Epidemiological Forecasting with Model Reduction of Compartmental Models.
Application to the COVID-19 pandemic.
Abstract
We propose a forecasting method for predicting epidemiological health series on a two-week horizon at the regional and interregional resolution. The approach is based on model order reduction of parametric compartmental models, and is designed to accommodate small amount of sanitary data. The efficiency of the method is shown in the case of the prediction of the number of infected and removed people during the two pandemic waves of COVID-19 in France, which have taken place approximately between February and November 2020. Numerical results illustrate the promising potential of the approach.
1 Introduction
Providing reliable epidemiological forecasts during an ongoing pandemic is crucial to mitigate the potentially disastrous consequences on global public health and economy. As the ongoing pandemic on COVID-19 sadly illustrates, this is a daunting task in the case of new diseases due to the incomplete knowledge of the behavior of the disease, and the heterogeneities and uncertainties in the health data count. Despite these difficulties, many forecasting strategies exist and we could cast them into two main categories. The first one is purely data-based, and involves statistical and learning methods such as time series analysis, multivariate linear regression, grey forecasting or neural networks [7, 1, 11, 28, 19]. The second approach uses epidemiological models which are appealing since they provide an interpretable insight of the mechanisms of the outbreak. They also provide high flexibility in the level of detail to describe the evolution of the pandemic, ranging from simple compartmental models that divide the population into a few exclusive categories, to highly detailed descriptions involving numerous compartments or even agent-based models (see, e.g., [16, 23, 6] for general references on mathematical epidemiological models and [22, 10, 13] for some models focused on Covid-19). One salient drawback of using epidemiological models for forecasting purposes lies in the very high uncertainty in the estimation of the involved parameters. This is due to the fact that most of the time the parameters cannot be inferred from real observations and the available data are insufficient or too noisy to provide any reliable estimation. The situation is aggravated by the fact that the number of parameters can quickly become large even in moderately simple compartmental models [10]. As a result, forecasting with these models involves making numerous a priori hypothesis which can sometimes be hardly justified by data observations.
In this paper, our goal is to forecast the time-series of infected, removed and dead patients with compartmental models that involve as few parameters as possible in order to infer them solely from the data. The available data are only given for hospitalized people, one can nevertheless estimate the total number of infected people through an adjustment factor hinted from the literature. Such a factor takes into account the proportion of asymptomatic people and infected people who do not go to hospital. The model involving the least number of parameters is probably the SIR model [17] which is based on a partition of the population into:
-
•
Uninfected people, called susceptible (S),
-
•
Infected and contagious people (I), with more or less marked symptoms,
-
•
People removed (R) from the infectious process, either because they are cured or unfortunately died after being infected.
If denotes the total population size that we assume to be constant over a certain time interval , we have
and the evolution from to and from to is given for all by
The SIR model has only two parameters:
-
•
represents the recovery rate. In other words, its inverse can be interpreted as the length (in days) of the contagious period.
-
•
is the transmission rate of the disease. It essentially depends on two factors: the contagiousness of the disease and the contact rate within the population. The larger this second parameter is, the faster the transition from susceptible to infectious will be. As a consequence, the number of hospitalized patients may increase very fast, and may lead to a collapse of the health system [2]. Strong distancing measures like confinement can effectively act on this parameter [29, 12], helping to keep it low.
Our forecasting strategy is motivated by the following observation: by allowing the parameters and to be time-dependent, we can find optimal coefficients and that exactly fit any series of infected and removed patients. In other words, we can perfectly fit any observed health series with a SIR model having time-dependent coefficients.
As we explain later on in the paper, the high fitting power stems from the fact that the parameters and are searched in , the space of essentially bounded measurable functions. For our forecasting purposes, this space is however too large to give any predictive power and we need to find a smaller manifold that has simultaneously good fitting and forecasting properties. To this aim, we develop a method based on model order reduction. The idea is to find a space of reduced dimension that can host the dynamics of the current epidemic. This reduced space is learnt from a series of detailed compartmental models based on precise underlying mechanisms of the disease. One major difficulty in these models is to fit the correct parameters. In our approach, we do not seek to estimate them. Instead, we consider a large range of possible parameter configurations with a uniform sampling that allows us to simulate virtual epidemic scenarios on a longer range than the fitting window . We next cast each virtual epidemics from the family of detailed compartmental models into the family of SIR models with time-dependent coefficients in a sense that we explain later on. This procedure yields time-dependent parameters and for each detailed virtual epidemics. The set of all such (resp. ) is then condensed into a reduced basis of small dimension. We finally use the available health data on the time window to find the functions and from the reduced space that fit at best the current epidemics over . Since the reduced basis functions are defined over a longer time range with (say, e.g., two weeks), the strategy automatically provides forecasts from to . Its accuracy will be related to the pertinence of the mechanistic mathematical models that have been used in the learning process.
We note that an important feature of our approach is that all virtual simulations are considered equally important on a first stage and the procedure automatically learns what are the best scenarios (or linear combinations of scenarios) to describe the available data. Moreover, the approach even mixes different compartmental models to accommodate these available data. This is in contrast to other existing approaches which introduce a strong a priori belief on the quality of a certain particular model. Note also that we can add models related to other illness, and use the large manifold to fit a possible new epidemic. It is also possible to mix the current approach with other purely statistical or learning strategies by means of expert aggregration. One salient difference with these approaches which is important to emphasize is that our method hinges on highly detailed compartmental models which have clear epidemiological interpretations. Our collapsing methodology into the time-dependent SIR is a way of “summarizing” the dynamics into a few terms. One may expect that reducing the number of parameters comes at the cost of losing interpretability of parameters, and this is in general true. Nevertheless, the numerical results of the present work show that a reasonable tradeoff between "reduction of the number of parameters" and "interpretability of these few parameters" can be achieved.
The paper is organized as follows. In Section 2, we present the forecasting method in the case of one single region with constant population. For this, we briefly introduce in Section 2.1 the epidemiological models involved in the procedure, namely the SIR model with time-dependent coefficients and more detailed compartmental models used for the training step. In Section 2.2, after proving that SIR models with time-dependent coefficients in is able to fit any admissible epidemiological evolution (in a sense that will be made rigorous), we present the main steps of the forecasting method. The method involves a collapsing step from detailed models to SIR models with time-dependent coefficients, and model reduction techniques. We detail these points in Sections 2.3 and 2.4. In Section 3 we explain how the method can easily be extended to a multi-regional context involving population mobility, and regional health data observations (provided, of course, that mobility data is available). We start in Section 3.1 by clarifying that the nature of the mobility data will dictate the kind of multi-regional SIR model to use in this context. In Section 3.2 we outline how to adapt the main steps of the method to the multi-regional case. Finally, in Section 4, we present numerical results for the the two pandemic waves of COVID-19 in France in year 2020, which have taken place approximately between February and November 2020. Concluding comments are given in Section 5 followed by two appendices A and B that present details about the processing of the data noise, and the forecasting error.
2 Methodology for one single region
For the sake of clarity, we first consider the case of one single region with constant population and no population fluxes with other regions. Here, the term region is generic and may be applied to very different geographical scales, ranging from a full country, to a department within the country, or even smaller partitions of a territory.
2.1 Compartmental models
The final output of our method is a mono-regional SIR model with time dependent coefficients as exposed below. This SIR model with time-dependent coefficients will be evaluated with reduced modeling techniques involving a large family of models with finer compartments proposed in the literature. Before presenting the method in the next section, we introduce here all the models that we use in this paper along with useful notations for the rest of the paper.
SIR models with time-dependent parameters:
We will fit and forecast the series of infected and removed patients (dead and recovered) with SIR models where the coefficients and are time-dependent:
In the following, we use bold-faced letters for past-time quantities. For example, for any function . Using this notation, for any given and we denote by
the solution of the associated SIR dynamics in .
Detailed compartmental models:
Models involving many compartments offer a detailed description of epidemiological mechanisms at the expense of involving many parameters. In our approach, we use them to generate virtual scenarios. One of the initial motivations behind the present work is to provide forecasts for the COVID-19 pandemic, thus we have selected the two following models which are specific for this disease, but note that any other compartmental model [18, 10, 22] or agent-based simulation could also be used .
-
•
First model, SEICHRD: This model is inspired from the one proposed in [10]. It involves 11 different compartments and a set of 19 parameters. The dynamics of the model is illustrated in Figure 1 and the system of equations reads
The different parameters involved in the model are described in Table 2 and detailed in the appendix of [10].
Figure 1: SEICHRD model Compartment Description Susceptible Exposed (non infectious) Infected and pre-symptomatic (already infectious) Infected and a-symptomatic (but infectious) Infected and paucisymptomatic Infected with mild symptoms Infected with severe symptoms Hospitalized Intensive Care Unit Removed Dead Table 1: Description of the compartments in Model SEICHRD Parameter Description Relative infectiousness of Relative infectiousness of Relative infectiousness of Relative infectiousness of Relative infectiousness of Relative infectiousness of Relative infectiousness of Latency period Duration of prodromal phase Probability of being asymptomatic Infectious period of , , , If symptomatic, probability of being paucisymptomatic If symptomatic, probability of developing mild symptoms If symptomatic, probability of developing severe symptoms (note that ) If severe symptoms, probability of going in C If in C, daily rate entering in If in C, daily rate entering in If hospitalized, daily rate entering in If hospitalized, daily rate entering in Table 2: Description of the parameters involved in Model SEICHRD We denote by
(1) (2) (3) the parameter-to-solution map where .
-
•
Second model, SEIUR: This model is a variant of the one proposed in [22]. It involves 5 different compartments and a set of 6 parameters. The dynamics of the model is illustrated in Figure 2 and the set of equations is
Figure 2: SEIUR model We denote by
the parameter-to-solution map where . The different parameters involved in the model are described in Table 4.
Compartment Description Susceptible Exposed (non infectious) Infected and pre-symptomatic (already infectious) Infected and symptomatic Un-noticed dead and removed Table 3: Description of the compartments in Model SEIUR Parameter Description Relative infectiousness of , , Latency period Duration of prodromal phase Proportion of among If , daily rate entering in If , daily rate entering in Table 4: Description of the parameters involved in Model SEIUR -
•
Generalization: In the following, we abstract the procedure as follows. For a any Detailed_Model with compartments involving a vector of parameters, we denote by
the parameter-to-solution map, where is some given time simulation that can be as large as wished because this is a virtual scenario. Note that, because the initial condition of the illness at time 0 is not known, we include in the parameter set the initial condition .
2.2 Forecasting based on model reduction of detailed models
We assume that we are given health data in a time window , where is assumed to be the present time. The observed data is the series of infected people, denoted , and removed people denoted . They are usually given at a national or a regional scale and on a daily basis. For our discussion, it will be useful to work with time-continuous functions and will denote the piecewise constant approximation in from the given data (and similarly for ). Our goal is to give short-term forecasts of the series in a time window whose size will be about two weeks. We denote by and the approximations to the series and at any time .
As already brought up, we propose to fit the data and provide forecasts with SIR models with time-dependent parameters and . The main motivation for using such a simple family is because it possesses optimal fitting and forecasting properties for our purposes in the sense that we explain next. Defining the cost function
| (4) |
such that
the fitting problem can be expressed at the continuous level as the optimal control problem of finding
| (5) |
The following result ensures the existence of a unique minimizer under very mild constraints.
Proposition 2.1.
Let and . For any real-valued functions of class , defined on satisfying
-
(i)
for every ,
-
(ii)
in nonincreasing on ,
-
(iii)
is nondeacreasing on ,
there exists a unique minimizer to problem (5).
Proof.
One can set
| (6) |
so that
and
which obviously implies that . ∎
Note that one can equivalently set
| (7) |
or again
| (8) |
This simple observation means that there exists a time-dependent SIR model which can perfectly fit the data of any (epidemiological) evolution that satisfies properties (i), (ii) and (iii). In particular, we can perfectly fit the series of sick people with a time-dependent SIR model (modulo a smoothing of the local oscillations due to noise). Since the health data are usually given on a daily basis, we can approximate by approximating the derivatives by classical finite differences in equation (6).
The fact that we can build and such that implies that the family of time-dependent SIR models is rich enough not only to fit the evolution of any epidemiological series, but also to deliver perfect predictions of the health data. However, this great approximation power comes at the cost of defining the parameters and in which is a space that is too large in order to be able to define any feasible prediction strategy.
In order to pin down a smaller manifold where these parameters may vary without sacrificing much on the fitting and forecasting power, our strategy is the following:
-
1.
Learning phase: The fundamental hypothesis of our approach is the confidence that the specialists of epidemiology have well understood the mechanisms of infection transmission. The second hypothesis is that these accurate models suffer from the proper determination of the parameters they contain. We thus propose to generate a large number of virtual epidemics, following these mechanistic models with parameters that can be chosen in a vicinity of the suggested parameters values, including the different initial conditions.
-
(a)
Generate virtual scenarios using detailed models with constant coefficients:
-
•
Define the notion of Detailed_Model which is most appropriate for the epidemiological study. Several models could be considered. For our numerical application, the detailed models were defined in Section 2.1.
-
•
Define an interval range where the parameters of Detailed_Model will vary. We call the solution manifold the set of virtual dynamics over , namely
(9) -
•
Draw a finite training set
(10) of parameter instances and we compute for . Each is a virtual epidemiological scenario. An important detail for our prediction purposes is that the simulations are done in , that is, we simulate not only in the fitting time interval but also in the prediction time interval. We call
the training set of all virtual scenarios.
-
•
-
(b)
Collapse: Collapse every detailed model into a SIR model following the ideas which we explain in Section 2.3. For every , the procedure gives time-dependent parameters and and associated SIR solutions in . This yields the sets
(11) -
(c)
Compute reduced models:
We apply model reduction techniques using and as training sets in order to build two basis
which are defined over . The space is such that it approximates well all functions (resp. all can be well approximated by elements of ). We outline in Section 2.4 the methods we have explored in our numerical tests.
-
(a)
-
2.
Fitting on the reduced spaces: We next solve the fitting problem (5) in the interval by searching (resp. ) in (resp. in ) instead of in , that is,
(12) Note that the respective dimensions of and can be different, for simplicity we take them equal in the following. Obviously, since and , we have that
but we numerically observe that the function decreases very rapidly as increases, which indirectly confirms the fact that the manifold generated by the two above models accommodates well the COVID-19 epidemics.
-
3.
Forecast: For a given dimension of the reduced spaces, propagate in the associated SIR model
The values and for are by construction close to the observed data (up to some numerical optimization error). The values and for are then used for prediction.
-
4.
Forecast Combination/Aggregation of Experts (optional step): By varying the dimension and using different model reduction approaches, we can easily produce a collection of different forecasts and the question of how to select the best predictive model arises. Alternatively, we can also resort to Forecast Combination techniques [26]: denoting the different forecasts, the idea is to search for an appropriate linear combination
and similarly for . Note that these combinations do not need to involve forecasts from our methodology only. Other approaches like time series forecasts could also be included. One simple forecast combination is the average, in which all alternative forecasts are given the same weight . More elaborate approaches consist in estimating the weights that minimize a loss function involving the forecast error.
Before going into the details of some of the steps, three remarks are in order:
-
1.
To bring out the essential mechanisms, we have idealized some elements in the above discussion by omitting certain unavoidable discretization aspects. To start with, the ODE solutions cannot be computed exactly but only up to some accuracy given by a numerical integration scheme. In addition, the optimal control problems (5) and (12) are non-convex. As a result, in practice we can only find a local minima. Note however that modern solvers find solutions which are very satisfactory for all practical purposes. In addition, note that solving the control problem in a reduced space as in (12) could be interpreted as introducing a regularizing effect with respect to the control problem (5) in the full space. It is to be expected that the search of global minimizers is facilitated in the reduced landscape.
-
2.
routine-IR and routine-: A variant for the fitting problem (12) which we have studied in our numerical experiments is to replace the cost function by the cost function
(13) In other words, we use the variables and from (6) as observed data instead of working with the observed health series , . In Section 4, we will refer to the standard fitting method as routine-IR and to this variant as routine-.
-
3.
The fitting procedure works both on the components of the reduced basis and the initial time of the epidemics to minimize the loss function but, for simplicity, this last optimization is not reported in the notation.
2.3 Details on Step 1-(b): Collapsing the detailed models into SIR dynamics
Let
be the solution in to a detailed model for a given vector of parameters . Here is possibly large ( in the case of SEICHRD model and in the case of SEIUR’s one). The goal of this section is to explain how to collapse the detailed dynamics into a SIR dynamics with time-dependent parameters. The procedure can be understood as a projection of a detailed dynamics into the family of dynamics given by SIR models with time-dependent parameters.
For the SEICHRD model, we collapse the variables by setting
Similarly, for the SEIUR model, we set
Note that , and depend on but we have omitted the dependence to lighten the notation.
Once the collapsed variables are obtained, we identify the time-dependent parameters and of the SIR model by solving the fitting problem
| (14) |
where
Note that problem (14) has the same structure as problem (5), the difference coming from the fact that the collapsed variables , in (14) play the role of the health data , in (5). Therefore, it follows from Proposition 2.1 that problem (14) has a very simple solution since it suffices to apply formula (6) for solving it. Note here that the exact derivatives of , and can be obtained from the Detailed_Model.
2.4 Details on Model Order Reduction
Model Order Reduction is a family of methods aiming at approximating a set of solutions of parametrized PDEs or ODEs (or related quantities) with linear spaces, which are called reduced models or reduced spaces. In our case, the sets to approximate are
where each is the vector of parameters of the detailed model which take values over , and and are the associated time-dependent coefficients of the collapsed SIR evolution. In the following, we view and as subsets of , and we denote by and its norm and inner product. Indeed, in view of Proposition 2.1, and .
Let us carry the discussion for (the same will hold for ). If we measure performance in terms of the worst error in the set , the best possible performance that reduced models of dimension can achieve is given by the Kolmogorov -width
where is the orthogonal projection onto the subspace . In the case of measuring errors in an average sense, the benchmark is given by
where is some given measure on .
In practice, building spaces that meet these benchmarks is generally not possible. However, it is possible to build sequences of spaces for which their error decay is comparable to the one given by or . As a result, when the Kolmogorov width decays fast, the constructed reduced spaces will deliver a very good approximation of the set with few modes (see [5, 9, 8, 20]).
We next present the reduced models that we have used in our numerical experiments. Other methods could of course be considered and we refer to [27, 4, 15, 21] for general references on model reduction. We carry the discussion in a fully discrete setting in order to simplify the presentation and keep it as close to the practical implementation as possible. All the claims below could be written in a fully continuous sense at the expense of introducing additional mathematical objects such as certain Hilbert-Schmidt operators to define the continuous version of the Singular Value Decomposition (SVD).
We build the reduced models using the two discrete training sets of functions and from and where denotes the number of virtual scenarios considered. The sets have been generated in step 1-(b) of our general pipeline (see Section 2.2).
We consider a discretization of the time interval into a set of points as follows where . Thus, we can represent each function as a vector of values
and hence assemble all the functions of the family into a matrix . The same remark applies for the family that gives a matrix .
-
1.
SVD: The eigenvalue decomposition of the correlation matrix writes
where is an orthogonal matrix and is a diagonal matrix with non-negative entries which we denote and order them in decreasing order. The -orthogonal basis functions are then given by the linear combinations
For , the space
is the best -dimensional space to approximate the set in the average sense. We have
and the average approximation error is given by the sum of the tail of the eigenvalues.
Therefore the SVD method is particularly efficient if there is a fast decay of the eigenvalues, meaning that the set can be approximated by only few modes. However, note that by construction, this method does not ensure positivity in the sense that may become negative for some although the original function for all . This is due to the fact that the vectors are not necessarily nonnegative. As we will see later, in our study, ensuring positivity especially for extrapolation (i.e., forecasting) is particularly important, and motivates the next methods.
-
2.
Nonnegative Matrix Factorization (NMF, see [25, 14]): NMF is a variant of SVD involving nonnegative modes and expansion coefficients. In this approach, we build a family of non-negative functions and we approximate each with a linear combination
(15) where for every and , the coefficients and the basis function . In other words, we solve the following constrained optimization problem
We refer to [14] for further details on the NMF and its numerical aspects.
-
3.
Enlarged Nonnegative Greedy (ENG): greedy algorithm with projection on an extended cone of positive functions: We now present our novel model reduction method, which is of interest in itself since it allows to build reduced models that preserve positivity and even other types of bounds. The method stems from the observation that NMF approximates functions in the cone of positive functions of since it imposes that in the linear combination (15). However, note that the positivity of the linear combination is not equivalent to the positivity of the coefficients since there are obviously linear combinations involving very small for some which may still deliver a nonnegative linear combination . We can thus widen the cone of linear combinations yielding positive values by carefully including these negative coefficients . One possible strategy for this is proposed in Algorithm 1, which describes a routine that we call Enlarge_Cone. The routine
takes a set of nonnegative functions as input, and modifies each function by iteratively adding negative linear combinations of the other basis functions for (see line 11 of the routine). The coefficients are chosen in an optimal way so as to maintain the positivity of the final linear combination while minimizing the -norm. The algorithm returns a set of functions
with . Note that the algorithm requires to set a tolerance parameter for the computation of the .
Once we have run Enlarge_Cone, the approximation of any function is then sought as
(16) We emphasize that the routine is valid for any set of nonnegative input functions. We can thus apply Enlarge_Cone to the functions from NMF, but also to the functions selected by a greedy algorithm such as the following:
-
•
For , find
-
•
At step , we have selected the set of functions . We next find
In our numerical tests, we call Enlarged Nonnegative Greedy (ENG) the routine involving the above greedy algorithm combined with our routine Enlarge_Cone.
Set of nonnegative functions . Tolerance .for doSetfor dowhile doend whileend forend forAlgorithm 1 We remark that if we work with positive functions that are upper bounded by a constant , we can ensure that the approximations, denoted as , and written as a linear combination of basis functions, will also be between these bounds and by defining, on the one hand and as we have just done, a cone of positive functions generated by the above family , and, on the other hand, by considering the base of the functions , being as above the set all greedy elements of the reduced basis to which we also apply an enlargement of these positive functions. We then impose that the approximation is written as a positive combination of the first (positive) functions and that is also written as a combination with positive components in the second basis.
In this frame, the approximation appears under the form of a least square approximation with linear constraints on the coefficients expressing the fact that in the two above transformed basis the coefficients are nonnegative.
-
•
In addition to the previous basis functions, it is possible to include more general/generic basis functions such as polynomial, radial, or wavelet functions in order to guarantee simple forecasting trends. For instance, one can add affine functions in order to include the possibility of predicting with simple linear extrapolation to the range of possible forecasts offered by the reduced model. Given the overall exponential behavior of the health data, we have added an exponential function of the form (respectively ) to the reduced basis functions and (respectively ) where the real-valued nonnegative parameters are obtained through a standard exponential regression from (respectively ) associated to the targeted profiles of infectious people, that is the profiles defined on the time interval that one wants to extrapolate to . In other words, the final reduced models that we use for forecasting are:
Indeed, including the exponential functions in the reduced models gives access cheaply to the overall behavior of the parameters and , the rest of basis functions generated from the training sets catch the high order approximations and allow then to improve the extrapolation.
Remark 2.2.
Reduced models on and Instead of applying model reduction to the sets and as we do in our approach, we could apply the same above techniques directly to the sets of solutions and of the SIR models with time-dependent coefficients in and . In this case, the resulting approximation would however not follow a SIR dynamics.
3 Methodology for multiple regions including population mobility data
The forecasting method of Section 2.2 for one single region can be extended to the treatment of multiple regions involving population mobility. The prediction scheme will now be based on a multiregional SIR with time-dependent coefficients. Compared to other more detailed models, its main advantage is that it reduces drastically the number of parameters to be estimated. Indeed, detailed multiregional models such as multiregional extensions of the above SEICHRD and SEIUR models from Section 2.3 require a number of parameters which quickly grows with the number of regions involved. Their calibration thus requires large amounts of data which, in addition, may be unknown, very uncertain, or not available. In a forthcoming paper, we will apply the fully multi-regional setting for the post-lockdown period.
The structure of this section is the same as the previous one for the case of a single region. We start by introducing in Section 3.1 the multi-regional SIR model with time-dependent coefficients and associated detailed models. As any multiregional model, mobility data are required as an input information, and the nature and level of detail of the available data motivates certain choices on the modelling of the multiregional SIR (as well as the other detailed models). We next present in Section 3.2 the general pipeline, in which we emphasize the high modularity of the approach.
3.1 Multi-regional compartmental models
In the spirit of fluid flow modeling, there are essentially two ways of describing mobility between regions:
-
•
In a Eulerian description, we take the regions as fixed references for which we record incoming and outgoing travels.
-
•
In a Lagrangian description, we follow the motion of people domiciled in a certain region and record their travels in the territory. We can expect this modeling to be more informative on the geographical spread of the disease but it comes at the cost of additional details on the people’s domicile region.
Note that both descriptions hold at any coarse or fine geographical level in the sense that what we call the regions could be taken to be full countries, departments within a country, or very small geographical partitions of a territory. We next describe the multi-regional SIR models with the Eulerian and Lagrangian description of population fluxes which will be the output of our methodology.
3.1.1 Multi-regional SIR models with time-dependent parameters
Eulerian description of population flux: Assume that we have regions and the number of people in region is for . Due to mobility, the population in each region varies, so depends on . However, the total population is assumed to be constant and equal to , that is
For any , let be the probability that people from travel to at time . In other words, is the number of people from region that have travelled to region between time and . Note that we have
Since, for any ,
dividing by and taking the limit yields
Note that we have
Thus , which is consistent with our assumption that the total population is constant.
The time evolution of the is known in this case if we are given the from Eulerian mobility data. In addition to this mobility data, we also have the data of the evolution of infected and removed people and our goal is to fit a multi-regional SIR model that is in accordance with this data. We propose the following model.
Denoting , an the number of Susceptible, Infectious and Removed people in region at time , we first have the relation
Note that from the second relation, it follows that
| (17) |
To model the evolution between compartments, one possibility is the following SIR model
| (18) | ||||
| (19) | ||||
| (20) |
The parameters , , depend on but we have omitted the dependence to ease the reading. Introducing the compartmental densities
| (21) |
the system equivalently reads
| (22) | ||||
| (23) | ||||
| (24) |
Before going further, some comments are in order:
-
•
The model is consistent in the sense that it satisfies (17) and when we recover the traditional SIR model.
-
•
Under lockdown measures, and the population remains practically constant. As a result, the evolution of each region is decoupled from the others and each region can be addressed with the mono-regional approach.
-
•
The use of in equation (22) is debatable. When the people from region arrive to region , it may be reasonable to assume that the contact rate is .
-
•
The use of in equation (22) is also very debatable. The probability was originally defined to account for the mobility of people from region to region without specifying the compartment. However, in equation (22), we need the probability of mobility of infectious people from region to region , which we denote by in the following. It seems reasonable to think that may be smaller than because as soon as people become symptomatic and suspect their illness, they will probably not move. Two possible options would be:
-
–
We could try to make a guess on . If the symptoms arise, say, 2 days after infection and if we recover in 15 days in average, then we could say that .
-
–
Since, the above seems however pretty empirical, another option is to use and absorb the uncertainty in the values of the that one fits.
-
–
-
•
We choose not to add mobility in the compartment as this does not modify the dynamics of the epidemic spread and only adjustments in the population sizes are needed.
Lagrangian description of population flux: We call the above description Eulerian because we have fixed the regions as a fixed reference. Another point of view is to follow the trajectories of inhabitants of each region, in the same spirit as when we follow the trajectories of fluid particles.
Let now , , the number of susceptible, infectious and Removed people who are domiciled in region . It is reasonable to assume that is constant in time. However, all the dwellers of region may not all be in that region at time . Let be the probability that susceptible people domiciled at travel from region to region at time . With this notation, is the probability that susceptible people domiciled at remain in region at time . Similarly, let be the probability that infectious people domiciled at travel from region to at time . Hence the total number of susceptible and infectious people that are in region at time is
| (25) | ||||
| (26) |
We can thus write the evolution over , , as
| (27) | ||||
| (28) | ||||
| (29) |
Note that is constant, which is consistent with the fact that in our model
We emphasize that, to implement this model, one needs the Lagrangian mobility data for all .
Notation: In the following, we gather the compartmental variables in vectors
as well as the time-dependent coefficients
For any and , we denote by
the output of any of the above multiregional SIR models. For simplicity in what follows, we will omit the initial condition in the notation.
3.1.2 Detailed multi-regional models with constant coefficients
In the spirit of the multi-regional SIR, one can formulate detailed multi-regional versions of more detailed models such as the ones introduced in Section 2.1. We omit the details for the sake of brevity.
3.2 Forecasting for multiple regions with population mobility
Similarly as in the mono-regional case, we assume that we are given health data in in all regions. The observed data in region is the series of infected people, denoted , and recovered people denoted . They are usually given at a national or a regional scale and on a daily basis.
We propose to fit the data and provide forecasts with SIR models with time-dependent parameters and for each region . Like in the mono-regional case, we can prove that such a simple family possesses optimal fitting properties for our purposes. In the current case, the cost function reads
and the fitting problem is the optimal control problem of finding
| (30) |
The following proposition ensures the existence of a unique minimizer under certain conditions. To prove it, it will be useful to remark that any of the above multi-regional SIR models (see (22), (27)) can be written in the general form
where, by a slight abuse of notation, the vectors , and are densities of population in the case of the Eulerian approach (see equation (22)). They are classical population numbers in the case of the Lagrangian approach (see equation (27)). is the diagonal matrix with diagonal entries given by the vector . is a matrix of size which depends on the vectors of susceptible and infectious people , and on the mobility matrix . In the case of the Eulerian description, and in the case of the Lagrangian approach is the tensor . For example, in the case of the Eulerian model (27), the matrix reads
| (31) |
Proposition 3.1.
If is invertible for all , then there exists a unique minimizer to problem (30).
Proof.
Since we assume that is invertible for every , we can set
| (32) |
or equivalently
| (33) |
so that
and
which implies that . ∎
Before going further, let us comment on the invertibility of which is necessary in Proposition 3.1. A sufficient condition to ensure it is if the matrix is diagonally dominant row-wise or column-wise. This yields certain conditions on the mobility matrix with respect to the values of , . For example, if is defined as in equation (31), the matrix is diagonally dominant per rows if for every ,
Similarly, if for every ,
then the matrix is diagonally dominant per columns, and guarantees invertibility. Note that any of the above conditions is satisfied in situations with little or no mobility where .
Now that we have exactly defined the set up for the multi-regional case, we can follow the same steps of Section 2.2 to derive forecasts involving model reduction for the time-dependent variables and .
4 Numerical results
In this section we apply our forecasting method to the ongoing COVID-19 pandemic spread in year 2020 in France which started approximately from February 2020. Particular emphasis is put on the first pandemic wave for which we consider the period going from March 19 to May 20, 2020. Due to the lockdown imposed between March 17 and May 11, inter-regional population mobility was drastically reduced in that period. Studies using anonymised Facebook data have estimated the reduction in 80% (see [3]). As a result, it is reasonable to treat each region independently from the rest, and we apply the mono-regional setting of Section 2. Here, we focus on the case of the Paris region, and we report different forecasting errors obtained using the methods described in Section 2. Some forecasts are also shown for the second wave for the Paris region between September 24 and November 25.
The numerical results are presented as follows. Section 4.1 explains the sources of health data. Sections 4.2.1 and 4.2.2 go straight to the core of the results and present a study of the forecasting power of the methods in a two week horizon. Section 4.2.3 displays forecasts on the second wave. Section 4.2.4 aims to illustrate the robustness of the forecasting over longer periods of time. A discussion on the fitting errors of the methods is given in Appendix A. Additional results highlighting the accuracy of the forecasts are shown in Appendix B.
4.1 Data
We use public data from Santé Publique France111https://www.data.gouv.fr/en/datasets/donnees-hospitalieres-relatives-a-lepidemie-de-covid-19/ to get the number of infected, and of removed people. As shown in Figure 3, the raw data present some oscillations at the scale of the week, which are due to administrative delays for the cases to be officially reported by hospitals. For our methodology, we have smoothed the data by applying a 7 days moving average filter. In order to account for the total number of infected people, we also multiply the data by an adjustment factor as hinted from the literature222Indeed, it is said in [24] that ”of the 634 confirmed cases, a total of 306 and 328 were reported to be symptomatic and asymptomatic” and in [10] claims that the probability of developing severe symptoms for a symptomatic patient is 0 for children, 0.1 for adults and 0.2 for seniors. Thus if one takes as an approximate value of these probabilities, one may estimate the adjustment factor as . Obviously, this factor is uncertain and could be improved in the light of further retrospective studies of the outbreak. However, note that when which is the case in the start of the epidemic, the impact of this factor is negligible in the dynamics as can be understood from (6). In addition, since we use the same factor down to provide a forecast on the hospitalized, the influence on the choice is minor.
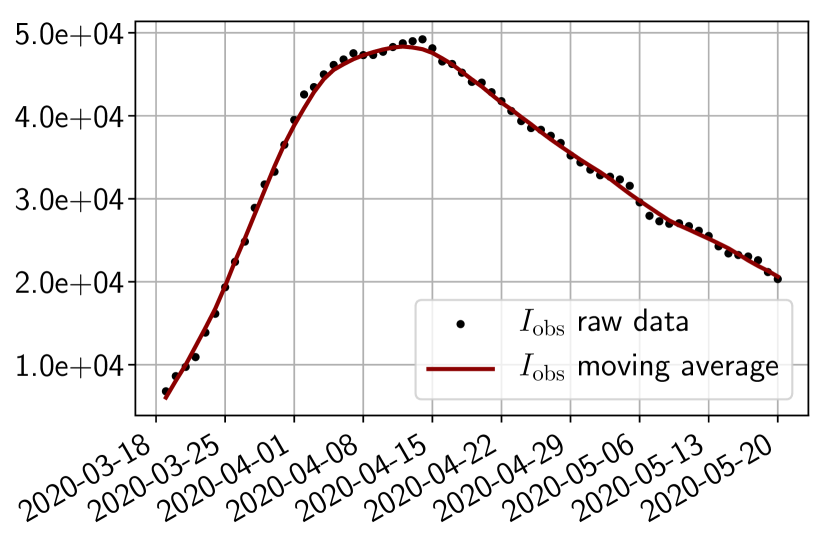
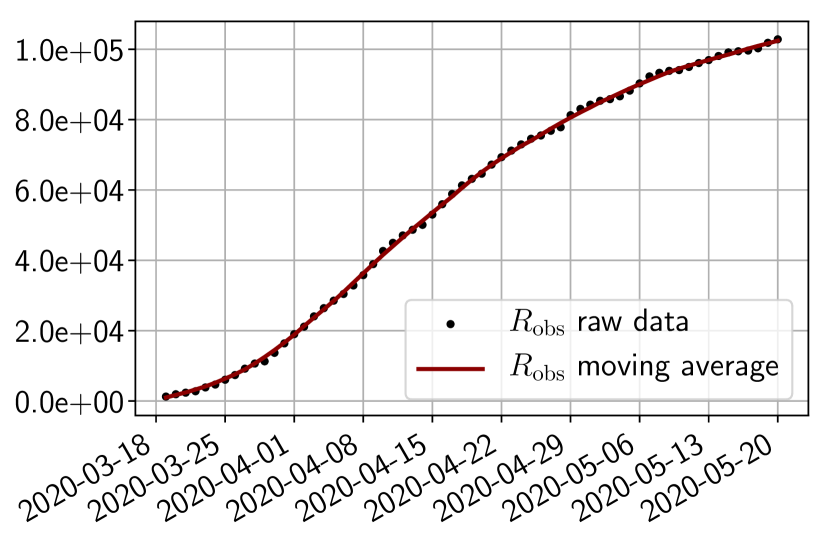
4.2 Results
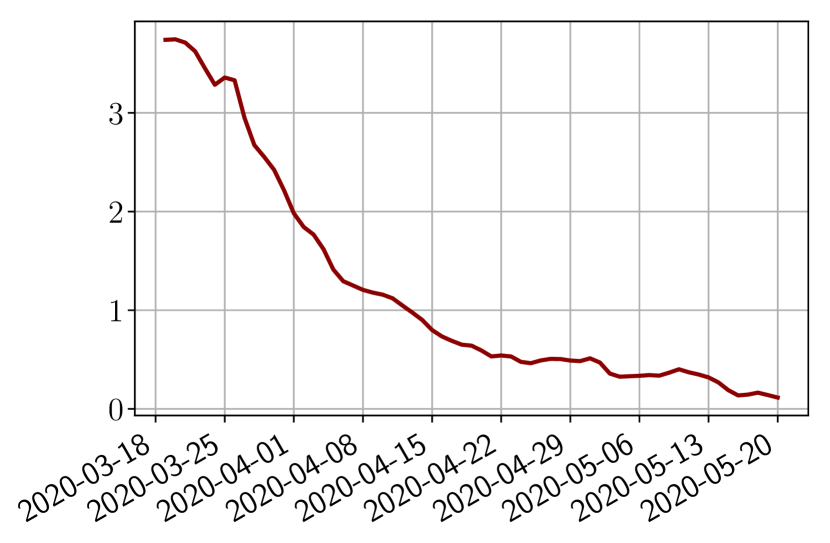
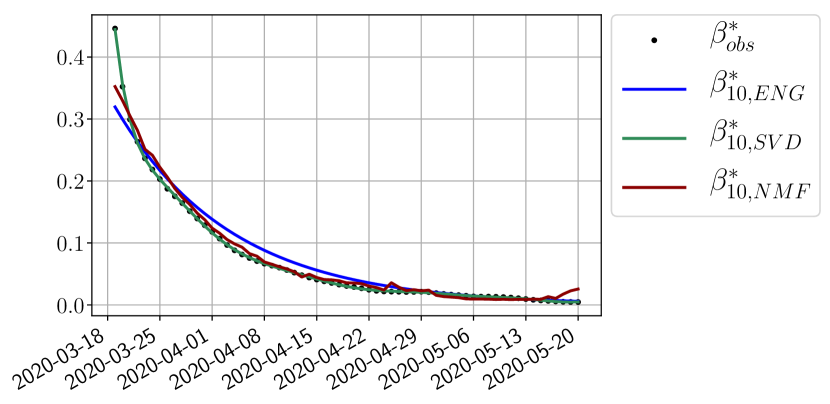
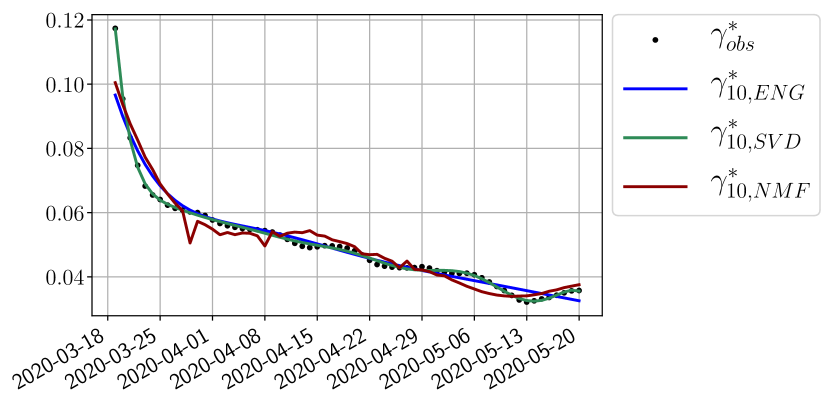
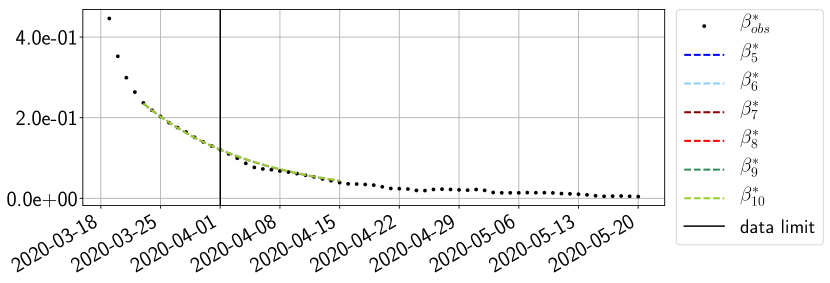
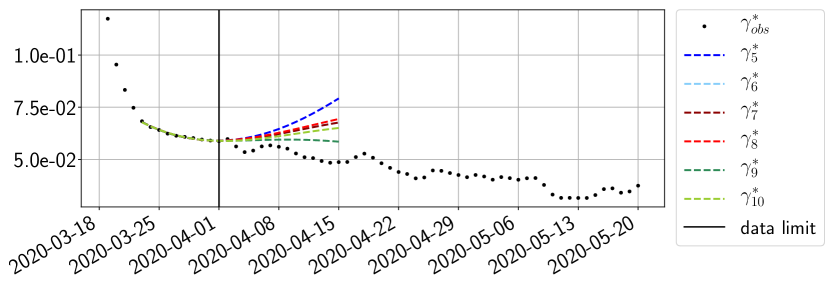
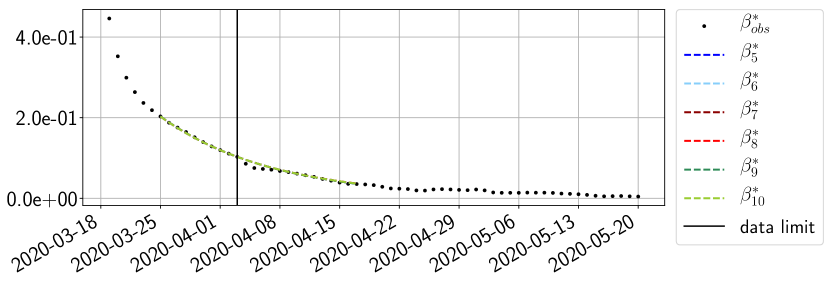
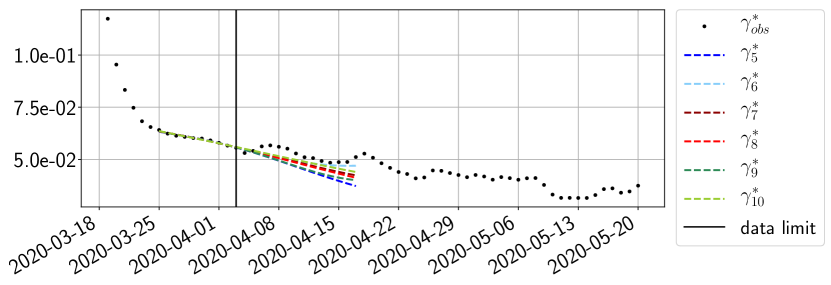
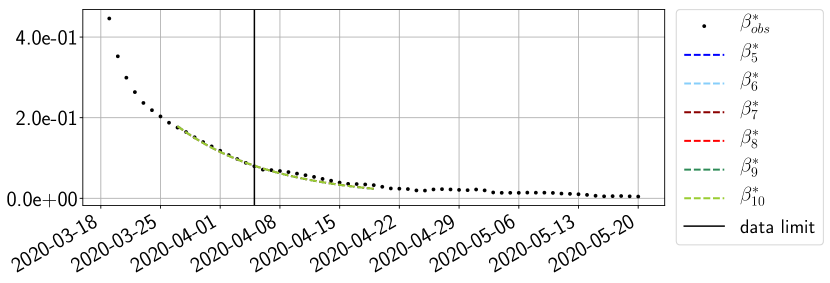
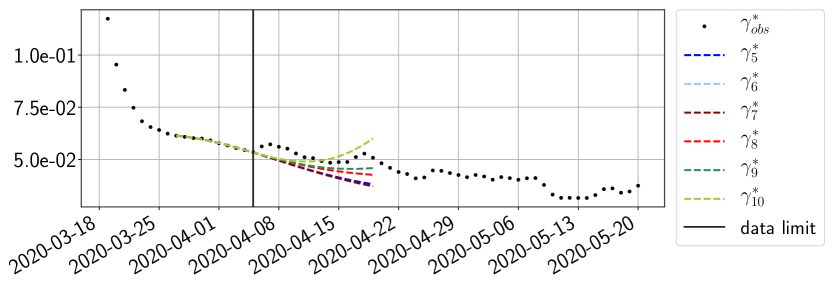
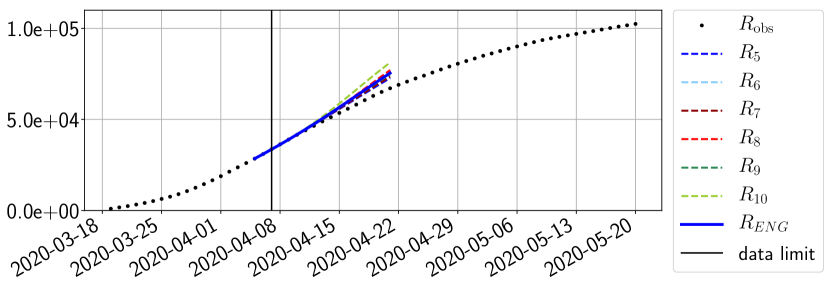
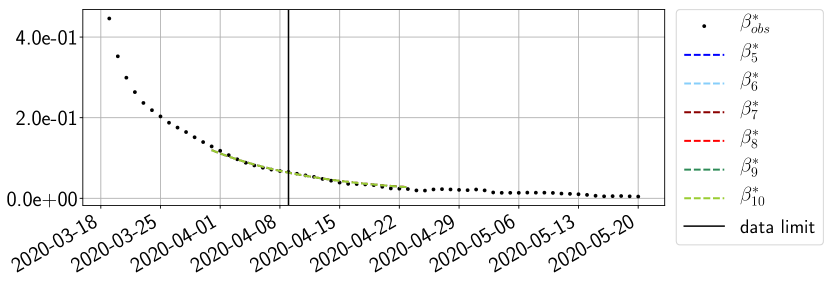
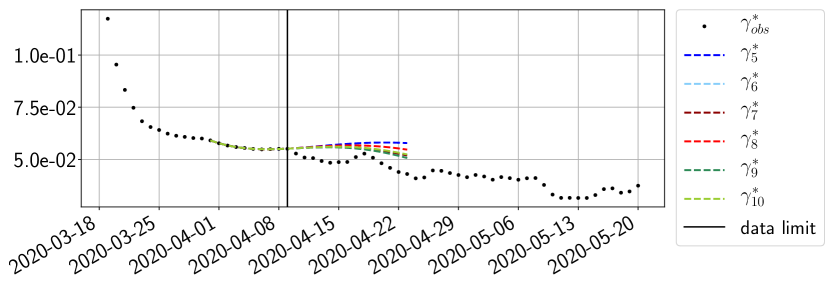
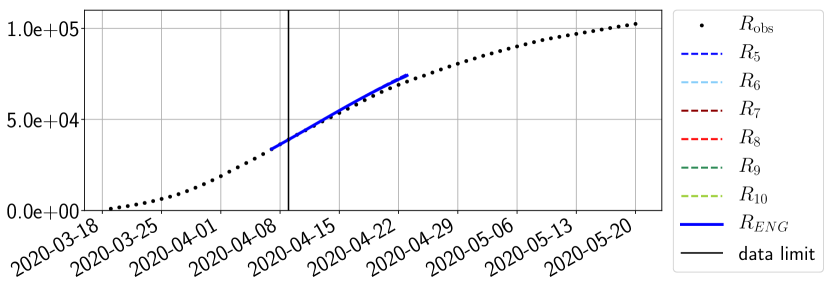
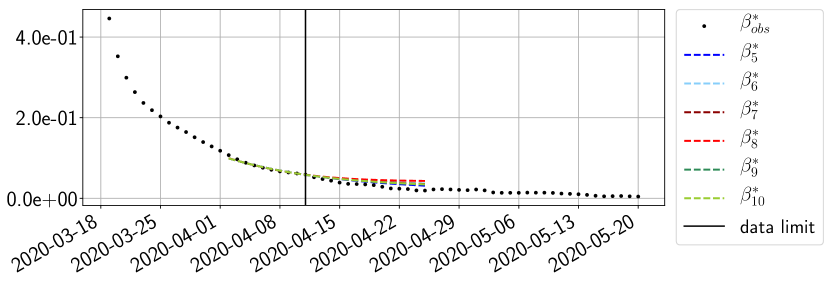
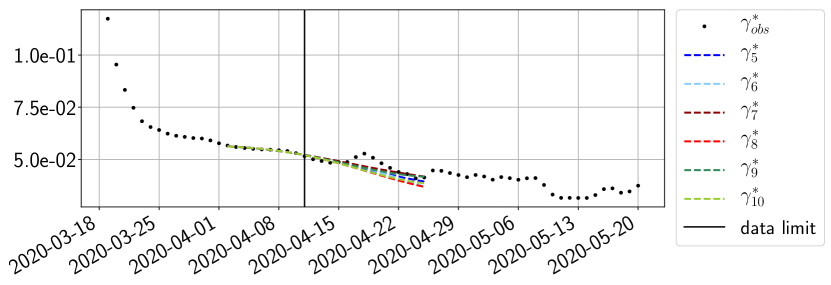
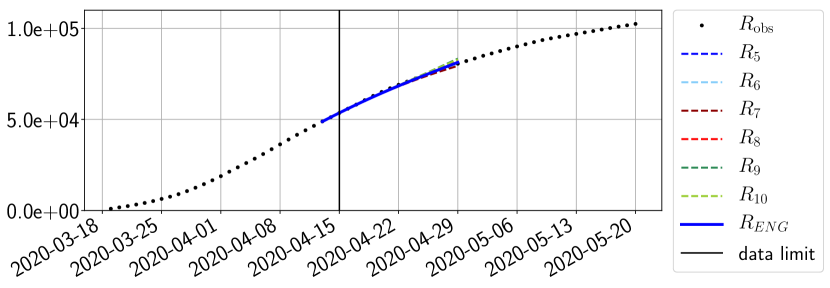
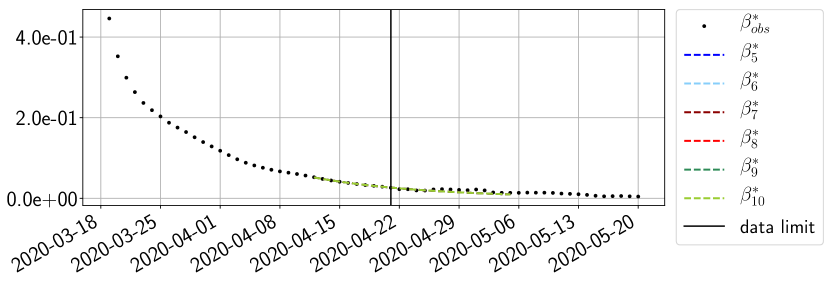
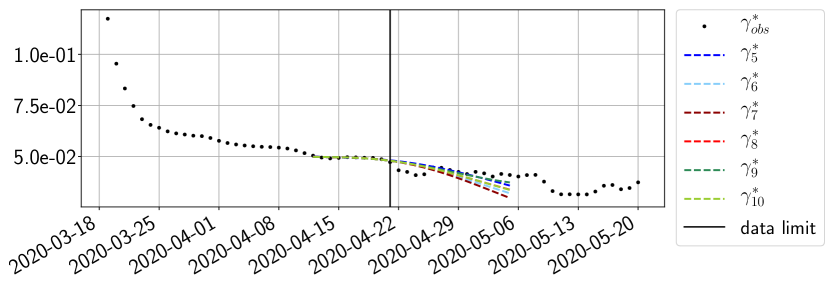
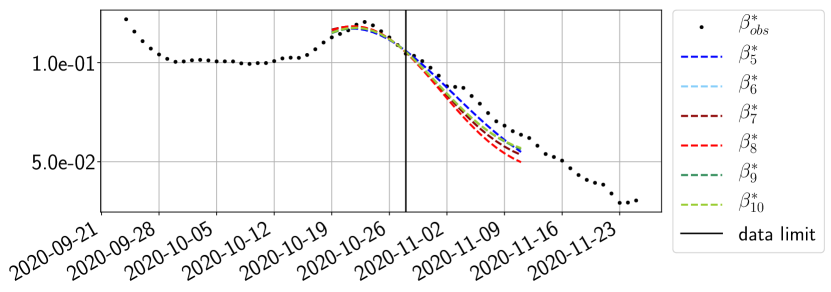
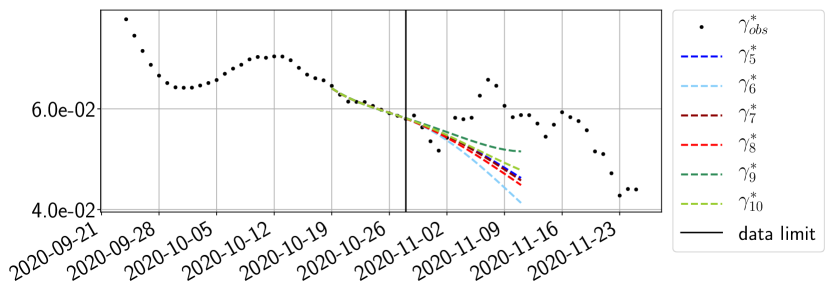
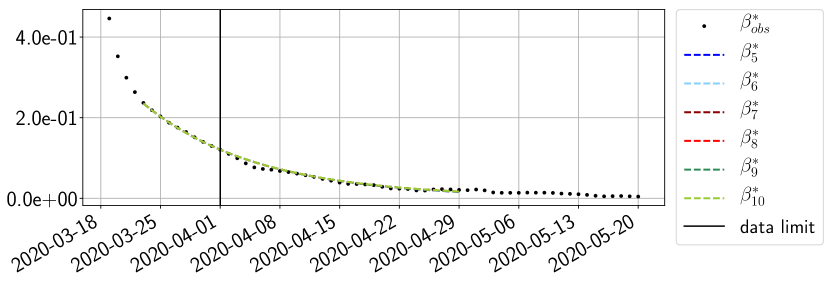
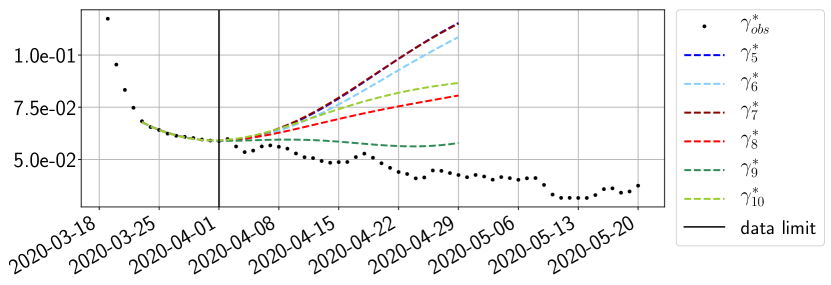
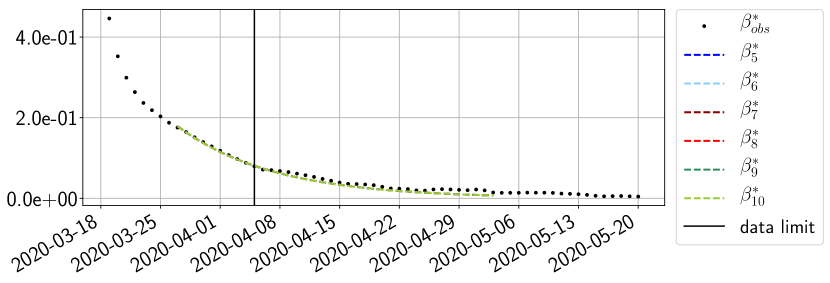
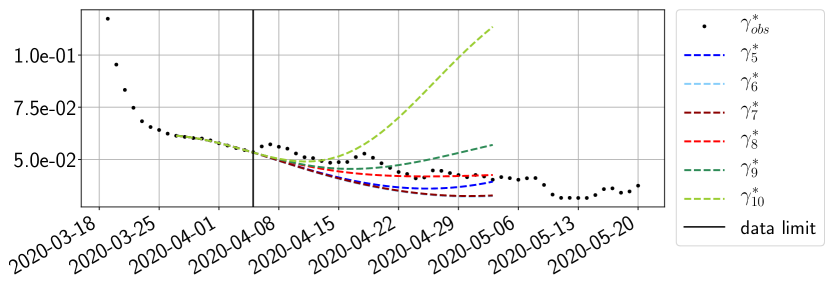
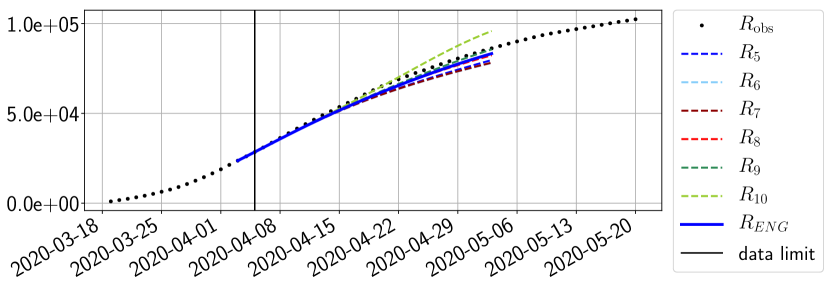
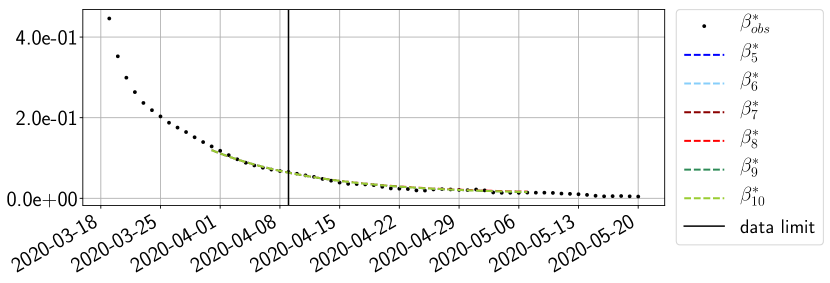
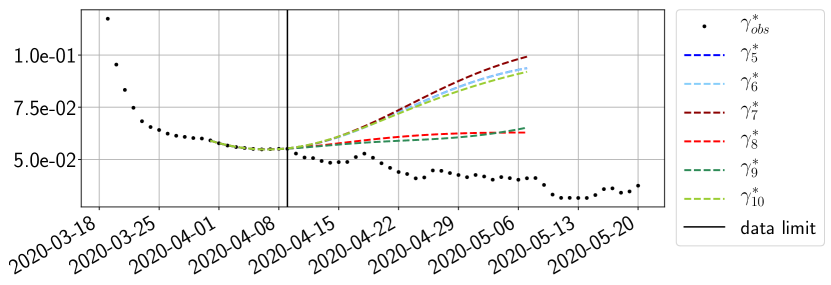
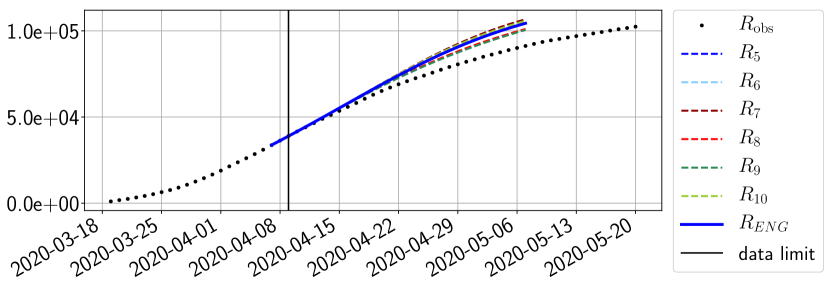
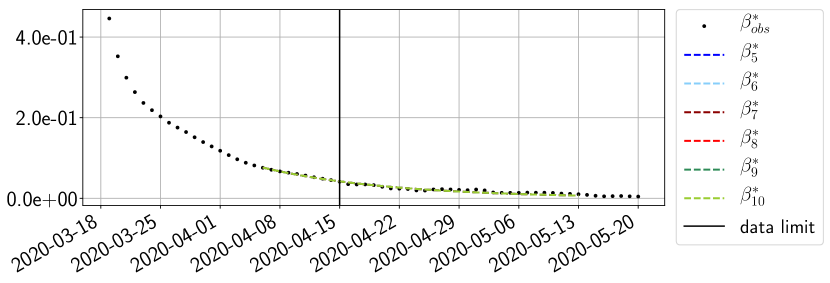
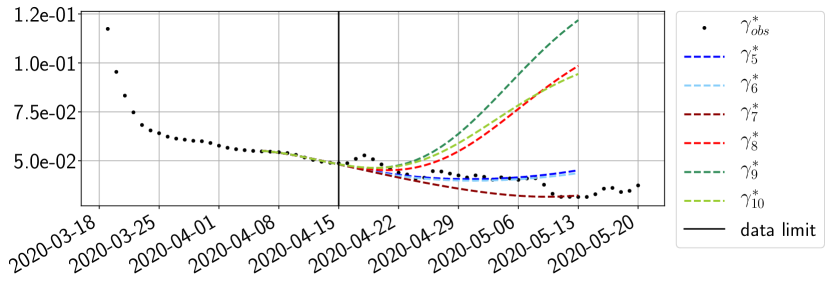
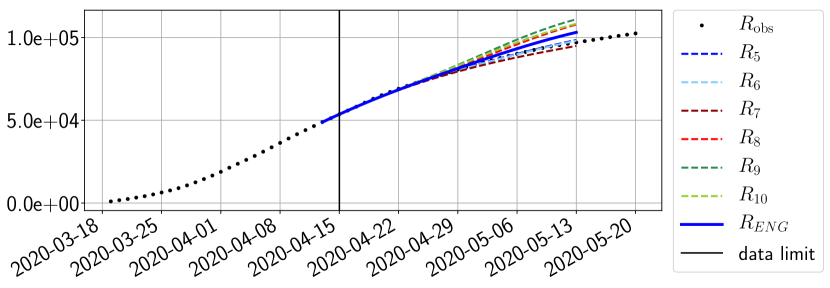
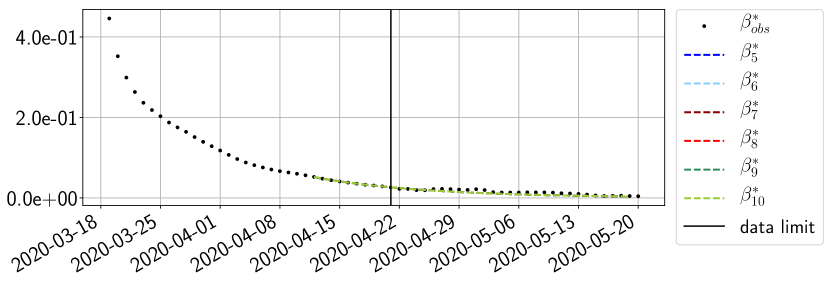
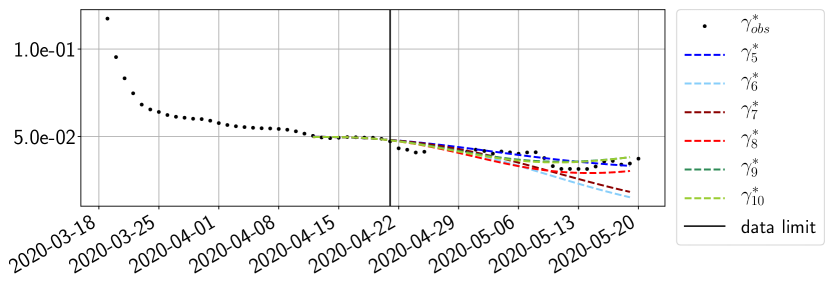
Using the observations and , we apply a finite difference scheme in formula (6) to derive and for . Figure 4 shows the values of these parameters as well as the basic reproduction number for the first pandemic wave in Paris.
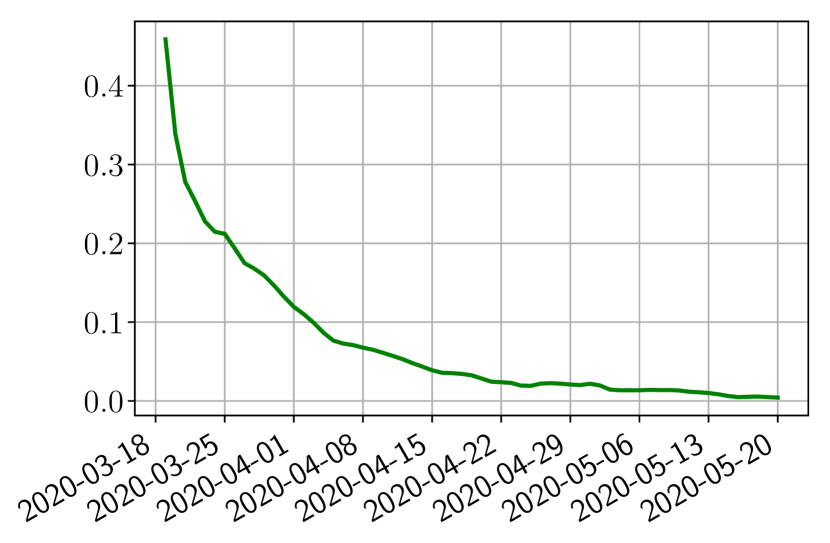
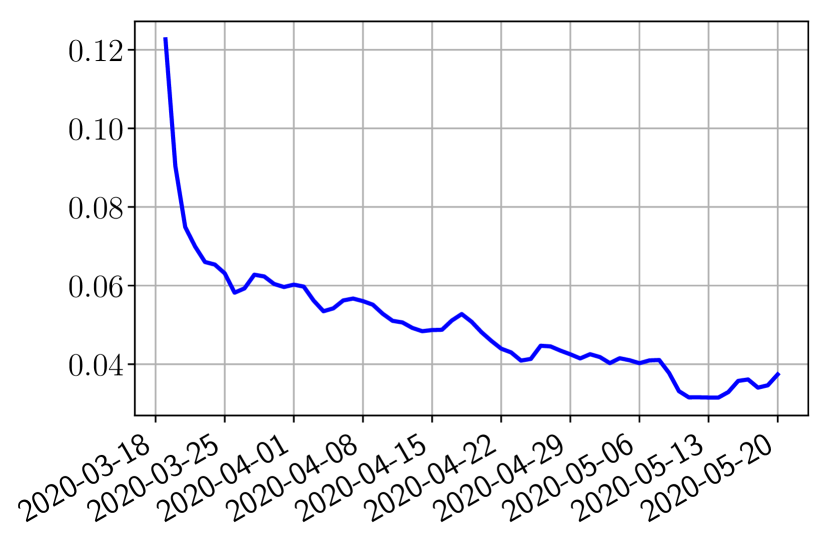
We next follow the steps of Section 2.2 to obtain the forecasts. In the learning phase (step 1), we use two parametric detailed models of type SEIUR and SEICHRD to generate training sets and composed of training functions and where are uniformly sampled in the set of parameters in the vicinity of the parameter values suggested in the literature [10, 22]. Based on these training sets, we finish step 1 by building three types of reduced models: SVD, NMF and ENG (see Section 2.4).
Given the reduced bases and , we next search for the optimal and that fit at best the observations (step 2 of our procedure). For this fitting step we consider two loss functions:
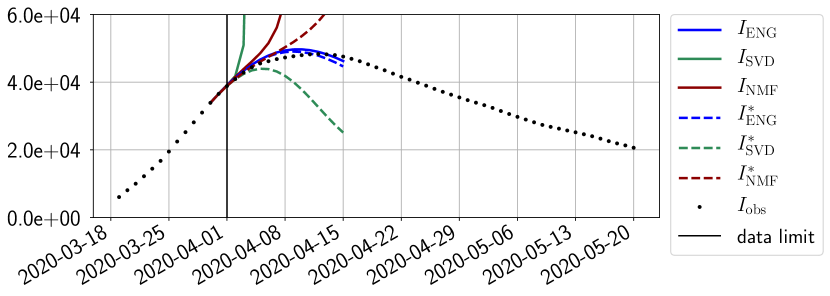
We study the performance of each of the three reduced models and the impact of the dimension of the reduced model in terms of fitting error. The presentation of these results is deferred to Appendix A in order not to overload the main discussion. The main conclusion is that the fitting strategy using SVD reduced bases provide smaller errors than NMF and ENG especially when we increase the number of modes . This is illustrated in Figure 5 where we show the fittings obtained with routine- and for the first wave (from to ). We observe that SVD is the best at fitting and while ENG produces a smoother fitting of the data. Although the smoother fitting with ENG yields larger fitting errors than SVD, we will see in the next section that it yields better forecasts.
4.2.1 Forecasting for the first pandemic wave on a 14 day horizon
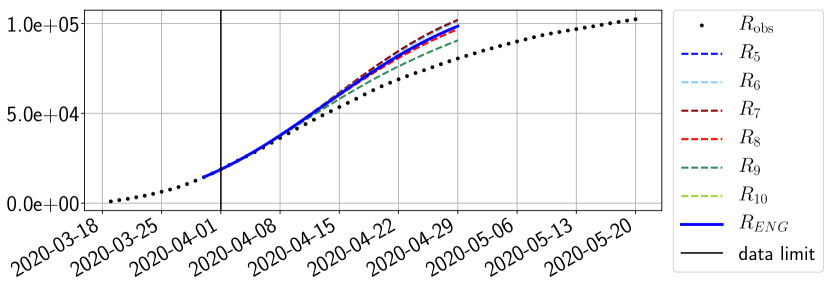
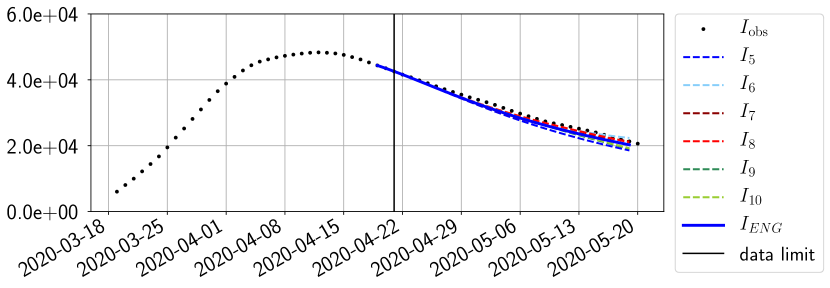
In this section we illustrate the short-term forecasting behavior of our method. We consider a forecasting window of days and we examine several different starting days in the course of the first pandemic wave. The results are shown in figures 6 to 14. Recall that that the forecasting uses the coefficients of the reduced basis obtained by the fitting procedure, but also the optimal initial condition of the forecast that minimizes the error on the three days prior to the start of the forecast. For each given fitting strategy (routine-IR, routine-), and each given type of reduced model (SVD, NMF, ENG), we have chosen to plot an average forecast computed with predictions using reduced dimensions . This choice is a simple type of forecast combination but of course other more elaborate aggregation options could be considered. The labels of the plots correspond to the following:
-
•
, , , , , are the average forecasts obtained using routine-.
-
•
, , , , , are the average forecasts obtained using routine-IR.
The main observation from Figures 6 to 14 is that the ENG reduced model is the most robust and accurate forecasting method. Fitting ENG with routine-IR or routine- does not seem to lead to large differences in the quality of the forecasts but routine- seems to provide slightly better results. This claim is further confirmed by the study of the numerical forecasting errors of the different methods that the reader finds in Appendix B.
Figures 6 to 14 also show that the SVD reduced model is very unstable and provides forecasts that blow up. This behavior illustrates the dangers of overfitting, namely that a method with high fitting power may present poor forecasting power due to instabilities. In the case of SVD, the instabilities stem from the fact that approximations are allowed to take negative values. This is the reason why NMF, which incorporates the nonnegative constraint, performs better than SVD. One of the reasons why ENG outperforms NMF relies in the enlargement of the cone of nonnegative functions (see Section 2.4). It is important to note that, with ENG the reduced bases are directly related to well chosen virtual scenarios, whereas SVD and NMF rely on matrix factorization techniques that provide purely artificial bases. This makes forecasts from ENG more realistic and therefore more reliable.
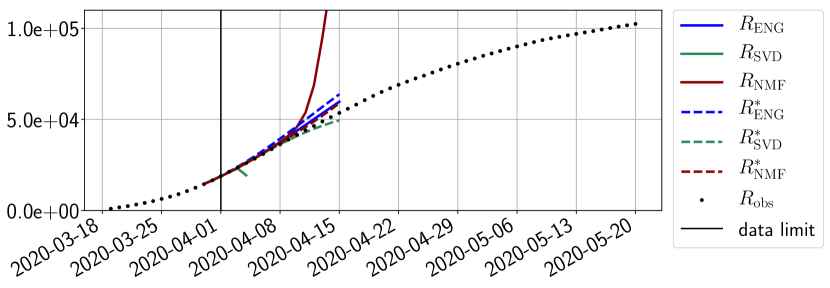
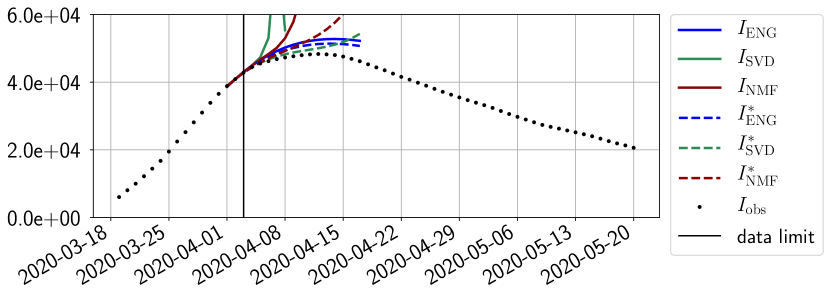
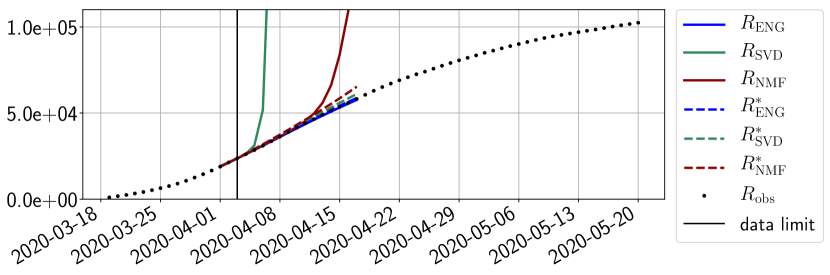
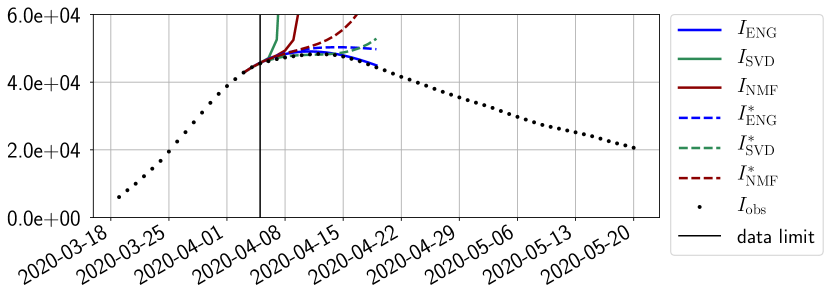
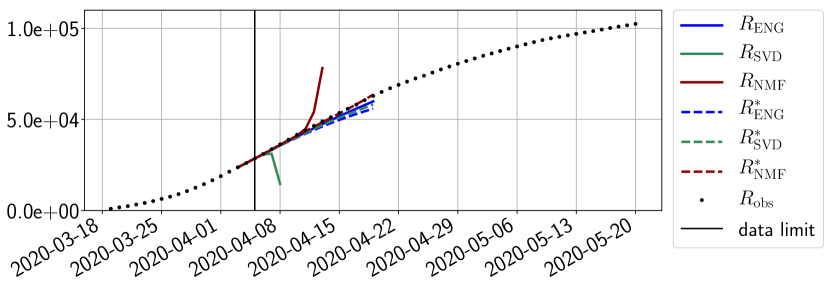
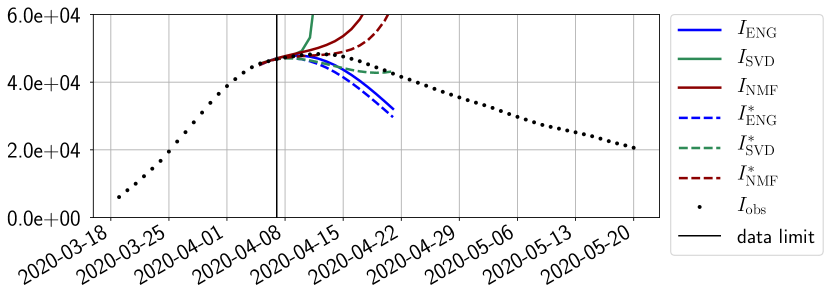
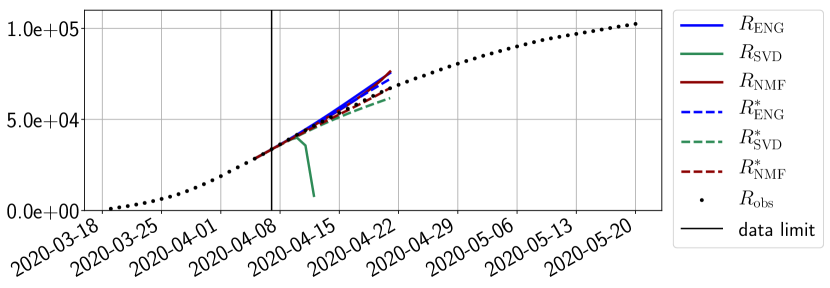
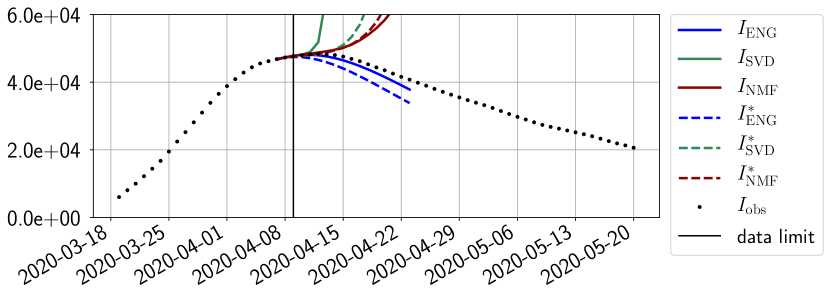
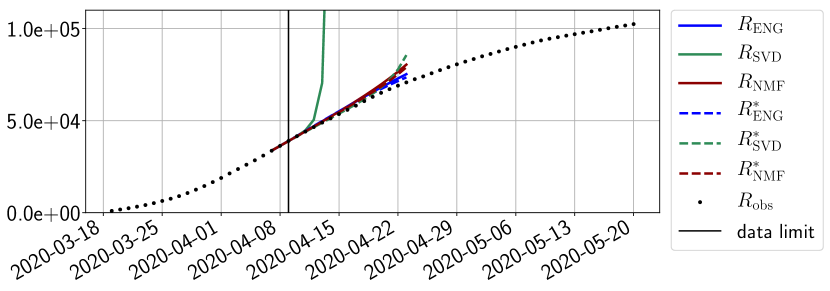
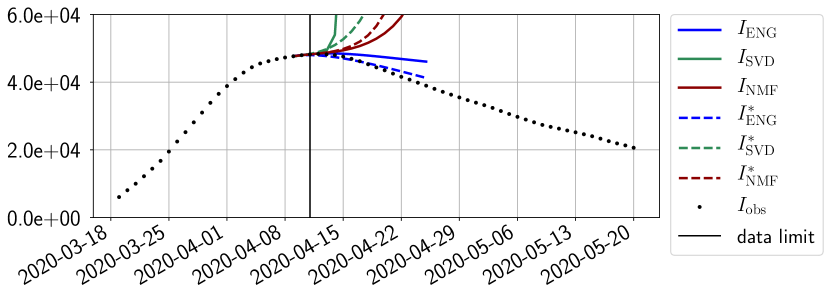
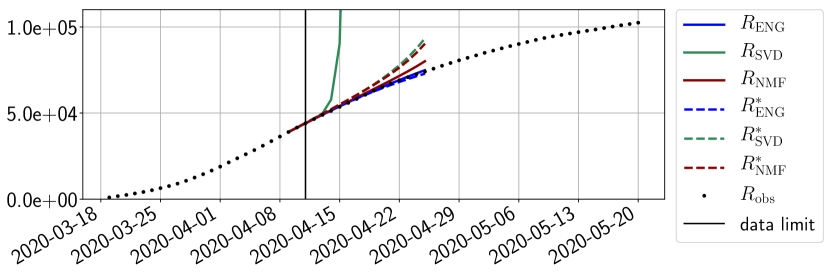
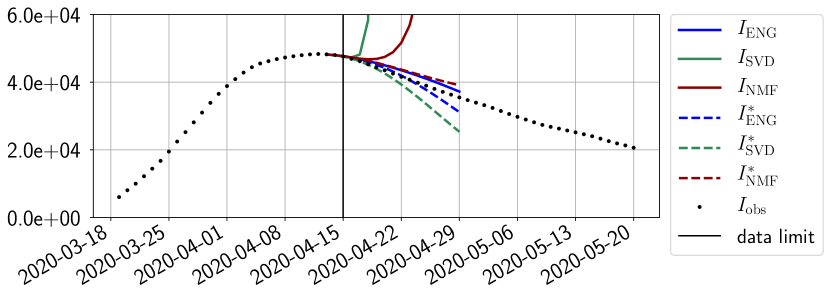
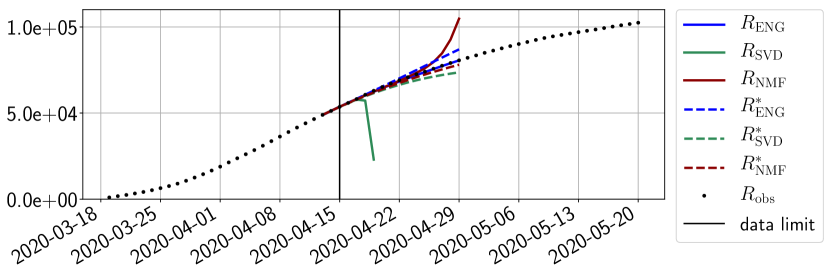
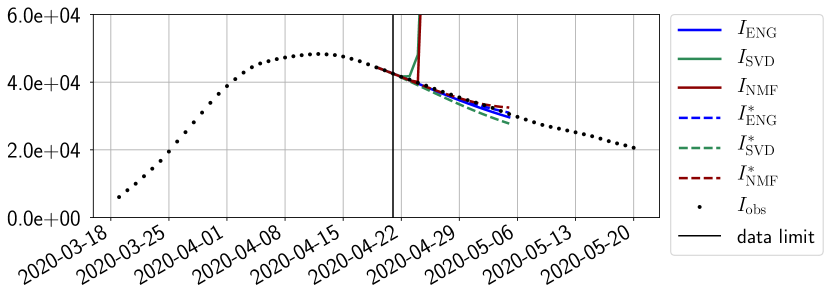
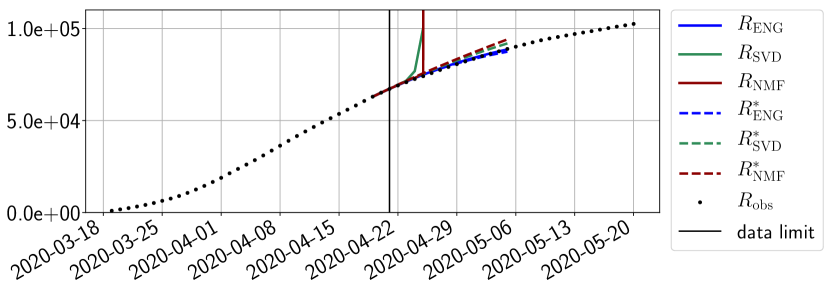
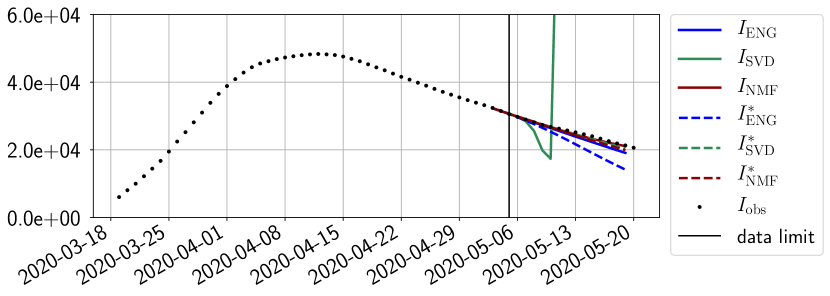
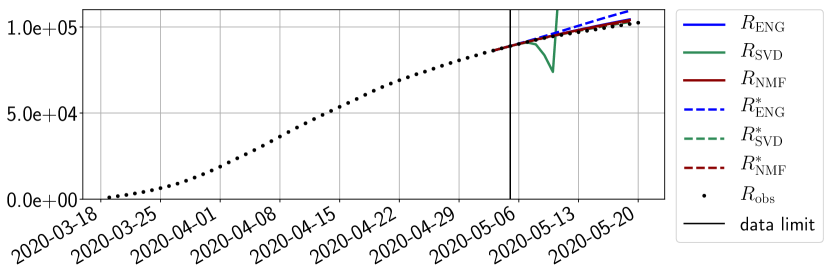
4.2.2 Focus on the forecasting with ENG
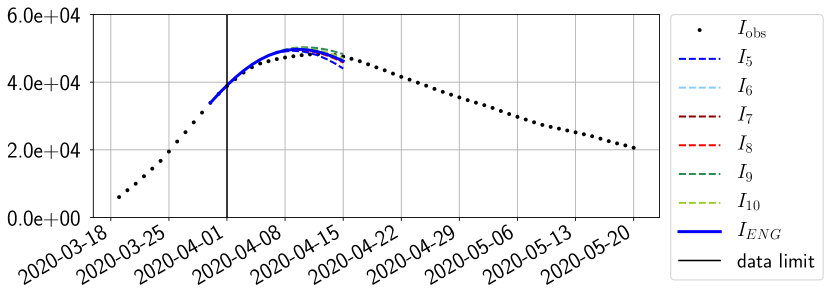
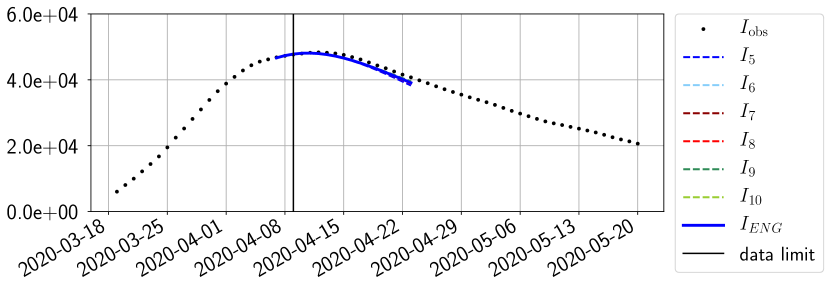
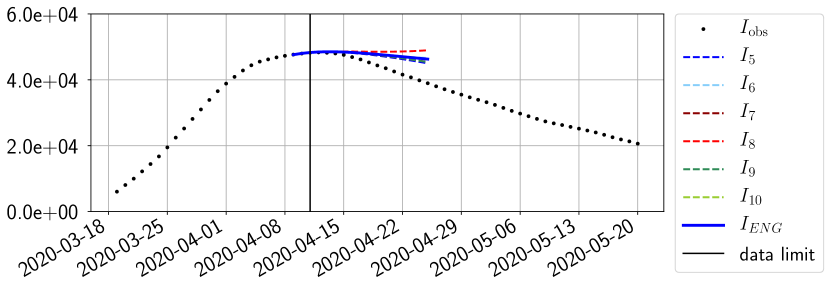
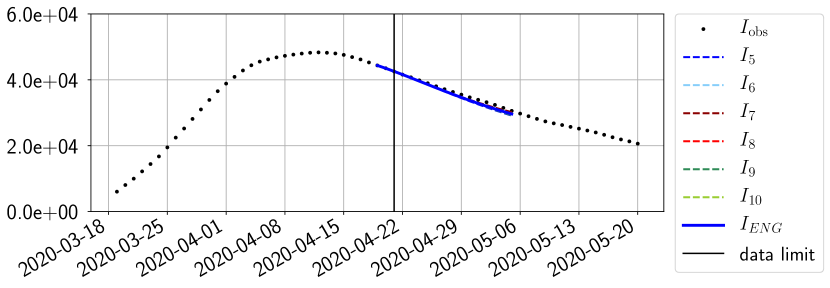
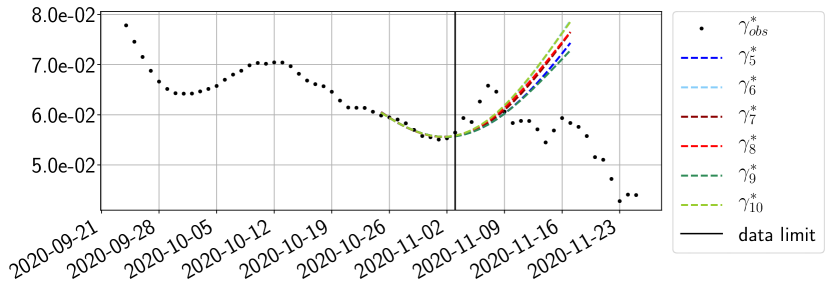
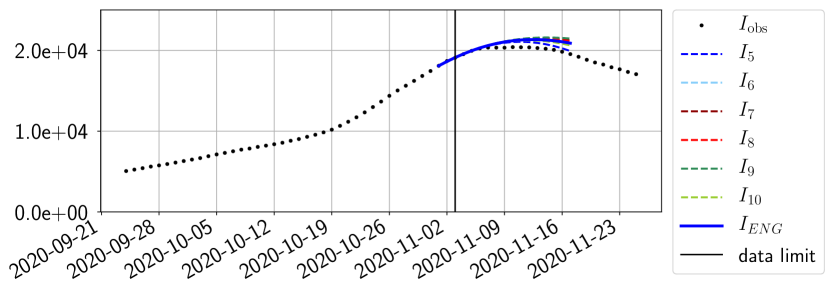
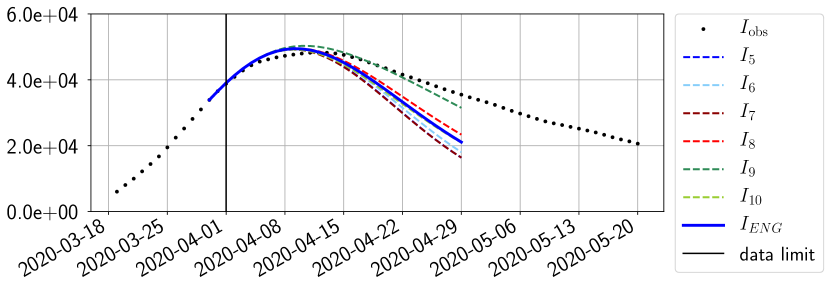
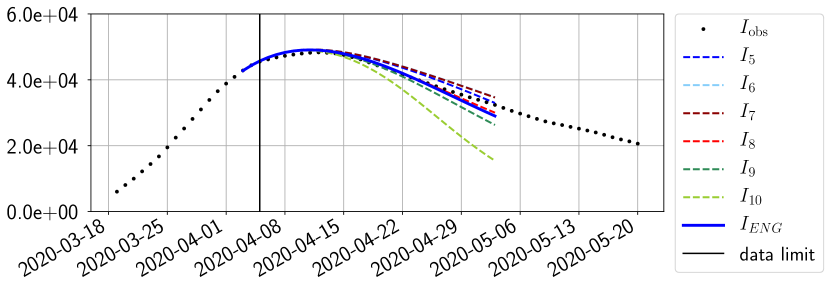
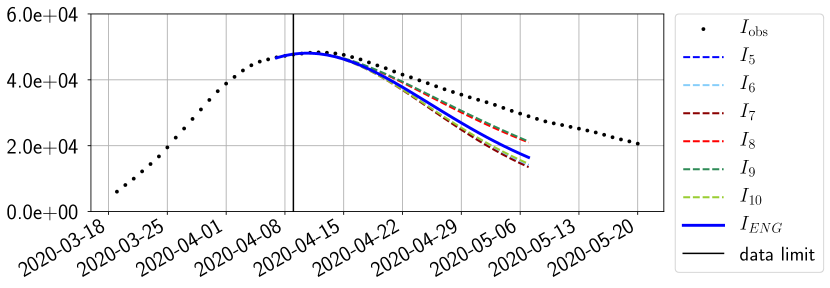
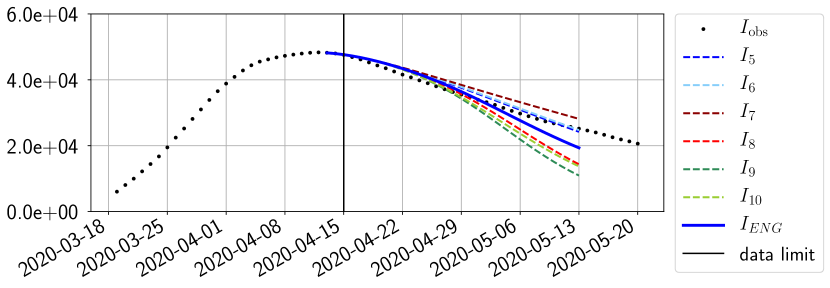
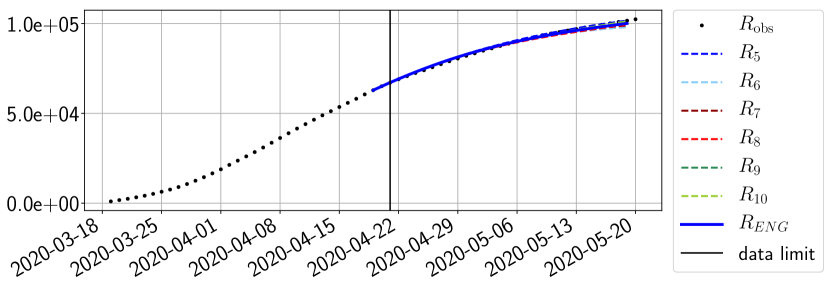
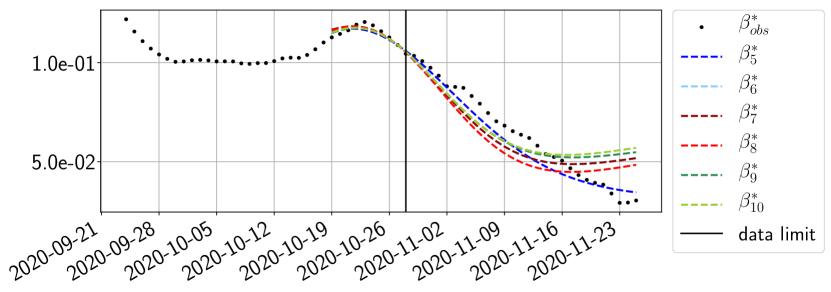
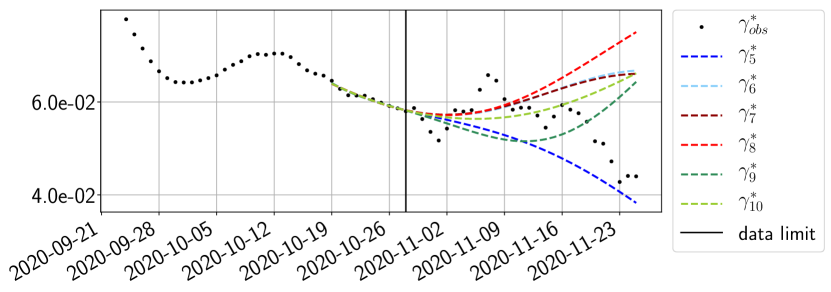
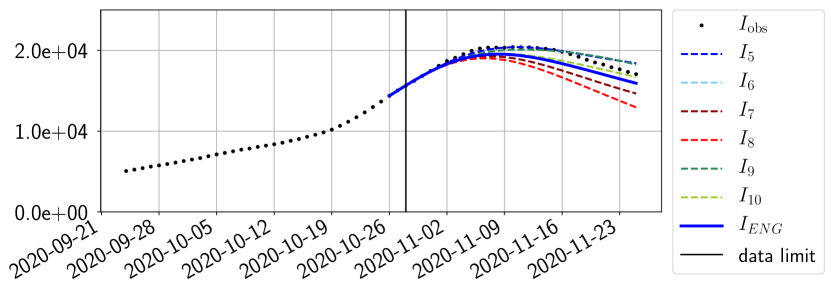
For our best forecasting method (routine- using ENG), we plot in Figures 15 to 23 the forecasts for each dimension to . The plots give the forecasts on a 14 day ahead window for , and the resulting evolution of the infected and removed . We see that the method performs reasonably well for all values of , and proves that the results of the previous section with the averaged forecast are not compensating spurious effects which could occur for certain values of . We intentionally chose to display the inaccurate forecasts from 03/04, 07/04 and 11/04 as they are among of the worst predictions obtained using this method, however, it is important to mention that despite the lack of accuracy for these cases it remains plausible epidemic behaviors with different but realistic evolutions for and compared to the actual evolution. Note that the method was able to predict the peak of the epidemic several days in advance (see Figure 15). We also observe that the prediction on is difficult at all times due to the fact that presents an oscillatory behavior. Despite this difficulty, the resulting forecasts for and are very satisfactory in general.
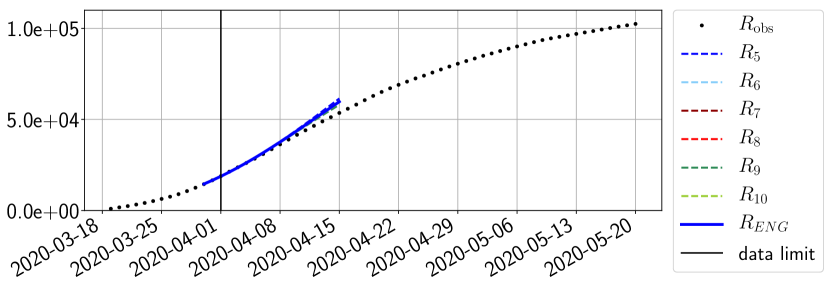
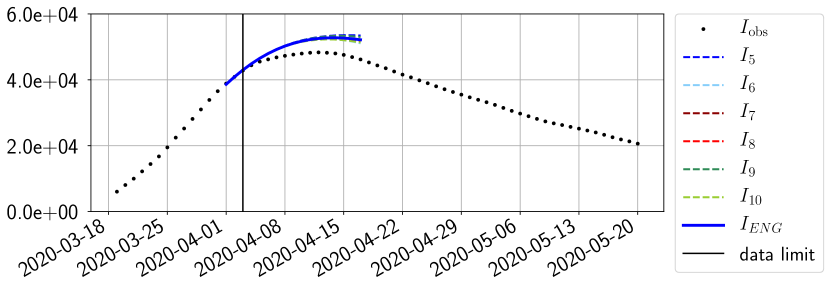
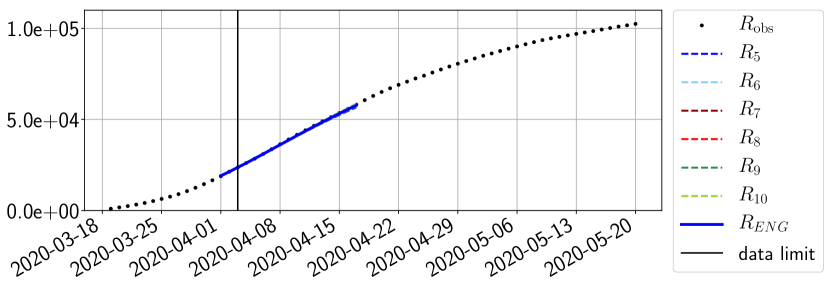
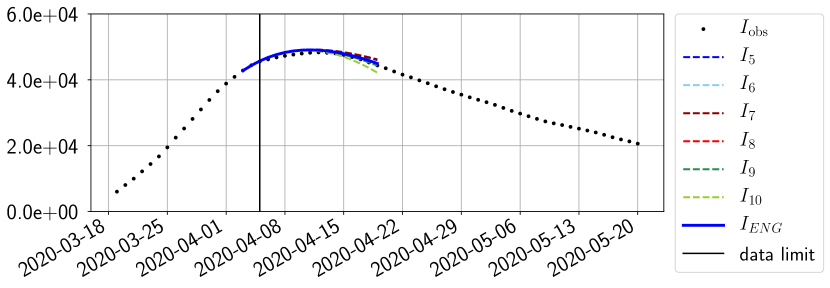
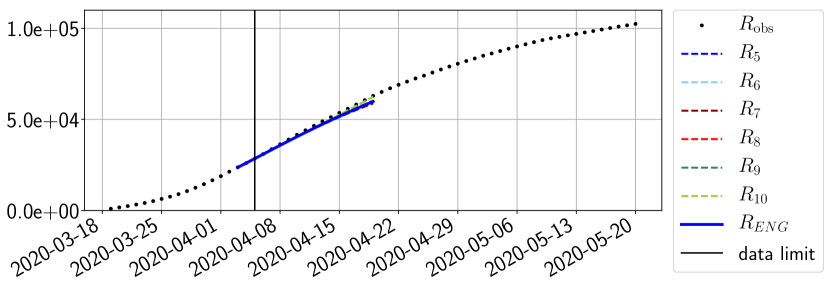
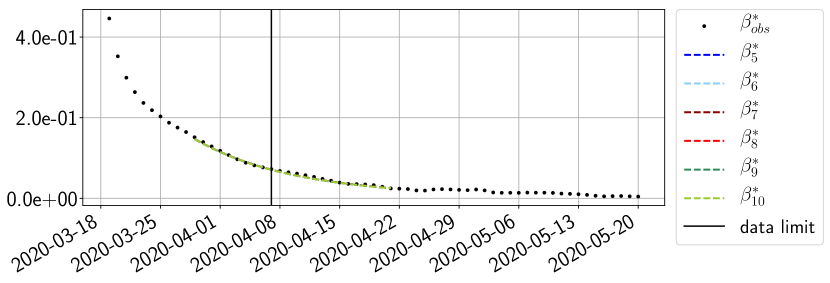
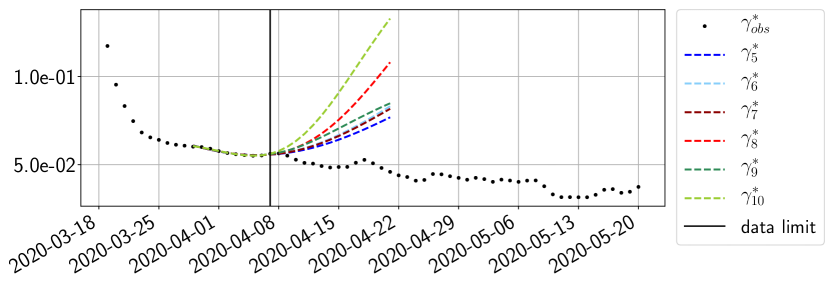
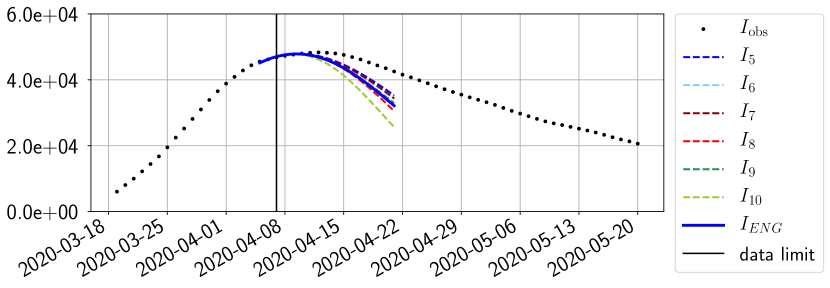
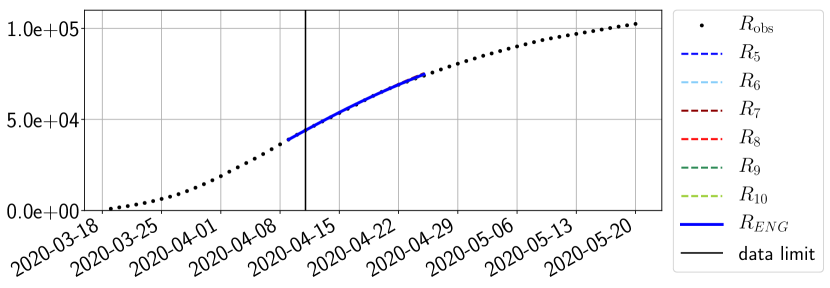
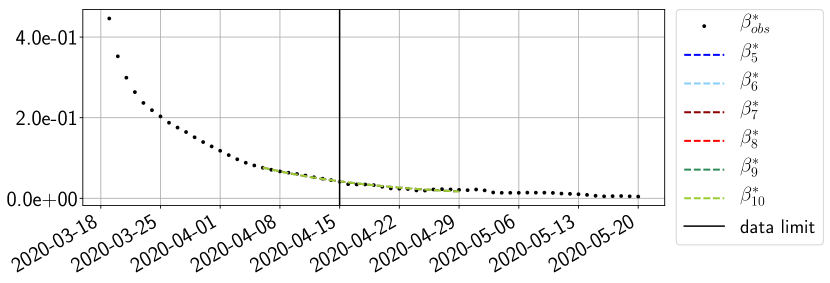
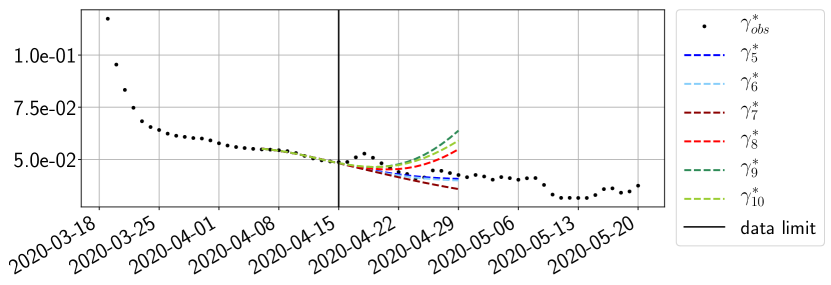
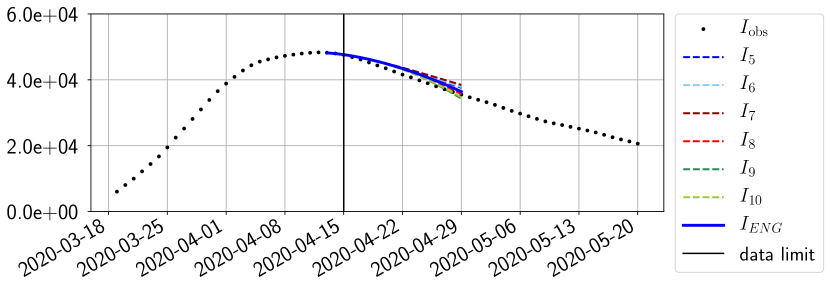
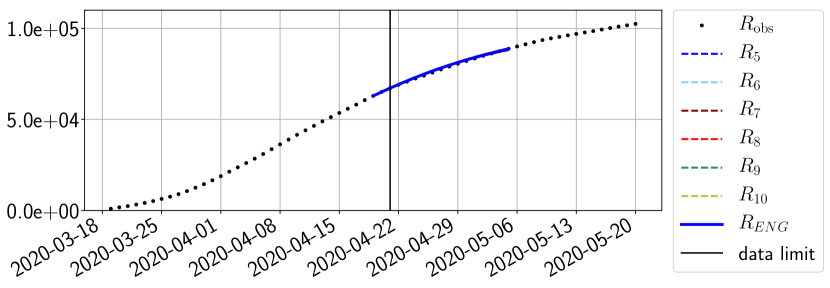
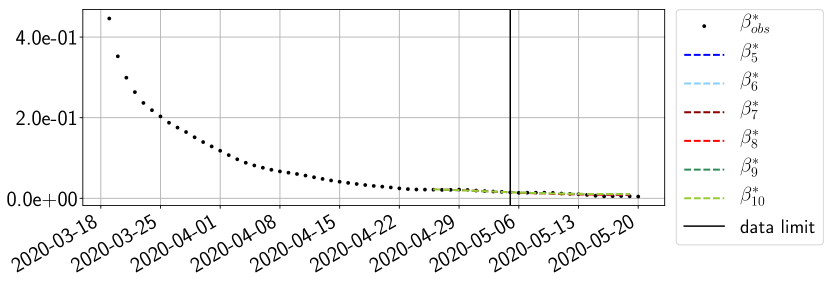
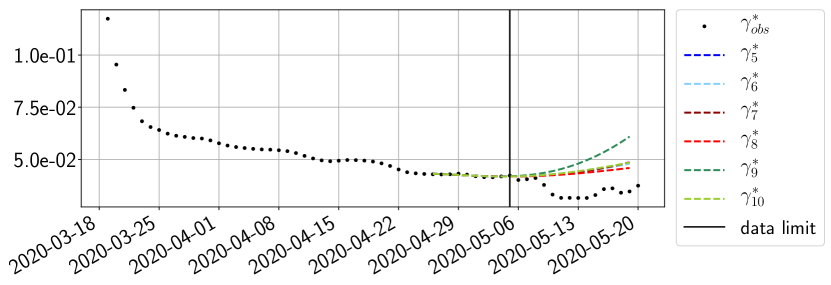
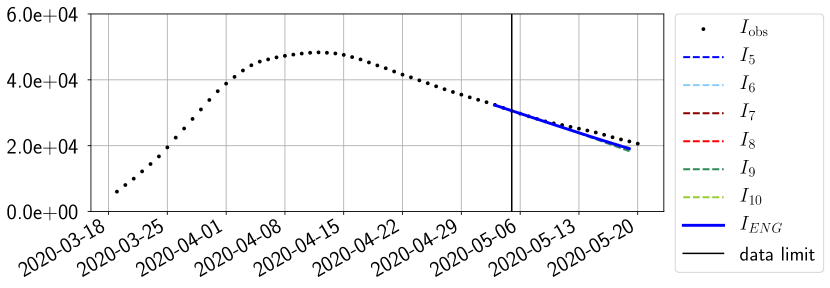
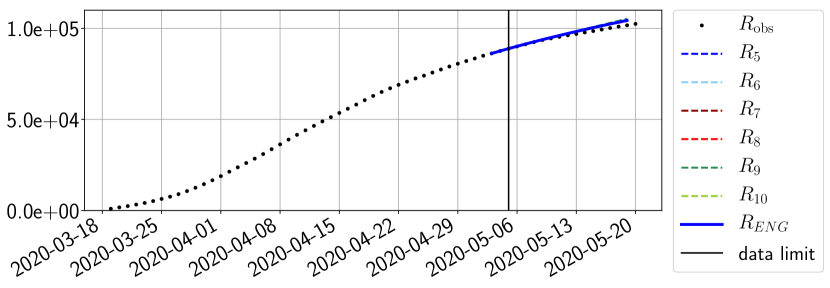
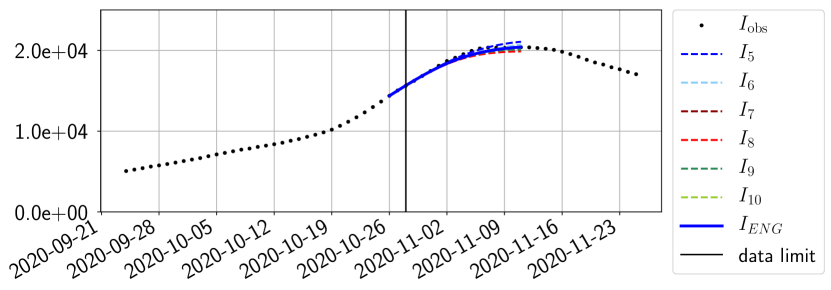
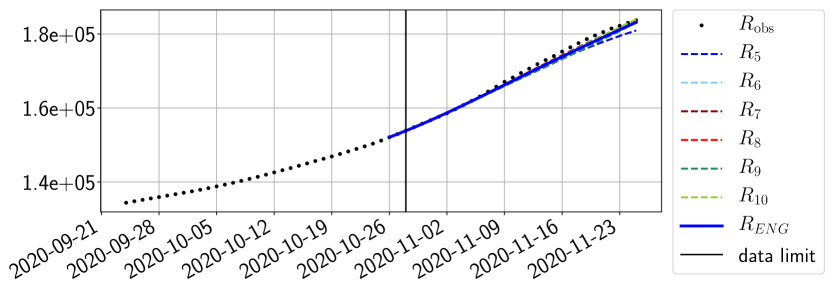
4.2.3 Forecasting of the second wave with ENG
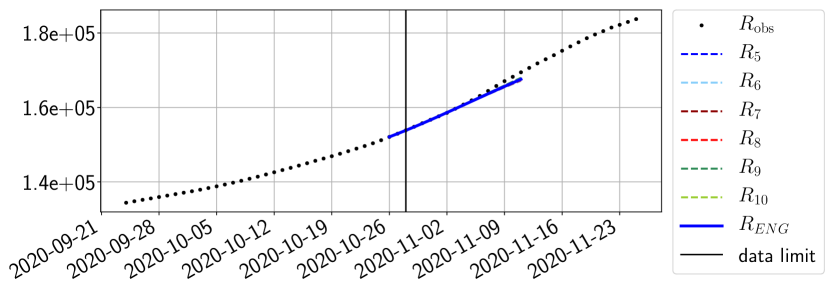
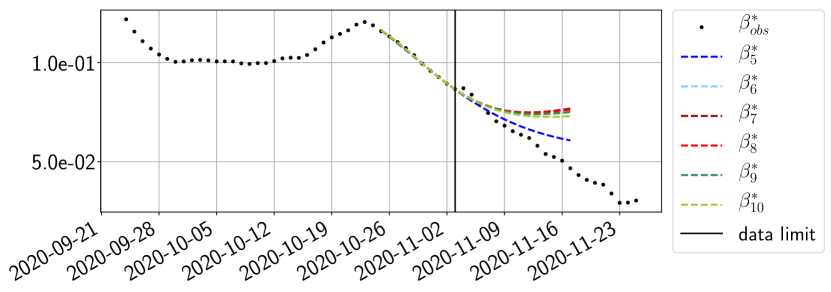
The review of the present paper took place during the month of November 2020 while the second COVID-19 pandemic wave hit France. We have taken the chance to enlarge the body of numerical results and we provide some example forecasts with ENG on this wave in figures 24 to 26. As the figures illustrate, the method provides very satisfactory forecasts on a 14 day ahead window. We again observe a satisfactory prediction of the second peak (figures 24, 25 and 26) and the same difficulty in forecasting due to the oscillations in but this has not greatly impacted on the quality of the forecasts for and .
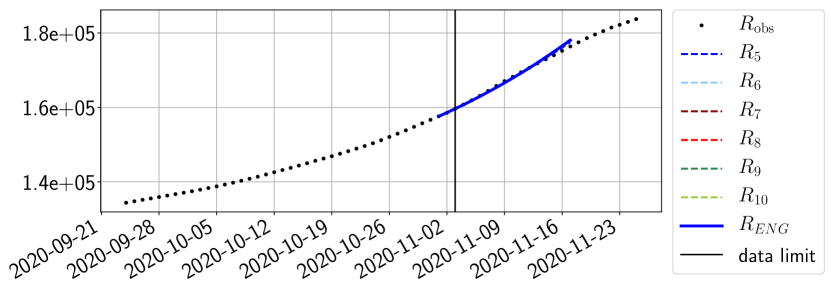
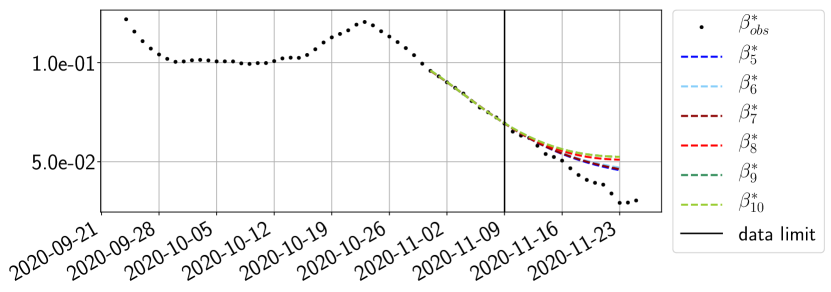
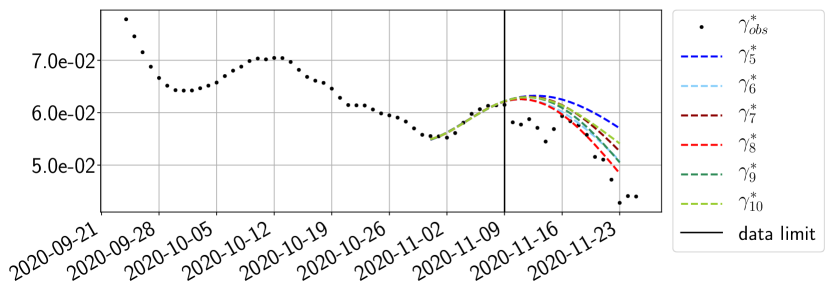
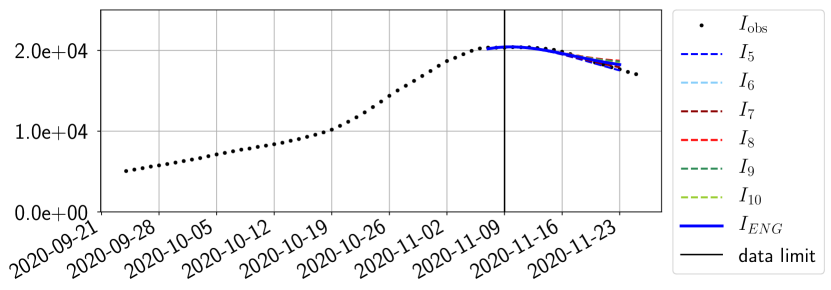
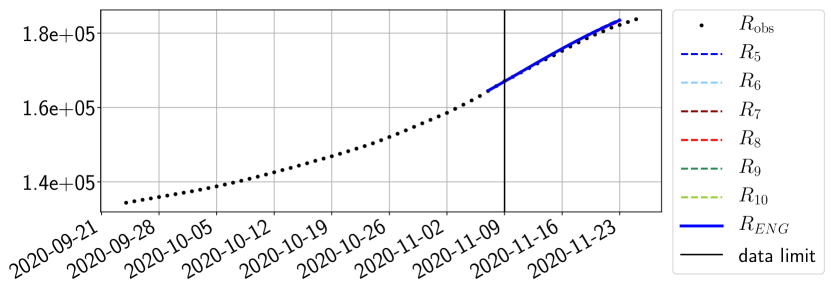
4.2.4 Forecasts with ENG on a 28-day-ahead window
To conclude this results section, we extend the forecasting window to 28 days instead of 14 and study whether the introduced ENG method still provides satisfactory forecasts. As shown in figures 27 to 32), the results of the methods are quite stable for large windows. This shows that in contrast to standard extrapolation methods using classical linear or affine regressions, the reduced basis catches the dynamics of and not only locally but also at extended time intervals.
5 Conclusion
We have developed an epidemiological forecasting method based on reduced modeling techniques. Among the different strategies that have been explored, the one that outperforms the rest in terms of robustness and forecasting power involves reduced models that are built with an Enlarged Nonnegative Greedy (ENG) strategy. This method is novel and of interest in itself since it allows to build reduced models that preserve positivity and even other types of bounds. Despite that ENG does not have optimal fitting properties (i.e. interpolation properties), it is well suited for forecasting since, due to the preservation of the natural constraints of the coefficients, it generates realistic dynamics with few modes. The results have been presented for a mono-regional test case, and we plan to extend the present methodology to a multi-regional setting using mobility data.
Last but not least, we would like to emphasize that the developed strategy is very general, and could be applied to the forecasting of other types of dynamics. The specificity of each problem may however require adjustments in the reduced models. This is exemplified in the present problem through the construction of reduced models that preserve positivity.
Acknowledgments and disclosure of funding
We would like to thank our colleagues from the “Face au virus” initiative in PSL University: Jamal Atif, Laurent Massoulié, Olivier Cappé, and Akin Kazakcy. We also thank Gabriel Turinici for his feedback on the multiregional models. Part of this research has been supported by the Emergences project grant “Models and Measures” of the Paris city council, by the generous donation made available by Alkan together with the complementary funding given by the Sorbonne University Foundation. This research is done in the frame of the project Pandemia/Covidia and also the GIS Obepine, both projects aiming at a better understanding of the Covid-19 pandemic.
Appendix A Analysis of model error and observation noise
In this section we study the impact of observation noise and model error in the quality and behavior of the fitting step. The elements that impact the accuracy of our procedure are the following:
-
1.
Observation noise: The observed health data and presents several sources of noise: there may be some inaccuracies in the reporting of cases, and the data are then post-processed. This eventually yields to noisy time series and for which it is difficult to estimate the uncertainty. These noisy data are then used to produce (through finite differences) and which are in turn also noisy.
-
2.
Model errors: Two types of model errors are identified
-
(a)
Intrinsic model error on and : The families of detailed models that we use are rich but they may not cover all possible evolutions of and . In other words, our manifolds and may not perfectly cover the real epidemiological evolution. Such error motivated the introduction of the exponential functions and described in Section 2.4.
-
(b)
Sampling error of and : The size of the training sets and and the dimension of the reduced models and also limit the approximation capabilities of the continuous target sets and
-
(a)
In this section, we aim at disentangling these effects in order to give a better insight of the fitting error behavior on the real data.
A.1 Study of the impact of the sampling error: Fitting a virtual scenario
Our set of virtual epidemiological dynamics is . After the collapsing step, the manifolds for and are and . These sets are potentially infinite and we have used finite training subsets and to build the reduced models and .
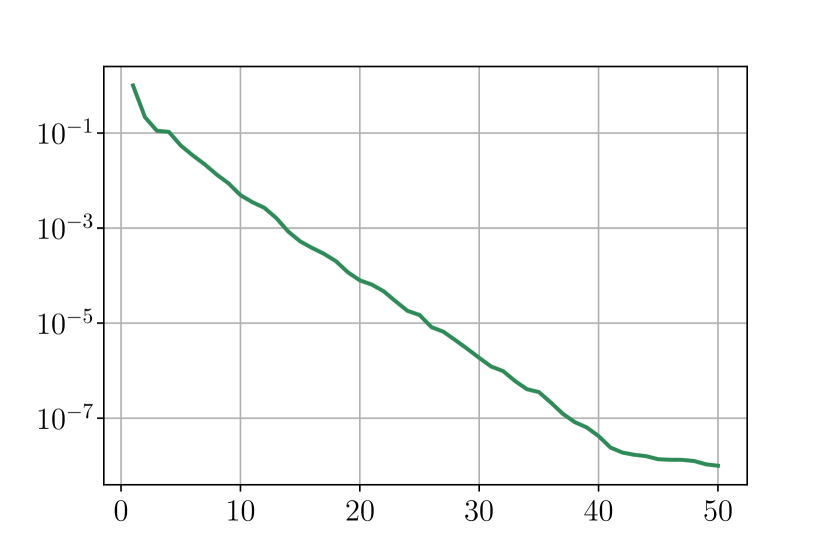
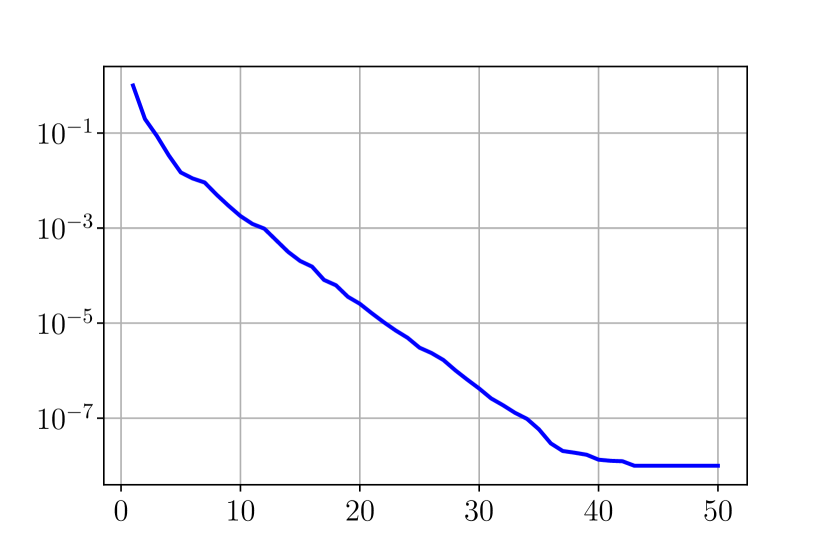
First we look at the eigenvalues for and when performing an SVD decomposition for the virtual scenarios. Figure 33 shows a rapid decay of the eigenvalues obtained by SVD decomposition, it shows that we can obtain a very good approximation of elements of and with only a few modes.
Among the sources of noise and model error given at the beginning of Appendix A, we can study the impact of the sampling error (point 2-b) as follows. For this, we start by examining the fitting error on an interval of days for two functions and which belong to the manifold and and are in the training sets and . This error will serve as a benchmark that we will use to compare fitting errors of functions that are not in the training sets.
Figure 34 shows relative fitting errors and using SVD, NMF and ENG reduced bases with , where the notation denotes the mean of the quantity over . We observe that for SVD the fitting errors behave similarly as the error decay of the training step (Figure 33).
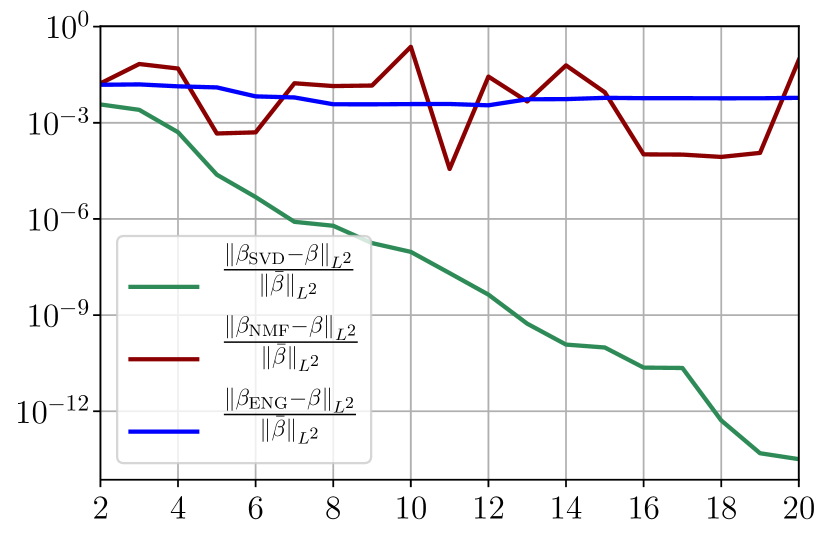
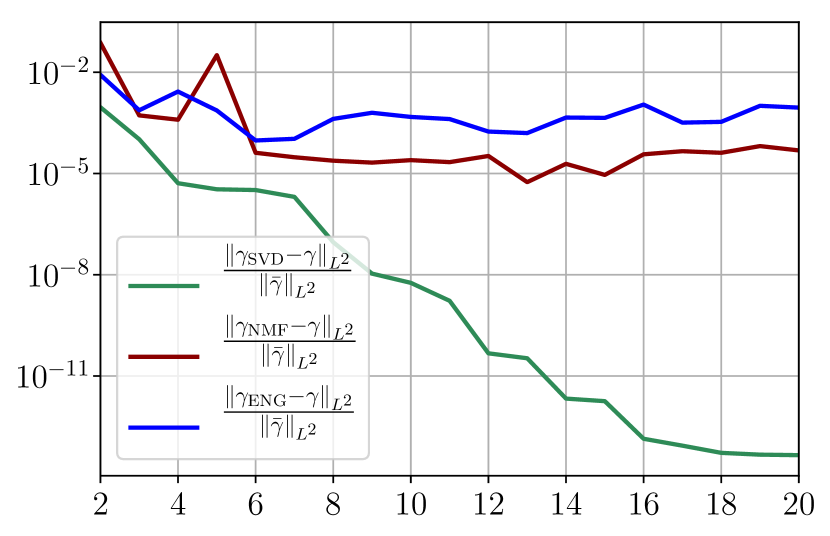
Figure 35 shows the and errors obtained after the propagation of the fittings of and . In both metrics, the error for I and R obtained using SVD is decreasing below . When the NMF and the ENG are used, the error decreases and stagnates at for both I and R.
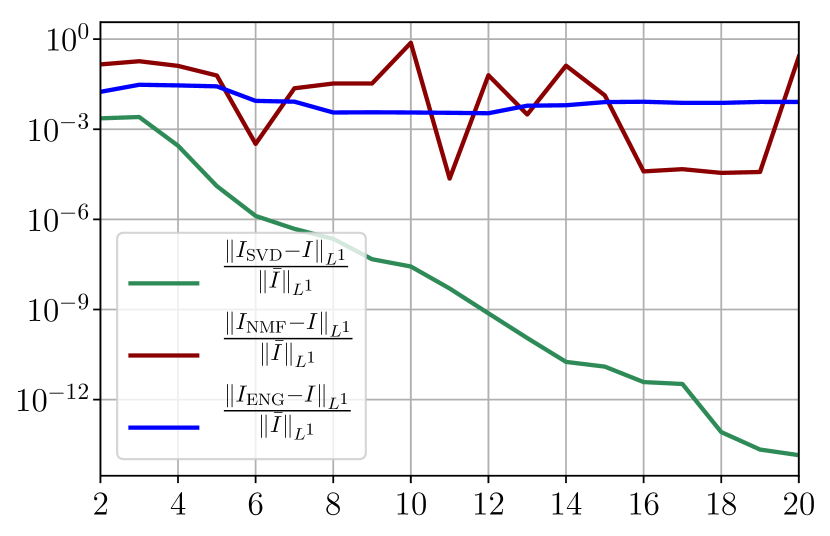
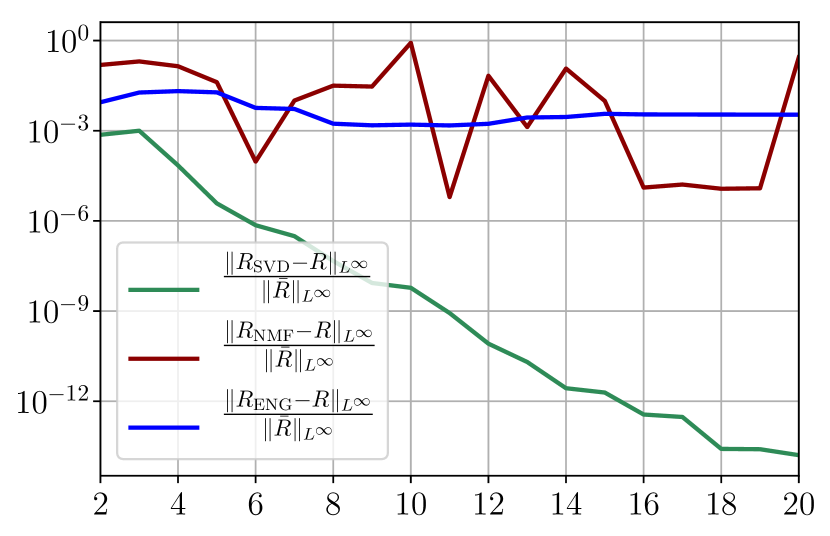
Now we consider the fitting error for two functions and which belong to the manifold and but which are not in the training sets and . Figure 36 shows the fitting error on the virtual scenario considered using SVD, NMF and ENG reduced bases for . We note that the quality of the fittings by each method is very similar to that of Figure 35 where the functions were taken in the training sets. This illustrates that the sampling error is not playing a major role in our experiments.
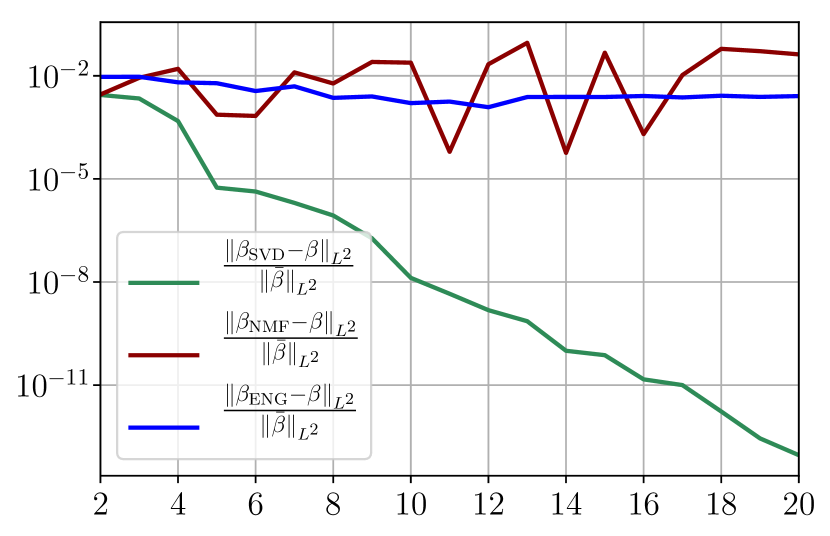
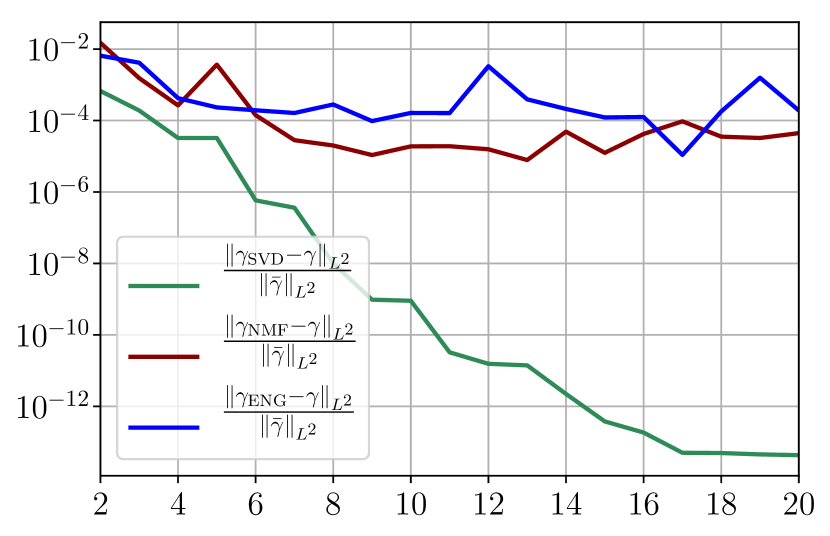
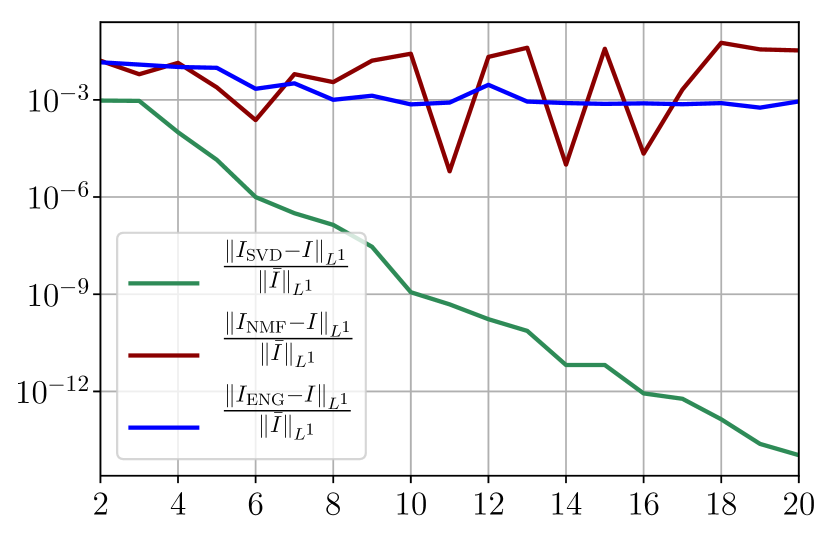
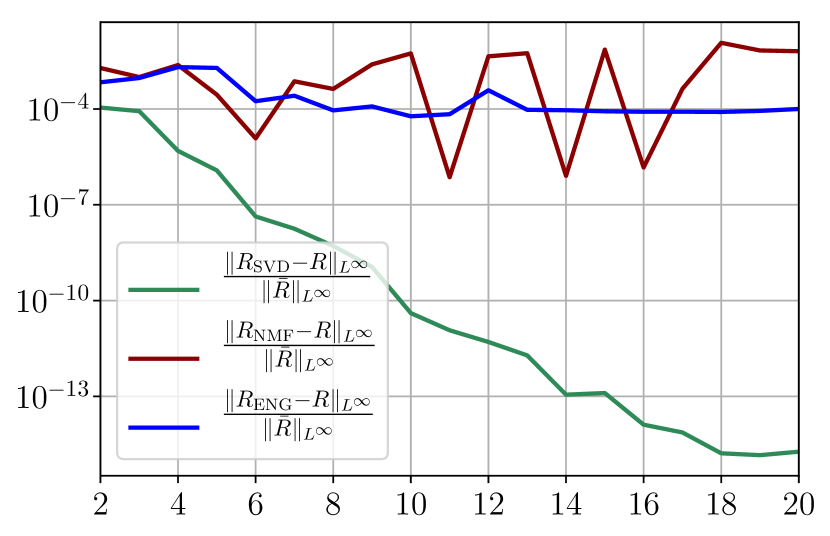
Figure 37 shows the and errors obtained after the propagation of the fittings of and . In both metrics, the error for I and R obtained using SVD is decreasing to each . When the NMF and the ENG are used, the error decreases and stagnates respectively at and for both I and R.
A.2 Study of the impact of noisy data and intrinsic model error
To investigate the impact of noise in the observed data, we now add noise to the two previously chosen functions and , and we study the fitting error on this noisy data. The level of the noise has been chosen to be of the same level as the one estimated for the real dynamics. In order to estimate the noise we performed a fitting of the real data using SVD reduced bases, the level of noise is defined as the difference between this fitting and the real data. This level of noise is then added to the virtual scenario considered here. Figure 38 shows the fitting error on and using SVD, NMF and ENG reduced bases for .
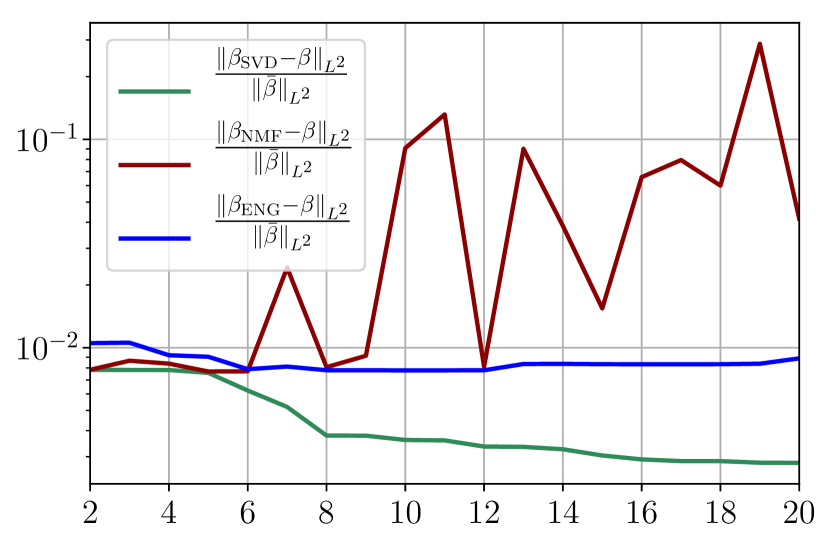
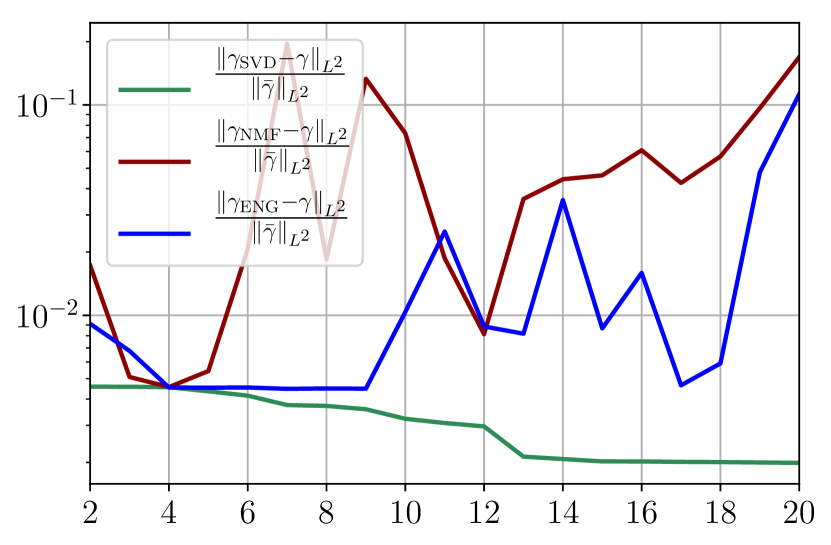
We observe that the noise strongly deteriorates the fitting error obtained using NMF, and the error becomes oscillatory and very unstable. For ENG, the error remains low and consistently around for . We observe the same behaviour for with instabilities arising for . For SVD the error is lower than in the ENG case and slowly decreases as increases. Figure 39 shows the and errors obtained after the propagation of the fittings of and . In line with the observations from Figure 38 the error obtained using NMF is very unstable. Using ENG, we observe a decay from to and oscillations that remain around for and for . The decay observed for SVD is slow and steady, the error nearly reaches for and for when .
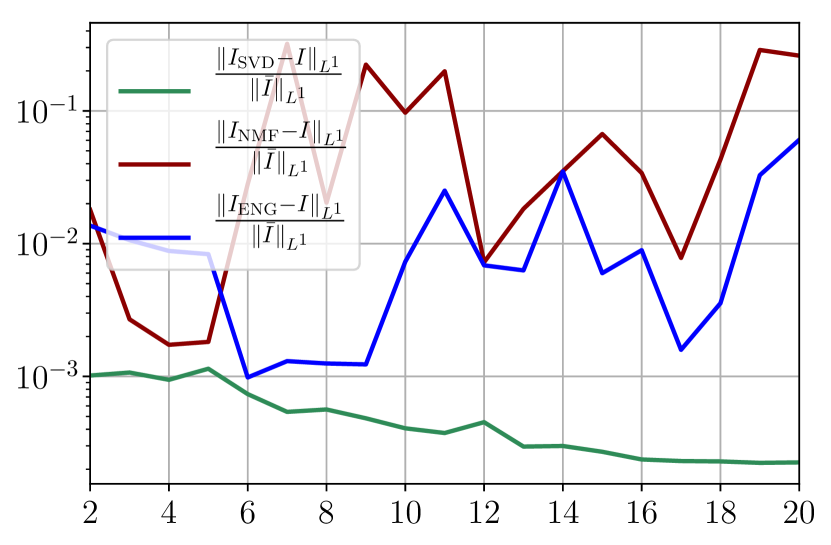
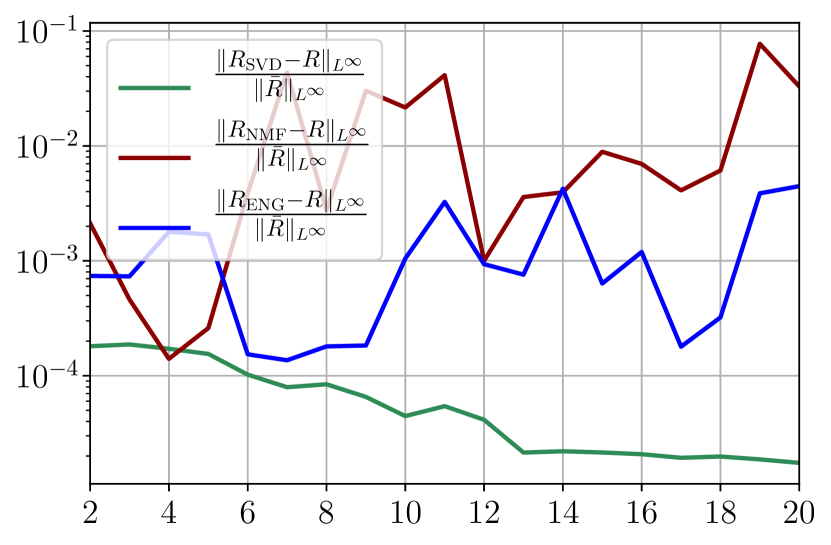
Finally, it remains to add intrinsic model error on top of the previous sampling error and observation noise. If we do so, the main change is that the previous fitting error plots from Figure 38 have essentially the same behavior but the error values are increased depending on the degree of model inaccuracy. We have therefore disentangled all the effects of model error and noisy data, and all the observations from this section give thus a better insight of the fitting on the real data.
Figure 40 summarizes the fitting results for an example fitting period taken from to . Figures 40(a) and 40(b) show the fitting error on and using SVD, NMF and ENG reduced bases for . Figures 40(c) and 40(d) show the and relative errors on and after the propagation of the fittings of and .
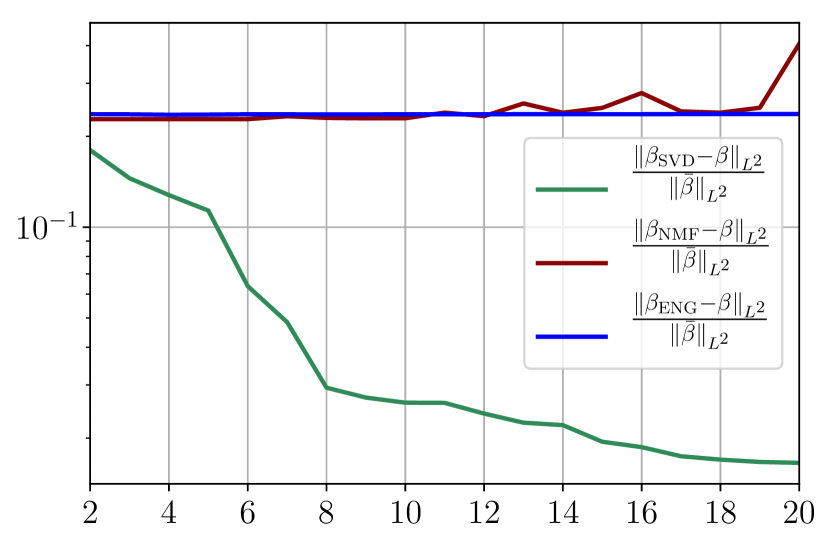
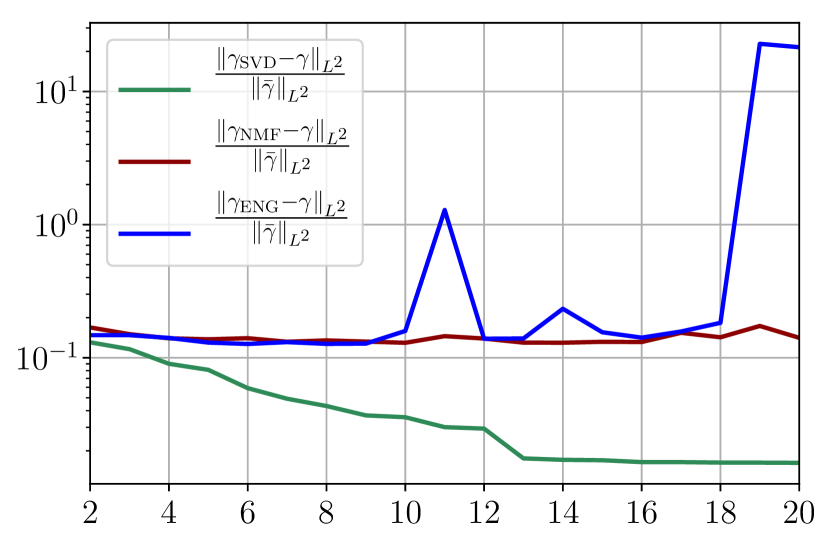
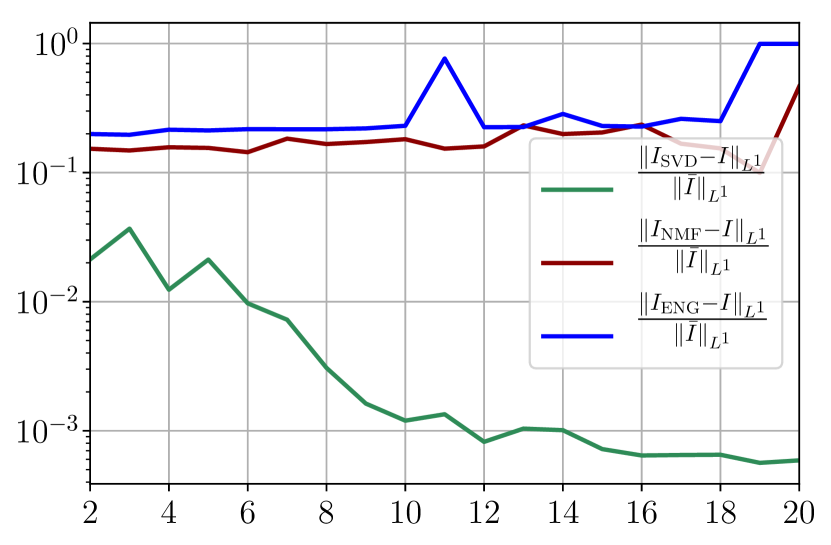
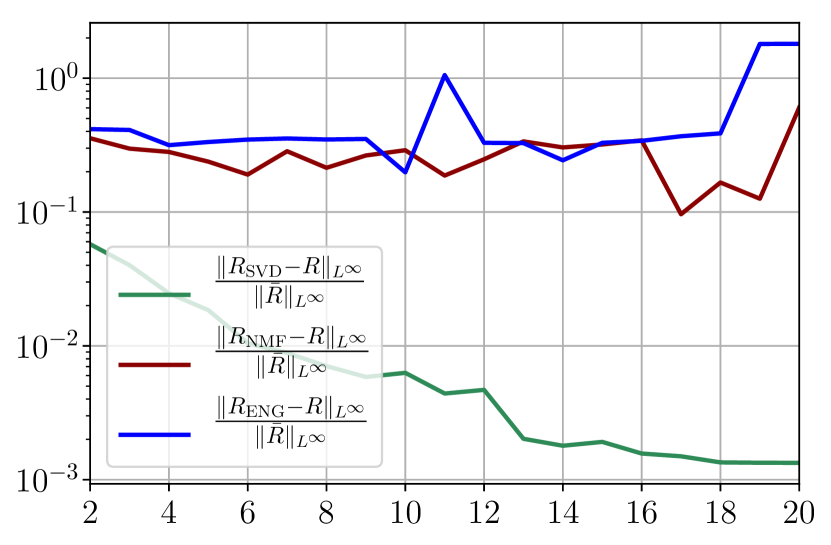
From figures 40(a) and 40(b), we observe that the fitting error with SVD decreases at a moderate rate as the dimension of the reduced basis is increased. The error with NMF and ENG does not decrease and oscillates around certain constant error value of order . Note that this value is small and yields to small errors in the approximation of I and R as figures 40(c) and 40(d) illustrate.
Appendix B Study of forecasting errors
In this section we give a detailed study of the forecasting errors for each different fitting strategy (routine-IR, routine-), reduced model (SVD, NMF, ENG) and starting date . We anticipate the main conclusion which we already announced in Section 4.2.1: ENG fitted with routine- outperforms the other reduced models and is the most robust and accurate reduced model to use in a forecasting strategy. Figure 41 shows the relative errors of a 14 days forecast from for each forecasting method and each reduced basis. Similarly figures 42 to 49 show forecasts relative errors respectively from different times.
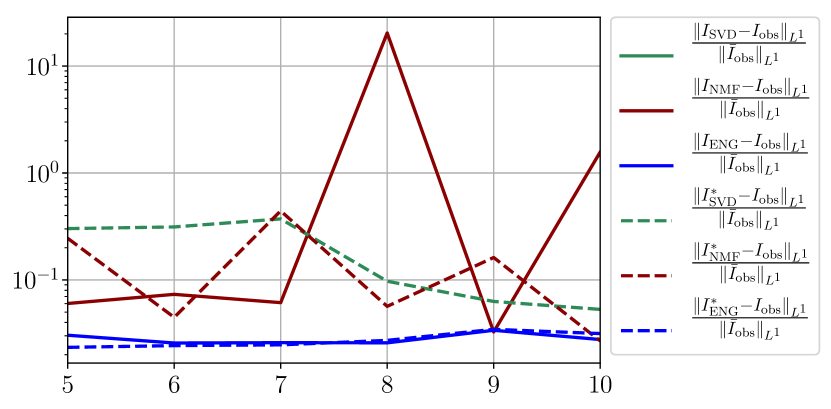
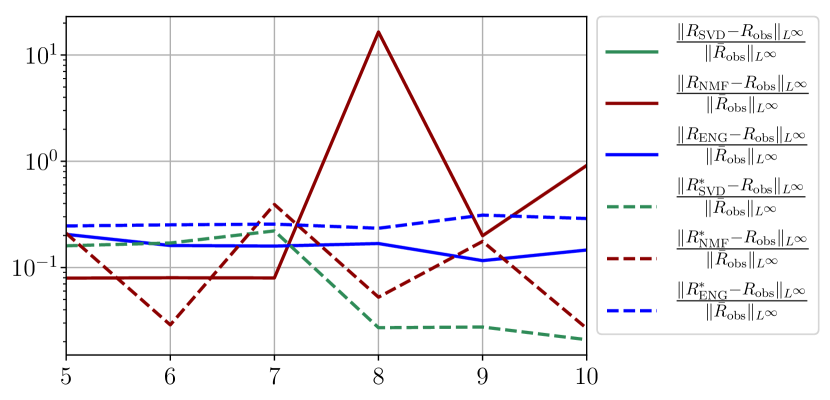
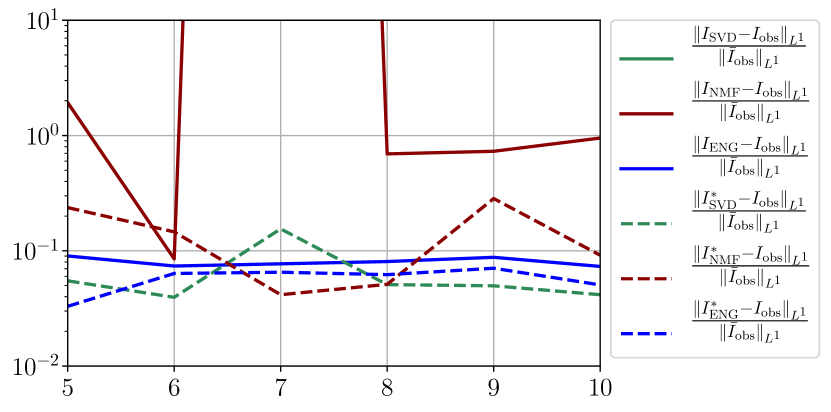
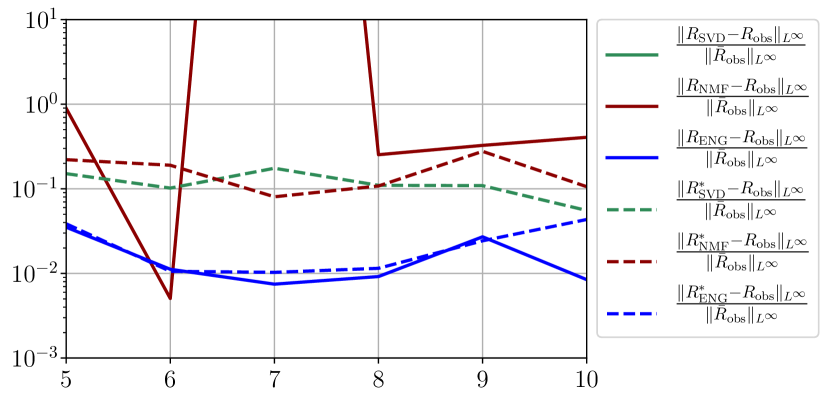
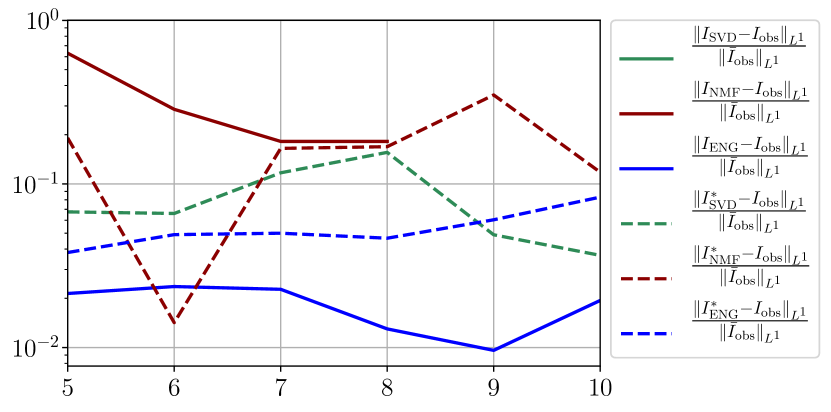
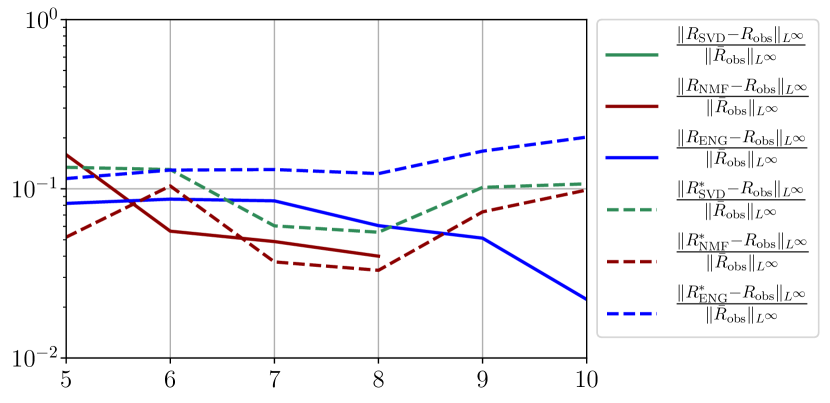
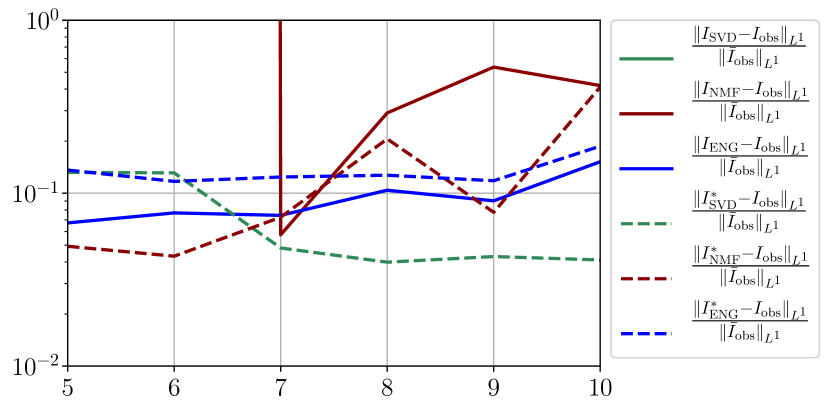
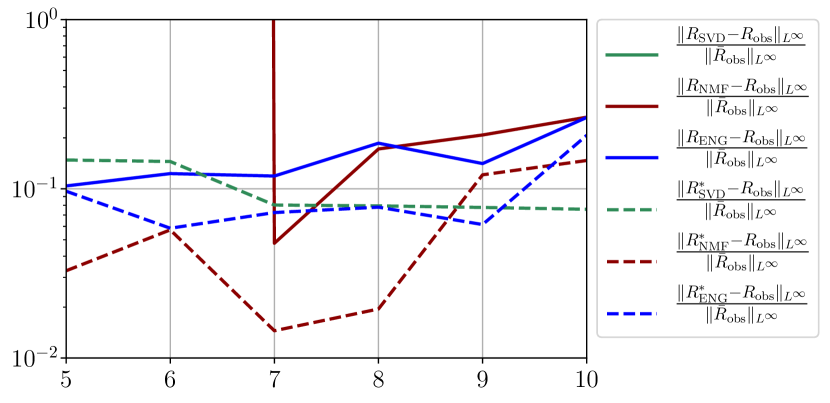
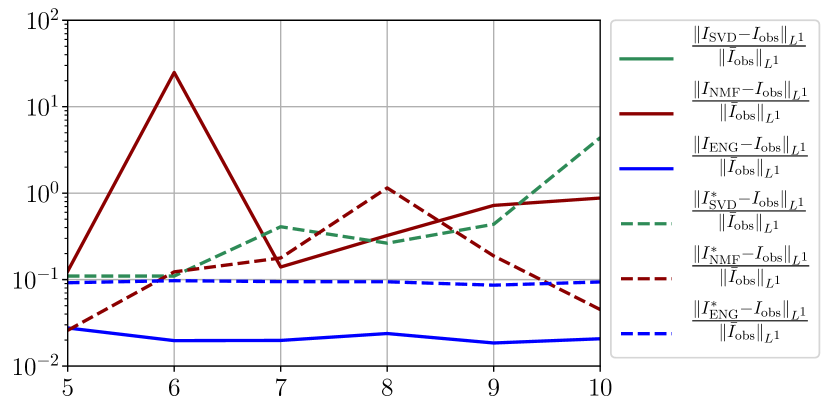
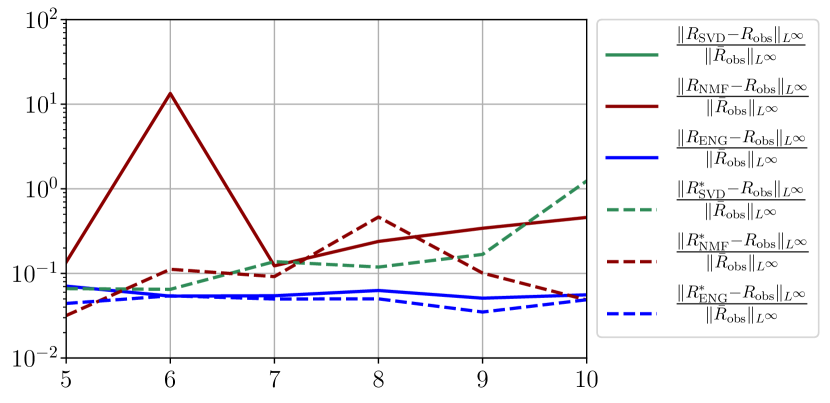
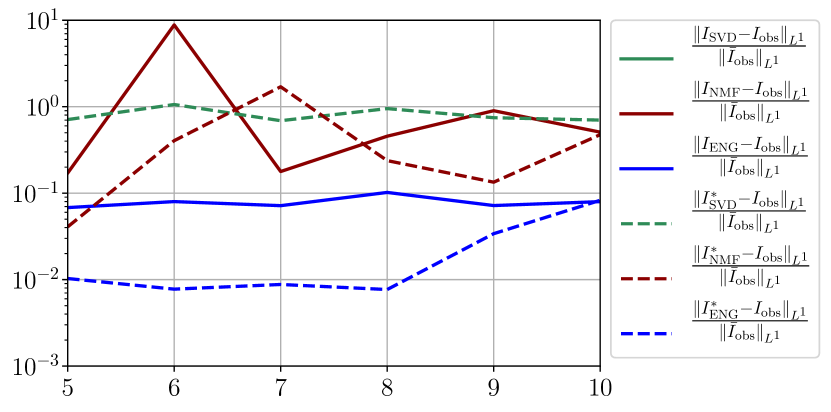
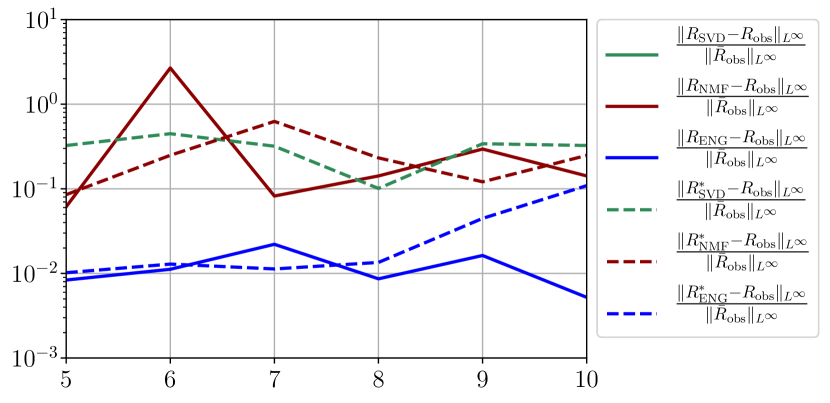
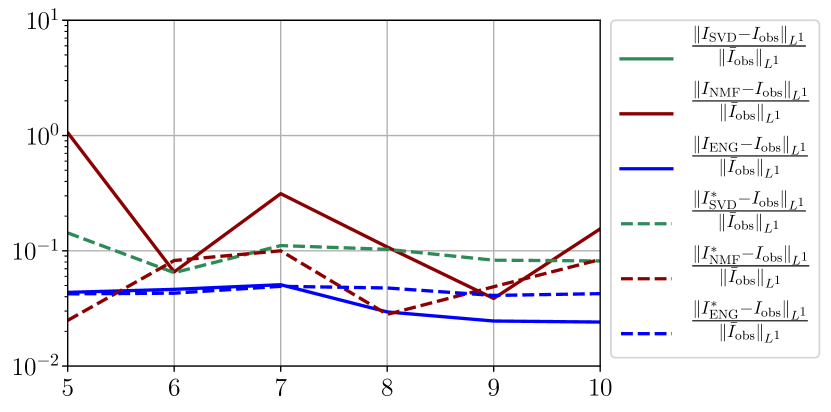
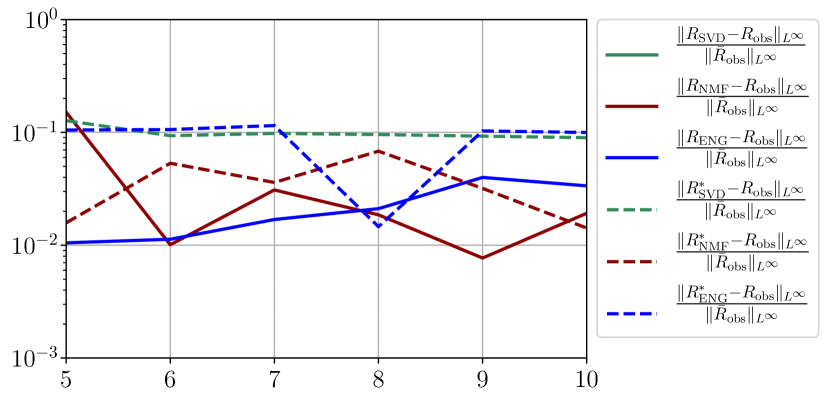
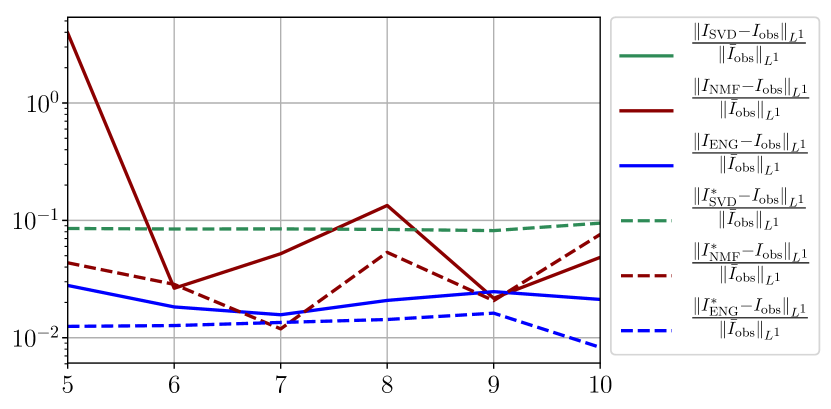
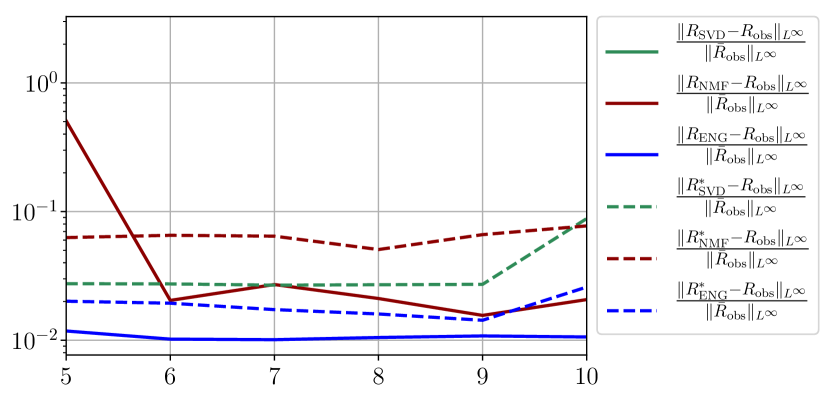
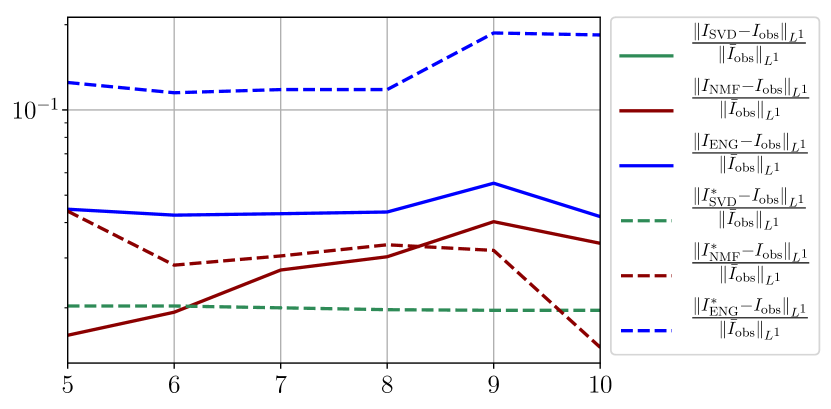
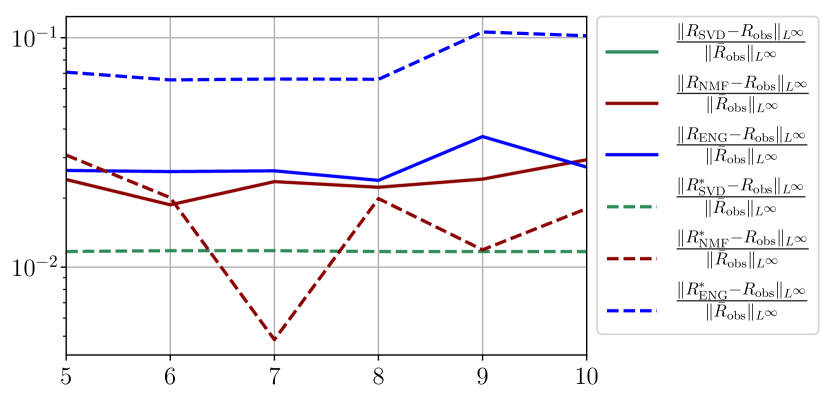
We observe that the quality of the forecast depends on the reduced basis but also strongly on the starting day from which the forecast is done. The forecasts using routine- with SVD and NMF are not accurate and most of the time exploding. When routine-IR is used with SVD and NMF, the forecasts are more robust as there is no explosion of the error observed. Reduced bases from ENG consistently lead to the the best forecast obtained using either routine- and routine-IR; by inspecting the error on figures 41 to 49 and the averaged forecasts obtained in Section 4.2.1 we conclude that routine- with ENG reduced bases provide slightly better forecasts.
References
- [1] Anastassopoulou, C., Russo, L., Tsakris, A. and Siettos, C. Data-based analysis, modelling and forecasting of the COVID-19 outbreak. PloS one, 15(3), p. e0230405, 2020.
- [2] Armocida, B., Formenti, B., Ussai, S., Palestra, F. and Missoni, E. The Italian health system and the COVID-19 challenge. The Lancet Public Health, 5(5), p. e253, 2020.
- [3] Atif, J., Cappé, O., Kazakçi, A., Léo, Y., Massoulié, L. and Mula, O. Initiative face au virus Observations sur la mobilité pendant l’épidémie de Covid-19. Technical report, PSL University, May 2020. URL https://hal.archives-ouvertes.fr/hal-02921194.
- [4] Benner, P., Cohen, A., Ohlberger, M. and Willcox, K. Model Reduction and Approximation: Theory and Algorithms, volume 15. SIAM, 2017.
- [5] Binev, P., Cohen, A., Dahmen, W., DeVore, R., Petrova, G. and Wojtaszczyk, P. Convergence Rates for Greedy Algorithms in Reduced Basis Methods. SIAM Journal on Mathematical Analysis, 43(3), pp. 1457–1472, 2011. URL http://dx.doi.org/10.1137/100795772.
- [6] Brauer, F. Mathematical epidemiology: Past, present, and future. Infectious Disease Modelling, 2(2), pp. 113–127, 2017.
- [7] Ceylan, Z. Estimation of COVID-19 prevalence in Italy, Spain, and France. Science of The Total Environment, p. 138817, 2020.
- [8] Cohen, A. and DeVore, R. Kolmogorov widths under holomorphic mappings. IMA Journal of Numerical Analysis, 36(1), pp. 1–12, 2016. URL http://dx.doi.org/10.1093/imanum/dru066.
- [9] DeVore, R., Petrova, G. and Wojtaszczyk, P. Greedy algorithms for reduced bases in Banach spaces. Constructive Approximation, 37(3), pp. 455–466, 2013.
- [10] Di Domenico, L., Pullano, G., Sabbatini, C. E., Boëlle, P.-Y. and Colizza, V. Expected impact of lockdown in Île-de-France and possible exit strategies. medRxiv, 2020.
- [11] Fang, X., Liu, W., Ai, J., He, M., Wu, Y., Shi, Y., Shen, W. and Bao, C. Forecasting incidence of infectious diarrhea using random forest in Jiangsu Province, China. BMC Infectious Diseases, 20(1), pp. 1–8, 2020.
- [12] Ferguson, N., Laydon, D., Nedjati Gilani, G., Imai, N., Ainslie, K., Baguelin, M., Bhatia, S., Boonyasiri, A., Cucunuba Perez, Z., Cuomo-Dannenburg, G. et al. Report 9: Impact of non-pharmaceutical interventions (NPIs) to reduce COVID19 mortality and healthcare demand. 2020. URL https://www.if.ufrgs.br/if/wp-content/uploads/Imperial-College-COVID19-NPI-modelling-16-03-2020.pdf.
- [13] Flaxman, S., Mishra, S., Gandy, A., Unwin, H. J. T., Mellan, T. A., Coupland, H., Whittaker, C., Zhu, H., Berah, T., Eaton, J. W. et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature, 584(7820), pp. 257–261, 2020.
- [14] Gillis, N. The why and how of nonnegative matrix factorization. Regularization, optimization, kernels, and support vector machines, 12(257), pp. 257–291, 2014.
- [15] Hesthaven, J. S., Rozza, G. and Stamm, B. Certified reduced basis methods for parametrized partial differential equations, volume 590. Springer, 2016.
- [16] Keeling, M. J. and Rohani, P. Modeling infectious diseases in humans and animals. Princeton University Press, 2011.
- [17] Kermack, W. O., McKendrick, A. G. and Walker, G. T. A contribution to the mathematical theory of epidemics. Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character, 115(772), pp. 700–721, 1927. URL http://dx.doi.org/10.1098/rspa.1927.0118.
- [18] Liu, Z., Magal, P., Seydi, O. and Webb, G. A COVID-19 epidemic model with latency period. Infectious Disease Modelling, 5, pp. 323–337, 2020.
- [19] Liu, Z., Magal, P., Seydi, O. and Webb, G. Predicting the cumulative number of cases for the COVID-19 epidemic in China from early data. arXiv preprint arXiv:2002.12298, 2020.
- [20] Maday, Y., Mula, O. and Turinici, G. Convergence analysis of the Generalized Empirical Interpolation Method. SIAM Journal on Numerical Analysis, 54(3), pp. 1713–1731, 2016. URL http://dx.doi.org/10.1137/140978843.
- [21] Maday, Y. and Patera, A. Reduced basis methods. In P. Benner, S. Grivet-Talocia, A. Quarteroni, G. Rozza, W. Schilders and L. Silveira (editors), Model Order Reduction, chapter 4, pp. 139–179. De Gruyter, Oxford, 16 Dec. 2020.
- [22] Magal, P. and Webb, G. Predicting the number of reported and unreported cases for the COVID-19 epidemic in South Korea, Italy, France and Germany. Medrxiv, 2020. URL https://doi.org/10.1101/2020.03.21.20040154.
- [23] Martcheva, M. An introduction to mathematical epidemiology, volume 61. Springer, 2015.
- [24] Mizumoto, K., Kagaya, K., Zarebski, A. and Chowell, G. Estimating the asymptomatic proportion of coronavirus disease 2019 (COVID-19) cases on board the Diamond Princess cruise ship, Yokohama, Japan, 2020. Eurosurveillance, 25(10), p. 2000180, 2020.
- [25] Paatero, P. and Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics, 5(2), pp. 111–126, 1994. URL https://doi.org/10.1002/env.3170050203.
- [26] Poncela, P., Rodríguez, J., Sánchez-Mangas, R. and Senra, E. Forecast combination through dimension reduction techniques. International Journal of Forecasting, 27(2), pp. 224–237, April 2011. URL https://ideas.repec.org/a/eee/intfor/v27yi2p224-237.html.
- [27] Quarteroni, A., Manzoni, A. and Negri, F. Reduced basis methods for partial differential equations: an introduction, volume 92. Springer, 2015.
- [28] Roda, W. C., Varughese, M. B., Han, D. and Li, M. Y. Why is it difficult to accurately predict the COVID-19 epidemic? Infectious Disease Modelling, 2020.
- [29] Roques, L., Klein, E. K., Papaïx, J., Sar, A. and Soubeyrand, S. Impact of Lockdown on the Epidemic Dynamics of COVID-19 in France. Frontiers in Medicine, 7, p. 274, 2020.