Every Bit Counts: Second-Order Analysis of Cooperation in the Multiple-Access Channel
Abstract
The work at hand presents a finite-blocklength analysis of the multiple access channel (MAC) sum-rate under the cooperation facilitator (CF) model. The CF model, in which independent encoders coordinate through an intermediary node, is known to show significant rate benefits, even when the rate of cooperation is limited. We continue this line of study for cooperation rates which are sub-linear in the blocklength . Roughly speaking, our results show that if the facilitator transmits bits, there is a sum-rate benefit of order . This result extends across a wide range of : even a single bit of cooperation is shown to provide a sum-rate benefit of order .
I Introduction
The multiple access channel (MAC) model lies at an interesting conceptual intersection between the notions of cooperation and interference in wireless communications. When viewed from the perspective of any single transmitter, codewords transmitted by other transmitters can only inhibit the first transmitter’s individual communication rate; thus each transmitter sees the others as a source of interference. When viewed from the perspective of the receiver, however, maximizing the total rate delivered to the receiver often requires all transmitters to communicate simultaneously; from the receiver’s perspective, then, the transmitters must cooperate through their simultaneous transmissions to maximize the sum-rate delivered to the receiver.
Simultaneous transmission is, perhaps, the weakest form of cooperation imaginable in a wireless communication model. Nonetheless, the fact that even simultaneous transmission of independent codewords from interfering transmitters can increase the sum-rate deliverable to the MAC receiver begs the question of how much more could be achieved through more significant forms of MAC transmitter cooperation.
The information theory literature devotes considerable effort to studying the impact of encoder cooperation in the MAC. A variety of cooperation models are considered. Examples include the “conferencing” cooperation model [1], in which encoders share information directly in order to coordinate their channel inputs, the “cribbing” cooperation model [2], in which transmitters cooperate by sharing their codeword information (at times causally), and the “cooperation facilitator” (CF) cooperation model [3] in which users coordinate their channel inputs with the help of an intermediary called the CF. The CF distinguishes the amount of information that must be understood to facilitate cooperation (i.e., the rate to the CF) from the amount of information employed in the coordination (i.e., the rate from the CF). Key results using the CF model show that for many MACs, no matter what the (non-zero) fixed rate , the curve describing the maximal sum-rate as a function of has infinite slope at [4]. That is, very little coordination through a CF can change the MAC capacity considerably. This phenomenon holds for both average and maximum error sum-rates; it is most extreme in the latter case, where even a finite number of bits (independent of the blocklength) — that is, — can suffice to change the MAC capacity region [5, 6, 7].
We study the CF model for 2-user MACs under the average error criterion. In this setting, the maximal sum-rate is a continuous function of at [6, 7], implying a first-order upper-bound on the benefit of cooperation for rates that are sub-linear. However, sub-linear CF cooperation may still increase sum-rate, albeit through second-order terms. In this work, we seek to understand the impact of the CF over a wide range of cooperation rates. Specifically, we consider a CF that, after viewing both messages, can transmit one of signals to both transmitters. We prove achievable bounds that express the benefit of this cooperation as a function of . These bounds extend all the way from constant to exponential . Interestingly, we find that even for (i.e., one bit of cooperation), there is a benefit in the second-order (i.e., dispersion) term, corresponding to an improvement of message bits. We prove two main achievable bounds, each of which is optimal for a different range of values. The proof of the first bound is based on refined asymptotic analysis similar to typical second-order bounds. The proof of the second bound is based on the method of types. For a wide range of values, we find that the benefit is message bits.
II Problem Setup
An facilitated multiple access code for multiple access channel (MAC)
is defined by a facilitator code
a pair of encoders
and a decoder
The encoder’s output is sometimes described using the abbreviated notation
The average error probability for the given code is
We also consider codes for the -length product channel, where are replaced by respectively, and where
An code for the -length channel achieving average probability of error at most is called an code. We assume that all alphabets are finite.
The following notation will be useful. Given a MAC
the sum-capacity without cooperation is given by
| (1) |
Let be the set of product distributions achieving the maximum in (1). For any , let be the resulting marginal on the channel output, giving
for all . We use , and to represent the joint and conditional information densities
where and are conditional marginals on under joint distribution
We denote the 3-vector of all three quantities as
It will be convenient to define
Let
| (2) | ||||
| (3) |
Roughly speaking, represents the information-variance of the codewords, whereas represents the information-variance of the channel noise. Given two distributions , let the divergence-variance be
Note that
III Main Results
Define the fundamental sum-rate limit for the facilitated-MAC as
In the literature on second-order rates, there are typically two types of results: (i) finite blocklength results, with no asymptotic terms, that are typically written in terms of abstract alphabets, and (ii) asymptotic results that derive from these finite blocklength results, which are typically easier to understand. The following is an achievable result which has some flavor of both: the channel noise is dealt with via an asymptotic analysis, but the dependence on the randomness in the codewords is written as in a finite blocklength result. We provide this “intermediate” result because, depending on the CF parameter , the relevant aspect of the codeword distribution may be in the central limit, moderate deviations, or large deviations regime. Thus, in this form one may plug in any concentration bound to derive an achievable bound. Subsequently, Theorem 2 gives specific achievable results based on two different concentration bounds. We also prove another achievable bound, Theorem 3, which does not rely on Theorem 1, but instead uses an approach based on the method of types that applies at larger values of .
Theorem 1.
Assume . For any distribution , let be an i.i.d. sequence from for each , with all sequences mutually independent. There exists an code if
| (4) | ||||
| (5) | ||||
| (6) |
where is a standard Gaussian, and where is a constant.
For fixed , let be drawn i.i.d. from . Let
and define the CDF of as
Also let be the inverse of the CDF; that is,
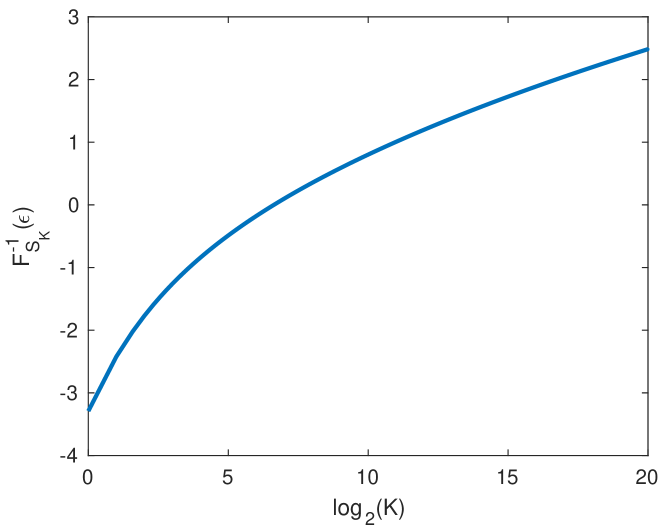
In what follows we use Theorem 1 and the function to explicitly bound from below the benefit in sum-rate when cooperating with varying measures of . A numerical computation of as a function of is shown in Fig. 1. The following is a technical estimate of .
Lemma 1.
For and that satisfy , is at least
Moreover, for all and ,
Proof:
Let . From [8], it holds that for . Moreover, . Combining these bounds gives the desired lower bound.
Theorem 2.
For any and the associated constants and , if , then
where
| (7) | |||||
| (8) | |||||
| (9) | |||||
| (10) |
For larger , our achievability bound employs the function
Note that . Lemma 2 captures the behavior of for small . (See Appendix A for the proof.)
Lemma 2.
In the limit as ,
where
| (11) |
Theorem 3.
For any such that ,
Remark 1.
III-A Comparison to prior work
In [4], an analog to Theorem 3 is proven for the asymptotic blocklength regime. Namely, in our notation, [4] proves that for any and , if we set then there exist such that,
Similarly, in [4, 7], an analog to Lemma 2 is shown for asymptotic blocklength. Specifically, it is shown that the existence of distributions and over such that (a) the support of is included in that of , and (b)
for
imply that there exists a constant such that
Although Theorem 3 and Lemma 2 (and their proof techniques) are similar in nature to those of [4, 7], the analysis presented here is refined in that it captures higher order behavior in blocklength and further optimized to address the challenges in studying values of that are sub-exponential in the blocklength .
We may also compare our results against prior achievable bounds without cooperation. Note that the standard MAC, with no cooperation, corresponds to . In fact, in this case Theorem 2 gives the same second-order term as the best-known achievable bound for the MAC sum-rate [11, 12, 13, 14, 15]. This can be seen by noting that , and so . Thus Theorem 2 gives
Moreover,
which, for the optimal input distribution, is precisely the best-known achievable dispersion. The proof of Theorem 2 uses i.i.d. codebooks, which, as shown in [14], can be outperformed in terms of second-order rate by constant combination codebooks. However, as pointed out in [15, Sec. III-B], the two approaches give the same bounds on the sum-rate itself.
Another interesting conclusion comes from comparing the no cooperation case () with a single bit of cooperation (). As long as , it is easy to see that for any (Fig. 1 shows an example). Thus, the second-order coefficient in Theorem 2 for is strictly improved compared to . Therefore, even a single bit of cooperation allows for additional message bits.
IV Proof of Theorem 1
We use random code design, beginning with independent design of the codewords for both transmitters. Precisely, we draw
The facilitator code is then designed in an attempt to maximize the likelihood under a received channel output . We begin by defining the threshold decoder employed in our analysis. Maximum likelihood decoding is expected to give the best performance, but instead we here employ a threshold decoder for simplicity. For notational efficiency, let
where is the (fixed) facilitator function to be defined below. Given a constant vector , we define the decoder to choose the unique message pair such that
where the vector inequality means that all three inequalities must hold simultaneously. Conversely we use the notation between vectors to mean that any one of the three inequalities fails. If the number of message pairs that meet this constraint is not one, we declare an error. In an attempt to ensure that is, in some sense, large for random channel outputs that may result from that codeword pair’s transmissions, for each , we define
where is a score function to be chosen below.
Under this code design, the expected error probability satisfies
To further upper bound the error probability, we define the following random variables. Let be the joint distribution of that results from our choice of CF. This distribution would be the same for any message pair. Let variables , , , , , have joint distribution
Under transmission of message pair , capture the relationship between channel inputs and output in a standard MAC, whereas capture the corresponding relationship with CF. Moreover, , , and capture the relationship between the channel output and one or more untransmitted codewords from our random code. Assume without loss of generality that ; i.e., . We now analyze the error probability by considering the following cases.
| Number of values | Distribution | |||
|---|---|---|---|---|
| 1 | 1 | |||
| 1 | ||||
| 1 | 1 | |||
| any |
Note that we have excluded cases where , since those are not errors (even if ). Moreover, the number of cases wherein has joint distribution is less than . We can upper bound the expected error probability as
Note that
Applying similar arguments to the other terms, we find
| (12) |
Note that (12) may be viewed as a finite blocklength achievable result. While our primary goal is asymptotic second-order analysis, we proceed by analyzing this bound on the -length product channel. Specifically, we now focus on the case where captures uses of a discrete, memoryless channel. We designate this special case by
and add superscript to all coding functions as a reminder of the scenario in operation. Assume that each codeword entry is drawn i.i.d. from or . Define the CF’s score function as
If we choose
then
| (13) |
We begin by bounding the second and third terms of (13) before returning to bound the first. For the second term in (13), recall that are drawn from the distribution of induced by the cooperation facilitator,
| (14) | |||
where the last inequality follows from Hoeffding’s inequality and the assumption that is bounded, where is a constant employed in this bound. By the assumption of in the statement of the theorem, this quantity is at most for a suitable constant . A similar bound can be applied to the third term in (13).
Now we consider the first term in (13). For fixed ,
Thus we can apply the Berry-Esseen theorem to write
where, as in the statement of the theorem, is a standard Gaussian random variable.
Assume
Let
Note that
By the assumption that , . By Hoeffding’s inequality, we may write
Thus, by the union bound
Thus
where is the Gaussian CDF. Similarly, let be the Gaussian PDF. Given , let
If , then we may bound
If , then we may bound
Since , combining the above bounds gives
Thus,
V Proof of Theorem 2
Given , our goal is to choose to satisfy the conditions of Theorem 1, while
| (15) |
where satisfies one of (7)–(10) depending on . Given , let be rates where
| (16) | ||||
| (17) | ||||
| (18) |
Let
This choice clearly satisfies (15). By Lemma 1, , so for sufficiently large , (5)–(6) are easily satisfied. It remains to prove (4). Let be the probability in (4). We divide the remainder of the proof into two cases.
Case 1: . We adopt the notation from the proof of Theorem 1, specifically
Thus
Note that is an i.i.d. sum where each term has expectation
and variance . Thus, by the Berry-Esseen theorem,
where . For any and any , we can bound
By the assumption that , for sufficiently large , . Thus
Recalling Theorem 1, we can achieve probability of error if
This condition is satisfied if
for suitable constants and sufficiently large . To simplify the second term, we need the following lemma, which is proved in Appendix B.
Lemma 3.
Fix and . Then
Case 2: and . For convenience, define
Thus,
To continue, we need the moderate deviations bound given by the following lemma.
Lemma 4 (Moderate deviations [16]).
Let be i.i.d. random variables with zero mean and unit variance, and let where for some . There exist constants and depending only on and such that, for any ,
where is the complementary CDF of the standard Gaussian distribution.
To apply the moderate deviations bound, we can write
where
Since in our integral, , in order to apply the moderate deviations bound, we need to prove that as long as . We have
From the target for in (15),
By the assumption that , , so
Thus , so indeed we may apply the moderate deviations bound. Let
Letting we now have
We now claim that for any and any ,
Indeed, it is easy to see that
where the last inequality holds if . Note that , so this inequality holds for sufficiently large . Thus,
Note that
At this point, we make the choice of slightly more precise; in particular, let
for suitable constants and . From Lemma 1,
Thus
where the last inequality holds for sufficiently large . From Theorem 1, there exists a code with probability of error at most
assuming are chosen properly. This proves that we can achieve the sum-rate
where in the last inequality we have used Lemma 3 as well as the bound on . This achives the ranges of given by (9)–(10).
VI Proof of Theorem 3
This proof uses the method of types. A probability mass function is an -length type on alphabet if is a multiple of for each . For an -length type , the type class is denoted .
Let be an -length joint type on alphabet . Note that the marginal distributions and are also -length types. We employ the following random code construction. Draw codewords uniformly from the type classes and . Given message pair , the cooperation facilitator chooses uniformly from the set of where
If there is no such , the CF chooses uniformly at random. These random choices at the CF are taken to be part of the random code design. For the purposes of this proof, the three information densities employ the joint distribution . The quantity is also defined as in (3) using information density for this joint distribution. The decoder is as follows. Given , choose the unique message pair such that
-
1.
,
-
2.
for a constant vector to be determined. If there is no message pair or more than one satisfying these conditions, declare an error. Note that, given
is uniformly distributed on . Let be the uniform distribution on the type class , with corresponding conditional distributions and . Define random variables to have distribution
Furthermore, define where
Now we may bound the expected error probability by
| (19) | |||
| (20) |
In the summation in (20), consider a term where and . In this case, is independent from , so we may write that
where has the same distribution as but is independent from ; i.e.,
Now consider a term in (20) where but . In this case, whether the transmitted signal from user 1 with message pair is the same as that with message pair depends on whether . Thus, the term in (20) is no more than
In the first term, is the channel output where is one of the channel inputs, but the channel input for user 2 is unrelated. However, by the condition that , these two codewords are distributed according to . Thus we may write that
where
In the second term, the transmitted signals are unrelated, and so the three sequences once again have the same distribution as . We may apply a similar analysis for the case where and , defining by
Therefore
For any ,
Thus, for any including those not in ,
By similar calculations
We bound as
Using similar bounds on the other terms, we have
Next, choose
Then
| (21) |
As in the proof of Thm. 2, let be a pair of rates satisfying (16)–(18). We now choose
where is an error term to be determined chosen below to satisfy . Thus
Consider the first term in (21). Note that only if
This occurs with probability bounded as
where the last inequality holds if
| (22) |
Appendix A Proof of Lemma 2
Through this proof, means that as . For small , implies that . Thus, the second-order Taylor approximation for the mutual information gives
Moreover, the first-order Taylor approximation of the mutual information is
where
As usual, let
Also let
be the mutual information where and are independent. We can now rewrite the optimization problem for in terms of the marginal distributions and
Note that
In particular, if we consider maximizing over only , the optimization problem is
| (23) |
The Lagrangian for this problem is
Differentiating with respect to and setting to zero, we find that the optimal is of the form
We first find the values of the dual variables and . For any , we need
where the expectations are with respect to . Combining this constraint with the equivalent one for , we must have
Taking the expectation of either constraint gives
Thus
and so
where
To find , we use the constraint
so
We may now derive the optimal objective value for the optimization problem in (23), which is
Now considering the optimization over , we may write
Note that for small , the RHS will be negative unless are such that (i.e., they are sum-capacity achieving). By the optimality conditions for the maximization defining the sum-capacity, this implies that
Thus, for where , we have
Thus , and
Therefore
Appendix B Proof of Lemma 3
We first need the following lemma.
Lemma 5.
Fix . Let and be independent random variables where
Then for ,
Proof:
We now complete the proof of Lemma 3. Recall that where . Let . Note that
and so
Thus it is sufficient to show that is bounded away from zero for all . Since ,
Thus, for ,
Moreover, for all ,
Now we prove a lower bound on . Specifically let for . Note that
so . We have
Suppose . Thus . Also, since , , we have
Thus
and so
Now suppose , so . We have
and so
Thus
In the limit as ,
Thus
This proves that there exists a such that for all in the range of interest. Similar is upper and lower bounded as shown above, we may apply Lemma 5 to complete the proof.
References
- [1] F. Willems, “The discrete memoryless multiple access channel with partially cooperating encoders,” IEEE Transactions on Information Theory, vol. 29, no. 3, pp. 441–445, 1983.
- [2] F. Willems and E. Van der Meulen, “The discrete memoryless multiple-access channel with cribbing encoders,” IEEE Transactions on Information Theory, vol. 31, no. 3, pp. 313–327, 1985.
- [3] P. Noorzad, M. Effros, M. Langberg, and T. Ho, “On the power of cooperation: Can a little help a lot?” in IEEE International Symposium on Information Theory, 2014, pp. 3132–3136.
- [4] P. Noorzad, M. Effros, and M. Langberg, “The unbounded benefit of encoder cooperation for the k-user MAC,” IEEE Transactions on Information Theory, vol. 64, no. 5, pp. 3655–3678, 2018.
- [5] M. Langberg and M. Effros, “On the capacity advantage of a single bit,” in 2016 IEEE Globecom Workshops (GC Wkshps). IEEE, 2016, pp. 1–6.
- [6] P. Noorzad, M. Effros, and M. Langberg, “Can negligible cooperation increase capacity? the average-error case,” in Proceedings of IEEE International Symposium on Information Theory (ISIT), 2018, pp. 1256–1260.
- [7] P. Noorzad, M. Langberg, and M. Effros, “Negligible Cooperation: Contrasting the Maximal- and Average-Error Cases,” Manuscript. Available on https://arxiv.org/pdf/1911.10449.pdf, 2019.
- [8] J. Hartigan et al., “Bounding the maximum of dependent random variables,” Electronic Journal of Statistics, vol. 8, no. 2, pp. 3126–3140, 2014.
- [9] C. Borell, “The Brunn-Minkowski inequality in Gauss space,” Inventiones Mathematicae, vol. 30, no. 2, pp. 207–216, 1975.
- [10] B. Tsirelson, I. Ibragimov, and V. Sudakov, “Norms of Gaussian sample functions,” Proceedings of the Third Japan-USSR Symposium on Probability Theory, vol. 550, pp. 20–41, 1976.
- [11] Y.-W. Huang and P. Moulin, “Finite blocklength coding for multiple access channels,” in 2012 IEEE International Symposium on Information Theory Proceedings. IEEE, 2012, pp. 831–835.
- [12] E. M. Jazi and J. N. Laneman, “Simpler achievable rate regions for multiaccess with finite blocklength,” in 2012 IEEE International Symposium on Information Theory Proceedings. IEEE, 2012, pp. 36–40.
- [13] V. Y. Tan and O. Kosut, “On the dispersions of three network information theory problems,” IEEE Transactions on Information Theory, vol. 60, no. 2, pp. 881–903, 2014.
- [14] J. Scarlett, A. Martinez, and A. G. i Fàbregas, “Second-order rate region of constant-composition codes for the multiple-access channel,” IEEE Transactions on Information Theory, vol. 61, no. 1, pp. 157–172, 2015.
- [15] R. C. Yavas, V. Kostina, and M. Effros, “Random access channel coding in the finite blocklength regime,” IEEE Transactions on Information Theory, 2020.
- [16] L. H. Y. Chen, X. Fang, and Q.-M. Shao, “From Stein identities to moderate deviations,” Ann. Probab., vol. 41, no. 1, pp. 262–293, 01 2013.