EndoSLAM Dataset and An Unsupervised Monocular Visual Odometry and Depth Estimation Approach for Endoscopic Videos: Endo-SfMLearner
Abstract
Deep learning techniques hold promise to develop dense topography reconstruction and pose estimation methods for endoscopic videos. However, currently available datasets do not support effective quantitative benchmarking. In this paper, we introduce a comprehensive endoscopic SLAM dataset consisting of 3D point cloud data for six porcine organs, capsule and standard endoscopy recordings as well as synthetically generated data. A Panda robotic arm, two commercially available capsule endoscopes, two conventional endoscopes with different camera properties, and two high precision 3D scanners were employed to collect data from eight ex-vivo porcine gastrointestinal (GI)-tract organs. In total, 35 sub-datasets are provided with 6D pose ground truth for the ex-vivo part: 18 sub-datasets for colon, 12 sub-datasets for stomach and 5 sub-datasets for small intestine, while four of these contain polyp-mimicking elevations carried out by an expert gastroenterologist. Synthetic capsule endoscopy frames from stomach, colon and small intestine with both depth and pose annotations are included to facilitate the study of simulation-to-real transfer learning algorithms. Additionally, we propound Endo-SfMLearner, an unsupervised monocular depth and pose estimation method that combines residual networks with spatial attention module in order to dictate the network to focus on distinguishable and highly textured tissue regions. The proposed approach makes use of a brightness-aware photometric loss to improve the robustness under fast frame-to-frame illumination changes that is commonly seen in endoscopic videos. To exemplify the use-case of the EndoSLAM dataset, the performance of Endo-SfMLearner is extensively compared with the state-of-the-art: SC-SfMLearner, SfMLearner and Monodepth2. The codes and the link for the dataset are publicly available at https://github.com/CapsuleEndoscope/EndoSLAM . A video demonstrating the experimental setup and procedure is accessible through https://www.youtube.com/watch?v=G_LCe0aWWdQ.
keywords:
SLAM Dataset, Capsule Endoscopy, Standard Endoscopy, Monocular Depth Estimation, Visual Odometry, Spatial Attention Module.1 Introduction
Gastrointestinal(GI) cancers affect over 28 million patients annually, representing about 26% of the global cancer incidence and 35% of all cancer-related deaths [American Cancer Society, 2018]. Besides, GI cancer is the second deadliest cancer type with reported 3.4 million GI related deaths globally in 2018 [Arnold et al., 2020]. Direct visual inspection(DVI) of these cancers is the simplest and most effective technique for screening. Esophagogastroduodenoscopy (EGD) and colonoscopy are used to visualize gastrointestinal diseases specifically in colon and rectum while capsule endoscopy (CE) is preferred for small bowel exploration [Redondo-Cerezo et al., 2014].
An endoscopic gastro-intestinal procedure analysis hold by iData Research reveals that over 19 million colonoscopies are performed annually, as reported in 2017, a tremendous contribution to the 75 million endoscopies applied each year in the United States [iDa, 2018]. Specifically, the malignant tumors developed in the small intestine like Adenocarcinoma, Intestinal Lymphoma, Leiomyosarcoma, and metastatic malignancy from lung or breast are severe diseases, mostly resulting in death. Among these, the small bowel involving polyposis syndromes include Familial Adenomatous Polyposis, generalized Juvenile polyposis, Peutz-Jeghers and Cronkhite-Canada syndromes are the most mortal types. The diagnosis of these polyps and small-bowel tumors are challenging due to rarity of lesions, lack of common symptoms across patients, and variety of the symptoms [Yano and Yamamoto, 2009]. In these cases, differential diagnosis from blood tests and symptoms alone are not sufficient, and visual examination through capsule endoscopy can provide valuable information. After visual confirmation of any feature of diagnostic importance, “where is it?” arises as natural question. In the following subsection, we overview the related work from literature which are all motivated by this critical question.
1.1 Related work
The direction of arrival estimation based localization techniques such as radio frequency based signal triangulation [Dey et al., 2017], received signal strength [Shah et al., 2006], electromagnetic tracking [Son et al., 2015], x-ray [Kuth et al., 2007] and positron emission markers [Than et al., 2014] have been widely investigated in robotics. In capsule endoscopes, visual information has been provided which drives the attention to the development of vision-based odometry and simultaneous localization and mapping (SLAM) systems, either to remove the need for added hardware for pose sensing or to provide additional information for 3D tracking. While current capsules are propelled by the peristaltic motion of the GI tract, active capsule endoscopes hold promise to provide drug delivery and biopsy [Ciuti et al., 2016]. Vision-based SLAM is of utmost importance to enable these functions and other forms of complementary situational awareness in decision support and augmented reality systems [Simaan et al., 2015]. With the rise of deep learning techniques [Turan et al., 2017a], public datasets enabling a broader research community to work on the localization and mapping problems became crucial [Pogorelov et al., 2017, Bernal et al., 2017, Borgli et al., 2019] in medical image analysis. Several datasets are available to support research and development of a variety of advanced diagnostic features across a wide range of tasks, including segmentation, disease classification, tissue deformation and motion detection, and depth estimation. Some of them are available in the context of endoscopy which are overviewed in Table 1 and explained more in detail in Appendix B.
| Dataset Name | Findings | Organs | Tasks | Size |
|---|---|---|---|---|
| Kvasir-SEG† | Polyps | Colon | Segmentation | 1,000 |
| Kvasir† [Pogorelov et al., 2017] | Z-line, pylorus, cecum, esophagitis, polyps, ulcerative colitis, dyed | Colon | Disease detection | 6,000 |
| Lifted polyps and dyed resection margins | Colon | Segmentation | 2,000 | |
| Hamlyn Centre Datasets†⋆ | Polyp | Colon | Segmentation | 7,894 |
| - | Kidney | Disparity | 40,000 | |
| Polyp | Colon | Polyp recognition Localisation | 2,000 | |
| - | Liver, ureter, kidney, abdomen | Tissue deformation Tracking | - | |
| KID Dataset⋄ [Koulaouzidis et al., 2017] | Angioectasias, apthae, chylous cysts and polypoid, vascular and inflammatory lesions | Small Bowel and colon | Classification | 2,448 |
| NBI-InFrames† [Moccia et al., 2018] | Angioectasias, apthae, chylous cysts and polypoid | Larynx | Classification | 720 |
| EndoAbs† [Penza et al., 2018] | - | Liver, kidney, spleen | Classification | 120 |
| ASU-MAYO Clinic† | Polyp | Colons | Segmentation | 22,701 |
| ROBUST-MIS Challenge⋆ | Rectal cancer | Abdomen | Segmentation | 10,040 |
1.1.1 Survey for Depth and Pose Estimation
Depth estimation from a camera scene and visual odometry are very challenging and active problems in computer vision. Various traditional multi-view stereo [Hartley and Zisserman, 2003] methods such as structure from motion [Wu et al., 2011, Leonard et al., 2018] and SLAM [Grasa et al., 2013] can be used to reconstruct 3D map based on the feature correspondence. However, their performances are still far from being perfect especially for endoscopic images suffering from lack of distinguishable feature. Despite the recent advances in image processing, colonoscopy remains as complicated procedure for depth estimation because of monocular camera with insufficient light source, limited working area and frequently changing environment due to the contractions of muscles. In that regard, deep-learning based methods have been applied for monocular depth estimation [Liu et al., 2020, Eigen et al., 2014, Liu et al., 2016]. CNN-based depth estimation methods have shown promising performance on a single image depth inference despite the scale inconsistency [Laina et al., 2016]. Nevertheless, using CNN in a fully supervised manner is challenging for endoscopy since dense depth map ground truth that correspond directly to the real endoscopic images are hard to obtain. Even if the labeled dataset is provided, patient-specific texture, shape and color make difficult to get generalizable results without a large amount of ground truth. These issues are mostly overcome by either synthetically generated data or the simultaneous depth and pose estimation methods where the output of pose network supervises the depth network instead of human expert annotations [Turan et al., 2018, Lu and Lu, 2019]. Mahmood et al. propose unsupervised reverse domain adaptation framework to avoid these annotation requirements which is accomplished by adversarial training removing patient specific details from real endoscopic images while protecting diagnostic details [Mahmood et al., 2018]. In [Mahmood and Durr, 2017], the monocular depth estimation is formulated as conditional random fields learning problem and CNN-CRF framework that consists of unary and pairwise parts are introduced as domain adaptable approach. Several self-supervised methods related with the single-frame depth estimation have been propounded in the generic field of computer vision [Garg et al., 2016, Zhang et al., 2020, Yin and Shi, 2018]. However, they are not generally applicable to endoscopy because of inter-frame photometric constancy assumptions of these works which is broken by the frequently appearing inconsistent illumination profile in endoscopic videos. The jointly moving camera and light source cause the appearance of the same anatomy differ substantially with varying camera poses, especially for tissue regions close to the camera surface. This might give rise to the network to get stuck in a local minima during training, specifically for textureless regions where extracting reliable information from photometric appearance is extremely difficult [Chen et al., 2019a]. There are also studies solely focusing on monocular localization problems utilized by CNN [Jiao et al., 2018, Meng et al., EasyChair, 2018]. Unlike traditional artificial neural networks, Turan et al. use RCNN which is able to process arbitrarily long sequences by its directed cycles between the hidden units and infer the correlative information across frames [Turan et al., 2017a]. However, estimating a global scale from monocular images is inherently ambiguous [Eigen et al., 2014]. Despite all efforts, visual odometry is insufficient in real-time localization and vSLAM methods come on the scene as a solution which can be tested only via a comprehensive vSLAM dataset with accurate ground truths. In the work of Mountney et al., a vSLAM method based on Extended Kalman Filter SLAM (EKF-SLAM) is used for localization and soft tissue mapping where sequential frames acquired by moving stereo endoscopes [Mountney et al., 2006]. In robotic surgical systems such as da Vinci™, real-time 3D reconstruction methods have been applied and validated on phantom models [Stoyanov et al., 2010, Lin et al., 2013]. Lin et al. adopt and extend Parallel Tracking and Mapping (PTAM) method to detect deformations on a non-rigid phantom to create 3D reconstruction of intestine model and to track endoscope position and orientation [Lin et al., 2013]. Some other works are focused on more commonly used monocular endoscopes. Mirota et al. generate a 3D reconstruction from endoscopic video during sinus surgeries by using feature detection and registered data from CT scan tracking endoscope location [Mirota et al., 2011]. In Grasa et al. [2013], another monocular vSLAM method is used to provide real-time 3D map of the abdominal cavity for hernia repair interventions. Apart from standard endoscopes, vSLAM techniques have also been used in capsule endoscopy [Chen et al., 2019b, Turan et al., 2017b]. A robust and reliable SLAM module is indispensable for next-generation capsule robots equipped with the functionalities including biopsy, drug delivery and automated polyp detection [Turan et al., 2017c], but several technical challenges such as low frame rate and low resolution due to space limitations make this need tough to meet. Specular reflections from extracellular fluids and rapidly changing environment due to peristaltic motions are further examples of inherent challenges. Those problems have motivated the exploration of deep learning based approaches that eschew complex physical models which ends up with the necessity of huge amount of dataset.
1.2 Contributions
In this work, we introduce the EndoSLAM dataset, a dedicated dataset designed for the development of 6-DoF pose estimation and dense 3D map reconstruction methods. The dataset is recorded using multiple endoscope cameras and ex-vivo porcine GI organs belonging to different animals and is designed to meet the following major requirements for scientific research and development of endoscopic SLAM methods:
-
1.
Time-synchronized, ground-truth 6 DoF pose data
-
2.
High precision, ground-truth 3D reconstructions
-
3.
Multiple organs from multiple individuals
-
4.
Images from cameras with varying intrinsic properties
-
5.
Image sequences with differing native frame rates
-
6.
Images acquired from different camera view angle such as perpendicular, vertical and tubular
-
7.
Images under a variety of lighting conditions
-
8.
Distinguishable features of diagnostic significance (e.g. presence/absence of polyps).
In addition to the experimentally collected data, synthetically generated data from a 3D simulation environment is included to facilitate study of the simulation to real-world problems such as domain adaptation and transfer learning. One of the biggest disadvantages of deep learning techniques is the fact that large networks need massive amounts of domain-specific data for training. Research in recent years has shown that large amounts of synthetic data can improve the performance of learning-based vision algorithms and can ameliorate the difficulty and expense of obtaining real data in a variety of contexts. However, due to the large gap between simulation data and real data, this path needs domain adaptation algorithms to be employed. With the synthetically generated data from Unity 3D environment, we aim to provide a test-bed to overcome the gap between simulation and real endoscopic data domain.
In addition to the EndoSLAM dataset, we propose an unsupervised depth and pose estimation approach for endoscopic videos based on spatial attention and brightness-aware hybrid loss. The main idea and details of the proposed architecture are depicted in Fig. 4. Our main contributions are as follows:
-
1.
Spatial Attention-based Visual Odometry and Depth-Estimation: We propose a spatial attention based ResNet architecture for pose estimation optimized for endoscopic images.
-
2.
Hybrid Loss: We propose a hybrid-loss function which is specifically designed to cope with depth of field related defocus issues and fast frame-to-frame illumination changes in endoscopic images. It collaboratively combines the power of brightness-aware photometric loss, geometry consistency loss, and smoothness loss.
Rest of the paper is organized as follows: Section 2 describes the experimental setup and gives details about the specifications of the devices used for dataset recording, introduces the overall datatree structure. In Section 3, Endo-SfMLearner is described. In Section 4, various use-cases of the EndoSLAM dataset are exemplified by benchmarking the Endo-SfMLearner and the state-of-the-art monocular depth and pose estimation methods SC-SfMLearner [Bian et al., 2019], SfMLearner [Zhou et al., 2017] and Monodepth2 [Godard et al., 2018]. Besides, fully dense 3D map reconstruction is exemplified using EndoSLAM dataset and Endo-SfMLearner. Finally, Section 5 discusses the future plans and offers some concluding remarks.
2 Dataset Shooting
In this section, we will introduce experimental setup, procedure and detailed structure of EndoSLAM dataset.
2.1 Experimental Setup
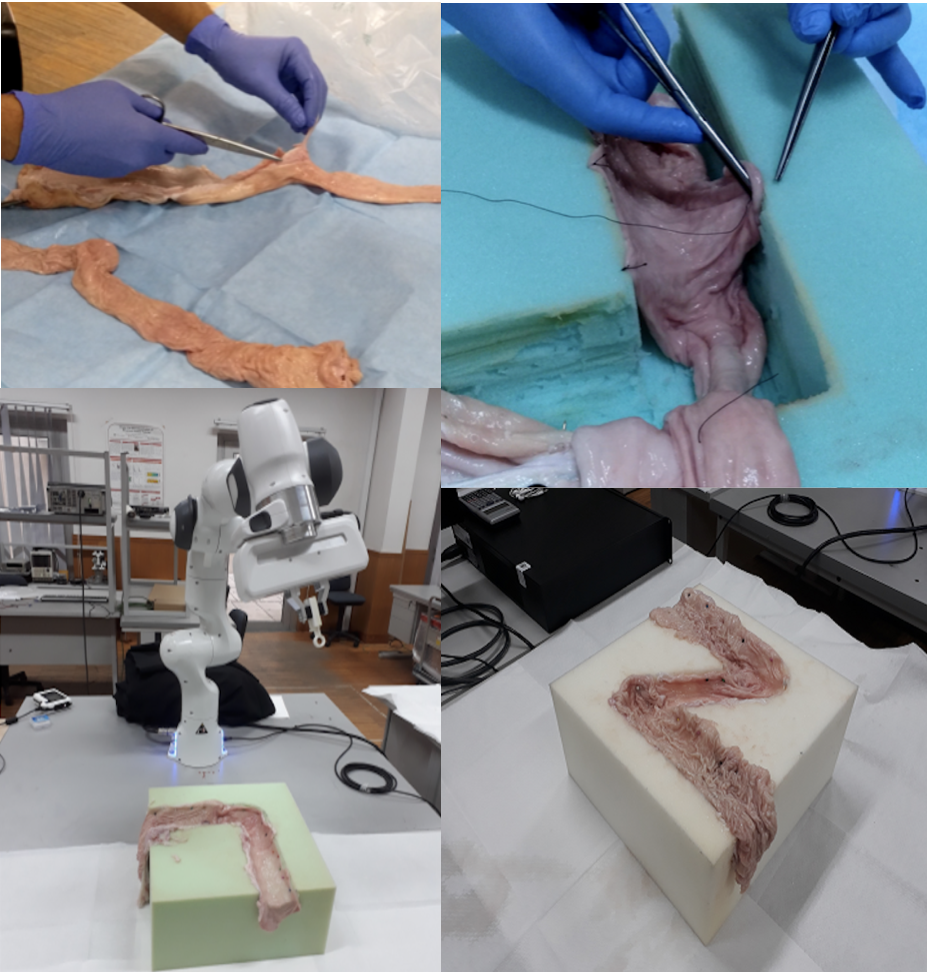
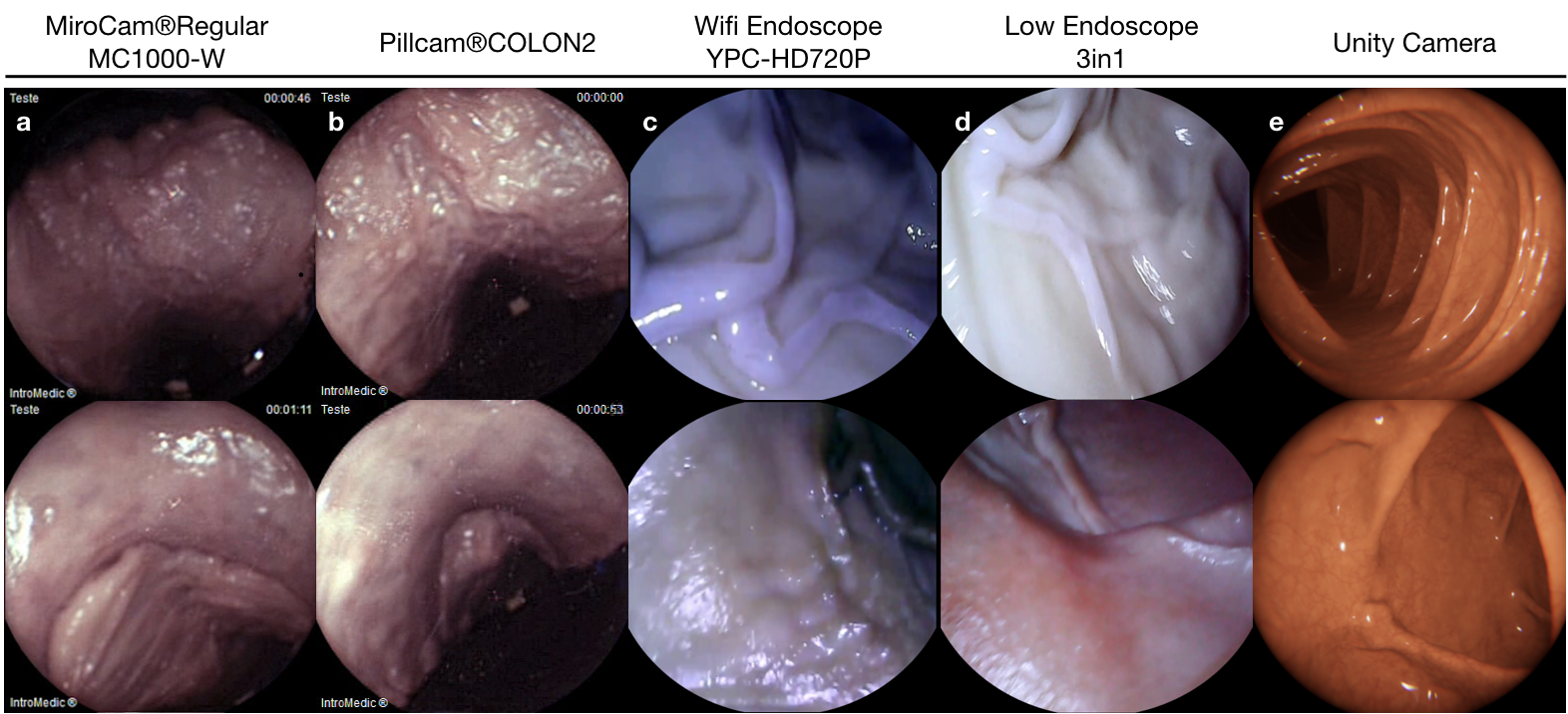
The experimental setup was specifically designed to support the collection of endoscopic videos, accurate 6-DoF ground truth pose, organ shape and topography data. The essential components are four endoscope video cameras (see Fig. A.1i, j, l, m), a robotic arm to track the trajectory and quantify the pose values (see Fig. A.1a), and high precision 3D scanners for ground truth organ shape measurement (see Fig. A.1g-h). All of the equipment are illustrated in Fig. A.1. As per camera devices, MiroCam® (see Fig. A.1m) and Pillcam® COLON2 (see Fig. A.1l) capsule endoscope cameras and two other cameras (HighCam and LowCam) representative of conventional endoscope cameras (see Fig. A.1i-j) were employed. Their specifications are as follows:
- 1.
- 2.
-
3.
High Resolution Endoscope Camera (YPC-HD720P): 1280720 image resolution, 20 fps frame rate, 120 field of view, 4-6 cm depth of field, 6 adjustable white LEDs, Fig. A.1i.
-
4.
Low Resolution Endoscope 3 in 1 Camera: 640480 image resolution, 20 fps frame rate, 130 field of view, 3-8 cm depth of field, 6 adjustable LEDs, Fig. A.1j.
Ground truth geometries of the organs were acquired via two commercially-available 3D scanners, the Artec 3D Eva and Shining 3D Einscan Pro 2x (see Fig. A.1g-h). 3D models of organs were reconstructed as in Fig. 3 and the depth distribution histograms for corresponding organs are given in Fig. F.3. Relevant performance specifications of the 3D scanners are as follows:
In the rest of the paper, we will call MiroCam® Regular MC1000-W endoscope video capsule as MiroCam, Pillcam® COLON2 as PillCam, High Resolution Endoscope Camera (YPC-HD720P) as HighCam and Low Resolution Endoscope 3 in 1 Camera as LowCam for brevity. Franka Emika Panda robotic arm with 7 degree of freedom and 0.1mm pose repeatability precision is utilized to provide trajectory stabilization and ground-truth pose recording of the camera motions. The robot controls the motion of the cameras in hand-guided mode and supplies pose recording at high-frequency, 1kHz (see Fig. A.1 a).
2.2 Dataset Collection
The ex-vivo part of dataset consists of a total of 42,700 frames. Of these, 21,428 images are from the HighCam, 17,978 images are from the LowCam, 239 images are from the PillCam and 3,055 images are from the MiroCam. The reader is referred to Fig. 2 and Fig. F.1 for the illustration of recorded frames. Fig. E.1 shows the overall data tree structure. Frames folder contains recorded endoscopic images in a given trajectory and Table F.3 summarizes the trajectory classes based on tumor comprising for each organ. Trajectories for each organ can be found in the folder Poses in (.csv) and (.txt ) format with 6D pose coordinates: four orientation parameters (x; y; z; w) in quaternions and three absolute position parameters (x; y; z) in meters. Calibration folder contains intrinsic-extrinsic calibration data of cameras in .mat extensions and calibration sessions. 3D_Scanners folder consists of reconstructed 3D figures and point cloud data for six organs with a size of 23.2 GB in total, the reader is referred to the Table F.4 for the detailed point cloud distributions.
2.3 Experimental Procedure
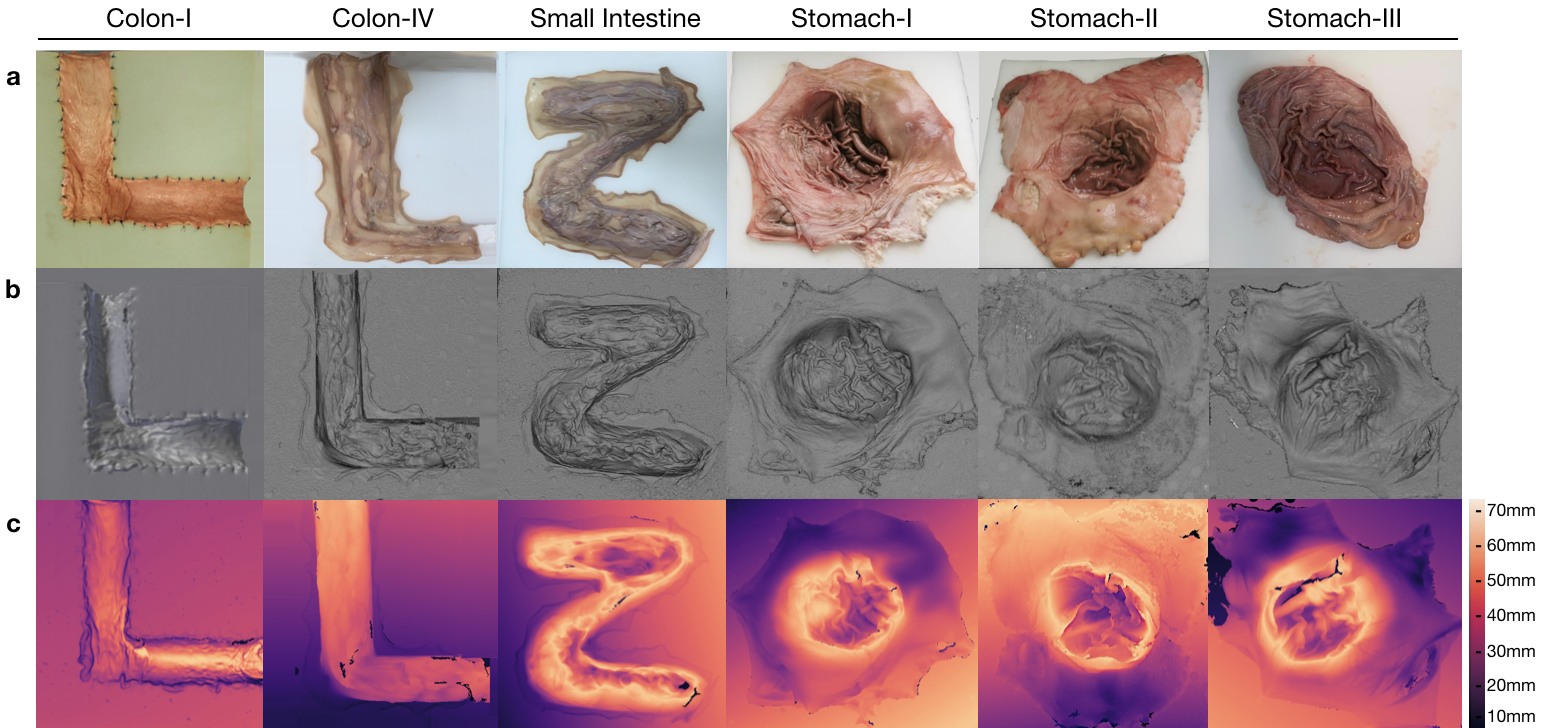
’L’-shaped, ’Z’-shaped semi-cylindrical and ’O’ shaped semi-spherical scaffolds were cut in rectangular high-density solid foams with dimensions cm to be used as substrate for colons, small intestine and stomachs, respectively. The shape for colons mimics the GI-tract path through the ascending colon to the transverse colon. Cleaned porcine organs were cut and sewn to the foam by a practitioner, see Fig. 1.
All the capsules require a specific recorder to be worn by the patient. PillCam and MiroCam differ in multiple features and, in particular, PillCam transmits video wirelessly whereas MiroCam transmits video via a wired connection. For both PillCam and MiroCam, the capsules are placed into a 3D-printed, non-conducting holder attached to the robotic arm. HighCam and LowCam were also used in place of the capsule cameras to record endoscopic images in a similar set-up but with different organs, Colon-IV, Small Intestine, Stomach-I, Stomach-II, and Stomach-III, which were sewn on white scaffold.
Recordings were made in a dark room with green and white background solid foams to create luminance and color contrast between the GI tract and environment. The orientations of the cameras (capsule and conventional) throughout the procedure are mostly along the longitudinal axis of the semi-cylindrical and semi-spherical surfaces. In most of the trajectories the capsule endoscopes do not contact with the tissue, whereas all cameras never contact with the tissue for all trajectories. In all the experiments the robot end-effector was driven by hand, with speeds ranging mostly between 16.76 mm/s to 25.97 mm/s with a peak speed of 286.68 mm/s and with accelerations mostly ranging from 279.254 mm/ to 519.361 mm/ with a peak acceleration of 14,680.15 mm/. Alternating speed and accelerations are quite important in terms of SLAM evaluations, since performance of SLAM methods in general are significantly dependent on the complexity of the trajectories. In that regard, we performed detailed quantitative analysis of robot motion, see Table F.1, F.2.
Experimental equipment calibration can be grouped into three parts as: camera calibration, the hand-eye transformation from robot to camera, and temporal synchronization between the camera frames and robot pose measurements. Each camera was calibrated against a pinhole camera model with non-linear radial lens distortion by Camera Calibration Toolbox MATLAB R2020a based on the theory of Zhang [Zhang, 1999] with the chessboard images illustrated in Fig. C.1. The hand-eye transformation between the robot end-effector coordinate frame and the camera frame was estimated with the procedure of Tsai and Lenz [Tsai and Lenz, 1989] and the resultant transformation matrices are given in Table C.1. Finally, temporal synchronization was performed by correlating camera motion computed by optical flow with velocity measurements from the robot. Table D.1 and Table D.2 shows the correspondence between the start frame of each sequence and the matching sampling instant of the robot pose data. Further details of the calibration procedures are given in Appendix C and D.
2.4 Dataset Augmentation
For the purpose of studying the robustness of SLAM algorithms against artefacts, the functions that are changing the property and quality of images were designed and exemplified in Fig. F.2. The transformations include resizing, Gaussian blur, fish-eye distortion, depth-of-field simulation via shift-variant defocus blurring, and frame-rate variation. The resize, vignetting and gaussian blur transformations were implemented with the opencv-python library (version 4.2.0.32), fish-eye distortion with the Pygame library (version 1.9.6), and depth-of-field with Matlab (version R2020a) [Pertuz, June 7, 2020]. All codes for dataset augmentation functions are available in https://github.com/CapsuleEndoscope/EndoSLAM.
2.5 Synthetic Data Generation
In addition to real ex-vivo part of EndoSLAM dataset, we have generated synthetic capsule endoscopy frames to facilitate the study of simulation-to-real transfer of learning-based algorithms. The simulation environment, VRCaps [Incetan et al., 2020], provides synthetic data which is visually as well as morphologically realistic. The platform was built with the use of real computed tomography (CT) images in DICOM format for topography and endoscopic images in RGB format for texture assignment. A cinematic rendering tool mimicking the effects in real capsule endoscopy records such as specular reflection, distortion, chromatic aberration, and field of view was used in order to obtain more photo-realistic images. Operating the virtual capsule inside the virtual 3D GI tract, we have recorded three sample endoscopic videos that containing 21,887 frames from colon, 12,558 frames from small intestine and 1,548 frames from stomach with pixel size of 320x320 and having both positional and pixel-wise depth ground truth.
3 Endo-SfMLearner
Recent works have proven that CNN-based depth and ego-motion estimators can achieve high performance using unlabelled monocular videos. However; static scene assumption, scale ambiguity between consecutive frames, brightness variety which basically stems from shallow depth-of-field and the organ tissues exhibiting non-lambertian surface property which are non-diffusely reflecting light particles make difficult to provide both locally and globally consistent trajectory estimations. We are proposing Endo-SfMLearner framework which specifically addresses these gaps.
Endo-SfMLearner jointly trains a camera pose and depth estimation networks from unlabeled endoscopic dataset. Our method proposes two solutions to the light source rooted problems in depth and pose estimation. First proposed solution is to equate brightness conditions throughout the training and validation sets with brightness transformation function and the other is to weight the photometric loss with the brightness coefficient to punish the depth estimation with higher cost under different enlightenment conditions. Apart from these, we are using geometry consistency loss for scale-inconsistency between consecutive frames caused by alternating distances between camera and organ tissue. In principal, we convert the predicted depth map in one frame to 3D space, then project it to the consecutive frame using the estimated ego-motion, and minimize the inconsistency of the estimated and the projected depth maps. This implicitly compels the depth network to predict geometrically consistent (i.e. scale-consistent) results over consecutive frames. With iterative sampling and training, the frame-to-frame consistency can eventually propagate through the entire video sequence. As the scale of depths is strictly linked to the scale of ego-motions, the ego-motion network can estimate scale-consistent relative camera poses over consecutive pairs. The detailed network architecture for both depth and pose networks will be introduced in the following subsections.
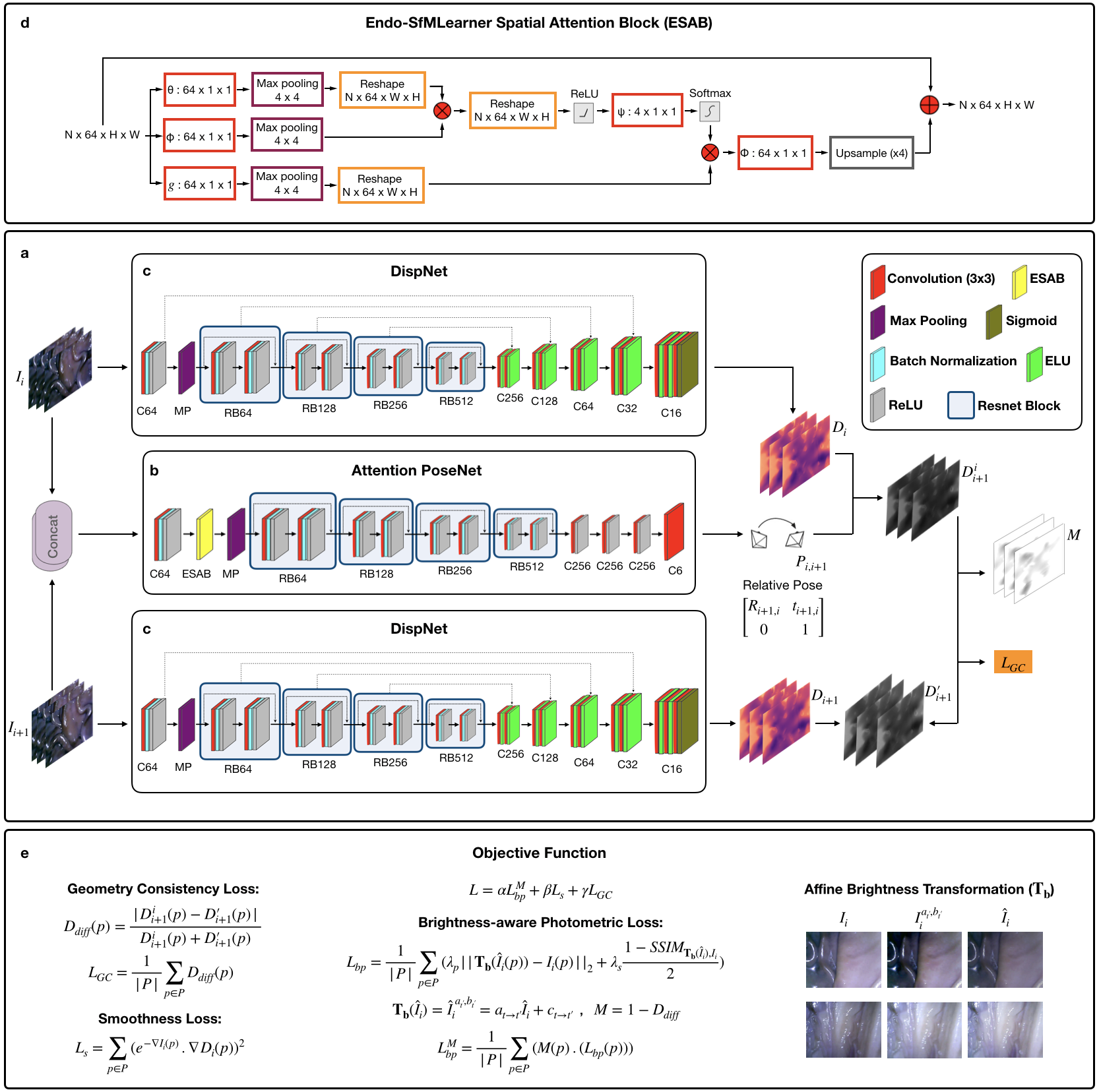
3.0.1 Endo-SfMLearner Depth Network (DispNet)
The depth network which consists of encoder and decoder parts takes single image as input and gives output the corresponding disparity map . For the sake of brevity, hereinafter we refer the batch normalization layer as BN, Rectified Linear Unit activation function as ReLU, exponential linear unit as ELU. Let RBk denote basic ResNet Block with k filters and Ck is 3x3 convolution layer with k filters. Cek, Csk and Crk stand for Ck followed by ELU, sigmoid and ReLU, respectively.
-
1.
DispNet Encoder DispNet encoder initializes with C64 with 7 kernel size, 2 stride and 3 padding followed by BN, ReLU activation function with a slope of 0.01 and max pooling operation with kernel size 3 and stride 2. Then, four ResNet basic blocks: RB64, RB128, RB256 and RB512 finalize the encoder structure. Each ResNet basic block consists of Ck(3x3), BN, ReLU, Ck, BN and ReLU with skip connection.
-
2.
DispNet Decoder DispNet decoder consists of five layers each consists of two convolution operations as follows:
Ce256(x2) -Ce128(x2)- Ce64(x2) - Ce32(x2) - Ce16(x2)-Cs16
To establish the information flow in between encoder and decoder, we are building skip connections from to layer where n indicating the total number of layers and i{0,1,2,3}, the reader is referred to Fig. 4 c to overview.
3.0.2 Endo-SfMLearner Pose Network (Attention PoseNet)
The pose network takes the consecutive image tuples as input by superposing and outputs the relative 6-DoF pose, .
-
1.
Attention PoseNet Encoder We have integrated attention module to the encoder of PoseNet between ReLU and maxpooling layers.
C64-BN-ReLU-ESAB-RB64-RB128-RB256-RB512
-
2.
Attention PoseNet Decoder
Cr256 - Cr256 - Cr256 - C6
The overview for Attention PoseNet is given in Fig. 4 b and the details of attention mechanism are introduced in next subsection.
3.0.3 Endo-SfMLearner Spatial Attention Block (ESAB)
The intuition behind ESAB module in encoder layers is to guide pose network by emphasizing texture details and depth differences of pixels. On the contrary to feature-based and object-based attentions, spatial attention selects a specific region of the input image and features in that regions are processed by attention block. The ESAB mechanism is non-local convolutional process. For any given input , our block operation can be overviewed as:
| (1) |
where stands for the pixelwise relations of input between each pixel. The non-local operator extracts the relative weights of all positions on the feature maps.
In ESAB Block, we employ the dot product operation on max-pooled and convolution, which is activated by ReLU function:
| (2) |
where is the ReLU activation function. The dot product, , gives a measurement for the input covariance, which can be defined as a degree of tendency between two feature maps at different channels. We activate the convolution operation in function and perform a matrix multiplication between the and the output of function. Then, we convolve and upsample the result of multiplication with to extract the attention map . Finally, an element-wise sum operation in between attention map and the input generates the output :
| (3) |
| (4) |
where denotes function. Short connection between the input and the output finalizes the block operations for the residual learning. The detailed flow diagram of block operations of ESAB module is given in Fig. 4 d.
3.0.4 Learning Objectives for Endo-SfMLearner
Endo-SfMLearner is trained both in forward and backward directions with losses calculated in forward direction. We are using three loss functions to guide the network without labels; brightness-aware photometric loss, smoothness loss and geometry consistency loss.
Apart from well-known way of defining photometric loss, we are proposing affine brightness transformation between consecutive frames to deal with the problems stem from brightness constancy assumption of previous methods. First of all, the new reference image, , is synthesized via interpolating . Previous methods calculate photometric loss directly comparing the synthesized image with target image, . However, the difference stem from illumination between consecutive frames might mislead the network. We propose to equate the brightness conditions between these two images as a robust way of supervising training phase. To the best of our knowledge, this is the first implementation of that approach for pose and depth estimation in literature. Moreover, quickly changing distance between organ tissue and camera results in scale inconsistency. We are using geometry consistency loss [Bian et al., 2019] to cope with that problem. The overall objective of the system is to minimize the weighted sum of brightness-aware photometric loss , smoothness loss and geometry consistency loss which can be formulated as:
| (5) |
where , , and are the weights for the related loss functions which are not necessarily adding up to one.
The well-known photometric loss functions are based on the brightness constancy assumption which can be violated due to auto-exposure of the camera and fast illumination changes to which both L2 and SSIM are no more invariant. To deal with that inconsistent illumination issue which is common in endoscopic image sequences, Endo-SfMLearner network predicts a brightness transformation parameter set which tries to align the brightness of input images during training on the fly and in a self-supervised manner. The evaluations demonstrate that the proposed brightness transformation significantly improves the pose and depth prediction accuracy. The brightness-aware photometric loss formulation is given as follows:
| (6) | ||||
| (7) |
where stands for synthesized image by warping , is the brightness alignment function with affine transformation parameters and , P stands for the successfully projected pixels from reference frame, is the image dissimilarity loss. By making use of contrast, luminance and structure values of and image; SSIM targets to measure perceived image quality by human visual system and more sensitive to high frequency content such as textures and edges in regard of PSNR.
Since the photometric loss is not sufficiently informative for the low-texture and homogeneous endoscopic images, we are also incorporating smoothness loss [Ranjan et al., 2018] which is calculated as a combination of predicted depth and input images for both reference and target frames.
| (8) |
where is the first derivative along spatial directions. Thanks to the smoothness loss, Endo-SfMLearner is guided by edges in the predicted depth and input images. Finally, geometry consistency loss is integrated to our methodology. The main idea behind this loss is to confirm if provides the same scene under the transformation of by predicted relative poses . The difference between predicted depths, , can be calculated as:
| (9) |
where is the depth map of by warping via and is the interpolated depth map from . The geometry consistency loss will be defined as summation of this difference across all pixel coordinates after normalization with valid pixel counts:
| (10) |
This consistency constrain between consecutive depth maps paves the way for long trajectory estimation with higher accuracy, the reader is referred to see Fig. 4 a. We also use depth inconsistency map results, , to weight the with M as follows:
| (11) |
| (12) |
Thanks to this operation, brightness-aware photometric loss is weighted with higher constant if the predicted and interpolated depth maps are inconsistent for each pixel.
4 EndoSLAM Use-Case with Endo-SfMLearner
To illustrate the use-case of the EndoSLAM dataset, Endo-SfMLearner, our proposed learning-based structure-from-motion method was benchmarked for the pose and depth estimation tasks. Additionally, we have tested both dataset and EndoSfMLearner with a traditional fully dense 3D-reconstruction pipeline based on SIFT feature-matching and non-lambertian surface reconstruction where the detailed overview is given in Algorithm 1. Error metrics that were used to quantitatively assess the performance of the algorithms are introduced in the following subsections.
4.1 Error Metrics
Endo-SfMLearner pose estimation performance is tested based on three metrics: absolute trajectory error(ATE), translational relative pose error(trans RPE) and rotational relative pose error(rot RPE). The monocular depth estimation performance is evaluated in terms of Root Mean Square Error(RMSE). Finally, the 3D-reconstruction results are evaluated with surface reconstruction error. These error metrics are defined as follows based on the estimated and ground truth trajectories represented by and , respectively, where the lower subscript is indexing frames and SE(3) is the Special Euclidean Group in three dimensions.
4.1.1 Absolute trajectory error (ATE)
The ATE is a measure of global consistency between two trajectories, comparing absolute distances between ground truth and predicted poses at each point in time. Let the rigid body transformation be the best (least-squares) alignment of the trajectories [Horn, 1987]. Then absolute trajectory error for the pose sample is calculated as follows:
| (13) |
The overall error throughout trajectory is defined by the root mean square of .
4.1.2 Relative Pose Error (RPE)
Relative pose error measures the difference in the change in pose over a fixed length between two trajectories. Defining , the translational and rotational RPE are given by:
| (14) | ||||
| (15) |
where is the rotation matrix of and is the positive angle of rotation. The errors are reported for equals to 1.
| Organ, Trajectory | Trajectory Length [m] | ATE (mean std) [m] | Trans. RPE (mean std) [m] | Rot. RPE (mean std) [deg] | Trajectory Length [m] | ATE (mean std) [m] | Trans RPE (mean std) [m] | Rot RPE (mean std) [deg] | |
|---|---|---|---|---|---|---|---|---|---|
| HighCam | LowCam | ||||||||
| EndoSfM | Colon-IV,Traj-I | 0.4286 | 0.0878 0.0549 | 0.0009 0.0027 | 0.488 0.3217 | 0.6785 | 0.1046 0.0343 | 0.0011 0.006 | 0.4666 1.3792 |
| Colon-IV,Traj-V | 1.2547 | 0.1731 0.1179 | 0.0014 0.002 | 0.2552 0.417 | 1.1699 | 0.1771 0.1177 | 0.0012 0.002 | 0.1493 0.2321 | |
| Intestine,Traj-IV | 1.0557 | 0.0812 0.0152 | 0.0010 0.0013 | 0.173 0.1942 | 0.8265 | 0.0558 0.0356 | 0.0011 0.0008 | 0.404 0.5052 | |
| Stomach-I,Traj-I | 1.4344 | 0.1183 0.1062 | 0.0013 0.0028 | 0.5988 0.8185 | 0.8406 | 0.1732 0.116 | 0.0021 0.0034 | 0.8424 1.0788 | |
| Stomach-III,Traj-III | 0.8908 | 0.1177 0.0543 | 0.0013 0.0033 | 0.5543 0.928 | 0.9714 | 0.1014 0.0491 | 0.0011 0.0007 | 0.6705 0.3817 | |
| Ew/oAtt | Colon-IV,Traj-I | 0.4286 | 0.0894 0.0274 | 0.0010 0.0029 | 0.3502 0.2621 | 0.6785 | 0.1548 0.0591 | 0.0010 0.3679 | 1.3613 1.5908 |
| Colon-IV,Traj-V | 1.2547 | 0.1855 0.0494 | 0.0014 0.0022 | 0.4569 0.5734 | 1.1699 | 0.1628 0.0375 | 0.0014 0.003 | 0.4168 0.3149 | |
| Intestine,Traj-IV | 1.0557 | 0.1055 0.0379 | 0.0011 0.0012 | 0.3343 0.2653 | 0.8265 | 0.0691 0.0305 | 0.001 0.0009 | 0.654 0.6042 | |
| Stomach-I,Traj-I | 1.4344 | 0.1889 0.0497 | 0.0015 0.0038 | 0.893 0.915 | 0.8406 | 0.1968 0.1417 | 0.0025 0.0037 | 1.1823 1.2112 | |
| Stomach-III,Traj-III | 0.8908 | 0.1362 0.068 | 0.0016 0.0032 | 0.8244 1.0127 | 0.9714 | 0.1204 0.0418 | 0.0010 0.0009 | 1.0907 0.5634 | |
| Ew/oBr | Colon-IV,Traj-I | 0.4286 | 0.1328 0.0431 | 0.0010 0.0026 | 0.7198 0.4764 | 0.6785 | 0.1402 0.0671 | 0.0010 0.0060 | 0.7257 1.424 |
| Colon-IV,Traj-V | 1.2547 | 0.1898 0.0709 | 0.0015 0.002 | 0.929 0.7525 | 1.1699 | 0.1503 0.0433 | 0.0013 0.002 | 0.8989 0.6199 | |
| Intestine,Traj-IV | 1.0557 | 0.1467 0.0848 | 0.002 0.0010 | 0.6607 0.3884 | 0.8265 | 0.1241 0.0436 | 0.0009 0.0008 | 1.106 0.8081 | |
| Stomach-I,Traj-I | 1.4344 | 0.1963 0.0478 | 0.002 0.0032 | 0.6899 1.0401 | 0.8406 | 0.1923 0.118 | 0.0023 0.0032 | 0.9215 1.1728 | |
| Stomach-III,Traj-III | 0.8908 | 0.1277 0.0805 | 0.0014 0.0033 | 0.3933 0.9258 | 0.9714 | 0.1101 0.0257 | 0.0010 0.0006 | 0.439 0.2672 | |
| SC-SfM | Colon-IV,Traj-I | 0.4286 | 0.1545 0.0441 | 0.0014 0.0028 | 1.3532 0.8541 | 0.6785 | 0.1898 0.0718 | 0.0015 0.0060 | 1.6388 1.5908 |
| Colon-IV,Traj-V | 1.2547 | 0.2054 0.1734 | 0.0024 0.0029 | 1.2452 0.965 | 1.1699 | 0.1667 0.1263 | 0.0021 0.003 | 1.2188 0.7715 | |
| Intestine,Traj-IV | 1.0557 | 0.1247 0.1327 | 0.0015 0.0009 | 0.9257 0.584 | 0.8265 | 0.0908 0.0819 | 0.0016 0.0009 | 0.8989 0.7854 | |
| Stomach-I,Traj-I | 1.4344 | 0.2325 0.127 | 0.002 0.0038 | 1.2937 1.2484 | 0.8406 | 0.191 0.1399 | 0.0028 0.0033 | 2.1322 1.2601 | |
| Stomach-III,Traj-III | 0.8908 | 0.0898 0.035 | 0.0016 0.0033 | 1.3071 1.3187 | 0.9714 | 0.1927 0.0561 | 0.0012 0.0007 | 2.041 0.8391 | |
| Mono2 | Colon-IV,Traj-I | 0.4286 | 0.1071 0.0756 | 0.0012 0.0028 | 0.3115 0.268 | 0.6785 | 0.215 0.1084 | 0.0009 0.006 | 0.1679 1.378 |
| Colon-IV,Traj-V | 1.2547 | 0.1872 0.1404 | 0.0016 0.002 | 0.1607 0.4226 | 1.1699 | 0.2158 0.1466 | 0.0018 0.002 | 0.3921 0.3362 | |
| Intestine,Traj-IV | 1.0557 | 0.1507 0.1165 | 0.009 0.0013 | 0.1092 0.1812 | 0.8265 | 0.1431 0.132 | 0.0014 0.001 | 0.3128 0.5288 | |
| Stomach-I,Traj-I | 1.4344 | 0.2878 0.2293 | 0.0029 0.0038 | 0.298 0.7968 | 0.8406 | 0.2033 0.0971 | 0.0019 0.0011 | 0.5296 0.3642 | |
| Stomach-III,Traj-III | 0.8908 | 0.5841 0.2742 | 0.0022 0.0033 | 0.8178 0.9059 | 0.9714 | 0.3876 0.2322 | 0.0032 0.0017 | 0.7345 0.8349 | |
| SfM | Colon-IV,Traj-I | 0.4286 | 0.15840.1064 | 0.0043 0.0042 | 2.6624 1.6822 | 0.6785 | 0.1946 0.1708 | 0.0037 0.0092 | 2.0718 2.3018 |
| Colon-IV,Traj-V | 1.2547 | 0.5849 0.5201 | 0.0092 0.0175 | 4.4083 4.6309 | 1.1699 | 0.2094 0.1613 | 0.005 0.0041 | 3.1999 1.8304 | |
| Intestine,Traj-IV | 1.0557 | 0.2119 0.2022 | 0.0083 0.016 | 3.9877 5.2134 | 0.8265 | 0.2387 0.1675 | 0.0048 0.005 | 2.7019 2.189 | |
| Stomach-I,Traj-I | 1.4344 | 0.1741 0.0744 | 0.0012 0.0038 | 0.7249 0.7904 | 0.8406 | 0.2226 0.0989 | 0.007 0.005 | 4.1709 2.3479 | |
| Stomach-III,Traj-III | 0.8908 | 0.3086 0.1774 | 0.0018 0.0035 | 0.6137 0.996 | 0.9714 | 0.1711 0.0548 | 0.0012 0.0008 | 0.802 0.4236 | |
4.1.3 Surface Reconstruction Error
We use the methodology propounded by [Handa et al., 2014] in order to evaluate the surface reconstruction quality. As the first step, one line segment is manually identified between the reconstructed and ground truth 3D maps. The match points are used to coarsely align both maps. This coarse alignment is used as an initialization for the iterative closest point (ICP) algorithm. ICP iteratively aligns both maps until a termination criteria of 0.001 cm deviation in RMSE is reached.
4.2 Pose Estimation with Endo-SfMLearner
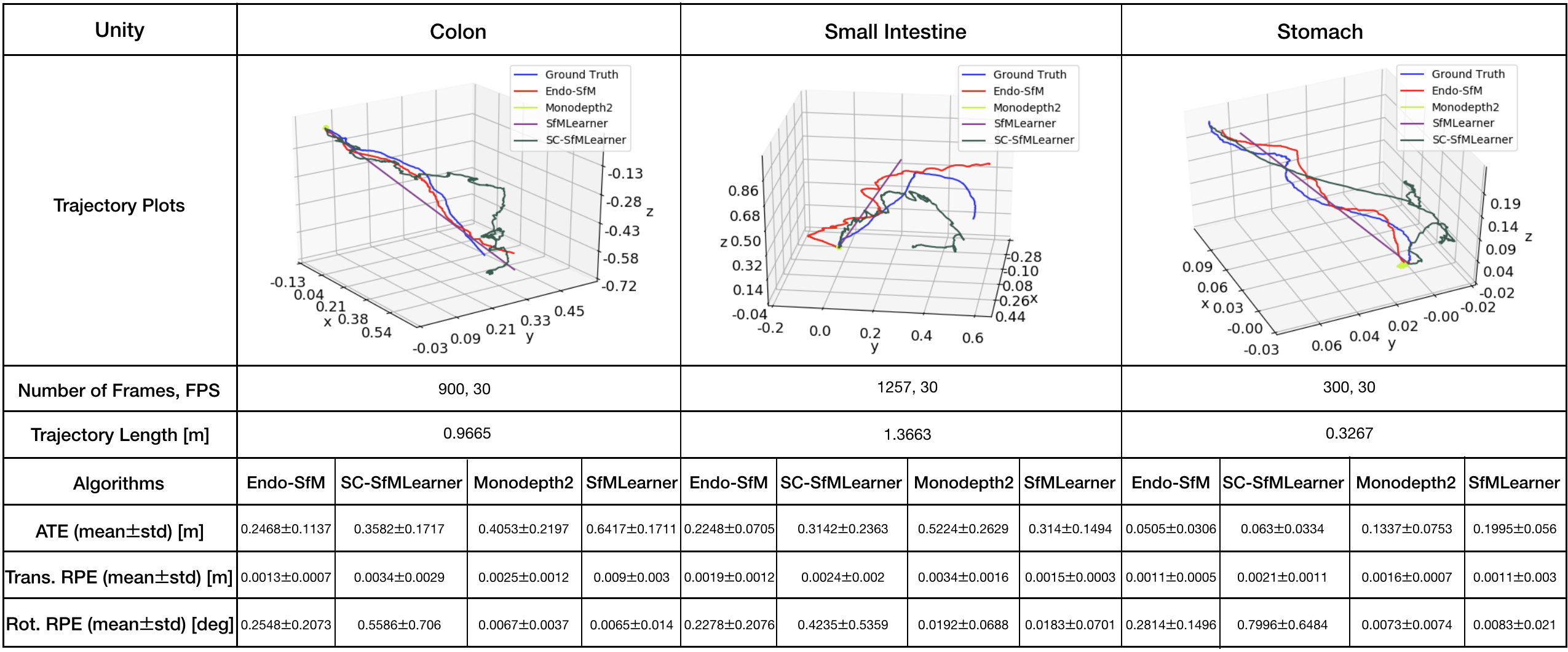
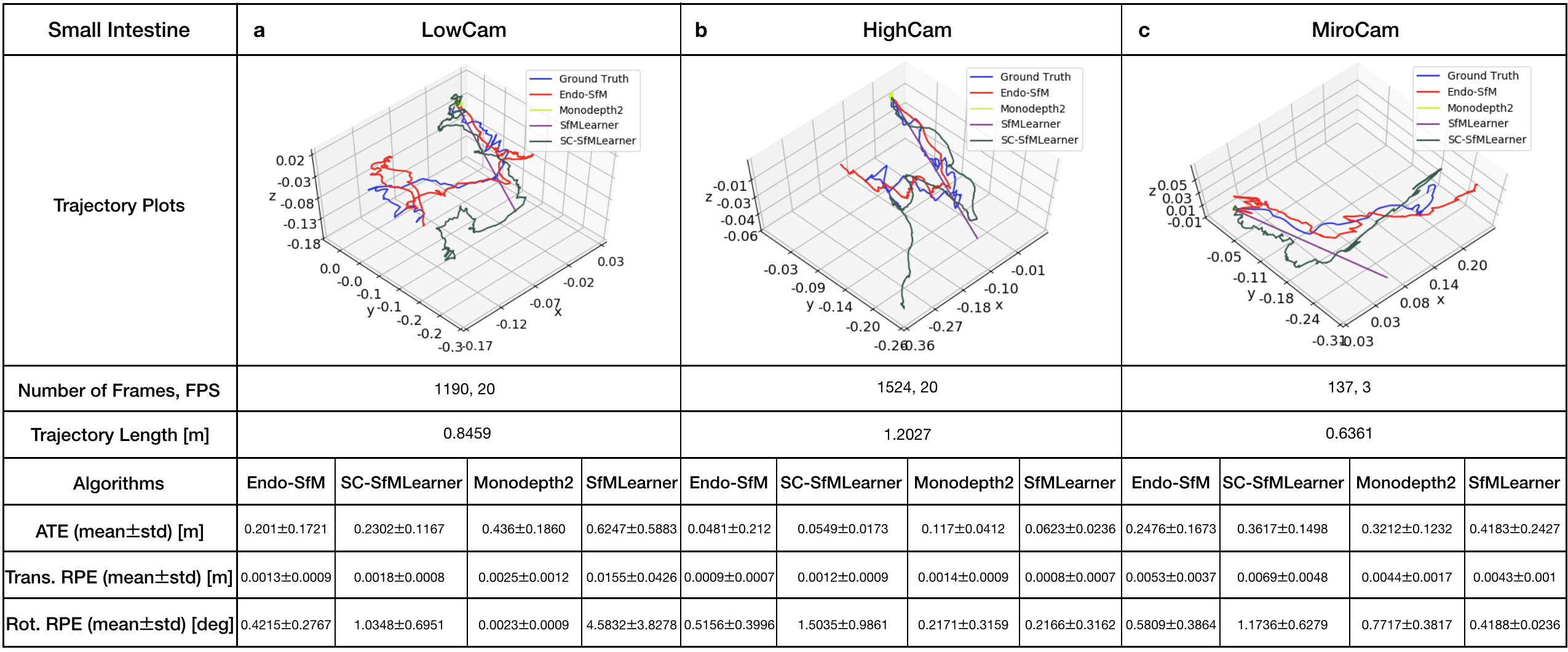
All methods including Endo-SfMLearner are trained with the same data and parameter set for the sake of fairness and unbiased results. The training and validation dataset consist of 2,039 and 509 colon images generated in the Unity simulation environment, respectively. We train the all networks in 200 epochs with randomly shuffled batches each size of 4 images, optimize by ADAM with initial learning rate and validate after each epoch. According to the tests in terms of ATE, trans RPE, and rot RPE on the data recorded via the HighCam and LowCam, Endo-SfMLearner achieves the state-of-the-art for most of the cases. The results in Table 2 show clear advantage of ESAB block integration and brightness-aware photometric loss. In the majority of Stomach-III results for both HighCam and LowCam, all models fail to follow trajectory with sufficient accuracy. However, the predicted trajectories aligned with ground truth for Endo-SfMLeaner in general are much better compared to other models.
Both quantitative and qualitative pose estimation results on sample trajectories of HighCam, LowCam and MiroCam are given in Fig. 5. Under the above mentioned training conditions, Monodepth2 and SfMLearner face with fatal failure on endoscopic videos. Even if SC-SfMLearner exhibits closest performance to our method in terms of absolute trajectory errors, we observe improvement specially on the rotational movement estimations which is reflected on rotational relative pose errors. A similar observation is also made on Unity trajectories, see Fig. G.1. Since the rotations cannot be changed frequently and easily while recording clear images in Unity environment, the trajectories are close to the straight lines which result in higher accuracy for all methods. It is seen that the Endo-SfMLearner outputs generally follow the shape of the ground truth, specifically it catches rotations more consistently which is the main reason for the decrease in rotational relative pose error.
For more comprehensive evaluations of results in terms of camera motions, descriptive analysis of the camera speeds and accelerations are given in Fig. F.4, Table F.1 and Table F.2. Since the robot motions are highly effective on image quality, we expect decrease in the pose estimation accuracy for the trajectories of Stomach-III which have highest mean speed and acceleration. The fact pave the way for the difficulty in alignment of those trajectories and also stitching of those frames for 3D reconstruction.
4.3 Depth Estimation with Endo-SfMLearner
In this subsection, we analyse the monocular depth estimation performance of Endo-SfMLearner quantitatively on synthetically generated data coming from EndoSLAM dataset.

Since EndoSLAM dataset also provides pixelwise depth ground truth for synthetically generated endoscopic frames, we show that Endo-SfMLearner quantitatively outperforms the benchmarked monocular depth estimation methods as given in Fig. 6. The results are evaluated in terms of root mean square error(RMSE) on 1,548 stomach, 1,257 small intestine and 1,062 colon frames. Even if the training and validation dataset consist of synthetic colon frames, Endo-SfMLearner depicts high performance on stomach and small intestine with 0.2966 and 0.1785 mean RMSE. The heatmaps are also indicating that the errors significantly decrease for the pixels representing regions far from 14mm.
4.3.1 Ablation Studies for Spatial Attention Block
In order to increase the pose and depth network sensitivity for the edge and texture details, we have integrated attention block in between ReLU and max pooling operations in PoseNet encoder. By this attention mechanism, we are expecting to preserve low and high-frequency information from the input endoscopic images by exploiting the feature-channel inter-dependencies. In this subsection, we specifically investigate the following cases:
-
1.
EndoSfMLearner with brightness-aware photometric loss and ESAB,
-
2.
EndoSfMLearner with ESAB and without brightness-aware photometric loss,
-
3.
EndoSfMLearner without ESAB and with brightness-aware photometric loss,
-
4.
EndoSfMLearner without ESAB and without brightness -aware photometric loss(SC-SfMLearner).
The results for the pose tracking given in Table 2 reveal the usefulness and effectiveness of the module. Although the attention module is only inserted in PoseNet, simultaneous training of networks causes the improvement in depth estimation which is depicted in Fig. 6. As seen from quantitative ablation analysis, attention module makes Endo-SfMLearner more responsive for depth alterations on the synthetically generated images from colon, intestine and stomach. Even for the stomach and small intestine that is not included in training phase, Endo-SfMLearner achieves acceptable RMSE values which is the indicator of its persistent effort to be adaptable for texture differences.
4.4 3D Reconstruction Pipeline
3D reconstruction approach used in this work is depicted in Algorithm1. The steps of the procedure can be summarized under four fundamental techniques which are Otsu threshold-based reflection detection, OPENCV inpainting-based reflection suppression, feature matching and tracking based image stitching and non-lambertion surface reconstruction. To establish feature point correspondences between frames, SIFT feature matching and RANSAC based pair elimination are employed [Brown and Lowe, 2007]. Then, the depth map is estimated using Tsai-Shah shape from shading approach.
This surface reconstruction method applies a discrete approximation of the gradients and then utilize the linear approximation of the reflectance function in terms of the depth directly. For further details of Tsai-Shah method, the reader is referred to the original paper [Ping-Sing and Shah, 1994]. Fig. 7 demonstrates the steps of the approach and output maps aligned with the ground truth scanned data. Using that pipeline, RMSEs of 0.65 cm, 0.54 cm and 0.73 cm are obtained for Colon-IV, Small Intestine and Stomach-III trajectories, respectively. Besides, we use the depth estimations of EndoSfMLearner and SC-SfMLearner on the stitched images and compared with the rule-based method. As a result, we get lower RMSE values on the aligned images for Endo-SfMLearner, see Fig. 7.
5 Discussion and Future Works
In this paper, we introduce a novel endoscopic SLAM dataset that contains both capsule and standard endoscope camera images with 6D ground truth pose and high precision scanned 3D maps of the explored GI organs. Four different cameras were employed in total to collect data from eight ex-vivo porcine GI-tract organs each from different animal instances. Various additional post processing effects such as fish eye distortions, Gaussian blur, downsampling and vignetting can be applied as optional to diversify and enrich the dataset. In addition to the EndoSLAM dataset, Endo-SfMLearner is proposed as a monocular pose and depth estimation method based on spatial attention mechanisms and brightness-aware hybrid loss. Although Endo-SfMLearner is specifically developed and optimized for endoscopic type of images, it also holds great promise for laparoscopy images due to similar texture characteristics. Our future work will focus on generalizing the EndoSLAM dataset concept to other visualization techniques and create datasets with various other imaging modalities. Furthermore, we aim to examine and improve the data adaptability of the Endo-SfMLearner and address these issues as next steps. Last but not least, we plan to investigate the combination of Endo-SfmLearner with segmentation, abnormality detection and classification tasks in the concept of multi-task and meta-learning to enhance the performance of state-of-the-art methods.
Acknowledgment
Mehmet Turan, Kutsev Bengisu Ozyoruk, Guliz Irem Gokceler, Gulfize Coskun, and Kagan Incetan are especially grateful to the Scientific and Technological Research Council of Turkey (TUBITAK) for International Fellowship for Outstanding Researchers. We would like to express deep gratitude to Abdullhamid Obeid and Ebru Sagiroglu for their valuable support during experiments.
References
- [1] , . Robust medical instrument segmentation (robust-mis) challenge 2019. https://www.synapse.org/#!Synapse:syn18779624/wiki/592660. Accessed: 2020-02-12.
- iDa [2018] , 2018. An astounding 19 million colonoscopies are performed annually in the united states. https://idataresearch.com/an-astounding-19-million-colonoscopies-are-performed//-annually-in-the-united-states/. Accessed: 08/08/2018.
- [3] 3D, S., . User handbook - shining 3d einscan. URL: https://www.einscan.com/wp-content/uploads/2020/05/EinScan-Pro-2X-Quick-Guide-1112.pdf. last accessed August 2019.
- American Cancer Society [2018] American Cancer Society, 2018. Global Cancer Facts and Figures 4th Edition. American Cancer Society.
- Arnold et al. [2020] Arnold, M., et al., 2020. Global burden of 5 major types of gastrointestinal cancer. Gastroenterology URL: http://www.sciencedirect.com/science/article/pii/S0016508520304522, doi:10.1053/j.gastro.2020.02.068.
- [6] Artec3D, . User handbook - artec3d eva. URL: https://www.artec3d.com/files/pdf/ArtecScanners-Booklet.pdf. last accessed August 2019.
- Bernal et al. [2012] Bernal, J., Sanchez, J., Vilariño, F., 2012. Towards automatic polyp detection with a polyp appearance model. Pattern Recognition 45, 3166–3182. doi:10.1016/j.patcog.2012.03.002,.
- Bernal et al. [2015] Bernal, J., et al., 2015. Wm-dova maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Computerized Medical Imaging and Graphics 43, 99—111. doi:10.1016/j.compmedimag.2015.02.007.
- Bernal et al. [2017] Bernal, J., et al., 2017. Comparative validation of polyp detection methods in video colonoscopy: Results from the miccai 2015 endoscopic vision challenge. IEEE Transactions on Medical Imaging 36, 1231–1249. doi:10.1109/TMI.2017.2664042.
- Bian et al. [2019] Bian, J.W., et al., 2019. Unsupervised scale-consistent depth and ego-motion learning from monocular video. arXiv:1908.10553.
- Borgli et al. [2019] Borgli, H., et al., 2019. Hyper-kvasir: A comprehensive multi-class image and video dataset for gastrointestinal endoscopy. doi:10.31219/osf.io/mkzcq.
- Brown and Lowe [2007] Brown, M., Lowe, D.G., 2007. Automatic panoramic image stitching using invariant features. International Journal of Computer Vision 74, 59–73.
- Chen et al. [2019a] Chen, R., Bobrow, T., Athey, T., Mahmood, F., Durr, N., 2019a. Slam endoscopy enhanced by adversarial depth prediction.
- Chen et al. [2019b] Chen, R.J., Bobrow, T.L., Athey, T.L., Mahmood, F., Durr, N.J., 2019b. Slam endoscopy enhanced by adversarial depth prediction. ArXiv abs/1907.00283.
- Ciuti et al. [2016] Ciuti, G., et al., 2016. Frontiers of robotic endoscopic capsules: a review. Journal of Micro-Bio Robotics 11, 1–18.
- Dey et al. [2017] Dey, N., Ashour, A.S., Shi, F., Sherratt, R.S., 2017. Wireless capsule gastrointestinal endoscopy: Direction-of-arrival estimation based localization survey. IEEE reviews in biomedical engineering 10, 2–11.
- Eigen et al. [2014] Eigen, D., Puhrsch, C., Fergus, R., 2014. Depth map prediction from a single image using a multi-scale deep network, in: Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q. (Eds.), Advances in Neural Information Processing Systems 27. Curran Associates, Inc., pp. 2366–2374. URL: http://papers.nips.cc/paper/5539-depth-map-prediction-from-a-single-image-using-a-//multi-scale-deep-network.pdf.
- Garg et al. [2016] Garg, R., G, V.K.B., Reid, I.D., 2016. Unsupervised CNN for single view depth estimation: Geometry to the rescue. CoRR abs/1603.04992. URL: http://arxiv.org/abs/1603.04992, arXiv:1603.04992.
- Godard et al. [2018] Godard, C., Aodha, O., Brostow, G., 2018. Digging into self-supervised monocular depth estimation. CoRR .
- Grasa et al. [2013] Grasa, O.G., Bernal, E., Casado, S., Gil, I., Montiel, J., 2013. Visual slam for handheld monocular endoscope. IEEE transactions on medical imaging 33, 135–146.
- Handa et al. [2014] Handa, A., Whelan, T., McDonald, J., Davison, A.J., 2014. A benchmark for rgb-d visual odometry, 3d reconstruction and slam, in: Robotics and automation (ICRA), 2014 IEEE international conference on, IEEE. pp. 1524–1531.
- Hartley and Zisserman [2003] Hartley, R., Zisserman, A., 2003. Multiple View Geometry in Computer Vision. 2 ed., Cambridge University Press, New York, NY, USA.
- Ho et al. [2017] Ho, H.W., de Croon, G.C., Chu, Q., 2017. Distance and velocity estimation using optical flow from a monocular camera. International Journal of Micro Air Vehicles 9, 198–208.
- Honegger et al. [2012] Honegger, D., Greisen, P., Meier, L., Tanskanen, P., Pollefeys, M., 2012. Real-time velocity estimation based on optical flow and disparity matching, in: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE. pp. 5177–5182.
- Hong et al. [2012] Hong, S.P., Cheon, J., Kim, T., Song, S., Kim, W., 2012. Comparison of the diagnostic yield of "mirocam" and "pillcam sb" capsule endoscopy. Hepato-gastroenterology 59, 778–81. doi:10.5754/hge10472.
- Horn [1987] Horn, B.K., 1987. Closed-form solution of absolute orientation using unit quaternions. Josa a 4, 629–642.
- Incetan et al. [2020] Incetan, K., Celik, I.O., Obeid, A., Gokceler, G.I., Ozyoruk, K.B., Almalioglu, Y., Chen, R.J., Mahmood, F., Gilbert, H., Durr, N.J., Turan, M., 2020. Vr-caps: A virtual environment for capsule endoscopy. arXiv:2008.12949.
- Jha et al. [2020] Jha, D., Smedsrud, P.H., Riegler, M.A., Halvorsen, P., de Lange, T., Johansen, D., Johansen, H.D., 2020. The Kvasir-SEG Dataset. https://datasets.simula.no/kvasir-seg/.
- Jiao et al. [2018] Jiao, J., Jiao, J., Mo, Y., Liu, W., Deng, Z., 2018. Magicvo: End-to-end monocular visual odometry through deep bi-directional recurrent convolutional neural network. CoRR abs/1811.10964. URL: http://arxiv.org/abs/1811.10964, arXiv:1811.10964.
- Koulaouzidis et al. [2017] Koulaouzidis, A., et al., 2017. KID Project: an internet-based digital video atlas of capsule endoscopy for research purposes. Endosc Int Open 5, E477–E483.
- Kuth et al. [2007] Kuth, R., Reinschke, J., Rockelein, R., 2007. Method for determining the position and orientation of an endoscopy capsule guided through an examination object by using a navigating magnetic field generated by means of a navigation device. US Patent App. 11/481,935.
- Laina et al. [2016] Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., Navab, N., 2016. Deeper depth prediction with fully convolutional residual networks. CoRR abs/1606.00373. URL: http://arxiv.org/abs/1606.00373, arXiv:1606.00373.
- Leonard et al. [2018] Leonard, S., Sinha, A., Reiter, A., Ishii, M., Gallia, G., Taylor, R., Hager, G., 2018. Evaluation and stability analysis of video-based navigation system for functional endoscopic sinus surgery on in-vivo clinical data. IEEE Transactions on Medical Imaging doi:10.1109/TMI.2018.2833868.
- Lin et al. [2013] Lin, B., Johnson, A., Qian, X., Sanchez, J., Sun, Y., 2013. Simultaneous tracking, 3d reconstruction and deforming point detection for stereoscope guided surgery, in: Augmented Reality Environments for Medical Imaging and Computer-Assisted Interventions. Springer, pp. 35–44.
- Liu et al. [2016] Liu, F., Shen, C., Lin, G., Reid, I., 2016. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence 38, 2024–2039.
- Liu [2002] Liu, G., 2002. On velocity estimation using position measurements, in: Proceedings of the 2002 American Control Conference (IEEE Cat. No. CH37301), IEEE. pp. 1115–1120.
- Liu et al. [2020] Liu, X., Sinha, A., Ishii, M., Hager, G.D., Reiter, A., Taylor, R.H., Unberath, M., 2020. Dense depth estimation in monocular endoscopy with self-supervised learning methods. IEEE Transactions on Medical Imaging 39, 1438–1447.
- Lu and Lu [2019] Lu, Y., Lu, G., 2019. Deep unsupervised learning for simultaneous visual odometry and depth estimation, in: 2019 IEEE International Conference on Image Processing (ICIP), pp. 2571–2575.
- Lucas and Kanade [1981] Lucas, B.D., Kanade, T., 1981. An iterative image registration technique with an application to stereo vision. Proceedings of the 7th international joint conference on Artificial intelligence .
- Mahmood et al. [2018] Mahmood, F., Chen, R., Durr, N.J., 2018. Unsupervised reverse domain adaptation for synthetic medical images via adversarial training. IEEE Transactions on Medical Imaging 37, 2572–2581.
- Mahmood and Durr [2017] Mahmood, F., Durr, N.J., 2017. Deep learning and conditional random fields-based depth estimation and topographical reconstruction from conventional endoscopy. CoRR abs/1710.11216. URL: http://arxiv.org/abs/1710.11216, arXiv:1710.11216.
- McCarthy et al. [2008] McCarthy, C., Barnes, N., Mahony, R., 2008. A robust docking strategy for a mobile robot using flow field divergence. IEEE Transactions on Robotics 24, 832–842.
- Meng et al. [EasyChair, 2018] Meng, X., Fan, C., Ming, Y., EasyChair, 2018. Visual odometry based on convolutional neural networks for large-scale scenes. EasyChair Preprint no. 413. doi:10.29007/mf57.
- Mirota et al. [2011] Mirota, D.J., Wang, H., Taylor, R.H., Ishii, M., Gallia, G.L., Hager, G.D., 2011. A system for video-based navigation for endoscopic endonasal skull base surgery. IEEE transactions on medical imaging 31, 963–976.
- Moccia et al. [2018] Moccia, S., et al., 2018. Learning-based classification of informative laryngoscopic frames. Computer Methods and Programs in Biomedicine 158. doi:10.1016/j.cmpb.2018.01.030.
- Mountney et al. [2006] Mountney, P., Stoyanov, D., Davison, A., Yang, G.Z., 2006. Simultaneous stereoscope localization and soft-tissue mapping for minimal invasive surgery, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer. pp. 347–354.
- Penza et al. [2018] Penza, V., Ciullo, A.S., Moccia, S., Mattos, L.S., De Momi, E., 2018. Endoabs dataset: Endoscopic abdominal stereo image dataset for benchmarking 3d stereo reconstruction algorithms. The International Journal of Medical Robotics and Computer Assisted Surgery 14, e1926.
- Pertuz [June 7, 2020] Pertuz, S., June 7, 2020. Defocus simulation. MATLAB Central File Exchange. URL: https://www.mathworks.com/matlabcentral/fileexchange/55095-defocus-simulation.
- Ping-Sing and Shah [1994] Ping-Sing, T., Shah, M., 1994. Shape from shading using linear approximation. Image and Vision computing 12, 487–498.
- Pogorelov et al. [2017] Pogorelov, K., et al., 2017. Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection, in: Proceedings of the 8th ACM on Multimedia Systems Conference, pp. 164–169. doi:10.1145/3083187.3083212.
- Puglisi [2015] Puglisi, L.J., 2015. On the velocity and acceleration estimation from discrete time-position signal of linear encoders. Journal of Control Engineering and Applied Informatics 17, 30–40.
- Ranjan et al. [2018] Ranjan, A., Jampani, V., Kim, K., Sun, D., Wulff, J., Black, M.J., 2018. Adversarial collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. CoRR abs/1805.09806. URL: http://arxiv.org/abs/1805.09806, arXiv:1805.09806.
- Redondo-Cerezo et al. [2014] Redondo-Cerezo, E., Sánchez-Capilla, A., Torre-Rubio, P., Teresa, J., 2014. Wireless capsule endoscopy: Perspectives beyond gastrointestinal bleeding. World journal of gastroenterology : WJG 20, 15664–15673. doi:10.3748/wjg.v20.i42.15664.
- Shah et al. [2006] Shah, T., Aziz, S.M., Vaithianathan, T., 2006. Development of a tracking algorithm for an in-vivo rf capsule prototype, in: 2006 International Conference on Electrical and Computer Engineering, IEEE. pp. 173–176.
- Silva et al. [2014] Silva, J.S., Histace, A., Romain, O., Dray, X., Granado, B., 2014. Towards embedded detection of polyps in WCE images for early diagnosis of colorectal cancer. International Journal of Computer Assisted Radiology and Surgery 9, 283–293. doi:10.1007/s11548-013-0926-3.
- Simaan et al. [2015] Simaan, N., Taylor, R.H., Choset, H., 2015. Intelligent surgical robots with situational awareness. Mechanical Engineering 137, S3–S6.
- Son et al. [2015] Son, D., Yim, S., Sitti, M., 2015. A 5-d localization method for a magnetically manipulated untethered robot using a 2-d array of hall-effect sensors. IEEE/ASME Transactions on Mechatronics 21, 708–716.
- Spyrou and Iakovidis [2013] Spyrou, E., Iakovidis, D.K., 2013. Video-based measurements for wireless capsule endoscope tracking. Measurement Science and Technology 25, 015002.
- Stoyanov et al. [2010] Stoyanov, D., Scarzanella, M.V., Pratt, P., Yang, G.Z., 2010. Real-time stereo reconstruction in robotically assisted minimally invasive surgery, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer. pp. 275–282.
- Tajbakhsh et al. [2016] Tajbakhsh, N., Gurudu, S.R., Liang, J., 2016. Automated polyp detection in colonoscopy videos using shape and context information. IEEE Transactions on Medical Imaging 35, 630–644. doi:10.1109/TMI.2015.2487997.
- Than et al. [2014] Than, T.D., et al., 2014. An effective localization method for robotic endoscopic capsules using multiple positron emission markers. IEEE Transactions on Robotics 30, 1174–1186.
- Tsai and Lenz [1989] Tsai, R.Y., Lenz, R.K., 1989. A new technique for fully autonomous and efficient 3d robotics hand/eye calibration. IEEE Transactions on Robotics and Automation 5, 345–358. doi:10.1109/70.34770.
- Turan et al. [2017a] Turan, M., Almalioglu, Y., Araújo, H., Konukoglu, E., Sitti, M., 2017a. Deep endovo: A recurrent convolutional neural network (RCNN) based visual odometry approach for endoscopic capsule robots. CoRR abs/1708.06822. URL: http://arxiv.org/abs/1708.06822, arXiv:1708.06822.
- Turan et al. [2017b] Turan, M., Almalioglu, Y., Araujo, H., Konukoglu, E., Sitti, M., 2017b. A non-rigid map fusion-based direct slam method for endoscopic capsule robots. International journal of intelligent robotics and applications 1, 399–409.
- Turan et al. [2017c] Turan, M., Pilavcı, Y., Jamiruddin, R., Araujo, H., Konukoglu, E., Sitti, M., 2017c. A fully dense and globally consistent 3d map reconstruction approach for gi tract to enhance therapeutic relevance of the endoscopic capsule robot.
- Turan et al. [2018] Turan, M., et al., 2018. Unsupervised odometry and depth learning for endoscopic capsule robots. arXiv preprint arXiv:1803.01047 .
- Wu et al. [2011] Wu, C., Agarwal, S., Curless, B., Seitz, S.M., 2011. Multicore bundle adjustment, in: In IEEE Conference on Computer Vision and Pattern Recognition (CVPR, IEEE. pp. 3057–3064.
- Yano and Yamamoto [2009] Yano, T., Yamamoto, H., 2009. Vascular, polypoid, and other lesions of the small bowel. Best practice & research. Clinical gastroenterology 23, 61–74. doi:10.1016/j.bpg.2008.12.001.
- Ye et al. [2016] Ye, M., Giannarou, S., Meining, A., Yang, G.Z., 2016. Online tracking and retargeting with applications to optical biopsy in gastrointestinal endoscopic examinations. Medical image analysis 30, 144–157.
- Ye et al. [2017] Ye, M., Johns, E., Handa, A., Zhang, L., Pratt, P., Yang, G.Z., 2017. Self-supervised siamese learning on stereo image pairs for depth estimation in robotic surgery. arXiv preprint arXiv:1705.08260 .
- Yin and Shi [2018] Yin, Z., Shi, J., 2018. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , 1983–1992.
- Zhang et al. [2020] Zhang, Y., Xu, S., Wu, B., Shi, J., Meng, W., Zhang, X., 2020. Unsupervised multi-view constrained convolutional network for accurate depth estimation. IEEE Transactions on Image Processing 29, 7019–7031.
- Zhang [1999] Zhang, Z., 1999. Flexible camera calibration by viewing a plane from unknown orientations, in: Proceedings of the Seventh IEEE International Conference on Computer Vision, Ieee. pp. 666–673.
- Zhou et al. [2017] Zhou, T., Brown, M., Snavely, N., Lowe, D.G., 2017. Unsupervised learning of depth and ego-motion from video, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6612–6619.
Appendix A Equipment

Appendix B Dataset Survey
-
1.
The KID Dataset is organized by The Medical Decision Support Systems (MDSS) research group of the University of Thessaly. The dataset is divided into two annotated sections. The first section has a total of 77 wireless capsule endoscopy (WCE) images acquired using MiroCam® (IntroMedic Co, Seoul, Korea) capsules and has some types of abnormalities such as angioectasias, apthae, chylous cysts and polypoid lesions. The second part consists of 2,371 MiroCam® WCE. This dataset not only includes small bowel lesions such as polypoid, vascular and inflammatory lesions but also images from healthy esophagus, stomach, small bowel and colon Given Imaging Atlas Dataset consists of 20 second video clips recorded using PillCam capsules with a resolution of 576x576 pixels. In this database, 117 WCE video clips have been acquired from the small bowel, 5 from esophagus and 13 from the colon [Spyrou and Iakovidis, 2013].
-
2.
The Kvasir dataset was collected via standard endoscopic equipments at Vestre Viken (VV) Health Trust in Norway. The initial dataset consists of 4,000 images with eight classes namely Z-line, pylorus, cecum, esophagitis, polyps, ulcerative colitis, dyed and lifted polyps and dyed resection margins of images, each represented with 500 images. All images are annotated and verified by experienced endoscopists [Pogorelov et al., 2017]. Later, the dataset extended to 8,000 images with the same eight classes [Borgli et al., 2019]. The Kvasir-SEG Dataset is an extension of the Kvasir dataset which is used for polyp segmentation. It comprises 1000 polyp images and their corresponding ground truth from the second version of the Kvasir dataset [Jha et al., 2020].
-
3.
The Hyper-Kvasir dataset is the largest online available dataset related to the gastrointestinal tract, containing 110,079 images (10,662 labeled and 99,417 unlabeled images) and 373 videos, making a total of 1.17 million frames. The entire dataset was collected in gastro- and colonoscopy examinations in Norway and 10,662 images are labeled for 23 classes by practitioners. [Borgli et al., 2019].
-
4.
The NBI-InfFrames dataset includes Narrow-band imaging(NBI) endoscopy which is commonly used as a diagnostic procedure to examine the back of throat, glottis, vocal cords and the larynx. To generate this in vivo dataset, 18 different patients affected by laryngeal spinocellular carcinoma (diagnosed after histopathological examination) were involved. It consists of 180 informative (I), 180 blurred (B), 180 with saliva or specular reflections (S) and 180 underexposed (U) frames with a total number of 720 video frames [Moccia et al., 2018].
-
5.
The EndoAbS(Endoscopic Abdominal Stereo Images) Dataset consists of 120 sub-datasets of endoscopic stereo images of abdominal organs (e.g., liver, kidney, spleen) with corresponding ground truth acquired via laser scanner. In order to create variations in the dataset, frames have been recorded under 3 different lighting conditions, presence of smoke and 2 different distances from endoscope to phantom ( 5 cm and 10 cm). The main purpose of generating this dataset was to validate 3D reconstruction algorithms for the computer assisted surgery community [Penza et al., 2018].
-
6.
CVC-ColonDB is a database of annotated video sequences consisting of 15 short colonoscopy sequences, where one polyp has been shown in each sequence. There are 1,200 different images containing original images, polyp masks, non-informative image masks and contour of polyp masks. It can be used for assessment of polyp detection [Bernal et al., 2012].
-
7.
MICCAI 2015 Endoscopic Vision Challenge [Bernal et al., 2017] provides three sub-databases which are CVC-ClinicDB, ETIS-Larib and ASU-Mayo Clinic polyp database and which can be used for polyp detection and localization. CVC-ClinicDB is a cooperative work of the Hospital Clinic and the Computer Vision Center, Barcelona, Spain. It contains 612 images from 31 different sequences. Each image has its annotated ground truth associated, covering the polyp [Bernal et al., 2015]. ETIS-Larib is a database consisting of 300 frames with polyps extracted from colonoscopy videos. Frames and their ground truths are provided by ETIS laboratory, ENSEA, University of Cergy-Pontoise, France [Silva et al., 2014]. The ASU-Mayo Clinic polyp database was acquired as a cooperative work of Arizona State University and Mayo Clinic, USA. It consists of 20 short colonoscopy videos (22,701 frames) with different resolution ranges and different area coverage values for training purposes. Each frame in its training dataset comes with a ground truth image or a binary mask that indicates the polyp region. In addition, it contains 18 videos without annotation for testing purposes [Tajbakhsh et al., 2016].
-
8.
The Hamlyn Centre Laparoscopic/Endoscopic Video Dataset consists of 37 subsets. The Gastrointestinal Endoscopic Dataset includes 10 videos and consists of 7,894 images with a size of 2.5 GB which were collected during standard gastrointestinal examinations. The dataset includes images for polyp detection, localization and optical biopsy retargeting. Apart from endoscopy dataset for depth estimation, one of the laparoscopy datasets contains 40,000 pairs of rectified stereo images collected in partial nephrectomy using Da Vinci surgery robot. Its primary use has been training and testing deep learning networks for disparity (inverse depth) estimation [Ye et al., 2016], [Ye et al., 2017].
-
9.
ROBUST-MIS Challenge provides a dataset which was created in the Heidelberg University Hospital, Germany during rectal resection and proctocolectomy surgeries. Videos from 30 minimal invasive surgical procedures with three different types of surgery and extracted 10,040 standard endoscopic image frames from these 30 procedures performed a basis for this challenge. These images were acquired using a laparoscopic camera (Karl Storz Image 1) with a 30° optic and a resolution of 1920x1080 pixels. The images are, then, downscaled to 960x540 pixels and annotated with numbers showing the absence or presence of medical instruments [Rob, ].
Appendix C Camera Calibration
For the coordinate transformation between robot pose data and capsule cameras, hand-eye calibration procedure was repeated with two different checkerboards: one with squares and one with squares, both patterns with squares in total. Four images of each checkerboard were acquired from different camera poses. For the pose conversions, only the checkerboard images from Mirocam capsule was used, with the support structure being the same for both capsules (Pillcam and Mirocam). Similarly, to calculate the transformation between the gripper holding HighCam-LowCam and the camera positions, same procedure was repeated by using the checkerboard squares with .
The Tsai and Lenz algorithm[Tsai and Lenz, 1989] was tested with 24 combinations of the 4 chessboard images in Fig. C.1. The transformation between a point in the reference frame of the camera and a point in the reference frame of the gripper is, thus, given by
| (16) |
with the rotation matrices and translation vectors given in Table C.1.
| Camera | Rotation | Translation (mm) |
|---|---|---|
| MiroCam | ||
| HighCam | ||
| LowCam |
For the detailed description of vision based calibration technique and its written codes in MATLAB R2020a, visit https://github.com/CapsuleEndoscope/EndoSLAM. Calibration was performed for both the Mirocam and Pillcam capsules, using images of a planar checkerboard with squares of dimension and also for HighCam and LowCam using squares of dimension . The calibration checkerboard was printed using a laser printer and then glued on the surface of a glass plate to ensure the planarity of the pattern.
The practical distance and orientation range at which the calibration checkerboard can be placed is limited by the low resolution and depth of field of the cameras. For each camera, 10 calibration images were used with the pattern placed at different poses. The average distance from the camera was approximately for capsule cameras. Fig. C.1 show examples of some of the calibration images.



Table C.2 summarizes the estimated intrinsic parameters for each of the calibration models. Note that the Pillcam capsule has both a front-facing and a backwards-facing camera. That dual camera setup can lead to interesting novel visual SLAM approaches that makes simultaneous use of front- and backwards-facing cameras. The reprojection errors associated with each calibration can be seen in Fig. C.2. Fig. C.3 shows some examples for the application of estimated intrinsic parameters to correct the lens distortion effects on capsule images to produce undistorted pinhole images. Note that eight images were used due to the limited operational volume to place the chessboard. Outside that volume the images become either less focused/blurry or if too far the corners are undetectable due to low image quality and resolution.
| PillCam | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| HighCam | LowCam | High-Modified | Low-Modified | MiroCam | Cam1 | Cam2 | |||
| H x W | |||||||||
| Pinhole | Focal length | 957.4119 | 816.8598 | 603.5105 | 317.6319 | 156.0418 | 74.2002 | 76.0535 | |
| 959.3861 | 814.8223 | 807.6887 | 423.1068 | 155.7529 | 74.4184 | 75.4967 | |||
| Skew | 5.6242 | 0.2072 | 4.2831 | -0.3334 | 0 | 0 | 0 | ||
| Optical center | 282.1921 | 308.2864 | 173.7160 | 121.3764 | 178.5604 | 129.9724 | 130.9419 | ||
| 170.7316 | 158.3971 | 133.7022 | 82.5754 | 181.8043 | 129.1209 | 128.4882 | |||
| Radial dist. coef. | 0.2533 | 0.2345 | 0.2645 | 0.2265 | -0.2486 | 0.1994 | 0.1985 | ||
| -0.2085 | -0.7908 | -0.4186 | -0.8877 | 0.0614 | -0.1279 | -0.1317 | |||
Appendix D Temporal-Synchronization
The apparent velocity field in the image, i.e. the optical flow, is the projection of the 3D velocity of the scene (w.r.t. the camera), and is, in general, dependent on scene depth [Honegger et al., 2012]. In the dataset, the camera moves, roughly, in a straight line along its optical axis and with limited rotation, for the most part of the trajectory. The scene is also relatively uniform and symmetric, in terms of relative depth. To estimate this "forward" motion, the divergence of the flow vector field can be used [Ho et al., 2017, McCarthy et al., 2008]. To provide insight, Fig. D.1a shows the divergent optical flow field that would be obtain as a pinhole camera moves towards a frontal-parallel plane. Fig. D.1b shows an example, obtained from the dataset, of divergent optical flow in image areas of high contrast.
The divergence at an image point is given by
| (17) |
where and are the velocity components of the optical flow field and denotes a partial derivative. The divergence measurement is averaged across all points, yielding a single estimated value for each image. MATLAB was used to compute the optical flow and the flow divergence, using the method in [Lucas and Kanade, 1981].
The robot encoder data provides the camera pose along the trajectory. The linear velocity is computed by applying a finite difference on the position data, followed by a low pass filter [Liu, 2002, Puglisi, 2015]. Specifically, the camera velocity is obtained from
| (18) |
where denotes the 3D position vector, denotes the sampling period, and the subscript indexes the sample instant. A low pass Butterworth filter (with a cutoff frequency of 300Hz) is then applied to the velocity measurement in order to reduce noise.
The optical flow divergence and camera velocity measurements are correlated along the time axis to determine the best alignment. As an example, Fig. D.1c shows the camera velocity (magnitude) during sequence/experiment for the sixth sequence of MiroCam record, calculated from the robot position data and estimated from the divergence of the optical flow field in the images. Both signals are shown already synchronized. Fig. D.1 d shows a detail of the plot corresponding to the end of the trajectory, when the camera stops moving.
Table D.1 and D.2 summarize the temporal synchronization for all trajectories in the dataset. They provide a correspondence between the start frame of each sequence and the matching sampling instant of the robot pose data.
| Camera | Robot | ||||
|---|---|---|---|---|---|
| Organ | Trajectory | HighCam Start Frame | LowCam Start Frame | HighCam Sample | LowCam Sample |
| Colon-IV | 1 | 741 | 393 | 35,295 | 15,845 |
| 2 | 44 | 128 | 2,561 | 2,561 | |
| 3 | 69 | 82 | 3,975 | 3,975 | |
| 4 | 138 | 120 | 15,792 | 15,092 | |
| 5 | 99 | 144 | 1,270 | 3,270 | |
| SmallIntestine | 1 | 149 | 95 | 5,162 | 4,512 |
| 2 | 133 | 112 | 4,913 | 2,763 | |
| 3 | 186 | 144 | 6,095 | 7,845 | |
| 4 | 121 | 79 | 3,205 | 3,205 | |
| 5 | 138 | 105 | 3,807 | 3,307 | |
| Stom-I | 1 | 60 | 135 | 4,443 | 8,093 |
| 2 | 111 | 144 | 4,177 | 2,277 | |
| 3 | 71 | 447 | 6,058 | 19,008 | |
| 4 | 47 | 316 | 2,839 | 13,289 | |
| Stom-II | 1 | 255 | 125 | 9,641 | 5,141 |
| 2 | 1 | 2 | 3,358 | 3,358 | |
| 3 | 150 | 83 | 5,797 | 2,247 | |
| 4 | 78 | 85 | 2,742 | 4,192 | |
| Stom-III | 1 | 195 | 89 | 6,746 | 2,846 |
| 2 | 302 | 108 | 1,523 | 2,725 | |
| 3 | 387 | 105 | 17,261 | 2,861 | |
| 4 | 125 | 60 | 4,451 | 2,101 | |
| Camera | Robot | ||||
|---|---|---|---|---|---|
| Sequence | start frame | framerate | sample instant | sampl. freq. | |
| Mirocam | 1 | 336 | 3 fps | 72,050 | 1kHz |
| 2 | 153 | 3 fps | 961 | 1kHz | |
| 3 | 321 | 3 fps | 47,667 | 1kHz | |
| 4 | 143 | 3 fps | 33,943 | 1kHz | |
| 5 | 254 | 3 fps | 2,886 | 1kHz | |
| 6 | 134 | 3 fps | 3,044 | 1kHz | |
| Pillcam | "L" | 1,127 | 0.117 fps | 15,800 | 1kHz |
| "Z" | 815 | 0.117 fps | 11,650 | 1kHz | |
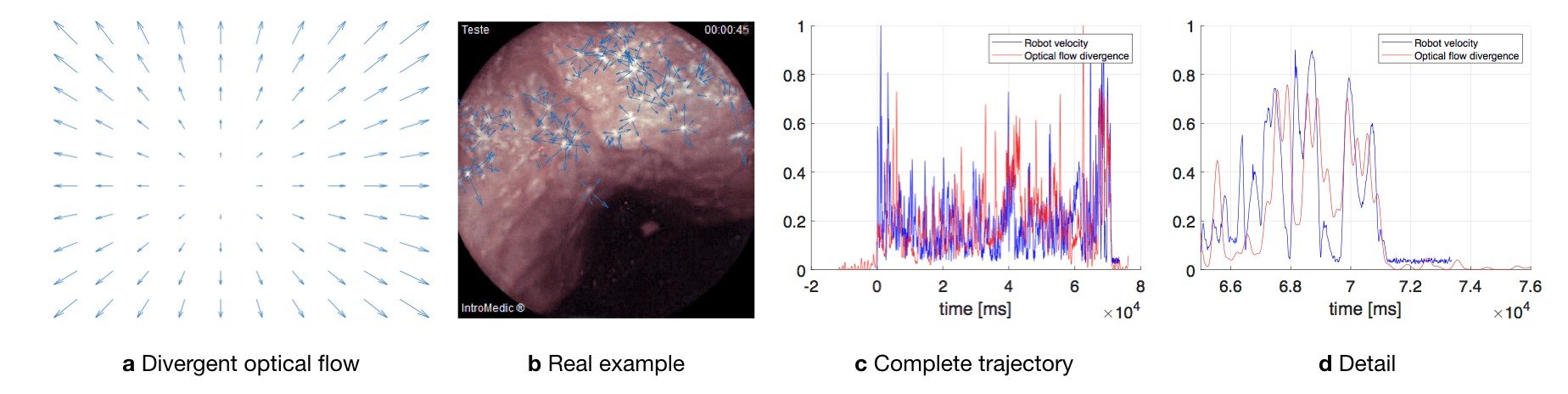
Appendix E Data Tree Structure

Appendix F Dataset Analysis
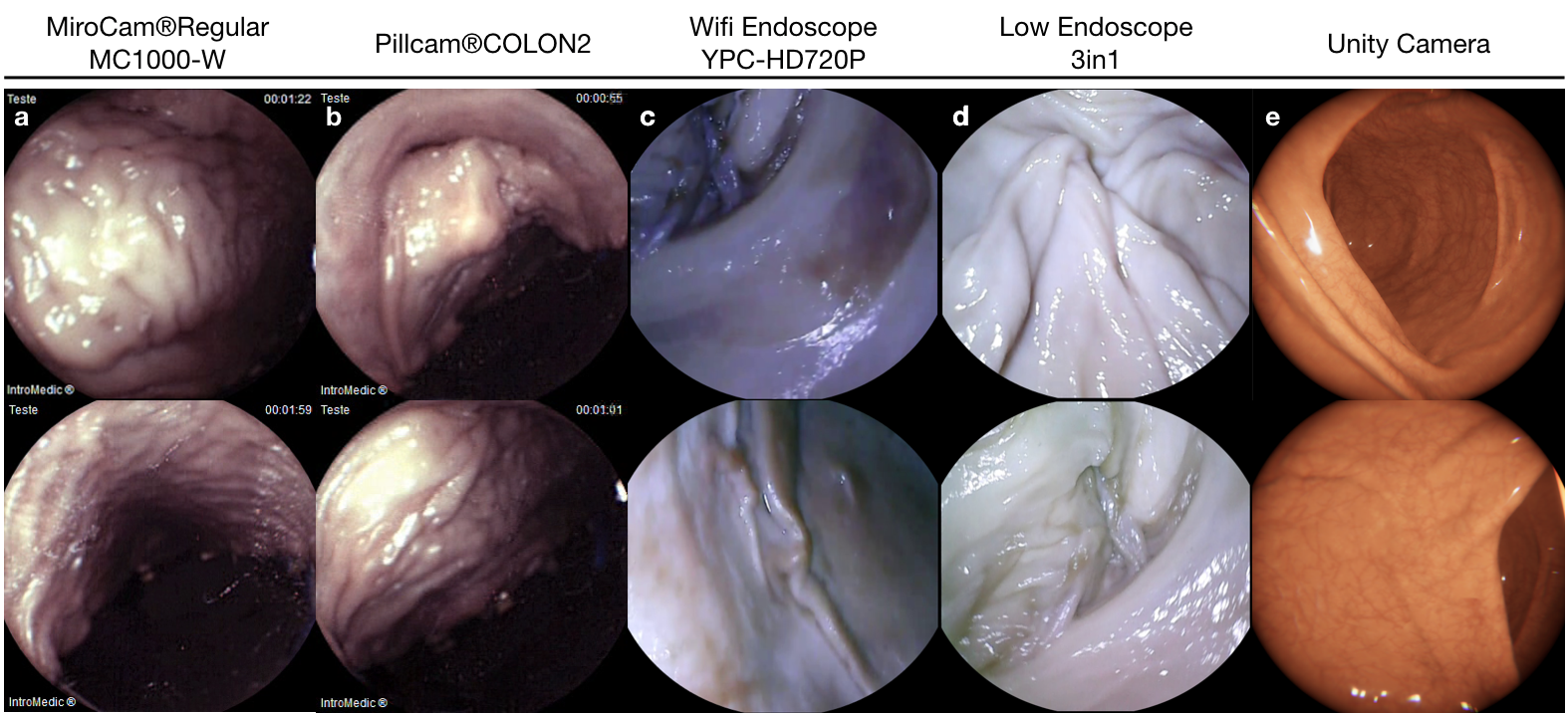
| Speed | Stomach-I | Stomach-II | Stomach-III | Small Intestine | Colon-IV | |
|---|---|---|---|---|---|---|
| frame count | 4695 | 3302 | 3230 | 6487 | 3697 | |
| mean[mm/s] | 18.256 | 19.471 | 20.031 | 16.764 | 17.123 | |
| std[mm/s] | 22.497 | 16.809 | 16.697 | 14.210 | 12.660 | |
| 1st QT | 5.931 | 7.606 | 7.055 | 5.684 | 7.658 | |
| median | 14.642 | 16.021 | 16.489 | 13.849 | 15.096 | |
| 3rd QT | 25.32 | 26.64 | 28.68 | 24.342 | 24.324 | |
| min[mm/s] | 0.02 | 0.028 | 0.02 | 0 | 0.007 | |
| max[mm/s] | 25.32 | 140.898 | 116.984 | 104.08 | 104.759 | |
| Acceleration | mean[mm/s] | 359.843 | 382.928 | 383.829 | 328.568 | 326.241 |
| std | 450.939 | 337.08 | 336.098 | 284.423 | 257.08 | |
| 1st QT | 110.408 | 140.982 | 111.71 | 103.129 | 122.807 | |
| median | 284.729 | 314.784 | 315.012 | 269.316 | 283.728 | |
| 3rd QT | 501.31 | 528.799 | 556.451 | 477.991 | 469.113 | |
| min[mm/s] | 0.4 | 0.0 | 0.0 | 0.0 | 0.015 | |
| max[mm/s] | 14,680.15 | 2,817.962 | 2,339.683 | 2,079.994 | 2,095.182 |
| Speed | Stomach-I | Stomach-II | Stomach-III | Small Intestine | Colon-IV | |
|---|---|---|---|---|---|---|
| frame count | 2302 | 2799 | 3900 | 5098 | 3857 | |
| mean[mm/s] | 15.599 | 18.928 | 25.97 | 17.918 | 17.144 | |
| std[mm/s] | 12.855 | 14.431 | 21.564 | 14.764 | 12.882 | |
| 1st QT | 5.407 | 8.259 | 10.789 | 6.126 | 7.401 | |
| median | 13.18 | 15.871 | 21.284 | 15.322 | 15.148 | |
| 3rd QT | 22.956. | 26.436 | 35.763 | 26.146 | 24.455 | |
| min[mm/s] | 0.02 | 0.0 | 0.02 | 0.0 | 0.028 | |
| max[mm/s] | 79.042 | 103.254 | 286.68 | 97.315 | 106.271 | |
| Acceleration | mean[mm/s] | 279.254 | 378.346 | 519.361 | 334.373 | 355.941 |
| std | 253.777 | 288.769 | 431.327 | 295.646 | 259.482 | |
| 1st QT | 66.573 | 164.972 | 215.786 | 119.299 | 130.256 | |
| median | 221.297 | 317.344 | 425.678 | 303.582 | 291.994 | |
| 3rd QT | 428.253 | 528.695 | 715.263 | 520.839 | 482.864 | |
| min[mm/s] | 0.4 | 0.0 | 0.0 | 0.0 | 0.015 | |
| max[mm/s] | 1,580.846 | 2.065,071 | 5,733.593 | 1,946.305 | 2,125.42 |
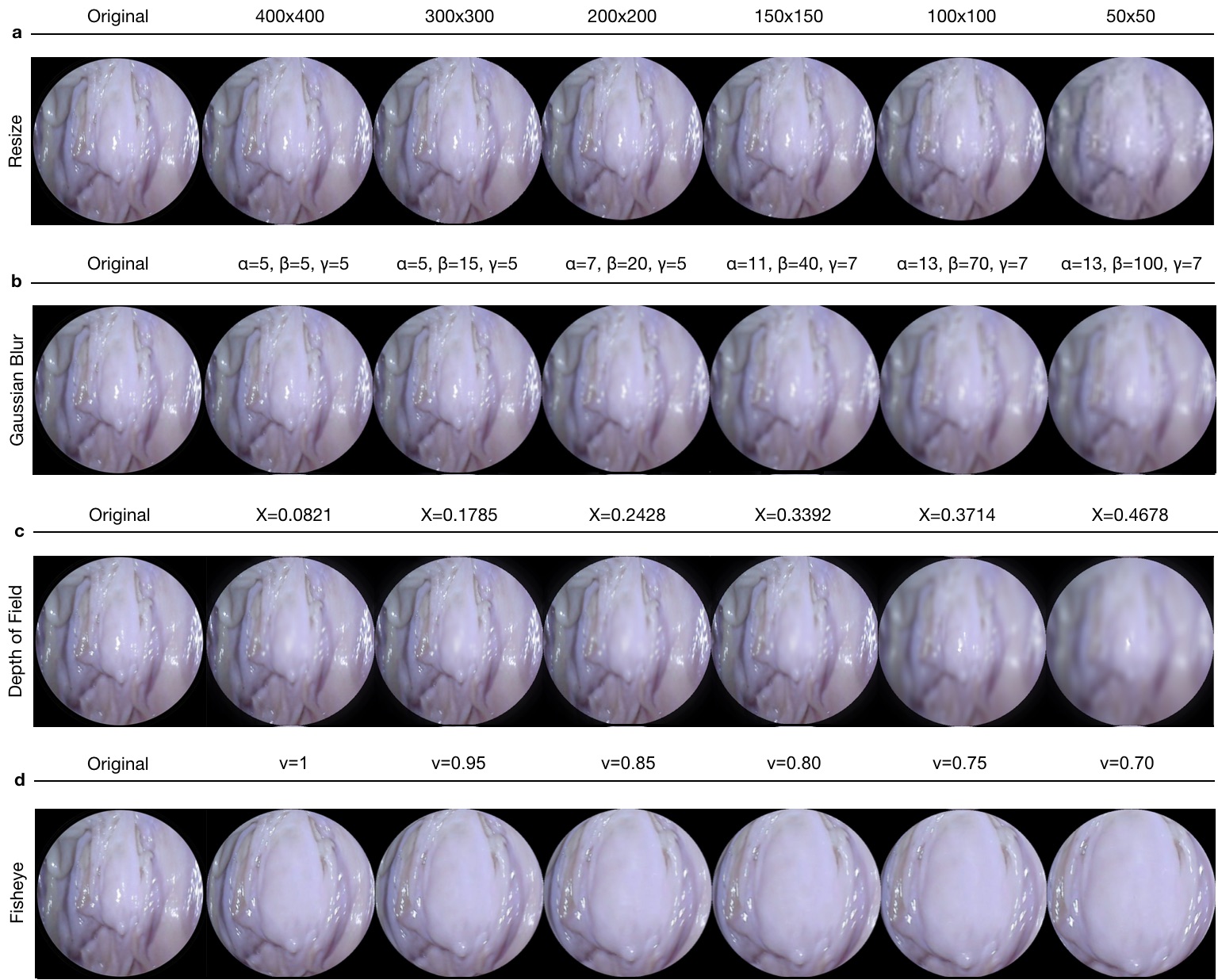
| Organs | Tumor-free Trajectory # | Tumor-containing Trajectory # |
|---|---|---|
| Colon-I | I,II,III, | IV |
| Colon-II | I,III,IV,V | VI,VII |
| Colon-III | I,II | III |
| Colon-IV | I,II,III,IV,V | - |
| Stomach-I | I,II,III,IV | - |
| Stomach-II | I,II,III,IV | - |
| Stomach-III | I,II,III,IV | - |
| Small Intestine | I,II,III,IV,V | - |
| Organ | 3D Point Count | Scanner | Precision |
|---|---|---|---|
| Colon-IV | 2,106,046 | 3D EinScan Pro 2x | |
| Small Intestine | 2,193,364 | 3D EinScan Pro 2x | |
| Stomach-I | 2,597,906 | 3D EinScan Pro 2x | |
| Stomach-II | 5,729,625 | 3D EinScan Pro 2x | |
| Stomach-III | 2,234,849 | 3D EinScan Pro 2x | |
| Colon-III | 151,846 | Artec 3D Eva |
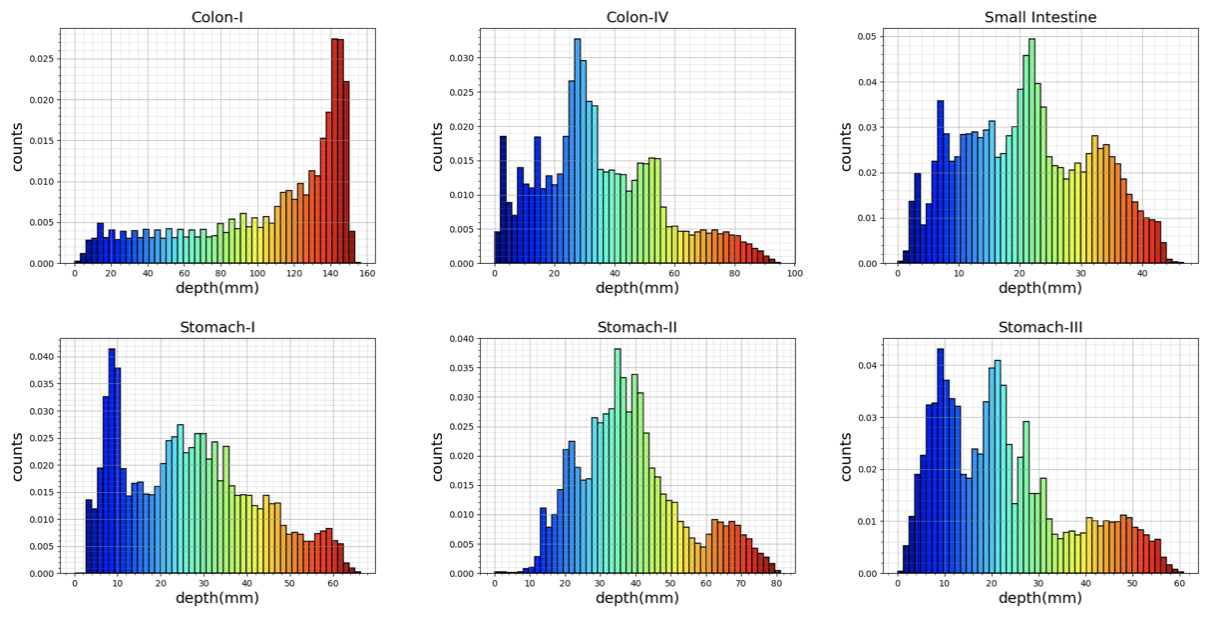
Appendix G Results