EuroPED-NN: Uncertainty aware surrogate model
Abstract
This work successfully generates an uncertainty-aware surrogate model of the EuroPED plasma pedestal model using the Bayesian neural network with noise contrastive prior (BNN-NCP) technique. This model is trained using data from the JET-ILW pedestal database and subsequent model evaluations, conforming to EuroPED-NN. The BNN-NCP technique has been proven to be a suitable method for generating uncertainty-aware surrogate models. It matches the output results of a regular neural network while providing confidence estimates for predictions as uncertainties. Additionally, it highlights out-of-distribution (OOD) regions using surrogate model uncertainties. This provides critical insights into model robustness and reliability. EuroPED-NN has been physically validated, first, analyzing electron density with respect to increasing plasma current, , and second, validating the relation associated with the EuroPED model. This affirms the robustness of the underlying physics learned by the surrogate model. On top of that, the method was used to develop a EuroPED-like model fed with experimental data, i.e. an uncertainty aware experimental model, which is functional in JET database. Both models have been also tested in AUG shots.
Introduction
A tokamak fusion reactor must achieve a sufficiently high core plasma pressure, density and temperature in order initiate and sustain fusion reactions for net energy generation. The standard operational scenarios in tokamak devices as based on the high confinement mode (H-mode) [1]. This regime is characterized by the formation of a transport barrier in the outer region of the confined plasma, leading to steep gradients in the density and temperature profiles within that region. As the core plasma parameters are effectively an integration of the transport equation from the edge boundary condition, this steep gradient region lifts up the core parameters and gives this feature its namesake, the plasma pedestal.
This edge transport barrier has been linked to an increase in the radial electric field, , shear [2] which drives a local bulk rotation shear that breaks up large turbulent eddies [3], suppressing the dominant transport mechanisms observed in that region in L-mode regimes [4]. It should be noted that the steep gradient region still contains turbulent transport processes, although they are driven by other mechanisms which are less affected by the flow shear [5, 6, 7]. While the precise mechanism of the -well formation for the L-H transition is still under investigation [8, 9, 10], the resulting transport reduction causes the plasma gradients to increase, along with the plasma current due to the bootstrap effect [11], up until a point where MHD instabilities occur, e.g. edge-localized modes (ELMs) [12]. These ELMs manifest as a discrete and periodic collapse of the pedestal, effectively reinstating another, albeit higher, limit on the pressure gradient. The predominant explanation of ELMs goes via MHD theory, specifically the interaction between instabilities in the pressure driven (ballooning) modes and current driven (peeling) modes [13], due to these steep gradients in the edge region. Within the EPED model [14], this theoretical pedestal limit is then located where the pedestal pressure, , and width, , lie on the intersection of the onset of ideal MHD instabilities and the onset of kinetic ballooning mode (KBM) turbulence, which the latter is represented by a semi-empirical relation. The large type-I ELMs are well described by this model [15], tracing out stability and instability regions in the current density-pressure gradient (-) space. The EuroPED model [16] effectively predicts these pedestal limits along these same theoretical principles.
Unfortunately, the computational cost of both EuroPED and EPED is too high for highly iterative applications such as plasma scenario optimization [17] and motivates the development of a surrogate model which uses less computational resources while to representing the original model reasonably accurately. Various approaches in the fusion community utilize machine learning algorithms to develop surrogate models and their subsequent applications [18, 19, 20, 21, 22, 23, 24, 25, 26]. The fast computational throughput also opens the door to explore the behaviour of the model and the physics behind it. This work investigates the applicability of Bayesian neural networks (BNNs) to generate a pedestal surrogate model, potentially incorporating their ability to provide uncertainty information in a single forward pass as part of a prediction application. This approach aligns with previous work in using machine learning to enhance plasma pedestal modeling [27, 21].
In the Bayesian approach, the variables in the neural networks are treated as distributions, which are propagated throughout the calculation to provide statistical information about the model prediction, labelled in this study as output uncertainties. The training process needs to determine the distributions of each output using a variational inference approximation [28] allowing the construction of a feasible loss function. However, the main drawback of variational inference is the high degree of sampling necessary for the training. This is circumvented using another acceleration technique called the Noise Contrastive Prior (NCP) [29], which has a secondary advantage of estimating both the epistemic and aleatoric uncertainties. The epistemic uncertainties (or model uncertainties) are defined as uncertainties due to the lack of knowledge about the system, such as missing input parameters or insufficent data volume, and the aleatoric uncertainties (or data uncertainties) are defined as uncertainties resulting from random chance, such as repeat measurements or experiments providing different results [30, 31]. This study expands on the methodology and interprets the results of the trained model based on these definitions.
Section 2 describes the specific application of the BNN-NCP model in this study, including the considerations in determining the user-defined parameters impacting the aleatoric and epistemic uncertainty predictions. In Section 3, the precision and practicality of this model is discussed, focusing on its capacity to accelerate computations, gather physics insights, and adapt to a different machine. Section 4 extends the methodology developed to experimental JET-ILW data and tests it in AUG data. Finally, Section 5 provides a summary of the main conclusions and potential future work inspired by this study.
Development of EuroPED-NN
In this section, the implementation of the BNN-NCP model towards building a plasma pedestal surrogate model is detailed.
Model description, inputs and outputs
The EuroPED model is conceptually identical to the EPED model, which uses an ideal MHD stability description to predict the critical plasma pressure gradient, , as a function of the pedestal width, . This curve is then crossed against a semi-empirical - relation reflecting the KBM constraint [14] to provide a prediction of the pedestal properties. The assumption of a two-species plasma in equilibrium is then used to estimate the top-pedestal electron pressure, , and further decompose that into the top-pedestal electron temperature, , by requiring the top-pedestal electron density, , as input.
Thus, for the EPED model, the required input parameters include:
-
•
plasma parameters:
-
–
plasma current, , in [MA];
-
–
toroidal magnetic field, , in [T];
-
–
line-integrated effective charge, ;
-
–
top-pedestal electron density, , in [ m-3];
-
–
normalized plasma pressure, ;
-
–
-
•
and magnetic geometry parameters:
-
–
triangularity, ;
-
–
elongation, ;
-
–
minor radius, , in [m];
-
–
major radius, , in [m].
-
–
In practice, one drawback of the EPED model is the necessity of providing , and as inputs, as this precludes the model from predictive exercises as these parameters are often unknown before performing an actual experiment.
To remedy this, the EuroPED model was developed by coupling an EPED-like pedestal parameter calculation workflow to the Bohm/gyro-Bohm (BgB) turbulent transport model [32] inside a 1D transport solver. This removes the need to explicitly define and , as the former is provided by the kinetic profiles resulting from the self-consistent transport calculation and the latter is defined either via a regression or a neutral penetration model provided within EuroPED. However, this model additionally requires two engineering parameters as input:
-
•
injected auxiliary heating power, ;
-
•
separatrix electron density, .
This is seen as an improvement over the EPED model as or are difficult to estimate prior to conducting an experiment. Although often the experiments are run in feedback mode where these parameters can actually be chosen. However, from the model point-of-view EPED is still not fully predictive. While the is equally difficult to know prior to an experiment, the option to estimate it via the fuelling gas flow rate, , and a neutral penetration model is provided within EuroPED. This connection was excluded from this study as it was not used in the construction of the particular database forming the training set.
The EuroPED model then returns as outputs:
-
•
the top-pedestal electron density, ;
-
•
the top-pedestal electron temperature, ;
-
•
and pedestal width, .
However, due to the implementation details connecting the EPED-like workflow to the transport model, the actual radial locations of the top-pedestal quantities may not coincide in practice. This has some implications on the construction of an appropriate surrogate model, which is further discussed in Section 2.4.
BNN-NCP Technique
As mentioned earlier, Bayesian neural networks are a specific class of NNs trained using Bayesian inference methods, involving an estimation of a posterior distribution over network weights given observed data. One of the difficulties with training BNNs is that they can be computationally expensive, particularly for large networks with many parameters. By providing a fast and efficient approximation to the posterior distribution, the Noise Contrastive Prior technique can speed up BNN training.
Within this technique, the posterior distribution is approximated by a mixture of the prior distribution over the output and a noise distribution. The network is trained to distinguish between observed data and noise samples generated by the noise distribution during training. Essentially, it uses simulated noise to shift the hypothesis from the probability distribution of the neural network weights to a probability distribution in the data space, requiring less computational resources. In practice, this means that a random point from the joint input distribution is sampled per training epoch. This sampled point is passed forward through the current BNN configuration, and the resulting mean and epistemic uncertainty is compared to a user-defined prior output distribution via some distance metric. This significantly reduces the number of samples required per epoch compared to a typical Monte Carlo method by leveraging the large number of epochs required for training the model to effectively accumulate the necessary statistics, which is similar to the training advantages offered by mini-batching and stochastic gradient descent. Furthermore, the NCP method improves the detection of out-of-distribution (OOD) regions in data space by directly accounting for input variations within its epistemic uncertainty estimation. In summary, this method allows for an approximate calculation of the output distribution without the need to sample the weights to arrive at a reliable estimate of the uncertainty. This approach is presented in [29] for one input and one output problems, in this study a multidimensional approach to fit the needs of the plasma pedestal models is built.
10cm
 {subcaptionblock}4cm
{subcaptionblock}4cm
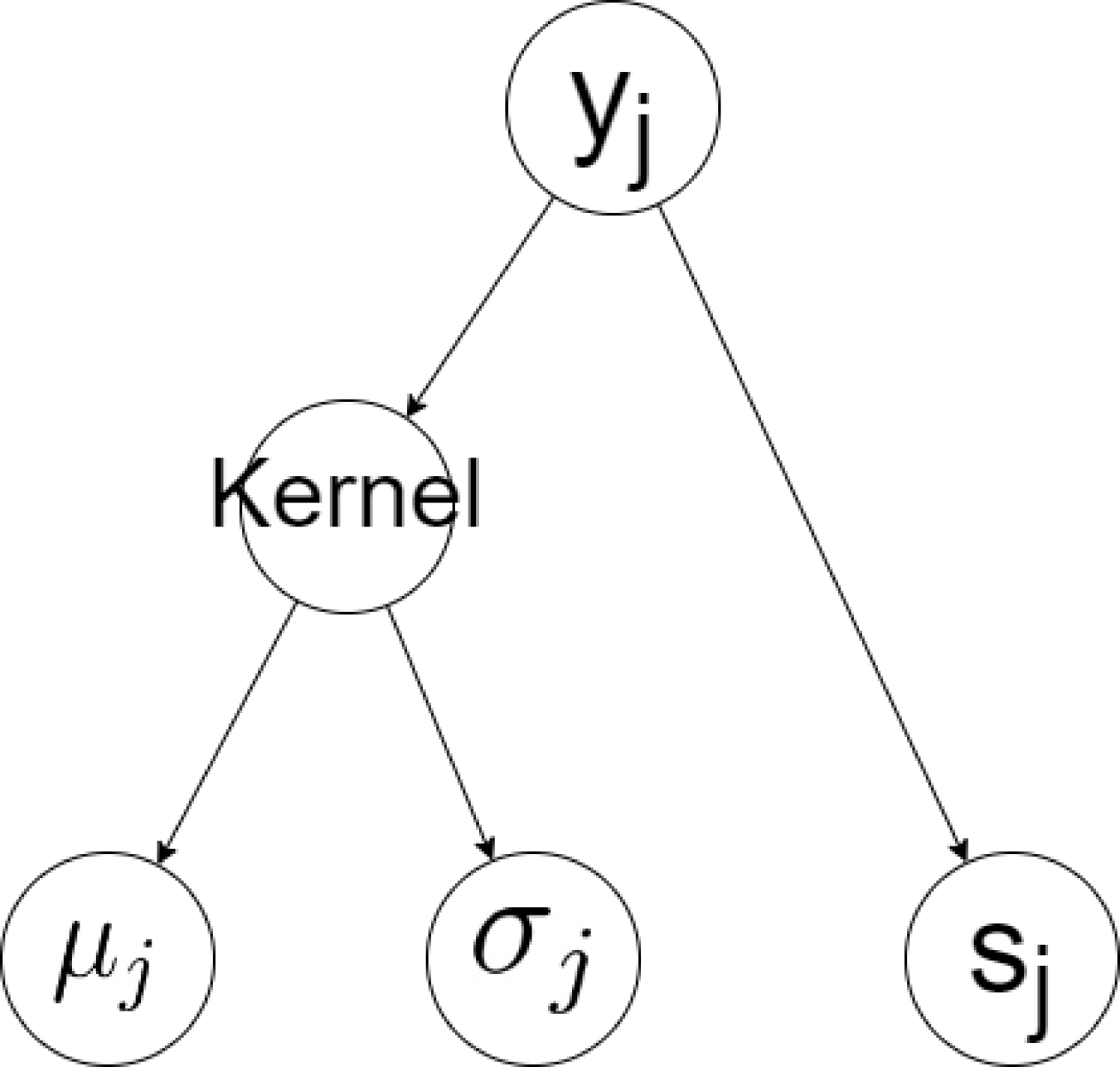
Neural network architecture and loss function
As a brief overview, the BNN-NCP architecture consists of a number of fully connected feed-forward (i.e. dense) layers with a custom layer inserted just before the output layer, as shown in Figure 3. This custom layer consists of a variational layer and a dense layer with a “softplus" activation function, as shown in Figure 3, each with only a single neuron. This variational layer represents its weights and biases as joint probability distribution, also known as a kernel, which effectively allows them to be sampled to assemble its predictive distribution, , where the ∗ notation is used to differentiate a generic point from one which is explicitly within the training dataset. The “softplus" activation function on the dense layer enforces its output to be positive, allowing it to represent an independent uncertainty estimate. All other neurons in the network have a “leaky ReLU" activation function, which is effectively a piecewise function of two linear components, both with non-zero gradients and joined together at the origin.
Due to the extension of this technique to multiple output variables, the final dense layer before the custom layer is separated into dedicated blocks per output variable. This serves as an attempt to ease the training process by reducing the amount of cross-talk between the network predictions of each variable. It also introduces a degree of flexibility in the last hidden layer, allowing adjustments to suit the complexity of each variable, e.g. the most difficult variables to fit can have a large number of neurons to account for their dependencies. This results in a multi-input multi-output model, transforming input points, , to output points, , which can then be trained on a labelled training dataset, denoted as .
As a result of the BNN-NCP architecture, there are two modes of evaluating it on a given input point, :
-
1.
By sampling the probability distribution represented by the kernel in the variational layer, resulting in a stochastic output, ;
-
2.
By computing the joint statistical moments of the kernel in the variational layer, resulting in a deterministic mean output, , and its standard deviation, .
Both of these evaluation modes return another deterministic output from the softplus neuron, . The predictive output value of the BNN-NCP model is taken as the mean value, i.e. , from the second evaluation method due to its deterministic nature, although the first evaluation method is still described here due to its importance for the training methodology. Thus, the entire BNN-NCP model can be mathematically represented as a black box function, .
Then, based on these descriptions, the output standard deviation from taking the statistical moment of the kernel, , was labelled as the epistemic uncertainty prediction and the output of the independent softplus neuron, , as the aleatoric uncertainty prediction. Both uncertainty outputs are taken to represent a value of one standard deviation when converting them from statistical moments back into probability distributions.
The cost function used in this study is similar to the one introduced in Ref. [29] except extended into the multidimensional approach. This results in expression provided in Equation (1). The terms are then summed over each output variable, represented by the subscript .
| (1) | ||||
where represents a user-defined weight coefficient used to adjust the associated loss term, represents the distribution of weights in the BNN, and the notation is used to indicate quantities related to the OOD region sampling. The sampled OOD input values, , were generated from a normal distribution about each dataset point, , according to a user-defined input noise term, . This input noise should generally be chosen as a large enough value to ensure the OOD sampling goes adequately beyond the training dataset input values, , but not so large that the OOD sampling would have difficulty resolving well the area just outside the training dataset.
The first term of the loss function corresponds to the negative log-likelihood (NLL) which represents a goodness-of-fit metric for the approximate predicted posterior distribution, selected to be:
| (2) |
By minimizing this term with respect to the weights and biases, , the maximum likelihood value is obtained for the network prediction. As the aleatoric uncertainty prediction, , is used as the weighting parameter for this metric, it also encourages the aleatoric uncertainty to grow where the network cannot match the specific data point where the combination of other data points and regularization discourage it, e.g. where data noise is present.
The second term represents a metric to anchor and regularize the predicted epistemic uncertainty with weight coefficients, , which are used to adjust its relative importance in the loss function per output variable. The last term represents the same anchoring and regularization metric for the predicted aleatoric uncertainty, with its own relative weight coefficients per output variable, .
Both uncertainty regularization terms use the Kullback-Leibler (KL) divergence metric, which effectively compares the similarity of two distributions. For the epistemic term, the approximate output distribution predicted by the network using an OOD input distribution, , was compared against an epistemic prior distribution, , selected to be:
| (3) |
This represents a normal distribution where the mean is the corresponding output value in the dataset, , and the standard deviation, , is a user-defined parameter encapsulating any expected epistemic uncertainty already known to be associated with the data-generating system. This term is expected to generate a significant loss for OOD samples far away from the training point, effectively encouraging the epistemic uncertainty at those OOD samples to grow in order to minimize the overall loss. In order to save computational time during training, only one OOD point is sampled per training point per epoch, which relies on the stochastic gradient descent process to generalize this feature to the entire OOD domain and is one of the essential acceleration tricks provided by the NCP methodology. For the aleatoric term, a normal distribution with zero mean created from the aleatoric uncertainty prediction of the network, , was compared against an aleatoric prior distribution, selected to be:
| (4) |
Again, this represents another normal distribution where the standard deviation, , is another user-defined parameter encapsulating any expected aleatoric uncertainty already known to be associated with the dataset output values. This is effectively meant to provide a competing pressure on the aleatoric uncertainty prediction, , preventing it from growing to the point where a flat prediction with infinite aleatoric uncertainties becomes the most likely solution.
Basically, this way of treating the output results into the loss function is the main difference with respect to a regular neural network. For this matter, it is particularly meaningful to define several parameters that will help to adjust for the problem to solve. These user-defined values, , and , are meaningful for the model as they are hyperparameters that introduce knowledge from the system and the data region to be modelled into the neural network. While in principle, this would allow extensions to the labelled training dataset, , for refining the uncertainty predictions, it was decided to leave these extra hyperparameters constant across the entire original training dataset, , for this study. This is primarily for ease of demonstration for the BNN-NCP methodology, as it simultaneously reduces the burden of collecting the information necessary to refine these priors and the complexity needed to be captured by the training process. More details about the values used for these priors is available in Section 2.5.
Zero-Dimensional Pedestal Database
During this study, the dataset is derived from a specialized collection JET-ILW plasma discharges [33] and their corresponding EuroPED predictions [16]. While the dataset includes several plasma quantities, this study focused on the input and output variables needed to predict the appropriate pedestal characteristics within a given plasma scenario accroding to EuroPED, as discussed in Section 2.1.
However, in order to improve the generality of the model via the introduction of dimensionless variables, the inverse aspect ratio, , was used instead of the minor radius, , and major radius, . This process was also applied to the plasma current, , replacing it by a safety-factor-like parameter, , expressed as:
| (5) |
where is expressed in units of A, in T and in m. While it is uncertain whether pedestal phenomena follow any specific dimensionless scaling, it was attempted to improve its extrapolation capability to other tokamaks.
However, due to the particular application of the pedestal predictions inside the 1D transport solver within EuroPED, the exact top-pedestal temperature and density outputs of the ideal MHD calculation are no longer representative of the plasma state described by the profiles. Thus, the variables provided in this dataset used as the target outputs were:
-
•
electron density at , ;
-
•
electron temperature at , ;
-
•
and pedestal width,
where is the poloidal magnetic flux, which is used as a geometry-independent radial coordinate, and for the purposes of this study. This specific flux coordinate value was chosen due to its statistical similarity to the computed from EuroPED.
The pedestal dataset is composed of 1317 entries. However, 257 of them were removed in the training and testing because some of the variables of interest were not available. During the training of the model, the dataset was split into 90% for training and 10% for testing.
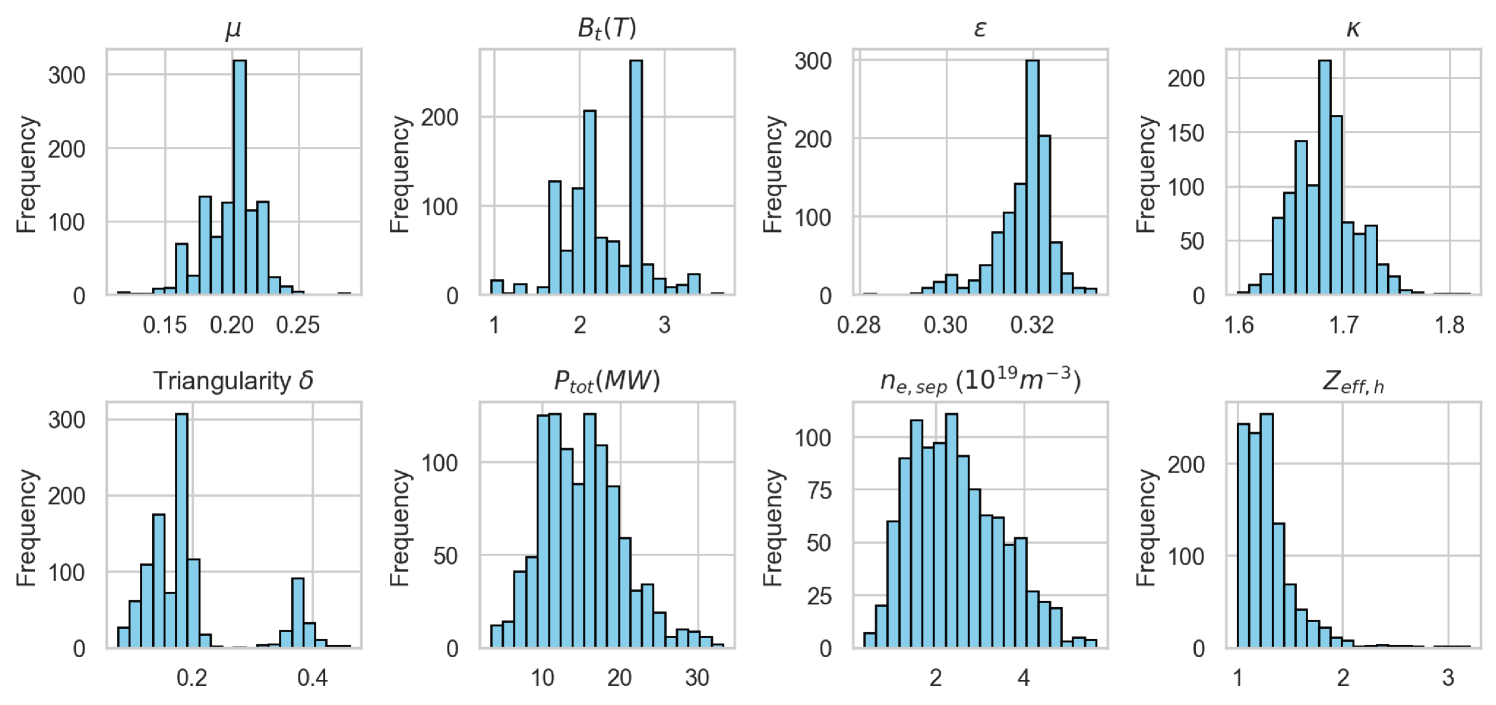
In Figure 4, the input data (train and test) used in EuroPED-NN is shown as histograms. The distribution of all the input variables as well as the range of values can be observed.
Hyperparameters for epistemic and aleatoric uncertainty
As observed in the loss function, Equation (1), several user-defined parameters and hyperparameters related with both the epistemic and aleatoric uncertainty predictions need to be determined. These values to the training routine such that the method to the particular problem. Therefore, additional considerations were required to provide reasonable targets for these values in training the EuroPED-NN.
The width of the OOD region for input sampling, , was chosen to span a constant proportion of the standard deviation within the dataset of the corresponding input quantity. These specific proportionality values are detailed Appendix A.
Regarding the target epistemic uncertainty, in Equation (3), a small constant value was chosen across the entire dataset. So that, when comparing, using KL divergence, in the training loop the target distribution and the output distribution with OOD input, the OOD output distribution will be forced to become wider to match the thin target distribution.
Regarding the target aleatoric uncertainty, in Equation (4), another small constant value was chosen across the entire dataset. This represents the prior knowledge that the EuroPED model is deterministic and thus, no data error should be present within the output values of the training dataset. The specific values used in this study are available in Appendix A.
All of these selections have been the result of different attempts and the personal reasoning of the authors regarding the nature of the model. Further details of these sensitivities are provided in Section 3, but the main reason is due to the fact that the epistemic and aleatoric uncertainties has been designated their own loss terms, each with their own weight coefficients, and , in Equation (1).
Once these parameters informing the BNN-NCP priors have been decided, a rudimentary configuration optimization exercise yielded an architecture with a common dense layer with 20 neurons and specialized dense layers with 8, 8, and 10 neurons for , , and outputs, respectively. Then, the BNN was trained using the Keras package [34] in Tensorflow [35] (version 2.15.0) with 2000 training epochs and a mini-batch size of 53, taking around 1.7 CPU-hours (10 minutes in 10 cores minutes). The Adam optimizer [36] was used with a learning rate of 0.001 and a exponential decay rate of 0.1.
In order to balance the relative importance of the various loss terms in Equation (1), a rudimentary optimization was performed. This resulted in the uncertainty weight coefficients of and for all outputs, , and individual NLL weight coefficients of for , , and , respectively.
Verification and Characterization of EuroPED-NN
Using the methods and principles described previously, the surrogate model of EuroPED, referred to as EuroPED-NN within this study, was trained. This section details the various methods used to verify its performance via whether it replicates expected behaviours.
Performance
6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
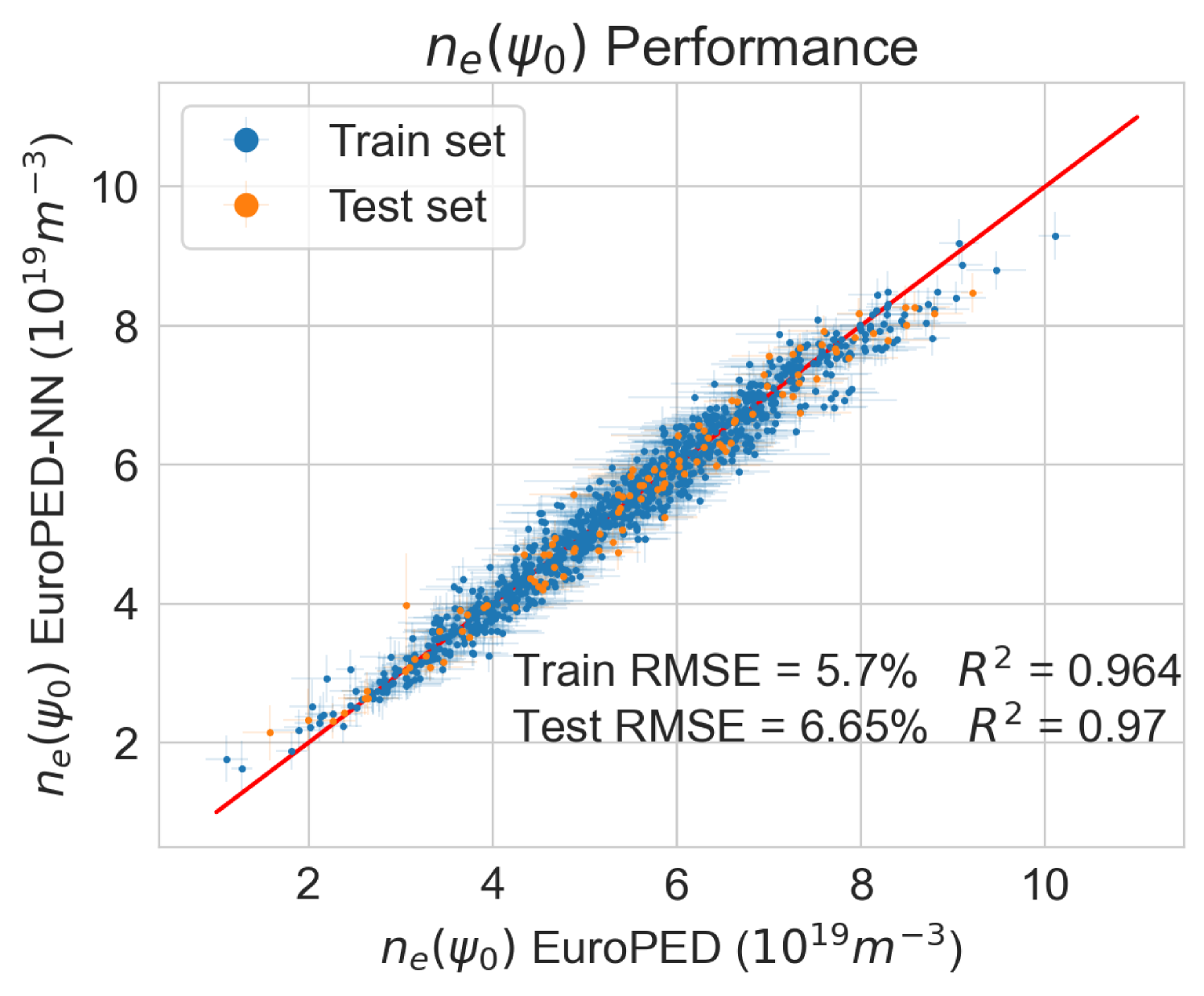
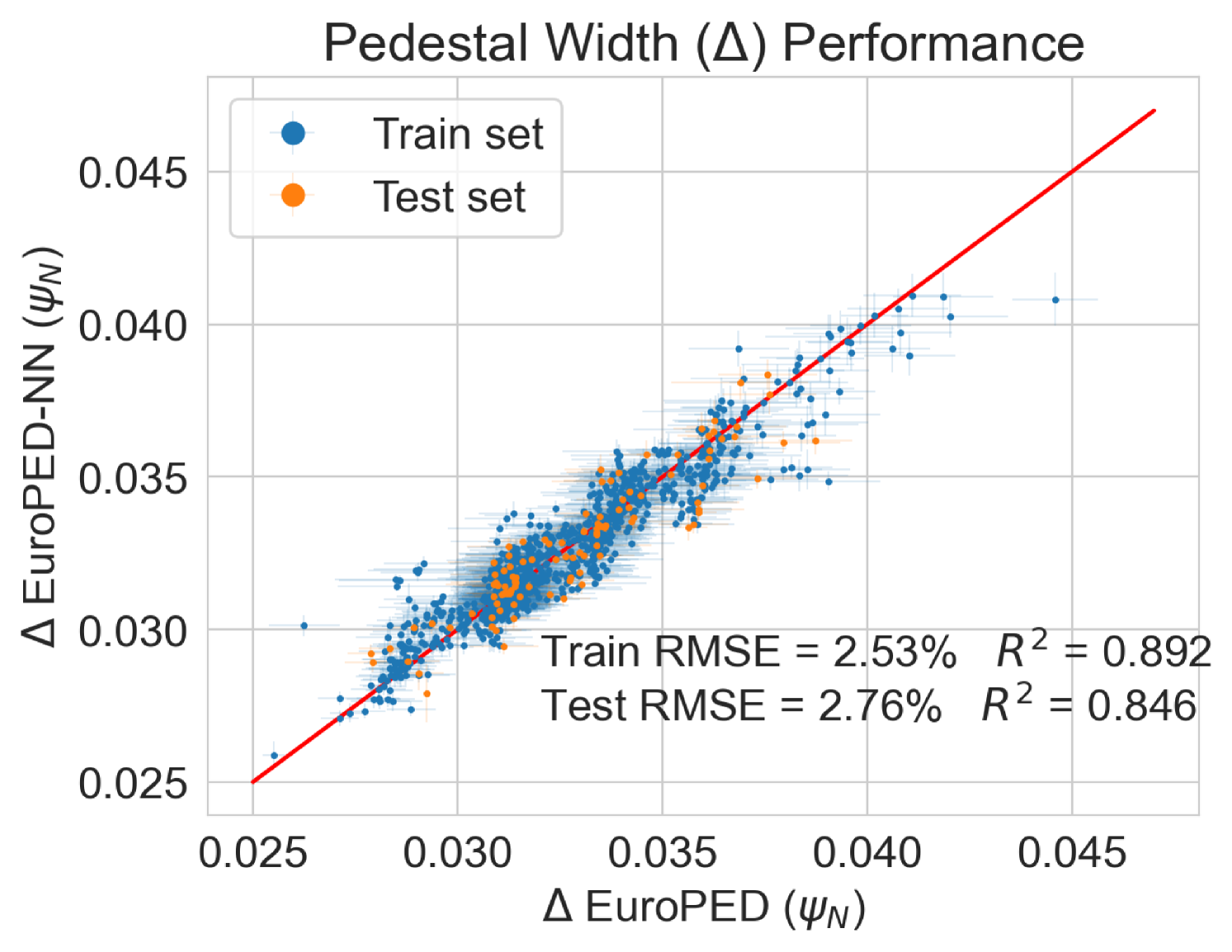
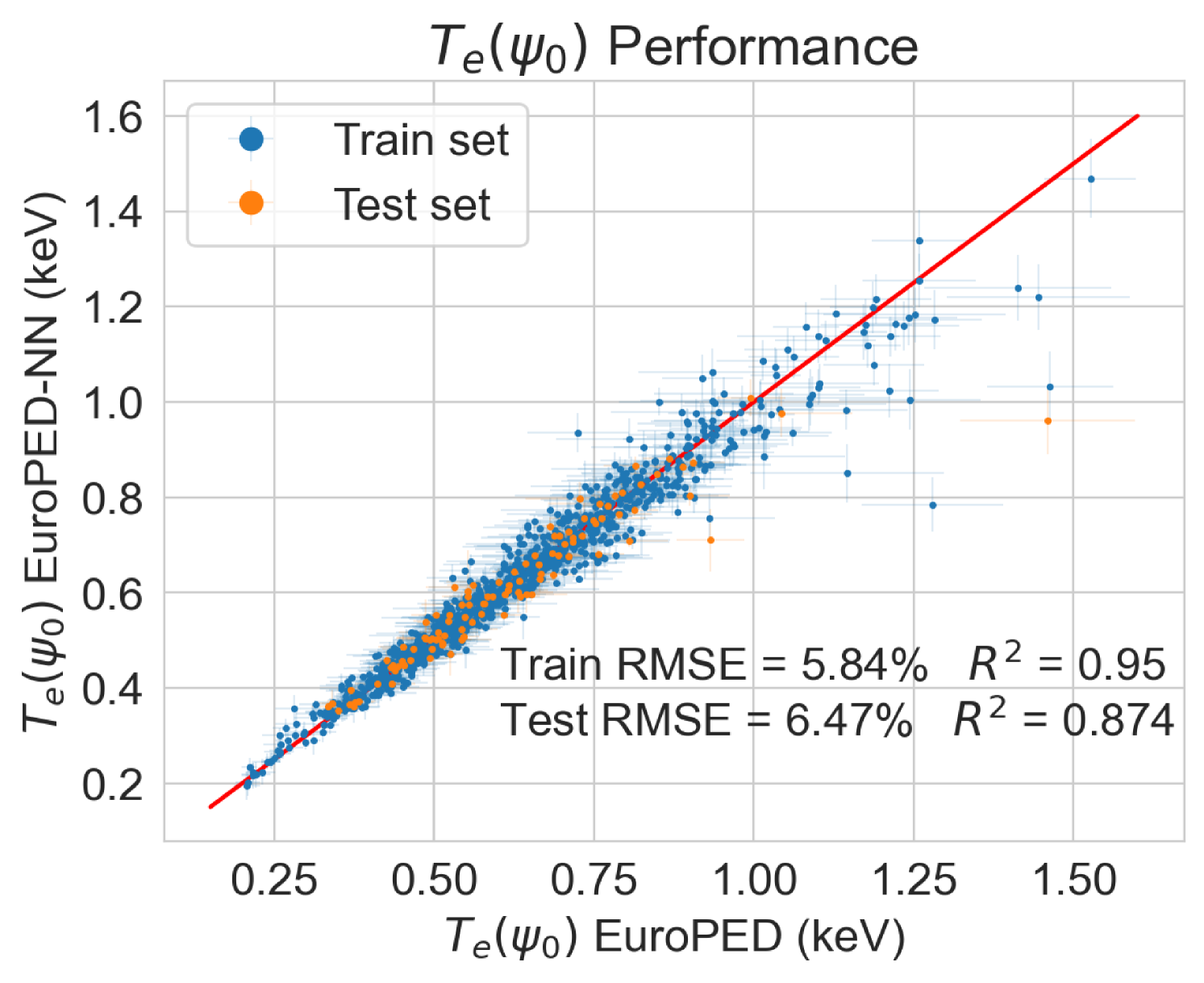
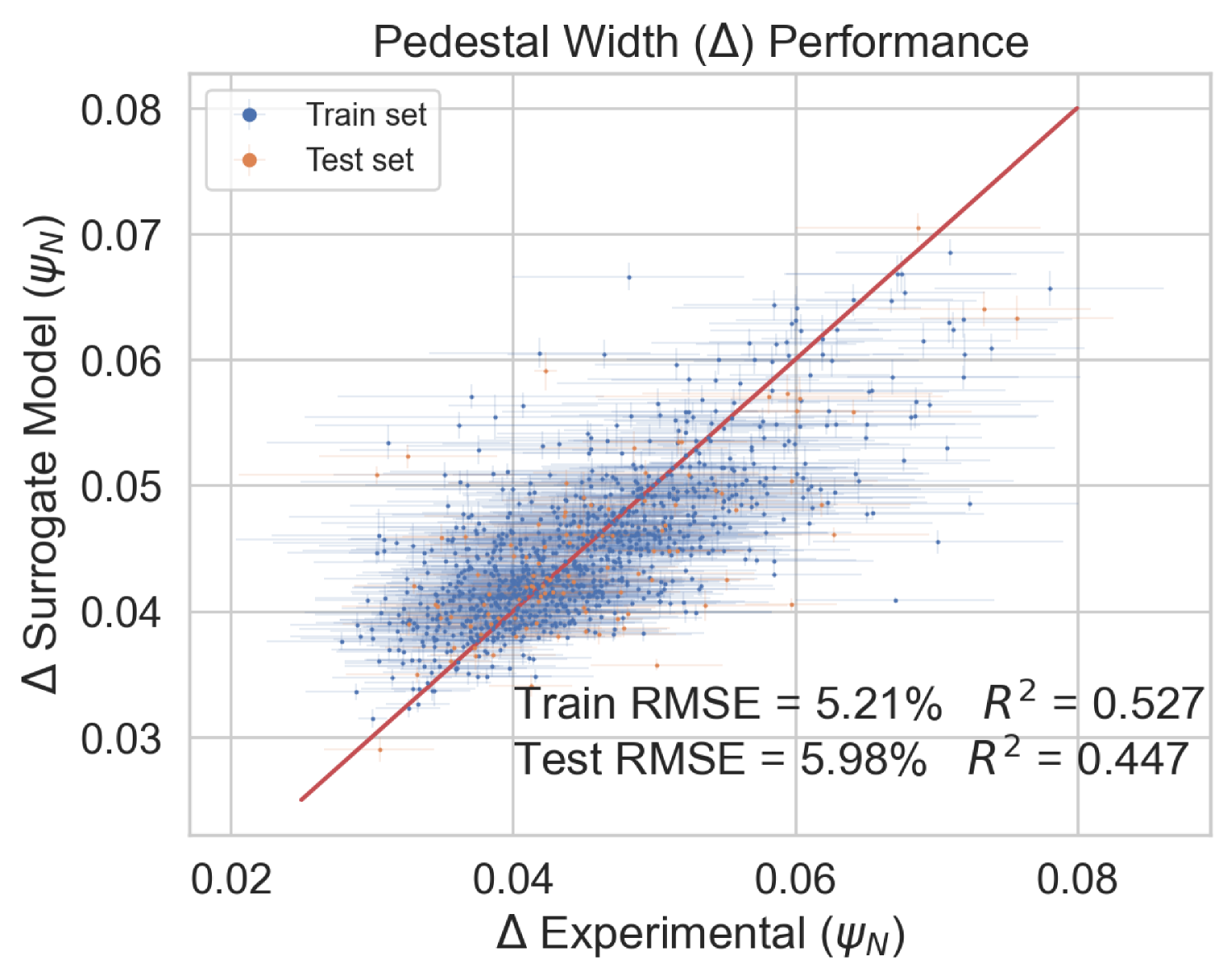
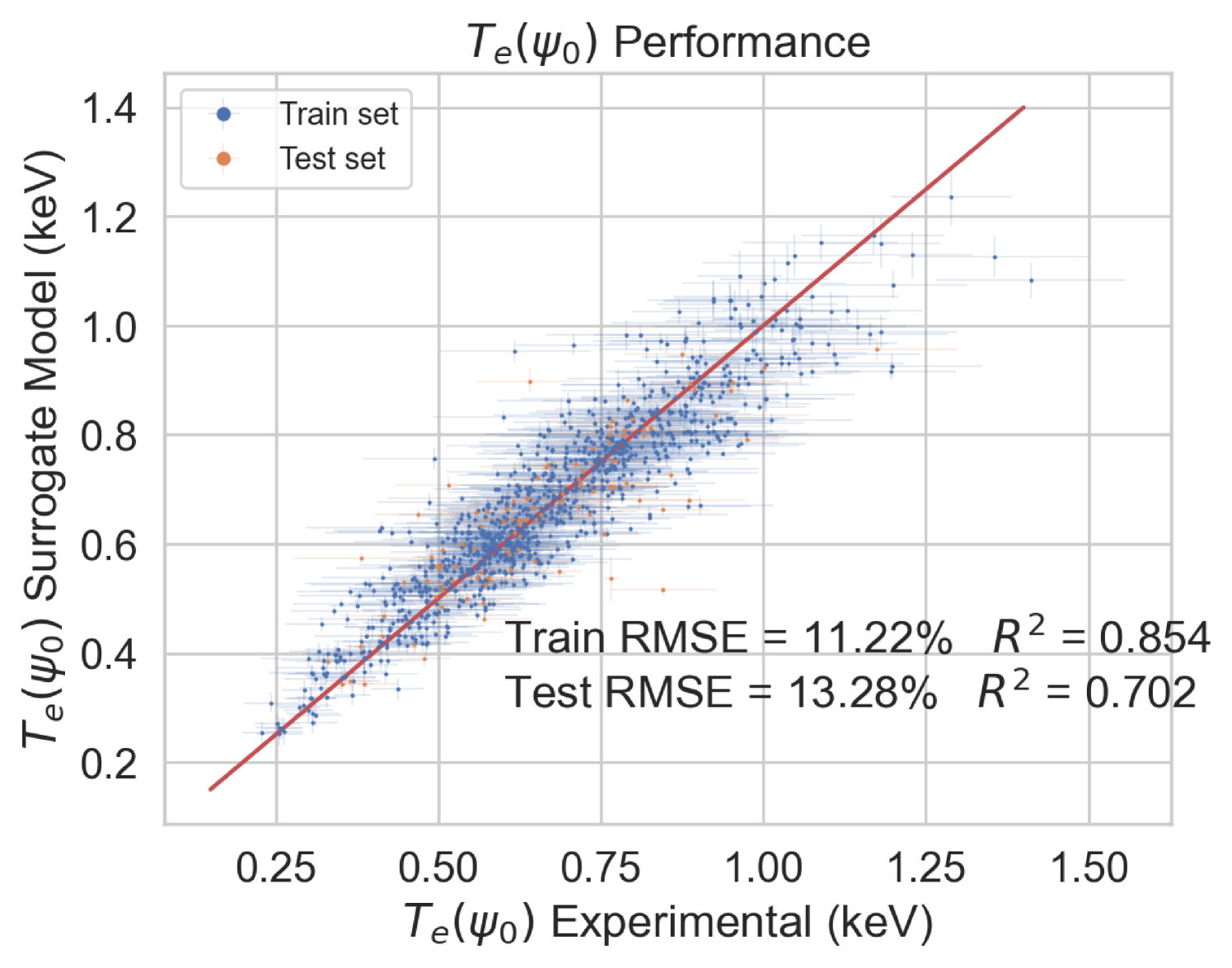
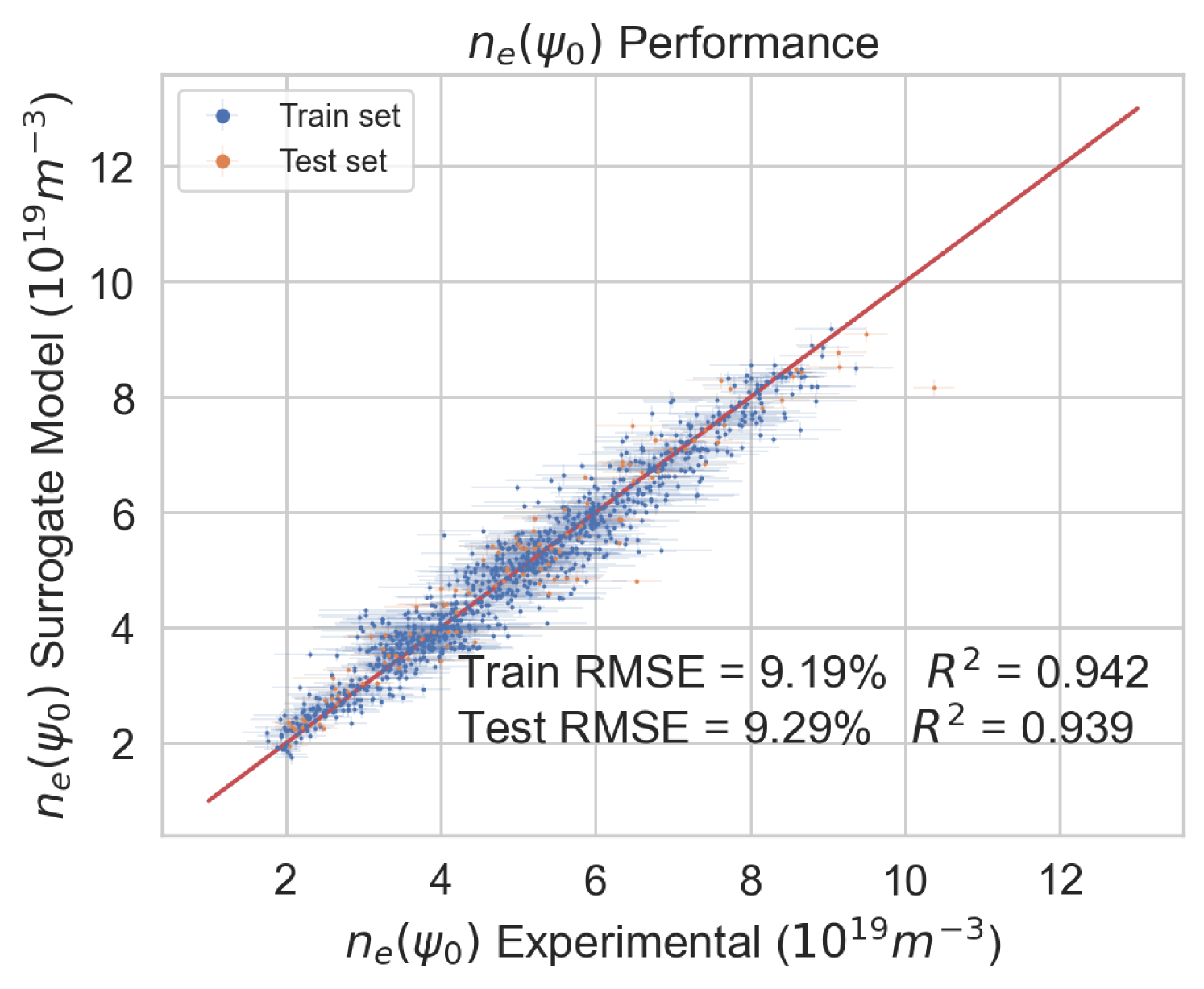
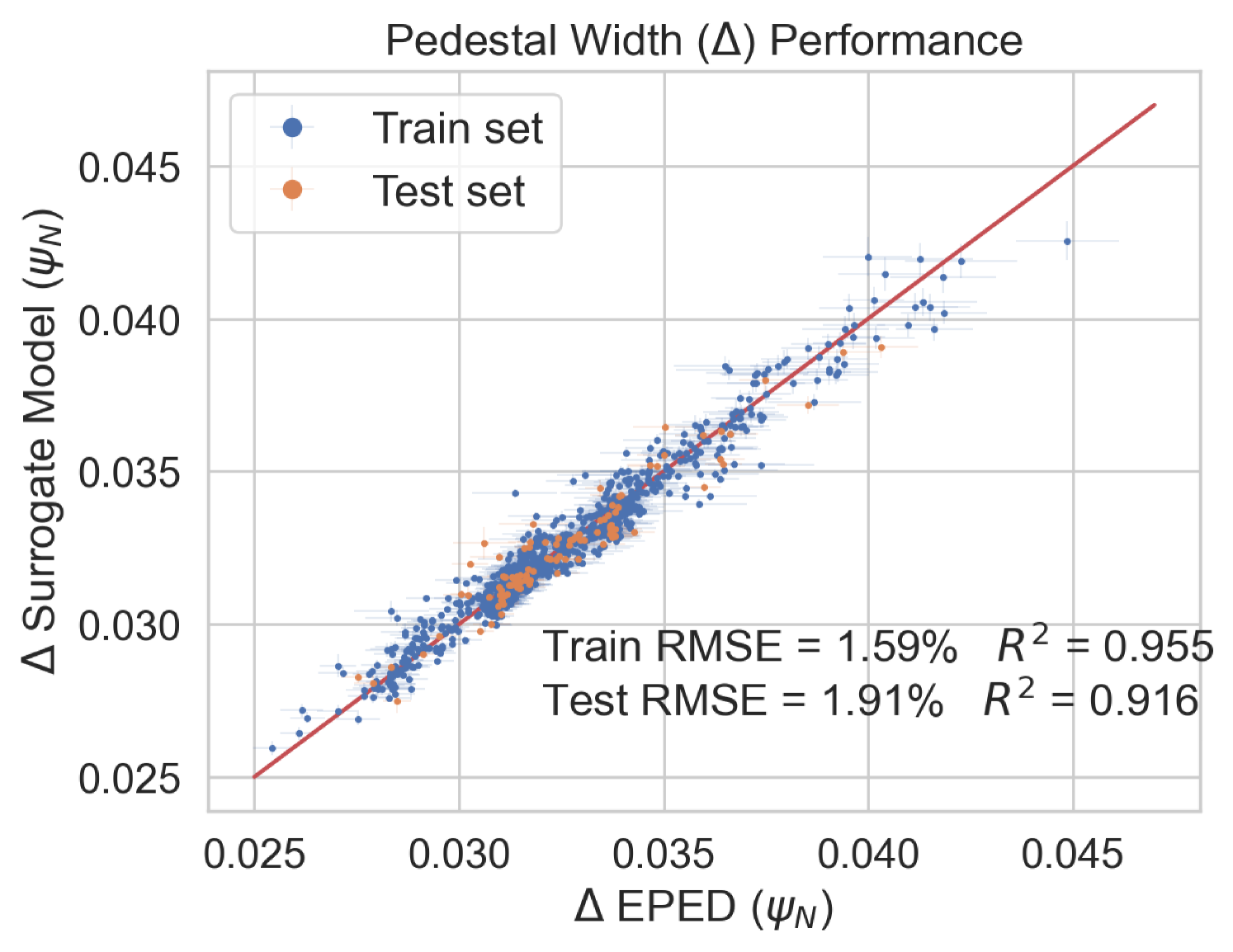
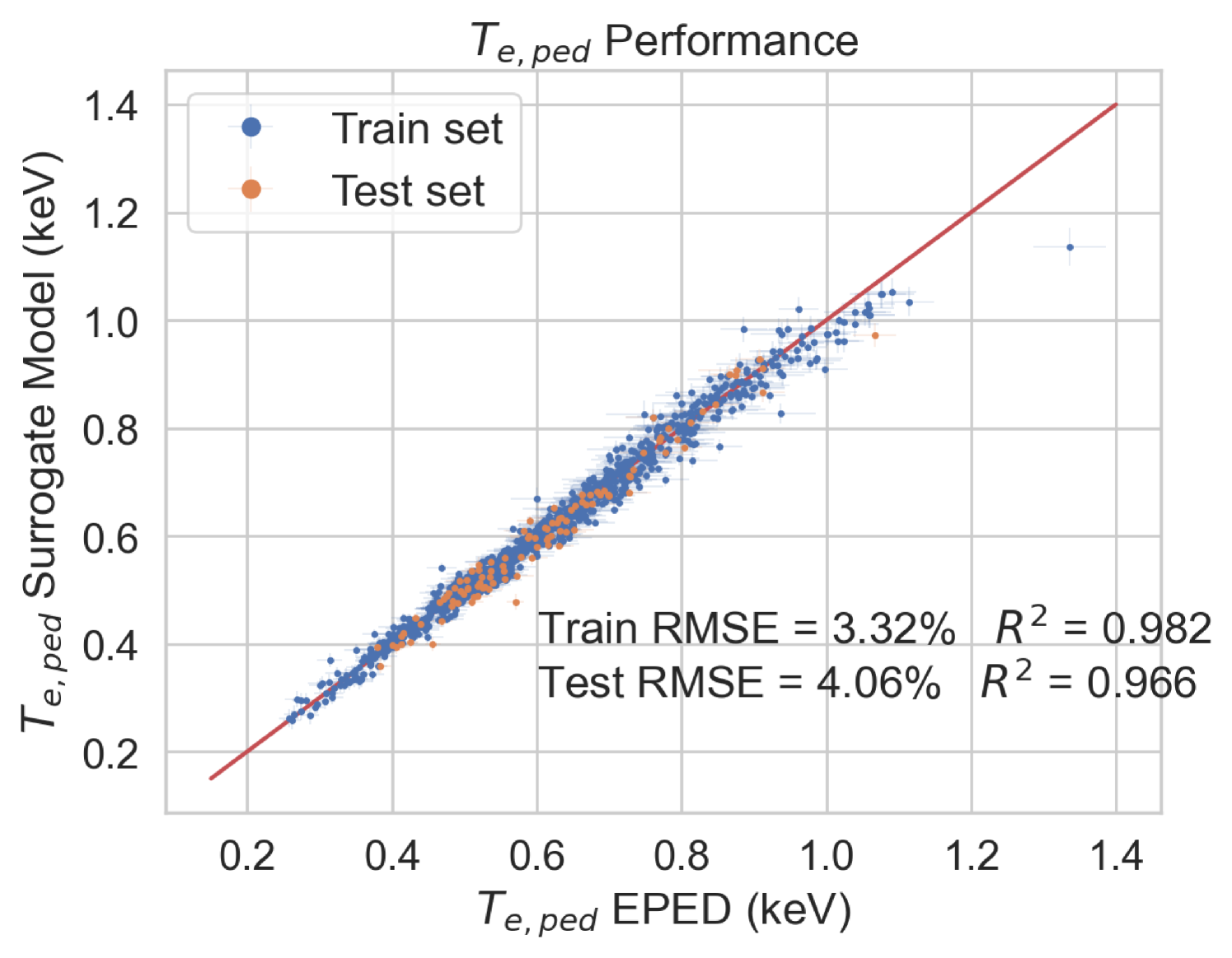
To test the performance of the model, the EuroPED-NN predictions are first compared against the data points within the training set itself. Figure 8 shows the accuracy for the output variables pedestal width, , electron temperature, , and electron density, , respectively. While they are all reasonably accurate, it can be visually inferred that returns a worse match with the EuroPED database. This may indicate a higher degree of complexity behind the determination of this particular output, as it was found that it already required more neurons in the last BNN layer to achieve this fit quality. Overall, it can be said that the accuracy obtained through the training of the neural network is remarkably good, in spite of the typical difficulties of training multi-output regression networks.
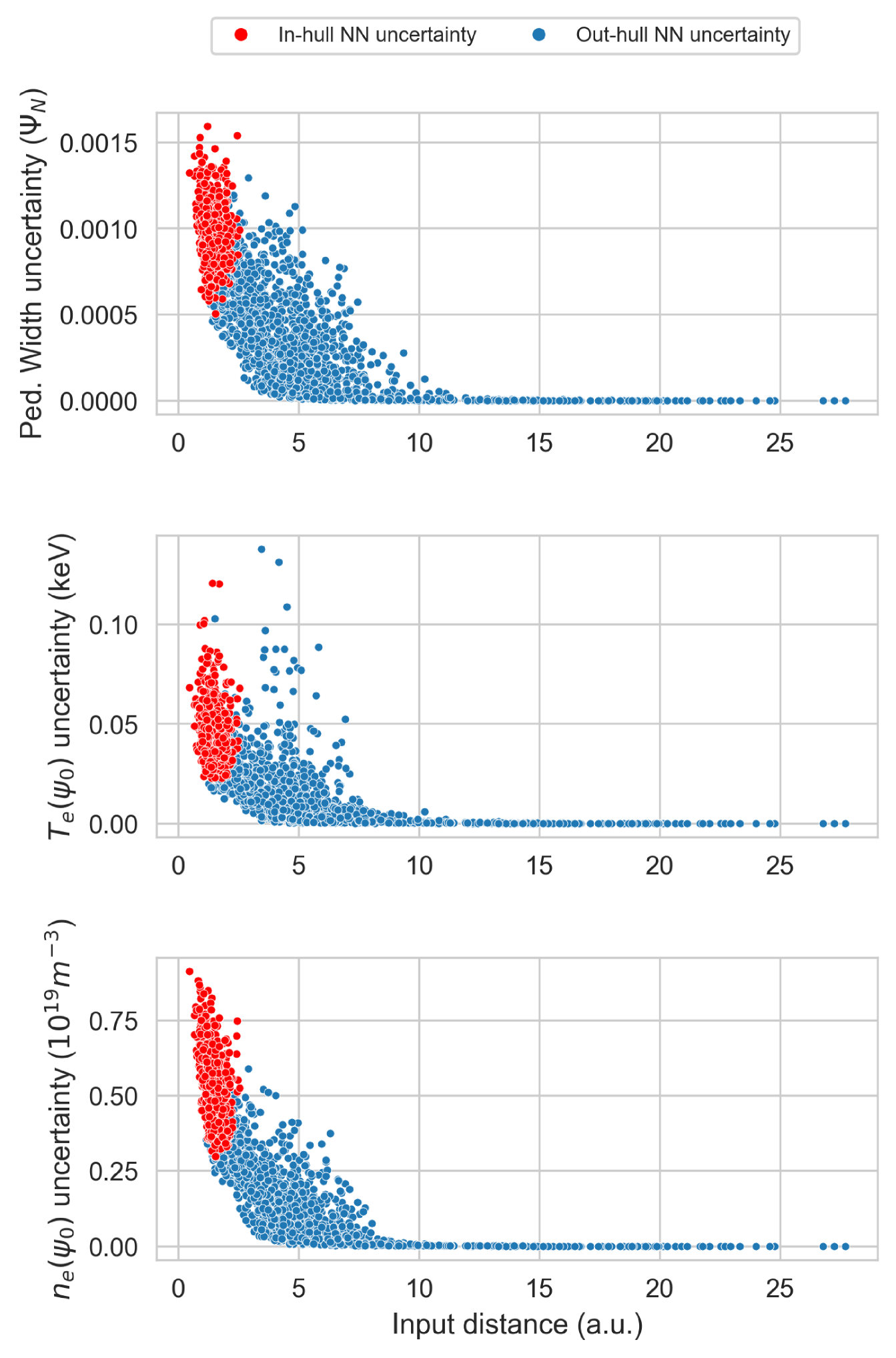
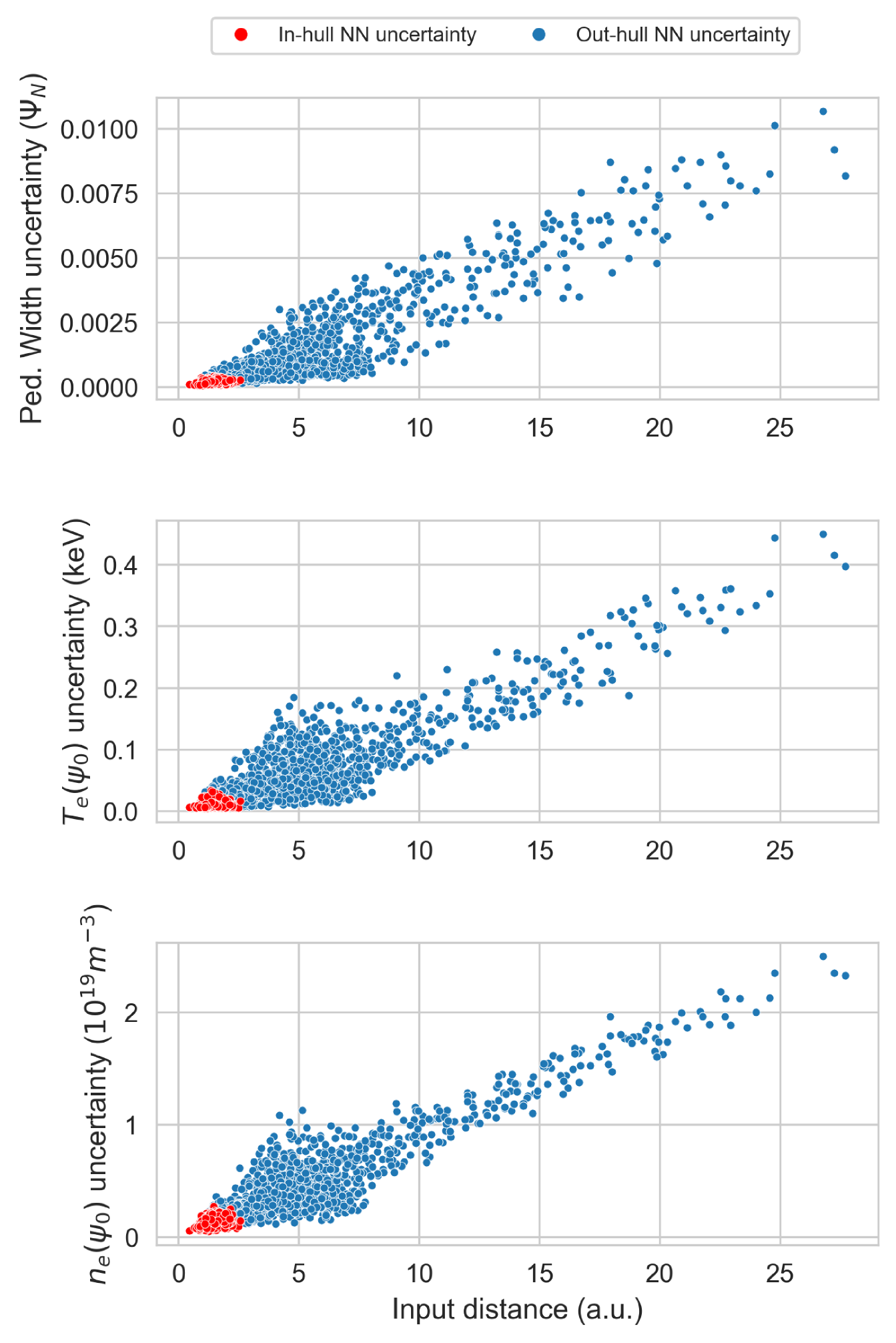
However, another important point of investigating the BNN architecture revolves around its potential to differentiate interpolation regions from extrapolation regions via its uncertainty predictions [29]. This study examines this capability using the epistemic uncertainty prediction, where a generally lower uncertainty is expected in the interpolation regions. Figure 11 shows the relative predicted epistemic and aleatoric uncertainty for , , and using randomly generated input data, as a function of the Euclidean distance of the input data to the centroid of the training input dataset. This distance is calculated after re-scaling these random samples with the same relation used to re-scale the input data distributions to have a mean of 0 and a standard deviation of 1. This is done to avoid introducing any bias on the distance metric due to the orders of magnitude differences spanned by the absolute values of the various input variables. It is also noted that some of the random input data points used may not resemble realistic operational plasma conditions, though this is not a requirement for demonstrating the characteristics of the uncertainty predictions under extrapolation. The training data centroid was chosen as the reference point as it should best represent the region which has the highest data density. Thus, as the distance increases, the epistemic error should increase as well because the neural network would have less information to train its predictive capability. 4000 input entries were randomly generated using two uniform distributions: the first one over the central 60 % of the dataset and the second over the central 98 %. This has been done intentionally to highlight both the points inside the training convex hull and those far from it.
Indeed, Figure 11 demonstrates that when the distance increases, the epistemic uncertainty also increases notably. The random points that fall inside the convex hull of the training data region are distinguished in these plots. In the epistemic case, the uncertainty is expected to be low inside the hull and growing as the points move further out of it. In the aleatoric case, the uncertainty should be higher inside the hull and decrease as the point move further out of it. Indeed, this is roughly observed in Figure 11. As the neural network catches the variance of the training input data through the aleatoric uncertainty, going far from training data means low aleatoric uncertainty as determined by the target values chosen in this study. On the other hand, epistemic uncertainty reflects the precision of the neural network regarding the stochastic variance of the weights and biases with respect the training data, then out of the data region this precision should be much lower, due to the lack of information. Although the general behavior of the uncertainty is well captured in Figure 11, a 1D toy example can is provided in Section 3.2 where it is more intuitively depicted while simultaneously verifying the model via a physical scan.
Additionally, in Appendix B a study over the input uncertainties effect on the output result of EuroPED-NN has been done. It can be observed that in most cases the aleatoric uncertainty accounts for the input uncertainty.
8cm
 {subcaptionblock}8cm
{subcaptionblock}8cm
Independent physical analysis
In order to verify the model based on existing physical intuition about pedestal behaviours, this section compares the EuroPED-NN predictions against known empirical relations.
scan
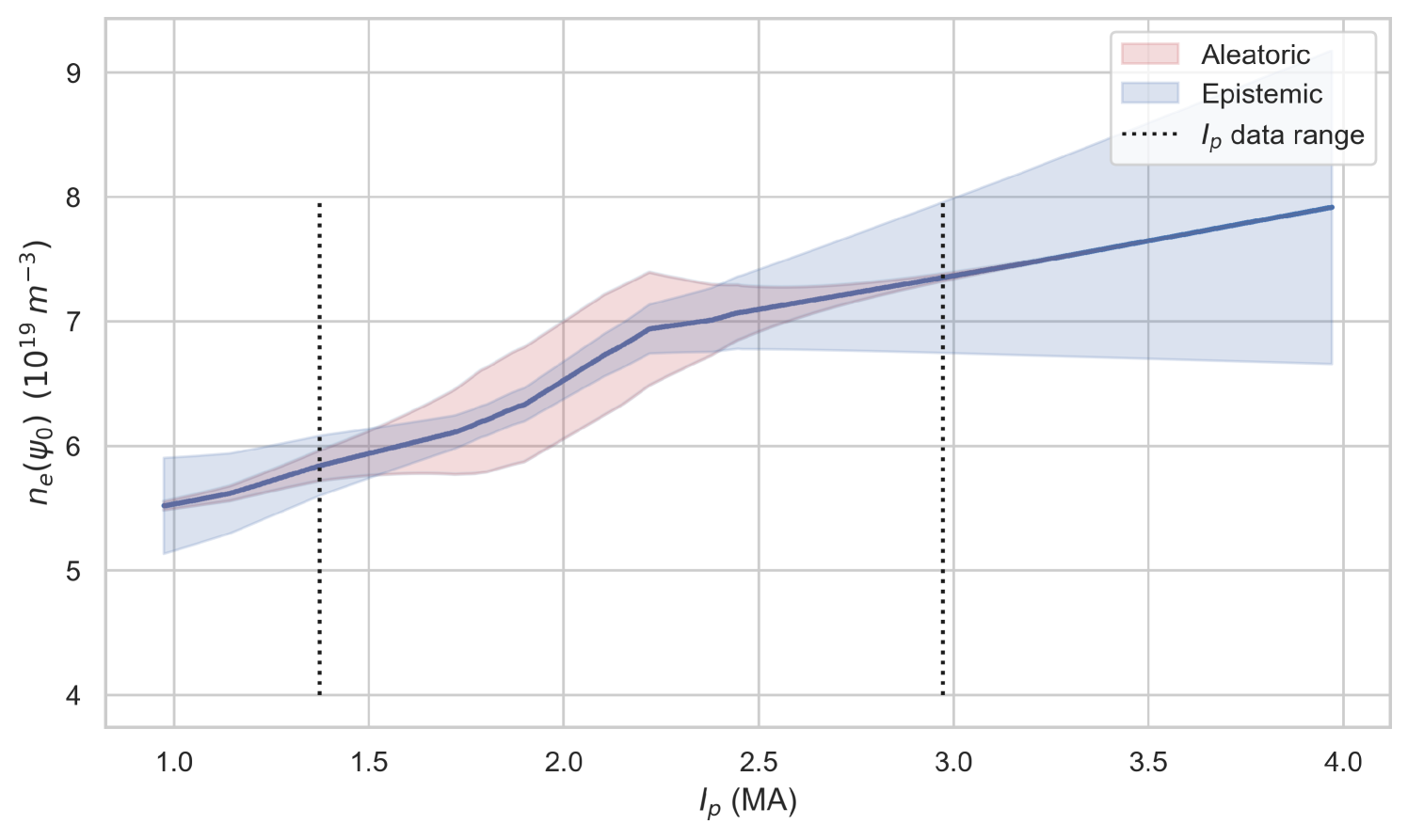
Although the precise behaviour is dependent on many variables, it is generally expected that grows when increasing [37]. As is one of the outputs of the model and is used in the calculation of the model input, , given in Equation (5), this trend should also be present in EuroPED-NN. To verify this, a 1D scan is performed over while keeping the other inputs at a fixed value.
Figure 12 clearly shows that increases with , especially in the training data region between the dotted lines. While it is expected that not all input combinations in this scan correspond to physically achievable plasma scenarios, this trend was found to be present across a majority of random combinations of the other input parameters, of which the 1D scan plots are not shown for brevity. It can then be inferred that it extends to the subspace of physically-relevant parameters as well. Additionally, as mentioned in Section 3.1, it is noticeable how the region populated by the training database exhibits significantly lower epistemic uncertainty and higher aleatoric uncertainty than the regions outside of it.
relation
As mentioned in Section 2.1, the semi-empirical relation between the pedestal width, , and the normalised plasma pressure, , is an important component of both EPED and EuroPED models. Thus, it is relevant to check whether the EuroPED-NN predictions replicate this relation. However, as the model outputs were reframed to provide the kinetic parameters at while retaining for purposes of consistency in integrated modelling, it is also important to illustrate that the surrogate model retains this feature by plotting against . This is due to the fact that the outputs of EuroPED-NN are: the electron temperature prediction , electron density prediction and the pedestal width , and all of them are included somehow in the plot. Due to the fact that and are needed for calculating . Moreover, to perform this calculation, given in Equation (6), some of the model inputs are required: plasma current, effective charge, triangularity, elongation and minor radius. These values are used to calculate , which ultimately is a measure of the confinement, expressed as:
| (6) |
where is the poloidal component of the magnetic field, and the angle brackets represent flux-surface averages made around the poloidal angle.
Then this representation shows roughly the behavior of the model, as it uses all the output information and some input information. The similarities between the plot generated from predictions of EuroPED and from the reduced model predictions will help to verify the model with a physics-based representation and to measure the performance of the surrogate model.
6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
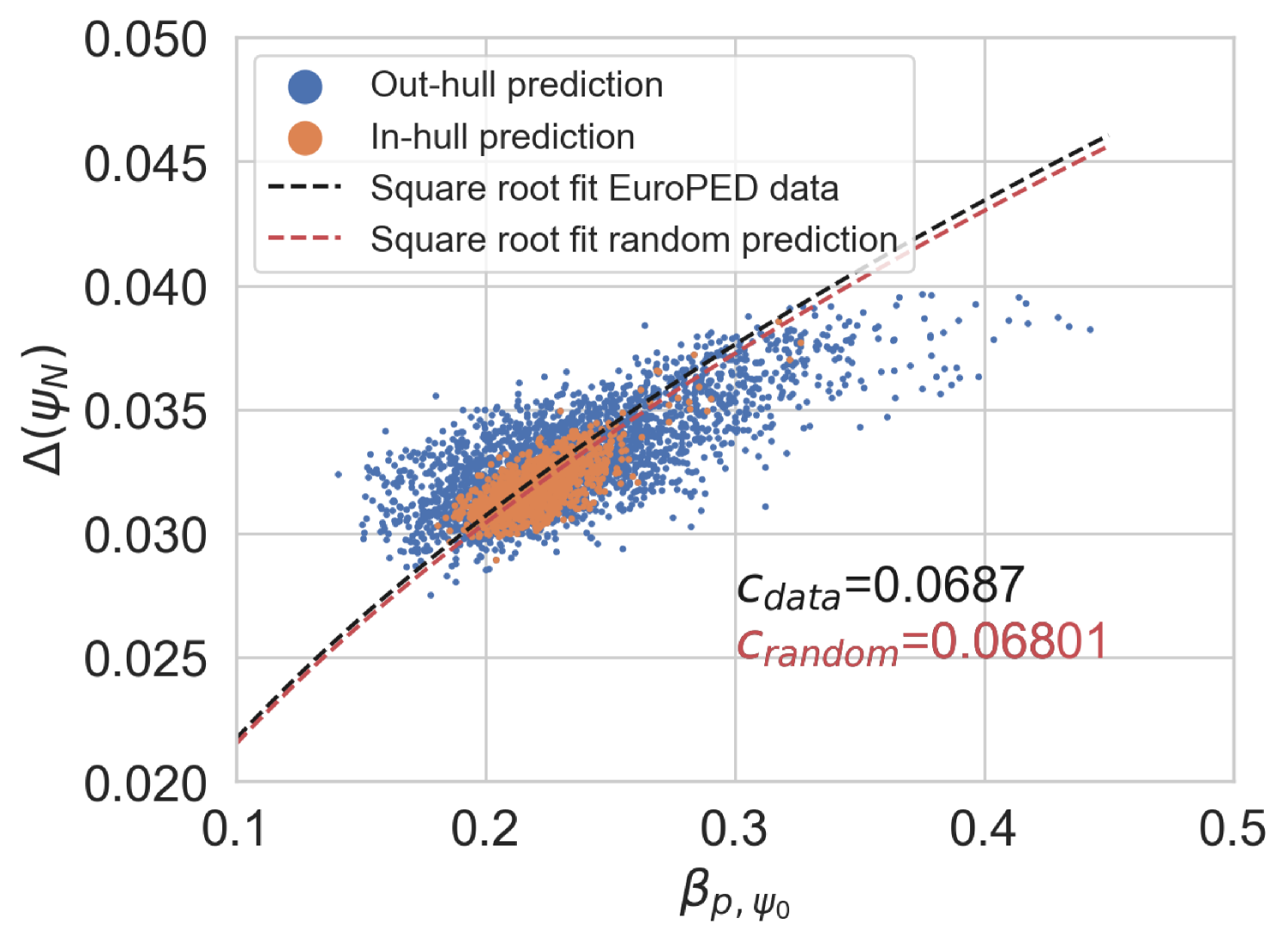
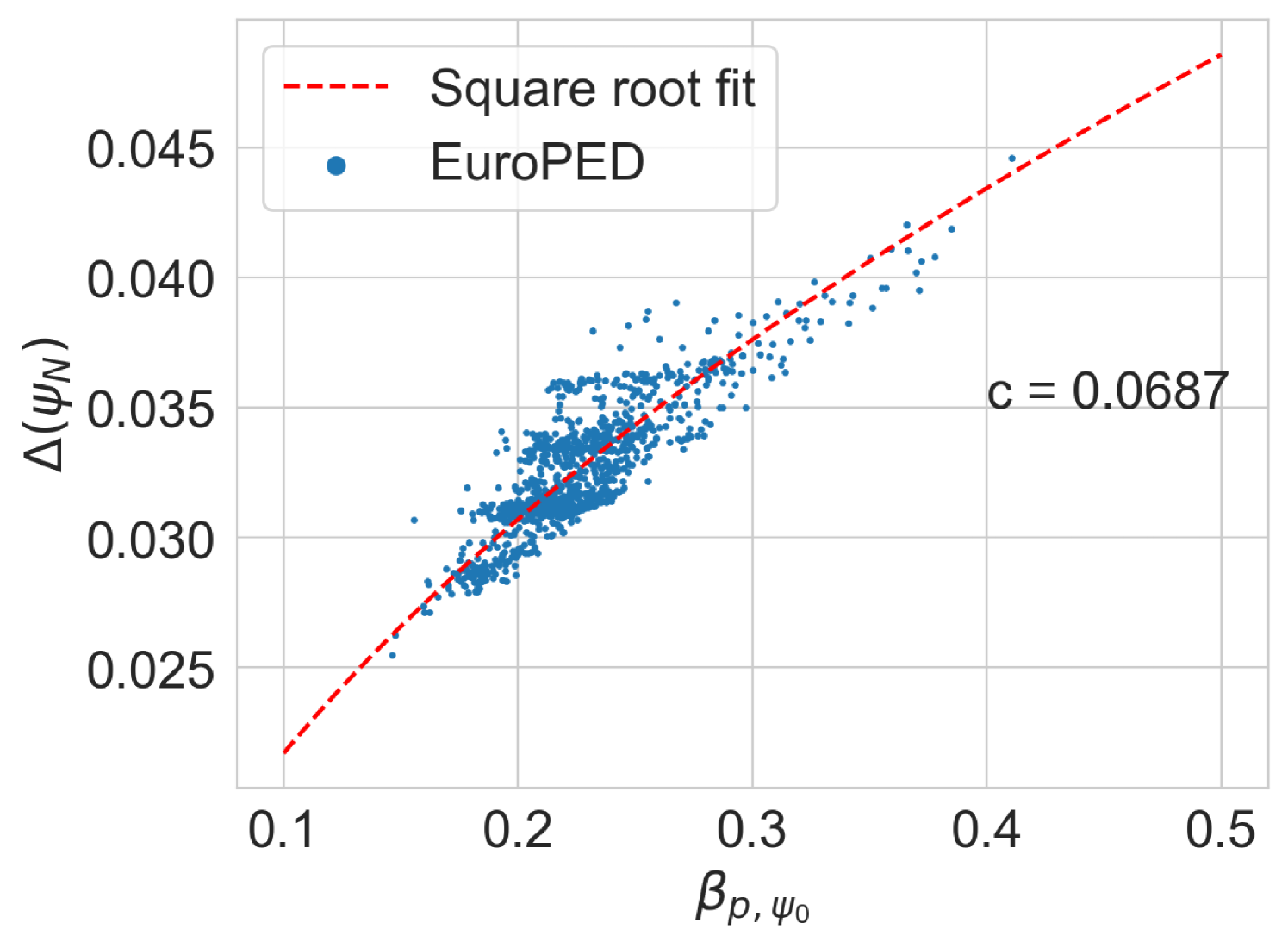
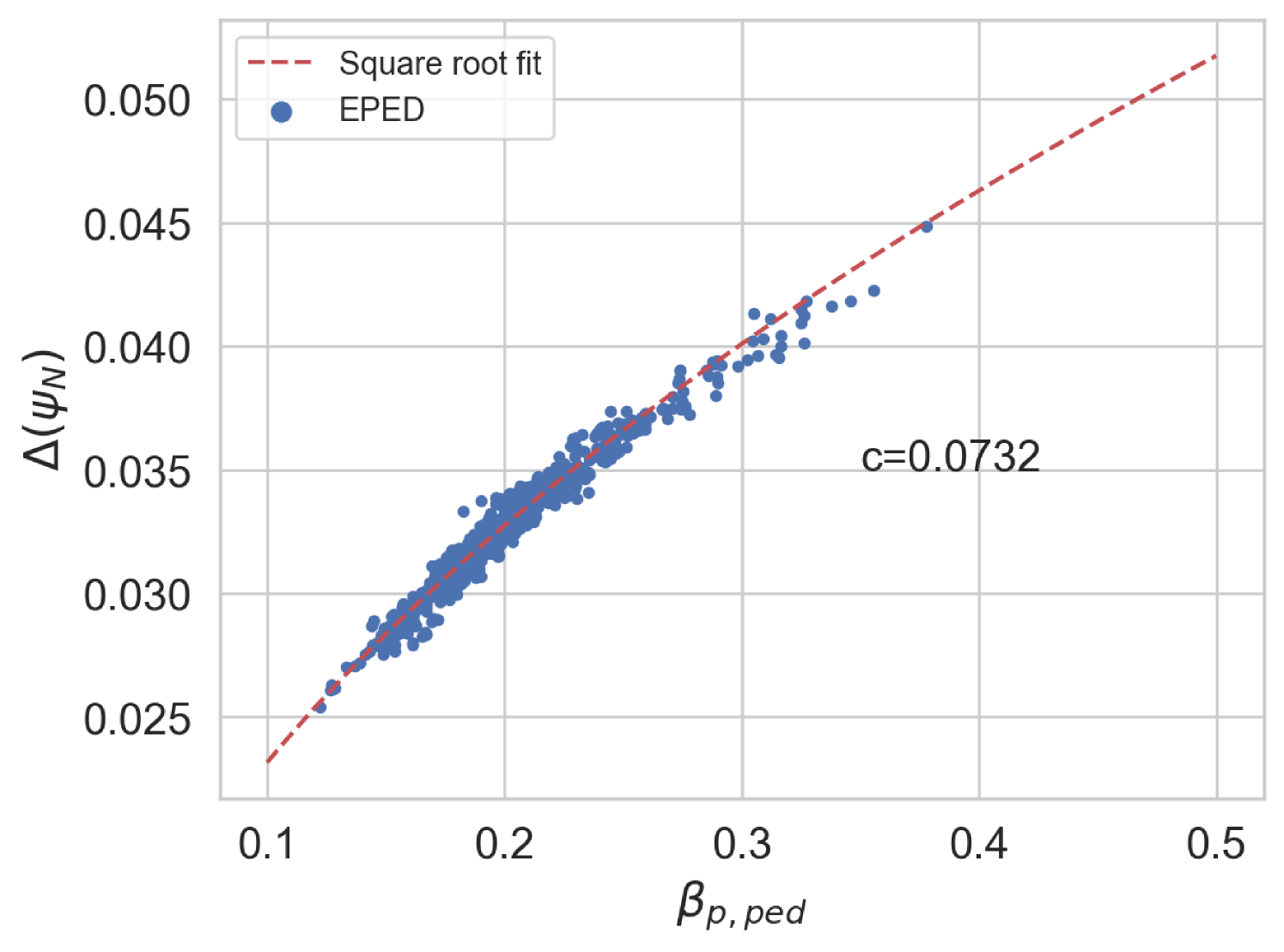
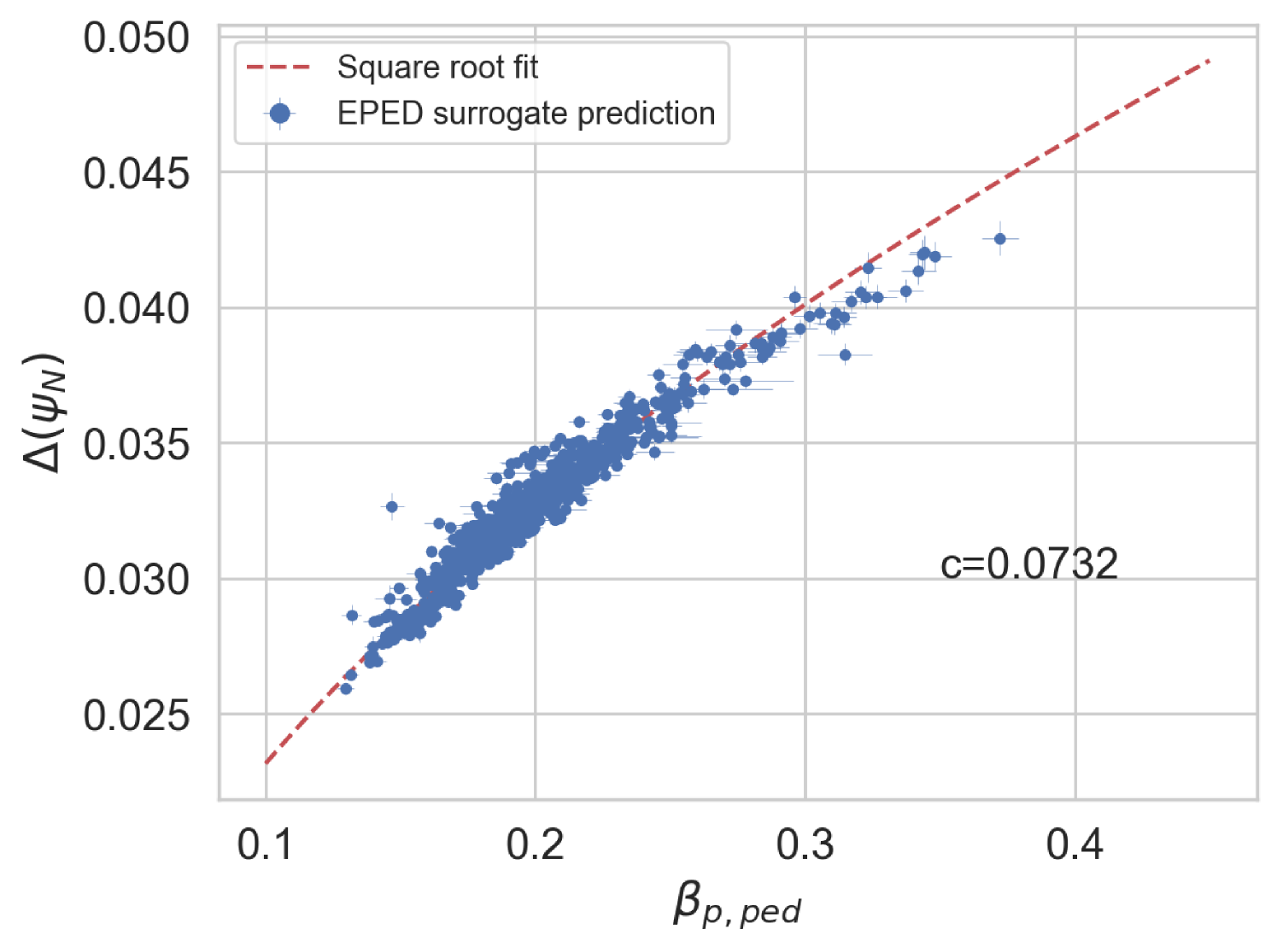
Figure 16 shows the behaviour of the original EuroPED original predictions for JET-ILW experiment database in the space. The original square root relation used in EuroPED and EPED models can be appreciated as: . This relation was found in the tokamak DIII-D to be held with [14]. However, as EuroPED-NN gives the outputs at and not at top pedestal for convenience purposes, the relation cannot be hold in the exact same way, then some scatter around the square root fit can be found for both EuroPED and EuroPED-NN predictions. This is a result from the discrepancy between and .
Figure 16 show the EuroPED-NN predictions with epistemic uncertainty, across both the training and test datasets from the pedestal database. This means that the plotted uncertainties should correspond to the interpolation region, where the surrogate model is expected to provide decent predictions.
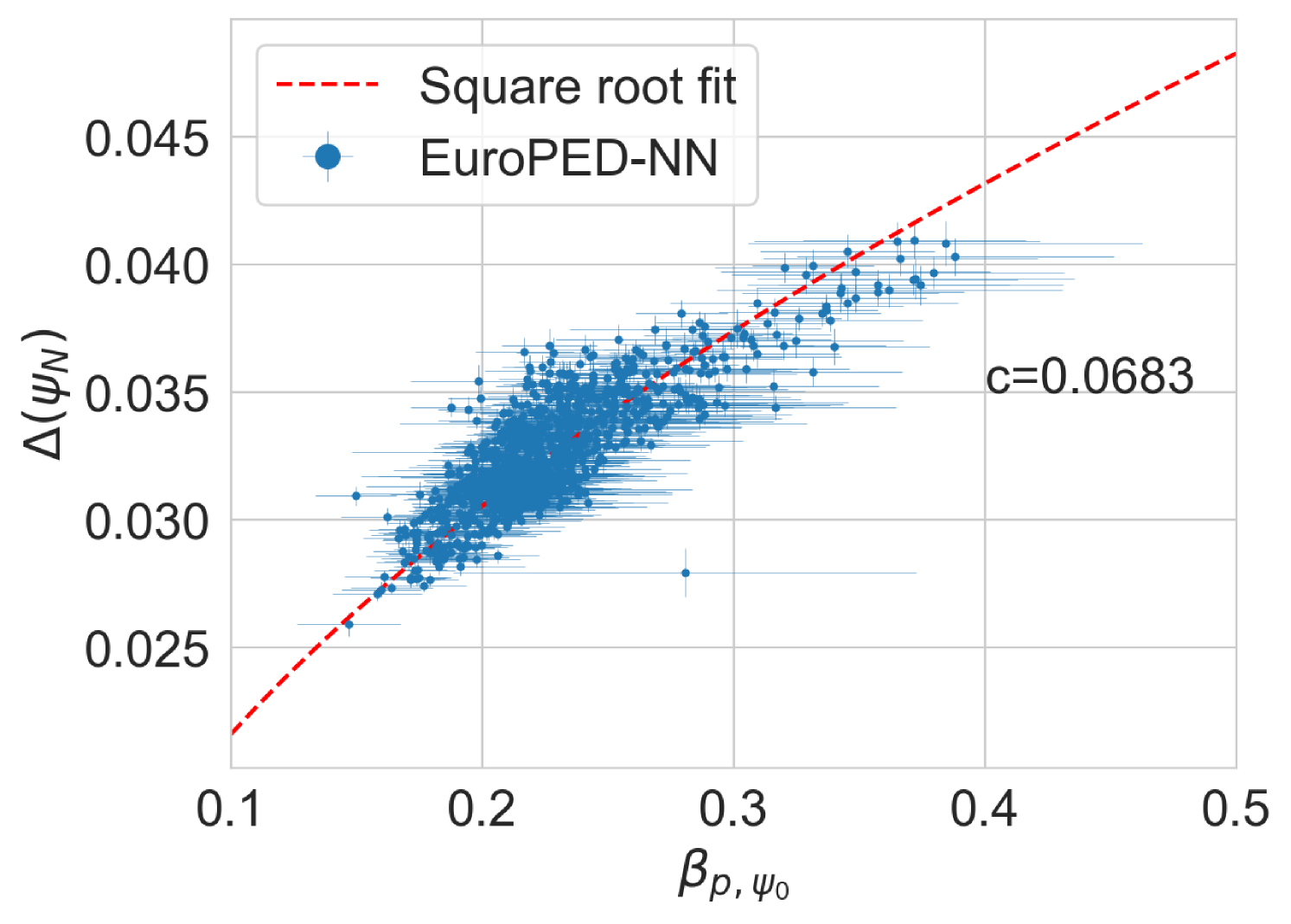
In Figure 16, the EuroPED-NN predictions for random inputs inside the range of the dataset inputs are shown. 4000 input entries have been generated using two uniform distributions, one using the central 90% range of the dataset and the other the central 60%, this has been done to adequately populate the space. A convex hull using the training data has been created in order to check which random points fall inside of it. It can be appreciated in the plot how the points inside the convex hull are following the square root fit with higher precision than the rest. Then the relation has been caught and generalized adequately to the training space by EuroPED-NN.
Overall, it is clear that the EuroPED-NN predictions in the space is quite similar to the original one in Figure 16, moreover the random points seem to follow the trend, specially those inside the training convex hull, so the model is capturing the behavior reasonably well.
Contextualization in data-driven pedestal models
Data-driven methods, in particular neural networks, have been applied to predict plasma pedestal quantities in the past. To put EuroPED-NN in its context a comparison will be carried out with EPED1-NN [21] and PENN [27] models, to know which are their main attributes and where EuroPED-NN stands in relation to them.
Regarding EPED1-NN, the model was developed to replicate EPED pedestal model [14]. The inputs of the model are the inputs of EPED: , , , , , , , and . The outputs are pedestal pressure and pedestal width. EPED1-NN is built using a regular feed-forward neural network, and its accuracy achieves values around and , for the respective outputs, when compared with EPED predictions as described in [21].
On the other hand PENN model is intended to replicate experimental data from JET-ILW pedestal database [33]. The inputs of the model are , , , , , , , , , NBI Power, Total Power, plasma volume and . Where , and stands for upper triangularity, lower triangularity and q value at respectively. PENN is also build using a regular feed-forward neural network and the output variables are the pedestal density and temperature , for which the accuracy in test data when compared with experimental data is and , respectively.
Therefore, we can compare both models characteristic with EuroPED-NN, where the set of inputs (explained in the Section 2.1) differ from both EPED1-NN and PENN, then the usage cases are different, as happens between EPED and EuroPED. Depending on the available data one model can be more suitable than the other. The accuracy is reasonably good in all of them, including EuroPED-NN with , , and (see Figure 8). However, this accuracy is quoted against the respective datasets of each model, meaning that the insights that can be extracted from this comparison are limited. Regarding uncertainty analysis, only EuroPED-NN is an uncertainty-aware model inherently providing its corresponding model and data uncertainty estimates. Regarding the model applicability, it is known that neither EPED nor EuroPED includes the effect of plasma resistivity. Thus, the empirical model PENN could be a better option when predicting the properties of a more resistive plasma. However, to explore the physics and behavior of the pedestal models in a fast way, both EPED1-NN and EuroPED-NN are also applicable.
Extrapolation of EuroPED-NN to AUG data
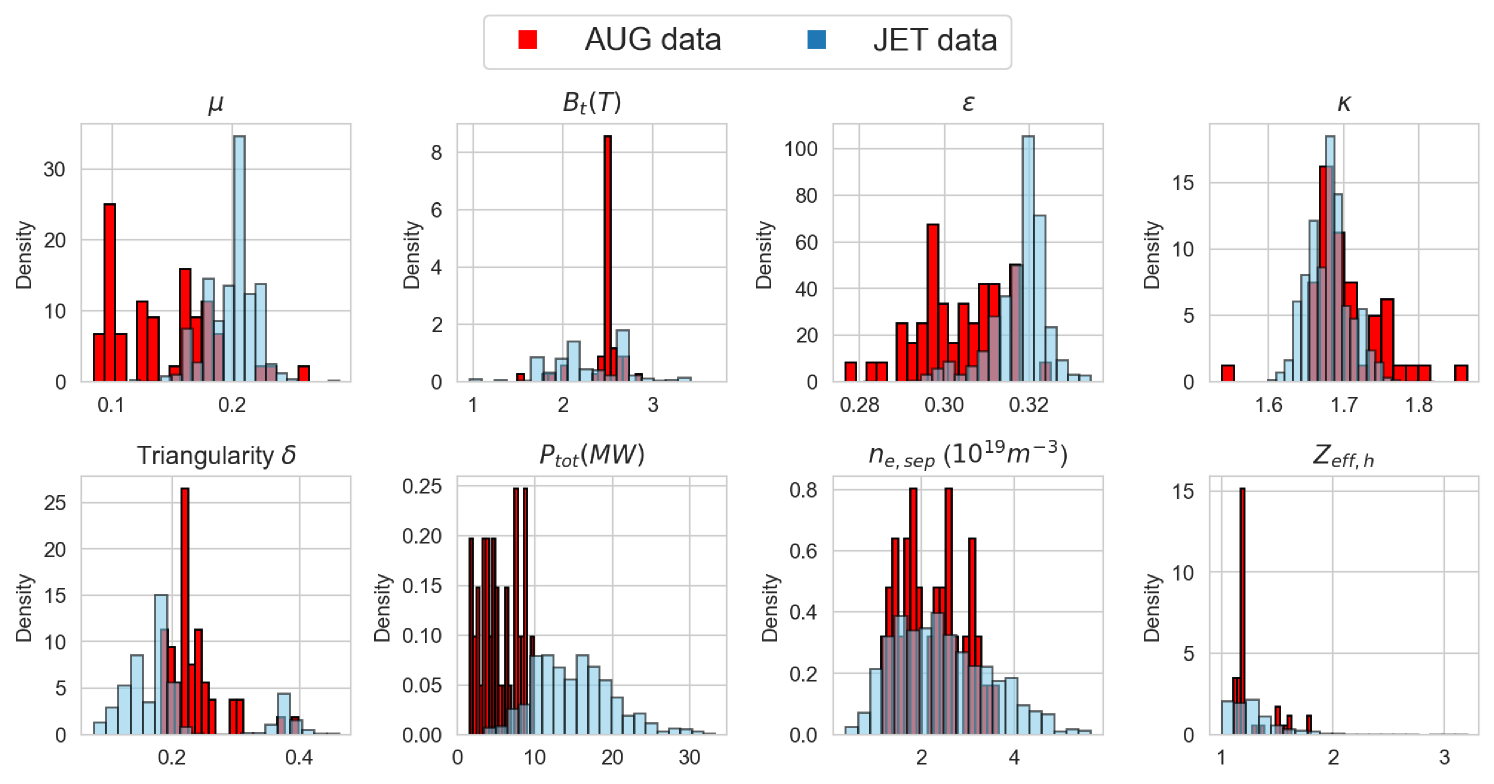
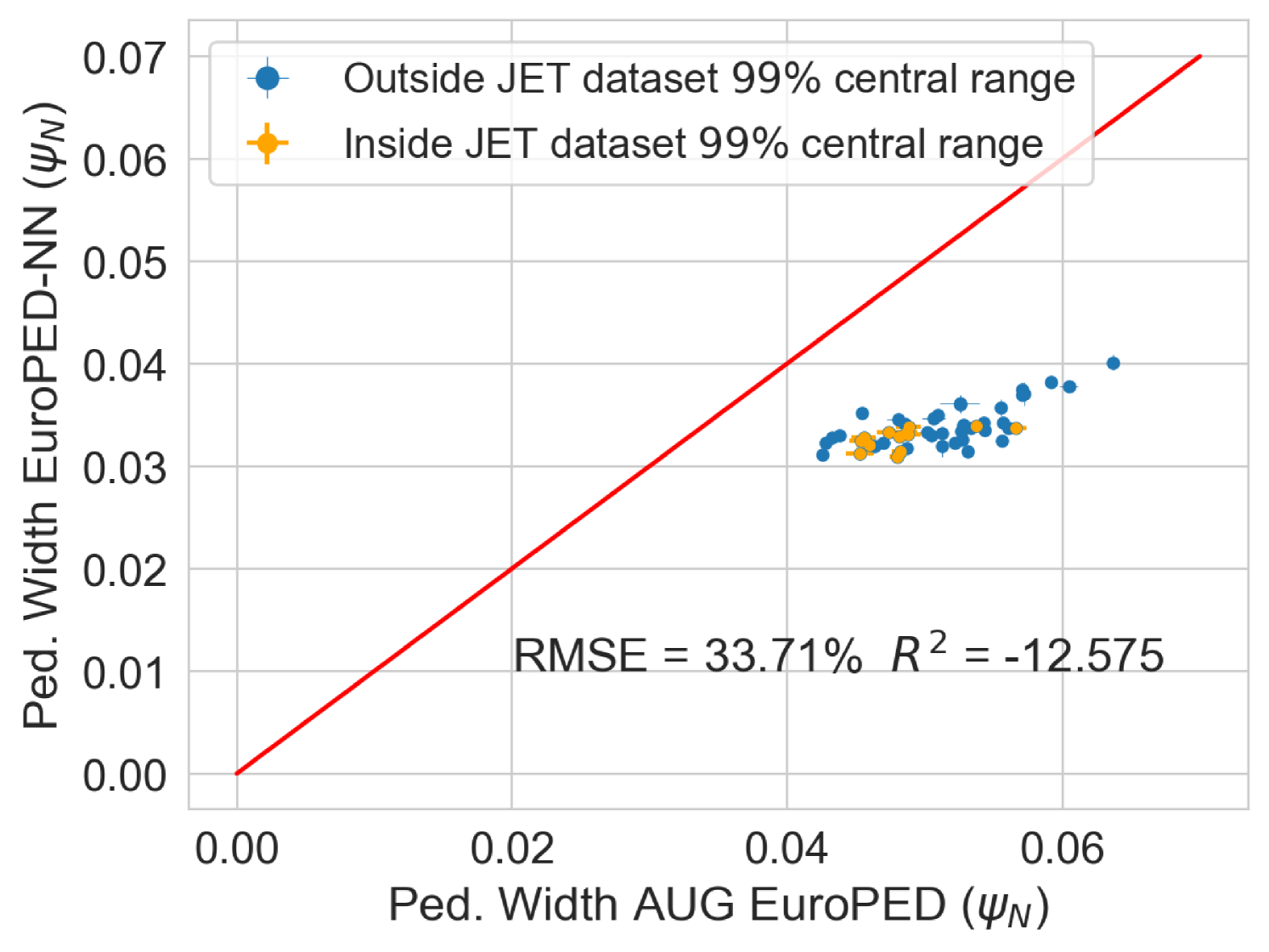
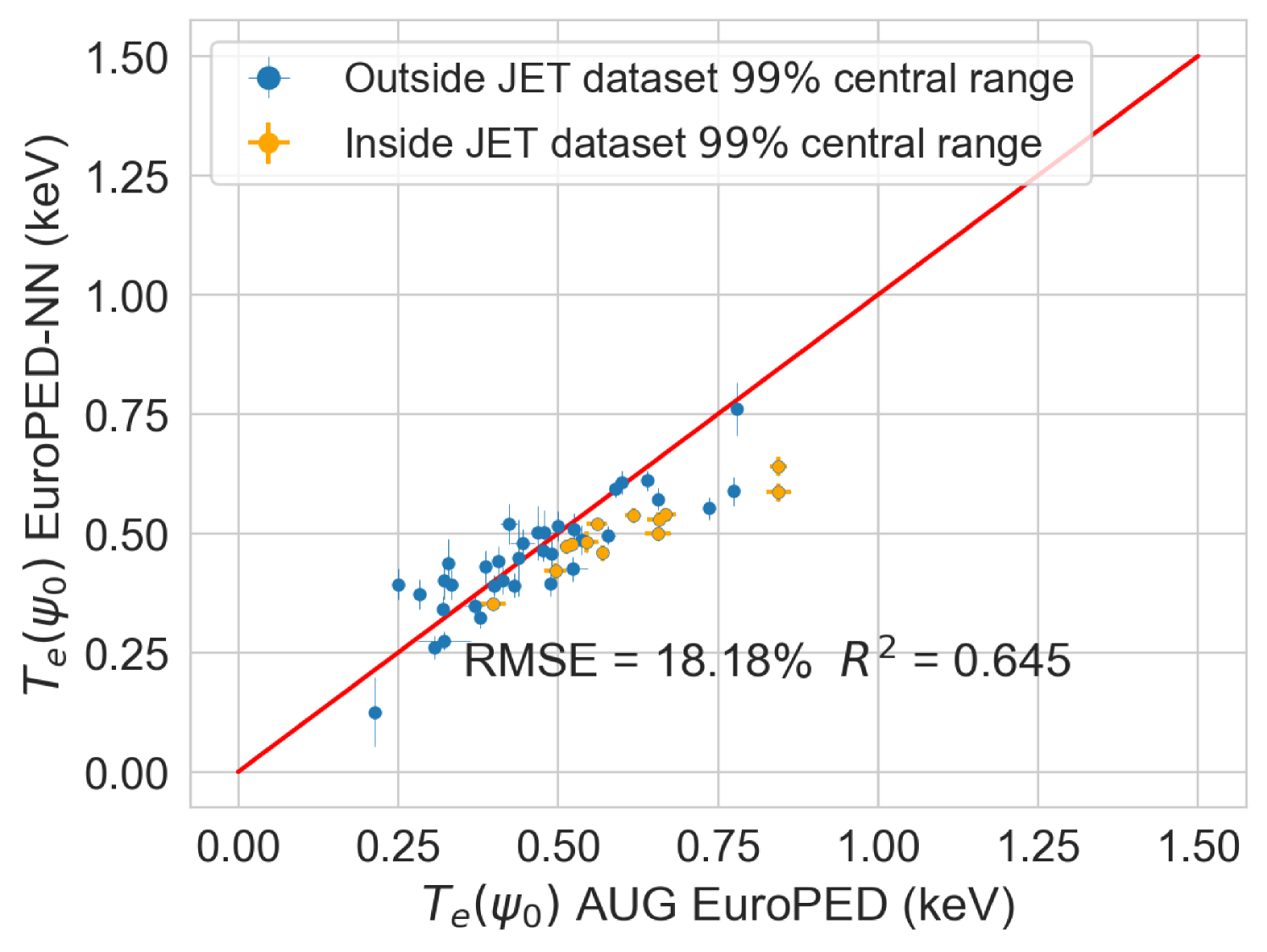
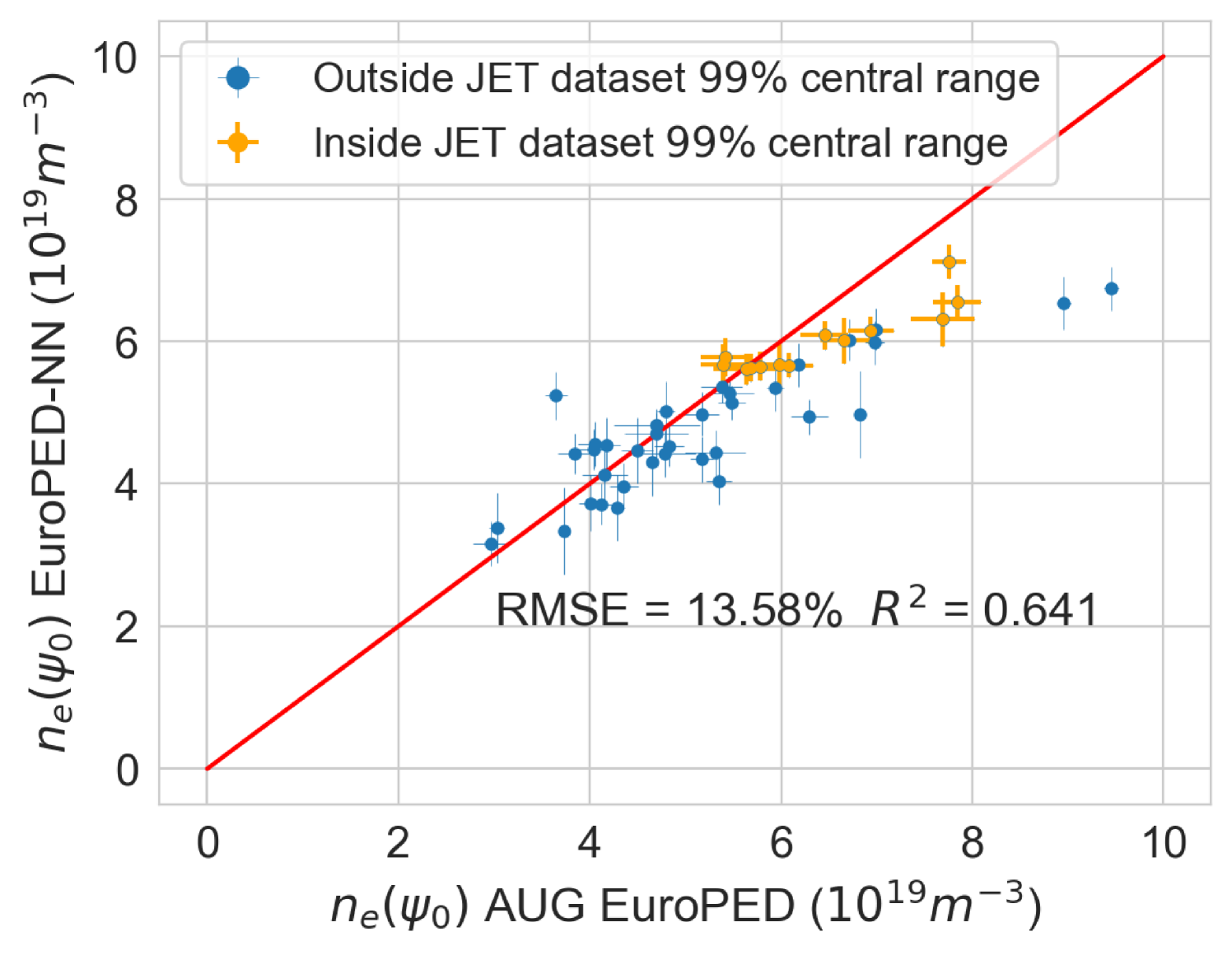
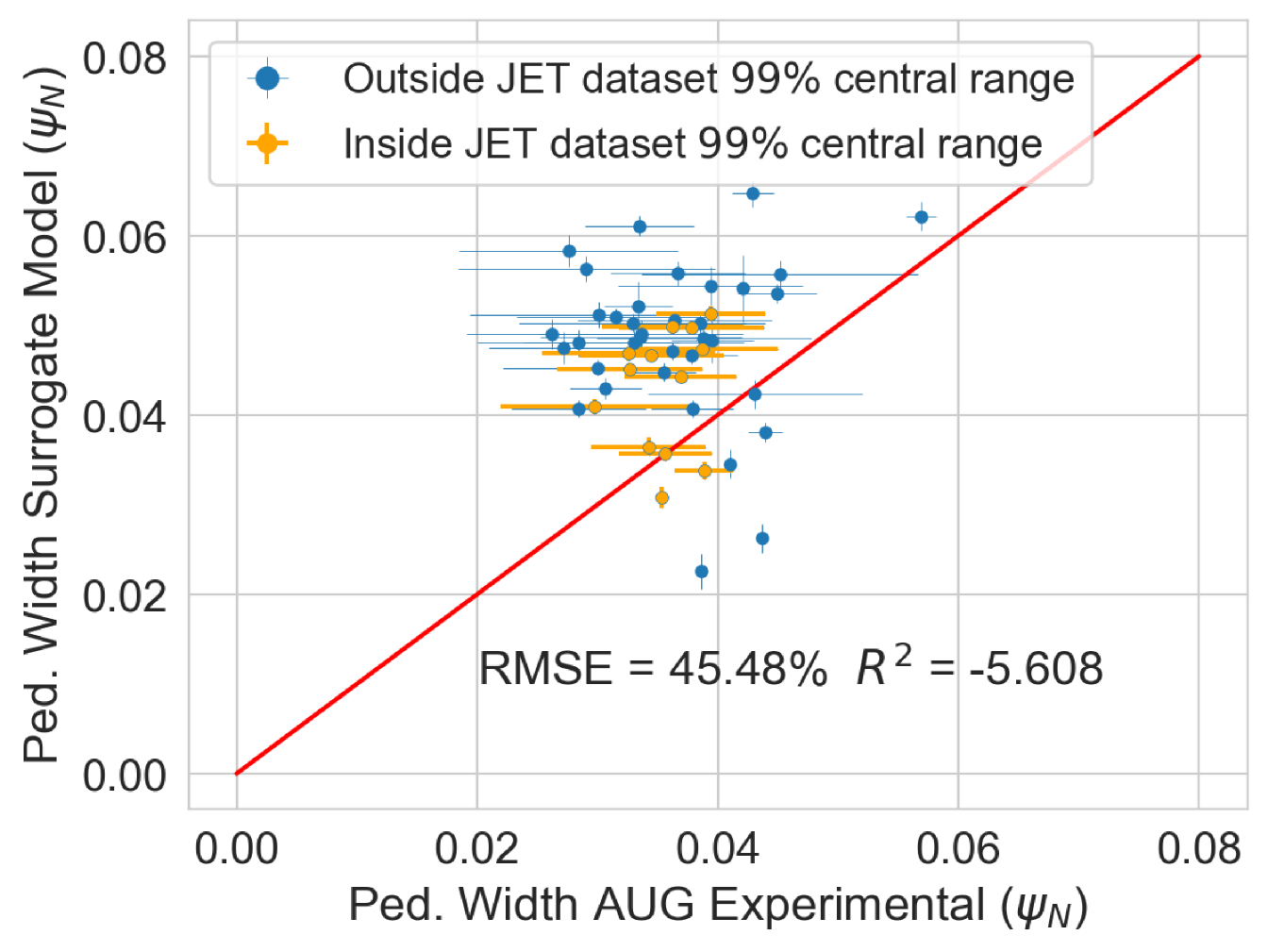
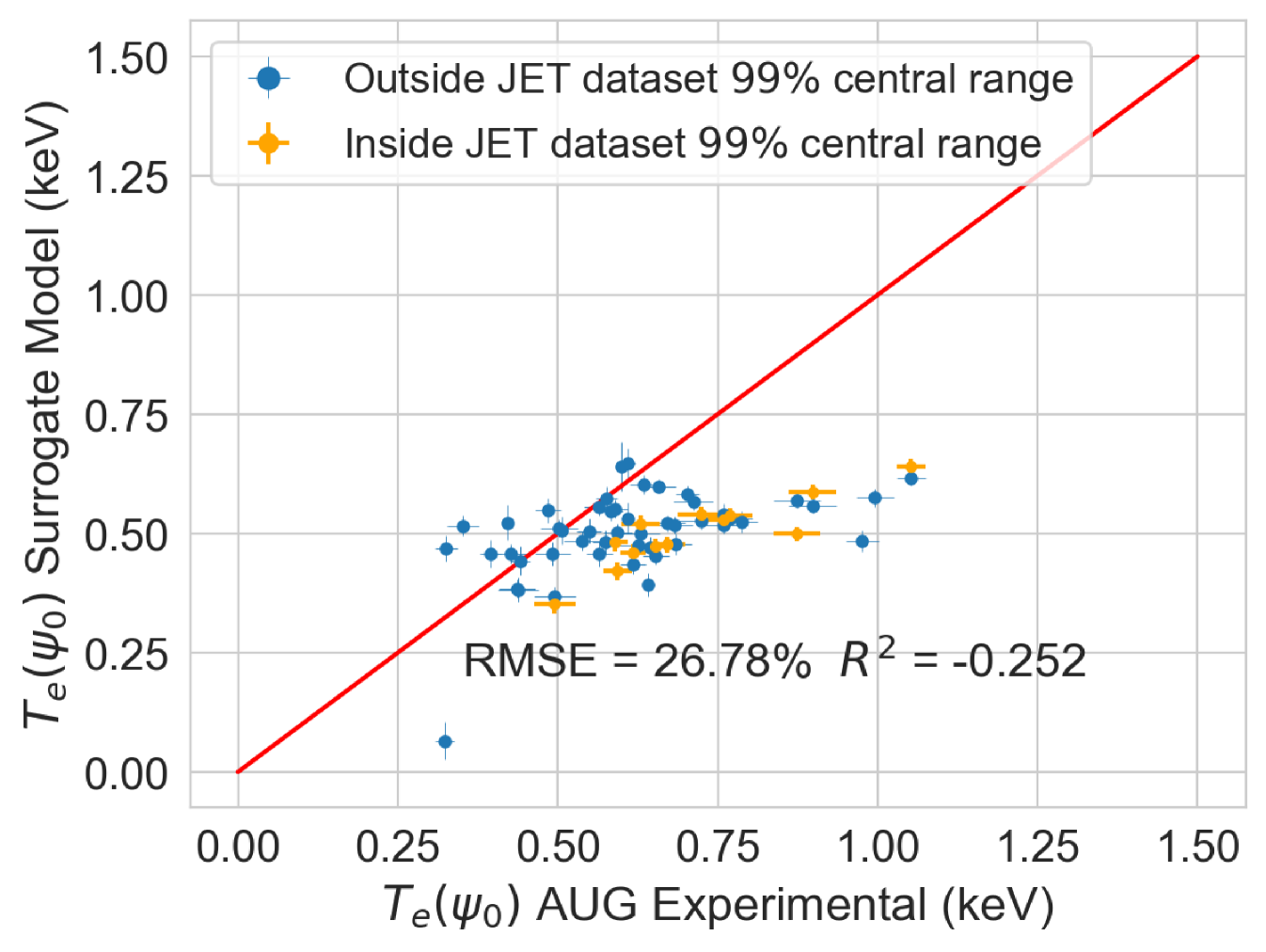
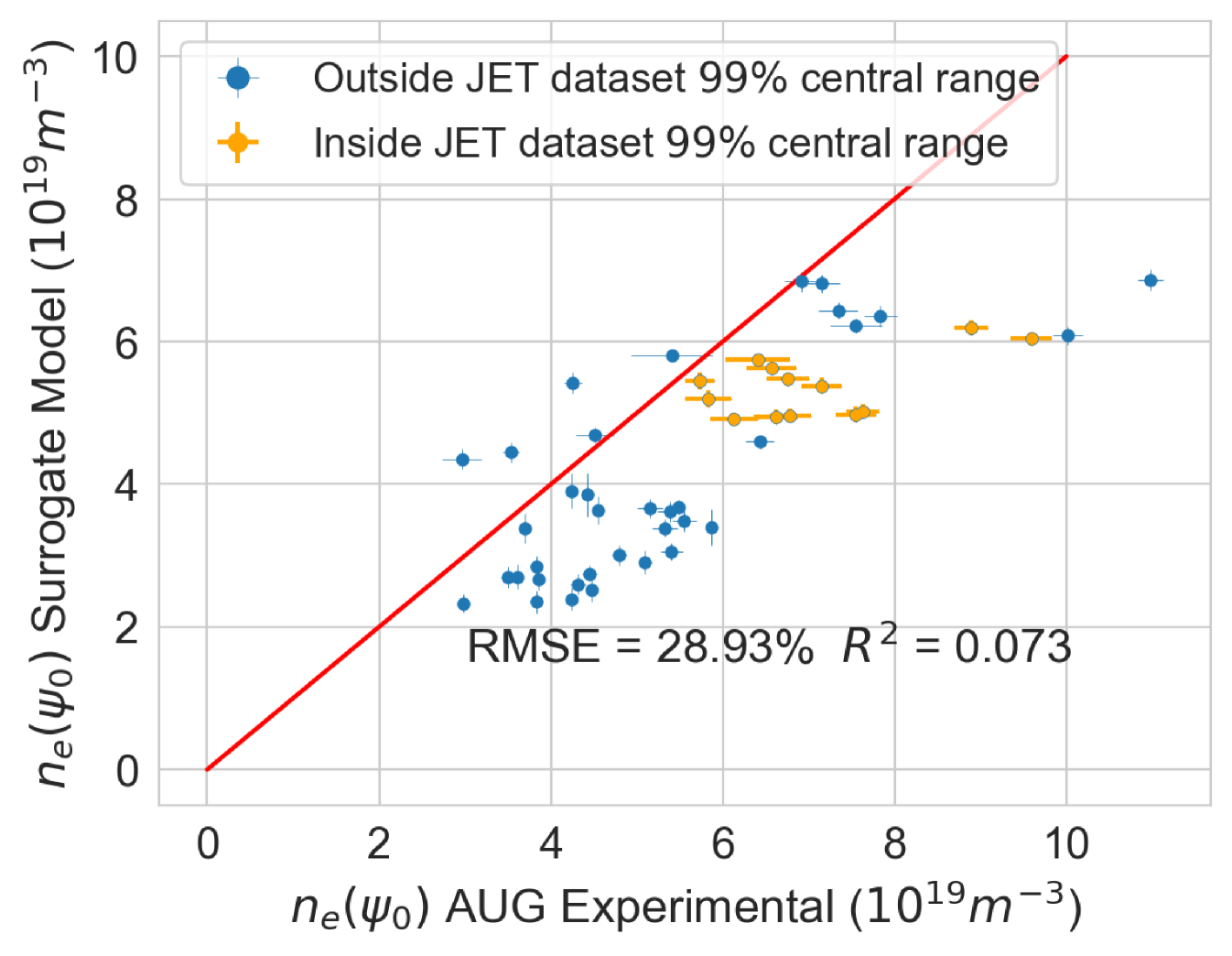
Finally, an experimental pedestal database from ASDEX-Upgrade (AUG) tokamak [38, 39] with 50 shots, and its subsequent EuroPED predictions were available. This data is used to compare the EuroPED-NN predictions with the EuroPED evaluations. As the AUG database parameters lie outside the hull of JET parameters, the exercise constitutes an extrapolation of the model. This will test the adaptability of EuroPED-NN out of JET database values. The distribution of input values from the 50 AUG shots can be compared in Figure 17 with the JET database. The biggest difference between both of them are found in , , and triangularity variables.
In the Figure 21 the EuroPED-NN predictions performance in AUG data is displayed for the three output variables. The points are split between those whose input points lie inside the central 99% of JET database range, and those who doesn’t. This central 99% boundary was chosen to effectively exclude outliers from artificially expanding the range limits. It can be appreciated how most of the points are outside this range, so it is therefore an extrapolating exercise. For and the match with the EuroPED predictions is reasonable with and , respectively. However, in the case of the pedestal width, the extrapolation does not look to have succeeded. The reason for this is that the AUG predictions were run using a KBM constant of 0.09 (instead of the standard 0.076) as AUG has found that the standard prediction gives too narrow values. For this reason, the pedestal width variable cannot be extrapolated, while the rest variables perform much better.
The fact that EuroPED-NN performance in AUG data is reasonable good in the pedestal height quantities, even though the model is extrapolating, might mean that EuroPED-NN is adequately catching the trend between the input data and the pedestal quantities, rather than just adapting to the training data. However, to increase its accuracy and generalization power, future work training EuroPED-NN with data from other machines is encouraged.
5.8cm
 {subcaptionblock}5.8cm
{subcaptionblock}5.8cm
 {subcaptionblock}5.8cm
{subcaptionblock}5.8cm
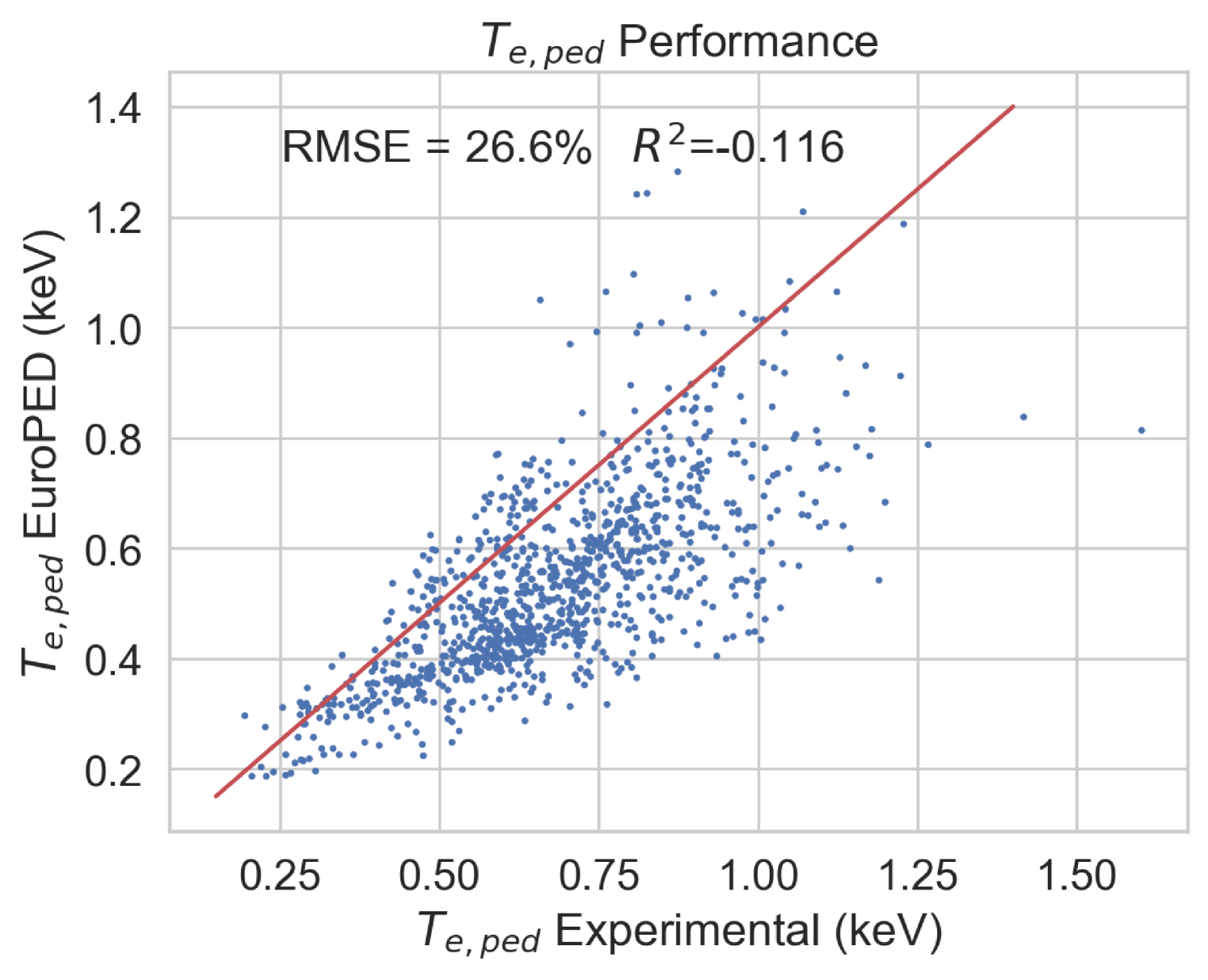
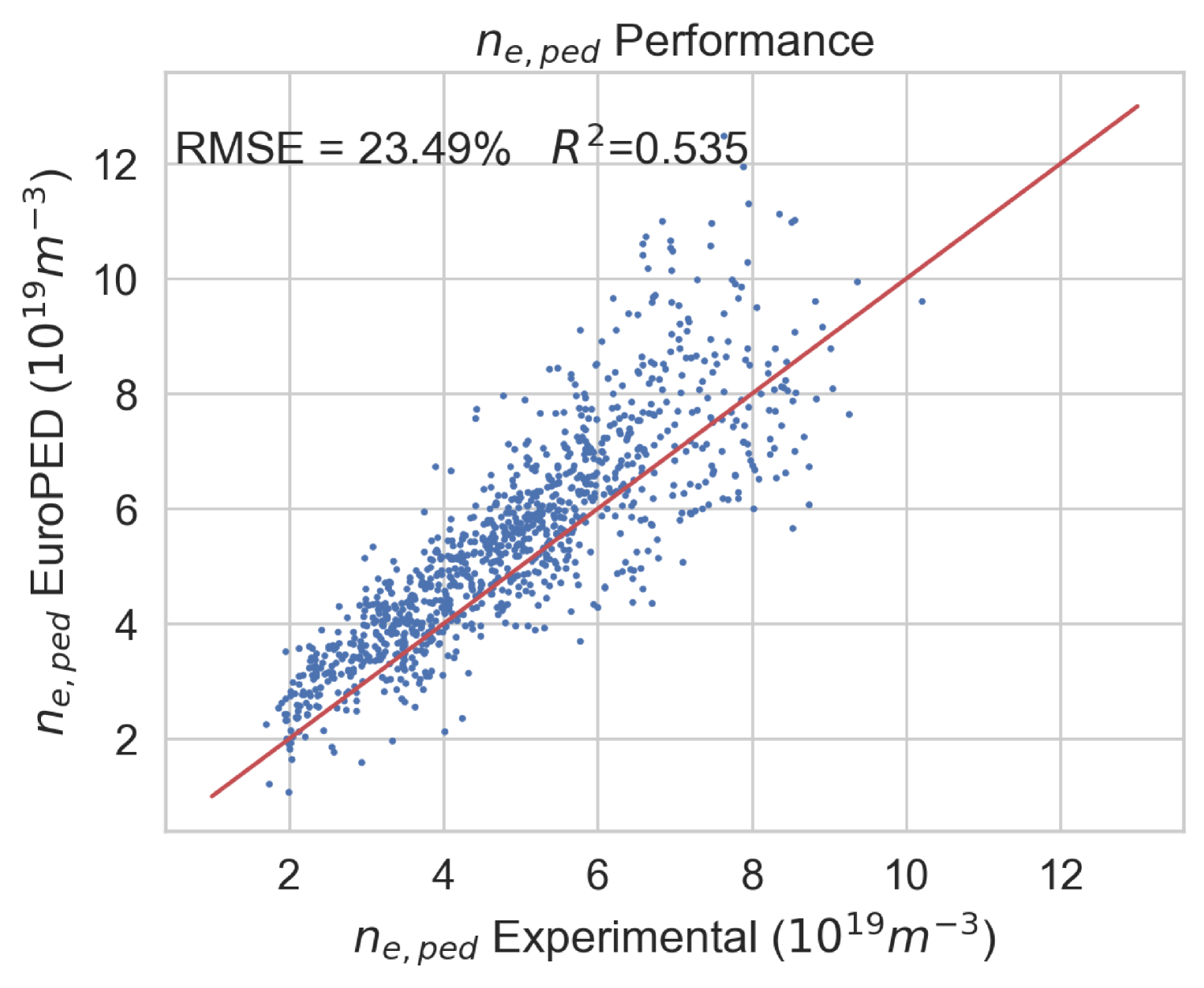
Extension of the methodology to experimental data and extrapolation to AUG experimental data.
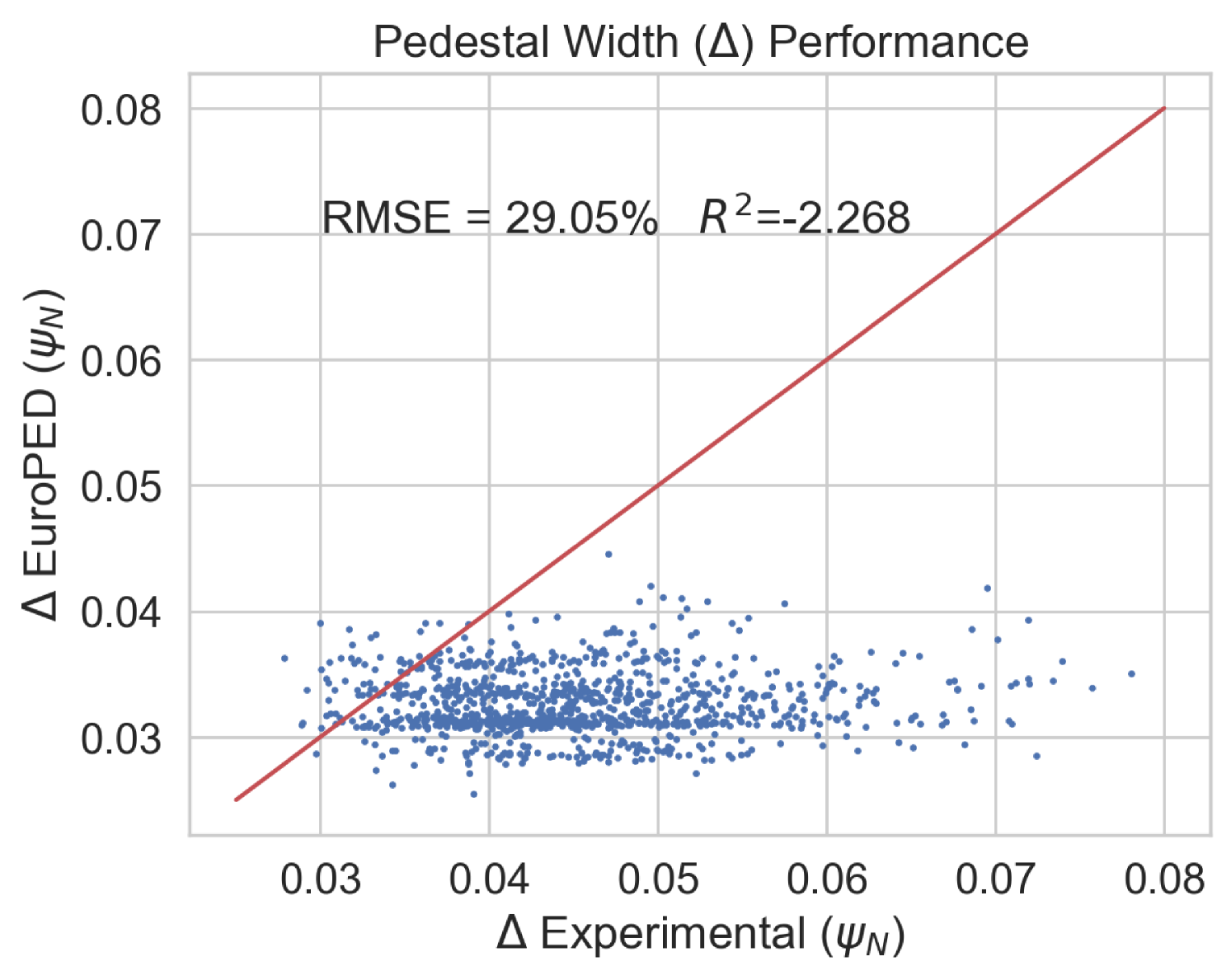
During the training of the EuroPED-NN model, it was found that some of the EuroPED output predictions do not appear to align with the experimental data. Figure 25 shows a comparison between the experimental data and EuroPED-predicted outputs in the database used in this study, where it becomes evident that the prediction points do not follow the 1:1 line. While the objective of this study was to train a surrogate model for EuroPED, its accuracy is ultimately constrained to the accuracy of EuroPED itself. To push the topic of general pedestal surrogate modelling further, an experimental model was constructed using the same EuroPED inputs while swapping the output data to their corresponding experimental values. By employing the same BNN-NCP structure to create this upgraded surrogate model, it exhibits a much better alignment for the same variable, as illustrated in Figure 29 if we compare it with Figure 25. Then this experimental model clearly outperforms EuroPED in the JET-ILW database.
6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
However, when comparing Figures 8 and 29, it becomes evident that the accuracy of this “experimentally-enhanced" surrogate model is significantly lower than that of the EuroPED surrogate model. This suggests that the chosen set of input variables for EuroPED may be insufficient to sufficiently characterize the pedestal physics contained in the dataset, based on its inability to obtain a similarly high model performance, as determined by its RMSE and . Guided by recent pedestal physics literature, an attempt was made to include the normalized plasma collisionality, , as an input variable. However, these efforts have proven inadequate in explaining why the model performance cannot be recovered between the models. Nevertheless, this marks a promising initial study into the development of a sufficient set of parameters to fully describe pedestal physics and further research in this direction is strongly recommended.
It may seem reasonable to compare this experimental pedestal model with the previously described PENN model [27] as both of them are based on experimental data, although the set of input variables differ from each other. As mentioned, PENN model has an accuracy in test data of and , for and respectively, while the experimental model developed in this section is associated with test set accuracy of and . Then it can be seen how the experimental model performs better for , while PENN performs significantly better for . The likely explanation lies in the input parameters of each model. The model utilized in this study benefits from as input parameter, which is closely related with . In contrast, the PENN model boasts a greater number of inputs, enhancing its ability to provide more comprehensive information for accurate predictions. It is worth noting that the experimental model inputs have been purposefully selected to correspond with the EuroPED inputs, so an input parameter analysis has not been carried out.
Finally, the experimental pedestal database from ASDEX-Upgrade (AUG) tokamak [38, 39] will be used to compare the experimental model predictions with the data from AUG. Again, as the AUG database parameters lie outside the hull of JET parameters, the exercise constitutes an extrapolation of the model. Also note that EuroPED model does not play any role in this exercise, as the experimental model has been trained exclusively with experimental data, not with the subsequent EuroPED evaluations, although both have the same set of inputs. In Figure 33, the accuracy of the experimental model in the AUG cases is represented for pedestal width, and , the prediction points are split between those whose input values fall inside the central 99% of JET training database range and those that do not. It can be inferred from the accuracy metrics that the experimental NN model performs significantly worse in experimental AUG pedestal values, although in the plots it can be seen how in the case of and it roughly gets the trend of the 1:1 line. Interestingly, the model does not return pedestal values corresponding to the AUG data even for the AUG points which lie within the JET training parameter space. A possible explanation for this can be due to the fact that the training dataset contains 1000 entries, which may not be enough for the NN to learn the necessary relations to generalize the problem in the experimental case, even within its own training space. Another explanation could be the election of input parameters, which, as commented, may not be enough to recover the experimental pedestal values. A more thorough investigation into the input variables selection or the incorporation of other physical constraints is recommended to improve the results of cross-machine comparisons, especially if the databases used cannot be significantly expanded for future studies.
6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
Conclusion
In this study, it has been shown that EuroPED-NN, trained using the BNN-NCP technique, is able to reproduce the results and behavior of EuroPED JET database with good accuracy, whose mean prediction provides similar performance to that of a simple feed-forward neural network, showing performances. Obtaining errors under 7 % for and and under 3 % for pedestal width. However the use of this BNN-NCP technique has allowed to identify extrapolation and interpolation regions via the epistemic and/or aleatoric uncertainties, as the epistemic uncertainty generally grows with distance from dataset convex hull, while the aleatoric uncertainty falls. On top of that, the use of these aleatoric and epistemic uncertainties allows the model to be uncertainty aware in the predictions, so that the prediction’s confidence can be known.
EuroPED-NN has also been tested using physical reasoning. First, a one-dimensional scan calculating for different values of has been performed proving the expected growth of , while showing the behavior of the prediction’s uncertainty. Second, the semi-empirical relation included inside EuroPED has been tested to hold in EuroPED-NN, using both JET dataset inputs and random inputs, so that the relation is correctly generalized.
Finally, after explaining the method, building the surrogate model and performing the posterior analysis, it can be said that the EuroPED-NN is completely functional in JET-ILW data. Additionally, the extrapolation of EuroPED-NN to AUG tokamak data has been tested, obtaining reasonable accuracy for and of around . However, the pedestal width accuracy was much lower as EuroPED was run in AUG data using a different constant for the KBM constraint. In general, better performance in this exercise would typically require a bigger set of training data and/or training data from other tokamaks. Future work is encouraged in this direction.
To sum up, EuroPED-NN predictions closely match EuroPED predictions in JET input data, with errors of less than 7% for both electron temperature () and electronic density (), and less than 3% for pedestal width (). The model identifies the areas where the prediction uncertainty is higher and lower, which is helpful for understanding its reliability. Furthermore, the model’s performance was validated by comparing its predictions with known physical principles, demonstrating its understanding of some plasma physics principles involved in EuroPED.
The surrogate model EuroPED-NN is mainly intended to be used in plasma control, scenario development and physics exploration of pedestal plasma. The advantage with respect to EuroPED model is not only the fast computation but also the uncertainty awareness. While this uncertainty is split in model uncertainty (epistemic) and data uncertainty (aleatoric) for further clarity. EuroPED-NN proves to be a valuable tool for various studies that can leverage any of this features. The model architecture and weights are located in this GitHub link https://github.com/alexpanera/EuroPED-NN, any feedback on the use of the model will be appreciated.
In Section 4, the same method and architecture developed for EuroPED-NN was also applied to experimental data using the same JET database, proving the adaptability of the method and bridging the gap between EuroPED predictions and experimental data, a challenge that EuroPED-NN inherently cannot address. While its performance surpassed that of EuroPED when compared with JET experimental data, it did not match the performance of EuroPED-NN compared to EuroPED. Furthermore, this experimental model was tested with AUG data, revealing its limited extrapolating power due to its low performance in this different tokamak. This could be due to the low number of training data points () and/or the election of the EuroPED input variables. Future work is encouraged towards building a pedestal experimental model that can be generalised to various machines, likely using data from different machines.
In the Appendix B, some additional analysis on EuroPED-NN uncertainties is performed, and in Appendix C the same methodology described has been implemented in the EPED model to prove again the adaptability of the method.
Furthermore, the method developed in this study (multidimensional BNN-NCP), based on a previous study detailing its methodology [29], can be extended to build uncertainty aware models even beyond plasma physics, offering opportunities in diverse fields. In essence, the multidimensional BNN-NCP model with modified architecture that has been developed in this study holds immense potential for both scientific and non-scientific applications, by enabling the construction of precise uncertainty aware neural network models across multiple dimensions, improving the speed of regular Bayesian neural networks.
Acknowledgements
This work has been carried out within the framework of the EUROfusion Consortium, funded by the European Union via the Euratom Research and Training Programme (Grant Agreement No 101052200 — EUROfusion). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the European Commission can be held responsible for them. In particular, the work has been carried out within the framework of ENR-MOD.01.FZJ project.
Data availability
Raw experimental data were generated at the Joint European Torus (JET) facility. Derived data and simulation results supporting the findings of this study are available from the corresponding author upon reasonable request.
References
- [1] F Wagner “A quarter-century of H-mode studies” In Plasma Physics and Controlled Fusion 49.12B, 2007, pp. B1 DOI: 10.1088/0741-3335/49/12B/S01
- [2] R.. Groebner, K.. Burrell and R.. Seraydarian “Role of edge electric field and poloidal rotation in the L-H transition” In Phys. Rev. Lett. 64 American Physical Society, 1990, pp. 3015–3018 DOI: 10.1103/PhysRevLett.64.3015
- [3] K.. Burrell “Effects of EB velocity shear and magnetic shear on turbulence and transport in magnetic confinement devices” In Physics of Plasmas 4.5, 1997, pp. 1499–1518 DOI: 10.1063/1.872367
- [4] P H Diamond, S-I Itoh, K Itoh and T S Hahm “Zonal flows in plasma – a review” In Plasma Physics and Controlled Fusion 47.5, 2005, pp. R35 DOI: 10.1088/0741-3335/47/5/R01
- [5] M.T. Curie et al. “Gyrokinetic simulations compared with magnetic fluctuations diagnosed with a Faraday-effect radial interferometer-polarimeter in the DIII-D pedestal” In Nuclear Fusion 62.12 IOP Publishing, 2022, pp. 126061 DOI: 10.1088/1741-4326/ac9b76
- [6] Guangzhi Ren, Jiquan Li, Lai Wei and Zheng-Xiong Wang “Role of secondary long wavelength fluctuation in nonlinear saturation of the kinetic ballooning mode in tokamak plasmas” In Nuclear Fusion 62.9 IOP Publishing, 2022, pp. 096034 DOI: 10.1088/1741-4326/ac7ac3
- [7] D.R. Hatch et al. “Microtearing modes as the source of magnetic fluctuations in the JET pedestal” In Nuclear Fusion 61.3 IOP Publishing, 2021, pp. 036015 DOI: 10.1088/1741-4326/abd21a
- [8] E.R. Solano et al. “Recent progress in L-H transition studies at JET: tritium, helium, hydrogen and deuterium” In Nuclear Fusion 62.7 IOP Publishing, 2022, pp. 076026 DOI: 10.1088/1741-4326/ac4ed8
- [9] L. Vermare et al. “Formation of the radial electric field profile in the WEST tokamak” In Nuclear Fusion 62.2 IOP Publishing, 2021, pp. 026002 DOI: 10.1088/1741-4326/ac3c85
- [10] C. Silva et al. “Structure of the JET edge radial electric field in He and D plasmas” In Nuclear Fusion 61.12 IOP Publishing, 2021, pp. 126006 DOI: 10.1088/1741-4326/ac2abb
- [11] A G Peeters “The bootstrap current and its consequences” In Plasma Physics and Controlled Fusion 42.12B, 2000, pp. B231 DOI: 10.1088/0741-3335/42/12B/318
- [12] A.. Leonard “Edge-localized-modes in tokamaks” In Physics of Plasmas 21.9, 2014, pp. 090501 DOI: 10.1063/1.4894742
- [13] H.. Wilson, P.. Snyder, G… Huysmans and R.. Miller “Numerical studies of edge localized instabilities in tokamaks” In Physics of Plasmas 9.4, 2002, pp. 1277–1286 DOI: 10.1063/1.1459058
- [14] P.. Snyder et al. “Development and validation of a predictive model for the pedestal height” In Physics of Plasmas 16.5, 2009, pp. 056118 DOI: 10.1063/1.3122146
- [15] Hartmut Zohm “The physics of edge localized modes (ELMs) and their role in power and particle exhaust” In Plasma Physics and Controlled Fusion 38.8, 1996, pp. 1213 DOI: 10.1088/0741-3335/38/8/012
- [16] S. Saarelma et al. “Self-consistent pedestal prediction for JET-ILW in preparation of the DT campaign” In Physics of Plasmas 26.7, 2019, pp. 072501 DOI: 10.1063/1.5096870
- [17] S. Mulders et al. “Rapid optimization of stationary tokamak plasmas in RAPTOR: demonstration for the ITER hybrid scenario with neural network surrogate transport model QLKNN” In Nuclear Fusion 61.8 IOP Publishing, 2021, pp. 086019 DOI: 10.1088/1741-4326/ac0d12
- [18] Jonas Degrave et al. “Magnetic control of tokamak plasmas through deep reinforcement learning” In Nature 602, 2022, pp. 414–419 DOI: 10.1038/s41586-021-04301-9
- [19] A. Ho et al. “Neural network surrogate of QuaLiKiz using JET experimental data to populate training space” In Physics of Plasmas 28.3, 2021, pp. 032305 DOI: 10.1063/5.0038290
- [20] K.. Plassche et al. “Fast modeling of turbulent transport in fusion plasmas using neural networks” In Physics of Plasmas 27.2, 2020, pp. 022310 DOI: 10.1063/1.5134126
- [21] O. Meneghini et al. “Self-consistent core-pedestal transport simulations with neural network accelerated models” In Nuclear Fusion 57.8 IOP Publishing, 2017, pp. 086034 DOI: 10.1088/1741-4326/aa7776
- [22] S.M. Morosohk, A. Pajares, T. Rafiq and E. Schuster “Neural network model of the multi-mode anomalous transport module for accelerated transport simulations” In Nuclear Fusion 61.10 IOP Publishing, 2021, pp. 106040 DOI: 10.1088/1741-4326/ac207e
- [23] J.X. Zhu et al. “Hybrid deep-learning architecture for general disruption prediction across multiple tokamaks” In Nuclear Fusion 61.2 IOP Publishing, 2020, pp. 026007 DOI: 10.1088/1741-4326/abc664
- [24] Julian Kates-Harbeck, Alexey Svyatkovskiy and William Tang “Predicting disruptive instabilities in controlled fusion plasmas through deep learning” In Nature 568.7753, 2019 DOI: 10.1038/s41586-019-1116-4
- [25] O. Meneghini et al. “Neural-network accelerated coupled core-pedestal simulations with self-consistent transport of impurities and compatible with ITER IMAS” In Nuclear Fusion 61.2 IOP Publishing, 2020, pp. 026006 DOI: 10.1088/1741-4326/abb918
- [26] Emi U. Zeger et al. “Prediction of DIII-D Pedestal Structure From Externally Controllable Parameters” In IEEE Transactions on Plasma Science 49.10, 2021, pp. 3212–3227 DOI: 10.1109/TPS.2021.3114608
- [27] A. Gillgren et al. “Enabling adaptive pedestals in predictive transport simulations using neural networks” In Nuclear Fusion 62.9 IOP Publishing, 2022, pp. 096006 DOI: 10.1088/1741-4326/ac7536
- [28] Diederik P Kingma and Max Welling “Auto-encoding variational bayes” In arXiv preprint arXiv:1312.6114, 2013
- [29] Danijar Hafner et al. “Noise Contrastive Priors for Functional Uncertainty” In Proceedings of The 35th Uncertainty in Artificial Intelligence Conference 115, Proceedings of Machine Learning Research PMLR, 2020, pp. 905–914 URL: https://proceedings.mlr.press/v115/hafner20a.html
- [30] Eyke Hüllermeier and Willem Waegeman “Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods” In Machine Learning 110, 2021, pp. 457–506 DOI: 10.1007/s10994-021-05946-3
- [31] Armen Der Kiureghian and Ove Ditlevsen “Aleatory or epistemic? Does it matter?” Risk Acceptance and Risk Communication In Structural Safety 31.2, 2009, pp. 105–112 DOI: https://doi.org/10.1016/j.strusafe.2008.06.020
- [32] M. Erba et al. “Validation of a new mixed Bohm/gyro-Bohm model for electron and ion heat transport against the ITER, Tore Supra and START database discharges” In Nuclear Fusion 38.7, 1998, pp. 1013 DOI: 10.1088/0029-5515/38/7/305
- [33] L. Frassinetti et al. “Pedestal structure, stability and scalings in JET-ILW: the EUROfusion JET-ILW pedestal database” In Nuclear Fusion 61.1 IOP Publishing, 2020, pp. 016001 DOI: 10.1088/1741-4326/abb79e
- [34] Francois Chollet “Keras” GitHub, 2015 URL: https://keras.io
- [35] Martı́n Abadi et al. “Tensorflow: Large-scale machine learning on heterogeneous distributed systems” In arXiv preprint arXiv:1603.04467, 2016
- [36] Diederik P. Kingma and Jimmy Ba “Adam: A Method for Stochastic Optimization” In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015 URL: http://arxiv.org/abs/1412.6980
- [37] A E Hubbard “Physics and scaling of the H-mode pedestal” In Plasma Physics and Controlled Fusion 42.5A, 2000, pp. A15 DOI: 10.1088/0741-3335/42/5A/302
- [38] T. Luda et al. “Validation of a full-plasma integrated modeling approach on ASDEX Upgrade” In Nuclear Fusion 61.12 IOP Publishing, 2021, pp. 126048 DOI: 10.1088/1741-4326/ac3293
- [39] T. Luda et al. “Integrated modeling of ASDEX Upgrade plasmas combining core, pedestal and scrape-off layer physics” In Nuclear Fusion 60.3 IOP Publishing, 2020, pp. 036023 DOI: 10.1088/1741-4326/ab6c77
Appendix A OOD Hyperparameters
This section provides some data for the OOD related hyperparameters referenced in the main body. These values were specifically chosen for this study based on the training attempts and expert reasoning of the authors. They must be reevaluated when applying the BNN-NCP technique to other applications.
In the case of the OOD sampling, as mentioned in the Section 2.5, the width of OOD region for input sampling was chosen to be 2 times the standard deviation of the dataset input variables. This range resulted wide enough to get the desired results.
Regarding the target epistemic uncertainty , the value chosen in the three output variables was in normalised units. The target aleatoric uncertainty was also chosen to be small, also in normalised units.
Appendix B Input uncertainty study in EuroPED-NN
In the methodology developed in this work two types of uncertainties are distinguished, epistemic and aleatoric. However, it is interesting to study how the input uncertainties are translated into the output uncertainties propagating them through the EuroPED-NN model. Those input uncertainties are estimated from the measurement signals and the values appear in Table 1.
| 0.02 | |
| (T) | 0.001 |
| 0.01 | |
| 0.01 | |
| Triangularity | 0.01 |
| (MW) | 0.5 |
| () | 0.7 |
| 0.05 |
The method to develop this study was similar to the procedure used in OOD sampling. The dataset input values were modified summing to each a sample of 1000 values generated by the distribution . Then this 1000 points generated with just one input entry are passed through EuroPED-NN, from this 1000 values for each of the outputs we obtain the standard deviation, which correspond with the input uncertainty translated to the output.
Figure 34 shows the results of this study comparing the sampled uncertainty with the aleatoric uncertainty for all the points in the dataset. Aleatoric uncertainty was chosen for comparison due to the closest relation with the data variation, on top of that epistemic uncertainty was consistently lower than both aleatoric and sampled uncertainty. It is noticeable how in the output variables and the aleatoric uncertainty accounts for all the sampled uncertainty, serving as a lower bound. In the case of both aleatoric and sampled uncertainty are in the same order. It is expected that the aleatoric uncertainty captures the input uncertainties translated to the outputs, as the aleatoric uncertainty catches the variance in the data, which is highly related with the measurements uncertainty.
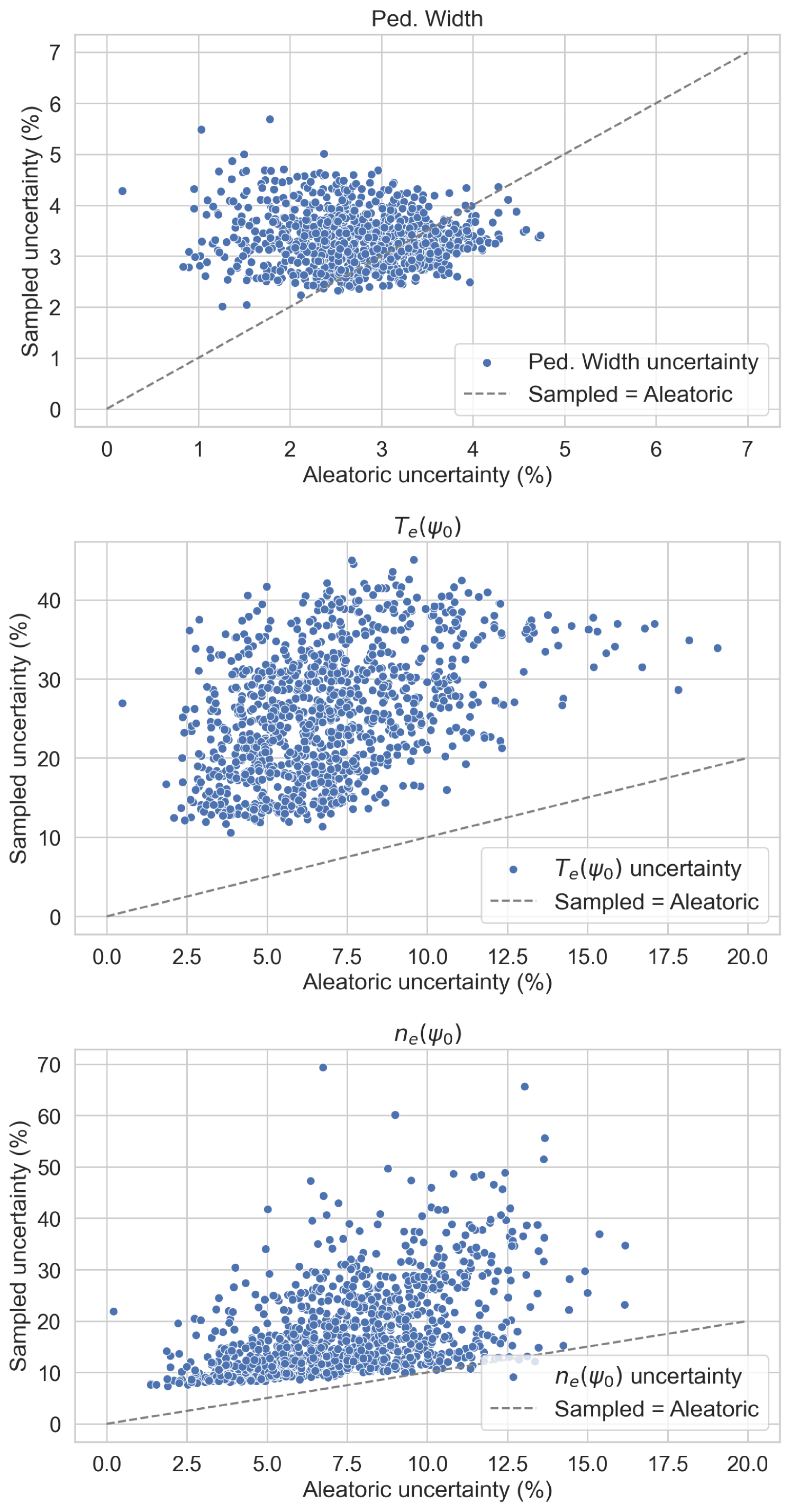
Note that the uncertainty dominates the results, due to the large values, as shown in Table 1, and due to the importance of the variable in the calculation of the final output. To test impact of this choice, the sampling was repeated with lower values of for , obtaining significantly lower sampled uncertainties.
Including the effect of the input uncertainty into the methodology of the neural network would be a desired feature for the model. In this work some attempts were performed, however the result was not satisfactory in most cases. Then it is suggested for future work.
Appendix C EPED surrogate
Following the same principles and methodology developed for EuroPED-NN, and also to show the adaptability of it, the surrogate model of EPED has been created. Taking the inputs and outputs of EPED listed in the Section 2.1, a BNN-NCP with the same number of neurons per layer and the same architecture has been trained to check if the BNN captures the model and the relation. In this case the outputs will correspond to the values of at top pedestal () and the pedestal width . The dataset used will be the same as in EuroPED-NN, where the columns for EPED runs were already present. The model has been trained for 1000 epochs. The performance is shown in the Figures 37 and 37. Both of them seem to have a good fit with the 1:1 line, and the performance is always lower than 5 % in both test and train datasets. RMSE is consistently lower than in EuroPED-NN, which evidence the lower complexity of EPED that allows better performance with the same neural network architecture.
7cm
 {subcaptionblock}7cm
{subcaptionblock}7cm
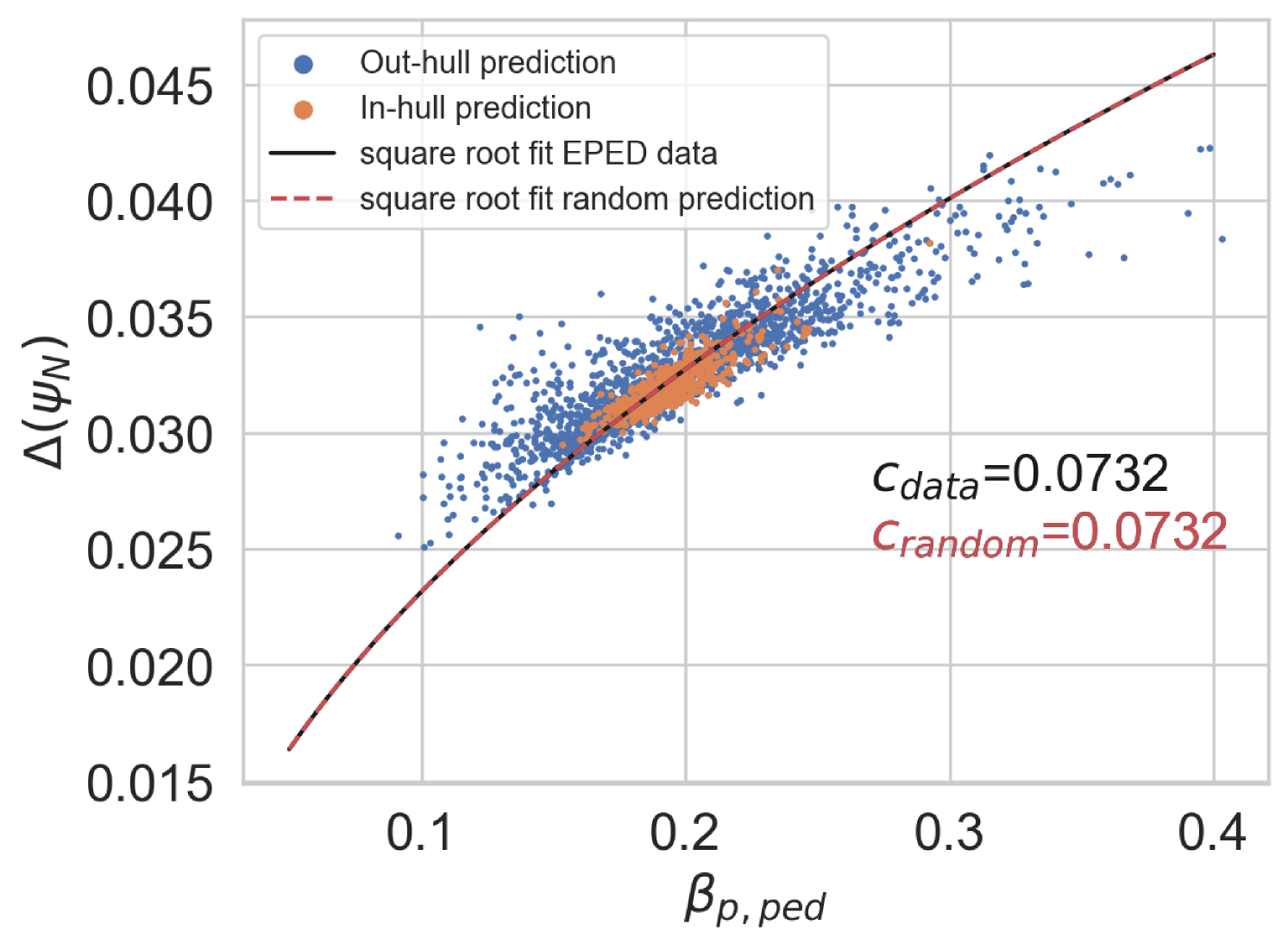
As in EuroPED, the semi empirical relation is quite relevant in EPED, so we expect the EPED surrogate to hold the same relation. Then we will perform the physical validation as before. Figure 41 shows the EPED predictions and the square root relation in them. In Figure 41 the predictions of the EPED surrogate are also shown in the pedestal width ()- space, where the square root fit coefficient is almost the same as in the original EPED model. Finally in Figure 41 4000 random input entries were generated in the same manner as in Section 3.2.2 and they were passed through EPED surrogate. It is appreciable that prediction points that fall inside the training convex hull follow better the trend line, although the out-hull points also follow it reasonably well. So again, the surrogate model generalises correctly the physic relation.
6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
 {subcaptionblock}6cm
{subcaptionblock}6cm
Additionally, it makes sense to compare this EPED surrogate model with the model EPED1-NN [21] that also replicates EPED using a neural network, as described in section 3.3. In both cases the inputs are the same, although EPED1-NN is trained in tokamak DIII-D range of values and the EPED surrogate developed in this study is trained in JET range of values. Output variables are different only because EPED1-NN uses and this study uses , however both of them are highly related. The architectures are different, EPED1-NN uses a regular feed-forward neural network while in this study the BNN-NCP technique has been applied to obtain uncertainty aware predictions. Regarding performance, EPED1-NN accuracy corresponds with and for and pedestal width , respectively, while, as depicted in figure 37, EPED surrogate model accuracy lies around for and for pedestal width . Both models have reasonably high accuracy for the intended outputs, although the one developed in this study is slightly lower.
Overall, in this section it has been shown the adaptability of the method to another plasma pedestal model, obtaining reasonably good performance and comparing it with a similar model.