Expected Sliced Transport Plans
Abstract
The optimal transport (OT) problem has gained significant traction in modern machine learning for its ability to: (1) provide versatile metrics, such as Wasserstein distances and their variants, and (2) determine optimal couplings between probability measures. To reduce the computational complexity of OT solvers, methods like entropic regularization and sliced optimal transport have been proposed. The sliced OT framework improves efficiency by comparing one-dimensional projections (slices) of high-dimensional distributions. However, despite their computational efficiency, sliced-Wasserstein approaches lack a transportation plan between the input measures, limiting their use in scenarios requiring explicit coupling. In this paper, we address two key questions: Can a transportation plan be constructed between two probability measures using the sliced transport framework? If so, can this plan be used to define a metric between the measures? We propose a "lifting" operation to extend one-dimensional optimal transport plans back to the original space of the measures. By computing the expectation of these lifted plans, we derive a new transportation plan, termed expected sliced transport (EST) plans. We prove that using the EST plan to weight the sum of the individual Euclidean costs for moving from one point to another results in a valid metric between the input discrete probability measures. We demonstrate the connection between our approach and the recently proposed min-SWGG, along with illustrative numerical examples that support our theoretical findings.
1 Introduction
The optimal transport (OT) problem (Villani, 2009) seeks the most efficient way to transport a distribution of mass from one configuration to another, minimizing the cost associated with the transportation process. It has found diverse applications in machine learning due to its ability to provide meaningful distances, i.e., the Wasserstein distances (Peyré & Cuturi, 2019), between probability distributions, with applications ranging from supervised learning (Frogner et al., 2015) to generative modeling (Arjovsky et al., 2017). Beyond merely measuring distances between probability measures, the optimal transportation plan obtained from the OT problem provides correspondences between the empirical samples of the source and target distributions, which are used in various applications, including domain adaptation (Courty et al., 2014), positive-unlabeled learning (Chapel et al., 2020), texture mixing (Rabin et al., 2011), color transfer (Rabin et al., 2014), image analysis (Basu et al., 2014), and even single-cell and spatial omics (Bunne et al., 2024), to name a few.
One of the primary challenges in applying the OT framework to large-scale problems is its computational complexity. Traditional OT solvers for discrete measures typically scale cubically with the number of samples (i.e., the support size) (Kolouri et al., 2017). This computational burden has spurred significant research efforts to accelerate OT computations. Various approaches have been developed to address this challenge, including entropic regularization (Cuturi, 2013), multiscale methods (Schmitzer, 2016), and projection-based techniques such as sliced-Wasserstein distances (Rabin et al., 2011) and robust subspace OT (Paty & Cuturi, 2019). Each of these methods has its own advantages and limitations.
For instance, the entropic regularized OT is solved via an iterative algorithm (i.e., the Sinkhorn algorithm) with quadratic computational complexity per iteration. However, the number of iterations required for convergence typically increases as the regularization parameter decreases, which can offset the computational benefits of these methods. Additionally, while entropic regularization interpolates between Maximum-Mean Discrepancy (MMD) (Gretton et al., 2012) and the Wasserstein distance (Feydy et al., 2019), it does not produce a true metric between probability measures. Despite not providing a metric, the entropic OT provides a transportation plan, i.e., soft correspondences, albeit not the optimal one. On the other hand, sliced-Wasserstein distances offer linearithmic computational complexity, enabling the comparison of discrete measures with millions of samples. These distances are also topologically equivalent to the Wasserstein distance and offer statistical advantages, such as better sample complexity (Nadjahi et al., 2020). However, despite their computational efficiency, the sliced-Wasserstein approaches do not provide a transportation plan between the input probability measures, limiting their applicability to problems that require explicit coupling between measures.
In this paper, we address two central questions: First, can a transportation plan be constructed between two probability measures using the sliced transport framework? If so, can the resulting transportation plan be used to define a metric between the two probability measures? Within the sliced transport framework, the "slices" refer to the one-dimensional marginals of the source and target probability measures, for which an optimal transportation plan is computed. Crucially, this optimal transportation plan applies to the marginals (i.e., one-dimensional probability measures) rather than the original measures. To derive a transportation plan between the source and target measures, this optimal plan for the marginals must be "lifted" back to the original space.
For discrete measures with equal support size, , and uniform mass, , the optimal transportation plan between marginals is represented by a correspondence matrix, specifically an permutation matrix. Previous works have used directly the correspondence matrix obtained for a slice as a transportation plan in the original space of measures (Rowland et al., 2019; Mahey et al., 2023). This paper provides a holistic and rigorous analysis of this problem for general discrete probability measures.
Our specific contributions in this paper are:
-
1.
Introducing a computationally efficient transportation plan between discrete probability measures, the Expected Sliced Transport plan.
-
2.
Providing a distance for discrete probability measures, the Expected Sliced Transport (EST) distance.
-
3.
Offering both a theoretical proof and an experimental visualization showing that the EST distance is equivalent to the Wasserstein distance (and to weak∗ convergence) when applied to discrete measures.
-
4.
Demonstrating the performance of the proposed distance and the transportation plan in diverse applications, namely interpolation and classification.
2 Expected Sliced Transport
2.1 Preliminaries
Given a probability measure and a unit vector , we define to be the -slice of the measure , where denotes the standard inner product in . For any pair of probability measures with finite -moment () , one can pose the following two Optimal Transport (OT) problems: On the one hand, consider the classical OT problem, which gives rise to the -Wasserstein metric:
| (1) |
where denotes the Euclidean norm in and is the subset of all probability measures with marginals and . On the other hand, for a given , consider the one-dimensional OT problem:
| (2) |
In this case, since the measures can be regarded as one-dimensional probabilities in , there exists a unique optimal transport plan, which we denote by (see, for e.g., (Villani, 2021, Thm. 2.18, Remark 2.19)], (Maggi, 2023, Thm. 16.1)).
2.2 On slicing and lifting transport plans
In this section, given discrete probability measures , we describe the process of slicing them according to a direction and lifting the optimal transportation plan , which solves the 1-dimensional OT problem (2), to get a plan in . Thus, we obtain a new measure, denoted as , in with first and second marginal and , respectively. For clarity, we first describe the process for discrete uniform measures and then extend it to any pair of discrete measures.
2.2.1 On slicing and lifting transport plans for uniform discrete measures
Given , consider the space of uniform discrete probability measures concentrated at particles in , that is,
Let , where and denotes a Dirac measure located at (respectively for ). Let us denote by the uniform measure on the hypersphere . In this case, the -slice of is represented by , and similarly for . Let denote the symmetric group of all permutations of the elements in the set . Let denote the sorted indices of the projected points and , respectively, that is,
| (3) |
The optimal matching from to for the problem (2) is induced by the assignment
| (4) |
We define the lifted transport map between and by:
| (5) |
Rigorously, is not necessarily a function defined on but on the the labels , as two projected points and could coincide for . As a result, it is more convenient to work with lifted transport plans. Indeed, the matrix given by
| (6) |
encodes the weights of optimal transport plan between and given by
| (7) |
as well as the weights of the lifted transport plan between the original measures and according to the -slice defined by
| (8) |
This new measure has marginals and . While is not necessarily optimal for the OT problem (1) between and , it can be interpreted as a transport plan in which is optimal when projecting and in the direction of . See Figure 1 (a) for a visualization.
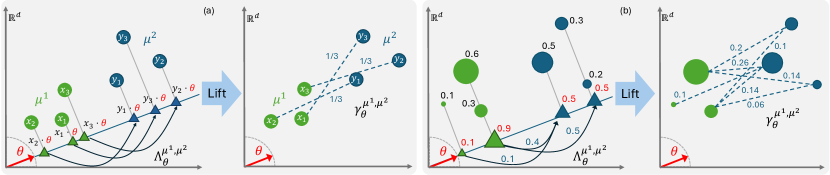
2.2.2 On slicing and lifting transport plans for general discrete measures
Consider discrete measures . In this section, we will use the notation , where for all , for at most countable many points , and . Similarly, for a non-negative density function in with finite or countable support and such that . Given , consider the equivalence relation defined by:
We denote by the equivalence class of . By abuse of notation, we will use interchangeably that is a point in the quotient space , and also the set , which is the orthogonal hyperplane to that intersects . The intended meaning of will be clear from the context. Notice that, geometrically, the quotient space is the line in the direction of .
Now, we interpret the projected measures , as 1-dimensional probability measures in given by , where , and similarly, , where .
Remark 2.1.
Notice that if , then for all , or, equivalently, if , then (where is any ‘representative’ of the class ). Similarly for .
Consider the optimal transport plan between and , which is unique for the OT problem (2) as we are considering 1-dimensional probability measures. Let us define
which allows us to generalize the lifted transport plan given in (6) in the general discrete case:
| (9) |
See Figure 1 (b) for a visualization.
Remark 2.2.
Notice that this lifting process can be performed by starting with any transport plan , but in this article we will always consider the optimal transportation plan, i.e., . The reason why we make this choice if because this will give rise to a metric between discrete probability measures: The EST distance which will be defined in Section 2.3.
Lemma 2.3.
Given general discrete probability measures and in , the discrete measure defined by (9) has marginals and , that is, .
We refer the reader to the appendix for its proof.
2.3 Expected Sliced Transport (EST) for discrete measures
Leveraging on the transport plans described before, in this section we propose a new transportation plan , which will give rise to a new metric in the space of discrete probability measures.
Definition 2.4 (Expected Sliced Transport plan).
Let . For discrete probability measures in , we define the expected sliced transport plan by
| (10) |
that is,
In other words, , where the new weights are given by
Remark 2.5.
Definition 2.6 (Expected Sliced Transport distance).
Let with . We define the Expected Sliced Transport discrepancy for discrete probability measures , in by
| (11) |
where is defined by (10).
Remark 2.7.
Remark 2.8.
Since the EST plan is a transportation plan, we have that
In Appendix B we will show that they define the same topology in the space of discrete probability measures.
Remark 2.9 (EST for discrete uniform measures and the Projected Wasserstein distance).
Consider uniform measures , and for , let be permutations that allow us to order the projected points as in (3). Notice that if , by using the formula (5) for each assignment given and noticing that , we can re-write (11) as
| (13) |
Therefore, we have that the expression for given by (13) coincides with the Projected Wasserstein distance proposed in (Rowland et al., 2019, Definition 3.1). Then, by applying (Rowland et al., 2019, Proposition 3.3), we have that the Expected Sliced Transport discrepancy defined in Equation (13) is a metric on the space . We generalise this in the next theorem.
Theorem 2.10.
The Expected Sliced Transport defined in (11) is a metric in the space of finite discrete probability measures in .
Sketch of the proof of Theorem 2.10.
For the detailed proof, we refer the reader to Appendix A. Here, we present a brief overview of the main ideas and steps involved in the proof.
The symmetry of follows from our construction of the transport plan , which is based on considering a family of optimal 1-d transport plans . The identity of indiscernibles follows essentially from Remark 2.8. To prove the triangle inequality we use the following strategy:
-
1.
We leverage the fact that is a metric for the space of uniform discrete probability measures concentrated at particles in (Rowland et al. (2019)) to prove that is also a metric on the set of measures in which the masses are rationals. To do so, we establish a correspondence between finite discrete measures with rational weights and finite discrete measures with uniform mass (see the last paragraph of Proposition A.7).
-
2.
Given finite discrete measures , we approximate them, in terms of the Total Variation norm, by sequences of probability measures with rational weights supported on the same points as and , respectively. We then turn our attention on how the various plans constructed behave as the increases and show the following convergence results in Total Variation norm:
-
(a)
The sequence converges to .
-
(b)
The sequence converges to .
-
(c)
The sequence converges to .
As a consequence, we obtain
-
(a)
Finally, given three finite discrete measures , we proceed as in point 2 by considering sequences of probability measures with rational weights supported on the same points as , , , respectively, that approximate the original measures in Total Variation, obtaining
where the equalities follows from point 2 and the middle triangle inequality follows from point 1. ∎
3 Experiments
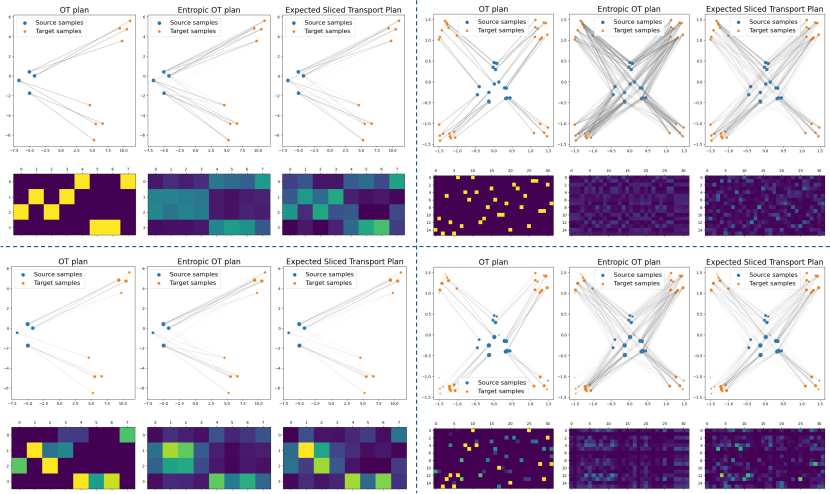
3.1 Comparison of Transportation Plans
Figure 2 illustrates the behavior of different transport schemes: the optimal transport plan for , the transport plan obtained by solving an entropically regularized transportation problem between the source and target probability measures, and the new expected sliced transport plan . We include comparisons with entropic regularization because it is one of the most popular approaches, as it allows for the use of Sinkhorn’s algorithm. From the figure, we observe that while promotes mass splitting, this phenomenon is less pronounced than in the entropically regularized OT scheme. This observation will be revisited in Subsection 3.2.
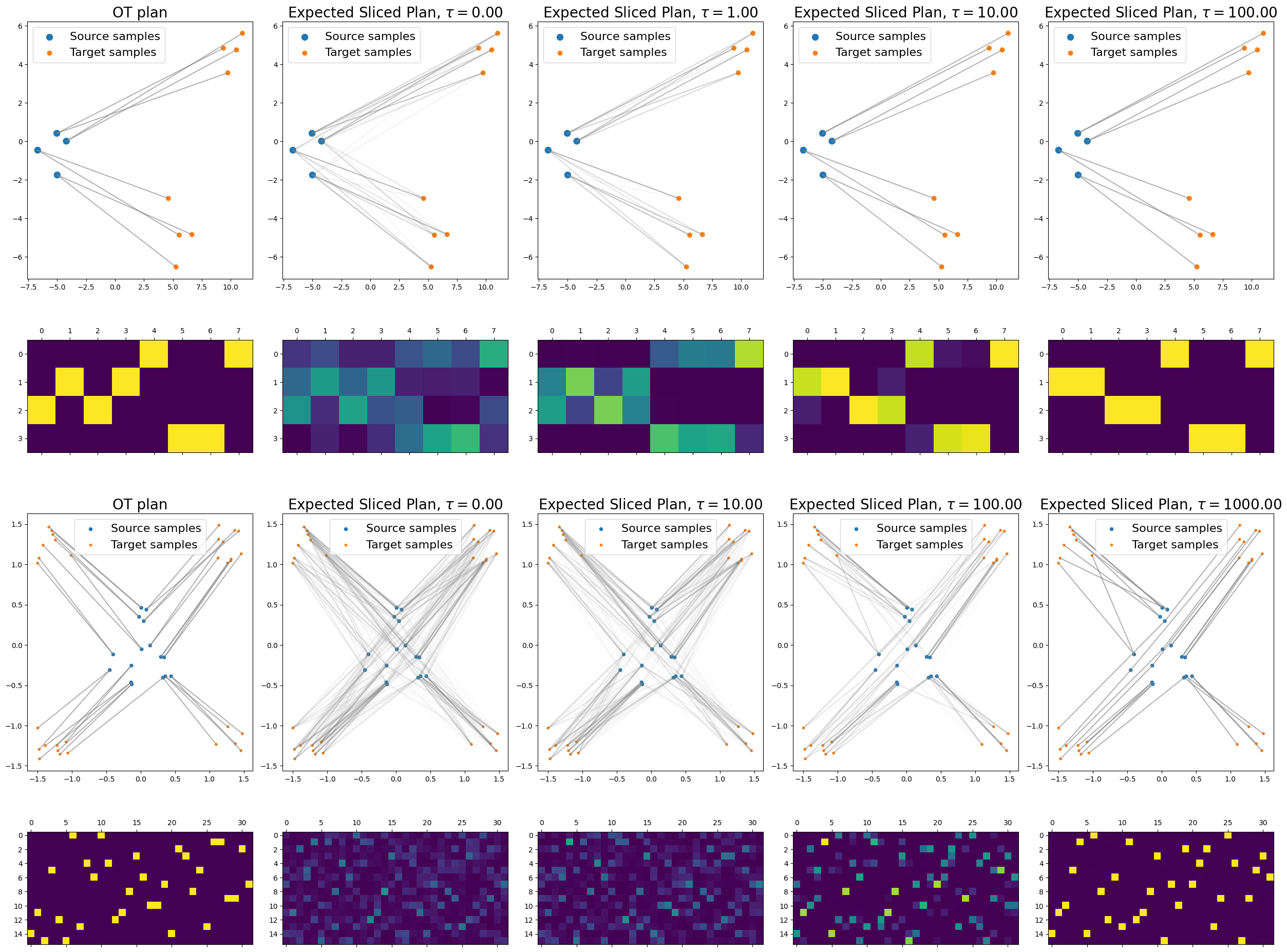

3.2 Temperature approach
Given discrete probability measures, we perform the new expected sliced transportation scheme by using the following averaging measure on the sphere:
| (14) |
where is given by (12), and is a hyperparameter we will refer to as the temperature (note that increasing corresponds to reducing the temperature). If , then . However, when , is a probability measure on with density given by (14), which depends on the source and target measures and . We have chosen this measure because it provides a general parametric framework that interpolates between our proposed scheme with the uniform measure () and min-SWGG (Mahey et al., 2023), as the EST distance approaches min-SWGG when . For the implementations, we use
| (15) |
where represents the number of slices or unit vectors . Figure 3 illustrates that as , the weights used for averaging the lifted transportation plans converge to a one-hot vector, i.e., the slice minimizing dominates, leading to a transport plan with fewer mass splits. For the visualization we have used source and target uniform probability measures concentrated on different number of particles. For consistency, the configurations are the same as in Figure 2.
3.3 Interpolation
We use the Point Cloud MNIST 2D dataset (Garcia, 2023), a reimagined version of the classic MNIST dataset (LeCun, 1998), where each image is represented as a set of weighted 2D point clouds instead of pixel values. In Figure 4, we illustrate the interpolation between two point clouds that represent digits 7 and 6. Since the point clouds are discrete probability measures with non-uniform mass, we perform three different interpolation schemes via where for different transportation plans , namely:
-
1.
, an optimal transportation plan for ;
-
2.
a transportation plan obtained from solving an entropically regularized transportation problem (performed for three different regularization parameters );
- 3.
As the temperature increases, the transportation plan exhibits less mass splitting, similar to the effect of decreasing the regularization parameter in entropic OT. However, unlike entropic OT, where smaller regularization parameters require more iterations for convergence, the computation time for expected sliced transport remains unaffected by changes in temperature.
3.4 Weak Convergence
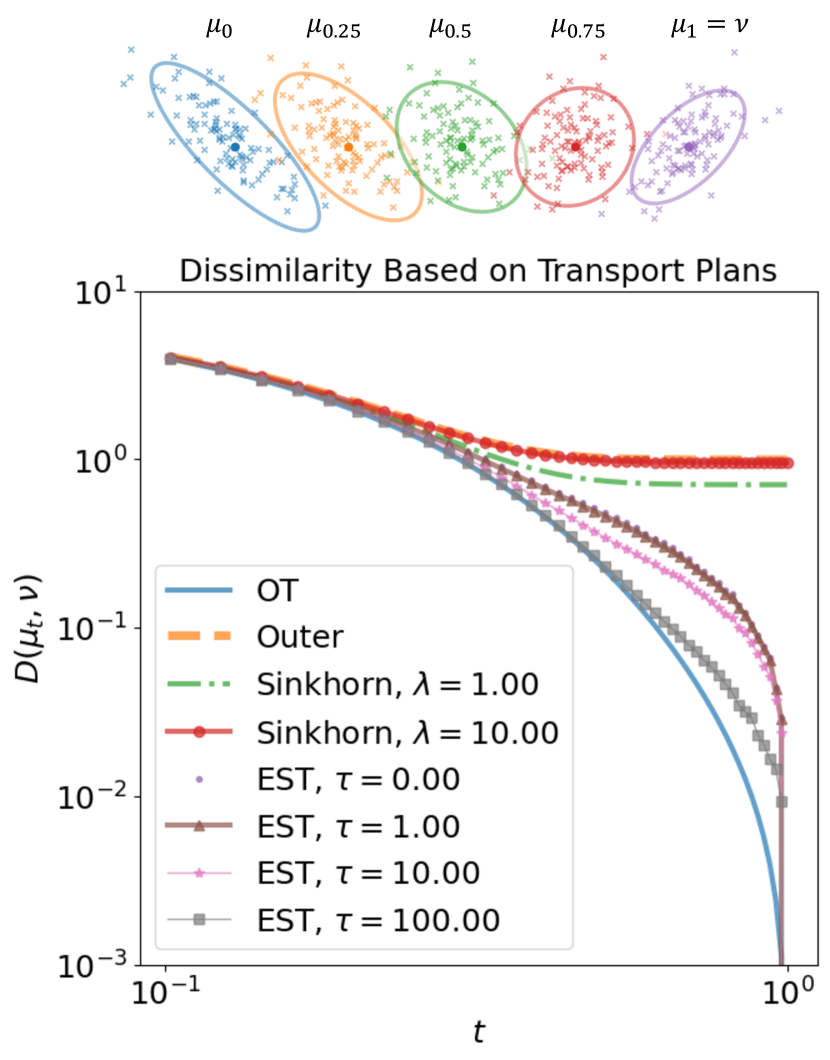
Given finite discrete probability measures and , we consider , for , the Wasserstein geodesic between and . In particular, is a curve of probability measures that interpolates and , that is and . Moreover, we have that as , or equivalently, we can say converges in the weak∗-topology to . Figure 5 illustrates that the expected sliced distance also satisfies as . Indeed, this experimental conclusion is justified by the following theoretical result:
Let be discrete measures with finite or countable support, where is compact. Assume . Then, if and only if .
We present its proof in Appendix B.
For the experiment, and are chosen to be discrete measures with particles of uniform mass, sampled from two Gaussian distributions (see Figure 5, top). For different values of time, , we compute different discrepancies, , calculated for various transport plans: (1) the optimal transport plan, (2) the outer product plan , (3) the plan obtained from entropic OT with two different regularization parameters , and (4) our proposed expected sliced plan computed with given in (14) for four different temperature parameters . As converges to , it is evident that both the OT and our proposed EST distance approach zero, while the entropic OT and outer product plans, as expected, do not converge to zero.
3.5 Transport-Based Embedding
Following the linear optimal transportation (LOT) framework, also referred to as the Wasserstein or transport-based embedding framework (Wang et al., 2013; Kolouri et al., 2021; Nenna & Pass, 2023; Bai et al., 2023; Martín et al., 2024), we investigate the application of our proposed transportation plan in point cloud classification. Let , denote a reference probability measure, and let denote a target probability measure. Let denote a transportation plan between and , and define the barycentric projection (Ambrosio et al., 2011, Definition 5.4.2) of this plan as:
| (16) |
Note that represents the center of mass to which from the reference measure is transported according to the transportation plan . When is the OT plan, the LOT framework of Wang et al. (2013) uses
as an embedding for the measure . This framework, as demonstrated in Kolouri et al. (2021), can be used to define a permutation-invariant embedding for sets of features and, more broadly, point clouds. More precisely, given a point cloud , where and represent the mass at location , we represent this point cloud as a discrete measure .
In this section, we use a reference measure with particles of uniform mass to embed the digits from the Point Cloud MNIST 2D dataset using various transportation plans. We then perform a logistic regression on the embedded digits and present the results in Figure 6. The figure shows a 2D t-SNE visualization of the embedded point clouds using: (1) the OT plan, (2) the entropic OT plan with two different regularization parameters, and (3) our expected sliced plan with two temperature parameters (using for all methods). In addition, we report the test accuracy of these embeddings for different reference sizes.
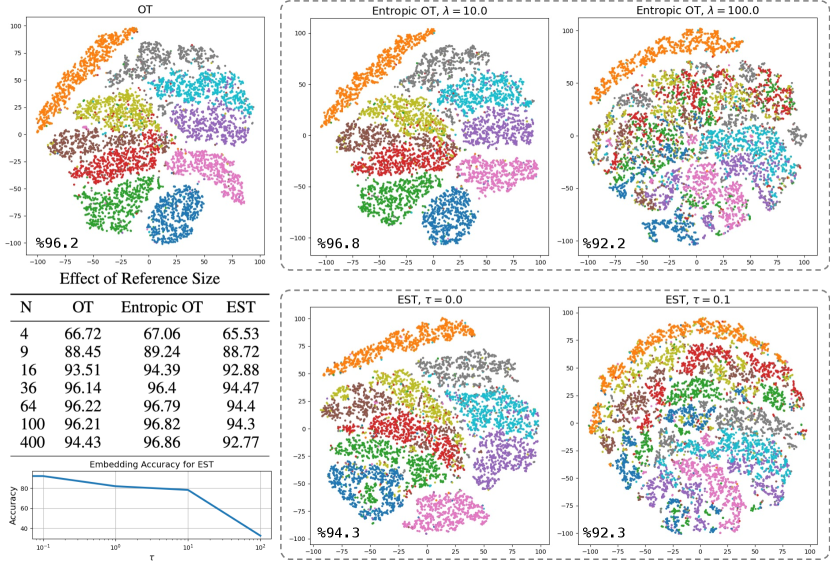
Lastly, we make an interesting observation about the embedding computed using EST. As we reduce the temperature, i.e., increase , the embedding becomes progressively less informative. We attribute this to the dependence of on . In other words, the embedding is computed with respect to different for different measures, leading to inaccuracies when comparing the embedded measures. This finding also suggests that the min-SWGG framework, while meritorious, may not be well-suited for defining a transport-based embedding.
4 Conclusions
In this paper, we explored the feasibility of constructing transportation plans between two probability measures using the computationally efficient sliced optimal transport (OT) framework. We introduced the Expected Sliced Transport (EST) framework and proved that it provides a valid metric for comparing discrete probability measures while preserving the computational efficiency of sliced transport and enabling explicit mass coupling. Through a diverse set of numerical experiments, we illustrated the behavior of this newly introduced transportation plan. Additionally, we demonstrated how the temperature parameter in our approach offers a flexible framework that connects our method to the recently proposed min-Sliced Wasserstein Generalized Geodesics (min-SWGG) framework. Finally, the theoretical insights and experimental results presented here open up new avenues for developing efficient transport-based algorithms in machine learning and beyond.
Acknowledgement
SK acknowledges support from NSF CAREER Award #2339898. MT was supported by the Leverhulme Trust Research through the Project Award “Robust Learning: Uncertainty Quantification, Sensitivity and Stability” (grant agreement RPG-2024-051) and the EPSRC Mathematical and Foundations of Artificial Intelligence Probabilistic AI Hub (grant agreement EP/Y028783/1).
References
- Ambrosio et al. (2011) Luigi Ambrosio, Edoardo Mainini, and Sylvia Serfaty. Gradient flow of the chapman–rubinstein–schatzman model for signed vortices. In Annales de l’IHP Analyse non linéaire, volume 28, pp. 217–246, 2011.
- Arjovsky et al. (2017) Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pp. 214–223. PMLR, 2017.
- Bai et al. (2023) Yikun Bai, Ivan Vladimir Medri, Rocio Diaz Martin, Rana Shahroz, and Soheil Kolouri. Linear optimal partial transport embedding. In International Conference on Machine Learning, pp. 1492–1520. PMLR, 2023.
- Basu et al. (2014) Saurav Basu, Soheil Kolouri, and Gustavo K Rohde. Detecting and visualizing cell phenotype differences from microscopy images using transport-based morphometry. Proceedings of the National Academy of Sciences, 111(9):3448–3453, 2014.
- Bunne et al. (2024) Charlotte Bunne, Geoffrey Schiebinger, Andreas Krause, Aviv Regev, and Marco Cuturi. Optimal transport for single-cell and spatial omics. Nature Reviews Methods Primers, 4(1):58, 2024.
- Chapel et al. (2020) Laetitia Chapel, Mokhtar Z Alaya, and Gilles Gasso. Partial optimal tranport with applications on positive-unlabeled learning. Advances in Neural Information Processing Systems, 33:2903–2913, 2020.
- Courty et al. (2014) Nicolas Courty, Rémi Flamary, and Devis Tuia. Domain adaptation with regularized optimal transport. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2014, Nancy, France, September 15-19, 2014. Proceedings, Part I 14, pp. 274–289. Springer, 2014.
- Cuturi (2013) Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26:2292–2300, 2013.
- Feydy et al. (2019) Jean Feydy, Thibault Séjourné, François-Xavier Vialard, Shun-ichi Amari, Alain Trouvé, and Gabriel Peyré. Interpolating between optimal transport and mmd using sinkhorn divergences. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 2681–2690. PMLR, 2019.
- Frogner et al. (2015) Charlie Frogner, Chiyuan Zhang, Hossein Mobahi, Mauricio Araya, and Tomaso A Poggio. Learning with a Wasserstein loss. Advances in neural information processing systems, 28, 2015.
- Garcia (2023) Cristian Garcia. Point cloud mnist 2d dataset, 2023. URL https://www.kaggle.com/datasets/cristiangarcia/pointcloudmnist2d. Accessed: 2024-09-28.
- Gretton et al. (2012) Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test. The Journal of Machine Learning Research, 13(1):723–773, 2012.
- Kolouri et al. (2017) Soheil Kolouri, Se Rim Park, Matthew Thorpe, Dejan Slepcev, and Gustavo K. Rohde. Optimal mass transport: Signal processing and machine-learning applications. IEEE Signal Processing Magazine, 34(4):43–59, 2017. 10.1109/MSP.2017.2695801.
- Kolouri et al. (2021) Soheil Kolouri, Navid Naderializadeh, Gustavo K. Rohde, and Heiko Hoffmann. Wasserstein embedding for graph learning. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=AAes_3W-2z.
- LeCun (1998) Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- Maggi (2023) Francesco Maggi. Optimal mass transport on Euclidean spaces, volume 207. Cambridge University Press, 2023.
- Mahey et al. (2023) Guillaume Mahey, Laetitia Chapel, Gilles Gasso, Clément Bonet, and Nicolas Courty. Fast optimal transport through sliced generalized wasserstein geodesics. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=n3XuYdvhNW.
- Martín et al. (2024) Rocío Díaz Martín, Ivan V Medri, and Gustavo Kunde Rohde. Data representation with optimal transport. arXiv preprint arXiv:2406.15503, 2024.
- Nadjahi et al. (2020) Kimia Nadjahi, Alain Durmus, Lénaïc Chizat, Soheil Kolouri, Shahin Shahrampour, and Umut Simsekli. Statistical and topological properties of sliced probability divergences. Advances in Neural Information Processing Systems, 33:20802–20812, 2020.
- Nenna & Pass (2023) Luca Nenna and Brendan Pass. Transport type metrics on the space of probability measures involving singular base measures. Applied Mathematics & Optimization, 87(2):28, 2023.
- Paty & Cuturi (2019) François-Pierre Paty and Marco Cuturi. Subspace robust wasserstein distances. In International conference on machine learning, pp. 5072–5081. PMLR, 2019.
- Peyré & Cuturi (2019) Gabriel Peyré and Marco Cuturi. Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning, 11(5-6):355–607, 2019.
- Rabin et al. (2011) Julien Rabin, Gabriel Peyré, Julie Delon, and Marc Bernot. Wasserstein barycenter and its application to texture mixing. In International Conference on Scale Space and Variational Methods in Computer Vision, pp. 435–446. Springer, 2011.
- Rabin et al. (2014) Julien Rabin, Sira Ferradans, and Nicolas Papadakis. Adaptive color transfer with relaxed optimal transport. In 2014 IEEE international conference on image processing (ICIP), pp. 4852–4856. IEEE, 2014.
- Rowland et al. (2019) Mark Rowland, Jiri Hron, Yunhao Tang, Krzysztof Choromanski, Tamas Sarlos, and Adrian Weller. Orthogonal estimation of wasserstein distances. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 186–195. PMLR, 2019.
- Santambrogio (2015) Filippo Santambrogio. Optimal transport for applied mathematicians, volume 55. Birkäuser, NY, 2015.
- Schmitzer (2016) Bernhard Schmitzer. A sparse multiscale algorithm for dense optimal transport. Journal of Mathematical Imaging and Vision, 56:238–259, 2016.
- Villani (2009) Cedric Villani. Optimal transport: old and new. Springer, 2009. URL https://www.cedricvillani.org/sites/dev/files/old_images/2012/08/preprint-1.pdf.
- Villani (2021) Cédric Villani. Topics in optimal transportation, volume 58. American Mathematical Soc., 2021.
- Wang et al. (2013) Wei Wang, Dejan Slepčev, Saurav Basu, John A Ozolek, and Gustavo K Rohde. A linear optimal transportation framework for quantifying and visualizing variations in sets of images. International journal of computer vision, 101:254–269, 2013.
Appendix A Proof of Theorem 2.10: Metric property of the expected sliced discrepancy for discrete probability measures
A.1 Preliminaries on Expected Sliced Transportation
Remark A.1 (Figure 1).
Let us elaborate on explaining Figure 1. (a) Visualization for uniform discrete measures (green circles), (blue circles) in with . Given an angle (red unit vector), when sorting and we use permutations and given by , and , , . The optimal transport map between (green triangles) and (blue triangles) is given by the following assignment: , , . This gives rise to the plan given in (7) with is represented by solid arrows in the first panel. The lifted plan defined in (8) is represented in the second panel by dashed assignments. (b) Visualization for finite discrete measures (green circles), (blue circles). When projection according a given direction , the locations with green masses and overlap, as well as the locations with blue masses and . Thus, the mass of is concentrated at two green points (triangles) on the line determined by , each one with and of the total mass, and similarly is concentrated at two points (blue triangles) each one with of the total mass.
Now, let us prove Lemma 2.3, that is, let us show that each measure defined in (9) is a transport plan in .
Proof of Lemma 2.3.
Let . First, if , then for every , and so . Now, assume that , then
Thus, for every . Similarly, , or equivalently, for every . ∎
Remark A.2 (Expected Sliced Transport for uniform discrete measures).
Let of the form , . Then, the expected sliced transport plan between and , , defines a discrete measure on supported on where it takes the values
| (17) |
Thus, it can be regarded as an matrix whose -entry is given by (17). Moreover, each matrix defined by (6) can be obtained by swapping rows from the identity matrix multiplied by , there are finitely many matrices (precisely, matrices in total). Hence, the function is a piece-wise constant matrix-valued function. Thus, the function (where is an in (8)) is a measurable function. This can be generalized for any pair of finite discrete measures as in the following remarks.
Remark A.3 (Expected Sliced Transport for finite discrete measures).
Consider arbitrary finite discrete measures and , i.e., discrete measures with finite support.
-
•
Fix , then for all but a finite number of directions. This is due to the fact that only for finitely many directions we obtain overlaps of the projected points .
-
•
The optimal transport plan is given by “matching from left to right until fulfilling the target bins”: that is, one has to order the points similarly as in (3) and consider an “increasing” assignment plan. Since the order of and changes a finite number of times when varying , the function takes a finite number of possible transportation plan options.
Thus, the range of is finite.
Remark A.4 ( is well-defined for finite discrete measures).
First, we notice that for each , the support of is finite or countable, and so the support of is also finite or countable. Given an arbitrary point , we have to justify that the function is (Borel)-measurable: If the supports of and are finite, by Remark A.3, is a piece-wise constant function, and so it is measurable and integrable on the sphere. For the general case, when the supports of and are countable, we refer to Remark A.14.
Lemma A.5 ( is a transportation plan between and ).
We have that , i.e., it has marginals and . This is because for each , and because is a probability measure on . Then, is a convex combination of transport plans , and since is a convex set, we obtain that. Precisely, for every test function
Similarly, and so has marginals and .
A.2 An auxiliary result
For simplicity, in this paper we consider the strictly convex cost (). Also, in this section we consider and in this case we denote .
Proposition A.6.
Let be a compact set, and let . Let be sequences such that, for , as , where the limit is in the weak*-topology. For each , consider optimal transportation plans . Then, there exists a subsequence such that , for some optimal transportation plan .
Proof.
As is a sequence of probability measures, their mass is 1, by Banach-Alaoglu Theorem, there exists a subsequence such that , for some . It is easy to see that the limit has marginals . Indeed, given any test functions , since each has marginals , we have
and taking limit as , we obtain
Now, we only have to prove the optimality of for the OT problem between and . Since is continuous and , are compactly supported, by using that for each , is optimal for the OT problem between and , we have
| (18) |
Also, by hypothesis and (Santambrogio, 2015, Theorem 5.10) we have that for any ,
So, by using the the triangle inequality for the -Wasserstein distance we get
| (19) |
Therefore, from (19) and (18) we have that
In particular, in (18) we have that the following equality holds:
As a result, is optimal for the OT problem between and . ∎
A.3 Finite discrete measures with rational weights
Let us denote by the set of finite discrete probability measures in with rational weights, that is, if and only if it is of the form with , for some , and . We have
In the definition of an uniform discrete measure one can allow for some pairs of indexes .
Proposition A.7.
defined by (11) is a metric in .
Proof.
This was essentially pointed out Remark 2.9: When restricting to the space , our and the Projected Wasserstein distance presented in (Rowland et al., 2019) coincide. Rowland et al. (2019) prove the metric property. We recall here their main argument, which is used for showing the triangle inequality. Given of the form , , . Fix , and consider permutations , so that
Thus, the key idea is that
where is such that is the probability that the tuple permutations are required, given that is drawn from . With these alternative expressions established by the authors in (Rowland et al., 2019), the triangle inequality follows from the standard Minkowski inequality for weighted finite -spaces.
Finally, notice that we have used the fact that each is associated to -indexes , without asking that the points do not overlap, i.e., they could be repeated. That is, given one can allow for some pairs of indexes (analogously for and ). Thus, the proof also holds for measures in : Indeed, let be of the form , , with . First, consider the as the least common multiple of and, for each , let so that . Thus, we can rewrite . Notice that, since is a probability measure, we have . Now, for each such that , consider copies of the corresponding point so that we can rewrite (where we recall that and the points in the new expression can be repeated, i.e., they are not necessarily all different). Repeat this process to rewrite , . Now, consider as the least common multiple of , and rewrite the measures as , , where the points , , can be repeated if needed. Thus, can be regarded as measures in where behaves as a metric. ∎
A.4 The proof for general finite discrete measures
We first introduce some notation. Consider a finite discrete probability measure of the form , with general weights such that . For each , consider an increasing sequence of rational numbers , with , such that . For , consider the sequence defined by . Thus, . Define the sequence of probability measures given by . It is easy to show that converges to in Total Variation (i.e., uniform convergence or strong convergence): Indeed, let . For each , let such that and define . Now, given any set we obtain, for ,
This shows that . Moreover, this shows that in this case, i.e., when approximating a finite discrete measure by a sequence of measures having the same support as , we only care about point-wise convergence.
We will now introduce some lemmas which together with the above proposition will allow us to prove the metric property of for finite discrete probability measures. For all of them we will consider:
-
•
two finite discrete probability measures in given by ,
-
•
, approximating sequences of probability measures , , with rational weights , , defined in analogy to what we have already done, i.e., so that, for we have that is a sequence of probability measures that converges to in Total Variation).
Also, for each , denotes the unique optimal transport plan between and ; denotes lifted transport plan between and given as in (9); and the expected sliced transport plan between and given as in (10). Similarly, for each we consider the plans , , and .
Lemma A.8.
The sequence converges to in Total Variation.
Lemma A.9.
The sequence converges to in Total Variation.
Lemma A.10.
The sequence converges to in Total Variation.
Lemma A.11.
.
In general, notice that since for every , we have that , and , then we obtain that , and , where , , and where, for each , and are analogously defined (see Subsection 2.2.2). Thus,
| (20) |
Proof of Lemma A.8.
The support of all the measures we are considering are finite and so, the measures have compact support. Hence, we can apply Proposition A.6 to , , . Specifically, given , there exists a subsequence and such that
| (21) |
As we are in one dimension, the set is a singleton, and so we have that is the unique optimal transport plan. Since the supports of all the measures are the same, (that is, ), the weak∗ convergence in (21) implies the stronger convergence in Total Variation.
Now, suppose that the original sequence does not converge to (in Total Variation). Then, given , there exists a subsequence such that
| (22) |
But again, from Proposition A.6, using that the supports of all the measures involved are the same set , and the fact that (only one optimal transport plan), we have that there exists a sub-subsequence such that
contradicting (22). Since the contradiction is achieved from assuming that the whole sequence does not converge to , we have that, in fact, it does converge to in Total Variation. ∎
Proof of Lemma A.9.
Proof of Lemma A.10.
As pointed out before, we only care about point-wise convergence: That is, since the supports of the measures involved coincide (are the same set ) weak∗ convergence, point-wise convergence and convergence in Total Variation are equivalent.
Since and is compact, by the convergence result from Lemma A.9 and using the Dominated Convergence Theorem, we have that for each ,
Theorem A.12.
is a metric for the space of finite discrete probability measures in .
Proof.
-
•
Symmetry: The way we constructed makes it so that .
-
•
Positivity: It is clear that by definition .
-
•
Identity of indiscernibles:
First, if , then for all . Hence which implies .
Secondly, if are such that , by having
we can use the fact that satisfies the identity of indiscernibles by being a distance. That is, implies .
-
•
Triangle inequality: Given arbitrary finite discrete measures with arbitrary real weights, consider approximating sequences , , in as before. Notice that every subsequence of (respectively of and ) will converge to (respectively, to and ), as every subsequence of a convergent sequence is convergent.
A.5 Discrete measures with countable support
Lemma A.13.
Let be a discrete probability measure with countable support . Let be an absolutely continuous probability measure with respect to the Lebesgue measure on the sphere (we write, ). Let
Then
Proof.
First, consider distinct points on the support of , and let
It is straightforward to verify that
where is the orthogonal subspace to the line in the direction of the vector . Thus, is a subset of a -dimensional sub-sphere in , and therefore
| (24) |
Since,
| (25) |
we have that
since M is countable (indeed, ). ∎
Remark A.14.
[ is well-defined for discrete measures with countable support] Let . Given two discrete probability measures and with countable support, from Lemma A.13, we have that for , and so . Therefore, similarly to the case of discrete measures with finite support, given any , we have that the map from to is equal to the constant function up to a set of -measure . This implies that the function is measurable. Finally, since for every , we have that is well-defined.
Appendix B Equivalence with Weak∗ Convergence
Lemma B.1.
Let be a compact set, and consider a sequence of probability measures defined in such that as . Then, for each , we have that as .
Proof.
Given , notice that is a -dimensional compact set, which contains the supports of and . Thus, when dealing with the weak∗-topology we can use continuous functions as test functions. Let be a continuous test function, then
since the composition is a continuous function from to . ∎
Lemma B.2.
Let be a compact set, , , and consider sequences of probability measures defined in such that as , for . Given , consider the unique optimal transport plan between and , and for each , consider the unique optimal transport plan between and . Then .
Proof.
The proof is similar to that of Lemma A.8. From Lemma B.1, Proposition A.6, and uniqueness of optimal plans in one-dimension, there exists a subsequence such that
Now, suppose that the original sequence does not converge to (in the weak∗-topology). Thus, there exists a continuous function such that for a given there exists a subsequence with
| (26) |
But again, from Lemma B.1, Proposition A.6, and uniqueness of optimal plans in one-dimension, we have that there exists a sub-subsequence such that
contradicting (26). Since the contradiction is achieved from assuming that the whole sequence does not converge to , we have that, in fact, it does converge to in the weak∗-topology. ∎
Lemma B.3.
Consider probability measures supported in a compact set such that . Let , then the sequence of lifted plans satisfies that there exists a subsequence such that for
where for all .
Proof.
Since , similar to the proof of Proposition A.6, by Banach-Alaoglu Theorem, there exists a subsequence , such that for some . Again, as in the proof of Proposition A.6, it can be shown that .
In addition, we have
(where the first one follows by similar arguments to those in Lemma B.1 and the second one follows by definition of the lifted plans). By the uniqueness of the limit (for the weak∗-convergence), we have . Thus, . ∎
Theorem B.4.
Let . Consider discrete probability measures measures in supported on a compact set . Consider sequences , of discrete probability measures defined on such that . Then -a.s. we have that as . Moreover, as .
Proof.
Let us define the set
Since we are considering discrete measures, notice that
where and .
By Lemma A.13, we have . Thus,
Let , and consider the lifted plans and . By Lemma B.3, there exists a subsequence of such that
Since , we have that contains only one element, which is . Hence,
Moreover, by uniqueness of weak convergence, proceeding similarly as in the proof of Lemma B.2, we have that the whole sequence converges to in the weak∗-topology.
Therefore, by definition of weak∗-convergence for measures supported in a compact set (in our case, ), since is a continuous function, we have
Combining this with the fact that and that is bounded, that is, , by Dominated Lebesgue Theorem we obtain
∎
Corollary B.5.
Let , where is compact, be of the form , where and are 0 at all but countably many . Assume . Then, if and only if .