EncT5: A Framework for Fine-tuning T5 as Non-autoregressive Models
Abstract
Pre-trained encoder-decoder transformer architectures have become increasingly popular recently with the advent of T5 models. T5 has also become more favorable over other architectures like BERT due to the amount of data that it is pre-trained on, increased scale of model parameter sizes and easy applicability to a diverse set of tasks due to the generative nature of the model. While being able to generalize to a wide variety of tasks, it is not clear that encoder-decoder architectures are the most efficient for fine-tuning tasks that don’t require auto-regressive decoding. In this work, we study fine-tuning pre-trained encoder-decoder models for tasks such as classification, multi-label classification, and structured prediction. We propose EncT5, a framework for these problems, and illustrate instantiations for these tasks. Our experiment results show that EncT5 has advantages over T5 such as efficiency and usability out performs BERT when evaluated on publicly available pre-trained checkpoints.
1 Introduction
The scaling law of Transformers Vaswani et al. (2017), availablity of massive textual corpora (such as C4 Raffel et al. (2020) or mC4 Xue et al. (2021b)) and increased compute available from accelerators Kaplan et al. (2020) to perform unsupervised pre-training have contributed to the steady progress and adoption of pretrained langauge models in NLP. Software frameworks like Mesh Tensorflow Shazeer et al. (2018) helped unlock greater model parallelism and pushed even further the limits of training large language model.
Pre-trained models Devlin et al. (2019); Yang et al. (2019); Clark et al. (2020) reduce the dependence on large amounts of task-specific training data and instead only need a more modest fine-tuning dataset. Because training large models from scratch can be data and compute heavy, users prefer to consume and adapt existing pretrained-models for their desired task. Platforms such as TF Hub111https://www.tensorflow.org/hub and HuggingFace Wolf et al. (2020) provide various families of such pre-trained models, and have become increasingly popular.
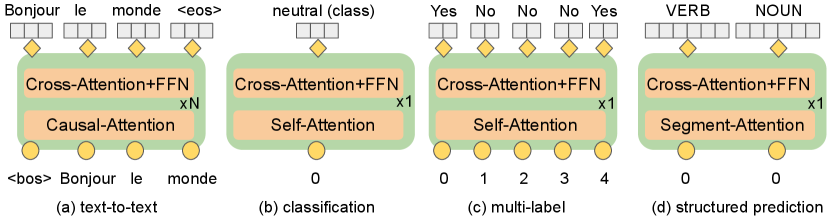
T5 Raffel et al. (2020) introduced a unified framework for converting a wide variety of NLP tasks (such as generation, regression and classification ones) into a text-to-text prediction task. While previous encoder-only models such as BERT Devlin et al. (2019) were only able to solve non-generation problems, T5’s unified framework permitted its model to train through a much more diverse set of tasks.
Despite the general flexibility of the text-to-text problem setup, we find in our experiments that this setup is an unnatural fit for discriminative tasks (such as classification, regression, and structured prediction tasks). We find that the decoder layers of the proposed encoder-decoder architecture of T5, are under-utilized in these types of tasks.
In this work, we study how to harvest T5’s pre-trained model parameters and produce a model optimized for fine-tuning of discriminative tasks. The resulting model uses fewer parameters (thus resulting in better training and serving efficiency) and has minimal quality loss (in some tasks quality improvements). We propose EncT5, a framework which reuses T5 encoder layers with non-intrusive code change. Our proposed approach preserves the pre-training of the encoder-decoder model, and can easily be applied to all T5 variants such as mT5 Xue et al. (2021b) or ByT5 Xue et al. (2021a).
Our contributions are:
-
•
Propose a framework to convert T5 models to be used in a non-autoregressive fashion with the same Transformer interface such that T5-style models can be used to solve problems in more task-appropriate ways with "non-intrusive code changes".
-
•
We show that EncT5 is a better in fit for classification, multi-label, and structured prediction tasks than T5 in quality, usability, and efficiency.
2 Text-to-Text Transfer Transformer
T5 is an encoder-decoder Transformer pre-trained on the Colossal Clean Crawled Corpus (C4) dataset with span-corruption objective. One important benefit of such encoder-decoder architecture Figure 2 (a) is that it can be applied to generative tasks, such as summarization, as well as discriminative tasks such as natural language inference.
Because the T5 model’s interface expects input and outputs to be text, natural language inference tasks are converted to a text-to-text format. For example, the target label in a classification task and the score in a regression task is cast to a string and later tokenized. The tokenization transformation can sometimes produce illegal labels (e.g. the labels are not represented in the vocabulary) Xue et al. (2021b) and it is also not always clear how to convert multi-label or structured prediction tasks into a target sequence. We will discuss the challenges of applying T5 on these tasks in future sections.
Below we give an introduction of the encoder-decoder interface and how it is used in general.
2.1 Encoder-Decoder Transformer Interface
T5 follows the Encoder-Decoder Transformer interface introduced by Vaswani et al. (2017) by taking the following inputs:
-
•
encoder_input_tokens: input data to the encoder. In general, it is the tokenized input text.
-
•
decoder_input_tokens: input token to the decoder. During training, it is the tokenized target text shifted to the right and pre-pended with a begin-of-sentence token. During inference, it is the tokenized text that the model has generated so far.
-
•
decoder_target_tokens: target text tokenized. Used to calculate loss during training.
-
•
encoder_segment_ids: Generally used to provide segmentation info for packed examples but can also be used to control how encoder_input_tokens can attend to each other.
-
•
decoder_segment_ids: Generally used to provide decoder segmentation info for packed examples but can also be used to control how decoder_input_tokens attend to each other and how decoder_input_tokens attends to encoder_input_tokens.
-
•
encoder_positions: Encoder subsequence positions for packed examples. Can be inferred from encoder_input_tokens when packing is not enabled.
-
•
decoder_positions: Decoder subsequence positions for packed examples. Can be inferred from decoder_input_tokens when packing is not enabled.
3 EncT5 Framework
In this section, we propose a framework (Framework 1) for converting a T5 checkpoint into a EncT5 checkpoint for non-autoregressive tasks and show instantiations for single-label classification/regression (Algorithm 1), multi-label classification (Algorithm 2), and structured prediction tasks (Algorithm 3). We also describe in more detail the modifications to the model inputs used by EncT5 for each of the above-mentioned tasks.
EncT5 uses the same Encoder-Decoder interface as T5 and supplies almost the same inputs to the model. Because T5 is autoregressive and EncT5 is not, the inputs in EncT5 are tailored for the non-autoregressive task setup.
In T5 at each timestep, decoder_input_tokens maps the input token fed to the decoder and decoder_target_tokens maps to the output token to be predicted.
In EncT5, we were inspired by recent work in feeding latent vectors to Transformers as queries Carion et al. (2020); Jaegle et al. (2021) and have modified the decoder inputs to be latent vectors that learn how to best pool encoded information through self-attention and cross-attention.
decoder_input_tokens are modified to be the latent vector id (out of a total latent vector vocab size) selected at each timestep. After self- and cross-attention are applied to the latent vectors, a projection to the final class label size is then applied.
Alternatives to the EncT5 framework are to simply reuse the encoder and either: (1) pre-pend a [CLS] token, mimicking BERT in the beginning of the input; or (2) max or mean pool the encoder tokens. For (1), the encoder does not see it during pre-training and this would cause a discrepancy between pre-training and fine-tuning. For (2), it has been shown that basic pooling is sub-optimal for sentence representation Reimers and Gurevych (2019). Both alternatives also require an intrusive change and are unfriendly to packing, a trick frequently used to improve accelerator utilization by packing multiple examples into a single example. We instead opted for a simpler design which minimized complex code changes and avoided the above mentioned drawbacks by decoupling the encoder logic and the pooling logic.
3.1 Classification/Regression
We describe the instantiation of fine-tuning classification and regression tasks in Algorithm 1 with EncT5 and the semantic meaning of the Transformer inputs. We find that the decoder is not helpful in this scenario. Our intuition is that, with a single token, the self-attention layer is simply an identity and the depth does not capture extra interaction.222For efficiency, users can remove the self-attention layer in the decoder.
-
•
encoder_input_tokens: Tokenized input text.
-
•
decoder_input_tokens: A single 0 token, which the mapped embedding will be learned to decide how to pool information from the encoder.
-
•
decoder_target_tokens: Target label or score.
-
•
encoder_segment_ids: Used for packing.
-
•
decoder_segment_ids: Used for packing.
-
•
encoder_positions: Used for packing.
-
•
decoder_positions: None.
3.2 Multi-label Classification
We describe the instantiation of fine-tuning multi-label classification in Algorithm 2 with EncT5 and the semantic meaning of the Transformer inputs. Unlike Algorithm 1, the length of the decoder_input_tokens is greater than 1 and the self-attention in the decoder is no longer an identity. Thus, increasing the number of decoder layers can result in performance gain. On the other hand, the attention complexity in the decoder is , where n is decoder_input_tokens. This instantiation is a problem when decoder_input_tokens is large. To tackle problem with large output space, one can always fallback to Alogirthm 2 which does not capture label interactions by setting the projection size to number of labels and loss to binary cross entropy. Another design difference is the projection that each decoder_output_logits uses. In the multi-label setup, we want each label to be treated as a binary classification problem so the projection head cannot be shared.
MNLI-m MNLI-mm QQP QNLI SST-2 CoLA STS-B MRPC RTE GLUE Acc F1 Acc Acc Mathew Spearman F1 Acc Avg BERT-base 83.1 83.7 87.8 90.4 92.2 56.9 84.6 90.6 70.0 82.1 T5-base 88.8 88.4 89.5 93.2 94.7 53.4 85.2 91.6 69.7 83.8 EncT5-base 88.6 88.7 89.6 93.4 94.6 56.6 84.4 89.7 74.4 84.4 BERT-large 87.1 86.9 88.4 93.0 94.0 63.9 86.4 92.4 75.5 85.1 T5-large 91.0 90.9 89.6 94.8 96.9 63.6 88.0 93.5 85.6 88.2 EncT5-large 91.1 91.4 90.0 95.4 97.2 63.6 88.0 93.3 86.3 88.5 T5-xl 92.1 91.7 90.3 96.2 97.0 70.9 87.4 93.5 92.1 90.1 EncT5-xl 91.9 91.7 90.4 96.1 97.1 69.2 86.9 93.1 89.2 89.5 T5-xxl 92.1 92.0 90.4 96.4 97.2 72.9 86.9 94.2 92.8 90.6 EncT5-xxl 92.4 92.1 90.1 96.7 97.5 71.9 86.9 93.7 92.8 90.4
-
•
encoder_input_tokens: Tokenized input text.
-
•
decoder_input_tokens: During training, we feed range( num_labels ) and label ids we are interested in during inference.
-
•
decoder_target_tokens: A boolean label for each decoder_input_tokens.
-
•
encoder_segment_ids: Used for packing.
-
•
decoder_segment_ids: Used for packing.
-
•
encoder_positions: Used for packing.
-
•
decoder_positions: None.
3.3 Structured Prediction (Part Of Speech Tagging)
We demonstrate how to design an instantiation for structured prediction using the Part of speech (POS) task as an example. The design should, however, be transferable to other structured prediction tasks. The main difference between Algorithm 3 with Algorithm 1 is that instead of predicting the whole input sentence, we predict a label for each text span. In order to constraint the decoder_input_tokens to only pool information for it’s assigned next span, we introduce a new argument to the interface — encdec_segment_ids. In the original interface, encoder_segment_ids controls the attention mask of the encoder’s self-attention pattern and the decoder’s cross-attention pattern. The newly introduced argument separates this dual responsibility and therefore allows encoder self-attention and decoder cross-attention pattern to be customized independently. With this new change, the encoder_input_tokens can now attend to all tokens while decoder_input_tokens cannot.
-
•
encoder_input_tokens: Tokenized input text.
-
•
decoder_input_tokens: A vector of zeros( num_text_spans ).
-
•
decoder_target_tokens: Class ids for each decoder_input_tokens.
-
•
encoder_segment_ids: Used for packing.
-
•
decoder_segment_ids: Used for packing.
-
•
encoder_positions: Used for packing.
-
•
decoder_positions: None.
-
•
encdec_segment_ids: Used for packing and controlling which encoded text span each decoder_input_tokens can attend to.
4 Experiments
We conduct our experiments on three tasks and compare Enc(M)T5 with (M)T5 and (m)BERT. All checkpoint used are publicly available. We hope the study can help readers decide which checkpoint to leverage when fine-tuning these tasks. For T5 checkpoints, we used the version333Changes made from T5 : https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511 because it does not mix the downstream task. Since there are many ways to convert these tasks to text-to-text, we provide a paragraph for each subsection describing or T5 baseline.
For all our T5 and EncT5 experiments, we use and follow the fine-tuning setup in the T5X library444https://github.com/google-research/t5x/blob/main/t5x/configs/runs/finetune.gin Roberts et al. (2022) . For example, we use a batch size of , dropout, train for 0.1M steps with learning rate with Adafactor. and report test set numbers (if available) with the checkpoint which achieved the best numbers from the validation set. We will describe task specific hyper-parameter choice such as sequence length in each subsection. One of the design choice is to make sure we are comparable with the BERT baseline.
We conduct our experiments with TPU-v3 ranging from 16 to 64 chips depending on the model size. All our experiments can be done within a week and varies by how often we run evaluation.
ALL LABELS FREQUENT FEW ZERO RP@5 nDCG@5 Micro-F1 RP@5 nDCG@5 RP@5 nDCG@5 RP@5 nDCG@5 BERT-base* 79.6 82.3 73.2 83.5 84.6 68.6 63.6 2.8 2.3 T5-base - - 73.4 - - - - - - EncT5-base 81.3 83.8 75.5 84.9 85.9 73.6 69.6 1.1 0.7 T5-large - - 73.9 - - - - - - EncT5-large 81.4 83.8 75.9 84.8 85.8 71.7 68.3 2.2 2.2 T5-xl - - 74.4 - - - - - - EncT5-xl 81.1 83.5 75.7 84.6 85.7 71.3 67.9 1.1 0.4 T5-xxl - - 75.0 - - - - - - EncT5-xxl 80.9 83.2 75.4 84.2 85.2 71.7 68.2 0.0 0.0
Cross-lingual zero-shot transfer Acc mBERT-base* 71.5 mT5-base 71.6 EncMT5-base 78.0 mT5-large 71.7 EncMT5-large 79.5 mT5-xl 74.6 EncMT5-xl 81.0 mT5-xxl 73.4 EncMT5-xxl 80.1
4.1 GLUE
We evaluate Algorithm 1 with GLUE, the General Language Understanding Evaluation benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems Wang et al. (2019). We use an input sequence length (in tokens) of 512 and target sequence length of 84. Packing555Packing reduces padding by putting multiple sequence in one example and avoid interaction from different sequence through attention masks., a trick to improve accelerator utilization, is enabled for both T5 and EncT5.
T5 baseline
We follow Raffel et al. to convert GLUE tasks to text to text format. Details can be found in Appendix D of the T5 paper Raffel et al. (2020).
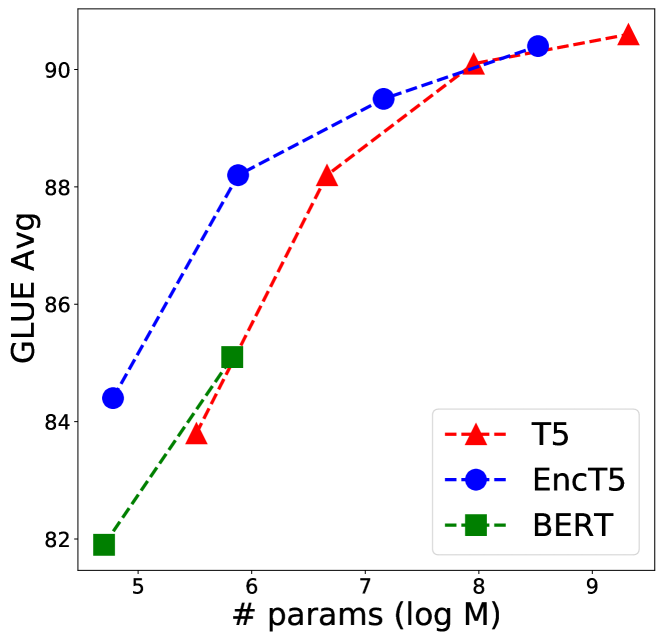
We draw 3 conclusions on the effectiveness of Algorithm 1 from Table 1. (1) In similar scale, base and large, both T5 and EncT5 outperforms BERT. (2) EncT5 is on par with T5 despite almost having half of the number of parameters as shown in Figure 1 and therefore EncT5 is more parameter efficient. (3) EncT5 also benefits from larger pre-trained T5’s.
4.2 EURLEX57K
We evaluate Algorithm 2 with EURLEX57K, containing 57k English EU legislative documents from the EUR-LEX portal, tagged with around 4.3k labels (concepts) from the European Vocabulary Chalkidis et al. (2019). We use an input sequence length (in tokens) of 512 for both T5 and EncT5. For target sequence length, we use 64 for T5 and 4271, which represents a latent vector for each label, for EncT5.
T5 baseline
The inputs are the same for all models where we concatenate the header, the recitals, and the main body. For targets, we concatenate all labels with a comma and a single white space. We only report Micro-F1 because T5 does not provide a straightfoward way to get per token score. We will discuss more T5 drawbacks in Section 5.
A similar conclusion with Section 4.1 can be drawn from Table 2 with two distinction. (1) EncT5 outperforms both BERT and T5 in similar model scale. (2) Though T5’s performance improves as we scale the model size, EncT5’s performance does not seem to improve. It is unclear if this is a limitation of Algoithm 2 or the dataset since to our knowledge we did not observe a Micro-F1 higher than our reported numbers and we will leave as future work to conclude this.
4.3 UDPOS
We evaluate Algorithm 2 with UDPOS, a Part Of Speech (POS) tagging data from the Universal Dependencies v2.5 (Nivre et al., 2018) treebanks, which cover 40 languages. Each word is assigned one of 17 universal POS tags. We report the average accuracy of 33 languages. Similar to XTREME Hu et al. (2020), we adopt the zero-shot cross-lingual transfer scenario, where annotated training data is provided in English and evaluated on all 33 languages. mT5 Xue et al. (2021b) checkpoints are used for this task. The mT5 architecture and the training recipe closely follows T5.1.1 but on the mC4 dataset.
T5 baseline
We mimic the span corruption task Raffel et al. (2020) to specify the input text spans in which the model should predict a Part of Speech tag on, and specify a sentinel token <i> after each text span. For targets, we specify the label after each corresponding sentinel token. For example in the example input text cat eats fish, the inputs are transformed to be cat <0> eats <1> fish <2> and the targets are <0> NOUN <1> VERB <2> NOUN. To calculate the metrics, we parse the targets and predictions with the following regular expression <\d+> and only count the predicted label as correct if the sentinel token also matches.
Despite moving to a multi-lingual setup, our conclusion is similar to the previous subsection. EncMT5 outperforms both mBERT when in similar model scale and outperforms mT5 in all model sizes. EncMT5 does seem to improve as we scale the model size but plateaus around xl/xxl size.
GLUE EURLEX UDPOS EncT5-base Avg Micro-F1 Acc 1d 84.4 75.5 78.0 12d 78.6 75.7 78.3 12d-T5-init 79.2 72.7 74.5
5 Effectiveness of decoder in EncT5
Despite being named EncT5, the framework does allow setting more than 1 decoder. The decoder weights can also be initialized from T5 weights other than from scratch. In this section, we study if these treatment results in better performance. We present the results in Table 4.
5.1 Number of decoder layers
We conducted a study to evaluate the effectiveness of decoder layers by using one or the same number of decoders as T5. We find that for GLUE, our classification experiment, the performance dropped. We further breakdown the summarized score in Table 4 and find that most of the drop comes from datasets containing only a few thousand training examples (such as cola or rte). This is reasonable as we now have more parameters to train. We also noticed that there is no improvement on large datasets such as MNLI. The reasoning for this is that the decoder does not play much of a role when there is only a single decoder token which makes self-attention an identity operation.
In EURLEX and UDPOS experiments, we do see some gains in the cost of almost doubling the number of parameters. One explanation of the improvement is that for these two tasks, we have more than one decoder inputs which can benefit from multi-layers of attention. Given that the improvement is not significant and comes at the cost of more compute, we set the number of decoder layers in Algorithm 2 and 3 to 1 and retained the EncT5 name for the framework.
5.2 Decoder layers initialization
Because we are given a pre-trained T5 checkpoint with a trained 12-layer decoder, an obvious step was to try initializing both the encoder and decoder weights. However, loading the weights from T5 or mT5 was worse than random initialization. We hypothesize that this is due to the fact that the latent embeddings are recognized as special tokens such as [BOS] from the beginning for training.
6 Why EncT5 over BERT?
6.1 Better performance
Shown on three tasks, EncT5 is better than BERT when the models are in a similar scale. The reason behind this is a mixed of better pre-trained checkpoint and the EncT5 framework design. In GLUE, the benefit seems to come from the T5 checkpoint; in EURLEX and UDPOS, the EncT5 treatment seems more dominant. The finding suggests that users hoping to fine-tune pre-trained weights to be used for classification, multi-label, structured prediction, should go for EncT5.
6.2 Large scale checkpoint availability
Architectures capable of serving the use cases of a larger variety of discriminative and generative tasks, such as the encoder-decoder transformer, have become increasingly popular and with more model checkpoints at increasing parameter sizes readily available for the public. Because of the increasing compute and energy cost to pre-train large-scale models, it is increasingly costly to regenerate encoder-only models and thus they have become less available. Therefore, it is important to find ways to reuse and repurpose existing pre-trained encoder-decoder models to conserve compute costs while still optimizing for discriminative tasks.
7 Why EncT5 over T5?
7.1 Efficiency
EncT5 is more efficient than T5 in two ways: (1) combining decoder inference in one single step increases parallelism, and (2) pruning parameters. Pruning the decoder layers improves efficiency in both training and inference time as well as number of parameters.
7.2 Additional Model Outputs (Usability)
In some cases, the user not only expects the prediction but also the score. For example, in multi-label classification, it is common to tune the binary decision threshold as opposed to using to adjust the decision boundary for business reasons. While it is possible for T5 to extract per-token score by calculating the likelihood of the inputs and a label, additional inference compute is needed. In the case of EURLEX57K where there is 4.3k labels, the user would need to run inference 4.3k times. In EncT5, the model can return the score and prediction together without additional compute cost.
7.3 Set Prediction (Quality)
The multi-label problem is essentially a set prediction problem where the order of the labels do not matter. However, the language model in T5 might learn from the order we provided. For instance, if always come after in the training set, it is very hard for the model to predict if is not generated. One solution is to provide all permutations when converting the labels to a string during training and ensemble the beam search results at inference. However, this would increase computation significantly.
7.4 Constrained Decoding Output (Quality)
In T5, the auto-regressive model determines when it is done emitting output and users are left to parse and transform the unstructured string output to their structured expectations. T5 does not have any constraint on the decoding algorithm, so there is no guarantee that the output follows an expected structure and may thereby hindering the output’s usability. We believe this is the main reason why EncT5 outperforms T5.
The T5 outputs from our UDPOS experiment in Section 4.3 encountered this shortcoming. For example, the model generated the prediction <0> ADJ <1> PART <2> VERB <3> PUNCT ... <26> which ends with 26 sentinel token while the target has 56 sentinel tokens. In EncT5, it is possible to encode the desired output structure and request 56 predictions by passing 56 decoder input tokens.
8 Related Work
Recent NLP progress can be attributed to un-supervised pre-training and scaling. Encoder-only Devlin et al. (2019); Roberts et al. (2022); Yang et al. (2019) and Encoder-decoder Lewis et al. (2020); Raffel et al. (2020) on one hand improves the transfer-learning scenario where the model is pre-trained and then fine-tuned with the downstream labeled task. Decoder-only models on the other hand improves the few-shot learning scenario where models are first pre-trained and then prompts Brown et al. (2020b) are used to provide instructions or examples of the downstream task. Our work falls in the transfer learning scenario where we fine-tune pre-trained checkpoints with downstream tasks.
The boundaries of transfer-learning has been pushed by scaling both model and data size through techniques like model parallelism Shazeer et al. (2018). The resources required scales with model size for unsupervised pre-traing scales. Thus, architecture that are capable of being used for many down-stream tasks are in favor. The introduction of decoders in T5 unlocks the ability to fine-tune generation tasks. However, in this work we show that T5 does not have to be used in an auto-regressive fashion through the following common Transformer Vaswani et al. (2017) tricks: (1) leveraging attention masks to control the access of the context to each token Dong et al. (2019); and (2) feeding a latent vector to the Transformer to learn how information should be aggregated Jaegle et al. (2021); Carion et al. (2020).
The closest to our work from a modeling perspective is the sentence representation work Montero et al. (2021), which pools the encoder tokens with a multi-head attention as the auto-encoder bottleneck while keeping the encoder fixed.
9 Conclusion and Future Work
In this work, we propose a framework, EncT5, which converts an encoder-decoder T5 model to a non-auto-regressive model for classification, multi-label, and structured prediction and results in better performance, efficiency and usability. We also show that with models of sizes in similar ballpark, EncT5 is a better choice than BERT. However, we have not yet concluded that Encoder-decoder pre-training is better than Encoder-only pre-training when everything else are hold the same (dataset, number of tokens seen). We did attempt to pre-train BERT on C4 but realized that designing an apple to apple comparison is a topic of its own.
For future work, there are two directions: (1) the encoder-only model direction; and (2) the decoder-only model direction. For (1), we would like to answer the question of whether the EncT5 gains over BERT comes from pre-training or fine-tuning. We can do this by also training BERT on C4 with a similar training schedule. For (2), as decoder-only model becomes prevalent Brown et al. (2020a); Chowdhery et al. (2022), we would also like to study how to convert them to a non-auto-regressive one to tackle the tasks we listed in the paper. These tasks covers most of the use cases in NLP application and is worth investigating if auto-regressive decoding is really necessary.
10 Limitations
Our work builds on top of publicly available pre-trained checkpoints and study the fine-tuning performance on top of these checkpoints. BERT and T5 are trained on different datasets with different objectives. Our work does not answer whether C4 is better than Wikipedia+Book Corpus nor whether span corruption (Encoder-Decoder) is better than next sentence prediction + masked language model (Encoder-only).
References
- Brown et al. (2020a) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020a. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Brown et al. (2020b) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020b. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer.
- Chalkidis et al. (2019) Ilias Chalkidis, Emmanouil Fergadiotis, Prodromos Malakasiotis, and Ion Androutsopoulos. 2019. Large-scale multi-label text classification on EU legislation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6314–6322, Florence, Italy. Association for Computational Linguistics.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Clark et al. (2020) Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: Pre-training text encoders as discriminators rather than generators. In ICLR.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dong et al. (2019) Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language understanding and generation. Advances in Neural Information Processing Systems, 32.
- Hu et al. (2020) Junjie Hu, Sebastian Ruder, Aditya Siddhant, Graham Neubig, Orhan Firat, and Melvin Johnson. 2020. Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalization. CoRR, abs/2003.11080.
- Jaegle et al. (2021) Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. 2021. Perceiver: General perception with iterative attention. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 4651–4664. PMLR.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
- Montero et al. (2021) Ivan Montero, Nikolaos Pappas, and Noah A Smith. 2021. Sentence bottleneck autoencoders from transformer language models. arXiv preprint arXiv:2109.00055.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084.
- Roberts et al. (2022) Adam Roberts, Hyung Won Chung, Anselm Levskaya, Gaurav Mishra, James Bradbury, Daniel Andor, Sharan Narang, Brian Lester, Colin Gaffney, Afroz Mohiuddin, Curtis Hawthorne, Aitor Lewkowycz, Alex Salcianu, Marc van Zee, Jacob Austin, Sebastian Goodman, Livio Baldini Soares, Haitang Hu, Sasha Tsvyashchenko, Aakanksha Chowdhery, Jasmijn Bastings, Jannis Bulian, Xavier Garcia, Jianmo Ni, Andrew Chen, Kathleen Kenealy, Jonathan H. Clark, Stephan Lee, Dan Garrette, James Lee-Thorp, Colin Raffel, Noam Shazeer, Marvin Ritter, Maarten Bosma, Alexandre Passos, Jeremy Maitin-Shepard, Noah Fiedel, Mark Omernick, Brennan Saeta, Ryan Sepassi, Alexander Spiridonov, Joshua Newlan, and Andrea Gesmundo. 2022. Scaling up models and data with t5x and seqio. arXiv preprint arXiv:2203.17189.
- Shazeer et al. (2018) Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, Ryan Sepassi, and Blake Hechtman. 2018. Mesh-TensorFlow: Deep learning for supercomputers. In Neural Information Processing Systems.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Wang et al. (2019) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In the Proceedings of ICLR.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Xue et al. (2021a) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. 2021a. Byt5: Towards a token-free future with pre-trained byte-to-byte models.
- Xue et al. (2021b) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021b. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498, Online. Association for Computational Linguistics.
- Yang et al. (2019) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32.