Estimating counterfactual treatment outcomes over time in complex multiagent scenarios
Abstract
Evaluation of intervention in a multiagent system, e.g., when humans should intervene in autonomous driving systems and when a player should pass to teammates for a good shot, is challenging in various engineering and scientific fields. Estimating the individual treatment effect (ITE) using counterfactual long-term prediction is practical to evaluate such interventions. However, most of the conventional frameworks did not consider the time-varying complex structure of multiagent relationships and covariate counterfactual prediction. This may lead to erroneous assessments of ITE and difficulty in interpretation. Here we propose an interpretable, counterfactual recurrent network in multiagent systems to estimate the effect of the intervention. Our model leverages graph variational recurrent neural networks and theory-based computation with domain knowledge for the ITE estimation framework based on long-term prediction of multiagent covariates and outcomes, which can confirm the circumstances under which the intervention is effective. On simulated models of an automated vehicle and biological agents with time-varying confounders, we show that our methods achieved lower estimation errors in counterfactual covariates and the most effective treatment timing than the baselines. Furthermore, using real basketball data, our methods performed realistic counterfactual predictions and evaluated the counterfactual passes in shot scenarios.
Index Terms:
multiagent modeling, causal inference, deep generative model, trajectory data, autonomous vehicle, sports.I Introduction
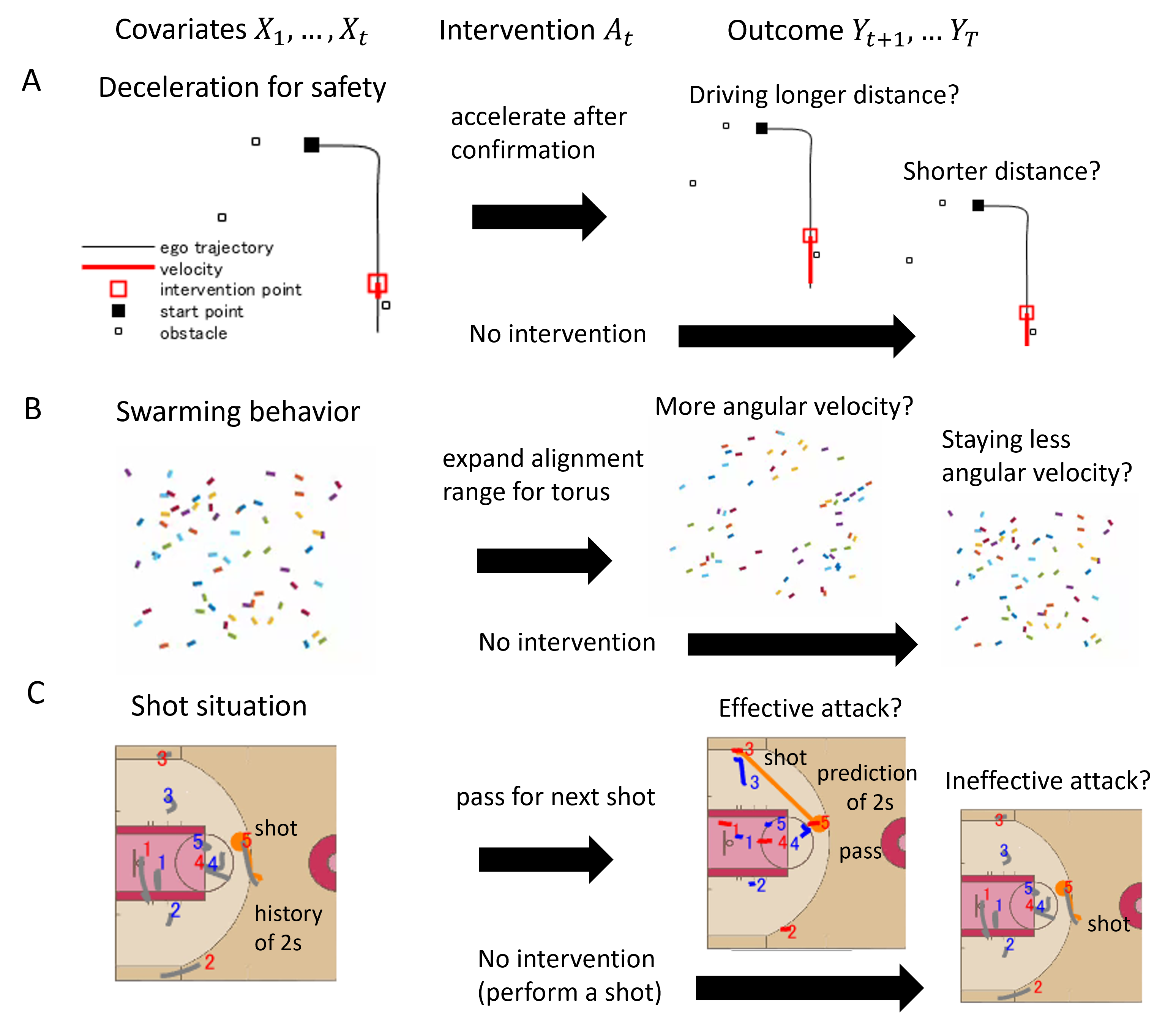
Evaluation of intervention in a real-world multiagent system is a fundamental problem in a variety of engineering and scientific fields. For example, a human driver in an autonomous vehicle, a player in team sports, and an experimenter on animals intervene in multiagent systems to obtain desirable results (e.g., safe driving, a good shot, and specific behavior, respectively) as shown in Fig. 1. In these processes and complex interactions between agents, it is often difficult to estimate the intervention (or treatment) effect to compare the outcomes with and without interventions. There have been many methods to estimate the individual treatment effect (ITE), which evaluates the causal effect of treatment strategies on some important outcomes at the individual level in various fields (e.g., [1, 2, 3]). In particular, some work has been proposed for dealing with time-varying [4, 5] and hidden confounders [6, 7, 8].
However, most of the conventional frameworks did not consider the time-varying complex structures of multiagent relationships and counterfactual covariate predictions, which may lead to erroneous assessments of ITE and difficulty of interpretation. The structures of multiagent relationships include bottom-up ones based on interactions between local agents (often represented as a graph), and top-down ones described by global statistics and/or theories with domain knowledge [9, 10]. Since real-world multiagent systems do not usually have explicit governing equations, both top-down and bottom-up approaches can be simultaneously required for the modeling [11, 12]. That is, in our problem, we need to model multiagent systems in both data-driven and theory-based approaches. In addition, for extracting insights from the ITE estimation results, the circumstances where intervention is effective must be analyzed. Therefore, plausible and interpretable modeling of time-varying multiagent systems is required for estimating ITE.
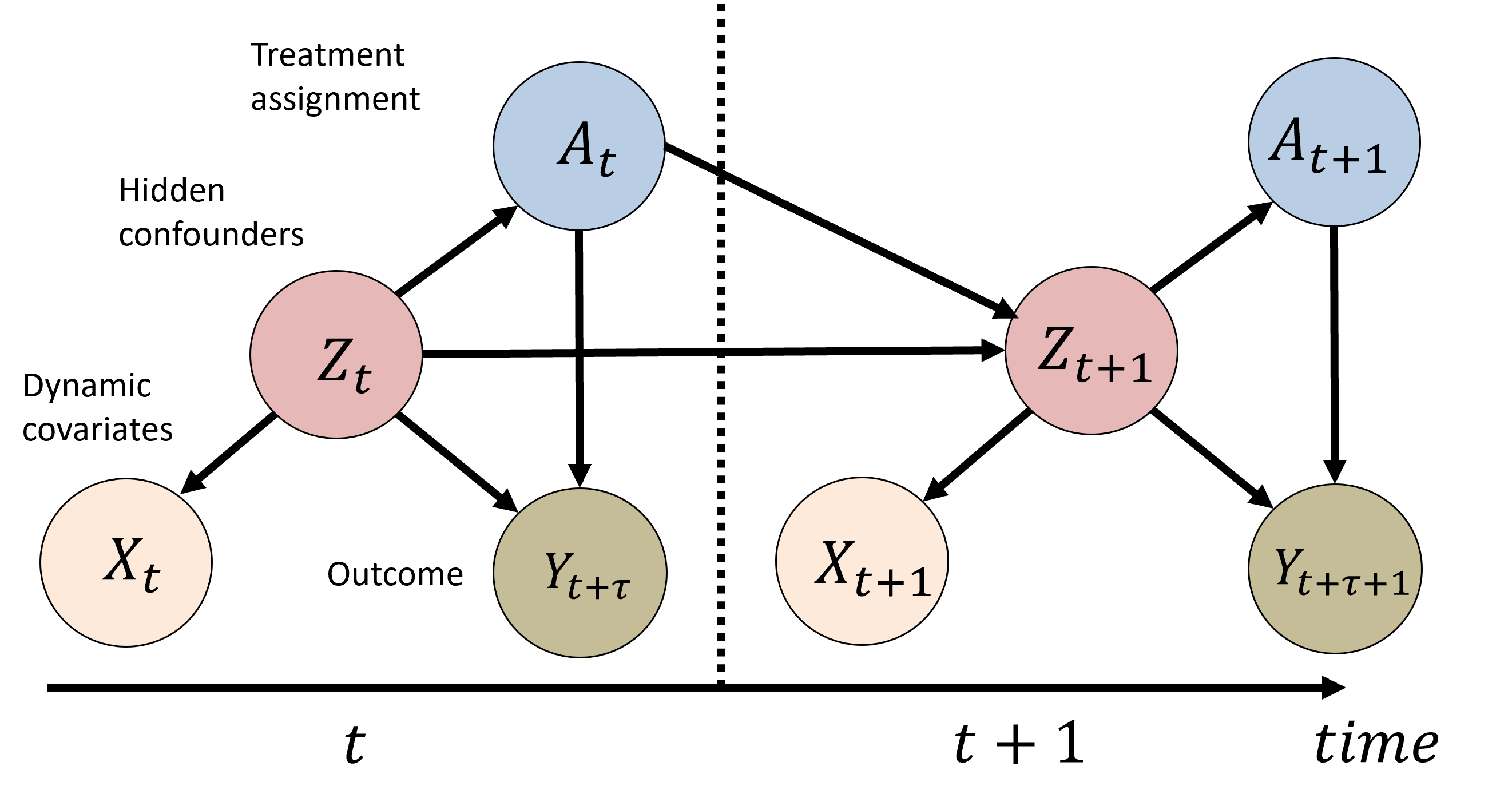
In this paper, we propose a novel causal inference framework called Theory-based and Graph Variational Counterfactual Recurrent Network (TGV-CRN), which estimates the effect of intervention in multiagent systems in interpretable ways. The causal graph of the problem setting is illustrated in Fig. 2, where the hidden confounders at a particular time stamp not only have causal relations to the observed variables at the same time stamp but also are causally affected by the hidden confounders from previous time stamps. To model the hidden confounders and other causal relationships from data for the ITE estimation framework, we leverage graph variational recurrent neural networks (GVRNNs) [13] to represent local agent interactions and theory-based computation for global properties of the multiagent behaviors based on domain knowledge. This framework is based on the long-term prediction of multiagent covariates and outcomes can confirm under what circumstances the intervention is effective.
Our general motivation is to estimate ITE over time in complex multiagent scenarios. Specifically, in team sports, decision-making skills (e.g., whether a player with the ball should perform a pass or shot) are important. However, we cannot observe both patterns as data (i.e., performing a pass and a shot) in the same situation. For autonomous driving or animal behavioral science, in real-world scenarios, we cannot obtain both data (i.e., with and without intervention) in the same situation (note that in the numerical experiment, we used synthetic data including both cases). For animal behavioral science, similarly, scientific experiments can hardly be performed with all possible intervention timing during movements and sometimes include the bias of the experimenters.
In summary, our main contributions are as follows. (1) We proposed a novel counterfactual recurrent network called TGV-CRN, which estimates the effect of intervention in multiagent systems in interpretable ways, compared with the previous counterfactual recurrent networks dealing with time-varying treatment [4, 5, 6, 7, 8]. (2) Methodologically, for the ITE estimation framework based on long-term prediction of multiagent covariates and outcomes, our model leverages GVRNN to represent local agent interactions and theory-based computation, which was not considered in the above previous work. This framework can confirm under what circumstances the intervention is effective. (3) In experiments using two simulated models of an automated vehicle and biological agents, we show that our methods achieved lower errors in estimating counterfactual covariates and the most effective treatment timing than the baselines. Furthermore, using real basketball data, our methods performed realistic counterfactual predictions. All of these subjects moved interactively in multiagent systems, which are not dealt with in the previous work. We extend our previous short paper [14] by adding theoretical background, experimental results of a synthetic Boid dataset and a real-world basketball dataset, and a sensitivity analysis using the CARLA dataset.
The remainder of this paper is organized as follows. First, in Section II, we describe our problem definition. Next, we describe our methods in Section III. We overview the related works in Section IV, present experimental results in Section V, and conclude this paper in Section VI.
II Background
In this section, we first give definitions of the notations used throughout the paper, present the assumptions of our methods for estimating ITE, and then introduce VRNNs (variational recurrent neural networks) [15] and GNN (graph neural network) [16] we used.
II-A Preliminary
The multiagent observational data is denoted as the following at time stamp . Examples of these variables are shown in Fig. 1. Let be the time-dependent covariates of the observational data such that , where the denotes the covariates for -th multiagent sample with agents, and denotes the number of samples. The relationships between agents are represented by the theory-based computation and GVRNN described in Section III. Although some related papers [5, 7] consider the static covariates , which do not change over time, here we do not explicitly consider because we can easily formulate and implement our methods to add by conditioning. The treatment (or intervention) assignments are denoted as , where denotes the treatments assigned in the -th sample. We consider , where is considered treated whereas is the control (i.e., a binary treatment setting), and we estimate the effect of the treatment assigned at time stamp on the outcomes at time stamp . Note that in observational data, a multiagent sample can only belong to one group (i.e., either a treated or control group), thus the outcome from the other group is always missing and referred to as counterfactual. To represent the historical sequential data before time stamp , we use the notation to denote the history of covariates observed before time stamp , and refers to the history of treatment assignments. Combining all covariates and treatments, we define as all the historical data collected before time stamp .
We adopt the potential outcomes framework (e.g., [17]) and extended by [18] to account for time-varying treatments. The potential outcome of the -th sample given the historical treatment can be formulated as , where . Then the ITE on the temporal observational data is defined as:
| (1) |
Here, the observed outcome under treatment is called factual outcome, while the unobserved one is the counterfactual outcome.
II-B Assumptions
Our estimation of ITE is based on the following standard assumptions [19, 4, 20], and we further extend the assumptions in our scenario to include time-varying observational data.
Assumption II.1 (Consistency).
The potential outcome under treatment history is equal to the observed outcome if the actual treatment history is .
Assumption II.2 (Positivity).
For any sample , if the probability , then the probability of receiving treatment or is positive, i.e., , for all .
Assumption II.2 means that, for each time , each treatment has a non-zero probability of being assigned. Besides these two assumptions, much of the existing work is based on the strong ignorability assumption as follows:
Definition 1 (Sequential Strong Ignorability).
Given the observed historical covariates of the -th sample, the potential outcome variables are independent of the treatment assignment, i.e., .
Definition 1 means that there are no hidden confounders, i.e., all covariates affecting both the treatment assignment and the outcomes are present in the observational dataset. However, this condition is difficult to be guaranteed in practice especially in real-world observational data (in other words, it is not testable in practice [19, 21]). In this paper, we relax such a strict assumption by acknowledging potential hidden confounders. Our proposed methods can learn the representations of the hidden confounders and eliminate the bias between the treatment assignments and outcomes at each time stamp.
In our approach, the learned representations (denoted by ) can be leveraged to infer the unobserved confounders and act as substitutes of hidden confounders. That is, we extend the strong ignorability assumption by considering the existence of hidden confounders , which influence the treatment assignment and potential outcomes . Given the hidden confounders , the potential outcome variables are independent of the treatment assignment at each time stamp. We aim to learn the representations of hidden confounders for bias elimination based on the following assumptions [8]:
Assumption II.3 (Existence of Hidden Confounders).
(i) The hidden confounders may not be accessible, but the covariates are correlated with the hidden confounders, and can be considered as proxy variables, and (ii) hidden confounders at each time stamp are also influenced by the hidden confounders and treatment assignments from previous time stamps.
Based on the premise, we study the identification of ITE:
Theorem 1 (Identification of ITE).
If we recover and , then the proposed methods can recover the ITE under the causal graph in Fig. 2.
We provide a proof in Appendix G. For simplicity, the sample superscript () will be omitted unless explicitly needed.
II-C Variational recurrent and graph neural networks
VRNN. Let denote a sequence of variables of length . The goal of sequential generative modeling is to learn the distribution over sequential data consisting of multiple demonstrations. A common approach to model the trajectory is to factorize the joint distribution and then maximize the log-likelihood where denotes the learnable parameters of models such as RNNs. However, RNNs with simple output distributions often struggle to capture highly variable and structured sequential data (e.g., multimodal behaviors) [22]. Recent work in sequential generative models addressed this issue by injecting stochastic latent variables into the model and optimization using amortized variational inference to learn the latent variables (e.g., [15, 23, 24]). Among these methods, a variational RNN (VRNN) [15] has been widely used in base models for multiagent trajectories [13, 22] with unknown governing equations. A VRNN is essentially a variational autoencoder (VAE) conditioned on the hidden state of an RNN and is trained by maximizing the (sequential) evidence lower-bound (ELBO):
| (2) |
where is a stochastic latent variable of VAE, and , , and are generative model, the approximate posterior or inference model, and the prior model, respectively. The first term is the reconstruction term. The second term is the Kullback-Leibler (KL) divergence between the approximate posterior and the prior.
GNN. We then overview a graph neural network (GNN) based on [16]. Let be a feature vector for each node of agents. Next, a feature vector for each edge is computed based on the nodes to which it is connected. The edge feature vectors are sent as “messages” to each of the connected nodes to compute their new output state . Formally, a single round of message passing operations of a graph net is characterized below:
| (3) | ||||
| (4) |
where is the set of neighbors of node and and are neural networks. In summary, a GNN takes in feature vectors and outputs a vector for each node , i.e., . The operations of the GNN satisfy the permutation equivariance property as the edge construction is symmetric between pairs of nodes and the summation operator ignores the ordering of the edges [25].
III Proposed Method
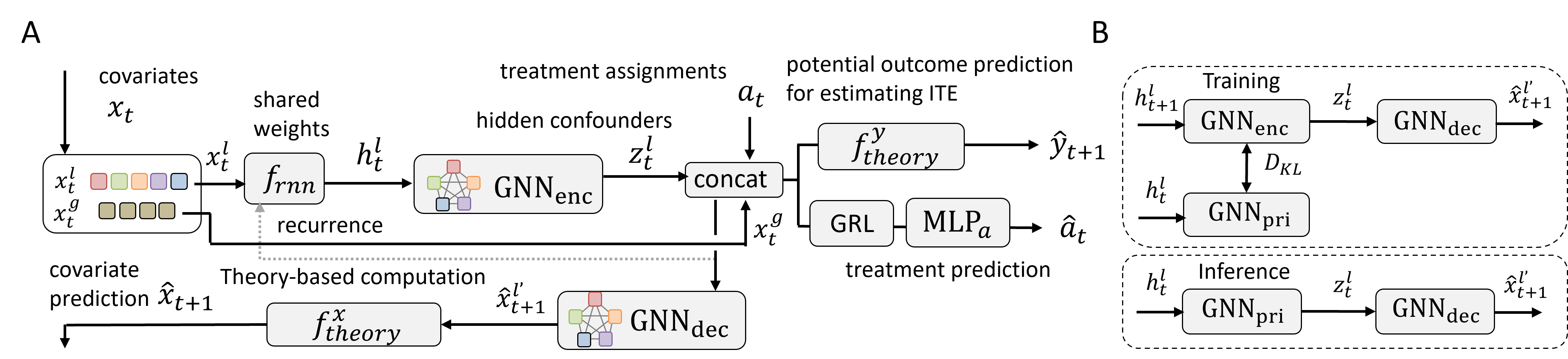
Here, we describe our TGV-CRN method for ITE estimation in multiagent observational data. The overall framework is illustrated in Fig. 3A. We aim to combine predictions of outcome and covariates using data-driven and theory-based approaches, while balancing the representations of treated and control groups to reduce the confounding bias. To this end, we first introduce the representation learning of hidden confounders with balancing by mapping the current multiagent observational data and historical information into the representation space. Next, we describe the prediction methods of the time-varying covariates, a potential outcome, and the treatment using the learned representations. Finally, we describe the loss function.
III-A Representation learning of confounders
Here, as a main approach in Fig. 3A, we extend a GVRNN [13] for local multiagent locations (i.e., specific for each agent) with theory-based computation. As its variant (e.g., used for the ablation study), a pure data-driven model combining GVRNN and VRNN [15] for global variables (i.e., common for all agents) is also considered. Since the global variables do not usually have the graph structure, VRNN without GNN is suitable. Here we describe the representation learning of hidden confounders.
GVRNN. We first describe Graph Variational RNN (GVRNN) [13] to obtain the representation from multiagent locations, which models the interactions between them at each step using GNNs. Let denote a sequence of covariates (here we consider multiagent locations). In this paper, GVRNN’s update equations are as follows:
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
where and are deterministic and stochastic latent variables, denotes a multivariate normal distribution with mean and covariance matrix diag(), and
| (9) | ||||
| (10) | ||||
| (11) |
The prior network , encoder , and decoder are GNNs with learnable parameters and . The relationship among them is illustrated in Fig. 3B. Here we used the mean value as input variables in the following theory-based computation. GVRNN is trained by maximizing the sequential ELBO in a similar way to VRNN as described in Eq. (2), which is denoted as .
Combined representation learning. To construct a fully data-driven model (instead of the theory-based computation in Fig. 3A), we propose a hierarchical GVRNN combining GVRNN for multiagent locations and VRNN for global inputs to learn the representation of hidden confounders. In summary, each agent’s trajectory and other global information are processed through gated recurrent units (GRUs). The GRU parameters for the agent’s trajectory are shared but keep its own individual recurrent state. At each time stamp, the model takes the current covariates and treatment assignments as input for learning representations of hidden confounders via GRUs, GNN, and MLP encoders.
III-B Prediction with learned representation
Our methods predict time-varying covariates, potential outcomes, and treatment for balancing by combining data-driven and theory-based approaches. Here our contributions are to propose the theory-based computation of global variables and the prediction of time-varying covariates. In this subsection, we describe the theory-based computation and the prediction of time-varying covariates, potential outcomes, and treatment for balancing.
Theory-based computation. Here we assume that we do not have simulators including governing equations (used e.g., in [16, 26]) of multiagent systems such as team sports. In such a situation, we can utilize theory or prior knowledge of the domain using two approaches. One is to partially incorporate rule-based models into the data-driven model such as a mathematical relationship [27] (e.g., between position and velocity), the biological constraints (e.g., turn angle in Sec. V-A), and critical behaviors (e.g., collision in Sec. V-A, ball movement in the air, and defending against the shot in Sec. V-B). Another is to compute auxiliary features for potential outcome predictions such as global variables (e.g., mean angular momentum in Sec. V-A or specific inter-agent distances in Secs. V-A and V-B). In our problem, we need to predict potential outcomes and covariates using predicted local variables from the data-driven model in Sec. III-A as shown in Fig. 3A. That is,
| (12) | |||
| (13) |
where and and are theory-based functions utilizing domain knowledge. For the details, see Sec. V.
Prediction of time-varying covariates. Another contribution of this paper is to propose methods to predict time-varying covariates, which can confirm under what circumstances the intervention is effective. The proposed TGV-CRN infers time-varying covariates via GNN decoders and the theory-based computation as illustrated in Fig. 3A. For a fully data-driven model, we use the VRNN decoder for global variables instead of the theory-based computation. We minimize the factual covariate loss function as follows:
| (14) |
Prediction of a potential outcome. Next, we describe a potential outcome prediction network to estimate the outcome as described in Eq. (12). Depending on the problem of various data domains, MLP was placed before or after the theory-based function to properly model the potential outcome (for details, see Section V). For a fully data-driven model, we use MLP instead of the theory-based computation. We minimize the factual loss function as follows:
| (15) |
Treatment prediction and balancing. We also predict the treatment assignments at each time stamp. The predicted treatments are obtained through a fully-connected layer with a sigmoid function as the last layer. That is, is the probability of receiving treatment based on the confounders at time , which can be typically referred to as propensity score [28] .
Since we consider the binary treatment in this paper, we use a cross-entropy loss for the treatment prediction as follows:
| (16) |
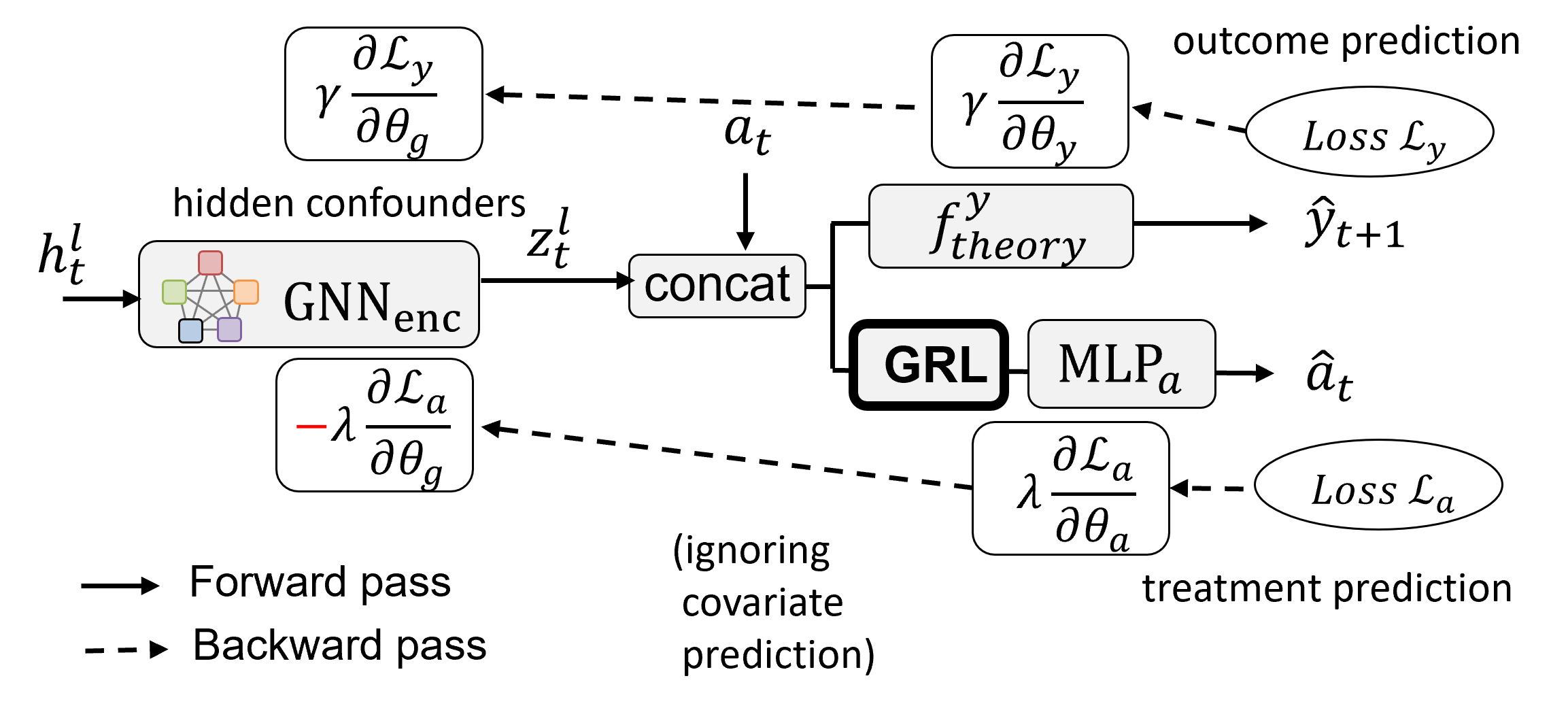
One critical consideration is balancing the representations of treated and control groups, which helps reduce the confounding bias [5, 7, 8] and minimize the upper bound of the outcome inference error [29]. In this paper, we incorporate the adversarial learning-based balancing method using a gradient reversal layer [30] according to the related studies [5, 8]. Figure 4 illustrates our adversarial training process. Let be the GNN encoder with parameters . Also, let and be the MLP for treatment and outcome prediction with parameters and (if is a neural network). and are the hyperparameters (or weights) of loss functions as described below. We add the gradient reversal layer before the treatment classifier to ensure the confounder representation distribution of the treated and that of the controlled are similar at the group level [5, 8]. The gradient reversal layer does not change the input during the forward-propagation, but in the back-propagation, reversing the gradient by multiplying by a negative scalar (i.e., in Fig. 4). Although the model will minimize the loss of the treatment prediction, the adversarial learning process will contribute to the distribution balancing during the prediction of the potential outcome and the covariates.
III-C Loss function
The loss function for our method is defined as
| (17) |
where is the factual outcome prediction loss, is the ELBO in GVRNN, is the covariate prediction loss, and is the treatment prediction loss. , , and are hyperparameters to balance the loss function. In a pure data-driven model, we add to . To prevent over-fitting, we select the best-performing model using the loss function on the validation set. The sensitivity analysis in the hyperparameters is presented in Appendix I.
IV Related work
Learning causal effects with time-varying data. Pioneering work to estimate the effects of time-varying exposures has developed such as g-computation, structural nested models, and marginal structural models (e.g., [31, 32, 19, 18]) in statistics and epidemiology domains. To handle complex time-dependencies, Bayesian non-parametric approaches based on Gaussian processes [33, 34, 35] and Dirichlet processes [36] have been proposed. Moreover, to model time-dependencies without strong assumptions on functional forms, RNN approaches have been intensively investigated such as recurrent marginal structural networks [4] and adversarial training to balance the historical confounders [5]. Recently, to estimate the treatment effects with hidden confounders, several methods have been proposed by relaxing the assumption of strong ignorability [6, 7, 8]. Our approach is related to these works, but they did not consider the utilization of domain knowledge and the explicit prediction of time-varying covariates, which is necessary for the proper interpretation of the results.
Representation learning for treatment effect estimation. Estimation methods of balanced representation between treated and control groups in hidden space have been proposed in the static setting [37, 38, 39]. In neural network approaches, methods with regularization for the balancing [40, 29], incorporating the local similarity among individuals [41], generative adversarial nets (GAN) [42], a multi-task learning [43], probabilistic modeling [44, 45], and optimal transport framework [46] have been proposed. In the dynamic setting, [5, 8] adopted adversarial training techniques with a gradient reversal layer, [6] proposed multi-task learning to build a factor model of the cause distribution, and [7] used inverse probability of treatment weighting. To model multiagent or networked systems, GNN-based approaches have been intensively used in prediction problems (e.g., [47, 48]). To obtain representations from the networked covariates, [8] incorporated graph convolutional networks and [49] incorporated hierarchical spatial graph structure into causal estimation frameworks (other counterfactual learning on graphs was surveyed by [50]). Recently, continuous-time causal inferences for dynamical systems [51, 52] have been proposed. We adopted the adversarial training to balance the representation and introduced GVRNN with prior (domain) knowledge for a more accurate long-term prediction of potential outcomes and covariates.
Counterfactual prediction for multiagent data. In past research of real-world multiagent movements, counterfactual prediction of human movements has been studied. As control problems, forward models such as in robotics, can be considered. However, our problem is inherently a backward problem to model the multiagent behaviors from data, then here we focus on such backward approaches. Counterfactual trajectory prediction methods have been proposed in pedestrians [53], animals [54], and team sports [13, 27, 55, 56]. Outside the context of causal inference based on the Rubin causal model, the causality of the physics-based system such as using neural rational inference [16] and learning physics in a game engine with randomized stability [57] have been considered (sometimes called causal reasoning). In the context of reinforcement learning, the counterfactual action prediction and evaluation can be considered in team sports [58, 59, 60, 61]. In traffic environments, methods to understand the reasons behind the maneuvers of other vehicles and pedestrians for escaping accidents [62, 63, 64] have been proposed. In the static setting of causal inference, [65] proposed a spatial convolutional counterfactual regression to estimate the effects of crowd movement guidance. In team sports, propensity score matching was used to investigate the causal effect of some plays or timeouts in many sports [66, 67, 68, 69]. In the dynamic setting, [70] applied a g-computation method to examine the effect of a specific pitch in baseball. We firstly propose a framework for estimating ITE in multiagent motions.
V Experiments
The purpose of our experiments is to validate the proposed methods for application to real-world multiagent trajectories, which usually have no ground truth of the interaction rules. Hence, for verification of our methods, we first compared their performances to infer the ITE to those in various baselines using two synthetic datasets with ground truth: the CARLA [71] autonomous driving simulator and a biological multiagent model called Boid [10]. In particular, for real-world applications, we need long-term counterfactual predictions. We mainly verified the estimation of ITE using the CARLA dataset (relatively fewer interactions) and that of the best intervention timing using the Boid dataset (relatively more and complex interactions) because the intervention timing is sensitive. Finally, we examined the applicability of our methods to real-world data using the basketball (NBA) dataset. In common, we separated the time into a burn-in period and a prediction period . The intervention point during the intervention period is denoted as (a similar interval to , but we set it differently in each problem). The hyperparameters of the models were determined by validation datasets in each experiment (for the details, see Appendices J, K, and L).
Here, we commonly compared our methods to four baseline methods: a simple RNN baseline using GRU [72], deep sequential weighting (DSW) [7] as a baseline considering hidden confounders, graph counterfactual recurrent network (GCRN: for clarity, we change the name) [8] , and the variant to predict covariates (GCRNX). These baselines were modified to our setting (e.g., multiagent and time-varying outcome: for details, see Appendix H). For verification, since the prediction of the covariates is required, the most appropriate baseline is GCRNX, which is compared via visualization because DSW and GCRN cannot predict the covariates. We also validated our approach with three variants: GV-CRN (without the theory-based computation, i.e., without global covariates), TV-CRN (removing GNN), and TG-CRN (replacing VRNN with RNN). To perform fair comparisons among the models, we trained all models with 20 epochs (the learning curves are shown in Appendix N). Other common training details are described in Appendix H and the codes are provided at https://github.com/keisuke198619/TGV-CRN.
V-A Synthetic datasets
To verify our method, we compared the performances to infer the causal effect with those in various baselines using two synthetic datasets with ground truth. We used two types of simulations: autonomous vehicle and biological agent (Boid) simulations. All simulations are rule-based rather than learning-based as described below. As for performance metrics, we first adopted commonly used potential outcome and covariate prediction errors. Potential outcome prediction errors were computed as an absolute error of all simulated outcomes: , where a treatment , time , simulated temporal variation of the treatment timing , and the burn-in period in RNN . Covariate prediction errors were computed as prediction error of all simulated covariates: . We took the average over all variables for evaluation.
We also adopted two widely-used evaluation metrics in causal inference: rooted precision in the estimation of heterogeneous effect (PEHE) [37] and mean absolute error of the average treatment effect (ATE) [73] to measure the quality of the estimated individual treatment effects at different time stamps: . We took the average over all time stamps for evaluation.
Regarding interpretability, we emphasize that there has been no previous work to visualize or interpret future covariates (i.e., multiagent trajectory), which can confirm under what circumstances the intervention is effective. We then illustrated trajectory prediction results in each domain. We compared the customized baselines to predict future covariates to demonstrate the superiority of our approach, which are also quantitatively shown as the covariate losses .
Autonomous vehicle simulation. We first validated the performances of our methods using an autonomous vehicle simulation using the CARLA simulator [71] (ver. 0.9.8). The CARLA environment contains dynamic obstacles (e.g., pedestrians and cars) that interact with the ego car. To generate data, we simulated autonomous driving at various towns, starting points, and obstacle positions, which were subsampled at 2 Hz (see also Appendix K). Since we did not use the future path as inputs for generality, we randomly split 7 towns data into 904 training, 129 validation, and 259 test scenarios. Here we used two types of autonomous vehicles: partial observation with Autoware [74] (ver. 1.12.0) and full observation types with a pre-installed CARLA simulator. The partial observation model often stops when dangerous situations arise for safety. The full observation model intervenes to accelerate the stopped vehicle after the safety confirmation. We set , and . For counterfactual data, since dangerous situations (i.e., requiring intervention) are limited, we only used with or without intervention at the same timing (not various timings).
We predict the safe driving distance of the ego car from the starting point as an outcome while driving without any collision with obstacles. That is, the treatment effect of the full observation model is defined as the difference between safe driving distances with and without interventions. As the local covariates , we used the position, velocity, pose, and size information of the ego car and obstacles in the 2D map. The maximum number of dynamic obstacles was , but since the obstacles related to the ego car were limited and the number changes over time, we used the nearest obstacles’ information as the covariates. As the global covariates , we used the current driving distance and (binary) collision information of the ego car. The theory-based function mathematically computed using the predicted velocity and pose information, and added the learned positive velocity in intervention. computed using the predicted as the output of the MLP such that based on the definition of the safe driving distance.
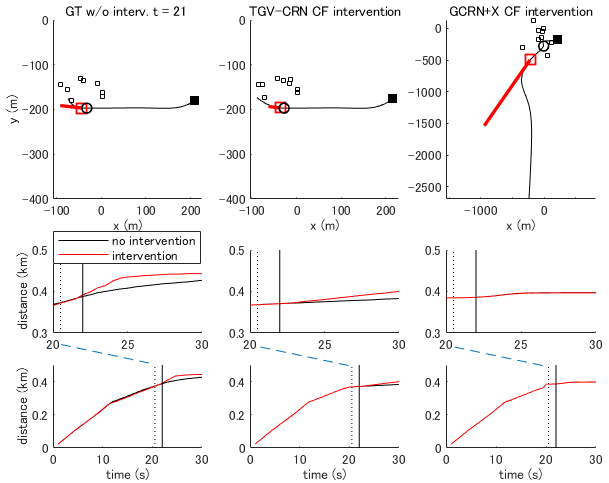
Quantitative verification results are shown in Table I. Our full model and its ablated variants show lower prediction errors of the outcome and covariates, and , and than other baselines. Totally, our full model and the variant without amortized variational inference (TG-CRN) show the best performances, suggesting that the necessity of complex modeling for long-term prediction using this dataset would be smaller than that using the following datasets. In our four models, we found that on this dataset the combination of theory-based computation and GNN worked well in the covariate prediction, but did not in the outcome prediction. Example results of our method are shown in Fig. 5, which can interpret the results. Our method (TGV-CRN) shows better counterfactual prediction with intervention than the baseline (GCRNX). On average, the outcome values with intervention compared to the absence of the intervention (i.e., ITE) were (km) in our full model, in the baseline (GCRN+X), and in the ground truth. As Fig. 5 shows, the baseline did not model the intervention effects. We expect that this method can be applied to the effect of human intervention in Level 3 autonomous vehicle simulations, which need human intervention. This approach can examine the effect of autonomous control in Level 4 or 5 autonomous vehicle simulations (without human intervention) in a case when human intervention is necessary in Level 3.
| RNN | 3.330 0.286 | 0.159 0.025 | 0.129 0.023 | 0.479 0.0011 |
| DSW [7] | 0.161 0.013 | 0.030 0.003 | 0.019 0.003 | — |
| GCRN [8] | 0.094 0.009 | 0.024 0.002 | 0.014 0.002 | — |
| GCRNX | 3.020 0.496 | 0.049 0.009 | 0.034 0.007 | 2.072 0.0098 |
| GV-CRN | 0.038 0.003 | 0.022 0.002 | 0.012 0.001 | 0.372 0.0010 |
| TG-CRN | 0.045 0.004 | 0.021 0.002 | 0.011 0.001 | 0.082 0.0004 |
| TV-CRN | 0.032 0.003 | 0.023 0.002 | 0.014 0.002 | 0.102 0.0004 |
| TGV-CRN (full) | 0.041 0.003 | 0.020 0.002 | 0.008 0.001 | 0.098 0.0004 |
| Boid simulation dataset | Real-world NBA dataset | |||||||
| Treatment timing | ||||||||
| RNN | 1.815 0.068 | 0.668 0.033 | 0.443 0.054 | 0.085 0.016 | 0.168 0.0002 | 0.291 0.003 | 0.170 0.0065 | 0.969 0.0024 |
| DSW [7] | 2.353 0.080 | 0.586 0.029 | 0.440 0.054 | 0.082 0.015 | — | 0.197 0.003 | 0.166 0.0064 | — |
| GCRN [8] | 2.290 0.081 | 0.587 0.028 | 0.443 0.055 | 0.088 0.016 | — | 0.170 0.003 | 0.149 0.0062 | — |
| GCRNX | 2.290 0.081 | 0.727 0.022 | 0.440 0.054 | 0.080 0.014 | 0.162 0.0001 | 0.431 0.004 | 0.154 0.0063 | 1.226 0.0032 |
| GV-CRN | 1.900 0.068 | 0.674 0.028 | 0.536 0.045 | 0.090 0.014 | 0.329 0.0003 | 0.475 0.005 | 0.151 0.0060 | 1.173 0.0028 |
| TG-CRN | 1.750 0.062 | 0.694 0.041 | 0.501 0.067 | 0.125 0.021 | 0.086 0.0002 | 0.347 0.005 | 0.205 0.0072 | 0.811 0.0022 |
| TV-CRN | 1.692 0.064 | 0.981 0.044 | 0.483 0.052 | 0.106 0.018 | 0.090 0.0002 | 0.165 0.002 | 0.192 0.0068 | 0.852 0.0023 |
| TGV-CRN (full) | 1.853 0.062 | 0.690 0.032 | 0.537 0.055 | 0.101 0.016 | 0.085 0.0002 | 0.231 0.004 | 0.261 0.0083 | 0.825 0.0023 |
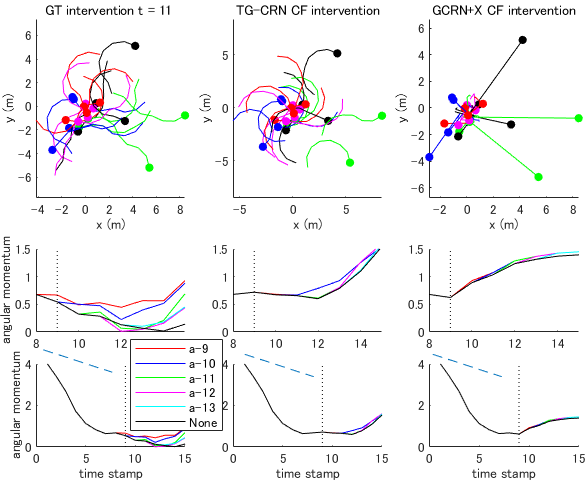
Biological multiagent simulation. Here, we validated our methods on the Boid model, which contains movement trajectories of 20 agents. The Boid model (originally, [75]) is a rule-based model to generate generic simulated flocking agents and we used a unit-vector-based (rule-based) model [10] (for details, see Appendix J). In this paper, we intervene the agents’ recognition to generate torus (circle) behaviors from the swarm (random) behaviors. The outcome is defined as the mean angular momentum of individuals about the center of the group (assuming the mass of each agent ). That is, the treatment effect of the change in the recognition is estimated as the difference in the future mean angular momentum between simulations with and without the interventions.
In this model, agents are described by a 2-D vector with a m/s constant velocity in a 15 15 m boundary square. At each time stamp, a member will change direction according to the positions of all other members based on three zones. The first is the repulsion zone with radius m, in which individuals within each other’s repulsion zone try to avoid each other by swimming in opposite directions. The second is the orientation zone, in which individuals try to move in the same direction; here we set radius to generate swarming behaviors before the intervention. To generate torus behaviors, we change , which is the intervention in this study. The third is the attractive zone (radius m), in which agents move towards each other and tend to cluster.
To simulate the treatment assignments, we generate factual samples ( training, validation, and test datasets). We set and and randomly pick the intervention point during the intervention period . The outcome is defined as the mean angular momentum among individuals at time . We also created a counterfactual dataset only in the test dataset. Here we created all combinations of treatment points during the intervention period . As the local covariates , we used position, velocity, and directional change of all agents. As the global covariates , we used the current mean angular momentum. The theory-based function mathematically computed using the direction change at the next step, maximum turn angle as body constraints (for and , see also Appendix J), and attraction rule when agents are far from the center of the group. In addition, we added the orientation rule when agents are in the orientation zone and not in the repulsion zone in . was replaced with a MLP such that .
The results are shown in Table II left. In addition to the four indices in the CARLA experiment, we investigated the estimation error of the best intervention timing . The results indicate that our model and its variants with theory-based computation show better prediction performances in covariates and the best intervention timing than all of the baselines. However, the outcome prediction errors in our models were worse than the causal inference baselines (DSW, GCRN, and GCFN+), which may lead to degraded performances in and of our models than the baselines. In our four models, all combination of core three components (T, G, and V) did not work well and on this dataset, TG-CRN without VRNN is the best performing model. On average, the ITE values were in our best model (TG-CRN), in the baseline (GCRN+X), and in the ground truth. From this viewpoint (both average and variance), our best model was closer to the ground truth than the baseline. Example interpretable results of our method are shown in Fig. 6. Our best model (TG-CRN) shows better counterfactual covariate prediction with intervention than the baseline (GCRNX). Moreover, the counterfactual prediction of the outcome in our model had variation among various intervention times, whereas that in the baseline did not. We consider that these were important properties in our problem, and improved prediction of the potential outcome was left for future work. We expect that our approach can estimate the effect of an experimenter’s interventions on multi-animal behaviors even if they did not perform the experiment in missing conditions. Our approach is expected to improve the efficiency of experimental procedures for observing desired movements.
V-B Real-world basketball dataset
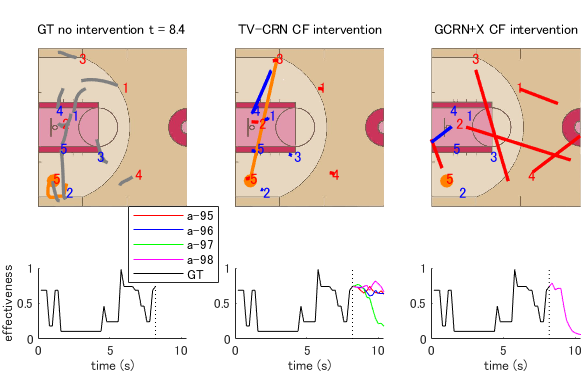
Finally, we examined the applicability of our methods to a real-world basketball dataset from the NBA. Data acquisition was based on the contract between the league (NBA) and the company (STATS LLC.), not between the players and us. They are top-level players and then the data was not anonymized. The company was licensed to acquire this data, and it was guaranteed that the use of the data would not infringe on any rights of players or teams. In this study, we used attack sequences from 630 games from the 2015/2016 NBA season (https://www.stats.com/data-science/), which contained the trajectories of 10 players and the ball. We extracted 47,467 attacks (i.e., offensive plays) as samples, which were subsampled at 5 Hz. We separated the dataset into 34,696 pre-training (458 games for training the following classifier of effective attack), 11460 training (154 games, 1/10 of that is used as validation), and 1,305 test samples (18 games) in chronological order. Since scoring predictions are difficult in general (e.g., [76, 11]), we define the attack effectiveness as the outcome by predicting whether the attack is effective or not in the future. This is because evaluating team movements based on scores alone may not provide a holistic view, due to factors such as the shooting skills of individual players. In addition, we predict the attack effectiveness at the next time stamp using the pre-training samples and a logistic regression. The details are provided in Appendix L.
We verified our methods using factual data and provided insights using counterfactual prediction. In model verification using factual data, we set and . For counterfactual predictions, we set and (at the end of attacks, i.e., a shot or turnover) and predicted all combinations of the counterfactual timing during the intervention period . As the local covariates , we used the position and velocity of all agents including the ball. As the global covariates , we used the ball player’s information and areas (see also Appendix L), distances from the nearest defender (about the ball player and other attackers), successful shot probabilities of all attackers, and game and shot clock. The theory-based function and computed and in rule-based manners. In addition, to perform long-term prediction, also computed the ball and the defender nearest to the next ball player during a counterfactual pass in rule-based manners.
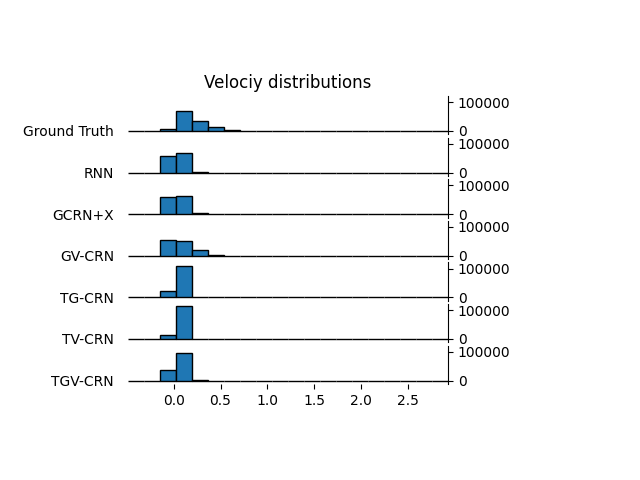
Our verification results using factual data are shown in Table I right. We examined the counterfactual pass effect in addition to the outcome and covariate prediction errors. Our methods show better prediction performances in the factual covariates than the fully data-driven baselines. In the factual outcomes, our methods outperformed the most appropriate baseline (GCFNX) and RNN, but only the method without GNN shows competitive performance with DSW and GCRN. One of the possible reasons may be the difficulty in modeling the relationship between the future outcome and current covariates, whereas GNN worked well in only the covariate prediction as the previous work [13]. As additional analysis, we indicate endpoint errors and distributions of long-term covariate prediction for basketball data in Appendix M. Again, the strength of our method is to model the covariates at the next timestep for interpretability of the model. Results in Appendix M that the tendency of the endpoint prediction error for all models is similar to the mean prediction error, in which our approach (TV-CRN and TGV-CRN) show the best performance. In addition, the distribution of the player velocity in the figure of Appendix M shows that our approach without theory-based computation had a wider distribution like ground truth than other models, and those with theory-based computation had less zero-velocity bins like ground truth than other models. Although our approach did not completely model the player’s velocity, we show that they were partially effective for covariate prediction using each component. In , since all models show positive values, it suggests that there may be a more promising shot opportunity by an extra pass in the shot situation. Figure 7 shows realistic counterfactual prediction from our model to demonstrate interpretable results. Our model completed the counterfactual pass and the nearest defender chase, but the baseline model failed and predicted unrealistic behaviors (e.g., the attackers moved toward the outside of the court). In practice, our approach can estimate the effect of the selection of passes in basketball shot scenarios. We expect that our approach can evaluate the decision-making skills of players in a competitive game. Again, we emphasize these important properties in our problem.
VI Conclusions
In this paper, we proposed an interpretable counterfactual recurrent network in multiagent systems to estimate the effect of the intervention. Using synthetic CARLA and Boid datasets, we showed that our model achieved lower errors in estimating counterfactual covariates and the most effective treatment timing than the baselines. Furthermore, using real basketball data, our model performed realistic counterfactual prediction. We consider a general ITE framework for various domains, but the experimental results show that for each domain the effective modeling was different. Possible future research directions are to realize better modeling of the future outcomes, and to apply our approach to other multiagent domains such as animals and pedestrians using domain knowledge.
Acknowledgments
This work was supported by JSPS KAKENHI (Japan Society for the Promotion of Science, Grant Numbers 20H04075, 21H04892, and 21H05300), JST PRESTO (Japan Science and Technology Agency, Precursory Research for Embryonic Science and Technology, Grant Number JPMJPR20CA), and JST CREST (Core Research for Evolutional Science and Technology, Grant Number JPMJCR1913).
Appendix
G A proof of Theorem 1
Proof.
Under the aforementioned assumptions in the main text, we can prove the identification of ITE:
| (18) | ||||
| (19) | ||||
| (20) | ||||
| (21) | ||||
| (22) |
where , is a factual outcome, and we drop the instance index for simplification. Eq. (18) is the definition of ITE in our setting, Eq. (19) is a straightforward expectation over , and Eq. (20) be inferred from the structure of the causal graph shown in Fig. 2. Eq. (21) is based on the assumption that contains all the hidden confounders, as well as the positivity assumption, and Eq. (22) can be inferred from the consistency assumption. Thus, if our framework can correctly model and , then the ITEs can be identified under the causal graph in Fig. 2. ∎
H Common training setup
H-A Model training and computation
The codes and data we used are provided at https://github.com/keisuke198619/TGV-CRN. This experiment was performed on an Intel(R) Xeon(R) CPU E5-2699 v4 ( GHz 16) with GeForce TITAN X pascal GPU. For the training of the proposed and baseline models, we used the Adam optimizer [77] with an initial learning rate of and training epochs. We set the batchsize to 256. For the hyper-parameters in the loss function, we set for all datasets and in the Boid and CARLA dataset and in the NBA experiment because the latter dataset was more difficult to predict than the Boid and CARLA experiments.
H-B Baseline models implementation
We compared the performances of our methods to infer ITE with those in the following baselines: a simple RNN using GRU [72], deep sequential weighting (DSW) [7], dynamic networked observational data deconfounder (but for clarity, we change the name into GCRN: graph counterfactual recurrent network) [8].
RNN. This approach is based on GRU [72]. This model predicts the input (covariates) at the next time stamp, the potential outcome, and the probability of receiving treatment. We also model the hidden confounder as the hidden state of GRU, but do not learn the representation to reduce the confounding bias.
DSW [7]. Compared with the original model, we modified it to our setting (e.g., multiagent, time-varying outcome, and long-term prediction), and to fairly compare with our model, we removed the attention module.
GCRN [8]. Similarly, compared with the original model, we modified it to our setting (e.g., multiagent and long-term prediction) based on DSW, and to fairly compare with our model, we removed the attention module.
I Sensitivity analysis in hyperparameters
We performed the sensitivity analysis in hyperparameters using the CARLA dataset. The hyperparameters are presented in Eq. (17). Results in Table III shows the existence of the trade-off between the prediction performances of the outcome and covariates ().
| (default) | 0.041 0.003 | 0.020 0.002 | 0.008 0.001 | 0.098 0.0004 |
| 0.040 0.003 | 0.020 0.002 | 0.009 0.001 | 0.102 0.0004 | |
| 0.041 0.003 | 0.019 0.002 | 0.007 0.001 | 0.097 0.0004 | |
| 0.041 0.003 | 0.019 0.001 | 0.005 0.001 | 0.086 0.0004 | |
| 0.031 0.002 | 0.020 0.002 | 0.009 0.001 | 0.146 0.0005 | |
| 0.062 0.005 | 0.019 0.002 | 0.007 0.001 | 0.121 0.0005 | |
| 0.041 0.003 | 0.020 0.002 | 0.008 0.001 | 0.098 0.0004 | |
J Boid dataset
The schooling model we used in this study was a unit-vector-based (rule-based) model [10], which accounts for the relative positions and direction vectors of neighboring fish agents, such that each fish tends to align its own direction vector with those of its neighbors. In this model, agents (length: 0.5 m) are described by a two-dimensional vector with a constant velocity (1 m/s) in a boundary square (30 30 m) as follows: and , where and are two-dimensional Cartesian coordinates, is a velocity vector, is the Euclidean norm, and is an unit directional vector for agent .
At each timestep, a member will change direction according to the positions of all other members. The space around an individual is divided into three zones where each modifying the unit vector of the velocity (for the zones, see the main text). Let , , and be the numbers in the zones of repulsion, orientation and attraction respectively. For , the unit vector of an individual at the next timestep is given by:
| (23) |
where . The velocity vector points away from neighbors within this zone to prevent collisions. This zone is given the highest priority; if and only if , the remaining zones are considered. The unit vector in this case is given by:
| (24) |
The first term corresponds to the orientation zone while the second term corresponds to the attraction zone. The above equation contains a factor of which normalizes the unit vector in the case where both zones have non-zero neighbors. If no agents are found near any zone, the individual maintains a constant velocity at each timestep.
In addition to the above, we constrain the angle by which a member can change its unit vector at each timestep to a maximum of deg. This condition was imposed to facilitate rigid body dynamics. Since we assumed point-like members, all information about the physical dimensions of the actual fish is lost, which leaves the unit vector free to rotate at any angle. In reality, however, the conservation of angular momentum will limit the ability of the fish to turn angle as follows:
| (25) |
If the above condition is not satisfied, the angle of the desired direction at the next timestep is rescaled to . In this way, any un-physical behavior such as having a 180∘ rotation of the velocity vector in a single timestep is prevented.
In the simulation, the ground truth of was , which indicates the intervention increased angular velocities (see also the main text).
K CARLA dataset
We used the CARLA simulator [71] (ver. 0.9.8). The CARLA environment contains dynamic obstacles (e.g., pedestrians and cars) that interact with the ego car. For generating data, we performed simulation through various towns, starting points, and obstacle positions, which were subsampled at 2 Hz. The obstacles’ positions and starting points of the ego car were randomly selected from the possible locations on the map for each run. Approximately 20-120 obstacles were placed on each map. Using the data collected in CARLA, the same driving conditions were reproduced in ROS (robot operating system) [78], and Autoware was used to make the vehicle drive the same route autonomously. Here we consider two types of autonomous vehicles: partial observation with Autoware [74] (ver.1.12.0) and full observation types with the pre-installed CARLA simulator. The partial observation model often stops when dangerous situations for safety. If an obstacle enters the deceleration or stopping range, the vehicle decelerates or stops in front of the obstacle. The deceleration range was set to be wider than usual for safety. The full observation model intervenes to accelerate the stopped ego car after the safety confirmation based on the speed information at the data collection.
We set , and . We evaluated and predicted the safe driving distance of the ego car from the starting point while driving without collision with any obstacle (for details, see the main text). In the simulation, the ground truth of was , which indicates the intervention increased safe driving distance.
L NBA dataset
Here, we describe the details of the computation using the NBA dataset. Dataset description is given in the main text. We describe the computation of the attack effectiveness used in this study. Then, we predict the effective attacks at the next time stamp using the pre-training samples and a logistic regression.
From the aforementioned reasons in the main text, we compute an interpretable and simple indicator from available statistics (i.e., based on the frequency) to evaluate whether a player attempts a better shot, rather than based on the shot label or learning-based score prediction. From available statistics, we focused on two basic factors for effective attacks at an individual player level: the shot zone on the court and the distance between a shooter and the nearest defender. These two factors have been considered to be important for basketball shot prediction [79, 76, 11]. In the NBA advanced stats (https://www.nba.com/stats/players/shots-closest-defender/), we can access probabilities of successful shots in each zone and distance for each player. The shot zones are separated into four areas: the restricted area, in-the-paint, mid-range, and the 3-point area. The restricted area is defined as the area within a radius of 2.44 m from the ring (distance between the side of the rectangle and the ring) from the ring. In-the-paint is defined as the area within a radius of 5.46 m (distance between the ring and the farthest vertex of the rectangle) from the ring. The 3-point area is defined as the outside of the 3-point line. Mid-range is the remaining area. The shooter’s distance from the nearest defender is categorized into four ranges: feet, feet, feet, and feet.
We define the attack effectiveness using the following criteria:
- •
The shooter’s position in the restricted area is effective at any distance because the defender often exists near the shooter.
- •
The shooter’s position in the paint and mid-range is effective at 6 feet or further (this range is regarded as “open” in the NBA advanced stats).
- •
The shooter’s position in the 3-point area is effective when a player with a probability of 0.35 and hits with 6 feet or more (because some players do not shoot tactically).
Based on the statistics before the game (e.g., for the pre-training data, we used the 2014/2015 season statistics) and the tracking data, we computed the probabilities of successful shots for each zone and the distances for each player. We computed the probability of the player who attempted shots less than 10 times as the probability of the same position player (i.e., guard, forward, center, guard/forward, and forward/center based on the registration information from the NBA 2014/2015 season). It should be noted that there are some strategies of a good shot in basketball that differ depending on the court location and context, for example, 2 pointers and 3 pointers. Note that, unfortunately, we can access those for only two areas (2-point and 3-point areas) with four distance categories, thus we computed the shot success probability at the restricted area, in-the-paint, and mid-range using that at the 2-point area. Based on the above definitions, for pre-training data, there were 13,681 shot successes, 15,443 shot failures, 5,572 turnovers, 16,976 effective attacks, and 17,720 ineffective attacks. For training data, there were 4,677 shot successes, 5,092 shot failures, 1,691 turnovers, 5,602 effective attacks, and 5,858 ineffective attacks. For test data, there were 517 shot successes, 577 shot failures, 211 turnovers, 664 effective attacks, and 641 ineffective attacks. The probabilities of scoring, given the attack was effective and ineffective, were 0.463/0.415/0.417 and 0.328/0.402/0.374 for pre-training, training, and test data, respectively. We confirmed that the effective attack had a higher probability of a successful shot than the ineffective attack.
After the computation of the attack effectiveness, we predict the effective attacks at the next time stamp using the pre-training samples and a logistic regression. In the soccer domain, there has been some work to evaluate players and teams (e.g., [80, 81]) based on the prediction model (i.e., classifier) on the assumption that a good play is a play that will bring good outcomes (e.g., score and ball recovery) in the future. These approaches can transform a discrete value (i.e., an outcome) into a continuous value (e.g., a probability). According to these papers, we also predict the effective attack at the next time stamp. To verify the prediction accuracy, we compared the accuracy of the logistic regression, LightGBM [82], which is a popular classifier using a highly efficient gradient boosting decision tree, and prediction with all effective attacks. For the training data, the accuracies of logistic regression, LightGBM, and the prediction with all the same labels were 0.838, 0.838, and 0.731, respectively. For the test data, these were 0.679, 0.676, and 0.568, respectively. We confirmed that the logistic regression had competitive performance compared with LightGBM, and higher accuracy than the prediction with all the same labels, even maintaining higher interpretability.
M Additional analysis in basketball dataset
As additional analysis, we indicate endpoint errors and distributions of long-term covariate prediction for basketball data. Results in Table IV that the tendency of the endpoint prediction error for all models is similar to the mean prediction error, in which our approach (TV-CRN and TGV-CRN) show the best performance. In addition, the distribution of the player velocity in Fig. 8 shows that our approach without theory-based computation had a wider distribution like ground truth than other models, and those with theory-based computation had less zero-velocity bins like ground truth than other models.
| at endpoint | |
| RNN | 1.637 0.0096 |
| DSW [7] | — |
| GCRN [8] | — |
| GCRNX | 2.266 0.0138 |
| GV-CRN | 1.937 0.0116 |
| TG-CRN | 1.482 0.0090 |
| TV-CRN | 1.566 0.0094 |
| TGV-CRN (full) | 1.510 0.0093 |
N Convergence in the learning of our models
We illustrate the change in the validation losses of our models over the course of training epochs as shown in Figs. 9, 10, and 11. Compared with CARLA dataset results, which show better outcome and covariate prediction results than other datasets, those in Boid and NBA datasets sometimes show unstable learning curves, but most of the models finally show convergence in all datasets. To perform fair comparisons among the models, we trained all models with 20 epochs.
References
- [1] T. A. Glass, S. N. Goodman, M. A. Hernán, and J. M. Samet, “Causal inference in public health,” Annual Review of Public Health, vol. 34, pp. 61–75, 2013.
- [2] N. Baum-Snow and F. Ferreira, “Causal inference in urban and regional economics,” in Handbook of regional and urban economics. Elsevier, 2015, vol. 5, pp. 3–68.
- [3] P. Wang, W. Sun, D. Yin, J. Yang, and Y. Chang, “Robust tree-based causal inference for complex ad effectiveness analysis,” in Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, 2015, pp. 67–76.
- [4] B. Lim, A. M. Alaa, and M. van der Schaar, “Forecasting treatment responses over time using recurrent marginal structural networks.” Advances in Neural Information Processing Systems, vol. 18, pp. 7483–7493, 2018.
- [5] I. Bica, A. M. Alaa, J. Jordon, and M. van der Schaar, “Estimating counterfactual treatment outcomes over time through adversarially balanced representations,” in International Conference on Learning Representations, 2020.
- [6] I. Bica, A. Alaa, and M. Van Der Schaar, “Time series deconfounder: Estimating treatment effects over time in the presence of hidden confounders,” in International Conference on Machine Learning. PMLR, 2020, pp. 884–895.
- [7] R. Liu, C. Yin, and P. Zhang, “Estimating individual treatment effects with time-varying confounders,” in 2020 IEEE International Conference on Data Mining (ICDM). IEEE, 2020, pp. 382–391.
- [8] J. Ma, R. Guo, C. Chen, A. Zhang, and J. Li, “Deconfounding with networked observational data in a dynamic environment,” in Proceedings of the 14th ACM International Conference on Web Search and Data Mining, 2021, pp. 166–174.
- [9] T. Vicsek, A. Czirók, E. Ben-Jacob, I. Cohen, and O. Shochet, “Novel type of phase transition in a system of self-driven particles,” Physical Review Letters, vol. 75, no. 6, pp. 1226–1229, 1995.
- [10] I. D. Couzin, J. Krause, R. James, G. D. Ruxton, and N. R. Franks, “Collective memory and spatial sorting in animal groups,” Journal of Theoretical Biology, vol. 218, no. 1, pp. 1–11, 2002.
- [11] K. Fujii, T. Kawasaki, Y. Inaba, and Y. Kawahara, “Prediction and classification in equation-free collective motion dynamics,” PLoS Computational Biology, vol. 14, no. 11, p. e1006545, 2018.
- [12] K. Fujii, N. Takeishi, M. Hojo, Y. Inaba, and Y. Kawahara, “Physically-interpretable classification of network dynamics for complex collective motions,” Scientific Reports, vol. 10, no. 3005, 2020.
- [13] R. A. Yeh, A. G. Schwing, J. Huang, and K. Murphy, “Diverse generation for multi-agent sports games,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4610–4619.
- [14] K. Fujii, K. Takeuchi, A. Kuribayashi, N. Takeishi, Y. Kawahara, and K. Takeda, “Estimating counterfactual treatment outcomes over time in multi-vehicle simulation,” in Proceedings of the 30th International Conference on Advances in Geographic Information Systems (SIGSPATIAL’22), 2022.
- [15] J. Chung, K. Kastner, L. Dinh, K. Goel, A. C. Courville, and Y. Bengio, “A recurrent latent variable model for sequential data,” in Advances in Neural Information Processing Systems 28, 2015, pp. 2980–2988.
- [16] T. Kipf, E. Fetaya, K.-C. Wang, M. Welling, and R. Zemel, “Neural relational inference for interacting systems,” in International Conference on Machine Learning, 2018, pp. 2688–2697.
- [17] D. B. Rubin, “Bayesian inference for causal effects: The role of randomization,” The Annals of statistics, pp. 34–58, 1978.
- [18] J. M. Robins and M. A. Hernán, “Estimation of the causal effects of time-varying exposures,” in Longitudinal Data Analysis, G. Fitzmaurice, M. Davidian, G. Verbeke et al., Eds. New York, NY: Chapman & Hall/CRC Press, 2009, pp. 553–597.
- [19] J. M. Robins, M. A. Hernan, and B. Brumback, “Marginal structural models and causal inference in epidemiology,” 2000.
- [20] M. A. Hernán and J. M. Robins, Causal inference. CRC Boca Raton, FL, 2010.
- [21] J. Pearl, Causality. Cambridge university press, 2009.
- [22] E. Zhan, S. Zheng, Y. Yue, L. Sha, and P. Lucey, “Generating multi-agent trajectories using programmatic weak supervision,” in International Conference on Learning Representations, 2019.
- [23] M. Fraccaro, S. K. Sønderby, U. Paquet, and O. Winther, “Sequential neural models with stochastic layers,” in Advances in Neural Information Processing Systems 29, 2016, pp. 2199–2207.
- [24] A. G. A. P. Goyal, A. Sordoni, M.-A. Côté, N. R. Ke, and Y. Bengio, “Z-forcing: Training stochastic recurrent networks,” in Advances in Neural Information Processing Systems 30, 2017, pp. 6713–6723.
- [25] M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. R. Salakhutdinov, and A. J. Smola, “Deep sets,” Advances in Neural Information Processing Systems, vol. 30, pp. 3394––3404, 2017.
- [26] N. Takeishi and A. Kalousis, “Physics-integrated variational autoencoders for robust and interpretable generative modeling,” Advances in Neural Information Processing Systems, vol. 34, pp. 14 809–14 821, 2021.
- [27] K. Fujii, N. Takeishi, Y. Kawahara, and K. Takeda, “Decentralized policy learning with partial observation and mechanical constraints for multiperson modeling,” Neural Networks, vol. 171, pp. 40–52, 2024.
- [28] P. R. Rosenbaum and D. B. Rubin, “The central role of the propensity score in observational studies for causal effects,” Biometrika, vol. 70, no. 1, pp. 41–55, 1983.
- [29] U. Shalit, F. D. Johansson, and D. Sontag, “Estimating individual treatment effect: generalization bounds and algorithms,” in International Conference on Machine Learning. PMLR, 2017, pp. 3076–3085.
- [30] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain-adversarial training of neural networks,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016.
- [31] J. Robins, “A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survivor effect,” Mathematical Modelling, vol. 7, no. 9-12, pp. 1393–1512, 1986.
- [32] J. M. Robins, “Correcting for non-compliance in randomized trials using structural nested mean models,” Communications in Statistics-Theory and methods, vol. 23, no. 8, pp. 2379–2412, 1994.
- [33] Y. Xu, Y. Xu, and S. Saria, “A bayesian nonparametric approach for estimating individualized treatment-response curves,” in Machine Learning for Healthcare Conference. PMLR, 2016, pp. 282–300.
- [34] P. Schulam and S. Saria, “Reliable decision support using counterfactual models,” Advances in Neural Information Processing Systems, vol. 30, pp. 1697–1708, 2017.
- [35] H. Soleimani, A. Subbaswamy, and S. Saria, “Treatment-response models for counterfactual reasoning with continuous-time, continuous-valued interventions,” in 33rd Conference on Uncertainty in Artificial Intelligence, UAI 2017. AUAI Press Corvallis, OR, 2017.
- [36] J. Roy, K. J. Lum, and M. J. Daniels, “A bayesian nonparametric approach to marginal structural models for point treatments and a continuous or survival outcome,” Biostatistics, vol. 18, no. 1, pp. 32–47, 2017.
- [37] J. L. Hill, “Bayesian nonparametric modeling for causal inference,” Journal of Computational and Graphical Statistics, vol. 20, no. 1, pp. 217–240, 2011.
- [38] S. Wager and S. Athey, “Estimation and inference of heterogeneous treatment effects using random forests,” Journal of the American Statistical Association, vol. 113, no. 523, pp. 1228–1242, 2018.
- [39] A. Alaa and M. Schaar, “Limits of estimating heterogeneous treatment effects: Guidelines for practical algorithm design,” in International Conference on Machine Learning. PMLR, 2018, pp. 129–138.
- [40] F. Johansson, U. Shalit, and D. Sontag, “Learning representations for counterfactual inference,” in International Conference on Machine Learning. PMLR, 2016, pp. 3020–3029.
- [41] L. Yao, S. Li, Y. Li, M. Huai, J. Gao, and A. Zhang, “Representation learning for treatment effect estimation from observational data,” Advances in Neural Information Processing Systems, vol. 31, 2018.
- [42] J. Yoon, J. Jordon, and M. Van Der Schaar, “Ganite: Estimation of individualized treatment effects using generative adversarial nets,” in International Conference on Learning Representations, 2018.
- [43] C. Shi, D. M. Blei, and V. Veitch, “Adapting neural networks for the estimation of treatment effects,” in Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019, pp. 2507–2517.
- [44] P. Grecov, A. N. Prasanna, K. Ackermann, S. Campbell, D. Scott, D. I. Lubman, and C. Bergmeir, “Probabilistic causal effect estimation with global neural network forecasting models,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–15, July 2022.
- [45] M. Abroshan, K. H. Yip, C. Tekin, and M. van der Schaar, “Conservative policy construction using variational autoencoders for logged data with missing values,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–11, 2022.
- [46] Q. Li, Z. Wang, S. Liu, G. Li, and G. Xu, “Causal optimal transport for treatment effect estimation,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2021.
- [47] Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,” in Proceedings of the 28th International Joint Conference on Artificial Intelligence, 2019, pp. 1907–1913.
- [48] Q. Zhang, J. Chang, G. Meng, S. Xiang, and C. Pan, “Spatio-temporal graph structure learning for traffic forecasting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 01, 2020, pp. 1177–1185.
- [49] K. Takeuchi, R. Nishida, H. Kashima, and M. Onishi, “Causal effect estimation on hierarchical spatial graph data,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 2145–2154.
- [50] Z. Guo, T. Xiao, C. Aggarwal, H. Liu, and S. Wang, “Counterfactual learning on graphs: A survey,” arXiv preprint arXiv:2304.01391, 2023.
- [51] N. Seedat, F. Imrie, A. Bellot, Z. Qian, and M. van der Schaar, “Continuous-time modeling of counterfactual outcomes using neural controlled differential equations,” in International Conference on Machine Learning. PMLR, 2022, pp. 19 497–19 521.
- [52] S. Jiang, Z. Huang, X. Luo, and Y. Sun, “Cf-gode: Continuous-time causal inference for multi-agent dynamical systems,” arXiv preprint arXiv:2306.11216, 2023.
- [53] G. Chen, J. Li, J. Lu, and J. Zhou, “Human trajectory prediction via counterfactual analysis,” arXiv preprint arXiv:2107.14202, 2021.
- [54] K. Fujii, N. Takeishi, K. Tsutsui, E. Fujioka, N. Nishiumi, R. Tanaka, M. Fukushiro, K. Ide, H. Kohno, K. Yoda, S. Takahashi, S. Hiryu, and Y. Kawahara, “Learning interaction rules from multi-animal trajectories via augmented behavioral models,” Advances in Neural Information Processing Systems, vol. 34, pp. 11 108–11 122, 2021.
- [55] H. Nakahara, K. Takeda, and K. Fujii, “Estimating the effect of hitting strategies in baseball using counterfactual virtual simulation with deep learning,” International Journal of Computer Science in Sport, vol. 22, no. 1, pp. 1–12, January 2022.
- [56] M. Teranishi, K. Tsutsui, K. Takeda, and K. Fujii, “Evaluation of creating scoring opportunities for teammates in soccer via trajectory prediction,” in International Workshop on Machine Learning and Data Mining for Sports Analytics. NY: Springer, 2022, pp. 53–73.
- [57] A. Lerer, S. Gross, and R. Fergus, “Learning physical intuition of block towers by example,” in International conference on machine learning. PMLR, 2016, pp. 430–438.
- [58] G. Liu and O. Schulte, “Deep reinforcement learning in ice hockey for context-aware player evaluation,” in Proceedings of the 27th International Joint Conference on Artificial Intelligence, 2018, pp. 3442–3448.
- [59] G. Liu, Y. Luo, O. Schulte, and T. Kharrat, “Deep soccer analytics: learning an action-value function for evaluating soccer players,” Data Mining and Knowledge Discovery, vol. 34, no. 5, pp. 1531–1559, 2020.
- [60] P. Rahimian, J. Van Haaren, T. Abzhanova, and L. Toka, “Beyond action valuation: A deep reinforcement learning framework for optimizing player decisions in soccer,” in 16th Annual MIT Sloan Sports Analytics Conference. Boston, MA, USA: MIT, 2022, p. 25.
- [61] H. Nakahara, K. Tsutsui, K. Takeda, and K. Fujii, “Action valuation of on-and off-ball soccer players based on multi-agent deep reinforcement learning,” IEEE Access, vol. 11, pp. 131 237–131 244, 2023.
- [62] V. Ramanishka, Y.-T. Chen, T. Misu, and K. Saenko, “Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7699–7707.
- [63] T. You and B. Han, “Traffic accident benchmark for causality recognition,” in European Conference on Computer Vision. NY: Springer, 2020, pp. 540–556.
- [64] D. McDuff, Y. Song, J. Lee, V. Vineet, S. Vemprala, N. Gyde, H. Salman, S. Ma, K. Sohn, and A. Kapoor, “Causalcity: Complex simulations with agency for causal discovery and reasoning,” arXiv preprint arXiv:2106.13364, 2021.
- [65] K. Takeuchi, R. Nishida, H. Kashima, and M. Onishi, “Grab the reins of crowds: Estimating the effects of crowd movement guidance using causal inference,” in Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, 2021, pp. 1290–1298.
- [66] D. R. Yam and M. J. Lopez, “What was lost? a causal estimate of fourth down behavior in the national football league,” Journal of Sports Analytics, vol. 5, no. 3, pp. 153–167, 2019.
- [67] A. Toumi and M. Lopez, “From grapes and prunes to apples and apples: Using matched methods to estimate optimal zone entry decision-making in the national hockey league,” in Carnegie Mellon Sports Analytics Conference 2019, 2019.
- [68] C. Gibbs, R. Elmore, and B. Fosdick, “The causal effect of a timeout at stopping an opposing run in the nba,” arXiv preprint arXiv:2011.11691, 2020.
- [69] H. Nakahara, K. Takeda, and K. Fujii, “Pitching strategy evaluation via stratified analysis using propensity score,” Journal of Quantitative Analysis in Sports, vol. 19, no. 2, pp. 91–102, 2023.
- [70] D. M. Vock and L. F. B. Vock, “Estimating the effect of plate discipline using a causal inference framework: an application of the g-computation algorithm,” Journal of Quantitative Analysis in Sports, vol. 14, no. 2, pp. 37–56, 2018.
- [71] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” in Conference on Robot Learning. PMLR, 2017, pp. 1–16.
- [72] K. Cho, B. Van Merriënboer, D. Bahdanau, and Y. Bengio, “On the properties of neural machine translation: Encoder-decoder approaches,” arXiv preprint arXiv:1409.1259, 2014.
- [73] C. J. Willmott and K. Matsuura, “Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance,” Climate Research, vol. 30, no. 1, pp. 79–82, 2005.
- [74] S. Kato, E. Takeuchi, Y. Ishiguro, Y. Ninomiya, K. Takeda, and T. Hamada, “An open approach to autonomous vehicles,” IEEE Micro, vol. 35, no. 6, pp. 60–68, 2015.
- [75] C. W. Reynolds, “Flocks, herds and schools: A distributed behavioral model,” in Proceedings of the 14th annual Conference on Computer Graphics and Interactive Techniques, 1987, pp. 25–34.
- [76] K. Fujii, Y. Inaba, and Y. Kawahara, “Koopman spectral kernels for comparing complex dynamics: Application to multiagent sport plays,” in European Conference on Machine Learning and Knowledge Discovery in Databases (ECML-PKDD’17). NY: Springer, 2017, pp. 127–139.
- [77] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations, 2015.
- [78] M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y. Ng et al., “Ros: an open-source robot operating system,” in ICRA workshop on open source software, vol. 3, no. 3.2. Kobe, Japan, 2009, p. 5.
- [79] K. Fujii, K. Yokoyama, T. Koyama, A. Rikukawa, H. Yamada, and Y. Yamamoto, “Resilient help to switch and overlap hierarchical subsystems in a small human group,” Scientific Reports, vol. 6, 2016.
- [80] T. Decroos, L. Bransen, J. Van Haaren, and J. Davis, “Actions speak louder than goals: Valuing player actions in soccer,” in KDD, 2019, pp. 1851–1861.
- [81] K. Toda, M. Teranishi, K. Kushiro, and K. Fujii, “Evaluation of soccer team defense based on prediction models of ball recovery and being attacked,” PLoS One, vol. 17, no. 1, p. e0263051, 2022.
- [82] G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” Advances in Neural Information Processing Systems, vol. 30, pp. 3146–3154, 2017.