Explainability and AI Confidence in Clinical Decision Support Systems: Effects on Trust, Diagnostic Performance, and Cognitive Load in Breast Cancer Care
Abstract
Artificial Intelligence (AI) has demonstrated potential in healthcare, particularly in enhancing diagnostic accuracy and decision-making through Clinical Decision Support Systems (CDSSs). However, the successful implementation of these systems relies on user trust and reliance, which can be influenced by explainable AI. This study explores the impact of varying explainability levels on clinicians’ trust, cognitive load, and diagnostic performance in breast cancer detection. Utilizing an interrupted time series design, we conducted a web-based experiment involving 28 healthcare professionals. The results revealed that high confidence scores substantially increased trust but also led to overreliance, reducing diagnostic accuracy. In contrast, low confidence scores decreased trust and agreement while increasing diagnosis duration, reflecting more cautious behavior. Some explainability features influenced cognitive load by increasing stress levels. Additionally, demographic factors such as age, gender, and professional role shaped participants’ perceptions and interactions with the system. This study provides valuable insights into how explainability impact clinicians’ behavior and decision-making. The findings highlight the importance of designing AI-driven CDSSs that balance transparency, usability, and cognitive demands to foster trust and improve integration into clinical workflows.
1 Introduction
In recent years, Artificial Intelligence (AI) has emerged as a transformative technology across various fields, offering the potential to significantly improve processes and outcomes. Healthcare has become a primary focus for AI research, given the vast amounts of data it generates and the opportunities to use this information to enhance patient care. AI systems have shown promise in improving diagnosis [1, 2, 3, 4], treatment planning [5, 6], and workflow efficiency, and also reducing human errors[7, 8, 9]. One area where AI is making significant progress is in breast cancer detection, with Clinical Decision Support Systems (CDSS) playing a key role. These AI-powered tools assist radiologists and oncologists by analyzing medical images, identifying abnormalities, and providing diagnostic recommendations[1].
Despite the potential benefits of integrating AI into Clinical Decision Support Systems (CDSSs), their value ultimately depends on user acceptance and adoption [10, 11, 12, 13]. Trust plays a pivotal role in this process, directly shaping clinicians’ willingness to rely on these systems [6, 14]. As AI continues to advance and find applications in various healthcare domains, addressing trust-related barriers has become critical to ensuring the successful implementation of AI-based CDSSs [10]. Among the factors influencing trust, explainability stands out as an important element [15]. AI systems often operate as ”black boxes“, offering results without clear reasoning, which can lead to skepticism among clinicians. When AI systems provide explanations for their recommendations, they are more likely to be trusted and integrated into clinical workflows.
On the other hand, the integration of explainability in AI-driven CDSSs requires an examination of their role in improving the user experience [16]. It is crucial to understand how explainability affects factors such as the mental demands and stress levels.
Additionally, system confidence scores play a crucial role in shaping trust[17, 18]. Confidence scores, which reflect the AI system’s level of certainty in its recommendations, serve as valuable information for clinicians to evaluate the reliability of the outputs. The varying levels of confidence scores, ranging from low to high certainty, can substantially impact how clinicians interpret and act upon AI recommendations.
To investigate the effects of varying levels of explainability on mental demand and stress, as well as the impact of system confidence scores on trust and performance, we designed a user-centered experiment. This study evaluated how clinicians interacted with our custom-built web application, which integrated an AI-based Clinical Decision Support System (CDSS).
The web application presented medical cases accompanied by AI-generated recommendations with varying levels of explainability and confidence scores. Participants included radiologists, oncologists, and other healthcare professionals who engaged with the system in a controlled setting. During the experiment, we collected data on trust, cognitive load, stress levels, and diagnostic performance through surveys and system interactions.
This study is guided by three key research questions: (1) How do different levels of explainability in AI-based Clinical Decision Support Systems affect clinicians’ cognitive load? and (2) How do varying system confidence scores influence trust and diagnostic performance? (3) How do clinicians’ demographic characteristics influence their mental demand and stress in AI-based clinical decision support systems (CDSS) in breast cancer detection?
By addressing these questions, we aim to deepen our understanding of how design features like explainability and confidence scores shape the interaction between clinicians and AI systems. Ultimately, this research seeks to inform the development of AI-based CDSS that are not only effective but also trusted and seamlessly integrated into clinical workflows.
2 Related Work
2.1 Technology Adoption And Trust
Numerous studies in the literature have explored various aspects of technology adoption, leading to the development of models such as the Technology Acceptance Model (TAM) [13], widely applied in healthcare studies [19], Task-Technology fit (TTF) [20] and the Unified Theory of Acceptance and Use of Technology (UTAUT) [21]. TAM, in particular, offers a foundational framework for understanding users’ adoption of technology by identifying two primary constructs, Perceived Usefulness (PU) and Perceived Ease of Use (PEOU). While TAM addresses the cognitive aspects of technology adoption, trust extends it by capturing emotional and psychological dimensions [22], making it a critical factor in overcoming situations involving uncertainty, dependency, and risks and enhancing acceptance [23, 24, 12, 25].
Trust has been defined in various ways by scholars [26, 27, 28], with a widely accepted definition describing it as an individual’s willingness to take risks and delegate critical tasks and responsibilities to another party, such as a technological system [26]. In healthcare, however, clinicians often hesitate to rely on automated systems, choosing instead to depend on their own expertise. This reluctance creates significant barriers to the acceptance and adoption of advanced technologies. Considering trust as a critical factor in technology acceptance [6, 14, 15], many studies have focused on understanding how it can be built between users and technological systems.
Some frameworks, such as Muir’s trust model [28] and Mayer et al.’s influential model focusing on ability, benevolence, and integrity [27], provide foundational insights into trust. In the context of human-technology interactions, Parasuraman et al. [11] expanded the understanding of trust by examining user reliance on automation and its potential for misuse or neglect. They highlighted the risks of ”automation abuse,” where over-automation can undermine human oversight, leading to errors or reduced performance. Studies such as [10] highlight the risks associated with overreliance on automation, including reduced monitoring of systems and the potential for biased decisions. These findings highlight the importance of designing systems that emphasize on calibrated trust to improve the humans’ task performance [10, 26, 29, 30, 31, 32].
Trust formation in human-technology interactions has been widely explored, with Hoff and Bashir [33] categorizing trust development into dispositional trust, situational trust, and learned trust. Building on these categories, other researchers have proposed alternative frameworks. For instance, Jermutus et al. [34] classify trust factors into user-related, AI-related, and contextual factors, while Lotfalian et al. [35] identify three key categories: human user attributes, intelligent system design, and task characteristics. Schaefer et al. [36] mentioned the factors differently as automated partner, the environment in which the task is occurring, and characteristics of the human interaction partner.
AI-related factors, such as explainability [37], transparency [25], and complexity [38], are fundamentals to enhancing user trust and reliance on AI systems. Improvements in these areas can directly address user uncertainties, ensuring outputs are clear, interpretable, and reliable. By enhancing these capabilities, AI systems empower users to make informed decisions with greater confidence, supporting appropriate reliance and facilitating broader system adoption. Explainability has been recognized as a key factor in improving trust and reliance on AI systems [15, 39, 40, 31, 41, 37]. Users need to understand how the system generates its decisions and the reasoning behind the algorithms [34].
2.2 AI Explainability
Explainable Artificial Intelligence (XAI) has become essential in fields like medicine[42, 31], finance, and autonomous systems, where understanding AI decisions is critical. As complex “black-box” models like deep learning grow in use, their lack of transparency raises concerns about trust and accountability. XAI aims to address this by providing clear, human-understandable explanations, making AI systems more transparent and reliable [43]. This not only builds user confidence but also supports effective human-AI collaboration [43, 17, 37, 34].
In the literature, various explainability methods have been introduced to address the black-box nature of AI models, which are often categorized into local and global approaches. Local methods, such as LIME (Local Interpretable Model-agnostic Explanations) [44], Saliency Maps [45], Grad-CAM (Gradient-weighted Class Activation Mapping) [46], Integrated Gradients [47],and example-based methods, such as counterfactual explanations [48] and prototype-based techniques [49], focus on explaining individual predictions by identifying specific features that influenced a particular output. In contrast, global methods, like SHAP (SHapley Additive Explanations) [50], Feature Importance, and Partial Dependence Plots (PDPs) [51], provide insights into the overall behavior of the model, showing how features contribute to predictions across the entire dataset.
Several studies in the literature have explored the impact of explainability methods on participants’ behavior, particularly focusing on trust and adoption. Some studies have demonstrated positive effects, showing that explainability enhances trust and supports adoption. For example, Wang et al. [43] found that using SHAP improved decision accuracy and behavioral trust in sales prediction tasks. similarly, Leichtmann et al. [52] conducted a 2×2 between-subject study on a mushroom-picking task, using Grad-CAM as an attribution-based explanation and ExMatchina as an example-based explanation. Both methods were found to significantly improve trust in AI systems, highlighting their effectiveness in enhancing user confidence.
However, other studies have reported limited or no significant effects of explainability on trust. For instance, in our previous study [53], no improvement was observed when providing different levels of explainability, such as AI confidence scores, localization, and other methods. Ahn et al. [54] found that while SHAP and LIME increased interpretability, they did not significantly enhance trust or task performance, emphasizing the role of outcome feedback over explainability. Similarly, Cecil [41] observed that explainability methods such as saliency maps and visual charts had minimal impact on mitigating the negative effects of incorrect AI advice in human resource management. Zhang et al. [17], also, used SHAP as a local explainability method in an income prediction task but found no significant impact on trust or user behavior.
Additionally, research comparing the effectiveness of different XAI methods has shown mixed results, with some methods being more impactful than others. For instance, Alam et al. [55] reported that richer explanations, such as a combination of written, visual, and example-based methods, were more effective in improving satisfaction and trust in AI diagnosis systems compared to simpler approaches. Similarly, Cai et al. [56] explored both normative and comparative example-based explanations in a sketch recognition task. Their findings revealed that normative explanations positively impacted system comprehension and user trust, while comparative explanations did not show significant effects. Wang et al. [57] also evaluated XAI methods in recidivism and forest cover prediction tasks, comparing global approaches like feature importance with local methods such as counterfactual explanations and nearest-neighbor examples. The study found that the effectiveness of XAI largely depends on users’ domain expertise, providing insights for tailoring XAI to support decision-making. The study most closely aligned with the goals of our research is by Evans et al. [58], which investigates how digital pathologists interact with various XAI tools, including saliency maps, concept attributions, prototypes, trust scores, and counterfactuals, to enhance clarity in medical imaging recommendations. While their study provides valuable insights into pathologists’ preferences for AI guidance, it does not examine how these tools and varying levels of explainability influence human-related behaviors, such as trust, reliance, cognitive load, and decision-making, which is a central focus of our work.
Several studies have investigated AI confidence scores as an explainability feature to build trust. Zhang et al. [17] found that confidence scores help calibrate trust by providing insights into the certainty of predictions. McGuirl and Sarter [59] showed that continually updated confidence information improves trust calibration in automated decision support systems. Similarly, Antifakos et al. [18] emphasized the importance of how confidence is presented in an automatic notification device. Rechkemmer and Yin [60] further demonstrated that confidence scores significantly influence trust, although accuracy remains a stronger factor.
2.3 Cognitive Load
Cognitive load refers to the mental effort required to process information and complete tasks [61]. Cognitive Overload can negatively impact decision-making and reduce trust in automated systems, as users may feel overwhelmed or struggle to understand the system’s outputs [62]..
Research has explored the relationship between cognitive load and trust across various domains. For instance, Choudhury et al. [61] found that increased cognitive workload reduced the intent to use a blood utilization calculator (BUC), an AI-based decision support system in healthcare. This underscores the importance of designing AI systems that minimize cognitive load to foster trust and encourage adoption. However, not all studies find a direct link between explainability and cognitive load; for example, Wang et al. [63] reported no significant differences in cognitive load between groups provided with XAI explanations versus AI-only systems.
In the context of explainable AI, the effect of explainability on cognitive load varies depending on the context and implementation. Few studies provide evidence of this variability. For instance, Herm [64] conducted an empirical study in medicine, using chest X-ray images of COVID-19-infected patients, and demonstrated how different XAI methods influence cognitive load. Similarly, Kaufman et al. [65] explored cognitive load in the context of autonomous driving, and Hudon et al. [66] examined the effects of XAI in image classification tasks. These findings highlight the critical need to consider human cognitive factors when designing XAI systems to ensure explanations are intuitive and do not inadvertently increase cognitive load. By carefully balancing transparency and usability, XAI can enhance trust without overwhelming users.
3 Method
3.1 Overview
This experimental study addresses research questions using online experiments with multiple intervention conditions. Each condition was designed to include different levels of explainability, to evaluate clinicians’ attitudes toward an AI-based Clinical Decision Support System (CDSS) for breast cancer diagnosis. During the experiment, participants interacted with the CDSS across various diagnostic cases, assessing their trust and agreement with the system’s suggestions. In addition, participants completed surveys provided demographic information before the experiment and evaluated their mental demands and stress after using each CDSS variant.
The following sections provide a detailed description of the study participants, experimental design and procedures, the specific AI configurations employed across intervention conditions, measurements, and the analytical methods used.
3.2 Participants
A total of 28 participants were recruited between January and August 2024 through medical associations, social platforms, and professional networks. All participants were U.S.-based, fluent in English, and over the age of 18. They were compensated $80 for their participation. The sample comprised primarily radiologists (), with the remaining participants identified as oncologists () or other healthcare professionals involved in breast cancer care ().
The demographic characteristics of the participants were as follows: The majority were male (), and the mean age was 42.6 years (), with most participants () in the 35-45 age. In terms of race and ethnicity, the majority identified as White (), followed by Asian (), Middle Eastern or North African (), Hispanic or Latino (), and other backgrounds ().
3.3 Experiment Design and Procedure
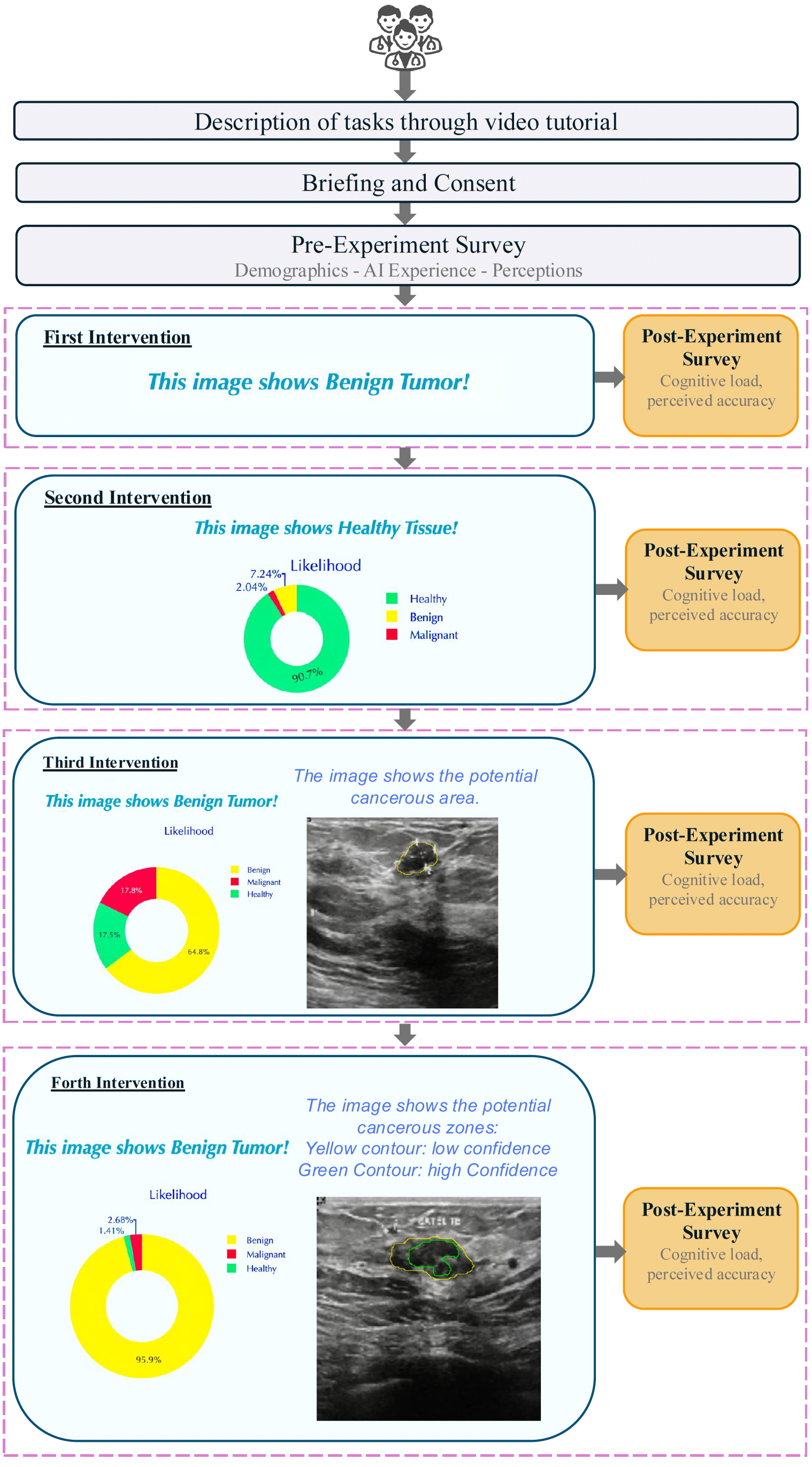
The primary goal of this study was to evaluate the effect of different levels of explainability on participants’ cognitive load. We used an interrupted time series design [67], where participants sequentially interacted with a breast cancer Clinical Decision Support System (CDSS) across multiple interventions, each offering a distinct level of explainability. Participants completed these interventions in a particular order, with key variables measured at multiple points to capture changes over time.
The main task required participants to diagnose ultrasound images of breast tissues as either healthy, benign, or malignant. Initially, they made these diagnoses without any decision support. As they progressed through the interventions, they were gradually provided with diagnostic suggestions from the CDSS, with varying levels of explanation generated through machine learning techniques. The experiment included pre-experiment surveys to collect demographic information and baseline attitudes toward AI. Each intervention involved diagnosing 10 images, followed by a brief post-intervention survey.
The entire experiment was conducted online on a web application developed using the Python-based Dash framework. The online application platform integrated all stages, from signing the consent form and completing surveys to participating in the experiment sessions and collecting data. This setup allowed us to recruit participants nationwide without requiring in-person supervision.
After recruitment, participants received a video tutorial and an experiment link via email. This approach ensured that only those genuinely interested and informed about the study participated, helping to maintain data authenticity. Upon accessing the link, participants first signed a consent form, completed a pre-experiment survey, and then proceeded through a series of experiment sessions as follows:
-
•
Baseline (Stand-alone): Clinicians review breast cancer tissue images and make diagnostic decisions independently, without any suggestions.
-
•
Intervention I (Classification): Clinicians receive diagnostic recommendations (healthy, benign tumor, malignant tumor) from the system, but without any explanatory details.
-
•
Intervention II (Probability Distribution): Expanding on the previous intervention, this stage includes probability scores for each diagnostic option (healthy, benign tumor, malignant tumor).
-
•
Intervention III (Tumor Localization): In addition to probability estimates, the system highlights the suspected location of the tumor within the breast tissue images.
-
•
Intervention IV (Enhanced Localization with Confidence Levels): Building on the third intervention, clinicians are provided with tumor localization information that includes areas marked with both high and low confidence levels.
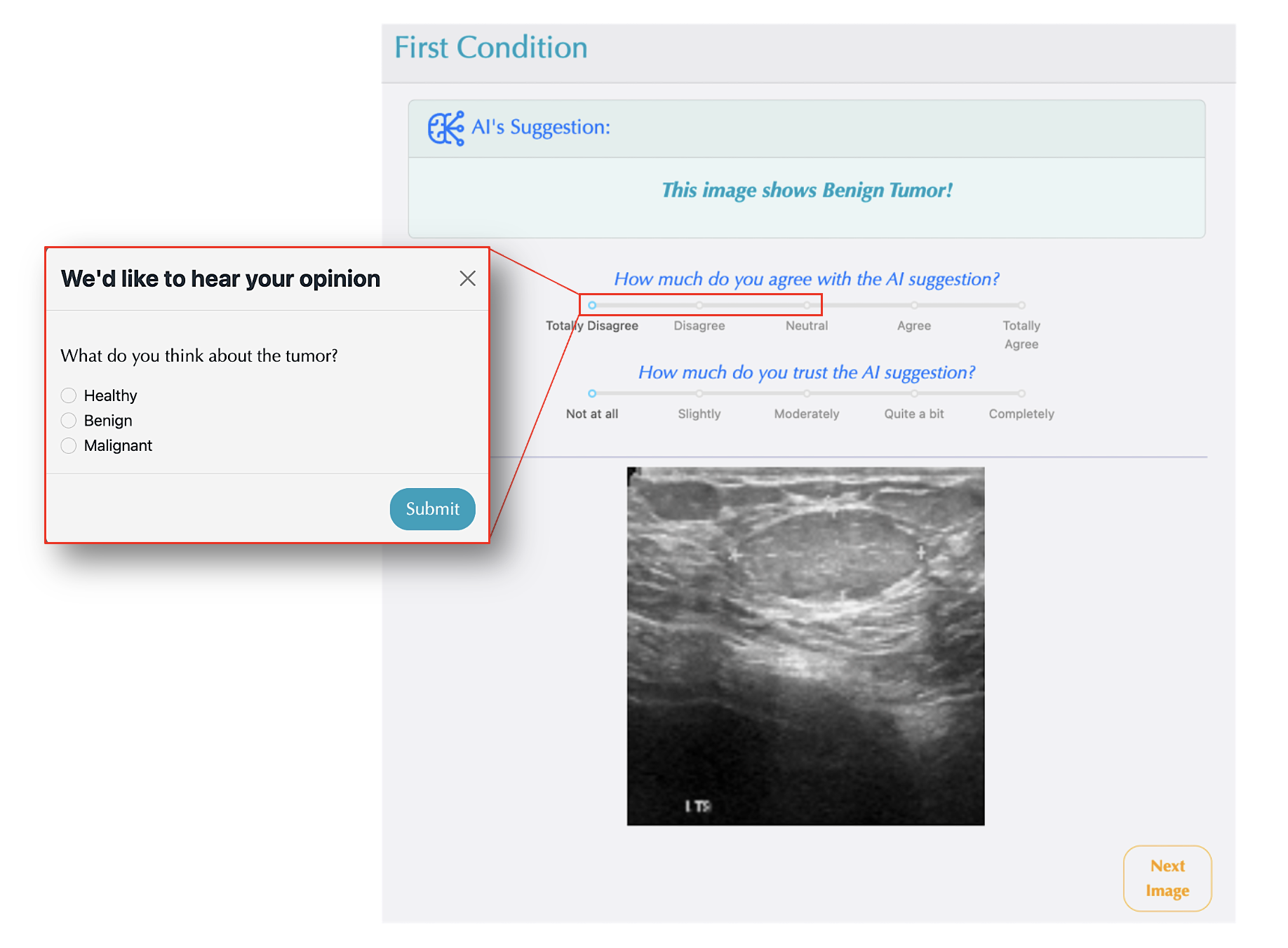
In the baseline condition, participants analyzed ultrasound images independently and provided their diagnosis as healthy, benign, or malignant. In the subsequent conditions, participants were given diagnostic suggestions and asked to rate their agreement and trust in these suggestions on a 5-point Likert scale (as shown in Figure 1). If their agreement rating was below 3, they were prompted to make their own diagnosis and share their opinion on the image (see Figure 1).
After completing each intervention, participants proceeded to a post-intervention survey designed to capture specific insights about that stage. Using a 5-point Likert scale, they rated aspects such as cognitive load and other relevant factors. The full procedure for the experiment is outlined in Figure 2.
The AI system supporting the CDSS is based on our previous work [68] and combines a U-Net model for precise image segmentation with a Convolutional Neural Network (CNN) for diagnostic classification. The U-Net architecture [69] is specifically designed to delineate the boundaries of suspicious regions within breast ultrasound images, effectively highlighting areas that may contain cancerous tissue. This segmentation step assists in localizing potential tumors and provides visual cues that clinicians can use to focus their analysis in 3rd and 4th Interventions. Following this step, the segmented images are analyzed by the CNN, a widely used method for analyzing medical images [70, 71, 72], which categorizes each image into one of three diagnostic classes: healthy, benign, or malignant. This classification model was trained using a publicly available breast cancer ultrasound dataset containing 780 images [73]. The training process enabled the model to learn and recognize distinguishing features associated with each diagnostic category, achieving an overall diagnostic accuracy of 81%.
3.4 Assessment Measures
In the pre-experiment survey, we assessed participants’ perceptions of AI through three key measures: AI role, AI usefulness, and complexity perception.
AI Role
To understand participants’ perspectives on AI’s potential in healthcare, we asked them to indicate their level of agreement with the statement, “Artificial Intelligence will play an important role in the future of medicine.” Responses were captured on a 5-point Likert scale, from Totally Disagree to Totally Agree.
AI Usefulness
This measure examined how relevant participants perceived AI to be for their specific roles. Participants rated their agreement with the statement, “AI would be useful in my job.” providing insight into AI’s perceived practical benefits in their professional contexts.
Complexity Perception
To assess perceived barriers to AI adoption, participants responded to the statement, “There are too many complexities and barriers in medicine for AI to help in clinical settings.” This measure, also rated on a 5-point Likert scale, helped identify potential challenges related to AI integration in clinical practice.
During the experiment, we recorded participants’ responses and interactions with the AI system using the following key measures:
Trust
We measured participants’ trust in AI on a 5-point Likert scale from 0 (No trust) to 5 (Complete trust). For each image, they rated their trust in the AI’s suggestions, answering, “How much do you trust the AI system?”
Agreement
We measured participants’ agreement in AI’s suggestions on a 5-point Likert scale from 0 (No trust) to 5 (Complete trust). For each image, they rated their agreement in the AI’s suggestions, answering, “How much do you agree with AI suggestion?”
Performance
Participants’ performance was evaluated based on their decisions for each image during the experiment. Performance was assessed in two ways: If a participant’s agreement level with the AI suggestion was above neutral, their decision was considered aligned with the AI’s suggestion. When the agreement level was below neutral, participants independently selected a diagnosis of “Healthy,” “Benign,” or “Malignant”. Performance for each intervention was calculated by comparing their choices to the ground truth across ten images, expressed as a percentage to represent decision accuracy relative to correct diagnoses.
Diagnosis Duration
We recorded the time participants took to make decisions for each image during the experiment.
AI Confidence Score
This measure represents the classification probabilities by the AI model in each category. Starting from 2nd intervention, we displayed the probability of classification in percentage for all three categories for each image. We recorded the highest probability assigned by the AI for each prediction. For images shown in 1st intervention, we did not record a value for this variable. For subsequent interventions, we categorized this variable as low confidence for predictions with less than 90% likelihood and high confidence for those with 90% or higher.
In the post-experiment survey after each intervention, we assessed participants’ experiences through two key questions extracted from NASA Task Load Index (TLX) [74] about mental demand and stress.
Mental Demand
After each intervention, we assessed mental demand by asking participants, “How mentally demanding was the task?” Responses were given on a 5-point Likert scale, from Very Low to Very High. This measure helped us understand the cognitive load experienced by participants at each stage.
Stress
After each intervention, we measured Stress by asking participants, “How stressed were you?” Responses were collected on a 5-point Likert scale, ranging from Very Low to Very High. This measure provided insights into participants’ stress levels throughout the experiment.
4 Results
4.1 Impact of AI Explainability on Cognitive Load: Mental Demand and Stress
The mixed-effects linear model analyses examined the impact of different levels of AI explainability on clinicians’ mental demand and stress. The models included intervention conditions as fixed effects and participant groups as random effects, controlling for inter-individual variability.
Mental Demand
The model for mental demand, as shown in Table 1 indicated that the intercept, representing the baseline (1st Intervention), had a significant effect (, ), suggesting that participants experienced a moderate level of mental demand in the baseline condition. However, none of the intervention levels (2nd, 3rd, or 4th Intervention) showed a statistically significant difference in mental demand compared to the baseline, although a slight decrease was observed. Specifically, the coefficients for the 2nd, 3rd, and 4th interventions were , , and , respectively, all with .
| Cognitive Load | Mental Demand | Stress | ||
|---|---|---|---|---|
| Variable | ||||
| Intercept | 1.714 | 0.000 | 1.071 | 0.000 |
| 2nd Intervention | -0.036 | 0.822 | 0.214 | 0.185 |
| 3rd Intervention | -0.179 | 0.262 | 0.393 | 0.015 |
| 4th Intervention | -0.107 | 0.501 | 0.214 | 0.185 |
| Group Var | -0.881 | 0.785 | ||
Stress
For stress (Table 1), the intercept (First Intervention) was also significant (, ), indicating a moderate baseline level of stress. Interestingly, the 3rd Intervention (which introduced tumor localization with probability estimates) significantly increased stress compared to the baseline (, ), suggesting that this specific level of explainability may add to participants’ stress levels. The 2nd and 4th interventions, however, showed an increase in comparison to the first intervention but did not produce significant effects (, for both), indicating no significant stress changes at these levels of explainability.
4.2 Impact of AI Confidence Score on Users’ Behavior
The mixed-effects model was used to assess the influence of AI confidence score (No confidence, low and high) on four key outcomes: trust, agreement, performance, and diagnosis duration. The results are summarized in Table 2.
Trust
Low confidence score significantly decreased trust (, ), indicating that participants reported lower trust when the AI’s confidence in its predictions was low compared to when no confidence score was provided. High confidence, while not significantly different from the baseline (, ), showed a slight increase in trust.
Agreement
Agreement levels also showed a significant decrease with low AI confidence score (, ), indicating that participants were less likely to agree with the AI’s recommendations when the confidence score was low. Similar to trust, high confidence score did not have a significant effect on agreement (, ).
| AI Confidence Score | Trust | Agreement | Performance | Diagnosis Duration | ||||
|---|---|---|---|---|---|---|---|---|
| Variable | ||||||||
| Intercept | 3.031 | 0.000 | 3.224 | 0.000 | 0.738 | 0.000 | 0.260 | 0.000 |
| Low Confidence | -0.163 | 0.023 | -0.186 | 0.005 | -0.087 | 0.675 | 0.131 | 0.009 |
| High Confidence | 0.103 | 0.169 | 0.108 | 0.121 | -0.015 | 0.020 | -0.012 | 0.818 |
| Group Var | 0.292 | 0.238 | 0.005 | 0.094 | ||||
Performance
Performance, as an outcome measure, showed a unique pattern. High confidence was associated with a small but statistically significant decrease in performance (, ), suggesting that participants may have been overly reliant on the AI’s suggestions, whose accuracy was approximately 80%, potentially reducing their diagnostic accuracy. In contrast, low confidence did not significantly affect performance (, ).
Diagnosis Duration
For diagnosis duration, low confidence led to a small but significant increase in the time taken (, ), suggesting that participants may have spent more time on their diagnoses when the AI expressed lower confidence. High confidence, however, did not significantly impact diagnosis duration compared to the baseline (, ).
Overall, low confidence from the AI system significantly decreased trust and agreement while increasing diagnosis duration, suggesting that participants were more cautious and took additional time on diagnoses when the AI’s confidence was low. In contrast, high confidence did not produce significant changes in these measures, highlighting a potential asymmetry in how confidence scores affect participant behavior. These findings emphasize the importance of AI confidence displays to encourage balanced reliance and avoid overconfidence in the AI’s recommendations.
4.3 Assessing the Effect of Participant Demographics on Study Outcomes
The ANOVA results presented in Table 3 represent the influence of demographic variables on various outcome measures concerning perceptions and experiences of participants. The outcome measures which were considered in this regard are mental demand, stress, AI role, complexity perception, and AI usefulness. Significant effects are identified based on the F-statistic along with p-values across these variables.
| Mental Demand | Stress | AI Role | Complexity Perception | AI Usefulness | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Variable | F | p | F | p | F | p | F | p | F | p |
| Age | 35.91 | 8.64e-16 | 12.47 | 5.51e-07 | 10.02 | 8.00e-06 | 62.31 | 1.03e-22 | 14.23 | 8.78e-08 |
| Experience Bracket | 8.91 | 2.77e-04 | 1.16 | 0.317 | 15.75 | 1.00e-06 | 1.46 | 0.237 | 5.91 | 3.76e-03 |
| Job | 1.93 | 0.151 | 1.11 | 0.334 | 8.26 | 4.82e-04 | 11.78 | 2.58e-05 | 4.48 | 1.37e-02 |
| Race | 2.82 | 2.88e-02 | 2.51 | 0.047 | 8.49 | 6.00e-06 | 4.78 | 1.44e-03 | 12.24 | 3.99e-08 |
| Gender | 1.46 | 0.231 | 0.015 | 0.901 | 0.31 | 0.579 | 92.97 | 6.61e-16 | 23.68 | 4.30e-06 |
Results reveal that age is a highly significant factor across all outcome measures, with extremely low p-values (all below ), indicating strong relationships between age groups and their responses. Similarly, experience bracket significantly affects certain outcome measures, namely, mental demand (), AI role (), and AI usefulness (), pointing to a relationship between participants’ experience levels and their perceptions of these specific factors.
Job role also shows a significant effect on perceptions, especially regarding AI role (), complexity perception (), and AI usefulness (). This implies that job responsibilities may shape how participants view AI functionality and complexity. Race has a significant impact on all outcome measures as well, highlighting potential differences in AI-related perceptions across racial backgrounds. Lastly, gender plays a significant role specifically in perceptions of complexity perception () and AI usefulness (), suggesting that men and women might perceive AI complexity and usefulness differently.
When it comes to AI usefulness, female oncologists perceive AI as the most useful, whereas male radiologists show lower ratings, suggesting that gender and job role impact how useful AI is perceived within these fields. Finally, for AI role, radiologists report a generally high perception of AI’s role, with male oncologists rating it lowest, indicating that radiologists may view AI as more integral to their field compared to other job roles. These findings underscore how gender and professional role shape perceptions of stress, mental demand, task complexity, and the role and usefulness of AI, with notable differences seen in the oncologist and radiologist groups.
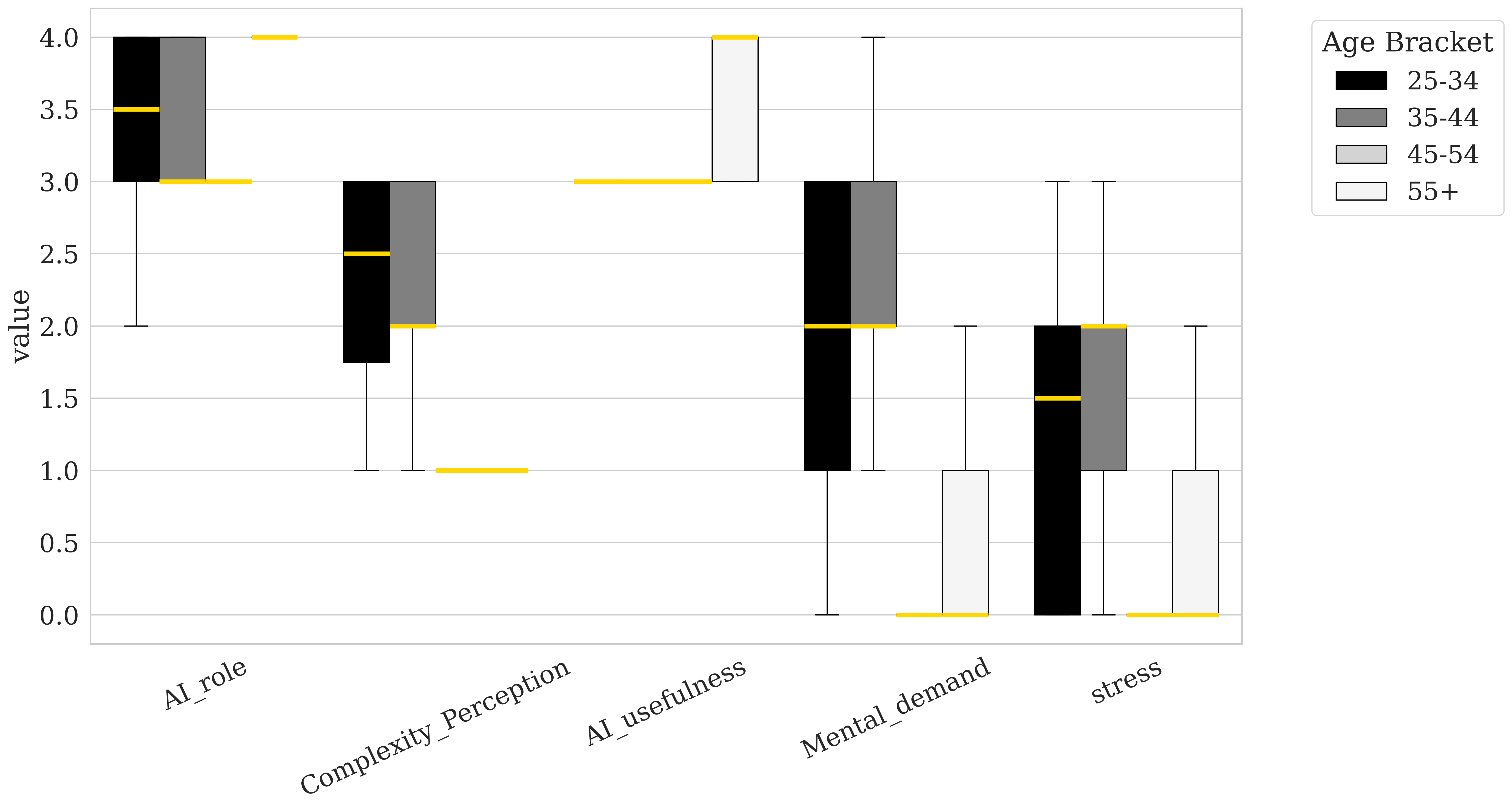
The box plots illustrate how participants’ perceptions of AI role, complexity perception, AI usefulness, mental demand, and stress vary across different demographic categories: age, gender, and race. For age (Figure 3), younger participants (25-34) tend to rate AI role and AI usefulness lower, while older participants, especially those 55 and above, rate these aspects higher, suggesting that older participants see more value in AI’s role and utility. Notably, older participants report lower mental memand and stress levels, suggesting that their greater experience may reduce the cognitive load required for these tasks compared to younger participants.
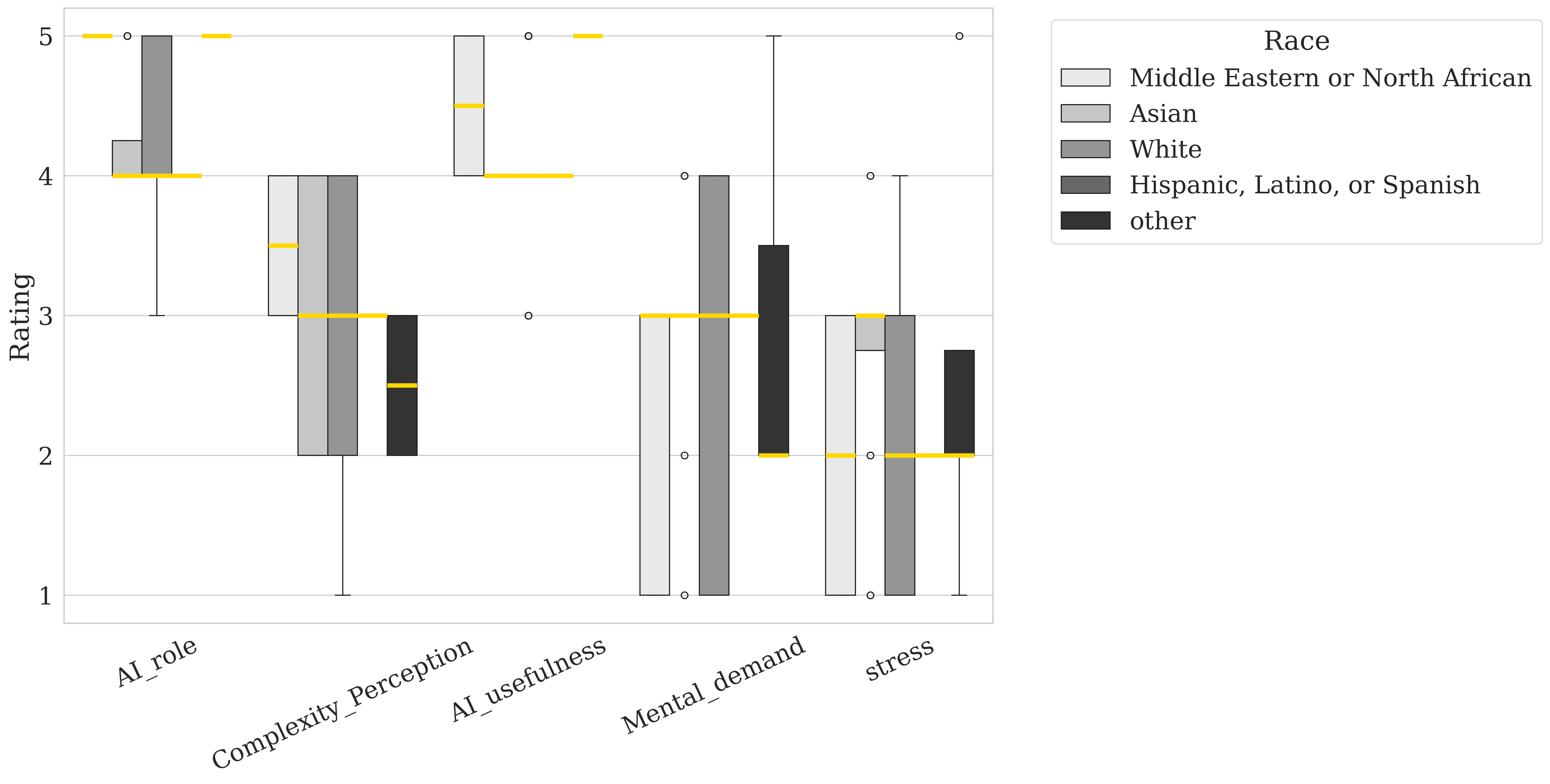
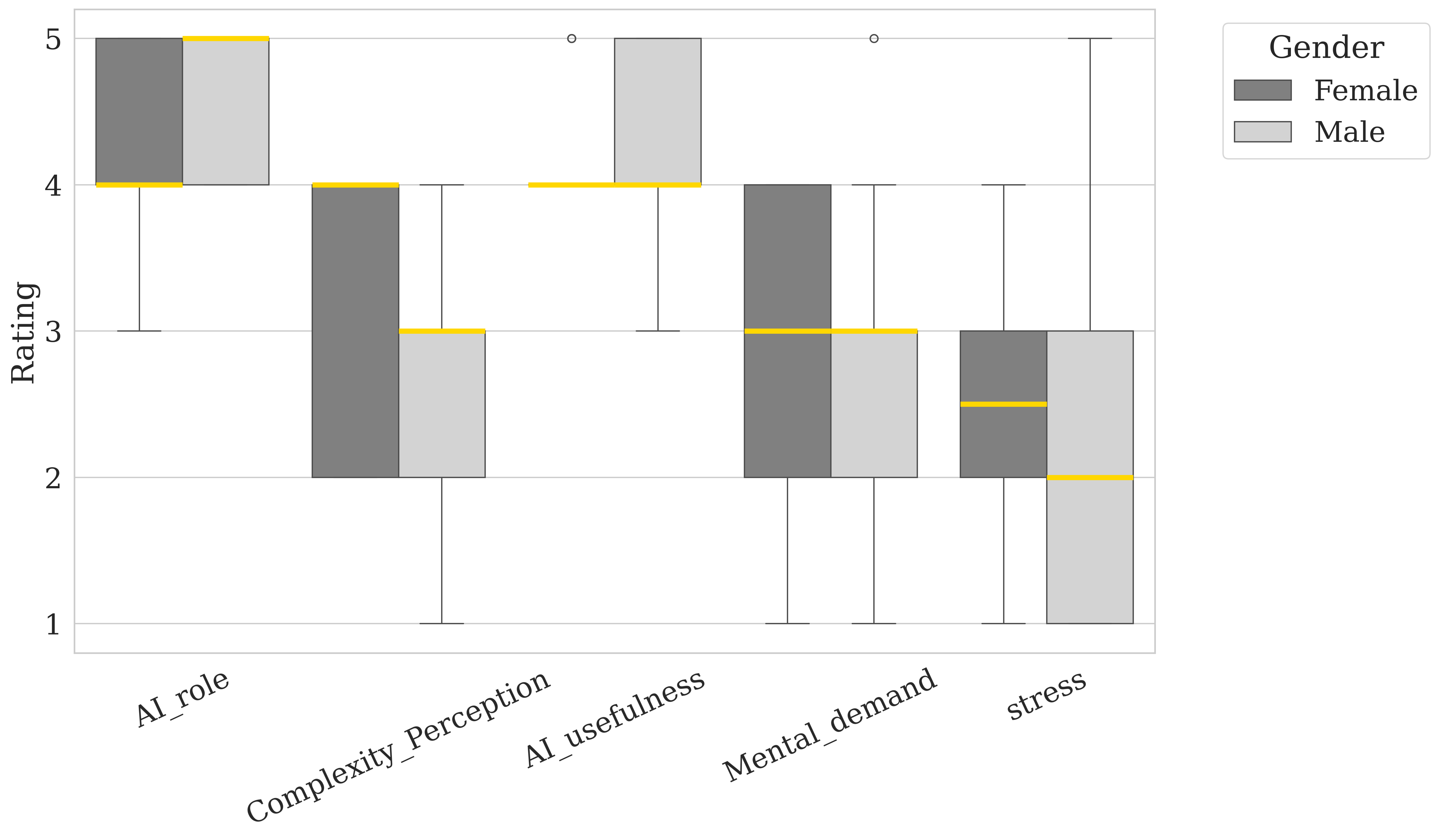
Gender differences (Figure 5) reveal that female participants perceive the AI role as less significant compared to male participants but report higher levels of complexity and stress. This suggests that, while females may view AI as having a lesser role, they find the tasks associated with it more complex and demanding than their male counterparts. Racial differences are also notable as shown in Figure 4: middle eastern or north African participants rate AI role, complexity, and AI usefulness highly, indicating a generally positive perception of AI’s potential and relevance. In contrast, participants from the Asian group report higher levels of Stress, suggesting that they may experience more cognitive or emotional strain when engaging with AI-related tasks. These findings suggest that age, gender, and race shape individuals’ views on AI’s utility and complexity, as well as the cognitive and emotional demands associated with interacting with AI systems.
5 Discussion
5.1 Impact of AI Explainability on Cognitive Load
Most studies focus on the effect of explainability on cognitive load by examining individual explanation models [75, 66] or comparing different models [64, 76]. To answer RQ1, this study broadens the scope by exploring the impact of varying levels of AI explainability, from no explanation to increasingly detailed explanations, on cognitive load, specifically mental demand and stress.
Karran et al. [77] argue that any form of XAI explanation can reduce cognitive effort by aligning users’ mental models with the task. Our findings align with this perspective, showing that increasing levels of explainability generally decreased mental demand. However, this reduction was not statistically significant, consistent with Wang et al. [63], who reported no significant differences in cognitive load between groups provided with XAI explanations and those using AI-only systems. Notably, explanations that were concise, visually clear, and focused on relevant information showed the greatest potential for reducing mental load.
In contrast, the fourth condition, which introduced more complex and detailed information, resulted in increased mental demand. This highlights that overly detailed or poorly aligned explanations can conflict with users’ mental models, requiring additional cognitive effort to process. These findings underscore the importance of designing explanations that are both clear and relevant, as their quality significantly affects cognitive load [64]. By prioritizing user-centered explanation design, XAI systems can better support users without introducing unnecessary cognitive strain.
On the other hand, stress levels increased for all levels of explainability, with the third condition, tumor localization with probability estimates, causing a statistically significant rise. This increase can be attributed to the distinct nature of the information introduced in this condition, which required greater cognitive effort to interpret and apply. Consistent with previous studies, such as [75], explanations can impose additional cognitive demands depending on the style and complexity of the information provided.
These findings highlight the need for clear and concise XAI design. Overly complex explanations can increase cognitive demands, while appropriate information helps reduce strain and improve usability [65].
5.2 Effect of AI Confidence Scores on User Behavior
Confidence scores play a crucial role in helping users calibrate their trust in AI systems, enabling them to determine when to trust or distrust AI outputs [17]. The effectiveness of displaying confidence information has been observed across diverse domains, such as air traffic control, military training, and mobile applications, highlighting its broad applicability [18]. In this study, we investigated the impact of varying levels of AI confidence on trust, agreement, performance, and diagnosis duration within the healthcare domain to address RQ2.
Research shows that dynamic confidence displays can reduce automation bias. For example, [59] found that pilots who had access to real-time AI confidence updates were less likely to blindly follow system recommendations. Similarly, we found that low AI confidence significantly decreased trust and agreement but increased diagnosis duration. This cautious behavior aligns with [18, 17], who noted that lower confidence scores encourage users to rely more on their own judgment, leading to more thoughtful decision-making.
On the other hand, high confidence slightly increased trust, consistent with findings by [17, 18]. However, it also led to a small but significant decrease in performance, likely due to overreliance on AI recommendations. This overreliance, often referred to as automation bias, has been introduced by Parasuraman and Riley [11], which highlight how users tend to trust high-confidence AI outputs without critically assessing them.
These findings highlights the paramount importance of designing AI confidence displays to encourage appropriate reliance on AI systems. While high confidence can enhance trustworthiness, it must be presented in a manner that mitigates automation bias and ensures balanced decision-making, particularly in critical domains such as healthcare.
5.3 Demographic Factors and Perceptions of AI
To address Research RQ3, we analyzed participant demographics and their perceptions of AI, revealing significant relationships between age, gender, job role, and user interaction with AI systems. Research indicates that individuals of different ages may adopt varied strategies when assessing the trustworthiness of automated systems [33]. In contrast to findings by Jermutus et al. [34], our results show that older participants rated the role and usefulness of AI more positively, whereas younger participants reported higher levels of mental demand and stress during interactions with AI.
Gender differences also emerged as a critical factor. Female participants perceived tasks involving AI as more complex and demanding and rated the usefulness of AI lower than their male counterparts, consistent with Tung’s [78] findings. These variations may be influenced by differences in how males and females respond to an automated system’s communication style and interface design [33, 78, 79].
Participants’ professional and technological backgrounds played a significant role in shaping their perceptions of AI. Research shows that users with higher digital literacy and greater exposure to AI systems are generally more comfortable and confident in adopting such technologies [80]. Radiologists, for instance, viewed AI as more integral to their work compared to other professional groups, likely due to their frequent exposure to AI systems specifically designed for radiology tasks. In contrast, oncologists found tasks involving AI to be more complex and demanding. This may reflect the relative lack of AI tools tailored to their specific workflows or the need for additional training to bridge gaps in familiarity and confidence. Social influences, including peer and family attitudes toward AI, also play a role in shaping users’ willingness to engage with these systems [25].
5.4 Limitations
While this study offers valuable insights, there are some important limitations to consider. Because the experiment was conducted in a controlled setting, it doesn’t fully reflect the complexities of real-world clinical environments. Factors like emotional involvement, high-pressure decision-making, and how the system fits into existing workflows weren’t part of this study. We also relied on self-reported measures like trust and cognitive load, which may not always match what participants actually think or do. Additionally, the participant group wasn’t large or diverse enough to capture the wide range of perspectives found in real-world clinical settings.
Future research should explore how these findings apply to different environments and longer-term use. By addressing these gaps, we can better understand how to design AI systems that are effective, trustworthy, and equitable in practice.
6 Conclusion
Artificial Intelligence (AI) has revolutionized various fields, including healthcare, by enhancing decision-making processes and outcomes. In the context of Clinical Decision Support Systems (CDSSs), the integration of explainability features has become increasingly important to ensure user trust and engagement. However, the relationship between explainability, trust, and cognitive load remains complex and requires further exploration.
This study investigated the effects of different explainability features, such as AI confidence scores, on trust and cognitive load in a controlled experimental setting. Our findings revealed some interesting relationships: high AI confidence substantially improved trust but led to overreliance, while low confidence decreased trust and agreement but increased diagnosis duration. AI confidence score also elevated stress levels, highlighting the need to carefully design these features to minimize cognitive load and avoid unintended consequences.
Demographic factors, including age, gender, and professional roles, significantly influenced participants’ perceptions of AI, emphasizing the importance of tailoring AI systems to meet the needs of diverse user groups. These findings underscore the importance of designing explainable AI systems that balance transparency and usability, ensuring they foster trust, reduce cognitive demands, and support effective decision-making in high-stakes domains like healthcare.
References
- [1] S. M. McKinney, M. Sieniek, V. Godbole, J. Godwin, N. Antropova, H. Ashrafian, T. Back, M. Chesus, G. S. Corrado, and A. Darzi, “International evaluation of an AI system for breast cancer screening,” Nature, vol. 577, no. 7788, pp. 89–94, 2020. Publisher: Nature Publishing Group UK London.
- [2] M. Micocci, S. Borsci, V. Thakerar, S. Walne, Y. Manshadi, F. Edridge, D. Mullarkey, P. Buckle, and G. B. Hanna, “Attitudes towards trusting artificial intelligence insights and factors to prevent the passive adherence of GPs: a pilot study,” Journal of Clinical Medicine, vol. 10, no. 14, p. 3101, 2021. Publisher: MDPI.
- [3] A. Janowczyk and A. Madabhushi, “Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases,” Journal of pathology informatics, vol. 7, no. 1, p. 29, 2016. Publisher: Elsevier.
- [4] H. Nahata and S. P. Singh, “Deep learning solutions for skin cancer detection and diagnosis,” Machine Learning with Health Care Perspective: Machine Learning and Healthcare, pp. 159–182, 2020. Publisher: Springer.
- [5] C. McIntosh and T. G. Purdie, “Voxel-based dose prediction with multi-patient atlas selection for automated radiotherapy treatment planning,” Physics in Medicine & Biology, vol. 62, no. 2, p. 415, 2016. Publisher: IOP Publishing.
- [6] A. Choudhury, O. Asan, and J. E. Medow, “Effect of risk, expectancy, and trust on clinicians’ intent to use an artificial intelligence system – Blood Utilization Calculator,” Applied Ergonomics, vol. 101, p. 103708, May 2022.
- [7] A. Čartolovni, A. Tomičić, and E. L. Mosler, “Ethical, legal, and social considerations of AI-based medical decision-support tools: A scoping review,” International Journal of Medical Informatics, vol. 161, p. 104738, 2022. Publisher: Elsevier.
- [8] S. Gaube, H. Suresh, M. Raue, A. Merritt, S. J. Berkowitz, E. Lermer, J. F. Coughlin, J. V. Guttag, E. Colak, and M. Ghassemi, “Do as AI say: susceptibility in deployment of clinical decision-aids,” npj Digital Medicine, vol. 4, pp. 1–8, Feb. 2021. Number: 1 Publisher: Nature Publishing Group.
- [9] E. J. Topol, “High-performance medicine: the convergence of human and artificial intelligence,” Nature medicine, vol. 25, no. 1, pp. 44–56, 2019. Publisher: Nature Publishing Group US New York.
- [10] O. Asan, A. E. Bayrak, and A. Choudhury, “Artificial Intelligence and Human Trust in Healthcare: Focus on Clinicians,” Journal of Medical Internet Research, vol. 22, p. e15154, June 2020. Company: Journal of Medical Internet Research Distributor: Journal of Medical Internet Research Institution: Journal of Medical Internet Research Label: Journal of Medical Internet Research Publisher: JMIR Publications Inc., Toronto, Canada.
- [11] R. Parasuraman and V. Riley, “Humans and automation: Use, misuse, disuse, abuse,” Human factors, vol. 39, no. 2, pp. 230–253, 1997. Publisher: SAGE Publications Sage CA: Los Angeles, CA.
- [12] M. Ghazizadeh, J. D. Lee, and L. N. Boyle, “Extending the technology acceptance model to assess automation,” Cognition, Technology & Work, pp. 39–49, 2012. Publisher: Springer.
- [13] F. D. Davis, “Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology,” MIS Quarterly, pp. 319–340, 1989. Publisher: Management Information Systems Research Center, University of Minnesota.
- [14] E. Glikson and A. W. Woolley, “Human trust in artificial intelligence: Review of empirical research,” Academy of Management Annals, pp. 627–660, 2020. Publisher: Briarcliff Manor, NY.
- [15] V. Tucci, J. Saary, and T. E. Doyle, “Factors influencing trust in medical artificial intelligence for healthcare professionals: A narrative review,” J. Med. Artif. Intell, vol. 5, no. 4, 2022.
- [16] A. Miller, C. Scheinkestel, and C. Steele, “The effects of clinical information presentation on physicians’ and nurses’ decision-making in ICUs,” Applied ergonomics, vol. 40, no. 4, pp. 753–761, 2009. Publisher: Elsevier.
- [17] Y. Zhang, Q. V. Liao, and R. K. Bellamy, “Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making,” in Proceedings of the 2020 conference on fairness, accountability, and transparency, pp. 295–305, 2020.
- [18] S. Antifakos, N. Kern, B. Schiele, and A. Schwaninger, “Towards improving trust in context-aware systems by displaying system confidence,” pp. 9–14, 2005.
- [19] M. Jalali Sepehr and N. Mashhadi Nejad, “Exploring Strategic National Research and Development Factors for Sustainable Adoption of Cellular Agriculture Technology,” Narges, Exploring Strategic National Research and Development Factors for Sustainable Adoption of Cellular Agriculture Technology (January 12, 2024), 2024.
- [20] D. L. Goodhue and R. L. Thompson, “Task-Technology Fit and Individual Performance,” MIS Quarterly, vol. 19, pp. 213–236, 1995. Publisher: Management Information Systems Research Center, University of Minnesota.
- [21] V. Venkatesh, M. G. Morris, G. B. Davis, and F. D. Davis, “User Acceptance of Information Technology: Toward a Unified View,” MIS Quarterly, pp. 425–478, 2003. Publisher: Management Information Systems Research Center, University of Minnesota.
- [22] S. C. Kohn, E. J. De Visser, E. Wiese, Y.-C. Lee, and T. H. Shaw, “Measurement of trust in automation: A narrative review and reference guide,” Frontiers in psychology, vol. 12, p. 604977, 2021. Publisher: Frontiers Media SA.
- [23] D. Gefen, E. Karahanna, and D. W. Straub, “Trust and TAM in Online Shopping: An Integrated Model,” MIS Q., pp. 51–90, 2003.
- [24] E. S. Vorm and D. J. Y. Combs, “Integrating Transparency, Trust, and Acceptance: The Intelligent Systems Technology Acceptance Model (ISTAM),” International Journal of Human–Computer Interaction, pp. 1828–1845, Dec. 2022. Publisher: Taylor & Francis.
- [25] M. Lotfalian Saremi, I. Ziv, O. Asan, and A. E. Bayrak, “Trust, Workload, and Performance in Human–Artificial Intelligence Partnering: The Role of Artificial Intelligence Attributes in Solving Classification Problems,” Journal of Mechanical Design, vol. 147, July 2024.
- [26] J. D. Lee and K. A. See, “Trust in automation: designing for appropriate reliance,” Human Factors, vol. 46, no. 1, pp. 50–80, 2004.
- [27] R. Mayer, “An Integrative Model of Organizational Trust,” Academy of Management Review, 1995.
- [28] B. M. Muir, “Trust between humans and machines, and the design of decision aids,” International journal of man-machine studies, vol. 27, no. 5-6, pp. 527–539, 1987. Publisher: Elsevier.
- [29] O. Vereschak, G. Bailly, and B. Caramiaux, “How to evaluate trust in AI-assisted decision making? A survey of empirical methodologies,” Proceedings of the ACM on Human-Computer Interaction, vol. 5, no. CSCW2, pp. 1–39, 2021. Publisher: ACM New York, NY, USA.
- [30] M. Naiseh, D. Al-Thani, N. Jiang, and R. Ali, “How the different explanation classes impact trust calibration: The case of clinical decision support systems,” International Journal of Human-Computer Studies, vol. 169, p. 102941, 2023. Publisher: Elsevier.
- [31] M. Naiseh, D. Al-Thani, N. Jiang, and R. Ali, “Explainable recommendation: when design meets trust calibration,” World Wide Web, pp. 1857–1884, 2021. Publisher: Springer.
- [32] C. Snijders, R. Conijn, E. de Fouw, and K. van Berlo, “Humans and Algorithms Detecting Fake News: Effects of Individual and Contextual Confidence on Trust in Algorithmic Advice,” International Journal of Human–Computer Interaction, pp. 1483–1494, Apr. 2023. Publisher: Taylor & Francis.
- [33] K. A. Hoff and M. Bashir, “Trust in automation: integrating empirical evidence on factors that influence trust,” Human Factors, vol. 57, pp. 407–434, May 2015.
- [34] E. Jermutus, D. Kneale, J. Thomas, and S. Michie, “Influences on User Trust in Healthcare Artificial Intelligence: A Systematic Review,” Wellcome Open Research, vol. 7, Feb. 2022. Publisher: F1000 Research Ltd.
- [35] M. Lotfalian Saremi and A. E. Bayrak, “A Survey of Important Factors in Human - Artificial Intelligence Trust for Engineering System Design,” in IDETC-CIE2021, (Volume 6: 33rd International Conference on Design Theory and Methodology (DTM)), Aug. 2021. V006T06A056.
- [36] K. E. Schaefer, J. Y. C. Chen, J. L. Szalma, and P. A. Hancock, “A Meta-Analysis of Factors Influencing the Development of Trust in Automation: Implications for Understanding Autonomy in Future Systems,” Human Factors, pp. 377–400, May 2016. Publisher: SAGE Publications Inc.
- [37] B. Leichtmann, A. Hinterreiter, C. Humer, M. Streit, and M. Mara, “Explainable artificial intelligence improves human decision-making: results from a mushroom picking experiment at a public art festival,” International Journal of Human–Computer Interaction, pp. 4787–4804, 2024. Publisher: Taylor & Francis.
- [38] C. A. Lehmann, C. B. Haubitz, A. Fügener, and U. W. Thonemann, “The risk of algorithm transparency: How algorithm complexity drives the effects on the use of advice,” Production and Operations Management, vol. 31, pp. 3419–3434, Sept. 2022. Publisher: SAGE Publications.
- [39] D. Shin, “The effects of explainability and causability on perception, trust, and acceptance: Implications for explainable AI,” International Journal of Human-Computer Studies, vol. 146, p. 102551, 2021.
- [40] E. Bernardo and R. Seva, “Affective Design Analysis of Explainable Artificial Intelligence (XAI): A User-Centric Perspective,” Informatics, vol. 10, p. 32, Mar. 2023. Number: 1 Publisher: Multidisciplinary Digital Publishing Institute.
- [41] J. Cecil, E. Lermer, M. F. C. Hudecek, J. Sauer, and S. Gaube, “Explainability does not mitigate the negative impact of incorrect AI advice in a personnel selection task,” Scientific Reports, vol. 14, p. 9736, Apr. 2024.
- [42] A. Holzinger, G. Langs, H. Denk, K. Zatloukal, and H. Müller, “Causability and explainability of artificial intelligence in medicine,” Wiley Interdisciplinary Reviews. Data Mining and Knowledge Discovery, vol. 9, no. 4, p. e1312, 2019.
- [43] P. Wang and H. Ding, “The rationality of explanation or human capacity? Understanding the impact of explainable artificial intelligence on human-AI trust and decision performance,” Information Processing & Management, vol. 61, p. 103732, July 2024.
- [44] M. T. Ribeiro, S. Singh, and C. Guestrin, “” Why should i trust you?” Explaining the predictions of any classifier,” in Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1135–1144, 2016.
- [45] K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” arXiv preprint arXiv:1312.6034, 2013.
- [46] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: visual explanations from deep networks via gradient-based localization,” International journal of computer vision, vol. 128, pp. 336–359, 2020. Publisher: Springer.
- [47] M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” pp. 3319–3328, PMLR, 2017.
- [48] S. Wachter, B. Mittelstadt, and C. Russell, “Counterfactual explanations without opening the black box: Automated decisions and the GDPR,” Harv. JL & Tech., vol. 31, p. 841, 2017. Publisher: HeinOnline.
- [49] B. Kim, R. Khanna, and O. O. Koyejo, “Examples are not enough, learn to criticize! criticism for interpretability,” Advances in neural information processing systems, vol. 29, 2016.
- [50] S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 4768–4777, Curran Associates Inc., 2017. event-place: Long Beach, California, USA.
- [51] J. H. Friedman, “Greedy Function Approximation: A Gradient Boosting Machine,” The Annals of Statistics, vol. 29, pp. 1189–1232, 2001. Publisher: Institute of Mathematical Statistics.
- [52] B. Leichtmann, C. Humer, A. Hinterreiter, M. Streit, and M. Mara, “Effects of Explainable Artificial Intelligence on trust and human behavior in a high-risk decision task,” Computers in Human Behavior, vol. 139, p. 107539, 2023.
- [53] O. Rezaeian, O. Asan, and A. E. Bayrak, “The Impact of AI Explanations on Clinicians Trust and Diagnostic Accuracy in Breast Cancer,” arXiv preprint arXiv:2412.11298, 2024.
- [54] D. Ahn, A. Almaatouq, M. Gulabani, and K. Hosanagar, “Impact of Model Interpretability and Outcome Feedback on Trust in AI,” in Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1–25, 2024.
- [55] L. Alam and S. Mueller, “Examining the effect of explanation on satisfaction and trust in AI diagnostic systems,” BMC Medical Informatics and Decision Making, vol. 21, p. 178, June 2021.
- [56] C. J. Cai, J. Jongejan, and J. Holbrook, “The effects of example-based explanations in a machine learning interface,” in Proceedings of the 24th international conference on intelligent user interfaces, pp. 258–262, 2019.
- [57] X. Wang and M. Yin, “Are explanations helpful? a comparative study of the effects of explanations in ai-assisted decision-making,” in Proceedings of the 26th International Conference on Intelligent User Interfaces, pp. 318–328, 2021.
- [58] T. Evans, C. O. Retzlaff, C. Geißler, M. Kargl, M. Plass, H. Müller, T.-R. Kiehl, N. Zerbe, and A. Holzinger, “The explainability paradox: Challenges for xAI in digital pathology,” Future Generation Computer Systems, vol. 133, pp. 281–296, Aug. 2022.
- [59] J. M. McGuirl and N. B. Sarter, “Supporting trust calibration and the effective use of decision aids by presenting dynamic system confidence information,” Human factors, vol. 48, no. 4, pp. 656–665, 2006. Publisher: SAGE Publications Sage CA: Los Angeles, CA.
- [60] A. Rechkemmer and M. Yin, “When confidence meets accuracy: Exploring the effects of multiple performance indicators on trust in machine learning models,” pp. 1–14, 2022.
- [61] A. Choudhury and O. Asan, “Impact of cognitive workload and situation awareness on clinicians’ willingness to use an artificial intelligence system in clinical practice,” IISE Transactions on Healthcare Systems Engineering, pp. 89–100, Apr. 2023. Publisher: Taylor & Francis.
- [62] J. Sweller, J. J. G. van Merrienboer, and F. G. W. C. Paas, “Cognitive Architecture and Instructional Design,” Educational Psychology Review, vol. 10, pp. 251–296, Sept. 1998.
- [63] D. Wang, C. Bian, and G. Chen, “Using explainable AI to unravel classroom dialogue analysis: Effects of explanations on teachers’ trust, technology acceptance and cognitive load,” British Journal of Educational Technology, 2024. Publisher: Wiley Online Library.
- [64] L.-V. Herm, “Impact of explainable ai on cognitive load: Insights from an empirical study,” arXiv preprint arXiv:2304.08861, 2023.
- [65] R. Kaufman, J. Costa, and E. Kimani, “Effects of multimodal explanations for autonomous driving on driving performance, cognitive load, expertise, confidence, and trust,” Scientific reports, vol. 14, no. 1, p. 13061, 2024. Publisher: Nature Publishing Group UK London.
- [66] A. Hudon, T. Demazure, A. Karran, P.-M. Léger, and S. Sénécal, “Explainable Artificial Intelligence (XAI): How the Visualization of AI Predictions Affects User Cognitive Load and Confidence,” in Information Systems and Neuroscience (F. D. Davis, R. Riedl, J. vom Brocke, P.-M. Léger, A. B. Randolph, and G. Müller-Putz, eds.), (Cham), pp. 237–246, Springer International Publishing, 2021.
- [67] D. P. Hartmann, J. M. Gottman, R. R. Jones, W. Gardner, A. E. Kazdin, and R. S. Vaught, “Interrupted time-series analysis and its application to behavioral data,” Journal of Applied Behavior Analysis, vol. 13, no. 4, pp. 543–559, 1980.
- [68] O. Rezaeian, A. E. Bayrak, and O. Asan, “An architecture to support graduated levels of trust for cancer diagnosis with ai,” in International Conference on Human-Computer Interaction, pp. 344–351, Springer, 2024.
- [69] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241, Springer, 2015.
- [70] L. Abdelrahman, M. Al Ghamdi, F. Collado-Mesa, and M. Abdel-Mottaleb, “Convolutional neural networks for breast cancer detection in mammography: A survey,” Computers in Biology and Medicine, vol. 131, p. 104248, Apr. 2021.
- [71] I. Khazrak, S. Takhirova, M. M. Rezaee, M. Yadollahi, R. C. Green II, and S. Niu, “Addressing Small and Imbalanced Medical Image Datasets Using Generative Models: A Comparative Study of DDPM and PGGANs with Random and Greedy K Sampling,” arXiv preprint arXiv:2412.12532, 2024.
- [72] S. S. Yadav and S. M. Jadhav, “Deep convolutional neural network based medical image classification for disease diagnosis,” Journal of Big Data, vol. 6, p. 113, Dec. 2019.
- [73] W. Al-Dhabyani, M. Gomaa, H. Khaled, and A. Fahmy, “Dataset of breast ultrasound images,” Data in Brief, vol. 28, p. 104863, 2020.
- [74] S. Hart, “Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research,” Human mental workload/Elsevier, 1988.
- [75] Z. Buçinca, P. Lin, K. Z. Gajos, and E. L. Glassman, “Proxy tasks and subjective measures can be misleading in evaluating explainable AI systems,” in Proceedings of the 25th International Conference on Intelligent User Interfaces, IUI ’20, (New York, NY, USA), pp. 454–464, Association for Computing Machinery, 2020. event-place: Cagliari, Italy.
- [76] Z. Buçinca, M. B. Malaya, and K. Z. Gajos, “To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making,” Proceedings of the ACM on Human-computer Interaction, vol. 5, pp. 1–21, 2021. Publisher: ACM New York, NY, USA.
- [77] A. J. Karran, T. Demazure, A. Hudon, S. Senecal, and P.-M. Léger, “Designing for confidence: The impact of visualizing artificial intelligence decisions,” Frontiers in neuroscience, vol. 16, p. 883385, 2022. Publisher: Frontiers Media SA.
- [78] F.-W. Tung, “Influence of Gender and Age on the Attitudes of Children towards Humanoid Robots,” in Human-Computer Interaction. Users and Applications (J. A. Jacko, ed.), (Berlin, Heidelberg), pp. 637–646, Springer Berlin Heidelberg, 2011.
- [79] T. Nomura, T. Kanda, T. Suzuki, and K. Kato, “Prediction of Human Behavior in Human–Robot Interaction Using Psychological Scales for Anxiety and Negative Attitudes Toward Robots,” IEEE Transactions on Robotics, vol. 24, pp. 442–451, Apr. 2008.
- [80] A. J. A. M. v. Deursen, P. S. de Boer, and T. J. L. van Rompay, “Smart Devices Require Skilled Users: Home Automation Performance Tests among the Dutch Population,” International Journal of Human–Computer Interaction, pp. 1–12, 2024. Publisher: Taylor & Francis.