EqvAfford: SE(3) Equivariance for Point-Level Affordance Learning
Abstract
Humans perceive and interact with the world with the awareness of equivariance, facilitating us in manipulating different objects in diverse poses. For robotic manipulation, such equivariance also exists in many scenarios. For example, no matter what the pose of a drawer is (translation, rotation and tilt), the manipulation strategy is consistent (grasp the handle and pull in a line). While traditional models usually do not have the awareness of equivariance for robotic manipulation, which might result in more data for training and poor performance in novel object poses, we propose our EqvAfford framework, with novel designs to guarantee the equivariance in point-level affordance learning for downstream robotic manipulation, with great performance and generalization ability on representative tasks on objects in diverse poses.
1 Introduction
Symmetry is a fundamental aspect of our physical world, readily apparent in how we perceive and interact with the world. In this work, we focus on object manipulation tasks with certain spatial symmetry, where the manipulation strategy is equivariant to the object’s 6D pose. This kind of spatial symmetry is called SE(3) Equivariance, where SE(3) is a group consists of 3D translation and rotation.
We humans can naturally recognize and exploit SE(3) equivariance in object manipulation tasks. For example, the method of opening a drawer, pulling on its handle in a vertical direction, is intuitively understood to be effective regardless of the drawer’s position, orientation, or tilt. However, the understanding of SE(3) equivariance poses a significant challenge for neural networks. Considering training a neural network to identify the grasp point on a drawer’s point cloud, if the point cloud is rotated and translated, the model’s output could be highly different, while the manipulation point and strategy should be consistent. This case underscores the limitations of data-driven approaches that lack an understanding of the physical world, leading to weak generalization across varied initial conditions. In this work, we develop a perception system designed to deduce potential affordance, which includes both the location of interaction and the manner of manipulation, by leveraging SE(3) equivariance to bolster the model’s generalization ability.
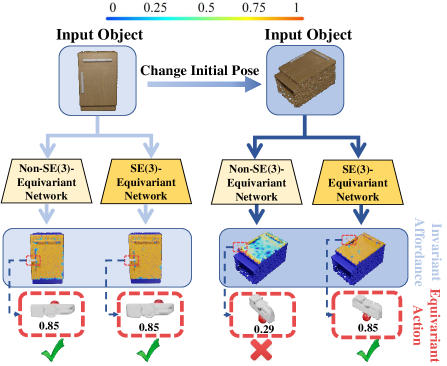
Object manipulation stands as a pivotal area of research in robotics, where a key challenge lies in identifying the optimal interaction points (i.e., affordable point that indicates where to interact with) and executing appropriate actions (how to interact). We discover that a large portion of object manipulation tasks exhibit SE(3) equivariance. Notably, for tasks where the interaction is independent of the object’s absolute spatial pose, leveraging equivariance can significantly help. In the case of the drawer opening task, the optimal strategy remains consistent regardless of the drawer’s rotation: grasp the handle and exert a vertical pull outwards. Therefore, we propose a framework that leverages SE(3) equivariance to predict per-point affordance and downstream manipulation strategy on each point, with theoretical guarantees and great performance.
In summary, our main contributions are:
-
•
We propose to leverage the inherent equivariance for point-level affordance learning and downstream robotic manipulation tasks;
-
•
We propose a framework with novel designs and multiple modules that can infer affordance for object manipulation with the theoretical guarantee of equivariance;
-
•
Experiments show the superiority of our framework on manipulating objects with diverse and novel object poses.
2 Related Work
2.1 Learning Affordance for Robotic Manipulation
For manipulation, it’s crucial to find suitable interaction points. Gibson proposed affordance – interaction opportunity. They leveraged observations as demonstrations, like videos showing agents interacting with scenarios, and trained models to learn what and how to interact. This kind of method has been used to learn possible contact locations[1] or grasp patterns[6]. However, using passive observations to learn possible interactions suffers from distribution shifts. [17] proposed an approach learning from interactions to obtain more informative samples for articulated object manipulation[10, 8]. Recent works expanded affordance to more diverse scenarios and tasks, such as articulated object manipulation [35, 25, 5], deformable object manipulation [16, 30, 28], clutter manipulation [14], bimanual manipulation [36], and zero-shot generalization to novel shapes [11, 12].
2.2 Leveraging SE(3) Equivariant Representations for Robot Manipulation
Many works focused on building SE(3) equivariant representations from 3D inputs[2, 3, 13, 18, 26, 21, 34, 15, 20]. to enable robust generalizations to out-of-distribution inputs by ensuring inherent equivariance. This allows the model to automatically generalize to inputs at novel 6D poses, without implementing strong data augmentation. Prior works have applied equivariant representations on diverse robot manipulation tasks [32, 22, 23, 29, 33, 24, 7, 9, 4, 19]. This work studies leveraging SE(3) equivariance for point-level affordance learning and thus complete articulated object manipulation.
3 Problem Formulation
We tackle 3D articulated object manipulation tasks. Given a point cloud of a 3D articulated object ( a cabinet with drawers and doors), our model predicts where and how to interact with the object. We define 6 types of short-term primitive actions like pushing or pulling, which are parameterized by the 6D pose of the robot gripper. For each primitive action, we predict the following features for each visible point of the 3D articulated object.
-
•
An affordances score , measuring how likely the point should be interacted with in the specific task.
-
•
A 6D pose to interact with the point .
-
•
A success likelihood score for an action proposal .
The affordance score should be invariant while the proposed 6D posed should be equivariant for any SE(3) transformation applied on the object. For example, “pulling drawer” task, if the cabinet is rotated or translated, the , which means how likely the point will be interacted with, should remain invariant. Because no matter how the cabinet is placed, the correct way to open the drawer is always to interact with the handle. And the 6D interaction pose needs to change corresponding to the pose change of the cabinet.
4 Method
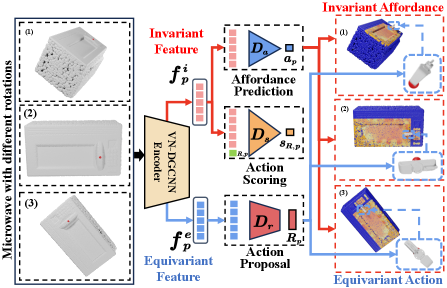
4.1 Network Designs
As shown in Fig.2, our framework consists of four modules: VN-DGCNN Encoder, Affordance Prediction Module, Action Proposal Module, and Action Scoring Module.
The VN-DGCNN Encoder is the first encoder of objects with invariant and equivariant features.
During inference, the Affordance Prediction Module predicts the point-level affordance score (whether an point is actionable for the task) and thus selects the manipulation point with the highest affordance score, the Action Proposal Module proposes many candidate actions of the gripper, and the Action Scoring Module rates the proposed actions and then selects the best action for manipulation.
During training, we first collect diverse interactions with corresponding interaction results to train the Action Scoring Module and Action Proposal Module, and the Affordance Prediction Module is then trained to aggregate the average scores rated by Action Scoring Module of actions proposed by Action Proposal Module.
SE(3) Equivariant Encoder. For each point of the input point cloud, we extract a SE(3) invariant feature and a SE(3) equivariant feature . Here we use the VN-DGCNN segment network [2] to extract the features. Denote the number of points in the input point cloud as , length of feature as . As [2] use vectors to represent neurons, . For each point in the input point cloud , we have
| (1) | ||||
| (2) |
When point cloud transformed by , we have
| (3) | ||||
| (4) |
Affordance Prediction Module. Our affordance prediction module, similar to Where2Act[17], is a MLP. It takes the SE(3) invariant feature of each point and outputs a per-point affordance . As the input is invariant to any translation and rotation, the affordance is SE(3) invariant. This means regardless of the position and orientation of the input object, we should always prefer to interact with the same part of the object (such as handle when opening a drawer). Formally,
| (5) |
Action Pose Proposal Module. For each point , it takes the SE(3) equivariant feature as input. We employ VN-DGCNN classification network[2] to implement this module, which is equivariant to any SE(3) transformation. The network predicts a gripper end-effector pose as a rotation matrix, which is equivariant to the input point cloud.
| (6) |
Action Scoring Module. For a proposed interaction orientation at point , we use a MLP to evaluate a success likelihood for this interaction. This score can be used to filter low-rated proposals or select the proposals that are more likely to succeed. Given a invariant feature of point , and a proposed interaction orientation , this module outputs a scalar. Namely,
| (7) |
At test time, the interaction is positive when . Due to the page limit, more details of point-level affordance designs can be found in [17, 27].
4.2 Data Collection
Following [17], we adopt a learning-from-interaction method to collect training data. In the SAPIEN[31] simulator, we place a random articulated object at the center of the scene and use a flying parallel gripper to interact with the object on a specific point and orientation . We tackle six types of primitive action and pre-program a short trajectory for each primitive action. When is specified, we can try different pre-programmed short trajectories to interact with the object.
We use both online and offline methods to collect training data. In offline collection, we randomly choose an object and load it into the simulator. We then sample an interaction point and an interaction orientation and roll out to see whether the gripper can complete the task.
As offline data collection is inefficient, we also add online adaptive data collection. When training the action scoring module with data pair , we infer the score predictions for all points on the articulated object. Then we sample a point with highest score to conduct an addition interaction with point and orientation .
4.3 Training and Losses
Our loss function is a combination of following three terms.
Action Scoring Loss. For a batch of data points , where is the ground-truth interaction result( for positive, for negative). We train the action scoring module with the standard binary cross-entropy loss.
Action Proposal Loss. For a batch of data points , we train the action pose proposal module on positive data pieces by calculating the geodesic distance between the predicted orientation with the ground truth orientation .
Affordance Prediction Loss. We technically train the affordance prediction module by supervising the expected success rate when executing a random orientation proposed by . Instead of rolling out this proposal in the simulator, we directly use the action scoring module to evaluate whether an interaction is successful.
5 Experiment
We use SAPIEN [31] simulator with realistic physical engine to evaluate our framework, and compare with Where2Act [17], with its same setting for fair comparison.
We select 15 object categories in the PartNet-Mobility dataset [31] to conduct our experiments and report the quantitative results on four commonly seen tasks: pushing and pulling doors and drawers. We train our method and baseline over training shapes and report performance over test shapes from the training categories and shapes from the test categories to test the generalization capabilities over novel shapes and unseen categories

| Where2Act | EqvAfford | |||
|---|---|---|---|---|
| z | SO(3) | z | SO(3) | |
| Pushing Door | 86.55 / 80.42 | 56.74 / 53.44 | 86.49 / 81.03 | 86.79 / 81.55 |
| Pulling Door | 64.29 / 59.87 | 56.39 / 51.82 | 63.81 / 58.55 | 65.70 / 62.65 |
| Pushing Drawer | 86.49 / 86.99 | 58.31 / 48.49 | 87.89 / 87.09 | 88.81 / 87.76 |
| Pulling Drawer | 67.05 / 60.35 | 58.83 / 52.15 | 67.74 / 61.01 | 68.22 / 61.96 |
| Where2Act | EqvAfford | |||
|---|---|---|---|---|
| z | SO(3) | z | SO(3) | |
| Pushing Door | 83.91 / 81.49 | 38.44 / 37.78 | 83.84 / 82.80 | 85.51 / 83.96 |
| Pulling Door | 62.76 / 57.28 | 11.95 / 11.77 | 62.06 / 56.98 | 62.78 / 59.23 |
| Pushing Drawer | 78.39 / 74.89 | 35.37 / 29.45 | 79.58 / 76.02 | 80.16 / 77.10 |
| Pulling Drawer | 68.26 / 64.45 | 12.65 / 12.26 | 68.88 / 65.96 | 69.16 / 67.10 |
Results and Analysis. To demonstrate our method keeps the inherent equivariance, we designed two test settings, and . Where stands for placing objects on an aligned orientation and generates novel with rotations only along the z-axis, and for arbitrary rotations. Table 1 and 2 provide quantitative analysis comparing our method to the Where2Act baseline, revealing that EqvAfford stands out as the most effective in both affordance learning and downstream robotic manipulation. In table 1, Our method adeptly captures invariant geometric features, outperforming Where2Act, whose features fluctuate with rotational poses. And we visualize the predicted action scores in Fig 3, where we can see that given Objects with different poses, our method learns to extract invariant geometric features that are action-equivariant. In contrast, the baseline models fail to achieve a comparable level of performance. Table 2 further underscores our superiority by showcasing the higher task success rates in manipulating articulated objects. At Last, our model exhibits enhanced generalization, effectively adapting to unseen novel object categories beyond the baseline models.
6 Conclusion
We propose a novel framework, EqvAfford, leveraging SE(3) equivariance for affordance learning and downstream robotic manipulation with novel designs to theoretically guarantee equivariance. Predicting per-point SE(3) Invariant affordance and Equivariant interaction orientation, our method generalizes well to diverse object poses. Experiments on affordance learning and robotic manipulation showcases our method qualitatively and quantitatively.
References
- Brahmbhatt et al. [2019] Samarth Brahmbhatt, Cusuh Ham, Charles C Kemp, and James Hays. Contactdb: Analyzing and predicting grasp contact via thermal imaging. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8709–8719, 2019.
- Deng et al. [2021] Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, and Leonidas J Guibas. Vector neurons: A general framework for so (3)-equivariant networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12200–12209, 2021.
- Fuchs et al. [2020] Fabian Fuchs, Daniel Worrall, Volker Fischer, and Max Welling. Se (3)-transformers: 3d roto-translation equivariant attention networks. Advances in neural information processing systems, 33:1970–1981, 2020.
- Gao et al. [2024] Chongkai Gao, Zhengrong Xue, Shuying Deng, Tianhai Liang, Siqi Yang, Lin Shao, and Huazhe Xu. Riemann: Near real-time se(3)-equivariant robot manipulation without point cloud segmentation, 2024.
- Geng et al. [2024] Haoran Geng, Songlin Wei, Congyue Deng, Bokui Shen, He Wang, and Leonidas Guibas. Sage: Bridging semantic and actionable parts for generalizable manipulation of articulated objects, 2024.
- Hamer et al. [2010] Henning Hamer, Juergen Gall, Thibaut Weise, and Luc Van Gool. An object-dependent hand pose prior from sparse training data. In CVPR, 2010.
- Hu et al. [2024] Boce Hu, Xupeng Zhu, Dian Wang, Zihao Dong, Haojie Huang, Chenghao Wang, Robin Walters, and Robert Platt. Orbitgrasp: -equivariant grasp learning, 2024.
- Hu et al. [2017] Ruizhen Hu, Wenchao Li, Oliver Van Kaick, Ariel Shamir, Hao Zhang, and Hui Huang. Learning to predict part mobility from a single static snapshot. ACM Transactions on Graphics (TOG), 36(6):1–13, 2017.
- Huang et al. [2022] Haojie Huang, Dian Wang, Xupeng Zhu, Robin Walters, and Robert Platt. Edge grasp network: A graph-based se(3)-invariant approach to grasp detection, 2022.
- Jain et al. [2021] Ajinkya Jain, Rudolf Lioutikov, Caleb Chuck, and Scott Niekum. Screwnet: Category-independent articulation model estimation from depth images using screw theory. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13670–13677. IEEE, 2021.
- Ju et al. [2024] Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Mingrun Jiang, and Huazhe Xu. Robo-abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation. ECCV 2024, 2024.
- Kuang et al. [2024] Yuxuan Kuang, Junjie Ye, Haoran Geng, Jiageng Mao, Congyue Deng, Leonidas Guibas, He Wang, and Yue Wang. Ram: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation, 2024.
- Lei et al. [2023] Jiahui Lei, Congyue Deng, Karl Schmeckpeper, Leonidas Guibas, and Kostas Daniilidis. Efem: Equivariant neural field expectation maximization for 3d object segmentation without scene supervision. In CVPR, 2023.
- Li et al. [2024] Yitong Li, Ruihai Wu, Haoran Lu, Chuanruo Ning, Yan Shen, Guanqi Zhan, and Hao Dong. Broadcasting support relations recursively from local dynamics for object retrieval in clutters. In Robotics: Science and Systems, 2024.
- Liu et al. [2023] Yunze Liu, Junyu Chen, Zekai Zhang, Jingwei Huang, and Li Yi. Leaf: Learning frames for 4d point cloud sequence understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 604–613, 2023.
- Lu et al. [2024] Haoran Lu, Yitong Li, Ruihai Wu, Chuanruo Ning, Yan Shen, and Hao Dong. Unigarment: A unified simulation and benchmark for garment manipulation. ICRA Workshop on Deformable Object Manipulation, 2024.
- Mo et al. [2021] Kaichun Mo, Leonidas J Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani. Where2act: From pixels to actions for articulated 3d objects. In ICCV, 2021.
- Ryu et al. [2023] Hyunwoo Ryu, Hong in Lee, Jeong-Hoon Lee, and Jongeun Choi. Equivariant descriptor fields: Se(3)-equivariant energy-based models for end-to-end visual robotic manipulation learning. In The Eleventh International Conference on Learning Representations, 2023.
- Ryu et al. [2024] Hyunwoo Ryu, Jiwoo Kim, Hyunseok An, Junwoo Chang, Joohwan Seo, Taehan Kim, Yubin Kim, Chaewon Hwang, Jongeun Choi, and Roberto Horowitz. Diffusion-edfs: Bi-equivariant denoising generative modeling on se(3) for visual robotic manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18007–18018, 2024.
- Scarpellini et al. [2024] Gianluca Scarpellini, Stefano Fiorini, Francesco Giuliari, Pietro Morerio, and Alessio Del Bue. Diffassemble: A unified graph-diffusion model for 2d and 3d reassembly, 2024.
- Seo et al. [2023] Joohwan Seo, Nikhil Potu Surya Prakash, Xiang Zhang, Changhao Wang, Jongeun Choi, Masayoshi Tomizuka, and Roberto Horowitz. Robot manipulation task learning by leveraging se (3) group invariance and equivariance. arXiv preprint arXiv:2308.14984, 2023.
- Simeonov et al. [2022] Anthony Simeonov, Yilun Du, Andrea Tagliasacchi, Joshua B Tenenbaum, Alberto Rodriguez, Pulkit Agrawal, and Vincent Sitzmann. Neural descriptor fields: Se (3)-equivariant object representations for manipulation. In 2022 International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2022.
- Simeonov et al. [2023] Anthony Simeonov, Yilun Du, Yen-Chen Lin, Alberto Rodriguez Garcia, Leslie Pack Kaelbling, Tomás Lozano-Pérez, and Pulkit Agrawal. Se (3)-equivariant relational rearrangement with neural descriptor fields. In Conference on Robot Learning, pages 835–846. PMLR, 2023.
- Wang et al. [2024a] Dian Wang, Stephen Hart, David Surovik, Tarik Kelestemur, Haojie Huang, Haibo Zhao, Mark Yeatman, Jiuguang Wang, Robin Walters, and Robert Platt. Equivariant diffusion policy, 2024a.
- Wang et al. [2024b] Junbo Wang, Wenhai Liu, Qiaojun Yu, Yang You, Liu Liu, Weiming Wang, and Cewu Lu. Rpmart: Towards robust perception and manipulation for articulated objects, 2024b.
- Weng et al. [2023] Thomas Weng, David Held, Franziska Meier, and Mustafa Mukadam. Neural grasp distance fields for robot manipulation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 1814–1821. IEEE, 2023.
- Wu et al. [2022] Ruihai Wu, Yan Zhao, Kaichun Mo, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas Guibas, and Hao Dong. Vat-mart: Learning visual action trajectory proposals for manipulating 3d articulated objects. ICLR, 2022.
- Wu et al. [2023a] Ruihai Wu, Chuanruo Ning, and Hao Dong. Learning foresightful dense visual affordance for deformable object manipulation. In IEEE International Conference on Computer Vision (ICCV), 2023a.
- Wu et al. [2023b] Ruihai Wu, Chenrui Tie, Yushi Du, Yan Zhao, and Hao Dong. Leveraging se (3) equivariance for learning 3d geometric shape assembly. In ICCV, 2023b.
- Wu et al. [2024] Ruihai Wu, Haoran Lu, Yiyan Wang, Yubo Wang, and Dong Hao. Unigarmentmanip: A unified framework for category-level garment manipulation via dense visual correspondence. CVPR, 2024.
- Xiang et al. [2020] Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive environment. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020.
- Xue et al. [2023] Zhengrong Xue, Zhecheng Yuan, Jiashun Wang, Xueqian Wang, Yang Gao, and Huazhe Xu. Useek: Unsupervised se (3)-equivariant 3d keypoints for generalizable manipulation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 1715–1722. IEEE, 2023.
- Yang et al. [2023] Jingyun Yang, Congyue Deng, Jimmy Wu, Rika Antonova, Leonidas Guibas, and Jeannette Bohg. Equivact: Sim (3)-equivariant visuomotor policies beyond rigid object manipulation. arXiv preprint arXiv:2310.16050, 2023.
- Yang et al. [2024] Jingyun Yang, Zi ang Cao, Congyue Deng, Rika Antonova, Shuran Song, and Jeannette Bohg. Equibot: Sim(3)-equivariant diffusion policy for generalizable and data efficient learning, 2024.
- Yuan et al. [2024] Chengbo Yuan, Chuan Wen, Tong Zhang, and Yang Gao. General flow as foundation affordance for scalable robot learning, 2024.
- Zhao et al. [2023] Yan Zhao, Ruihai Wu, Zhehuan Chen, Yourong Zhang, Qingnan Fan, Kaichun Mo, and Hao Dong. Dualafford: Learning collaborative visual affordance for dual-gripper manipulation. ICLR, 2023.