11email: bohuizha@usc.edu, {ilievski,pszekely}@isi.edu
Enriching Wikidata with Linked Open Data
Abstract
Large public knowledge graphs, like Wikidata, contain billions of statements about tens of millions of entities, thus inspiring various use cases to exploit such knowledge graphs. However, practice shows that much of the relevant information that fits users’ needs is still missing in Wikidata, while current linked open data (LOD) tools are not suitable to enrich large graphs like Wikidata. In this paper, we investigate the potential of enriching Wikidata with structured data sources from the LOD cloud. We present a novel workflow that includes gap detection, source selection, schema alignment, and semantic validation. We evaluate our enrichment method with two complementary LOD sources: a noisy source with broad coverage, DBpedia, and a manually curated source with a narrow focus on the art domain, Getty. Our experiments show that our workflow can enrich Wikidata with millions of novel statements from external LOD sources with high quality. Property alignment and data quality are key challenges, whereas entity alignment and source selection are well-supported by existing Wikidata mechanisms. We make our code and data available to support future work.
Keywords:
Wikidata Linked Open Data Knowledge Enrichment Schema Alignment Semantic Validation1 Introduction
Commonly used knowledge graphs (KGs) today have wide coverage, recording information for many millions of entities through thousands of properties. Wikidata [28], the largest public KG, contains nearly 1.5B statements about 90M entities. This breadth of information inspires various use cases to exploit such KGs. Museum curators can use Wikidata to describe their art collections and artists comprehensively. Movie critics could quickly query and aggregate statistics about recent movies, and analyze them based on their genre or actor cast.
However, while Wikidata’s data model allows for this information to be present, practice shows that much of the relevant information is still missing in Wikidata. For example, around half of the artists in Wikidata have a date of birth, and only 1.88% of the movies recorded in 2020 have information about their cost. Thus, if a user wants to analyze the cost of the films produced in 2020, Wikidata will provide cost information for only 60 out of its 2,676 recorded films. As this information is unlikely to be found in an aggregated form, and gathering information about thousands of films is a tedious process, one must rely on automated tools that can enrich Wikidata with relevant information. Such information might be readily available in external linked open data (LOD)111https://lod-cloud.net/ sources like DBpedia [1] or LinkedMDB [17]; yet, no existing methods can enrich Wikidata with missing information. Conversely, link prediction [6] accuracy is not sufficient to use it to impute missing information with representation learning.
The traditional LOD workflow includes declarative language tools for schema mapping and templated rewritting of CSV files into RDF [9, 20, 11]. A subsequent ontology alignment step [7] can be employed to discover owl:sameAs links between the two datasets. Yet, prior work [4] has shown that collapsing nodes based on owl:sameAs relations is not feasible, as it leads to combining related but dissimilar nodes (e.g., Barack Obama and the US government) into a single node. Moreover, while prior efforts have focused on schema alignment between two sources, this challenge may be less significant when augmenting Wikidata, which provides 6.8k external identifier properties that explicitly link to entities in other sources.222https://www.wikidata.org/wiki/Category:Properties_with_external-id-datatype, accessed March 2, 2022. Further challenge is data quality [23], as external sources may contain information that is noisy, contradictory, or inconsistent with existing knowledge in Wikidata. Table 1 presents candidate enrichment statements retrieved from DBpedia infoboxes. Here, only one out of four statements is correct, whereas the other three have an incorrect datatype, semantic type, or veracity. It is unclear how to employ principled solutions for schema alignment and quality validation to for large-scale and high-quality enrichment of Wikidata.
| DBpedia statement | Wikidata mapping | Assessment |
|---|---|---|
| dbr:Lesburlesque dbp:genre dbr:Burlesque | Q6530279 P136 Q217117 | Correct |
| dbr:Amanda_de_Andrade dbp:position ’Left back’en | Q15401730 P413 ’Left back’en | Wrong datatype |
| dbr:Diego_Torres_(singer) dbp:genre dbr:Flamenco | Q704160 P2701 Q9764 | Wrong semantic type |
| dbr:Eternal_Moment dbp:director dbr:Zhang_Yibai | Q5402674 P4608 Q8070394 | Logical, inaccurate |
In this paper, we investigate how to enrich Wikidata with freely available knowledge from the LOD cloud. We introduce a novel LOD workflow to study the potential of the external identifier mechanism to facilitate vast high-quality extensions of Wikidata. Assuming that we can link Wikidata entities to external sources robustly through external identifiers, we start by aligning the entities automatically, followed by inferring the property in the external source that corresponds to the Wikidata property we seek to augment. This alignment of entities and properties yields candidate enrichment statements, which are rigorously checked through datatype comparison, semantic constraints, and custom validators. We demonstrate the effectiveness of the augmentation workflow on two LOD knowledge sources: Getty [16] and DBpedia [1]. Getty is a manually curated domain-specific knowledge graph with a narrow focus on art, whereas DBpedia is a broad coverage KG which has been automatically extracted from Wikipedia. Extensive experiments on these sources show that our method facilitates vast and high-quality extension of Wikidata with missing knowledge.
We make our code and data available to facilitate future work.333https://anonymous.4open.science/r/hunger-for-knowledge-315D/
2 Related work
Schema mapping languages, like R2RML [9], Karma [20], and RML [11] enable users to map relational databases into RDF, optionally followed by a semi-automatic ontology alignment step. Recent ontology alignment methods [7] typically align two ontologies in the vector space. Compared to prior works that align two schemas or ontologies, we seek to improve the coverage of a single large knowledge graph, by selective augmentation with external knowledge.
Ontology enrichment deals with noise, incompleteness, and inconsistencies of ontologies, by discovering association rules [8], or by extracting information from WWW documents [13]. Ontology evolution seeks to maintain an ontology up to date with respect to the domain that it models, or the information requirements that it enables [30]. Notably, there have been no efforts to enrich or improve the evolution of large-scale hyperrelational KGs, like Wikidata.
Prior work has attempted to enrich Wikidata with satellite data for a given domain, including frame semantics [21], biodiversity data [29], and cultural heritage data [14]. By learning how to represent entities in a KG like Wikidata, link prediction models [6] can predict missing values by associating them to known statements. Our work complements prior efforts that enrich Wikidata with domain-specific data or predict missing links, as we aim to devise a method for generic, large-scale enrichment of Wikidata with external LOD sources.
The linked open data cloud contains many identity links which could be explored to combine information from different sources. LOD Laundromat [5] is a centralized infrastructure which captures a static version of the LOD cloud, which could be queried in order to obtain information from multiple sources at once. However, as we show in this paper, identity links between entities by themselves are insufficient for enrichment of knowledge graphs. The correspondence between the properties in two graphs may not be one-to-one, requiring inference about property paths. Furthermore, semantic validation needs to be performed to ensure that the mapped properties indeed have compatible semantics. In that sense, our work relates to prior work that explores identity links in the LOD cloud [4] or devises mechanisms to discover latent identity links [24]. The goal of our work is different - to enrich Wikidata by finding high-quality knowledge in well-connected sources.
The automatic validation of our method relates to prior work on analyzing the quality of large KGs. Beek et al. [3] propose a framework for analyzing the quality of literals on the LOD Laundromat, but it is unclear how to generalize this framework to entity nodes. Prior work has studied the quality of Wikidata [22, 26] and compared it to the quality of other knowledge graphs, like YAGO [27] and DBpedia [15]. Compared to Wikidata, YAGO4 takes a step further and it defines constraints on domain and range, disjointness, functionality, and cardinality. The authors report that enforcing these constraints leads to a removal of 132M statements from Wikidata, i.e., 28% of all facts. In [26], the authors apply five semantic constraints, including value type, on Wikidata in order to measure its quality. None of these works has investigated how to automatically validate external statements that can be used to enrich Wikidata.
Wikidata’s property constraint pages define existing property constraints and report number of violations for a single dump.444https://www.wikidata.org/wiki/Help:Property_constraints_portal Moreover, Wikidata includes several tools that monitor, analyze, and enforce aspects of quality, such as the primary sources tool (PST),555https://www.wikidata.org/wiki/Wikidata:Primary_sources_tool#References the Objective Revision Evaluation Service (ORES),666https://www.wikidata.org/wiki/Wikidata:ORES and Recoin (“Relative Completeness Indicator”) [2]. Recoin computes relative completeness of entity information by comparing the available information for an entity against other similar entities. Our work complements these efforts by Wikidata, by providing mechanisms for automatic alignment and semantic validation of knowledge from the LOD cloud before it is submitted to Wikidata.
3 Method
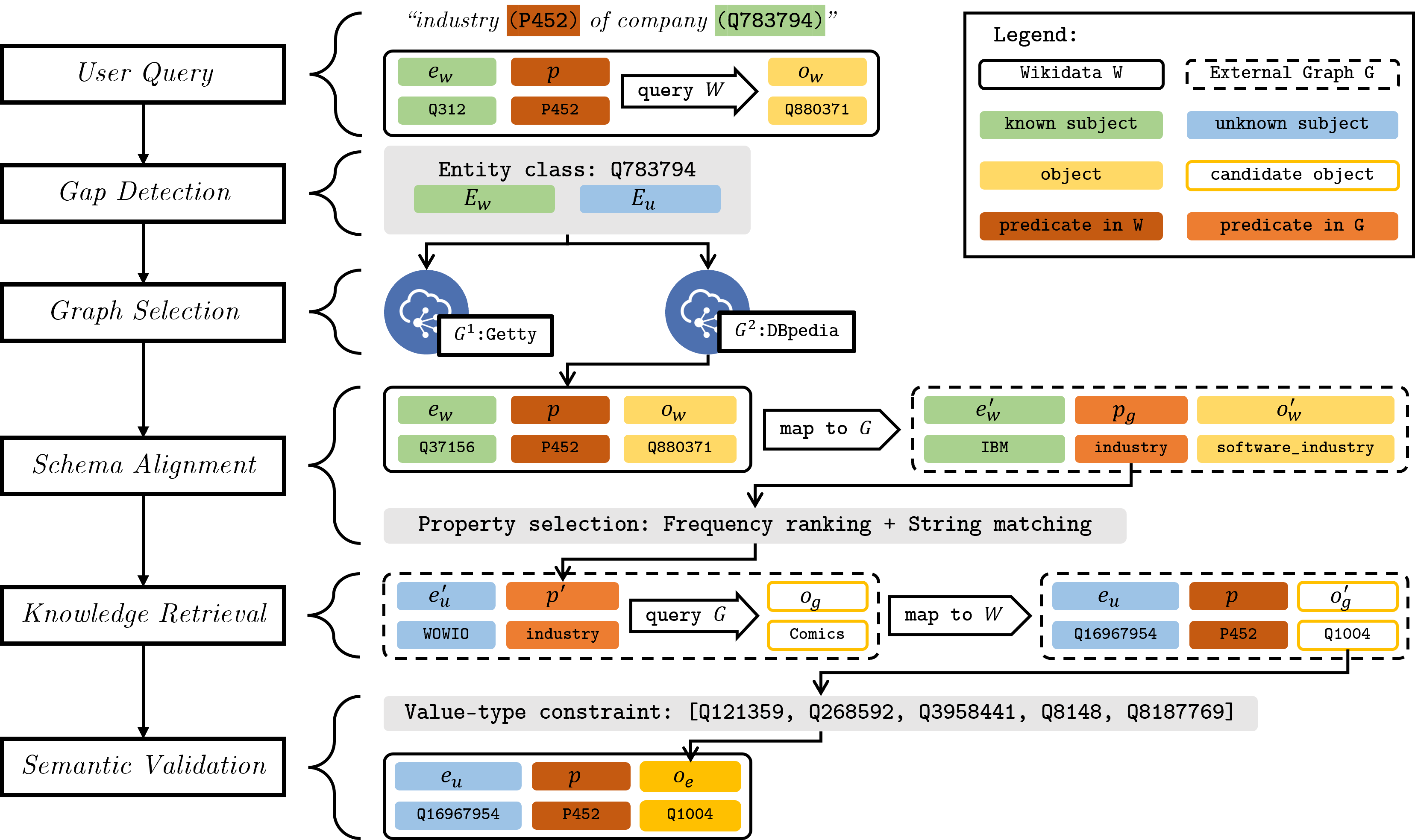
Our enrichment method is shown in Figure 1. Given a user query, our method queries Wikidata (), obtaining a set of known statements for subjects , and a set of subjects with unknown values . We call this step gap detection, as it generates a set of entities for which we seek missing knowledge in order to satisfy the user’s query needs. Considering that the LOD cloud contains other sources that are likely to contain information about the same entities, we perform a KG selection step to determine a relevant set of KGs to consult for the entities in . Here, the sources are assumed to overlap with in terms of the entities they describe. Our schema alignment step consolidates the entities and properties of with those of each , since their entity and property identifiers are generally different. After aligning the two schemas, a knowledge retrieval step queries the external KG to obtain new statements for the entities in . A semantic validation step is employed in order to ensure that the semantics of the newly found statements in corresponds to the semantics intended by Wikidata. The set of validated statements is finally used to enrich . This procedure yields a more complete response to the user query consisting of a union of the original and the enriched statements, formally: .
We show this procedure by querying Wikidata for “industry of companies” in Figure 1. The gap detection step splits the overall set of target companies into two groups: 1) companies with known industry in Wikidata (); and 2) companies with unknown industry (), for which lacks industry information. The KG selection step decides that DBpedia may contribute missing knowledge for company industries. The schema alignment step relies on the statements in Wikidata, about the known companies . Each pair is aligned to a DBpedia-valued pair . Similarly, the unknown entities are mapped in the same way to DBpedia entities . Then, the external KG DBpedia is queried for property paths which correspond to the known subject-object pairs . The DBpedia path (dbp:industry) that corresponds to the Wikidata property is discovered with our method. The knowledge retrieval step obtains values from DBpedia, by querying for pairs comprised of DBpedia entities and property paths, resulting in a new set of statements . The newly found values are inversely mapped back to ‘found’ (candidate) Wikidata values . Each of these newly obtained values is semantically validated, resulting in a subset of enrichment values , which form the statements .
3.1 Gap detection
We consider a structured query against a target knowledge graph for a query property (e.g., industry). The gap detection step generates a set of subject entities for which the value for the property is known in Wikidata, and a set of entities for which the value of the property is missing in . and are subsets of the overall set of target entities and they are mutually disjoint, formally: , , , and .
This work focuses on finding values for entities in that have zero values for a property in Wikidata. We note that it is possible that the statements in do not fully answer the query for the entities , as these entities may have multiple values for , e.g., a politician may have several spouses throughout their life. Enriching multi-valued properties will be addressed in future work.
3.2 Graph selection
The graph selection step provides a set of LOD sources that can be used to enrich the results of the query. In this work, we consider an automatically extracted general-domain KG (DBpedia) and a domain-specific curated KG (Getty). We experiment with using both KGs, or selecting one based on the posed query.
DBpedia [1] is an open-source KG derived from Wikipedia through information extraction. Follow Wikipedia’s guidelines, DBpedia’s entity documents are language-specific. DBpedia describes 38 million entities in 125 languages, while its English subset describes 4.58 millions of entities. Large part of the content in DBpedia is based on Wikipedia’s infoboxes: data structures containing a set of property–value pairs with information about its subject entity, whose purpose is to provide a summary of the information about that subject entity. We use DBpedia infoboxes in order to enrich Wikidata, as this data is standardized, relevant, and expected to be extracted with relatively high accuracy.
Getty [16] is a curated LOD resource with focus on art. In total, Getty contains information about 324,506 people and 2,510,774 places. Getty consists of three structured vocabularies: (1) Art & Architecture Thesaurus (AAT) includes terms, descriptions, and other information (like gender and nationality) for generic concepts related to art and architecture; (2) the Getty Thesaurus of Geographic Names (TGN) has 321M triples with names, descriptions, and other information for places important to art and architecture; and (3) the Union List of Artist Names (ULAN) describes names, biographies, and other information about artists and architects, with 64M statements.
3.3 Schema alignment
As Getty and DBpedia have a different data model compared to Wikidata, we first align their schemas to Wikidata in order to query them based on missing information in Wikidata. The schema alignment consists of two sequential steps:
1. Entity resolution maps all known subject entities in Wikidata, , unknown subjects , and the known objects to external identifiers , , and , respectively. We map Wikidata nodes to nodes in external KGs automatically, by leveraging external identifiers and sitelinks available in Wikidata. In total, Wikidata contains 6.8K external-id properties. Wikidata contains 46,595,392 sitelinks, out of which 5,461,631 link to the English Wikipedia pages. Our method leverages sitelinks to map Wikidata entities to DBpedia nodes,777Wikipedia page URIs can trivially be translated to DBpedia URIs. while for Getty we use vocabulary-specific external-id properties in Wikidata: Art & Architecture Thesaurus ID (P1014) for AAT items, Getty Thesaurus of Geographic Names ID (P1667) for TGN items, and Union List of Artist Names ID (P245) for ULAN items. We note that, while the entity mapping is automatic, the selection of the external-id property itself in the current method is manual, e.g., the user has to specify that P1667 should be used for TGN identifiers.
2. Property alignment We map the property from Wikidata to a corresponding property path in by combining structural and content information. We query for property paths with maximum length that connect the mapped known pairs (, ). We aggregate the obtained results, by counting the number of results for each property path that connects the known pairs. We preserve the top-10 most common property paths, and we use string similarity to select the optimal one. Here, we rerank the top-10 candidates based on Gestalt Pattern Matching [25].888Our empirical study showed that this function leads to comparable accuracy like Levenshtein distance, but it is more efficient. If the most similar property path has similarity above a threshold (0.9), then we select it as a mapped property , otherwise we select the top-1 most frequent property. In the example in Figure 1, the Wikidata property P452 (industry) would map to dbp:industry in DBpedia, which is both the top-1 most frequent property in the aligned results, and it has maximum string similarity with . We expect that string similarity and value frequency can complement each other. For example, the top-1 most frequent property for P149 (architectural style) is dbp:architecture, while string similarity correctly reranks the top-10 candidates to select the right mapping dbp:architecturalStyle. The property chain can be quite complex, e.g., Wikidata’s P19 (place of birth) maps to a 4-hop path in Getty: foaf:focus gvp:biographyPreferred schema:birthPlace skos:exactMatch.
3.4 Knowledge Retrieval
The schema alignment step produces external identifiers for the unknown entities and an external property path that corresponds to the property in the original query. The user can query the external graph with the mapped subject-property pair , in order to automatically retrieve knowledge. In Fig. 1, an example of pair is (dbr:WOWIO, dbp:industry). We denote the candidate objects found with this step with . As the candidate object identifiers belong to the external graph, the user can perform inverse entity resolution by following sitelinks or external identifiers from the external graph to . This step results in newly found Wikidata objects for the unknown entities , completing their statements .
3.5 Semantic Validation
Despite the schema alignment, the candidate objects may be noisy: they may have a wrong datatype (e.g., date instead of a URI), an incorrect semantic type (e.g., a nationality instead of a country), or a literal value that is out of range (e.g., death year 2022). We trim noisy objects with three validation functions.
Datatypes Each Wikidata property has a designated datatype and the candidate objects have to conform with it. For instance, the spouse values are expected to be Qnodes, movie costs should be numeric values with units (e.g., 4 million dollars), while founding years – dates with a year precision (e.g., 2015). To infer the expected datatype of a property, we count the datatypes of the known objects , and select the top-1 most common datatype. This function returns a subset of statements with candidate objects that belong to the expected datatype.

Property constraints We validate the object values further based on property constraints defined in Wikidata. Specifically, we use value-type constraints to validate the semantic type of the objects in . Value type constraints are similar to property range constraints [26], but they provide a more extensive definition that includes exception nodes and specifies whether the type property is: P31 (instance of), P279 (subclass of), or both. Figure 2 shows an example of a value type constraint for the property P452 (industry). We automatically validate the value type of all statements for a property, by comparing their object value to the expected type. Following [26], we encode the value type constraint for a property as a KGTK [19] query template. Each template is instantiated once per property, allowing for efficient constraint validation in parallel. Constraint violations for a property are computed in a two-step manner: we first obtain the set of statements that satisfy the constraint for a property, and then we subtract this set from the overall number of statements for that property. The constraint validation function yields a set of validated statements .
Literal range validation We validate date properties (e.g., date of birth) by ensuring that they do not belong to the future, i.e., that every recorded date is smaller than the year 2022. This function outputs a set of valid statements .
The set of validated statements is the intersection of the results returned from the three validation functions: for Qnodes and for date values. This validated statements in have the form . The total set of statements for the user query becomes .
4 Experimental Setup
Knowledge graphs We experiment with batch enrichment for Wikidata properties that have value-type constraints, 955 in total. We use the Wikidata 2021-02-15 dump in a JSON format and the sitelinks file from 2021-10-27. We use the 2021-12-01 DBpedia infobox file in a Turtle (.ttl) format.999https://databus.dbpedia.org/dbpedia/generic/infobox-properties/ We select its cannonicalized version, as it ensures that its subjects and objects can be mapped to English Wikipedia pages. For the Getty vocabularies, we download the current dump in N-Triples (.nt) from their website.101010http://vocab.getty.edu/
Evaluation To evaluate the quality of the overall enrichment, we randomly sample candidate statements and annotate their validity manually. Specifically, we sample 100 statements from the DBpedia set and 30 statements from Getty. Two annotators annotate 130 statements independently by searching each one on Internet and determine whether it is correct or not. The annotation resulted in nearly perfect agreement, and the remaining two conflicts were resolved with a discussion between the annotators. After this annotation, we observe that 20/100 of the DBpedia statements and 11/30 of the Getty statements are correct, while the rest are incorrect. We annotate three reasons for incorrect statements: wrong datatype, wrong semantic type, and inaccurate information. Out of the 80 incorrect DBpedia statements, 66 have incorrect datatype, 7 incorrect semantic type, and 7 are inaccurate. For Getty, 11 are correct, 0 have incorrect datatype, 17 incorrect semantic type, and 2 are inaccurate.
To investigate the quality of our property alignment, we use property mappings provided by owl:equivalentProperty in DBpedia and P1628 (equivalent property) in Wikidata as ground truth to evaluate the property alignment of our method. We dub this data Equivalence. In the property mapping pairs we collected, each Wikidata property is mapped to one or multiple DBpedia properties. In total, 88 Wikidata properties are mapped to 101 DBpedia properties. We formulate a task where the goal is to map a Wikidata property to its corresponding DBpedia property/properties. We accept any of the DBpedia mappings according to the gold standard data as correct. Besides correct and incorrect mappings, we annotate an intermediate category of close match for properties that match partially. We show two F1-values of our method: hard, which only counts exact matches, and soft, which includes partial matches. We compare our method to three baselines. The string matching and frequency matching baselines are ablations of our method that only consider string similarity or frequency, but not both. The third baseline embeds all DBpedia labels with BERT [10] and uses cosine distance to select the closest property label.
Implementation We implement our method using the Knowledge Graph ToolKit (KGTK) [19]. For Getty we obtain paths with maximum length of , for DBpedia . In the schema alignment step, we count property frequency based on a sample up to 200,000 pairs of known subjects and objects .
5 Results
In this Section, we present six experimental findings that concern the potential of our method, its overall accuracy, its accuracy per component, and its consistency when the external information is covered by Wikidata.
| DBpedia | 582 | 106,104,551 | 41,309,864 | 21,023,187 | 127,127,738 |
|---|---|---|---|---|---|
| Getty | 3 | 195,153 | 10,518 | 5,766 | 200,919 |
| Both | 582 | 106,104,551 | 41,320,382 | 21,028,953 | 127,328,657 |
Finding 1: Our method can enrich Wikidata with millions of statements about millions of entities. Table 2 shows the results of our method for all properties in Wikidata that have a value-type constraint. Out of 955 Wikidata properties, our method is able to align 582 properties with DBpedia and 3 can be mapped with Getty. For the Wikidata properties aligned with DBpedia and Getty, we gather 21 million statements, enriching the original Wikidata knowledge by 16.54%. Interestingly, while the original Wikidata focuses on a broad coverage of entities, our method is able to enrich more properties for a smaller set of entities, signifying a higher density and a more narrow focus. The column shows that our method collects 41 million candidate statements from DBpedia and Getty, out of which 21 million pass the semantic validation. The median number of novel statements per property is 982. For 161 (27.66%) properties, our method provides double or more statements relative to the original set of statements. The relative increase of knowledge is the lowest for the properties P538 (fracturing), P209 (highest judicial authority), P1283 (filmography), and P534 (streak color). Meanwhile, the properties P66 (ancestral home), P500 (exclave of), and P3179 (territory overlaps) are relatively sparse in Wikidata, and receive many more statements from DBpedia. Comparing the two external KGs, we observe that DBpedia overall contributes many more statements and entities than Getty. DBpedia is also bringing a higher enrichment per property, averaging at 16.54% vs 2.87% for Getty.
Finding 2: The overall quality of the enriched statements is relatively high. Table 3 shows that our method can distinguish between correct and incorrect statements with a relatively high accuracy of over 88%. As the majority of the candidates are incorrect, we observe that the F1-score is lower than the accuracy. The precision of our method is lower than the recall on both DBpedia and Getty, which indicates that most of the disagreement of our method with human annotators is because of false positives, i.e., incorrect statements identified as correct by our semantic validator. This indicates that our semantic validation is accurate but it is not complete and it can benefit from additional validators. This observation is further supported by the relatively higher precision and recall of our method on Getty in comparison to DBpedia. As Getty is manually curated and enforces stricter semantics, is has a smaller range of data quality aspects to address, most of which are already covered by our method. The quality issues in the case of DBpedia are heterogeneous, as a result of its automatic extraction and lack of curation. We find that out of 130 triples, 52 had incorrect property mappings, and the semantic validation is able to correct 44 of them. For example, Wikidata property P208 (executive body) got mapped to dbp:leaderTitle in DBpedia, and its value Q30185 was not allowed by the Wikidata constraint for P208. We evaluate the property alignment and the semantic validation in more detail later in this Section.
| KG | Accuracy | Precision | Recall | F1-score | Accuracy per category | |||
|---|---|---|---|---|---|---|---|---|
| Correct | Datatype | Sem. type | Inaccurate | |||||
| DBpedia | 87.00% | 61.54% | 84.21% | 71.11% | 80.00% | 96.97% | 71.43% | 28.57% |
| Getty | 93.33% | 84.62% | 100.0% | 91.67% | 100.0% | - | 100% | 0% |
| Both | 88.46% | 69.23% | 90.00% | 78.26% | 87.10% | 96.97% | 91.67% | 22.22% |
Finding 3: Property mapping performance is relatively high, but sparse properties are difficult. Table 2 showed that around 40% of the target Wikidata properties had no match found in DBpedia with our method. To investigate whether this is because of misalignment between the two schemas or a limitation of our method, we evaluate the property alignment precision and recall of our method on the Equivalence data. The results are shown in Table 4. Our method achieves the best F1-score for both the soft match cases (89%) and the hard match cases (66%).111111We also manually evaluate the property matching methods on a separate randomly chosen set of 20 properties, and observe similar results. As frequency and string matching are ablations from our method, their lower performance supports our decision to combined them to get the best of both worlds. For instance, frequency matching tends to prefer more general properties over specific ones, mapping P30 (continent) to dbp:location. Thanks to string matching, our method predicts the right property dbp:continent in this case. Conversely, string matching is easily confused by cases where the labels are close but the actual meaning is not related, e.g., it maps P161 (cast member) to dbp:pastMember, whereas our method correctly maps it to the ground truth result dbp:starring owing to its frequency component. As our method still largely relies on the frequency of statements, we hypothesize that its performance decreases for properties with fewer example statements. To investigate this hypothesis, we divide the ground truth properties into four quartiles (of 22 properties) based on the descending size of their original Wikidata statements. We evaluate the accuracy or our property matching per quartile. We note that the performance of the first three quartiles with larger number of statements is relatively better than the last quartile, which indicates that the precision of our method is positively correlated with the size of known statements. This limitation can be addressed in the future with more robust methods, e.g., based on learned property representations.
| Method | Hard match | Soft match | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-score | Precision | Recall | F1-score | |
| BERT Embedding | 47.73% | 47.73% | 47.73% | 72.73% | 72.73% | 72.73% |
| Frequency Matching | 52.33% | 51.14% | 51.72% | 81.40% | 79.55% | 80.46% |
| String Matching | 52.27% | 52.27% | 52.27% | 86.36% | 86.36% | 86.36% |
| Our Method | 66.28% | 64.77% | 65.52% | 89.53% | 87.50% | 88.51% |
| Our method (Q1) | 71.43% | 68.18% | 69.77% | 90.48% | 86.36% | 88.37% |
| Our method (Q2) | 63.64% | 63.64% | 63.64% | 100.0% | 100.0% | 100.0% |
| Our method (Q3) | 81.82% | 81.82% | 81.82% | 86.36% | 86.36% | 86.36% |
| Our method (Q4) | 47.62% | 45.45% | 46.51% | 80.95% | 77.27% | 79.07% |
Finding 4: Semantic validation can detect wrong datatypes and semantic types. Table 2 shows that the semantic validation has a very large impact on the results: out of 41 million candidate statements initially found by our method, around half of them satisfy the datatype and semantic type constraints of our validation. The compatibility ratios are similar for both Getty and DBpedia (50.89% to 54.82%), which is surprising, considering that DBpedia has been largely extracted automatically and is error-prone, whereas Getty is well-curated and considered an authority. To study the precision and recall of our semantic validation, we annotate three reasons for incorrect statements: wrong datatype, wrong semantic type, and inaccurate information. We found that (Table 2) our method performs well on identifying correct statements (F1-score 93.10%), as well as detecting errors due to wrong datatypes (F1-score 96.97%) and incorrect semantic types (F1-score 91.67%). Our method performs relatively worse when the statements satisfy the value-type constraints but are inaccurate. For example, the enriched statement (Q6712846 P19 Q49218) for the property P19 (place of birth) from Getty is logical but inaccurate, since the value Q49218 satisfies the value-type constraints while it is not the actual birth place of Q6712846. Among 130 triples, our method produces 7 false positive cases that are factually incorrect. These results are expected, given that our method is designed to filter out illogical information, while analyzing veracity is beyond its current scope.
| KG (Property) | ||||||
|---|---|---|---|---|---|---|
| DBpedia (P19) | 2,711,621 | 467,976 | 884,078 | 461,089 | 422,989 | 52.15% |
| DBpedia (P20) | 1,080,900 | 119,161 | 219,447 | 128,523 | 90,924 | 58.57% |
| Getty (P19) | 65,411 | 2,939 | 16,304 | 13,607 | 2,697 | 83.46% |
| Getty (P20) | 50,295 | 2,556 | 14,722 | 12,594 | 2,128 | 85.55% |
Finding 5: Most results for functional properties are consistent between external graphs and Wikidata, many disagreements are due to different granularities. The analysis so far focused on the statements that are novel, i.e., provide novel object values for subject-property pairs that do not have them in Wikidata. Here, we measure consistency between the validated statements from the external graph with the known statements of Wikidata, we select two functional properties: P19 (place of birth) and P20 (place of death), and count the agreements and disagreements for both DBpedia and Getty. The results in Table 5 for P19 and P20 show that 52-59% of the overlapping statements between Wikidata and DBpedia, and 83-86% of the overlapping statements between Wikidata and Getty coincide. Qualitative inspection of the disagreements reveals that many of the disagreements are due to different granularity choices between the two graphs. For instance, in Wikidata, the place of death of Q1161576 (Daniel Lindtmayer II) is Q30978 (Central Switzerland) which is a region, while Getty provides the specific city Q4191 (Lucerne).
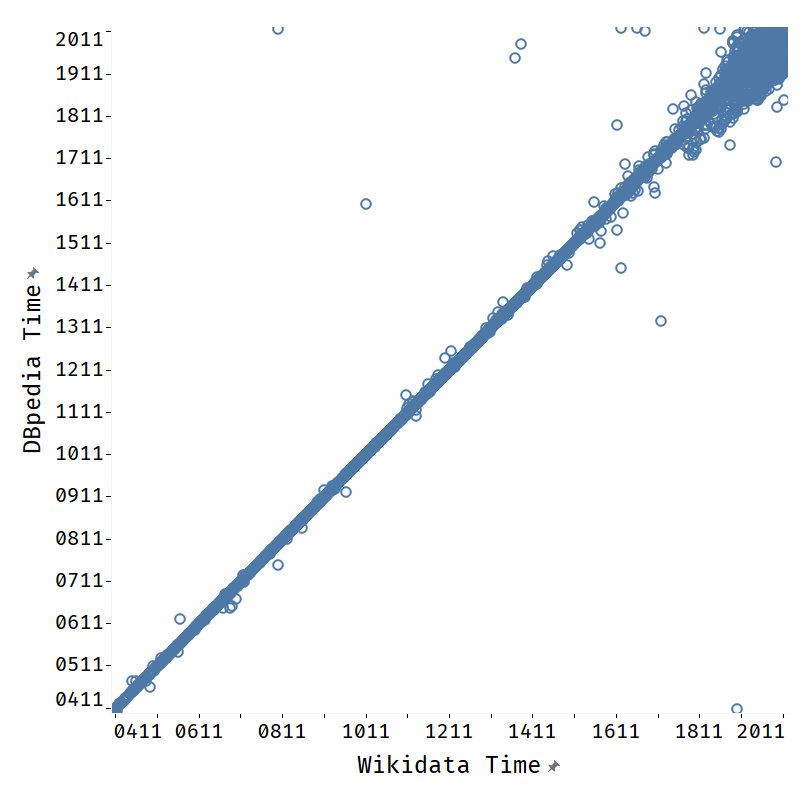
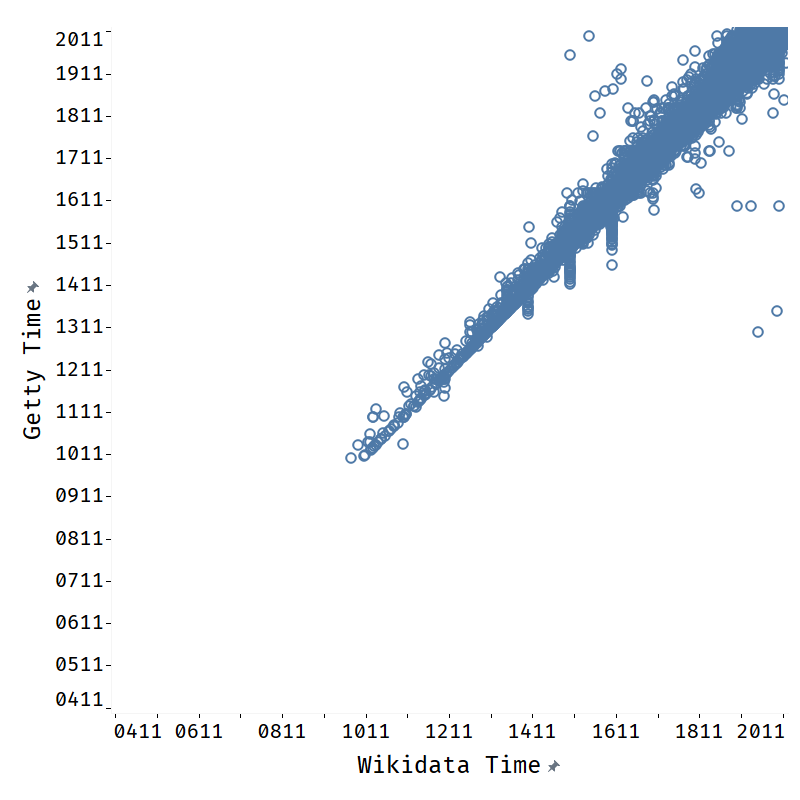
Finding 6: The method can help enrich literals as well. Our method can also be used to enrich literal information about entities. We run our method on two functional properties: P569 (date of birth) and P570 (date of death). We compare the obtained results from the external graphs to those found in Wikidata, for entity-property pairs where both Wikidata and the external graph have a value. We compare the results on the finest granularity provided by the the two graphs, which is dates for DBpedia and years to Getty. The results for property P570 in Figure 3 show a clear trend of the points in scatter plots distributed along the line of , which shows high consistency of the date data between the Wikidata and the external KGs.121212We observe a similar trend for P569. Specifically, we observe that the agreement rate with Wikidata values is 89.28% (1,271,862 out of 1,424,526) for DBpedia and 82.39% for Getty (125,913 out of 152,824). From Getty and DBpedia, our method can enhance Wikidata with novel P569 values for 35,459 entities and novel P570 values for 20,664 entities.
6 Discussion and Future Work
Our enrichment method has been shown to quickly retrieve millions of novel property values in the LOD cloud for entities in Wikidata. As some of the LOD knowledge is extracted in an automatic way, ensuring quality is important - our semantic validation based on datatypes and constraints found around half of the candidate statements to be invalid. Analysis of a subset of the enriched statements revealed that the accuracy of our method is close to 90%, which is reasonably high. Still, our method is merely a step towards the ambitious goal of addressing the notorious challenge of sparsity of today’s large KGs [12]. Here, we discuss three key areas of improvement for our method:
1. Evaluation on more KGs - We showed that our method is effective with two external KGs: a general-domain and automatically extracted knowledge graph, DBpedia, and a domain-specific, well-curated knowledge graph, Getty. As Wikidata is still largely incomplete after this enrichment, we can use the 6.8k external identifier properties provided by Wikidata to enrich with thousands other sources. While we expect that our method can be applied on these thousands of sources, an in-depth investigation of the potential and the quality of this enrichment is beyond the scope of the current paper.
2. Semantic validation - Our method validates candidate statements through datatype and value type constraints. Value type constraints ensure semantic type compatibility of the retrieved statements, yet they are only one of the 30 property constraint types defined in Wikidata. Other Qnode constraints in Wikidata can be employed to generalize our method to properties that do not have a value type constraint. Qnode-valued statements can be further validated via constraints like one-of (Q21510859), whereas literals can, for instance, be checked with range (Q21510860).
3. Validating veracity Table 3 shows that our method performs relatively well on detecting statements with incorrect datatype or semantic type, whereas it is usually unable to detect inaccurate statements. The accuracy of detecting inaccurate statements ranges from 0 to 28%. As discussed by Piscopo [23], veracity is a key aspect of quality of knowledge in KGs. Our method can be further enhanced with models that detect KG vandalism [18] or estimate trust of sources (e.g., through references) [22] to estimate veracity.
7 Conclusions
Recognizing the notorious sparsity of modern knowledge graphs, such as Wikidata, and the promise of linked data information, like external identifiers, to facilitate enrichment, this work proposed a method for enriching Wikidata with external KGs found in the LOD cloud. The method consisted of five steps: gap detection, external graph selection, schema alignment, knowledge retrieval, and semantic validation. We evaluated our method on enriching Wikidata with two LOD graphs: DBpedia and Getty. Our experiments showed that our LOD-based method can enrich Wikidata with millions of new high-quality statements in a short time. High-quality enrichment is achieved based on large-scale automated semantic validation based on datatypes and value type constraints, as well as a hybrid algorithm for property alignment. A key future direction is evaluating the generalization of our method on thousands of LOD sources that Wikidata points to, which opens novel challenges of source selection, more extensive semantic validation, and trust. We make our code and data available to facilitate future research on LOD-based knowledge enrichment.
References
- [1] Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., Ives, Z.: Dbpedia: A nucleus for a web of open data. In: The semantic web, pp. 722–735. Springer (2007)
- [2] Balaraman, V., Razniewski, S., Nutt, W.: Recoin: relative completeness in wikidata. In: Companion Proceedings of the The Web Conference 2018. pp. 1787–1792 (2018)
- [3] Beek, W., Ilievski, F., Debattista, J., Schlobach, S., Wielemaker, J.: Literally better: Analyzing and improving the quality of literals. Semantic Web 9(1), 131–150 (2018)
- [4] Beek, W., Raad, J., Wielemaker, J., Van Harmelen, F.: sameas. cc: The closure of 500m owl: sameas statements. In: European semantic web conference. pp. 65–80. Springer (2018)
- [5] Beek, W., Rietveld, L., Bazoobandi, H.R., Wielemaker, J., Schlobach, S.: Lod laundromat: a uniform way of publishing other people’s dirty data. In: International semantic web conference. pp. 213–228. Springer (2014)
- [6] Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., Yakhnenko, O.: Translating embeddings for modeling multi-relational data. Advances in neural information processing systems 26 (2013)
- [7] Chu, S.C., Xue, X., Pan, J.S., Wu, X.: Optimizing ontology alignment in vector space. Journal of Internet Technology 21(1), 15–22 (2020)
- [8] d’Amato, C., Staab, S., Tettamanzi, A.G., Minh, T.D., Gandon, F.: Ontology enrichment by discovering multi-relational association rules from ontological knowledge bases. In: Proceedings of the 31st Annual ACM Symposium on Applied Computing. pp. 333–338 (2016)
- [9] Das, S.: R2rml: Rdb to rdf mapping language. http://www. w3. org/TR/r2rml/ (2011)
- [10] Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. CoRR abs/1810.04805 (2018), http://arxiv.org/abs/1810.04805
- [11] Dimou, A., Vander Sande, M., Colpaert, P., Verborgh, R., Mannens, E., Van de Walle, R.: Rml: a generic language for integrated rdf mappings of heterogeneous data. In: Ldow (2014)
- [12] Dong, X., Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K., Strohmann, T., Sun, S., Zhang, W.: Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In: Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 601–610 (2014)
- [13] Faatz, A., Steinmetz, R.: Ontology enrichment with texts from the www. Semantic Web Mining 20 (2002)
- [14] Faraj, G., Micsik, A.: Enriching wikidata with cultural heritage data from the courage project. In: Research Conference on Metadata and Semantics Research. pp. 407–418. Springer (2019)
- [15] Färber, M., Bartscherer, F., Menne, C., Rettinger, A.: Linked data quality of dbpedia, freebase, opencyc, wikidata, and yago. Semantic Web 9(1), 77–129 (2018)
- [16] Harpring, P.: Development of the getty vocabularies: Aat, tgn, ulan, and cona. Art Documentation: Journal of the Art Libraries Society of North America 29(1), 67–72 (2010)
- [17] Hassanzadeh, O., Consens, M.P.: Linked movie data base. In: LDOW (2009)
- [18] Heindorf, S., Potthast, M., Stein, B., Engels, G.: Vandalism detection in wikidata. In: Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. pp. 327–336 (2016)
- [19] Ilievski, F., Garijo, D., Chalupsky, H., Divvala, N.T., Yao, Y., Rogers, C., Li, R., Liu, J., Singh, A., Schwabe, D., et al.: Kgtk: a toolkit for large knowledge graph manipulation and analysis. In: International Semantic Web Conference. pp. 278–293. Springer, Cham (2020)
- [20] Knoblock, C.A., Szekely, P., Ambite, J.L., Goel, A., Gupta, S., Lerman, K., Muslea, M., Taheriyan, M., Mallick, P.: Semi-automatically mapping structured sources into the semantic web. In: Extended Semantic Web Conference. pp. 375–390. Springer (2012)
- [21] Mousselly-Sergieh, H., Gurevych, I.: Enriching wikidata with frame semantics. In: Proceedings of the 5th Workshop on Automated Knowledge Base Construction. pp. 29–34 (2016)
- [22] Piscopo, A., Kaffee, L.A., Phethean, C., Simperl, E.: Provenance information in a collaborative knowledge graph: an evaluation of wikidata external references. In: International semantic web conference. pp. 542–558. Springer (2017)
- [23] Piscopo, A., Simperl, E.: What we talk about when we talk about wikidata quality: a literature survey. In: Proceedings of the 15th International Symposium on Open Collaboration. pp. 1–11 (2019)
- [24] Raad, J., Pernelle, N., Saïs, F.: Detection of contextual identity links in a knowledge base. In: Proceedings of the knowledge capture conference. pp. 1–8 (2017)
- [25] Ratcliff, J.W., Metzener, D.E.: Pattern matching: The gestalt approach. Dr. Dobb’s Journal p. 46 (1988)
- [26] Shenoy, K., Ilievski, F., Garijo, D., Schwabe, D., Szekely, P.: A study of the quality of wikidata. Journal of Web Semantics (Community-based Knowledge Bases) (2021)
- [27] Turki, H., Jemielniak, D., Taieb, M.A.H., Gayo, J.E.L., Aouicha, M.B., Banat, M., Shafee, T., Prud’Hommeaux, E., Lubiana, T., Das, D., Mietchen, D.: Using logical constraints to validate information in collaborative knowledge graphs: a study of COVID-19 on Wikidata (Aug 2020). https://doi.org/10.5281/zenodo.4445363
- [28] Vrandečić, D., Krötzsch, M.: Wikidata: a free collaborative knowledgebase. Communications of the ACM 57(10), 78–85 (2014)
- [29] Waagmeester, A., Schriml, L., Su, A.: Wikidata as a linked-data hub for biodiversity data. Biodiversity Information Science and Standards 3, e35206 (2019)
- [30] Zablith, F., Antoniou, G., d’Aquin, M., Flouris, G., Kondylakis, H., Motta, E., Plexousakis, D., Sabou, M.: Ontology evolution: a process-centric survey. The knowledge engineering review 30(1), 45–75 (2015)