Exploiting Data Locality to Improve Performance of Heterogeneous Server Clusters
Abstract
We consider load balancing in large-scale heterogeneous server systems in the presence of data locality that imposes constraints on which tasks can be assigned to which servers. The constraints are naturally captured by a bipartite graph between the servers and the dispatchers handling assignments of various arrival flows. When a task arrives, the corresponding dispatcher assigns it to a server with the shortest queue among randomly selected servers obeying the above constraints. Server processing speeds are heterogeneous and they depend on the server-type. For a broad class of bipartite graphs, we characterize the limit of the appropriately scaled occupancy process, both on the process-level and in steady state, as the system size becomes large. Using such a characterization, we show that data locality constraints can be used to significantly improve the performance of heterogeneous systems. This is in stark contrast to either heterogeneous servers in a full flexible system or data locality constraints in systems with homogeneous servers, both of which have been observed to degrade the system performance. Extensive numerical experiments corroborate the theoretical results.
††1Georgia Institute of Technology, Email: zhisheng@gatech.edu††2Georgia Institute of Technology, Email: debankur.mukherjee@isye.gatech.edu††3Iowa State University, Email: ruoyu@iastate.edu††Keywords and phrases. Heterogeneous load balancing system, data locality, compatibility constraint, Power-of-Two, Mean-field, McKean-Vlasov Process, Stochastic Coupling††Acknowledgements. The work was partially supported by the NSF grant CIF-2113027.1 Introduction
Over the last two decades, large-scale load balancing has emerged as a fundamental research problem. In simple terms, the goal is to investigate how to efficiently allocate tasks in large-scale service systems, such as data centers and cloud networks? As modern data centers continue to process massive amounts of data with increasingly stringent processing time requirements, the need for more efficient and scalable, dynamic load balancing algorithms is greater than ever. The study of scalable load balancing algorithms started with the seminal works of Mitzenmacher [17, 1, 16] and Vvedenskaya et al. [32], where the popular ‘power-of- choices’ or the JSQ() algorithm was introduced. Here a canonical model was considered that consists of identical parallel servers, each serving a dedicated queue of tasks. Arriving tasks are routed to the shortest of randomly selected queues by a centralized dispatcher, irrevocably and instantaneously, at the time of arrival. Since then, this model has received significant attention from the research community and we have seen tremendous progress in our understanding of performance of various algorithms; see [31] for a recent survey.
Despite this phenomenal progress, when it comes to modern large-scale systems, many of the existing wisdoms can be observed to be false. This is primarily due to the fact that the above classical model fails to capture two of the most significant factors that impact the performance of these systems:
(a) Data locality constraints: In simple terms, it means that tasks of a particular type can only be routed to a small subset of servers that are equipped with the appropriate resources to execute them [33, 22, 27, 29].
For example, an image classification request must be routed to a server that is trained with appropriate machine learning models such as, deep convolutional neural network.
Also, in online video services like Netflix and YouTube, users’ requests may only be routed to servers that are equipped with the required data (e.g., movies, music).
The classical model ignores this effect and assumes full flexibility, that is, that any task can be assigned to any server in the system.
In the presence of data locality constraints, the delay performance of the system may degrade drastically as compared to fully flexible systems.
(b) Heterogeneity in service rates:
Servers in any modern large-scale server clusters do not process tasks at equal speeds.
This heterogeneity of the service rates is a major bottleneck in implementing the existing heuristics of the classical model.
For example, if there are two groups of servers in the system, one faster and the other slower, then popular dynamic algorithms like JSQ() that has a provably excellent delay performance when all server speeds are identical, can be observed to be unstable (i.e., their queue lengths blow up) [10, 13, 21, 20].
In other words, heterogeneity shrinks the stability region as formally established in [13].
This happens simply because if all the servers are treated equally, then the slower server pool may receive a higher flow of arrivals than what it can process.
Takeaway. In summary, both data locality and heterogeneity of server speeds may significantly degrade the system performance. The main contribution of the current work is to establish that when these two aspects are considered together, then the performance can in fact be drastically improved. That is, if servers are heterogeneous, then efficiently designing the data locality constraints (by appropriately placing the resource files in the server network) can regain the full stability region, which was shrunk for fully flexible systems. Moreover, we also establish that a carefully designed data locality constraints can ensure the celebrated double-exponential decay of tail probability of the steady-state queue length distribution even for the heterogeneous systems.
1.1 Our Contributions
Motivated by this, in the current paper, we consider a bipartite graph model for large-scale load balancing systems, which has recently gained popularity in the research community. In this model, a bipartite graph between the servers and task types describes the compatibility between the two, where an edge represents the server’s ability to process the corresponding task type. This encompasses the classical full-flexibility models as those having a complete bipartite compatibility graph. An immediate difficulty of the new model is that when the graph is non-trivial (i.e., not a collection of isolated pairs or a complete bipartite graph), the mean-field techniques break down. This is because, the queues no longer remain exchangeable, making the aggregate processes such as the vector of number of servers with queue length with non-Markovian. In addition, we also consider that each dispatcher handles the arrival flow of one of possible task types and that there are server types. The rate of service at a server depends on its type. Throughout the paper, the key quantity of interest will be the global occupancy process , where represents the fraction of servers of type with queue-length at least at time in the -th system with servers, and we will look at the large-system asymptotic regime: .
Due to the compatibility constraints, the servers become non-exchangeable, even if they belong to the same type. This causes most of the existing frameworks [8, 17, 24] to break down. To characterize the process-level limit of the queue length process, we take resort to the theory of weakly interacting particle systems and asymptotically couple the evolution of the -dimensional vector of queue lengths with an appropriately defined infinite system of independent McKean-Vlasov processes [26, 15]. We also show the asymptotic independence of any finite number of queue length processes, also know as the propagation of chaos property. This convergence of the queue length processes (in sense) is then used to establish the transient convergence of the occupancy process. One downside of the above convergence is that it depends on the assumption that the initial queue lengths within each set of servers of the same type are independent and identically distributed (i.i.d.) and are independent across the the set of servers of different types. Due to this assumption, this convergence result cannot be used to establish the interchange of and limits, which is crucial in studying the limit of steady states.
To overcome this issue, we use the framework of [22], recently introduced in the context of homogeneous systems. Here, a notion called proportional sparsity for graph sequences was introduced, which ensures that the empirical queue length distribution within the set of compatible servers of any dispatcher is close to the empirical queue length distribution of the entire system. This was used in [22] to construct conditions on graphs that match the performance of a fully flexible system. In the current setup, however, this notion is inadequate, since our goal is not to match the performance of the fully flexible system (which is usually poor under heterogeneity). That is why, we extend this notion to what we call the clustered proportional sparsity for a sequence of graphs with increasing size, to accommodate the heterogeneous systems. The clustered proportional sparsity property allows us to construct a stochastic coupling between the system and another intermediate system whose task allocation is done by a carefully constructed algorithm called GWSQ() (Algorithm 1). This coupling with the intermediate system, along with clustered proportional sparsity, helps us establish that if the initial occupancy of two systems are close, then the distance (in the -norm) between their global occupancy remains small uniformly over any finite time interval. In turn, it implies that their limits of the global occupancy systems are the same. As a consequence, we can remove the i.i.d. assumption of the initial queue lengths, since the above guarantees that under clustered proportional sparsity, the convergence of the occupancy process depends only on the initial occupancy and not on how the individual queues are distributed.
The above process-level limit result shows that the transient limit of the occupancy process can be described as a system of ODEs that depend on various graph parameters. Next, we also show that the interchange of limits holds and that the sequence of occupancy states in stationarity, converges weakly to the unique fixed point of the ODE. One celebrated feature of the classical JSQ() policy for homogeneous systems under full flexibility is that the steady-state queue length decays doubly exponentially as , where is the load per server [17, 32]. We establish this double-exponential decay property for the heterogeneous system.
It is worthwhile to note that the strength of the above results lie in that they hold for arbitrary deterministic sequence of graphs satisfying certain properties. However, we show that all these properties are satisfied almost surely by a sequence of inhomogeneous random graphs with parameters prescribed by the theorems. This makes it easy to design graphs with the desired favorable properties.
1.2 Related Works
The research on task allocation systems with limited flexibility can be traced back to the works of Turner [30] and Foss and Chernova [9]. Of particular importance to the current work, Foss and Chernova [9] considered stability properties of the system using the fluid model. Later, Bramson [4] generalized some parts of results in [9] to a broad class of Join-Shortest-Queue (JSQ)-type systems, including the JSQ() policy, via the Lyapunov function approach. Stolyar [23] considered optimal routing in output-queued flexible server system, which is essentially the bipartite graph model for the load balancing system. Here the author considered a system with a fixed number of servers and dispatchers in the conventional heavy traffic regime and proposed a routing policy that is optimal in terms of server workload. Recently, Cruise et al. [7] considered load balancing problems on hypergraphs and proved its stability conditions. The above works, however, did not aim to precisely characterize the system performance in the large-scale scenario.
The analysis in the large-scale scenario became prominent in the last decade, with the emergence of its applications to load balancing in data centers and cloud networks. In the full-flexibility setup, the analysis of heterogeneous-server systems gained some attention. In this case, Stolyar [24, 25] studied the zero-queueing property of the Join-Idle-Queue (JIQ) policy, Mukhopadhyay et al. [21] and Mukhopadhyay and Mazumdar [20] analyzed the JSQ() policy in heterogeneous systems with processor-sharing service discipline, Hurtado-Lange and Maguluri [13] studied the throughput and delay optimality properties of JSQ(), and Bhambay and Mukhopadhyay [3] studied a speed-aware JSQ policy. The above works on the JSQ() policy observe that the stability region shrinks if the dispatcher applies the JSQ() policy blindly. One way to mitigate this performance degradation is to take the server speeds into consideration while sampling servers or while assigning tasks to the sampled servers. Such a ‘hybrid JSQ()’ scheme is able to recover the stability region. The current work can be contrasted with this approach. First, in the presence of data locality, both the server speeds and the underlying compatibility constraints need to be taken into account during the sampling procedure, and the approach becomes significantly more complicated. Second, we show how exploiting the data locality, the blind JSQ() policy can recover the stability region and even achieve the double-exponential decay of tail probabilities of the stead-state queue length distribution. One advantage of the latter approach is that the dispatchers can be oblivious to the server speeds, which reduces the implementation complexity and also, makes it robust against changes to the servers (e.g., when servers are add/removed).
Recently, Allmeier and Gast [2] studied the application of (refined) mean-field approximations for heterogeneous systems. Their method is using an ODE to approximate the evolution of each server, and the error vanishes as the system scales. However, this method cannot be directly used in our case. Due to the bipartite compatibility graph structure, it is hard to capture the interactions between two servers, which means that we cannot write the transition rates of the underlying Markov chain as [2] does. Also, one important assumption in their work is the finite buffer, but we consider the infinite buffer case here.
The aspect of task-server compatibility constraints in large-scale load balancing and scheduling gained popularity only recently, as the data locality became prominent in data centers and cloud networks. This led to many works in this area [11, 18, 5, 22, 33, 29, 28]. All these works consider homogeneous processing speeds at the servers. The initial works [30, 11] focused on certain fixed-degree graphs and showed that the flexibility to forward tasks to even a few neighbors with possibly shorter queues may significantly improve the waiting time performance as compared to dedicated arrival streams or a collection of independent M/M/1 queues. Tsitsiklis and Xu [28, 29] considered asymptotic optimality properties of the bipartite graph topology in an input-queued, dynamic scheduling framework. Later, in the (output-queued) load balancing setup, Mukherjee et al. [18] considered the JSQ policy and Budhiraja et al. [5] considered the transient analysis of the JSQ() policy on non-bipartite graphs. The goal in these papers was to provide sufficient condition on the graph sequence to asymptotically match the performance of a complete graph. Here we should mention that the non-bipartite graph model cannot be used to capture the data locality constraints. In the presence of data locality constraints, the analysis of the JSQ() policy for homogeneous systems, including both transient and interchange of limits, was performed by Rutten and Mukherjee [22]. Weng et al. [33] is the first to consider the large-scale heterogeneous-server model under data locality. They showed that the Join-the-Fastest-Shortest-Queue (JFSQ) and Join-the-Fastest-Idle-Queue (JFIQ) policies achieve asymptotic optimality for minimizing mean steady-state waiting time when the bipartite graph is sufficiently well connected. However, these results fall in the category of JSQ-type policies where the asymptotic behavior is degenerate in the sense that the queue lengths at servers can be either 0 or 1. Naturally, the results and their analysis are very different from the JSQ()-type policies where queues of any length is possible.
1.3 Notations
Let . For a set , its cardinality is denoted as . For a polish space , the space of right continuous functions with left limits from to is denoted as , endowed with the Skorokhod topology. The distribution of -valued random variable will be denoted as . For a function , let . The distribution of -valued random variable will be denoted as . For , the Dirac measure at the point is denoted as . represents the -norm. Define if and is 0, otherwise. RHS is the acronym of Right Hand side.
2 Model Description
The model below for large-scale systems with limited flexibility was considered by Tsitsiklis and Xu [28, 29] in the context of scheduling algorithms for input-queued systems. Subsequently, it was considered in [18, 5, 22, 33] for output-queued load balancing systems. Let be a system with single servers, each serving its own queue, and dispatchers, where and denote the sets of dispatchers and servers, respectively. Similar to [28, 29], we assume that where is a constant. The set of edges represents hard compatibility between the dispatchers and servers in the -th system. In other words, tasks of type can be assigned to a server if and only if . Tasks arriving at a dispatcher must be assigned instantaneously and irrevocably to one of the compatible servers.
-
•
Task types: A task can be of one of possible types labelled in and each dispatcher handles arrivals of exactly one task type. Thus, we will interchangeably use the terms task-type and dispatcher-type throughout the article. Let denote the set of all dispatchers handling type- tasks. As , assume that for with . Tasks arrive at each dispatcher as an independent Poisson process with rate .
-
•
Server types: Each server belongs to one of possible types labelled in . Let denote the set of type- servers, and as , for with .
-
•
Service times: The processing time at a type- server is exponentially distributed with mean , where is a positive constant. Throughout, we will assume that asymptotically, the system has sufficient service capacity in the sense that
(2.1) Note that the left and right hand side above represents the scaled total arrival rate and scaled maximum departure rate, respectively.
For all the asymptotic results, we consider a general class of systems where the compatibility graph satisfies certain asymptotic criteria as specified in Condition 2.1 below. Define
Namely, is the number of the dispatcher ’s neighboring servers whose type is . Similarly, is the number of the server ’s neighboring dispatchers whose type is .
Condition 2.1.
The sequence satisfies the following:
-
(a)
For each and , let
(2.2) We call the matrix as the compatibility matrix.
-
(b)
For each and ,
Intuitively, the condition implies that the ‘asymptotic density’ of edges between type- dispatchers and type- servers is given by and for each task-type-server-type pair, the servers have similar levels of flexibility.
The classical, well-studied setup where any task can be processed by any server, corresponds to the complete bipartite graph with , .
In Section 3.5, we show that for any given , a sequence of graphs satisfying Condition 2.1 can be obtained simply by putting edges suitably randomly.
This is a certain class of inhomogeneous random graphs, which we call irg(); see Definition 3.15 for details.
In fact, the irg() sequence of graphs will be proved to satisfy the required conditions for all the results of this article to hold.
State Space. In the -th system, let be the number of tasks (including those in service) in the queue of server at time . Let be the proportion of servers of type with queue length at least at time , namely,
| (2.3) |
Let . Then is a process with sample paths in where
is equipped with the -topology.
Note that the space is a complete metric space.
Local JSQ() Policy. For any fixed , each dispatcher uses the JSQ() policy [17, 32] to assign the incoming tasks to servers. To describe the policy, define the neighborhood of dispatcher , with . When a new task arrives at the dispatcher with , it is immediately assigned to the server with the shortest queue among servers selected uniformly at random from . Ties are broken uniformly at random. If , then the task is assigned to one server selected from uniformly at random. This scenario is asymptotically not relevant for us since all the graphs that we will consider have diverging degrees as .
3 Main Results
3.1 Mitigating the Stability Issue
As discussed earlier, when the server speeds are heterogeneous, the fully flexible systems (with the complete bipartite compatibility graph) may not be stable under the JSQ() policy, even if we assume that the sufficient service capacity in (2.1) is satisfied. The next lemma provides a necessary and sufficient condition for ergodicity of the queue length process. Recall . For any fixed , define
| (3.1) |
Lemma 3.1.
The queue length process under the local JSQ() policy is ergodic if and only if .
The above lemma is an immediate consequence of [9, Theorem 2.5]; see also [4]. We omit its proof. Intuitively, means that in the -th system, for any subset of servers with possibly long queues (compared to the rest servers), the total rate at which tasks are assigned to some server in this set must be less than the rate of departure from this set.
Since we are interested in large- behavior, we will assume certain asymptotic version of the above stability criterion. This is fairly standard in the large-system analysis, as one would want to avoid the ‘heavy-traffic’ regime when as . The behavior in the latter scenario is typically qualitatively different from the so-called ‘subcritical’ regime as defined below.
Definition 3.2 (Subcritical Regime).
The sequence of systems defined as above is said to be in the subcritical regime with asymptotic load if , as .
Throughout this paper we will assume that the sequence of systems under consideration is in subcritical regime. From Lemma 3.1, it is immediate that if a sequence of systems is in subcritical regime, then its queue length process is ergodic for all large enough . The potential non-ergodicity of fully flexible, heterogeneous server clusters brings us to the question that when the sufficient service capacity in (2.1) is satisfied, whether we can design the underlying compatibility structure carefully so that the queue length process is ergodic. In other words, can we regain the stability region? Proposition 3.3 below shows that this is indeed the case. In some sense, this highlights the first-order improvements (i.e., in terms of stability properties) of a careful compatibility structure design in contrast to a fully flexible system.
Proposition 3.3.
In the following sections, we will demonstrate, in addition to the first-order improvements, how asymptotic queue length distribution can be improved as well, for example, in terms of having a double-exponential decay of tail probabilities.
The proof of Proposition 3.3 is provided in Appendix A. It relies on first building a simple criteria involving the system parameters, which, for sequence of systems satisfying Condition 2.1, ensures stability for all large-enough (Lemma 3.4). Then we show that given other parameters, a value of satisfying this criteria can be found by checking the feasibility region defined by inequalities.
We end this subsection by presenting the above-mentioned simple asymptotic criteria for subcriticality. The proof is given in Appendix A. Denote for each .
Lemma 3.4.
Let be a sequence satisfying Condition 2.1. The sequence of systems is in subcritical regime if
| (3.2) |
3.2 Process-level Limit: IID Case
Our first main result characterizes the process-level limit of the queue-length process , , as , when the starting states are i.i.d. for all and independent across different -values. When the sequence of graphs satisfies a stronger condition, called clustered proportional sparsity (Definition 3.8), the i.i.d. condition can be removed. This is the content of Section 3.3.
Now, note that for a fixed , is a system of stochastic processes with mean-field type interactions. Exploiting tools from the theory of weakly interacting particles, we show in Theorem 3.5 below that as the system size becomes large, queue-length processes converge weakly to those of an infinite system of independent McKean-Vlasov processes (see e.g. [26, 15]). In fact, using a suitable coupling to be described in more details in Section 4.1, the convergence holds in . For ease of describing such processes and coupling, although we only assumed that certain fractions of servers are of certain task types in the model description, it will be convenient to fix the type of each server in this subsection, by defining a membership map , so that with and for each . With such fixed server types and , let
| (3.3) | ||||
| (3.4) |
where and
| (3.5) | ||||
Here, are i.i.d. Poisson processes with rate for each , are i.i.d. Poisson random measures on with intensity , and all ’s and ’s are independent. Loosely speaking, corresponds to the arrival processes and corresponds to the departure processes at servers. We note that the existence and uniqueness of solutions to (3.3) and (3.4) can be proved by standard arguments (see e.g., [26, 15]) using the boundedness and Lipschitz property of the functions and on .
Theorem 3.5 (Convergence to McKean-Vlasov process and propagation of chaos).
Consider any fixed . Assume that all ’s are independent, and for each , is i.i.d. with , . On any finite time interval , , for any and , the queue length process at server weakly converges to the process in (3.3). In fact, one can suitably couple with such that
| (3.6) |
and hence the propagation of chaos property holds, that is, for any and distinct , ,
| (3.7) |
Theorem 3.5 gives us the limit law of all individual queues. Next, in Theorem 3.6, we will show how such a server-level convergence can be used to obtain a convergence result for the global occupancy process to a deterministic dynamical system, which was our primary goal. The proofs of Theorem 3.5 and Theorem 3.6 are provided in Section 4.
Theorem 3.6 (Process-level convergence for i.i.d. starting state).
Assume that all ’s are independent, and for each , is i.i.d. with , for some . Then on any finite time interval, the occupancy process converges weakly with respect to Skorokhod topology to the deterministic limit given by the unique solution to the following system of ODEs: For all , , , and
| (3.8) |
where for all .
3.3 Process-level Limit: General Case
Theorem 3.6 requires the strong assumption that for each , , , are i.i.d.. In order to argue the interchange of limits, we need to relax this assumption on initial states. This is because the arguments for the interchange of limits involves initiating the prelimit system at the steady state and then showing that as , the system must converge to the unique fixed point of the limiting ODE. The above requires us to characterize the (process-level) limiting trajectory of the system starting from arbitrary occupancy state. We achieve this in this section.
Intuitively, the assumption of i.i.d. in Theorems 3.5 and 3.6 ensures that the local occupancy observed by any dispatcher , is ‘close’, in suitable sense, to the average occupancy at the entire system. This phenomenon can be ensured asymptotically, even without the i.i.d. assumption if the graph sequence satisfies a property we call the clustered proportional sparsity. This notion was first introduced for the homogeneous systems in [22]. The definition below is a modified notion that is suitable for the current heterogeneous setting.
Definition 3.8 (Clustered Proportional Sparsity).
Recall . The sequence is called clustered proportionally sparse if for any ,
| (3.9) |
where .
Remark 3.9.
We can view the subset in the definition as a test set, say , where is the set of type servers with queue length at least at time . Hence, Definition 3.8 ensures that for all but dispatchers, the observed empirical queue length distribution within its neighborhood, is close to the global weighted empirical queue length distribution (Definition 4.6) of its corresponding type. Then, the global occupancy process evolves similarly to (and converges to the same limit as) the case when the initial states are i.i.d..
Theorem 3.10 (Process-level convergence).
Let be a clustered proportionally sparse sequence of graphs. Assume that weakly converges to . Then on any finite time interval, the occupancy process converges weakly with respect to the Skorokhod topology to the deterministic limit given by the unique solution to the system of ODEs defined by (3.8) with initial state .
3.4 Convergence of Steady States
In the last section, we showed the process-level convergence of global occupancy process to a mean-field limit . In this section, we will establish the convergence of the sequence of stationary distributions to the unique fixed point of the mean-field limit by establishing the interchange of large- and large- limits: . Throughout this section, we will assume that the sequence of systems is in subcritical regime (recall Definition 3.2). The first result below states that the limiting system of ODEs have a unique fixed point and it satisfies the global stability property, i.e., for any initial point , .
Theorem 3.11 (Global stability).
Let be the solution to the system of ODEs in (3.8) with the initial point . Then there exists a unique fixed point such that
The proof of Theorem 3.11 is given in Section 5. It relies on a monotonicity property of the system, which ensures that for two processes and , if , then for all (see ref. [24, 14]).
The last ingredient that we need in order to prove the interchange of limits is to establish tightness of the sequence of random variables under suitable metric, where . Here, as before, we should note that the process is not Markovian. That is why, the random variable should be interpreted as the functional applied to the steady-state system. The tightness result is stated in the next theorem.
Theorem 3.12 (Tightness).
For any , there exists a compact subset , when is equipped with the -topology, such that
Theorem 3.12 is proved in Section 5. The key idea is to use Lyapunov function approach to bound the expected sum of tails . Combining Theorems 3.10, 3.11, and 3.12 we can prove the following interchange of limits result.
Theorem 3.13 (Convergence of steady states).
One major discovery about the JSQ() policy for the classical, homogeneous, fully flexible system is that the limit of the stationary distribution (which, in our case, is given by ) has a double-exponential decay of tail [17, 32] for any . This is in sharp contrast with the (single) exponential decay of the corresponding tail for random routing or . In fact, in this case, for any , can be characterized explicitly as: , where is the (limiting) steady-state fraction of servers with queue length at least . In the current case of heterogeneous systems, it is intractable to characterize the fixed point explicitly. However, as stated in the next theorem, we can still prove that the doubly exponential decay of the tails for each holds.
Theorem 3.14 (Double-exponential tail decay).
Let be the unique fixed point of the system of ODEs in (3.8). Then, for all , the sequence decreases doubly exponentially, i.e., there exist positive constant , and such that for all ,
| (3.10) |
3.5 Simple Data Locality Design using Randomization
Sections 3.1–3.4 characterize the performance of the occupancy process for arbitrary deterministic sequence of systems where the underlying graph sequence satisfies certain properties. In particular, Condition 2.1 and Definition 3.8 provide a sufficient criteria under which both the process-level convergence (Theorem 3.10) and interchange of limits (Theorem 3.13) hold. In this section, we show that graphs satisfying the above required criteria can be obtained easily if the compatibility graph is designed suitably randomly. Given the asymptotic edge-density parameters in Condition 2.1, we define a certain sequence of inhomogeneous random graphs or irg as follows.
Definition 3.15 (irg()).
Given , the -th system of irg() is constructed as follows: For any and , dispatcher and server shares an edge with probability for all and , independently of each other.
For any for which the asymptotic stability criterion holds, we have the following result for the sequence of irg().
Theorem 3.16.
The proof of Theorem 3.16 is provided in Appendix I. It relies on verifying that the sequence of irg() graphs satisfies Condition 2.1 and the property of clustered proportional sparsity almost surely. The verification involves using concentration of measure arguments to establish structural properties of the compatibility graphs.
4 Proof of Transient Limit Results
In this section, we will prove the results of transient limit results, Theorems 3.5, 3.6 and 3.10 in Sections 4.2, 4.3, and 4.4, respectively. We start by proving a few auxiliary results in Section 4.1.
4.1 Auxiliary Results
First, we will need a characterization of the evolution of the queue length process at each server. To describe this evolution, let us introduce the following notations:
| (4.1) | ||||
| (4.2) |
To represent the graph, define the edge occupancy to be the binary variable:
Recall the function , Poisson processes and Poisson random measures in and below (3.5). By Condition 2.1, for all large enough , all dispatchers in the -th system have at least neighbors. Hence, WLOG, in the rest of this section, we will only consider the case , . In that case, due to the Poisson thinning property, note that we can write as follows:
| (4.3) |
where
| (4.4) | ||||
The RHS of the first summation in (4.4) represents the probability that a job arriving at the dispatcher will be assigned to the server given the state . Moreover, by Condition 2.1, the term for all can be upper bounded, uniformly for all , by a constant for all large enough , which is stated in Lemma 4.2 below.
When we do some estimation, like bounding the term , we need to uniformly bound the number of the neighbors of servers or dispatchers. Such uniformity is stated in Lemma 4.1 and is a direct result of Condition 2.1. Recall and .
Lemma 4.1.
For each ,
| (4.5) |
and
| (4.6) |
Also, for each ,
| (4.7) |
Lemma 4.2.
For all large enough , we have that for any , , and ,
| (4.8) |
Proof.
By the definition of , for any and large enough ,
where the first inequality is due to and the last inequality comes from Lemma 4.1. ∎
By Lemma 4.1, we know that the neighborhoods of dispatchers of the same type are almost the same. With the scale of the system size, the local graph structure for each dispatcher of the same type will converge to the average one. The following two lemmas give necessary approximation of the graph structures for large- systems. Their proofs are combinatorial and are based on Condition 2.1 and Lemma 4.1. They are provided in Appendix B.
Lemma 4.3.
Consider a sequence satisfying Condition 2.1. For each ,
| (4.9) |
Lemma 4.4.
Consider any and . For large enough ,
| (4.10) |
where is a positive constant. Similarly,
| (4.11) |
where is a positive constant.
4.2 Convergence to McKean-Vlasov Process: IID Case
Proof of Theorem 3.5.
It suffices to prove (3.6). Fix any , and . We have that for any fixed and any s.t. ,
| (4.12) |
where , and are positive constants. The first two inequalities are by Doob’s inequalities and Cauchy-Schwarz, respectively. The last inequality is due to Lemma 4.1. By adding and subtracting terms, we have
| (4.13) |
where
First, consider . For large enough ,
| (4.14) |
where is constant. The first inequality is from the that is Lipschitz continuous with Lipschitz constant 1 and the last inequality is from (4.9).
Second, consider .
| (4.15) | |||
| (4.16) |
where the first inequality is due to the fact that is i.i.d. for and independent for different , so for each , are also i.i.d., and the independence across the server pools holds for any fixed . Hence, if are distinct, then
and and are both in . The last inequality of (4.16) is by (4.10) and (4.11).
Third, consider .
| (4.17) |
where only depends on and goes to as and the inequality comes from (4.9) and the fact that . Now, by (4.12), (4.13), (4.2), (4.16) and (4.17), we have that for large enough ,
where is a constant and is a function which goes to 0 as . Last by Gronwall’s inequality, we have (3.6) and this completes the proof. ∎
4.3 Convergence of the Occupancy Process: IID Case
In this section, we want to show the convergence of the occupancy process to the limit process represented by the ODE (3.8). The first step is to investigate the existence and uniqueness of the solution of the ODE (3.8). Define
and clearly, .
Lemma 4.5.
If , then the ODE system (3.8) has a unique solution denoted as , in .
The proof of Lemma 4.5 is based on the Picard successive approximation method ([14, Theorem 1(i)]) and is provided in Appendix C.
Proof of Theorem 3.6.
Fix any . For each , consider random measures and on , where is defined in (3.3). Denote the joint measures and . Denote by the bounded-Lipschitz metric for probability measures on :
From (3.6) we have
which implies that for each . Since by LLN, we have by Slutsky’s theorem. Also, it is easy to check that
Thus, we have . Next, we need to show that satisfies (3.8). Define , . By (3.3), we have that for any and ,
For any , if , then for . Hence,
| (4.18) |
Also,
| (4.19) |
where and given . Plugging (4.3) into (4.3), we get the desired result. ∎
4.4 Convergence of the Occupancy Process: General Case
In this section, we will discuss the case that the sequence is clustered proportionally sparse, which helps us remove the i.i.d. assumption in Theorem 3.10. Intuitively, if is clustered proportionally sparse, then for each and each dispatcher , the queue-length distribution of its neighborhood will always be close (in appropriate sense) to the corresponding global weighted queue-length distribution. Clustered proportional sparsity ensures that this statement holds uniformly for all occupancy states. Loosely speaking, this statement enables us to make sure that the evolution of the occupancy process happens in the same way for any initial state as in the case of i.i.d. initial state. For the case of homogeneous systems, the notion of proportional sparsity was introduced in [22]. Here, proportional sparsity was defined in a way that for most dispatcher , the fraction of its neighbors within any subset of servers is proportional to the size of the subset . However, due to the heterogeneous compatibility between dispatchers and servers, such fraction, in the current setup, depends on the corresponding type of the dispatcher as well (see the term in Definition 3.8). Thus, unlike the homogeneous case where the local queue-length distribution is directly compared to the global queue-length distribution of the system, for the heterogeneous case, we need to define types of global weighted queue-length distribution (see Definition 4.6), where the weights are determined by the asymptotic properties of the graph structure: and . Then, we compare the local queue-length distribution of dispatcher to the global weighted queue-length distribution of the corresponding type as defined below.
Definition 4.6.
Consider any fixed and . Given the global occupancy of the -th system, the global weighted queue-length distribution (GWQD) of type k is defined as , where
Also, the local queue-length distribution is defined as follows.
Definition 4.7.
Consider any fixed and . Given the state of the -th system, the local queue-length distribution (LQD) of dispatcher is defined as , where
Although the dispatcher following the JSQ() policy selects a target server based on its LQD, if its LQD is close (in suitable sense) to its corresponding GWQD, then the selection can be viewed as if the decision was based on the GWQD. The latter case is easier to analyze. Hence, if a dispatcher’s LQD is close to its corresponding GWQD, we call it a good dispatcher:
Definition 4.8 (-Good Dispatcher).
Consider any fixed and an . Given the state of the -th system. A dispatcher , , is -good if
| (4.20) |
Also, a dispatcher is -bad if it is not -good.
4.4.1 Consequences of Clustered Proportional Sparsity
The proof of Theorem 3.10 relies on the idea that if the local occupancy of each dispatcher within a particular type evolves similar to the global occupancy of that type, then the process-level limiting behavior should not depend on any specific initial state. That is, it will enable us to go beyond the i.i.d. assumption. First step, for this approach to work, is to show that almost all dispatchers are -good for any . Here is where we need the property of clustered proportional sparsity. This is stated in the next proposition.
Proposition 4.9.
Let be a sequence of clustered proportionally sparse graphs. For any and ,
| (4.21) |
where is the number of -bad dispatchers at time .
The intuition behind Proposition 4.9 is that the servers of type with queue length forms a subset of the server set . If this set is large, then by the clustered proportional sparsity, for any fixed and almost all , the fraction of the dispatcher ’s neighbors within is close to , which is close to for large enough by Condition 2.1. Also, in order to deal with the sum over , we will need to establish uniform bounds of the tail of the occupancy process on any finite time interval. The complete proof is given in Appendix D.
4.4.2 Coupling with an intermediate system
The main methodology for the proof of Theorem 3.10 is a stochastic coupling with a sequence of carefully constructed systems where the evolution of each system can be coupled with that of the system . For each , the system has the same sets of dispatchers and servers as , i.e., and . However, the task assignment in happens differently. To describe the task assignment policy, let us introduce the following notations: Let be the number of tasks (including those in service) in the queue of server at time . Let be the corresponding global occupancy at time , which is defined in the same way as for the system . Then, the system assigns tasks under the Global Weighted Shortest Queue (GWSQ()) policy as described in Algorithm 1. The GWSQ() policy is essentially a variant of the JSQ(d) policy since for each new task, the dispatcher selects a target set of servers of size according to the global weighted queue-length distribution.
-
•
Let be the number of servers of type with queue length
satisfies
The probability of selecting is
where .
Get ;
Next, we couple the evolution of the system with that of the system by the optimal coupling method. The optimal coupling for two stochastic processes is similar to the maximal coupling for two discrete random variables (say, and ), maximizing the probability .
Optimal Coupling.
Fix any . In both systems, within the pool of servers of each type, arrange the servers in the non-decreasing order of their queue lengths (ties are broken arbitrarily). Now, couple the evolution of the system with the system in the following way:
-
•
Departure. For any and , synchronize the departure epochs of the ordered servers of type in the two systems.
-
•
Arrival. The coupling of arrivals is the tricky part. For this, first synchronize the arrival epochs at each dispatcher in both systems and . At an arrival epoch of dispatcher , let be the local empirical distribution of dispatcher in the system and be the weighted global empirical distribution of type dispatchers in the system . Then, in the system , probability that the task will be assigned to a server of type with queue length is given by
(4.22) In the system , the probability that the task will be assigned to a server of type with queue length is given by
(4.23) For convenience, we denote and as and , respectively. Denote for and .
Now, to couple the task assignment, let us draw a random variable , independently of any other processes and across various arrival epochs. is used to generate the random variables and for the system and the system , respectively. In the system , set , if
(4.24) where , and assign the task to a server of type with queue length . Similarly, in the system , set , if
(4.25) and assign the task to a server of type with queue length .
As alluded to before, the above coupling is constructed in a way that maximizes the probability of the two systems to assign an arriving task to some server with the same queue length. Next, the difference in the occupancy processes of the two systems, on any finite time interval, can be upper-bounded by the number of times the two systems assign to two different queue lengths. This is formalized by the notion of mismatch below, which was originally introduced in [19].
Definition 4.10 (Mismatch).
At an arrival epoch, the system and the system are said to mismatch if , that is, the arriving task is not assigned to servers of the same type with the same queue length in the two systems. Denote by the cumulative number of times the systems mismatch in queue length up to time .
The next proposition provides a deterministic bound on the difference between the occupancy processes of the two systems in terms of the number of mismatches.
Proposition 4.11.
For any , consider the system and the system coupled as above. Then the following holds almost surely on the coupled probability space: for ,
| (4.26) |
provided the inequality holds at . and represent the number of servers of type with queue length at least in the system and the system at time , respectively.
Bounds of the form as given in (4.26) was originally established in [19, Proposition 4], and is later used in various contexts [18, 22]. The proof does not depend on any specific assignment policy and relies on showing inductively that if the inequality in (4.26) holds before an event time epoch, then it is preserved after the event time epoch as well. The proof of Proposition 4.11 can be obtained following the similar arguments. We omit the details.
Lemma 4.12.
Given . Then, there exist and a positive constant such that for any ,
| (4.27) |
Proof.
By the model assumption, there exists such that for all , , , which gives us that
| (4.28) |
where . ∎
The final ingredient that we need is the probability of mismatch in a particular epoch, under the optimal coupling method. The next lemma bounds this probability in terms of the -distance between the LQD of the system and the GWQD of the system.
Lemma 4.13.
Consider an arrival epoch at dispatcher , and assume that in this epoch, the LQD in the system is given by and the GWQD of type- servers in the system is given by . Then there exists exists a finite positive constant , such that for all large enough ,
| (4.29) |
4.4.3 Proof of Theorem 3.10
Now we have all the ingredients to prove Theorem 3.10. Let us explain the high-level proof scheme first.
Step 1. Using the optimal coupling, we will show that the global occupancy processes and must converge to the same limit process as , if their initial states are the same, for all . In other words, with the same initial states,
Step 2. Since there is no graph structure in the system , all servers of the same type in the system are exchangeable. Hence, is Markovian, which implies that given , its evolution does not depend on how individual ’s are distributed. Denote the system with i.i.d. assumption as , where the i.i.d. assumption refers to that for any , , , are i.i.d.. Also, denote the system without the i.i.d. assumption as . Their occupancy processes are and , respectively. Since task assignment policy in does not distinguish between two servers having same type and queue lengths, by a natural coupling, holds for all , implying that
Step 3. Denote the system with i.i.d. assumption as and the system without the i.i.d. assumption as and their occupancy processes by and , respectively. Combining Step 1 and Step 2, the following equation holds. With the same initial global occupancy state,
where the first and last equalities are due to Step 1 and the second equality is due to Step 2.
Step 4. Use Theorem 3.6 to note that when the sequence satisfies the assumption that for each , , , are i.i.d., the scaled global occupancy process converge weakly to described by the system of ODEs in (3.8).
Step 5. By Steps 3 and 4, Theorem 3.10 holds.
In the above proof scheme, observe that all that remains is to show Step 1, which is given below.
Proof of Theorem 3.10.
For Step 1 described in the proof scheme above, by Proposition 4.11, it is sufficient to show that for any and , there exists an such that
| (4.30) |
Fix an , which will be chosen later. Let and be the number of -good and -bad dispatchers in the system at time , respectively. We couple the evolution of the system with that of the system by the optimal coupling method. In system , let be the global weighted queue-length distribution of type and be the local queue-length distribution of the dispatcher , . Also, let be the global weighted queue-length distribution of type in system . Denote . At an arrival epoch , if a task arrives at an -good dispatcher , then
| (4.31) |
Recall the uniform random variable and defined in the description of the optimal coupling method. The probability that the systems have a mismatch at such arrival epoch is bounded by
| (4.32) |
where the second inequality is from Lemma 4.13. At an arrival epoch , if a task arrives at an -bad dispatcher , then with probability at most one, the systems have a mismatch. Due to the Poisson thinning property, we can construct an independent unit-rate Poisson process , so that can be upper bounded by a random time change of as the following: for all ,
| (4.33) |
where the second inequality is due to Lemma 4.12. By Proposition 4.9, we have that for any , there exists an such that for all ,
| (4.34) |
Hence, by (4.33), (4.34), and Tonelli’s theorem, we have that for all and ,
| (4.35) |
Also, by the assumption that , there exists such that . Hence, we have that for all and ,
| (4.36) |
By applying Grönwall’s inequality to (4.36), we have
| (4.37) |
Since is nonnegative, by Markov’s inequality and (4.37), we have
| (4.38) |
and we can choose small enough and such that (4.30) holds. ∎
5 Proof of Interchange of Limits
5.1 Properties of the Limiting System of ODEs
First, we define the fixed point of the ODE (3.8). Recall and . Let be a fixed point of the ODE (3.8) if for all ,
| (5.1) |
with , . The next proposition shows some important properties of the fixed point of the ODE (3.8).
Proposition 5.1.
If there exists a fixed point of the ODE (3.8) such that for each , and , then for each , the sequence decreases doubly exponentially.
The proof of Proposition 5.1 is provided in Appendix F. The key observation used in the proof is that by (5.1), can be expressed in terms of and . Thus, we can recursively characterize the values of , , if we know and , .
By Proposition 5.1, we know that if is a fixed point of the ODE (3.8) and, for all , , then such must be in so we only need to show that such exists. For the proof of the existence of such , we need a technical lemma, which will be used in (5.4).
Lemma 5.2.
Consider a sequence satisfying Condition 2.1. If is proportionally sparse and in the subcritical regime, then for any with , the following holds:
| (5.2) |
Proof of Theorem 3.11.
We prove the existence of the fixed point first. From (5.1), we know that if are fixed, then all are determined as well. Hence, can be the viewed as the function of . Moreover, in the steady state, , which implies that can be decided by the values of , . Hence, we construct the sequence as functions of the vector as follows:
| (5.3) |
Since, for all , should be in , then must lie in the polyhedron defined as follows:
For all , we have , . Consider . By (5.3), we have that when , ,
implying that ; when , ,
implying that ; when , ,
implying that
Let , be the maximum number which satisfies the following:
-
(1)
,
-
(2)
with such that .
Define as the following:
Again, by using (5.3), we get that when (i.e., ),
implying that ; when (i.e., ),
implying that .
Let be the minimum number which satisfies the following:
-
1.
,
-
2.
There exists such that and .
Define as the following:
Hence, for all , we have , . Continuing this process, we can define a sequence of polyhedra such that for all , we have , . Thus, we can get decreasing sequences , for some . Since , , then , such that . Next, we need to show that , . By (F.2), we have
| (5.4) |
Clearly, , is a solution of (5.4). It must be the unique solution, since by Lemma 5.2, for all with ,
implything that (5.4) does not hold. Now, let , .
Now, we are going to show the uniqueness. The proof of the uniqueness is based on a monotonicity property of the system, which is stated in the following claim.
Claim 5.3.
If for , then for all .
Proof.
Consider any . It is easy to construct two copies of the -th systems with initial states and satisfying:
-
1.
For all , ;
-
2.
has the corresponding global occupancy ; similarly, has .
By a natural coupling, we have that for all and , implying that . Since systems are stable, then for all . Moreover, by Theorem 3.6, the claim follows. ∎
We continue the proof of the uniqueness. Now, it is sufficient to show that which either or in component-wise, since Claim 5.3 implies that
We will prove the case that if , then
Since the case that is similar. Also, Note that , can be solved recursively by (5.1) when , are determined so it is sufficient to show that , . By ODE (3.8), we have
Since , then . Observe that . Hence, if for some , , then , which implies that
Since for all and , , then must hold for all .
∎
5.2 Proof of Tightness and Interchange of Limits
Next, we are going to prove the tightness of the steady state occupancy processes . Let and . In order to show the tightness of , it is sufficient to show that the sequence is , which is stated in the next proposition. For showing the above tightness, we will bound the tail of the expected global occupancy of the stationary state first.
Lemma 5.4.
Let be a sequence of proportionally sparse graphs satisfying Condition 2.1. There exists an such that for all and ,
| (5.5) |
Furthermore,
| (5.6) |
The proof of Lemma 5.4 is similar to [22, Lemma 3]. We define a sequence of Lyapunov functions and bound the drift of which enables us to bound the tail sum of starting from . Given the -th system state . Let be the set of servers of type with queue length at least . For each , we define a sequence of Lyapunov functions , . The complete proof is provided in Appendix H.
The next lemma from [18] gives us the criterion for -tightness.
Lemma 5.5 ([19, Lemma 2]).
Let be a sequence of random variables in . Then, the following are equivalent:
-
(i)
is tight with respect to the product topology, and for all ,
(5.7) -
(ii)
is tight with respect to the -topology.
Proof of Theorem 3.12.
Proof of Theorem 3.13.
By Theorem 3.12, is tight with respect to the -topology. Then, any subsequence has a convergent further subsequence. Let be such convergent subsequence and assume . Clearly, must be in the space . Now, initiate the -th system at its stationarity. Then the system is in steady state at any fixed finite time . That is, we have for all . Also by Theorem 3.10,
| (5.10) |
Thus, for all ,
| (5.11) |
which implies that is a stationary point of the limiting system. By Theorem 3.11, we know that is unique. Therefore, the desired result holds. ∎
6 Numerical Results
In this section, we will present the simulation to validate the theoretical results. Using the insights from the theoretical results, we will also show that systems with carefully designed compatibility structure perform much better than the classical, fully flexible systems. Throughout this section, we set the system parameters as follows:
-
•
: two types of dispatchers;
-
•
: three types of servers;
-
•
: the system follows the JSQ() policy;
-
•
, where each , , is the service rate of type servers;
-
•
, which is the arrival rate at each dispatcher is ;
-
•
, where each is the probability that type , server’s initial queue length is , ;
-
•
Fraction of types of dispatchers: ;
-
•
Fraction of types of servers: ;
-
•
: the relationship between the number of dispatchers and that of servers in the system.
By the above setting, the capacity sufficiency is satisfied, . The first experiment is to compare the performance of the classical, fully flexible system with that of the system with carefully designed compatibility structure.
Complete Bipartite vs. Designed Compatibility Structure.
The complete bipartite is the case that the compatibility matrix is a matrix with all elements equal to 1. From Lemma 3.1, we have that an -th system under JSQ(d) is stable if and only if it should satisfies the following:
By Lemma 5.2, for the complete bipartite case, we have that
which implies that for large enough , the system under JSQ() is unstable. The bottleneck here is that the type 1 servers with poor performance receive heavy workload. By Proposition 3.3, if the capacity sufficiency is satisfied, then there always exists a compatibility matrix making all large enough systems stable under JSQ(). Checking the feasible region defined in Lemma 3.4, we get one of appropriate matrices defined as
The intuition for designing the compatibility matrix, like , is to lower the traffic intensity for type 1 servers by decreasing the fraction of the type 1 servers in the neighborhood of each dispatcher. For the experiment, we set the number of servers , and consider two systems and . is a system with complete bipartite graph structure; , generated by irg() (Definition 3.15), is a system with compatibility matrix . We simulate the evolution of each system for 100 times and plot the mean sample path in Figure 1.
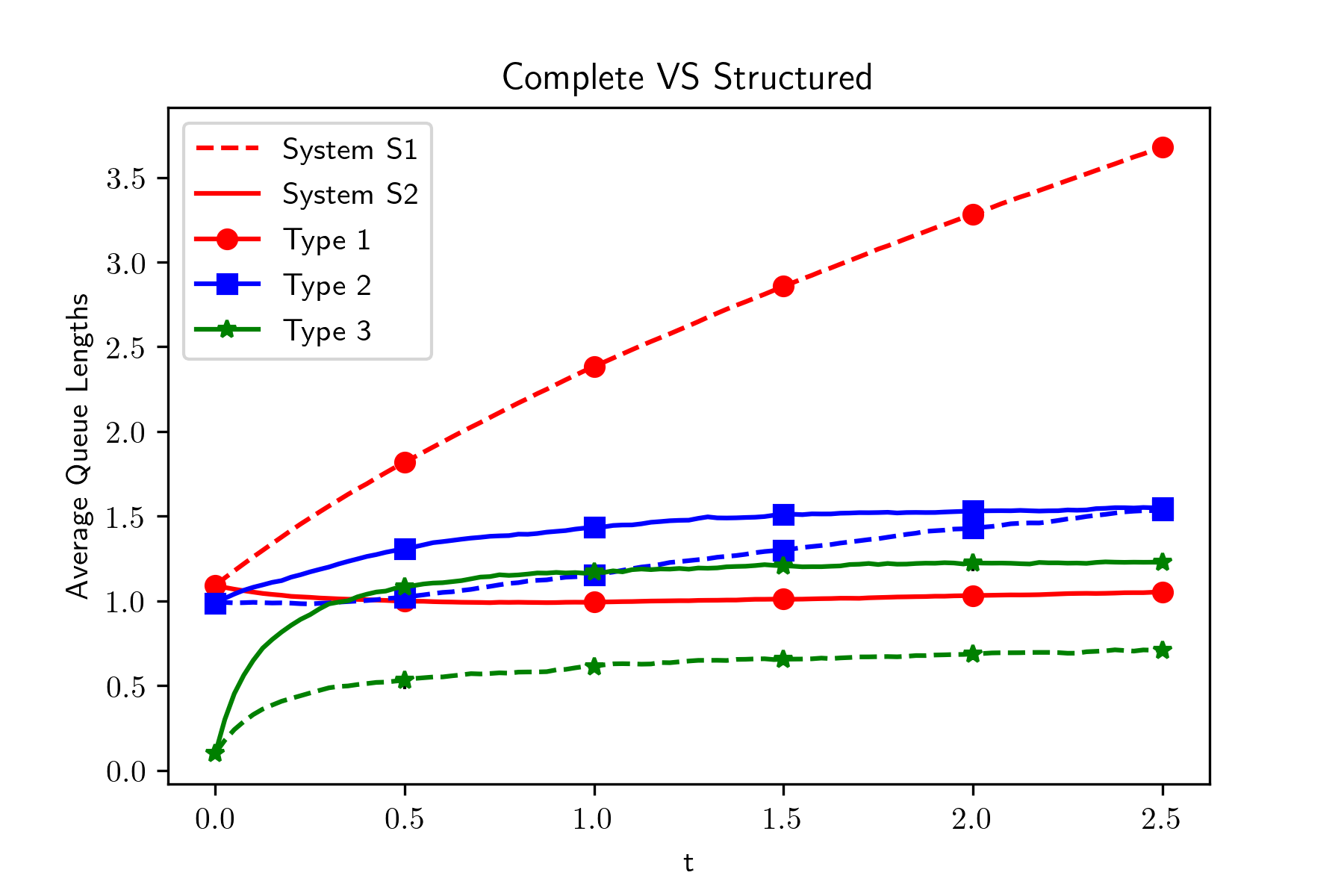
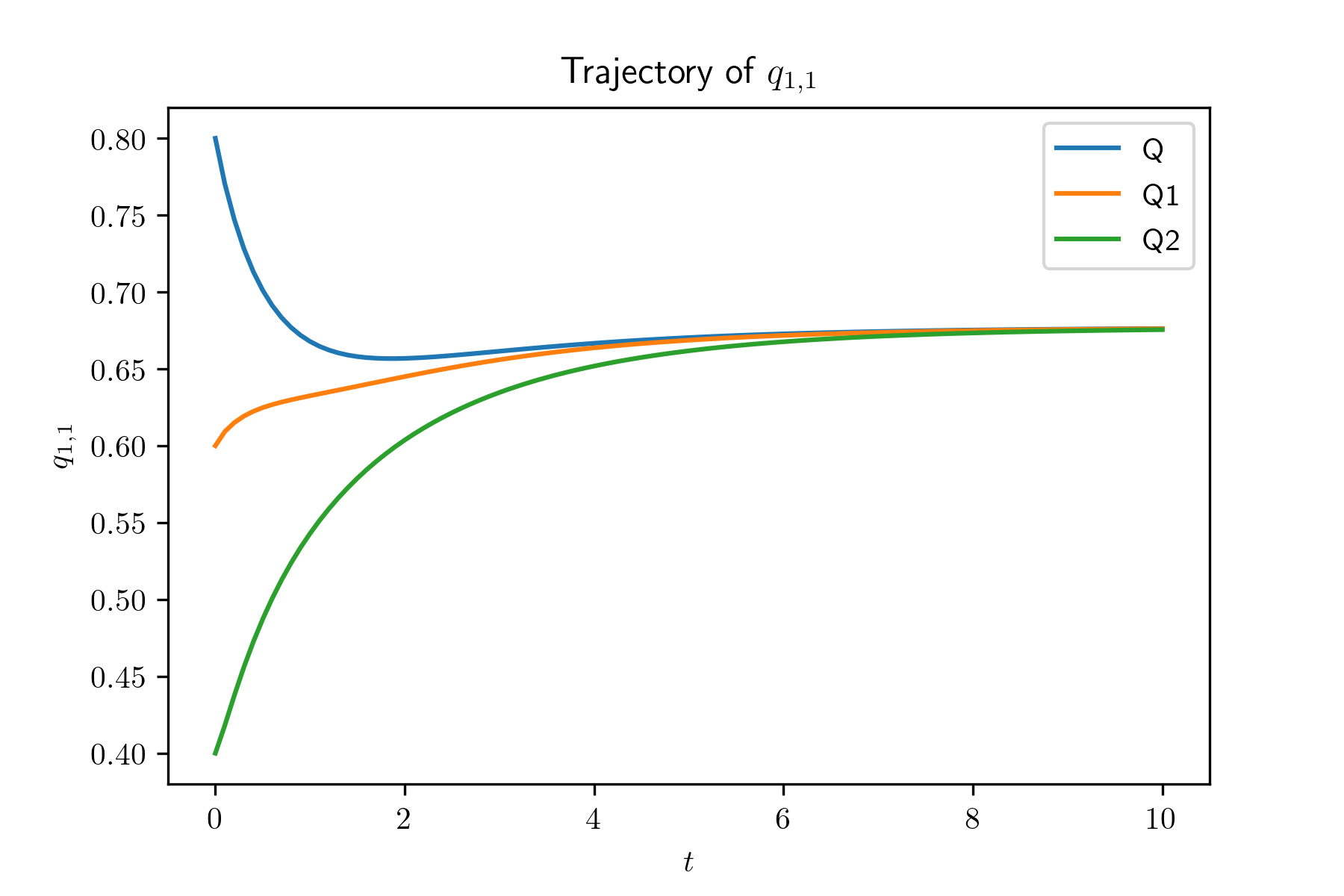
Figure 1 shows that the average queue length of type 1 servers in almost monotonically increases as increases, which implies that the average queue length of type 1 servers in is unbounded. However, in the system , the average queue length of each type of servers is bounded. From this numerical result, we observer that with appropriately designed graph structure, the performance of the system can be improved. Although we tried to plot the confidence interval (CI) for each point , the CI is narrow and its size is smaller than that of markers in the plot.
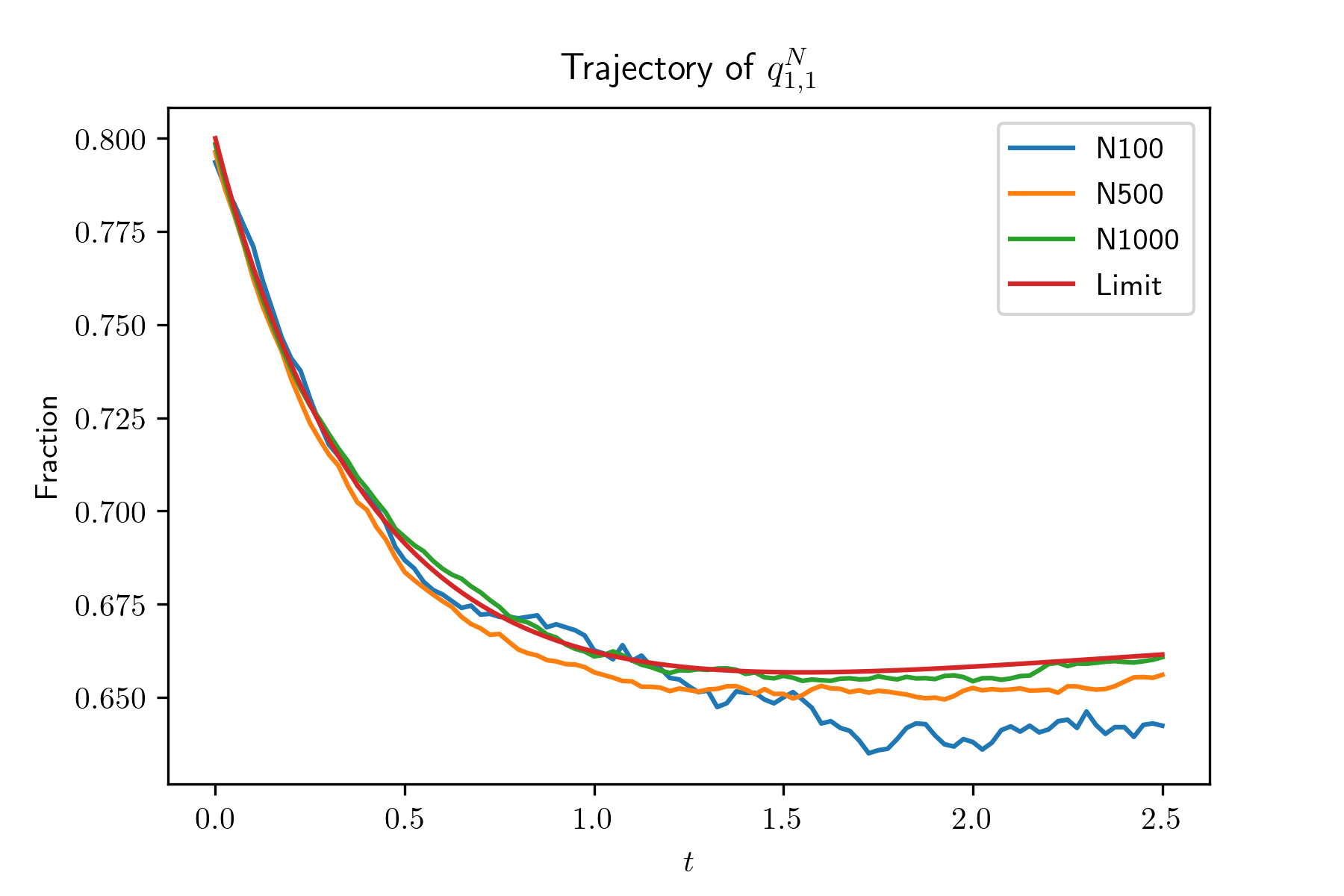
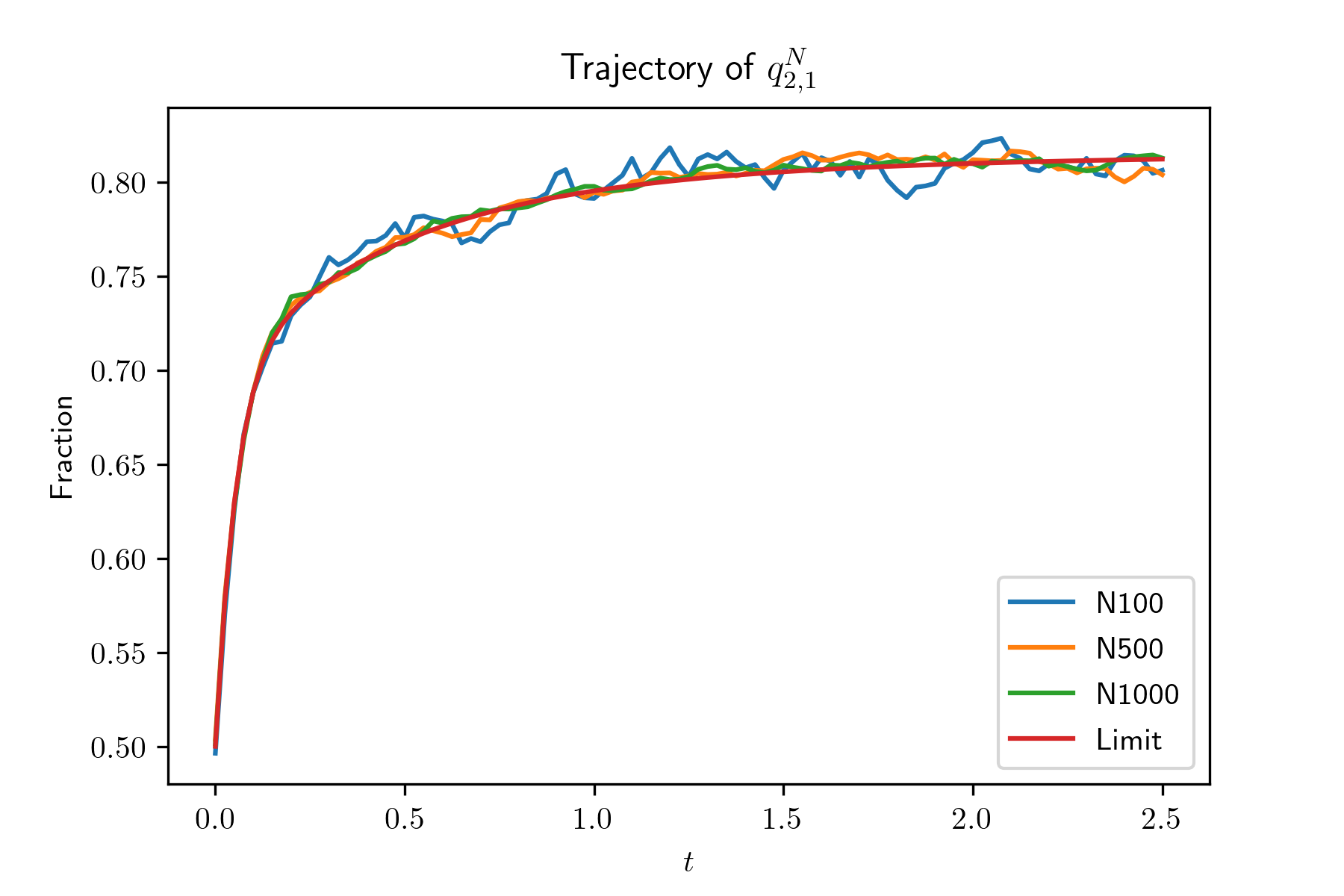
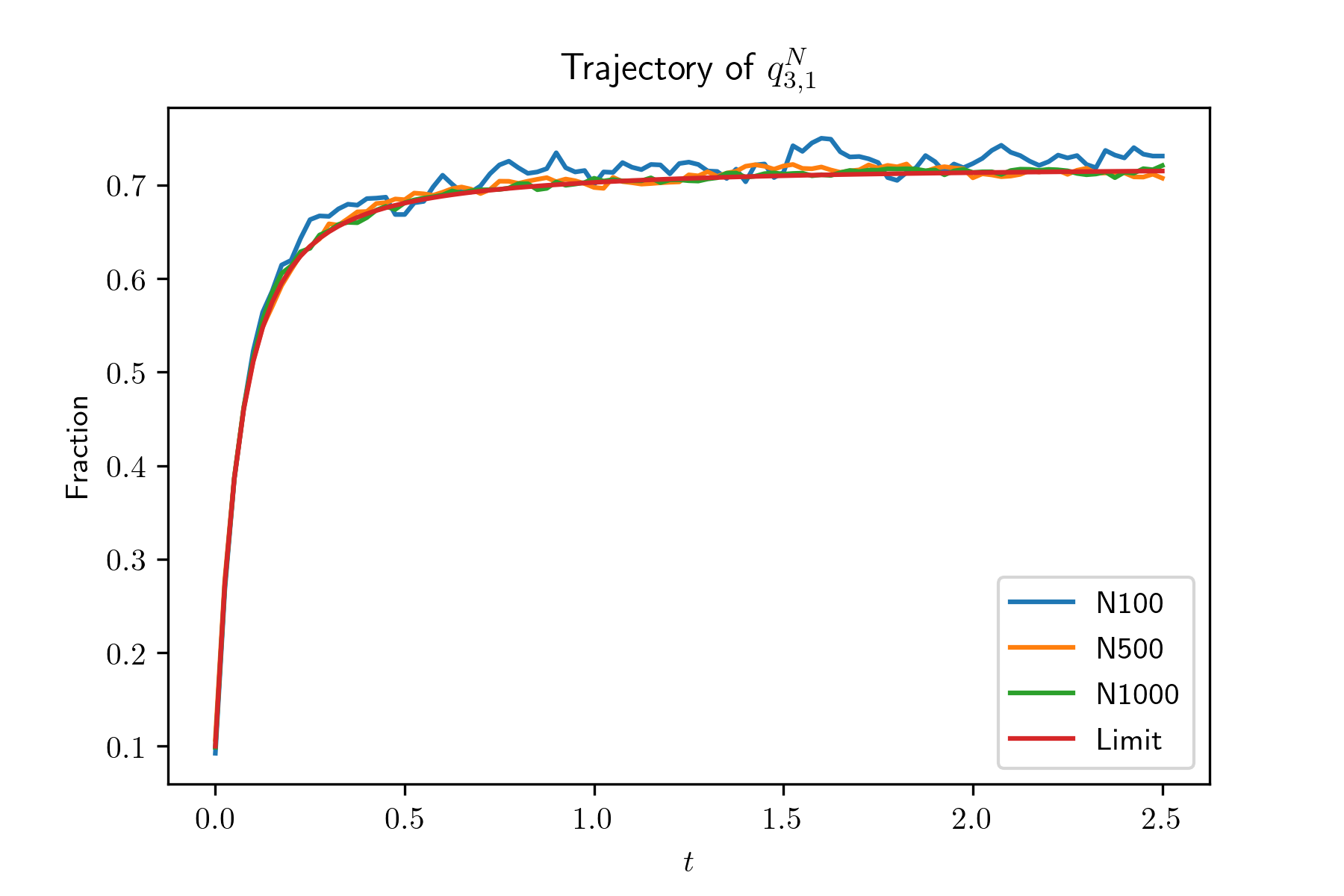
Convergence of global occupancy states.
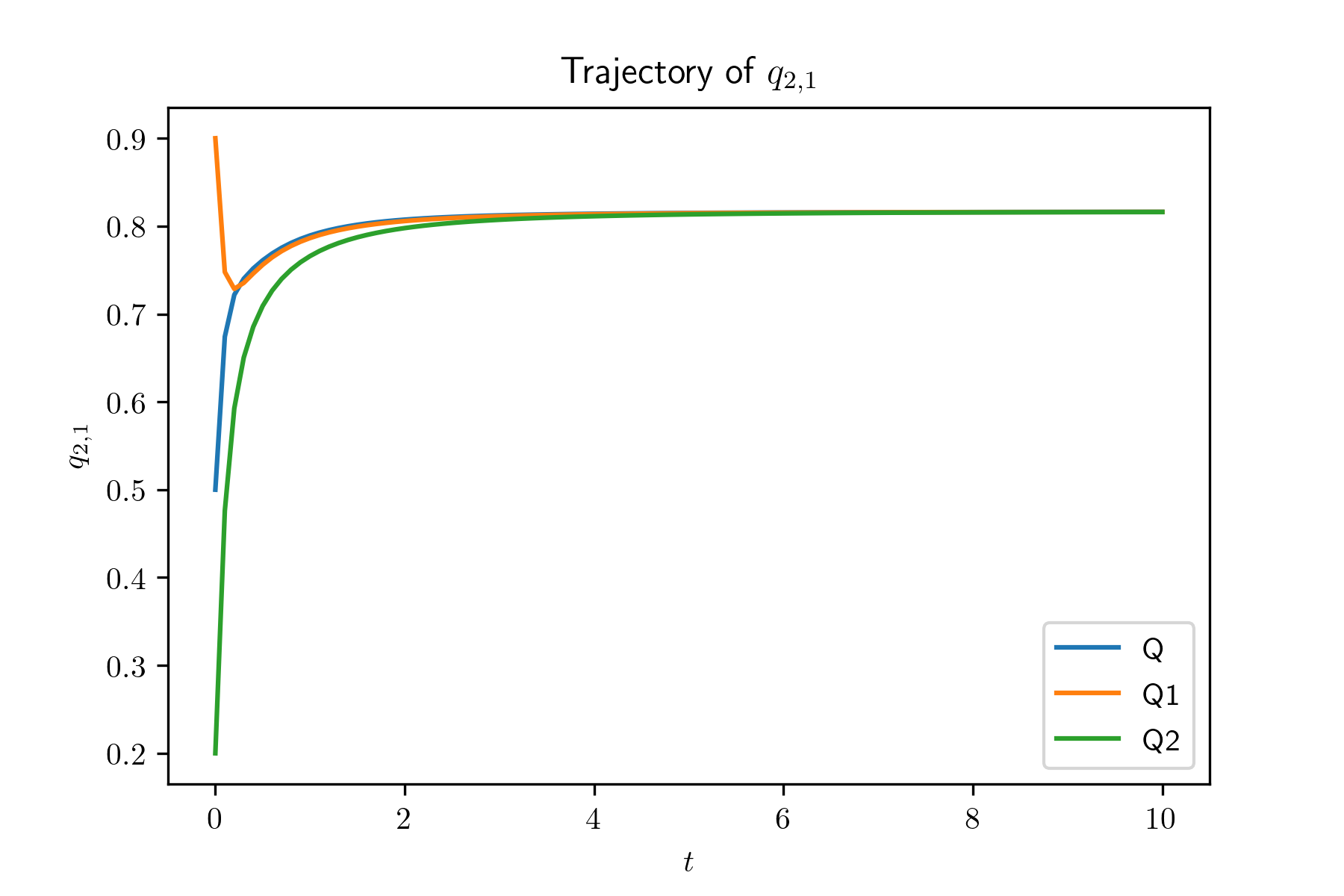
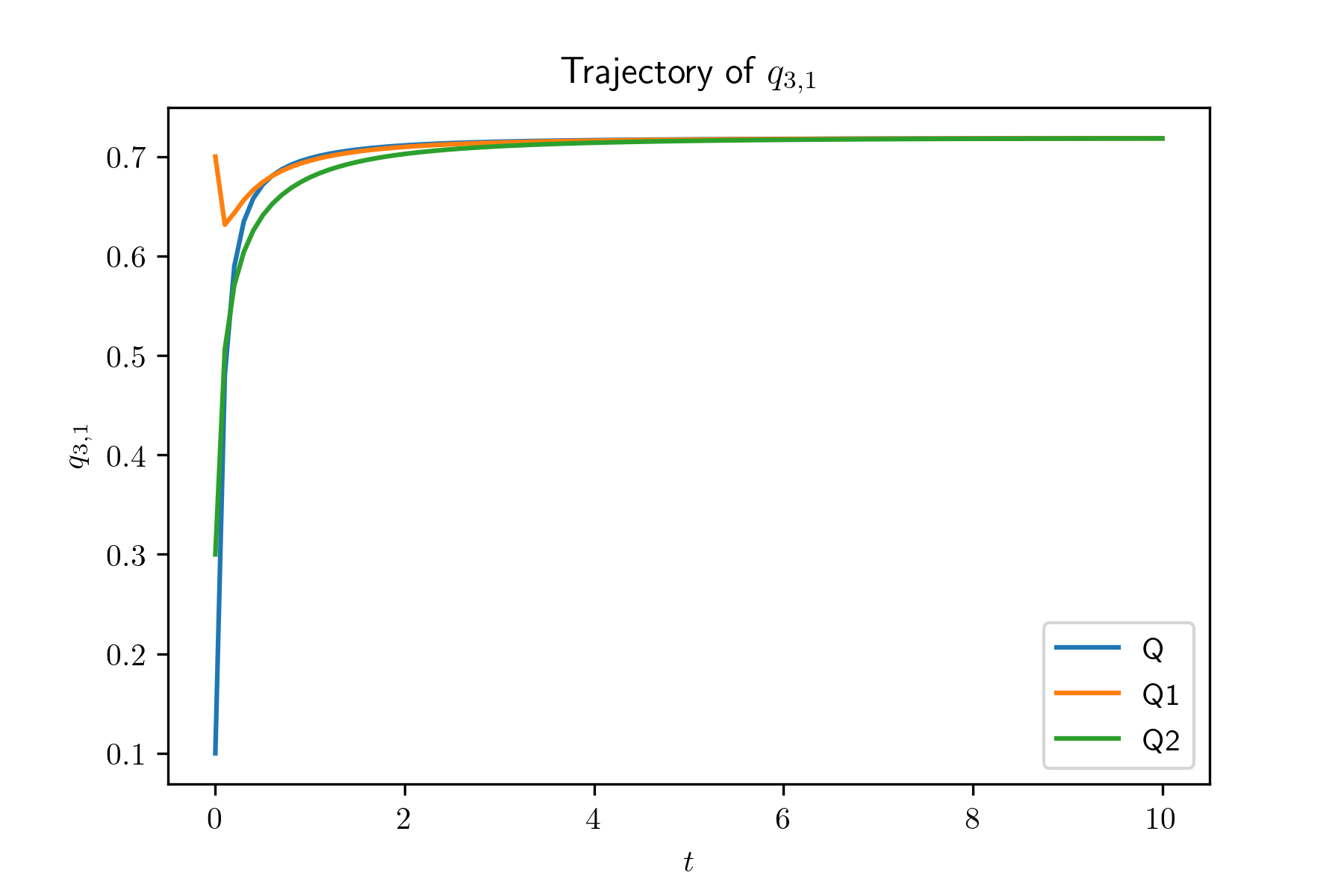
In this experiment, we generate systems by irg() and simulate the evolution of systems with size . For each system, we also simulate for 100 times and plot the mean trajectories of and , in Figure 2. Also, we plot the evolution of and , , of the limit system. The simulation results show that the evolution of the global occupancy of the -th system converges to that of the limit system as goes to infinity. From the simulation result, we find that , and especially , decrease very fast when their initial value are large. In other words, when the average queue length of type 1 servers is large, it will decrease very fast. The reason is due to our designed compatibility matrix such that compared with other type servers, type 1 servers are sampled much less often.
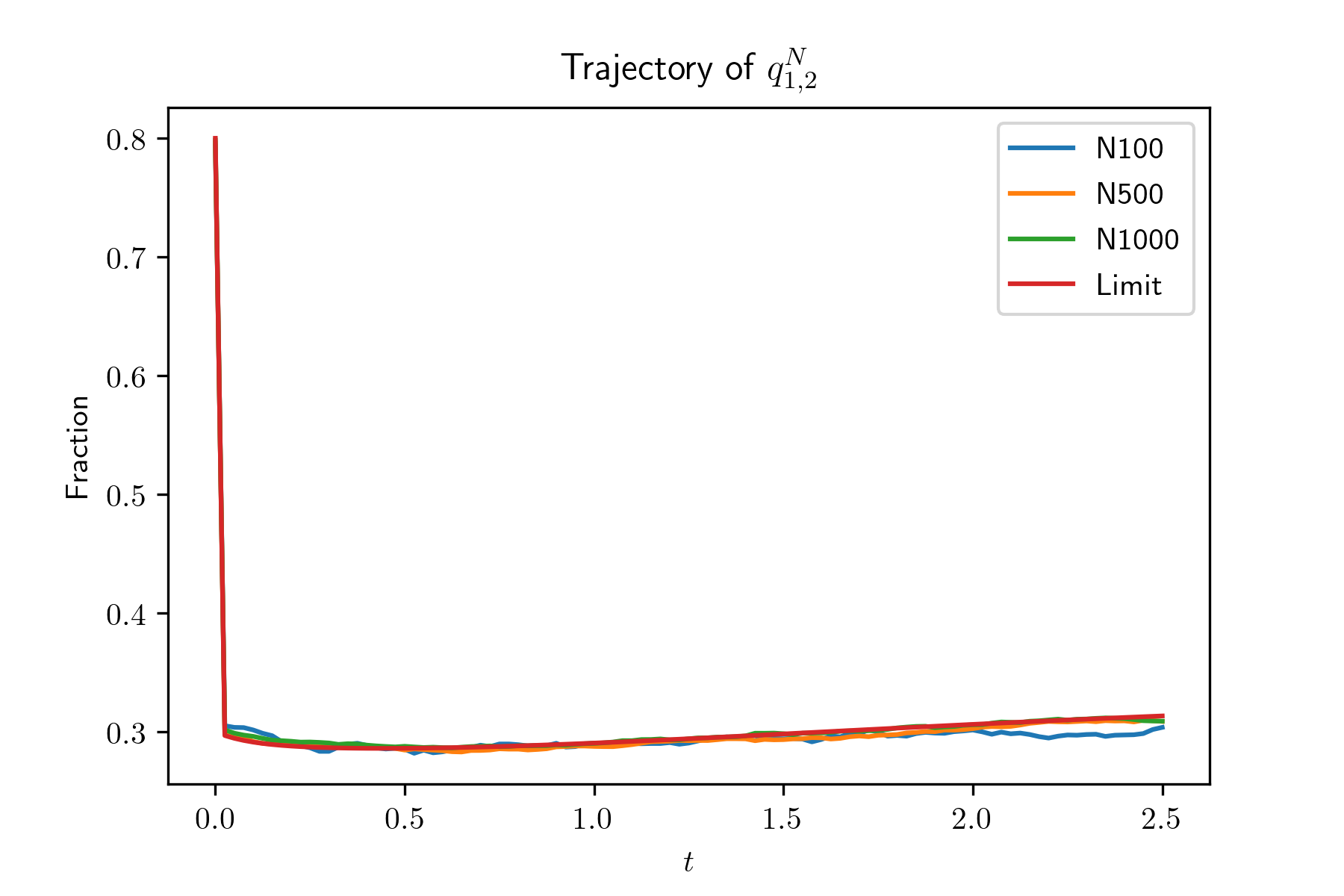
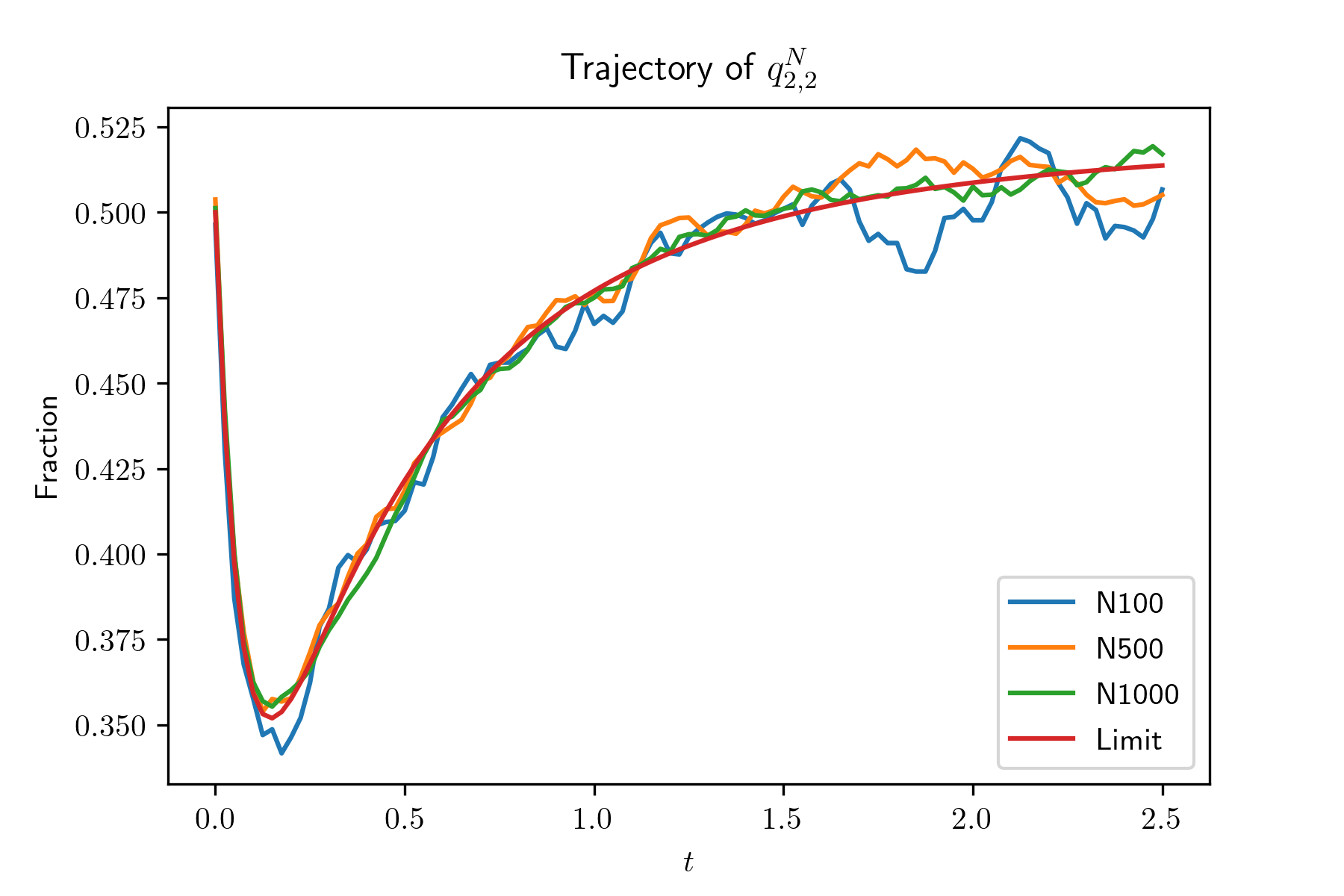
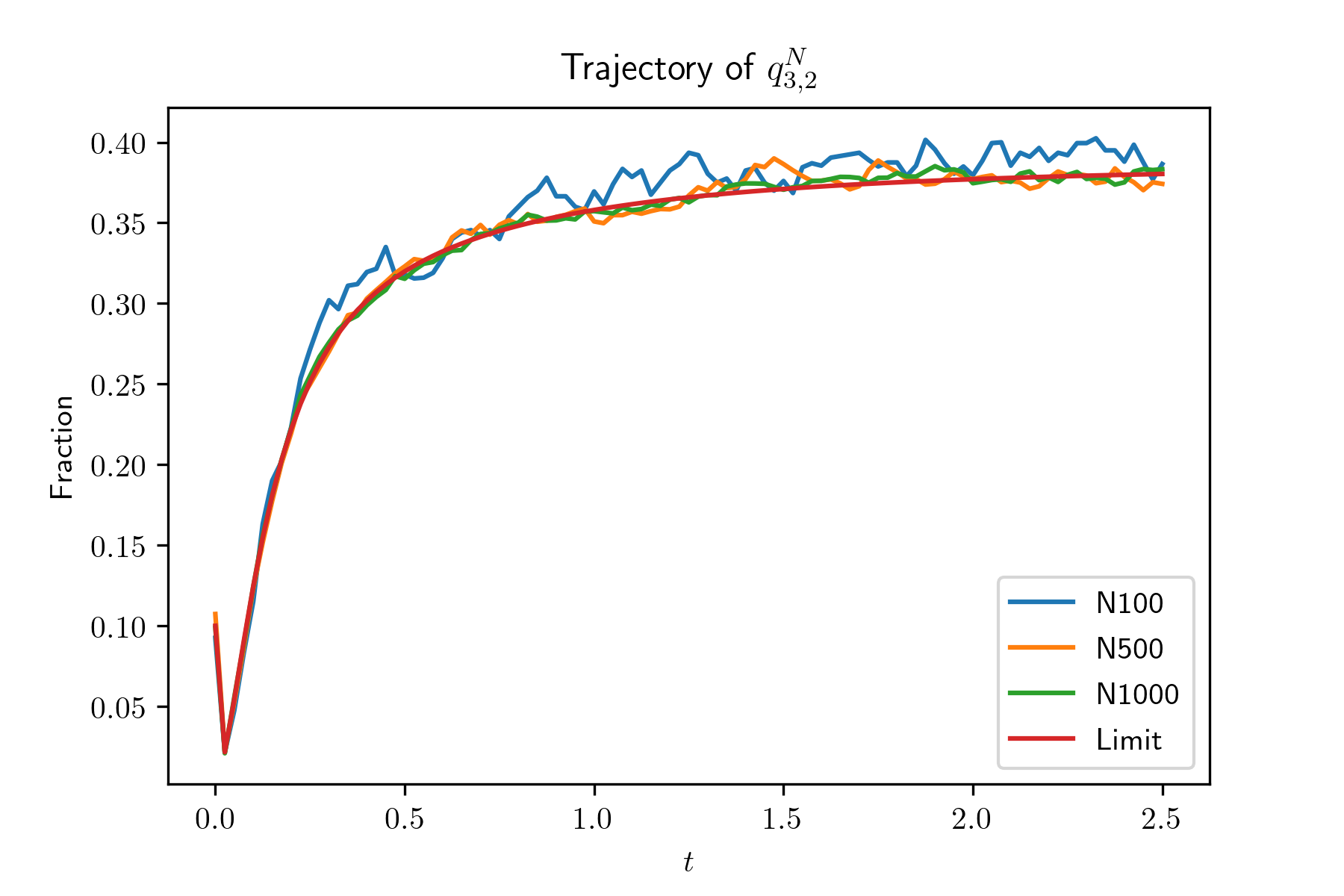
Uniqueness of the fixed point of the limit system.
From Theorem 3.11, we have that for all , . In order to verify this, we simulation of the evolution of with different (i.e., consider different mentioned above). We also simulate the system with and . Figure 3 shows that with different , , , are the same. If , are fixed, then the values of all , , are fixed as well by using (5.1). Hence, Figure 3 verifies the uniqueness of the fixed point.
References
- [1] Micah Adler, Soumen Chakrabarti, Michael Mitzenmacher, and Lars Rasmussen. Parallel randomized load balancing. In Proc. STOC ’95, pages 238–247, 1995.
- [2] Sebastian Allmeier and Nicolas Gast. Mean field and refined mean field approximations for heterogeneous systems: It works! Proc. ACM Meas. Anal. Comput. Syst., 6(1), 2 2022.
- [3] Sanidhay Bhambay and Arpan Mukhopadhyay. Asymptotic optimality of speed-aware JSQ for heterogeneous service systems. Perform. Eval., 157-158:102320, 2022.
- [4] Maury Bramson. Stability of join the shortest queue networks. Ann. Appl. Probab., 21(4):1568–1625, 2011.
- [5] Amarjit Budhiraja, Debankur Mukherjee, and Ruoyu Wu. Supermarket model on graphs. Ann. Appl. Probab., 29(3):1740–1777, 2019.
- [6] Qing-Ming Cheng and Hongcang Yang. Inequalities for eigenvalues of a clamped plate problem. Trans. Am. Math. Soc., 358(6):2625–2635, 10 2005.
- [7] James Cruise, Matthieu Jonckheere, and Seva Shneer. Stability of JSQ in queues with general server-job class compatibilities. Queueing Syst., 95(3-4):271–279, 2020.
- [8] J. G. Dai. On positive Harris recurrence of multiclass queueing networks: A unified approach via fluid limit models. Ann. Appl. Probab., 5(1):49–77, 1995.
- [9] Serguei G. Foss and Natalia I. Chernova. On the stability of a partially accessible multi‐station queue with state‐dependent routing. Queueing Syst., 29(1):55–73, 1998.
- [10] Kristen Gardner, Jazeem Abdul Jaleel, Alexander Wickeham, and Sherwin Doroudi. Scalable load balancing in the presence of heterogeneous servers. Performance Evaluation, 145:102151, 2021.
- [11] Nicolas Gast. The power of two choices on graphs: The pair-approximation is accurate. Performance Evaluation Review, 43(2):69–71, 2015.
- [12] Michel Habib, Colin McDiarmid, Jorge Ramirez-Alfonsin, and Bruce Reed. Probabilistic Methods for Algorithmic Discrete Mathematics, volume 16. Springer Berlin, Heidelberg, 1998.
- [13] Daniela Hurtado-Lange and Siva Theja Maguluri. Throughput and delay optimality of power-of-d choices in inhomogeneous load balancing systems. Oper. Res. Lett., 49(4):616–622, 2021.
- [14] J. B. Martin and Yu. M. Suhov. Fast Jackson Networks. Ann. Appl. Probab., 9(3):854–870, 1999.
- [15] Sylvie Méléard. Asymptotic behaviour of some interacting particle systems; Mckean-Vlasov and Boltzmann models. In Probabilistic Models for Nonlinear Partial Differential Equations, pages 42–95. Springer Berlin Heidelberg, Berlin, Heidelberg, 1996.
- [16] M. Mitzenmacher. Load balancing and density dependent jump Markov processes. In Proc. FOCS ’96, pages 213–222, 1996.
- [17] Michael Mitzenmacher. The power of two choices in randomized load balancing. PhD thesis, University of California, Berkeley, 1996.
- [18] Debankur Mukherjee, Sem C. Borst, and Johan S. H. Van Leeuwaarden. Asymptotically optimal load balancing topologies. Proc. ACM Meas. Anal. Comput. Syst., 2(1):1–29, 2018.
- [19] Debankur Mukherjee, Sem C Borst, Johan S H van Leeuwaarden, and Philip A Whiting. Universality of power-of-d load balancing in many-server systems. Stoch. Syst., 8(4):265–292, 2018.
- [20] A Mukhopadhyay and R R Mazumdar. Analysis of randomized Join-the-Shortest-Queue (JSQ) schemes in large heterogeneous processor-sharing systems. IEEE Trans. Control Netw. Syst., 3(2):116–126, 2016.
- [21] Arpan Mukhopadhyay, A Karthik, and Ravi R Mazumdar. Randomized assignment of jobs to servers in heterogeneous clusters of shared servers for low delay. Stoch. Syst., 6(1):90–131, 2016.
- [22] Daan Rutten and Debankur Mukherjee. Load balancing under strict compatibility constraints. Math. Oper. Res., 2022.
- [23] Alexander L. Stolyar. Optimal Routing in Output-Queued Flexible Server Systems. Probab. Eng. Inf. Sci., 19:141–189, 2005.
- [24] Alexander L. Stolyar. Pull-based load distribution in large-scale heterogeneous service systems. Queueing Syst., 80(4):341–361, 8 2015.
- [25] Alexander L. Stolyar. Pull-based load distribution among heterogeneous parallel servers: the case of multiple routers. Queueing Syst., 85(1):31–65, 2017.
- [26] A.-S. Sznitman. Topics in propagation of chaos. Springer, Berlin., 1991.
- [27] Muhammad Tirmazi, Adam Barker, Nan Deng, Md E Haque, Zhijing Gene Qin, Steven Hand, Mor Harchol-Balter, and John Wilkes. Borg: The next generation. In Proc. EuroSys ’20, EuroSys ’20, New York, NY, USA, 2020. ACM.
- [28] John N. Tsitsiklis and Kuang Xu. Queueing system topologies with limited flexibility. In Proc. SIGMETRICS ’13, pages 167–178, 2013.
- [29] John N. Tsitsiklis and Kuang Xu. Flexible queueing architectures. Oper. Res., 65(5):1398–1413, 2017.
- [30] Stephen R.E. Turner. The effect of increasing routing choice on resource pooling. Probab. Eng. Inf. Sci., 12(01):109–124, 1998.
- [31] M. van der Boor, S.C. Borst, J.S.H. van Leeuwaarden, and D. Mukherjee. Scalable load balancing in networked systems: A survey of recent advances. SIAM Rev., 64(3):554–622, 2022.
- [32] Nikita Dmitrievna Vvedenskaya, Roland L’vovich Dobrushin, and Fridrikh Izrailevich Karpelevich. Queueing system with selection of the shortest of two queues: An asymptotic approach. Problemy Peredachi Informatsii, 32(1):20–34, 1996.
- [33] Wentao Weng, Xingyu Zhou, and R. Srikant. Optimal load balancing with locality constraints. Proc. ACM Meas. Anal. Comput. Syst., 4(3):1–37, 2020.
Appendix A Proofs for Stability Results
The goal of this appendix is to prove Proposition 3.3. We start by proving Lemma 3.4, for which we need the next technical lemma. This lemma will help us to upper bound the probability that a new task will be assigned to a specific subset of servers (in particular, (A.5)).
Lemma A.1.
Consider the following optimization problem:
where and are positive integers. Let . Then, the optimal value is , if ; otherwise, the optimal value is .
Proof.
We will prove by contradictions. Suppose the maximizer contains some for some . Note that
where and , that is, the pair gives smaller value than the extremer pair . This contradicts the assumption that is the maximizer. Therefore the maximizer must contain at most one with all the other being either or . This completes the proof. ∎
Proof of Lemma 3.4.
Suppose that (3.2) holds. Since is finite, then there exists a such that for all . Fix any . Recall . By our model assumption and Condition 2.1, there exists such that for all and ,
| (A.1) |
and for all and ,
| (A.2) |
Consider the -th system. Consider any nonempty subset of servers. If , then there exists an such that for all ,
since for all , goes to infinity as uniformly by (A.2). Next, consider the case . Denote for each . Then,
| (A.3) |
By (A.1), we have that for each
| (A.4) |
By Lemma A.1 and (A.2), (A.4),
| (A.5) |
where only depends on and goes to 1 as . Let
If , then
| (A.6) |
Consider the case . Then, we get
| (A.7) |
By (3.2), we have that for all and ,
which implies that
| (A.8) |
Since is nonempty, then we assume is in , i.e., . Hence,
| (A.9) |
which implies that there exists such that for all ,
| (A.10) |
We choose such that . By (A.8) and (A.10), we have that there exists a positive integer such that for all ,
| (A.11) |
We choose such that . Now, since the subset is arbitrary, then for all , the -th system is stable under JSQ() policy. ∎
Proof of Proposition 3.3.
By Lemma 3.4, it is sufficient to show that there exists some such that for each ,
| (A.12) |
Let , , with . Now, we can formulate a linear optimization problem as the following: the objective is and the constraints are
| (A.13) |
Next we construct a specific solution satisfying the above constraints (A.13) with . Note that by (2.1). For convenience, we denote for all . First, consider . Let and for ,
Since , then and . Then, consider . For all , let . Let
and
Again, since , then and . We can construct , , by following the steps of the construction of , . Hence, we get a specific solution satisfying (A.13) with . Therefore, is strictly less than 1 and our desired result holds. ∎
Appendix B Approximation of Graph Structure for Large Systems
Proof of Lemma 4.3.
Consider any fixed and fixed . Also, fix any and .
| (B.1) | |||
| (B.2) |
First,
For large enough ,
| (B.3) |
where goes to 1 as goes to infinity, and only depends on and for each . The last inequality comes from Condition 2.1, Lemma 4.1, and . Similarly, we have
| (B.4) |
where depends on . By (B.3) and (B.4), we have
| (B.5) |
where depends on . By Lemma 4.1, we have
Then,
| (B.6) |
where only depends on and .
Proof of Lemma 4.4.
Fix any and . Consider (4.10). When , by the definition (4.2) of ,
Also, by Lemma 4.1, we have that for all and ,
where only depends on and goes to as . By Lemma 4.1, we have that for all , where only depends on and , and goes to as . Hence,
Let with . Then, we have that for large enough ,
| (B.10) |
Since and for some constant , then by choosing appropriately, (4.10) holds for all large enough . We can get (4.11) in a similar way. ∎
Appendix C Unique Solution of ODE (3.8)
Proof of Lemma 4.5.
Recall is a solution of (3.8) given the initial point . For convenience, we denote as and write the ODE (3.8) as the following:
| (C.1) |
where for all ,
| (C.2) |
observe that under (C.2), if for some , then and ; if for some , then . Hence, if , then any solution of (C.1)-(C.2) remains within . In order to show the existence and the uniqueness, we use the Picard successive approximation method([14, Theorem 1(i)]). In the rest of the proof, we use the norm:
For any , ,
| (C.3) |
where and . For , let , and by Picard successive approximation method, let
By induction, we have that is continuous w.r.t. on for all , and that
Hence, for all , exists uniformly for . Also, by (C.3) and Dominated Convergence Theorem, the following holds
| (C.4) |
Next, we show the uniqueness by contradiction. Assume that also satisfies
Then, we have
Similarly, we get
which implies that . ∎
Appendix D Proof of Proposition 4.9
Lemma D.1.
If weakly converges to , then for any , , and , there exist and , depending on , , , and , such that, for all ,
| (D.1) |
Proof.
Fix any and . Since , then there exists such that . By the weak convergence , there exists such that for all ,
| (D.2) |
Let . Hence,
| (D.3) |
Since given , i.e., for all , , then if for some and , , i.e., , there must be at least tasks arriving in the system. By using the standard concentration inequality for Poisson random variables (see [12, Theorem 2.3(b)]), we have
| (D.4) |
where is a unit-rate Poisson random variable, and is a positive constant only dependent on and goes to as goes to infinity. The second inequality comes from the assumption that and , . By (D.4), there exists such that for all ,
| (D.5) |
Let . By (D.2), (D.3) and (D.5),
∎
Lemma D.2.
For each and ,
| (D.6) |
Proof.
Proof of Proposition 4.9.
Consider any fixed . Also, fix and . By the triangle inequality, we have
| (D.12) |
By the triangle inequality and Markov’s inequality,
| (D.13) |
By Lemma D.2, there exists such that for all ,
| (D.14) |
implying
| (D.15) |
Similarly, we have that there exists such that ,
| (D.16) |
By (D),(D.15) and (D), there exists such that for all ,
| (D.17) |
Fix any By Definition 3.8, there exists such that for all ,
| (D.18) |
By Lemma D.1, there exists such that for all ,
| (D.19) |
Hence,
| (D.20) |
Since are arbitrary, then the desired result holds. ∎
Appendix E Bound the Mismatch
Proof.
Define a function as: for ,
| (E.1) |
Also, define a function as: for ,
| (E.2) |
Note that for any and , . Then, we have
| (E.3) |
Let and . By (4.22) and (4.23), and . By the Optimal Coupling, we have
| (E.4) |
Next, we are going to show that is Lipschitz continuous for .
| (E.5) |
Let . By (E), (E) and (E), we have that for large enough ,
| (E.6) |
∎
Appendix F Doubly Exponential Decay
Proof of Proposition 5.1.
Since is a fixed point of (3.8), then we have
Multiplying both sides by and summing over gives,
| (F.1) |
Also, since , , then for , by adding , we have
| (F.2) |
From (F.2) and , we have
where . Hence, for all ,
where . Since we assume that for all , then we can choose a large enough such that . By definition, for each ,
which implies that and
By induction, we obtain that for ,
| (F.3) |
where . (F.3) implies that decreases doubly exponentially. ∎
Appendix G Proof of Lemma 5.2
Proof of Lemma 5.2.
Fix any with . Consider any sequence of subsets with and for all . By Condition 2.1, we have that for all and ,
| (G.1) |
Fix any which will be chosen later. Let and . By (G.1), for all large enough and ,
| (G.2) |
Also, by Condition 2.1, for all large enough ,
| (G.3) |
Since the sequence is in the subcritical, then for large enough ,
| (G.4) |
where is a constant only depending on with . Since the sequence is proportionally sparse, then . Then, we have
| (G.5) |
Since (G.5) holds for all , then
| (G.6) |
∎
Appendix H Proof of Lemma 5.4
Proof of Lemma 5.4.
Given the system state . When a task arrives at the system, by the Poisson thinning property, the probability that the task will be assigned to a server in the set is
| (H.1) |
where . Fix any . Since the sequence is subcritical, then for large enough , we have that
| (H.2) |
We consider the system state at event times ; for all , can be an arrival or a potential departure epoch. Define the drift as
| (H.3) |
Again, by the Poisson thinning property, we have that for all large ,
| (H.4) |
By the definition of the steady state, . Choosing such that , we have
| (H.5) |
Finally, summing over , we get the desired result. ∎
Appendix I Proof for the Sequence of Random Graphs
Proof of Proposition 3.16.
First to show that the sequence satisfies Condition 2.1. Consider any fixed and . Let be a Bernoulli random variable with probability for each and . Then, , and by the L.L.N., we have that
which implies that Condition 2.1 holds. Next, we prove that Condition 2.1 holds. Based on the definition , we have which is a binomial random variable . By the Chernoff bound ([6, Theorem 2.4]), it follows that for ,
Let . Then, for some ,
| (I.1) |
for sufficiently large . Also by , , and the union bound, we have that there exists such that for large enough ,
| (I.2) |
Then, the RHS of (I.2) is summable over . From the Borel-Cantelli lemma, we get that a.s., for all large enough ,
which implies that the following equation holds
Thus, Condition 2.1 holds.
Now, we show that the sequence is clustered proportionally sparse. Fix any , , , and . Let be the event that the dispatcher is bad w.r.t. the set , i.e.,
| (I.3) |
Define for each . By the union bound, we have that
| (I.4) |
We will bound each term of the RHS of (I.4). By choosing , and satisfying
| (I.5) |
we have that
| (I.6) |
and
| (I.7) |
which implies that the first term is equal to 0 with , and . Using the Chernoff bound again, we can bound the second term and the third term as follows: for some and large enough ,
| (I.8) |
and
| (I.9) |
Therefore, for large enough , we have
| (I.10) |
and
| (I.11) |
Moreover, for some and large enough ,
| (I.12) |
The RHS of (I.12) is summable over and the set is finite, so by the Borel Cantelli lemma, the sequence is clustered proportionally sparse.