Exploiting Latent Codes: Interactive Fashion Product Generation, Similar Image Retrieval, and Cross-Category Recommendation using Variational Autoencoders
Abstract
The rise of deep learning applications in the fashion industry has fueled advances in curating large-scale datasets to build applications for product design, image retrieval, and recommender systems. In this paper, the author proposes using Variational Autoencoder (VAE) to build an interactive fashion product application framework that allows the users to generate products with attributes according to their liking, retrieve similar styles for the same product category, and receive content-based recommendations from other categories. Fashion product images dataset containing eyewear, footwear, and bags are appropriate to illustrate that this pipeline is applicable in the booming industry of e-commerce enabling direct user interaction in specifying desired products paired with new methods for data matching, and recommendation systems by using VAE and exploiting its generated latent codes.
1 Introduction
The rise of machine learning and deep learning applications in the fashion industry has fueled more progress in curating large-scale datasets such as Zou et al. (2019); Liu et al. (2016). These advances in the availability of huge datasets have been the starting point of new methods in using deep learning for integration in e-commerce for the fashion industry to adapt to the ever-changing shoppers’ preferences and to increase profits by being more collaborative with the customer in terms of learning from their buying patterns. Recommendation engines have been one of the most heavily studied topics in the areas of computer science, specifically in machine learning and artificial intelligence because of its tangible use in the daily lives of users aiming to personalize user experience by modelling their preferences. In addition, it also allows users to discover new content within the platform. One such example is recommending a new movie to watch in an online streaming platform.
Given all of the possible applications of recommender systems such as social media, streaming platforms, e-commerce websites, dating applications, and the rest, most of the research has been directed towards a specific domain. In this paper, the author focuses on the applicability of recommender systems specifically for fashion product recommendations. In the realm of online shopping, users would want to see products similar to their tastes, such as different pant designs or sneakers. At the same time, these users would also want to be able to mix and match different fashion products not far from their own tastes. Hence, an interactive fashion product application is developed that allows the users to generate products with attributes according to their liking, retrieve similar styles for the same product category and also allow users to perform cross-category recommendations which might be of interest for users who would want to buy a set of fashion products according to their designed look.
The author proposes using Variational Autoencoders (VAE) where the author exploits its capability to regularise the latent space for generating new samples from the distribution and to generate a latent representation of data as features and introduces two methods in utilizing the latent variables for similar image retrieval, recommendation. This enables a base framework that can be used for the e-commerce industry that implements collaborative design for product styles, product clustering, image retrieval and recommender systems using only one architecture to solve multiple problems.
2 Related Work
2.1 Variational Autoencoders
Variational Autoencoders (VAEs) are similar to the structure of autoencoders but with a different approach for latent representation learning. An autoencoder (AE) is a type of Artificial Neural Network (ANN) where the expected output is exactly the input by finding an efficient latent representation of the data or encodings using a hidden or latent layer called ”bottleneck” layer (often called latent codes in this paper). Both AE and VAE have similar structures made of an encoder that maps the input into a latent space , the bottleneck layer, and a decoder that takes to reconstruct the input data into , in which the target is to minimize the reconstruction loss or the difference between and Torres Fernandez (2018). The main challenge for autoencoders in general is to accurately learn a representation that embeds the most important features of the data and encode them to generalise beyond the training set by being able to gain control over the latent space to produce images with similar characteristics.
Instead of using the output of the encoder (i.e. the bottleneck), VAEs allow generative modelling by causing the latent variables to be normally distributed by forming a new layer in the architecture consisting of parameters mean and standard deviation of a normal distribution () Spinner et al. (2018). During optimization and training, the target reference is is a standard normal distribution (0,1) where we force our normal distribution to diverge as close as possible to our target reference using Kullback-Leibler (KL divergence) Odaibo (2019). VAE now calculates loss function consisting two terms - KL-loss, which is dependent on the parameters of the distribution and can be computed easily, and reconstruction loss which is based on random and discrete outcome of that means its gradients are not computable preventing backpropagation over parameters and .
| (1) |
To solve this, Kingma and Welling (2013) proposed a method called reparameterization trick which tries to transform and approximate a normal distribution () into (0,1), allowing calculation of the gradients over and by introducing a random component sampled from as seen in Equation 1 which eliminates randomness since the last remaining random entity in the equation is . This enables the training of VAE to achieve both the generative and feature extraction capability applicable on this pipeline. Techniques and methods in this paper focus on how to take advantage of this inherent structure in VAE. The overall structure of VAE is seen in Figure 1.

2.2 Fashion Product Generation
The fashion industry has been quick to adapt in designing new products using deep learning. Two popular deep learning models for generative modelling are Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Deverall et al. (2017) experimented with a traditional GAN and DiscoGAN trained on athletic shoes using UT-Zap50K dataset and tested the generated images using a classifier based on GoogleNet and achieving 88% validation accuracy. Rostamzadeh et al. (2018) created a baseline results on high-resolution image generation conditioned on the given text description using their own created dataset of 293,008 high definition fashion images paired with item decriptions. Variational Autoencoders are also popular in generating new product designs. Zhu et al. (2018) used VAE on popular fashion image styles trained on DeepFashion dataset and was able to generate new products based on 30 discovered styles using Nonnegative matrix factorization (NMF). Current generative modelling puts emphasis on synthesizing new product designs that are realistic but enabling the end-user to be the one interacting with the model to create desired designs are still missing.
2.3 Image Retrieval
Deep learning has been used in content-based image retrieval and matching for quite a long time such as for medical images Qayyum et al. (2017) which uses deep Convolutional Neural Network (CNN) achieving 99.97% classification accuracy for retrieval tasks and for clothing products that uses CNN to match a real-world example of garment into same item in an online shop.
Traditional autoencoders and variational autoencoders are often used for image reconstruction or generation, but they can be used for image retrieval because of its capability to extract features. Krizhevsky and Hinton (2011) used a very deep autoencoder and semantic hashing for image retrieval by mapping images to short binary codes for extreme fast retrieval, while Torres Fernandez (2018) implemented a simple VAE with only 2 layers depth in both encoder and decoder and yielded good results using approximation of the latent space to = evaluated by mAP.
2.4 Recommendation Systems
Content-based Recommendation has been dominated by deep learning where there is emphasis on finding similarity on two images using deep neural networks. Chen et al. (2017) used two convolutional neural network where the first neural network is used for classification and the second neural network to model similarity score between pair of images using Jaccard similarity. This method was able to achieve 0.5 accuracy on both classification and similarity score. Another work by Tuinhof et al. (2018) utilized a combination of CNN and a modified k-NN algorithm used for ranking in feature space. GANs can also be used to recommend products. A work by Kumar and Gupta (2019) implemented GAN which tweaks traditional c-GAN where it recommends a generated pair of pants that might go well with the given shirt.
A work by Lin et al. (2019) proposed a neural co-supervision learning framework which they called FAshion Recommendation Machine (FARM) which is a neural network architecture similar to variational autoencoders that improves visual understanding and enhances visual matching by incorporating a layer-to-layer matching mechanism for combining aesthethic information. This was able to outperform state-of-the-art models for outfit recommendation. Works on cross-domain recommendation typically revolve around recommending one category.
Researches in fashion product generation, content-based similar image retrieval and recommendation have utilized deep learning to an extent but each study only focus on solving one problem using one deep learning architectures. In this work, the author experimented on using VAE by exploiting its ability to produce a latent representation of the image for generative modelling and feature extraction and introduced new ways to utilize these latent codes as features to solve all the problems aforementioned that are related in nature and can be integrated in a pipeline for fashion industry.
3 Proposed Approach
Many machine learning technologies have been applied for generating new designs for products, matching images on databases, and recommendation systems. These architectures are utilized on specific single use-cases to solve one problem.
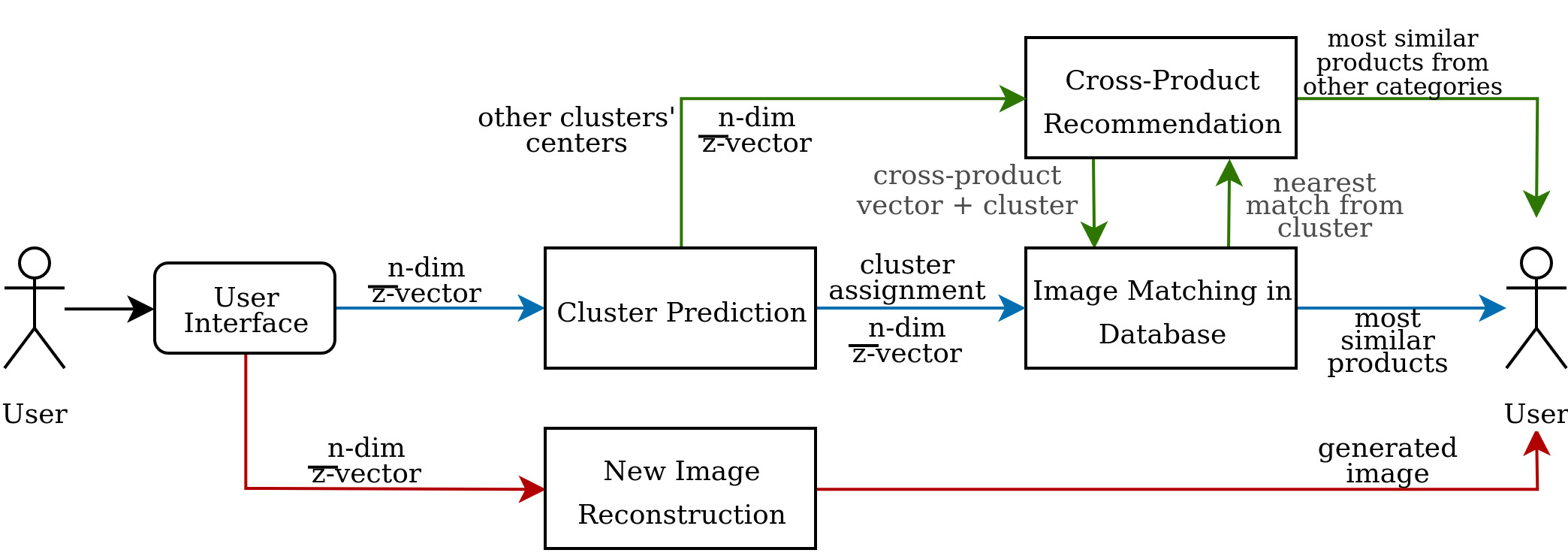
The simplified diagram is shown in Figure 2 where it illustrates how the user-generated -vector is used in the entire pipeline. This section discusses how user interaction with the application and controlling the latent code generates new product images and how this pipeline capitalizes on the use of the given latent code variables as features in clustering, similar image retrieval, and recommendation.
3.1 Dataset
The dataset is obtained from the combination of Fashion Product Images Dataset from Kaggle and scraping images from Zappos website. The dataset is intentionally limited to footwear (8919 entries), eyewear (3378 entries) and bags (9462 entries) which totals to 21,759 data samples. Topwears and bottomwears are not considered given that majority of topwear and bottomwear includes human faces and poses that could add entropy and more features for the variational autoencoder to represent. The size of the images are 180 x 240 pixels.
3.2 Training
The model is trained in Google Colab that uses K80 Tesla as GPU and includes 25GB of RAM for 200 epochs which took approximately four hours. The model architecture is composed of three Convolution layers and Dense layers for the encoder and three Deconvolution layers and Dense layers for the decoder and is built in Keras. The bottleneck layer is size 16.
3.3 Interactive Synthesizing of New Fashion Products
Here, the user is able to directly control the z-vector that is used to synthesize new images by using range sliders. By controlling the range slider, the user is able to manipulate certain attributes such as length, color, thickness, etc. of the fashion products according to their preference. As the range slider is moved, the latent code is changed and is given to the decoder in the back-end of the application for reconstructing the image. For consistency, the user-generated vector from using the application sliders is denoted as -vector.
3.4 Similar Image Retrieval Using Latent Codes
After the user interacts with the slider and synthesizes the image, its -vector is used to find similar images from the database. For this purpose, the author proposes two methods that tries to solve the problem in different manners. The first one takes advantage of the objective function being optimized by VAEs while the second one exploits the sampling process from reparameterization trick used to derive from and .
In order to use these techniques for image retrieval, encodings of each images are generated using the trained encoder and stored in a database. The encoding for an image is composed of n-dimensional -vector and -vector and an n-dimensional vector computed from a fixed epsilon sampling that will be discussed in the next sections.
3.4.1 Log-Likelihood Maximization in Image Retrieval
Distance metrics are used in calculating the similarity of two points. In this image retrieval technique, the objective is to find the closest images in the database by calculating the distance between the user-generated vector and the and encoding vectors generated earlier.
On training, the encoder is essentially parameterizing the variational posterior distribtion of given , (i.e. Equation 2. Think of the problem as if the are parameters of the probability distribution while are some observations you made. This implies that the nearest encoding from the training data would be the encoding with the highest likelihood evaluated by the equation taking the with the maximal value. The log-likelihood provides something similar to a negative euclidean distance between and , but scales and shifts by terms determined by the standard deviation.
|
|
(2) |
Intuitively, by maximizing the log-likelihood using Equation 2, you are minimizing the euclidean distance between a given , which in this case is from the user interaction with the application, and the encoding of from the encoding of each images stored.
3.4.2 Fixed Epsilon Sampling Encoding Trick in Image Retrieval
The problem that these methods are trying to solve is finding a way to calculate the difference between two image encodings given that (1) the encoder only gives and vectors, (2) a random sampling is involved to get the -vector of the image, and (3) that the user only provides us a -vector.
The biggest problem is that in order to generate a -vector encoding of each images, random sampling of from a Gaussian distribution is involved as seen in Equation 1. This random sampling implies different variations of used to calculate . The previous method considers computing the distance between the user-generated -vector and the and vector encodings of each images in the database, in which case, there is no -sampling required.
The trick is to use a fixed, n-sized vector randomly sampled once from a Gaussian distribution for each encoding process of the images. In other words, instead of randomly sampling for every encoding process, the is held constant and is calculated using the same Equation 1. This method allows us to directly measure the distance between -vector and each encoded -vector in the database using any traditional distance metric such as Euclidean distance, Manhattan Distance, etc.
3.5 Clustering Images using its Latent Codes
Image retrieval is computationally expensive, most especially if the algorithm has to compare the -vector to every entry in the database. In order to reduce the number of comparisons, images could be clustered using their generated latent codes. Creating clusters also allows us to find a method of recommending products from other clusters and categories that also uses the latent encodings.
To cluster each products, K-Means Clustering can be used as it allows choosing the number of clusters to group the data and provides the value of the centers for each clusters. These centers will be used for cross-product recommendation. In K-Means clustering, given a set of n data points in a high-dimensional space and integer , the objective is to determine points called centers that minimizes the mean squared distance from each point to its nearest designated centerKhan and Ahmad (2004). Since the dataset comes with a subcategory tag, would be equal to three.
The author experimented with Euclidean distance as metric for K-means and evaluated using -vector in comparison to using the fixed epsilon sampled -vectors. Also, before the image retrieval process, the image constructed from the user-generated -vector is assigned to a cluster by calculating the distance in comparison to the stored cluster centers.
3.6 Cross-Product Recommendation using Latent Codes
Aside from providing the most similar images to the user, latent codes can also be employed in recommending products from other clusters or categories. This also takes full advantage of the nature of the latent space VAEs generate which enables smooth interpolation and smooth mix of features a decoder can understand.
Simple vector arithmetic in the latent space can be utilized to navigate through the smooth interpolation of the latent space. For example, to generate specific features such as generating glasses on faces, we find two samples, one with glasses and one without and obtain the difference of their encoded vectors from the encoded. We add the difference as ”glasses” vector to the encodings of any other image that has no glasses.
| (3) |
Here, the clusters or categories are defined by the cluster centers. Take the difference of each center vectors (e.g. - ) as from one another where is the cluster assignment of -vector and is a cluster not equal to . In order to recommend products from other clusters, add each difference vector to -vector as seen in Equation 3.
This does not recommend a reconstructed image using the decoder with . It does, however, recommend a retrieved image from the database with the nearest to the calculated vector from the th cluster using the presented image retrieval techniques.
4 Results and Discussion
4.1 Fashion Product Image Synthesis
Figure 3 shows comparison of the original image and the reconstruction of the image using the trained model. VAEs are known to produce blurry images due to the small bottleneck layer and latent space, but the reconstruction is still very recognizable as the original. The reconstruction of the first image in Figure 3 caught the right colors and structure but missed out some intricate details while the reconstruction of the glasses had some washed out colors.

Since the bottleneck layer is size sixteen, the user is provided sixteen range sliders for synthesizing images by manipulating the -vector. This is decoded by the decoder in the backend. The application provides the user an encoding from the database selected randomly as starting point. The user is given sixteen sliders to interactively control the latent vector (Fig. 4).
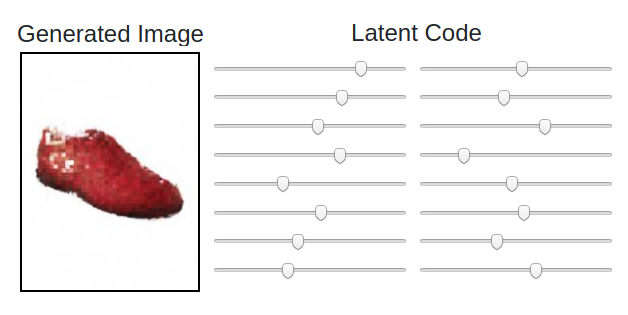
Moving one slider changes some attribute of the the product image. In Figure 5, it illustrates how the product reconstructed image changes as the sixth slider is moved from left to right changing mostly its color and texture.

In traditional Variational Autoencoders, it is difficult to determine which specific attributes of the image will transform upon changing one latent code in the -vector.
4.2 Clustering the Dataset
Each image from the training dataset is encoded using the encoder of the trained model and stored in the database. Both the and vectors and fixed vectors are part of the encodings upon finishing training the model. These encodings will be used for retrieving similar images, clustering and recommendations.
K-means clustering with = 3 is used to cluster the entries in the database using both vector and fixed vector. Each entry has a subcategory tag (e.g. footwear, eyewear, or bag) and will be used for evaluating both clustering and similar image retrieval. All fashion products in the database are included in this clustering procedure.
| Class | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Bags | 0.863 | 1.0 | 0.69 | 0.81 |
| Footwear | 0.985 | 0.98 | 0.98 | 0.98 |
| Eyewear | 0.864 | 0.53 | 1.0 | 0.70 |
| Class | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Bags | 0.866 | 1.0 | 0.69 | 0.82 |
| Footwear | 0.985 | 0.98 | 0.98 | 0.98 |
| Eyewear | 0.865 | 0.54 | 1.0 | 0.70 |
As seen in Table 1 and 2, the F1 score of the two cases are almost similar. The F1 scores are decent considering that only a feature consisting of 16 dimensions is used to cluster images which resembles image classification although the scores are relatively lower on eyewear as K-means often tries to produce clusters of relatively uniform sizes and is very sensitive to skewed or imbalanced dataset Kumar et al. (2014). This means that using K-Means on this imbalanced dataset caused very low precision for eyewears and low recall for bags. This leads to having wrongly categorized items and cross-product recommendations that is not a member of the category. Even though each images have correct tags, the cluster assignments predicted by K-Means and the cluster centers shall be used.
4.3 Getting Most Similar Images
The most similar images are retrieved using log-likelihood maximization and Euclidean distance on fixed-epsilon sampling encoding as discussed earlier. But before retrieving similar images to the one generated by the user, its cluster is predicted first using Euclidean distance between -vector and the cluster centers. The application retrieves similar images from the cluster it was assigned.
| Config | Top-10 | Top-25 | Top-50 | Top-500 |
|---|---|---|---|---|
| Full / Log-Like | 0.946 | 0.918 | 0.894 | 0.762 |
| Full / Fixed- | 0.955 | 0.947 | 0.899 | 0.846 |
| Cluster /Log-Like | 0.954 | 0.942 | 0.942 | 0.896 |
| Cluster / Fixed- | 0.953 | 0.950 | 0.948 | 0.922 |
One evaluation metric for image retrieval is Mean Average Precision (mAP) Torres Fernandez (2018). Here, it is calculated on a randomly sampled 500 images for each category in retrieving top-10, top-25, top-50, and top-500 similar images. Figure 3 shows that using Euclidean Distance on Fixed-Epsilon Sampling Encodings yield higher mAP score most especially if the image retrieval is done on those which belong to the same cluster. Not only it is quicker but it has less false positives. This is highly encouraging since Torres Fernandez (2018) had mAP score of 0.95 on their best model using VAE for MNIST images which are a less complex dataset.


Figure 6 and 7 shows comparison of using these two methods for similar image retrieval. By observation, both techniques present the same image as the best match from the database but deviates on the second and third best match. From these two figures (Fig. 6 and 7), the first technique seems to prioritize similarities in color and texture while the second method tries to give emphasis on overall structure.
4.4 Recommending Products From Other Categories
In recommending products from other categories, after getting (as discussed in 3.4), the closest image match from the database in that cluster is provided to the user using the two image matching techniques discussed in the paper so far.
Figures 8 and 9 illustrate sample recommendations for other clusters. Similar to the observation in Section 4.5, both similar image retrieval techniques for the cluster assignment of the generated product obtain the same output for the best match (b) but are different in the second best match (c). Recommendations using both methods are quite different from each other as observed both figures.

Figure 9 shows the fixed-epsilon sampling technique seems to provide a better suggestion of products to pair with the eyeglasses emphasizing color and patterns recommending a blue bag and blue footwear to go with an eyewear with bluish tint. This is not the case recommendations for eyewear in Figure 8 which tries to suggest a bag and a shoe of mostly white in color.
Both suggestions provide almost a similar items - a brown, leather bag and a thick-framed eyeglases. Fixed-epsilon sampling technique (Fig. 9 tries to recommend an eyeglass grayish tint similar to the generated image while the other method brings out the brown hue similar to the suggested bag and second best matching image.

5 Conclusion
In this work, the author starts with the idea that applications of deep learning in e-commerce, most especially in the fashion industry have been given more attention with the availability of new datasets. Product design generation, image retrieval mechanisms, and recommender systems are applications of deep learning but solutions only focus on using one architecture to solve one specific problem.
The author used Variational Autoencoders (VAEs) in a simple interactive application that aims to solve these problems with only one central architecture. Using the capability of VAEs in generating latent codes for generative modelling and feature extraction, new methods have been introduced on how to use these in generating product designs according to the user’s preference, retrieve and cluster similar images, and recommend products from other categories. The user is able to design fashion products by their preference by adjusting a set of interactive sliders. Log-likelihood maximization and Euclidean Distance for Fixed Epsilon Sampling Encodings in retrieving similar and clustering using the latent codes showed promising results. Clustering with K-Means using these two methods showed good F1 score as high as 0.98 even with imbalanced data. Similar image retrieval using the latent codes also had astonishing results with mAP as high as 0.95 for top-10, top-25, and top-50 most similar image retrieval consistently scoring higher when using Fixed Epsilon Sampling Encodings compared to Log-Likelihood Maximization. The application is also able to use the user-generated latent codes, image retrieval techniques, and cluster centers from prior clustering for multiple cross-product recommendation. It was able to recommend items that are of the same attribute in color, texture, patterns, etc. with the product designed by the user. Overall, the pipeline was able to make full use of one deep learning architecture for multiple areas in e-commerce industry.
Acknowledgments
The author would like to express his gratitude to his professor, Rowel Atienza. for imparting him knowledge in this study. The author would also like to express his gratitude and thanks to his colleagues and friends, especially Joanne Madridejos, who helped him in finishing the paper and the application.
References
- Chen et al. [2017] Luyang Chen, Fan Yang, and Heqing Yang. Image-based product recommendation system with convolutional neural networks, 2017.
- Deverall et al. [2017] Jaime Deverall, Jiwoo Lee, and Miguel Ayala. Using generative adversarial networks to design shoes: the preliminary steps. CS231n in Stanford, 2017.
- Khan and Ahmad [2004] Shehroz S Khan and Amir Ahmad. Cluster center initialization algorithm for k-means clustering. Pattern recognition letters, 25(11):1293–1302, 2004.
- Kingma and Welling [2013] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Krizhevsky and Hinton [2011] Alex Krizhevsky and Geoffrey E Hinton. Using very deep autoencoders for content-based image retrieval. In ESANN, volume 1, page 2, 2011.
- Kumar and Gupta [2019] Sudhir Kumar and Mithun Das Gupta. gan: Complementary fashion item recommendation. arXiv preprint arXiv:1906.05596, 2019.
- Kumar et al. [2014] Ch N Santhosh Kumar, K Nageswara Rao, A Govardhan, and K Sudheer Reddy. Imbalanced k-means: An algorithm to cluster imbalanced-distributed data. International Journal of Engineering and Technical Research (IJETR), 2(2), 2014.
- Lin et al. [2019] Yujie Lin, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Jun Ma, and Maarten de Rijke. Improving outfit recommendation with co-supervision of fashion generation. In The World Wide Web Conference, pages 1095–1105. ACM, 2019.
- Liu et al. [2016] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1096–1104, 2016.
- Odaibo [2019] Stephen Odaibo. Tutorial: Deriving the standard variational autoencoder (vae) loss function. arXiv preprint arXiv:1907.08956, 2019.
- Qayyum et al. [2017] Adnan Qayyum, Syed Muhammad Anwar, Muhammad Awais, and Muhammad Majid. Medical image retrieval using deep convolutional neural network. Neurocomputing, 266:8–20, 2017.
- [12] ReNom. Variational auto-encoder.
- Rostamzadeh et al. [2018] Negar Rostamzadeh, Seyedarian Hosseini, Thomas Boquet, Wojciech Stokowiec, Ying Zhang, Christian Jauvin, and Chris Pal. Fashion-gen: The generative fashion dataset and challenge. arXiv preprint arXiv:1806.08317, 2018.
- Spinner et al. [2018] Thilo Spinner, Jonas Körner, Jochen Görtler, and Oliver Deussen. Towards an interpretable latent space: an intuitive comparison of autoencoders with variational autoencoders. In IEEE VIS 2018, 2018.
- Torres Fernandez [2018] Sara Torres Fernandez. Designing variational autoencoders for image retrieval, 2018.
- Tuinhof et al. [2018] Hessel Tuinhof, Clemens Pirker, and Markus Haltmeier. Image-based fashion product recommendation with deep learning. In International Conference on Machine Learning, Optimization, and Data Science, pages 472–481. Springer, 2018.
- Zhu et al. [2018] Jiating Zhu, Yu Yang, Jiannong Cao, and Esther Chak Fung Mei. New product design with popular fashion style discovery using machine learning. In International Conference on Artificial Intelligence on Textile and Apparel, pages 121–128. Springer, 2018.
- Zou et al. [2019] Xingxing Zou, Xiangheng Kong, Waikeung Wong, Congde Wang, Yuguang Liu, and Yang Cao. Fashionai: A hierarchical dataset for fashion understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.