Exact Statistical Inference for the Wasserstein Distance by
Selective Inference
Abstract
In this paper, we study statistical inference for the Wasserstein distance, which has attracted much attention and has been applied to various machine learning tasks. Several studies have been proposed in the literature, but almost all of them are based on asymptotic approximation and do not have finite-sample validity. In this study, we propose an exact (non-asymptotic) inference method for the Wasserstein distance inspired by the concept of conditional Selective Inference (SI). To our knowledge, this is the first method that can provide a valid confidence interval (CI) for the Wasserstein distance with finite-sample coverage guarantee, which can be applied not only to one-dimensional problems but also to multi-dimensional problems. We evaluate the performance of the proposed method on both synthetic and real-world datasets.
1 Introduction
The Wasserstein distance, which is a metric used to compare the probability distributions, has been attracted significant attention and being used more and more in Statistics and Machine Learning (ML) (Kolouri et al., 2017). This distance measures the cost to couple one distribution with another, which arises from the notion of optimal transport (Villani, 2009). The utilization of the Wasserstein distance benefits to several applications such as supervised learning (Frogner et al., 2015), generative modelling (Arjovsky et al., 2017), biology (Evans and Matsen, 2012), and computer vision (Ni et al., 2009).
When the Wasserstein distance calculated from noisy data is used for various decision-making problems, it is necessary to quantify its statistical reliability, e.g., in the form of confidence intervals (CIs). However, there is no satisfactory statistical inference method for the Wasserstein distance. The main reason is that the Wasserstein distance is defined based on the optimal solution of a linear program (LP), and it is difficult to analyze how the uncertainty in the data is transmitted to the uncertainty in the Wasserstein distance. Several studies have been proposed in literature (Bernton et al., 2017; Del Barrio et al., 1999, 2019; Ramdas et al., 2017; Imaizumi et al., 2019). However, they all rely on asymptotic approximation to mitigate the difficulty stemming from the fact that the Wasserstein distance depends on the optimization problem, and thus most of them can only be applied to one-dimensional problems (the details will be discussed in the related work section).
When an optimization problem such as LP is applied to random data, it is intrinsically difficult to derive the exact (non-asymptotic) sampling distribution of the optimal solution. In this paper, to resolve the difficulty, we introduce the idea of conditional Selective Inference (SI). It is well-known that the optimal solution of an LP depends only on a subset of variables, called basic variables. Therefore, the LP algorithm can be interpreted as first identifying the basic variables, and then solving the linear system of equations about the basic variables.
Our basic idea is based on the fact that, in the LP problem for the Wasserstein distance, the identification of the basic variables corresponds to the process of determining the coupling between the source and destination of the probability mass. Since the optimal coupling is determined (selected) based on the data, the selection bias must be properly considered. Therefore, to address the selection bias, we propose an exact statistical inference method for the Wasserstein distance by conditioning on the basic variables of the LP, i.e., optimal coupling.
The main advantage of the proposed method is that it can provide exact (non-asymptotic) CI for the Wasserstein distance, unlike the asymptotic approximations in the existing studies. Moreover, while the existing methods are restricted to one-dimensional problems, the proposed method can be directly extended to multi-dimensional problems because the proposed CI is derived based on the fact that the Wasserstein distance depends on the optimal solution of the LP.
1.1 Contributions
Regarding the high-level conceptual contribution, we introduce a novel approach to explicitly characterize the selection bias of the data-driven coupling problem inspired by the concept of conditional Selective Inference (SI). In regard to the technical contribution, we provide an exact (non-asymptotic) inference method for the Wasserstein distance. To our knowledge, this is the first method that can provide valid CI, called selective CI, for the Wasserstein distance that guarantees the coverage property in finite sample size. Another practically important advantage of this study is that the proposed method is valid when the Wasserstein distance is computed in multi-dimensional problem, which is impossible for almost all the existing asymptotic methods since the limit distribution of the Wasserstein distance is only applicable for univariate data. We conduct experiments on both synthetic and real-world datasets to evaluate the performance of the proposed method.
1.2 Related works
In traditional statistics, reliability evaluation with Wasserstein distance has been based on asymptotic theory, i.e., sample size . In the univariate case, instead of solving the optimization problem, the Wasserstein can be described by using an inverse of the distribution function. For example, let be the quantile function of the data and be the empirical quantile function of the generated data, the Wasserstein distance with distance is computed by . Based on the quantile function, several studies (Del Barrio et al., 1999, 2019; Ramdas et al., 2017) derived the asymptotic distribution of the Wasserstein distance. Obviously, these methods can not guarantee the validity in finite sample size. Moreover, since the quantile function is only available in univariate case, these methods can not be extended to multivariate cases which are practically important.
Recently, Imaizumi et al. (2019) has proposed an approach on multidimensional problems. However, it is important to clarify that this study does not provide statistical inference for the “original” Wasserstein distance. Instead, the authors consider an approximation of the Wasserstein distance, which does not require solving a LP. Besides, this method also relies on asymptotic distribution of the test statistic which is approximated by the Gaussian multiplier bootstrap. Therefore, to our knowledge, statistical inference method for the Wasserstein distance in multi-dimensional problems is still a challenging open problem.
Conditional SI is a statistical inference framework for correcting selection bias. Traditionally, there are mainly two types of approaches for selection bias correction. The first approach is family-wise error rate (FWER) control, which includes standard multiple comparison methods such as traditional Bonferroni correction. However, the FWER control is too conservative and it is difficult to utilize it for selection bias correction in complex adaptive data analysis. Another approach is false discovery rate (FDR) control, in which the target is to control the expected proportion of discoveries that are false at a given significance level. The FDR control is less conservative than FWER control, and it is used in many high-dimensional statistical inference problems.
Conditional SI is the third approach for selection bias correction. The basic idea of conditional SI was known before, but it becomes popular by the recent seminal work proposed by Lee et al. (2016). In that study, exact statistical inference on the selected features by Lasso was considered. Their basic idea is to employ the sampling distributions of the selected parameter coefficients conditional on the selection event that a subset of features is selected by the Lasso. By using the conditional distribution in statistical inference, the selection bias of the Lasso (i.e., the fact that the Lasso selected the features based on the data) can be corrected. Their contribution was to show that, even in complex data analysis methods such as Lasso, the exact sampling distribution can be characterized if appropriate selection events are considered.
After the seminal work (Lee et al., 2016), many conditional SI approaches for various feature selection methods were proposed in the literature (Loftus and Taylor, 2015; Yang et al., 2016; Tibshirani et al., 2016; Suzumura et al., 2017). Furthermore, theoretical analyses and new computational methods for conditional SI are still being actively studied (Fithian et al., 2014; Le Duy and Takeuchi, 2021; Duy and Takeuchi, 2021; Sugiyama et al., 2021a). However, most of conditional SI studies are focused on feature selection problems. Although there have been applications to several problems such as change point detection (Hyun et al., 2018; Duy et al., 2020b; Sugiyama et al., 2021b), outlier detection (Chen and Bien, 2019; Tsukurimichi et al., 2021), and image segmentation (Tanizaki et al., 2020; Duy et al., 2020a), these problems can also be interpreted as feature selection in a broad sense. Our novelty in this study is to first introduce conditional SI framework for statistical inference on the Wasserstein distance, which is a data-dependent adaptive distance measure. Our basic idea is based on the facts that the Wasserstein distance is formulated as the solution of a linear program (LP), and the optimal solution of an LP is characterized by the selected basic variables. In this study, we consider the sampling distribution of the Wasserstein distance conditional on the selected basic variables, which can be interpreted as considering the selection event on the optimal coupling between the two distributions.
2 Problem Statement
To formulate the problem, we consider two vectors corrupted with Gaussian noise as
| (1) | ||||
| (2) |
where and are the number of instances in each vector, and are unknown mean vectors, and are Gaussian noise vectors with covariances matrices and assumed to be known or estimable from independent data. We denote by and the corresponding empirical measures on and .
2.1 Cost matrix
We define the cost matrix of pairwise distances ( distance) between elements of and as
| (3) |
We can vectorize in the form of
| (4) |
where is an operator that transforms a matrix into a vector with concatenated rows. The matrix is defined as
| (5) | ||||
where the operator is element-wise product, is the operator that returns an element-wise indication of the sign of a number, is the vector of ones, is the vector of zeros, and is the identity matrix.
2.2 The Wasserstein distance
To compare two empirical measures and with uniform weight vectors and , we consider the following Wasserstein distance, which is defined as the solution of a linear program (LP),
| (6) | ||||
| s.t. | ||||
Given and respectively sampled from models (1) and (2) 111To make a distinction between random variables and observed variables, we use superscript obs, e.g., is a random vector and is the observed data vector., the Wasserstein distance in (6) on the observed data can be re-written as
| (7) | ||||
| s.t. |
where , is defined in (4), in which
that performs the sum over the rows of and
that performs the sum over the columns of , and 222 We note that there always exists exactly one redundant equality constraint in linear equality constraint system in (7). This is due to the fact that sum of all the masses on is always equal to sum of all the masses on (i.e., they are all equal to 1). Therefore, any equality constraint can be expressed as a linear combination of the others, and hence any one constraint can be dropped. In this paper, we always drop the last equality constraint (i.e., the last row of matrix and the last element of vector ) before solving (7). .
2.3 Optimal solution and closed-form expression of the distance
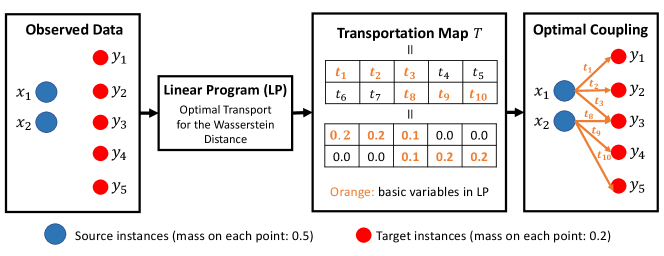
Let us denote the set of basis variables (the definition of basis variable can be found in the literature of LP, e.g., Murty (1983)) obtained when applying the LP in (7) on and as
| (8) |
We would like to note that the identification of the basic variables can be interpreted as the process of determining the optimal coupling between the elements of and in the optimal transport problem for calculating the Wasserstein distance. Therefore, in (8) can be interpreted as the observed optimal coupling obtained after solving LP in (7) on the observed data 333We suppose that the LP is non-degenerate. A careful discussion might be needed in the presence of degeneracy.. An illustration of this interpretation is shown in Figure 1. We also denote by a set of non-basis variables. Then, the optimal solution of (7) can be written as
where is a sub-matrix of made up of all rows and columns in the set .
Example 1.
Given a matrix
then is constructed by extracting the first, second and fourth columns of the matrix , i.e,
In the literature of LP, the matrix is also referred to as a basis. After obtaining , the Wasserstein distance can be re-written as
| (9) |
where is defined in (5), and is a sub-matrix of made up of rows in the set and all columns.
2.4 Statistical inference (confidence interval)
The goal is to provide a confidence interval (CI) for the Wasserstein distance. The in (9) can be written as
| (10) |
where is the test-statistic direction. It is important to note that is a random vector because is selected based on the data. For the purpose of explanation, let us suppose, for now, that the test-statistic direction in (10) is fixed before observing the data; that is, non-random. Let us define
| (11) |
Thus, we have . Given a significance level (e.g., 0.05) for the inference, the naive (classical) CI for
with -coverage is obtained by
| (12) |
where and is the c.d.f of the normal distribution with a mean and variance . With the assumption that in (10) is fixed in advance, the naive CI is valid in the sense that
| (13) |
However, in reality, because the test-statistic direction is actually not fixed in advance, the naive CI in (12) is unreliable. In other words, the naive CI is invalid in the sense that the -coverage guarantee in (13) is no longer satisfied. This is because the construction of depends on the data and selection bias exists.
In the next section, we introduce an approach to correct the selection bias which is inspired by the conditional SI framework, and propose a valid CI called selective CI () for the Wasserstein distance which guarantees the -coverage property in finite sample (i.e., non-asymptotic).
3 Proposed Method
We present the technical details of the proposed method in this section. We first introduce the selective CI for the Wasserstein distance in §3.1. To compute the proposed selective CI, we need to consider the sampling distribution of the Wasserstein distance conditional on the selection event. Thereafter, the selection event is explicitly characterized in a conditional data space whose identification is presented in §3.2. Finally, we end the section with the detailed algorithm.
3.1 Selective Confidence Interval for Wasserstein Distance
In this section, we propose an exact (non-asymptotic) selective CI for the Wasserstein distance by conditional SI. We interpret the computation of the Wasserstein distance in (7) as a two-step procedure:
- •
- •
Since the distance is computed in data-driven fashion, for constructing a valid CI, it is necessary to remove the information that has been used for the initial calculation process, i.e., steps 1 and 2 in the above procedure, to correct the selection bias. This can be achieved by considering the sampling distribution of the test-statistic conditional on the selection event; that is,
| (14) |
where is the sign vector explained in the construction of in (5).
Interpretation of the selection event in (14). The first and second conditions in (14) respectively represent the selection event for steps 1 and 2 in the procedure described in the beginning of this section. The first condition indicates that for . In other words, for , we condition on the event whether is greater than or not. The second condition indicates that the set of selected basic variables for random vectors and is the same as that for and . This condition can be interpreted as conditioning on the observed optimal coupling between the elements of and , which is obtained after solving the LP in (7) on the observed data (see Figure 1).
Selective CI. To derive exact statistical inference for the Wasserstein distance, we introduce so-called selective CI for that satisfies the following -coverage property conditional on the selection event:
| (15) |
for any . The selective CI is defined as
| (16) |
where the pivotal quantity
| (17) |
is the c.d.f of the truncated normal distribution with a mean , variance , and truncation region (the detailed construction of will be discussed later in §3.2) which is calculated based on the selection event in (17). The in the additional third condition is the sufficient statistic of nuisance parameter defined as
in which with is defined in (11). Here, we note that the selective CI depends on because the pivotal quantity in (17) depends on this component, but the sampling property in (15) is kept satisfied without this additional condition because we can marginalize over all values of . The corresponds to the component in the seminal paper of Lee et al. (2016) (see Section 5, Eq. 5.2 and Theorem 5.2). We note that additionally conditioning on is a standard approach in the SI literature and it is used in almost all the SI-related works that we cited in this paper.
3.2 Conditional Data Space Characterization
We define the set of that satisfies the conditions in Equation (17) as
| (18) |
According to the third condition , the data in is restricted to a line in as stated in the following Lemma.
Lemma 1.
Proof.
According to the third condition in (18), we have
By defining , , , and incorporating the first and second conditions in (18), we obtain the results in Lemma 1. We note that the fact of restricting the data to the line has been already implicitly exploited in the seminal conditional SI work of Lee et al. (2016), but explicitly discussed for the first time in Section 6 of Liu et al. (2018). ∎
Lemma 1 indicates that we do not have to consider the -dimensional data space. Instead, we only to consider the one-dimensional projected data space in (23), which is the truncation region that is important for computing the pivotal quantity in (17) and constructing the selective CI in (16).
Characterization of truncation region . We can decompose into two separate sets as , where
We first present the construction of in the following Lemma.
Lemma 2.
For notational simplicity, we denote . Then, the is an interval defined as:
where and .
Proof.
Next, we present the construction of . Here, can be interpreted as the set of values of in which we obtain the same set of the selected basic variables when applying the LP in (7) on the prametrized data .
Lemma 3.
Proof.
We consider the LP in (7) with the parametrized data as follows:
| (24) |
Here, we remind that is the vectorized version of the cost matrix defined in (4). The optimization problem in (24) is well-known as the parametric cost problem in LP literature (e.g., see Section 8.2 in Murty (1983)). Let us denote and , the LP in (24) can be re-written as
| (25) |
Given a fixed value , let be an optimal basic index set of the LP in (25) at and be its complement. Then by partitioning , , , and as
the LP in (25) becomes
| s.t. | (26) | |||
The value of can be computed as
and this general expression when substituted in the objective (cost) function of (25) yields
which expresses the cost of (3.2) in terms of . Let us denote
we can write which is known as the relative cost vector in the LP literature. Then, is an optimal basic index set of (25) for all values of the parameter satisfying
| (27) |
which is also explicitly discussed in Section 8.2 of Murty (1983). Finally, the results in Lemma 3 are obtained by respectively replacing and by and , and solving the linear inequality system in (27). ∎
Once and are identified, we can compute the truncation region . Finally, we can use to calculate the pivotal quantity in (17) which is subsequently used to construct the proposed selective CI in (16). The details of the algorithm is presented in Algorithm 1.
4 Extension to Multi-Dimension
In §2 and §3, we mainly focus on the Wasserstein distance in one-dimension, i.e., and . In this section, we generalize the problem setup and extend the proposed method for the Wasserstein distance in multi-dimension. We consider two random sets and of -dimensional vectors
| (28) |
corrupted with Gaussian noise as
where and are the number of instances in each set, and are unknown mean vectors, and are Gaussian noise vectors with covariances matrices and assumed to be known or estimable from independent data.
Cost matrix. The cost matrix of pairwise distances ( distance) between elements of and as
| (29) |
Then, the vectorized form of can be defined as
| (30) |
where
the matrix is defined in (5), the operator is Kronecker product, and is a -dimensional unit vector with 1 at position .
The Wasserstein distance in multi-dimension. Given and sampled from (28), after obtaining as in (30), the Wasserstein distance in multi-dimension is defined as
| (31) | ||||
| s.t. |
where and are defined in (7). By solving LP in (31), we obtain the set of selected basic variables
| (32) |
Then, the Wasserstein distance can be re-written as
| (33) |
where is the test-statistic direction, is the optimal solution of (31), and the matrix is defined in (30).
Selection event and selective CI. Since we are dealing with multi-dimensional case, the selection event is slightly different from but more general than the one presented in (17) of §3. Specifically, we consider the following conditional inference
| (34) |
where
Once the selection event has been identified, the pivotal quantity can be computed:
where with , and truncation region is calculated based on the selection event which we will discuss later. After is identified, the selective CI is defined as
| (35) |
The remaining task is to identify .
Characterization of truncation region . Similar to the discussion in §3, the data is restricted on the line due to the conditioning on the nuisance component . Then, the set of data that satisfies the condition in (34) is defined as
where
with . Next, we can decompose into two separate sets as , where
From now, the identification of and is straightforward and similar to the construction of and discussed in §3. Once and are identified, we can compute the truncation region and use it to compute the selective CI in (35).
5 Experiment
In this section, we demonstrate the performance of the proposed method in both univariate case and multi-dimensional case. We present the results on synthetic data in §5.1. Thereafter, the results on real data are shown in §5.2. In all the experiments, we set the significance level , i.e., all the experiments were conducted with the coverage level of .
5.1 Numerical Experiment
In this section, we evaluate the performance of the proposed selective CI in terms of coverage guarantee, CI length and computational cost. We also show the results of comparison between our selective CI and the naive CI in (12) in terms of coverage guarantee. We would like to note that we did not conduct the comparison in terms of CI length because the naive CI could not guarantee the coverage property. In statistical viewpoint, if the CI is unreliable, i.e., invalid or does not satisfy the coverage property, the demonstration of CI length does not make sense. Besides, we additionally compare the performance of the proposed method with the latest asymptotic study (Imaizumi et al., 2019).
5.1.1 Univariate case ()
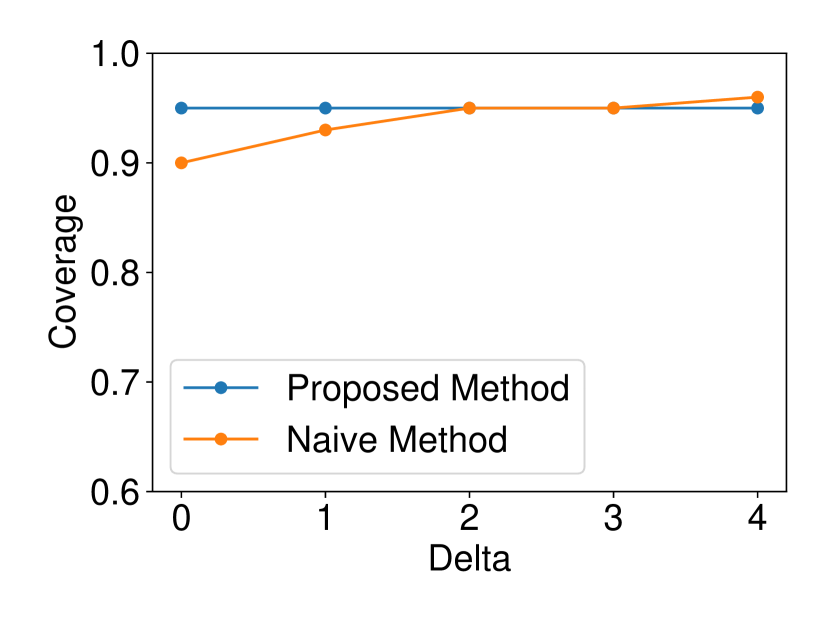
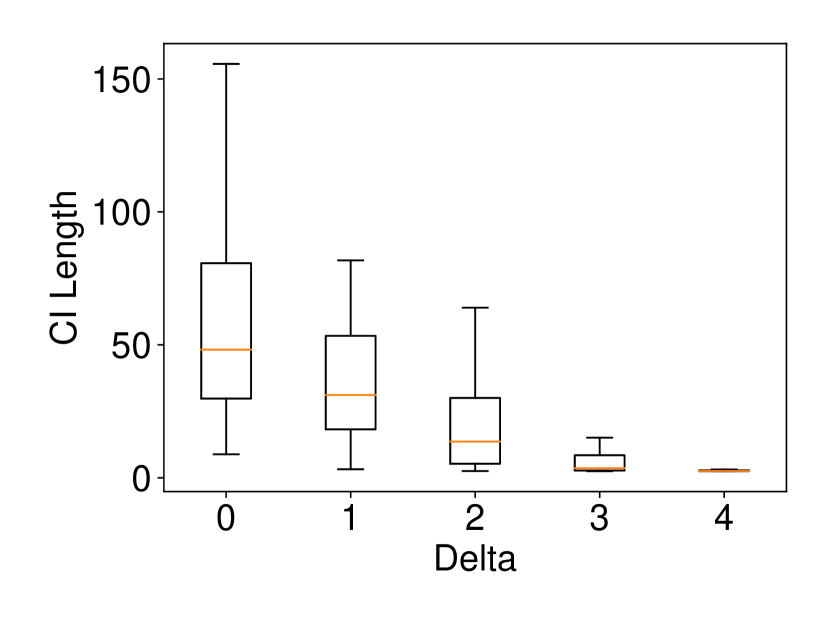
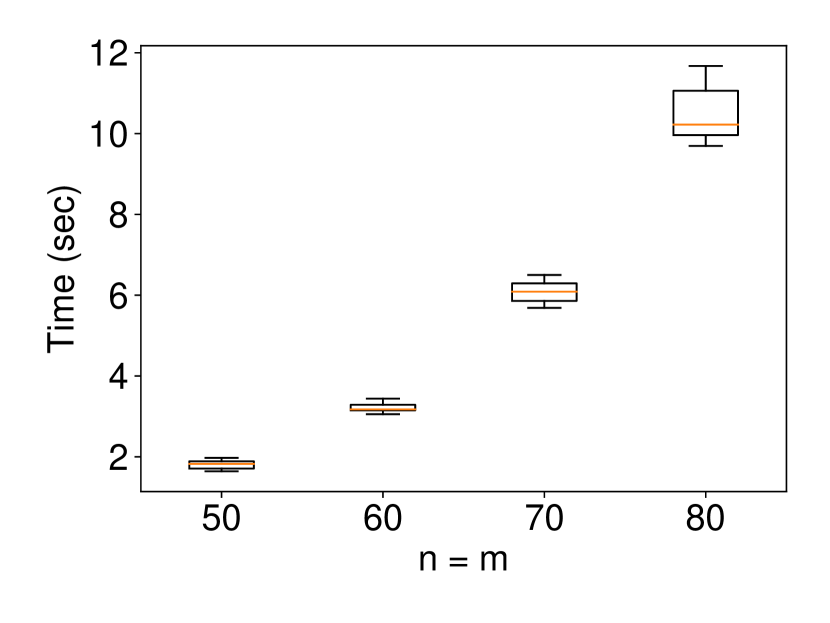
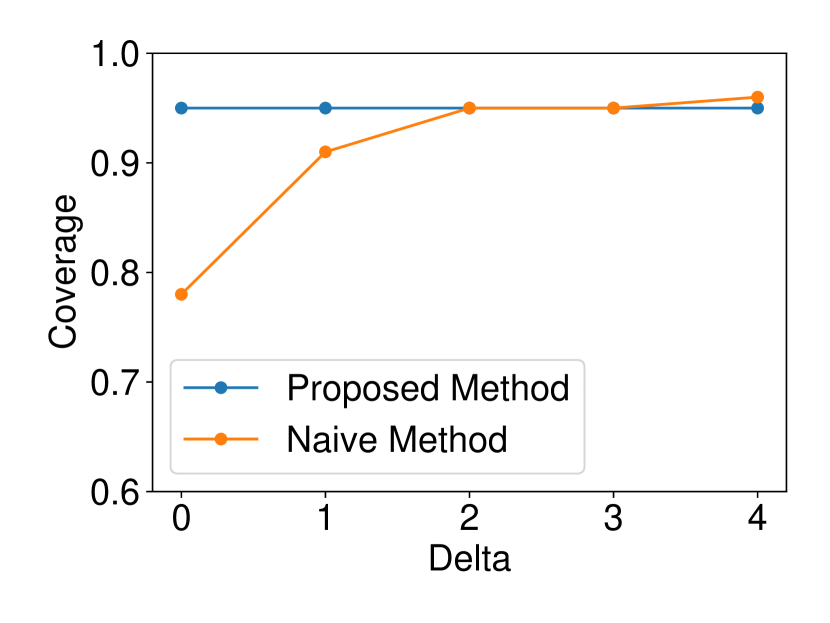
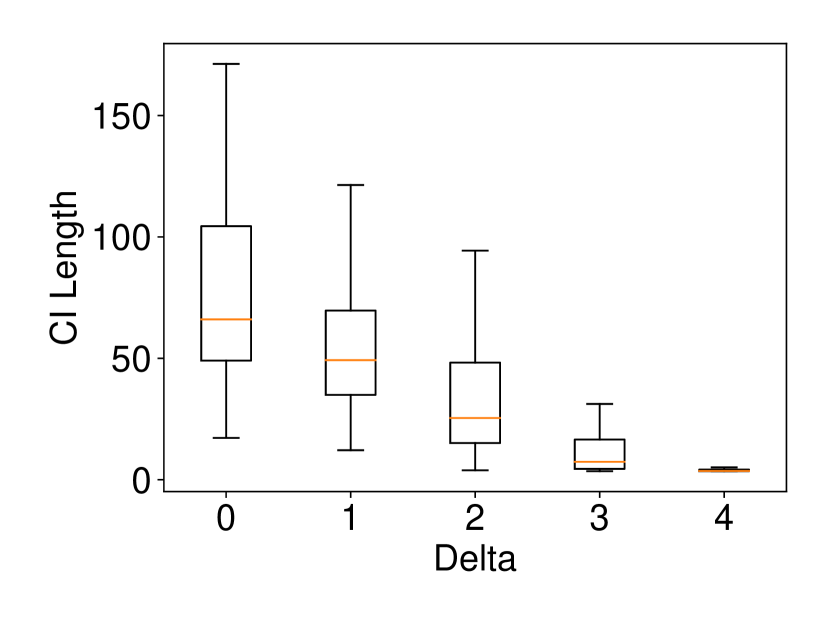
We generated the dataset and with , (element-wise addition), , . Regarding the experiments of coverage guarantee and CI length, we set and ran 120 trials for each . In regard to the experiments of computational cost, we set and ran 10 trials for each . The results are shown in Figure 2. In the left plot, the naive CI can not properly guarantee the coverage property while the proposed selective CI does. The results in the middle plot indicate that the larger the true distance between and , the shorter selective CI we obtain. The right plot shows that the proposed method also has reasonable computational cost.
5.1.2 Multi-dimensional case ()
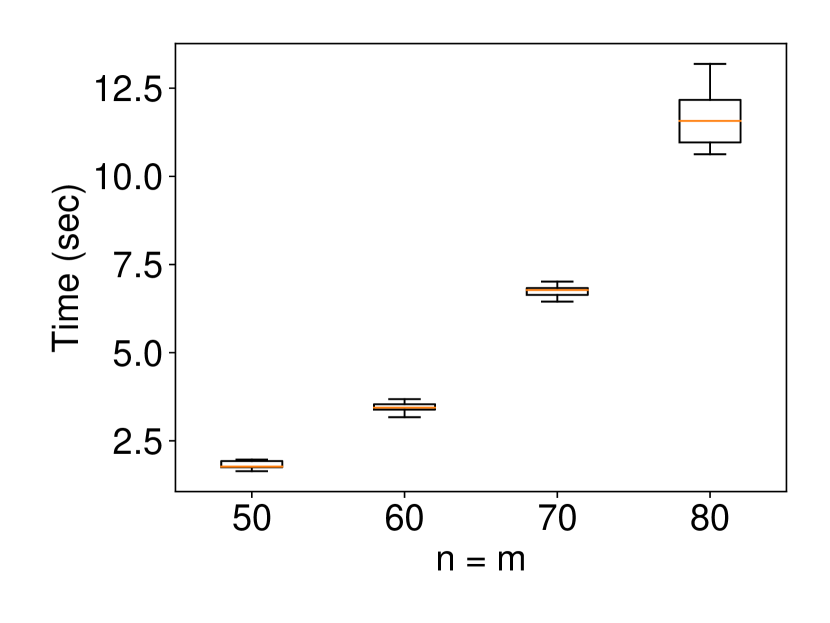
We generated the dataset with and with (element-wise addition). Similar to the univariate case, we set and ran 120 trials for each for the experiments of coverage guarantee and CI length as well as setting and ran 10 trials for each for the experiments of computational cost. The results are shown in Figure 3. The interpretation of the results is similar and consistent with the univariate case.
5.1.3 Robustness of the proposed selective CI in terms of coverage guarantee
We additionally demonstrate the robustness of the proposed selective CI in terms of coverage guarantee by considering the following cases:
-
•
Non-normal noise: we considered the noises and following the Laplace distribution, skew normal distribution (skewness coefficient: ), and distribution.
-
•
Unknown variance: we considered the case in which the variance of the noises was also estimated from the data.
The dataset and were generated with , . We set and ran 120 trials for each . We confirmed that our selective CI maintained good performance in terms of coverage guarantee. The results are shown in Figure 4.
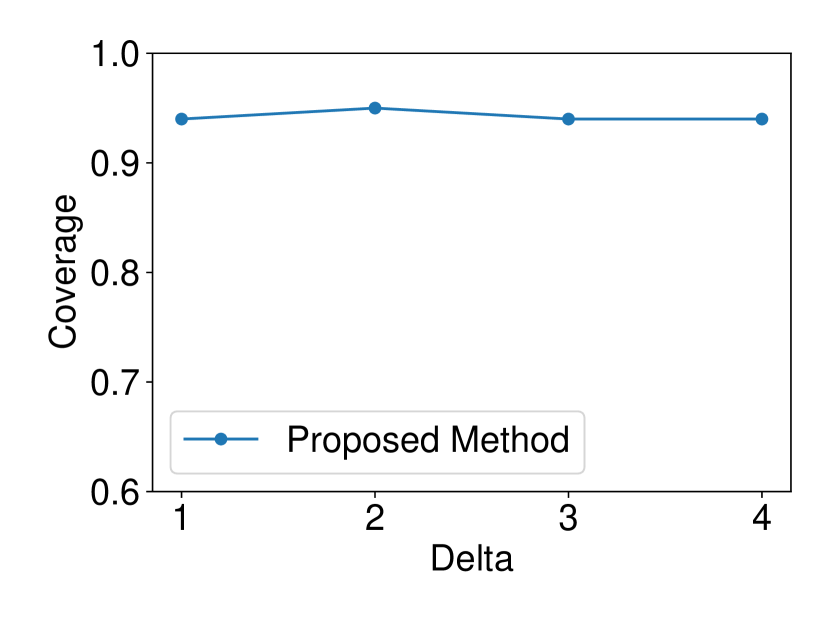
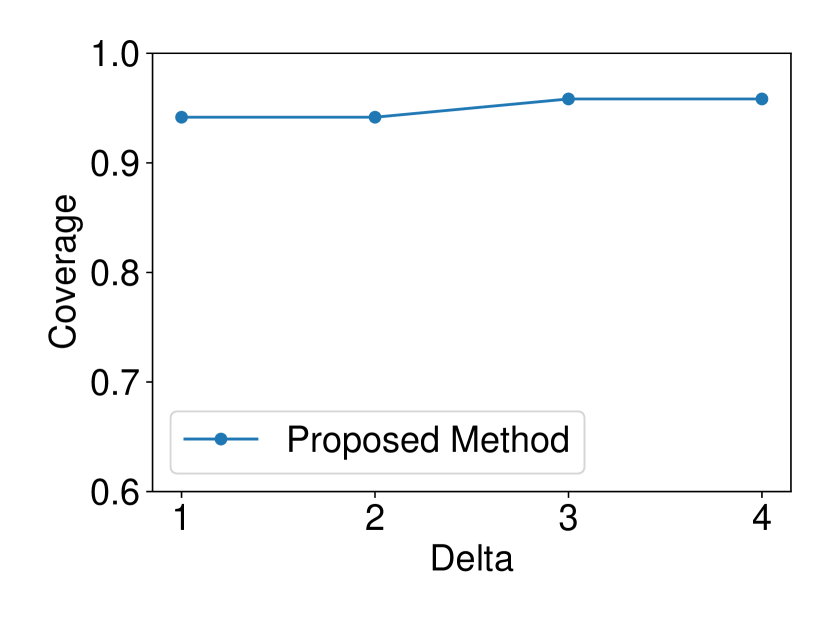
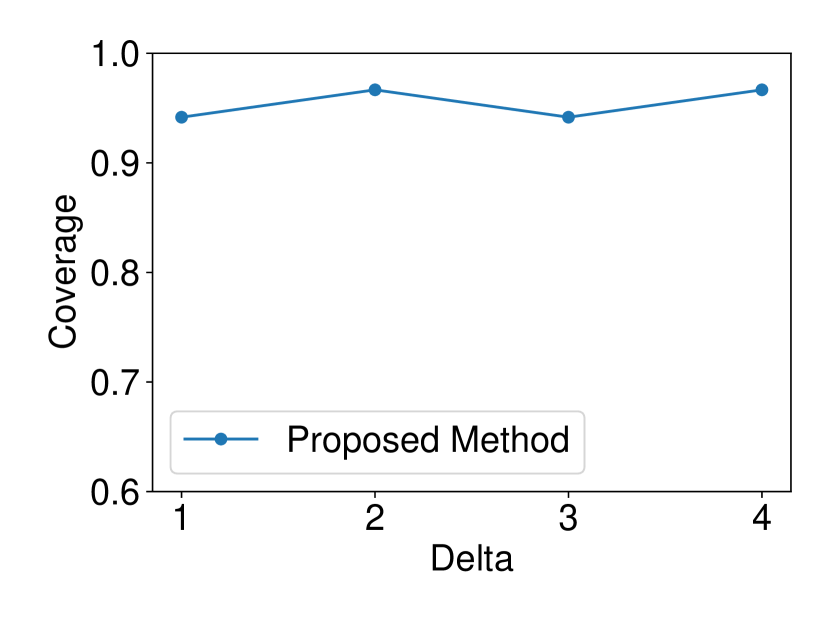
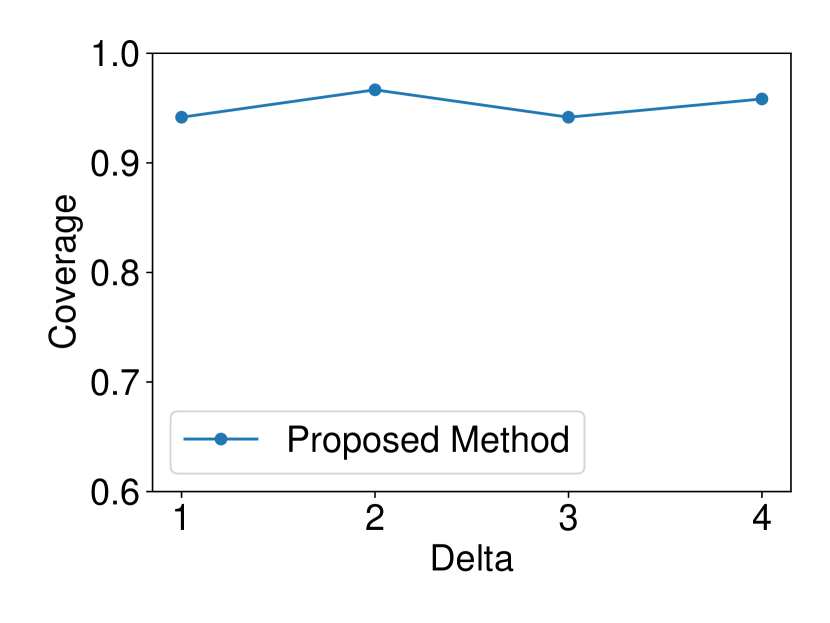
5.1.4 Comparison with asymptotic method in Imaizumi et al. (2019)
The authors of Imaizumi et al. (2019) provided us their code of computing the -value in hypothesis testing framework. Therefore, we conducted the comparisons in terms of false positive rate (FPR) control and true positive rate (TPR). Although we mainly focused on the CI in the previous sections, the corresponding hypothesis testing problem is defined as follows:
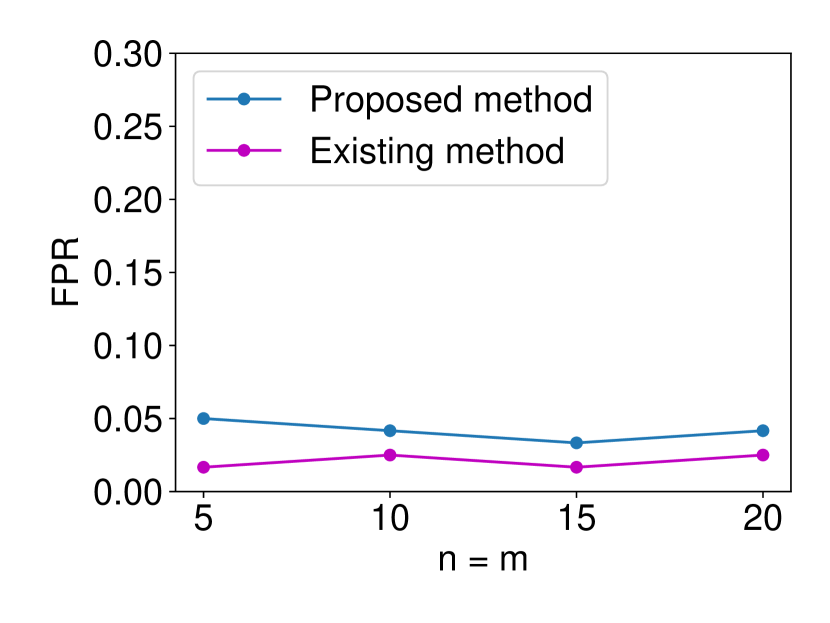
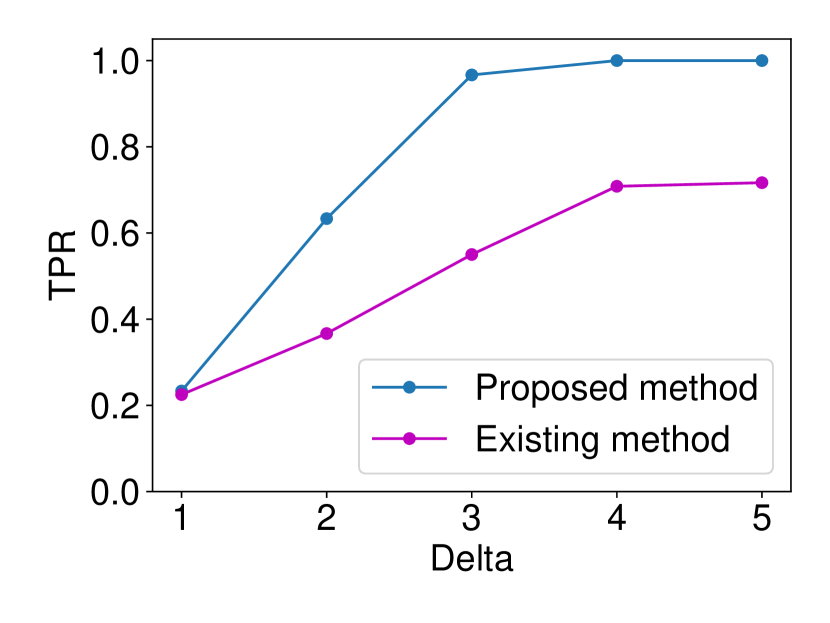
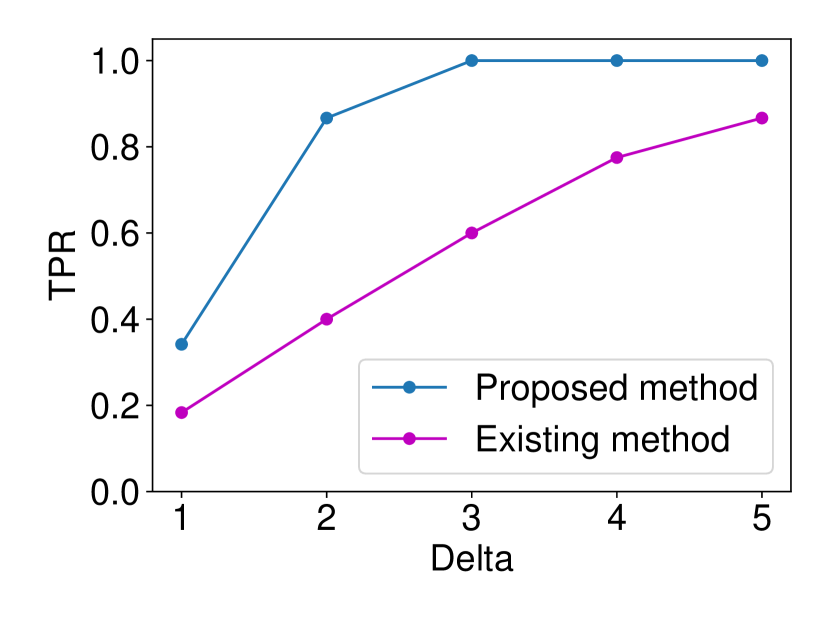
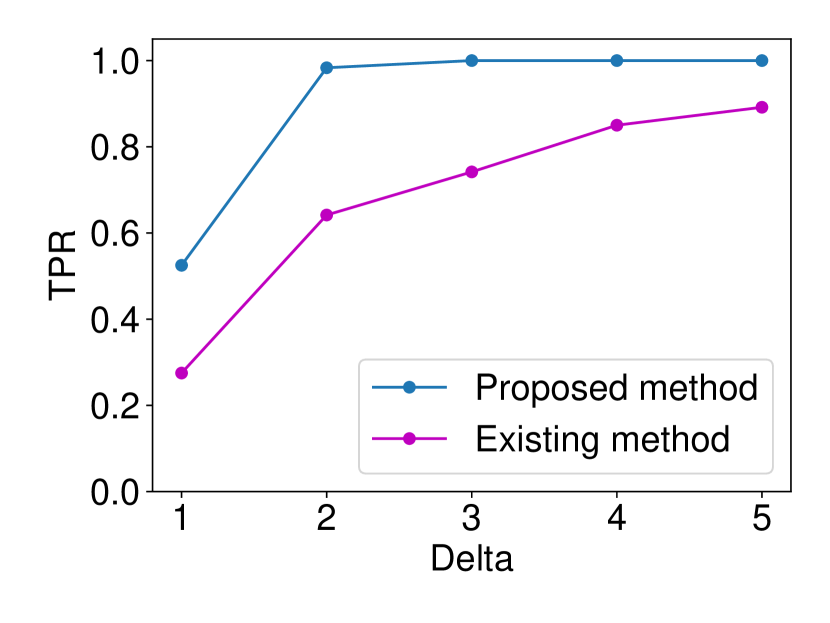
The details are presented in Appendix A. We generated the dataset and with , (element-wise addition), , . Regarding the FPR experiments, we set and and ran 120 trials for each . In regard to the TPR experiments, we set and ran 120 trials for each . The results are shown in Figure 5. In terms for FPR control, both methods could successfully control the FPR under . However, in terms of TPR, the proposed method outperformed the existing asymptotic one in all the cases. As observed in Figure 5 (a), the existing method is conservative in the sense that the FPR is smaller than the specified significance level = 0.05. As a consequence of this conservativeness, the power of their method was consistently lower than ours. Such a phenomenon is commonly observed in approximate statistical inference.
5.2 Real Data Experiment
In this section, we evaluate the proposed selective CI on four real-world datasets. We used Iris dataset, Wine dataset, Breast Cancer dataset which are available in the UCI machine learning repository, and Lung Cancer dataset 444We used dataset Lung_GSE7670 which is available at https://sbcb.inf.ufrgs.br/cumida. (Feltes et al., 2019). The experiments were conducted with the following settings:
-
•
Setting 1: For each pair of classes in the dataset:
-
–
Randomly select instances from each class. Here, each instance is represented by a -dimensional vector where is the number of features.
-
–
Compute the selective CI.
-
–
Repeat the above process up to 120 times.
-
–
-
•
Setting 2: Given a dataset with two classes C1 and C2, we either chose instances from C1 and instances from C2 ( and are from different classes); or both and from either C1 or C2 ( and are from the same class). Then, we compute the selective CI. We repeated this process up to 120 times.
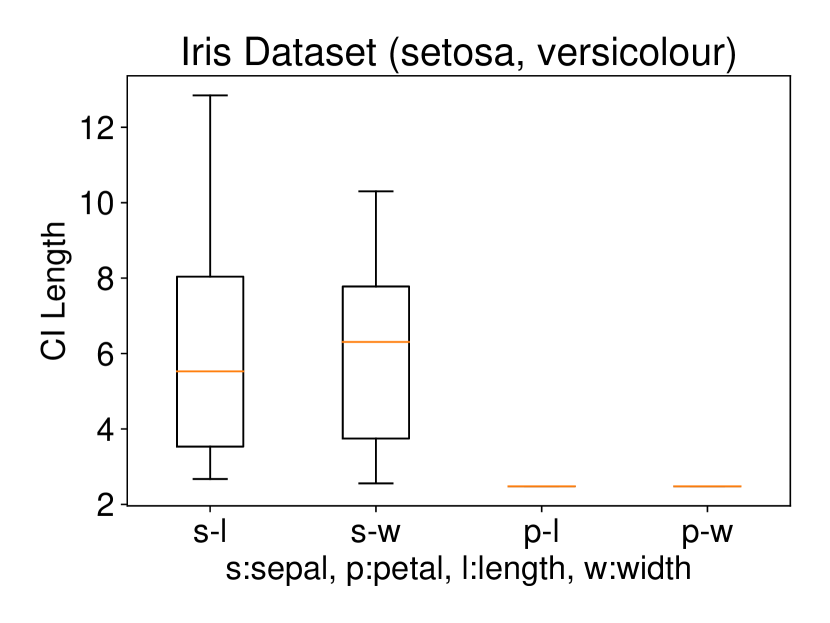
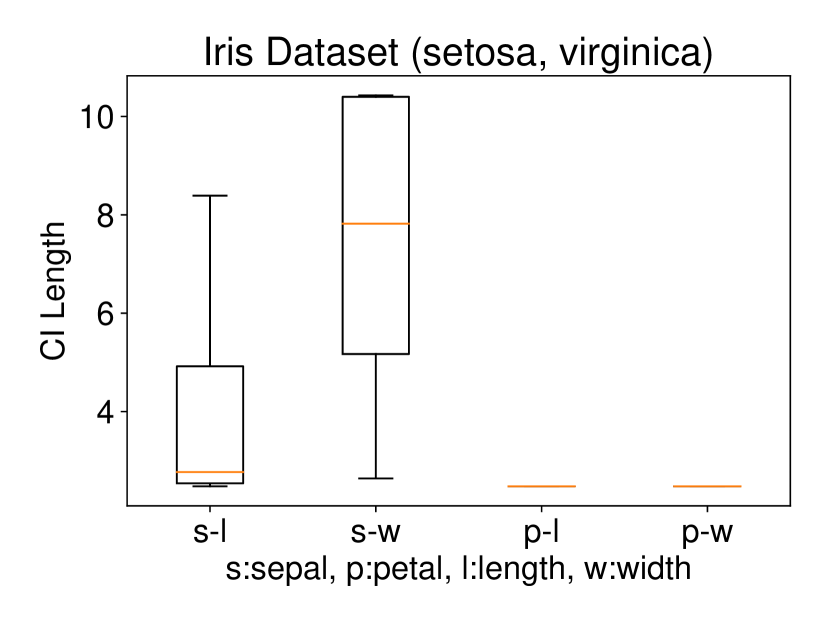
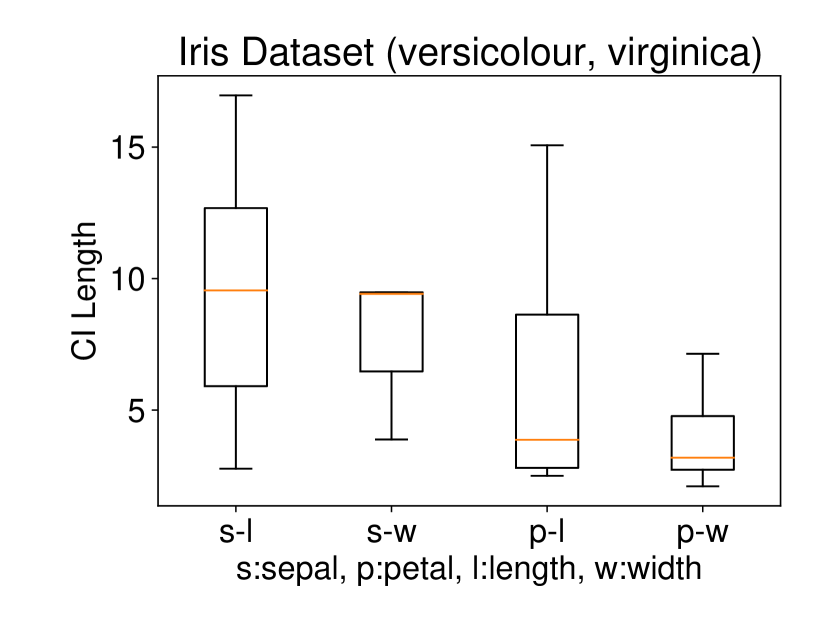
5.2.1 Univariate case () with Setting 1
We conducted the experiments on Iris dataset which contains three classes: Iris Setosa (C1), Iris Versicolour (C2), and Iris Virginica (C3). This dataset also contains four features: sepal length (s-l), sepal width (s-w), petal length (p-l), and petal width (p-w). We ran the procedure described in Setting 1 on each individual feature. The results are shown in Figure 6. In all three plots of this figure, the two features p-l and p-w always have the shortest CI length among the four features which indicates that these two features are informative to discriminate between the classes. Besides, the results of Figure 6 are also consistent with the results obtained after plotting the histogram of each feature in each class. In other words, the farther the two histograms, the smaller the length of selective CI.
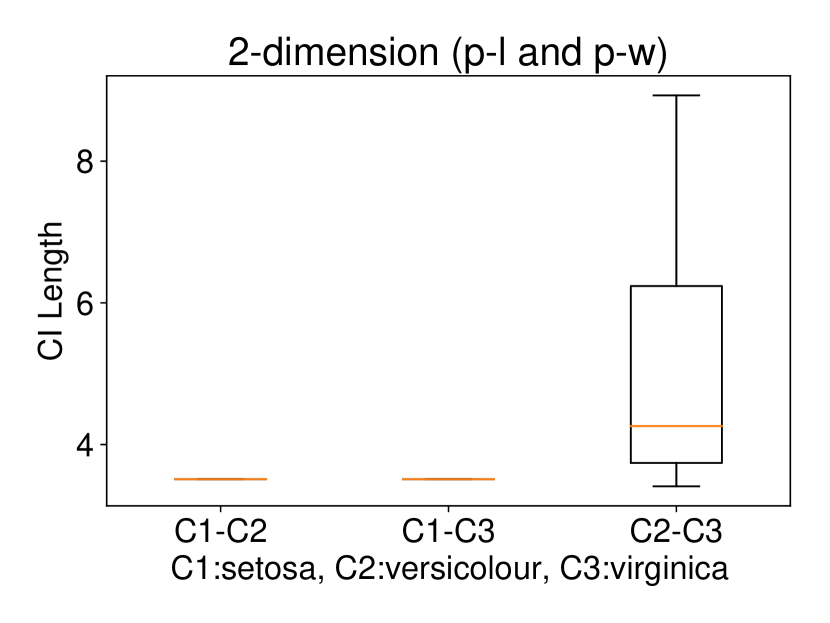
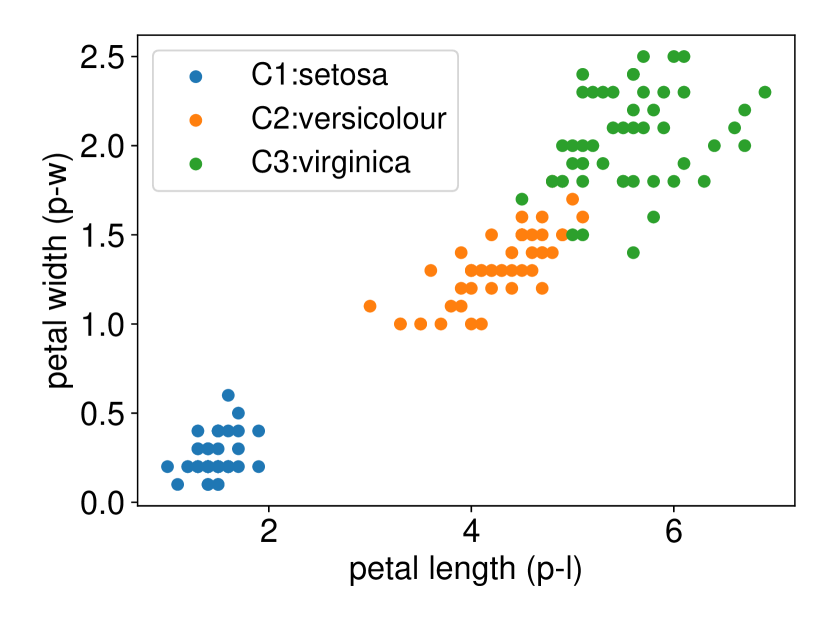
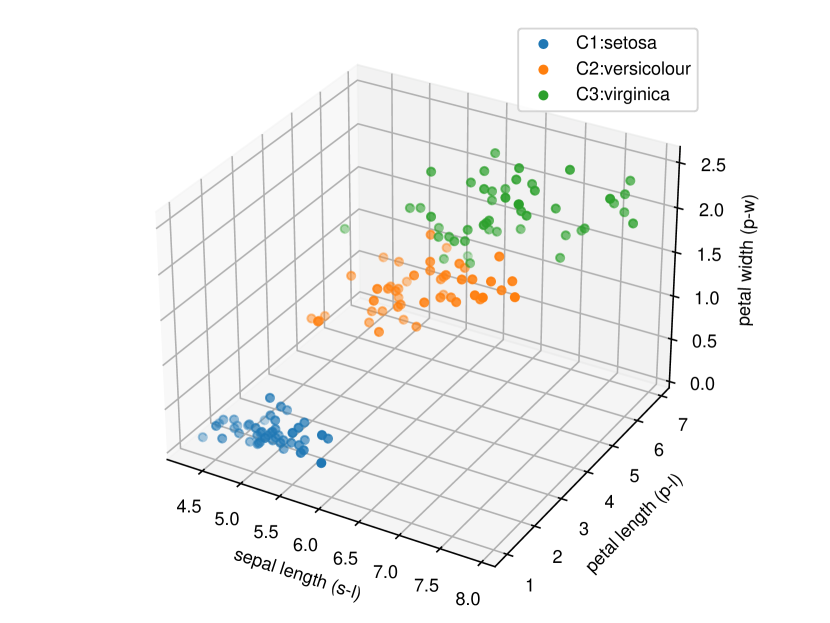
5.2.2 Multi-dimensional case () with Setting 1
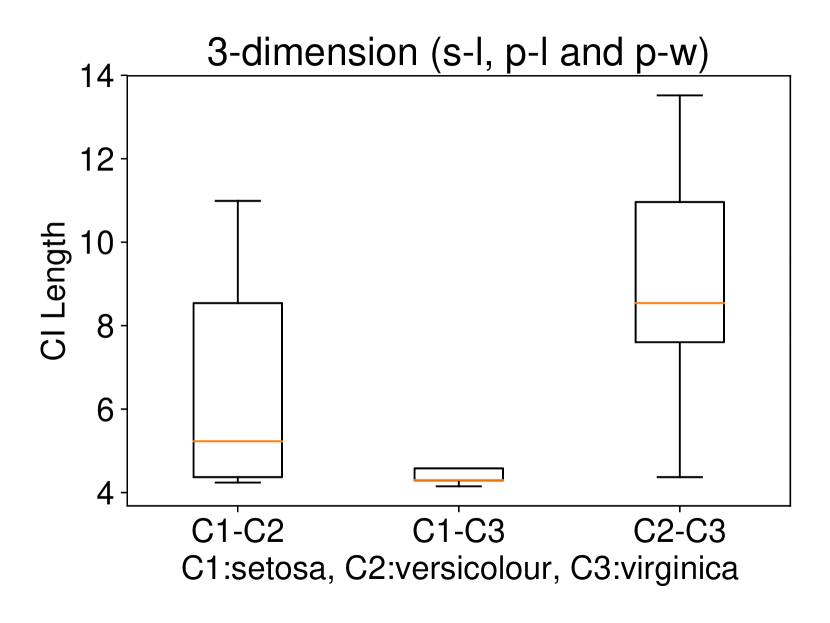
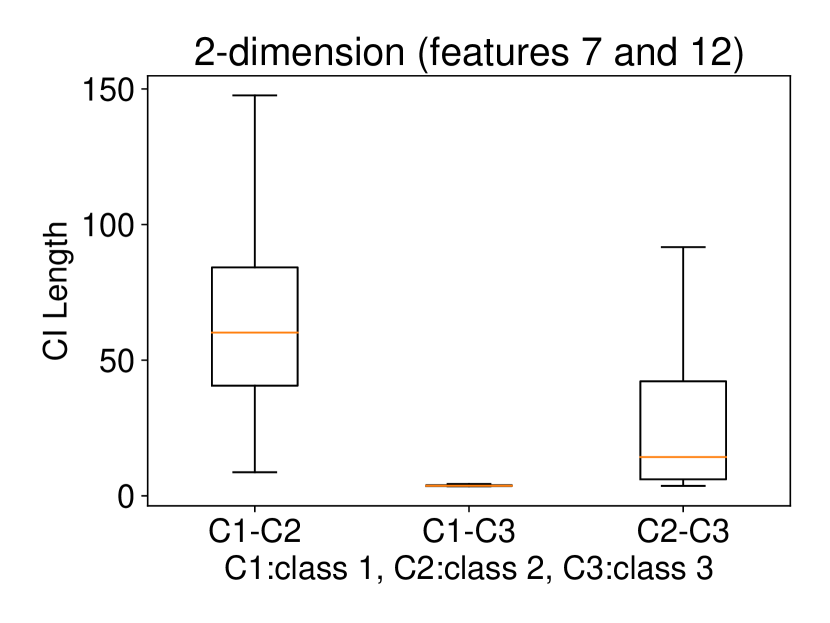
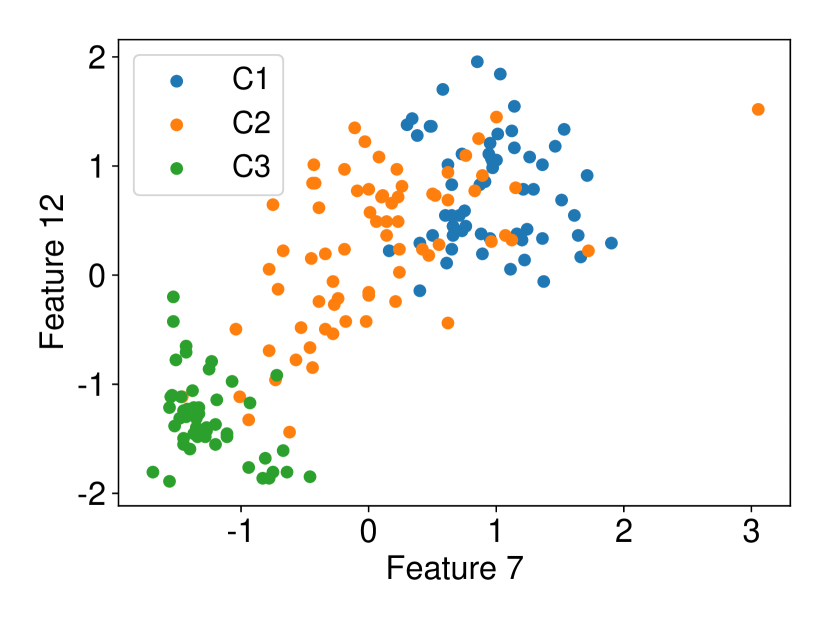
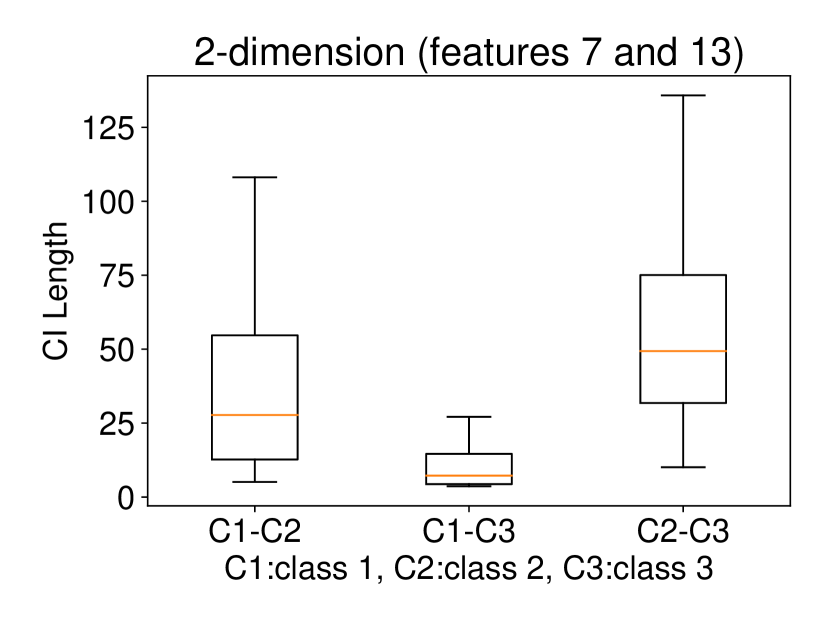
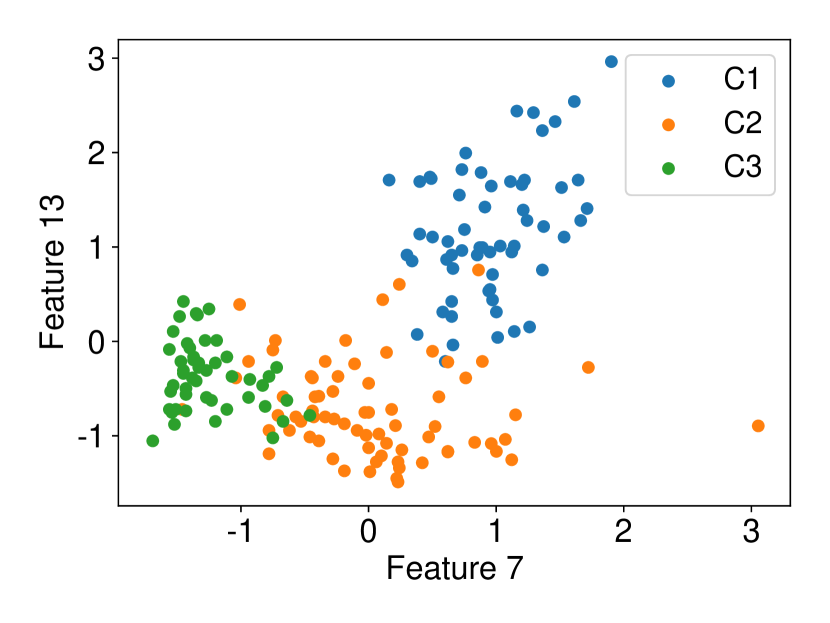
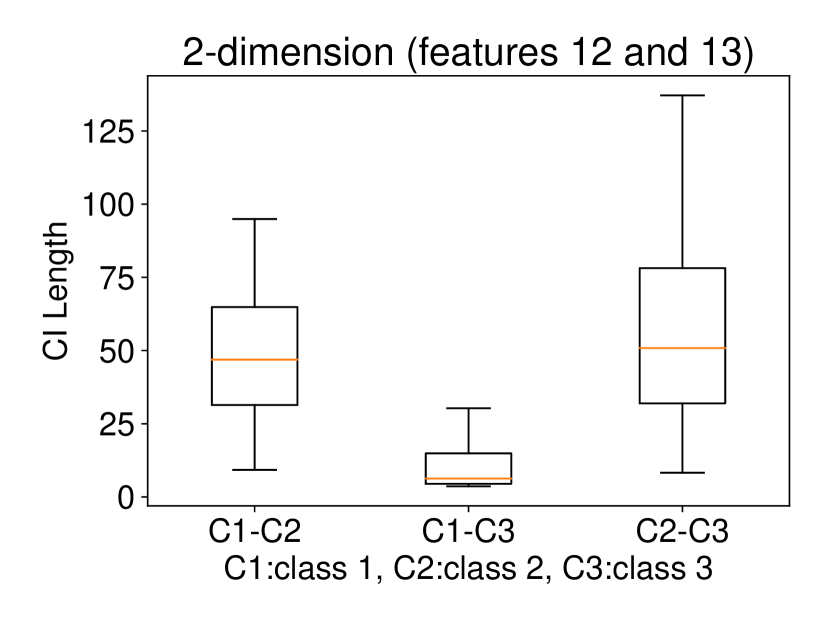
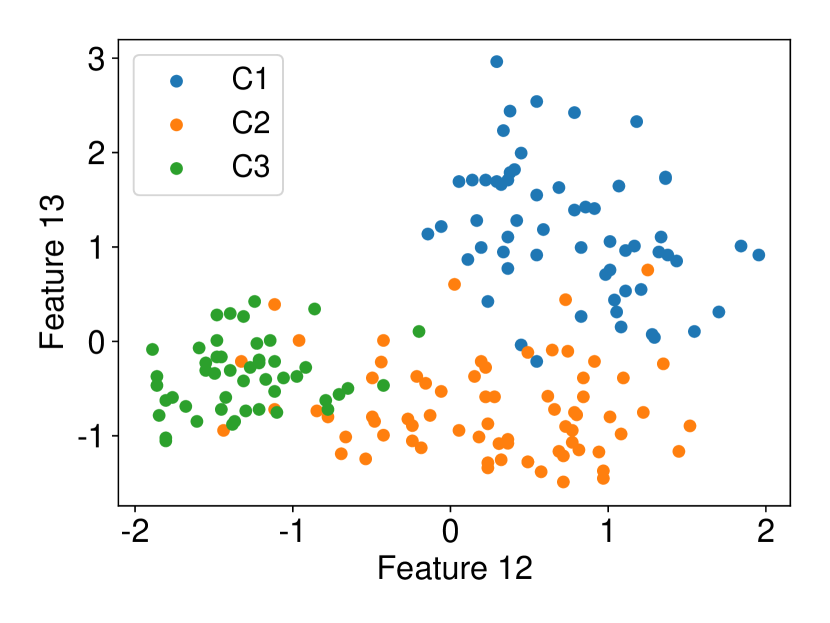
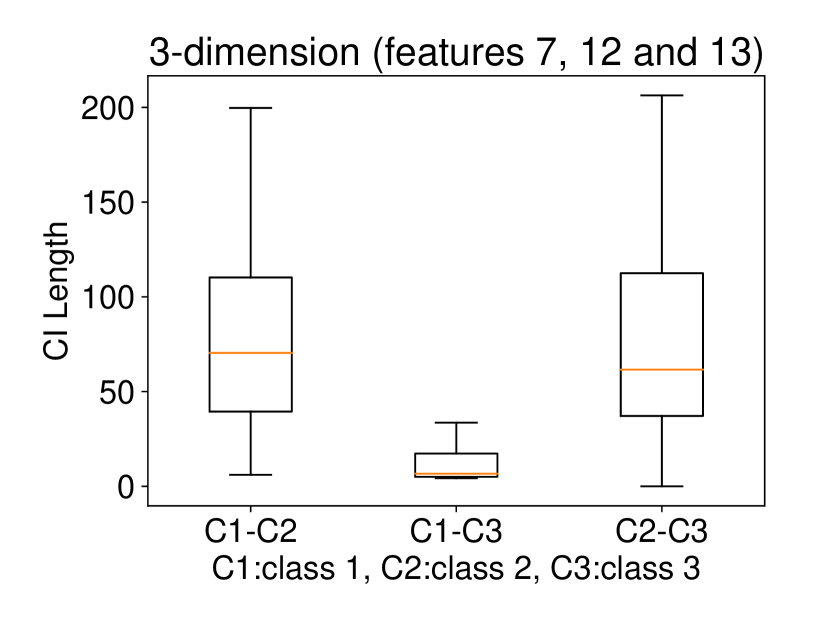
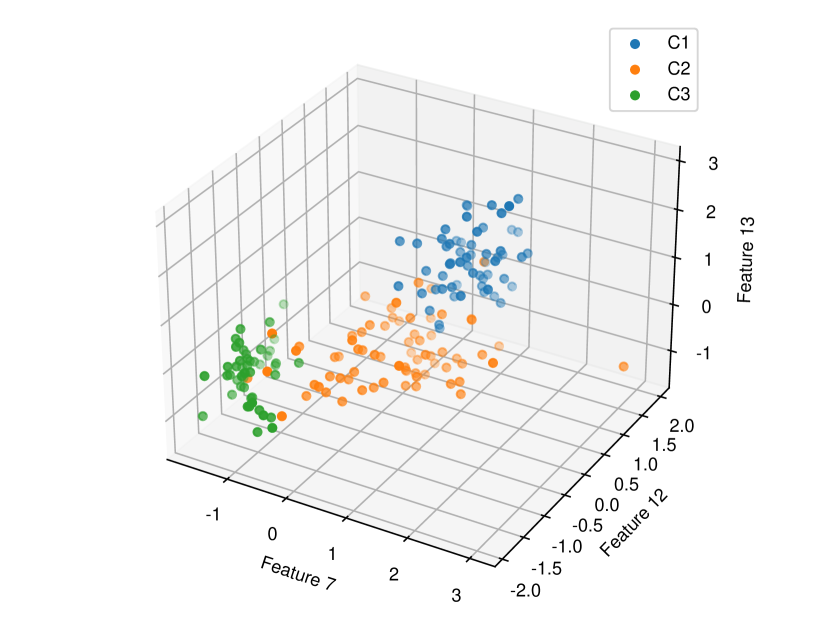
Regarding the experiments on Iris dataset in multi-dimensional case, we chose two features p-l and p-w when and additionally include feature s-l when . The results are shown in Figure 7. In each sub-plot, we show the results of the length of selective CI and the corresponding scatter plot which is used to verify the CI length results. For example, in Figure 7a, it is obvious that the distance between C1 and C2 as well as the distance between C1 and C3 are larger than the distance between C2 and C3 by seeing the scatter plot. Therefore, the CI lengths of C1-C2 and C1-C3 tend to be smaller than that of C2-C3. Besides, we also additionally conducted experiments on Wine dataset. This dataset contains 3 classes of wine and 13 features. In the case of , we conducted the experiments on each pair features in the set (feature 7: flavanoids, features 12: od280/od315 of diluted wines, feature 13: proline). In the case of , we conducted the experiments on both three features. The results are shown in Figure 8. In general, the results of CI length are consistent with the scatter plots, i.e., the farther the scatter plots between two classes, the smaller the length of selective CI.
5.2.3 Multi-dimensional case with Setting 2
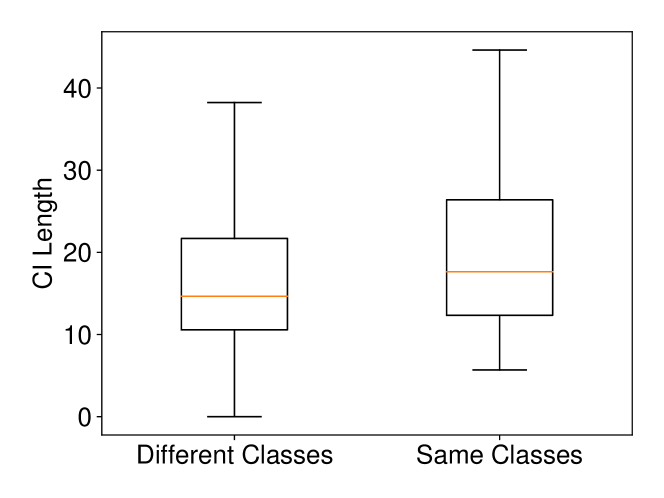
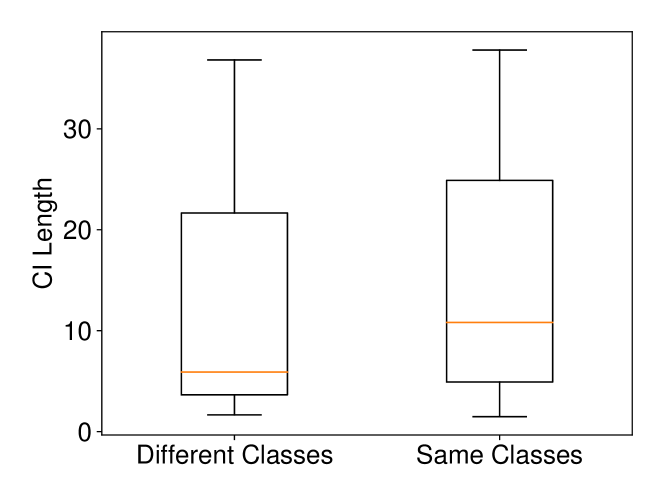
We conducted experiments on Breast Cancer and Lung Cancer datasets. In Breast Cancer dataset, there are two classes (malignant and benign) and features. In Lung Cancer dataset, there are two classes (normal and adenocarcinoma) and we choose (we selected the top 1,000 genes which have the largest standard deviations as it is commonly done in the literature). The results on these datasets with Setting 2 are shown in Figure 9. The results are consistent with the intuitive expectation. When and are from different classes, the Wasserstein distance tends to be larger than the one computed when and are from the same class. Therefore, the CI for the Wasserstein distance in the case of different classes is shorter than the one computed in the case of same class. In other words, the larger the Wasserstein distance is, the shorter the CI becomes.
6 Conclusion
In this paper, we present an exact (non-asymptotic) statistical inference method for the Wasserstein distance. We first introduce the problem setup and present the proposed method for univariate case. We next provide the extension to multi-dimensional case. We finally conduct the experiments on both synthetic and real-world datasets to evaluate the performance of our method. To our knowledge, this is the first method that can provide a valid confidence interval (CI) for the Wasserstein distance with finite-sample coverage guarantee. We believe this study is an important contribution toward reliable ML, which is one of the most critical issues in the ML community.
References
- Arjovsky et al. [2017] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pages 214–223. PMLR, 2017.
- Bernton et al. [2017] E. Bernton, P. E. Jacob, M. Gerber, and C. P. Robert. Inference in generative models using the wasserstein distance. arXiv preprint arXiv:1701.05146, 1(8):9, 2017.
- Chen and Bien [2019] S. Chen and J. Bien. Valid inference corrected for outlier removal. Journal of Computational and Graphical Statistics, pages 1–12, 2019.
- Del Barrio et al. [1999] E. Del Barrio, J. A. Cuesta-Albertos, C. Matrán, and J. M. Rodríguez-Rodríguez. Tests of goodness of fit based on the l2-wasserstein distance. Annals of Statistics, pages 1230–1239, 1999.
- Del Barrio et al. [2019] E. Del Barrio, P. Gordaliza, H. Lescornel, and J.-M. Loubes. Central limit theorem and bootstrap procedure for wasserstein’s variations with an application to structural relationships between distributions. Journal of Multivariate Analysis, 169:341–362, 2019.
- Duy and Takeuchi [2021] V. N. L. Duy and I. Takeuchi. More powerful conditional selective inference for generalized lasso by parametric programming. arXiv preprint arXiv:2105.04920, 2021.
- Duy et al. [2020a] V. N. L. Duy, S. Iwazaki, and I. Takeuchi. Quantifying statistical significance of neural network representation-driven hypotheses by selective inference. arXiv preprint arXiv:2010.01823, 2020a.
- Duy et al. [2020b] V. N. L. Duy, H. Toda, R. Sugiyama, and I. Takeuchi. Computing valid p-value for optimal changepoint by selective inference using dynamic programming. In Advances in Neural Information Processing Systems, 2020b.
- Evans and Matsen [2012] S. N. Evans and F. A. Matsen. The phylogenetic kantorovich–rubinstein metric for environmental sequence samples. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 74(3):569–592, 2012.
- Feltes et al. [2019] B. C. Feltes, E. B. Chandelier, B. I. Grisci, and M. Dorn. Cumida: an extensively curated microarray database for benchmarking and testing of machine learning approaches in cancer research. Journal of Computational Biology, 26(4):376–386, 2019.
- Fithian et al. [2014] W. Fithian, D. Sun, and J. Taylor. Optimal inference after model selection. arXiv preprint arXiv:1410.2597, 2014.
- Frogner et al. [2015] C. Frogner, C. Zhang, H. Mobahi, M. Araya-Polo, and T. Poggio. Learning with a wasserstein loss. arXiv preprint arXiv:1506.05439, 2015.
- Hyun et al. [2018] S. Hyun, K. Lin, M. G’Sell, and R. J. Tibshirani. Post-selection inference for changepoint detection algorithms with application to copy number variation data. arXiv preprint arXiv:1812.03644, 2018.
- Imaizumi et al. [2019] M. Imaizumi, H. Ota, and T. Hamaguchi. Hypothesis test and confidence analysis with wasserstein distance with general dimension. arXiv preprint arXiv:1910.07773, 2019.
- Kolouri et al. [2017] S. Kolouri, S. R. Park, M. Thorpe, D. Slepcev, and G. K. Rohde. Optimal mass transport: Signal processing and machine-learning applications. IEEE signal processing magazine, 34(4):43–59, 2017.
- Le Duy and Takeuchi [2021] V. N. Le Duy and I. Takeuchi. Parametric programming approach for more powerful and general lasso selective inference. In International Conference on Artificial Intelligence and Statistics, pages 901–909. PMLR, 2021.
- Lee et al. [2016] J. D. Lee, D. L. Sun, Y. Sun, and J. E. Taylor. Exact post-selection inference, with application to the lasso. The Annals of Statistics, 44(3):907–927, 2016.
- Liu et al. [2018] K. Liu, J. Markovic, and R. Tibshirani. More powerful post-selection inference, with application to the lasso. arXiv preprint arXiv:1801.09037, 2018.
- Loftus and Taylor [2015] J. R. Loftus and J. E. Taylor. Selective inference in regression models with groups of variables. arXiv preprint arXiv:1511.01478, 2015.
- Murty [1983] K. Murty. Linear Programming. Wiley, 1983. ISBN 9780471097259.
- Ni et al. [2009] K. Ni, X. Bresson, T. Chan, and S. Esedoglu. Local histogram based segmentation using the wasserstein distance. International journal of computer vision, 84(1):97–111, 2009.
- Ramdas et al. [2017] A. Ramdas, N. G. Trillos, and M. Cuturi. On wasserstein two-sample testing and related families of nonparametric tests. Entropy, 19(2):47, 2017.
- Sugiyama et al. [2021a] K. Sugiyama, V. N. Le Duy, and I. Takeuchi. More powerful and general selective inference for stepwise feature selection using homotopy method. In International Conference on Machine Learning, pages 9891–9901. PMLR, 2021a.
- Sugiyama et al. [2021b] R. Sugiyama, H. Toda, V. N. L. Duy, Y. Inatsu, and I. Takeuchi. Valid and exact statistical inference for multi-dimensional multiple change-points by selective inference. arXiv preprint arXiv:2110.08989, 2021b.
- Suzumura et al. [2017] S. Suzumura, K. Nakagawa, Y. Umezu, K. Tsuda, and I. Takeuchi. Selective inference for sparse high-order interaction models. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3338–3347. JMLR. org, 2017.
- Tanizaki et al. [2020] K. Tanizaki, N. Hashimoto, Y. Inatsu, H. Hontani, and I. Takeuchi. Computing valid p-values for image segmentation by selective inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9553–9562, 2020.
- Tibshirani et al. [2016] R. J. Tibshirani, J. Taylor, R. Lockhart, and R. Tibshirani. Exact post-selection inference for sequential regression procedures. Journal of the American Statistical Association, 111(514):600–620, 2016.
- Tsukurimichi et al. [2021] T. Tsukurimichi, Y. Inatsu, V. N. L. Duy, and I. Takeuchi. Conditional selective inference for robust regression and outlier detection using piecewise-linear homotopy continuation. arXiv preprint arXiv:2104.10840, 2021.
- Villani [2009] C. Villani. Optimal transport: old and new, volume 338. Springer, 2009.
- Yang et al. [2016] F. Yang, R. F. Barber, P. Jain, and J. Lafferty. Selective inference for group-sparse linear models. In Advances in Neural Information Processing Systems, pages 2469–2477, 2016.
Appendix A Proposed method in hypothesis testing framework
We present the proposed method in the setting of hypothesis testing and consider the case when the cost matrix is defined by using squared distance.
Cost matrix. We define the cost matrix of pairwise distances (squared distance) between elements of and as
| (36) |
Then, the vectorized form of can be defined as
| (37) |
where is defined as in (5) and the operation is element-wise product.
The Wasserstein distance. By solving LP with the cost vector defined in (37) on the observed data and , we obtain the set of selected basic variables
Then, the Wasserstein distance can be re-written as (we denote for notational simplicity)
Hypothesis testing. Our goal is to test the following hypothesis:
Unfortunately, it is technically difficult to directly test the above hypothesis. Therefore, we propose to test the following equivalent one:
where is defined as in (5) and .
Conditional SI. To test the aforementioned hypothesis, we consider the following selective -value:
where the conditional selection event is defined as
Our next task is to identify the conditional data space whose data satisfies .
Characterization of the conditional data space. Similar to the discussion in §3, the data is restricted on the line due to the conditioning on the nuisance component . Then, the conditional data space is defined as
where
The remaining task is to construct . We can decompose into two separate sets as , where
The construction of is as follows (we denote for notational simplicity):
which can be obtained by solving the system of linear inequalities. Next, we present the identification of . Because we use squared distance to define the cost matrix, the LP with the parametrized data is written as follows:
where
and and are the same as in (7). By fixing as the optimal basic index set, the relative cost vector w.r.t to the set of non-basic variables is defines as
where
The requirement for to be the optimal basis index set is (i.e., the cost in minimization problem will never decrease when the non-basic variables become positive and enter the basis). Finally, the set can be defined as
which can be obtained by solving the system of quadratic inequalities.
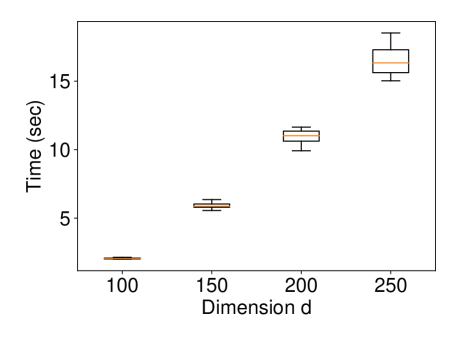
Appendix B Experiment on High-dimensional Data
We generated the dataset with and with (element-wise addition). We set , and ran 10 trials for each . The results in Figure 10 show that the proposed method still has reasonable computational time.