Evaluation of creating scoring opportunities for teammates in soccer via trajectory prediction
Abstract
Evaluating the individual movements for teammates in soccer players is crucial for assessing teamwork, scouting, and fan engagement. It has been said that players in a 90-min game do not have the ball for about 87 minutes on average. However, it has remained difficult to evaluate an attacking player without receiving the ball, and to reveal how movement contributes to the creation of scoring opportunities for teammates. In this paper, we evaluate players who create off-ball scoring opportunities by comparing actual movements with the reference movements generated via trajectory prediction. First, we predict the trajectories of players using a graph variational recurrent neural network that can accurately model the relationship between players and predict the long-term trajectory. Next, based on the difference in the modified off-ball evaluation index between the actual and the predicted trajectory as a reference, we evaluate how the actual movement contributes to scoring opportunity compared to the predicted movement. For verification, we examined the relationship with the annual salary, the goals, and the rating in the game by experts for all games of a team in a professional soccer league in a year. The results show that the annual salary and the proposed indicator correlated significantly, which could not be explained by the existing indicators and goals. Our results suggest the effectiveness of the proposed method as an indicator for a player without the ball to create a scoring chance for teammates.
Keywords:
multi-agent deep learning trajectory sports football1 Introduction
Assessing the movements of individual players for teammates in team sports is an important aspect of building teamwork, assessment of players’ salaries, player recruitment, and scouting. In soccer, most analytics has focused on the outcomes of discrete events near the ball (on-ball) [34, 12, 39, 40, 3, 10, 33, 32] whereas much of the importance in player movements exist in the events without the ball (off-ball). For example, it is said that players in a 90-min game do not have the ball for about 87 minutes on average [15]. However, continuous off-ball movements are usually not discretized and difficult to understand except for core fans, experienced players, and coaches. Also for the media and building fan engagement, quantitative evaluation of off-ball players is an issue in demand, which provides a common reference for beginners and experts in the sport e.g., when arguing a play of a favorite player.
Regarding the off-ball player evaluation methods, the positioning itself related to the goal was evaluated from the location data of all players and the ball. For example, the method called off-ball scoring opportunity (OBSO) to evaluate the player who receives the ball [45] and the method to evaluate the movement to create space [15] have been proposed. However, it has been still difficult to clarify how movements contribute to the creation of scoring opportunities for teammates, to evaluate other attacking players who do not receive it (e.g., a player moving tactically for teammates), and often to evaluate a score prediction to reflect the position of the multiple defenders.
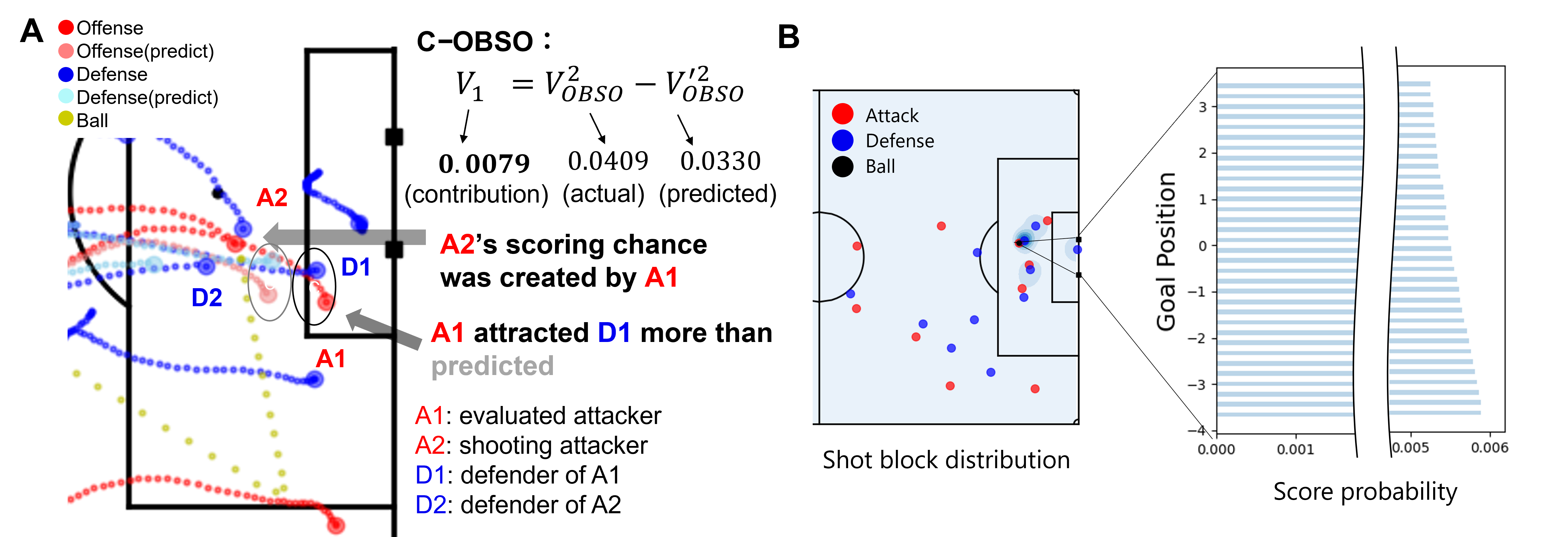
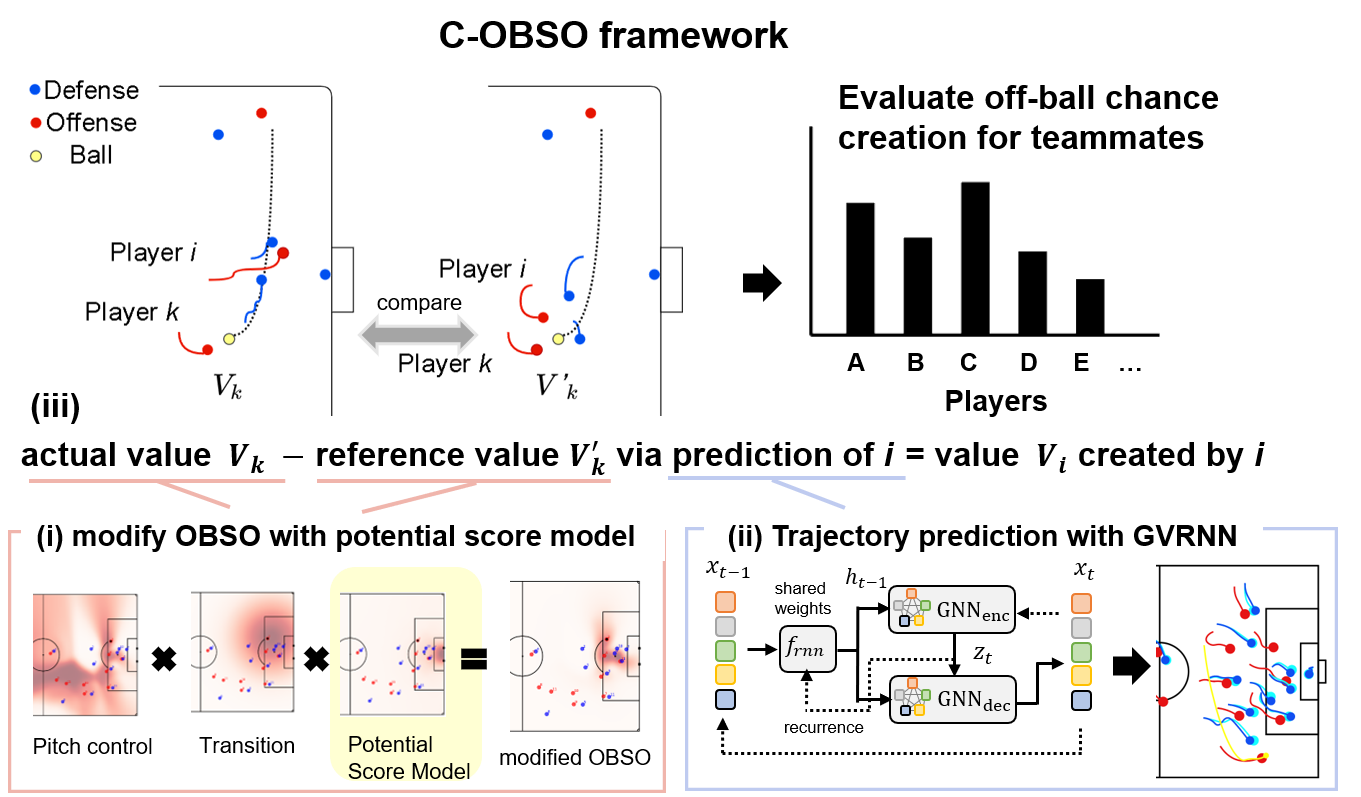
In this paper, we propose a new evaluation indicator, Creating Off-Ball Scoring Opportunity (C-OBSO in Fig. 1A), aiming for evaluating players who create scoring opportunities when the attacking player is without the ball. The overview of our method is shown in Fig. 6. (i) First, we modify the score model in the framework of OBSO [45] with the potential score model that reflects the positions of multiple defenders with a mixed Gaussian distribution (Fig. 1B). (ii) Next, we accurately model the relationship between athletes and perform long-term trajectory predictions (Fig. 1A) using the graph variational recurrent neural network (GVRNN) [51]. (iii) Finally, based on the difference in the modified off-ball evaluation index between the actual and the predicted trajectory (Fig. 1A), we evaluate how the actual movement contributes to scoring opportunity relative to the predicted movement as a reference.
In summary, our main contributions were as follows. (1) We proposed an evaluation method of how movements contributed to the creation of scoring opportunities compared to the predicted movements of off-ball players in team sports attacks. (2) As a score predictor, we proposed a potential score model that considers the positions of multiple defenders in a mixed Gaussian distribution. (3) In the experiment, we analyzed the relationship between the annual salary, the goals, and the game rating by experts, and show the effectiveness of the proposed method as an indicator for an off-ball player to create scoring opportunities for teammates. Our approach can evaluate continuous movements of players by comparing with the reference (here predicted) movements, which are difficult to be discretized or labeled but crucial for teamwork, scouting, and fan engagement. The structure of this paper is as follows. First, we overview the related works in Section 4 and present experimental results in Section 3. Next, we describe our methods in Section 2 and conclude this paper in Section 5.
2 Proposed framework
Here, we propose C-OBSO based on the motivation to evaluate players who create off-ball scoring opportunities for teammates. To this end, in Section 2.1, we first propose a potential score model that reflects the positions of multiple defenders with a mixed Gaussian distribution. Next, in Section 2.2, we predict multi-agent trajectory using GVRNN [51] and evaluate the difference between the actual value of the modified OBSO and the predicted value (as a reference) to evaluate how the movement contributed to the creation of scoring opportunities.
2.1 Potential score model in modified OBSO
First, we describe the base model of our evaluation method called OBSO [45] and then propose the potential score model. OBSO evaluates off-ball players by computing the following joint probability
| (1) | ||||
| (2) |
where is the instantaneous state of the game (e.g., player positions and velocities). The details in OBSO are given in Appendix 0.B. is the probability of scoring from an arbitrary point on the pitch, assuming the next on-ball event occurs there. is the probability that the passing team will control a ball at point . is the probability that the next on-ball event occurs at point . Here, for simplicity, we can assume that are independent if the parameter in the original work implementation (Eq. (6) in [45]). Then, the joint probability can be decomposed into a series of conditional probabilities as follows:
| (3) |
is the probability that the attacking team will control the ball at point assuming the next on-ball event occurs there, which is called the potential pitch control field (PPCF). is defined as a two-dimensional Gaussian distribution with the current ball coordinates as the mean. is simply calculated as a value that decreases with the distance from the goal. We used the grid data and computed and based on the code at https://github.com/Friends-of-Tracking-Data-FoTD/LaurieOnTracking.
In the original OBSO [45], the scoring probability was calculated as the output of the score model as a function of the distance from the goal. However, the scoring probability may depend on the angle to the goal and the defensive position of the opponent. Therefore, in this paper, we propose a score model that reflects the angle to the goal and the position of multiple defenders. Here, we consider the shot-blocking distribution of the defenders who can block shots in the field, and propose a potential model where the scoring probability decreases when defenders exist. The basic idea shown in Fig. 1B is to calculate the scoring probability from the angle to the goal at which the shot tends to be scored, considering the mixed distribution of the positions of multiple defenders. The proposed scoring probability at a certain point is calculated as the sum of the shot value as follows:
| (4) | ||||
| (5) |
where is determined by the angle from the shooting position to the goal, and is a shot vector per degree ( is larger when the shot from the center and smaller from the side). The shot value is calculated by subtracting the shot block value from a certain constant ( are parameters determined from data to be adjusted so that and ). Let be the sum of the shot block distribution values along the shot vector . The shot blocking distribution is the sum of the normal distributions (variance ) assigned to each defender on the goal side of the shooting position (shot blockable players using legs), where is the distance between the shooting position and the defender. We consider that goalkeepers have a shot blocking distribution with twice the value of normal defenders because of a higher shot-blocking ability. Here, we assume that the block distribution is not changed with the distance from the ball. A defender near to the ball may affect the ball, but far players use the flight time of the ball for their movement. This formulation is left for future work.
2.2 C-OBSO with trajectory prediction
Here, we describe the base model of our trajectory prediction method called GVRNN [51] and then describe our C-OBSO framework. Our contribution here is to evaluate how the actual “off-ball” movement contributes to scoring opportunity compared to the predicted movement (or trajectory) as a reference. In our method, we use GVRNN [51], which is a VRNN [9] combined with a graph neural network (GNN [26]). For the details in VRNN and GVRNN, see Appendices 0.C and 0.D. In GVRNN, the graph encoder-decoder network models the relationship between players as a graph, which is one of the best performing models for predicting player trajectories in team sports [51]. This is a probabilistic model which can sample multiple possible trajectories.
Based on the trajectory prediction, we propose an evaluation index C-OBSO of players who create scoring opportunities for teammates. The basic idea is to evaluate an off-ball player from the difference in the modified OBSO values between the predicted and actual movements of the players. The C-OBSO value of a player without the ball can be expressed as follows.
| (6) |
where the player is the ball carrier who performs a final action (e.g., shot), is the modified OBSO in the actual game situation, and is the modified OBSO based on the predicted trajectory as a reference. For example, in Fig. 1A, C-OBSO is positive and the player to be evaluated (A1) contributes more to the shooter (A2) than the referenced (predicted) player. Specifically, A1 has created a more advantageous situation for A2 by attracting D1 more than expected. C-OBSO can evaluate a player in such situations with an interpretable value (i.e., the increase in scoring probability). Theoretically, if perfectly predicted, C-OBSO is always zero, but actually, if we apply this to a test data, the perfect prediction is impossible. In other words, we assume the imperfect trajectory prediction in this framework.
3 Experiments
In this section, we validate the proposed method of the potential score model, the trajectory prediction model (GVRNN), and the C-OBSO itself. For our implementation, the code is available at https://github.com/keisuke198619/C-OBSO.
3.1 Dataset
In this study, we used all 34 games data of Yokohama F Marinos in the Meiji J1 League 2019 season to perform specific player-level evaluations in limited data. Note that the tracking data for all players and timesteps were not publicly shared in such amounts. The dataset includes event data (i.e., labels of actions, e.g., passing and shooting, recorded at 30 Hz and the simultaneous xy coordinates of the ball) and tracking data (i.e., xy coordinates of all players recorded at 25 Hz) provided by Data Stadium Inc. The company was licensed to acquire this data and sell it to third parties, and it was guaranteed that the use of the data would not infringe on any rights of the players or teams. For annual salaries, we used the salaries of the same team (Yokohama) in 2019 [44] because they were different valuation criteria for different teams and the transfer of the players took place during the season. The goals for each player in each match were collected from [23]. The rating by experts in each match [43] was also used for verification, which was scored in 0.5 point increments with a maximum of 10 points.
3.2 Data processing for verification
We used the attacking data of Yokohama F Marinos for the test and those of the opponent teams for training the model or parameter fitting. Again, since the data was limited in this study, we split the data in such a way, and if we have more data, we can analyze all teams with the training data with the same team. Here we describe the processing of the potential score model, the trajectory prediction model, the C-OBSO, and their statistical analyses.
3.2.1 Potential score model.
To validate the potential score model, the opponent’s shots (345 shots, 34 goals) were used for fitting the parameters and , and Yokohama F Marinos’ shots (494 shots, 59 goals) were used for verification. The parameters of the potential score model were determined to be using the data of the opponents. The potential score model was verified by the root mean square error (RMSE) between the actual score and the calculated scoring probability. We compared the RMSE with that of a simple score model as a function of distance from the goal for implementing the original OBSO [45] (see also Section 2.1). Although there have been more holistic score models such as [16, 1], to fairly compare with our potential model as a component of the modified OBSO, we consider the simple score model as an appropriate baseline.
3.2.2 Trajectory prediction model.
For the test data of trajectory prediction and C-OBSO, we used 412 shot scenes of Yokohama F Marinos (we selected the sequences of consecutive events and excluded too short events such as a free kick). The trajectory prediction model was trained using the opponents’ data to generate “league average” trajectories. The tracking data were down-sampled to 10 Hz (after prediction, up-sampled at the original 25 Hz) based on [19]. To verify the accuracy of the long-term trajectory prediction, we set various time lengths (6, 8, 10, and 12 s) using mean trajectories in 10 samples. We divided into the opponent data for batch training (6 s: 94208 sequences, 8 s: 49152 sequences, 10 s: 33536 sequences, 12 s: 24320 sequences) and the validation (6 s: 10477 sequences, 8 s: 5479 sequences, 10 s: 3730 sequences, 12 s: 2721 sequences). Note that the end of all sequences was the moment of a shot. The input feature has 92 dimensions (the xy coordinates and the velocity of 22 players and the ball). During training, the model was trained based on the one-step prediction error of all combinations of the two attackers who invaded the attacking third. We simultaneously predicted the three players: one of the off-ball attackers and the defenders closest to each attacker. Note that we only consider the three players’ interactions and ignore others’ interactions, because the prediction error will increase if the numbers increase, and the increase of the predicted players is left for future work.
For the test data of the 412 sequences, the three relevant players and the attacker from the same criterion were predicted. At the inference, using 2 s sequences as burn-in period, we predicted the sequences for the subsequent time lengths (i.e., 4, 6, 8, and 10 s) by updating the estimated position and velocity (i.e., performed long-term prediction). For the training of the proposed and baseline models, we used the Adam optimizer [24] with a learning rate of and training epochs. We set the batchsize to 256. For the performance metrics, we used the endpoint error (mean absolute error: MAE) from the actual trajectory.
3.2.3 C-OBSO.
To compute C-OBSO, predicted trajectories with 4 s (total 6 s) were used. This is because a longer prediction time will result in a larger prediction error, while a shorter prediction time will not make a difference in the evaluation of C-OBSO. Although the negative values of C-OBSO are also calculated by comparison with the reference, the negative values were calculated as 0, assuming that they may not have a negative effect on the behavioral players. This is because there were many situations with negative values in which the shooter’s defender did not take an appropriate defensive position in the predicted trajectory.
3.2.4 Statistical analysis.
For the verification of C-OBSO, we examined the relationship with the annual salary, the goals, and the expert’s rating. Note that there is no ground truth available for the verification. We also compared them with the existing OBSO [45]. Since some of the data often did not follow normal distributions, we used Spearman’s rank correlation coefficient for these relationships. Regarding the RMSE in the potential score model and MAE in the trajectory prediction, for the same reason, we used nonparametric statistical tests to compare with the baselines. Regarding the potential score model, we used the Wilcoxon rank sum test. For all statistical calculations, was considered as significant.
3.3 Our model verification
First, we validated the potential score model needed to calculate the C-OBSO. The RMSE with the actual scores was 0.324 0.014 for the conventional score model [45] without considering the defenders and goal angles, and 0.309 0.0014 for the potential score model (). This result suggests that the proposed method models the scores more accurately.
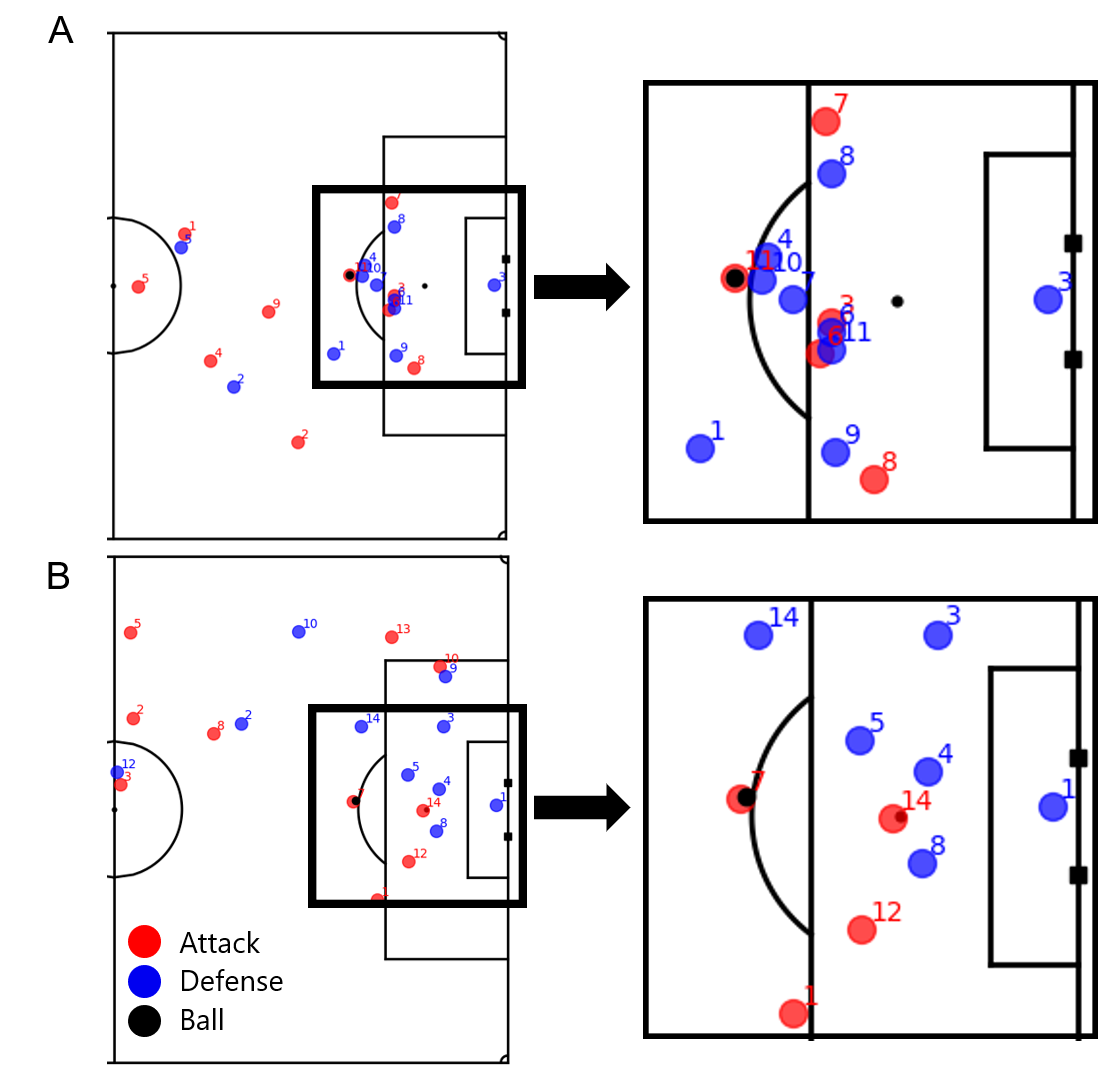
Figure 2 shows an example of the two methods in two actual situations where a shot is attempted from a similar distance. In the existing method, the probabilities were the same (both 0.1237) because the shots were taken from almost the same distance. The proposed method had a lower scoring probability with more defenders (upper: 0.0489, lower: 0.1202). We indicate that the proposed method reflects the position of multiple defenders and can model the score accurately.
Next, we show the results of the trajectory prediction model for computing C-OBSO. Endpoint errors (MAE and standard error, [m]) in GVRNN were in 4, 6, 8, 10 s prediction. In GVRNN, longer predictions show larger prediction errors except for the difference between 8 s and 10 s. Since the 4 s prediction of GVRNN achieved a low the MAE of less than 0.7 m, the GVRNN trajectory prediction of 4 s was used in the next C-OBSO. For details, see also Appendix 0.E.
3.4 C-OBSO results
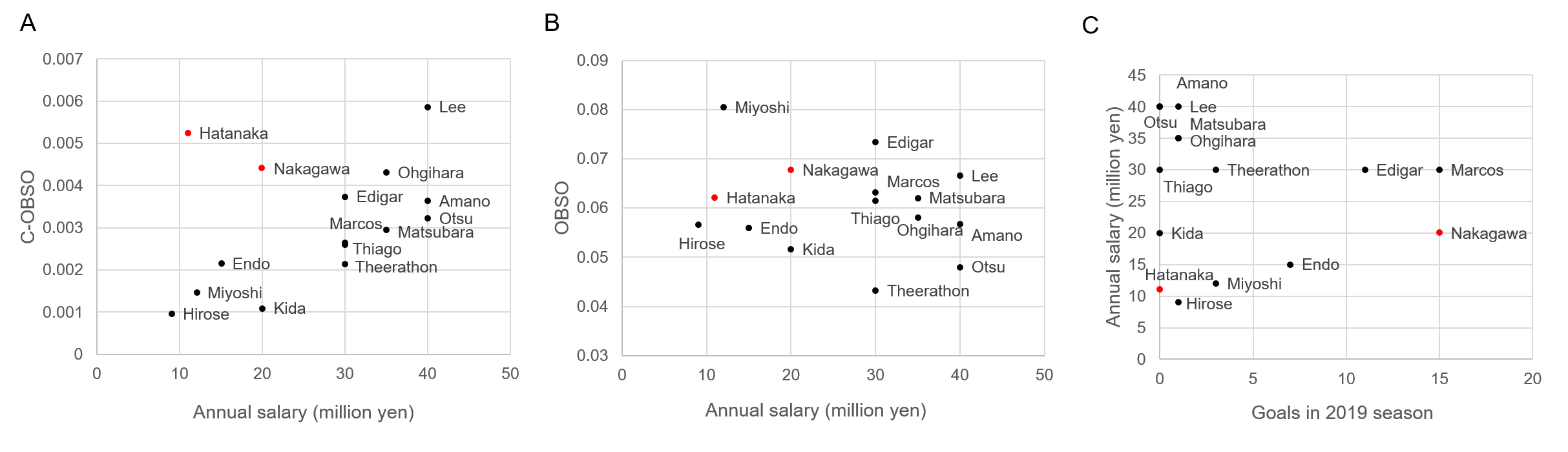
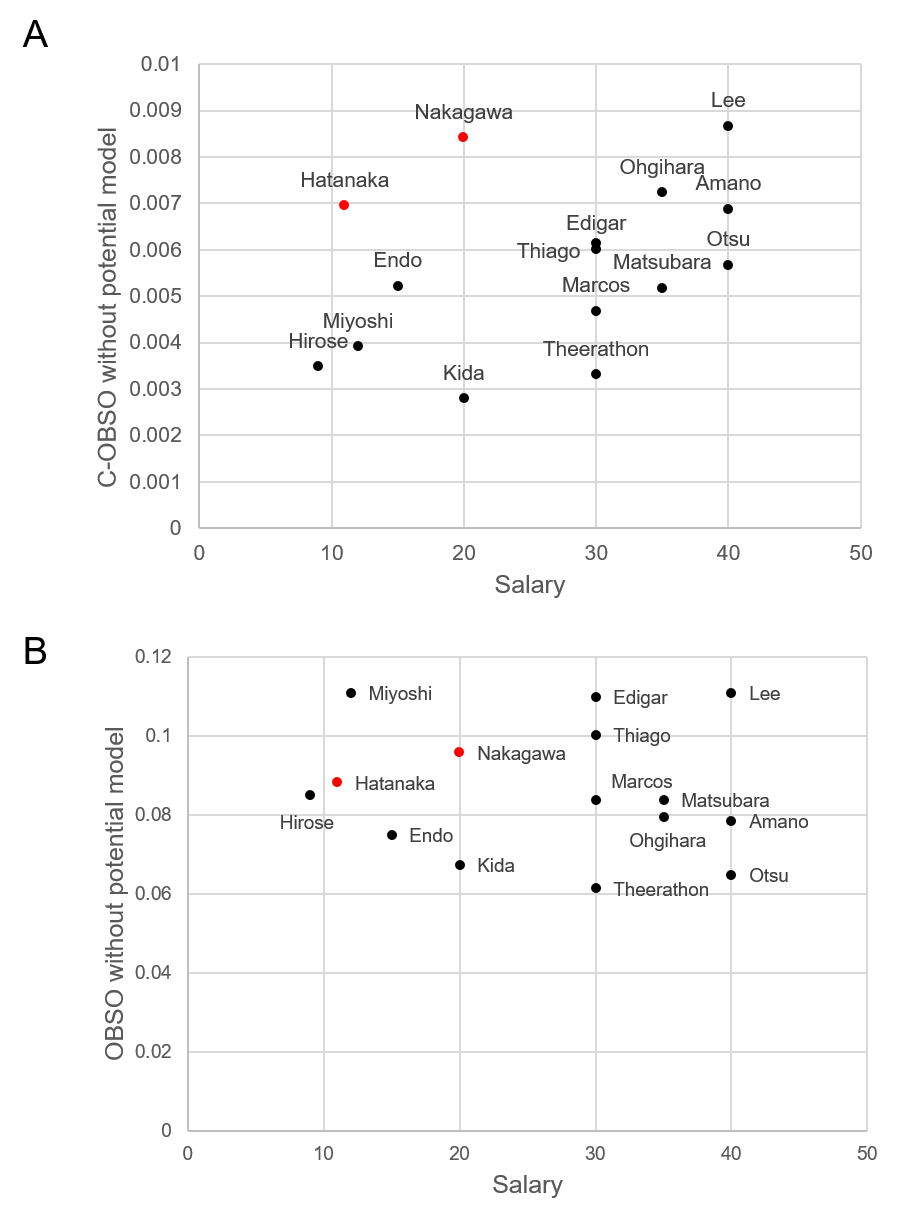
Verification of C-OBSO is challenging because of no ground truth values or player ratings. Therefore, we analyzed the relationship with the annual salary, the goals, and the game rating by experts, whereas we admit that these variables include various confounding factors. The relationships between the average C-OBSO and OBSO values of each player of Yokohama F Marinos in 2019 and the annual salary of each player in 2019 are shown in Fig. 3 (note that the tracking data for all players and timesteps were not publicly shared). Here we analyzed 15 players with more than 10 sequences under evaluation. As a result, there was a significant positive correlation between annual salary and C-OBSO (). In addition, the two players with the higher evaluation values but lower salaries (in red in Fig. 3A) were highly evaluated players, who won the individual awards (the most valuable player and valuable player award). In fact, their annual salary for the following year (2020) was also increased (valuable player: increased from 11 million yen to 40 million yen; the most valuable player: increased from 20 million yen to 60 million yen).
We found that these tendencies were similar to the C-OBSO and OBSO without the potential score model (see Appendix 0.F). On the other hand, there was no significant correlation () for OBSO, which evaluates a player’s own scoring opportunities (Fig. 3B). We also examined the relationship between annual salary and goals (Fig. 3C), and found no significant correlation (). Therefore, there was no relationship between annual salary and goals. There were many players with zero goals, and it is difficult to evaluate them only with the goals.
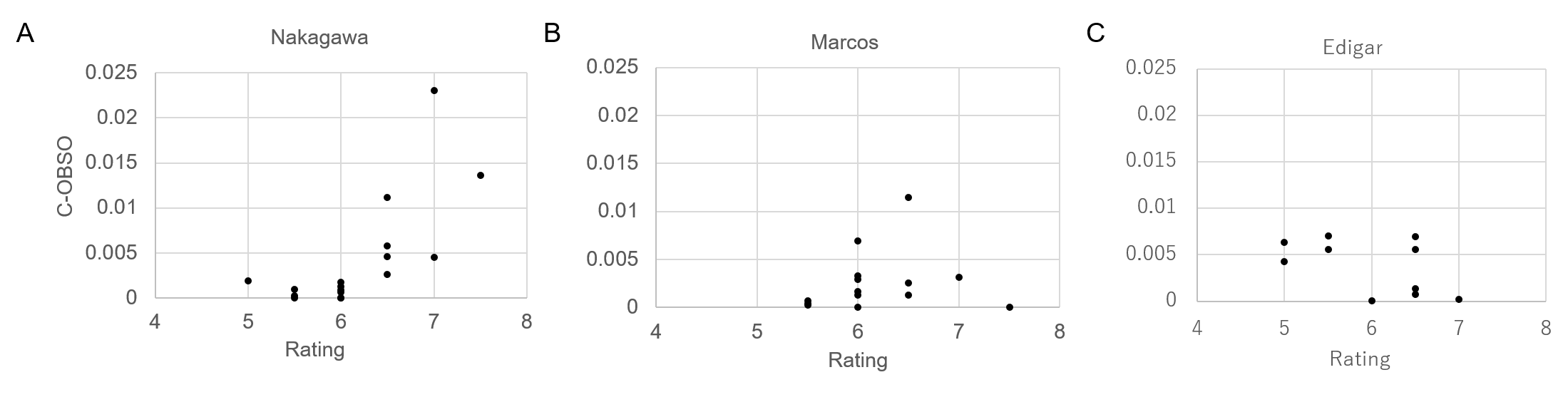
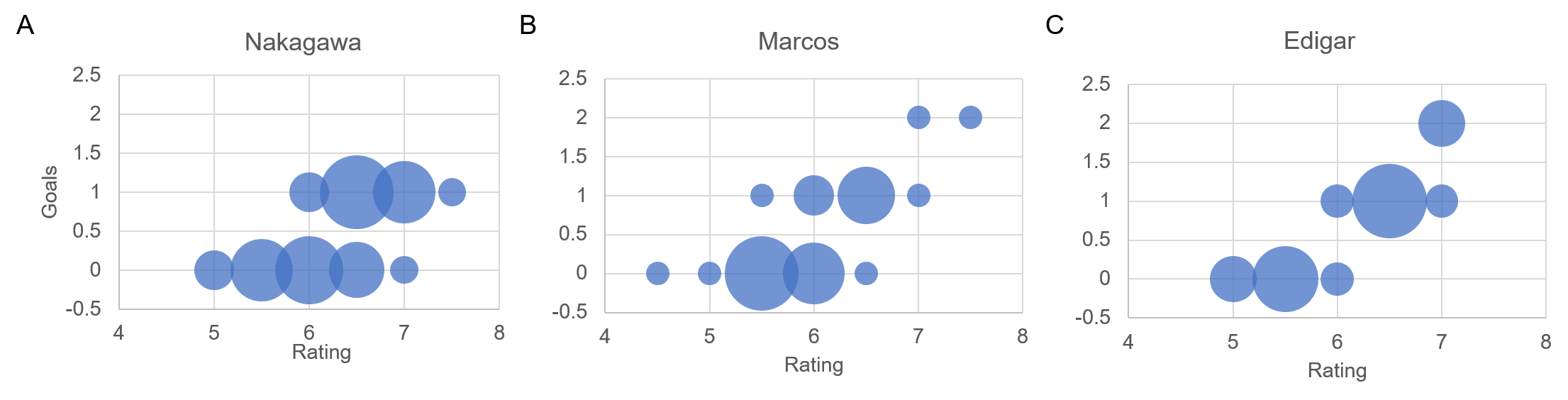
Next, in order to examine the relationship with player performance in more detail, we show the relationship between C-OBSO and the rating by experts of the top three scorers (Nakagawa with 15 goals, Marcos with 15 goals, and Edigar with 11 goals in this season) in Fig. 4. We analyzed the games in which there were two or more C-OBSO evaluations using the average of C-OBSO values on each game (17 games for Nakagawa, 14 games for Marcos, and 10 games for Edigar). A strong positive correlation was found only for Nakagawa () but not for Marcos () and Edigar (). In Appendix 0.G, we show the results of the other four players who played seven games or more and had two related scoring opportunities or more (for C-OBSO). Similarly, there were no significant correlations between them for all players (). In addition to the number of scoring opportunities for teammates (17 times), the results found that Nakagawa would be subjectively and quantitatively an outstanding player.
For reference, we also show the relationship between the goals of the top three scorers and the ratings by experts in Fig. 5. We analyzed the games in which each player played (33 games for Nakagawa, 33 for Marcos, and 16 for Edigar). For each player, there were strong correlations between the goals and the rating (Nakagawa , Marcos , Edigar ). We found that the rating of each game depends on a rare event (i.e., goals). In Appendix 0.G, we show the results of the other four players who scored two points or more. Similarly, there were significant correlations between them for all players (). Recall that there was a stronger correlation between C-OBSO and Nakagawa’s rating than for the other two players. Nakagawa also had higher average ratings than the other players (6.26 for Nakagawa, 5.97 for Marcos, and 6.09 for Edigar), and he was the player who won the most valuable player award. The game rating by experts would depend on the goals, but it may also evaluate the creation of scoring opportunities only for Nakagawa. From these results, we speculate that Nakagawa was highly evaluated not only for his scoring but also for his contribution to other attacking players. Our method can also evaluate players difficult to be evaluated by conventional indicators, which is crucial for assessing teamwork and player salary, player recruitment, and scouting.
4 Related work
In the tactical behaviors of team sports, agents select an action that follows a policy (or strategy) in a state, receives a reward from the environment and others, and updates the state [18]. This is similar to a reinforcement learning framework (e.g., [Bernstein02]). Due to the difficulty in modeling the entire framework from data for various reasons [49] (e.g., a sparse reward and difficulty in estimating intents), we can adopt two approaches: to estimate the related variables and functions from data (i.e., inverse approach) as a sub-problem, and to build a model (e.g., reinforcement learning model) to generate data in virtual space (i.e., forward approach, e.g., [27, 41]). Here, we focus on the former approach and introduce the research from the view of inverse approaches.
There have been many approaches to quantitatively evaluate the actions of attacking players about the scoring, such as based on the expected scores using tracking data [34, 12, 39, 40, 3], action data such as dribbling and passing [10, 14], and estimating state-action value function (Q-function) [50, 33, 32]. Some researchers have evaluated passes [36, 4, 13], and others evaluated actions to receive a ball by assigning a value to the location with the highest expected score [45, 31] and a rule-based manner [21]. In particular, Spearman [45] proposed an evaluation metric called OBSO to evaluate behavior based on location data and rule-based modeling. Defensive behaviors have also been evaluated based on data-driven [38, 48] and rule-based manners (e.g., [47]). However, these score evaluations do not often reflect the position of multiple defenders and goal angles in rule-based manner.
From the perspective of reinforcement learning, there have been many studies on inverse approaches. As for the study of state evaluation, there are several studies based on score expectation (e.g., [6, 7, 16]) and based on the value of space (e.g., [5, 15]). There is also research on estimating reward functions by inverse reinforcement learning [35, 37]. Researchers performed trajectory prediction sometimes in terms of the policy function estimation, as imitation learning [29, 28, 47, 19] and behavioral modeling [53, 51, 30, 20] to mimic (not optimize) the policy using neural network approaches. In this paper, we first propose a method to evaluate how the actual “off-ball” movement contributes to scoring opportunity based on the difference between the state values generated from the actual and the reference policies.
5 Conclusion
In this paper, we evaluated players who create off-ball scoring opportunities by comparing actual movements with the reference movements generated by trajectory prediction. Our results suggest the effectiveness of the proposed method as an indicator for a player without the ball to create scoring opportunities for teammates. For future work, although the number of players to be evaluated was determined in the minimum setting, it is possible to evaluate the contribution to the scoring opportunities for teammates in a less limited way by predicting a larger number of players in both offense and defense. Furthermore, since our method evaluates off-ball players by comparing them with the referenced trajectory, the value becomes too small. Computing the evaluation value in a more interpretable way (e.g., in a score scale) would be future work. Finally, computing our indicators from broadcast videos (e.g., [11]) or other videos (e.g., top- or side-view [42]) would also be future work.
Acknowledgments
This work was supported by JSPS KAKENHI (Grant Numbers 20H04075 and 21H05300) and JST Presto (Grant Number JPMJPR20CA).
References
- [1] Anzer, G., Bauer, P.: A goal scoring probability model for shots based on synchronized positional and event data in football (soccer). Frontiers in Sports and Active Living 3, 53 (2021)
- [2] Becker, S., Hug, R., Hübner, W., Arens, M.: Red: A simple but effective baseline predictor for the trajnet benchmark. In: European Conference on Computer Vision. pp. 138–153. Springer (2018)
- [3] Bransen, L., Van Haaren, J.: Measuring football players’ on-the-ball contributions from passes during games. In: International workshop on machine learning and data mining for sports analytics. pp. 3–15. Springer (2018)
- [4] Brooks, J., Kerr, M., Guttag, J.: Developing a data-driven player ranking in soccer using predictive model weights. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 49–55 (2016)
- [5] Cervone, D., Bornn, L., Goldsberry, K.: Nba court realty. In: 10th MIT Sloan Sports Analytics Conference (2016)
- [6] Cervone, D., D’Amour, A., Bornn, L., Goldsberry, K.: Pointwise: Predicting points and valuing decisions in real time with nba optical tracking data. In: Proceedings of the 8th MIT Sloan Sports Analytics Conference, Boston, MA, USA. vol. 28, p. 3 (2014)
- [7] Cervone, D., D’Amour, A., Bornn, L., Goldsberry, K.: A multiresolution stochastic process model for predicting basketball possession outcomes. Journal of the American Statistical Association 111(514), 585–599 (2016)
- [8] Cho, K., Van Merriënboer, B., Bahdanau, D., Bengio, Y.: On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259 (2014)
- [9] Chung, J., Kastner, K., Dinh, L., Goel, K., Courville, A.C., Bengio, Y.: A recurrent latent variable model for sequential data. Advances in neural information processing systems 28, 2980–2988 (2015)
- [10] Decroos, T., Bransen, L., Van Haaren, J., Davis, J.: Actions speak louder than goals: Valuing player actions in soccer. In: KDD. pp. 1851–1861 (2019)
- [11] Deliege, A., Cioppa, A., Giancola, S., Seikavandi, M.J., Dueholm, J.V., Nasrollahi, K., Ghanem, B., Moeslund, T.B., Van Droogenbroeck, M.: Soccernet-v2: A dataset and benchmarks for holistic understanding of broadcast soccer videos. In: 7th International Workshop on Computer Vision in Sports (CVsports) at IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’ 21). pp. 4508–4519 (2021)
- [12] Decroos, T., Dzyuba, V., Van Haaren, J., Davis, J.: Predicting soccer highlights from spatio-temporal match event streams. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 31 (2017)
- [13] Dick, U., Link, D., Brefeld, U.: Who can receive the pass? a computational model for quantifying availability in soccer. Data Mining and Knowledge Discovery 36(3), 987–1014 (2022)
- [14] Dick, U., Tavakol, M., Brefeld, U.: Rating player actions in soccer. Frontiers in Sports and Active Living p. 174 (2021)
- [15] Fernandez, J., Bornn, L.: Wide open spaces: A statistical technique for measuring space creation in professional soccer. In: 12th MIT sloan sports analytics conference (2018)
- [16] Fernández, J., Bornn, L., Cervone, D.: Decomposing the immeasurable sport: A deep learning expected possession value framework for soccer. In: 13th MIT Sloan Sports Analytics Conference (2019)
- [17] Fraccaro, M., Sønderby, S.K., Paquet, U., Winther, O.: Sequential neural models with stochastic layers. In: Advances in Neural Information Processing Systems 29. pp. 2199–2207 (2016)
- [18] Fujii, K.: Data-driven analysis for understanding team sports behaviors. Journal of Robotics and Mechatronics 33(3), 505–514 (2021)
- [19] Fujii, K., Takeishi, N., Kawahara, Y., Takeda, K.: Policy learning with partial observation and mechanical constraints for multi-person modeling. arXiv preprint arXiv:2007.03155 (2020)
- [20] Fujii, K., Takeuchi, K., Kuribayashi, A., Takeishi, N., Kawahara, Y., Takeda, K.: Estimating counterfactual treatment outcomes over time in complex multi-agent scenarios. arXiv preprint arXiv:2206.01900 (2022)
- [21] Fujii, K., Yoshihara, Y., Matsumoto, Y., Tose, K., Takeuchi, H., Isobe, M., Mizuta, H., Maniwa, D., Okamura, T., Murai, T., et al.: Cognition and interpersonal coordination of patients with schizophrenia who have sports habits. PLoS One 15(11), e0241863 (2020)
- [22] Goyal, A.G.A.P., Sordoni, A., Côté, M.A., Ke, N.R., Bengio, Y.: Z-forcing: Training stochastic recurrent networks. In: Advances in Neural Information Processing Systems 30. pp. 6713–6723 (2017)
- [23] JLEAGUE: Jleague.jp 2019 data (2019), https://www.jleague.jp/stats/2019/goal.html
- [24] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: International Conference on Learning Representations (2015)
- [25] Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: International Conference on Learning Representations (2014)
- [26] Kipf, T., Fetaya, E., Wang, K.C., Welling, M., Zemel, R.: Neural relational inference for interacting systems. In: International Conference on Machine Learning. pp. 2688–2697 (2018)
- [27] Kurach, K., Raichuk, A., Stańczyk, P., Zając, M., Bachem, O., Espeholt, L., Riquelme, C., Vincent, D., Michalski, M., Bousquet, O., et al.: Google research football: A novel reinforcement learning environment. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 4501–4510 (2020)
- [28] Le, H.M., Carr, P., Yue, Y., Lucey, P.: Data-driven ghosting using deep imitation learning. In: Proceedings of MIT Sloan Sports Analytics Conference (2017)
- [29] Le, H.M., Yue, Y., Carr, P., Lucey, P.: Coordinated multi-agent imitation learning. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70. pp. 1995–2003. JMLR. org (2017)
- [30] Li, L., Yao, J., Wenliang, L., He, T., Xiao, T., Yan, J., Wipf, D., Zhang, Z.: Grin: Generative relation and intention network for multi-agent trajectory prediction. Advances in Neural Information Processing Systems 34 (2021)
- [31] Link, D., Lang, S., Seidenschwarz, P.: Real time quantification of dangerousity in football using spatiotemporal tracking data. PloS one 11(12), e0168768 (2016)
- [32] Liu, G., Luo, Y., Schulte, O., Kharrat, T.: Deep soccer analytics: learning an action-value function for evaluating soccer players. Data Mining and Knowledge Discovery 34(5), 1531–1559 (2020)
- [33] Liu, G., Schulte, O.: Deep reinforcement learning in ice hockey for context-aware player evaluation. arXiv preprint arXiv:1805.11088 (2018)
- [34] Lucey, P., Bialkowski, A., Monfort, M., Carr, P., Matthews, I.: quality vs quantity: Improved shot prediction in soccer using strategic features from spatiotemporal data. In: Proceedings of MIT Sloan Sports Analytics Conference. pp. 1–9 (2014)
- [35] Luo, Y., Schulte, O., Poupart, P.: Inverse reinforcement learning for team sports: Valuing actions and players. In: Bessiere, C. (ed.) Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20. pp. 3356–3363. International Joint Conferences on Artificial Intelligence Organization (7 2020)
- [36] Power, P., Ruiz, H., Wei, X., Lucey, P.: Not all passes are created equal: Objectively measuring the risk and reward of passes in soccer from tracking data. In: KDD. pp. 1605–1613 (2017)
- [37] Rahimian, P., Toka, L.: Inferring the strategy of offensive and defensive play in soccer with inverse reinforcement learning. In: Machine Learning and Data Mining for Sports Analytics (MLSA 2018) in ECML-PKDD Workshop (2020)
- [38] Robberechts, P.: Valuing the art of pressing. In: Proceedings of the StatsBomb Innovation In Football Conference. pp. 1–11. StatsBomb (2019)
- [39] Routley, K., Schulte, O.: A markov game model for valuing player actions in ice hockey. In: Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence. p. 782–791. UAI’15, AUAI Press, Arlington, Virginia, USA (2015)
- [40] Schulte, O., Khademi, M., Gholami, S., Zhao, Z., Javan, M., Desaulniers, P.: A markov game model for valuing actions, locations, and team performance in ice hockey. Data Mining and Knowledge Discovery 31(6), 1735–1757 (2017)
- [41] Scott, A., Fujii, K., Onishi, M.: How does AI play football? An analysis of RL and real-world football strategies. In: 14th International Conference on Agents and Artificial Intelligence (ICAART’ 22). vol. 1, pp. 42–52 (2022)
- [42] Scott, A., Uchida, I., Onishi, M., Kameda, Y., Fukui, K., Fujii, K.: Soccertrack: A dataset and tracking algorithm for soccer with fish-eye and drone videos. In: 8th International Workshop on Computer Vision in Sports (CVsports) at IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’ 22). pp. 3569–3579 (2022)
- [43] Soccer-digest: Soccer digest web j1 rating (2019), https://www.soccerdigestweb.com
- [44] Soccer-Money.net: Soccer-money.net (2019), https://www.soccer-money.net
- [45] Spearman, W.: Beyond expected goals. In: Proceedings of the 12th MIT sloan sports analytics conference. pp. 1–17 (2018)
- [46] Spearman, W., Basye, A., Dick, G., Hotovy, R., Pop, P.: Physics-based modeling of pass probabilities in soccer. In: Proceeding of the 11th MIT Sloan Sports Analytics Conference (2017)
- [47] Teranishi, M., Fujii, K., Takeda, K.: Trajectory prediction with imitation learning reflecting defensive evaluation in team sports. In: 2020 IEEE 9th Global Conference on Consumer Electronics (GCCE). pp. 124–125. IEEE (2020)
- [48] Toda, K., Teranishi, M., Kushiro, K., Fujii, K.: Evaluation of soccer team defense based on prediction models of ball recovery and being attacked. PLoS One 17(1), e0263051 (2022)
- [49] Van Roy, M., Robberechts, P., Yang, W.C., De Raedt, L., Davis, J.: Learning a markov model for evaluating soccer decision making. In: Reinforcement Learning for Real Life (RL4RealLife) Workshop at ICML 2021 (2021)
- [50] Wang, J., Fox, I., Skaza, J., Linck, N., Singh, S., Wiens, J.: The advantage of doubling: a deep reinforcement learning approach to studying the double team in the nba. arXiv preprint arXiv:1803.02940 (2018)
- [51] Yeh, R.A., Schwing, A.G., Huang, J., Murphy, K.: Diverse generation for multi-agent sports games. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
- [52] Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R.R., Smola, A.J.: Deep sets. Advances in Neural Information Processing Systems 30 (2017)
- [53] Zhan, E., Zheng, S., Yue, Y., Sha, L., Lucey, P.: Generating multi-agent trajectories using programmatic weak supervision. In: International Conference on Learning Representations (2019)
Appendix
Appendix 0.A Overview of our method
The overview of our method is shown in the Fig. 6. (i) First, we modify the score model in the framework of OBSO [45] with the potential score model that reflects the positions of multiple defenders with a mixed Gaussian distribution (Fig. 1B). (ii) Next, we accurately model the relationship between athletes and perform long-term trajectory predictions (Fig. 1A) using the graph variational recurrent neural network (GVRNN) [51]. (iii) Finally, based on the difference in the modified off-ball evaluation index between the actual and the predicted trajectory (Fig. 1A), we evaluate how the actual movement contributes to scoring opportunity relative to the predicted movement as a reference.
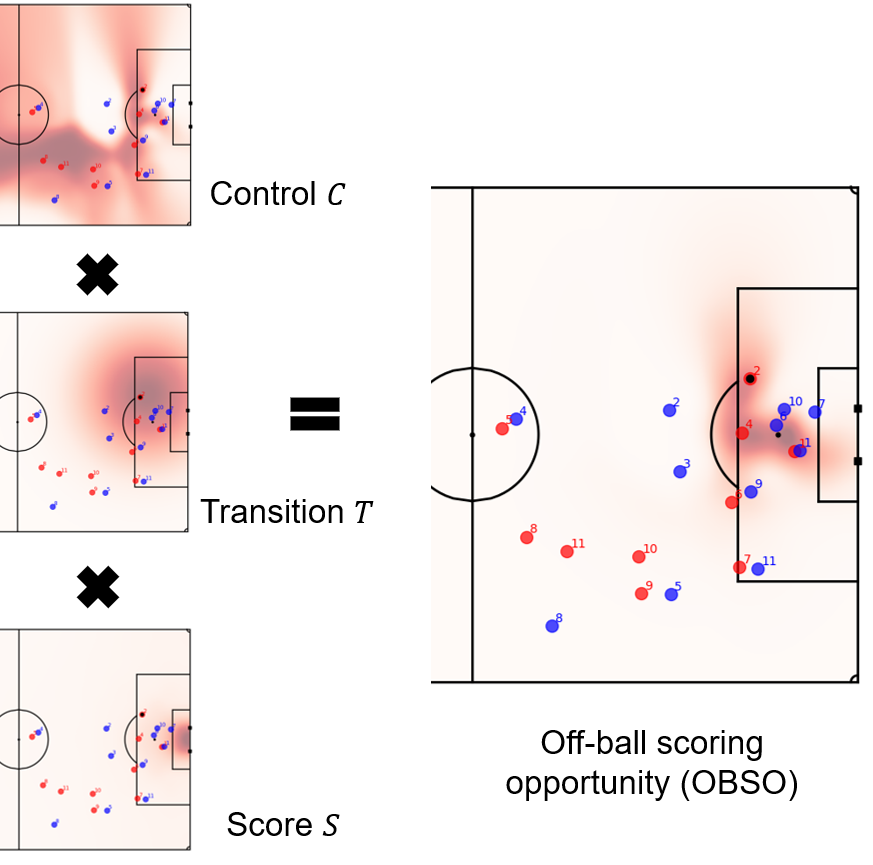
Appendix 0.B Off-ball scoring opportunity [45]
Here, we describe the base model of our evaluation method called OBSO [45]. OBSO evaluates off-ball players by computing the following joint probability
| (7) | ||||
| (8) |
where is the instantaneous state of the game (e.g., player positions and velocities). is the probability of scoring from an arbitrary point on the pitch, assuming the next on-ball event occurs there. is the probability that the passing team will control a ball at point . is the probability that the next on-ball event occurs at point . Here, for simplicity, we can assume that are independent if the parameter in the original work implementation (Eq. (6) in [45]). Then, the joint probability can be decomposed into a series of conditional probabilities as follows:
| (9) |
We show the illustrative example of OBSO in Fig 7. is the probability that the attacking team will control the ball at point assuming the next on-ball event occurs there, which is called the potential pitch control field (PPCF). is defined as a two-dimensional Gaussian distribution with the current ball coordinates as the mean. The standard deviation is set to 14 m, which is the average distance of the next event [45]. is simply calculated as a value that decreases with the distance from the goal. We used the grid data and computed and based on the code at https://github.com/Friends-of-Tracking-Data-FoTD/LaurieOnTracking.
Although and are simple functions, we need to explain (PPCF) in more detail. PPCF [45] (a previous version is [46]) assumes that a player’s ability to make a controlled touch on the ball (when near the ball) can be treated as a Poisson point process. That is, the longer a player is near the ball without another player interfering, the more likely it becomes that they can make a controlled touch on the ball. The model quantifies the probability of control for each player at each location on the pitch. The differential equation used to compute the control probability for each player at a specified location at time is:
| (10) |
where represents the probability that player at time can reach location within time . The parameter is the temporal uncertainty of player-ball intercept time (has units of ), which is used in (we set based on [46]). The parameter is the rate of control representing the inverse of the mean time (has units of ) which would take a player to make a controlled touch on the ball. Conceptually, we consider the probability that player will be able to control the ball during time to with the decay rate . We set for the attacking or defending team if the opponent team can arrive significantly before the attacking or defending team. By integrating Eq. (10) over from to , we obtain a per-player probability of control. We integrate it over the players of the attacking team. is represented as a logistic function such that
| (11) |
where is a expected intercept time computed from the location and velocity of the player (including other constants, see [45] for the details). Conceptually, if , the player will tend to intercept the ball and a temporal uncertainty is assumed. For the control rate parameter , higher values of mean less time is required before the player can control the ball. We set based on [46].
Appendix 0.C Variational recurrent neural network [9]
In this section, we briefly overview recurrent neural networks (RNNs), variational autoencoders (VAEs), and variational RNNs (VRNNs).
From the perspective of a probabilistic generative model, an RNN models the conditional probabilities with a hidden state that summarizes the past history in the first timesteps:
| (12) |
where maps the hidden state to a probability distribution over states and is a deterministic function such as LSTMs or GRUs. RNNs with simple output distributions often struggle to capture highly variable and structured sequential data. Recent work in sequential generative models addresses this issue by injecting stochastic latent variables into the model and using amortized variational inference to infer latent variables from data. VRNNs [9] is one of the methods using this idea and combining RNNs and VAEs.
VAE [25] is a generative model for non-sequential data that injects latent variables into the joint distribution and introduces an inference network parameterized by to approximate the posterior . The learning objective is to maximize the evidence lower-bound (ELBO) of the log-likelihood with respect to the model parameters and :
| (13) |
The first term is known as the reconstruction term and can be approximated with Monte Carlo sampling. The second term is the Kullback-Leibler divergence between the approximate posterior and the prior, and can be evaluated analytically if both distributions are Gaussian with diagonal covariance. The inference model , generative model , and prior are often implemented with neural networks.
VRNNs combine VAEs and RNNs by conditioning the VAE on a hidden state :
| (prior) | (14) | ||||
| (inference) | (15) | ||||
| (generation) | (16) | ||||
| (recurrence) | (17) |
VRNNs are also trained by maximizing the ELBO, which can be interpreted as the sum of VAE ELBOs over each timestep of the sequence:
| (18) | ||||
Note that the prior distribution of latent variable depends on the history of states and latent variables (Eq. (14)).
Appendix 0.D Graph variational recurrent neural network [51]
Here, we briefly describe VRNN, GNN, and GVRNN.
In general, RNNs with simple output distributions often struggle to capture highly variable and structured sequential data (e.g., multimodal behaviors) [53]. Recent work in sequential generative models addressed this issue by injecting stochastic latent variables into the model and optimization using amortized variational inference to learn the latent variables (e.g., [9, 17, 22]). Among these methods, a variational RNN (VRNN) [9] has been widely used in base models for multi-agent trajectories [51, 53, 19] with unknown governing equations. A VRNN is essentially a variational autoencoder (VAE) conditioned on the hidden state of an RNN and is trained by maximizing the (sequential) evidence lower-bound (ELBO), described in Appendix A.
Next, we overview a graph neural network (GNN) based on [26]. Let be a feature vector for each node of agents. Next, a feature vector for each edge is computed based on the nodes to which it is connected. The edge feature vectors are sent as “messages” to each of the connected nodes to compute their new output state . Formally, a single round of message passing operations of a graph net is characterized below:
| (19) | ||||
| (20) |
where is the set of neighbors of node , and and are neural networks. In summary, a GNN takes in feature vectors and outputs a vector for each node , i.e., . The operations of the GNN satisfy the permutation equivariance property as the edge construction is symmetric between pairs of nodes and the summation operator ignores the ordering of the edges [52].
Next, we describe GVRNN [51], which models the interactions between them at each step using GNNs. Let denote a sequence of locations. In this paper, GVRNN update equations are as follows:
| (21) | ||||
| (22) | ||||
| (23) | ||||
| (24) |
where and are deterministic and stochastic latent variables. , , and are generative model, the approximate posterior or inference model, and the prior model, respectively. denotes a multivariate normal distribution with mean and covariance matrix diag(), and
| (25) | ||||
| (26) | ||||
| (27) |
The prior network , encoder , and decoder are GNNs with learnable parameters and . Here we used the mean value as input variables in the following theory-based computation. GVRNN is trained by maximizing the sequential ELBO in a similar way to VRNN as described in Appendix 0.C.
Appendix 0.E Validation results of trajectory prediction model
To verify the accuracy of the trajectory prediction model, We compared our approach with two baselines: VRNN [9] and RNN (RNNGauss) implemented using a gated recurrent unit (GRU) [8] and a decoder with Gaussian distribution for prediction [2].
For the MAE in the trajectory, to compare the various methods and time lengths, we first performed the Kruskal-Wallis test. As the post-hoc comparison, since we are interested in the differences from GVRNN (VRNN and RNN for four time lengths) and time lengths in GVRNN (4 and 6, 6 and 8, and 8 and 10 s), we performed the Wilcoxon rank sum test with Bonferroni correction such that the p-value was multiplied by 11 ().
We show the results of the trajectory prediction model for computing C-OBSO. The endpoint errors (MAE) of the three players are shown in Table 1. In the statistical evaluation, there were significant differences in all classification performance and tasks () using the Kruskal-Wallis test. In the following evaluations, we indicate the post-hoc comparison results. The trajectory prediction model used in C-OBSO (GVRNN) shows a lower prediction error than other models ().
In GVRNN, longer predictions show larger prediction errors () except for the difference between 8 s and 10 s (). Note that we verified the existing GVRNN [51] performance, which uses a centralized optimization whereas VRNN and RNNGauss use the decentralized optimization (for each player). Since the 4 s prediction of GVRNN achieved a low the MAE of less than 0.7 m, the GVRNN trajectory prediction of 4 s was used in the next C-OBSO.
| 4 s | 6 s | 8 s | 10 s | |
| GVRNN | 0.608 0.014 | 0.867 0.022 | 1.701 0.045 | 1.606 0.042 |
| VRNN | 5.952 0.118 | 7.767 0.160 | 9.127 0.188 | 10.168 0.225 |
| RNN+Gauss | 9.101 0.144 | 11.396 0.202 | 13.312 0.245 | 15.327 0.302 |
Appendix 0.F C-OBSO and OBSO results without the potential score model
To investigate the effect of the potential model on the C-OBSO and OBSO computations, we also computed C-OBSO and OBSO results without the potential score model. Results shown in Fig. 8 were similar to those with the potential model, but there were no significant correlations between the C-OBSO and salary () and between the OBSO and salary ().
Appendix 0.G Relationship between rating, C-OBSO, and goal
We additionally analyzed the relationship between the game rating by experts, C-OBSO, and the number of goals. First, we show the relationship between C-OBSO and the rating by experts of the top seven scorers in Table 2. We analyzed seven players who played seven games or more and had two related scoring opportunities or more (for C-OBSO). There were no significant correlations between them for all players () except for Nakagawa.
Next, we also show the relationship between the goals of the top seven scorers and the ratings by experts in Table 3. We analyzed the games in which each player scored two points or more. There were significant correlations between them for all players ().
| Name | Position | No. of games | Rating | C-OBSO | ||
| Nakagawa | FW | 17 | 6.18 0.64 | 0.0043 0.00624 | 0.751 | 0.0003 |
| Marcos | FW | 14 | 6.05 0.60 | 0.0032 0.00324 | 0.272 | 0.1738 |
| Edigar | FW | 10 | 6.00 0.71 | 0.0038 0.00291 | -0.371 | 0.1454 |
| Endo | MF | 7 | 5.86 0.56 | 0.0020 0.00248 | -0.418 | 0.1751 |
| Amano | MF | 7 | 5.86 0.38 | 0.0086 0.00617 | -0.116 | 0.4024 |
| Ohgihara | MF | 7 | 6.00 0.29 | 0.0123 0.01073 | -0.134 | 0.3876 |
| Matsubara | DF | 7 | 6.14 0.63 | 0.0079 0.01335 | 0.189 | 0.3426 |
| Name | Position | No. of games | No. of goals | Rating | ||
| Nakagawa | FW | 33 | 15 | 6.33 0.79 | 0.630 | 4.33E-05 |
| Marcos | FW | 33 | 15 | 6.09 0.92 | 0.709 | 1.98E-06 |
| Edigar | FW | 16 | 11 | 6.14 0.75 | 0.912 | 4.40E-07 |
| Erik | FW | 12 | 8 | 6.13 0.77 | 0.599 | 1.97E-02 |
| Endo | MF | 29 | 7 | 5.88 0.61 | 0.613 | 2.03E-04 |
| Theerathon | DF | 25 | 3 | 5.88 0.62 | 0.517 | 4.09E-03 |
| Miyoshi | MF | 16 | 3 | 6.03 0.64 | 0.529 | 1.75E-02 |