Estimating mixed memberships in multi-layer networks
Abstract
Community detection in multi-layer networks has emerged as a crucial area of modern network analysis. However, conventional approaches often assume that nodes belong exclusively to a single community, which fails to capture the complex structure of real-world networks where nodes may belong to multiple communities simultaneously. To address this limitation, we propose novel spectral methods to estimate the common mixed memberships in the multi-layer mixed membership stochastic block model. The proposed methods leverage the eigen-decomposition of three aggregate matrices: the sum of adjacency matrices, the debiased sum of squared adjacency matrices, and the sum of squared adjacency matrices. We establish rigorous theoretical guarantees for the consistency of our methods. Specifically, we derive per-node error rates under mild conditions on network sparsity, demonstrating their consistency as the number of nodes and/or layers increases under the multi-layer mixed membership stochastic block model. Our theoretical results reveal that the method leveraging the sum of adjacency matrices generally performs poorer than the other two methods for mixed membership estimation in multi-layer networks. We conduct extensive numerical experiments to empirically validate our theoretical findings. For real-world multi-layer networks with unknown community information, we introduce two novel modularity metrics to quantify the quality of mixed membership community detection. Finally, we demonstrate the practical applications of our algorithms and modularity metrics by applying them to real-world multi-layer networks, demonstrating their effectiveness in extracting meaningful community structures.
keywords:
Multi-layer networks, community detection , spectral methods , mixed membership, modularity1 Introduction
Multi-layer networks have emerged as a powerful tool for describing complex real-world systems. Unlike single-layer networks, these structures consist of multiple layers, where nodes represent entities and edges represent their interactions [30, 24, 5]. In this paper, we focus on multi-layer networks with the same nodes set in all layers and nodes solely interacting within their respective layers, excluding any cross-layer connections. Such networks are ubiquitous, spanning from social networks to transportation systems, biological networks, and trade networks. For instance, in social networks, individuals tend to form connections within different platforms (e.g., Facebook, Twitter, WeChat, LinkedIn), while cross-platform connections are typically not allowed. In transportation networks, layers might represent different modes of transportation (roads, railways, airways), with nodes corresponding to locations and edges indicating the availability of a specific mode between two locations [5]. The absence of cross-layer connections indicates the inability to directly switch modes without intermediate stops. Biological networks also exhibit rich multi-layer structures. In gene regulatory networks, layers could represent different types of gene interactions, with nodes representing genes and edges depicting their specific interactions [31, 4, 46]. The absence of cross-layer connections underscores the specialized nature of interactions within each layer and their vital role in governing cellular functions. The FAO-trade multi-layer network gathers trade relationships between countries across various products sourced from the Food and Agriculture Organization of the United Nations [10]. Figure 1 illustrates the networks of the first three products within this dataset.
Community detection in multi-layer networks is a crucial analytical tool, revealing latent structures within networks [23, 18]. A community (also known as a group, cluster, or block) typically comprises nodes more densely interconnected than those outside [35, 36, 11, 12, 19]. In social networks, individuals often form distinct communities based on interests, occupations, or locations. For instance, on Facebook, users might belong to hobby-based communities like photography or hiking, identifiable by dense interaction patterns among members. In transportation networks, communities emerge due to geographical proximity or functional similarity. For instance, cities might form communities linked by tightly integrated railways. In practical applications, a node can simultaneously belong to multiple communities. For example, in social networks, an individual may be a member of several different social groups. Similarly, in transportation networks, a specific location can function as a hub for multiple modes of transportation, bridging diverse communities. Likewise, in biological networks, a gene can belong to several overlapping communities, participating in a wide range of processes.
In the last few years, community detection in multi-layer networks, where each node belongs exclusively to a single community, has attracted considerable attention. For instance, several studies have been proposed under the multi-layer stochastic block model (MLSBM), a model that assumes the network for each layer can be modeled by the well-known stochastic block model (SBM) [17]. MLSBM also assumes that the community information is common to all layers. Under the framework within MLSBM, [16] studied the consistent community detection for maximum likelihood estimate and a spectral method designed by running the K-means algorithm on a few eigenvectors of the sum of adjacency matrices when only the number of layers grows. [37] studied the consistency of co-regularized spectral clustering, orthogonal linked matrix factorization, and the spectral method in [16] as both the number of nodes and the number of layers grow within the MLSBM context. Moreover, [26] established consistency results for a least squares estimation of community memberships within the MLSBM framework. Recently, [27] studied the consistency of a bias-adjusted (i.e., debiased) spectral clustering method using a novel debiased sum of squared adjacency matrices under MLSBM. Their numerical experiments demonstrated that this approach significantly outperforms the spectral method proposed by [16]. Also see [39, 21, 9, 43] for other recent works exploring variants of MLSBM.
However, the MLSBM model has one significant limitation, being tailored exclusively for multi-layer networks with non-overlapping communities. The mixed membership stochastic block (MMSB) model [1] is a popular statistical model for capturing mixed community memberships in single-layer networks. Under MMSB, some methods have been developed to estimate mixed memberships for single-layer networks generated from MMSB, including variational expectation-maximization [1, 15], nonnegative matrix factorization [40, 45], tensor decomposition [2], and spectral clustering [29, 20]. In this paper, we consider the problem of estimating nodes’ common community memberships in multi-layer networks generated from the multi-layer mixed membership stochastic block (MLMMSB) model, a multi-layer version of MMSB. The main contributions of this paper are summarized as follows:
-
1.
We introduce three spectral methods for estimating mixed memberships in multi-layer networks generated from MLMMSB. These methods employ vertex-hunting algorithms on a few selected eigenvectors of three aggregate matrices: the sum of adjacency matrices, the debiased sum of squared adjacency matrices, and the sum of squared adjacency matrices.
-
2.
We establish per-node error rates for these three methods under mild conditions on network sparsity, demonstrating their consistent mixed membership estimation as the number of nodes and/or layers increases within the MLMMSB framework. Our theoretical analysis reveals that the method utilizing the debiased sum of squared adjacency matrices consistently outperforms the method using the sum of squared adjacency matrices in terms of error rate. Additionally, both methods generally exhibit lower error rates than the method based on the sum of adjacency matrices. This underscores the advantage of debiased spectral clustering in mixed membership community detection for multi-layer networks. To the best of our knowledge, this is the first work to estimate mixed memberships using the above three aggregate matrices and the first work to establish consistency results within the MLMMSB framework.
-
3.
To assess the quality of mixed membership community detection in multi-layer networks, we introduce two novel modularity metrics: fuzzy sum modularity and fuzzy mean modularity. The first is derived from computing the fuzzy modularity of the sum of adjacency matrices, while the second is obtained by averaging the fuzzy modularity of adjacency matrices across individual layers. To the best of our knowledge, our two modularity metrics are the first to measure the quality of mixed membership community detection in multi-layer networks.
-
4.
We conduct extensive simulations to validate our theoretical findings and demonstrate the practical effectiveness of our methods and metrics through real-world multi-layer network applications.
The remainder of this paper is structured as follows: Section 2 introduces the model, followed by Section 3 outlining the methods developed. Section 4 presents the theoretical results. Subsequently, Section 5 includes experimental results on computer-generated multi-layer networks, while Section 6 focuses on real-world multi-layer networks. Lastly, Section 7 concludes the paper and technical proofs are provided in A.
Notation. We employ the notation to denote the set . Furthermore, stands for the -by- identity matrix. For a vector , represents its norm. When considering a matrix and an index set that is a subset of , refers to the sub-matrix of comprising the rows indexed by . Additionally, denotes the transpose of , is its Frobenius norm, represents the maximum absolute row sum, signifies the maximum row-wise norm, gives its rank, and stands for the -th largest eigenvalue of in magnitude. The notation is used to denote expectation, while represents probability. Finally, is defined as the indicator vector with a 1 in the -th position and zeros elsewhere.
2 Multi-layer mixed membership stochastic block model
Throughout, we consider undirected and unweighted multi-layer networks with common nodes and layers. For the -th layer, let the symmetric matrix be its adjacency matrix such that if there is an edge connecting node and node and otherwise, for all , i.e., . Additionally, we allow for the possibility of self-edges (loops) in this paper. We assume that the multi-layer network consists of common communities
| (1) |
Throughout, we assume that the number of communities is known in this paper. The challenging task of theoretically estimating in multi-layer networks exceeds the scope of this paper. Let be the membership matrix such that represents the “weight” that node belongs to the -th community for . Suppose that satisfies the following condition
| (2) |
We call node a “pure” node if one entry of is 1 while the other elements are zeros and a “mixed” node otherwise. Assume that
| (3) |
Based on Equation (3), let be the index set of pure nodes such that with being an arbitrary pure node in the -th community for . Similar to [29], without loss of generality, we reorder the nodes such that .
Suppose that all the layers share a common mixed membership matrix but with possibly different edge probabilities. In particular, we work with a multi-layer version of the popular mixed membership stochastic block model (MMSB) [1]. To be precise, we define the multi-layer MMSB below:
Definition 1.
Since can vary for different , generated by Equation (4) may have different expectation for . Notably, when , the MLMMSB model degenerates to the popular MMSB model. When all nodes are pure, MLMMSB reduces to the MLSBM studied in previous works [16, 37, 26, 27]. Define . Equation (4) says that MLMMSB is parameterized by , and . For brevity, we denote MLMMSB defined by Equation (4) as . Since , we see that decreasing the value of results in a sparser multi-layer network, i.e., controls the overall sparsity of the multi-layer network. For this reason, we call the sparsity parameter in this paper. We allow the sparsity parameter to go to zero by either increasing the number of nodes , the number of layers , or both simultaneously. We will study the impact of on the performance of the proposed methods by considering in our theoretical analysis. The primal goal of community detection within the MLMMSB framework is to accurately estimate the common mixed membership matrix from the observed adjacency matrices . This estimation task is crucial for understanding the underlying community structure in multi-layer networks.
3 Spectral methods for mixed membership estimation
In this section, we propose three spectral methods designed to estimate the mixed membership matrix within the MLMMSB model for multi-layer networks in which nodes may belong to multiple communities with different weights. We recall that is the expectation of the -th observed adjacency matrix for and contains the common community memberships for all nodes. To provide intuitions of the designs of our methods, we consider the oracle case where are directly observed. First, we define two distinct aggregate matrices formed by : and , where the former represents the sum of all expectation adjacency matrices, the latter is the sum of all squared expectation adjacency matrices, and both matrices contain the information about the mixed memberships of nodes in the multi-layer network since and . Since , it is easy to see that if and if . Assuming that the number of communities is much smaller than the number of nodes , we observe that and possess low-dimensional structure. This low-rank property is crucial for the development of our spectral methods, as it allows us to efficiently extract meaningful information from the high-dimensional data. Building on these insights, we present the following lemma that characterizes the geometries of the two aggregate matrices and . This lemma forms the theoretical foundation for our methods, enabling us to develop accurate and computationally efficient algorithms for estimating the mixed membership matrix within the MLMMSB model.
Lemma 1.
(Ideal Simplexes) Under the model , depending on the conditions imposed on the set , we arrive at the following conclusions:
-
1.
When : Let denote the top eigen-decomposition of where the matrix satisfies and the -th diagonal entry of the diagonal matrix represents the -th largest eigenvalue (in magnitude) of for . Then, we have .
-
2.
When : Let represent the top eigen-decomposition of where the matrix fulfills and the -th diagonal entry of the diagonal matrix is the -th largest eigenvalue (in magnitude) of for . In this case, we have .
Recall that satisfies Equations (2) and (3), by according to Lemma 1, the rows of forms a -simplex in , referred to as the Ideal Simplex of ( for brevity). Notably, the rows of serve as its vertices. Given that satisfies Equations (2) and (3), and , it follows that for . This implies that is a convex linear combination of the vertices of with weights determined by . Consequently, a pure row of (call pure row if node is a pure node and mixed row otherwise) lies on one of the vertices of the simplex, while a mixed row occupies an interior position within the simplex. Such simplex structure is also observed in mixed membership estimation for community detection in single-layer networks [29, 20, 41] and in topic matrix estimation for topic modeling [22]. Notably, the mixed membership matrix can be precisely recovered by setting provided that the corner matrix is obtainable. Thanks to the simplex structure in , the vertices of the simplex can be found by a vertex-hunting technique such as the successive projection (SP) algorithm [3, 13, 14]. Applying SP to all rows of with clusters enables the exact recovery of the corner matrix . Details of the SP algorithm are provided in Algorithm 1 [14]. SP can efficiently find the distinct pure rows of . Similarly, also exhibits a simplex structure, leading to the recovery of via by Lemma 1. Consequently, applying the SP algorithm to with clusters also yields an exact reconstruction of the mixed membership matrix .
Remark 1.
Let represent another index set, consisting of arbitrary pure nodes from respective communities for . According to the proof of Lemma 1, we have . Furthermore, this implies that , which in turn signifies that is equivalent to . In essence, the corner matrix remains unchanged regardless of the specific pure nodes chosen to form the index set. An analogous argument holds for .
For real-world multi-layer networks, the adjacency matrices are observed instead of their expectations. For our first method, set . We have under MLMMSB. Subsequently, let be the top eigen-decomposition of where is an orthogonal matrix with and is a diagonal matrix with its -th diagonal element representing the -th largest eigenvalue of in magnitude for . Given that the expectation of is , it follows that can be interpreted as a slightly perturbed version of . To proceed, we apply the SP algorithm to all rows of with clusters, resulting in an estimated index set of pure nodes, denoted as . We infer that should closely approximate the corner matrix . Finally, we estimate the mixed membership matrix by computing . Our first algorithm, called “Successive projection on the sum of adjacency matrices” (SPSum, Algorithm 1) summarises the above analysis. It efficiently estimates the mixed membership matrix by executing the SP algorithm on the top eigenvectors of .
In our second methodological approach, we define the aggregate matrix as the sum of the squared adjacency matrices, adjusted for bias, specifically as . Here, represents a diagonal matrix, with its -th diagonal entry being the degree of node in layer , i.e., for and . The matrix was first introduced in [27] within the context of MLSBM, serving as a debiased estimate of the sum of squared adjacency matrices. This debiasing is necessary as alone provides a biased approximation of . By subtracting the diagonal matrix from each squared adjacency matrix, we can effectively remove this bias, rendering a reliable estimator of as demonstrated in [27]. Subsequently, let be the top eigen-decomposition of . Given that provides a close approximation of , applying the SP algorithm to all rows of yields a reliable estimate of the corner matrix . In summary, our second spectral method, centered on , is outlined in Algorithm 2. We refer to this method as “Successive projection on the debiased sum of squared adjacency matrices” (SPDSoS for brevity).
The third method utilizes the summation of squared adjacency matrices, expressed as , as a substitute for in Algorithm 2. Notably, this approach excludes the crucial bias-removal step inherent in . We call this method “Successive projection on the sum of squared adjacency matrices”, abbreviated as SPSoS. In the subsequent section, we will demonstrate that SPDSoS consistently outperforms SPSoS, and both methods are generally theoretically superior to SPSum.
4 Main results
In this section, we demonstrate the consistency of our methods by presenting their theoretical upper bounds for per-node error rates as the number of nodes and/or the number of layers increases within the context of the MLMMSB model. Assumption 1 provides a prerequisite lower bound for the sparsity parameter to ensure the theoretical validity of SPSum.
Assumption 1.
(sparsity requirement for SPSum) , where .
In Assumption 1, the choice of plays a crucial role in determining the level of sparsity regime. Since , has an upper bound . However, to consider an even sparser scenario, we introduce a constant positive value that is strictly less than and remains fixed regardless of the growth of or . This ensures that the aggregate number of edges connecting any two nodes and across all layers remains below even in the limit as or approaches infinity. Under these conditions, Assumption 1 is revised to reflect a more stringent requirement: . This revised assumption characterizes the most challenging scenario for community detection. To establish the theoretical bounds for SPSum, we need the following requirement on .
Assumption 2.
(SPSum’s requirement on ) for some constant .
Assumption 2 is mild as represents the smallest singular value resulting from the summation of matrices, and it is reasonable to presume that is on the order of . To simplify our theoretical analysis, we also introduce the following condition:
Condition 1.
and .
Condition 1 is mild as implies that the number of communities remains constant, while ensures the balance of community sizes, where the size of the -th community is defined as for . Our main result for SPSum offers an upper bound on its per-node error rate in terms of , and under the MLMMSB framework.
Theorem 1.
According to Theorem 1, it becomes evident that as (and/or ) approaches infinity, SPSum’s error rate diminishes to zero, highlighting the advantage of employing multiple layers in community detection and SPSum’s consistent community detection. Additionally, Theorem 1 says that to attain a sufficiently low error rate for SPSum, the sparsity parameter must decrease at a rate slower than (i.e., must be significantly greater than ). This finding aligns with the sparsity requirement stated in Assumption 1 for SPSum. It is noteworthy that the theoretical upper bound for SPSum’s per-node error rate, given as in Theorem 1, is independent of how we select the value of in Assumption 1. This underscores the generality of our theoretical findings.
The assumption 3 stated below establishes the lower bound of the sparsity parameter that ensures the consistency of both SPDSoS and SPSoS.
Assumption 3.
(sparsity requirement for SPDSoS and SPSoS) , where .
Analogous to Assumption 1, when considering an extremely sparse scenario where does not exceed a positive constant , Assumption 3 dictates that must satisfy . This requirement aligns with the sparsity requirement in Theorem 1 of [27]. The subsequent assumption serves a similar purpose to Assumption 2.
Assumption 4.
(SPDSoS’s and SPSoS’s requirement on ) for some constant .
Theorem 2.
Theorem 3.
(Per-node error rate of SPSoS) Under the same conditions as in Theorem 2 and suppose , let be obtained from the SPSoS algorithm, with probability at least , we have
According to Theorems 2 and 3, it is evident that both SPDSoS and SPSoS enjoy consistent mixed membership estimation. This consistency arises from the fact that their per-node error rates tend towards zero as the number of nodes (and/or the number of layers ) approaches infinity. Furthermore, similar to Theorem 1, the theoretical bounds outlined in Theorems 2 and 3 are independent of the selection of in Assumption 3.
By the proof of Theorem 3, we know that SPSoS’s theoretical upper bound of per-node error rate is the summation of SPDSoS’s theoretical upper bound of per-node error rate and . Therefore, SPDSoS’s error rate is always smaller than that of SPSoS and this indicates the benefit of the bias-removal step in . Furthermore, to compare the theoretical performances between SPSum and SPSoS, we consider the following two simple cases:
-
1.
When SPSoS’s error rate is at the order , if SPSum significantly outperforms SPSoS, we have .
-
2.
When SPSoS’s error rate is at the order , if SPSum significantly outperforms SPSoS, we have . Since , we have . Combine with , we have .
The preceding points indicate that SPSum’s superior performance over SPSoS is limited to scenarios where the number of layers is exceptionally large ( or ). However, this requirement is unrealistic for the majority of real-world multi-layer networks. Given that SPDSoS consistently outperforms SPSoS, it follows that SPDSoS also prevails over SPSum in most scenarios. Additionally, even in the rare scenarios where SPSum significantly surpasses SPDSoS for a significantly large , Theorem 2 assures that SPDSoS’s error rate is negligible. Therefore, among these three methods, we arrive at the following conclusions: (a) SPDSoS consistently outperforms SPSoS; (b) SPSum’s significant superiority over SPDSoS and SPSoS necessitates an unreasonably high number of layers, , which is impractical for most real-world multi-layer networks. Consequently, we can confidently assert that SPDSoS and SPSoS virtually always surpass SPSum.
5 Numerical results on synthetic multi-layer networks
In this section, we evaluate the performance of our proposed methods through the utilization of computer-generated multi-layer networks. For these simulated networks, we possess knowledge of the ground-truth mixed membership matrix . To quantify the performance of each method, we employ two metrics: the Hamming error and the Relative error. The Hamming error is defined as , while the relative error is given by . Here, represents the set of all -by- permutation matrices, accounting for potential label permutations. For each parameter setting in our simulation examples, we report the average of each metric for each proposed approach across 100 independent repetitions.
For all simulations conducted below, we set and let be the number of pure nodes within each community. For mixed nodes, say node , we formulate its mixed membership vector in the following manner. Initially, we generate two random values and , where represents a random value drawn from a Uniform distribution over the interval . Subsequently, we define the mixed membership vector as . Regarding the connectivity matrices, for the -th matrix , we assign for all and . Finally, the number of nodes , the sparsity parameter , the number of layers , and the number of pure nodes within each community are independently set for each simulation.
Experiment 1: Changing . Fix and let range in. The multi-layer network becomes denser as increases. The results shown in panel (a) and panel (b) of Figure 2 demonstrate that SPDSoS performs slightly better than SPSoS, and both methods significantly outperform SPSum. Meanwhile, the error rates of SPDSoS and SPSoS decrease rapidly as the sparse parameter increases while SPSum’s error rates decrease slowly.
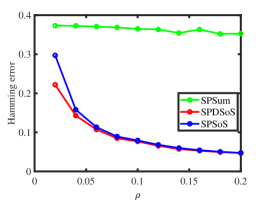
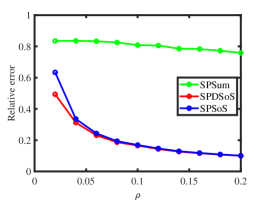
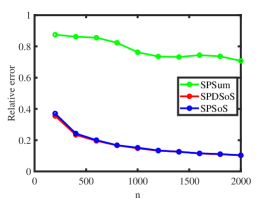
Experiment 2: Changing . Fix and let range in. More layers are observed as increases. The results are presented in panel (c) and panel (d) of Figure 2. It is evident that SPDSoS and SPSoS exhibit comparable performance, both significantly surpassing SPSum. Furthermore, as increases, SPDSoS and SPSoS demonstrate improved performance, whereas SPSum’s performance remains relatively unchanged throughout this experiment.
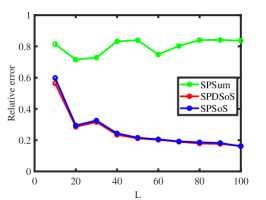
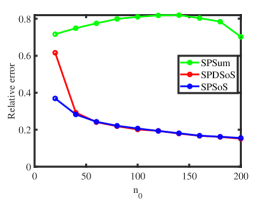
Experiment 3: Changing . Fix , let range in , and let for each choice of . Panel (e) and panel (f) of Figure 2 display the results, which demonstrate that SPDSoS and SPSoS enjoy similar performances and that both methods perform better than SPSum. Meanwhile, we also observe that the error rates of all methods decrease as increases here.
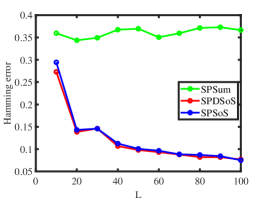
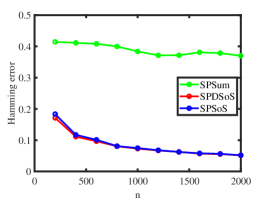
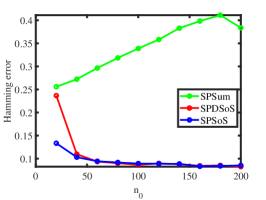
Experiment 4: Changing . Fix and let range in . The number of pure nodes increases as grows. The results are displayed in the final two panels of Figure 2. Our observations indicate that SPDSoS and SPSoS exhibit notably superior performance compared to SPSum. Furthermore, both SPDSoS and SPSoS exhibit improved performance in scenarios with a higher number of pure nodes, whereas SPSum demonstrates weaker performance in this experiment.
6 Real data applications
In this section, we demonstrate the application of our methods to multi-layer networks in the real world. The application of a mixed membership estimation algorithm to such networks consistently yields an estimated mixed membership matrix, denoted as . Notably, may vary depending on the specific algorithm used. Consequently, accurately assessing the quality of the estimated mixed membership community partition becomes a crucial problem. To address this challenge, we introduce two modularity metrics in this paper, designed to quantitatively evaluate the quality of mixed membership community detection in real-world multi-layer networks.
Recall that represents the summation of all adjacency matrices. This summation effectively quantifies the weight between nodes. Given that nodes sharing similar community memberships tend to exhibit stronger connections than those with different memberships, can be interpreted as the weighted adjacency matrix of an assortative network [33, 34]. Our fuzzy sum modularity, , is defined as follows:
where fsum stands for “fuzzy sum”, for , and . Notably, when , our fuzzy sum modularity simplifies to the fuzzy modularity introduced in Equation (14) of [32]. Furthermore, when and all nodes are pure, our modularity metric reduces to the classical Newman-Girvan modularity [36].
Our second modularity metric is the fuzzy mean modularity, defined as the average of fuzzy modularities across all layers. Here’s how it is formulated:
where fmean stands for “fuzzy mean” and represents the sum of diagonal elements in the degree matrix for layer for . When all nodes are pure, our fuzzy mean modularity simplifies to the multi-normalized average modularity introduced in Equation (3.1) of [38]. When there is only a single layer (), reduces to the fuzzy modularity described in [32]. Furthermore, if both conditions hold ( and all nodes are pure), degenerates to the classical Newman-Girvan modularity [36].
Analogous to the Newman-Girvan modularity [36], the fuzzy modularity [32], and the multi-normalized average modularity [38], a higher value of the fuzzy sum modularity indicates a better community partition. Consequently, we consistently favor a larger value of . Similarly, a larger also indicates a better community partition. To the best of our knowledge, our fuzzy sum modularity and fuzzy mean modularity are the first metrics designed to evaluate the quality of mixed membership community detection in multi-layer networks.
For real-world multi-layer networks, where the number of communities is usually unknown, we adopt the strategy introduced in [32] to estimate . Specifically, we determine by selecting the one that maximizes the fuzzy sum modularity (or the fuzzy mean modularity ). This strategy ensures that we obtain an optimal community partition based on the chosen modularity metric.
In this paper, we consider the following real-world multi-layer networks, which can be accessed at https://manliodedomenico.com/data.php:
- 1.
-
2.
C.Elegans: This data is from biology and it collects the connection of Caenorhabditis elegans [7]. It has nodes and layers with nodes denoting Caenorhabditis elegans and layers being different synaptic junctions (Electric, Chemical Monadic, and Chemical Polyadic).
-
3.
CS-Aarhus: This data is a multi-layer social network with nodes and layers, where nodes represent employees of the Computer Science department at Aarhus and layers denote different relationships (Lunch, Facebook, Coauthor, Leisure, Work) [28].
-
4.
FAO-trade: This data collects different types of trade relationships among countries from FAO (Food and Agriculture Organization of the United Nations) [10]. It has nodes and layers, where nodes represent countries, layers denote products, and edges denote trade relationships among countries.
The estimated number of communities and the corresponding modularity of each method for the real data analyzed in this paper are comprehensively presented in Table 1 and Table 2. After analyzing the results in these tables, we arrive at the following conclusions:
-
1.
and consistently demonstrate similar values for each method, indicating a high degree of agreement. Specifically, SPSum achieves the highest modularity score using both metrics across multiple datasets, including Lazega Law Firm, CS-Aarhus, and FAO-trade. It is worth mentioning that this observation (SPSum surpassing the other two methods) contrasts with both theoretical and numerical discoveries. A plausible explanation for this discrepancy could be that and are computed directly from rather than . Similarly, for SPSoS, its and scores for CS-Aarhus rank second among all methods, with scores that are closely aligned. This consistency across measures suggests that both and effectively capture similar aspects of community structure, providing reliable and comparable assessments of different methods.
-
2.
While SPSum may not perform as well in numerical studies, it nevertheless exhibits superior performance in terms of modularity for real-world datasets compared to SPDSoS and SPSoS. The only exception is the C.Elegans network, where SPSum’s modularity score is slightly lower than SPDSoS’s.
-
3.
The CS-Aarhus network exhibits a more distinct community structure compared to the other three real multi-layer networks, as evidenced by the higher modularity scores obtained by our methods for CS-Aarhus. Conversely, the FAO-trade network possesses the least discernible community structure among all real multi-layer networks, as the modularity scores achieved by all proposed methods for FAO-trade are lower than those of the other three networks.
-
4.
The results presented in Table 1 and Table 2 indicate that the optimal number of communities for the four real-world multi-layer networks, namely Lazega Law Firm, CS-Aarhus, CS-Aarhus, and FAO-trade, are 3, 2, 5, and 2, respectively. This determination is based on selecting the value of that yields the highest modularity score across all methods for each dataset.
| Dataset | SPSum | SPDSoS | SPSoS |
| Lazega Law Firm | (3,0.2025) | (3,0.1604) | (3,0.1993) |
| C.Elegans | (2,0.2778) | (2,0.2808) | (2,0.2509) |
| CS-Aarhus | (5,0.3575) | (4,0.3474) | (4,0.3559) |
| FAO-trade | (2,0.1508) | (2,0.1329) | (2,0.1412) |
| Dataset | SPSum | SPDSoS | SPSoS |
| Lazega Law Firm | (3,0.1990) | (3,0.1572) | (3,0.1961) |
| C.Elegans | (2,0.2779) | (2,0.2780) | (2,0.2495) |
| CS-Aarhus | (5,0.3681) | (4,0.3404) | (4,0.3529) |
| FAO-trade | (2,0.1487) | (2,0.1274) | (2,0.1403) |
To simplify our analysis and consider the fact that SPSum generates modularity scores that are either higher or comparable to those of SPDSoS and SPSoS for the four real-world multi-layer networks under consideration, we focus our further analysis on the SPSum method. Let represent the estimated mixed membership matrix obtained by SPSum for a given real-world multi-layer network. For a node within the network, we define its estimated home base community as the one that corresponds to the maximum value in the -th row of , denoted as . Furthermore, we categorize nodes based on their membership distribution: a node is considered highly mixed if , highly pure if , and neutral otherwise. We introduce two additional metrics, and , which represent the proportions of highly mixed and highly pure nodes, respectively. Additionally, we define the balanced parameter as the ratio of the minimum to the maximum norm of the columns of , i.e., . A higher value of indicates a more balanced multi-layer network. Table 3 presents the values of these three indices obtained by applying SPSum to the real-world multi-layer networks studied in this paper. Based on the results in Table 3, we draw the following conclusions:
-
1.
Across all networks, the number of highly pure nodes significantly exceeds the number of highly mixed nodes, indicating that most nodes are strongly associated with a single community, while only a few exhibit mixed membership.
-
2.
In the Lazega Law Firm network, approximately 10 nodes are highly mixed, 35 nodes are highly pure, and 26 are neutral. Meanwhile, this network exhibits the highest proportion of highly mixed nodes among the four real-world multi-layer networks analyzed.
-
3.
The C.Elegans network has the lowest proportion of highly mixed nodes and the highest proportion of highly pure nodes. Its balanced parameter, , is 0.9512, the highest among all networks, indicating that the sizes of the two estimated communities in C.Elegans are nearly identical.
-
4.
The CS-Aarhus network exhibits indices that are comparable to those of the Lazega Law Firm network.
-
5.
FAO-trade displays a proportion of highly mixed (and pure) nodes similar to C.Elegans. However, its balanced parameter is the lowest among all networks, indicating that FAO-trade exhibits the most unbalanced community structure among the four real-world datasets.
| Dataset | |||
| Lazega Law Firm | 0.1408 | 0.4930 | 0.7276 |
| C.Elegans | 0.0609 | 0.6882 | 0.9512 |
| CS-Aarhus | 0.1311 | 0.4590 | 0.7006 |
| FAO-trade | 0.0701 | 0.6449 | 0.5480 |
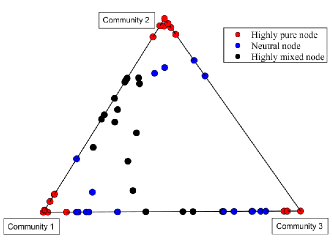
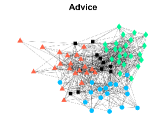

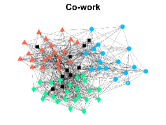
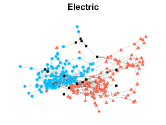
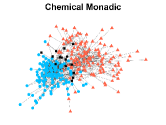
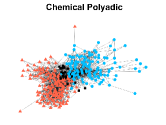
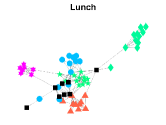
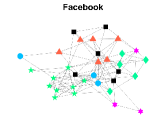
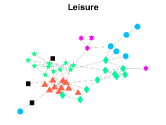
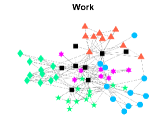
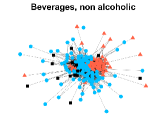
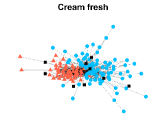

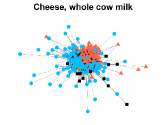
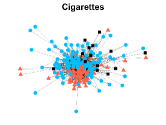
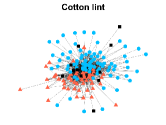
Figure 3 presents a ternary diagram that visualizes the estimated community membership matrix obtained from the SPSum algorithm for the Lazega Law Firm network when there are three communities. In this diagram, we observe that node is positioned closer to one of the triangle’s vertices compared to node if for . A pure node is located at one of the triangle’s vertices, and a neutral node is closer to a vertex than a highly mixed node. Therefore, Figure 3 indicates the purity of each node for the Lazega Law Firm network.
Figures 4-7 present the communities estimated by our SPSum method for the four real multi-layer networks. In these figures, nodes sharing the same color represent nodes belonging to the same home base community, while black squares denote highly mixed nodes. From these figures, we can clearly find the communities detected by SPSum in each layer for each multi-layer network.
7 Conclusion
This paper considers the problem of estimating community memberships of nodes in multi-layer networks under the multi-layer mixed membership stochastic block model, a model that permits nodes to belong to multiple communities simultaneously. We have developed spectral methods leveraging the eigen-decomposition of some aggregate matrices, and have provided theoretical guarantees for their consistency, demonstrating the convergence of per-node error rates as the number of nodes and/or layers increases under MLMMSB. To the best of our knowledge, this is the first work to estimate the mixed community memberships for multi-layer networks by using these aggregate matrices. Our theoretical analysis reveals that the algorithm designed based on the debiased sum of squared adjacency matrices always outperforms the algorithm using the sum of squared adjacency matrices, while they generally outperform the method using the sum of adjacency matrices in the task of estimating mixed memberships for multi-layer networks. Such a result is new for mixed membership estimation in multi-layer networks to the best of our knowledge. Extensive simulated studies support our theoretical findings, validating the efficiency of our method using the debiased sum of adjacency matrices. Additionally, the proposed fuzzy modularity measures offer a novel perspective for evaluating the quality of mixed membership community detection in multi-layer networks.
For future research, first, developing methods with theoretical guarantees for estimating the number of communities in MLMMSB remains a challenging and meaningful task. Second, accelerating our methods for detecting mixed memberships in large-scale multi-layer networks is crucial for practical applications. Third, exploring more efficient algorithms for estimating mixed memberships would further enrich our understanding of community structures in multi-layer networks. Finally, extending our framework to directed multi-layer networks would broaden the scope of our work and enable the analysis of even more complex systems.
CRediT authorship contribution statement
Huan Qing: Conceptualization; Data curation; Formal analysis; Funding acquisition; Methodology; Project administration; Resources; Software; Validation; Visualization; Writing-original draft; Writing-review editing.
Declaration of competing interest
The author declares no competing interests.
Data availability
Data and code will be made available on request.
Acknowledgements
H.Q. was sponsored by the Scientific Research Foundation of Chongqing University of Technology (Grant No: 0102240003) and the Natural Science Foundation of Chongqing, China (Grant No: CSTB2023NSCQ-LZX0048).
Appendix A Proofs
A.1 Proof of Lemma 1
Proof.
Since and , we have
Since , we have , i.e., . Therefore, holds. Similarly, we have . ∎
A.2 Proof of Theorem 1
Proof.
The following lemma bounds .
Lemma 2.
Under , when Assumption 1 holds, with probability at least , we have
Proof.
Recall that , next we bound it by using the Bernstein inequality below.
Theorem 4.
(Theorem 1.4 of [44]) Let be independent, random, self-adjoint matrices with dimension . When and almost surely. Then, for all ,
where and denotes spectral norm.
Let be any vector. Set for , and for , we have:
-
1.
for .
-
2.
for .
-
3.
Let denote the variance of any random variable . Combine for with the fact that and are independent when , we have
By Theorem 4, for any , we have
Set for any , if , we have
Set , we have: when , with probability at least for any ,
Set , when , with probability at least , we have
∎
By Theorem 4.2 of [6], when , there is an orthogonal matrix such that
Since , we get
Since by Lemma 3.1 of [29] and Condition 1, we get
For , by Condition 1 and Assumption 4, we have
which gives that
By the proof of Theorem 3.2 of [29], there is a -by- permutation matrix such that,
By Lemma 2, this theorem holds. Finally, recall that when we use Theorem 4.2 of [6], we require . Since , it is easy to see that as long as , this requirement holds. The condition holds naturally because we need the row-wise error bound to be much smaller than 1. ∎
A.3 An alternative proof of Theorem 1
Proof.
Set and let be its top singular value decomposition. Define as . Under , the following results are true.
-
1.
for .
-
2.
for .
-
3.
for .
- 4.
-
5.
Set . gives by Assumption 1.
The above results ensure that conditions in Assumption 4.1. [8] are satisfied. Then, by Theorem 4.2. [8], when , with probability at least , we have
Since and , we have
By Assumption 2 and Condition 1, we have and , which gives that and
Since , we have
By the proof of Theorem 3.2 in [29], there is a permutation matrix such that,
Recall that and we need hold. It is easy to see that as long as , always holds. The condition holds naturally since we require the row-wise error bound to be much smaller than 1. ∎
A.4 Proof of Theorem 2
Proof.
Since , i.e., for , we can not use Theorem 4.2 in [8] to obtain the row-wise eigenspace error for and . To obtain SPDSoS’s error rate, we use Theorem 4.2 in[6]. By Bernstein inequality, we have the following lemma that bounds .
Lemma 3.
Under , when Assumption 3 holds, with probability at least , we have
Proof.
Since , we have for , which gives that
Next, we bound for . Let be any vector. Set for and for . The following results hold:
-
1.
since and are independent when for .
-
2.
for .
-
3.
Combine for with the fact that and are independent when , we have
By Theorem 4, for any , we have
Set for any . If , we have
Recall that is any vector, setting gives the following result: when , with probability at least for any , we have
Set , when , with probability at least , we have
Hence, we have
∎
By Theorem 4.2 of [6], if , there is an orthogonal matrix such that
Since by basic algebra, we have
Since by Lemma 3.1 [29] and Condition 1, we have
For , by Condition 1 and Assumption 4, we have
which gives that
Proof of Theorem 3.2 in [29] gives that, there is a permutation matrix such that,
By Lemma 3, this theorem holds. Finally, since , the requirement is satisfied as long as which holds naturally since we need the row-wise error bound to be much smaller than 1. ∎
A.5 Proof of Theorem 3
Proof.
Lemma 4 bounds .
Lemma 4.
Under , if , with probability at least , we have
Proof.
Since and each is a diagonal matrix for , we have
Since Lemma 3 provides an upper bound of , we only need to bound . To bound it, we let for , The following results hold:
-
1.
for .
-
2.
for .
-
3.
Since and for Bernoulli distribution, we have
By Theorem 4, for any , we have
Set for any , if , we have
Hence, when , with probability at least , we have
Let , when , with probability at least , we have
for gives since we require to hold. Therefore, we have and this lemma holds. ∎
References
- Airoldi et al. [2008] Airoldi, E. M., Blei, D. M., Fienberg, S. E., & Xing, E. P. (2008). Mixed Membership Stochastic Blockmodels. Journal of Machine Learning Research, 9, 1981–2014.
- Anandkumar et al. [2014] Anandkumar, A., Ge, R., Hsu, D., & Kakade, S. M. (2014). A tensor approach to learning mixed membership community models. Journal of Machine Learning Research, 15, 2239–2312.
- Araújo et al. [2001] Araújo, M. C. U., Saldanha, T. C. B., Galvao, R. K. H., Yoneyama, T., Chame, H. C., & Visani, V. (2001). The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemometrics and Intelligent Laboratory Systems, 57, 65–73.
- Bakken et al. [2016] Bakken, T. E., Miller, J. A., Ding, S.-L., Sunkin, S. M., Smith, K. A., Ng, L., Szafer, A., Dalley, R. A., Royall, J. J., Lemon, T. et al. (2016). A comprehensive transcriptional map of primate brain development. Nature, 535, 367–375.
- Boccaletti et al. [2014] Boccaletti, S., Bianconi, G., Criado, R., Del Genio, C. I., Gómez-Gardenes, J., Romance, M., Sendina-Nadal, I., Wang, Z., & Zanin, M. (2014). The structure and dynamics of multilayer networks. Physics Reports, 544, 1–122.
- Cape et al. [2019] Cape, J., Tang, M., & Priebe, C. E. (2019). The two-to-infinity norm and singular subspace geometry with applications to high-dimensional statistics. Annals of Statistics, 47, 2405–2439.
- Chen et al. [2006] Chen, B. L., Hall, D. H., & Chklovskii, D. B. (2006). Wiring optimization can relate neuronal structure and function. Proceedings of the National Academy of Sciences, 103, 4723–4728.
- Chen et al. [2021] Chen, Y., Chi, Y., Fan, J., & Ma, C. (2021). Spectral methods for data science: A statistical perspective. Foundations and Trends® in Machine Learning, 14, 566–806.
- Chen & Mo [2022] Chen, Y., & Mo, D. (2022). Community detection for multilayer weighted networks. Information Sciences, 595, 119–141.
- De Domenico et al. [2015] De Domenico, M., Nicosia, V., Arenas, A., & Latora, V. (2015). Structural reducibility of multilayer networks. Nature Communications, 6, 6864.
- Fortunato [2010] Fortunato, S. (2010). Community detection in graphs. Physics Reports, 486, 75–174.
- Fortunato & Hric [2016] Fortunato, S., & Hric, D. (2016). Community detection in networks: A user guide. Physics Reports, 659, 1–44.
- Gillis & Vavasis [2013] Gillis, N., & Vavasis, S. A. (2013). Fast and robust recursive algorithmsfor separable nonnegative matrix factorization. IEEE transactions on Pattern Analysis and Machine Intelligence, 36, 698–714.
- Gillis & Vavasis [2015] Gillis, N., & Vavasis, S. A. (2015). Semidefinite programming based preconditioning for more robust near-separable nonnegative matrix factorization. SIAM Journal on Optimization, 25, 677–698.
- Gopalan & Blei [2013] Gopalan, P., & Blei, D. (2013). Efficient discovery of overlapping communities in massive networks. Proceedings of the National Academy of Sciences of the United States of America, 110, 14534–14539.
- Han et al. [2015] Han, Q., Xu, K., & Airoldi, E. (2015). Consistent estimation of dynamic and multi-layer block models. In International Conference on Machine Learning (pp. 1511–1520). PMLR.
- Holland et al. [1983] Holland, P. W., Laskey, K. B., & Leinhardt, S. (1983). Stochastic blockmodels: First steps. Social Networks, 5, 109–137.
- Huang et al. [2021] Huang, X., Chen, D., Ren, T., & Wang, D. (2021). A survey of community detection methods in multilayer networks. Data Mining and Knowledge Discovery, 35, 1–45.
- Javed et al. [2018] Javed, M. A., Younis, M. S., Latif, S., Qadir, J., & Baig, A. (2018). Community detection in networks: A multidisciplinary review. Journal of Network and Computer Applications, 108, 87–111.
- Jin et al. [2024] Jin, J., Ke, Z. T., & Luo, S. (2024). Mixed membership estimation for social networks. Journal of Econometrics, 239, 105369.
- Jing et al. [2021] Jing, B.-Y., Li, T., Lyu, Z., & Xia, D. (2021). Community detection on mixture multilayer networks via regularized tensor decomposition. Annals of Statistics, 49, 3181–3205.
- Ke & Wang [2024] Ke, Z. T., & Wang, M. (2024). Using SVD for topic modeling. Journal of the American Statistical Association, 119, 434–449.
- Kim & Lee [2015] Kim, J., & Lee, J.-G. (2015). Community detection in multi-layer graphs: A survey. ACM SIGMOD Record, 44, 37–48.
- Kivelä et al. [2014] Kivelä, M., Arenas, A., Barthelemy, M., Gleeson, J. P., Moreno, Y., & Porter, M. A. (2014). Multilayer networks. Journal of Complex Networks, 2, 203–271.
- Lazega [2001] Lazega, E. (2001). The collegial phenomenon: The social mechanisms of cooperation among peers in a corporate law partnership. Oxford University Press, USA.
- Lei et al. [2020] Lei, J., Chen, K., & Lynch, B. (2020). Consistent community detection in multi-layer network data. Biometrika, 107, 61–73.
- Lei & Lin [2023] Lei, J., & Lin, K. Z. (2023). Bias-adjusted spectral clustering in multi-layer stochastic block models. Journal of the American Statistical Association, 118, 2433–2445.
- Magnani et al. [2013] Magnani, M., Micenkova, B., & Rossi, L. (2013). Combinatorial analysis of multiple networks. arXiv preprint arXiv:1303.4986, .
- Mao et al. [2021] Mao, X., Sarkar, P., & Chakrabarti, D. (2021). Estimating mixed memberships with sharp eigenvector deviations. Journal of the American Statistical Association, 116, 1928–1940.
- Mucha et al. [2010] Mucha, P. J., Richardson, T., Macon, K., Porter, M. A., & Onnela, J.-P. (2010). Community structure in time-dependent, multiscale, and multiplex networks. Science, 328, 876–878.
- Narayanan et al. [2010] Narayanan, M., Vetta, A., Schadt, E. E., & Zhu, J. (2010). Simultaneous clustering of multiple gene expression and physical interaction datasets. PLoS Computational Biology, 6, e1000742.
- Nepusz et al. [2008] Nepusz, T., Petróczi, A., Négyessy, L., & Bazsó, F. (2008). Fuzzy communities and the concept of bridgeness in complex networks. Physical Review E, 77, 016107.
- Newman [2002] Newman, M. E. (2002). Assortative mixing in networks. Physical Review Letters, 89, 208701.
- Newman [2003a] Newman, M. E. (2003a). Mixing patterns in networks. Physical Review E, 67, 026126.
- Newman [2003b] Newman, M. E. (2003b). The structure and function of complex networks. SIAM Review, 45, 167–256.
- Newman & Girvan [2004] Newman, M. E., & Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review E, 69, 026113.
- Paul & Chen [2020] Paul, S., & Chen, Y. (2020). Spectral and matrix factorization methods for consistent community detection in multi-layer networks. Annals of Statistics, 48, 230 – 250.
- Paul & Chen [2021] Paul, S., & Chen, Y. (2021). Null models and community detection in multi-layer networks. Sankhya A, (pp. 1–55).
- Pensky & Zhang [2019] Pensky, M., & Zhang, T. (2019). Spectral clustering in the dynamic stochastic block model. Electronic Journal of Statistics, 13, 678 – 709.
- Psorakis et al. [2011] Psorakis, I., Roberts, S., Ebden, M., & Sheldon, B. (2011). Overlapping community detection using bayesian non-negative matrix factorization. Physical Review E, 83, 066114.
- Qing & Wang [2024] Qing, H., & Wang, J. (2024). Bipartite mixed membership distribution-free model. a novel model for community detection in overlapping bipartite weighted networks. Expert Systems with Applications, 235, 121088.
- Snijders et al. [2006] Snijders, T. A., Pattison, P. E., Robins, G. L., & Handcock, M. S. (2006). New specifications for exponential random graph models. Sociological Methodology, 36, 99–153.
- Su et al. [2024] Su, W., Guo, X., Chang, X., & Yang, Y. (2024). Spectral co-clustering in multi-layer directed networks. Computational Statistics Data Analysis, (p. 107987).
- Tropp [2012] Tropp, J. A. (2012). User-friendly tail bounds for sums of random matrices. Foundations of Computational Mathematics, 12, 389–434.
- Wang et al. [2011] Wang, F., Li, T., Wang, X., Zhu, S., & Ding, C. (2011). Community discovery using nonnegative matrix factorization. Data Mining and Knowledge Discovery, 22, 493–521.
- Zhang & Cao [2017] Zhang, J., & Cao, J. (2017). Finding common modules in a time-varying network with application to the drosophila melanogaster gene regulation network. Journal of the American Statistical Association, 112, 994–1008.