Energetic Variational Gaussian Process Regression for Computer Experiments
Abstract
The Gaussian process (GP) regression model is a widely employed surrogate modeling technique for computer experiments, offering precise predictions and statistical inference for the computer simulators that generate experimental data. Estimation and inference for GP can be performed in both frequentist and Bayesian frameworks. In this chapter, we construct the GP model through variational inference, particularly employing the recently introduced energetic variational inference method by Wang et al. (2021). Adhering to the GP model assumptions, we derive posterior distributions for its parameters. The energetic variational inference approach bridges the Bayesian sampling and optimization and enables approximation of the posterior distributions and identification of the posterior mode. By incorporating a normal prior on the mean component of the GP model, we also apply shrinkage estimation to the parameters, facilitating mean function variable selection. To showcase the effectiveness of our proposed GP model, we present results from three benchmark examples.
1 Introduction
Uncertainty Quantification (Ghanem et al., 2017) is a highly interdisciplinary research domain that involves mathematics, statistics, optimization, advanced computing technology, and various science and engineering disciplines. It provides a computational framework for quantifying input and response uncertainties and making model-based predictions and their inferences for complex science or engineering systems/processes. One fundamental research problem in uncertainty quantification is to analyze computer experimental data and build a surrogate model for the computer simulation model. Gaussian process (GP) regression model, sometimes known as “kriging”, has been widely used for this purpose since the seminal paper by Sacks et al. (1989).
In this book chapter, we plan to re-introduce Gaussian process models under the Bayesian framework. Among the various model assumptions, we choose the one from Santner et al. (2003). It has a mean function that can be helpful in model interpretation and an anisotropic covariance function that provides more flexibility to improve prediction accuracy. Different from most existing works on Bayesian GP models, we provide an alternative computational tool based on variational inference to replace the common Markov Chain Monte Carlo (MCMC) sampling method. Specifically, we propose using a particle-based energetic variational inference approach (EVI) developed in Wang et al. (2021) to generate samples and approximate the posterior distribution. For short, we name the method EVI-GP. Depending on the number of particles, EVI-GP can be used to compute the maximum a posteriori (MAP) estimate of the parameters or obtain a large number of samples to approximate the posterior distribution of the parameters. The estimations and inference of parameters and predictions can be obtained from the MAP estimate or the posterior samples. Thanks to the conjugate prior of the regression coefficients of the mean function, -regularization is adopted to achieve model sparsity for the mean function of the GP.
The rest of the chapter is organized as follows. In Section 2, we review the Gaussian process model, including its assumption and prior distributions, and derive the posterior and posterior predictive distributions. In Section 3, the preliminary background on variational inference and the particle energetic variational inference methods are briefly reviewed. The EVI-GP method is also summarized at the end of this section. Section 4 shows three main simulation examples in which different versions of EVI-GP are compared with other existing methods. The chapter concludes in Section 5.
2 Gaussian Process Regression: Bayesian Approach
2.1 Gaussian Process Assumption
Denote as the pairs of input and output data from a certain computer experiment, and are the th experimental input values and is the corresponding output. In this chapter, we only consider the case of univariate response, but the proposed EVI-GP can be applied to the multi-response GP model which involves the cross-covariance between responses (Cressie, 2015).
Gaussian process regression is built on the following model assumption of the response,
| (1) |
where is a -dim vector of user-specified basis functions and is the -dim vector of linear coefficients corresponding the basis functions. Usually, contains the polynomial basis functions of up to a certain order. For example, if , contains the intercept, the linear, the quadratic and the interaction effects of the two input variables. The random noise ’s are independently and identically distributed following . They are also independent of the other stochastic components of (1). We assume the GP prior on the stochastic function , which is denoted as , i.e., and the covariance function
In most applications of computer experiments, we use the stationary assumption of , and thus the variance is a constant. The function is the correlation of the stochastic process with hyperparameters . For it to be valid, must be a symmetric positive definite kernel function. Gaussian kernel function is one of the most commonly used kernel functions and its definition is
with and . Although we only demonstrated the examples using the Gaussian kernel, the EVI-GP method can be applied in the same way for other kernel functions.
In terms of response , it follows a Gaussian Process with the following mean and covariance,
| (2) | ||||
| (3) | ||||
| (4) |
where if and 0 otherwise, and . So is interpreted as the noise-to-signal ratio. For deterministic computer experiments, the noise component is not part of the model, i.e., . However, a nugget effect, which is a small value, is usually included in the covariance function to avoid the singularity of the covariance matrix (Peng and Wu, 2014). The unknown parameter values of the GP model are . We are going to show how to obtain the estimation and inference of the parameters using the Bayesian framework.
2.2 GP under Bayesian Framework
We assume the following prior distributions for the parameters ,
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
These distribution families are commonly used in the literature such as Gramacy and Lee (2008); Gramacy and Apley (2015). However, the choice of parameters of the prior distributions should require fine-tuning using testing data or cross-validation procedures. In some literature, parameters , , and are considered to be hyperparameters. The conditional posterior distribution of given data and is a multivariate normal distribution, which is shown later.
Next, we derive the posterior distributions and some conditional posterior distributions. Based on the data, the sampling distribution is
| (9) |
where is the vector of ’s and is a matrix of row vectors ’s. The matrix is the kernel matrix with entries and is a symmetric and positive definite matrix, and is an identity matrix. The density function of is
| (10) |
Following Bayes’ Theorem, the joint posterior distribution of all parameters is
The conditional posterior distribution of can be easily obtained through conjugacy. It is also straightforward to obtain the posterior distribution as shown in the appendix. The results are summarized in Proposition 1.
Proposition 1.
The posterior distribution of can be significantly simplified if a non-informative prior is used for , as described in Proposition 2.
Proposition 2.
If using a non-informative prior distribution for , i.e., , and the prior distributions (6)-(8) for the remaining parameters, the conditional posterior distribution of is still , but the covariance and mean are
The conditional posterior distribution for is
| (14) |
where
The marginal posterior of is
| (15) |
If we use non-informative prior distributions for all the parameters, i.e., , for , , and , the Bayesian framework is equivalent to the empirical Bayesian or maximum likelihood estimation method. The GP regression model estimated via this frequentist approach is common in both methodology research and application (Santner et al., 2003; Fang et al., 2005; Gramacy, 2020). In this chapter, we consider the empirical Bayesian estimation as a special case of the Bayesian GP model. The choice between the two different types of prior distributions for , informative or non-informative, is subject to the dimension of the input variables, the assumption on basis functions , the goal of GP modeling (accurate prediction v.s. interpretation), and sometimes the application of the computer experiment. Both types have their unique advantages and shortcomings. The non-informative prior distribution for reduces the computation involved in the posterior sampling for , but we would lose the regularization effect on brought by the informative prior .
One issue with the informative prior distribution is to choose its parameters, i.e., the constant variance and the correlation matrix . Here we recommend using a cross-validation procedure to select . If the mean function is a polynomial function of the input variables, we specify the matrix to be a diagonal matrix , where is a user-specified parameter. The power index of is the same as the order of the corresponding polynomial term. For example, if with is a full quadratic model and contains the terms , the corresponding prior correlation matrix should be specified as . In this way, the prior variance of the effect decreases exponentially as the order of effect increases, following the effect hierarchy principle (Hamada and Wu, 1992; Wu and Hamada, 2021). It states that lower-order effects are more important than higher-order effects, and the effects of the same order are equally important. The hierarchy ordering principle can reduce the size of the model and avoid including higher-order and less significant model terms. Such prior distribution was firstly proposed by Joseph (2006), and later used in Kang and Joseph (2009); Ai et al. (2009); Kang et al. (2018); Kang and Huang (2019); Kang et al. (2021, 2023).
Proposition 3.
Given the parameters , the posterior predictive distribution of at any query point is the following normal distribution.
| (16) |
where
| (17) | ||||
| (18) |
where
For non-informative prior, the posterior predictive distribution is the same except is replaced by .
Thanks to the Gaussian process assumption and the conditional conjugate prior distributions for and , Proposition 1, 2, and 3 give the explicit and easy to generate conditional posterior distribution of (and ) and posterior predictive distribution. Therefore, how to generate samples from in (13) or in (15) is the bottleneck of the computation for GP models. Since and are not from any known distribution families, Metropolis-Hastings (MH) algorithm (Robert et al., 1999; Gelman et al., 2014), Hamiltonian Monte Carlo (HMC) (Neal, 1996), or Metropolis-adjusted Langevin algorithm (MALA) can be used to for sampling (Roberts and Rosenthal, 1998). In this chapter, we introduce readers to an alternative computational tool, namely, a variational inference approach to approximate the posterior distribution or . More specifically, we plan to use energetic variational inference, a particle method, to generate posterior samples.
3 Energetic Variational Inference Gaussian Process
Variational inference-based GP models have been explored in prior works such as Tran et al. (2016), Cheng and Boots (2017), and Wynne and Wild (2022). Despite sharing the variational inference idea, the proposed Energetic Variational Inference (EVI) GP differs significantly from these existing methods regarding the specific variational techniques employed. Tran et al. (2016) utilized auto-encoding, while Cheng and Boots (2017) and Wynne and Wild (2022) employed the mean-field variational inference (Blei et al., 2017).
The EVI approach presented in this chapter is a newly introduced particle-based method. It offers simplicity in implementation across diverse applications without the need for training any neural networks. Notably, EVI establishes a connection between the MAP procedure and posterior sampling through a user-specified number of particles. In contrast to the complexity of auto-encoding variational methods, the particle-based approach is much simpler, devoid of any network intricacies. Moreover, in comparison to mean-field methods, both particle-based and MAP-based approaches (auto-encoding falls into the MAP-based category) can exhibit enhanced accuracy, as they do not impose any parametric assumptions on a feasible family of distributions in the optimization to solve the variational problem.
This section provides a brief introduction to the Energetic Variational Inference (EVI) approach. Subsequently, we adapt this method for the estimation and prediction of the GP regression model.
3.1 Preliminary: Energetic Variational Inference
Motivated by the energetic variational approaches for modeling the dynamics of non-equilibrium thermodynamical systems (Giga et al., 2017), the energetic variational inference framework uses a continuous energy-dissipation law to specify the dynamics of minimizing the objective function in machine learning problems. Under the EVI framework, a practical algorithm can be obtained by introducing a suitable discretization to the continuous energy-dissipation law. This idea was introduced and applied to variational inference by Wang et al. (2021). It can also be applied to other machine learning problems similar to Trillos and Sanz-Alonso (2020) and E et al. (2020).
We first introduce the EVI using the continuous formulation. Let be the dynamic flow map at time that continuously transforms the -dimensional distribution from an initial distribution toward the target one and we require the map to be smooth and one-to-one. The functional is a user-specified divergence or other machine learning objective functional, such as the KL-divergence in Wang et al. (2021). Taking the analogy of a thermodynamics system, is the Helmholtz free energy. Following the First and Second Law of thermodynamics (Giga et al., 2017) (kinetic energy is set to be zero)
| (19) |
where is a user-specified functional representing the rate of energy dissipation, and is the derivative of with time . So can be interpreted as the “velocity” of the transformation. Each variational formulation gives a natural path of decreasing the objective functional toward an equilibrium.
The dissipation functional should satisfy so that decreases with time. As discussed in Wang et al. (2021), there are many ways to specify and the simplest among them is a quadratic functional in terms of ,
where denotes the pdf of the current distribution which is the initial distribution transformed by , is the current support, and for . This simple quadratic functional is appealing since it has a simple derivative, i.e.,
where is the variation operator, i.e., functional derivative.
With the specified energy-dissipation law (19), the energy variational approach derives the dynamics of the systems through two variational procedures, the Least Action Principle (LAP) and the Maximum Dissipation Principle (MDP), which leads to
The approach is motivated by the seminal works of Raleigh (Rayleigh, 1873) and Onsager (Onsager, 1931a, b). Using the quadratic , the dynamics of decreasing is
| (20) |
In general, this continuous formulation is difficult to solve, since the manifold of is of infinite dimension. Naturally, there are different approaches to approximate an infinite-dimensional manifold by a finite-dimensional manifold. One such approach, as used in Wang et al. (2021), is to use particles (or samples) to approximate the in (19) with kernel regularization, before any variational steps. It leads to a discrete version of the energy-dissipation law, i.e.,
| (21) |
Here is the locations of particles at time and is the derivative of with , and thus is the velocity of the th particle as it moves toward the target distribution. The subscript of and denotes the bandwidth parameter of the kernel function used in the kernelization operation. Applying the variational steps to (21), we obtain the dynamics of decreasing at the particle level,
| (22) |
This leads to an ODE system of and can be solved by different numerical schemes. The solution is the particles approximating the target distribution.
Due to limited space, we can only briefly review the EVI framework and explain it intuitively. Readers can find the rigorous and concrete explanation in Wang et al. (2021). It also suggested many different ways to specify the energy dissipation, the ways to approximate the continuous formulation, and different ways to solve the ODE system.
3.2 EVI-GP
In this chapter, we use the KL-divergence as the energy functional as demonstrated in Wang et al. (2021),
| (23) |
where is the density function of the target distribution with support region and is to approximate . For EVI-GP, is the posterior distribution of or .
Using the KL-divergence, the divergence functional at time is
where , which is known up to a scaling constant. The discrete version of the energy becomes
| (24) |
and the discrete dissipation is
| (25) |
Applying variational step to (21), we obtain (22) which is equivalent to the following nonlinear ODE system:
| (26) |
for . The iterative update of particles involves solving the nonlinear ODE system (26) via optimization problem (27) at the -th iteration step
| (27) |
where
| (28) |
Wang et al. (2021) emphasized the advantages of using the Implicit-Euler solver for enhanced numerical stability in this process. We summarize the algorithm of using the implicit Euler scheme to solve the ODE system (26) into Algorithm 1. Here MaxIter is the maximum number of iterations of the outer loop. The optimization problem in the inner loop is solved by L-BFGS in our implementation.
We propose two adaptations of the EVI-Im algorithm for GP model estimation and prediction. The first approach involves generating particles using Algorithm 1 to approximate the posterior when an informative normal prior distribution is adopted for , or when a non-informative prior distribution is used for . These particles serve as posterior samples. Conditional on their values, we can generate samples for based on its conditional posterior distribution (Proposition 1) or generate samples for both and according to their conditional posterior distribution (Proposition 2). Following Proposition 3, we can generally predict and confidence intervals conditional on the posterior samples.
In the second approach, we employ EVI-Im solely as an optimization tool for Maximum A Posteriori (MAP), entailing the minimization of . This can be done by simply setting the free energy as and . As a result, the optimization problem (27) at the th iteration becomes
which is the celebrated proximal point algorithm (PPA) Rockafellar (1976). Therefore, EVI is a method that connects the posterior sampling and MAP under the same general framework. Based on the MAP, we can obtain the posterior mode for (or and ) and the mode of the prediction and the corresponding inference based on the posterior mode. For short, we name the first approach EVI-post and the second EVI-MAP.
4 Numerical Examples
In this section, we demonstrate the performances of EVI-GP and compare it with three commonly used GP packages in R, which are gpfit (MacDonald et al., 2015), mlegp (Dancik and Dorman, 2008), laGP (Gramacy and Apley, 2015; Gramacy, 2016).
The comparison is illustrated via three examples.
The first one is a 1-dim toy example and the other two are the OTL Circuit and Borehole examples chosen from the online library built by Surjanovic and Bingham (2013).
All three examples are frequently used benchmarks in the computer experiment literature.
The codes for EVI-GP and all the examples are available on GitHub with the link. https://github.com/XavierOwen/EVIGP
The EVI-GP is implemented in Python.
The proximal point optimization in Algorithm 1 is solved by the LBFGS function of Pytorch library (Paszke et al., 2019).
Some arguments of the EVI-GP codes are set the same for all three examples.
The argument history_size of the LBFGS function is set to 50 and to perform line search, line_search_fn is set to strong_wolfe, the strong Wolfe conditions.
In the EVI algorithm, the maximum allowed iteration of the inner loop is set to 100 and the maximum allowed iteration of the outer loop (or maximum epoch) is set to 500.
The outer loop of the EVI is terminated either when the maximum epoch is reached or when the convergence condition is achieved.
We consider the convergence is achieved if and .
These parameter settings are done through many experiments and they lead to satisfactory performance in the following examples.
In each example, we use the same pair of training and testing datasets for all the methods under comparison.
The designs for both datasets are generated via maximinLHS procedure from the lhs package in R (Carnell, 2022).
We run 100 simulations.
In each simulation, we compute the standardized Root Mean Square Prediction Error (RMSPE) on the test data set, which is defined as follows
where is the predicted value at the test point and is the corresponding true value. Box plots of the 100 standardized RMSPEs of all methods are shown for comparison.
4.1 One-Dim Toy Example
In the one-dim example, the data are generated from the test function for The size of the training and test data sets are and , respectively. The variance of the noise is .
The parameters of the prior distributions of the EVI-GP are , , and which is equivalent to . We consider two possible mean functions for the GP model, the constant mean and the linear mean . There is no need for parameter regularization for these simple mean functions, and thus we use non-informative prior for . We use the EVI-post to approximate and set the number of particles , kernel bandwidth and stepsize in the EVI procedure. The initial particles are sampled from the uniform distribution in . Figure 1 and 2 show the posterior modes and particles returned by EVI-MAP and EVI-post, as well as the prediction and predictive confidence interval returned by both methods.
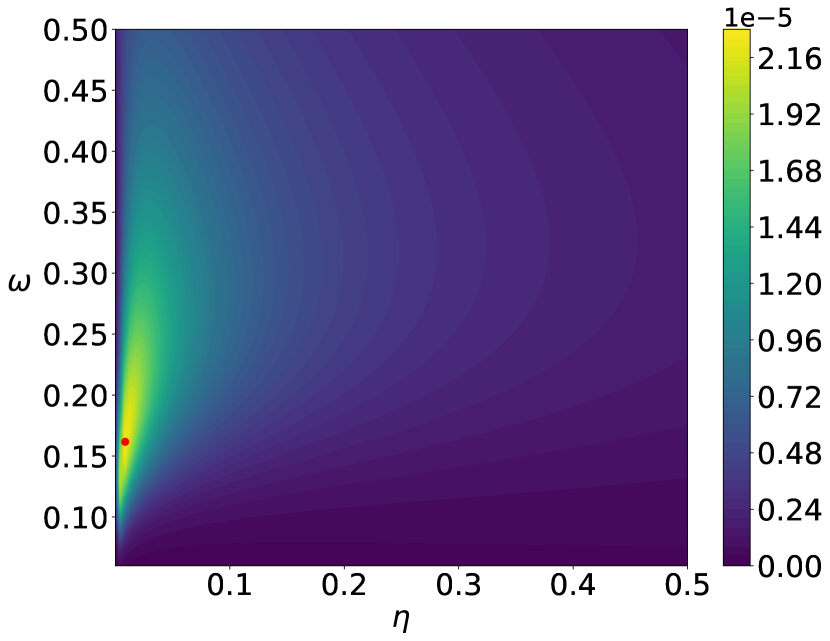
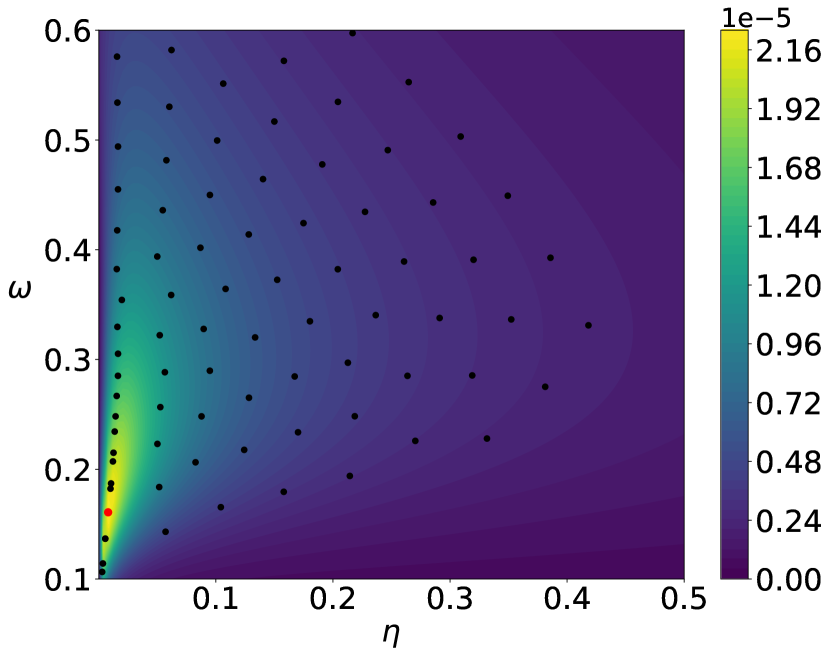
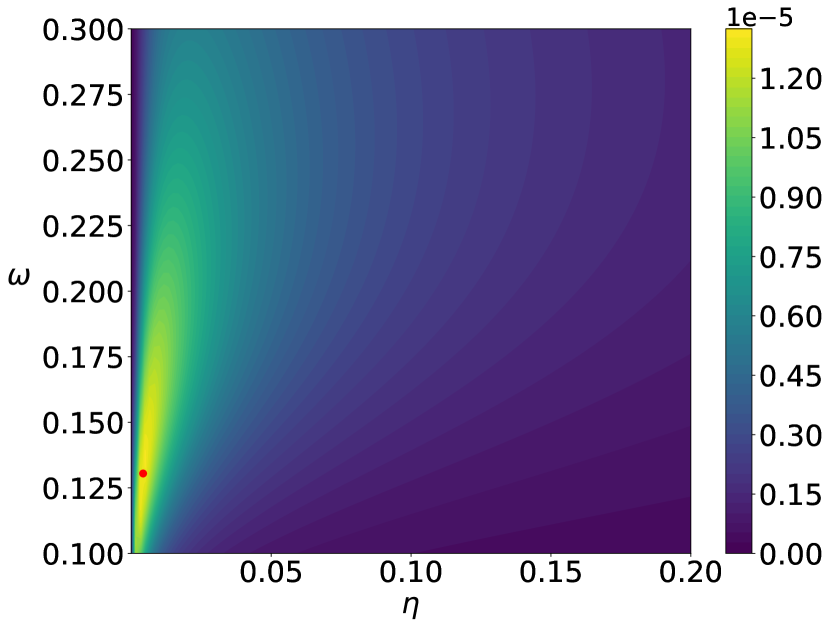
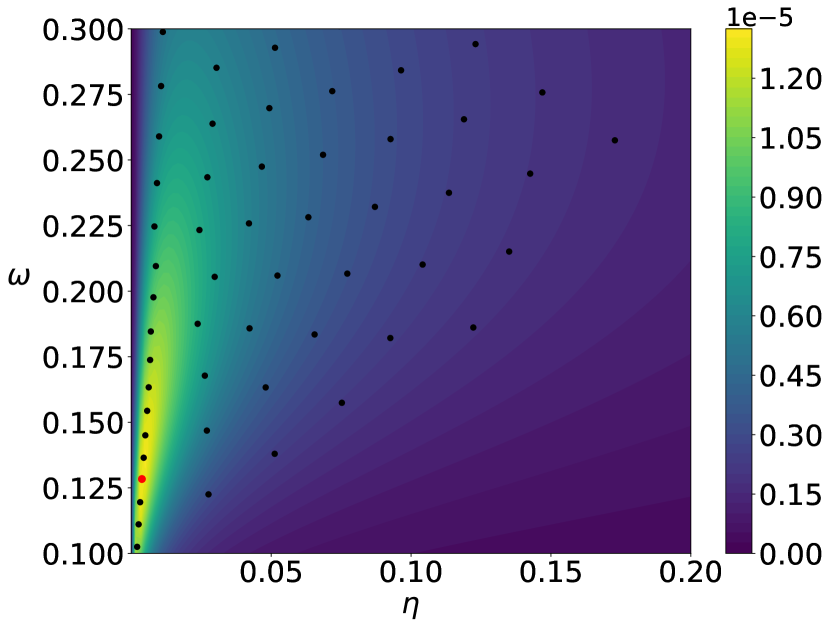
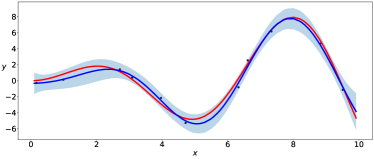
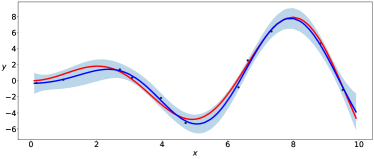
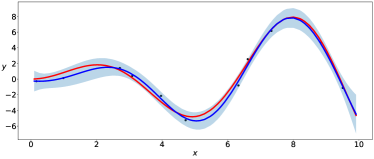
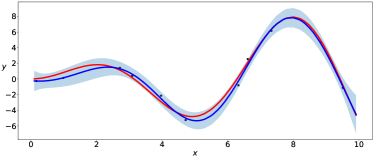
We compare the EVI-GP with three R packages.
For the gpfit package, we set the nugget threshold to be , corresponding to in our method, and the correlation is the Gaussian kernel function.
For the mlegp package, we set the argument constMean to be 0 for the constant mean model and 1 for the linear mean model.
The optimization-related arguments in mlegp are set as follows.
The number of simplexes tries is 5.
Each simplex maximum iteration is 5000.
The relative tolerance is , BFGS maximum iteration is 500, BFGS tolerance is , and BFGS bandwidth is .
Other parameters in these two packages are set to default.
For the laGP package, we set the argument start at 6, end at 10, d at null, g at , method to a list of ”alc”, ”alcray”, ”mspe”, ”nn”, ”fish”, and Xi.ret at True.
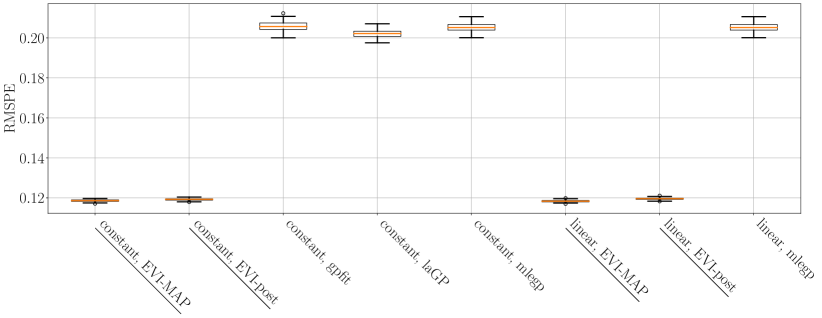
The comparison in terms of prediction accuracy is shown in Table 1 and Figure 3.
Table 1 shows the mean of RMSPEs from 100 simulations and Figure 3 shows the box plots of the RMSPEs.
In the third column of Table 1, we only list the best result from the three R packages.
The prediction accuracy of both versions of the EVI-GP performs almost equally well and both significantly outperform the three R packages.
| Mean Model | EVI-post | EVI-MAP | gpfit/mlegp/lagp |
|---|---|---|---|
| Constant | 0.1310 | 0.1311 | 0.1500 |
| Linear | 0.1195 | 0.1194 | 0.1584 |
4.2 OTL-Circuit function
We test the proposed method using the OTL-circuit function of input dimension . The OTL-circuit function models an output transformerless push-pull circuit. The function is defined as follows,
where , is the resistance of b1 (K-Ohms), is the resistance of b2 (K-Ohms), is the resistance of f (K-Ohms), is the resistance of c1 (K-Ohms), is the resistance of c2 (K-Ohms) and is the current gain (Amperes).
The size of training and testing datasets is 200 and 1000, respectively. We set the variance of the noise . For the prior distributions of , we let for , but . The prior distribution of . Both non-informative and informative prior distributions are considered. When using the informative prior, we set and for the prior distribution of and . For the variance of the prior distribution of , we choose , which was the result of 5-fold cross-validation when the biggest mean model is used. After variable selection, the 5-fold cross-validation is conducted again to find the optimal to fit the finalized GP model, which leads to . In both cross-validation procedures, is searched in an evenly spaced grid from 0 to 5 with grid size.
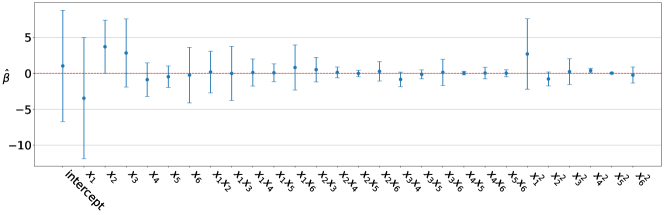
For both EVI-post and EVI-MAP, we set and . For the EVI-post approach, we use particles, and the initial particles of are sampled uniformly in . The two versions of EVI-GP perform very similarly, so we only return the result of EVI-MAP. The initial mean model of the GP is assumed as a quadratic function of the input variables, including the 2-way interactions. Based on the posterior confidence interval in Figure 4 of the , we select and as the significant terms to be kept for the final model.
For comparison, we choose the R package mlegp because only this package allows the specification of the mean model.
We set the argument constMean to be 0 for the constant mean and 1 for the linear mean model.
For the full quadratic mean model, we manually add all the second-order effect terms as the input and set constMean to 1.
Unfortunately, the input of the mean and correlation cannot be separately specified in mlegp.
So once we specify the mean part to have all the quadratic terms, the input of the correlation function also contains the quadratic terms.
But we believe this might give more advantage for mlegp because the correlation involves more input variables.
If some of the variables are not needed, their corresponding correlation parameter estimated by mlegp can be close to zero.
The other arguments in mlegp are set in the same way as the previous example.
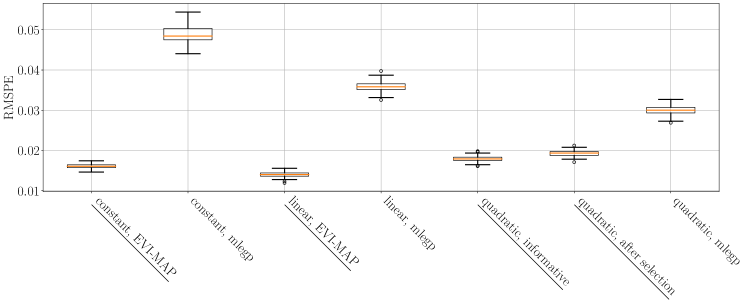
Table 2 compares the mean of 100 standardized RMSPEs of the 100 simulations of EVI-GP and mlegp and Figure 5 shows the box plots of the RMSPEs of different models returned by the two methods.
The EVI-GP is much more accurate than mlegp package in terms of prediction.
However, for this example, variable selection does not improve the model in terms of prediction.
The most accurate model is the GP with a linear function of the input variables as the mean model.
| Type of mean | EVIGP | mlegp |
|---|---|---|
| Constant | 0.01608 | 0.04882 |
| Linear | 0.01399 | 0.03584 |
| Quadratic | 0.01792 | 0.03006 |
| Quadratic, after selection | 0.01625 | N/A |
4.3 Borehole function
In this subsection, we test the EVI-GP with the famous Borehole function, which is defined as follows:
where is the radius of the borehole (m), is the radius of influence (m), is the transmissivity of the upper aquifer (m2/yr), is the potentiometric head of upper aquifer (m), is the transmissivity of the lower aquifer (m2/yr), is the potentiometric head of lower aquifer (m), is the length of the borehole (m), is the hydraulic conductivity of borehole (m/yr).
We use a training dataset of size 200 and 100 testing datasets of size 100.
The noise variance is .
We use the same parameter settings for the prior distributions and EVI-GP method as in the OTL-Circuit example.
Regarding the variance of the prior distribution of , was the result of 5-fold cross-validation when the biggest mean model was used.
After variable selection, the 5-fold cross-validation is conducted again to find the optimal to fit the finalized GP model.
Coincidently, the optimal is also .
The initial mean model of the GP is assumed as a quadratic function of the input variables, including the 2-way interactions.
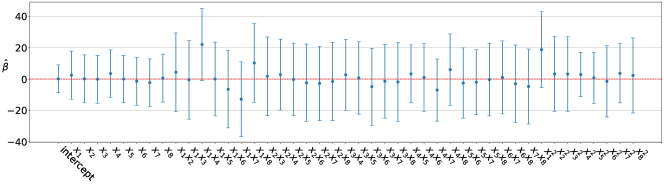
Based on the posterior confidence interval in Figure 6 of the , we select intercept, , and as the significant terms to be kept for the final model.
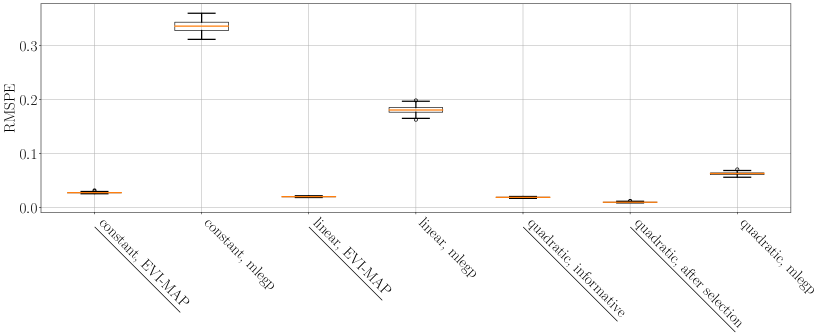
Similarly, we compare the EVI-GP with the mlegp package, and the RMSPEs of the 100 simulations are shown in Table 3 and Figure 7.
Again, EVI-GP is much better than the R package.
More importantly, variable selection proves to be essential for the Borehole example, as the final GP model with the reduced mean model is more accurate than both the quadratic and linear mean models.
| Type of mean | EVIGP | mlegp |
|---|---|---|
| Constant | 0.01151 | 0.3354 |
| Linear | 0.04191 | 0.1810 |
| Quadratic | 0.01212 | 0.2019 |
| Quadratic, after selection | 0.01019 | N/A |
5 Conclusion
In this book chapter, we review the conventional Gaussian process regression model under the Bayesian framework.
More importantly, we propose a new variational inference approach, called Energetic Variational Inference, as an alternative to traditional MCMC approaches to estimate and make inferences for the GP regression model.
Through comparing with some commonly used R packages, the new EVI-GP performs better in terms of prediction accuracy.
Although not completely revealed in this book chapter, the true potential of variational inference lies in transforming the MCMC sampling problem into an optimization problem.
As a result, it can be used to solve a more complicated Bayesian framework.
For instance, we can adapt the GP regression and classification by adding fairness constraints on the parameters such that it can meet the ethical requirements in many social and economic contexts.
In this case, variational inference can easily solve the constrained optimization whereas it is very challenging to do MCMC sampling with fairness constraints.
We are pursuing in this direction in the future work.
Acknowledgment
The authors’ work is partially supported by NSF Grant # 2153029 and # 1916467.
Appendix
Derivation of Proposition 1
Proof.
The marginal posterior distribution of can be obtained by integration as follows.
∎
Derivation of Proposition 2
Based on the non-informative prior,
Define
Then is
Due to the conditional conjugacy, we can see the conditional posterior distribution of is
| (29) |
where
Based on it, we can obtain the integration
References
- Ai et al. (2009) Ai, M., Kang, L., and Joseph, V. R. (2009), “Bayesian optimal blocking of factorial designs,” Journal of Statistical Planning and Inference, 139, 3319–3328.
- Blei et al. (2017) Blei, D. M., Kucukelbir, A., and McAuliffe, J. D. (2017), “Variational inference: A review for statisticians,” Journal of the American statistical Association, 112, 859–877.
- Carnell (2022) Carnell, R. (2022), lhs: Latin Hypercube Samples, r package version 1.1.5.
- Cheng and Boots (2017) Cheng, C.-A. and Boots, B. (2017), “Variational Inference for Gaussian Process Models with Linear Complexity,” in Advances in Neural Information Processing Systems, eds. Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R., Curran Associates, Inc., vol. 30.
- Cressie (2015) Cressie, N. (2015), Statistics for spatial data, John Wiley & Sons.
- Dancik and Dorman (2008) Dancik, G. M. and Dorman, K. S. (2008), “mlegp: statistical analysis for computer models of biological systems using R,” Bioinformatics, 24, 1966–1967.
- E et al. (2020) E, W., Ma, C., and Wu, L. (2020), “Machine learning from a continuous viewpoint, I,” Science China Mathematics, 1–34.
- Fang et al. (2005) Fang, K.-T., Li, R., and Sudjianto, A. (2005), Design and modeling for computer experiments, CRC press.
- Gelman et al. (2014) Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2014), Bayesian Data Analysis, Third Edition, New York: Chapman and Hall/CRC.
- Ghanem et al. (2017) Ghanem, R., Higdon, D., and Owhadi, H. (2017), Handbook of uncertainty quantification, Springer.
- Giga et al. (2017) Giga, M.-H., Kirshtein, A., and Liu, C. (2017), “Variational Modeling and Complex Fluids,” in Handbook of Mathematical Analysis in Mechanics of Viscous Fluids, eds. Giga, Y. and Novotny, A., Springer International Publishing, pp. 1–41.
- Gramacy (2016) Gramacy, R. B. (2016), “laGP: Large-Scale Spatial Modeling via Local Approximate Gaussian Processes in R,” Journal of Statistical Software, 72, 1–46.
- Gramacy (2020) — (2020), Surrogates: Gaussian Process Modeling, Design and Optimization for the Applied Sciences, Boca Raton, Florida: Chapman Hall/CRC, http://bobby.gramacy.com/surrogates/.
- Gramacy and Apley (2015) Gramacy, R. B. and Apley, D. W. (2015), “Local Gaussian process approximation for large computer experiments,” Journal of Computational and Graphical Statistics, 24, 561–578.
- Gramacy and Lee (2008) Gramacy, R. B. and Lee, H. K. H. (2008), “Bayesian treed Gaussian process models with an application to computer modeling,” Journal of the American Statistical Association, 103, 1119–1130.
- Hamada and Wu (1992) Hamada, M. and Wu, C. J. (1992), “Analysis of designed experiments with complex aliasing,” Journal of quality technology, 24, 130–137.
- Joseph (2006) Joseph, V. R. (2006), “A Bayesian approach to the design and analysis of fractionated experiments,” Technometrics, 48, 219–229.
- Kang et al. (2023) Kang, L., Deng, X., and Jin, R. (2023), “Bayesian D-Optimal Design of Experiments with Quantitative and Qualitative Responses,” The New England Journal of Statistics in Data Science, 1–15.
- Kang and Huang (2019) Kang, L. and Huang, X. (2019), “Bayesian A-Optimal Design of Experiment with Quantitative and Qualitative Responses,” Journal of Statistical Theory and Practice, 13, 1–23.
- Kang and Joseph (2009) Kang, L. and Joseph, V. R. (2009), “Bayesian optimal single arrays for robust parameter design,” Technometrics, 51, 250–261.
- Kang et al. (2018) Kang, L., Kang, X., Deng, X., and Jin, R. (2018), “A Bayesian hierarchical model for quantitative and qualitative responses,” Journal of Quality Technology, 50, 290–308.
- Kang et al. (2021) Kang, X., Ranganathan, S., Kang, L., Gohlke, J., and Deng, X. (2021), “Bayesian auxiliary variable model for birth records data with qualitative and quantitative responses,” Journal of statistical computation and simulation, 91, 3283–3303.
- MacDonald et al. (2015) MacDonald, B., Ranjan, P., and Chipman, H. (2015), “GPfit: An R Package for Fitting a Gaussian Process Model to Deterministic Simulator Outputs,” Journal of Statistical Software, 64, 1–23.
- Neal (1996) Neal, R. M. (1996), Bayesian Learning for Neural Networks, New York, NY: Springer New York, chap. Monte Carlo Implementation, pp. 55–98.
- Onsager (1931a) Onsager, L. (1931a), “Reciprocal relations in irreversible processes. I.” Phys. Rev., 37, 405.
- Onsager (1931b) — (1931b), “Reciprocal relations in irreversible processes. II.” Phys. Rev., 38, 2265.
- Paszke et al. (2019) Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. (2019), “PyTorch: An Imperative Style, High-Performance Deep Learning Library,” in Advances in Neural Information Processing Systems 32, Curran Associates, Inc., pp. 8024–8035.
- Peng and Wu (2014) Peng, C.-Y. and Wu, C. F. J. (2014), “On the Choice of Nugget in Kriging Modeling for Deterministic Computer Experiments,” Journal of Computational and Graphical Statistics, 23, 151–168.
- Rasmussen and Williams (2006) Rasmussen, C. E. and Williams, C. K. I. (2006), Gaussian Processes for Machine Learning, Adaptive Computation and Machine Learning, MIT Press.
- Rayleigh (1873) Rayleigh, L. (1873), “Some General Theorems Relating to Vibrations,” Proceedings of the London Mathematical Society, 4, 357–368.
- Robert et al. (1999) Robert, C. P., Casella, G., and Casella, G. (1999), Monte Carlo statistical methods, vol. 2, Springer.
- Roberts and Rosenthal (1998) Roberts, G. O. and Rosenthal, J. S. (1998), “Optimal scaling of discrete approximations to Langevin diffusions,” Journal of the Royal Statistical Society: Series B (Statistical Methodology), 60, 255–268.
- Rockafellar (1976) Rockafellar, R. T. (1976), “Monotone operators and the proximal point algorithm,” SIAM J. Control Optim., 14, 877–898.
- Sacks et al. (1989) Sacks, J., Welch, W. J., Mitchell, T. J., and Wynn, H. P. (1989), “Design and Analysis of Computer Experiments,” Statistical Science, 4.
- Santner et al. (2003) Santner, T. J., Williams, B. J., Notz, W. I., and Williams, B. J. (2003), The design and analysis of computer experiments, vol. 1, Springer.
- Surjanovic and Bingham (2013) Surjanovic, S. and Bingham, D. (2013), “Virtual Library of Simulation Experiments: Test Functions and Datasets,” Retrieved October 1, 2023, from http://www.sfu.ca/~ssurjano.
- Tran et al. (2016) Tran, D., Ranganath, R., and Blei, D. M. (2016), “The variational Gaussian process,” in 4th International Conference on Learning Representations, ICLR 2016.
- Trillos and Sanz-Alonso (2020) Trillos, N. G. and Sanz-Alonso, D. (2020), “The Bayesian Update: Variational Formulations and Gradient Flows,” Bayesian Analysis, 15, 29 – 56.
- Wang et al. (2021) Wang, Y., Chen, J., Liu, C., and Kang, L. (2021), “Particle-based energetic variational inference,” Statistics and Computing, 31, 1–17.
- Wu and Hamada (2021) Wu, C. J. and Hamada, M. S. (2021), Experiments: planning, analysis, and optimization, Hoboken, NJ: John Wiley & Sons, Inc.
- Wynne and Wild (2022) Wynne, G. and Wild, V. (2022), “Variational gaussian processes: A functional analysis view,” in International Conference on Artificial Intelligence and Statistics, PMLR, pp. 4955–4971.