Enhancing Clean Label Backdoor Attack with Two-phase Specific Triggers
Abstract
Backdoor attacks threaten Deep Neural Networks (DNNs). Towards stealthiness, researchers propose clean-label backdoor attacks, which require the adversaries not to alter the labels of the poisoned training datasets. Clean-label settings make the attack more stealthy due to the correct image-label pairs, but some problems still exist: first, traditional methods for poisoning training data are ineffective; second, traditional triggers are not stealthy which are still perceptible. To solve these problems, we propose a two-phase and image-specific triggers generation method to enhance clean-label backdoor attacks. Our methods are (1) powerful: our triggers can both promote the two phases (i.e., the backdoor implantation and activation phase) in backdoor attacks simultaneously; (2) stealthy: our triggers are generated from each image. They are image-specific instead of fixed triggers. Extensive experiments demonstrate that our approach can achieve a fantastic attack success rate (98.98%) with low poisoning rate (5%), high stealthiness under many evaluation metrics and is resistant to backdoor defense methods.
1 Introduction
Deep Neural Networks (DNNs) have shown its great power to many crucial tasks which human beings may not work well such as image classification, voice recognition, auto-driving, natural language processing, etc. Chen et al. (2015); He et al. (2016). However, training models are time and resource costly. Not everyone can burden that, so people who want to use DNNs may use the third-party or public service and resource like the pre-trained models and datasets to gain a model for their specific tasks.
Backdoor attacks become the potential threat with significant harm in such a scenario. BadNets Gu et al. (2017) first revealed this attack where adversaries can implant hidden backdoors in the victim model. The backdoor model behave normally on the clean images in the inference phase. However, when adversaries activate the hidden backdoor with a trigger, the backdoor model will behave maliciously, producing the target results as adversaries expected.
Existing methods for backdoor attacks include two categories. The first one is altering-label type attack Gu et al. (2017); Liu et al. (2017); Liao et al. (2018); Yao et al. (2019); Li et al. (2020). The adversaries will replace the correct labels of poisoned images with the target label. The second one is clean-label type attacksTurner et al. (2018); Barni et al. (2019); Saha et al. (2020); Quiring and Rieck (2020). The adversaries will keep the correct image-label pairs of poisoned images.
In the altering-label type backdoor attacks, the mislabeled poisoned images are straightforward for the human reviewers to remove. So we focus on the clean-label backdoor attacks. However, some problems still exist: first, implanting a backdoor through under clean-label settings is more difficult. Our experiments demonstrate that former clean-label backdoor attacks CLBA Turner et al. (2018) may fail under high-resolution datasets. Second, former clean-label backdoor attacks’ triggers are not stealthy, which are often fixed square patterns. In this case, these triggers are still easy for the human reviewers to remove because they look very abrupt upon the images. Our experiments also show such triggers is not stealthy under some evaluation metrics.
We start from effectiveness and stealthiness to consider our trigger generation methods. For the effectiveness, we consider different tasks in backdoor implantation and activation phases. In the backdoor implantation phase, inspired by CLBA Turner et al. (2018), we argue that the key to implant backdoor in pretrained victim models is that the poisoned data can be sufficiently learnt. Once the victim model learns the poisoned images, it will build the connection between triggers and target labels. For example, the clean-label type backdoor attack CLBA uses an adversarial perturbation to erase poisoned images’ original features to promote the victim model to learn the trigger’s features. In the backdoor implantation phase, previous triggers are only effective when the backdoor is implanted. We consider building more powerful triggers that can be effective before and after backdoor implantation. Our later experiments demonstrate this type of trigger is effective. For the stealthiness problems, we build triggers generated from each image instead of fixed triggers. They are more stealthy than the fixed triggers.
To achieve image-specific triggers which can enhance the effectiveness and stealthiness in backdoor implantation and activation phases, we utilize a U-Net autoencoder to generate triggers from each image. We propose a loss function containing target images loss (aims to enhance backdoor implantation) and non-target images (aims to enhance backdoor activation), and perceptual loss (aims to enhance the stealthiness) for the autoencoder. After obtaining a pretrained trigger generator, we use it to build poisoned images in the backdoor implantation phase and build malicious input to manipulate the backdoor model in the backdoor activation phase.
Our contributions are as follow:
-
•
We propose a novel trigger generation method that can generate image-specific triggers. We train trigger generators with U-Net autoencoder architecture and well-design losses for different images.
-
•
We utilize this pretrained trigger generator to perform effective and stealthy backdoor attacks under clean-label settings. We compare our approach with other backdoor attacks and study our approach’s performance under different parameters.
-
•
Extensive experiments prove our approach is effective and stealthy. We can achieve the highest attack success rate at 98.98% with only 5% poisoning rate, remaining benign accuracy at 97.98%, which only drop 0.34% compared to the clean model. Besides, Our attacks are more stealthy than other backdoor attacks under evaluation metrics; and our attacks can be resistant to backdoor defense methods.
2 Related Work
BadNets. Gu et al. (2017) first discovered the backdoor attack threat in the supply chain which use deep learning methods. BadNets stamps a simple trigger (i.e., one pixel or multi-pixel matrix) on the images which are selected randomly from the training datasets. For those images which are crafted, their labels should also altered into the target label. This inconsistency between the changed label and the image is quite distinct, therefore, it’s easy for the human reviewers or some simple data filtering methods to remove this malicious data. Later works analyze the reason of the success of BadNet is that there a huge difference between the altered labels and the poisoned images, This difference promotes the victim model to learn connection with the trigger pattern and target label.
Clean-Label Backdoor Attacks. Turner et al. (2018) explored the backdoor attacks under higher constraints, which we refer to as clean-label settings. This work suggested a less obvious attack, the adversaries do not alter the label of the image when building malicious retraining datasets, the adversaries will first choose one attack target. Then craft images belong to this class. They first add perturbation generated by FGSM Goodfellow et al. (2014b) or GAN Goodfellow et al. (2014a) on images to build the poisoned datasets and then stamp a fixed trigger on each poisoned images. They use such datasets to train a backdoor model and then use the trigger to activate the hidden backdoor. This work opens the study of clean-label type backdoor attacks, but there are some shortcuts. First, This work is operated on CIFAR-10 Krizhevsky et al. (2009) datasets, our experiments demonstrate that this work may not work well in high-resolution images datasets like ImageNette Jeremy Howard (2021).

Generative Adversarial Perturbation. Poursaeed et al. (2018) proposed generative models for creating adversarial examples, slightly perturbed images resembling natural images but maliciously crafted to fool pre-trained models. They presented trainable deep neural networks for transforming images to adversarial perturbations. This perturbation can achieve impressive results on high-resolution datasets such as ImageNet. Inspired by this work, in this paper, we utilize the autoencoder to build image-specific triggers from clean images which can both enhance the backdoor implantation and the backdoor activation.
3 Methodology
3.1 Attack Overview
We assume our backdoor attack happens when the adversaries have a pre-trained model , retraining dataset , where the data pair is denoted as . The target class is is randomly chosen as the 7th class ”gas pump” in this example.
Our proposed backdoor attack consists of two phases: (A) the backdoor implantation phase and (B) the backdoor activation phase. Before performing backdoor attacks, we will train a trigger generator . The details of the trigger generator will be described in Section 3.4. In the backdoor implantation phase (Fig. 1 (A)), we first select a portion of the images in the target class and use the trigger generator to build the poisoned data image with an image-specific trigger . For other clean images of the target class, we keep them in the retraining datasets. Second, we mix these poisoned images with the other clean images of the rest classes. Finally, We use this mixed datasets to fine-tune the pretrained model to obtain the backdoor model . In the backdoor activation phase, we first feed the non-targeted clean image into the trigger generator to obtain the malicious input with an image-specific trigger . Then we feed this malicious input into the backdoor model , the model will produce the target label. This process is shown in Fig. 1 (B-2). Besides, the backdoor model should produce correct prediction results for clean images without triggers. As shown in Fig. 1 (B-1), the backdoor model will output a correct prediction “parachute” when the input is clean.
3.2 Two-phase Triggers
To promote our backdoor attack, we want the image-specific triggers of target, and non-target images can promote both the backdoor implantation and activation phases. Specifically, in the backdoor implantation phase, we want the poisoned target data with added trigger to facilitate the classifier model to learn the features between the trigger and the target class label . Inspired by clean-label backdoor attack Turner et al. (2018), we generate specific triggers for the target class images , which can erase the features of the original image and thus enhance the backdoor implantation. i.e., we want the victim model can not predict the correct result when the input is added with a specific trigger . We can represent this process as Eq. (1).
| (1) |
Standard triggers are only effective when the backdoor is implanted. In our approach, we generate the triggers which can achieve some attack success rate even before backdoor implantation. Moreover, this type of trigger can be more effective after backdoor implantation. Specifically, in the backdoor activation phase, we want the crafted non-target image with the added trigger to activate the backdoor efficiently, causing the backdoor model to output the target label expected by the adversaries. We can represent this process as Eq. (2).
| (2) |
3.3 Image-specific Trigger Generator
Inspired by GAP Poursaeed et al. (2018), we use a U-Net architecture Ronneberger et al. (2015) autoencoder as the trigger generator to generate the image-specific triggers used in backdoor implantation phase and backdoor activation phase. This autoencoder is with skip connections between the encoder and the decoder.
In order to obtain a trigger generator that can generate specific triggers used in different phases depend on each image, we train this trigger generator before performing the backdoor attack. This training process is described in Algorithm 1. We calculate different losses depend on different types of images. i.e., we calculate the target images loss , non-target images loss and LPIPS loss , then add up these loss terms with hyperparameters () linearly to a total loss (represented as Eq. (3)). Then use an optimizer to minimize the loss and update the weights of the generator .
| (3) |
The target images loss is represented as Eq. (4), is the cross-entropy function, is the th crafted target image which is added by clean target image and an image-specific trigger , is the total amount of target images. The trigger is generated by trigger generator and clipped with a norm limit . is the least likely class of clean classifier model . (as proposed by Poursaeed et al. (2018)). We find shows good results on Eq. (1).
| (4) |
Similar to , the non-target images loss is represented as Eq. (5), but this loss is calculated on non-target images , is the total amount of target images. and we use target label instead of . We find shows good results on Eq. (2).
| (5) |
The LPIPS loss is represented as Eq. (6). LPIPS is perceptual metric proposed by Zhang et al. (2018), we use this loss to minimize perceptual distortion on crafted images and clean images both on target images and non-target images. is the total amount of all images, note that .
| (6) |
Note that, in order to keep the target image loss and the non-target image loss converge at the same speed, the amount of non-targeted images and target images in the dataset for training trigger generator is 1:1, and the amount of each class images in non-targeted images is the same. (i.e., if there are 900 images in the target class, there are 100 images in each of the other nine classes)

3.4 Backdoor Implantation and Activation
In backdoor implantation phase: First, we use the pretrained trigger generator to generate triggers and build poisoned images from target class images . We use poisoning rate to indicate ratio of the poisoned images amount to total images amount (Note that, our attacks can be effective even with poison rate ). Then mix them with other clean images (including clean target class images and clean non-target class images ) to obtain a mixed retraining dataset . Third, will be used by the victim to fine-tune his classifier model from a pretrained classifier model . After training, we will obtain a backdoor model . In the backdoor activation phase: First, for the a non-target image , we use the trigger generator to generate its image-specific triggers , then add on the to obtain a malicious input . Then we feed into the backdoor model , the prediction will be the target class .
Input: Victim model , generator , target class , epoch number , clean datasets , parameters for AdamOptimizer ;
Output: Trigger Generator;
4 Experiments
4.1 Experimental Settings
Dataset: We perform experiments on the ImageNet Deng et al. (2009) dataset, and for the convenience, we use a subset of ImageNet—Imagenette Jeremy Howard (2021), which contains 10 classes, each with about 1000 training images and about 400 validation images as our dataset .
Models: We choose the ResNet18 He et al. (2016) as the architecture of our classifier . We obtain the pretrained model from Pytorch library Paszke et al. (2019) and then modify the output of the last fc layer to 10 for our tasks.
Training Trigger Generator: The datasets used for training trigger generator is split from the training set of the clean dataset . The amount of the target class (7th) images is 931, the amount of each non-target class images is 103 (total amount of non-target images is 927); The batch size, iterations and max epoch for training is set to 30, 50 and 15; for fuction, we set hyperparameters (); we utilize Adam optimizer Kingma and Ba (2014) with learning rate = 0.0002, betas = (0.5, 0.999).
Backdoor Implantation and Activation: In backdoor implantation phase, for comparison with other backdoor attacks, we set poisoning rate to 5%; for performance evaluation, we set from 1% to 10%. The batch size, and retraining epoch in backdoor model retraing is set to 100 and 1. We utilize Adam optimizer Kingma and Ba (2014) with learning rate = 0.0001, betas = (0.5, 0.999)
Evaluation Metric: We evaluate with Fooling Rate (FR), Attack Success Rate (ASR) for effectiveness, and Benign Accuracy (BA), LPIPS, PSNR and for stealthiness.
| Backdoor Phases | Backdoor Implantation Phase | Backdoor Activation Phase | ||||
|---|---|---|---|---|---|---|
| LPIPS | PSNR | ASR | BA | Drop of BA | ||
| Clean Model | - | - | - | - | 0.9832 | - |
| CLBA | 0.4527 | 18.34 | 242.2 | 0.1503 | 0.9798 | 0.0034 |
| GRTBA | 0.5409 | 16.56 | 40.00 | 0.4129 | 0.9788 | 0.0044 |
| Ours-1 | 0.2838 | 20.95 | 25.00 | 0.9549 | 0.9811 | 0.0020 |
| Ours-2 | 0.3295 | 19.53 | 30.00 | 0.9898 | 0.9798 | 0.0034 |
4.2 Compare with other Backdoor Attacks
In this section, we demonstrate the effectiveness and stealthiness of our methods. We mainly compare our attack method with other backdoor attacks under clean-label settings, including Clean-Label Backdoor Attack (CLBA) Turner et al. (2018) and Global-Random-Trigger Backdoor Attack (GRTBA). CLBA is the first work to consider backdoor attacks under clean-label settings. This work first adds an adversarial perturbation to the clean image and then add a fixed square trigger on the right corner of the images. In this experiment, We utilize the FGSM as the perturbation and set , which can achieve FR at 95.69%. For the trigger, we set it to 5050 size. GRTBA is a backdoor attack that uses a global random noise as the trigger. In this attack, adversaries first generate a random noise (by Numpy Library Harris et al. (2020)) of the same size as the clean images, then clip it with a limit. Note that we do this experiment to demonstrate that global random trigger is not able to achieve attack success even with a higher limits. In this experiment, We set the . For our methods, we train two trigger generators with trigger clip limit and . We use these two trigger generators to conduct our attack. Final, all poisoned images, relevant triggers and perturbations of CLBA, GRTBA and Ours, are visualized in Fig.(2).
Table. 1. shows the results. All experiments are conducted on ImageNette, and the poisoning rate, retraining epoch is set to 5% and 1. In terms of effectiveness, our methods can achieve high ASR (0.9898 and 0.9549 for Ours-1 and Ours-2) while CLBA and GRTBA can only achieve ASR at 0.1503 and 0.4129. Meanwhile, the BA of Ours remains very close to the clean model, the drop of BA is less than 0.004. In terms of stealthiness, Ours-1 achieve the best results on LPIPS, PSNR, and and BA with a second-best ASR. Ours-2 achieve the best results on ASR with second-best LPIPS, PSNR, and .
We also compare some other backdoor attacks on stealthiness, including BadNets, Clean-Label Backdoor Attacks on Video Recognition Models (CLBA-V) Zhao et al. (2020), Hidden Trigger Backdoor Attack (HDTBA) Saha et al. (2020), Backdoor Attack with Sample-Specific Triggers (SSTBA) Li et al. (2020). Clean label settings and image-specific trigger are two properties making backdoor attacks more stealthy. Clean-label settings play an essential role in stealthy backdoor attacks. Compare with altering-label type backdoor attacks, we think, even the triggers used in altering-label type backdoor attacks are invisible to humans, the huge inconsistency between the original features of the poisoned images and the target label is still apparent to human reviewers, then the human may remove these data, resulting in the failure of the backdoor attacks. Clean-label settings are the first-level stealthy properties. After applying clean-label settings, we can consider applying more stealthy triggers. The fixed triggers used in former clean-label type backdoor attacks are still apparent to human reviewers. Thus, we think image-specific triggers are more stealthy than the fixed triggers. As Table.2 shows, our methods both satisfy the clean-label settings and the specific trigger, that is more stealthy than other backdoor attacks.
| Clean Label | Fixed Trigger | Specific Trigger | |
|---|---|---|---|
| BadNets | |||
| CLBA-V | |||
| HDTBA | |||
| SSTBA | |||
| Ours |
4.3 Effect of Poisoning Rate
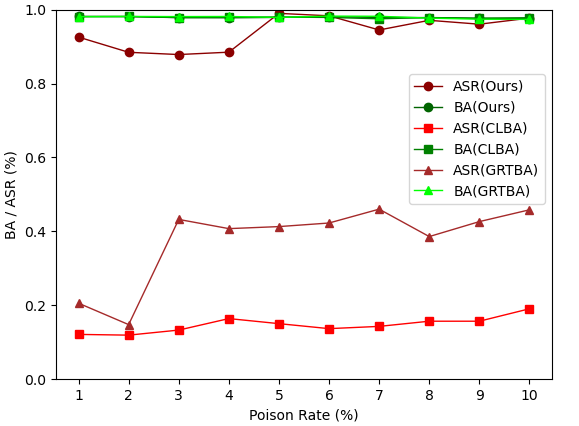
The poisoning rate is an essential aspect of stealthiness. We do experiments on poisoning rate vary from 1% to 10% to evaluate our methods, CLBA and GRTBA. The experimental settings expect poisoning rate are the same with Section 4.2. Fig. 3 shows that our methods can achieve high ASR while maintaining high BA with a low poisoning rate (highest ASR at 0.9898 with ). CLBA and GRTBA can only achieve ASR 0.1905 and 0.4601.
4.4 Effect of limits
We study the effect on FR and ASR with different limits. And we test on the clean model and the backdoor model to demonstrate the effect of our triggers. We set .
As Table. 3 shows, our triggers can achieve some FR and ASR before backdoor implantation (highest FR at 0.7808, highest ASR at 0.4565). After backdoor implantation, we can achieve higher FR and ASR on the backdoor model than the clean model (highest FR at 0.8756, highest ASR at 0.9898). The distance of FR and ASR between the clean model and the backdoor model proves that our triggers can promote the backdoor implantation.
Besides, as Table. 3 shows, with limits grows, FR and ASR also grow gradually. but there is a trade-off between stealthiness and effectiveness. the higher ASR means higher for the trigger. However, we still can achieve ASR = 0.8547 with , the drop of ASR is only 0.1351.
4.5 Resistance to Defense Methods
Resistance to Data Augmentation: Previous works found that data augmentation can reduce the performance of backdoor attacks. Because data augmentation may remove, destroy or alter the position of the fixed trigger.
To study this impact on CLBA, GTRBA and Ours, we performed data augmentation consisting of RandomRotation, RandomResizeCrop, RandomHorizontalFlip on the dataset for training backdoor models. We find that ASR of CLBA drops to 0.1054 (drop 0.0449); ASR of GTRBA increases to 0.6333 (increase 0.2204); ASR of Ours stays at 0.9335 (drop only 0.0214). And the BAs of these methods drop to 0.9579, 0.9600, and 0.9564, respectively.
Based on these observations, we believe that data augmentation has a destructive effect on backdoor attacks using fixed triggers. In contrast, it is less effective in defending against or even enhancing backdoor attacks using global triggers. We consider this is because the global triggers can be resistant to those data augmentation methods due to the robustness.
| Tested Model | Clean Model | Backdoor Model | ||
|---|---|---|---|---|
| FR | ASR | FR | ASR | |
| 0.1778 | 0.2349 | 0.2835 | 0.3610 | |
| 0.5949 | 0.4157 | 0.7587 | 0.8547 | |
| 0.6848 | 0.4290 | 0.7903 | 0.8928 | |
| 0.7954 | 0.4565 | 0.8705 | 0.9549 | |
| 0.7808 | 0.4140 | 0.8756 | 0.9898 | |
Resistance to STRIP: Gao et al. (2019) propose the STRIP method to defense against backdoor attacks. STRIP superimposes various clean images on a suspicious image, then check the prediction results. If the suspicious image is with a trigger, the predictions will be invariant; if without a trig ger, the predictions will vary greatly because of the randomness. Fig. 4 shows the entropy distribution of the clean images (blue histogram) and malicious images with the trigger (red histogram). Our attacks are resistant to STRIP. The entropy distribution of images with the trigger is similar to the clean images. Fig. 4 (a) shows our attack with trigger limit , in this case, our attack can achieve ASR at 0.9549, the entropy median of clean images and malicious images are 0.6359 and 0.8199. Fig. 4 (b) shows our attack with a smaller trigger limit , in this case, our attack achieve ASR at 0.8547, the entropy median of clean images and malicious images are 0.5961 and 0.7347.

5 Conclusion
In this paper, we study effectiveness and stealthiness problems in clean-label type backdoor attacks. We find former clean-label backdoor attacks will fail under high-resolution datasets and their triggers are not stealthy. We propose a novel trigger generation method that can generate image-specific triggers that can promote the two phases (i.e., the backdoor implantation and activation phases) in clean-label backdoor attacks. Extensive experiments show that our approaches can achieve a high AS with a low poisoning rate and are more stealthy than other backdoor attacks. Besides, our approaches are resistant to backdoor defense methods.
References
- Barni et al. [2019] Mauro Barni, Kassem Kallas, and Benedetta Tondi. A new backdoor attack in cnns by training set corruption without label poisoning. In 2019 IEEE International Conference on Image Processing (ICIP), pages 101–105. IEEE, 2019.
- Chen et al. [2015] Chenyi Chen, Ari Seff, Alain Kornhauser, and Jianxiong Xiao. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, pages 2722–2730, 2015.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Gao et al. [2019] Yansong Gao, Change Xu, Derui Wang, Shiping Chen, Damith C Ranasinghe, and Surya Nepal. Strip: A defence against trojan attacks on deep neural networks. In Proceedings of the 35th Annual Computer Security Applications Conference, pages 113–125, 2019.
- Goodfellow et al. [2014a] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27:2672–2680, 2014.
- Goodfellow et al. [2014b] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Gu et al. [2017] Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733, 2017.
- Harris et al. [2020] Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin Sheppard, Tyler Reddy, Warren Weckesser, Hameer Abbasi, Christoph Gohlke, and Travis E. Oliphant. Array programming with NumPy. Nature, 585(7825):357–362, September 2020.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Jeremy Howard [2021] Kerem Turgutlu Jeremy Howard, Hamel Husain. Imagenette. https://github.com/fastai/imagenette, 2021. Accessed: 2021-04-20.
- Kingma and Ba [2014] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Li et al. [2020] Yuezun Li, Yiming Li, Baoyuan Wu, Longkang Li, Ran He, and Siwei Lyu. Backdoor attack with sample-specific triggers. arXiv preprint arXiv:2012.03816, 2020.
- Liao et al. [2018] Cong Liao, Haoti Zhong, Anna Squicciarini, Sencun Zhu, and David Miller. Backdoor embedding in convolutional neural network models via invisible perturbation. arXiv preprint arXiv:1808.10307, 2018.
- Liu et al. [2017] Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning attack on neural networks. 2017.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in neural information processing systems, pages 8026–8037, 2019.
- Poursaeed et al. [2018] Omid Poursaeed, Isay Katsman, Bicheng Gao, and Serge Belongie. Generative adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4422–4431, 2018.
- Quiring and Rieck [2020] Erwin Quiring and Konrad Rieck. Backdooring and poisoning neural networks with image-scaling attacks. arXiv preprint arXiv:2003.08633, 2020.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- Saha et al. [2020] Aniruddha Saha, Akshayvarun Subramanya, and Hamed Pirsiavash. Hidden trigger backdoor attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11957–11965, 2020.
- Turner et al. [2018] Alexander Turner, Dimitris Tsipras, and Aleksander Madry. Clean-label backdoor attacks. 2018.
- Yao et al. [2019] Yuanshun Yao, Huiying Li, Haitao Zheng, and Ben Y Zhao. Latent backdoor attacks on deep neural networks. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, pages 2041–2055, 2019.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
- Zhao et al. [2020] Shihao Zhao, Xingjun Ma, Xiang Zheng, James Bailey, Jingjing Chen, and Yu-Gang Jiang. Clean-label backdoor attacks on video recognition models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14443–14452, 2020.