Estimation of ill-conditioned models using penalized sums of squares of the residuals
Abstract
This paper analyzes the estimation of econometric models by penalizing the sum of squares of the residuals with a factor that makes the model estimates approximate those that would be obtained when considering the possible simple regressions between the dependent variable of the econometric model and each of its independent variables. It is shown that the ridge estimator is a particular case of the penalized estimator obtained, which, upon analysis of its main characteristics, presents better properties than the ridge especially in reference to the individual boostrap inference of the coefficients of the model and the numerical stability of the estimates obtained. This improvement is due to the fact that instead of shrinking the estimator towards zero, the estimator shrinks towards the estimates of the coefficients of the simple regressions discussed above.
Keywords: ridge estimator, penalized estimation, mean error squared, variance inflation factor, condition number,
1 Introduction
Given the following multiple linear regression model for observations and independent variables (constant term included):
| (1) |
where is the random disturbance (which is assumed to be spherical), the most common estimation method is Ordinary Least Squares (OLS), which consists of minimizing with respect to the sum of squares of the residuals given by the expression:
However, there are several situations where the objective function to be minimized has been modified, as in the case of the method of Restricted Least Squares (RSM). In this case, the modification seeks to incorporate certain information into the model in order to obtain a more efficient estimation.
It is also common to modify it in order to achieve greater stability in the estimates of model (1). In this sense, according to O’Driscoll and Ramirez [34], it was Tikhonov [50] who first proposed the idea of regularization to estimate ill-conditioned problems by introducing additional information.
Other examples with alternative objective functions are the ridge estimator (Hoerl and Kennard [18, 19]) or LASSO regression (Tibshirani [48, 49]), widely used to mitigate the approximate multicollinearity existing in the linear model.
In the former, is minimized subject to the constraint where is fixed, and implies minimizing with respect to the Lagrangian:
The solution obtained corresponds to the following expression:
| (2) |
where denoted the identity matrix of appropriate dimensions. In addition, its variance-covariance matrix is:
| (3) |
In the second, is minimized subject to the constraint where is fix which implies minimizing with respect to the Lagrangian:
The difference between the two lies in the fact that due to the behavior of the norm, LASSO contracts and selects variables, while ridge only contracts. It can also be seen that both methods can be viewed as particular situations of the general case in which the penalty added in the objective function is considered to be given by the norm, i.e., it is of the form . Other shrinkage estimators can be found in Liu [22, 23], Gao and Liu [12] or Liu and Gao [24].
More recently, the methodology proposed by Zou and Hastie [55], known as elastic-net, has emerged as a particularly noteworthy approach. This technique allows the contraction of estimators and the automatic selection of variables by combining the penalty factors (in the sum of squares of the residuals) of the ridge and LASSO regressions. It is also particularly useful when the number of independent variables is much higher than the number of observations and to deal with the problem of multicollinearity (see, for example, Bingzhen et al. [4] or Zou and Zhang [56]).
Since its publication, this work has been received111 Figures as of May 8, 2024 in Scopus and Google Scholar. 11820 citations according to SCOPUS and 20777 according to Google Scholar (2260 in 2021, 2345 in 2022 and 2100 in 2023). These figures show that the development of techniques to deal with multicollinearity and variable selection is currently an interesting econometric research topic, probably due to the fact that are essential tools in high-dimensional data analysis (see Ding et al. [5]).
Within this line of research, Wang et al. [52] proposes a novel method called average least squares-centered penalized regression (ALPR). This penalized regression method shrinks the parameters toward the weighted average OLS estimator. This paper provides a theoretical development to obtain the mean square error of the proposed estimator, as well as a simulation study comparing this estimator with the estimators provided by OLS and ridge regression. Some issues to be considered with respect to this paper are the following:
-
•
If the OLS estimates have coefficients with different signs, it is possible that the weighted average is close to zero, so there is not much difference between the penalized estimator they propose and the ridge regression.
-
•
Shrinking the penalized estimators around the weighted average OLS estimator is just as arbitrary as shrinking them around zero (ridge regression).
-
•
ALPR shrinks all the parameters to the same single value. Again, this is a completely arbitrary question without any theoretical justification.
-
•
The intercept is not penalized by ALPR, then the approximate non-essential multicollinearity (see footnote in Example 1 about essential and non-essential multicollinearity) is ignored.
Recently, Lukman et al. [25] have integrated ALPR with the principal component dimension reduction method to improve its performance in terms of root mean square error.
Alternatively, the present work proposes to minimize the Lagrangian with respect to the Langragian:
| (4) |
where is a vector that collects the estimates of the slope in all simple linear regressions of the form with , where denotes the constant term.
The choice of the parameter around which to shrink the penalized estimators, , is intended to overcome the drawbacks of ALPR highlighted above (see section 2). In addition, the obtained estimator is analyzed in depth (sections 3 to 7), providing a consolidated methodology.
Specifically, the work is structured as follows: Section 2 justifies the usefulness of the proposal made to mitigate the approximate multicollinearity existing in the model (1) and achieve stability in the estimation of the coefficients of the independent variables, while in section 3 we obtain the expression of the estimator provided by minimizing the lagrangian given in (4) and its main characteristics: trace, norm, variance-covariance matrix, goodness-of-fit and mean square error. To highlight in this section the Monte Carlo simulation performed to analyze the behavior of the mean square error of the proposed penalized estimator. The implications of this methodology in multicollinearity mitigation are discussed in section 4. The above results are used in section 5 to propose procedures for determining the ideal value of the penalty parameter, . An interpretation of the same is also provided. From these values, the section 6 shows how to perform inference from bootstrap methods. Section 7 analyzes the stability of the estimates obtained from the proposed penalized estimator and section 8 illustrates the results obtained by means of an example with real data. The paper ends with the section 9, where the main results obtained are highlighted. Finally, the code utilized in R [35] to generate the results presented in this study is accessible on GitHub, specifically at https://github.com/rnoremlas/Penalized-estimator.
2 Justification of the proposed restriction
Taking into account the following notions of partial and full effect given in Novales [31]:
-
•
What is the impact on of a unit variation in if the other explanatory variables in the model did not vary? Answer: partial effect (multiple linear regression).
-
•
What is the total impact on of a unit variation in if the rest of the explanatory variables vary as would be expected given the correlations observed between them throughout the sample? Answer: total effect (simple linear regression).
Both effects should coincide (see example 1) if the ceteris paribus, i.e., when one variable varies the rest remain constant, were really verified.
Example 1
Given the model , 100 observations are simulated assuming that and are distributed according to a normal distribution of mean 1 and variance 100, according to a normal distribution of mean 0 and variance 2 and the dependent variable is generated as .
It is verified that the coefficient of simple correlation between and is equal to -0.01684487. This leads to a variance inflation factor equal to 1.000284 which is very close to its minimum value of 1. This indicates that the degree of approximate multicollinearity of the essential type222 Marquardt [27], Marquardt and Snee [28] and Snee and Marquardt [47] distinguish between approximate multicollinearity of the essential type (relationship between the independent variables of the model excluding the constant term) and non-essential (relationship between the constant term and at least one of the remaining independent variables of the model). Salmerón et al. [41] shows that the variance inflation factor only detects variance of the essential type and that the coefficient of variation must be used to detect the non-essential multicollinearity. According to these authors, a coefficient of variation below 0.1002506 indicates that the existing approximate multicollinearity of nonessential type is of concern. is not troubling. The high values for the coefficients of variation, 5.898071 for and 3.022512 for , indicate that the nonessential type is not troubling either.
OLS estimation provides the estimates , and . Note that the estimates practically coincide with the real coefficients.
On the other hand, given the simple linear regressions , with , the following OLS estimators are obtained: and . Once again, very similar to the true values of and .
Developing the previous example from a theoretical point of view:
-
•
Estimates of simple linear regressions with are given by the expression:
-
•
Assuming orthogonality in the model (1), the OLS estimator responds to the expression:
since, for , it is verified that and finding that by the orthogonality condition between and the intercept.
For this reason, in the expression (4) it will be considered that:
| (6) |
that is, is a known fixed vector.
In short, in the restriction imposed on the sum of squares of the penalized residuals represented in the lagrangian of the expression (4) it will be considered that will take the value given in (6). In this way, the purpose is to make the estimates of the coefficients of the multiple linear regression model as close as possible to the estimates obtained in the corresponding simple linear regressions.
Example 2 (continuation of Example 1)
If, on the other hand, it is generated como , where it is verified that the coefficient of simple correlation between and is equal to 0.9997975, which leads to a variance inflation factor equal to 2468.787. In this case, the coefficient of variation of is equal to 5.279348. Thus, the approximate multicollinearity of the essential type is troubling while the non-essential type is not.
The estimates obtained in this case are as follows:
being the estimates of and significantly different from zero (with 5% of significance level), contrary to that of .
It is found that the estimation of differs from the true value of the coefficient of , while the value of captures the true value of the coefficient obtained by substituting en . It is to say, : as captured by simple regression rather than multiple regression, the real relationship between and is actually -18 rather than 2.
To summarize, it can be observed that in the first case, the degree of essential approximate multicollinearity is not troubling while in the second case it is. Note also that the consequence of high linear relationships between the independent variables is to obtain different values for the partial and total effect.
3 Penalized estimator
In this section we obtain the estimator that verifies the above conditions, as well as its norm, variance-covariance matrix, goodness-of-fit and mean square error. We also consider the augmented model whose OLS estimation leads to the penalized estimator obtained. In the latter case, the effect of this augmented model on the detection of the degree of multicollinearity existing once the proposed estimator has been applied is analyzed.
With this purpose, instead of working with the expression (4), expression (7) will be minimized where previously a parameter has been introduced as follows:
| (7) |
note that for the Hoerl and Kennard estimator would be obtained. [18, 19]. That is, the ridge estimator is a particular case of the one presented here.
While it makes sense that , it will be considered only that (for further details see subsection 3.1.1).
3.1 Estimation
Minimizing with respect to the expression (7) the following estimator is obtained:
| (8) |
where it is clear that if , the penalized estimator coincides with the ridge (the expressions (2) and (8) are the same) and if the OLS estimation is obtained.
Remark 1
Note that if it is verified that , where is a vector of zeros of appropriate dimensions, the penalized estimator also coincides with the ridge estimator. That is, the ridge estimator could be considered to be the particular case of the penalized estimator in which all the coefficients of the possible simple regressions are zero and the dependent variable is centered:
This implies that the total impact of the variations of each independent variable (excluding the constant term) on the dependent variable is null, assuming that the rest of the independent variables vary as would be expected given the correlations observed between them in the sample.
Remark 2
Note that in the case where and where is a p-dimensional vector in which all the elements are one and is the OLS estimator, the ALPR estimator is obtained.
On the other hand, denoting and taking into account that , it is obtained that expression (8) can be rewritten as:
| (9) |
and in this case:
i.e., the estimator given in (8) is a biased estimator of as long as .
Remark 3
Considering that the expression (7) is equivalent to:
| (11) |
just considering that with . Minimize with respect to the expression (11) leads to :
donde:
Note that if the variables are centered, i.e., where s a vector of zeros of appropriate dimensions, the expression (3) is rewritten as:
| (13) | |||||
where now:
3.1.1 Orthogonal case
Section 2 shows that in the orthogonal case it is verified that , therefore, taking into account that the expression (8) can be rewritten as:
where is denoted as the element (i,i) of , it is to say, for . In this case:
-
•
If , the penalized estimator coincides with the ridge and it is found that for values of different from zero.
-
•
If , then for any value of .
-
•
If , then for values of different from zero.
Thus, although technically can be any non-negative value, the only advisable value for would be 1, since in this case it is assured that the penalized estimator coincides with the OLS estimator when there is orthogonality in the model (1). The case will be also considered to work with the ridge estimator as a particular case of the penalized estimator.
3.2 Trace and norm of the penalized estimator
From expression (8) the trace of the estimator can be obtained by simply plotting for different values of (it will be considered that ). In this way, it is possible to obtain graphically which values of stabilize the estimates of obtained from .
3.3 Matrix of variances-covariances
3.4 Goodness-of-fit
Taking into account that from the expression (8) the residuals of the penalized estimate would be obtained from , it is clear that . In this case the following equality is verified:
Consequently, a measure of goodness-of-fit can be given by:
| (16) | |||||
where . Note that
- •
-
•
For there would be a goodness of fit for the ridge estimator.
- •
- •
3.5 Mean Square Error
Since the penalized estimator is biased, it is interesting to calculate its mean square error (MSE) in order to establish when it is lower than that obtained by OLS. In this case, the MSE corresponds to the following expression:
| (17) |
where .
Since the variance-covariance matrix of the penalized estimator coincides with that of the ridge estimator, the expression (17) can be rewritten as:
| (18) |
where is the MSE of ridge estimator and .
Hoerl and Kennard [18] showed that the mean square error of the ridge estimator is equal to the sum of two terms::
such that the first is decreasing in and the second is increasing, therefore, the monotonicity of is not clear. However, due to
when , it is verified that has a horizontal asymptote.
Also, section A.5 of Appendix A shows that the first term of has no definite monotonicity while the second is increasing in . Since both terms have a horizontal asymptote, there must be a value of for which the value of is stable. This is an important consideration because if it is verified that , then .
Finally, it should be noted that has a horizontal asymptote because when the it is verified333 Note that for : when . that:
Therefore, there must be a value of at which the is stabilized.
3.5.1 Monte Carlo Simulation
In order to obtain information on the comparison of the ECM of the penalized estimator with that of the OLS and ridge estimator, and due to the impossibility of analytically establishing the behavior of the ECM monotonicity, a Monte Carlo simulation is proposed below where values are simulated from:
where , , con randomly obtained from the set and and . This way of simulating data has been previously used, for example, by McDonald and Galarneau [29], Wichern and Churchill [53], Gibbons [15], Kibria [21], Salmerón et al. [38, 40] or Rodríguez et al. [36, 37]; and the goal is that each pair of independent variables has a correlation coefficient equal to .
Once the data has been simulated (1440 simulations are performed), the matrix is generated and also where the elements of are obtained randomly according to and .
For each case, considering that , it is calculated:
-
•
The mean square error in OLS, , the minimum value of the mean square error for the ridge estimator, and for the penalized estimator for , . The Algorithm 1 has been applied in this case. Note that this algorithm also calculates whether the minimum obtained is a unique minimum or not: in all cases where the minimum has been reached, it is unique.
-
•
The minimum coefficient of variation (CV), the maximum variance inflation factor (VIF) and the condition number (CN). In this way, the existence of approximate multicollinearity of essential and non-essential type in the simulated data is analyzed. Calculations were performed with the package “multiColl” [30] of R [35] (for further details see Salmerón et al. [43, 44]).
Table 1 shows the minimum, mean, median and maximum values for the minimum coefficient of variation, maximum variance inflation factor and condition number. Considering the traditional thresholds for these multicollinearity detection measures, it is observed that situations have been simulated where the existing approximate multicollinearity (both essential and nonessential) is and is not troubling. In addition, the significant difference between the mean and median of the values obtained for the number of condition is notable, indicating the existence of very high values that shift the distribution to the right.
| Minimum CV | Maximum VIF | CN | |
|---|---|---|---|
| Minimum | 0.00123 | 6.394 | 5.966 |
| Mean | 2.48557 | 71.689 | 1752.275 |
| Median | 1.03504 | 52.495 | 33.489 |
| Maximum | 42.55852 | 367.690 | 25384.87 |
| Case | Number (%) | Minimum CV | Maximum VIF | CN |
| (A) | 0 (0%) | |||
| 1.85 | 31.199 | 12.726 | ||
| (B) | 408 (46.52%) | 4.6786 | 65.957 | 18.934 |
| 5.8266 | 80.703 | 23.334 | ||
| 0.00274 | 32.45 | 199.889 | ||
| (C) | 469 (53.48%) | 0.57782 | 76.68 | 3260.171 |
| 0.05795 | 99.5 | 4678.892 | ||
| (D) | 0 (0%) | |||
| (E) | 0 (0%) | |||
| (F) | 0 (0%) |
Table 2 compares the values obtained. It is observed that:
-
•
A total of 877 simulations were finally worked with. This is because there are 563 cases where it is not possible to calculate the minimum MSE for the ridge and/or penalized estimator either because the discretization is not fine enough or because the interval stop, 1, is insufficient. In this regard, tests have been performed by modifying the interval stop:
-
–
If the interval stop is equal to 2: there are 903 cases in which both minima are obtained, in 432 cases (B) is verified and in 471 cases (C) is verified.
-
–
IIf the interval stop is equal to 5: there are 921 cases in which both minima are obtained, in 445 cases (B) is verified and in 476 cases (C) is verified.
-
–
If the interval stop is equal to 10: there are 923 cases in which both minima are obtained, in 447 cases (B) is verified and in 476 cases (C) is verified.
It can be seen that this increase results in a decreasing incorporation of simulations and that the new incorporations are mostly in case (B).
-
–
-
•
Case B: In 46.52% of the cases the penalized estimator has a lower mean square error and the ridge the worst. These cases are characterized by a high coefficient of variation, so that the multicollinearity treated is of the essential type.
-
•
Case C: In 53.48% of the cases the penalized estimator has a worse mean square error than the ridge, but better than that of OLS. These cases are characterized by a low coefficient of variation, so that the multicollinearity treated is of a non-essential type.
-
•
The values shown by the condition number explain that the shift to the right discussed above is due to the detection by the condition number of non-essential multicollinearity, which is ignored by the variance inflation factor.
In short, the simulation shows that the penalized estimator performs better in terms of mean square error than the ridge estimator when the existing multicollinearity is of the essential type.
4 Augmented model and multicollinearity
From expression (8) the penalized estimator can be obtained by OLS estimation of the augmented model , where:
However, the variance-covariance matrices would be different since:
Similarly, the goodness-of-fit would also change since the dependent variable is different, .
It should be noted that the design matrix of the augmented model, , coincides with that of the augmented model of the ridge estimator (see Marquardt [26]), then all operations based on them will coincide. Consequently, papers presented by García et al. [13] and Salmerón et al. [39] to calculate, respectively, the extension of the Variance Inflation Factor (VIF) and the Condition Number (CN) to the ridge estimator are applicable to the penalized estimator. Thus, more specifically:
-
•
García et al. [13] states that to obtain an extension of the VIF, with , with the desirable properties of continuity (for the calculated VIF coincides with that obtained in OLS), decreasing monotonicity as increases (since it is assumed that when applying the ridge estimate the degree of approximate multicollinearity decreases) and that a value greater than 1 is always obtained (since this is the minimum value of the VIF); data must be standardized444 To standardize a set of data, center the data (subtract its mean) and divide it by its standard deviation multiplied by the square root of the number of observations. and subsequently the model is augmented. In other words, to calculate the VIF for the ridge estimator, the following matrix must be used:
where the matrix is the matrix resulting from the standardization of the columns of .
-
•
Salmerón et al. [39] it is recommended that to obtain an extension of the CN, , that verifies the above desirable properties (continuity at , decreasing monotonicity at and being greater than 1 for any value of ) it has to be calculated from the expression:
where and are, respectively, the minimum and maximum eigenvalues of where denotes the matrix transformed. These authors recommend that the transformation should be typing555 To typify a set of data it is necessary to center it (subtract its mean) and divide it by its standard deviation. the data, since in such a case the results obtained are similar to those obtained from the VIF. However, this transformation ignores nonessential type multicollinearity (see, for example, Salmerón et al. [40, 41]), so this transformation is not going to be used in this paper. In accordance with the recommendations of Belsley et al. [1] or Belsley [3, 2] the eigenvalues of the matrix will be calculated. where the transformation used is that of unit length666 To transform a set of data into unit length, divide it by the square root of the sum of each element squared. Note that if the data have zero mean (a property that is obtained by centering them), it is verified that this transformation coincides with the standardization. .
5 The penalty parameter
In order to obtain the value of the above expressions it is necessary to use a concrete value of the penalty parameter, . For this reason, some possible criteria for determining a concrete value of the parameter, as well as its interpretation, are proposed below.
5.1 Interpretation of the penalty parameter
Taking into account Remark 3 in which for and considering that , it is possible to obtain the relative importance of each of the two summands of the expression (11) in the minimization performed.
That is, assuming that it is obtained thaat and . Thus, for example:
-
•
If , then and . In this case, the same importance would be given to and to .
-
•
If , then and . In this case, double importance is given to que a .
In general:
-
•
If it is obtained that and, then, it would be giving more relevance to than.
-
•
If it is obtained that and, then, it would be giving more relevance to a than .
Note that in the ridge estimator the value of has traditionally been considered to belong to the interval . hat is, preference is given to minimizing the sum of squares of the residuals over the shrinkage of the coefficients.
Moreover, the fact that is imposed to be greater than zero implies that the SSR is always minimized. At the same time, since the higher the value of the lesser the role of , it is intuited that the goodness-of-fit calculated from will be decreasing..
5.2 Selection of the penalty parameter
A first option, following Hoerl and Kennard [18, 19], is to select that value of that stabilizes the estimates of the coefficients of the independent variables of the model. For this purpose, it is necessary to plot the values of as a function of nd observe at what value of the estimates are stable.
On the other hand, following García et al [13] and Salmerón et al [39], could be considered the first value of that makes the extension of VIF or CN below the thresholds (10 and 20, respectively) above which multicollinearity is traditionally considered to be troubling.
Furthermore, since the goal is to make the estimates similar to those obtained in , could be considered the value of that makes and close to each other. For example, the difference between the two could be imposed to be less than 10%:
Section A.6 of Appendix A shows that decreases toward zero when increases and .
Finally, by following Hoerl et al [20], the value of that minimizes the mean square error (if it exists) could be considered..
Example 3 (continuation of Example 2)
In example 2 (where the degree of essential multicollinearity is troubling) considering that and , the following values of are obtained by considering different criteria:
-
•
is the value of for which the maximum , , is less than 10 (concretely 9.060921);
-
•
is the value of for which the is lower that 20 (concretely 14.2435) and is the value of for which the lower that 10 (concretely 8.316654)
-
•
is the value of for which the mean square error is minimum, concretely is equal to 4.284018 taht is lower that the one obtained by OLS 4.311986.
On the other hand, in the considered discretization of the interval [0, 100] there does not exist such that . The minimum value obtained in this case is 0.4402975.
Finally, with these values of we would be giving more weight to the minimization of than to according to the values shown in the following table:
| 0.01 | 0.990099 | 0.00990099 |
| 0.03 | 0.9708738 | 0.02912621 |
| 0.06 | 0.9433962 | 0.05660377 |
6 Inference
Although there are various attempts to address inference in the ridge estimator (see, e.g., Obenchain [32, 33], Halawa and El Bassiouni [17], Gökpınar and Ebegil [16], Sengupta and Sowell [45] or Vanhove [51]), in this paper we will focus on the use of bootstrap methods (see, for example, Efron [6, 7, 8, 9], Efron and Gong [10] or the a review of the above-mentioned works presented by Efron and Tibshirani [11]).
Thus, given a fixed value of obtained by one of the methods proposed in subsection 5.2 and a value of , the following steps will be taken:
-
(i)
Generate randomly and with replacement subsamples of equal size to the original one. The value of must be large.
-
(ii)
For each sub-sample above, the statistic of interest is calculated. Therefore, we have values for this statistic: .
-
(iii)
Calculate the mean, , and sample quasi-variance, , for the values obtained in previous step. Both measures can be used to obtain the approximation of a confidence interval by using expression .
Similarly, can be used as an approximation of the point estimator of . -
(iv)
Another confidence region can be obtained alternatively by considering the lower and upper percentiles, 0.025 and 0.975, as the lower and upper extremes respectively, of the values calculated in the second step: .
EWhat is interesting in this work are the cases in which is equal to or .
Example 4 (continuation of the Example 3)
Considering:
-
•
values 0.01, 0.03 and 0.06 of which make, respectively, that ; the mean square error is minimum and ; or for (see Example 3),
-
•
y
-
•
,
Table 3 shows the approximation of the point and interval estimators of and .
It can be seen that the approximation of the point estimators, , are very close to the estimators of and calculation of obtained from expressions (8) and (16), respectively. This facilitates that the values of and belong to the two calculated confidence intervals.
Moreover, from these ranges it could be argued that the coefficient estimates and are significantly different from zero for the three values of considered since the intervals obtained do not contain zero, while it cannot be discarded that the estimate of the coefficient is null. The same behaviour is observed as in OLS, perhaps due to the fact that the estimates obtained are still far from the values for .
In this context, considering that (maximum value of considered in Example 3 to determine a value for this parameter), it is observed that the estimates of change substantially from the previous ones. In this case, all the coefficients can be considered significantly different from zero, although the estimation of the constant and the third coefficient are far from the values proposed in .
It is curious to note that there has been a distancing of from -3.601057: the value -3.6767991 for changes to for . Note hat for a weight of 0.00990099 would be given to minimisation of against a value of 0.990099 for .
Finally, it is considered that , the estimation of is equal to 0.03183904 with approximations of the associated confidence intervals equal to and , i.e., a coefficient not significantly different from zero is obtained. Once again, it is interesting to note that the third variable initially has values for and very similar between them (see Example 2) and that as a consequence of the linear relationship with the second variable, the coefficient becomes not significantly different from zero using the penalized estimator.
| , | |||||
| 1 | 4.3580904 | 4.3637278 | 0.2876449 | [3.803312, 4.924143] | [3.790357, 4.914893] |
| 2 | 0.3809489 | 0.3793928 | 0.9808815 | [-1.550971, 2.309756] | [-1.564748, 2.283066] |
| 3 | -3.6770687 | -3.6767991 | 0.1959585 | [-4.062437, -3.291161] | [-4.057372, -3.287766] |
| , | |||||
| 1 | 4.3264551 | 4.3226154 | 0.281187 | [3.757987, 4.887244] | [3.743654, 4.876066] |
| 2 | 0.2552237 | 0.2439003 | 0.9683303 | [-1.667152, 2.154952] | [-1.708548, 2.117196] |
| 3 | -3.6519522 | -3.6496978 | 0.1934983 | [-4.031710, -3.267686] | [-4.025403, -3.259135] |
| , | |||||
| 1 | 4.2795271 | 4.27471093 | 0.2873334 | [3.717146, 4.832276] | [3.695980, 4.823938] |
| 2 | 0.0691914 | 0.05400399 | 0.9622777 | [-1.831101, 1.939109] | [-1.810631, 1.918534] |
| 3 | -3.6147874 | -3.61174146 | 0.1923354 | [-3.988318, -3.235165] | [-3.984625, -3.238844] |
| , | |||||
| 1 | -14.7479306 | -14.8279630 | 0.3758633 | [-15.564655, -14.0912709] | [-15.6807864, -14.1957101] |
| 2 | -19.3578449 | -19.3543196 | 0.2441033 | [-19.832762, -18.8758772] | [-19.8351704, -18.8815710] |
| 3 | 0.3169069 | 0.3170817 | 0.05212487 | [0.214917, 0.4192465] | [0.2151219, 0.4176053] |
| 0.01 | 0.999884 | 0.9998847 | 2.468503 | [0.9998363, 0.9999331] | [0.9998286, 0.9999254] |
| 0.03 | 0.999884 | 0.9998847 | 2.476162 | [0.9998362, 0.9999333] | [0.9998297, 0.9999260] |
| 0.06 | 0.9998838 | 0.9998844 | 2.470472 | [0.9998360, 0.9999329] | [0.9998289, 0.9999251] |
| 100 | 0.992539 | 0.9924073 | 0.001157019 | [0.9901396, 0.9946751] | [0.9898363, 0.9943386] |
7 Stability of the penalized estimator
In order to study the stability of the estimators, the independent variables of the multiple linear regression model will be perturbed by 1% following the procedure shown in Belsley [3]. Thus, given a vector of size , a perturbation of it by 1% is given by the expression::
where is a random vector, of equal dimension to , and .
The effect of the perturbation on the estimation of the coefficients is quantified by the following expression:
| (19) |
where denotes an estimator of the parameter and the subindex refers to the estimates obtained in the perturbed model, i.e. in the model in which all the independent variables have been perturbed.777 In this case it is considered that all variables are quantitative. If there were any binary variables, it would be advisable to use a different perturbation method than the one described. (without considering the intercept).
To obtain consolidated results, the above procedure will be performed 1000 times and its mean and confidence region determined by the 0.025 and 0.975 percentiles will be used for interpretations.
Example 5 (continuation of example 4)
In example 2 in which the degree of essential approximate multicollinearity is troubling, the independent variables have been perturbed 1000 times for and for each value of considered in the Example 4: .
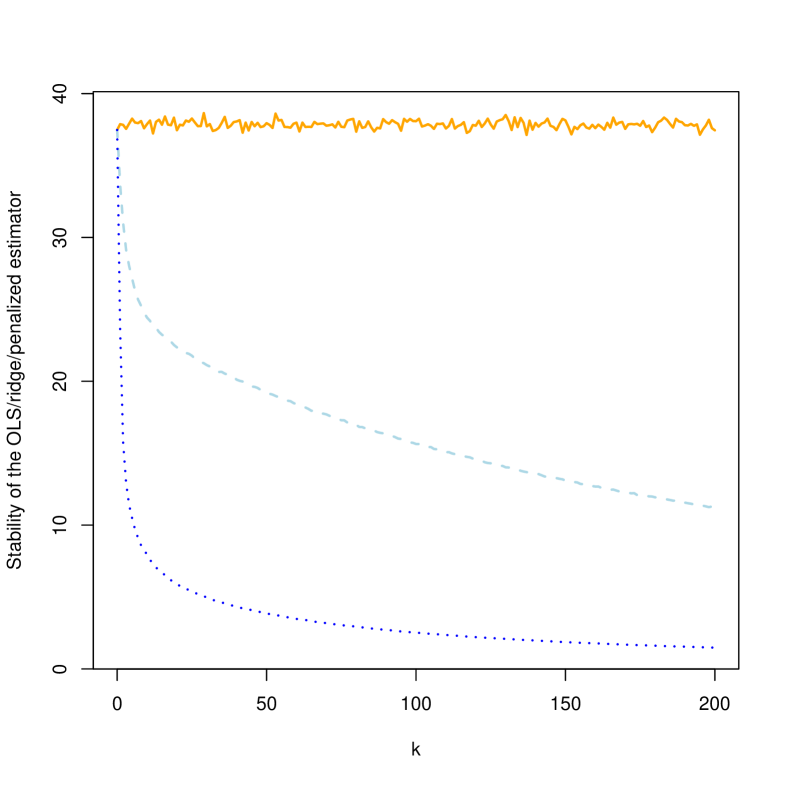
For (i.e., when OLS is applied), is obtained that perturbing the independent variables by 1% implies a variation of 38.27699%. Therefore, this would be a case in which the multicollinearity in the model causes numerical instability, since a small change in the independent variables implies a significant variation in the estimates of their coefficients.
Table 4 shows the mean, 0.025 percentile and 0.095 percentile of the percent variance of the 1000 iterations performed for and for each estimator: OLS, ridge and penalized:
-
•
When , it is observed that the values obtained for both the mean value and the percentiles are very similar to those of OLS, i.e., those values of that make the quadratic error minimal or measures such as the condition number or variance inflation factor fall below the established thresholds do not substantially improve the numerical instability of the model.
-
•
It is observed that for the high values of considered, , stable estimators are achieved in the presence of small changes in the independent variables.
To finish, Figure 1 shows the average percentage change (out of 1000 iterations) that occurs in the coefficient estimates in the presence of a 1 percent perturbation in the independent variables for . It is observed that the penalized estimator (blue - dotted) has a higher stability to the discussed perturbations than the ridge estimator (lightblue - dashed) as the value of increases.
| Ridge | Penalized | |||||
|---|---|---|---|---|---|---|
| Mean | Mean | |||||
| 0 | 38.27699 | 23.95753 | 55.43604 | 38.27699 | 23.95753 | 55.43604 |
| 0.01 | 38.22262 | 23.95097 | 55.33613 | 38.20928 | 24.02455 | 55.36458 |
| 0.03 | 38.11476 | 23.94311 | 55.13764 | 38.06461 | 24.15165 | 55.20508 |
| 0.06 | 37.95507 | 23.93155 | 54.84321 | 37.82431 | 24.26060 | 54.92455 |
| 100 | 15.65896 | 13.62525 | 17.41957 | 2.535079 | 2.156762 | 2.913410 |
| 1000 | 3.256717 | 2.822840 | 3.643900 | 0.3383532 | 0.3016403 | 0.3746771 |
8 Example
| Year | |||
|---|---|---|---|
| 1996 | 3.80510 | 4.7703 | 4.8786 |
| 1997 | 3.94580 | 4.7784 | 5.0510 |
| 1998 | 4.05790 | 4.9348 | 5.3620 |
| 1999 | 4.19130 | 5.0998 | 5.5585 |
| 2000 | 4.35850 | 5.2907 | 5.8425 |
| 2001 | 4.54530 | 5.4335 | 6.1523 |
| 2002 | 4.81490 | 5.6194 | 6.5206 |
| 2003 | 5.12860 | 5.8318 | 6.9151 |
| 2004 | 5.61510 | 6.1258 | 7.4230 |
| 2005 | 6.22490 | 6.4386 | 7.8024 |
| 2006 | 6.78640 | 6.7394 | 8.4297 |
| 2007 | 7.49440 | 6.9104 | 8.7241 |
| 2008 | 8.39930 | 7.0993 | 8.8819 |
| 2009 | 9.39510 | 7.2953 | 9.1636 |
| 2010 | 10.68000 | 7.5614 | 9.7272 |
| 2011 | 12.07100 | 7.8036 | 10.3010 |
| 2012 | 13.44821 | 8.0441 | 10.9830 |
Table 5 shows the outstanding mortgage debt, , personal consumption, , personal income, , and outstanding consumer credit, , for years from 1996 to 2012 in relation to credit in the United State. This dataset was previously applied by [54]. Results of the OLS estimation are shown in Table 6.
| Variable | Estimate | p-value |
|---|---|---|
| Intercept | 5.469264 | 0.681 |
| (13.016791) | ||
| -4.252429 | 0.423 | |
| (5.135058) | ||
| 3.120395 | 0.149 | |
| (2.035671) | ||
| 0.002879 | 0.626 | |
| (0.005764) | ||
| F-statistic | 52.3 | 0.0000001629 |
| 0.9235 | ||
It is observed that the OLS estimates of the coefficients on consumption, income and credit outstanding are not significantly888Throughout the section, it is considered to work at 5% significance different from zero, while at the same time the model is found to be jointly valid. This contradiction suggests that the degree of approximate multicollinearity in the model affects the statistical analysis of the model.
For this model, the following simple regressions can be performed:
which in all cases have coefficients for the slopes significantly different from zero and lead to establish .
8.1 Diagnosis of troubling approximate multicollinearity.
This possible worrying approximate multicollinearity is confirmed with the conclusions obtained from the following diagnosis measures (calculated by “multiColl” package [30] R [35]):
-
•
the coefficients of variation of the independent variables are equal to 0.1718940, 0.2482804 and 0.3607848 (not lower than the threshold of 0.1002506 established as troubling by Salmerón et al. [41]),
-
•
the values for the variance inflation factor are equal to 589.7540, 281.8862 and 189.4874 (higher than the threshold of 10 established as troubling, for example, by Marquardt [26]),
- •
-
•
the determinant of the correlation matrix is equal to 0.00002007699 (below the threshold of 0.1013 established as troubling by Garcia et al. [14]).
More specifically, it can be stated that the degree of essential multicollinearity existing in model is troubling, while that of the non-essential type is not.
8.2 Traces
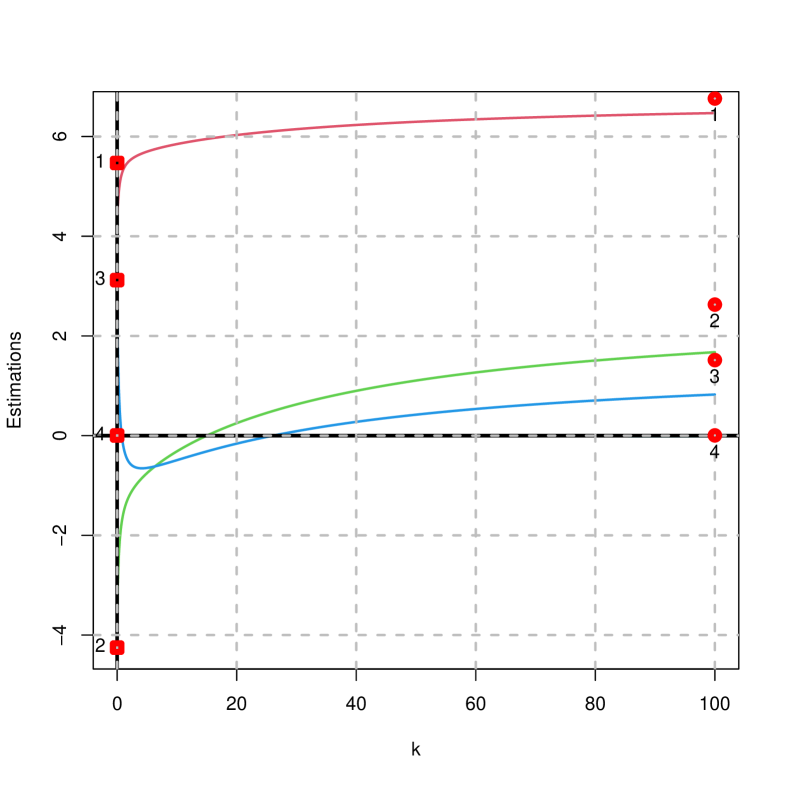
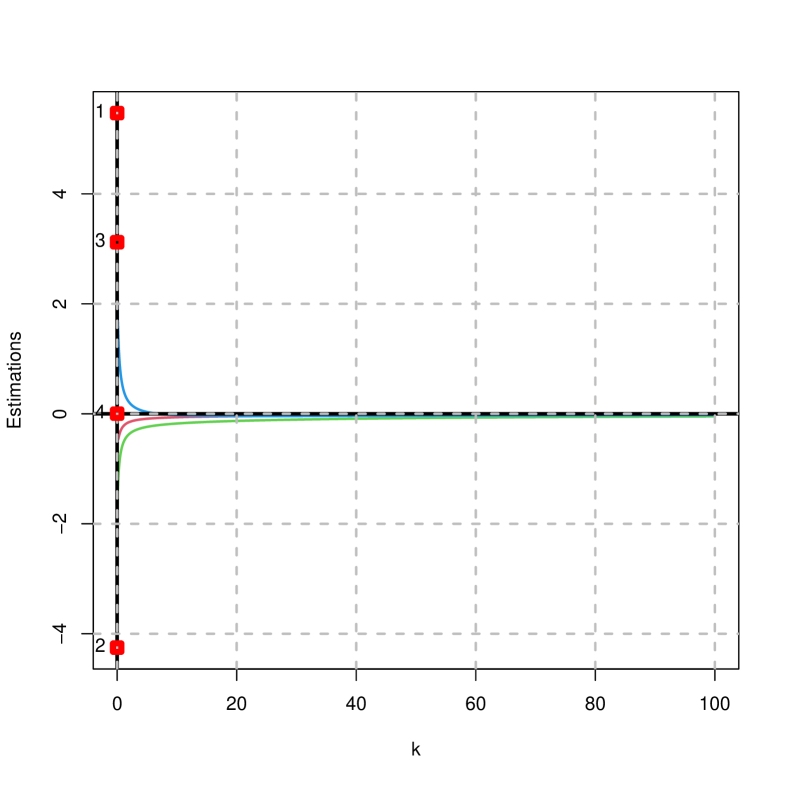
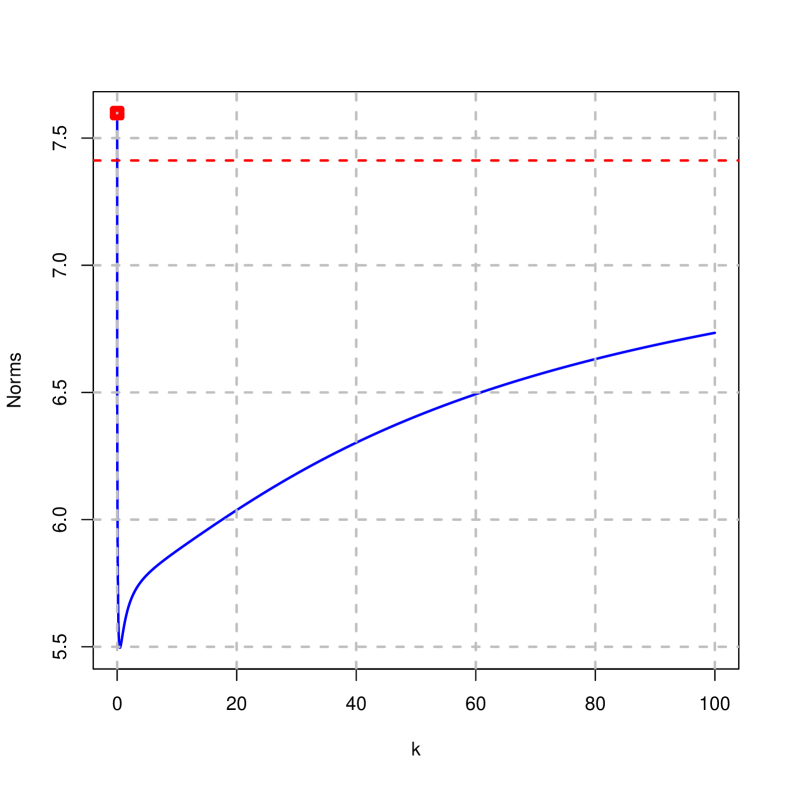
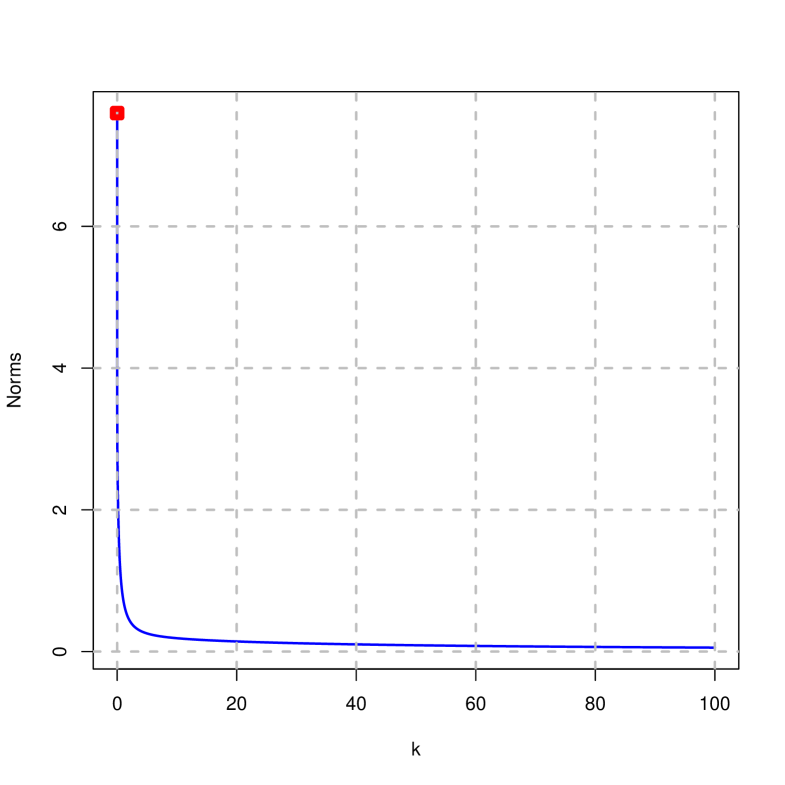
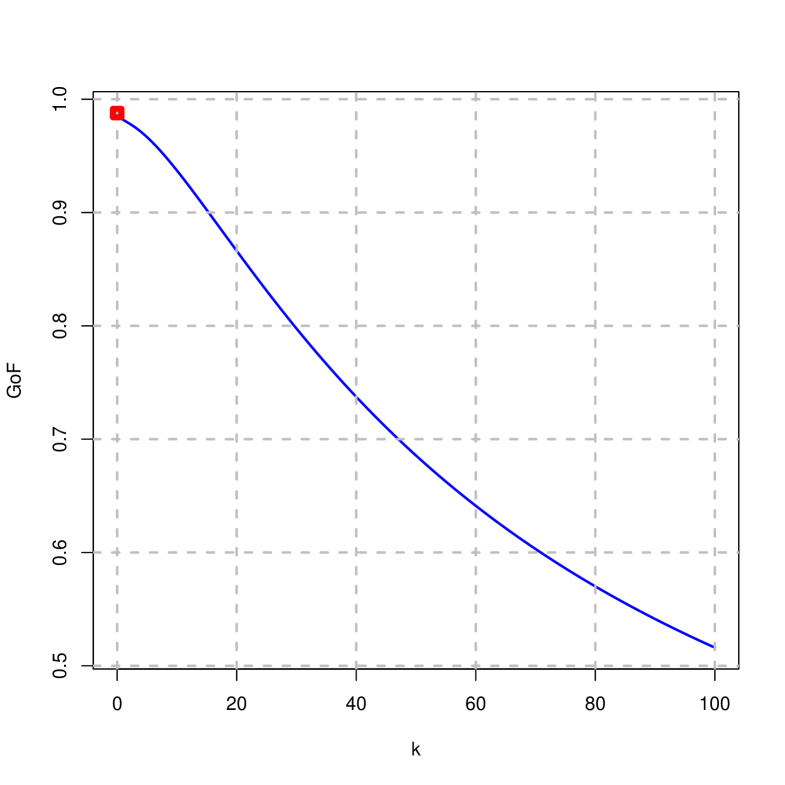
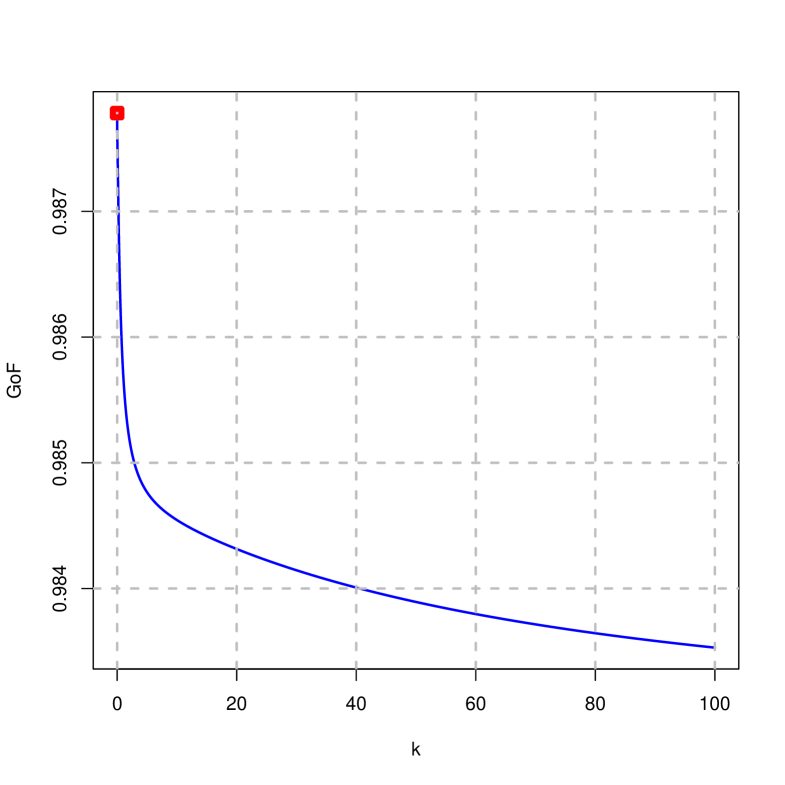
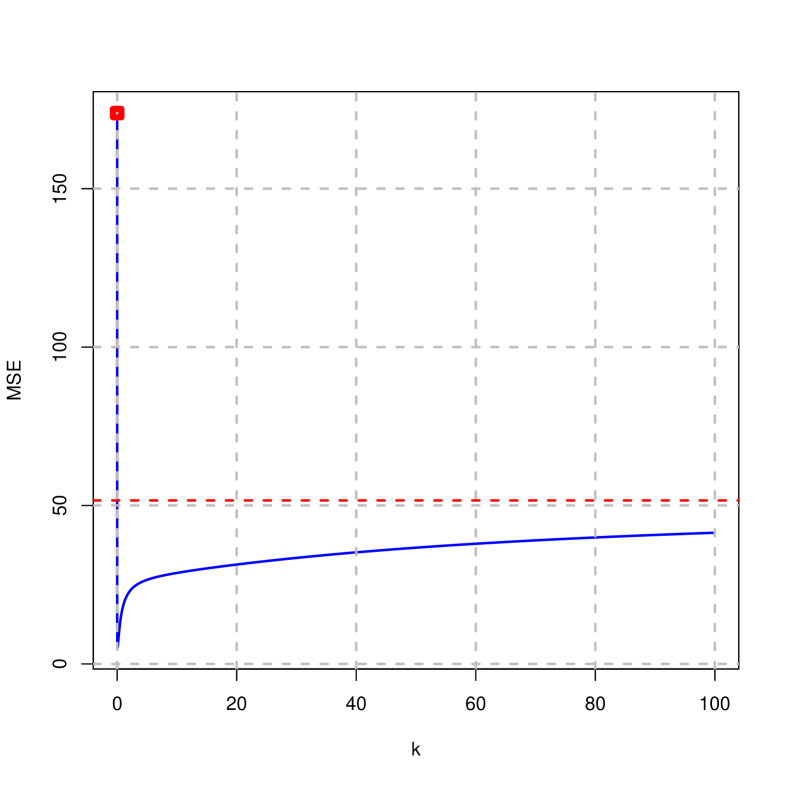
Figures 2 to 4 show the traces of the estimates, mean squared error, goodness of fit and norms on the difference of the penalized estimator (right) and ridge (left) considering that . It is concluded that:
-
•
The estimates of the ridge estimator decay rapidly towards zero; while that of the penalized estimator do not, as they converge to the values given for the vector .
-
•
The norm of the penalized estimator decreases until it reaches a minimum value, from which it grows in the direction of its horizontal asymptote; while the norm of the ridge estimator is clearly strictly decreasing towards zero.
-
•
The goodness of fit in both cases is decreasing, although in the case of the penalized estimator it takes smaller values than in the ridge (it decreases more rapidly).
-
•
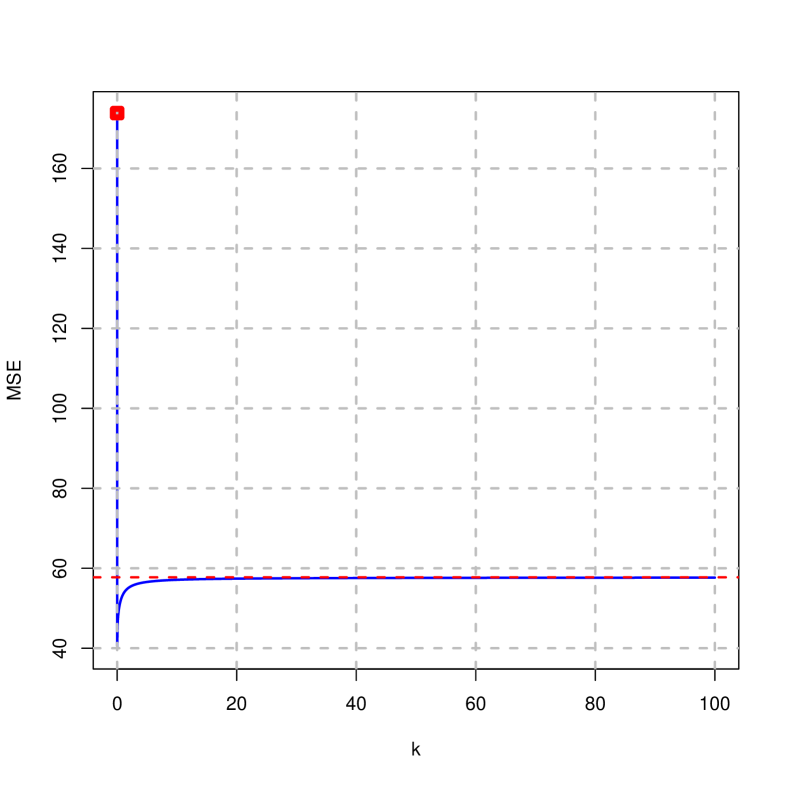
It is observed that in both cases there is a value of that implies a minimum squared error that is smaller than that of OLS. Moreover, it is found that the mean squared error of the penalized and ridge estimator is smaller than that of OLS for all positive values of considered.
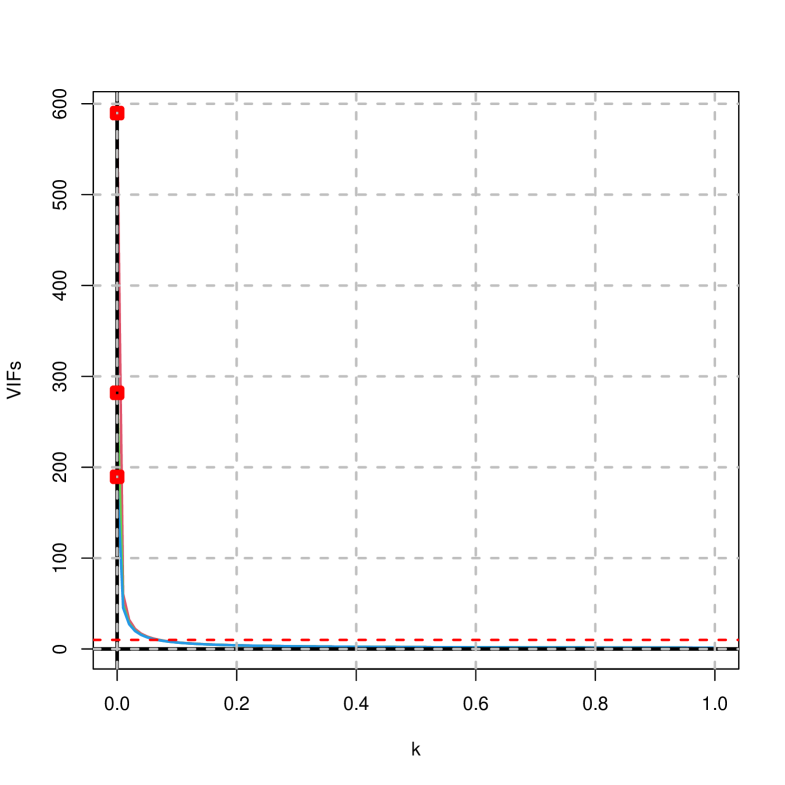
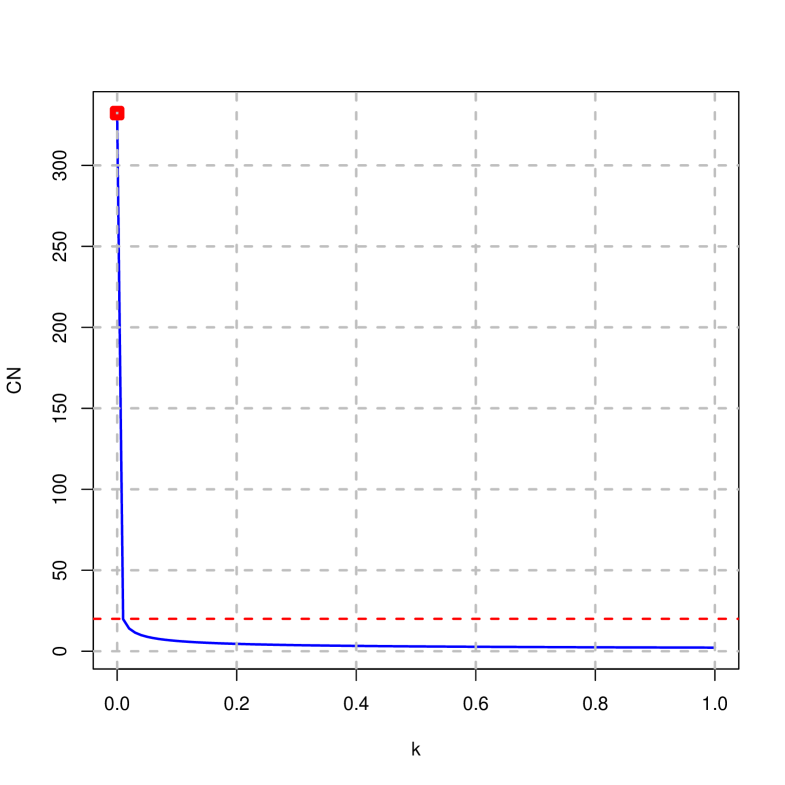
On the other hand, considering that, Figure 6 shows the traces of the variance inflation factor and the condition number. Note that in this case they coincide for the ridge and penalized estimator since the expanded matrix from which these measures are calculated coincide in both cases.
It is observed that in both cases they decrease towards their minimum values and that there are values of that are below the thresholds considered to be troubling.
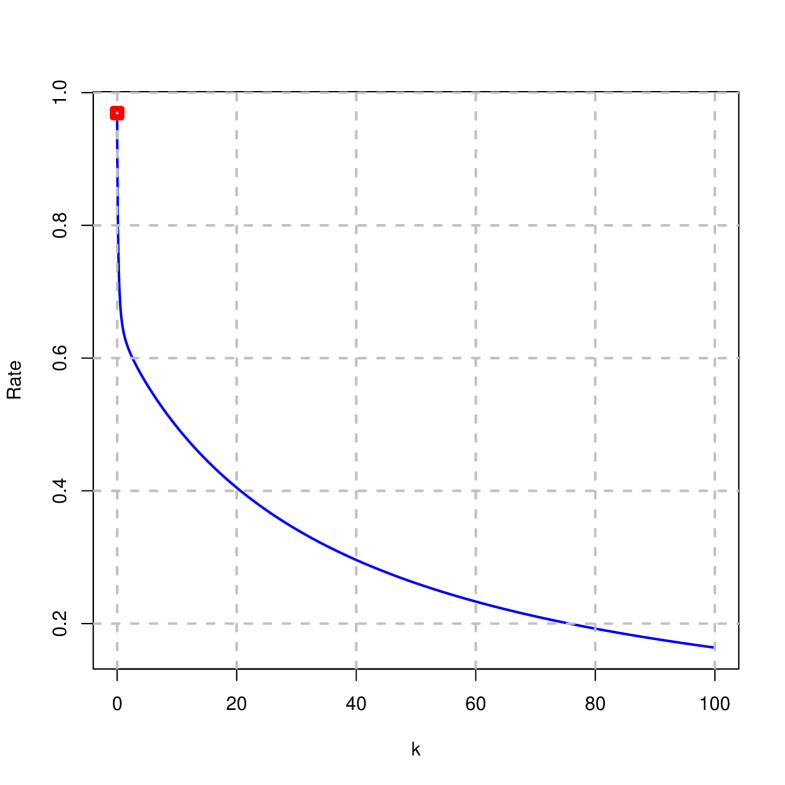
Finally, considering once again that , Figure 7 shows the trace of . It is observed that it is strictly monotonically decreasing, obtaining for the highest values of values less than 20%.
8.3 Choice of penalty parameter and analysis of the model
As noted in the previous graphical representations, following the guidelines in subsection 5.2, it is possible to make a choice of that implies a variance inflation factor or condition number below the established thresholds or for a minimum mean square error. As a summary, Table 7 shows the values of leading to the minimum square error and the first value of the variance inflation factor and condition number that falls below the thresholds traditionally set as troubling. Note that the penalized estimator has a smaller minimum square error than that of the ridge estimator.
| Criterion | Penalized estimator () | Ridge estimator () |
|---|---|---|
| minimum MSE | k=0.07 (5.131445) | k=0.02 (40.14453) |
| NC lower than 30 | k=0.01 (19.83053) | |
| NC lower than 20 | k=0.01 (19.83053) | |
| NC lower than 10 | k=0.04 (9.966163) | |
| Maximum VIF lower than 10 | k=0.08 (8.980033) | |
For these values (including ), Table 8 shows the results obtained with the application of the ridge estimator while Table 9 shows the results obtained with the application of the penalized estimator. Note that in this last table, the bootstrap approximations to the confidence interval obtained from the 0.025 and 0.975 percentiles are coded as type 1 and those obtained from the mean and quasi-variance as type 2.
Estimation of coefficients
It is observed that the estimates of the ridge estimator decrease towards zero; contrary to those of the penalized estimator, although they are still far from the values fixed in the vector .
On the other hand, inference using bootstrap methods from 10000 iterations indicates that the estimates obtained by the ridge estimator are not significantly different from zero for the values considered. However, this is not the case for the estimates obtained from the penalized estimator. Thus, for example, in the case where :
-
•
The intercept is significantly different from zero with positive sign.
-
•
The coefficient of personal consumption is significantly different from zero with a negative sign. That is, higher personal consumption is associated with a decrease in mortgage debt, which could be interpreted as higher consumption in situations where there is less mortgage debt. However, it should be noted that this estimated sign is the opposite 999 Considering that , it is obtained that , all of them being coefficients significantly different from zero.In this case, the sign of the second coefficient has been corrected in accordance with the specifications of vector , although the fourth coefficient now has a negative sign. This situation is more understandable because the value set in the vector for this parameter, 0.00519, is susceptible to this possible change of sign.
It is also obtained a root mean square error equal to 41.3982 (increases with respect to the minimum value although it is still lower than that of OLS), a condition number equal to 1.019 and maximum variance inflation factor equal to 1.000193. That is, the multicollinearity detection measures are very close to their minimum value, so the degree of multicollinearity is very low. This issue is reflected in the fact that the average variance of the coefficient estimates when the independent variables are perturbed by 1% is 0.1607%. of that fixed in the vector . -
•
The coefficient of outstanding credit is significantly different from zero with a positive sign. That is, higher credit outstanding is associated with an increase in mortgage debt, which could be interpreted as meaning that there is higher credit outstanding when mortgage debt is higher.
Note that in this case we obtain a mean square error very close to the minimum value and much lower than that of OLS; at the same time we verify that the degree of existing approximate multicollinearity is considered not to be troubling since the number of condition and all the variance inflation factor are less than 10.
Goodness-of-fit
Considering that for the results obtained coincide with those of OLS, it is observed that the value of the goodness-of-fit, 0.9878, does not coincide with the value of the coefficient of determination, 0.9235, provided in Table 6. This discrepancy is due, as discussed, to the fact that the proposed goodness-of-fit coincides with the coefficient of determination when only if the dependent variable has zero mean, a condition that in this case is not verified.
On the other hand, it is observed that the goodness-of-fit is very similar in the ridge and penalized estimator and, in addition, does not differ substantially from the value obtained in OLS.
Mean Square Error
With respect to the mean square error, lower values are obtained in all cases in the case of the penalized estimator. This result is in line with the results shown in the Monte Carlo simulation of subsection 3.5.1: the penalized estimator performs better in terms of MSE than the peak estimator when the troubling approximate multicollinearity is of the essential type.
This result is interesting as both the ridge and penalized estimators are biased estimators.
Existence of approximate multicollinearity
As previously discussed, in both cases the same values are obtained for the variance inflation factor and the condition number. The condition number is less than 20 in all cases considered, while the maximum VIF is less than 10 only for .
Numerical stability of the obtained estimates
By perturbing the observations 10000 times by 1% as indicated in the section 7 and calculating their effect on the coefficient estimates according to the expression (19), the average values shown in the tables are obtained.
It can be seen that initially small changes in the data result in an average variation in the coefficient estimates of 73.9726%. This indicates a significant instability in the estimates obtained by OLS. This value decreases as the value of increases, the decrease being more pronounced in the case of the penalized estimator. Thus, for example, in the case where we have that a perturbation of 1% in the independent variables implies an average variation of 7.6294% in the coefficient estimates.
| k=0 | k=0.01 | k=0.02 | k=0.04 | k=0.08 | ||||||
| Ridge | Bootstrap | Ridge | Bootstrap | Ridge | Bootstrap | Ridge | Bootstrap | Ridge | Bootstrap | |
| 5.4693 | 2.2482 | 1.0412 | 0.2857 | 0.2629 | -0.0943 | -0.21 | -0.3216 | -0.428 | -0.412 | |
| -4.2524 | -2.466 | -2.4673 | -1.7351 | -2.1056 | -1.5493 | -1.814 | -1.379 | -1.5481 | -1.2016 | |
| 3.1204 | 2.0841 | 2.5273 | 1.887 | 2.3586 | 1.789 | 2.1596 | 1.6495 | 1.8911 | 1.4441 | |
| 0.0029 | 0.0028 | 0.0014 | 0.002 | 0.0013 | 0.002 | 0.0014 | 0.0021 | 0.0017 | 0.0025 | |
| DS for | 2947.0815 | 13.9162 | 902.4274 | 3.2142 | 532.7874 | 1.8279 | 292.8689 | 1.004 | 154.0945 | 0.5946 |
| DS for | 1146.1535 | 6.1901 | 350.9741 | 2.167 | 207.2237 | 1.6559 | 113.9276 | 1.3197 | 59.9713 | 1.0715 |
| DS for | 338.336 | 3.0476 | 103.6891 | 1.9856 | 61.3139 | 1.8011 | 33.8661 | 1.6106 | 18.0615 | 1.382 |
| DS for | 1.0981 | 0.0055 | 0.3364 | 0.0032 | 0.1987 | 0.0031 | 0.1095 | 0.0029 | 0.0579 | 0.0025 |
| GoF | 0.9878 | 0.991 | 0.9877 | 0.9905 | 0.9876 | 0.9903 | 0.9876 | 0.9902 | 0.9874 | 0.99 |
| BIT1 for | (-23.3118, 28.5705) | (-5.4661, 6.7827) | (-3.4506, 3.648) | (-2.2583, 1.7004) | (-1.6039, 0.6764) | |||||
| BIT1 for | (-13.1453, 9.7675) | (-5.1669, 2.8114) | (-4.0082, 1.9754) | (-3.2576, 1.4472) | (-2.7288, 1.0429) | |||||
| BIT1 for | (-4.5941, 6.4143) | (-2.4435, 4.7682) | (-2.1057, 4.4248) | (-1.7724, 4.0229) | (-1.4312, 3.5192) | |||||
| BIT1 for | (-0.0082, 0.0135) | (-0.004, 0.0081) | (-0.0035, 0.0081) | (-0.0028, 0.0079) | (-0.0018, 0.0074) | |||||
| BIT1 for GoF | (0.9852, 0.998) | (0.9848, 0.9974) | (0.9845, 0.9972) | (0.9843, 0.997) | (0.9841, 0.9968) | |||||
| BIT2 for | (-25.0275, 29.5239) | (-6.0141, 6.5856) | (-3.6769, 3.4884) | (-2.2895, 1.6464) | (-1.5774, 0.7535) | |||||
| BIT2 for | (-14.5985, 9.6666) | (-5.9824, 2.5121) | (-4.7948, 1.6962) | (-3.9655, 1.2076) | (-3.3018, 0.8986) | |||||
| BIT2 for | (-3.8892, 8.0574) | (-2.0049, 5.7788) | (-1.7411, 5.3191) | (-1.5072, 4.8063) | (-1.2646, 4.1529) | |||||
| BIT2 for | (-0.0081, 0.0136) | (-0.0043, 0.0083) | (-0.004, 0.008) | (-0.0035, 0.0077) | (-0.0024, 0.0074) | |||||
| BIT2 for GoF | (0.9847, 0.9973) | (0.9843, 0.9967) | (0.9841, 0.9966) | (0.9839, 0.9965) | (0.9837, 0.9963) | |||||
| MSE | 199.9497 | 44.3756 | 41.3225 | 43.3614 | 45.9795 | |||||
| CN | 332.3 | 19.8305 | 14.0525 | 9.9662 | 7.0841 | |||||
| VIF(1,k) | 589.754 | 60.3983 | 32.2129 | 16.9411 | 8.98 | |||||
| VIF(1,k) | 281.8862 | 48.7101 | 28.4015 | 15.8204 | 8.6686 | |||||
| VIF(1,k) | 189.4874 | 45.2022 | 27.2576 | 15.4841 | 8.5752 | |||||
| Stability | 73.9726 | 50.4276 | 36.4043 | 24.5117 | 17.0305 | |||||
| k=0 | k=0.01 | k=0.04 | k=0.07 | k=0.08 | ||||||
| Penalized | Bootstrap | Penalized | Bootstrap | Penalized | Bootstrap | Penalized | Bootstrap | Penalized | Bootstrap | |
| 5.4693 | 2.2482 | 4.585 | 4.0199 | 4.4378 | 4.3899 | 4.4938 | 4.5378 | 4.5171 | 4.5763 | |
| -4.2524 | -2.466 | -3.8019 | -3.1602 | -3.4622 | -3.0343 | -3.247 | -2.8617 | -3.1853 | -2.8093 | |
| 3.1204 | 2.0841 | 2.8777 | 2.2792 | 2.4876 | 1.9617 | 2.182 | 1.6749 | 2.0917 | 1.5909 | |
| 0.0029 | 0.0028 | 0.0028 | 0.0035 | 0.0035 | 0.0043 | 0.0041 | 0.0049 | 0.0042 | 0.0051 | |
| DS for | 2947.0815 | 13.9162 | 902.4274 | 3.1633 | 292.8689 | 0.9857 | 174.8012 | 0.6339 | 154.0945 | 0.5787 |
| DS for | 1146.1535 | 6.1901 | 350.9741 | 2.1118 | 113.9276 | 1.3152 | 68.0214 | 1.1398 | 59.9713 | 1.1021 |
| DS for | 338.336 | 3.0476 | 103.6891 | 1.9337 | 33.8661 | 1.6009 | 20.4131 | 1.4532 | 18.0615 | 1.4139 |
| DS for | 1.0981 | 0.0055 | 0.3364 | 0.0032 | 0.1095 | 0.0028 | 0.0656 | 0.0026 | 0.0579 | 0.0025 |
| GoF | 0.9878 | 0.991 | 0.9878 | 0.9905 | 0.9877 | 0.9901 | 0.9875 | 0.9899 | 0.9874 | 0.9898 |
| BIT1 for | (-23.3118, 28.5705) | (-1.615, 10.4396) | (2.5116, 6.3897) | (3.2787, 5.7392) | (3.4191, 5.6548) | |||||
| BIT1 for | (-13.1453, 9.7675) | (-6.4747, 1.3367) | (-4.8868, -0.193) | (-4.4573, -0.4378) | (-4.3505, -0.4793) | |||||
| BIT1 for | (-4.5941, 6.4143) | (-1.9709, 5.1374) | (-1.4629, 4.3341) | (-1.3739, 3.8329) | (-1.3547, 3.6979) | |||||
| BIT1 for | (-0.0082, 0.0135) | (-0.0025, 0.0096) | (-0.0006, 0.01) | (0.00005, 0.0101) | (0.0008, 0.0101) | |||||
| BIT1 for GoF | (0.9852, 0.998) | (0.9849, 0.9969) | (0.9845, 0.9964) | (0.9842, 0.9963) | (0.9841, 0.9962) | |||||
| BIT2 for | (-25.0275, 29.5239) | (-2.1802, 10.2199) | (2.4578, 6.3219) | (3.2954, 5.7803) | (3.442, 5.7106) | |||||
| BIT2 for | (-14.5985, 9.6666) | (-7.2993, 0.9789) | (-5.612, -0.4566) | (-5.0956, -0.6277) | (-4.9695, -0.6491) | |||||
| BIT2 for | (-3.8892, 8.0574) | (-1.5109, 6.0694) | (-1.1761, 5.0996) | (-1.1733, 4.5232) | (-1.1804, 4.3622) | |||||
| BIT2 for | (-0.0081, 0.0136) | (-0.0027, 0.0097) | (-0.0013, 0.0099) | (-0.0002, 0.01) | (0.0001, 0.0101) | |||||
| BIT2 for GoF | (0.9847, 0.9973) | (0.9845, 0.9965) | (0.9842, 0.9961) | (0.9839, 0.9959) | (0.9838, 0.9958) | |||||
| MSE | 199.9497 | 22.2729 | 6.3279 | 5.4749 | 5.4808 | |||||
| CN | 332.3 | 19.8305 | 9.9662 | 7.5635 | 7.0841 | |||||
| VIF(1,k) | 589.754 | 60.3983 | 16.9411 | 10.131 | 8.98 | |||||
| VIF(2,k) | 281.8862 | 48.7101 | 15.8204 | 9.7315 | 8.6686 | |||||
| VIF(3,k) | 189.4874 | 45.2022 | 15.4841 | 9.6116 | 8.5752 | |||||
| Stability | 73.9726 | 29.8586 | 12.0844 | 8.3133 | 7.6294 | |||||
9 Conclusions
This paper proposes the estimation of the coefficients of a multiple linear regression model by penalizing the function to be minimized with the objective of getting the estimates to be as close as possible to the relationships given by the corresponding simple linear regressions, since then the relationships of each of the independent variables to the dependent variable are obtained if the rest of the explanatory variables vary as would be expected.
The main characteristics of the proposed penalized estimator (trace and norm of the estimator, variance-covariance matrix, goodness-of-fit and mean square error) and its implications in the detection and treatment of multicollinearity have been thoroughly analyzed. This analysis has served to propose different possibilities for choosing the penalty parameter, so that for a fixed value of this parameter, inference can be performed by bootstrap methodology. The fact that the objective is that the estimates converge to the estimates of the simple regressions means that the bootstrap inference proposed can provide estimates of the coefficients of the independent variables significantly different from zero, contrary to what occurs in the ridge estimator, since in this case it is established that the estimates converge to zero.
It has also been found that the ridge estimator of Hoerl and Kennard [18, 19] is a particular case of the proposed estimator. Due to this relationship, several characteristics coincide in both estimators, such as the variance-covariance matrix, the calculation of the variance inflation factor (VIF) and the condition number (CN). This makes it possible that studies on these measures in the ridge estimator will be directly applicable to the penalized estimator obtained.
It is also important to note that this estimator mitigates the numerical instability that can occur when estimating by OLS a multiple linear regression model where the approximate multicollinearity is troubling, so its application is interesting when this consequence of multicollinearity is present in the econometric model analyzed.
On the other hand, in the works of García et al. [13], Salmerón et al. [39] and Rodríguez et al. [37, 36] where the VIF, CN, goodness of fit and Stewart index, are respectively extended (see [46]) to ridge estimator, it is stated that the transformation of the data is not optional but is required for the correct application of these measures in ridge regression. This issue has already been addressed by Marquardt in his work entitled “You should standardize the predictor variables in your regression models” ([27]). While Obenchain [32] indicated that when working with the ridge estimator the anaylisis should be completely redone if any transformation of regressors is adopted. In this sense, this work establishes that for the penalized estimator it is not necessary to perform any transformation of the data except to consider the standardization of the data to calculate the VIF and the unit length to calculate the CN.
Finally, future lines of work include the combination with the LASSO estimator to emulate the elastic net methodology and perform variable selection, analyze the possibilities of the proposed estimator when there are outliers in the data and compare its performance in terms of MSE with the proposals from Wang et al. [52] and Lukman et al. [25]. A future goal is also the creation of a package in R [35] from the code available in Github that allows the application of the methodology presented to any user in the teaching, research and/or business environment.
Appendix A Results of interest
A.1 Norm of the penalized estimator
Taking into account the decomposition donde is an orthogonal matrix () which contains the eigenvectors of and is a diagonal matrix () of dimension containing its eigenvalues (which are real and positive), it is verified that:
| (20) |
Deriving with respect to :
| (21) | |||||
| (22) | |||||
| (23) |
the first term is decreasing when increases while the third term is increasing since and then its derivatives are, expressions (21) and (23) respectively, negatives and positives. At the same time the sign of the derivative of the second term (expression (22)) is undefined since, on the one hand, it depends on the sign of and, on the other hand, on the sign of .
In short, when cannot be concluded about the monotony of the , although it is certain that there exists a value of that stabilizes this norm, since when :
Finally, when (the penalized estimator coincides with the ridge estimator), it is clear that is decreasing in .
A.2 Optimality of the variance-covariance matrix
Starting with the expression (20), it follows that . Since , it is clear that:
Considering a non-zero vector and taking into account that and for , it is verified that:
where . Therefore, es a negative definite matrix and, since , it is verified:
A.3 Estimation errors
Following the development of Rodríguez et al. [37] (Proposition 1), taking into account that the expression (8) comes from the system of normal equations:
it must be verified that the first row of , multiplied by :
has to be equal to the first element of , that is to say to . Consequently:
or equivalently:
| (25) |
On the other hand, based on , it is obtained that:
In this case:
| (26) |
A.4 Monotony of goodness-of-fit
From expression (20) and taking into account that , it is obtained:
And, then:
where and .
Thus,
Then, expression (16) can be rewritten as:
| (27) | |||||
Deriving with respect to :
| (28) | |||||
| (29) | |||||
| (30) |
Due to and para , it is evident that the derivatives of the expressions (28) and (30) are negatives, lwhich implies that the first and third summands of expression (27) are decreasing in . Note that this implies that for (ridge regression), the goodness-of-fit is decreasing in .
On the contrary, the sign of the derivative of expression (29) depends on the sign of , for , and therefore no statement can be made about the monotonicity of this second summand. . However, it is verified that this term has a horizontal asymptote:
i.e., there must be a value of from which the value of this term stabilizes.
Taking into account the above analysis, it is to be expected that decreasing when increases, aalthough it is not assured. In such case, it would be verified that , where is the coefficient of determination of the model (1).
A.5 Monotony of
On the other hand:
and, then:
| (32) |
Deriving with respect to :
| (33) | |||||
| (34) |
Due to and for , it is clear that the derivative of the expression (33) has a sign which depends on , for , and the derivative of the expression (34) has a positive sign, then the second term of is increasing in .
Finally, considering that :
This is to say, has a horizontal asymptote, so there must be a value of at which it stabilizes.
A.6 Monotony of
Since the main objective of the proposed penalty is to ensure that the estimates of are close to , it is interesting to analyze the behavior of .
Taking into account thata con (see expression (10)), it is obtained that . In this case:
From , and remembering that and , it is obtained that:
Deriving with respect to :
| (35) | |||||
| (36) | |||||
| (37) |
From the above expressions it can only be stated that the third term is decreasing in (since its derivative, expression (37), has a negative sign), so it is difficult to analyze the monotony of the . The one thing that is clear is that when :
However, for it is verified that:
which clearly decreases to zero as increases.
References
- [1] Belsley, D.A., Kuh, E and Welsch, R.E. (1980). Regression diagnostics: Identifying influential data and sources of collinearity. Wiley, New York.
- [2] Belsley, D.A. (1982). Assessing the presence of harmful collinearity and other forms of weak data through a test for signal-to-noise. Journal of Econometrics, 20, 211-253.
- [3] Belsley, D.A. (1984). Demeaning conditioning diagnostics through centering. The American Statistician, 38(2), 73-77.
- [4] Bingzhen, C., Wenjuan, Z. and Lingchen, K. (2022). Variable selection and collinearity processing for multivariate data via row-elastic-net regularization. AStA Advances in Statistical Analysis, 106, 79-96.
- [5] Ding, Y., Oeng, Q., Song, Z. and Chen, H. (2023). Variable selection and regularization via arbitrary rectangle-range generalized elastic net. Statistics and Computing, 33, article 72.
- [6] Efron, B. (1979). Bootstrap methods: another look at the jackknife. The Annals of Statistics, 7(1), 1-26.
- [7] Efron, B. (1981). Nonparametric estimates of standard error: the jackknife, the bootstrap, and other resampling methods. Biometrika, 68(3), 589-599.
- [8] Efron, B. (1982). The jackknife, the bootstrap, and other resampling plans. Society for Industrial and Applied Mathematics, CBMS-NSF Regional Conference Series in Applied Mathematics, Monograph 38.
- [9] Efron, B. (1987). Better bootstrap confidence intervals. Journal of the American Statistical Association, 82(397), 171-185.
- [10] Efron, B. and Gong, G. (1983). A leisurely look at the bootstrap, the jackknife, and cross-validation. The American Statistician, 37(1), 36-48.
- [11] Efron, B. and Tibshirani, R. (1936). Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Statistical Science, 1(1), 54-75.
- [12] Gao, F. and Liu, X.Q. (2011). Linearized ridge regression estimator under the mean squared error criterion in a linear regression model. Communications in Statistics - Theroy and Methods, 40(9), 1434-1443.
- [13] García, J., Salmerón, R., García, C.B. and López Martín, M.M. (2015). Standardization of variables and collinearity diagnostic in ridge regression. International Statistical Review, 84(2), 245-266.
- [14] García, C., Salmerón, R. and García, C.B. (2018). Choice of the ridge factor from the correlation matrix determinant. Journal of Statistical Computation and Simulation, 89(2), 211-231.
- [15] Gibbons, D.G. (1981). A simulation study of some ridge estimators. Journal of American Statistical Association, 76, 131-139.
- [16] Gökpınar, E. and M. Ebegil (2016). A study on tests of hypothesis based on ridge estimator. Gazi University Journal of Science 29(4), 769-781.
- [17] Halawa, A. and M. El Bassiouni (2000). Tests of regression coefficients under ridge regression models. Journal of Statistical Computation and Simulation 65(1-4), 341-356.
- [18] Hoerl, A.E. and Kennard, R.W. (1970a). Ridge regression. Biased estimation for nonorthogonal problems. Technometrics, 12, 55-67.
- [19] Hoerl, A.E. and Kennard, R.W. (1970b). Ridge regression. Applications to nonorthogonal problems. Technometrics, 12, 69-82.
- [20] Hoerl, A., Kennard, R. and Baldwin, K. (1975). Ridge regression: some simulation. Communications in Statistics - Theory and Methods, 4(2), 105-123.
- [21] Kibria, B. (2003). Performance of some new ridge regression estimators. Communications in Statistics - Simulation and Computation, 32(2), 419-435.
- [22] Liu, K. (1993). A new class of blased estimate in linear regression. Communications in Statistics - Theroy and Methods, 22(2), 393-402.
- [23] Liu, K. (2003). Using Liu-type estimator to combat collinearity. Communications in Statistics - Theroy and Methods, 32(5), 1009-1020.
- [24] Liu, X.Q. and Gao, F. (2011). Linearized ridge regression estimator in linear regression. Communications in Statistics - Theroy and Methods, 40(12), 2182-2192.
- [25] Lukman, A. F., Adewuyi, E. T., Alqasem, O. A., Arashi, M., and Ayinde, K. (2024). Enhanced Model Predictions through Principal Components and Average Least Squares-Centered Penalized Regression. Symmetry, 16(4), 469.
- [26] Marquardt, D.W. (1970). Generalized Inverses, Ridge Regression, Biased Linear Estimation and Nonlinear Estimation. Technometrics, 12(3), 591-612.
- [27] Marquandt, D.W. (1980). You should standardize the predictor variables in your regression models. Journal of the American Statistical Association, 75(369), 87-91.
- [28] Marquardt, D.W. and Snee, R. (1975). Ridge regression in practice. The American Statistician, 29(1), 3-20.
- [29] McDonald G.C. and Galarneau, D.I. (1975). A Monte Carlo evaluation of some ridge-type estimators. Journal of the American Statistical Association, 70(350), 407-416.
- [30] Salmerón, R., García, C., García, J. (2019) multiColl: collinearity cetection in a multiple linear regression model. R package version 2.0, https://CRAN.R-project.org/package=multiColl.
- [31] Novales. A. Análisis de Regresión. URL: https://www.ucm.es/data/cont/docs/518-2013-11-13-Analisis%20de%20Regresion.pdf. Fecha de consulta: 21 de noviembre de 2023.
- [32] Obenchain, R.L. (1975). Ridge analysis following a preliminary test of the shrunken hypothesis. Technometrics, 17(4), 431-441.
- [33] Obenchain, R.L. (1977). Classical f-tests and confidence regions for ridge regression. Technometrics 19(4), 429-439.
- [34] O’Driscoll, D. and Ramirez, D.E. (2016). Limitations of the Least Squares Estimators; a teaching perspective. Conference: 10th Annual International Conference on Statistics: Teaching, Theory and Applications. ATINER’S Conference Paper Series, STA2016-2074.
- [35] R Core Team (2022) R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/.
- [36] Rodríguez, A., Salmerón, R. and García, C. (2021). Obtaining a threshold for the stewart index and its extension to ridge regression. Computational Statistics, 36, 1011-1029.
- [37] Rodríguez, A., Salmerón, R. and García, C.B. (2022). The coefficient of determination in the ridge regression. Communications in Statistics - Simulation and Computation, 51(1), 201-219.
- [38] Salmerón, R., García, J., López, M.M. and García, C.B. (2016). Collinearity diagnostic in ridge estimation through the variance inflation factor. Journal of Applied Statistics, 43(10), 1831-1849.
- [39] Salmerón, R., García, J., García, C.B. and López, M.M. (2017). Transformation of variables and the condition number in ridge estimation. Computational Statistics, 33(3), 1497-1524.
- [40] Salmerón, R. and García, C. and García, J. (2018). Variance inflation factor and condition number in multiple linear regression. Journal of Statistical Computation and Simulation, 88, 2365-2384.
- [41] Salmerón, R., Rodríguez, A. and García, C.B. (2020). Diagnosis and quantification of the non-essential collinearity. Computational Statistics, 35, 647-666.
- [42] Salmerón, R., García, C.B. and García, J. (2020). Detection of near-multicollinearity through centered and noncentered regression. Mathematics, 8, 931.
- [43] Salmerón, R., García, C., García, J. (2021) A guide to using the R package “multiColl” for detecting multicollinearity. Computational Economics 57, 529-536.
- [44] Salmerón, R., García, C., García, J. (2022) The “multiColl” package versus other existing packages in R to detect multicollinearity. Computational Economics 60, 439-450.
- [45] Sengupta, N. and F. Sowell (2020). On the asymptotic distribution of ridge regression estimators using training and test samples. Econometrics 8(4), 39.
- [46] Stewart, G.W. (1987). Collinearity and least squares regression. Statistical Science, 2(1), 68-84.
- [47] Snee, R.D. and Marquardt, D.W. (1984). Collinearity diagnostics depend on the domain of prediction, the model, and the data. The American Statistician, 38(2), 83-87.
- [48] Tibshirani, R. (1996). Regression shrinkage and selection via the LASSO. Journal of the Royal Statistical Society. Series B (Methodological), 58(1), 267–288.
- [49] Tibshirani, R. (2011). Regression shrinkage and selection via the lasso: a retrospective. Journal of the Royal Statistical Society, 73, 273-282.
- [50] Tikhonov, A.N. (1943). On the stability of inverse problems. Doklady Akademii Nauk SSSR, 39(5), 195-198.
- [51] Vanhove, J. (2021). Collinearity isn’t a disease that needs curing. Meta-Psychology 5.
- [52] Wang, W., Li, L., Li, S., Yin, F., Liao, F., Zhang, T. ,Li, X., Xiao, X. and Ma, Y. (2021). Average ordinary least squarest-centered penalized regression: a more efficient way to address multicollinearity than ridge regression. Statistica Neerlandica, 76, 347-368.
- [53] Wichern, D.W. and Churchill, G.A. (1978). A comparison of ridge estimators. Technometrics, 20, 301-311.
- [54] Wissel, J. (2009). A new biased estimator for multivariate regression models with highly collinear variables. Ph.D. thesis, Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universitt Wrzburg.
- [55] Zou, H. and Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(2), 301-320.
- [56] Zou, H. and Zhang, H. (2009). On the adaptive elastic-net with a diverging number of parameters. The Annals of Statistics, 37(4), 1733-1751.