Evaluation of Safety Constraints in Autonomous Navigation with Deep Reinforcement Learning ††thanks: This is a preprint version of the extended abstract accepted to TAROS’23.
Abstract
While reinforcement learning algorithms have had great success in the field of autonomous navigation, they cannot be straightforwardly applied to the real autonomous systems without considering the safety constraints. The later are crucial to avoid unsafe behaviors of the autonomous vehicle on the road. To highlight the importance of these constraints, in this study, we compare two learnable navigation policies: safe and unsafe. The safe policy takes the constraints into account, while the other does not. We show that the safe policy is able to generate trajectories with more clearance (distance to the obstacles) and makes less collisions while training without sacrificing the overall performance.
Keywords:
Autonomous Navigation Reinforcement Learning Safety Constraints.1 Introduction
Deep Reinforcement Learning has demonstrated tremendous success in many high-dimensional control problems, including autonomous navigation. Within RL, the interaction of the agent with the environment is modeled as a Markov decision process (MDP) [1], where the goal is to optimize the expected cumulative reward. The agent in MDP has a big freedom to explore any behavior which could improve its performance, including those that might cause damage. To this end, it is crucial to ensure safety constraints. A well-known approach to consider safety constraints in RL is a Constrained Markov Decision Process (CMDP) [2]. A survey of methods for solving CMDP can be found in [3]. In this short paper, we will apply safety constraints to ensure the safe behavior of the autonomous vehicle. Particularly, we will use the Lagrangian method [4] that is one of the most widely used approaches for solving CMDP.
2 Problem Statement
We are interested in algorithms for autonomous navigation which provide certain safety guarantees. To this end, we model our problem as a CMDP, where the agent (autonomous vehicle) must generate a sequence of actions (trajectory) that drives it to a goal while avoiding obstacles and ensuring a tolerable safety cost limit. The latter in our work is interpreted as an upper limit of the vehicle’s velocity when it is moving near to the obstacles.
Trajectory generation We are interested in autonomous vehicles whose dynamics is described as [5]: , where , are the coordinates of the vehicle’s rear axle, is the orientation, is the wheel-base, is the linear velocity, is the steering angle. The former three variables comprise the state vector: . The latter two variables form the control vector: , which can also be re-written using the acceleration and the rotation rate as follows: .
The robot is operating in the 2D workspace populated with static obstacles. Their shapes are rectangular (as the one of the robot). Let denote the set of obstacles. Denote by all the configurations of the robot which are not in collision with the obstacles. The problem is to find the actions that move the vehicle from its start configuration to the goal one , s.t. that the kinodynamic constraints are met and the resultant trajectory lies in . These controls are generated using a sequential decision making based on CMDP.
Constrained Markov Decision Process Formally, CMDP can be represented as a tuple , where is the state space, is the action space, is the state-transition model, is the reward function, is a constraint cost function and is the discounting factor. During learning at each time step the agent being in a state takes an action and receives a reward and a cost . The goal is to learn a policy, i.e. the mapping from the states to the distributions of actions, . The policy should maximize the expected return from the start state while satisfying the discounted cost with tolerable limit trough the discounted cost under policy :
where denotes a trajectory. The objective of CMDP for the policy is to find: .
3 Method
To evaluate the influence of safety constraints, we will use a policy-gradient algorithm PPO [6] and its safe version – LagrangianPPO (LPPO) [4]. The learning and evaluation of these two algorithms are conducted in a gym environment from [7]. Next, we will briefly introduce some details of environment.
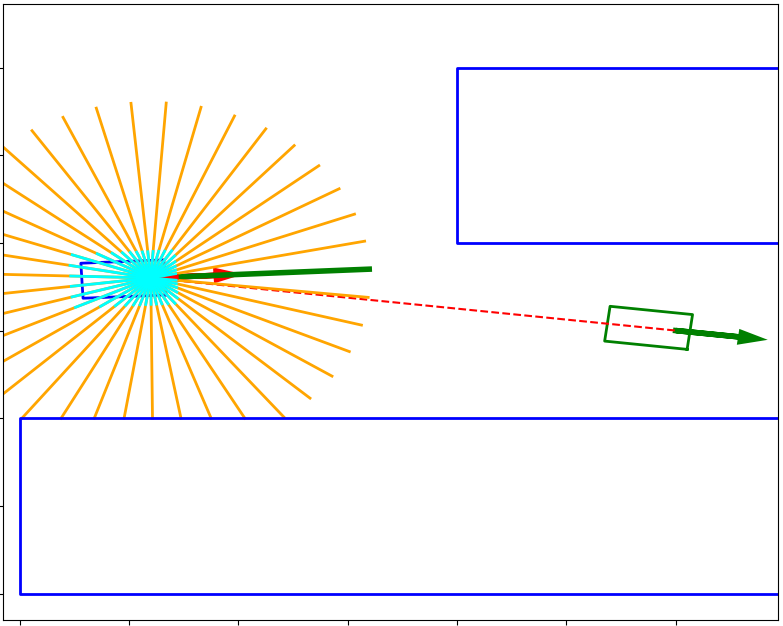
Environment Our environment provides an autonomous vehicle equipped with kinematic bicycle model and lidar-sensor in an environment which is populated with static obstacles as shown in Fig. 1. The vehicle state is described as a tuple . We consider agent’s state where is the difference between the j-element of the tuple between goal and current vehicle state, are elements of current vehicle state and is a tuple of rays-measurements from lidar. In this paper, we consider the same actions and reward function from [7]. The actions are composed of the linear acceleration and rotation rate . For details of the actions, kinematic model and reward function we refer the readers to [7].
Safety Constraints The safety constraint cost is induced by a velocity of the autonomous vehicle at which it moves near to the obstacles due to the risk of collision like the method proposed in [8]. We impose an immediate constraint cost as , where is the safety radius – see Fig. 1, is the current lidar signal, and is boolean function. This safety constraint allows to the agent to move near obstacles at tolerable velocity so as not to violate the tolerable limit .
4 Evaluation
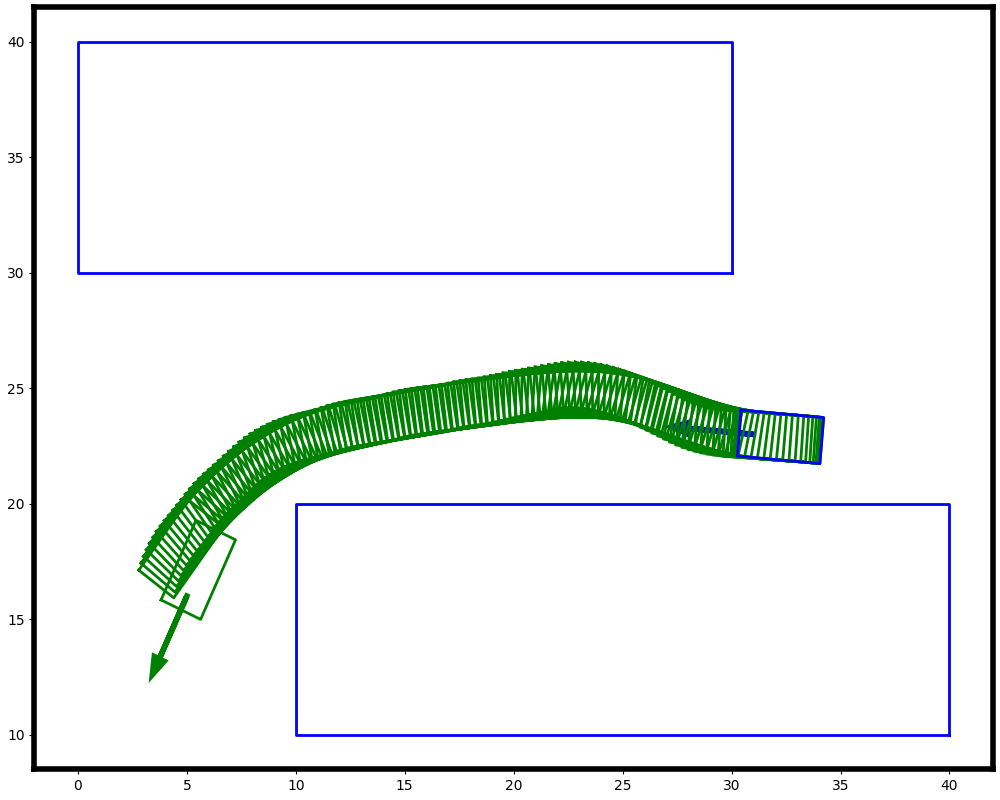
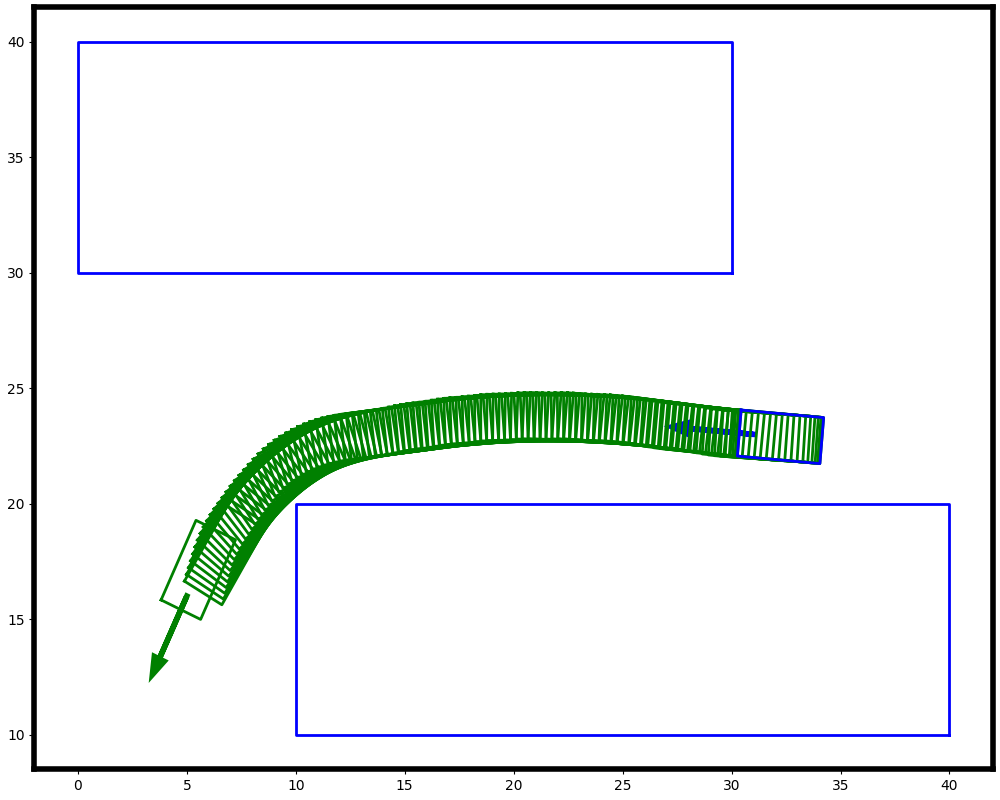
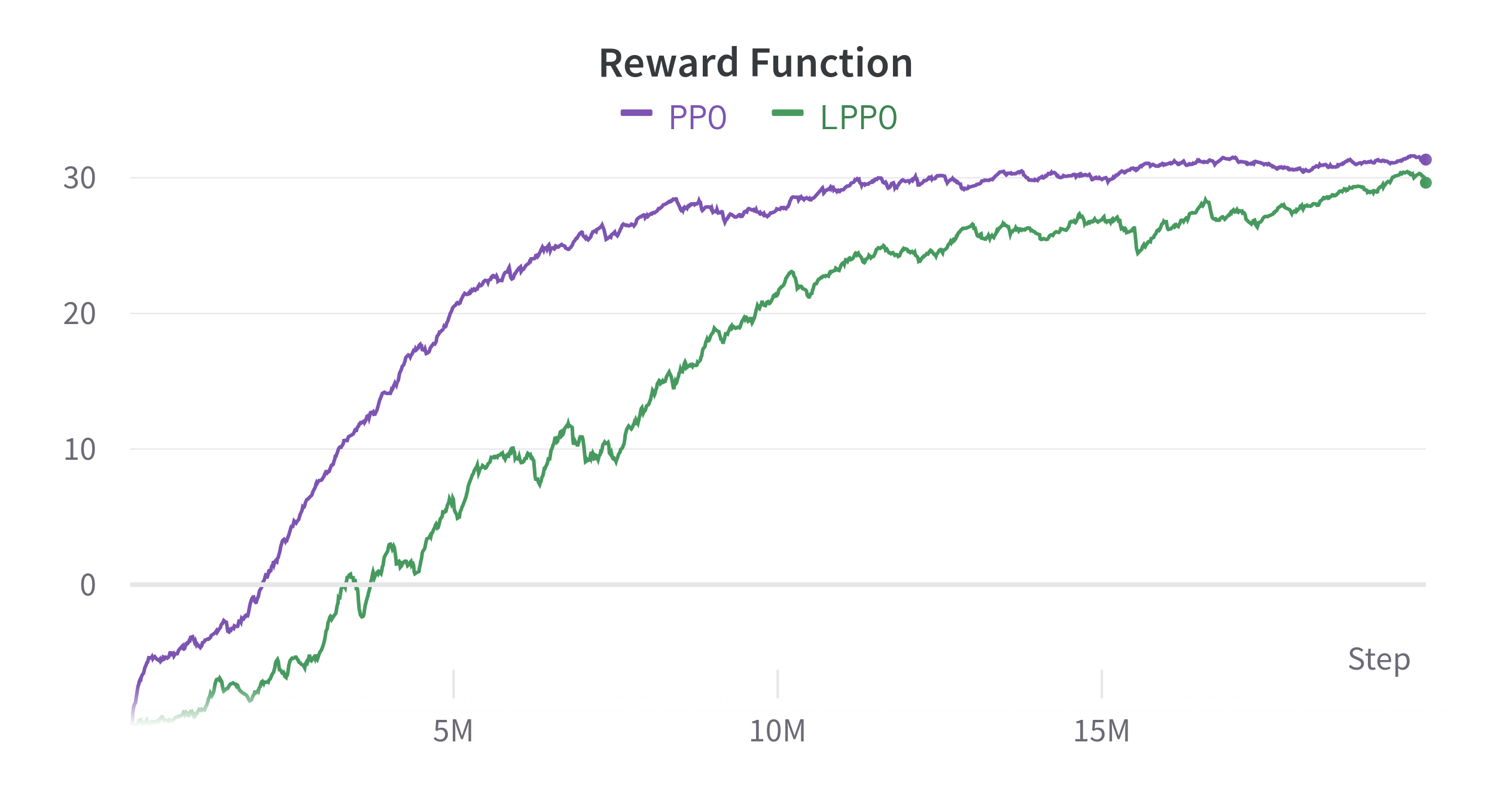
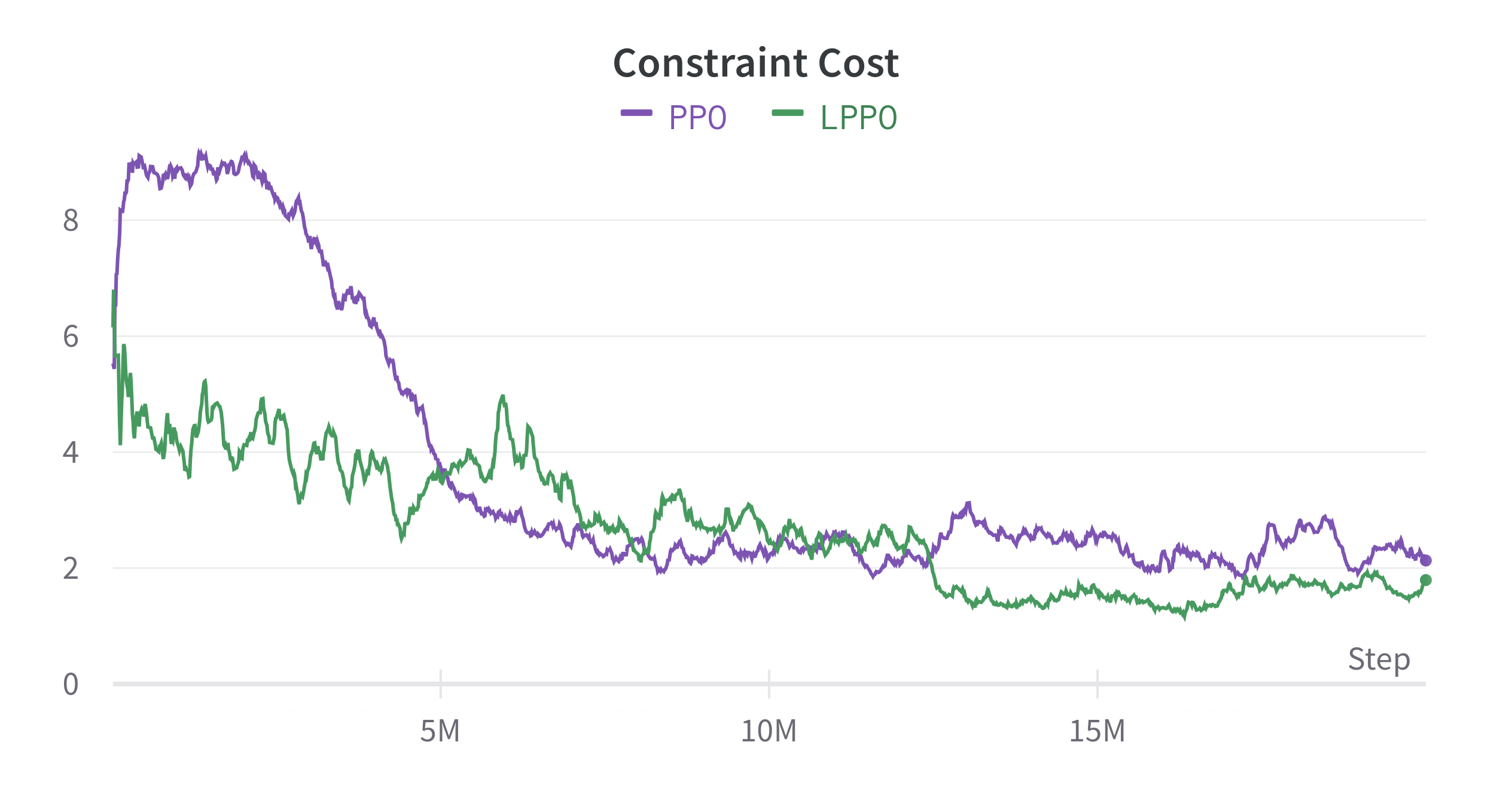
We trained two policies, i.e. PPO [6] and LPPO [4] on a dataset from [7]. The dataset is comprised of tasks which consist of start, goal and a set of static obstacles. The goal is to generate a trajectory from start to goal. In the Fig. 2 we show the learning process of these algorithms. We can see that PPO starts to converge earlier in comparison with LPPO. But at the same time it violates more safety constraints. On the other hand, the LPPO agent tries to find a trade-off.
After training we evaluate these two policies on a validation dataset through the following metrics: success rate (SR, %), collision rate (CR, %) and mean minimum clearance distance (MMC, m) of the successfully generated trajectories. The results for PPO are , , , and for LPPO are , , . We see that the LPPO agent tends to avoid the obstacles with more clearance in order to guarantee the safety constraints as shown in the Fig. 1. On the other hand, the PPO agent acquired more aggressive behavior that tries to reach the goal as soon as possible regardless of the risk of collision. Additionally, we can see that LPPO agent finishes some tasks without success or collision. In this cases, the LPPO agent prefers to make an abrupt stop instead of colliding with an obstacle. The latter is a safe behavior that agent acquired thanks to the safety constraints.
5 Conclusion
In this short paper, we have evaluated the consideration of safety constraints during the optimization process for policy gradient algorithm PPO. While PPO can converge earlier and has a slightly high success rate, the learned behavior of LPPO is more conservative due to taking the safety constraints into account. Overall, considering safety constraints in the optimization problem provides a more conservative and safe behavior without sacrificing of performance.
References
- [1] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [2] E. Altman, Constrained Markov decision processes. CRC press, 1999, vol. 7.
- [3] Y. Liu, A. Halev, and X. Liu, “Policy learning with constraints in model-free reinforcement learning: A survey,” in The 30th International Joint Conference on Artificial Intelligence (IJCAI), 2021.
- [4] Y. Chow, M. Ghavamzadeh, L. Janson, and M. Pavone, “Risk-constrained reinforcement learning with percentile risk criteria,” The Journal of Machine Learning Research, vol. 18, no. 1, pp. 6070–6120, 2017.
- [5] B. Paden, M. Čáp, S. Z. Yong, D. Yershov, and E. Frazzoli, “A survey of motion planning and control techniques for self-driving urban vehicles,” IEEE Transactions on Intelligent Vehicles, vol. 1, no. 1, pp. 33–55, 2016.
- [6] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” CoRR, vol. abs/1707.06347, 2017. [Online]. Available: http://arxiv.org/abs/1707.06347
- [7] B. Angulo, A. Panov, and K. Yakovlev, “Policy optimization to learn adaptive motion primitives in path planning with dynamic obstacles,” IEEE Robotics and Automation Letters, 2022.
- [8] Y. Chow, O. Nachum, A. Faust, E. Duenez-Guzman, and M. Ghavamzadeh, “Lyapunov-based safe policy optimization for continuous control,” arXiv preprint arXiv:1901.10031, 2019.