Enhancing Multi-Hop Knowledge Graph Reasoning through Reward Shaping Techniques
Abstract
In the realm of computational knowledge representation, Knowledge Graph Reasoning (KG-R) stands at the forefront of facilitating sophisticated inferential capabilities across multifarious domains. The quintessence of this research elucidates the employment of reinforcement learning (RL) strategies, notably the REINFORCE algorithm, to navigate the intricacies inherent in multi-hop KG-R. This investigation critically addresses the prevalent challenges introduced by the inherent incompleteness of Knowledge Graphs (KGs), which frequently results in erroneous inferential outcomes, manifesting as both false negatives and misleading positives. By partitioning the Unified Medical Language System (UMLS) benchmark dataset into rich and sparse subsets, we investigate the efficacy of pre-trained BERT embeddings and Prompt Learning methodologies to refine the reward shaping process. This approach not only enhances the precision of multi-hop KG-R but also sets a new precedent for future research in the field, aiming to improve the robustness and accuracy of knowledge inference within complex KG frameworks. Our work contributes a novel perspective to the discourse on KG reasoning, offering a methodological advancement that aligns with the academic rigor and scholarly aspirations of the Natural journal, promising to invigorate further advancements in the realm of computational knowledge representation.
Index Terms:
Knowledge Graph Reasoning, Reinforcement Learning, Reward Shaping, Transfer LearningI Introduction
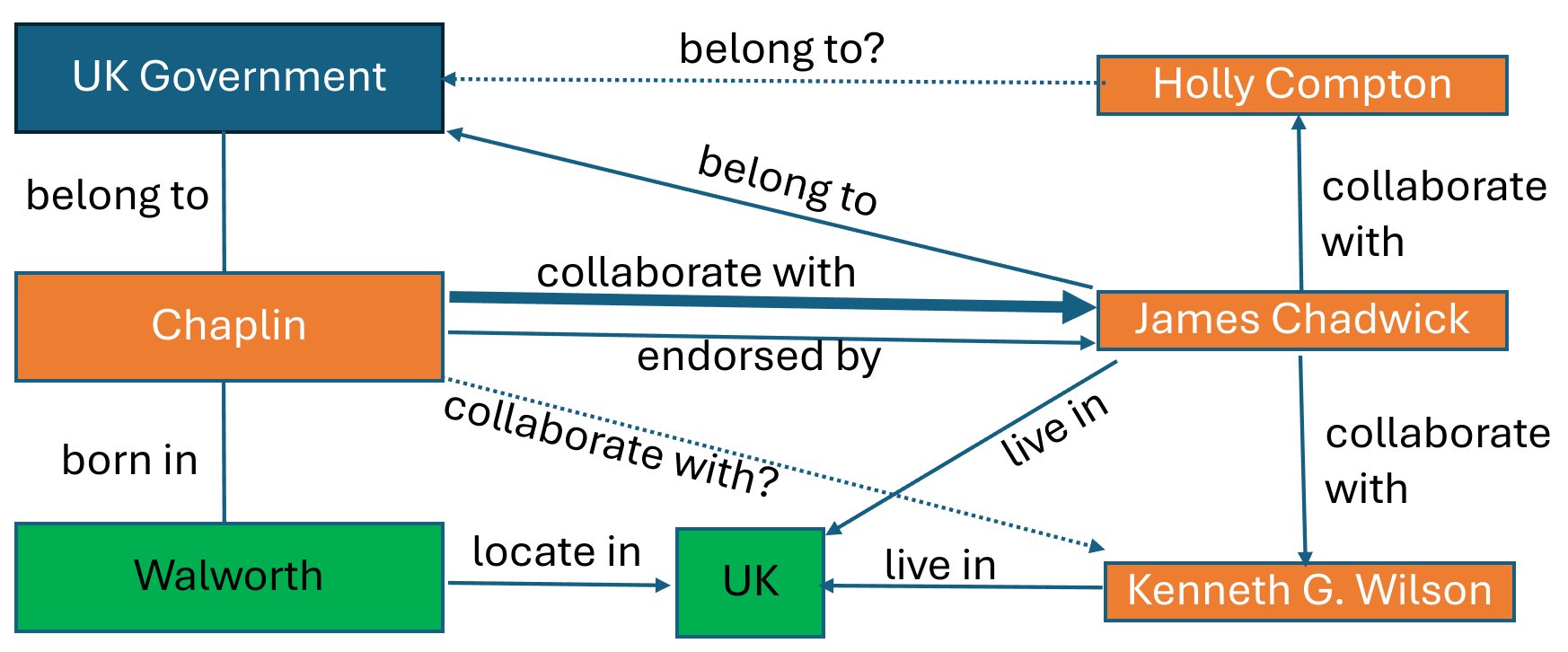
Knowledge Graphs (KGs) manifest as sophisticated relational schemas, comprising nodes (symbolizing subjects or entities) and edges (indicative of verbs or dependencies) that interlink these nodes in either a unidirectional or bidirectional fashion. Such constructs are epitomized by an aggregation of factual triplets, articulated as ⟨h, r, t⟩, delineating a head node, relational edge, and tail node, respectively. This elementary yet potent framework facilitates the representation of mathematical symmetries/asymmetries, inversions, and compositions, thereby serving a plethora of applications[1]. Within this paradigm, Knowledge Graph Reasoning (KG-R) endeavors to address diverse logical reasoning tasks through the extrapolation of novel knowledge from extant datasets, as depicted in Fig.1. Illustratively, path information inherent within the KG may be leveraged to prognosticate missing links[2, 3], whilst the structural integrity of the KG could be harnessed to elucidate answers to complex queries[4].
A particular strand of KG-R inquiry posits the challenge as one of sequential decision-making, resolved via the application of reinforcement learning (RL). In this vein, the MINERVA framework adopts the REINFORCE algorithm to forge an end-to-end model adept at executing multi-hop KG query resolution. This model, through a trained agent, navigates the KG from an initial source entity to identify potential answers pertinent to the query relation, eschewing reliance on pre-computed paths for answer derivation[5]. Notwithstanding, this walk-based query-answering (QA) methodology encounters obstacles in training efficacy due to the frequent incompleteness of practical KGs, which precipitates both false negatives and positives in trajectory outcomes. Moreover, the intrinsic on-policy nature of REINFORCE potentially predisposes the policy towards errant paths encountered in the training’s infancy.
In extension of these preliminaries, our research extrapolates upon the aforementioned paradigms through the prism of transfer learning, specifically within the context of the UMLS benchmark dataset. Herein, we delineate our methodology for bifurcating the dataset into rich and sparse KGs, subsequently delving into diverse pre-training regimes for a ”Reward Shaper” module tasked with the finesse of reward-shaping dynamics across these dichotomized KGs. This exploration is benchmarked against prior models as a baseline for comparative analysis[6]. Moreover, we venture into the realm of leveraging pre-trained BERT[7] embeddings alongside an array of Prompt Learning strategies to further refine and enhance the reward shaping process, positing a significant leap forward in the domain of KG reasoning.
II Prior Work
A knowledge graph is represented formally a , where denotes the entities set and . Each link in the graph is directed and can be represented as , indicating a fact or triple. Given a query where denotes the source entity and denotes the relation of interest, the aim of KG Reasoning is to efficiently search and gather the set of possible answers such that . From this set, usually the softmax is taken and the top answer returned as the prediction. This algorithm is representable as a Markov Decision Process (MDP): starting from , the agent sequentially selects an outgoing edge and deterministically transitions to a new entity in connection with until it selects a terminal action. The MDP is comprised of the following components:
-
•
State. Each state is a tuple where is the entity visited at step and are the source entity and query relation. can be viewed as state-dependent information while are the global context shared by all states. This is an important distinction because the agent will ideally learn the rich relationships between various while conditioning on .
-
•
Actions. At time , the set of possible actions, , is (the collection of outgoing edges belonging to ). To introduce the agent to a terminating action, a self-loop edge is added to every .
-
•
Transition. A transition function is defined by .
-
•
Rewards. The RL agent will obtain a terminal reward of 1 if it arrives at a correct target entity and 0 otherwise. As we will see, this is a brittle approach and does not allow for policies to learn when they achieve close but incorrect predictions.
(1)
II-A Reward Shaping
The given reward function provides a binary reward based solely on the observed answers in , which is incomplete. False negative search results receive the same reward as true negatives, which can be problematic[8]. To address this issue, the authors propose a reward-shaping strategy using existing KG embedding models designed for KG completion. These embedding models map entities and relations to a vector space and estimate the likelihood of each fact using a composition function of the entity and relation embeddings This function is trained by maximizing the likelihood of all facts in .
III Problem Statement
In the foundational research, the initial training phase of the Reward Shaper is predominantly predicated upon the utilization of three seminal path-based knowledge graph embedding algorithms, namely ConvE, ComplEx, and DistMult. These methodologies are designed to encapsulate entities and their interrelations within a compact, low-dimensional vectorial space, employing disparate strategies to delineate the spatial interconnections of entities within the Knowledge Graph (KG).
Within the ambit of this project, we endeavor to augment the contextual embeddings of entities and their interrelations within the framework of reward shaping. This is achieved through the pretraining of the Reward Shaper utilizing an enriched KG, which is a simulation of the original KG, thereby emulating the real-world context of an expansive, readily accessible, general KG that encompasses a more sparse KG of specific interest. Our conjecture posits that incorporating contextual data into this enriched, general KG will enhance the generalization capabilities of the reward-shaping mechanism. This, in turn, is anticipated to facilitate the policy’s guidance towards achieving more accurate predictions by providing a more nuanced understanding of the entities and their relationships within the KG.
IV Methodology
A significant obstacle encountered in the practical application of Knowledge Graph (KG) Reasoning pertains to scenarios wherein an expansive, intricately interconnected general KG is at one’s disposal, yet the objective shifts towards formulating a policy over a diminutive, comparatively manageable KG characterized by constrained sampling opportunities. An astute strategy to navigate this predicament involves the extraction of general knowledge from the voluminous KG, followed by a meticulous fine-tuning process on the sparsely populated KG.
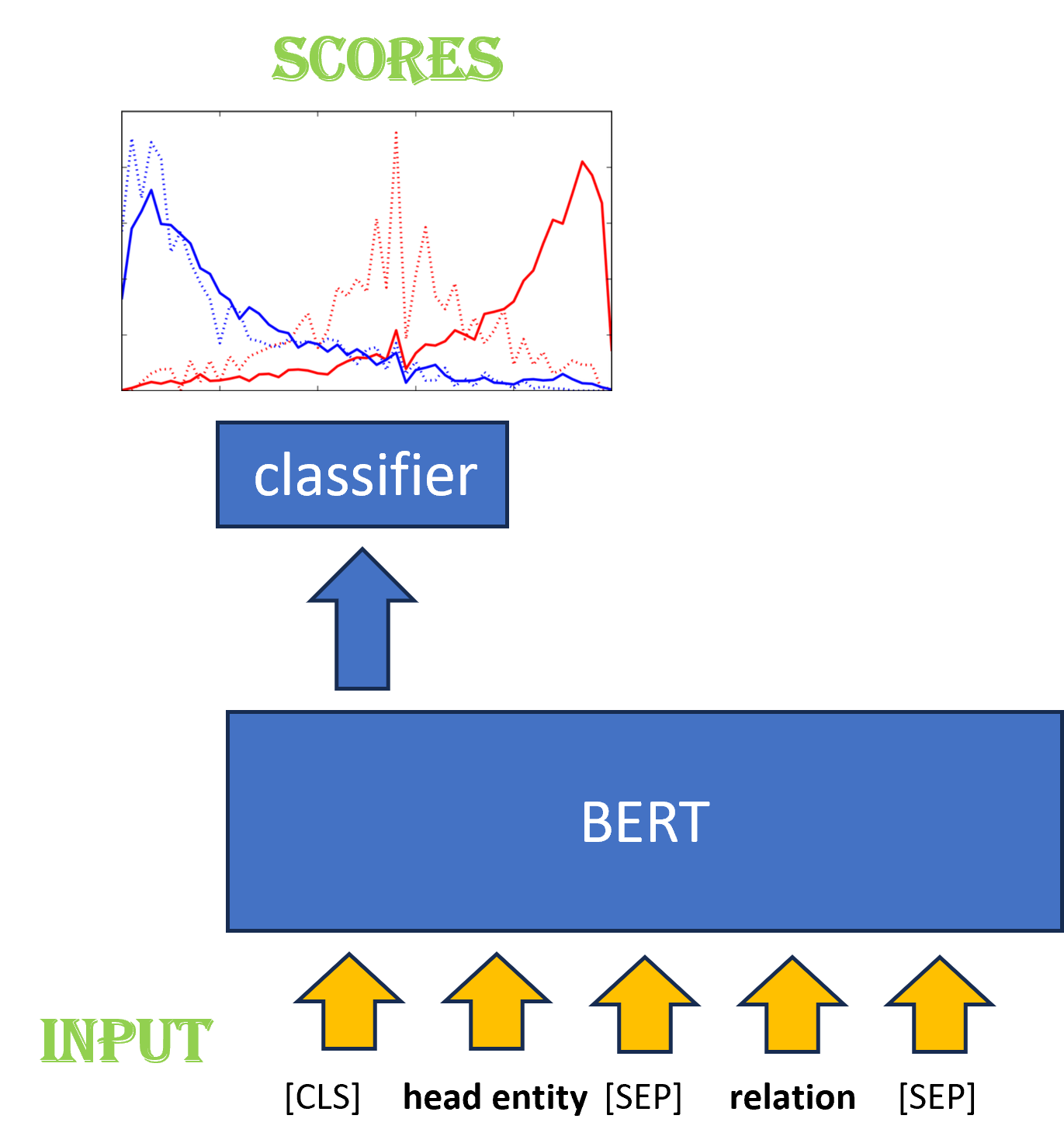
We simulate these KGs by masking. In our experiments, we simply treat a source KG dataset as our “rich” KG and we mask of the nodes and edges to obtain a “sparse” KG, dubbed “Split Multi-Hop KG Reasoning”. Through this, we simulate a well-trained Reward Shaper on some incomplete KG. To ascertain reward scores for each terminal entity contingent upon a given initial entity and its corresponding relation, the inaugural methodology entails conceptualizing this scenario as a multi-label classification quandary. The architectural delineation of the model is depicted in Fig.2. This process involves refining the Bidirectional Encoder Representations from Transformers (BERT) model, augmented with a classification mechanism. Each terminal entity is considered a discrete label, and the Sigmoid function is employed to prognosticate the score attributable to each terminal entity, premised on the initial entity and its relation.
During the supervised training regimen, the presence of a nexus between an initial entity and a terminal entity mandates that the veridical label for said terminal entity is assigned a value of one. In the absence of such a relationship, the assigned score defaults to zero. Nonetheless, the actual training regimen deviates by incorporating a label smoothing technique to the veridical labels and adopting Binary Cross Entropy as the loss function to refine the entirety of the model framework meticulously.
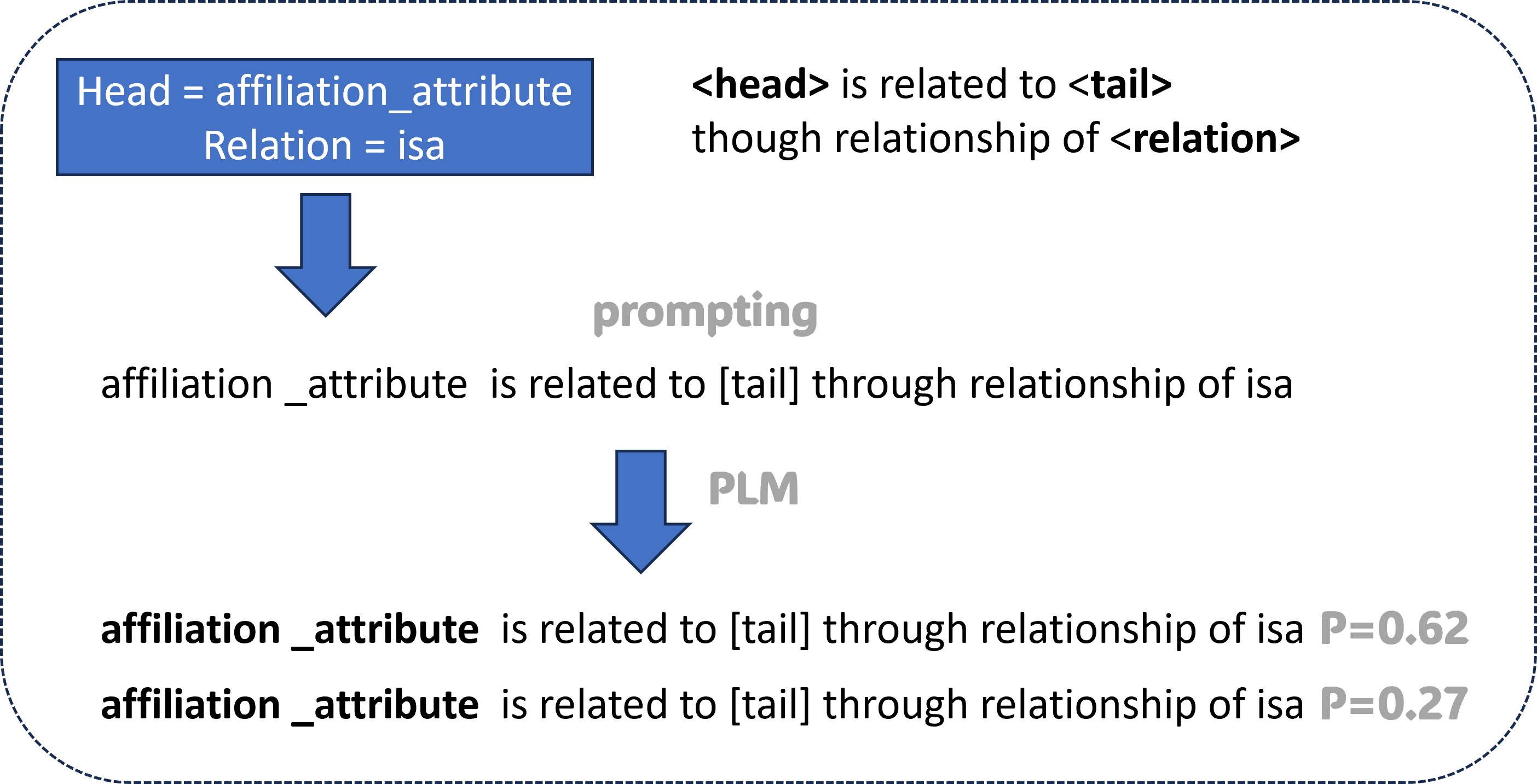
An alternative approach for the preliminary training of the Reward Shaper incorporates the utilization of Prompt Learning, as delineated in Fig.3. Initially, a template is established to facilitate the language model in constructing the nexus between the head entity and the tail entity within the training Knowledge Graph (KG). This template is articulated as: ”[head entity] is interconnected with [tail entity] via the relationship of [relation].” Subsequently, during the training phase, upon specifying the head entity and the relation, we populate the corresponding token to prepare the prompt for the pre-trained language model. It is pertinent to mention that the T5 model was chosen for prompting purposes due to its exemplary efficacy across a diverse array of Natural Language Processing (NLP) tasks and its proficiency in generating high-caliber natural language texts. Leveraging the T5 model enables the calculation of the probability of the masked token, specifically the tail entity token, which is then employed as the score. The training regimen and the loss function are maintained identically to the preceding methodology involving BERT Contextualization.
V Experiments
To rigorously assess the efficacy of reward shaping alongside Reinforcement Learning (RL) methodologies[9], our approach entails the conversion of each triplet within the testing corpus into a distinct query comprising a head entity and an associative relation. This process is delineated by initially identifying a head entity and its corresponding relation, subsequent to which the models are tasked with engendering a prioritized compendium of candidate tail entities, each adjudged and sequenced based upon their respective confidence indices. Following this, we embark on the computation of two distinct ranking-oriented performance indicators for a comprehensive evaluation[10]. The first metric, denoted as Hits@k, quantifies the proportion of instances wherein the veracious answer is ascertained within the uppermost k echelons of the prioritized enumeration. Concurrently, the Mean Reciprocal Rank (MRR) is derived through the computation of the multiplicative inverse of the ordinal position attributed to the inaugural correct entity within the said enumeration, with the ensuing values subjected to an arithmetic mean across the entirety of the query spectrum. This methodology facilitates a nuanced understanding of the models’ predictive acumen, thereby enabling a meticulous appraisal of their performance within the evaluative framework.
First, we split the UMLS dataset into two KGs using the Algorithm 1.
| Model Configuration | UMLS | ||||
| Hits@1 | Hits@3 | Hits@5 | Hits@10 | MRR | |
| Sparse KG Policy Gradient | 0.854 | 0.911 | 0.871 | 0.913 | |
| Rich KG Policy Gradient | 0.625 | 0.974 | 0.845 | 0.969 | 0.734 |
| Sparse KG Policy Gradient + Rich Reward Shaping | 0.850 | ||||
| Sparse KG Policy Gradient + Sparse Reward Shaping | 0.775 | ||||
| BERT Contextualization RS trained on Rich KG(ours) | 0.810 | ||||
| Prompt Learning based RS trained on Rich KG (ours) | 0.860 | ||||
In the pursuit of advancing the efficacy of reinforcement learning (RL) agents[9, 10] in multi-hop reasoning tasks, our study embarked on an experimental investigation into the impact of pre-training reward shaping methodologies on comprehensive knowledge graphs, followed by the application of reward shaping techniques during the training phase on sparsely populated knowledge graphs. The empirical results, as delineated in Table I, underscore the superior performance of our novel contextual embedding reward-shaping approach in enhancing RL-based multi-hop reasoning capabilities.
Central to our investigation was a comparison of a baseline reward shaping framework, which utilizes the conventional embedding technique ConvE, against our proposed methodologies. Notably, the incorporation of a prompt learning-based reward shaping module, pre-trained on densely populated knowledge graphs, emerged as the most efficacious strategy, demonstrating unparalleled generalization capabilities for RL agents engaged in multi-hop reasoning across sparsely populated knowledge graphs. This prompt learning-based paradigm exhibited a marked superiority over the ConvE-based approach across most of the evaluated metrics.
Our initial hypothesis posited that integrating contextual semantics about entities and relations within the knowledge graph would significantly enhance the agent’s ability to generalize scoring mechanisms in subsequent RL training phases. Contrary to our expectations, the method is leveraging BERT for contextual understanding underperformed compared to both the prompt learning and ConvE-based methodologies. This outcome suggests a complex interplay between the nature of embedding techniques and their applicability to the nuanced requirements of RL training in sparse knowledge graph environments, warranting further investigation into the mechanisms underpinning effective reward shaping in such contexts.
CONCLUSION
To implement the methodologies delineated in reference, the precondition of possessing an expansive Knowledge Graph (KG) is imperative, as it facilitates the derivation of meaningful embeddings. This prerequisite, however, is frequently unmet, prompting the introduction of an innovative approach termed Split Multihop KG Reasoning. This methodology augments the framework proposed in by incorporating elements of transfer learning, specifically through the preliminary training of the Reward Shaper module within a densely populated KG before its application within a sparsely populated KG. Furthermore, this study enriches the reward-shaping process by integrating BERT pretraining alongside Prompt Learning techniques, thereby leveraging the intrinsic natural language representations embedded within a KG to enhance performance. The empirical validation of these methodologies was conducted using the Unified Medical Language System (UMLS), a KG characterized by its limited scale yet considerable diversity. The outcomes of this investigation revealed a significant enhancement in the performance metrics of the Reinforcement Learning (RL) agent attributable to the reward-shaping process[11, 12, 13]. Contrary to the initial hypothesis, the Reward Shaper’s training on a densely populated KG yielded satisfactory results; however, it was surpassed by the performance achieved through training on a sparsely populated KG, suggesting a potential overfitting scenario when utilizing a rich Reward Shaper. The study’s insights into KG utilization and reward shaping through transfer learning and natural language processing techniques present a promising avenue for wider applications[14, 15].
References
- [1] Z. Zhibin, S. Liping, and C. Xuan, “Labeled box-particle cphd filter for multiple extended targets tracking,” Journal of Systems Engineering and Electronics, vol. 30, no. 1, pp. 57–67, 2019.
- [2] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” Advances in neural information processing systems, vol. 26, 2013.
- [3] R. Das, S. Dhuliawala, M. Zaheer, L. Vilnis, I. Durugkar, A. Krishnamurthy, A. Smola, and A. McCallum, “Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning,” arXiv preprint arXiv:1711.05851, 2017.
- [4] C. Wang, “Intelligent agricultural greenhouse control system based on internet of things and machine learning,” arXiv preprint arXiv:2402.09488, 2024.
- [5] Z.-b. Zou, L.-p. Song, and Z.-l. Song, “Labeled box-particle phd filter for multi-target tracking,” in 2017 3rd IEEE International Conference on Computer and Communications (ICCC), pp. 1725–1730, IEEE, 2017.
- [6] Z. Zou, M. Careem, A. Dutta, and N. Thawdar, “Unified characterization and precoding for non-stationary channels,” in ICC 2022-IEEE International Conference on Communications, pp. 5140–5146, IEEE, 2022.
- [7] J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of naacL-HLT, vol. 1, p. 2, 2019.
- [8] Y. Zhang, X. Wang, L. Gao, and Z. Liu, “Manipulator control system based on machine vision,” in International Conference on Applications and Techniques in Cyber Intelligence ATCI 2019: Applications and Techniques in Cyber Intelligence 7, pp. 906–916, Springer, 2020.
- [9] Z. Mo, Y. Fu, D. Xu, and X. Di, “Trafficflowgan: Physics-informed flow based generative adversarial network for uncertainty quantification,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 323–339, Springer, 2022.
- [10] L. Yu, B. Liu, Q. Lin, X. Zhao, and C. Che, “Semantic similarity matching for patent documents using ensemble bert-related model and novel text processing method,” arXiv preprint arXiv:2401.06782, 2024.
- [11] Z. Zou, M. Careem, A. Dutta, and N. Thawdar, “Joint spatio-temporal precoding for practical non-stationary wireless channels,” IEEE Transactions on Communications, vol. 71, no. 4, pp. 2396–2409, 2023.
- [12] W. Wang, B. Joshi, N. Burgdorfer, K. Batsosc, A. Q. Lid, P. Mordohaia, and I. Rekleitisb, “Real-time dense 3d mapping of underwater environments,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 5184–5191, 2023.
- [13] C. Che, Q. Lin, X. Zhao, J. Huang, and L. Yu, “Enhancing multimodal understanding with clip-based image-to-text transformation,” in Proceedings of the 2023 6th International Conference on Big Data Technologies, pp. 414–418, 2023.
- [14] L. Gao, G. Cordova, C. Danielson, and R. Fierro, “Autonomous multi-robot servicing for spacecraft operation extension,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 10729–10735, IEEE, 2023.
- [15] S. Ott, C. Meilicke, and M. Samwald, “Safran: An interpretable, rule-based link prediction method outperforming embedding models,” arXiv preprint arXiv:2109.08002, 2021.