Environment-adaptive machine learning potentials
Abstract
The development of interatomic potentials that can accurately capture a wide range of physical phenomena and diverse environments is of significant interest, but it presents a formidable challenge. This challenge arises from the numerous structural forms, multiple phases, complex intramolecular and intermolecular interactions, and varying external conditions. In this paper, we present a method to construct environment-adaptive interatomic potentials by adapting to the local atomic environment of each atom within a system. The collection of atomic environments of interest is partitioned into several clusters of atomic environments. Each cluster represents a distinctive local environment and is used to define a corresponding local potential. We introduce a many-body many-potential expansion to smoothly blend these local potentials to ensure global continuity of the potential energy surface. This is achieved by computing the probability functions that determine the likelihood of an atom belonging to each cluster. We apply the environment-adaptive machine learning potentials to predict observable properties for Ta element and InP compound, and compare them with density functional theory calculations.
I Introduction
Molecular dynamics (MD) simulations require an accurate calculation of energies and forces to analyze the physical movements of atoms. While electronic structure calculations provide accurate energies and forces, they are restricted to analyzing small length scales and short time scales due to their high computational complexity. Interatomic potentials represent the potential energy surface (PES) of an atomic system as a function of atomic positions and thus leave out the detailed electronic structures. They can enable MD simulations of large systems with millions or even billions of atoms over microseconds.
Over the years, empirical interatomic potentials (EIPs) such as the Finnis-Sinclair potential [1], embedded atom method (EAM) [2], modified EAM (MEAM) [3], Stillinger-Weber (SW) [4], Tersoff [5], Brenner [6], EDIP [7], COMB [8], ReaxFF [9] have been developed to treat a wide variety of atomic systems with different degrees of complexity. EAM potential has its root from the Finnis-Sinclair potential [1] in which the embedding function is a square root function. The MEAM potential [3] was developed as a generalization of the EAM potential by including angular-dependent interactions in the electron density term. The SW potential takes the form of a three-body potential in which the total energy is expressed as a linear combination of two- and three-body terms. The Tersoff potential is fundamentally different from the SW potential in that the strength of individual pair interactions is affected by the presence of surrounding atoms. The Brenner potential is based directly on the Tersoff potential but has additional terms and parameters which allow it to better describe various chemical environments. EDIP is designed to more accurately represent interatomic interactions by considering the effects of the local atomic environment on these interactions. Because EAM, MEAM, Tersoff, Brenner, EDIP, ReaxFF and COMB potentials dynamically adjust the strength of the bond based on the local environment of each atom, they can describe several different bonding states and complex behaviors of atoms in various states, including defects, phase transitions, surfaces, and interfaces within materials. One of the key features of ReaxFF and COMB is their ability to handle charge equilibration in a manner that includes long-range electrostatic interactions and reflects changes in the electronic environment of atoms during chemical reactions.
The past decade has seen a tremendous interest in machine learning interatomic potentials (MLIPs) due to their promising quantum accuracy at significantly lower computational complexity than electronic structure calculations. The descriptors play a central role in the construction of accurate and efficient MLIPs. In recent years, a wide variety of descriptors has been developed to represent atomic structures. There are two main approaches to mapping a configuration of atoms onto descriptors [10]: atom density approach and internal coordinate approach. Examples of internal coordinate descriptors include permutation-invariant polynomials (PIPs) [11, 12, 13], atom-centered symmetry functions (ACSFs) [14, 15, 16], and proper orthogonal descriptors (PODs) [17, 18, 19]. These internal coordinate descriptors are intrinsically invariant with respect to translation and rotation because they are functions of angles and distances. They are made to be permutationally invariant by summing symmetry functions over all possible atomic pairs and triplets within local atomic environments. However, achieving permutation invariance by such a way leads to the exponential scaling in terms of the number of neighbors. The computational cost can be kept under control by restricting the range of interactions, the number of descriptors, and the body orders.
The atom density approach describes a local atomic environment around a central atom as an atom density function which is obtained by summing over localized functions centered on the relative positions of all atoms in the local environment. Such a density is naturally invariant to translation and permutation. The atomic neighborhood density is then expanded as a linear combination of appropriate basis functions, where the expansion coefficients are given by the inner products of the neighborhood density with the basis functions. Rotationally invariant descriptors are computed as appropriate sums of products of the density coefficients. In the atom density approach, the choices of the basis set (e.g., radial basis functions, spherical harmonics, angular monomials, hyperspherical harmonics) lead to different sets of descriptors. The power spectrum and bispectrum descriptors [20] are constructed from spherical harmonics, while the spectral neighbor analysis potential (SNAP) descriptors [21] are based on hyperspherical harmonics. The moment tensor potential (MTP) [22] projects the atomic density onto a tensor product of angular vectors to construct the moment tensors whose contraction results in invariant descriptors. The atomic cluster expansion (ACE) [23, 24] extends the power and bispectrum construction to obtain a complete set of invariant descriptors with arbitrary number of body orders. The E3 equivariant graph neural network potentials [25] use spherical harmonics. The atom density representation of POD descriptors employs angular monomials and radial basis functions constructed from the proper orthogonal decomposition [26].
The main advantage of atom density descriptors is that their computational complexity scales linearly with the number of neighbors irrespective of the body orders. The computational complexity of internal coordinate descriptors scales exponentially with the body order in terms of the number of neighbors. However, the cost of internal coordinate descriptors scales linearly with the number of basis functions, whereas that of atom density descriptors scales exponentially with the body order in terms of the number of basis functions. In general, atom density descriptors are more efficient than internal coordinate descriptors when there are many neighbors and the body order is higher than 3. Despite the rather fundamental difference in their construction, some internal coordinate descriptors and atom density descriptors can be shown to span the same descriptor space. This is the case for the POD descriptors in which the atom density representation is shown to be equivalent to the internal coordinate representation [26]. The POD formalism allows other internal coordinate descriptors like PIPs and ACSFs, as well as empirical potentials like EAM, MEAM, and SW, to be implemented using the atom density approach.

Despite considerable progress that has been made in recent years, there remain open problems to be addressed with regard to the accuracy, efficiency, and transferability of interatomic potentials. The development of interatomic potentials that can effectively capture a wide range of atomic environments is a complex challenge due to several reasons. Materials can exist in numerous structural forms (e.g., crystalline, amorphous, defects, interfaces) and phases (solid, liquid, gas, plasma). Atoms interact through various forces such as electrostatic, van der Waals, ionic bonding, covalent bonding, and metallic bonding, which manifest differently depending on the chemical elements and their electronic structures. Furthermore, the effective interaction among atoms can change with external conditions like temperature, pressure, and chemical environment. Consequently, creating an interatomic potential that performs well across diverse conditions is difficult because optimizing the potential for one set of conditions can lead to poorer performance in others. Each of these factors contributes to the complexity of developing interatomic potentials that are effective and efficient to capture a diverse range of local atomic environments.
In this paper, we introduce a method for the systematic construction of accurate and transferable interatomic potentials by adapting to the local atomic environment of each atom within a system. Local atomic environment of an atom comprises the positions and chemical species of the atom and its neighbors within a cutoff radius. These atom positions and chemical species can be mapped onto a vector of invariant descriptors by using either the internal coordinate approach or the atom density approach. For a dataset of atoms, we obtain a descriptor matrix of size by . Each row of the descriptor matrix encapsulates the local atomic environment of the corresponding atom. Since is typically large, a dimensionality reduction technique is used to compress the descriptor matrix into a lower-dimensional matrix of size by , where is considerably less than . A clustering method is then employed to partition the compressed data into separate clusters. In other words, the original dataset of atoms is divided into subsets and the atoms in any subset have similar atomic environments. The clustering scheme allows us to divide the diverse dataset into smaller subsets, each characterized by data points sharing the common attributes. This approach captures the diversity inherent in the dataset by identifying distinct atomic environments within the dataset. By training MLIPs on these subsets separately, we can obtain MLIPs that are tailored to specific atomic environments. Each MLIP may accurately predict configurations in the subset on which it is trained. However, it may not be accurate for predicting configurations in the other subsets.
The above approach raises the question: How do we combine these separately localized MLIPs to construct a global potential energy surface? To this end, we propose a many-body many-potential (MBMP) expansion designed to seamlessly blend the individual MLIPs and ensure that the potential energy surface remains continuous across cluster boundaries. This continuity is achieved by calculating probability functions that assess the likelihood of an atom belonging to specific clusters identified within the dataset. These probability functions are critical in guiding how contributions from different MLIPs are weighted and combined, providing a systematic way to maintain the integrity and accuracy of the model across different atomic environments. This integration is crucial for achieving a comprehensive model that can accurately capture diverse environments in the original dataset. This model can also capture atomic environments that are a mixture of several distinct environments when the probability functions are close to each other, thereby potentially making the model more transferable than the individual MLIPs.
Although the formulation of the environment-adaptive machine learning (EAML) potentials is descriptor agnostic and can be developed for any set of descriptors, in this work we employ the proper orthogonal descriptors [17, 26]. To this end, we extend the proper orthogonal descriptors to deal with multi-element systems. This enables us to construct EAML potentials that are finely tuned to the complexities of various material compositions under diverse conditions. We apply the EAML potentials to predict observable properties for Ta element and InP compound, and compare them with density functional theory calculations.
The paper is organized as follows. In Section II, we extend proper orthogonal descriptors to multi-element systems. In Section III, we describe our approach for constructing EAML potentials. In Section IV, we present results to demonstrate the EAML potentials for Tantalum and Indium Phosphide. Finally, we provide some concluding remarks in Section V.
II Multi-Element proper orthogonal descriptors
This section outlines a systematic approach for constructing internal coordinate and atom density descriptors to represent the local atomic environments of multi-element systems. Building on our previous work [17, 18, 19], we develop invariant descriptors for multi-element systems by leveraging orthogonal proper decomposition to generate radial basis functions and employing the trinomial expansion of angular monomials to achieve rotational symmetry. The resulting descriptors combine elements of both internal coordinates and atom density fields, as illustrated in Figure 1.
II.1 Many-body potential energy surface
We consider a multi-element system of atoms with unique elements. We denote by and position vector and type of an atom in the system, respectively. Thus we have , , and . The potential energy surface (PES) of the system of atoms can be expressed as a many-body expansion of the form
| (1) |
The superscript on each potential denotes its body order. Each potential must also depend on a set of parameters used to parametrize it for a specific application. To simplify the notation, we have chosen not to explicitly denote these parameters in the potentials. A separation of the PES into atomic contributions yields
| (2) |
where is obtained from (1) by removing the sum over index . To make the PES invariant with respect to translation and rotation, the potentials should depend only on internal coordinates as follows
| (3) |
where , , , . The internal coordinates include both distances and angles . The number of internal coordinates for is equal to . Typically, the one-body terms are set to the isolated energies of atom .
II.2 Two-body proper orthogonal descriptors
We briefly describe the construction of two-body PODs and refer to [17, 26] for further details. We assume that the direct interaction between two atoms vanishes smoothly when their distance is greater than the cutoff distance . Furthermore, we assume that two atoms can not get closer than the inner cutoff distance . Letting , we introduce the following parametrized radial functions
| (4) |
where the scaled distance function is given by
| (5) |
The function in (4) is related to the zeroth spherical Bessel function, while the function is inspired by the n-m Lennard-Jones potential. Although the parameter can be real number, we choose a set of consecutive positive integers to compute instances of the parametrized function by making use of the relation . Similarly, we choose a set of consecutive integers for to generate instances of the parametrized function by making use of the formula , where are Chebyshev polynomials of the second kind. We take values for the parameter such that for , where .
We introduce the following function as a convex combination of the two functions in (4)
| (6) |
where , and . The two-body parametrized potential is defined as follows
| (7) |
where the cut-off function is
| (8) |
with . This cut-off function ensures the smooth vanishing of the two-body potential and its derivative for .
Given parameter tuples , we introduce the following set of snapshots
| (9) |
We next employ the proper orthogonal decomposition [17] to generate an orthogonal basis set which is known to be optimal for representation of the snapshot family . In particular, the orthogonal radial basis functions are computed as follows
| (10) |
where the number of radial basis functions is typically in the range between 5 and 10. Note that are a matrix whose columns are eigenvectors of the following eigenvalue problem
| (11) |
where the covariance matrix is given by
| (12) |
The covariance matrix is computed by using the trapezoidal rule on a grid of 2000 subintervals on the interval . The eigenvector matrix is pre-computed and stored.
Finally, the two-body proper orthogonal descriptors at each atom are computed by summing the orthogonal basis functions over the neighbors of atom and numerating on the atom types as follows
| (13) |
for . The number of two-body descriptors per atom is thus .
For the purpose of complexity analysis, we assume that each atom has the same number of neighbors . The total number of neighbors is thus for all atoms. The cost of evaluating the radial basis functions in (10) is , while the cost of evaluating the two-body descriptors in (13) is . The total cost is thus independent of the number of elements .
II.3 Three-body proper orthogonal descriptors
For any given integer , where is the highest angular degree, we introduce a basis set of angular monomials
| (14) |
where the exponents are nonnegative integers such that . Note that the index satisfies for any given , and that the total number of angular monomials is . Table 1 shows the basis set of angular monomials for . By applying the trinomial expansion to the power of the angle component , we obtain
| (15) |
where and correspond to the multinomial coefficients of the trinomial expansion. Table 2 shows the multinomial coefficients for .
| 0 | |
|---|---|
| 1 | , , |
| 2 | , , , , , |
| 3 | , , , , , , , |
| , , | |
| 4 | , , , , , , , |
| , , , , | |
| 0 | |
|---|---|
| 1 | , , |
| 2 | , , , , , |
| 3 | , , , , , , , , , |
| 4 | , , , , , , , , , , , , , , |
Next, we define the atom basis functions at atom as the sum over all neighbors of atom of the products of radial basis functions and angular monomials
| (16) |
The cost of evaluating the atom basis functions is , which is independent of the number of elements. These atom basis functions are used to define the atom density descriptors as follows
| (17) |
for . The number of three-body descriptors per atom is thus . The cost of evaluating (17) is , which is usually less than that of evaluating the atom basis functions. Therefore, the total cost of computing the atom density descriptors is .
Substituting (16) into (17) yields the internal coordinate form of the three-body descriptors
| (18) |
for . The cost of evaluating the internal coordinate descriptors is . Although the atom density descriptors (17) and the internal coordinate descriptors (18) are mathematically equivalent, their computational complexity are not the same. The complexity of the atom density descriptors is linear in the number of neighbors and cubic in the angular degree, whereas that of the internal coordinate descriptors is quadratic in the number of neighbors and linear in the angular degree. Therefore, if the number of neighbors is large and the angular degree is small, it is faster to evaluate the the atom density descriptors. On the other hand, if the number of neighbors is small and the angular degree is high, it is more efficient to compute the internal coordinate descriptors.
II.4 Four-body proper orthogonal descriptors
We begin by introducing the following four-body angular functions
| (19) |
where are integers such that and . The four-body angular functions are listed in Table 3. The four-body internal coordinate descriptors at each atom are defined as
| (20) |
for , where are given by
| (21) |
for . Here is the number of four-body angular basis functions, which depends on . The number of four-body descriptors per atom is thus . The cost of evaluating the four-body internal coordinate descriptors is , which is independent of the number of elements.
| 0 | |
|---|---|
| 1 | |
| 2 | |
| 3 | , |
| 4 | , , |
We note from the trinomial expansion that
where are the angular monomials defined in (14). By considering , , , we obtain
where , , , and the index depends on and , on and , on and . It thus follows that the four-body angular functions can be expressed as
where . Hence, the internal coordinate form (20) is equivalent to the atom density form
| (22) |
The four-body atom density descriptors are expressed in terms of the sums of the products of the atom basis functions. In general, they are more efficient to evaluate than their internal coordinate counterparts because they scale linearly with the number of neighbors. The complexity analysis of the four-body atom density descriptors is detailed in [26].
It is possible to exploit the symmetry and hierarchy of the four-body descriptors to reduce the computational cost. In particular, the four-body descriptors associated with are the products of three two-body descriptors. For (e.g., in Table 3) the four-body descriptors are the products of two-body descriptors and three-body descriptors. Those four-body descriptors can be computed very fast without using the atom density form (22). The remaining four-body descriptors are calculated by using (22). They share many common terms, which can be exploited to further reduce the cost. For instance, since and , the descriptors associated with and have many common terms with those associated with .
III Environment-Adaptive Machine Learning Potentials
This section describes a method for constructing EAML potentials from a given set of invariant descriptors. The method leverages the principal component analysis and -means algorithm to partition the dataset into atom clusters. The method relies on a many-body many-potential expansion that combines several different potentials to define a single potential energy surface. This is done by calculating probability functions that assess the likelihood of an atom belonging to specific clusters. These probability functions determine how contributions from different potentials are weighted and combined and provide a systematic way to maintain the continuity of the potential energy surface.
III.1 Linear regression models
Linear regression is the most simple and efficient method for building MLIP models [21, 27, 28, 22]. Let be a set of local descriptors at atom . The atomic energy at an atom is expressed as a linear combination of the local descriptors
| (23) |
where are the coefficients to be determined by fitting against QM database. The PES is given by
| (24) |
where are the global descriptors. The coefficients are sought as solution of a least squares problem
| (25) |
where the matrix is formed from the global descriptors, while is formed from the derivatives of the global descriptors for all configurations in the training database. The vector is comprised of DFT energies, while is comprised of DFT forces. Note that is the energy weight parameter, is the force weight parameter, and is a regularization parameter. They are hyperparameters of the linear regression model.
In order to accurately model atomic forces in MD simulations, the training dataset must be diverse and rich enough to cover structural forms (e.g., crystalline, amorphous, defects, interfaces), multiple phases (solid, liquid, gas, plasma), and a wide range of temperature, pressure, and chemical environment. Training a linear model on the entire training set may not produce an accurate and efficient potential it the dataset contains very diverse environments. We partition the training dataset into separate subsets, whose DFT energies and forces are denoted by . On each subset, we introduce an associated PES
| (26) |
where the coefficient vectors are sought as solutions of the least squares problems
| (27) |
Here the superscript is used to indicate the quantities associated with the th subset. This training strategy yields an ensemble of separate potentials. Each potential may accurately predict configurations in the subset on which it is trained. However, it may not be accurate for predicting configurations in the other subsets.
A hypothetical issue here is to guarantee the continuity of PES when predicting forces with an ensemble of potentials. It is not obvious how to combine these separate potentials, as they are trained on different datasets. A simple strategy is to select the best potential among these potentials to predict the physical properties of a given configuration at hand, if the criterion of selecting the best potential can be defined. While this strategy may work for property prediction, it does not work for MD simulations. This is because using different potentials in an MD simulation will result in discontinuity in the PES and thus forces. The remainder of this section describes a method that allows us to combine these separate potentials to construct a global, differentiable and continuous PES.
III.2 Dataset partition
We describe a clustering method to partition the dataset into subsets of similar attributes. Local atomic environment of an atom comprises the positions and chemical species of the atom and its neighbors within a cutoff radius. These atom positions and chemical species can be mapped onto a vector of invariant descriptors, , by using either the internal coordinate approach or the atom density approach. For a dataset of atoms, we obtain a descriptor matrix of size by . Each row of the descriptor matrix encapsulates the local atomic environment of the corresponding atom. The similarity between two local atomic environments can be measured by the dot product of the two corresponding descriptor vectors. Therefore, partitioning the dataset of atoms into clusters can be done by dividing the rows of the descriptor matrix into similarity subsets. One can use a clustering method such as -means clustering algorithm to partition vectors in dimensions into separate clusters. However, clustering in very high dimensions can be very expensive, since is typically large.
To reduce computational cost, we consider a dimensionality reduction method to compress the descriptor matrix into a lower-dimensional matrix of size by , where is considerably less than . In this paper, principal component analysis is used to obtain the low-dimensional descriptor matrix as follows
| (28) |
Here consists of the first eigenvectors of the eigenvalue decomposition , and the eigenvalues are ordered from the largest to the smallest.
For multi-element systems, the clustering method is applied to the local descriptor matrix for each element as follows. The matrix is split into , where is formed by gathering the rows of for all atoms of the element . For each element , we compute
| (29) |
where consists of the eigenvectors of the eigenvalue decomposition .
Next, we apply -means clustering method to partition the rows of the matrix into separate clusters. We denote the centroids of the clusters by . The clustering scheme allows us to divide the diverse dataset into smaller subsets, each characterized by similar data points which share the common attributes. This approach captures the diversity inherent in the dataset by identifying distinct atomic environments within the dataset. Figure 2 illustrates the process of partitioning the dataset into several atom clusters.
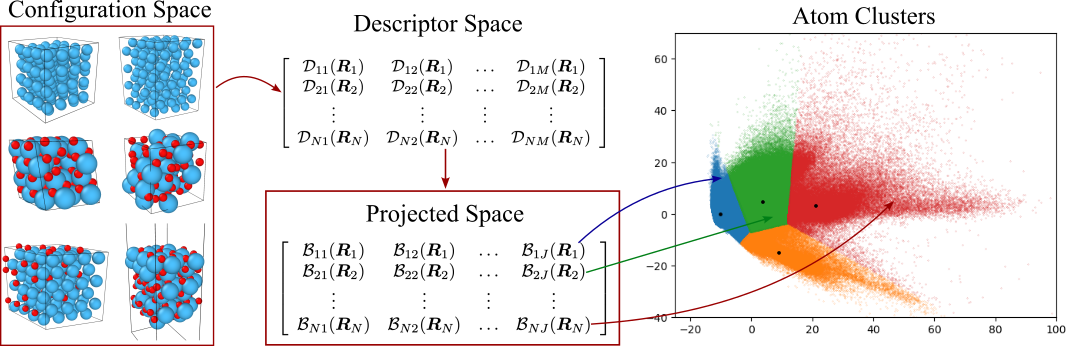
While local descriptors are used to partition atoms of the data set into subsets of atoms for each element, global descriptors can be used for partitioning the configurations of the dataset into subsets of configurations. For the dataset of configurations, we sum the relevant rows of the local descriptor matrix to obtain the global descriptor matrix of size by . We then apply the above procedure to to obtain the desired configuration subsets. By training potentials on these subsets separately, we can construct MLIPs that are tailored to specific atomic environments.
III.3 Many-body many-potential expansion
We begin by introducing the atomic energies associated with the partitioned subsets
| (30) |
where the coefficients are fitted against the QM data. For simplicity of exposition, the same local descriptors are used to define the atomic energies, although we allow for different local descriptors to be used for each subset. To construct a single potential energy surface, we introduce a many-body many-potential expansion
| (31) |
where
| (32) |
Thus, the atomic energy at atom is a weighted sum of the individual contributions from the subsets. Note that denotes the probability of atom belonging to the th subset. Like the local descriptors, the probabilities depend on the local atomic environment of the central atom .
By inserting (30) into the many-potential expansion (31) and summing over index , we obtain the PES as
| (33) |
The quantities shall be called environment-adaptive descriptors. Hence, we can write the PES as follows
| (34) |
where is a linear indexing of and . The coefficients are sought as solution of a least squares problem that minimizes a loss function defined as the weighted mean squared errors between the predicted energies/forces and the QM energies/forces for all configurations in the training dataset.
For the single cluster case , the EA model (33) reduces to the standard linear model
| (35) |
Hence, the EA model (34) has times more descriptors and coefficients than the standard linear model (35). Because the size of the EA model increases with , it can describe diverse environments in the dataset better than the standard linear model. Nonetheless, it is necessary to assess the EA model while varying and compare it against the standard linear model.
III.4 The probability functions
It remains to calculate the probabilities . They are defined in terms of the local descriptors as follows. First, we compute the low-dimensional descriptors.
| (36) |
where are the PCA matrices. Next, we calculate the inverse of the square of the distance from the th centroid as
| (37) |
Recall that are the centroids obtained from partitioning the dataset. Finally, the probabilities are calculated as
| (38) |
Hence, the probabilities are high when the distances between the low-dimensional descriptor vector and the centroids are small. The additional cost of evaluating the probabilities is only per atom. This cost can be neglected, as it is considerably less than the cost of computing the local descriptors.
III.5 Force calculation
Forces on atoms are calculated by differentiating the PES (33) with respect to atom positions. To this end, we first compute the partial derivatives of the probabilities with respect to the local descriptors as
| (39) |
Here the Einstein summation convention is used to indicate the implicit summation over repeated indices except for the index . The cost of evaluating the terms in (39) is per atom. Next, we note that
| (40) |
Differentiating the PES (33) with respect to atom positions yields
| (41) |
By inserting (40) into (41), we obtain
| (42) |
The additional cost of evaluating the terms in the parenthesis is only per atom.
In summary, the additional cost of evaluating the forces on atoms is per atom for any . Since this cost is independent of the number of neighbors and linear in the number of local descriptors, it can be much smaller than the cost of computing the local descriptors and their derivatives with respect to atom positions. We can thus expect that the EA potentials are almost as fast as the standard linear potential. Therefore, the proposed method enhances the EA potentials without increasing computational cost.
IV Results and Discussions
The EA potentials will be demonstrated and compared with the standard linear potential for Tantalum element and Indium Phosphide compound. For all potentials, the hyperparameters are fixed to . In order to assess their performance, all potentials are trained on the same training datasets and validated on the same test datasets. We evaluate the potentials using the mean absolute errors (MAEs) of the predicted energies and forces
| (43) |
where is the number of configurations in a data set, and is the total number of force components for all the configurations in the same data set. Both the source code and the data are available upon request to facilitate the reproduction of our work.
IV.1 Results for Tantalum
The Ta data set contains a wide range of configurations to adequately sample the important regions of the potential energy surface [21]. The data set includes 12 different groups such as surfaces, bulk structures, defects, elastics for BCC, FCC, and A15 crystal structures, and high temperature liquid. The database was used to create a SNAP potential [21] which successfully describes a wide range of properties such as energetic properties of solid tantalum phases, the size and shape of the Peierls barrier for screw dislocation motion in BCC tantalum, as well as both the structure of molten tantalum and its melting point. We train eight EAML models on the Ta dataset for different values of and . Table 4 shows the number of descriptors for the eight EAML potentials. Note that all potentials have a one-body descriptor to account for isolated energies. The inner and outer cut-off distances are set to Å and Å, respectively. Furthermore, we use in all cases.
| Ta | two-body | three-body | four-body | All | |||||
| Case | |||||||||
| 1 | 4 | 4 | 2 | 2 | 4 | 0 | 0 | 0 | 8 |
| 2 | 5 | 5 | 3 | 3 | 9 | 0 | 0 | 0 | 14 |
| 3 | 6 | 6 | 4 | 4 | 16 | 0 | 0 | 0 | 22 |
| 4 | 7 | 7 | 5 | 5 | 25 | 0 | 0 | 0 | 32 |
| 5 | 8 | 8 | 6 | 5 | 30 | 3 | 2 | 6 | 44 |
| 6 | 9 | 9 | 7 | 5 | 35 | 4 | 4 | 16 | 60 |
| 7 | 10 | 10 | 8 | 6 | 48 | 5 | 4 | 20 | 78 |
| 8 | 11 | 11 | 9 | 6 | 54 | 5 | 7 | 35 | 100 |
| Case | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 74.6 | 132.65 | 35.02 | 161.45 | 25.47 | 178.24 | 20.01 | 179.69 |
| 2 | 55.37 | 237.93 | 22.98 | 228.11 | 14.43 | 208.26 | 6.72 | 130.22 |
| 3 | 37.63 | 209.94 | 8.60 | 128.45 | 5.98 | 99.94 | 4.94 | 101.05 |
| 4 | 10.47 | 106.69 | 4.43 | 95.77 | 2.51 | 70.99 | 2.00 | 67.16 |
| 5 | 8.02 | 96.94 | 3.14 | 74.04 | 1.75 | 62.49 | 1.49 | 59.05 |
| 6 | 4.00 | 88.38 | 1.58 | 62.49 | 1.19 | 52.46 | 1.02 | 50.82 |
| 7 | 2.37 | 76.73 | 1.20 | 55.82 | 0.80 | 49.94 | 0.60 | 45.51 |
| 8 | 1.77 | 64.11 | 0.83 | 48.91 | 0.56 | 43.10 | 0.49 | 39.56 |
Table 5 displays training errors in energies and forces predicted by EAML potentials for different values of the number of the descriptors listed in Table 4 and for . We see that both the energy and force errors decrease as the number of descriptors increases. As increases from to 100, the energy errors drop by a a factor of 20, while the force errors drop by a factor of 4. As increases from to , the energy errors decrease by a factor of 4, while the force errors decrease by a factor of 1.5. The energy errors reach 1.77 meV/atom, 0.83 meV/atom, 0.56 meV/atom, and 0.48 meV/atom for and 4, respectively. These energy errors are below the typical numerical errors of DFT calculations. The force errors reach 64.11 meV/Å, 48.91 meV/Å, 43.10 meV/Å, and 39.56 meV/Å. These force errors are acceptable for most applications. The errors decrease quite rapidly as increases from 1 to 2. However, as increases from to , the rate of error decrease slows down considerably for this dataset and we observe a smaller improvement. Hence, we may only gain marginal improvements by increasing beyond 4.
Table 6 provides the training errors in energy and forces for each of the 12 groups for . The force errors for Bulk A15, Bulk BCC, and Bulk FCC are zero, because their structures are at equilibrium states and thus have zero atomic forces. The Surface group tends to have high energy errors than other groups, while the Liquid group has the highest force errors. The liquid structures depend strongly on the repulsive interactions that occur when two atoms approach each other. Consequently, it is more difficult to predict atomic forces of the liquid phase since the liquid configurations are very different from those of the equilibrium solid crystals. It is also more difficult to predict energies of surface configurations because the surfaces of BBC crystals tend to be rather open with surface atoms exhibiting rather low coordination numbers.
| Group | ||||||||
|---|---|---|---|---|---|---|---|---|
| Disp. A15 | 1.94 | 125.28 | 0.42 | 80.82 | 1.66 | 76.02 | 1.35 | 71.27 |
| Disp. BCC | 11.71 | 140.57 | 5.81 | 110.24 | 5.47 | 92.13 | 5.13 | 89.89 |
| Disp. FCC | 1.79 | 106.22 | 3.36 | 77.38 | 2.95 | 51.53 | 2.84 | 51.88 |
| Elas. BCC | 0.91 | 0.04 | 0.55 | 0.01 | 0.38 | 0.01 | 0.38 | 0.00 |
| Elas. FCC | 0.72 | 0.16 | 0.47 | 0.13 | 0.38 | 0.13 | 0.34 | 0.12 |
| GSF 110 | 3.78 | 41.35 | 2.03 | 15.84 | 1.53 | 17.09 | 1.26 | 15.8 |
| GSF 112 | 5.43 | 59.10 | 3.27 | 51.41 | 2.30 | 42.01 | 2.12 | 41.55 |
| Liquid | 11.28 | 371.38 | 2.40 | 262.04 | 2.12 | 223.8 | 2.81 | 216.9 |
| Surface | 13.66 | 62.00 | 5.66 | 40.02 | 4.67 | 28.97 | 3.60 | 28.06 |
| Bulk A15 | 4.87 | 0 | 2.19 | 0 | 1.32 | 0 | 1.16 | 0 |
| Bulk BCC | 11.96 | 0 | 3.47 | 0 | 2.32 | 0 | 1.49 | 0 |
| Bulk FCC | 13.59 | 0 | 2.74 | 0 | 1.69 | 0 | 1.31 | 0 |
Next, we investigate the influence of training datasets on model performance. To this end, we train four potentials on different training datasets with . The first three potentials are standard linear models, while the fourth potential is an EAML potential with clusters. Table 7 displays the MAEs in energies for the four potentials. The first potential, trained exclusively on the Bulk A15 group, demonstrates a small error of 2.54 meV/atom for this group but a very large error of 1070.7 meV/atom for the Bulk FCC group. Conversely, the second potential, trained on the Bulk FCC group, shows a small error of 11.41 meV/atom for its training group and a significant error of 218.57 meV/atom for the Bulk A15 group. While each potential performs well on the dataset it was trained on, its predictions for the other group are highly inaccurate. The third potential, trained on both the Bulk A15 and Bulk FCC groups, exhibits more balanced errors of 37.63 meV/atom and 41.57 meV/atom for the Bulk A15 and Bulk FCC groups, respectively. The fourth potential, trained on both groups with clusters, achieves superior accuracy with errors of 2.06 meV/atom and 3.88 meV/atom for the Bulk A15 and Bulk FCC groups, respectively. These results underscore the importance of diverse training datasets and demonstrate the substantial improvement of the EAML model over the standard linear model.
| Training data | Clusters | Test Groups | |
|---|---|---|---|
| Bulk A15 | Bulk FCC | ||
| Bulk A15 | 1 | 2.54 | 1070.7 |
| Bulk FCC | 1 | 218.57 | 11.41 |
| Bulk A15 & Bulk FCC | 1 | 37.63 | 41.57 |
| Bulk A15 & Bulk FCC | 2 | 2.06 | 3.88 |
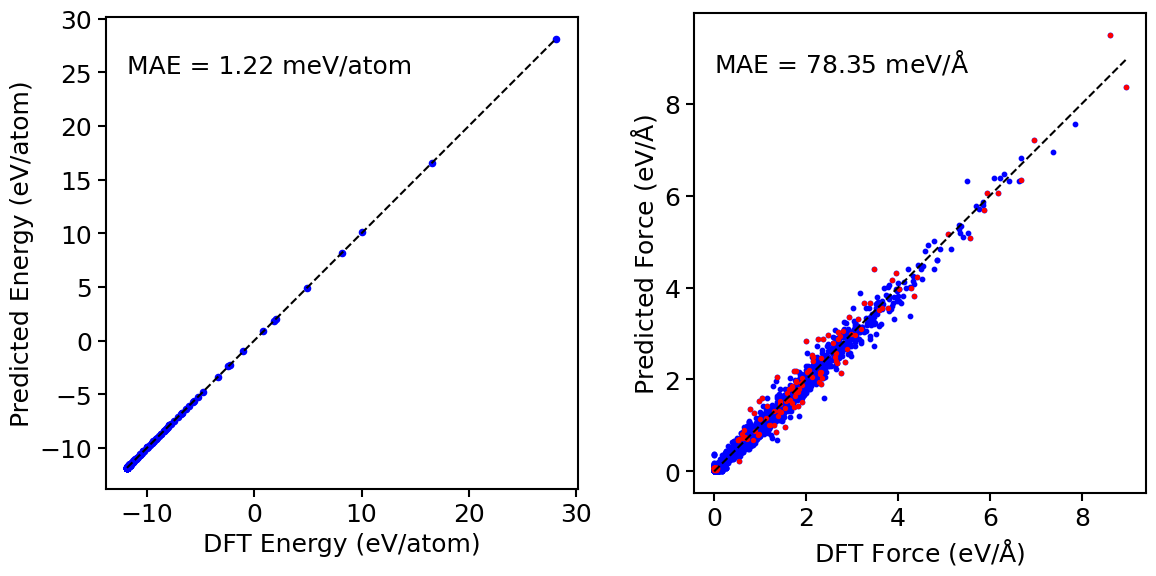
Figure 3 shows the energy and atomic force parity plots for Ta for with environments from Table 4. We note that atoms with that do not belong exclusively to one environment have similar force errors as the other atoms. This shows the ability of the EAML model to capture atomic environments that are a mixture of several distinct environments, thereby making itself more transferable than the standard linear model. The transferability of the EAML model can be attributed to several factors. First, the EAML model has more capacity than the standard linear potential because it has times more trainable coefficients. Second, owing to the probability functions that vary with the neighborhood of the central atom, the EAML model adapts itself according to the local atomic environments to capture atomic interactions more accurately than the linear model. Third, the products of the probability functions and the descriptors contain higher body interactions than the descriptors themselves, rendering the EAML model higher body order than the linear model.
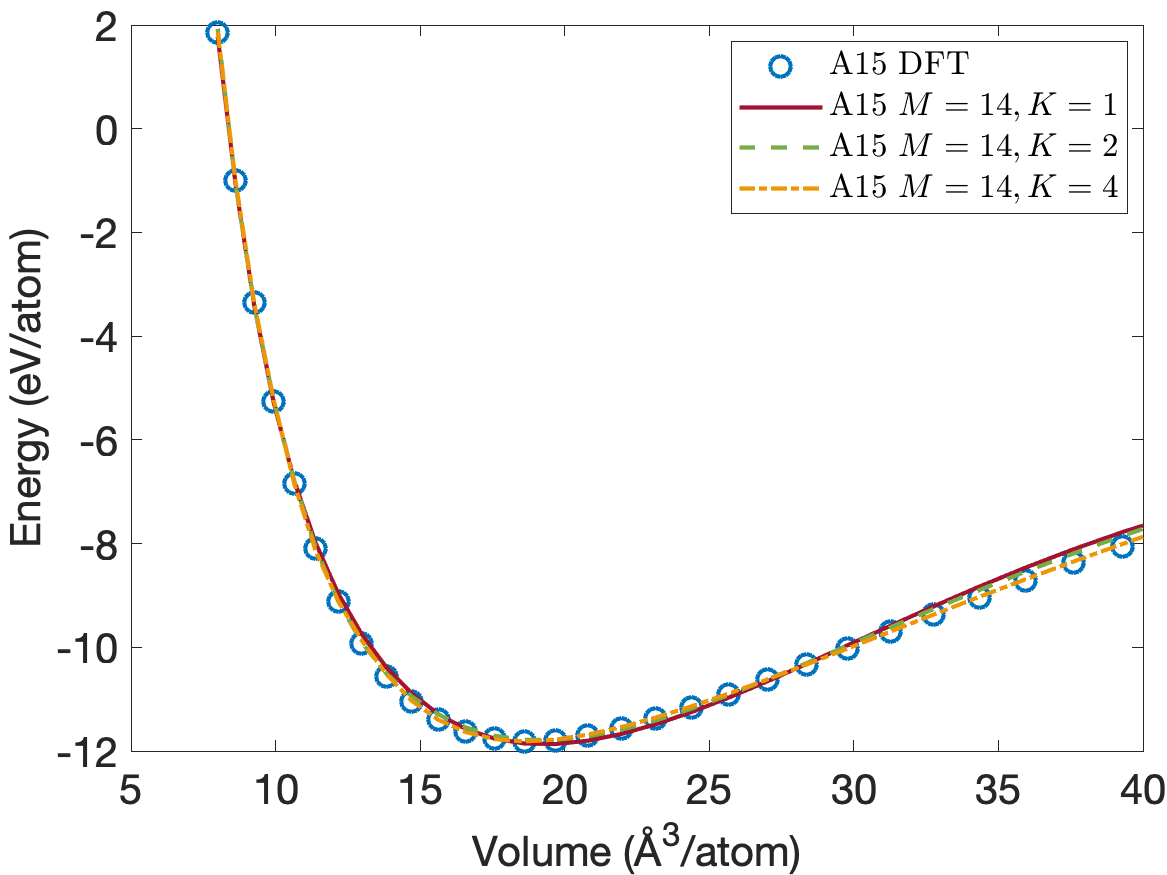
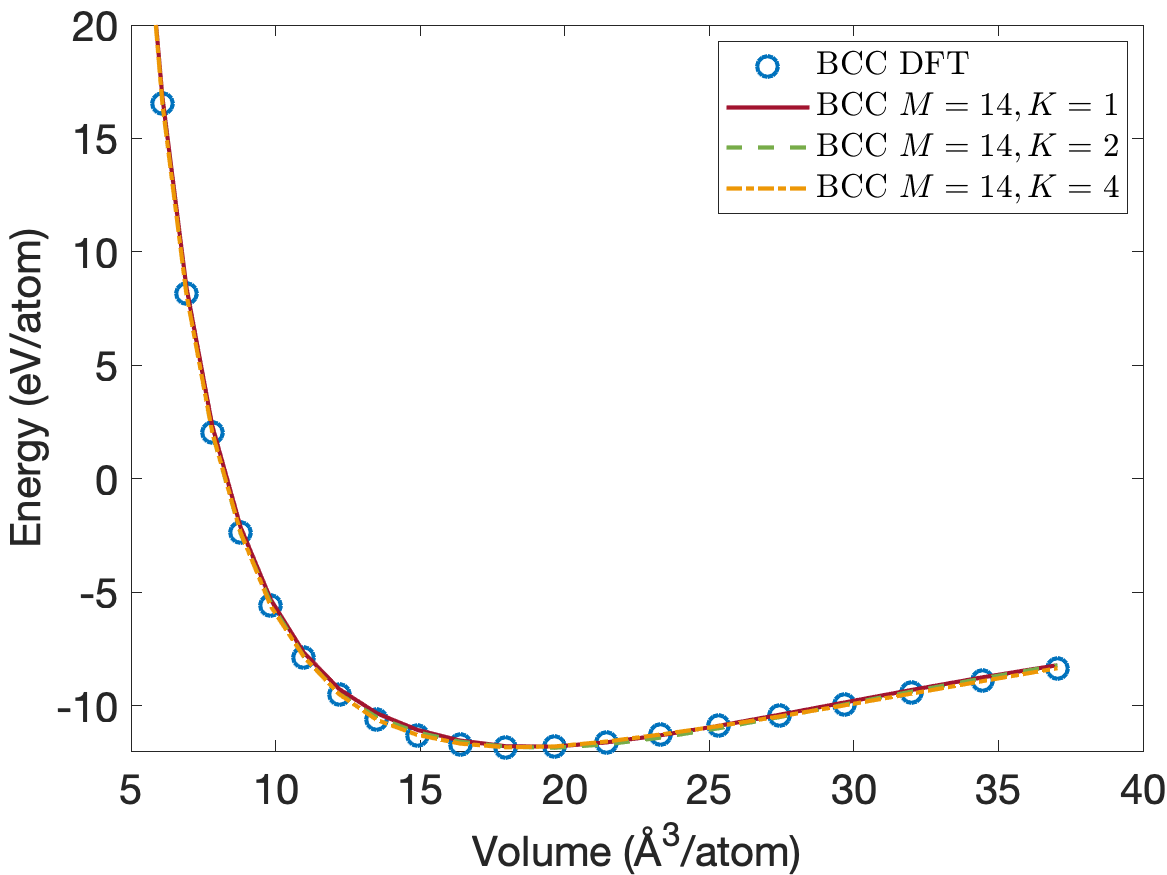
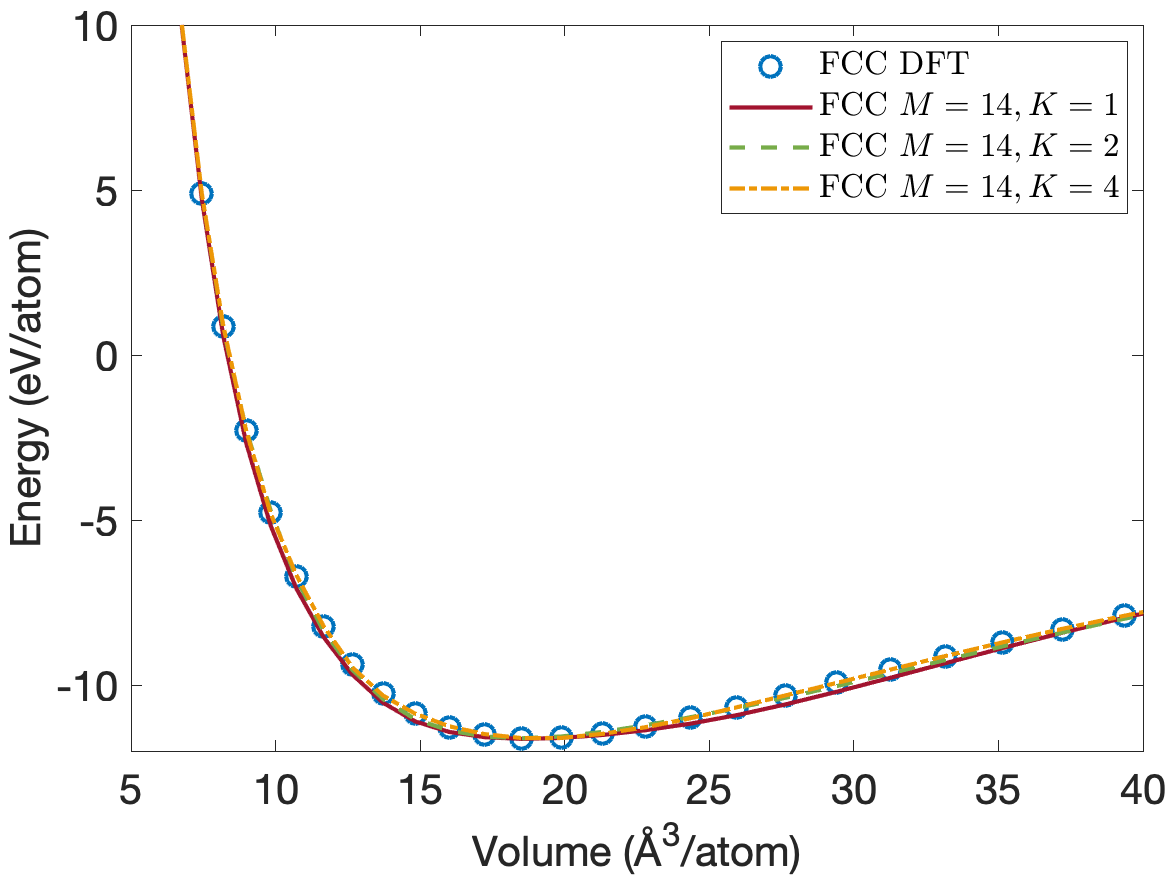
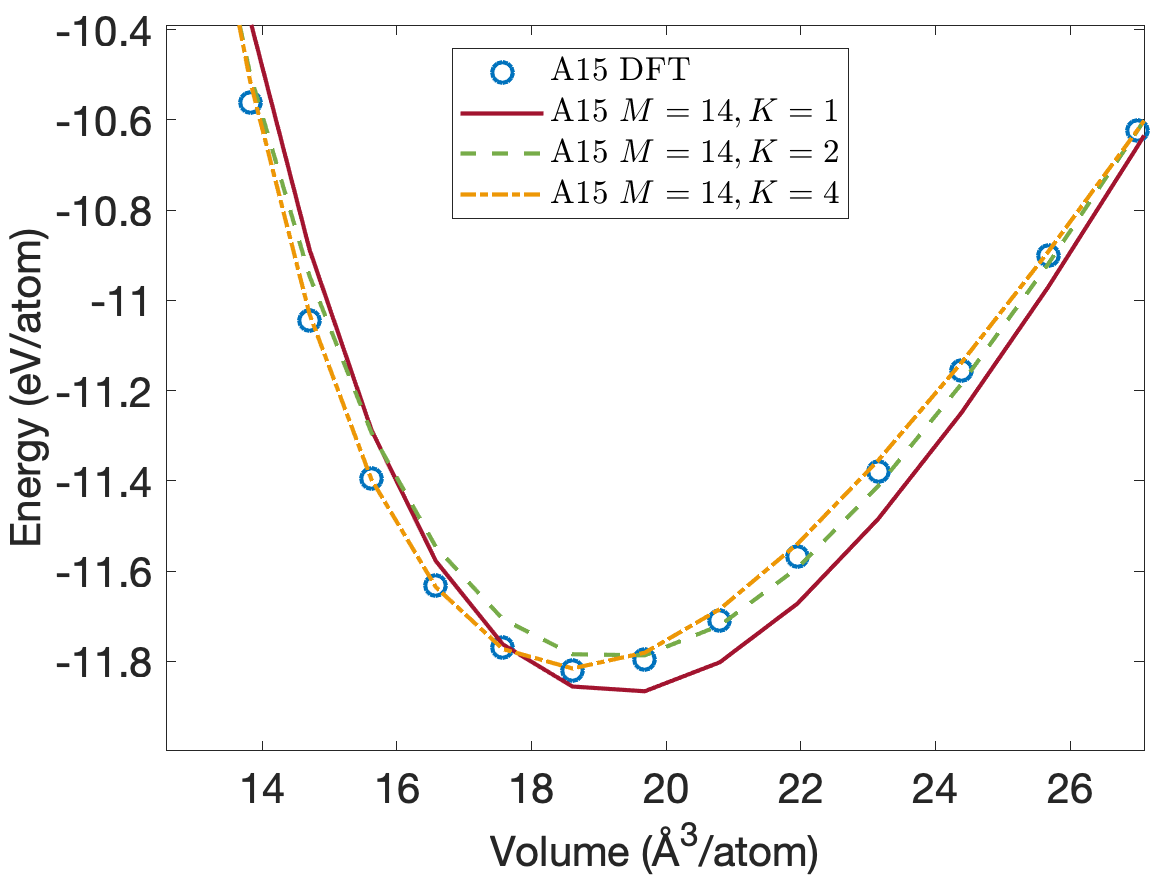
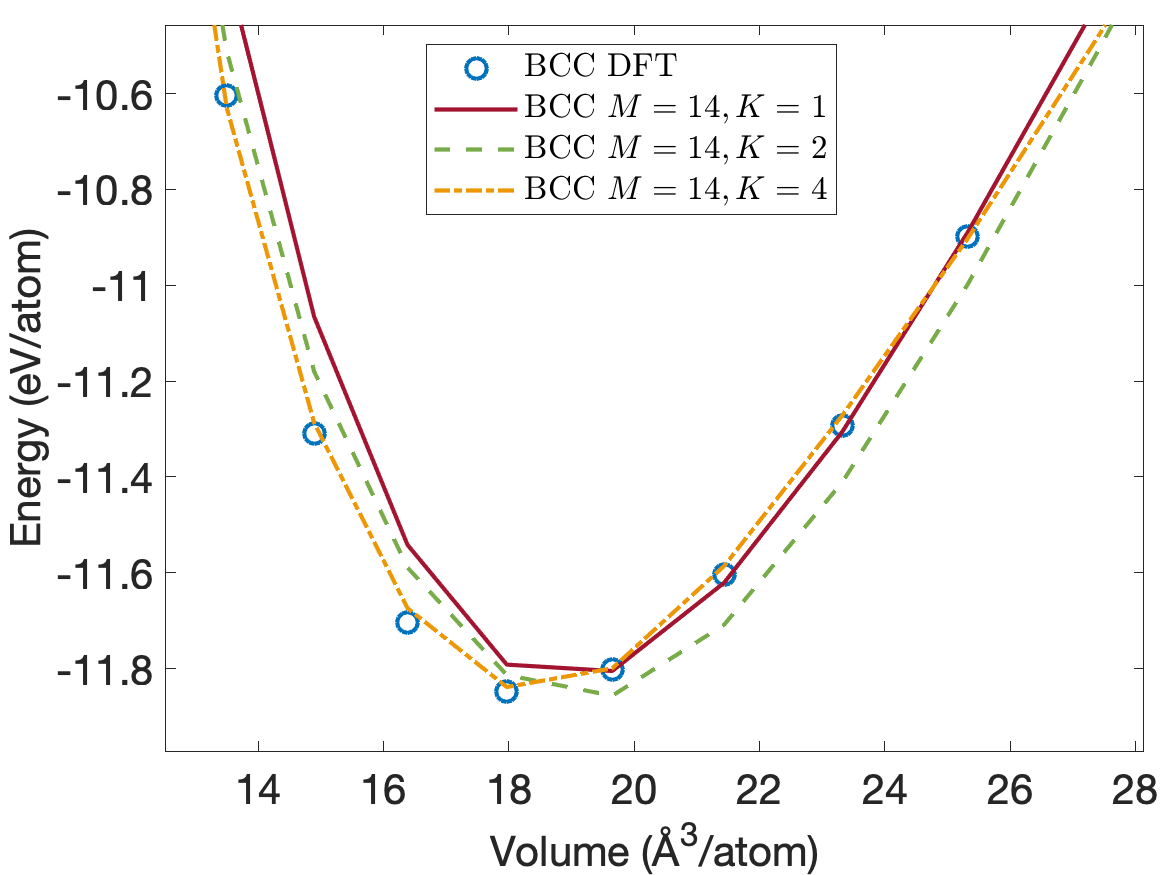
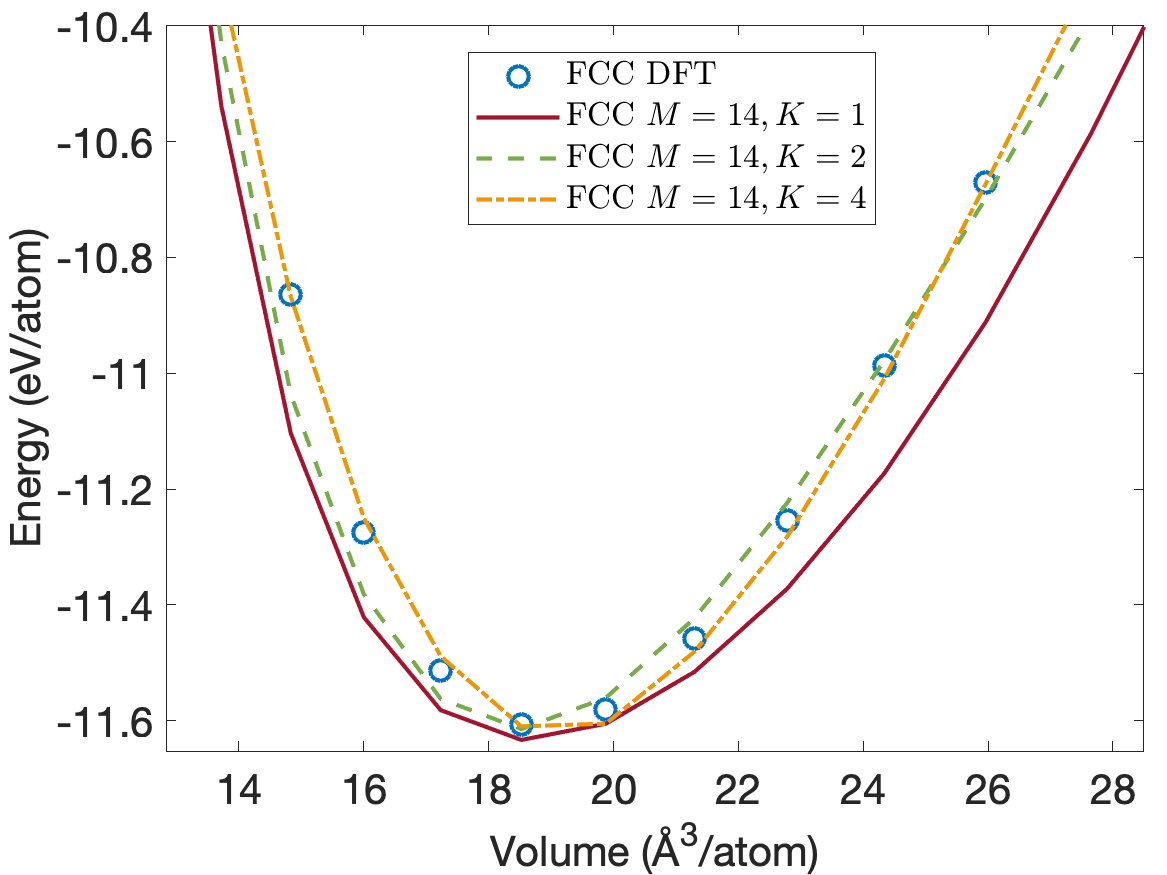
Figure 4 plots the energy per atom as a function of volume per atom for A15, BCC, FCC crystal structures. The FCC phase has a minimum energy about 0.2eV/atom above the BCC and A15 phases. We see that the energies are predicted accurately for the whole volume range with using only descriptors. Figure 5 plots the close-up view of the energy curve near the minimum energy. The predicted energy curves for are almost indistinguishable from the DFT energy curves for BCC, FCC and A15 phases.
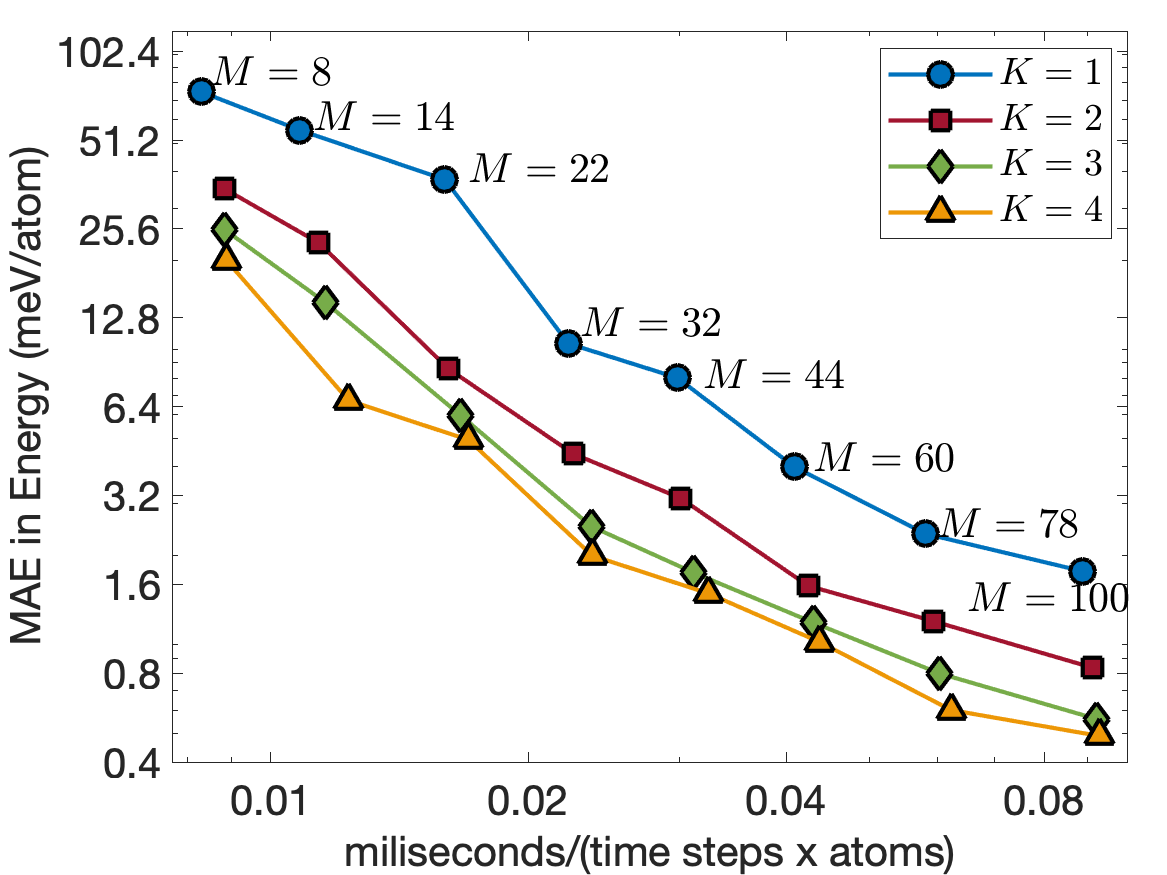
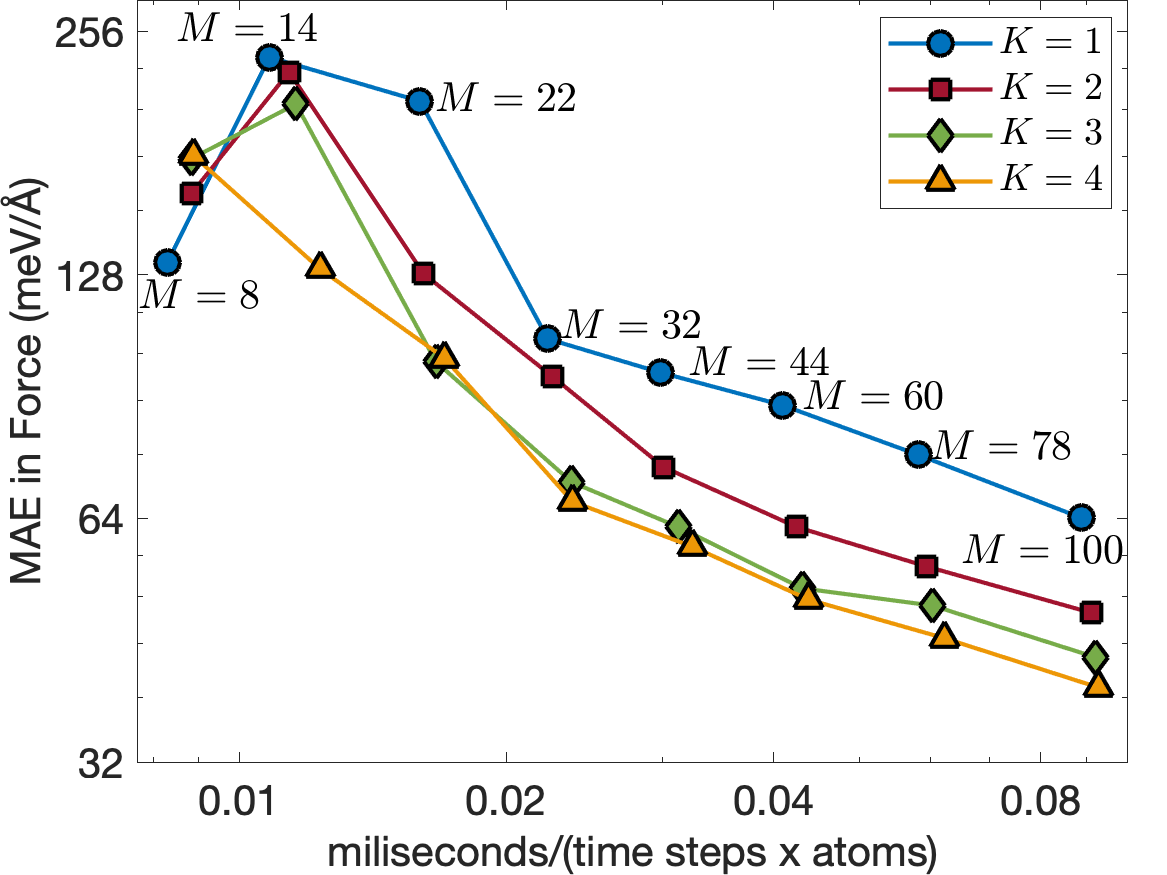
Figure 6 illustrates the trade-off between computational cost and training error for . The computational cost is measured in terms of milisecond per time step per atom for MD simulations. These MD simulations are performed using LAMMPS [29] on a CPU core of Intel i7-1068NG7 2.3 GHz with bulk supercell containing 16000 Tantalum atoms. The EAML potentials with are almost as fast as the standard linear potential for the same number of descriptors, having the computational cost almost independent of . This is consistent with the computational complexity analysis discussed in Subsection III.5. Furthermore, the EAML potential with is more accurate and 3 times faster than the standard linear potential with . The results show the superior performance of the EAML potentials.
IV.2 Results for Indium Phosphide
The InP dataset contains a wide range of configurations to adequately sample the important regions of the potential energy surface. It was generated by Cusentino et. al [30] using the Vienna Ab Initio Simulation Package to demonstrate the explicit multi-element SNAP potential. The InP dataset also contains high-energy defects which are intended to study radiation damage effects where collision cascades of sufficiently high energy leave behind high formation energy point defects. Furthermore, the dataset includes configurations for uniform expansion and compression (Equation of State), random cell shape modifications (Shear group), and uniaxially strained (Strain group) unit cells for zincblende crystal structure. In total, the dataset has 1894 configurations with atom counts per configuration ranging from 8 to 216. The training set is 80% of the InP dataset, while the entire InP dataset is used as the test set. The inner and outer cut-off distances are set to Å and Å, respectively.
Table 8 displays the number of descriptors for six different cases. Table 9 provides test errors in energies and forces for cases listed in Table 8 and for . Both the energy and force errors decrease as and increases. As increases from to , the energy errors drop more than a factor 10, while the force errors drop by a factor of 4. As increases from to , the energy errors decrease by a factor of and the force errors decrease by a factor 2. The MAEs in energies reach 0.97 meV/atom for , 0.42 meV/atom for , 0.31 meV/atom for , and 0.23 meV/atom for . These energy errors are generally below the limits of DFT errors. The MAEs in forces reach 16.70, 11.16, 9.05, 7.79 meV/Å for , respectively. These force errors are acceptable for most applications.
| InP | two-body | three-body | four-body | All | |||||
| Case | |||||||||
| 1 | 4 | 16 | 2 | 2 | 24 | 0 | 0 | 0 | 40 |
| 2 | 5 | 20 | 3 | 3 | 54 | 0 | 0 | 0 | 74 |
| 3 | 6 | 24 | 4 | 4 | 96 | 0 | 0 | 0 | 120 |
| 4 | 7 | 28 | 5 | 5 | 150 | 0 | 0 | 0 | 178 |
| 5 | 8 | 32 | 6 | 5 | 180 | 3 | 2 | 48 | 260 |
| 6 | 9 | 36 | 7 | 5 | 210 | 4 | 4 | 128 | 374 |
| Case | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 11.63 | 61.00 | 6.44 | 48.13 | 4.67 | 36.76 | 4.11 | 33.30 |
| 2 | 4.97 | 38.71 | 3.49 | 30.27 | 2.52 | 24.00 | 2.01 | 22.05 |
| 3 | 3.30 | 33.80 | 1.55 | 21.28 | 1.11 | 17.30 | 0.91 | 15.34 |
| 4 | 2.67 | 27.26 | 1.20 | 17.81 | 0.68 | 14.56 | 0.46 | 12.74 |
| 5 | 1.71 | 20.91 | 0.70 | 14.28 | 0.52 | 12.03 | 0.38 | 10.98 |
| 6 | 0.97 | 16.70 | 0.43 | 11.10 | 0.28 | 8.91 | 0.20 | 7.79 |
Table 10 provides the test errors in energy and forces for each of the 19 groups in the dataset for . Point defects are created when atoms become vacant at lattice sites (vacancy defect), occupy locations in the crystal structure at which there is usually no atom (interstitial defect), or exchange positions with other atoms of different types (antisite defect). The defect groups have higher errors than the other groups. The In group has the highest mean absolute error in energies, while the InP group has the highest mean absolute error in forces. We see that increasing reduces the energy and force errors across all groups.
| Group | ||||||||
|---|---|---|---|---|---|---|---|---|
| Bulk | 5.79 | 0.00 | 2.26 | 0.00 | 1.50 | 0.00 | 0.91 | 0.00 |
| EOS | 2.60 | 0.70 | 0.96 | 0.83 | 0.80 | 0.89 | 0.49 | 0.42 |
| Shear | 0.26 | 25.56 | 0.50 | 8.45 | 0.17 | 5.23 | 0.11 | 3.64 |
| Strain | 2.53 | 0.02 | 1.24 | 0.02 | 0.90 | 0.03 | 0.91 | 0.05 |
| In | 3.05 | 10.77 | 1.05 | 7.49 | 0.55 | 6.30 | 0.23 | 6.48 |
| P | 4.09 | 29.6 | 1.30 | 18.22 | 1.03 | 14.32 | 0.72 | 12.10 |
| InP | 6.68 | 23.23 | 3.00 | 16.83 | 1.71 | 13.96 | 1.14 | 13.52 |
| In | 4.68 | 19.82 | 1.82 | 13.80 | 1.13 | 11.36 | 0.73 | 10.35 |
| P | 3.34 | 15.68 | 1.28 | 9.96 | 0.87 | 8.55 | 0.61 | 7.69 |
| P | 3.65 | 7.95 | 0.73 | 5.17 | 0.22 | 5.62 | 0.09 | 5.09 |
| InP | 4.20 | 27.21 | 1.85 | 21.76 | 1.18 | 18.91 | 0.69 | 17.38 |
| In | 3.66 | 15.54 | 0.67 | 10.29 | 0.36 | 7.82 | 0.22 | 7.31 |
| P | 4.16 | 42.85 | 1.77 | 33.30 | 0.70 | 26.03 | 0.41 | 23.33 |
| InP | 6.46 | 58.35 | 3.76 | 35.68 | 1.36 | 25.29 | 0.82 | 24.00 |
| In | 3.05 | 51.51 | 1.18 | 33.05 | 0.65 | 25.96 | 0.39 | 21.89 |
| P | 2.95 | 40.13 | 1.39 | 24.51 | 0.69 | 20.46 | 0.45 | 16.90 |
| In | 11.23 | 40.15 | 6.92 | 27.99 | 4.54 | 20.10 | 2.90 | 14.65 |
| P | 0.92 | 26.00 | 0.49 | 18.94 | 0.36 | 16.15 | 0.24 | 14.88 |
| InP | 4.33 | 57.06 | 2.69 | 38.85 | 1.16 | 32.05 | 0.74 | 27.61 |
One of the crucial requirements for interatomic potentials is that they predict the formation and cohesive energies accurately. In addition to defect formation energies, we also study cohesive energies for different low-energy crystal structures. Figure 7 plots the energy per atom as a function of volume per atom for the rocksalt (RS) and zincblende (ZB) crystal structures. We see that the predicted cohesive energies are very close to the DFT cohesive energies for both the rocksalt (RS) and zincblende (ZB) crystal structures. Furthermore, the EAML potentials correctly predict ZB as the most stable structure and reproduce the experimental cohesive energy of -3.48 eV/atom at a volume of 24.4 /atom [31]. The predicted cohesive energies for the RS structure match exactly the DFT value of -3.30eV/atom at a volume of 19.7 /atom. While not plotted in Figure 7, the predicted cohesive energies for the wurtzite ground state structure agree well with the DFT value of -3.45eV/atom at a volume of 25.1 /atom.
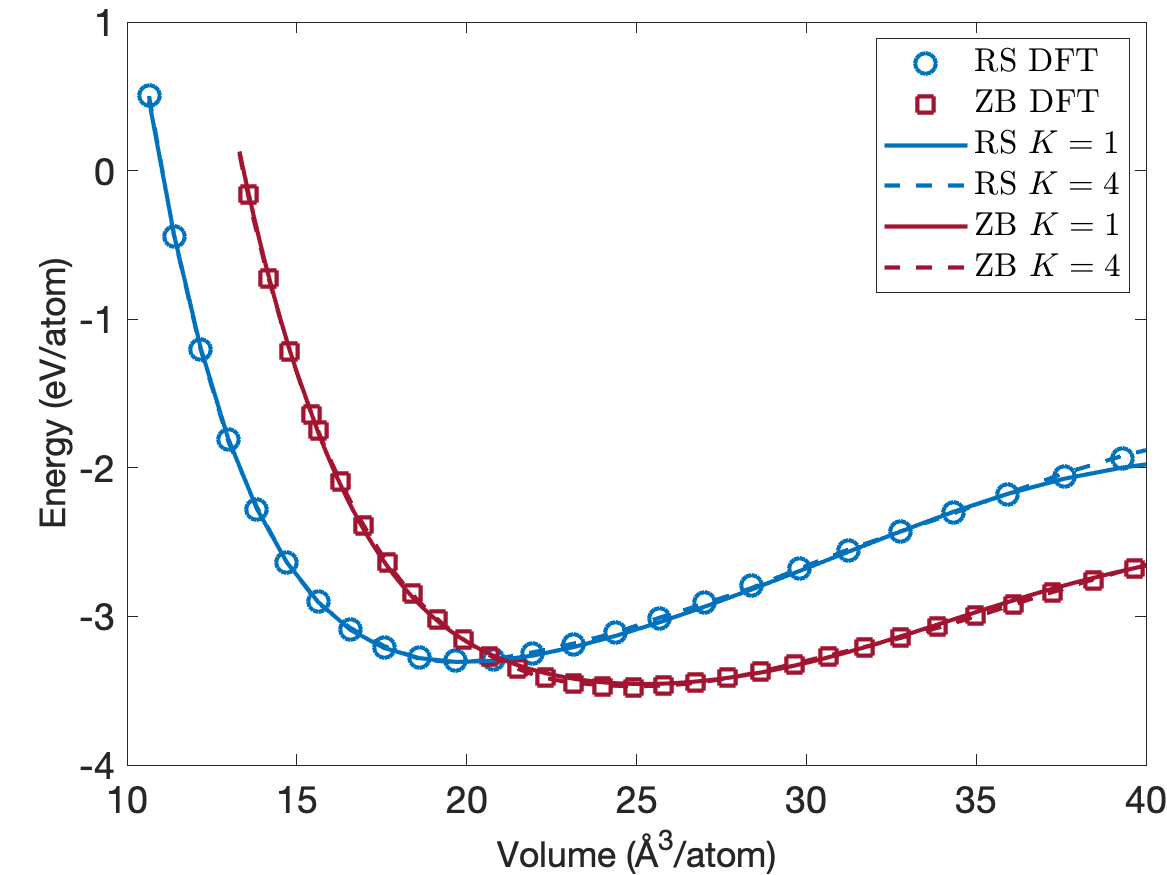
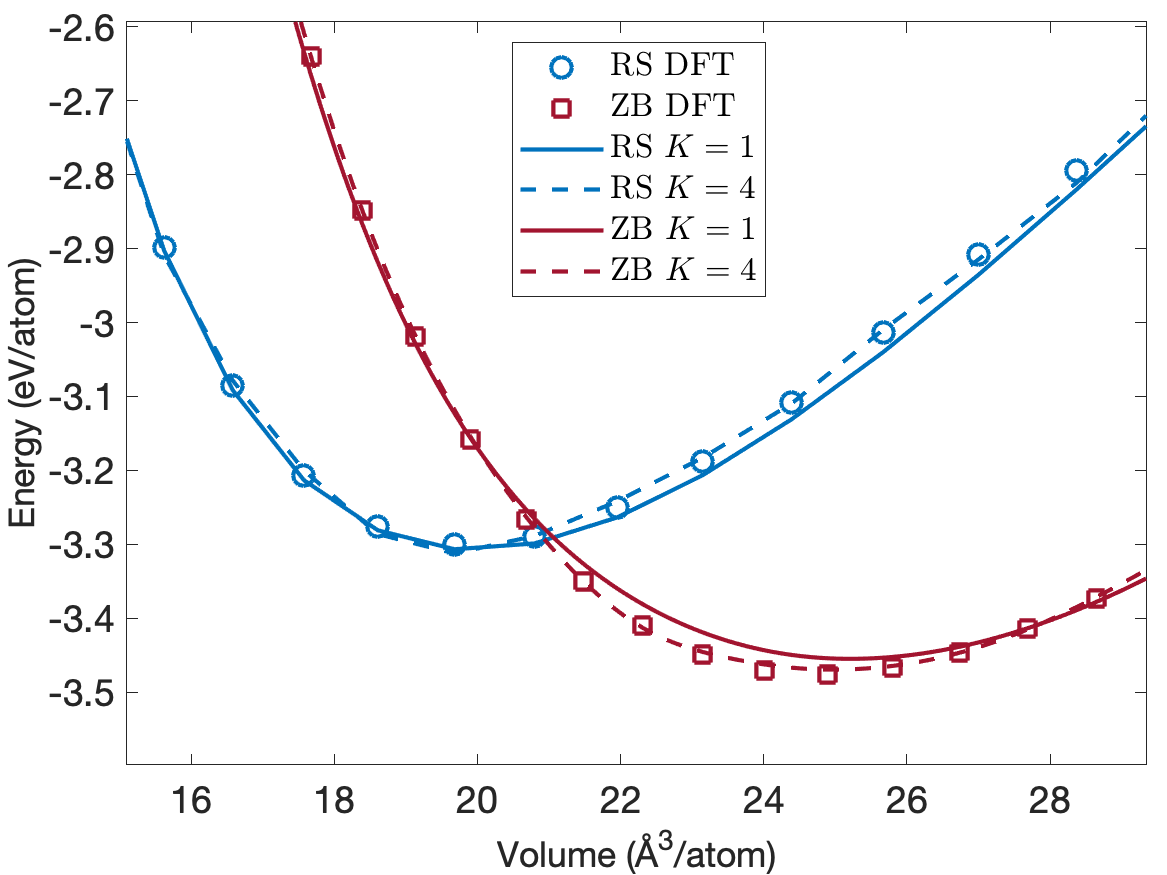
Figure 8 illustrates the trade-off between computational cost and accuracy for MD simulations of 8000 InP atoms performed on a single CPU core of Intel i7-1068NG7 2.3 GHz. The computational cost is measured in terms of second per time step per atom. We clearly see that the potentials for are almost as fast as the potential for for the same number of descriptors. We also see that increasing reduces the test errors. The energy errors for are about 4 times smaller than those for , while the force errors for are about 2 times smaller than those for . As a result, the EAML potential with is more accurate and 3 times faster than the standard linear potential with .
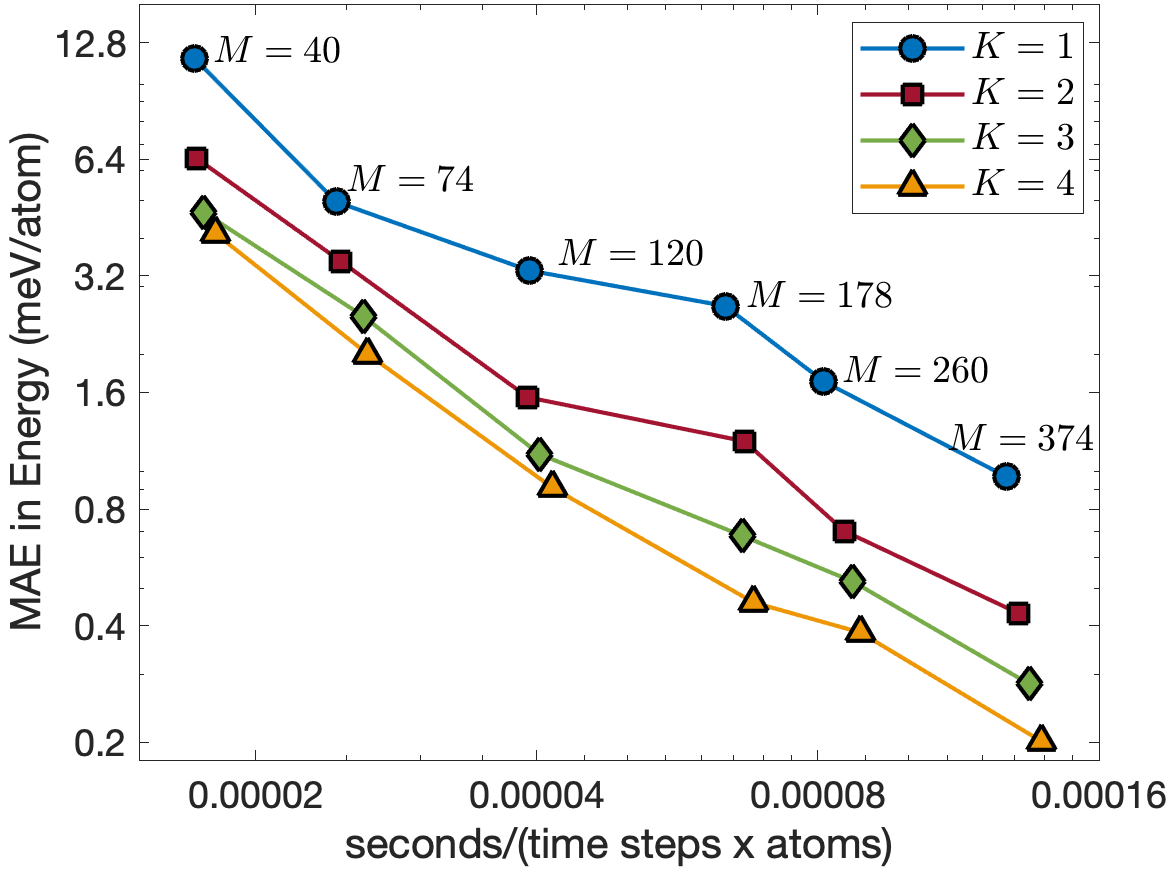
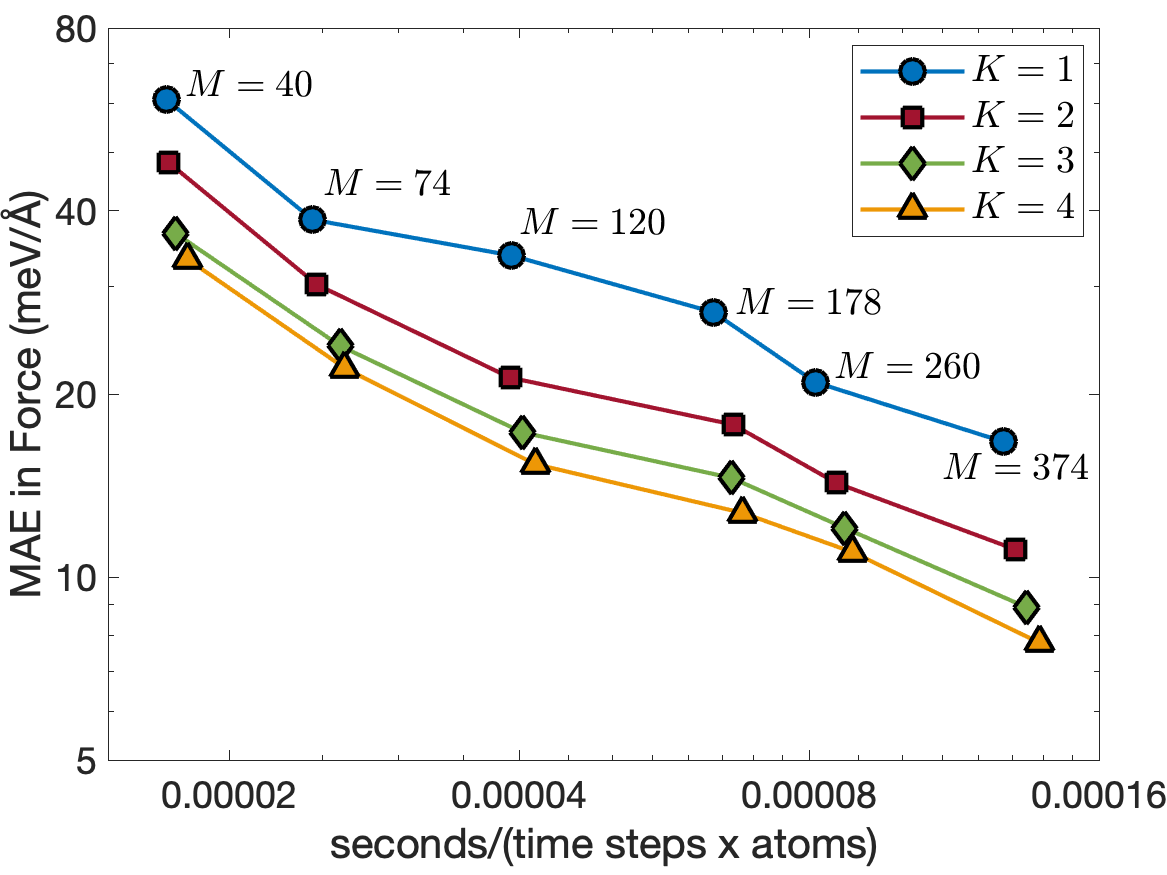
V Conclusions
We have introduced multi-element Proper Orthogonal Descriptors (PODs) for constructing machine-learned interatomic potentials. The POD descriptors incorporate elements of both internal coordinate descriptors and atom density descriptors. Our approach can be extended to arbitrary body orders and can be used to compute atom-centered symmetry functions and empirical potentials with a cost that scales only linearly with the number of neighbors. The method brings about the possibility of constructing many-body empirical potentials, while maintaining the computational cost that scales linearly with the number of neighbors. For instance, the SW and EAM potentials can be extended to include four-body terms, while atom-centered symmetry functions can be formed from the four-body POD descriptors.
We have presented an environment-decomposition method to construct accurate and transferable interatomic potentials by adapting to the local atomic environment of each atom within a system. For a dataset of atoms, atom positions and chemical species are mapped to a descriptor matrix by using the POD method. Principal component analysis (PCA) is used to reduce the dimension of the descriptor space. The means clustering scheme is applied to the reduced matrix to partition the dataset into subsets of similar environments. Each cluster represents a distinctive local environment and is used to define a corresponding local potential. We introduce a many-body many-potential expansion to smoothly blend these local potentials to ensure global continuity of the potential energy surface. This continuity is achieved by calculating probability functions that assess the likelihood of an atom belonging to specific clusters identified within the dataset.
We have applied the EAML potentials to Ta and InP datasets. The results show that EAML models provide significantly more accurate predictions than the standard linear model for the same number of descriptors . There are several reasons behind the better accuracy of EAML potentials. First, EAML potentials have more capacity than the standard linear potential because they have a larger number of fitting coefficients (i.e., versus ). Second, owing to the probability functions that vary with the neighborhood of the central atom, EAML potentials adapt their descriptors according to the local atomic environments to capture atomic interactions more accurately than the linear potential. Third, the products of the probability functions and the descriptors contain higher body interactions than the descriptors themselves. As a result, EAML potentials can capture higher-order interactions than the linear potential. Since EAML potentials have computational complexity similar to that of the linear potential, they are more accurate and efficient.
While PCA is used for its simplicity and straightforward implementation, nonlinear dimensionality reduction techniques may offer some advantage. Autoencoders, Variational Autoencoders, t-Distributed Stochastic Neighbor Embedding (t-SNE) and Isomap offer the ability to uncover and preserve intricate structures in high-dimensional data that PCA might overlook. These methods are particularly useful in scenarios where the relationships among data points involve complex patterns. While means clustering is used for its simplicity and straightforward implementation, there are several other clustering techniques that can be use to deal with very large and diverse datasets. Techniques such as hierarchical clustering, Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and Gaussian Mixture Models (GMMs) offer alternative methods that can yield better clusters than means clustering.
In this paper, we consider linear regression to construct EAML models. Linear models are easy to understand and interpret because the relationship between the output and trainable parameters is linear. They are computationally inexpensive to train and require relatively low computational resources. Indeed, it takes only a few seconds to a few minutes to train EAML potentials on a personal computer. However, linear regression may be insufficient to capture complex atomic interactions without transformation of input features. Significant performance improvement can be achieved by using more sophisticated regression methods such as nonlinear regression, kernel regression, and neural networks. While these nonlinear models require much longer training times than linear models, they often yield more accurate predictions for the same computational cost [18].
Acknowledgements
We would like to thank Jaime Peraire, Robert M. Freund, Youssef Marzouk, Nicolas Hadjiconstantinou, and Spencer Wyant at MIT for the fruiful discussions on a wide ranging of topics related to this work. We would also like to thank Andrew Rohskopf, Axel Kohlmeyer and Aidan Thompson for fruitful discussions about LAMMPS implementation of POD potentials. We gratefully acknowledge the United States Department of Energy under contract DE-NA0003965 and the the Air Force Office of Scientific Research under Grant No. FA9550-22-1-0356 for supporting this work.
References
- Finnis and Sinclair [1984] M. W. Finnis and J. E. Sinclair, A simple empirical N-body potential for transition metals, Philosophical Magazine A: Physics of Condensed Matter, Structure, Defects and Mechanical Properties 50, 45 (1984).
- Daw and Baskes [1984] M. S. Daw and M. I. Baskes, Embedded-atom method: Derivation and application to impurities, surfaces, and other defects in metals, Physical Review B 29, 6443 (1984).
- Baskes [1992] M. I. Baskes, Modified embedded-atom potentials for cubic materials and impurities, Physical Review B 46, 2727 (1992).
- Stillinger and Weber [1985] F. H. Stillinger and T. A. Weber, Computer simulation of local order in condensed phases of silicon, Physical Review B 31, 5262 (1985).
- Tersoff [1988] J. Tersoff, New empirical approach for the structure and energy of covalent systems, Physical Review B 37, 6991 (1988).
- Brenner et al. [2002] D. W. Brenner, O. A. Shenderova, J. A. Harrison, S. J. Stuart, B. Ni, and S. B. Sinnott, A second-generation reactive empirical bond order (REBO) potential energy expression for hydrocarbons, Journal of Physics Condensed Matter 14, 783 (2002).
- Bazant et al. [1997] M. Z. Bazant, E. Kaxiras, and J. Justo, Environment-dependent interatomic potential for bulk silicon, Physical Review B - Condensed Matter and Materials Physics 56, 8542 (1997), arXiv:9704137 [cond-mat] .
- Shan et al. [2010] T. R. Shan, B. D. Devine, T. W. Kemper, S. B. Sinnott, and S. R. Phillpot, Charge-optimized many-body potential for the hafnium/hafnium oxide system, Physical Review B - Condensed Matter and Materials Physics 81, 10.1103/PhysRevB.81.125328 (2010).
- Van Duin et al. [2001] A. C. Van Duin, S. Dasgupta, F. Lorant, and W. A. Goddard, ReaxFF: A reactive force field for hydrocarbons, Journal of Physical Chemistry A 105, 9396 (2001).
- Musil et al. [2021] F. Musil, A. Grisafi, A. P. Bartók, C. Ortner, G. Csányi, and M. Ceriotti, Physics-Inspired Structural Representations for Molecules and Materials, Chemical Reviews 121, 9759 (2021), arXiv:2101.04673 .
- Braams and Bowman [2009] B. J. Braams and J. M. Bowman, Permutationally invariant potential energy surfaces in high dimensionality, International Reviews in Physical Chemistry 28, 577 (2009).
- Nguyen et al. [2018] T. T. Nguyen, E. Székely, G. Imbalzano, J. Behler, G. Csányi, M. Ceriotti, A. W. Götz, and F. Paesani, Comparison of permutationally invariant polynomials, neural networks, and Gaussian approximation potentials in representing water interactions through many-body expansions, Journal of Chemical Physics 148, 241725 (2018), arXiv:1802.00564 .
- Van Der Oord et al. [2020] C. Van Der Oord, G. Dusson, G. Csányi, and C. Ortner, Regularised atomic body-ordered permutation-invariant polynomials for the construction of interatomic potentials, Machine Learning: Science and Technology 1, 015004 (2020), arXiv:1910.06010 .
- Behler and Parrinello [2007] J. Behler and M. Parrinello, Generalized neural-network representation of high-dimensional potential-energy surfaces, Physical Review Letters 98, 10.1103/PhysRevLett.98.146401 (2007).
- Behler [2011] J. Behler, Atom-centered symmetry functions for constructing high-dimensional neural network potentials, Journal of Chemical Physics 134, 10.1063/1.3553717 (2011).
- Behler [2014] J. Behler, Representing potential energy surfaces by high-dimensional neural network potentials, Journal of Physics Condensed Matter 26, 10.1088/0953-8984/26/18/183001 (2014).
- Nguyen and Rohskopf [2023] N. C. Nguyen and A. Rohskopf, Proper orthogonal descriptors for efficient and accurate interatomic potentials, Journal of Computational Physics 480, 112030 (2023).
- Rohskopf et al. [2023] A. Rohskopf, J. Goff, D. Sema, K. Gordiz, N. C. Nguyen, A. Henry, A. P. Thompson, and M. A. Wood, Exploring model complexity in machine learned potentials for simulated properties, Journal of Materials Research 38, 5136 (2023), arXiv:2306.02255 .
- Nguyen [2024] N. C. Nguyen, Proper orthogonal descriptors for multi-element chemical systems, Journal of Computational Physics 511, 113102 (2024).
- Bartók et al. [2013] A. P. Bartók, R. Kondor, and G. Csányi, On representing chemical environments, Physical Review B - Condensed Matter and Materials Physics 87, 10.1103/PhysRevB.87.184115 (2013), arXiv:1209.3140 .
- Thompson et al. [2015] A. P. Thompson, L. P. Swiler, C. R. Trott, S. M. Foiles, and G. J. Tucker, Spectral neighbor analysis method for automated generation of quantum-accurate interatomic potentials, Journal of Computational Physics 285, 316 (2015).
- Shapeev [2016] A. V. Shapeev, Moment tensor potentials: A class of systematically improvable interatomic potentials, Multiscale Modeling and Simulation 14, 1153 (2016), arXiv:1512.06054 .
- Drautz [2019] R. Drautz, Atomic cluster expansion for accurate and transferable interatomic potentials, Physical Review B 99, 10.1103/PhysRevB.99.014104 (2019).
- Drautz [2020] R. Drautz, Atomic cluster expansion of scalar, vectorial, and tensorial properties including magnetism and charge transfer, Physical Review B 102, 10.1103/PhysRevB.102.024104 (2020), arXiv:2003.00221 .
- Batzner et al. [2022] S. Batzner, A. Musaelian, L. Sun, M. Geiger, J. P. Mailoa, M. Kornbluth, N. Molinari, T. E. Smidt, and B. Kozinsky, E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials, Nature Communications 13, 2453 (2022).
- Nguyen [2023] N. C. Nguyen, Fast proper orthogonal descriptors for many-body interatomic potentials, Physical Review B 107, 144103 (2023), arXiv:2212.14446 .
- Wood and Thompson [2018] M. A. Wood and A. P. Thompson, Extending the accuracy of the SNAP interatomic potential form, Journal of Chemical Physics 148, 241721 (2018), arXiv:1711.11131 .
- Novoselov et al. [2019] I. I. Novoselov, A. V. Yanilkin, A. V. Shapeev, and E. V. Podryabinkin, Moment tensor potentials as a promising tool to study diffusion processes, Computational Materials Science 164, 46 (2019), arXiv:1812.02946 .
- Thompson et al. [2022] A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. in ’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyen, R. Shan, M. J. Stevens, J. Tranchida, C. Trott, and S. J. Plimpton, LAMMPS - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales, Computer Physics Communications 271, 108171 (2022).
- Cusentino et al. [2020] M. A. Cusentino, M. A. Wood, and A. P. Thompson, Explicit Multielement Extension of the Spectral Neighbor Analysis Potential for Chemically Complex Systems, The Journal of Physical Chemistry A 124, 5456 (2020).
- Nichols et al. [1980] D. N. Nichols, D. S. Rimai, and R. J. Sladek, Elastic anharmonicity of InP: Its relationship to the high pressure transition, Solid State Communications 36, 667 (1980).