Orabona, Alexander Immer, Gunnar Ratsch, and Hadi Daneshmand. Towards training without depth limits: Batch normalization without gradient explosion. In The Twelfth International Conference on Learning Representations, 2024.
- Noci et al. [2022] Lorenzo Noci, Sotiris Anagnostidis, Luca Biggio, Antonio Orvieto, Sidak Pal Singh, and Aurelien Lucchi. Signal propagation in Transformers: Theoretical perspectives and the role of rank collapse. Advances in Neural Information Processing Systems, 35:27198–27211, 2022.
- Pennington et al. [2017] Jeffrey Pennington, Samuel Schoenholz, and Surya Ganguli. Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice. Advances in neural information processing systems, 30, 2017.
- Pennington et al. [2018] Jeffrey Pennington, Samuel Schoenholz, and Surya Ganguli. The emergence of spectral universality in deep networks. In International Conference on Artificial Intelligence and Statistics, pages 1924–1932, 2018.
- Poole et al. [2016] Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expressivity in deep neural networks through transient chaos. Advances in Neural Information Processing Systems, 29, 2016.
- Saxe et al. [2013] Andrew M. Saxe, James L. McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv preprint arXiv:1312.6120, 2013.
- Schoenholz et al. [2017] Samuel S Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep information propagation. International Conference on Learning Representations, 2017.
- Schölkopf and Smola [2002] Bernhard Schölkopf and Alexander J Smola. Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, 2002.
- Smola and Schölkopf [2004] Alex J Smola and Bernhard Schölkopf. A tutorial on support vector regression. Statistics and computing, 14:199–222, 2004.
- Williams and Rasmussen [2006] Christopher KI Williams and Carl Edward Rasmussen. Gaussian processes for machine learning, volume 2. MIT press Cambridge, MA, 2006.
- Yang [2019] Greg Yang. Scaling limits of wide neural networks with weight sharing: Gaussian process behavior, gradient independence, and neural tangent kernel derivation. arXiv preprint arXiv:1902.04760, 2019.
- Yang et al. [2019] Greg Yang, Jeffrey Pennington, Vinay Rao, Jascha Sohl-Dickstein, and Samuel S. Schoenholz. A mean field theory of batch normalization. In International Conference on Learning Representations, 2019.
Appendix A Supplementary theorems and proofs
This section is dedicated to the proof of main theoretical results presented in the paper.
Theorem S.2, which is closely aligned with Theorem A2 of Joudaki et al. [2023b], and for historical reasons, it is kept here, while Theorem 1, which is the general version, is citing Theorem S.2 as one specific case. Likewise, Lemma 1’s statement is a close replica of Lemma A8 in Joudaki et al. [2023b]. Thus, in both cases, we have skipped the proofs here, and refer the interested reader to Joudaki et al. [2023b] for the proofs.
Proof of Proposition 1.
The proof is a straightforward application of the law of large numbers, as the mean-field regime implies that the sample means converge to the population means. Let us inductively assume that at layer , it holds and and . Thus, defining and their elements ’s and ’s follow , and have covariance Thus, again by construction we have , and Finally, because ’s and ’s are i.i.d. copies of their respective distributions, based on the law of large numbers, we can conclude the samples means will converge to their expectations:
Thus, we have proved the induction hypothesis for step . This concludes the proof. ∎
Theorem S.2.
Let be a nonlinear activation with kernel map that is centered and . Let be the kernel sequence generated by , given the initial value . Then, the sequence contracts towards the fixed point at zero with rate :
| (8) |
where The only other fixed points can be , and none of them is locally or globally attractive.
Proof of Theorem 1.
We will proof all cases individually, starting with the first case that falls directly under a previous theorem.
Case 1:
We can observe that the case where falls directly under Theorem 1, and thus there is no need to prove it again.
Cases 2,3: and
In this part, we jointly consider two cases where and and Let us consider the ratio between distances :
Clearly, the term is is always non-negative. Thus, if then we have the contraction
Otherwise, if we have
Now, observe that the first term for is zero. Furthermore, the sequence is monotonically increasing in . Thus, the smallest value the weighted sum can achieve is if all of the weights of terms above are concentrated in which leads to the contraction
Now, define sequence and observe that we have
where if the activation is nonlinear. We can prove inductively that
If we plug in the definition of we have proven
Case 4: and
The main strategy is to prove some contraction of towards , under the kernel map . In other words, we need to show is smaller than under some potential. First, we assume there is a such that and show this contraction, and later prove its existence and uniqeness.
To prove contraction towards when , we consider three cases: 1) If , 2) If , and 3) If . However, the bounds will be of different potential forms and will have to be combined later. Let be the kernel map with with fixed point that satisfies
-
•
. we will prove:
We have the series expansion around : . For points , we will have , thus we can write
where in the last line the inequality is due to the fact that we are only retaining the terms corresponding to and in the denominator. Now, note the right hand side maximizes when is maximized, which is obtained when :
Now we can observe that the numerator and denominator correspond to
Thus, we have proven that
-
•
. Consider . For these is always monotonically increasing, implying that . Thus, . Thus, by Banach fixed point theorem, we have that is a contraction in this range with a rate :
-
•
. Finally, let us consider . Recall that we have . Thus, we can express as product of with some power series :
In fact, we can expand in terms of these new coefficients
Due to the non-negativity of coefficients of , we can conclude . Based on this observation, for , we can conclude . Because we can pair each odd and even term for all odd , and because coefficients and for , we can argue . Now, plugging this value into the kernel map for , we have:
Now, if we assume then
Now, if we assume , knowing that , which necessitates , which implies . Thus, we have
Combining both cases we have
We can further prove that , which implies that . Thus, we can conclude that
Combining the cases Let us summarize the results so far. We have proven the existence of a unique fixed point such that and we have proven contraction rates for each of the three cases.
Let us now define the joint decay rate:
In other words, this is the worst-case rate for any of the above cases.
Now, let us assume we are starting from initial and define . One important observation is that if we have then by monotonicity of in the range, it will remain the same range, and similarly if it will remain in the same range. Thus, from that index onwards, we can apply the contraction rate of the respective case. The only case that there might be a transition is if .
Assuming that , let be the first index that we have . Thus, from to we can apply the contraction rate of the third case:
Now, we have two possibilities, either or . If , we can apply the contraction rate of the first case, and if we can apply the contraction rate of the second case:
If we plug in our contraction up to step and use the fact that the norm of the sequence is non-increasing we have
We can now take the worst case of these two and conclude that
So far in the proof, we assumed the existence of that obeys We can now prove that such a fixed point exists. It is unique, and it is necessarily in the range
Positivity, uniqueness, and existence of a globally attractive fixed point Here, the goal is to prove there is exactly one point such that and We will prove the properties of positivity, uniqueness, and existence separately.
Positivity: Let us assume that is a fixed point. Then, we can apply the contraction rate proven for Case 3, which shows that which is a contradiction.
Uniqueness: Assume that there are two fixed points and that satisfy Let us assume wlog that Then we can invoke the contraction rate proven so far to argue that all points in including are attracted towards both and which is a contradiction. Thus, there can be at most one fixed point.
Existence of : Because the set of all fixed points is non-empty. Let us assume that is the first (smallest) fixed point of which because of the positivity result is necessarily If we assume that then in the small -neighborhood of it we have Because is continuous, and is above identity line at and under identity line there must be a point where it is at identity which is a contradiction with assumption that is the smallest fixed point. Thus, we must have If we assume that then the must align with the identity line from to which implies that all higher order terms must be zero, which in turn implies that is a linear function. This is a contradiction with the assumption that the activation is nonlinear. Thus, we must have which proves the desired existence. ∎
Proof of Proposition 2.
First, we ought to prove that in the mean-field regime, the kernel map is transformed according to the equation that is given. To do so, we can consider one layer update. Assume that with covariance Now, is an independent copy of with the same variance and covariance structure. This is due to the presence of skip connection weights Now, defined the joint layer update
where in the third line we use the independence assumption and the fact that and have zero mean.
Observe that or Now, let us consider the conditions for the four cases of Theorem 1. The decision boundaries are if is positive or not, if is above, equal to, or below Now, note that for strict positivity of remains the same as Furthermore, is a weighted average of and Thus, for all values it holds is above, equal to, or below if and only if has the corresponding property. Now, we can turn our focus on the convergence rates. For this, we can focus on in each one of the four cases.
-
•
If then and we have Now, note that is a weighted average between and and thus, the larger the value of the larger would be, and the slower the convergence.
-
•
If and then we have and and Thus, the larger the residual, the closer becomes to and the slower the convergence will be.
-
•
If and then we have the same for and
Now, recall that we have and and thus we have which is necessarily positive for a nonlinear activation:
We can now see that for larger will be smaller, which in this case implies a slower convergence.
-
•
If and then same holds for and the convergence rate .
∎
Proof of Proposition 3.
Recall the assumption that obeys Let us assume that represents the Gaussian pre-activations from the previous layer We can consider the joint normalization and activation layer in the mean-field regime:
-
•
and : Because each element of has zero mean and unit variance, in the mean field regime, the sample mean and variances will be equal to the their population counterparts, implying that and In other words, they act as identity. Thus, in both cases, in the mean-field regime we have Thus, the kernel map also remains the same.
-
•
: In this case, because of the assumption on activation for Gaussian preactivations we have for all Because elements of are i.i.d., by law of large numbers will converge to its expected value Thus, again, the normalization step in RN becomes ineffective, implying that in the mean-field we have Thus, the kernel map also remains the same.
-
•
: By definition of kernel map of activation, we have
Thus, again by law of large numbers we will have
Now, if we look at the kernel map of this affine transformation, we have
which concludes the proof.
∎
Remark S.1.
Another interesting implication is that if we take a look at discrete and continuous kernel dynamics for a very strong residual (when ), the kernel ODE becomes exact. Let us denote the Hermite coefficients of the residual kernel by For the first term, we have and for all other terms . Note that as we have and for all other terms Thus, in the discrete kernel dynamics, the right-hand side will converge to zero. This implies that in the limit of very strong residuals, the kernel ODE gives the exact solution to the kernel dynamics.
Remark S.2.
Suppose there is an activation with a negative fixed point Let be an integer such that Let be vectors that have non-zero inner products. Construct an MLP with activation and let be the output of this MLP. Thus, if the depth is sufficiently large, the pairwise similarity between each pair will converge to Thus, their output Gram matrix has unit diagonals and off diagonals equal to By analyzing the eigenvalues of , we find: The top eigenvalue corresponding to the all-ones eigenvector is . Because we assumed , we have , which is a contradiction. Because by construction must be positive and semi-definite.
Corollary S.1.
If Hermite coefficients of has Hermite expansion then kernel sequence of MLP with activation converges to zero with double exponential rate
The proof of corollary is by simply observing that, the slowest convergence happens when the weight of coefficients is concentrated at term, and for that case, we can observe that and by induction over we can prove the claim.
Appendix B Validation of the global convergence theorem
Here we will provide some numerical validation of the global convergence theorem.
Remark S.3.
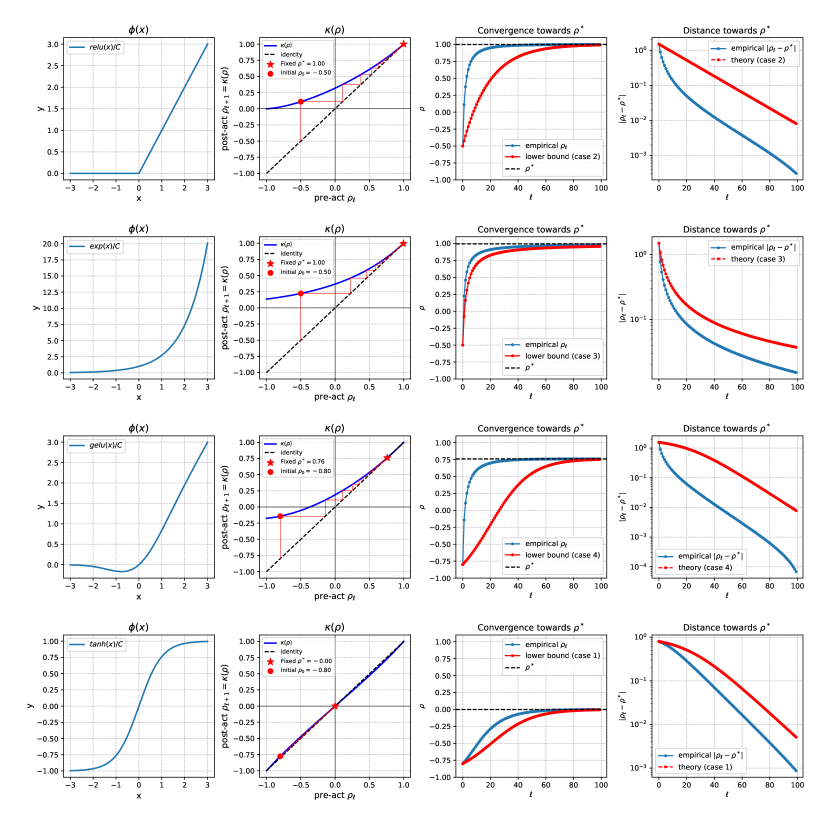
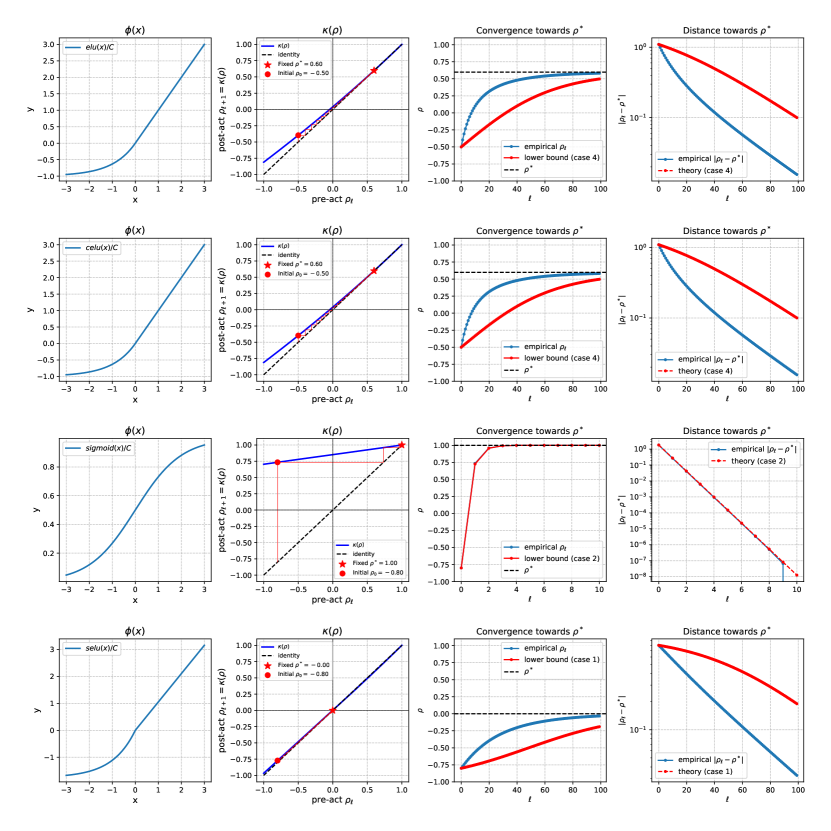
First off, note that Theorem 1 requires that the activation functions preserve (do not increase or decrease) the energy of the pre-activations, for While some activation functions, namely SeLU Klambauer et al. [2017], have this property, we can achieve it for all activation functions by inversely scaling them by a constant factor, equal to After this step, we can quantify various values relevant to Theorem 1. This step is applied for both the results in the table, as well as Figures S.1 and S.2. The scaling constant for each activation function is shown in Table S.1.
Recall the conditions for each convergence from Theorem 1:
-
•
: Case 1, exponential convergence towards
-
•
:
-
–
: Case 2, exponential convergence towards
-
–
: Case 3, polynomial convergence towards
-
–
: Case 4: exponential convergence towards some
-
–
In Table S.1, we have quantified the fixed points, relevant quantities, and convergence rates for each activation function. This table shows that for the most popular activation functions that are used in practice, we can quantify a fixed point and explicit rate that their kernel sequence will converge to.
It is worth noting that because Theorem 1 provides an upper bound, we cannot directly compare the quantified value of for different cases, particularly when they correspond to different cases. In other words, because this is a worst-case bound, it is possible that an activation function manifests a much higher convergence than predicted. We will further explore the gaps between the empirical values and the upper bound in the subsequent figures.
| Convergence | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| tanh | 0.63 | 0.93 | 0.00 | 0.00 | 0.00 | 0.93 | 1.18 | 0.93 | case 1 /Exp. |
| SeLU | 1.00 | 0.97 | 0.00 | 0.00 | 0.00 | 0.97 | 1.06 | 0.97 | case 1 /Exp. |
| ReLU | 0.71 | 0.95 | 1.00 | 1.00 | 0.32 | 0.50 | 0.95 | 0.95 | case 2/Exp. |
| sigmoid | 0.54 | 0.15 | 1.00 | 1.00 | 0.85 | 0.15 | 0.15 | 0.15 | case 2 /Exp. |
| exp | 2.72 | 0.74 | 1.00 | 1.00 | 0.37 | 0.37 | 1.00 | 1.00 | case 3 /Poly. |
| GELU | 0.65 | 0.93 | 0.76 | 0.76 | 0.19 | 0.59 | 1.07 | 0.93 | case 4 /Exp. |
| CELU | 0.80 | 0.97 | 0.60 | 0.60 | 0.04 | 0.90 | 1.04 | 0.97 | case 4 /Exp. |
| ELU | 0.80 | 0.97 | 0.60 | 0.60 | 0.04 | 0.90 | 1.04 | 0.97 | case 4 /Exp. |
B.1 Figures S.1 and S.2
Each row of the figures shows one activation function and each column is dedicated to the following (from left to right). The First column shows the activation function itself, up to some scaling (see Remark S.3). In the following, we will describe the last three columns.
Kernel map and fixed point iterations
The second column shows the kernel map of each activation function (blue), as defined in Definition 1, and the fixed iterations over this kernel (red), as defined by pairs of points
where indicates the initial value that is arbitrarily chosen (shown as a red dot marker). As the iterations progress, they converge to the fixed point (, red star marker). The identity map is shown to demonstrate visually how the iterations lead to the fixed point.
It is worth noting that kernel maps of all activation functions are analytic, i.e., smooth up to an arbitrary degree, even when the activation function itself is non-smooth, which is the case for ReLU and SeLU at We can also see that despite the non-monotonicity of some activation functions, such as GELU, the kernel map maintains its unique properties, such as having a unique globally attracting fixed point.
These kernel map plots give important insight into the global convergence of the kernel and the predictions of Theorem 1. Intuitively, the fixed point is where the kernel map intersects with the identity line, and the speed at which it converges to the fixed point is inversely related to the slope at For example, tanh and SeLU are close to the identity line, and they exhibit very slow convergence, while sigmoid deviates the most from the identity and shows the fastest convergence rate. Overall, we can see here why deviation from the identity, as captured by and other terms, play an important role in the convergence of the kernel sequence.
It is worth noting that while sigmoid and tanh are tightly related by the formula their convergence properties are drastically different, with tanh converging exponentially towards zero (orthogonality or independence bias), while sigmoid converges exponentially towards (strong similarity bias). We can explain this by observing that the shifting ensures that the activation function has zero-mean postactivations, making a fixed point.
Kernel convergence theory vs empirical results.
The third and fourth columns show the kernel sequence (empirical: blue, theory: red) as a function of depth The theoretical bound corresponds to Theorem 1. In the fourth column, we plot the upper bound provided by the theorem, and in the third column, we use the upper bound on the distance to to give a lower or upper bound on the kernel sequence curve. One of the most important takeaways is that for all activation functions except exp, the distances shown on the log-scale, decay linearly with depth This is perfectly aligned with the prediction of Theorem 1, because exp is the only activation function that has polynomial convergence (See Table S.1). The gap between theory and empirical values corresponds to the worst-case analysis for the global convergence rate.