Enabling Atomic Durability for Persistent Memory with Transiently Persistent CPU Cache
Abstract
Persistent memory (pmem) products bring the persistence domain up to the memory level. Intel recently introduced the eADR feature that guarantees to flush data buffered in CPU cache to pmem on a power outage, thereby making the CPU cache a transient persistence domain. Researchers have explored how to enable the atomic durability for applications’ in-pmem data. In this paper, we exploit the eADR-supported CPU cache to do so. A modified cache line, until written back to pmem, is a natural redo log copy of the in-pmem data. However, a write-back due to cache replacement or eADR on a crash overwrites the original copy. We accordingly develop Hercules, a hardware logging design for the transaction-level atomic durability, with supportive components installed in CPU cache, memory controller (MC), and pmem. When a transaction commits, Hercules commits on-chip its data staying in cache lines. For cache lines evicted before the commit, Hercules asks the MC to redirect and persist them into in-pmem log entries and commits them off-chip upon committing the transaction. Hercules lazily conducts pmem writes only for cache replacements at runtime. On a crash, Hercules saves metadata and data for active transactions into pmem for recovery. Experiments show that, by using CPU cache for both buffering and logging, Hercules yields much higher throughput and incurs significantly fewer pmem writes than state-of-the-art designs.
I Introduction
A few companies have shipped byte-addressable persistent memory (pmem) products that are put on the memory bus for CPU to load and store data [63, 28, 49, 18, 62, 31, 21]. In order to popularize the use of pmem, Intel and other manufacturers have gradually upgraded architectural facilities. Intel introduced more efficient cache line flush instructions (e.g., clwb) to substitute the legacy clflush [29, 68, 23]. Cache line flush enables programmers to flush modified cache lines to the persistence domain, in which data can be deemed to be persistent upon a power outage [68, 24, 13, 84]. The concept of persistence domain was initially linked to the feature of Asynchronous DRAM Refresh (ADR). ADR keeps DRAM in self-refresh mode and, more important, places pmem and the write pending queue (WPQ) of memory controller (MC) in the persistence domain [72, 26, 27], as it guarantees to flush data staying in the WPQ to pmem in case of a power outage. Later Intel extended ADR as eADR that further manages to flush all cache lines to pmem on a crash [30, 2, 3, 24, 13]. As a result, eADR frees programmers from manually flushing cache lines to pmem. Platforms with the eADR feature are commercially available today. However, eADR factually builds a transient persistence domain, because the eventual persistence of data buffered in WPQ entries and CPU cache lines is made by an uninterruptible power supply flushing all such data to pmem.
The advent of pmem has motivated programmers to directly operate with persistent data in pmem. It is non-trivial to enable the atomic durability for in-pmem data regarding unexpected system failures, e.g., a power outage. For example, inserting a key to a sorted array is likely to move existing keys that may span a few cache lines. Programmers make such an insertion into a transaction that shall be atomically modified as a unit. In other words, the change of cache lines for the insertion must be done in an all-or-nothing fashion. If a crash occurs, after reboot involved cache lines should either contain all keys including the new one, or retain only original keys without any movement. Programmers can use the software logging strategy to back up data for a transaction. Whereas, software logging is ineffectual. Firstly, it incurs double writes, which impair both performance and lifetime for pmem products [59, 32, 69, 77, 75, 11, 46]. Secondly, it executes extra instructions for logging and consumes more architectural resources, such as double WPQ entries and pmem spaces for data and log copies. Thirdly, software logging must explicitly enforce the ordering of persisting log copies before updating data through memory fence instructions (e.g., sfence) to render the backup copy reliable. The eADR helps to avoid cache line flushes but still necessitates the use of memory fences, which are costly for achieving the in-pmem atomic durability [48, 39, 71, 68].
Computer architects have explored how to enable the atomic durability in various hardware approaches for applications to gain the data consistency with pmem [92, 66, 19, 72, 35, 39, 53, 33, 54, 26, 9, 79]. They mostly exploit either a redo or undo log copy, or both, for data to be atomically modified in a hardware-controlled transaction. Some of them considered persistent CPU caches made of non-volatile memory (NVM) technologies to keep redo log copies [92, 39]. Some others used in-pmem areas for logging and added on-chip redo or undo log buffers, or both, within the cache hierarchy [19, 35, 54, 33, 79, 9]. Recently researchers explored the transient persistence domain of limited WPQ entries protected by the ADR feature to temporarily hold log or data copies [72, 26].
In this paper, we consider leveraging the eADR-supported CPU cache to enable the atomic durability for applications. The eADR guarantees all cache lines to be flushed back to pmem on a power outage, thereby promising substantial space in numerous megabytes to secure crash recoverability for applications. Modified data staying in a cache line is a natural redo log of the in-pmem copy. However, a normal cache replacement or the eADR on a power failure writes the cache line back to its home address. If the cache line belongs to an uncommitted transaction, the transaction cannot be recovered, as the overwrite destroys the original copy. We hence develop Hercules to overcome this challenge with supportive hardware components and comprehensive transactional protocols. The main points of Hercules are summarized as follows.
-
•
Hercules makes CPU cache be both the working memory and main transaction log. It enhances a part of CPU cache lines with transactional tags (TransTags) and manages an in-pmem log zone holding transaction profiles and log entries for spatial extension and emergency use. It also customizes the MC between CPU and pmem to handle cache lines evicted due to cache replacement or eADR on a power-off.
-
•
Hercules places data that programmers put in a transaction into cache lines with TransTags. On a transaction’s commit, Hercules commits on-chip the transaction’s data buffered in CPU cache by modifying TransTags. For cache lines evicted before the commit, Hercules makes the MC map and persist them to in-pmem log entries. It keeps their mappings for proper reloading until the commit, at which it commits them off-chip by changing their states in the MC. Then Hercules silently migrates them to their home addresses.
-
•
A crash initiates the emergency use of in-pmem log zone. With eADR, Hercules dumps cache lines with TransTags and mappings in the MC into a dedicated area of log zone. To recover, it discards uncommitted transactions and carries on unfinished data write-backs for committed transactions.
Hercules exploits CPU cache to log and coalesce data updates. Only on cache replacement or power outage will Hercules passively flush cache lines, which is in contrast to prior works that proactively write undo or redo log copies to pmem for backup. As a result, Hercules both achieves high performance and minimizes pmem writes. We have prototyped Hercules within the gem5 simulator [22] and evaluated it thoroughly with micro- and macro-benchmarks. Experimental results confirm that Hercules well supports ordinary workloads of typical applications and inflicts the least writes to impact the write endurance of NVM. For example, running with prevalent workloads, Hercules yields about 89.2%, 29.2%, and 51.3% higher throughput on average than software logging, Kiln [92], and HOOP [9], while the data Hercules writes to pmem is 29.8%, 37.4%, and 1.4% that of them, respectively.
II Persistence Domain and Atomic Durability
II-A Persistence Domain
Pmem. Pmem embraces both byte-addressability and persistency. Researchers have considered building pmem with various memory technologies, such as phase-change memory [59, 40, 41, 69, 60, 77, 4], spin-transfer torque RAM (STT-RAM) [21, 80, 12, 91, 1, 25], resistive RAM [83, 90, 75, 88, 14], 3D XPoint [28, 31], and DRAM backed by flash [18, 62, 64, 49, 87]. Applications can directly load and store data with pmem [76, 45, 15, 28, 87, 44, 78, 38, 86, 3, 68, 5, 66].
Persistence Domain. Persistence domain is a region of computer system in which data would not be lost but retrievable when the system crashes or power failures occur [68, 30]. It conventionally includes disk drives at the secondary storage level. The advent of pmem brings it up to the memory level.
ADR. The ADR further extends the persistence domain to the WPQ of MC [13, 26, 72, 27]. ADR guarantees that data received at the WPQ can be flushed to pmem upon a power outage. Though, the persistence enabled by ADR is transient, as it is the pmem that eventually makes data persistent. Also, CPU cache is still volatile and cache lines would be lost on a crash. Thus, programmers must explicitly flush data staying in cache lines (e.g., clwb) to pmem. Flushing data from CPU cache to pmem is not only synchronized and time-consuming, but is also error-prone and hurts programmability [65, 2].
eADR. Intel extended ADR as eADR which guarantees to flush all cache lines to pmem in case of a power outage by employing extra power supply [30, 68]. Alshboul et al. [2] proposed BBB that employs a battery-backed persist buffer alongside each core’s L1D cache and achieves an identical effect as eADR with much less cost. They help programmers avoid explicit cache line flushes. More important, they make the multi-level CPU cache hierarchy provide a transient persistence domain in dozens of megabytes on top of pmem.
II-B Atomic Durability
The atomic durability, or failure-atomic durability, refers to the crash consistency of modifying in-pmem data in case of a crash. The insertion with an in-pmem sorted array mentioned in Section I is a typical transaction programmers would define with their desired semantics. A transaction must be done in an atomic (all-or-nothing) fashion. Otherwise, a half-done change may leave data in ambiguity or uncertainty after a crash.
II-B1 Software Solution
Modern 64-bit CPUs allow an atomic write of up to 8 bytes. Programmers bundle multiple data operations for a task in one transaction and seek software or hardware solutions. Software logging is a common technique. Programmers explicitly record original (resp. modified) data in an undo (resp. redo) log. However, software logging is not effectual with several factors. Firstly, logging incurs double writes due to writing both log and data copies [92, 42, 33, 43]. Double writes jeopardize performance and impair lifetime for NVM technologies that have limited write endurance [59, 32, 69, 77, 75, 11, 46]. Secondly, logging demands extra instruction to be executed. Log and data copies also consume more architectural resources. For example, they need double locations in pmem. If programmers use CPU cache to buffer them, they take double cache lines. Thirdly, the ordering of writing log copies prior to data must be retained by using memory fences, the cost of which, albeit the presence of eADR, is essential and substantial [48, 39, 71].
II-B2 Hardware Designs
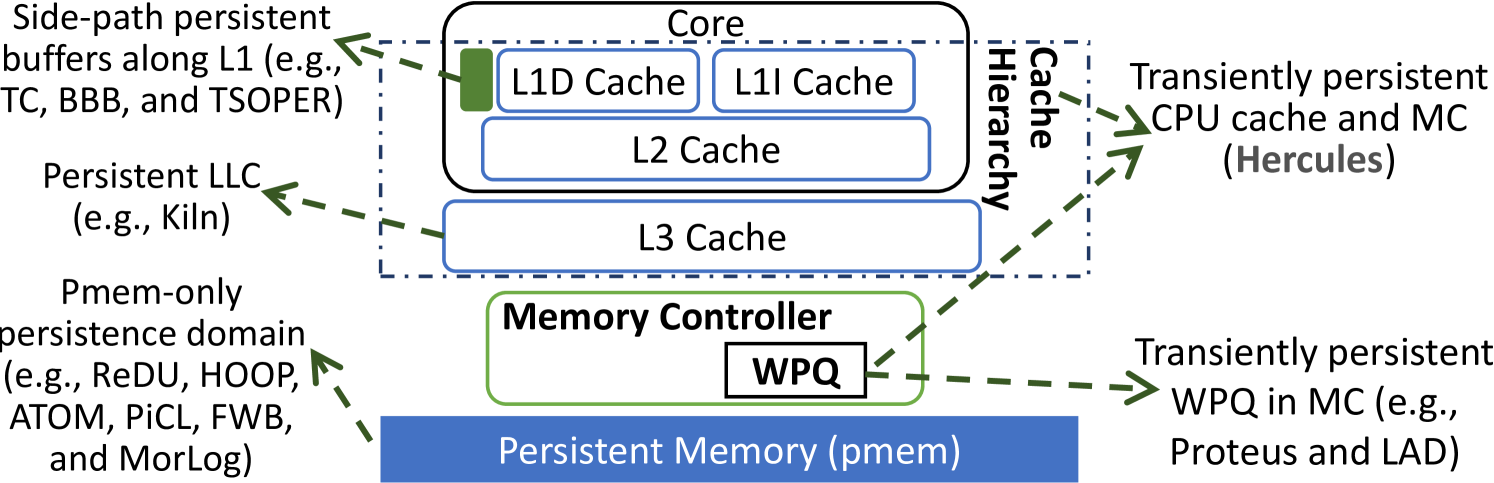
The essence of gaining atomic durability is to make a backup copy before modifying data in place. In order to back up data, state-of-the-art hardware designs explore different persistence domains, which categorize them into three classes.
Persistent CPU cache. As shown in Figure 1, Kiln works with a persistent last-level cache (LLC) [92]. The persistence domain covers LLC and pmem. Kiln manages redo log copies in LLC to back up in-pmem data. Later, Lai et al. [39] employed a side-path persistent transaction cache (TC) along L1 cache in each CPU core. TC is similar to the persistent buffers used in other works [2, 20]. Modified cache lines of a transaction are first-in-first-out (FIFO) put in the TC and serially written to pmem on committing a transaction.
Pmem. A few hardware designs were built on a pmem-only persistence domain. Doshi et al. [19] proposed to use a victim cache to hold evicted cache lines that would be subsequently written to an in-pmem redo log. These cache lines are eventually written to their home addresses by copying log entries via non-temporal stores. Similarly, Jeong et al. [33] proposed ReDU that utilizes a DRAM cache to hold evicted cache lines from the LLC. ReDU directly writes modified data from DRAM cache to home addresses, as it installs a log buffer alongside L1 cache to collect and write the in-pmem redo log.
Cai et al. [9] designed HOOP with a physical-to-physical address indirection layer in the MC, which helps it write modified data to a different pmem address for backup and later move data to home addresses. Joshi et al. [35] noted that the MC loads a cache line for a write request and proposed ATOM to write the loaded copy to an in-pmem undo log in a parallelized manner. Nguyen and Wentzlaff [53] proposed PiCL that also uses the idea of undo logging with an on-chip log buffer. PiCL makes a trade-off between performance and durability by snapshotting and saving data in an epoch-based periodical checkpointing manner [12]. Ogleari et al. [54] and Wei et al. [79] both chose the undo+redo logging approach. Ogleari et al. captured data’s redo and undo log copies from the in-flight write operation and the write-allocated cache line, respectively. They also used a force write-back (FWB) mechanism to control pmem writes. Wei et al. studied data encoding with hardware logging so as to only record necessary changes for a transaction’s data, thereby reducing pmem writes. Both designs add on-chip undo and redo log buffers.

ADR-supported transient persistence domain. The ADR places the WPQ of MC in the transient persistence domain. Shin et al. [72] designed Proteus that considers the WPQ to keep log copies. When a transaction commits, Proteus discards relevant log copies in the WPQ and hence reduces pmem writes. Gupta et al. [26] proposed LAD that also leverages the ADR-supported MC as a staging buffer to accumulate data updates before committing a transaction. Whereas, for Proteus and LAD, the limited capability of WPQ entails a high likelihood of falling back to the use of an in-pmem log.
III Motivation
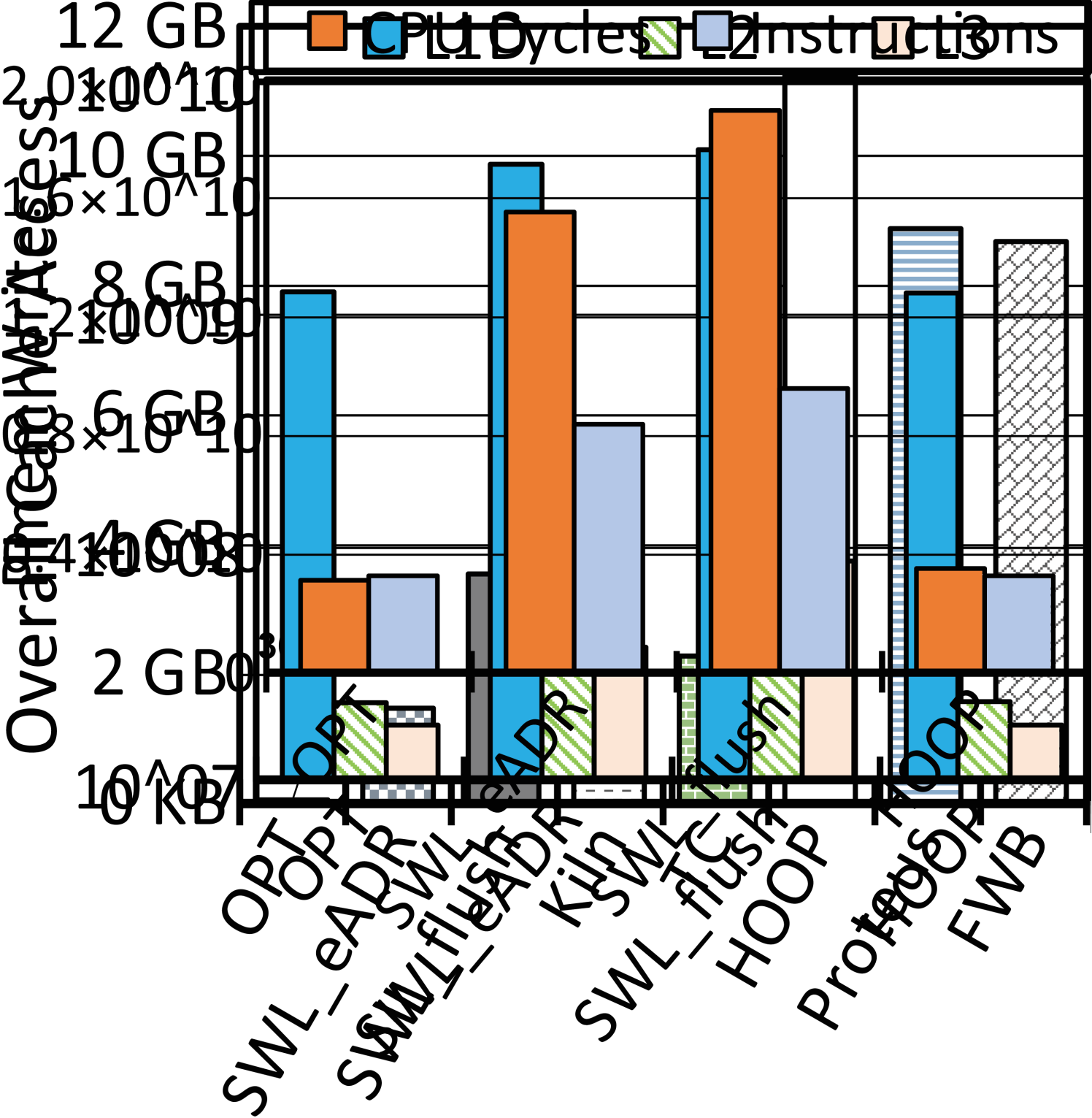
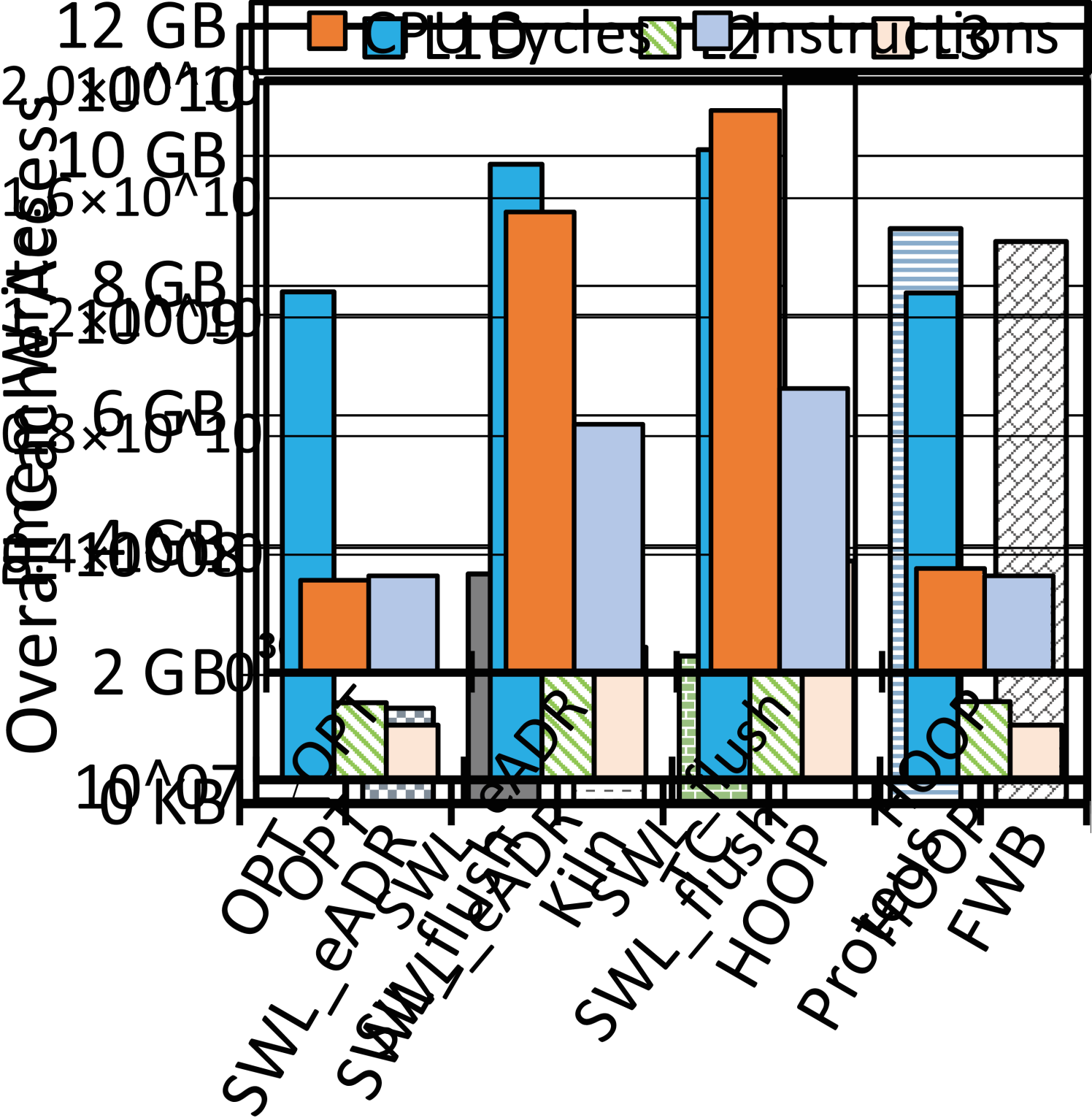
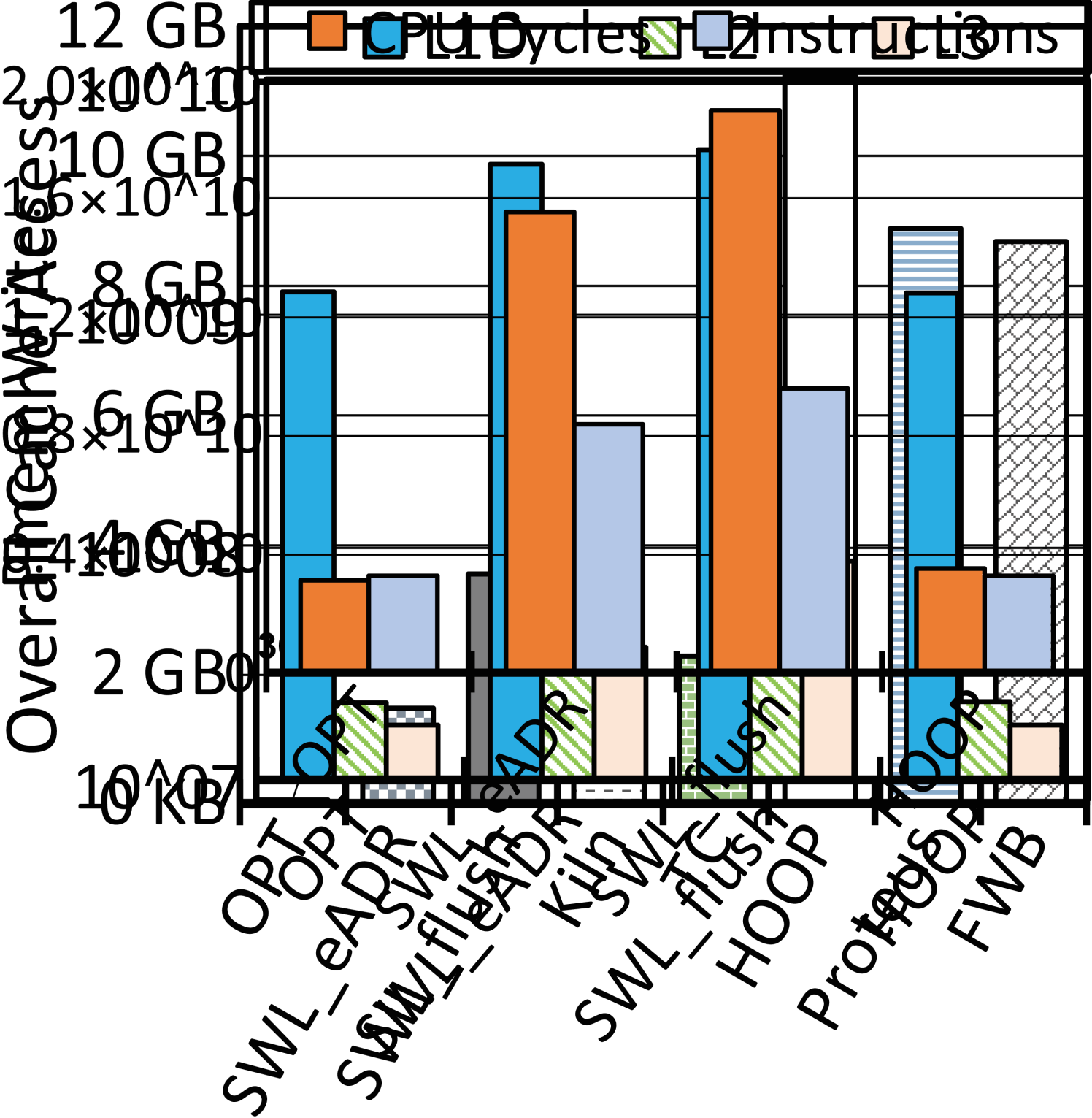
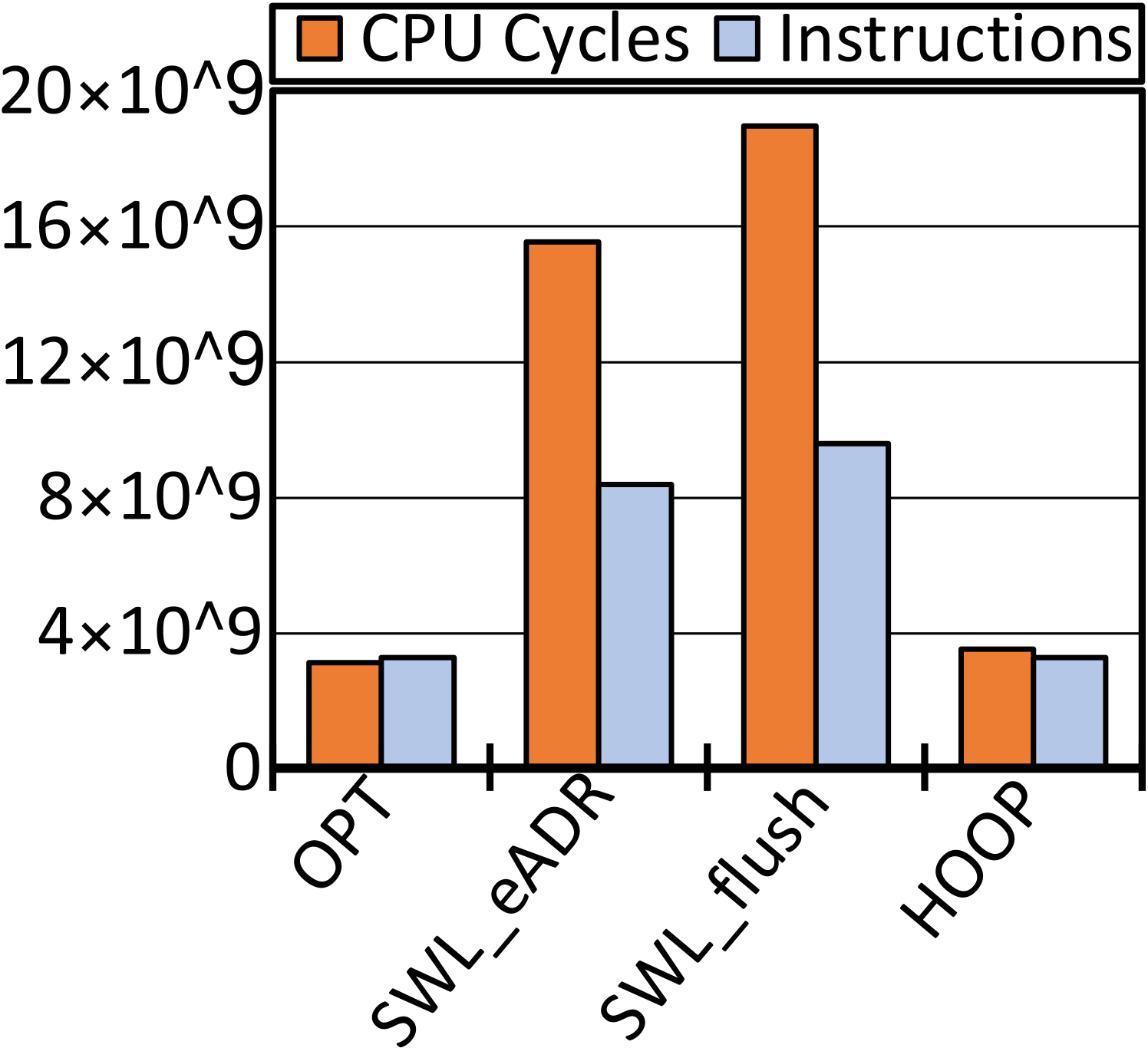
We consider leverage the transient persistence domain in CPU caches made by eADR and BBB to enable atomic durability. We have conducted a motivational study to analyze the potential gain introduced by using CPU cache to process transactions. 2(a) captures four sample code snippets, i.e., a vanilla ‘volatile’ program without guarantee of atomic durability, two software redo logging versions without and with the eADR (both using CPU cache to buffer log copies), and one version using a typical hardware transactional design. Accordingly we have tailored B+-Tree with the volatile version for the optimal performance (OPT), two versions of software logging (SWL_eADR and SWL_flush), and five prior hardware designs (see 2(b)). We run them with gem5 [22] to insert one million key-value (KV) pairs (8B/8B for K/V). We set each insertion as one transaction. Section V would detail our evaluation setup and methodology. 2(b), 2(c), 2(d), and 2(e) show a quantitative comparison on the throughputs normalized against that of OPT, the quantity of pmem writes, and other CPU execution results, respectively. We can obtain three observations from these diagrams.
O1: The eADR improves the performance of software logging and using CPU cache significantly reduces pmem writes. Comparing SWL_eADR to SWL_flush in 2(b) tells that the avoidance of cache line flushes makes SWL_eADR gain \fpevalround((0.064537952 - 0.052903335) / 0.052903335 * 100, 1.0).0% higher throughput. This performance improvement justifies the usefulness of transient persistence domain for atomic durability in the software logging approach. Moreover, as shown in 2(c), except Kiln that employs a large persistent LLC for buffering, the quantity of data written by SWL_eADR is \fpevalround(1453802048 / 2261137664 * 100, 1)%, \fpevalround(1453802048 / 8671028160 * 100, 1)%, \fpevalround(1453802048 / 8869065600 * 100, 1)%, and \fpevalround(1453802048 / 11229635200 * 100, 1)% that of TC, FWB, Proteus, and HOOP, respectively. The reason is twofold. Firstly, the eADR-supported CPU cache in sufficient megabytes holds both log and data copies over time, so SWL_eADR substantially brings down data to be written to pmem. Secondly, hardware designs mostly need to write backup copies to pmem for crash recoverability, because they have been developed without a transiently persistent CPU cache hierarchy. Therefore, hardware designs generally incur much more pmem writes than SWL_eADR.
O2: Compared to software logging with eADR, hardware designs gain higher performance without the use of eADR, which indicates the potential of a new hardware design utilizing extensive CPU cache for atomic durability. Double writes make a crucial innate defect for software logging. As shown in 2(b), despite no explicit flush of data with eADR, SWL_eADR is still inferior to hardware designs. Without loss of generality, we take HOOP as a representative for illustration. 2(d) and 2(e) capture the accesses to L1D/L2/L3 caches and the number of instructions and clock cycles, for OPT, SWL_flush, SWL_eADR, and HOOP, respectively. SWL_eADR underuses the eADR-supported CPU cache, incurring \fpevalround((4437079723 - 1241304814) / 1241304814 * 100, 1)%, \fpevalround((40893504 - 21949352) / 21949352 * 100, 1)%, and \fpevalround((37391687 - 17357741)/ 17357741 * 100, 1)% more loads and stores to L1D, L2, and L3 caches than HOOP, respectively. HOOP conducts address indirection in the MC for hardware-controlled out-of-place backups. Consequently, it performs backup operations without using CPU cache and achieves comparable cache accesses and instructions against OPT. Due to the unawareness of CPU cache used as an ample transient persistence domain, hardware designs like HOOP, Proteus, and FWB must directly write data into pmem for backup or rely on limited WPQ entries. To sum up, SWL_eADR wastes valuable cache space despite the boost of eADR while prior hardware designs did not foresee transiently persistent CPU caches.
O3: The eADR promises an ample transient persistence domain and shall be well utilized to achieve the atomic durability, high performance, and minimum pmem writes. As shown in 2(b), an evident gap still exists between OPT and hardware or software designs. The eADR-supported CPU cache is certainly a promising feature with a transiently persistent space in dozens of megabytes. As justified by our test results, SWL_eADR does not make the most out of it, while no hardware design has ever exploited it. Kiln, one using STT-RAM as the persistent LLC, implicitly manifests the potential of eADR-supported CPU cache. The throughput of Kiln is not high, partly because of the slower access latency of STT-RAM compared than that of SRAM (see 2(b)). Yet due to the higher density of STT-RAM, Kiln’s LLC can absorb more pmem writes (see 2(c)). Additionally, platforms with the eADR feature are commercially available today, while STT-RAM-based cache is being under development.
These observations motivate us to consider how to utilize the eADR-supported CPU cache when developing a hardware design to efficiently guarantee the atomic durability for applications. A modified cache line and its in-pmem copy naturally form a pair of redo log and backup copies, which implies an opportunity for hardware logging. However, the very nature of transient persistence alludes a challenge. Let us assume that we directly use the transiently persistent CPU cache to make a redo log. In case of a cache replacement or power outage, the eADR writes a cache line back to its home address. For data belonging to an uncommitted transaction, the write-back destroys the intact backup copy in pmem and renders the transaction unrecoverable. As a result, to achieve atomic durability, we need to ensure that cache lines of an uncommitted transaction should be written elsewhere on write-backs. Also, we shall make the most out of CPU cache to simultaneously hold data and log copies for minimizing pmem writes. These summarize Hercules’ main tactics and aims.
IV The Design of Hercules
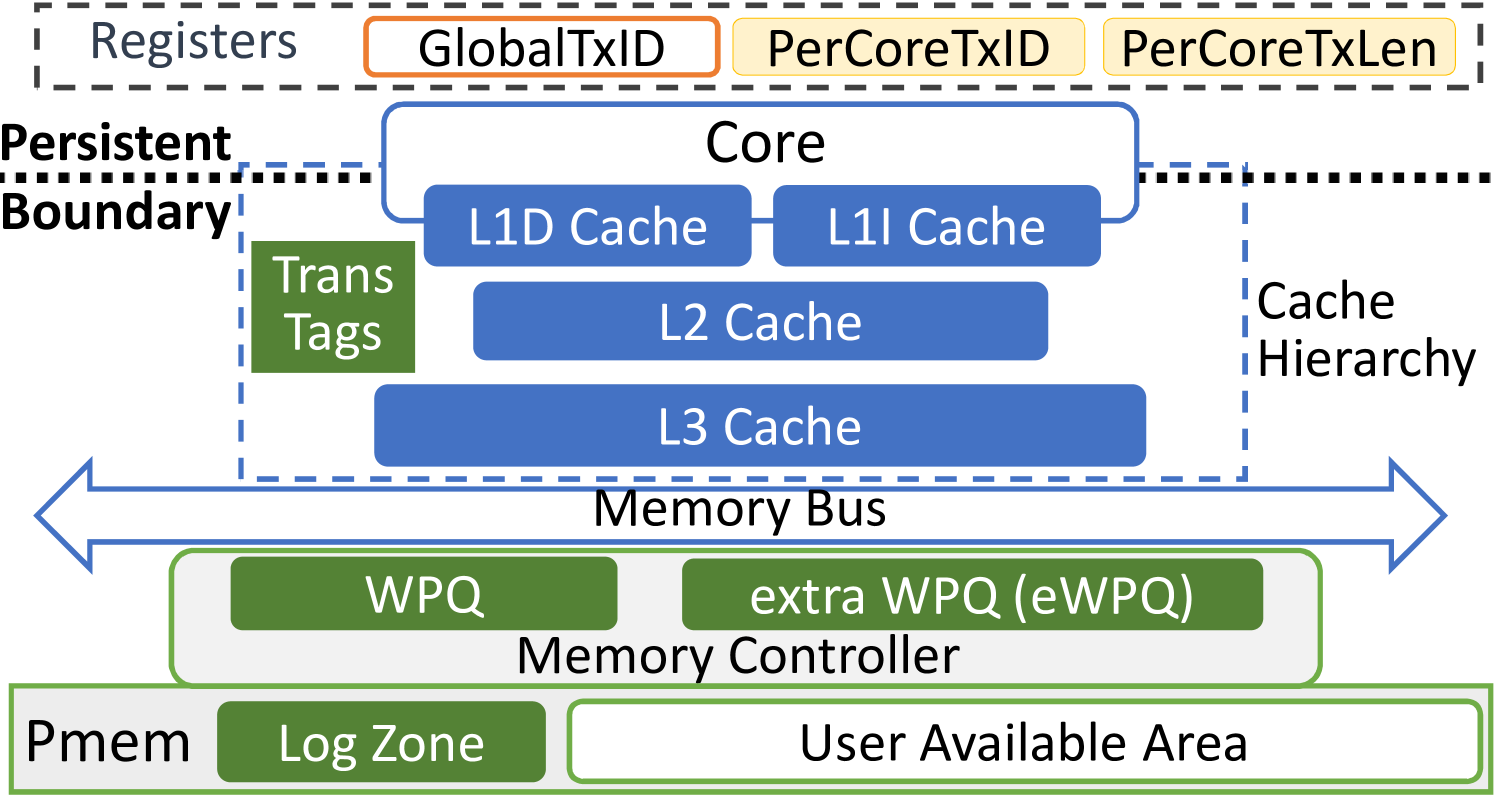
Overview. Hercules makes a transiently persistent CPU cache hierarchy function both as working memory and hardware-controlled redo log. It installs transactional tags (TransTags) to a part of cache lines to hold data for transactions. When a transaction commits, Hercules commits data tracked by TransTags on-chip to reduce pmem writes. On evicting cache lines of an uncommitted transaction to pmem, it places them in an in-pmem log zone rather than their home addresses to avoid overwriting original data. It manages and commits them off-chip upon a committing request through managing an extended WPQ (eWPQ) in the MC. With a suite of self-contained transactional protocols, Hercules efficiently achieves atomic durability with minimized pmem writes and collaboratively works with other architectural mechanisms.
IV-A Hercules’ Hardware Components
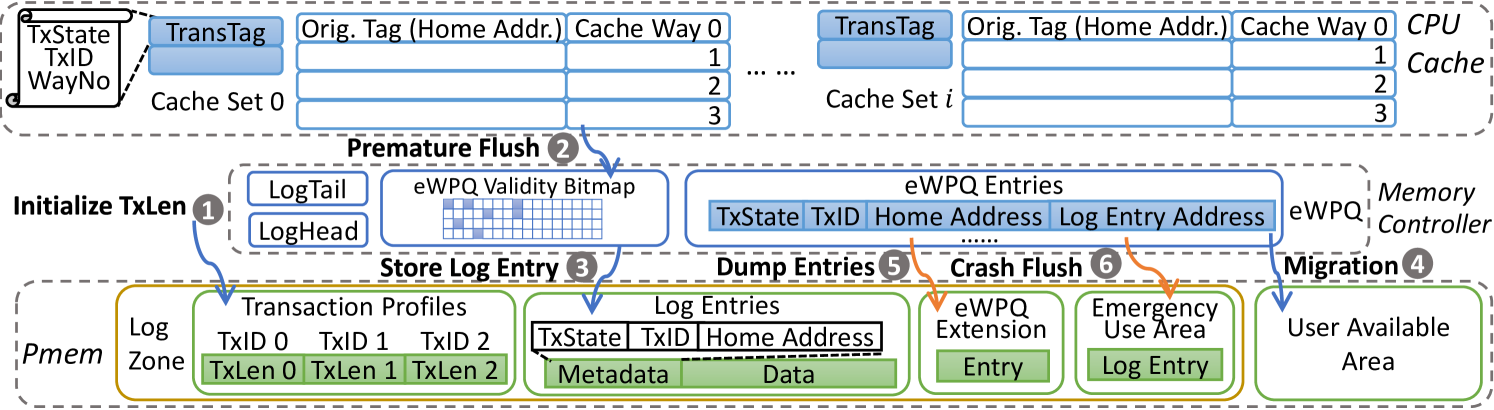
Hercules uses components distributed in CPU cache, MC, and pmem to jointly control the procedure of transactions and manage the versions of data for each transaction. 3(a) captures the main components of Hercules.
TransTag. A transaction of Hercules is a contiguous series of data operations covering one or multiple cache lines. In order to manage a transaction’s data, Hercules adds TransTags per cache set. A TransTag has WayNo, TxID, and TxState. The WayNo indicates which actual cache line in the cache set Hercules is using for a transaction that is identified with a unique 21-bit TxID. The reason why 21 bits are used is twofold. Firstly, Hercules demands extra costs such as energy, transistors, and wires to enable the atomic durability. More than 21 bits per TxID may further increase such costs and entail more challenges to achieve systematic efficiency and reliability (see Sections V-D). Secondly, 21 bits support up to (2 million) transactions, which can satisfy the needs of typical applications at runtime.
The TxState in one bit shows if the transaction is committed or not. We call a cache line being occupied by an uncommitted transaction transactional cache line, of which the TxState is ‘1’. Otherwise, it is non-transactional without a TransTag or with TxState being ‘0’. In short, we configure a logical part of a cache set by filling WayNos for the use of Hercules, without fixing some cache lines for transactions. This brings in spatial efficiency and flexibility. Given a small amount of transactional data, non-transactional data can freely take cache lines with TxStates unset. Also, non-transactional and transactional data can be placed without swaps. For the illustrative example in 3(b), half cache lines of a four-way set (WayNo in two bits) are usable with two TransTags that cost bits per set.
Hercules manages and uses TransTags in a similar form of the directory used to track cache lines for coherence [93, 51, 73, 89, 85]. It places TransTags alongside L1D and L2 caches in each core and has a joint bunch of them for the shared LLC. This organization accelerates filling and changing fields in them. The ratio of TransTag per cache set is defined as the percentage of TransTags installed over all cache ways of a set. As suggested by 2(d), we shall consider a higher TransTags ratio for more usable space to caches that are closer to CPU, as they serve more transactional requests. The ratio of TransTags is thus practically decided by a cache’s proximity to CPU. In practice, we allot TransTags to all cache lines of L1D cache. The ratio can be half or a quarter for L2 and L3 caches. We have a discussion on this ratio in Section V-B.
Registers. Hercules adds a register GlobalTxID that is monotonically increasing, shared by all cores to compose the next transaction ID. Hercules installs PerCoreTxID and PerCoreTxLen to each CPU core, holding the current running transaction’s ID and length (number of transactional cache lines), respectively. These two are critical for the context switch between threads and stay dormant for threads doing non-transactional operations. A register has 64 bits and Hercules uses the lower bits only for extension. They are kept volatile, not saved in pmem on a crash (see Section IV-C).
eWPQ. Cache lines are evicted over time. Hercules regularly writes back non-transactional ones but handles transactional ones specifically in order not to harm in-pmem original copies. It adds two registers and an extended WPQ (eWPQ) along WPQ in the MC. LogHead records the address of next available log entry in the in-pmem log zone while LogTail points to the last valid log entry (see Section IV-D). On evicting a transactional cache line, the MC allocates a log entry to put data of the cache line by atomically fetching and increasing LogHead. Hercules retains that cache line’s metadata in an eWPQ entry, including TxID, TxState, and and the mapping from home address to log entry’s address.
Log zone. 3(b) shows three areas of in-pmem log zone. The first area (transaction profiles) is an array of transaction lengths (TxLens) indexed by TxIDs. Hercules keeps the runtime length of a transaction in the corresponding thread’s context while it only allows two legal values for the in-pmem TxLen, i.e., an initial zero and a non-zero eventual length. It uses the atomic change of TxLen to be non-zero to mark the commit of a transaction (see Sections IV-B and IV-C). Using a transaction’s TxID to index and find the transaction’s TxLen is fast and brings about lock-free parallel loads/stores for concurrent transactions. We set a TxLen in 4B, so a transaction can cover up to (4 billion) cache lines.
In the second area, a log entry keeps a cache line evicted from the eWPQ with its data and metadata including the home address and TxState. The third area of eWPQ extension receives eWPQ entries evicted at runtime. The next area of emergency use is used upon an unexpected crash. We show a contiguous log zone in 3(b) while it can be partitioned to support concurrent accesses with distributed MCs [26].
IV-B Hercules’ Transaction
Primitives. Like prior works [92, 35, 72, 54, 9, 39], Hercules has three primitives for programmers to proceed a transaction, i.e., tx_start, tx_commit, and tx_abort to respectively start, commit, and abort a transaction in applications.
Let us first illustrate how Hercules proceeds a transaction in an optimistic situation, i.e., 1) the transaction manages to commit, 2) all cache lines of the transaction stay in CPU cache until the commit, i.e., with no cache line evicted in the entire course of transaction, 3) Hercules can find a cache line with TransTag available whenever needed, and 4) no crash occurs.
Optimistic procedure. On a tx_start, Hercules atomically fetches a TxID from the GlobalTxID and increments the register by one for subsequent transactions. Hercules finds its entry with TxID in the array of transaction profiles and initialize the TxLen to be zero ( in 3(b)). Until tx_commit is encountered, Hercules manages and processes cache lines for data that programmers put in the transaction. It adopts the write-allocate caching policy. Modifying data causes a cache miss if the data is not in CPU cache and Hercules allocates a cache line with TransTag before loading the cache line from pmem. It then fills TxID, WayNo, and data and sets the TxState as ‘1’. If data already stays in a clean cache line, Hercules obtains and configures a TransTag. Given a dirty cache line which might be originally non-transactional or belong to a committed transactions, Hercules sends that to the next level in the memory hierarchy, e.g., L1DL2, before getting a TransTag, in order not to taint the latest update. When the transactional cache line is evicted to the lower level, Hercules first sends the older dirty non-transactional version to the next lower-level cache or pmem. On a crash, the older version is firstly persisted to the home address. The upper-level transactional cache line, if committed, refills the home address; if not, Hercules writes it to the area of emergency use (to be presented). This rules out any inconsistency and uses lower-level caches for staging to further reduce pmem writes.
Hercules follows generic rules in programming transactions. It disallows nested or overlapped transactions in one thread, so at most one transaction is ongoing within a thread. Inspired by Intel TSX [29], Hercules provides a configurable option to support applications with a fundamental read committed isolation level [55, 7] to defeat against semantic isolation bugs. Programmers may consider concurrency control mechanisms like locks or semaphores between transactions in multi-threading programs. More details can be found in Section IV-D.
When a thread enters a transaction for the first time, the transaction’s TxID and length are used to fill PerCoreTxID and PerCoreTxLen of the running CPU core, respectively. PerCoreTxLen is incremented by one every time Hercules is going to launch a transactional update on an uncovered cache line. If a context switch occurs, the values of PerCoreTxID and PerCoreTxLen are saved as part of the thread’s context for an afterward execution. On committing a transaction, Hercules atomically sets the in-pmem TxLen with PerCoreTxLen and resets the TxState to be ‘0’ for each transactional cache line to make it visible to other threads.
The foregoing procedure shows that Hercules efficiently handles a transaction and commits on-chip. The eADR guarantees committed cache lines would be flushed to their home addresses in case of a crash. Next we present how Hercules handles conditions not covered in the optimistic circumstance.
Premature flush. The eADR enables Hercules to write back data on cache replacements rather than explicit cache line flushes, so updates to a cache line are coalesced and pmem bandwidths are saved. Hercules handles the write-back of a non-transactional cache line with the MC’s WPQ in the ordinary way. For an evicted cache line recorded in a TransTag, if TxState is ‘0’, i.e., being non-transactional, the MC writes back the cache line to the home address. If TxState is ‘1’, Hercules initiates a premature flush with the MC’s eWPQ ( in 3(b)). As shown in 3(b), the eWPQ is made of eWPQ entries and an eWPQ validity bitmap to track the validity status of each eWPQ entry. The MC finds a free eWPQ entry for the evicted transactional cache line and allocates a log entry by atomically fetching and increasing the LogHead. The MC copies TxID, TxState, home address, and log entry’s address to the eWPQ entry and asynchronously writes back the transactional cache line in the log entry ( in 3(b)).
Hercules employs the eWPQ both for logging uncommitted data and loading proper data. When a thread resumes execution, it may use a cache line that has been prematurely flushed. The cache line may be from any transaction that is already committed or this resumed transaction. Hercules references cache lines regarding their home addresses. On a load request, the MC checks if the target address matches any eWPQ entry and simultaneously tests the TxState. Given a match and ‘1’ TxState, if the TxID is compared to be the same as ongoing TxID, Hercules gets a potential hit. A match with ‘0’ TxState is also likely a hit, because the cache line had been evicted before the relevant transaction committed, but not migrated to the home address yet. No match results in a miss.
Regardless of a hit or miss, once receiving a request, the MC starts loading the cache line from the home address. A hit at the eWPQ fetches the corresponding log entry and halts the load from home address. MC checks the full address stored in the log entry and forwards it to the CPU cache in case of a true match. When CPU cache receives the log entry, MC nullifies the matching eWPQ entry. A miss continues the load of cache line from home address. In addition, a forbidden access from an ongoing transaction may happen to an eWPQ entry with mismatched TxID and ‘1’ TxState. Hercules aborts that transaction with an exception (see Section IV-D for isolation).
The other reason for employing the eWPQ is to commit and migrate cache lines that have been prematurely flushed. A transaction may commit without reusing them. Hercules exploits the eWPQ to deal with them. There are two ways to deal with such cache lines. One is to load them into CPU cache for committing on-chip and store them to home addresses by cache replacements. The other one is to commit them off-chip by resetting the TxStates in corresponding eWPQ entries and migrating them from log entries to home addresses via non-temporal stores. We choose the second way to reduce cache pollution. For efficiency, we periodically scan eWPQ entries for data migrations. The period is configurable, set to be every three million instructions in our tests. A completion of migrating a log entry clears the validity bit for the eWPQ entry ( in 3(b)). A load request that happens before the reset of validity bit still fetches data from the log entry.
Previous works have justified the efficacy and efficiency of using a part of address for cache management [81, 36, 37, 70]. We accordingly devise a compact eWPQ entry that holds one bit of TxState and three fields of 63 bits evenly partitioned for TxID, home address, and log entry’s address. Our evaluation shows that transactions of typical applications are empirically small and generally take few to dozens of cache lines (see Section V-B), so a home address and a TxID in overall 42 bits are sufficient for indexing. If duplicate matches occur, an eWPQ entry leads to a log entry that holds the full home address to rule out ambiguity. We manage the eWPQ like a fully associative cache and set a default size of 4KB for 512 entries, which are ample to serve ordinary workloads found in typical applications (see Section V-B). We believe a larger eWPQ is practically viable [26, 27]. Yet we take into account the very low likelihood of a full eWPQ, wherein Hercules evicts the least-recently-used (LRU) entries to an in-pmem eWPQ extension area that is ten times larger than the eWPQ ( in 3(b)). If a request misses in the eWPQ, Hercules checks the eWPQ extension area with a target home address to properly fetch the corresponding log entry.
Flush on a power-off. When a power-off occurs, Hercules flushes WPQ, LogHead, LogTail, eWPQ, and then all cache lines to pmem. Hercules writes non-transactional cache lines to home addresses. In case of a crash, it dumps transactional ones to the area of emergency use in the log zone with home addresses and TransTags ( in 3(b)). These metadata and data are useful for recovery (see Section IV-C).
Cache replacement. Transactional and non-transactional cache lines flexibly share a cache set. Hercules considers an effective algorithm [81, 36, 37, 70, 34] to select a victim for eviction, but entitles a higher priority to transactional ones for staying in cache. A request to place a non-transactional cache line only replaces a non-transactional one in the set. To place a transactional one, Hercules tries to find a free TransTag and may replace a non-transactional victim. If all TransTags are being occupied, Hercules evicts a transactional cache line.
Transaction abortion. A transaction may abort due to various events like exception, fault, or running out of memory. On an abortion, data recorded in the TransTags and eWPQ entries with TxIDs matched and TxStates being ‘1’s are invalidated and discarded, incurring no harm to original data.
IV-C The Crash Recoverability of Hercules
Hercules puts a specific flag in the log zone to mark a normal shutdown or not. The flag is not set if any transactional cache line is saved to the area of emergency use on power-off. Regarding an unset flag, Hercules recovers at the transaction level in order to support applications recovering with semantics. As modifying TxStates of multiple cache lines cannot be atomic, Hercules atomically sets the TxLen to commit a transaction. In recovery, it fetches eWPQ, LogHead, and LogTail into the MC and scans transaction profiles.
Hercules discards transactions with zero TxLens. As to a committed one, Hercules scans the area of emergency use to find out cache lines with TxIDs matched and TxStates being ‘1’s. Hercules moves them to their home addresses. In addition, some cache lines of the transaction might have been prematurely flushed before the commit, being tracked by the eWPQ, but not migrated yet prior to the power-off. That explains why Hercules has saved the entire eWPQ. If an entry with a matching TxID is valid in the eWPQ validity bitmap, Hercules migrates the mapped log entry and then clears the corresponding validity bit. LogTail may be moved after the migration. Once moving all such cache lines is completed, Hercules resets the transaction’s TxLen to be zero. This atomic write rules out ambiguity if a crash takes place in an ongoing recovery. After resetting GlobalTxID and clearing the eWPQ, Hercules is ready to recommence new transactions.
IV-D Discussion
Granularity. A cache line is the unit transferred between CPU cache and memory, so Hercules chooses it as the unit for transactional operations. Using programmer-defined variables is more fine-grained but must incur higher cost and complexity.
Exclusion of transactional cache lines. Hercules has no restriction of inclusion or exclusion on non-transactional cache lines. It enforces an exclusive multi-level cache hierarchy to transactional cache lines, which means an evicted transactional cache line, once reloaded into the higher-level cache, will be removed from the lower-level cache. The reason of doing so is twofold. Firstly, an exclusive housing of transactional cache lines substantially saves TransTags and cache space. Secondly, an exclusion management helps to reduce microarchitectural actions. Given a transactional cache line loaded to a higher level, e.g., L2L1D, for read purpose, an inclusive cache hierarchy has it at both levels holding the latest version. When the transaction commits, Hercules needs to reset TxStates twice for the same cache line across levels. Given a transactional cache line loaded to a higher level for updating, cache coherence protocols like MESI or MESIF help an inclusive cache hierarchy to invalidate the older version at L2 upon a modification, but that costs a microarchitecture-level coherence state transition (). Hercules’ exclusion circumvents these inessential state resets or transitions.
Isolation. Not all pmem systems supporting transactions provide thread-atomicity (isolation) [6].Like using prior hardware designs [92, 19, 35, 9, 72], with Hercules programmers are responsible for the isolations between threads via concurrency control methods (e.g., locks or semaphores). We consider that an error-prone application may misbehave on isolations and provide a configurable option for Hercules. In brief, following Intel TSX [29], Hercules aborts a transaction when threads contend to modify transactional data. Also, uncommitted data is invisible to other threads. If one thread does a read-only operation on data updated in an ongoing transaction, Hercules loads the data’s original copy with customized non-temporal hint and data-path [16, 67, 61] either from lower-level caches or pmem, depending on where the data’s original copy is (see Section IV-B). Thus, Hercules enables an optional support of the read committed isolation [55, 7] while software concurrency control can promote higher isolation levels.
Coherence. Hercules collaboratively works with cache coherence protocols like MESI or MOESI. TransTags and the directory for cache coherence [93, 51, 73, 85] share similarities in use and we can integrate them to jointly track cache lines. Hercules does not affect the sharing of non-transactional cache lines. As to transactional ones, the application’s concurrency control and architectural TxIDs in TransTags prevent other cores from modifying or fetching uncommitted versions of them. The exclusion and isolation of transactional cache lines also avoid broadcasting invalidation messages to all cores upon committing a transaction. In all, Hercules inflicts no harm but reduces state transitions to maintain cache coherence.
State reset. Because cache lines of a transaction are likely to be scattered in a multi-level cache/memory hierarchy, all prior designs commit them with concrete efforts for atomic durability [92, 39, 9, 54, 35, 33]. For example, TC forcefully persists data in the side-path cache to pmem [39] while Kiln flushes down cache lines from upper-level volatile caches [92]. HOOP migrates all data staying in its out-of-place (OOP) buffer installed in the MC to its in-pmem OOP region [9]. FWB has to wait for the drain of current log updates [54]. Comparatively, Hercules’ commit is much more efficient and lightweight, as it just sets TxLen and resets TxStates for cache lines that a transaction covers. Since TransTags form a structure similar to the directory for cache coherenceused to track and transit states for cache lines, Hercules employs an auxiliary circuit to select ones with a TxID and clear their TxStates. For data that might be prematurely flushed before the commit, Hercules uses the auxiliary circuit to notify the integrated MC and wait for the completion of resetting TxStates in relevant eWPQ entries.Generally these resets can be swiftly done like state transitions for cache coherence. We preset a uniform state reset latency in which Hercules is supposed to finish, with a discussion presented in Section V-C.
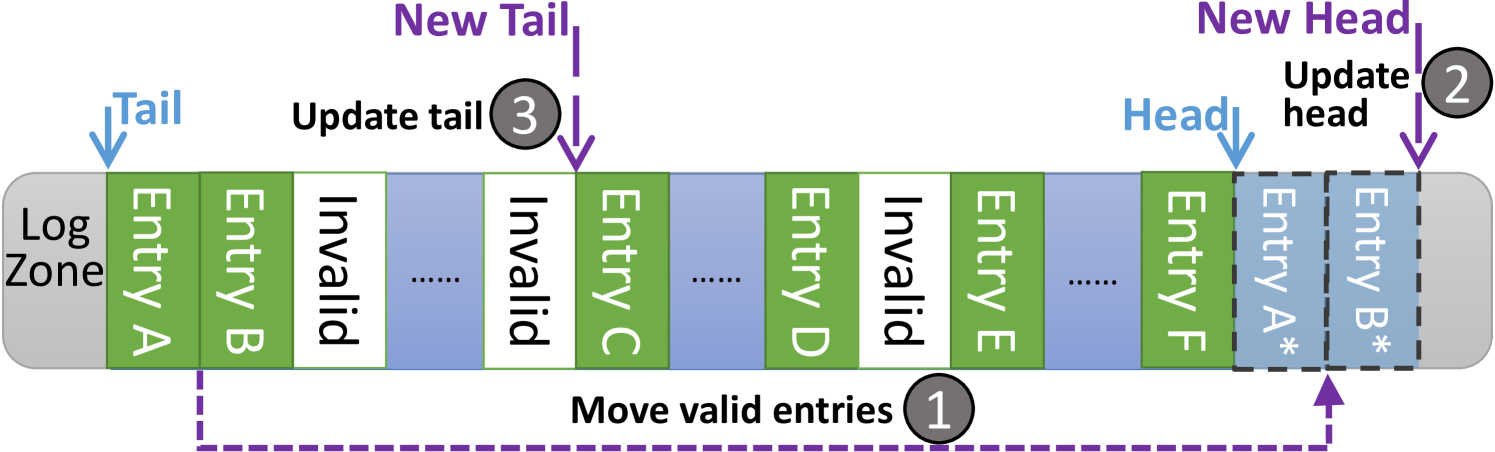
Garbage collection (GC) on log entries. Concurrent transactions commit at different time and take up discontinuous log entries. Committed log entries become invalid, scattered across the log zone. Figure 4 shows how Hercules cleans them up. LogHead and LogTail frame a window of log entries Hercules is using while the eWPQ tracks all valid ones. When LogTail has not moved for a while, numerous invalid entries might accumulate in the window. If Hercules monitors that the distance between LogTail and LogHead is greater than a threshold, e.g., , it will initiate a GC ( in Figure 4). Hercules fetches a chunk (e.g., 32) of successive log entries starting at LogTail ( ). It appends valid uncommitted ones to the locations pointed by LogHead and updates corresponding eWPQ entries ( ). Only after updating each eWPQ entry will Hercules move LogHead by one. Then it slides LogTail over the chunk to the next valid entry ( ). Hercules orderly performs these steps to preclude any crash inconsistency. Note that the system may crash in a GC, particularly when a power outage has happened after a movement, which results in a moved log entry existing both at LogHead and LogTail. Such a log entry can be ignored as it belongs to an uncommitted transaction with TxLen being zero, without any loss of Hercules’ crash recoverability.
Log extension. In a very low likelihood, excessive transactional data might occasionally overfill the entire CPU cache in dozens of megabytes or even flood the log zone. Hercules continues cache placements and replacements to swap in and out data, respectively, to proceed transactions. We can configure a log zone in gigabytes or even larger. In case that such a large space is still to be used up, we extend the log zone by using the end part of default log zone to store indirect indexes to the space in a new log zone allocated on-demand elsewhere. This is like the strategy of indirect blocks used by file systems to manage big files [82]. We also enhance the eWPQ with more entries and extend an eWPQ entry with one more bit to tell the MC if it needs to do indirect references or not to find actual data for a prematurely flushed cache line.
V Evaluation
We implement Hercules with gem5 in the syscall emulation (SE) mode and ‘classic caches’ model. Table I captures the settings of CPU with three-level caches that align with prior works [92, 39, 72, 9, 53]. We configure an in-pmem log zone in 256MB. We set default TransTag ratios to be 100%/50%/25% for L1D/L2/L3 caches. As L1D cache impacts the most on performance in CPU cache hierarchy, in order to make a fair and strict evaluation on Hercules, we reduce L1D size from 32KB to 30KB for Hercules by evenly removing some ways in cache sets within gem5 to counterbalance the spatial cost of it. We further estimate the spatial and energy costs for Hercules in Section V-D. For a cache line access involving a TransTag, we increase the tag latency by 30% as extra time cost. We set the state reset latency in ten clock cycles by defaultwith a discussion in Section V-C. We also set ten clock cycles for searching the eWPQ to check if a cache line has been prematurely flushed.
| Component | Setting | Remarks |
| Processor | 3GHz, out-of-order, 8 cores, ROB size=192 [51, 94, 52], | Generic |
| issue/write-back/commit width=8, MESI protocol | ||
| L1I Cache | 32KB, 4-way, 2-cycle latency | |
| L1D Cache | 32KB, 4-way, 2-cycle latency | |
| L2 Cache | 256KB, 8-way, 8-cycle latency | |
| LLC | 16MB, 16-way, 30-cycle latency | |
| Pmem | Read/write latency=150ns/100ns, capacity=512GB, | |
| single channel, read/write buffer size=64 | ||
| Smaller L1D | 30KB, 4-way, 2/2 cycles read/write latencies | Hercules |
| Side-path TC | 4KB, FIFO, 40/50 cycles read/write latencies | TC [39] |
| STT-RAM LLC | 64MB, 16-way, 40/50 cycles read/write latencies | Kiln [92] |
| Category | Benchmark | Remarks |
| Array Swap | Swaps two elements in an array | |
| Binary Heap | Inserts/deletes entries in a binary heap | |
| Micro- | B+-Tree | Inserts/deletes KV pairs in a B+-Tree |
| benchmarks | Hash Table | Inserts/deletes KV pairs in a hash table |
| Linked List | Inserts/deletes entries in a linked list | |
| RB-Tree | Inserts/deletes KV pairs in a RB-Tree | |
| SDG | Inserts/deletes edges in a scalable large graph | |
| Macro- | TPC-C | OLTP workload (New-order transactions) |
| benchmarks | YCSB | 80%/20% of write/read |
Table II lists micro- and macro-benchmarks we use. We consider ones that have been widely used in prior works [92, 9, 35, 54, 33, 27] and our evaluation methodology strictly follows them. We run one million transactions with each benchmark.




We compare Hercules to state-of-the-art hardware designs, including Kiln, TC, HOOP, Proteus, FWB, and PiCL. They represent different approaches to guarantee atomic durability for in-pmem data (see Section II-B). As PiCL is with periodical checkpointing, we discuss it separately at the end of Section V-A. In Table I, the STT-RAM LLC and side-path cache are for Kiln and TC, respectively, both configured in line with STT-RAM’s characteristics [92, 50]. Software logging with eADR (SWL_eADR) is also compared while software logging with cache line flushes is omitted for brevity.
V-A Micro-benchmark
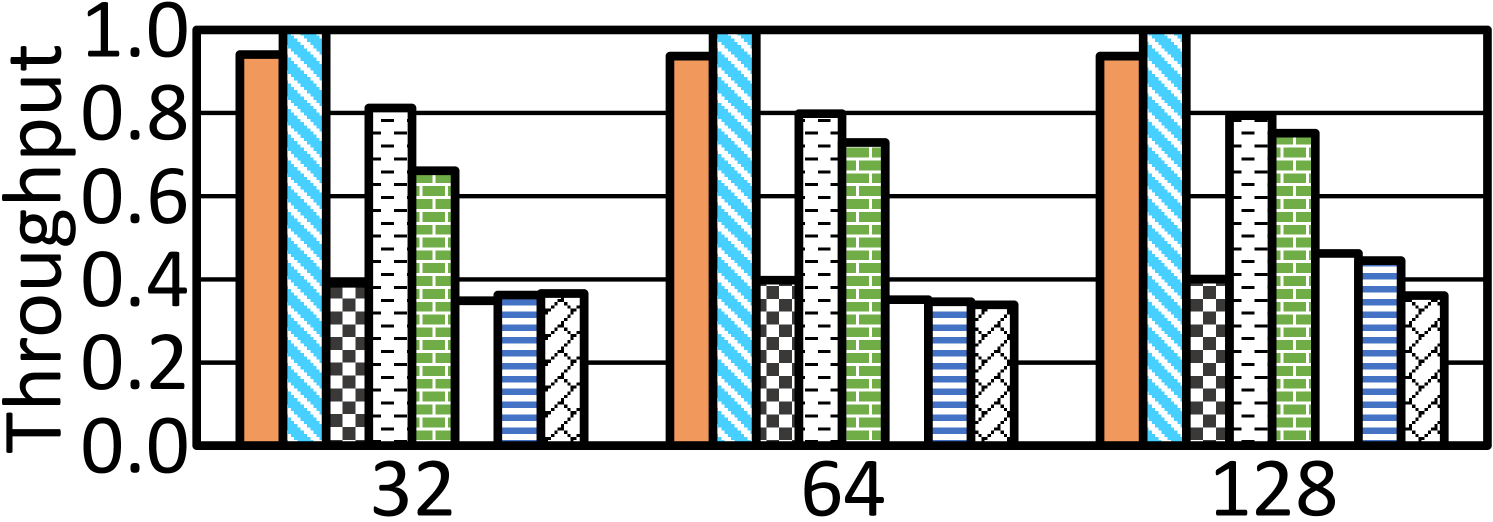
Throughput. We normalize the throughputs (txn/, transactions per microsecond) of all designs against that of OPT. As shown in Figure 6, we include the geometric mean of throughputs over benchmarks for a high-level overview [92, 39, 72, 9, 53]. Hercules achieves comparable performance to OPT. It significantly outperforms prior works with on average 89.2%, 29.2%, 15.2%, 51.3%, 48.0%, and 57.0% higher throughput than SWL_eADR, Kiln, TC, HOOP, Proteus, and FWB, respectively. Hercules leverages CPU cache hierarchy to absorb and coalesce transactional updates and mainly commits them on-chip. It gains superior efficacy in handling continuous transactions with such a spacious transient persistence domain.
The throughputs of Kiln and TC are limited by two factors. One is due to STT-RAM’s longer write/read latencies. The other one is that Kiln and TC have enforced limits in using persistent caches, such as using a small side-path cache [39] or taking a fall-back path to write pmem for backup in case of an almost full request queue [92]. Other hardware designs, such as HOOP, Proteus, and FWB, exploit hardware components like undo/redo log buffers, WPQ, or pmem to compose and persist backup copies. Continuous transactions keep limited log buffers or WPQ entries being fully occupied over time. They are hence inferior to Hercules that leverages the extensive CPU cache hierarchy to absorb and process data.
Figure 6 exhibits different observations across benchmarks, as their transactions are with different semantics and complexities. For example, two insertions with Linked List and RB-Tree differ a lot. Unlike prior designs varying significantly across benchmarks, Hercules shows consistently superior performance. Its strong robustness is mainly accredited to CPU cache it exploits. A multi-level cache hierarchy has been proved to be effectual for various workloads over decades.
Pmem writes. To minimize pmem writes is another goal of Hercules. Figure 8 captures the quantity of pmem writes caused in running transactions with micro-benchmarks (Y axis in the logarithmic scale). Hercules significantly reduces pmem writes. On average, the data it writes is 29.8%, 37.4%, 5.3%, 1.4%, 1.5%, and 2.1% that of other designs in the foregoing order, respectively. Write-backs of Hercules only happen upon normal cache replacement or power-off, so it performs pmem writes in a passive and lazy way. SWL_eADR incurs double writes. Kiln takes a fall-back path that forcefully sends cache lines to pmem with an overflowing request queue. TC has a similar fall-back path to write pmem when its side-path cache is almost full. Also, whenever a transaction commits, TC issues relevant stores to pmem. Other hardware designs explicitly write backup copies to pmem. HOOP, for example, does address indirection at the MC and migrates data between pmem locations over time for out-of-place updating. Proteus leverages the WPQ for buffering to reduce pmem writes, but the limited capacity of WPQ impedes its efficacy. By using CPU cache in numerous megabytes to absorb and coalesce data updates, Hercules effectively minimizes pmem writes.
Tail latencies. Without loss of generality, we record 99P/99.9P (99- and 99.9-percentile) tail latencies for transactions and show them for three benchmarks in Figure 6 and 8, respectively, with Y axes in the logarithmic scales. These results further justify Hercules’ efficacy as it makes much shorter tail latencies with various workloads. Take B+-Tree for example. Hercules’ 99.9P tail latency is 40.5% and 55.1% shorter than that of Kiln and HOOP, respectively.
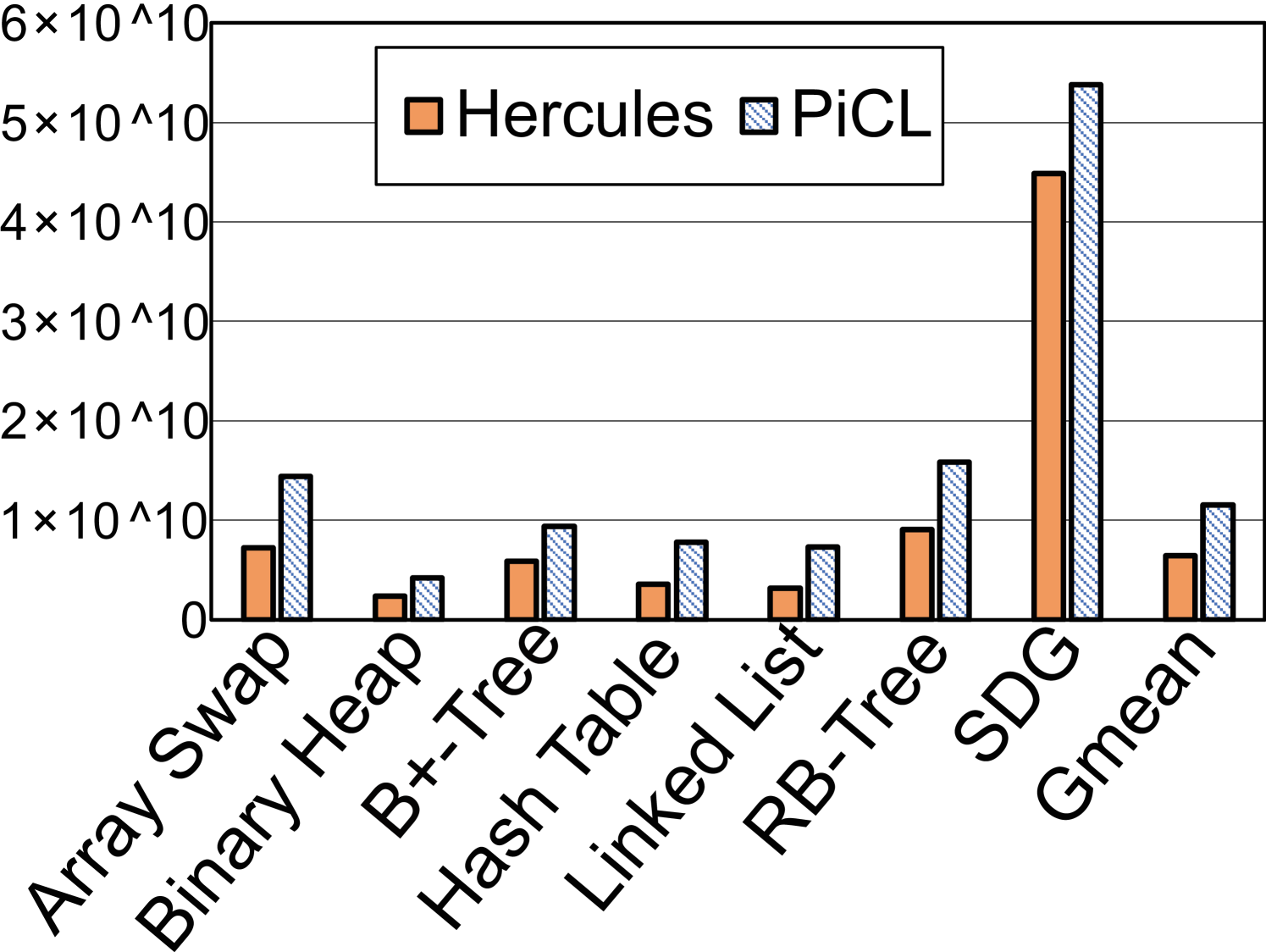
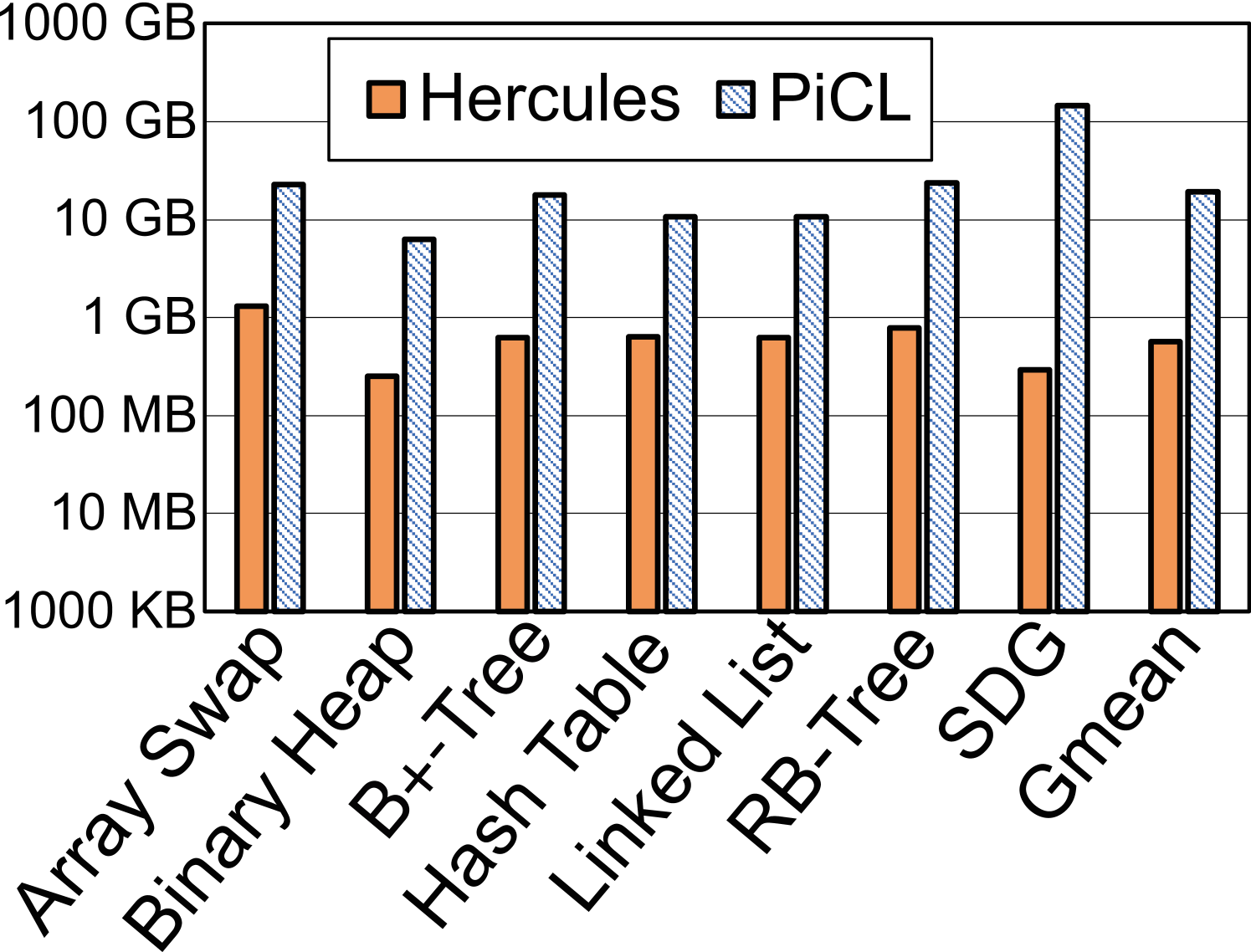
A comparison to the approach of checkpointing. PiCL checkpoints data periodically in pmem for recovery without forming transactions [12, 53]. In Figure 9 we present the number of clock cycles and the quantity of pmem writes Hercules and PiCL have done to complete all operations for each benchmark. PiCL’s checkpointing is like undo-logging all data at the start of every epoch, which, albeit being simplistic, causes on average 78.3% more time and 34.1 pmem writes than Hercules. Hercules only covers data programmers place in fine-grained transactions and leverages CPU cache to log and buffer them. This is why Hercules costs both much less time and dramatically fewer pmem writes than PiCL.
| Benchmark | Array | Binary | B+- | Hash | Linked | RB- | SDG |
| Swap | Heap | Tree | Table | List | Tree | ||
| Min. TxLen | 7 | 8 | 15 | 3 | 12 | 2 | 22 |
| Max. TxLen | 9 | 1,021 | 143 | 7 | 18 | 71 | 149 |
| Avg. TxLen | 8.0 | 11.6 | 34.4 | 6.2 | 12.5 | 50.6 | 33.8 |
V-B Tests for Premature Flush and TransTag Ratios
We summarize TxLens on finishing all transactions for each micro-benchmark in Table III. Modern cache hierarchy has no difficulty in putting few to dozens of cache lines. Hercules hence effectually suits ordinary workloads and almost all transactions can be committed on-chip. Meanwhile, ordinary transactions in small sizes are hardly affected by the change of TransTag ratios and seldom cause premature flushes or GC.
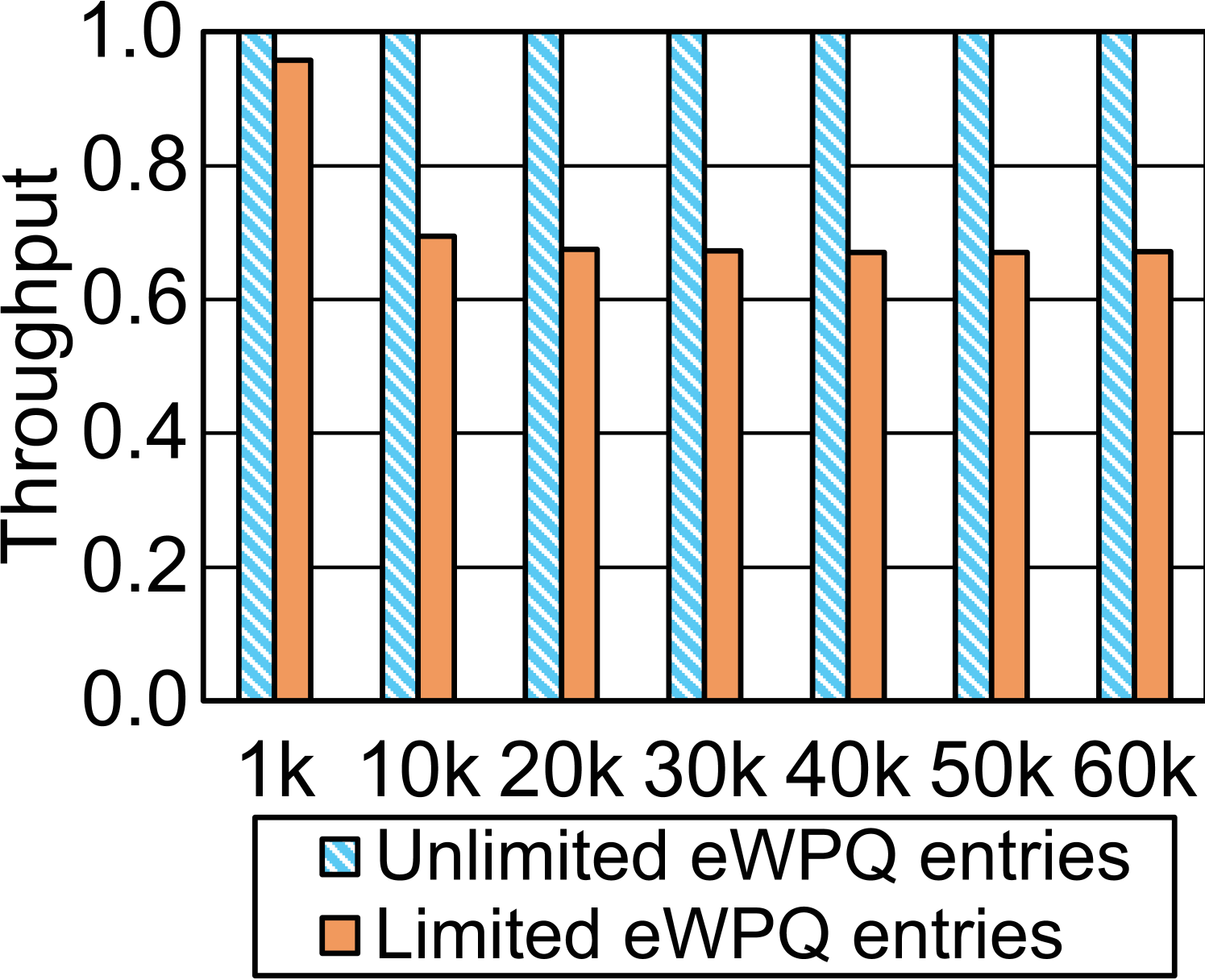
To thoroughly evaluate Hercules, we run unrealistic artificial tests executed in a shrunk cache hierarchy. We scale down L1D/L2/L3 caches by 8 to be 3840B/32KB/2MB and synthesize test cases in which a huge transaction updates massive cache lines. We set the length of a transaction to be 1k, 10k, 20k to 60k (k: ) and run with unlimited and 512 eWPQ entries, respectively. 10(a) shows the throughputs normalized against that with unlimited eWPQ. For a huge transaction involving tens of thousands of cache lines, CPU cache and eWPQ would be saturated and Hercules must use the in-pmem eWPQ extension. The impact of premature flushes grows up. For example, the throughput with 512 eWPQ entries declines by 32.8% at the 60k case.
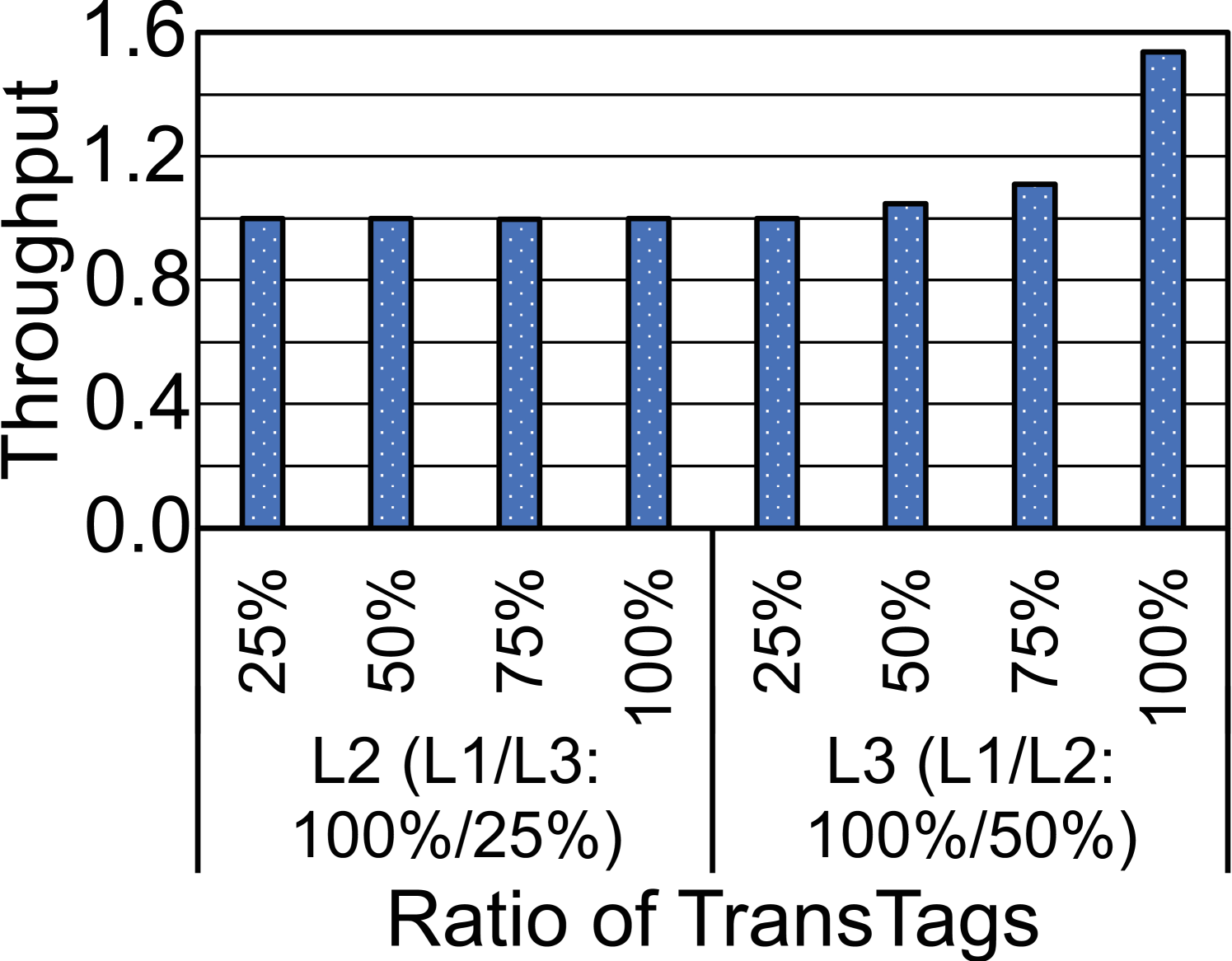
We also run unrealistically huge transactions when varying TransTag ratios at L1D, L2, and L3. Without loss of generality, we illustrate with the 30k test case upon changing TransTag ratios at L2 and L3. In 10(b), we normalize the throughputs against that of default 100%/50%/25% ratios. There is an evident uptrend along an increasing ratio at L3. A 2MB L3 cache has 32,768 cache lines. An increased ratio means more space to house the working set of 30k case. Only 100% ratio at L3 manages to fit all 30,000 cache lines of 30k and yields the highest throughput without premature flush.
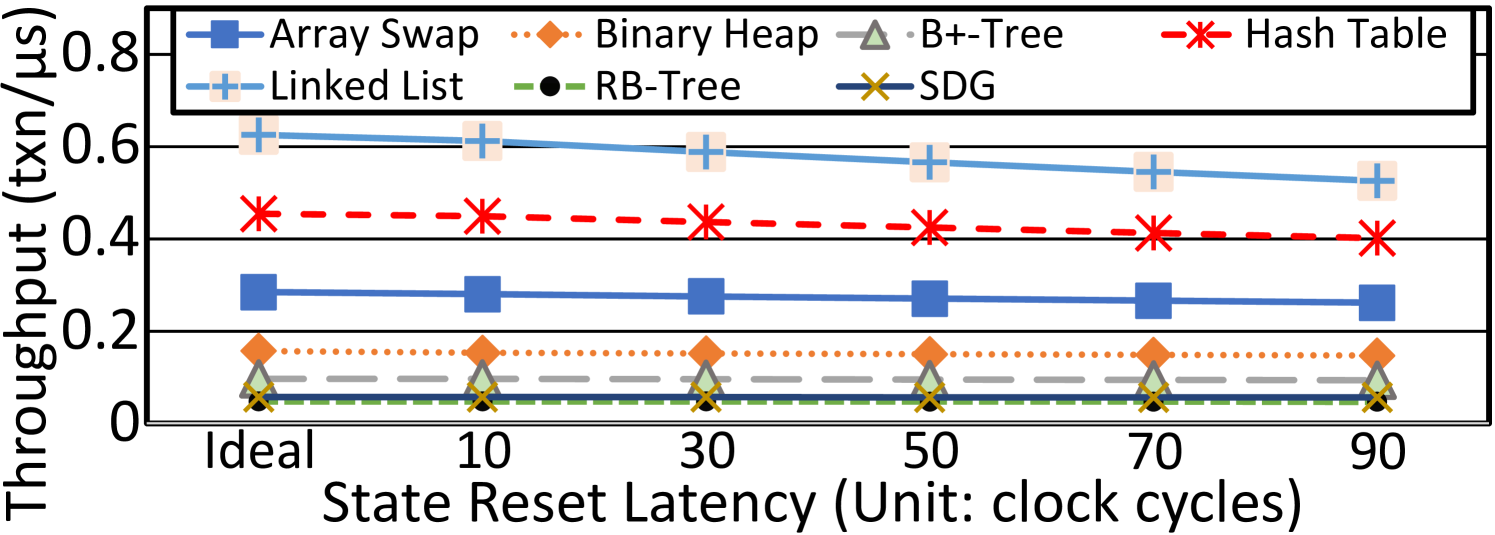


V-C The Impacts of Factors on Hercules
State reset latency. We set the default state reset latency per transaction as ten clock cycles to toggle TxStates of aggregated TransTags with auxiliary circuit. We can deploy circuits in different complexities to gain different latencies. Figure 11 shows the throughput (txn/s) curves on running micro-benchmarks when we vary the latency duration from the ideal (zero) to 90 cycles. With a longer latency, the throughputs of Linked list, Hash Table, Array Swap, and Binary Heap decrease more severely than those of B+-Tree, RB-Tree, and SDG. The curves in Figure 11 complement TxLens in Table III. The throughput of a benchmark with smaller transactions is surely more sensitive to the increase of state reset latency, since a smaller transaction itself takes less execution time. Take RB-Tree and Linked List for comparison again. An insertion to RB-Tree is generally more complicated and involves 50.6 transactional cache lines per transaction. Yet an insertion to Linked List deals with 12.5 cache lines per transaction on average. As a result, increasing the state reset latency more affects lighter benchmarks like Linked List.
WPQ size. We further test when varying the size of WPQ. Without loss of generality, we choose Linked List and present throughputs of all designs in Figure 13. Hercules’ bottleneck is not on write-backs via the WPQ to pmem, so its performance has no evident fluctuations. This justifies the robustness of Hercules in utilizing extensive CPU cache for atomic durability. A larger WPQ helps prior works like HOOP and Proteus yield performance improvements. Proteus leverages the WPQ of MC for transactional operations while HOOP depends on the MC to do address indirection and data movements. They hence benefit more from an increase of WPQ entries.
Pmem latency. The default write latency of pmem is 100ns. We vary it to emulate different pmem products. Figure 15 captures the throughputs of all designs again on Linked List with three write latencies. By keeping all transactional data in CPU caches without incurring pmem writes, Hercules is unaffected by varying pmem latencies. Notably, the performances of prior works that rely on writing data to pmem for backup badly degrade. In summary, leveraging the capacious transient persistence domain made of CPU caches enables Hercules with high adaptability to various pmem products.
| TransTags (Unit: KB) | eWPQ (Unit: Bytes) | ||||
| L1D | L2 | L3 | Entries | Validity Bitmap | Pointers |
| 1.29 (per core) | 6.25 (per core) | 208 | 4,096 | 64 | 16 |
V-D Recoverability, Energy and Spatial Costs of Hercules
Recovery. We tailor gem5’s checkpoint function to save all metadata and data into the log zone backed by files and emulate a crash by encountering a simulator magic instruction. Hercules manages to recover properly and resume execution.
Spatial cost. Table IV summarizes the overall spatial cost of Hercules such that removing 2KB at L1D per core is sound to evaluate it. Similar to on-chip buffers used by prior works [2, 39, 33, 53, 54, 79], TransTags incur the main on-chip spatial cost for Hercules. Due to the space limitation, we brief an estimate with a 4-way L1D cache in 30KB. As we use all L1D cache lines, a TransTag needs 22 bits (21-bit TxID and 1-bit TxState) without WayNo. The original metadata per line, such as cache tag and state, takes at most 48 bits for a VIPT cache [94, 57]. TransTags thus cost % () more space. This also explains why we increase the tag latency by 30% on accessing a transactional cache line ( 31.4%). Similarly we estimate the proportions of TransTags at L2 and L3 to be % and %, respectively. In all, the spatial cost of Hercules is insignificant.
Energy cost. If a crash occurs, besides the eADR’s ordinary flushes, Hercules persists the TransTag and home address that are estimated as at most 10B (e.g., at L1D) for a transactional cache line. The energy costs per store from L1D, L2, and L3 caches to pmem on a crash are respectively B, B, and B [2, 56]. The base cost of flushing the entire cache hierarchy is thus 214.831 for 8-core CPU. Regarding 3840/ 16384/ 65536 transactional cache lines at L1D/L2/L3 with eight cores, all of them are dirty and uncommitted in the worst case. The cost to flush TransTags and home addresses for them is about 9.653. Hercules also needs to identify transactional cache lines by comparing WayNo in each TransTag and all comparisons cost about 84.045 with an up-to-date comparator taking per comparison [74]. Overall, Hercules maximally brings about 4.49 () extra energy cost, which is practicable in upgrading the eADR. In addition, a TxID in more bits may increase such extra cost to be beyond 5.0% or even greater, and also impose further challenges on designing and producing chips with efficiency and reliability [8, 10, 52, 58].
V-E Macro-benchmark
We utilize TPC-C and YCSB workloads from WHISPER [17, 33, 27] to evaluate Hercules for two purposes. Firstly, we measure the performance and robustness of Hercules with more sophisticated workloads of realistic applications. Secondly, we run with multi-threads to test the scalability of Hercules in serving concurrent transactions. TPC-C’s New-order follows the de facto semantics. As to YCSB, we vary the value size for a comprehensive test.
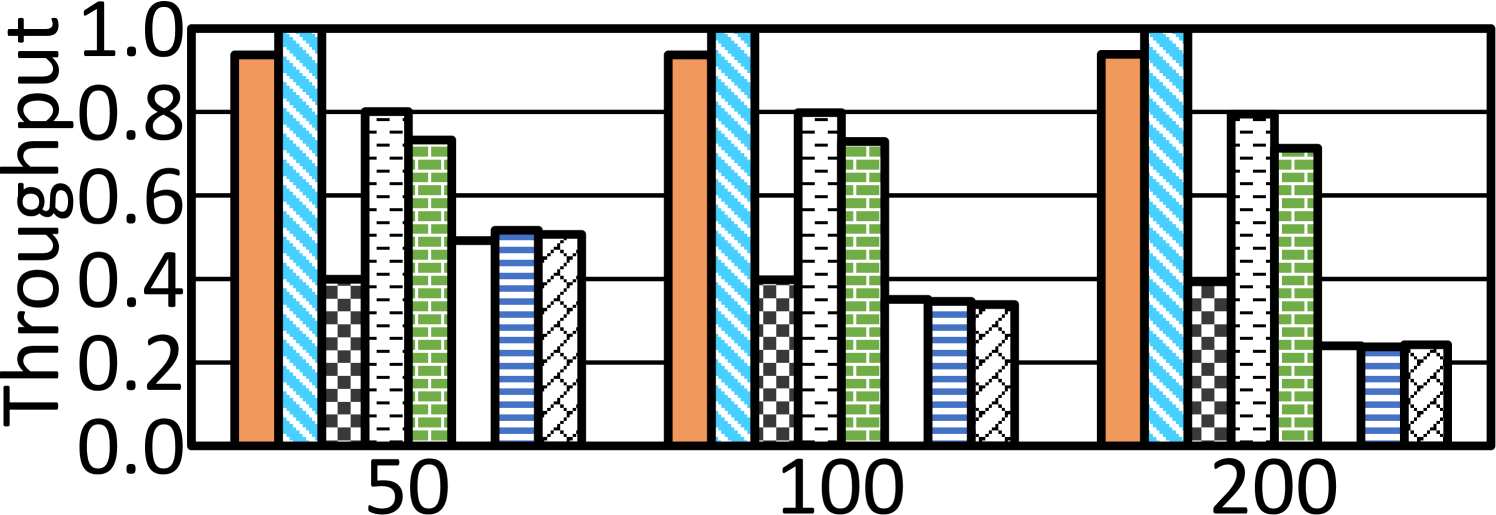
As shown in Figure 13, on dealing with more complicated transactions of macro-benchmarks, Hercules still yields a higher throughput than SWL_eADR, Kiln, TC, HOOP, Proteus, and FWB by 39.2%, 20.5%, 19.0%, 31.5%, 41.1%, and 41.7% on average, respectively. Furthermore, with a larger value, the performance gap between Hercules and prior designs generally becomes wider. The root cause is Hercules’ robust design. It leverages the sufficient CPU cache to take in transactions. The eADR renders a value almost persistent in CPU cache. A larger value does not greatly increase the cost of persisting the value, especially on the critical path. Comparatively, the double writes of logging again hinder SWL_eADR from achieving high performance. As to Kiln and TC, a larger value imposes more burdens in using FIFO queues and side-path cache, respectively, and triggers more executions through fall-back paths that severely affect their throughputs. For FWB and Proteus, larger transactions still make immense data updates that continually run out of their log buffer and WPQ entries, respectively. As to HOOP, larger values consume more pmem bandwidths and incur longer time for the MC to wait for the completion of data migrations.
The results with running four threads in Figure 15 justify the scalability of Hercules, which produces 43.7%, 20.1%, 27.8%, 31.6%, 42.9%, and 43.7% higher throughput, respectively, than prior designs on average. A multi-level private/shared cache hierarchy with the set-associativity management implies an innate scalability to support multi-threading with multi-cores. Hercules gains scalability accordingly. Threads may share GlobalTxID register at the start of a transaction and eWPQ outside of the critical path for prematurely flushed cache lines. Though, getting a TxID can be swiftly done in an atomic operation while the probability of massive synchronizations under a spacious cache hierarchy is low. For prior designs, the contention on resources between multi-threads is much fiercer. Take HOOP for illustration again. As it depends on the MC for out-of-place data updates, multiple threads contend flushing data through the MC. This offsets the effect of CPU cache for concurrency and makes the MC a busy synchronization point being shared at runtime, thereby limiting HOOP’s scalability.
VI Conclusion
We propose Hercules, a systematic hardware design leveraging the transient persistence domain made of CPU cache to enable the transaction-level atomic durability for in-pmem data. Hercules has comprehensive control logics and data-paths installed in CPU cache, MC, and pmem. It provides transactional primitives and protocols to define and proceed transactions. Hercules well serves typical applications. Experiments confirm that it significantly outperforms prior works with higher performance. Hercules also substantially minimizes pmem writes with ample CPU cache buffering data.
References
- [1] A. H. Aboutalebi and L. Duan, “RAPS: Restore-aware policy selection for STT-MRAM-based main memory under read disturbance,” in 2017 IEEE International Conference on Computer Design (ICCD), 2017, pp. 625–632.
- [2] M. Alshboul, P. Ramrakhyani, W. Wang, J. Tuck, and Y. Solihin, “BBB: Simplifying persistent programming using battery-backed buffers,” in 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2021, pp. 111–124.
- [3] M. Alwadi, V. R. Kommareddy, C. Hughes, S. D. Hammond, and A. Awad, “Stealth-persist: Architectural support for persistent applications in hybrid memory systems,” in 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2021, pp. 139–152.
- [4] M. Arjomand, M. T. Kandemir, A. Sivasubramaniam, and C. R. Das, “Boosting access parallelism to PCM-based main memory,” in Proceedings of the 43rd International Symposium on Computer Architecture, ser. ISCA ’16. IEEE Press, 2016, pp. 695–706.
- [5] A. Baldassin, J. a. Barreto, D. Castro, and P. Romano, “Persistent memory: A survey of programming support and implementations,” ACM Comput. Surv., vol. 54, no. 7, July 2021.
- [6] A. Baldassin, J. a. Barreto, D. Castro, and P. Romano, “Persistent memory: A survey of programming support and implementations,” ACM Comput. Surv., vol. 54, no. 7, jul 2021.
- [7] H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O’Neil, and P. O’Neil, “A critique of ANSI SQL isolation levels,” in Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’95. New York, NY, USA: Association for Computing Machinery, 1995, pp. 1–10.
- [8] D. Bertozzi, L. Benini, and G. De Micheli, “Error control schemes for on-chip communication links: the energy-reliability tradeoff,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 24, no. 6, pp. 818–831, 2005.
- [9] M. Cai, C. C. Coats, and J. Huang, “HOOP: Efficient hardware-assisted out-of-place update for non-volatile memory,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 2020, pp. 584–596.
- [10] B. H. Calhoun, Y. Cao, X. Li, K. Mai, L. T. Pileggi, R. A. Rutenbar, and K. L. Shepard, “Digital circuit design challenges and opportunities in the era of nanoscale CMOS,” Proceedings of the IEEE, vol. 96, no. 2, pp. 343–365, 2008.
- [11] Y. Chen, Y. Lu, F. Yang, Q. Wang, Y. Wang, and J. Shu, “FlatStore: An efficient log-structured key-value storage engine for persistent memory,” in Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. New York, NY, USA: Association for Computing Machinery, 2020, pp. 1077–1091.
- [12] P. Chi, C. Xu, T. Zhang, X. Dong, and Y. Xie, “Using multi-level cell STT-RAM for fast and energy-efficient local checkpointing,” in Proceedings of the 2014 IEEE/ACM International Conference on Computer-Aided Design, ser. ICCAD ’14. IEEE Press, 2014, pp. 301–308.
- [13] K. Cho, S.-H. Lee, A. Raad, and J. Kang, “Revamping hardware persistency models: View-based and axiomatic persistency models for Intel-x86 and Armv8,” in Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, ser. PLDI 2021. New York, NY, USA: Association for Computing Machinery, 2021, pp. 16–31.
- [14] T. Chou, W. Tang, J. Botimer, and Z. Zhang, “CASCADE: Connecting RRAMs to extend analog dataflow in an end-to-end in-memory processing paradigm,” in Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’52. New York, NY, USA: Association for Computing Machinery, 2019, pp. 114–125.
- [15] J. Coburn, A. M. Caulfield, A. Akel, L. M. Grupp, R. K. Gupta, R. Jhala, and S. Swanson, “NV-Heaps: Making persistent objects fast and safe with next-generation, non-volatile memories,” in Proceedings of the Sixteenth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS XVI. New York, NY, USA: Association for Computing Machinery, 2011, pp. 105–118.
- [16] L. Cojocar, J. Kim, M. Patel, L. Tsai, S. Saroiu, A. Wolman, and O. Mutlu, “Are we susceptible to Rowhammer? an end-to-end methodology for cloud providers,” in 2020 IEEE Symposium on Security and Privacy (SP), 2020, pp. 712–728.
- [17] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears, “Benchmarking cloud serving systems with YCSB,” in Proceedings of the 1st ACM Symposium on Cloud Computing, ser. SoCC ’10. New York, NY, USA: Association for Computing Machinery, 2010, pp. 143–154.
- [18] Dell, “Dell EMC NVDIMM-N persistent memory: user guide,” https://dl.dell.com/topicspdf/nvdimm_n_user_guide_en-us.pdf, February 2021, accessed: 06-15-2022.
- [19] K. Doshi, E. Giles, and P. Varman, “Atomic persistence for SCM with a non-intrusive backend controller,” in 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2016, pp. 77–89.
- [20] P. Ekemark, Y. Yao, A. Ros, K. Sagonas, and S. Kaxiras, “TSOPER: Efficient coherence-based strict persistency,” in 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2021, pp. 125–138.
- [21] Everspin, “Everspin releases highest density MRAM products to create fastest and most reliable non-volatile storage class memory,” https://www.everspin.com/sites/default/files/Everspin%20Releases%20Highest%20Density%20MRAM%20Products%20FINAL%20041216.pdf, April 2016, accessed: 07-10-2022.
- [22] Gem5, “The gem5 simulator,” https://www.gem5.org/, accessed: 01-30-2022.
- [23] V. Gogte, A. Kolli, and F. T. Wenisch, A Primer on Memory Persistency, 1st ed., ser. Synthesis Lectures on Computer Architecture. Springer Cham, 2022, no. 1935-3243.
- [24] S. Gugnani, A. Kashyap, and X. Lu, “Understanding the idiosyncrasies of real persistent memory,” Proc. VLDB Endow., vol. 14, no. 4, pp. 626–639, dec 2020.
- [25] X. Guo, M. N. Bojnordi, Q. Guo, and E. Ipek, “Sanitizer: Mitigating the impact of expensive ECC checks on STT-MRAM based main memories,” IEEE Transactions on Computers, vol. 67, no. 6, pp. 847–860, June 2018.
- [26] S. Gupta, A. Daglis, and B. Falsafi, “Distributed logless atomic durability with persistent memory,” in Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’52. New York, NY, USA: Association for Computing Machinery, 2019, pp. 466–478.
- [27] X. Han, J. Tuck, and A. Awad, “Dolos: Improving the performance of persistent applications in ADR-supported secure memory,” in MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’21. New York, NY, USA: Association for Computing Machinery, 2021, pp. 1241–1253.
- [28] Intel, “3D XPoint: A breakthrough in non-volatile memory technology,” https://www.intel.com/content/www/us/en/architecture-and-technology/intel-micron-3d-xpoint-webcast.html, accessed: 04-22-2022.
- [29] Intel, “Intel® 64 and IA-32 architectures software developer manuals,” https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html, accessed: 05-12-2022.
- [30] Intel, “eADR: New opportunities for persistent memory applications,” https://www.intel.com/content/www/us/en/developer/articles/technical/eadr-new-opportunities-for-persistent-memory-applications.html, January 2021, accessed: 07-15-2022.
- [31] Intel, “Intel® OptaneTM memory - responsive memory, accelerated performance,” https://www.intel.com/content/www/us/en/products/details/memory-storage/optane-memory.html, July 2022, accessed: 07-13-2022.
- [32] E. Ipek, J. Condit, E. B. Nightingale, D. Burger, and T. Moscibroda, “Dynamically replicated memory: Building reliable systems from nanoscale resistive memories,” in Proceedings of the Fifteenth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS XV. New York, NY, USA: Association for Computing Machinery, 2010, pp. 3–14.
- [33] J. Jeong, C. H. Park, J. Huh, and S. Maeng, “Efficient hardware-assisted logging with asynchronous and direct-update for persistent memory,” in Proceedings of the 51st Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-51. IEEE Press, 2018, pp. 520–532.
- [34] D. Joseph, J. L. Aragón, J.-M. Parcerisa, and A. González, “TCOR: A tile cache with optimal replacement,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2022, pp. 662–675.
- [35] A. Joshi, V. Nagarajan, S. Viglas, and M. Cintra, “ATOM: Atomic durability in non-volatile memory through hardware logging,” in 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2017, pp. 361–372.
- [36] J. Kim, E. Teran, P. V. Gratz, D. A. Jiménez, S. H. Pugsley, and C. Wilkerson, “Kill the program counter: Reconstructing program behavior in the processor cache hierarchy,” in Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’17. New York, NY, USA: Association for Computing Machinery, 2017, pp. 737–749.
- [37] K. Korgaonkar, I. Bhati, H. Liu, J. Gaur, S. Manipatruni, S. Subramoney, T. Karnik, S. Swanson, I. Young, and H. Wang, “Density tradeoffs of non-volatile memory as a replacement for SRAM based last level cache,” in 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), 2018, pp. 315–327.
- [38] R. M. Krishnan, J. Kim, A. Mathew, X. Fu, A. Demeri, C. Min, and S. Kannan, Durable Transactional Memory Can Scale with TimeStone. New York, NY, USA: Association for Computing Machinery, 2020, pp. 335–349.
- [39] C.-H. Lai, J. Zhao, and C.-L. Yang, “Leave the cache hierarchy operation as it is: A new persistent memory accelerating approach,” in Proceedings of the 54th Annual Design Automation Conference 2017, ser. DAC ’17. New York, NY, USA: Association for Computing Machinery, 2017.
- [40] B. C. Lee, E. Ipek, O. Mutlu, and D. Burger, “Architecting phase change memory as a scalable DRAM alternative,” in Proceedings of the 36th Annual International Symposium on Computer Architecture, ser. ISCA ’09. New York, NY, USA: Association for Computing Machinery, 2009, pp. 2–13.
- [41] B. C. Lee, P. Zhou, J. Yang, Y. Zhang, B. Zhao, E. Ipek, O. Mutlu, and D. Burger, “Phase-change technology and the future of main memory,” IEEE Micro, vol. 30, no. 1, pp. 143–143, 2010.
- [42] E. Lee, H. Bahn, and S. H. Noh, “Unioning of the buffer cache and journaling layers with non-volatile memory,” in 11th USENIX Conference on File and Storage Technologies (FAST 13). San Jose, CA: USENIX Association, February 2013, pp. 73–80.
- [43] G. Liu, K. Li, Z. Xiao, and R. Wang, “PS-ORAM: Efficient crash consistency support for oblivious RAM on NVM,” in Proceedings of the 49th Annual International Symposium on Computer Architecture, ser. ISCA ’22. New York, NY, USA: Association for Computing Machinery, 2022, pp. 188–203.
- [44] M. Liu, M. Zhang, K. Chen, X. Qian, Y. Wu, W. Zheng, and J. Ren, “DudeTM: Building durable transactions with decoupling for persistent memory,” in Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’17. New York, NY, USA: Association for Computing Machinery, 2017, pp. 329–343.
- [45] R.-S. Liu, D.-Y. Shen, C.-L. Yang, S.-C. Yu, and C.-Y. M. Wang, “NVM Duet: Unified working memory and persistent store architecture,” in Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’14. New York, NY, USA: Association for Computing Machinery, 2014, pp. 455–470.
- [46] S. Longofono, S. M. Seyedzadeh, and A. K. Jones, “Virtual coset coding for encrypted non-volatile memories with multi-level cells,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2022, pp. 1128–1140.
- [47] Y. Lu, J. Shu, and L. Sun, “Blurred persistence: Efficient transactions in persistent memory,” ACM Trans. Storage, vol. 12, no. 1, January 2016.
- [48] Y. Lu, J. Shu, L. Sun, and O. Mutlu, “Loose-ordering consistency for persistent memory,” in 2014 IEEE 32nd International Conference on Computer Design (ICCD), 2014, pp. 216–223.
- [49] Micron, “NVDIMM: Persistent memory performance,” https://media-www.micron.com/-/media/client/global/documents/products/product-flyer/nvdimm_flyer.pdf?rev=0c295086bb4c43729b89f369219259bc, December 2017, accessed: 06-15-2022.
- [50] A. K. Mishra, X. Dong, G. Sun, Y. Xie, N. Vijaykrishnan, and C. R. Das, “Architecting on-chip interconnects for stacked 3D STT-RAM caches in CMPs,” in Proceedings of the 38th Annual International Symposium on Computer Architecture, ser. ISCA ’11. New York, NY, USA: Association for Computing Machinery, 2011, pp. 69–80.
- [51] D. Molka, D. Hackenberg, R. Schone, and W. E. Nagel, “Cache coherence protocol and memory performance of the Intel Haswell-EP architecture,” in Proceedings of the 2015 44th International Conference on Parallel Processing (ICPP), ser. ICPP ’15. USA: IEEE Computer Society, 2015, p. 739–748.
- [52] A. Naithani and L. Eeckhout, “Reliability-aware runahead,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2022, pp. 772–785.
- [53] T. M. Nguyen and D. Wentzlaff, “PiCL: A software-transparent, persistent cache log for nonvolatile main memory,” in Proceedings of the 51st Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-51. IEEE Press, 2018, pp. 507–519.
- [54] M. A. Ogleari, E. L. Miller, and J. Zhao, “Steal but no force: Efficient hardware undo+redo logging for persistent memory systems,” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018, pp. 336–349.
- [55] Oracle, “MySQL :: MySQL 8.0 reference manual :: 15.7.2.1 transaction isolation levels,” https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html, accessed: 03-18-2022.
- [56] D. Pandiyan and C.-J. Wu, “Quantifying the energy cost of data movement for emerging smart phone workloads on mobile platforms,” in 2014 IEEE International Symposium on Workload Characterization (IISWC), Oct 2014, pp. 171–180.
- [57] M. Parasar, A. Bhattacharjee, and T. Krishna, “SEESAW: Using superpages to improve VIPT caches,” in 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), 2018, pp. 193–206.
- [58] L. Pentecost, A. Hankin, M. Donato, M. Hempstead, G.-Y. Wei, and D. Brooks, “NVMExplorer: A framework for cross-stack comparisons of embedded non-volatile memories,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2022, pp. 938–956.
- [59] M. K. Qureshi, J. Karidis, M. Franceschini, V. Srinivasan, L. Lastras, and B. Abali, “Enhancing lifetime and security of PCM-based main memory with start-gap wear leveling,” in 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2009, pp. 14–23.
- [60] M. K. Qureshi, A. Seznec, L. A. Lastras, and M. M. Franceschini, “Practical and secure PCM systems by online detection of malicious write streams,” in Proceedings of the 2011 IEEE 17th International Symposium on High Performance Computer Architecture, ser. HPCA ’11. USA: IEEE Computer Society, 2011, pp. 478–489.
- [61] A. Raad, L. Maranget, and V. Vafeiadis, “Extending Intel-X86 consistency and persistency: Formalising the semantics of Intel-X86 memory types and non-temporal stores,” Proc. ACM Program. Lang., vol. 6, no. POPL, January 2022.
- [62] Hewlett Packard Enterprise, “HPE NVDIMMs,” https://www.hpe.com/psnow/doc/c04939369.html, November 2021, accessed: 06-15-2022.
- [63] SK Hynix, “SK Hynix developed the world’s highest density 16GB NVDIMM,” https://news.skhynix.com/sk-hynix-developed-the-worlds-highest-density-16gb-nvdimm/, October 2014, accessed: 06-15-2022.
- [64] SMART Modular Technologies, “Advanced memory - DDR4 NVDIMM,” https://www.smartm.com/api/download/fetch/17, January 2022, accessed: 06-15-2022.
- [65] J. Ren, Q. Hu, S. Khan, and T. Moscibroda, “Programming for non-volatile main memory is hard,” in Proceedings of the 8th Asia-Pacific Workshop on Systems, ser. APSys ’17. New York, NY, USA: Association for Computing Machinery, 2017.
- [66] J. Ren, J. Zhao, S. Khan, J. Choi, Y. Wu, and O. Mutlu, “ThyNVM: Enabling software-transparent crash consistency in persistent memory systems,” in Proceedings of the 48th International Symposium on Microarchitecture, ser. MICRO-48. New York, NY, USA: Association for Computing Machinery, 2015, pp. 672–685.
- [67] A. Rudoff, “Non-temporal loads in pmem,” https://groups.google.com/g/pmem/c/Z5Lv72K9FFg, May 2021, accessed: 01-14-2022.
- [68] S. Scargall, Programming persistent memory: A comprehensive guide for developers, 1st ed. Berlin, Germany: APress, 2020.
- [69] N. H. Seong, D. H. Woo, and H.-H. Lee, “Security refresh: Protecting phase-change memory against malicious wear out,” IEEE Micro, vol. 31, no. 1, pp. 119–127, January 2011.
- [70] S. Sethumurugan, J. Yin, and J. Sartori, “Designing a cost-effective cache replacement policy using machine learning,” in 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2021, pp. 291–303.
- [71] S. M. Shahri, S. Armin Vakil Ghahani, and A. Kolli, “(Almost) fence-less persist ordering,” in 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2020, pp. 539–554.
- [72] S. Shin, S. K. Tirukkovalluri, J. Tuck, and Y. Solihin, “Proteus: A flexible and fast software supported hardware logging approach for NVM,” in Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-50 ’17. New York, NY, USA: Association for Computing Machinery, 2017, pp. 178–190.
- [73] Y. Solihin, Fundamentals of Parallel Multicore Architecture, 1st ed. Berlin, Germany: Chapman and Hall/CRC, 2015.
- [74] X. Tang, L. Shen, B. Kasap, X. Yang, W. Shi, A. Mukherjee, D. Z. Pan, and N. Sun, “An energy-efficient comparator with dynamic floating inverter amplifier,” IEEE Journal of Solid-State Circuits, vol. 55, no. 4, pp. 1011–1022, 2020.
- [75] M. K. Tavana, A. K. Ziabari, and D. Kaeli, “Block cooperation: Advancing lifetime of resistive memories by increasing utilization of error correcting codes,” ACM Trans. Archit. Code Optim., vol. 15, no. 3, aug 2018.
- [76] H. Volos, A. J. Tack, and M. M. Swift, “Mnemosyne: Lightweight persistent memory,” in Proceedings of the Sixteenth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS XVI. New York, NY, USA: Association for Computing Machinery, 2011, pp. 91–104.
- [77] R. Wang, L. Jiang, Y. Zhang, and J. Yang, “SD-PCM: Constructing reliable super dense phase change memory under write disturbance,” in Proceedings of the Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’15. New York, NY, USA: Association for Computing Machinery, 2015, pp. 19–31.
- [78] Z. Wang, X. Liu, J. Yang, T. Michailidis, S. Swanson, and J. Zhao, “Characterizing and modeling non-volatile memory systems,” in 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2020, pp. 496–508.
- [79] X. Wei, D. Feng, W. Tong, J. Liu, and L. Ye, “MorLog: Morphable hardware logging for atomic persistence in non-volatile main memory,” in Proceedings of the ACM/IEEE 47th Annual International Symposium on Computer Architecture, ser. ISCA ’20. IEEE Press, 2020, pp. 610–623.
- [80] W. Wen, Y. Zhang, M. Mao, and Y. Chen, “State-restrict MLC STT-RAM designs for high-reliable high-performance memory system,” in Proceedings of the 51st Annual Design Automation Conference, ser. DAC ’14. New York, NY, USA: Association for Computing Machinery, 2014, pp. 1–6.
- [81] C.-J. Wu, A. Jaleel, W. Hasenplaugh, M. Martonosi, S. C. Steely, and J. Emer, “SHiP: Signature-based hit predictor for high performance caching,” in Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-44. New York, NY, USA: Association for Computing Machinery, 2011, pp. 430–441.
- [82] X. Wu and A. L. N. Reddy, “SCMFS: A file system for storage class memory,” in Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’11. New York, NY, USA: Association for Computing Machinery, 2011.
- [83] C. Xu, D. Niu, N. Muralimanohar, R. Balasubramonian, T. Zhang, S. Yu, and Y. Xie, “Overcoming the challenges of crossbar resistive memory architectures,” in 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), 2015, pp. 476–488.
- [84] S. Yadalam, N. Shah, X. Yu, and M. Swift, “ASAP: A speculative approach to persistence,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2022, pp. 892–907.
- [85] M. Yan, R. Sprabery, B. Gopireddy, C. Fletcher, R. Campbell, and J. Torrellas, “Attack directories, not caches: Side channel attacks in a non-inclusive world,” in 2019 IEEE Symposium on Security and Privacy (SP), 2019, pp. 888–904.
- [86] J. Yang, J. Kim, M. Hoseinzadeh, J. Izraelevitz, and S. Swanson, “An empirical guide to the behavior and use of scalable persistent memory,” in 18th USENIX Conference on File and Storage Technologies (FAST 20). Santa Clara, CA: USENIX Association, February 2020, pp. 169–182.
- [87] J. Yang, Q. Wei, C. Chen, C. Wang, K. L. Yong, and B. He, “NV-Tree: Reducing consistency cost for NVM-based single level systems,” in Proceedings of the 13th USENIX Conference on File and Storage Technologies, ser. FAST’15. USA: USENIX Association, 2015, pp. 167–181. [Online]. Available: https://www.usenix.org/conference/fast15/technical-sessions/presentation/yang
- [88] T.-H. Yang, H.-Y. Cheng, C.-L. Yang, I.-C. Tseng, H.-W. Hu, H.-S. Chang, and H.-P. Li, “Sparse ReRAM engine: Joint exploration of activation and weight sparsity in compressed neural networks,” in Proceedings of the 46th International Symposium on Computer Architecture, ser. ISCA ’19. New York, NY, USA: Association for Computing Machinery, 2019, pp. 236–249.
- [89] F. Yao, M. Doroslovacki, and G. Venkataramani, “Are coherence protocol states vulnerable to information leakage?” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018, pp. 168–179.
- [90] L. Zhang, B. Neely, D. Franklin, D. Strukov, Y. Xie, and F. T. Chong, “Mellow writes: Extending lifetime in resistive memories through selective slow write backs,” in Proceedings of the 43rd International Symposium on Computer Architecture, ser. ISCA ’16. IEEE Press, 2016, pp. 519–531.
- [91] H. Zhao, L. Xue, P. Chi, and J. Zhao, “Approximate image storage with multi-level cell STT-MRAM main memory,” in Proceedings of the 36th International Conference on Computer-Aided Design, ser. ICCAD ’17. IEEE Press, 2017, pp. 268–275.
- [92] J. Zhao, S. Li, D. H. Yoon, Y. Xie, and N. P. Jouppi, “Kiln: Closing the performance gap between systems with and without persistence support,” in Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-46. New York, NY, USA: Association for Computing Machinery, 2013, pp. 421–432.
- [93] L. Zhao, R. Iyer, S. Makineni, D. Newell, and L. Cheng, “NCID: A non-inclusive cache, inclusive directory architecture for flexible and efficient cache hierarchies,” in Proceedings of the 7th ACM International Conference on Computing Frontiers, ser. CF ’10. New York, NY, USA: Association for Computing Machinery, 2010, p. 121–130.
- [94] T. Zheng, H. Zhu, and M. Erez, “SIPT: Speculatively indexed, physically tagged caches,” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018, pp. 118–130.