*
11email: {f.denijs,d.w.h.wilmer}@student.tudelft.nl
Evaluation and Improvement of Laruelle-Widgrén Inverse Banzhaf Approximation
Abstract
The goal of this paper is to critically evaluate a heuristic algorithm for the Inverse Banzhaf Index problem by Laruelle and Widgrén. Few qualitative results are known about the approximation quality of the heuristics for this problem. The intuition behind the operation of this approximation algorithm is analysed and evaluated. We found that the algorithm can not handle general inputs well, and often fails to improve inputs. It is also shown to diverge after only tens of iterations. We present three alternative extensions of the algorithm that do not alter the complexity but can result in up to a factor improvement in solution quality.
1 Introduction
Many decisions are made using voting. A good example of voting are the presidential elections of the United States of America. This follows a two-step process, which nicely illustrates two types of voting. In the first step the citizens vote in each state. Every vote has the same weight and the candidate with the most votes in that state wins that state. The second step illustrates another type of voting: weighted voting. In this step every state votes for the candidate that won in that state. However, it would not be fair if each state has the same vote: the state of California represents over 37 million citizens while little over 560,000 live in Wyoming. Therefore each state has a certain weight, represented by a number of electors. The new president is then chosen by the majority of electors.
With such weighted voting situations, and especially when they are used to elect one of the most powerful men on earth, it is the question how fair the voting is. We can measure this, for example, by using the Banzhaf power index [2] and comparing that to a fair power distribution. Instead of trying to create a fair index – which is much more a philosophical and political question, rather than an algorithmic problem – we try to find a distribution of weights of which the power index matches a target power index.
For this we first introduce the problem in a formal way and present an overview of some existing algorithms for this problem. Then we will discuss and analyse one of the algorithms and try to improve it, after which we evaluate the algorithm and our modifications.
2 Problem statement
The first step to measuring power is modeling a weighted voting situation, using a weighted voting game (WVG). A weighted voting game consists of a set of players , each with a voting weight , along with a quota . We write a WVG as . A coalition is a subset of players, and every coalition has a value . A coalition with value is called winning, and a coalition with value is called losing.
A generally accepted (though not the only) method to measure a priori power is the Banzhaf power index [2]. It measures the power of a player by dividing the number of coalitions of other players for which player is critical (meaning that the coalition is losing, and that player can make it winning by joining it), by the total number of coalitions of other players [10]. Or in mathematical terms:
Often not the regular Banzhaf index is used, but the normalized version [10]. This abstraction is made when it is not interesting in how many cases players can actually exert power, but only how the power is distributed among players. Because that is what we need, we use the normalized Banzhaf index as well:
Just computing the power of a weighted voting game is an NP-hard problem [11] (see [4] for a thorough survey of problems related to power indices and algorithms for solving them). However, our goal is not to measure power. Our goal is to find a quota and an assignment of weights, such that the power is distributed the way we want. Because we use the Banzhaf power index to define the power distribution, our problem is the inverse Banzhaf problem. Formally written it looks as follows:
Given a target power index , find a weighted voting game (in weighted representation) such that the Banzhaf index of is as close to as possible, according to some distance measure.
3 Current algorithms
De Keijzer, Klos and Zhang propose a method to enumerate all weighted voting games for a given number of agents [5]. This algorithm can be used to find a voting game that is closest to a given target vector : enumerate over all possible games, calculate the Banzhaf index for every game and store every game for which the resulting Banzhaf index is closer to according to the distance measure than the best game found so far. Finally, output the best game found. Their algorithm runs in , and calculating the Banzhaf index takes time. The combined algorithm is therefore . For an exact enumeration approach this is a significant result, however it is still highly intractable. Therefore, we think the algorithm is not really practical for larger instances (for example for computing the weights for the shareholders of a company).
Fatima, Wooldridge and Jennings designed an iterative approximation algorithm [7]. The algorithm shifts small amounts of power from players that have too much power, to players that have too little power, according to a comparison of the game’s power index with the target. The authors approximate the power index using randomisation [8]. As a consequence the algorithm is per iteration. Their update rules have a property that makes the algorithm anytime: it can be stopped at any iteration and every iteration gives a better or equal result. Unfortunately, it is focused on the Shapley-Shubik power index [12]—which is similar, but not equal to the Banzhaf power index.
Aziz, Paterson and Leech also designed an iterative approximation algorithm [1]. Their algorithm is used to approximate the Banzhaf index, but instead of calculating it directly they use generating functions [3]. This way the Banzhaf index can be calculated efficiently, but only if the weights are integer. They use interpolation of the current voting power and the desired voting power to determine the next set of weights, multiply them with a certain factor and then round them to integers. They don’t provide an analysis of the approximation quality of their algorithm.
3.1 Laruelle-Widgrén
In our paper we focus on the algorithm by Laruelle and Widgrén. It is a relatively simple algorithm that uses the fact that every input (the weight of the player) has a corresponding output (the power of the player) and that there is a correlation between input (weights) and output (power distribution) of the Banzhaf algorithm – increasing or decreasing the input often leads to similar changes in the output.
Using that fact, Laruelle and Widgrén constructed an iterative algorithm. In every step, they update the weights of the players by calculating the Banzhaf index, calculating the ratio of the banzhaf index divided by the target power index per player and then dividing the weight of each player by its corresponding ratio. That way the weights are adjusted according to the error in the Banzhaf index.
The target vector is used as the first set of weights. This makes sense because the power and the weight distribution are roughly correlated. From this starting point it is possible to iterate as many times as desired. A distance threshold can be set so the algorithm will stop when it is close enough, and a maximum number of iterations can be given to make sure the algorithm takes only a limited amount of time.
A pseudocode version of this algorithm is given in Algorithm 1. It takes as input the vector ‘target’ (also called below) and the numbers ‘maxDistance’ (the distance threshold) and ‘maxIterations’ (the maximum number of iterations). The vectors weight, banzhafIndex and ratio are all vectors of equal size equal to the number of players.
The authors do not give any guarantees about the algorithm. In their paper it is shown to give a good approximation for some cases, but the general case is not analyzed.
4 Analysis
Besides the target power distribution (called by the authors of the algorithm), the Laruelle-Widgrén algorithm also requires a valuation function . The target power distribution must be a vector inside the regular Simplex, i.e. a vector where the elements sum to , because in the computation of the ratio, is compared to normalized Banzhaf vectors, which are all elements of the regular Simplex. The order of the elements in does not matter for the algorithm, as a reordering in the input simply leads to an equal reordering of the outputs. Thus, without loss of generality we may assume the elements in the vector to be in non-increasing order. Therefore, whenever we apply the algorithm to a vector , we take to be an element of the ordered regular Simplex.
The authors consider four different valuation functions in their evaluation of the EU voting system:
-
1.
Unanimity , which returns a iff all players are in the coalition.
-
2.
Simple Majority , which returns a iff the size of the coalition exceeds in the EU case, or in general.
-
3.
Qualified Majority , which returns a iff the weight of the coalition exceeds out of points in the EU case, or quota in general.
-
4.
Qualified Majority with minimum size , which returns a iff the weight of the coalition exceeds and the size exceeds in the EU case, or quota and size in general.
Since the valuation functions and always return the same Banzhaf power index regardless of the player weights, it is not interesting to consider them for the algorithm as no improvement can be made by manipulating the weights. Thus, for our analysis we will focus on the effect of for different choices of . The valuation function is also interesting to consider, however it is more general than since is equal to with , which makes it harder to analyse. Section 4.1 presents our analysis of the expected effect of on the algorithm results.
We also want to investigate the effect of the initial weights determined in step of algorithm 1. We will refer to this initial weight vector as , the weight vector computed in iteration zero. The authors of the algorithm start with the initial weights set to the target power distribution , without any further explanation as to why this choice was made. We propose an adaptation to the algorithm where the choice of is also passed as a parameter, and investigate the expected effect of three choices for in section 4.2.
4.1 Expected effect of
The quota determines when a coalition has enough weight to win. There has been some work on the effect of manipulating the quota by Zuckerman et al. [13]. In particular, they show that the worst case difference in power under a change in is bounded for a given set of players. This is relevant when we consider what will happen to the Banzhaf power of the initial weight, as it means that small changes in for a fixed produce stable changes in its power.
Our intuition is that determines the average swinging coalition size, where we call a coalition swinging iff it is winning but contains at least one player which can make it losing by leaving the coalition. A good example of this effect can be seen for the weights . Under these weights the power vector is always the same since all players have equal weight. However the underlying game changes with . When every player can win on its own, and the average swinging coalition size is (when there is a coalition of two or more, no single player can make it losing of leaving because the remaining players are sufficient for winning, hence it is not a swinging coalition). When every pair of players can win, and the average swinging coalition has size , and so on.
If determines the average size of the swinging coalitions, then the best value of should be . This is due to the fact that the number of possible coalitions of a given size out of behaves as a binomial distribution, with the largest number of possible coalitions occurring for . Having more coalitions to choose from is better because it gives a higher granularity in the Banzhaf vectors available, which should lead to a Banzhaf vector that is closer to . Because of the nature of the binomial distribution, we expect to behave symmetrically.
Another way to analyze the effect of is to look at its behavior for small numbers of players. In particular, when the number of players is three, we can visualize the Simplex in D. This is done in figure 1, for three different values of . Because we’re looking at the ordered Simplex, we only have to show the part of the regular simplex where the value (in these figures we show both weights and power) of the first player is not smaller than that of the second player, whose value is not smaller than the third player’s. The figures show how different weight vectors (points in the ordered simplex) map to the four available Banzhaf vectors for 3 players (the four different colors), for three values of (Figures a through c). Only four Banzhaf vectors are attainable in WVGs on three players: (red, at the top), (blue, on the left), (green, directly below red), and (yellow, directly below green).
As we can see in the figures, not all Banzhaf vectors are always represented by 2D planes or segments of the Simplex. When one Banzhaf vector maps to a line (a green line between the red and the yellow areas), while another (blue) maps to a point. When the first player has more weight than the quota of , the others must have less and thus he becomes a dictator. On the other hand, when he has less than the same holds for the other two and no-one can win without a second player. Thus only when the first player has weight exactly equal to can the other two vectors be reached. This is a challenge for any iterative algorithm, since they must potentially converge to a very small segment of the Simplex.
Also, from figure 1 we can see that the size of a segment of the Simplex that maps to a specific Banzhaf vector does not behave linearly for increasing . Starting at , the segment for first shrinks to a point towards , and then grows to be a plane again when .
The meaning of such a D segment for the algorithm can be explained by looking at the ratio calculation in step six. For any Banzhaf vector and the given target power distribution, the ratio is uniquely defined. In other words, when the algorithm considers weights , the update operation is uniquely defined by the Banzhaf vector that maps to. Where maps to is only controlled by parameter .
The particular challenge for the algorithm is that the update step is not always defined. When the Banzhaf power vector contains a (red or blue in figure 1) the ratio is also , and the algorithm cannot continue. Such Banzhaf vectors appear only at the edges of the Simplex.
The effect of on the algorithm is thus not easily predicted. On the one hand, the algorithm does not always preserve weights, and therefore is not restricted to exploring just the weight vectors in the Simplex. On the other hand, the size differences between Banzhaf segments and existence of segments that stop the algorithm poses challenges.
4.2 Expected effect of
The authors of the original algorithm select the target vector as initial weights (the weights in the th iteration) under the implicit assumption that this is a close guess to the final power distribution. However, we have seen in the previous section that this can lead to initial weights that produce a powerless player. This results in the algorithm dividing the weights by a zero ratio, and thus stopping after only one iteration. This may lead to poor approximation, and therefore this section attempts to find different guesses for to avoid this situation.
When considering choices for we may try the vertices of the ordered regular Simplex. However, all but one of the vertices contain at least one zero. The ‘outer’ vertices of the regular Simplex thus immediately lead to a zero in the Banzhaf vector. For the same reason we should avoid the edges and higher dimensional ‘sides’ of the regular Simplex. This leads us to the intuition that a good starting point is far from the edges.
The vertex of the ordered regular -Simplex without a zero power player has the form . This point is also the centroid of the regular Simplex. A centroid is a type of center, intuitively defined as the average of all vectors in the body, or alternatively as the center of its mass. The centroid of a general Simplex is computed as the normalized sum of its vertices ( through ):
This point seems to be a good candidate for , as it is the furthest from all sides. It is also the starting point used by the approximation algorithm of Fatima et al. [7]. However, it actually leads to the same situation as choosing the target vector, only one iteration later. The explanation for this is that when all weights are equal the Banzhaf vector is the same as the weights. Then the computation for , the weights in the first iteration, becomes (for each player):
However, we can still use the notion of centroid applied to the ordered Simplex. This point is also far from all sides, and furthermore appears to be in a region of the Simplex where there are many Banzhaf vectors. We base this intuition on the views of Kurz [9] on the location of Banzhaf vectors in the ordered Simplex. Starting close to many Banzhaf vectors is desirable, because then each iteration is likely to jump to a new Banzhaf vector which in turn results in a slightly different ratio. Changing the ratio often introduces variance in the direction of update which intuitively leads to better convergence.
The interior vertex can also be used in another way: We may manipulate the starting weight vector based on the target vector , so that it is less likely to start with a powerless player. Players are powerless when they only have a very small weight which in the Simplex means that some other players have a very large weight. We can smooth this initial weight distribution by averaging with the interior vertex, intuitively ‘pulling’ the target towards the center, away from the zero edges. This initial weight vector is computed as
Because the relative effect of these alternative starting points on the performance of the algorithm is hard to assess analytically, we evaluate them empirically. We consider three choices of in our evaluation.
-
1.
Target, the starting point used by Laruelle and Widgrén.
-
2.
Centroid, the center of mass of the ordered Simplex.
-
3.
Offset Target, the starting point halfway between the target and the centroid of the regular Simplex.
Each choice attempts to satisfy different conditions. Starting point is likely closest to the desired power. Starting point is in an area that is dense in Banzhaf vectors. Starting point attempts to combine both aspects.
4.3 Evaluation Metrics and Experimental Design
In this section we present the metrics used to evaluate the effect of various parameter combinations. Since the purpose of the algorithm is to find a Banzhaf vector that is closest to the input target vector it is natural to consider the distance between and the algorithm’s output, for some notion of distance. For our evaluation we use the concept of Manhattan or Taxicab distance , or . We chose this distance norm because it relates to the results in [9] on the lower bound on the distance between and , and because it is cheap to compute. Formally:
The maximum value of in the regular Simplex is , for example when comparing and . In the ordered regular -Simplex this maximum is , when comparing and .
In order to illustrate our evaluation metrics, Figure 2 presents an example of the distance between and a number of related Banzhaf vectors. In the figure, we consider the following Banzhaf vectors:
-
•
, an unknown optimal answer.
-
•
, a best known (closest) algorithm output found in a database of previously returned Banzhaf vectors.
-
•
, the algorithm output for certain parameter settings .
There may be more than one optimal answer, for example when for two players the target there exist two optimal Banzhaf vectors and , both at distance . Thus there can also be more than one best known Banzhaf vector, for example when both are present in the database. A given algorithm parameter setting always produces the same result since the algorithm is deterministic.
We thus propose two metrics of interest:
-
1.
The relative improvement obtained by using a parameter setting compared to ,
-
2.
The error in the output produced by a run of the algorithm defined as
The relative improvement tells us something about the usefulness of a specific parameter setting. In other words, it tells us how the algorithm should be used to get the best possible results. In figure 2 we can see that the point for lies inside the black diamond indicating . Thus, it is an improvement over . In the computation for improvement we do not compare the points directly, but rather the distance to , or the minimum Manhattan distance between and a point on the diamond for in figure 2.
The improvement can be computed exactly since it only uses the known vectors. We note that the improvement may be negative, for example in figure 2 this is the case for compared to . We consider an improvement to be significant if it exceeds .
The error tells us something about the general usefulness of the algorithm. The error is the minimum Manhattan distance between two points on the green and black diamonds in figure 2. Since we do not know the error must be estimated.
An upper bound on the error is . This corresponds to the distance between a point on the black diamond and in figure 2. This upper bound is tight, since it could be that , in which case .
A lower bound on the error is . In figure 2 it is the minimum Manhattan distance between any two points on the black and blue diamonds. This lower bound is also tight, since we may have stored the optimal answer in which case .
The upper bound is a biased estimate of the actual error, since it is in general not the case that . This is a consequence of the fact that Banzhaf vectors are discrete. Kurz proves in [9] that there exists a lower bound on the largest of , and conjectures that this bound is actually .
The bias of the lower bound depends on the bias that originates from our method of obtaining Banzhaf vectors. The quality of the lower bound further depends on the percentage of all Banzhaf vectors we have in our database. We generated Banzhaf vectors by running the algorithm on random samples and storing the vector computed in each iteration of the algorithm (step four) until the database remained constant for samples. For players this resulted in Banzhaf vectors, which compared to the weighted voting games that exists for players [6, 9] means that there exists at least vector for every games at this size.
The conjectured lower bound of on the largest distance between and can be used to determine the size of a significant error for the upper bound estimate. We say that the upper bound error of an algorithm (parameter setting) is significant if the average value of the error exceeds of , or . Further, we say a change in the error is significant if the difference exceeds of the maximum value of . Then a significant error for the lower bound estimate is at least of the maximum value of .
4.4 Experiments
For our experiments we need a number of target vectors to apply the algorithm on. Since a target vector is a vector in the simplex, we produce samples by drawing a vector uniformly at random from the -dimensional ordered regular Simplex. If function returns a value drawn uniformly at random from the interval , such a sample is constructed as:
The elements from the vector are then normalized so that the resulting vector sums to :
This results in a vector that is a random vector in the regular Simplex. To obtain a random vector in the ordered regular Simplex, the elements of the vector are sorted so that they are in descending order.
In order to evaluate empirically what choices of and produce the best results, we performed a number of experiments. For our experiments we drew samples from the ordered D Simplex. On each sample we applied the algorithm for all choices of initial weight vector discussed in Section 4.2, and for ranging from to in steps of . Each parameter combination was run for iterations.
Figures 3 present the relative improvement obtained by running the algorithm with varying values of compared to running the algorithm with for each . We expect to be the best setting, and that the effect of is symmetric. Thus we expect the relative improvement to be negative when , with equal magnitude on either side.
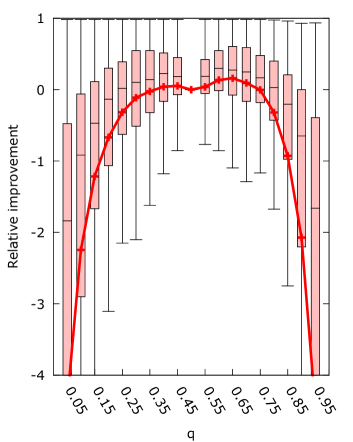
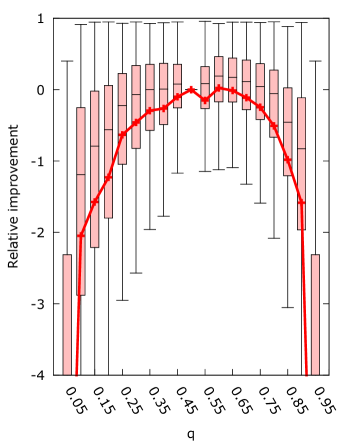
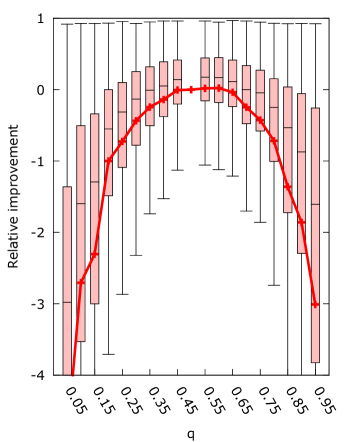
The figures show that the effect of on the mean improvement is generally symmetric. However, the algorithm does seem to perform better on values of , with the best mean performance occurring for for set to the target, and for the other choices of . This average improvement on is only significant for set to the target. The asymmetry in the results may be caused by the update rule of the algorithm. In step six, the weight is updated as . The ratio is independent of as it is computed from the normalized Banzhaf vector and the desired power. However the magnitude of the weights is dependent on since as becomes smaller an equal change in weights has a bigger relative effect.
Furthermore, choosing results in significant improvements for the majority of samples when is chosen to be within of for all . We expect that this is caused by the reduction in the area of the ordered Simplex that maps to the Banzhaf vector . When a weight vector maps to whenever the first player has weight of or higher. As increases this area shrinks because the first player must have a higher weight to surpass . Conversely, when decreases this area also shrinks because the other players need less weight to surpass themselves. We suspect this gives the algorithm more room to adjust the weights.
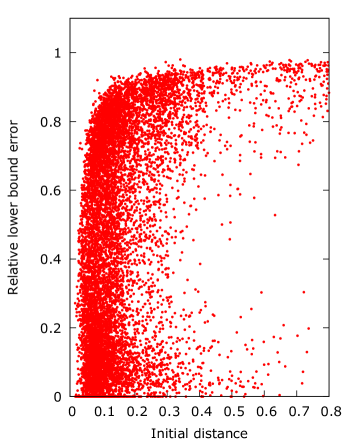
Figure 4 presents the effect of when . The y-axis shows the relative lower bound error, computed as the lower bound on the error divided by the initial distance , and the initial distance on the x-axis. This should show if there is a correlation between the error and the initial distance as produced by the choice of .
Table 1 presents the key features of the data in figure 4. The first column shows the method for selecting the initial weight vector for the algorithm. The second column shows the average initial distance to , and therefore the upper bound on the average initial error. The third column presents the worst case distance to after applying the algorithm, and thus the worst case error. Columns four and five present the average upper and lower bound error, where we note the average upper error is the average distance to after applying the algorithm.
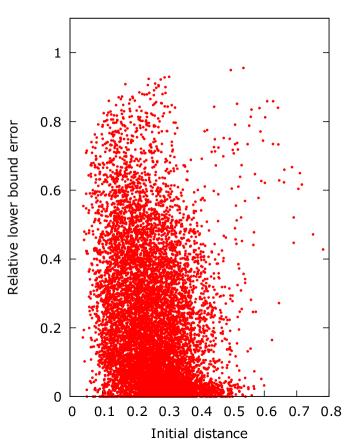
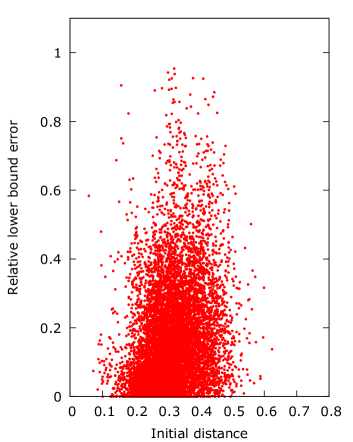
| Initial | Worst Error | Error Upper | Error Lower | |
|---|---|---|---|---|
| Target | ||||
| Centroid | ||||
| Offset |
The figures show how the initial distance is affected by the choice of , with set to the target having the smallest initial distance and offset having the largest. For set to either target or offset a higher initial distance generally results in a higher relative error, while for set to centroid the opposite appears to happen where the higher initial distances are improved more.
Another aspect of set to the target is that a large number of samples seem to be unimprovable, which is visible as a large number of samples with relative error near . This may be caused by samples starting in a segment with a power player, which therefore cannot be improved beyond their initial guess.
The consequence of these unimprovable samples is that set as offset or centroid gives a significant improvement in both the upper and lower bound error compared to as target. However, the total magnitude of the error is still significant in all cases. The difference between offset and centroid is not significant, but offset does produce the lowest worst case distance to , and it can thus be seen as the most robust. Overall we can conclude that starting close to the target is less important than starting in a position where the algorithm can improve the result.
Because a large portion of samples could not be improved when is set to the target vector, we want to examine how general this behavior is. For our second experiment we varied the number of iterations from to for and the three different choices of . We drew samples from the D Simplex and counted how often a sample ended in a Banzhaf vector with a zero power player for increasing number of iterations. This is a cumulative figure: when the algorithm stops on sample at iterations performing iterations will also stop the algorithm. Figure 5(a) contains the results, with the number of iterations set on a log scale. Additionally, figure 5(b) shows the mean relative improvement between iterations for this experiment, with the improvement also set on a log scale.
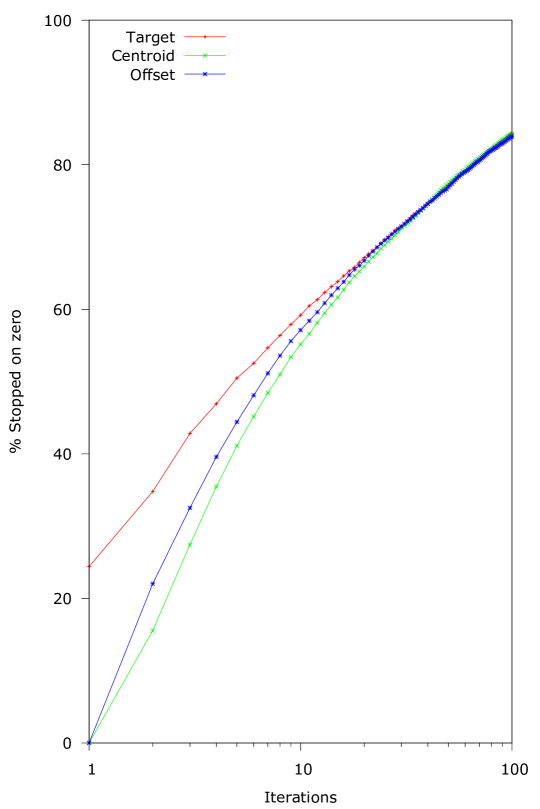
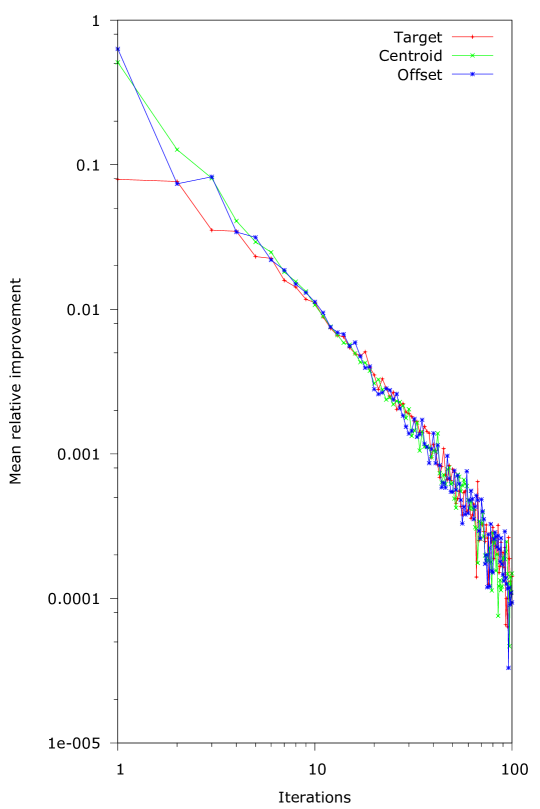
Figure 5(a) shows that the choice of only has a significant effect on the operation of the algorithm for the first iterations. At iterations the difference between starting at the target and starting in the centroid of the ordered simplex is still , but this drops to less than when the number of iterations is more than . We can also see that starting in the centroid of the ordered Simplex actually has the best chance of avoiding a zero power player initially. On the other hand, setting as target gives a chance to start with a zero power player, which results in an unimprovable first guess.
In general, it is obvious that the number of cases where the algorithm stops due to a in the Banzhaf vector grows with the number of iterations, going from more than at iterations to above for iterations. Further, the effect of an iteration is only significant for the first iterations. This means that generally the algorithm will not manage to converge to the target value, and it also suggests a possible area of improvement.
5 Improvements
In order to factor out the premature stop due to zeros in the Banzhaf vector we propose and evaluate three possible changes:
-
1.
Restarting the algorithm on different weights. By applying a different transformation to the weights when a player has power the algorithm can ‘restart’ on a new guess.
-
2.
Imposing a minimum coalition size. By enforcing a minimum coalition size powerless players in the original algorithm can become powerful by helping a coalition reach its size quota.
-
3.
Introducing a scaling factor in the coefficient computation. By enforcing a strictly positive value for powerless players in the ratio computation we can continue with the algorithm even when a player has no power.
The following sections describe these three improvements in more detail.
5.1 Multiple Start
As we have seen in figure 5(a), the algorithm 1 quickly encounters the situation where computing the ratio results in a divide by zero from a player with power in its Banzhaf vector. To continue with the algorithm at this point, we may try to find a different transformation to perform on the weights. The resulting new weights are in effect a second guess, leading to a restart with better initial weights. This procedure can then be repeated as often as we can make better guesses, resulting in the Multiple Start version of the algorithm.
The restart guess should be a transformation on the weights discovered during past iterations to make it meaningful. If the restart guess was not based off earlier results, it would be possible to simply apply the original algorithm to this better guess instead. It is also not useful to restart on a set of weights that has already been tried, since the algorithm is deterministic.
A promising place to start from is the set of weights that produced the best power distribution thus far. We propose to use the Offset Target procedure on this set of best weights to obtain a new set of weights halfway between the centroid of the regular simplex and the best weights, as shown in algorithm 2. Our motivation for this choice is threefold:
-
•
We know from the exploration of the Banzhaf vector locations that the majority is located near the center, and thus approaching our target from the center out gives the best chance of finding a closer vector to jump to.
-
•
In our initial experiments, the Offset Target heuristic provided good final results, with the best worst case error and a robust average case.
-
•
We can reason about its positive effect for some non-improvable samples. For example, consider the case when the first player has all the power because he has a weight . Then this operation brings his weight below . Because the first player had the most weight, this means that all weights are reduced to below and no player can be a dictator in the transformed sample.
We expect this version of the algorithm to never return a solution that is worse than the standard version for the same number of iterations, since it uses the standard version up until the first restart. Restarting may also provide a bigger benefit when the standard algorithm frequently cannot improve beyond the initial guess, which is for values of near , or . We know that in the limit all inputs tend to go to a power vector with a zero power player, but if the standard algorithm can perform many iterations, there may not be any room for further improvement by starting somewhere else. Thus we expect this algorithm is likely to produce the biggest improvement early on.
5.2 Minimum Coalition Size
Instead of recovering from a situation where a player has no power, we may try to manipulate the algorithm so that it will not produce weights where a player has no power. Laruelle and Widgrén evaluate the EU for different rules, and some of these rules have valuation functions that impose a minimum coalition size (for example, QM+ requires out of countries to vote in favor). One aspect of the minimum coalition size is that it gives power to players that normally would not have any.
To show that this is the case, assume a weight distribution where only . Even though player has all the power, if we impose minimum coalition sizes of and up, player 1 must form coalitions with others to win. In this way, the other players get some power. Note that for minimum coalition sizes smaller than the others still get less power than player , since only he is present in all of these coalitions. More generally, the number of possibly winning coalitions is without restrictions, or for an imposed minimum coalition size .
As a consequence, while this method can resolve cases where the Banzhaf vector would otherwise contain zeros, it also restricts the number of Banzhaf vectors available. For example, the vector has four winning coalitions . But the first coalition has size , so it would not be winning if minimum coalition size were set to .
Therefore, we expect that imposing minimum coalition sizes sometimes produces worse results than the standard algorithm. Furthermore, when the minimum coalition size increases, fewer Banzhaf vectors are available, resulting in larger errors. We can thus expect the ideal minimum coalition size to be relatively small.
5.3 Scaling Factor
Another way to work around the case where a player has no power is to always use a strictly positive update coefficient . We may introduce a scaling factor in both the numerator and denominator of the calculation, i.e. . This ensures that for the coefficient is still a positive real.
The secondary effect of this scaling factor is that the magnitude of adjustment is smaller, which leads to slower convergence. This may on its own also lead to better results, since it reduces the risk of overshooting the target vector. On the other hand, it will take more iterations to get to the desired value. Another risk is that the algorithm no longer manages to jump out of local minima.
Since the scaling factor changes the operation of the algorithm, the effect of this change is somewhat uncertain. We may expect better results when the standard algorithm stops in one iteration due to a zero power player. Its effect in general is more difficult to predict. We may need more iterations to get the same or better results as the standard version, if convergence is indeed slower. In other words, there is a possibility of returning worse results in general.
6 Evaluation
Since each suggested improvement has its own parameters, we should look at the effect of these parameters in isolation. To examine what relative improvement can be obtained, we drew samples from the ordered D Simplex and compared the result with that of the standard algorithm, with parameters , set to target, and run for iterations. For the restart improvement we increased the number of iterations performed from through . For the minimum coalition improvement we varied the minimum coalition size from through . And finally, for the scaling improvement we varied the scaling factor from through . Other parameters set equal to the standard version. The results can be seen in figure 6.
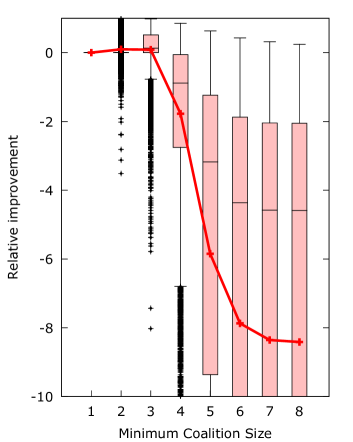
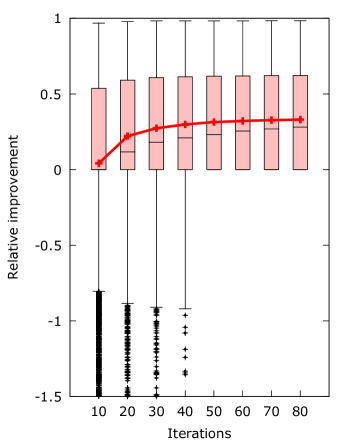
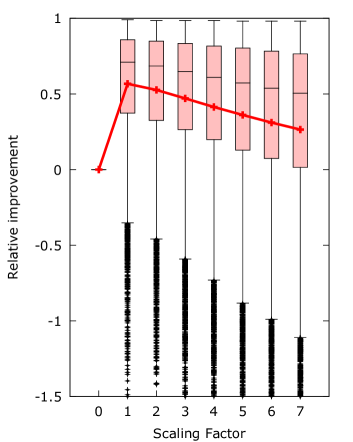
The results show that indeed not all improvements are universal improvements. Both minimum coalition and scaling have samples that have worse distance than the base algorithm. The restart algorithm also needs at least the same amount of iterations to obtain a universal improvement.
Minimum coalition has the largest fluctuation in performance, going from significant improvement at and to almost always producing worse results at and higher. This confirms our prediction that the imposed minimum coalition size should be kept small.
Restarting shows very significant improvements (more than in the mean) when the number of iterations is or higher. This means that the restart version can typically be used with fewer iterations than the base version of the algorithm, which can be important if runtime is a consideration.
The size of the scaling factor does seem to have a large impact on the quality of improvement, but even for the factor set to the algorithm shows very significant improvement. Improvement for and exceeds . It may be that the high factors obtain the same quality results when the algorithm is given more iterations, but in general it is better to use a small scaling factor.
A second experiment to look at the improvement compared to the input parameter was performed to determine how the new algorithms compare to the original for sensible parameter settings. We again varied from to and applied all the algorithms on new D samples. Each algorithm was allowed iterations, minimum coalition size was set to and the scaling factor was set to for the respective algorithms. Figure 7 presents the results.
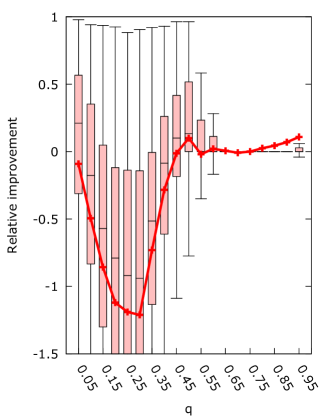
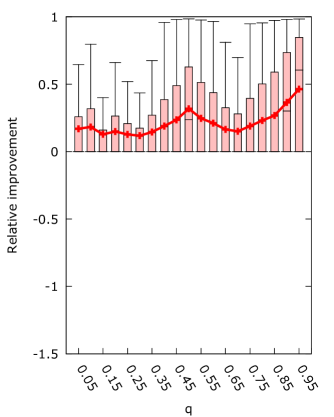
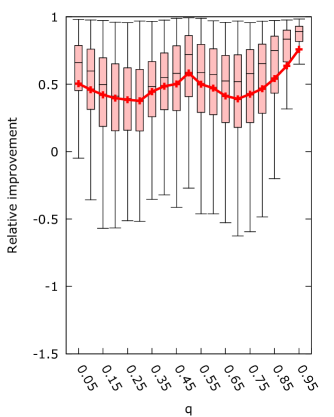
From figure 7 it is immediately clear that a scaling factor is the superior improvement, giving the best mean improvement for the entire range of . We can also see that the general asymmetry of the algorithm with respect to the choice of is maintained, with lower behaving worse than higher for all algorithms. Interestingly, all algorithms show a peak in improvement when , supporting our intuition that it is the ideal selection of . For scaling, setting actually produced the best absolute results. However, all algorithms actually make the best improvement for very high . This does not have much practical use, since the original algorithm performs very poorly for such high .
We see further confirmation of the effect of on average coalition sizes when looking at the results of minimum coalition. There, results are strongly negative for low , while almost no samples are affected for high . This can be explained by considering that for these low the average coalition size is smaller than the minimum imposed coalition size, while for high almost no set of weights produces a game with coalitions of size .
In order to be able to say something about the improvement of the proposed additions with respect to the error we performed an experiment with tuned parameters for each. Every algorithm was run on samples of D Simplex, with parameters set to produce the best results: iterations, except for scaling which performed better for , set to centroid, minimum coalition size , scaling factor . Table 2 contains the results. The first column shows the algorithm under consideration. The second column details how many of the samples were improved compared to the base, while the third contains the amount of samples that were made worse. Column four shows how often an addition produced strictly the best result compared to all the others, including the base version. The fifth column presents the average distance to the target vector. Column six displays the average distance to the best known power vector. The last row of the table shows what the results would be like if we could always pick the best algorithm for a sample.
| Algorithm | % Improved | % Worse | % Best | Error upper | Error lower |
|---|---|---|---|---|---|
| Base | - | - | - | ||
| Coalition | |||||
| Restart | |||||
| Scaling | |||||
| Sum/Best | - | - |
In column four we can see that in of the samples, one of the improvements produced a game that was closest to . For most samples scaling produced the closest result, however all three improvements have samples they performed best on. The base algorithm never produced a game closest to since restarting was given the same number of iterations as the base version, which means it always produced at least the same output. However we can see in column three that both coalition and scaling do produce output that is worse than the base version in more than of the samples.
The table shows that all additions reduce the error on average, however the magnitude of improvement can only be considered significant for scaling. Additionally, for scaling the upper bound on the error is below , and the lower bound is below of the maximum , which is for players. Therefore we can say that the error made by scaling is not significant in size. Compared to the base algorithm with ideal parameters, introducing a scaling factor improves the lower bound performance by a factor .
The other approaches have their own strengths, as restarting does not make the result worse, and minimum coalition actually returns the best result more often than restarting does. In a sense the approaches can be seen to complement each other. If we always take the best result, the improvement compared with scaling is still another in the lower bound which indicates it could be worthwhile to find a new version of the algorithm that combines the effect of the three approaches in some way.
7 Conclusion and Future Work
The algorithm by Laruelle and Widgrén works quite well in most cases, but it has some major shortcomings. Our proposals remove the possibility of the algorithm getting stuck in a case where one or more zeroes are in the weight vector, and experiments show that our scaling factor algorithm also improve the average approximation performance. However, in some cases it performs worse than the original algorithm. Our multiple start proposal performs at least as well as the original algorithm, but improves the solution not nearly as much as the scaling factor algorithm. Further work could be done to find an algorithm that improves on these proposals: either by giving a better worst-case performance or by improving the average case approximation, or both.
Our experiments also show that the algorithm is not anytime: an iteration often improves the solution, but it could also deteriorate. Our improvements do not counter that, other than storing the best found solution. This is also something that could be researched in the future.
References
- [1] H. Aziz, M. Paterson, and D. Leech. Efficient algorithm for designing weighted voting games. In Multitopic Conference, 2007. INMIC 2007. IEEE International, pages 1 –6, dec. 2007.
- [2] John F. Banzhaf. Weighted voting doesn’t work: A mathematical analysis. Rutgers Law Review, 19(2):317– 343, 1965.
- [3] J. Bilbao, J. Fernández, A. Losada, and J. López. Generating functions for computing power indices efficiently. TOP: An Official Journal of the Spanish Society of Statistics and Operations Research, 8(2):191–213, December 2000.
- [4] Bart de Keijzer. A survey on the computation of power indices, and related topics. Technical report, Faculty of EEMCS, Delft University of Technology, 2008.
- [5] Bart de Keijzer, Tomas Klos, and Yingqian Zhang. Enumeration and exact design of weighted voting games. In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems: volume 1 - Volume 1, AAMAS ’10, pages 391–398, Richland, SC, 2010. International Foundation for Autonomous Agents and Multiagent Systems.
- [6] Bart de Keijzer, Tomas Klos, and Yingqian Zhang. Solving weighted voting game design problems optimally: Representations, synthesis, and enumeration. http://arxiv.org/abs/1204.5213, 2012.
- [7] Shaheen Fatima, Michael Wooldridge, and Nicholas R. Jennings. An anytime approximation method for the inverse Shapley value problem. In Proceedings of the 7th international joint conference on Autonomous agents and multiagent systems - Volume 2, AAMAS ’08, pages 935–942, Richland, SC, 2008. International Foundation for Autonomous Agents and Multiagent Systems.
- [8] S.S. Fatima, M. Wooldridge, and N.R. Jennings. A linear approximation method for the Shapley value. Artificial Intelligence, 172(14):1673–1699, 2008.
- [9] Sascha Kurz. On the inverse power index problem. Optimization, 0(0):1–23, 2011.
- [10] Annick Laruelle and Mika Widgrén. Is the allocation of voting power among EU states fair? Public Choice, 94:317–339, 1998. 10.1023/A:1004965310450.
- [11] K. Prasad and J. S. Kelly. NP-completeness of some problems concerning voting games. International Journal of Game Theory, 19(1):1–9, 1990.
- [12] L. S. Shapley and M. Shubik. A method for evaluating the distribution of power in a committee system. American Political Science Review, 48(3):787–792, 1954.
- [13] Michael Zuckerman, Piotr Faliszewski, Yoram Bachrach, and Edith Elkind. Manipulating the quota in weighted voting games. In Proceedings of the 23rd national conference on Artificial intelligence - Volume 1, AAAI’08, pages 215–220. AAAI Press, 2008.