Exploring and Mitigating Gender Bias in Recommender Systems with Explicit Feedback
Abstract
Recommender systems are indispensable because they influence our day-to-day behavior and decisions by giving us personalized suggestions. Services like Kindle, Youtube, and Netflix depend heavily on the performance of their recommender systems to ensure that their users have a good experience and to increase revenues. Despite their popularity, it has been shown that recommender systems reproduce and amplify the bias present in the real world. The resulting feedback creates a self-perpetuating loop that deteriorates the user experience and results in homogenizing recommendations over time. Further, biased recommendations can also reinforce stereotypes based on gender or ethnicity, thus reinforcing the filter bubbles that we live in. In this paper, we address the problem of gender bias in recommender systems with explicit feedback. We propose a model to quantify the gender bias present in book rating datasets and in the recommendations produced by the recommender systems. Our main contribution is to provide a principled approach to mitigate the bias being produced in the recommendations. We theoretically show that the proposed approach provides unbiased recommendations despite biased data. Through empirical evaluation on publicly available book rating datasets, we further show that the proposed model can significantly reduce bias without significant impact on accuracy. Our method is model agnostic and can be applied to any recommender system. To demonstrate the performance of our model, we present the results on four recommender algorithms, two from the K-nearest neighbors family, UserKNN and ItemKNN, and the other two from the matrix factorization family, Alternating least square and Singular value decomposition.
Keywords Book Recommender systems, Gender Bias, Fairness
1 Introduction
Recommender systems influence a significant portion of our digital activity. They are responsible for keeping the user experience afresh by recommending varied items from a catalog of millions of items and also adapt their recommendations according to the personality and taste of the user. Therefore, a sound recommender system may go a long way in improving user experience quality, hence the user retentivity of a digital outlet.
Recommender systems have historically been judged on their accuracyHerlocker et al. (2004); Shani and Gunawardana (2011). When it is concerned with other factors such as novelty, user satisfaction, and diversityHurley and Zhang (2011); Ziegler et al. (2005a); Knijnenburg et al. (2012), the focus continues to be just on the satisfaction of the information needs of the users. Although of immense importance to the relevance of a recommender system, these criteria do not capture the complete picture. In recent years, the public and academic community have scrutinized artificial intelligence systems regarding their fairness. It has been observed that the results generated by various recommender systems reflect the social biases that exist in human stratumEkstrand et al. (2018); Shakespeare et al. (2020); Boratto et al. (2019). Scholars have focused on identifying, quantifying, and mitigating the bias present in the results generated by recommendation systems. Burke (2017) presents a taxonomy of classes for fair recommendation systems. The author suggests different recommendation settings with fairness requirements such as fairness for only users, fairness for only items, and fairness for both users and items. Our work falls into fairness for only items category where bias is shown by a particular set of users against a specific set of items in the dataset. In particular, we are interested in studying and eliminating users’ biasedness against the items associated with a specific gender in recommendation systems.
Bias prevention approaches can be classified according to the phase of the data mining process in which they operate: pre-processing, in-processing, and post-processing methods. Pre-processing methods aim to control distortion of the training set. In particular, they transform the training dataset so that the discriminatory biases contained in the dataset are smoothed, hampering the mining of unfair decision models from the transformed data. In-processing methods modify recommendation algorithms such that the resulting models do not entail unfair decisions by introducing a fairness constraint in the optimization problem. Lastly, post-processing methods act on the extracted data mining model results instead of the training data or algorithm. The method presented in our work is a hybrid of a pre-processing phase and a post-processing phase.
Two prominent studies have focused on gender bias in recommender systems. The work by Shakespeare et al. (2020) establishes the existence of bias in the results of the music recommender systems, and the work by Ekstrand et al. (2018) focuses on bias shown by Collaborative Filtering (CF) algorithms while recommending books written by women authors. Both the studies establish that the CF algorithms produced biased results after being fed the biased data from various socio-cultural factors. While both the works focus just on showing the existence of bias in the presence of the users’ implicit feedback, we also consider the explicit feedback ratings and the bias that may arise out of it. Thus, our model handles the case when the items associated with specific gender might have received worse feedback than they otherwise ought to achieve by a set of users. We go one step further and propose a model to mitigate these biases by quantifying a particular user’s bias and debiasing his or her feedback ratings. We theoretically show that the debiased ratings are unbiased estimators of the true preference of the user. Once the ratings are debiased, they are fed into the recommender algorithms as input to produce recommendations for the desired set of users. Since the recommender system is now fed with the debiased ratings, the resulting recommendations are free from the bias factor and avoid a self-perpetuating loop in the future.
The bias of an individual user reflects his or her taste. However, the KNN based algorithms produce recommendations based on similar characteristics between a set of users and naive implementation of these algorithms reflects the bias of one user in the recommendations produced for the other user. While not directly comparing the rating history of different users or items, Matrix Factorization algorithms rely on deriving latent factors, which depend on the rating history. Both the approaches make the system increasingly biased and homogenized after users interact with their biased recommendations and generate data for the next iteration. The above discussion suggests that though it is necessary to reflect the user’s preference in the recommendations produced for him or her to achieve accuracy, it is equally necessary to prevent the bias of one user from reflecting in the recommendations of another similar user. Our research focuses on this particular objective.
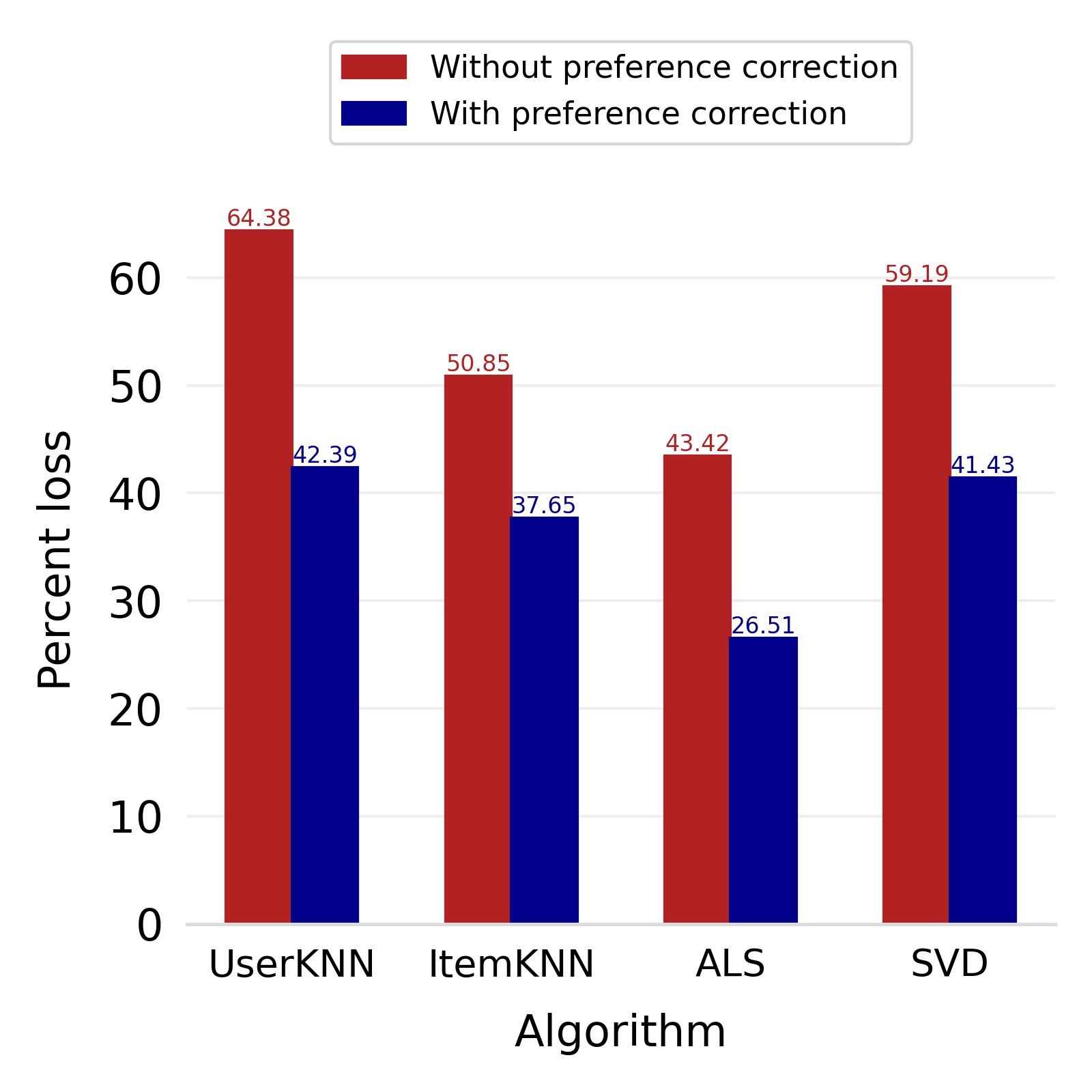
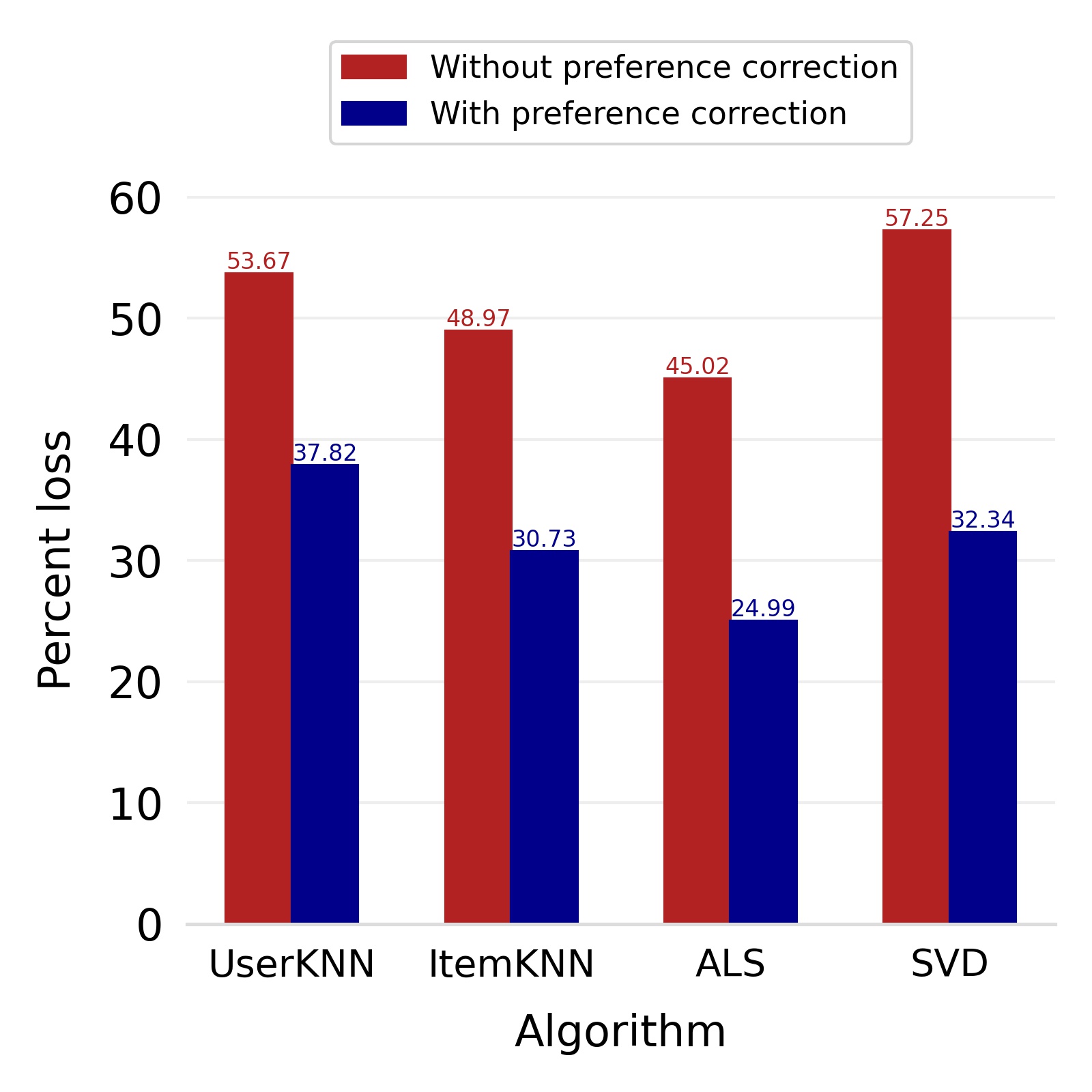
Our debiased ratings assure that the biases of one user do not affect other users; however, it may lead to loss of accuracy because of not reflecting the user’s own preferences. We introduce a new step called preference correction which injects the user’s preference parameter into his/her own debiased recommendation to maintain the accuracy of the system. On the publicly available Book-Crossing dataset (Ziegler et al. (2005b)) and Amazon Book Review dataset (Ni et al. (2019)), we empirically show that this approach retained the significant reduction in bias and had minimal effect on the accuracy of the system. The bias reflected in the recommendations produced by the UserKNN, ItemKNN, ALS, and SVD algorithms is reduced by as much as , , , and respectively for the Amazon dataset and by , , , and for the Book-Crossing dataset. When measured with respect to Root Mean Squared Error(RMSE), the final accuracy loss in the case of the Amazon dataset comes out to be , , , and respectively for the four algorithms. In the case of the Book-Crossing dataset, the RMSE loss comes out to be , , , and respectively. In particular, the following are our main contributions.
1.1 Contributions
-
•
We propose a model to quantify the gender bias in the recommender system when explicit feedback is present.
-
•
We propose a principled approach to debias the ratings given and theoretically show that the debiased ratings represent the unbiased estimator of the true preference of the user.
-
•
We empirically evaluate our model on publicly available book datasets and show that the approach significantly reduced the biasedness in the system. To show the generality of our proposed approach, we show the results on four algorithms, UserKNN, ItemKNN, ALS, and SVD.
-
•
In order to further enhance the accuracy of the debiased system, we propose an approach of preference correction that respects the user’s own preferences towards his/her recommendations. We show that the final recommender system significantly reduces the bias in the system while not deteriorating the accuracy much.
2 Related Works
The problem of gender bias and discrimination has received lots of attention in recent works Hajian et al. (2016). Many proposals like Pedreschi et al. (2008), Pedreschi et al. (2009), Ruggieri et al. (2010), Thanh et al. (2011), Mancuhan and Clifton (2014), Ruggieri et al. (2014) are dedicated to detecting and measuring the existing biases in the datasets while other efforts Kamiran et al. (2010), Kamiran et al. (2012), Hajian and Domingo-Ferrer (2013), Hajian et al. (2014a), Hajian et al. (2014b), Dwork et al. (2011), Zemel et al. (2013) are focused on ensuring that data mining models do not produce discriminatory results even though the input data may be biased. Most of these works focus on the classical problem of classification. Amatriain et al. (2011) discuss the application of various classification methods like Support Vector Machines, Artificial Neural Networks, Bayesian classifiers, and decision trees in recommender systems. Their findings indicated that a more complex classifier need not give a better performance for recommender systems, and more exploration is needed in this direction.
When considering "fairness for only users" according to the taxonomy presented by Burke (2017), Boratto et al. (2019) and Tsintzou et al. (2018) discuss the bias with respect to the preferential recommending of certain items only to the users of a specific gender. While weighted regularization matrix factorization studied in Boratto et al. (2019) is only appropriate for implicit feedback, the Group Utility Loss Minimization proposed in Tsintzou et al. (2018) works only with respect to the UserKNN algorithm. Both the papers address the issue of gender bias by employing post-processing algorithms that work only in limited settings. Though Boratto et al. (2019) and Tsintzou et al. (2018) have addressed the issue of fairness of recommender systems with respect to gender, they have done so from the perspective of recommending certain items only to the users of a specific gender. The difference between their work and our study lies in the fact that we focus on the more direct issue of gender bias in recommendations shown to items associated with a specific gender.

Shakespeare et al. (2020) in their research highlight the artist gender bias in music recommendations produced by Collaborative Filtering algorithms. The work traces the causes of disparity to variations in input gender distributions and user-item preferences, highlighting the effect such configurations can have on user’s gender bias after recommendation generation. Mansoury et al. (2020) discuss the biases from the perspective of a specific group of individuals (for example, a particular gender) receiving less calibrated and hence unfair recommendations. Ekstrand et al. (2018) explores the gender bias present in the book rating dataset. Our work is different from the works by Shakespeare et al. (2020), Mansoury et al. (2020) and Ekstrand et al. (2018) in primarily two factors: (i) we consider explicit feedback as opposed to the implicit feedback, and (ii) we propose a principled approach to debias the ratings and theoretically show that the debiased ratings are unbiased estimators of true ratings.
The research by Leavy et al. (2020) focuses on algorithmic gender bias and proposes a framework whereby language-based data may be systematically evaluated to assess levels of gender bias prevalent in training data for machine learning systems. Our work is different from this study as this study is focused on evaluating gender bias in the language and textual data settings, while ours deals with gender bias in a more traditional user-item rating setting.
3 The Model
Consider a recommender system having users and items. Let and denote the set of items associated with disadvantaged group and advantaged group, respectively. For example, in a book recommender system, the books represent the items; and represent the set of books written by women and men authors respectively. With respect to book recommender system, researchers have already shown that the data is biased against female authors’ books Ekstrand et al. (2018).
Let denote the rating that user has given to the item . As opposed to previous works, we consider explicit feedback wherein biases may not only arise from not giving the rating to the item but may also come from giving a bad rating to the item. The user profile represents the set of books () and the ratings () that user has given to those items.
The proposed recommender system first pre-processes the data that: 1) finds the log-bias of each user and 2) generates the debiased rating of each user and item using the computed bias in the first step. We then theoretically show that the debiased ratings generated are unbiased estimators of the true preferences of the user for the items rated by them. Thus, the debiased dataset can then be fed into various recommender algorithms to generate an unbiased predicted rating of a user for the item , denoted by . This debiasing step ensures that the existing biases are not boosted further in the system. Our debiasing model is independent of any recommendation algorithm. We show the performance of our debiasing model on both K-nearest neighbors-based algorithms (UserKNN, ItemKNN) as well as matrix factorization-based algorithms (Alternating Least Square and Singular Value Decomposition) to produce the recommendations.
In the next step, we use preference corrector to reintroduce the preferences of a particular user to his/her own recommendations. This is achieved via producing a user specific rating from the debiased rating . The recommendations are re-ranked according to the adjusted ratings, and the recommendations are presented to the user. This step ensures that the system does not lose accuracy for not considering the preferences of the users. Figure 1 shows the schematic diagram of our model. Consider that the ratings are continuous values ranging from to , then mathematically, a biased recommender system can be represented as follows:
-
1.
Each user , while rating an item , scales down the maximum rating by . is a random variable, drawn from a distribution function , which has a mean value of . represents the logarithm of the true preference of the user for the item . For the sake of brevity, we call it log-preference of the user for the item . Hence is a representation of the true preference of user for the item .
-
2.
In case the item is associated with the disadvantaged group, the user further scales down the rating of the item by a factor . is a random variable, drawn from a distribution function having a mean value of . represents the logarithm of the biasedness of the user shown to the item . For the sake of brevity, we call it the log-bias of the user for the book . Hence represents the biasedness of the user for the book .
-
3.
For each user , is sampled from the a distribution function which governs the global log-bias tendency of the users. We denote the mean value of by .
Thus, ratings can be expressed as:
| (1) |
We now present a detailed description of each of the step.
3.1 Estimating the mean value for log-bias
The geometric mean of the ratings given by a user to the items associated with disadvantaged and advantaged groups, denoted by and respectively, are given by the following expressions:
Further, the log bias in the user profile , is given by .
We use geometric mean to compute the average rating of a user due to the following reasons: 1) It is less biased towards very high scores as compared to arithmetic meanNeve and Palomares (2019) and 2) when cold users are involved, aggregating recommendations using the geometric mean is more robust as compared to arithmetic meanValcarce et al. (2020).
The below lemma shows that is an unbiased estimator of .
Lemma 1.
The expectation of log-bias, in the user profile represents the mean value of the log-bias, of the user .
Proof.
Let us denote and to be the number of items associated with disadvantaged and advantaged group respectively in user profile . Then,
| (Using equation 1) | ||||
Taking expectation both sides:
| (2) |
Using linearity of expectation and some simplification, we get:
Thus, . ∎
Once we get the log biasedness tendencies of users, we use them to produce the debiased ratings for the given dataset.
3.2 Debiasing the Dataset
The debiased rating of the item associated with disadvantaged group and rated by user is given as We now provide the main theorem of our paper.
Theorem 2.
is the unbiased estimator of the log of the true rating of the item .
Proof.
As we can see, the expected value of contains only the term representing the true preference of the item for user . ∎
Thus, instead of , ratings are fed into the recommender system to generate the predicted unbiased ratings . Simply removing the bias from the user’s rating could severely affect the system’s accuracy because the bias of an individual user reflects their taste. However, the debiasing step helps prevent the bias of one user from affecting the recommendation of other users. Next, we use preference corrections by correcting the predicted rating of the user with respect to his/her own preference parameter.
3.3 Preference Correction to Improve Accuracy
Note that when the users are inherently biased against a group of items, then showing the items from naively to these users will severely affect the accuracy of the system. The goal of this work is not just to promote the exposure of the items among the two groups but is to not let the bias of one user creep into the bias of the other user. This was achieved via debiasing the dataset. Once the debiased ratings are generated, the accuracy of the system is maintained by introducing a correction factor. Although providing us with higher accuracy, the idea to re-introduce the correction factor may lead to an overall increase in the individual biases. This on a prima-facie may look self-defeating, but we need to note that final ratings still have significantly less bias than original ratings. If we do not introduce the correction factor, the users might flock to a substantial bias platform due to poor accuracy.
The correction is achieved via multiplying the predicted ratings of items associated with disadvantaged group by a factor . Thus, the final recommended ratings will be given as . Similar to the calculation of bias in the dataset, we can now compute the bias in the recommendation profile.
3.4 Bias in recommendation profile
We generate recommendations for the users in the test set . The recommendation profile for a user is denoted by , which represents the set of recommended books () for the user and their predicted ratings (). Let the set of items associated with disadvantaged and advantaged groups be denoted by and respectively. The average predicted ratings of the items associated with disadvantaged and advantaged groups, denoted by and respectively, are given by: where is the predicted rating given to item in the recommendation-profile generated for a user . The log-bias in the recommendation-profile , denoted by , is then given by . For an unbiased recommendation-profile, . A profile biased against disadvantaged groups will have . We can then compute the overall bias of the recommender system by taking the average overall users, and this average gives us the estimated value of .
4 Dataset
To evaluate the proposed model, we run experiments on two publicly available book rating datasets, the Book-Crossing dataset, originally put together by Ziegler et al. (2005b) and the Amazon Book Review dataset, put together by Ni et al. (2019). We further process this dataset through the following stages:
4.1 Book Author Identification
Their unique ISBNs identify the books in both datasets. We identified the authors of the books present in the datasets via their ISBN numbers using the following three API services: Google Books API APIs (2 24), ISBNdb API ISBNDB (2 27), and Open Library API OpenLibrary (3 02). We could not identify the authors of some of the books. Hence we discarded those books from the dataset.
4.2 Author Gender Identification
We identified the genders of the authors via their first names. We used Genderize.io the gender of a name (03 5), an API service dedicated to identifying the gender given the first name of the person. We used a minimum confidence threshold of for gender identification. We could not identify the gender of some of the authors. We discard the books written by those authors from the dataset.
4.3 Filtering
We filtered the Book-Crossing dataset to include only those books with at least ratings and only those users who have rated at least books. Amazon dataset was significantly larger as compared to the Book-Crossing dataset. We filtered it to include only those books with at least ratings and only those users who have rated at least books. We did this filtering so that recommender algorithms have much data to produce accurate recommendations. The statistics of filtered datasets are mentioned in Table 1. The number of books written by male authors is almost equal to that of female authors for both datasets.
| Statistic | Amazon | Book-Crossing |
|---|---|---|
| Number of male authored books | 58369 | 829 |
| Number of female authored books | 58220 | 806 |
| Number of users | 44792 | 376 |
5 Experimental Results
5.1 Input Bias
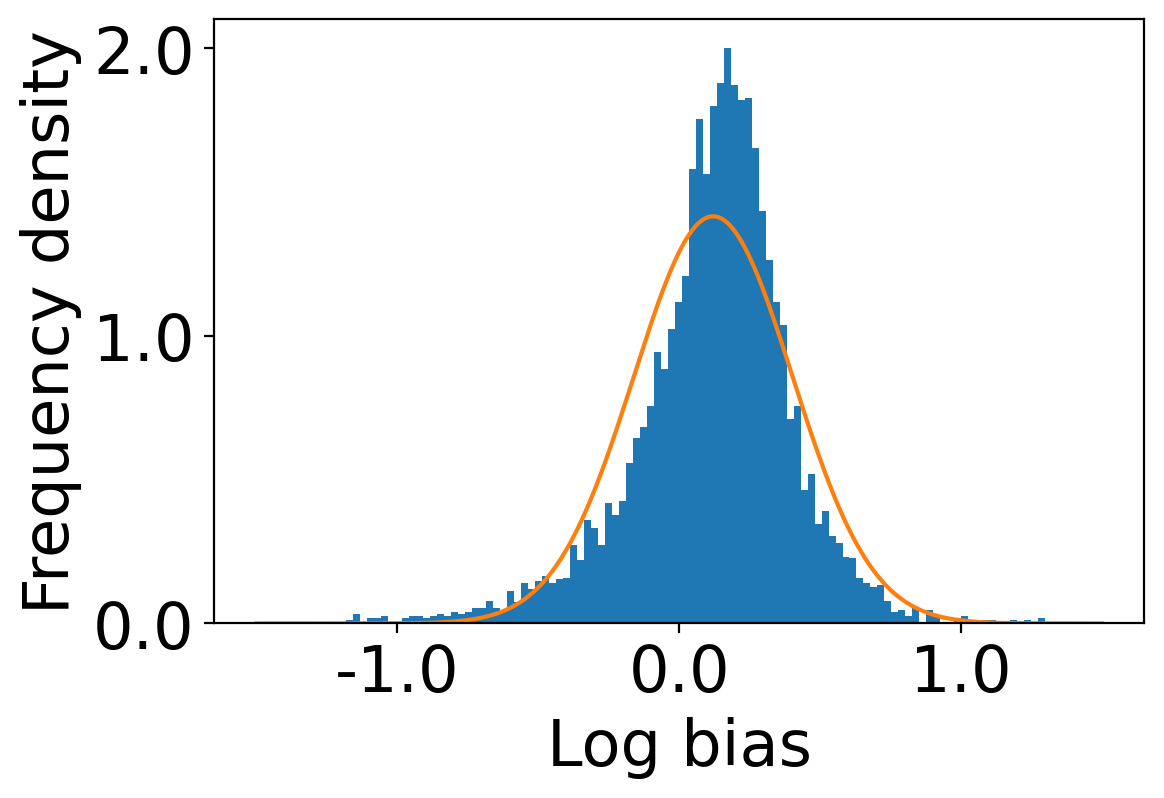
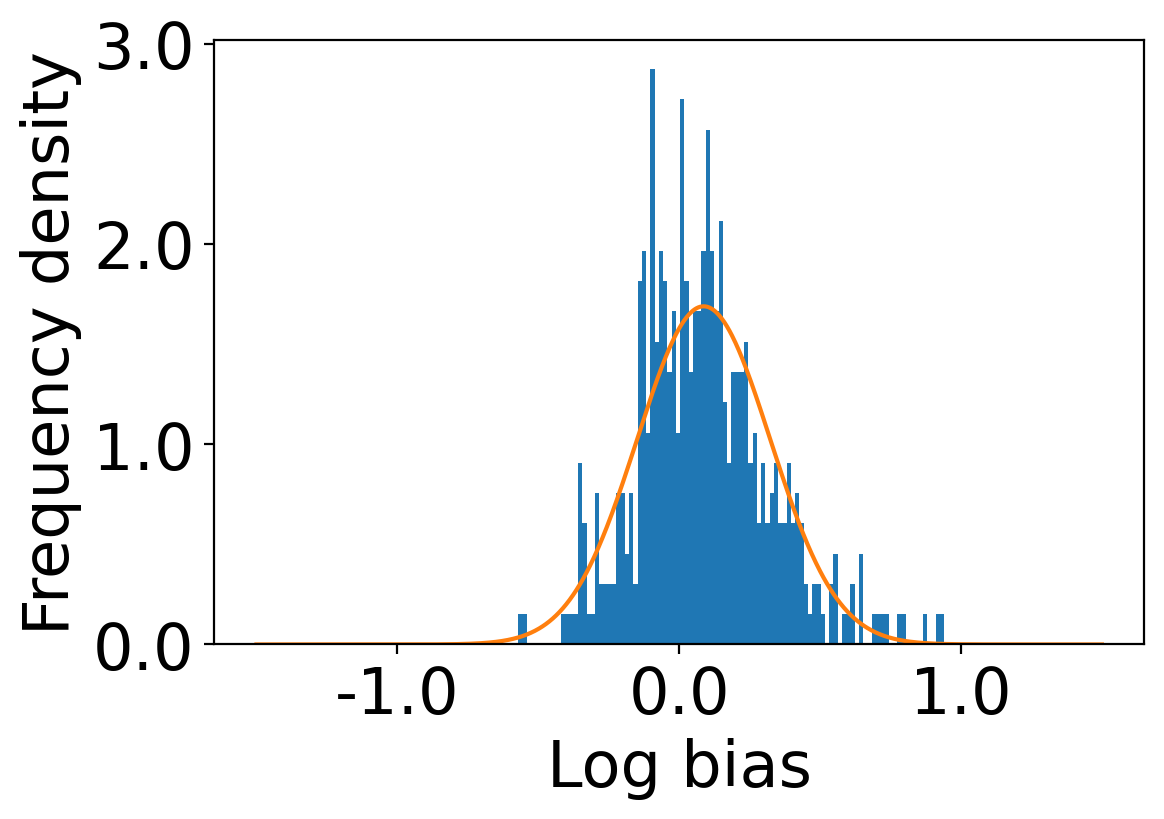
We show the distributions of log-bias tendency () of the users in the Amazon dataset and the Book-Crossing dataset in Figure 2. We observe that the mean log-bias tendency over all the users in the Amazon dataset is higher (0.176) than that of the Book-Crossing dataset (0.157)111code is available at https://github.com/venomNomNom/genderBias.git .
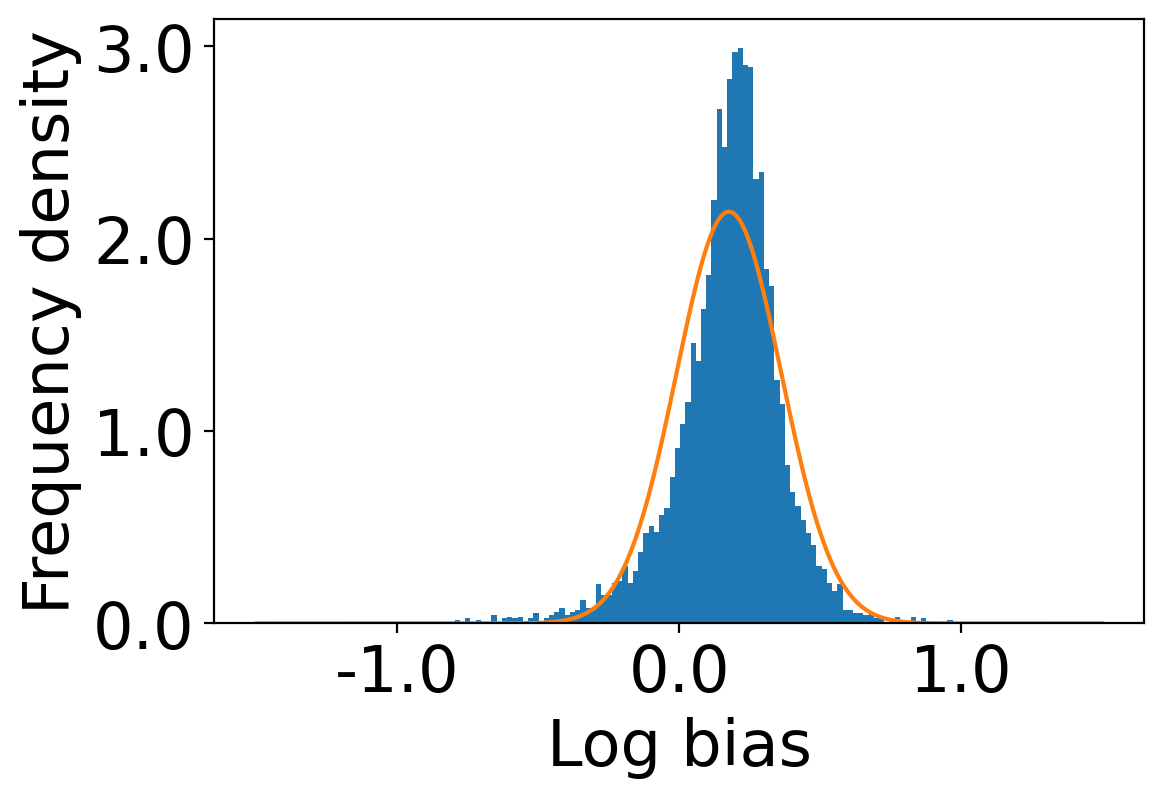
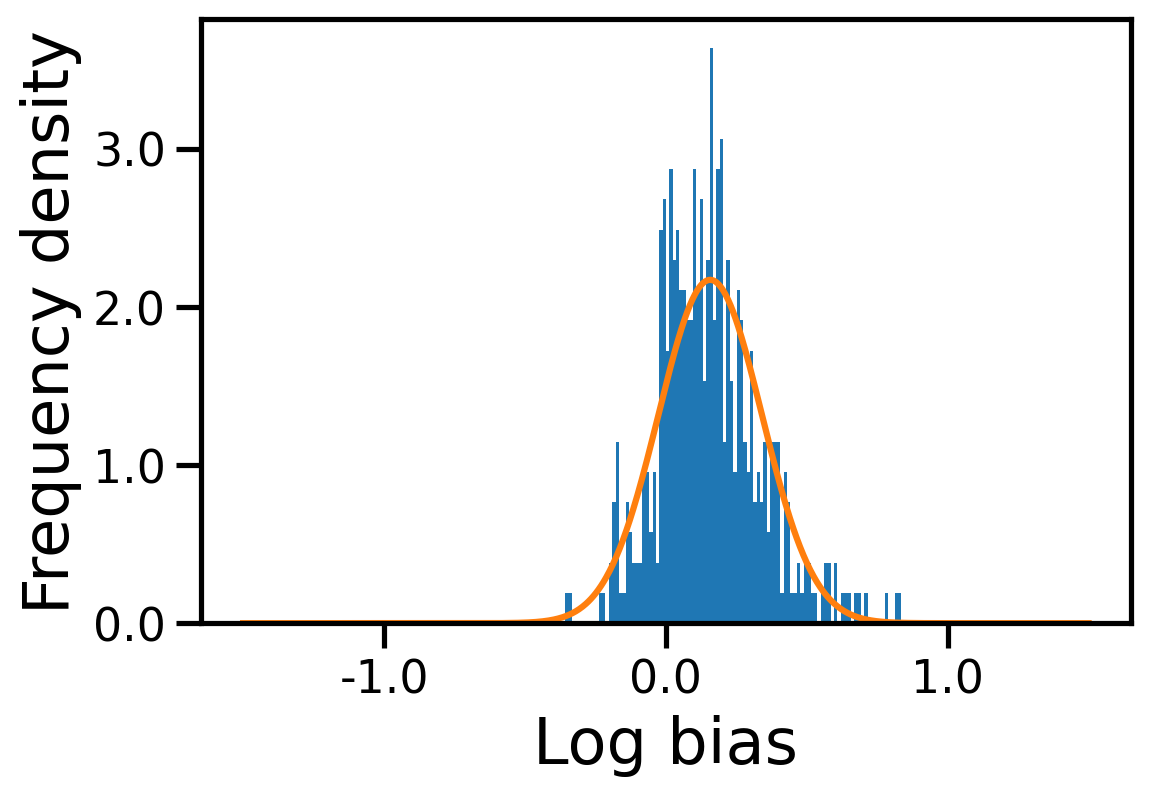
5.2 Output Bias
We randomly separate of users in each dataset as the test group. We generate the recommendations for the users in the test group using two K-nearest neighbors-based algorithms, UserKNN and ItemKNN, and two matrix factorization-based algorithms, Alternating Least Square and Singular Value Decomposition. These algorithms were selected because the accuracy and ranking relevancy of the recommendations produced by them were among the highest values compared with other algorithms. Hence coupling our model with them would best highlight the effects brought about by the same. We calculate the estimated value of log-bias () and accuracy in the recommendations separately for each algorithm applied on the two datasets. For this, we use two error measures, the Root Mean Squared Error (RMSE) and the Mean Absolute Error (MAE), and two ranking relevance parameters, Normalized Discounted Cumulative Gains and Mean Reciprocal Rank.
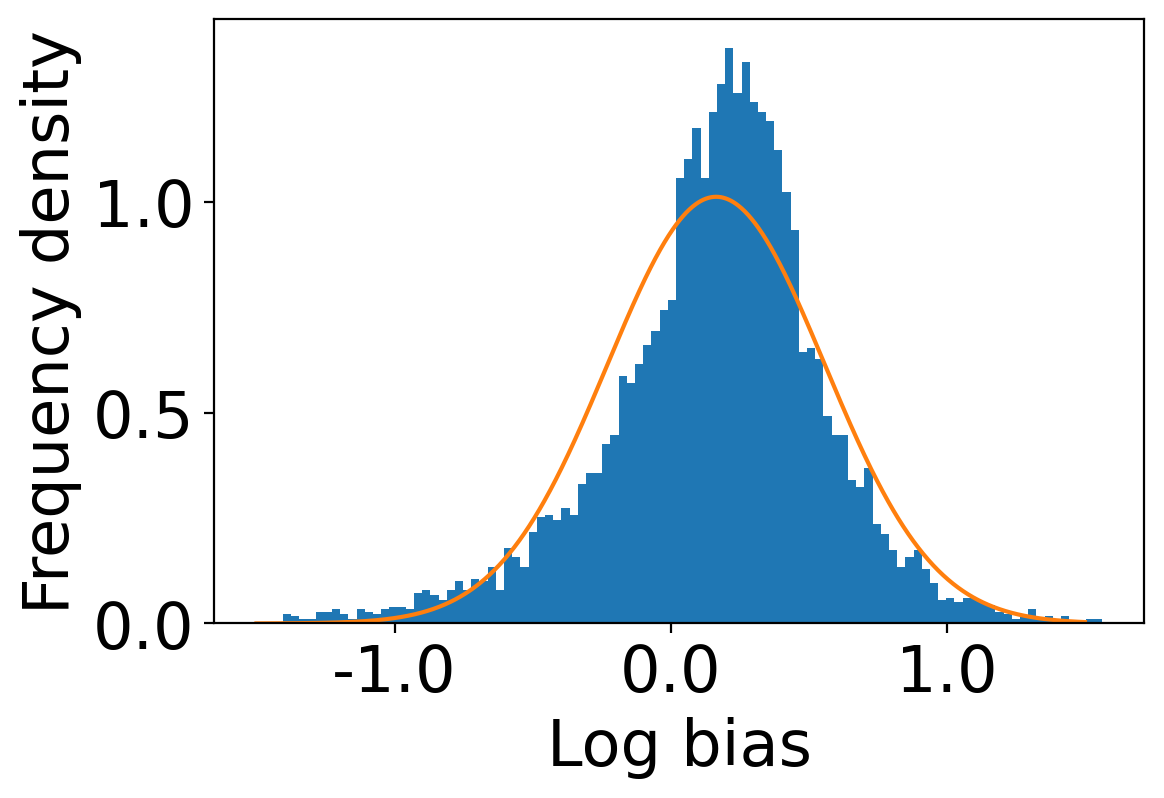
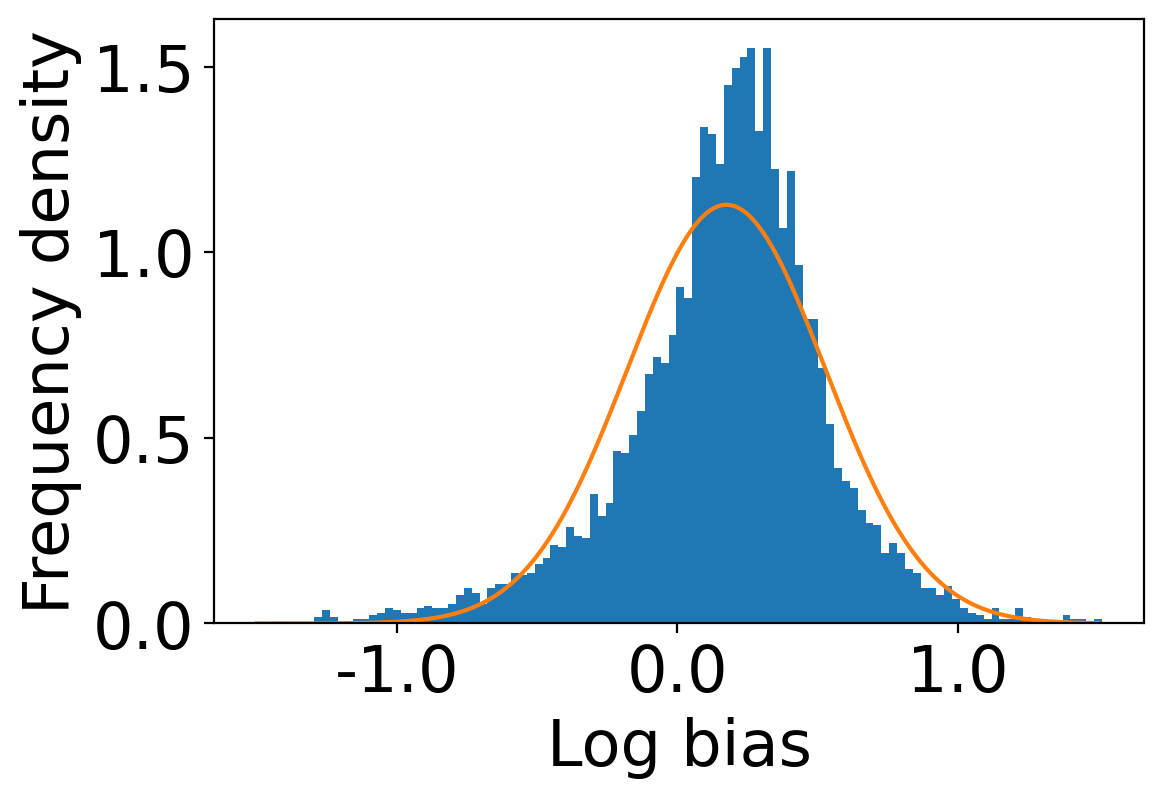
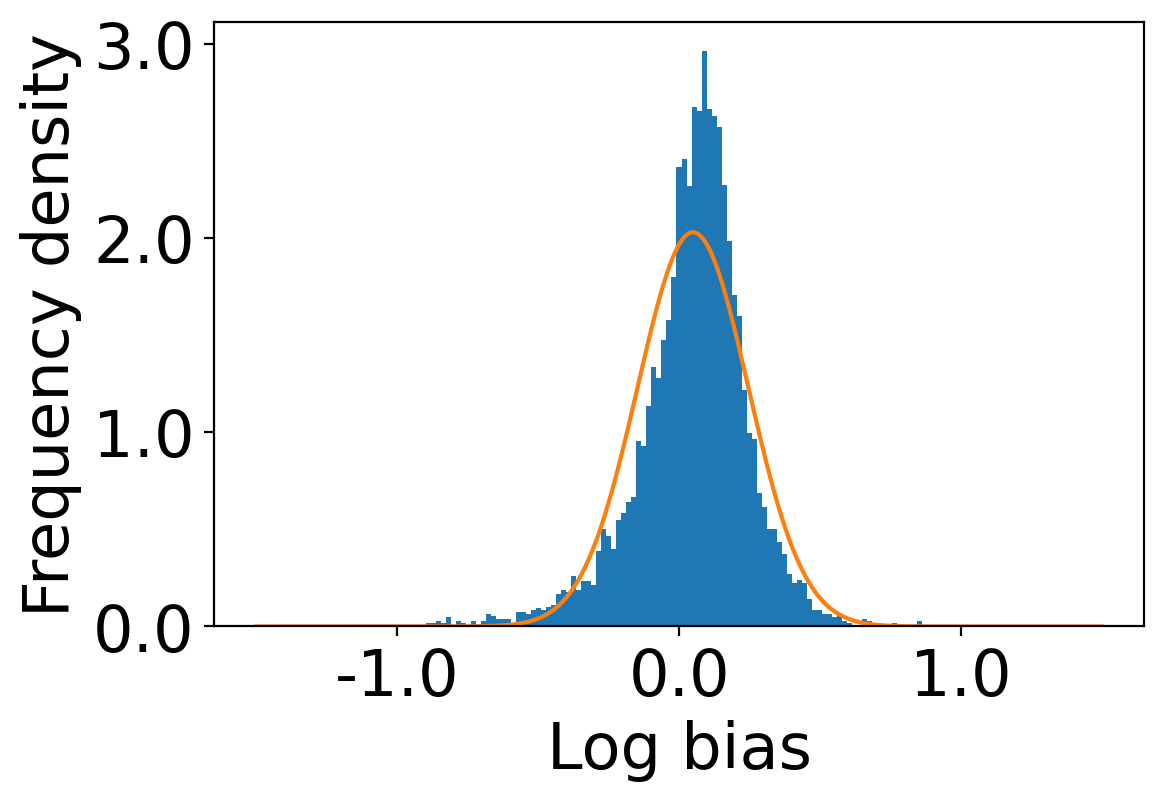
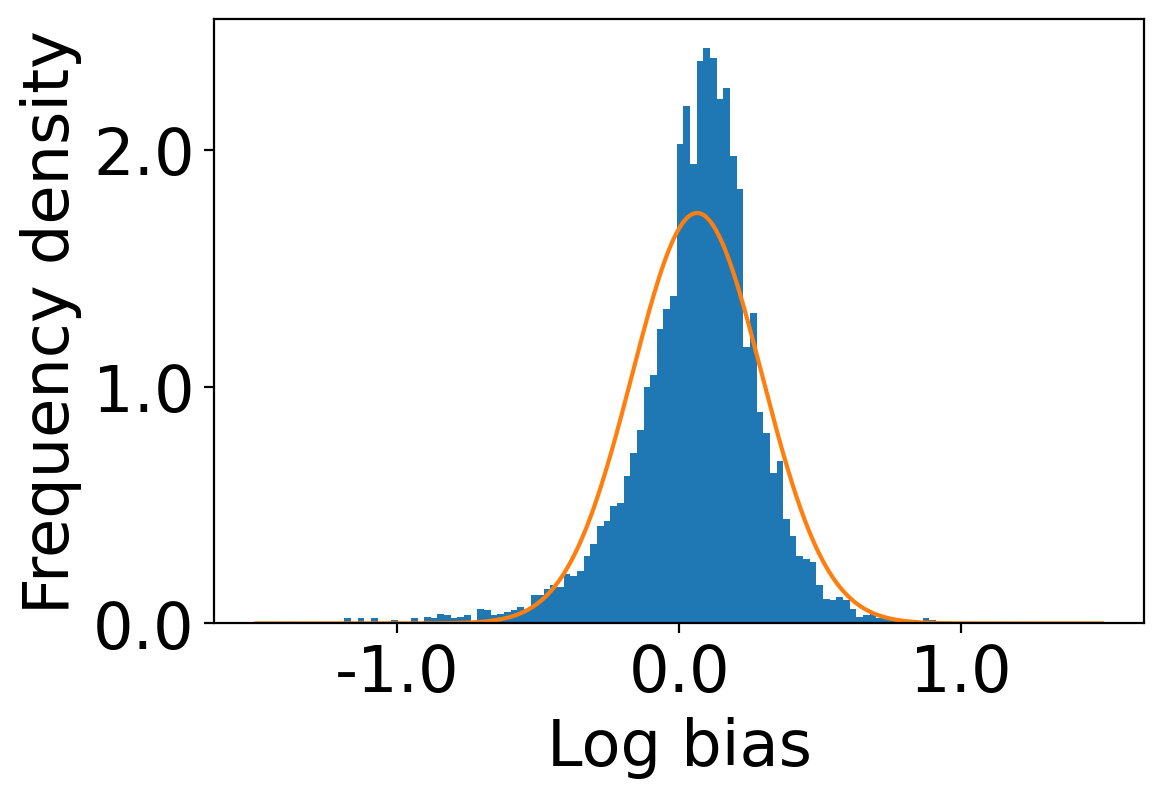
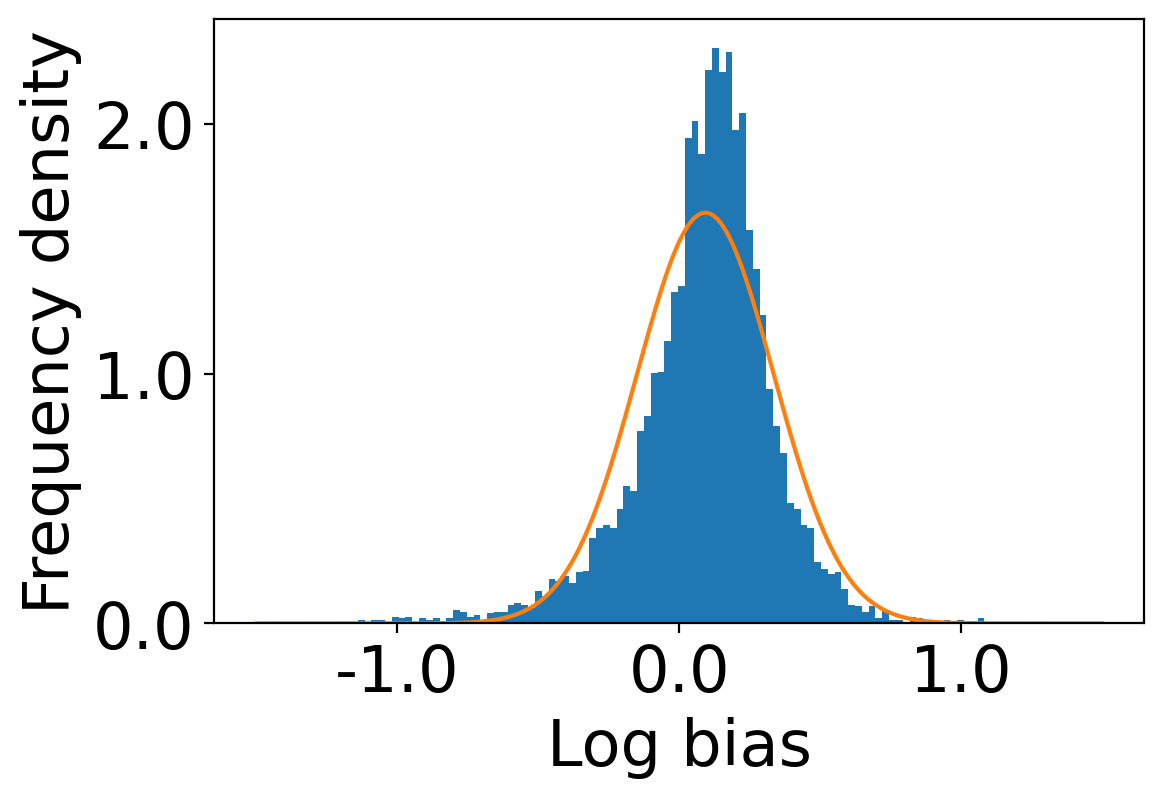
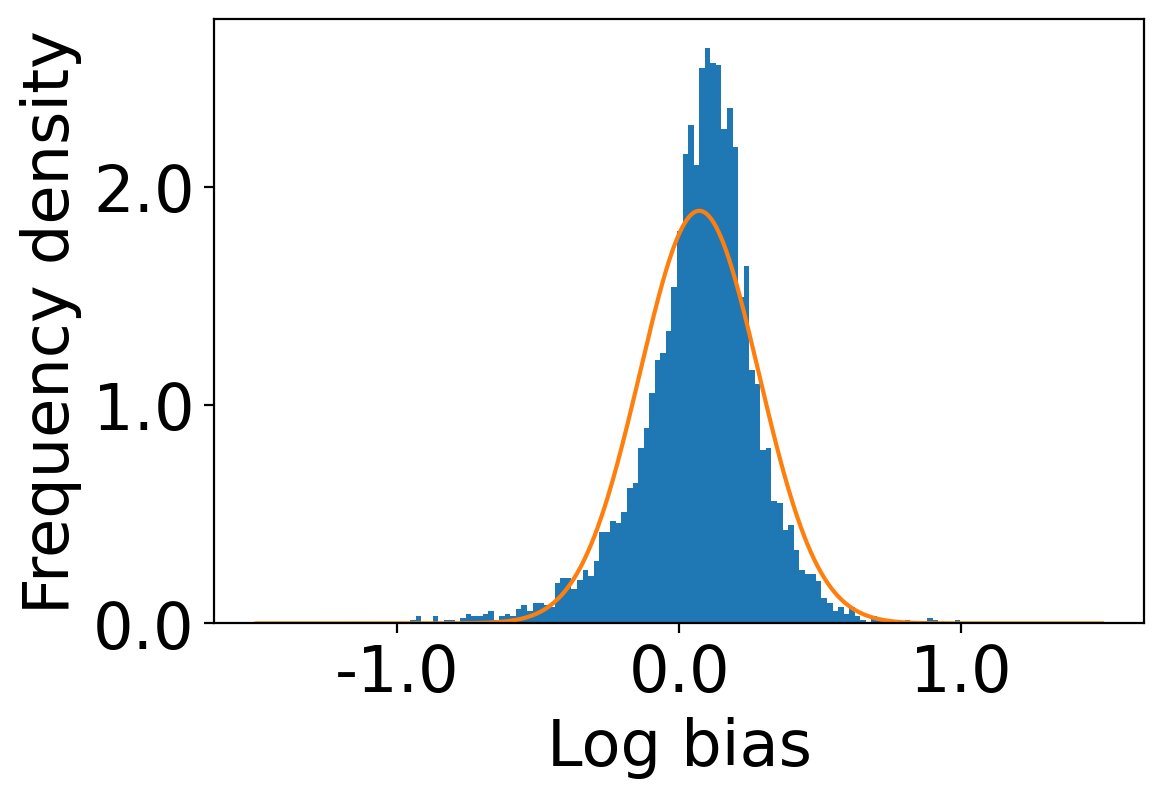
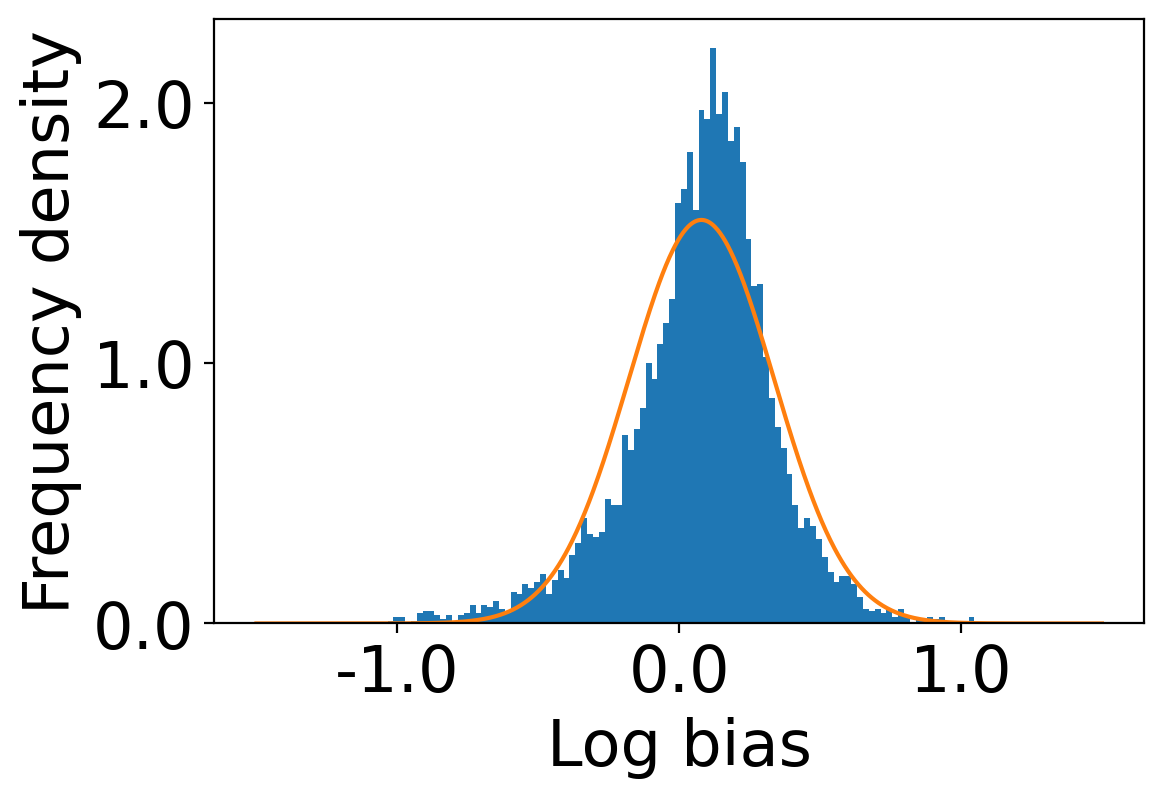
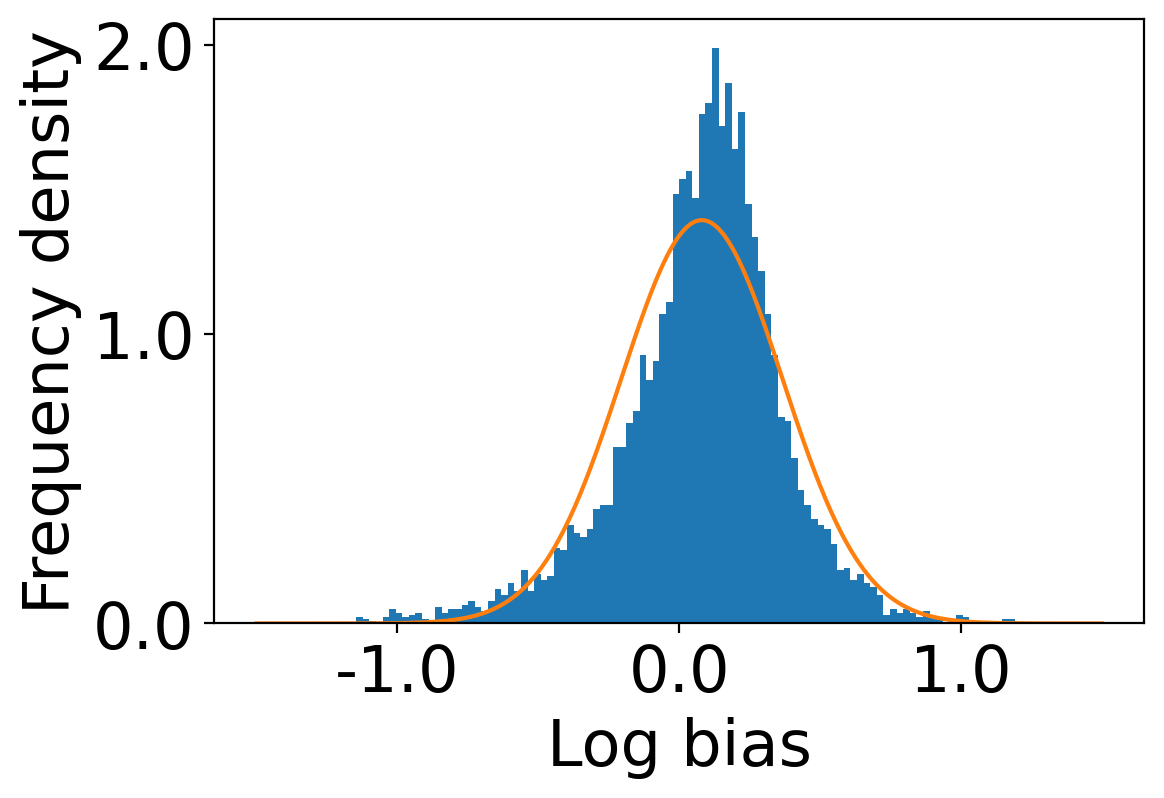
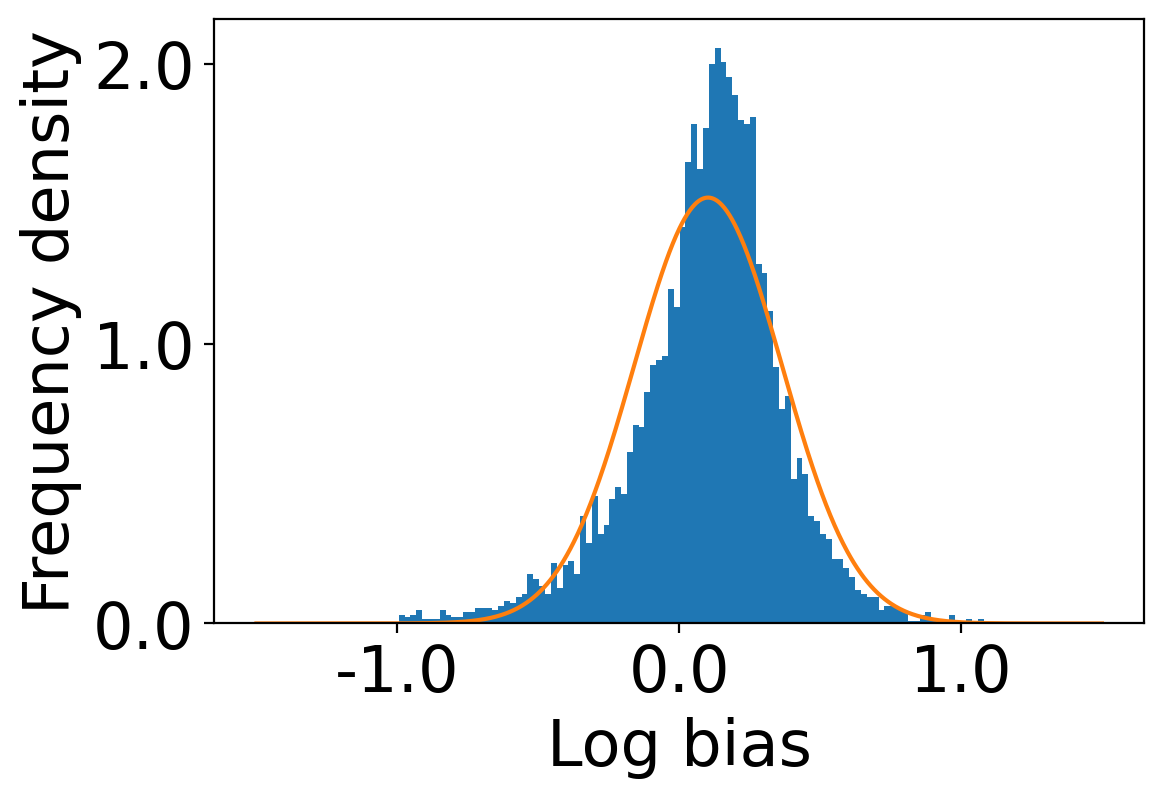
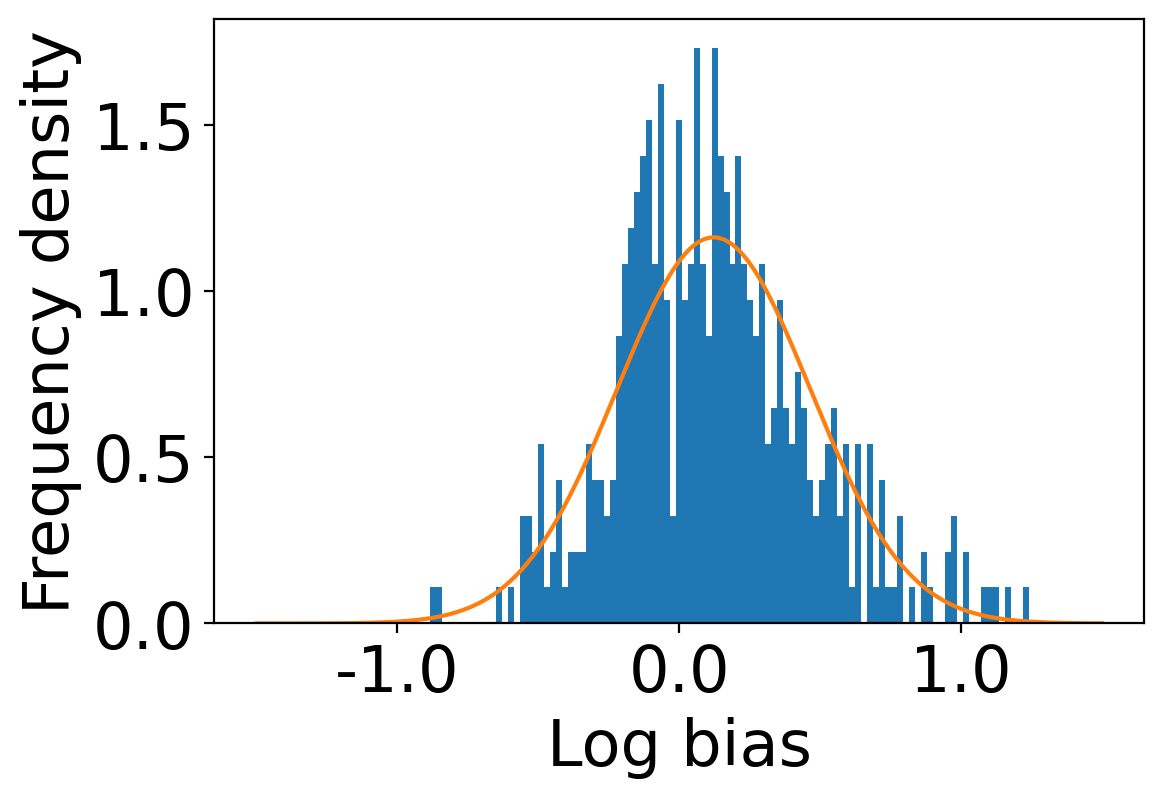
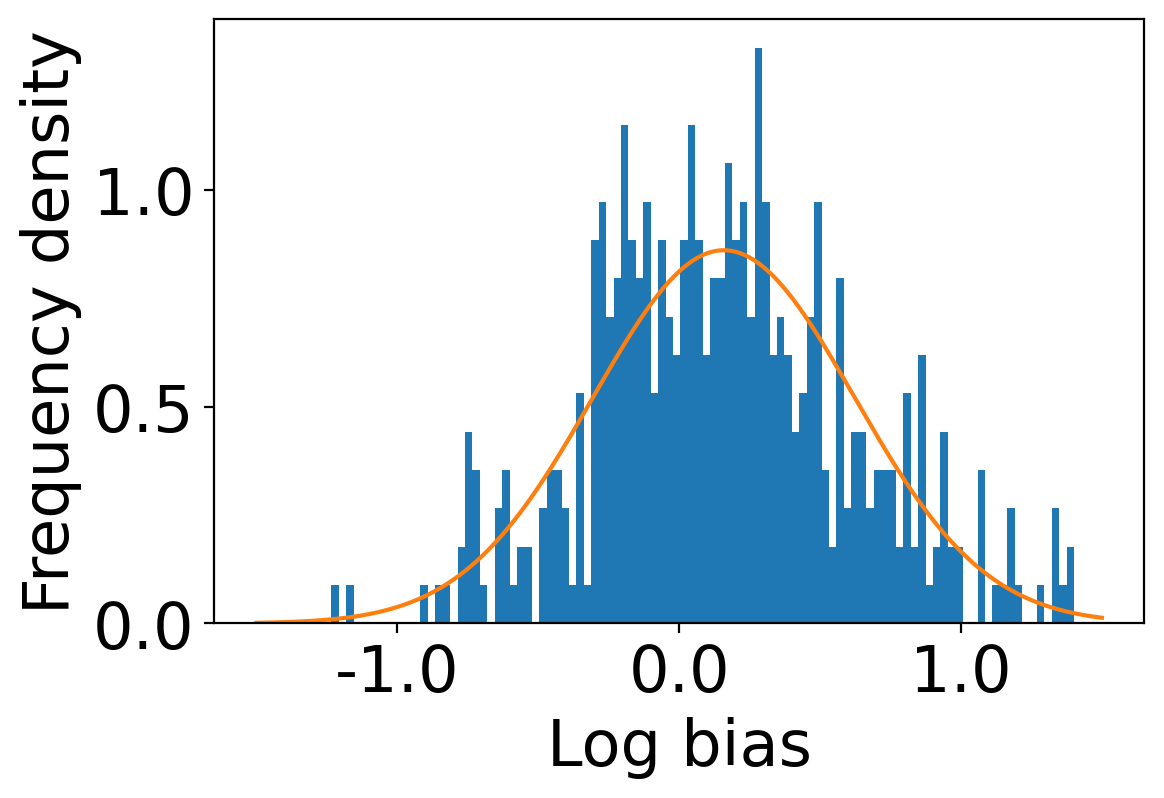
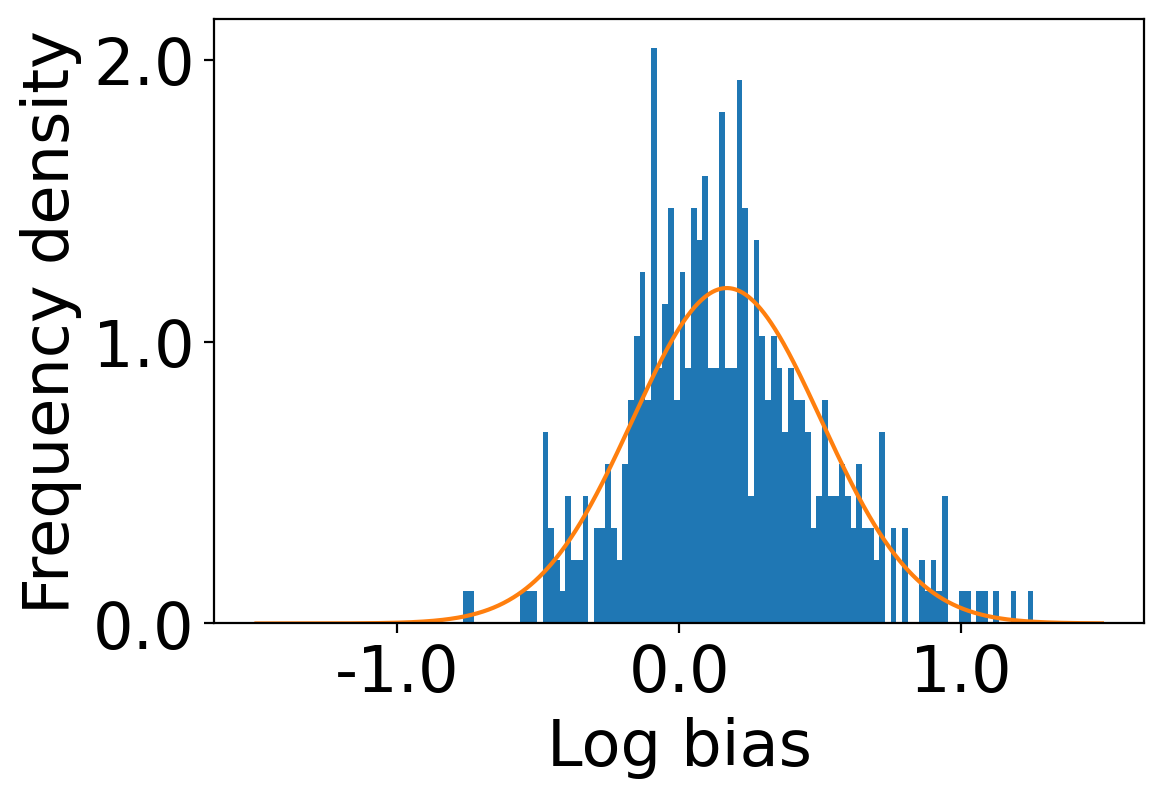
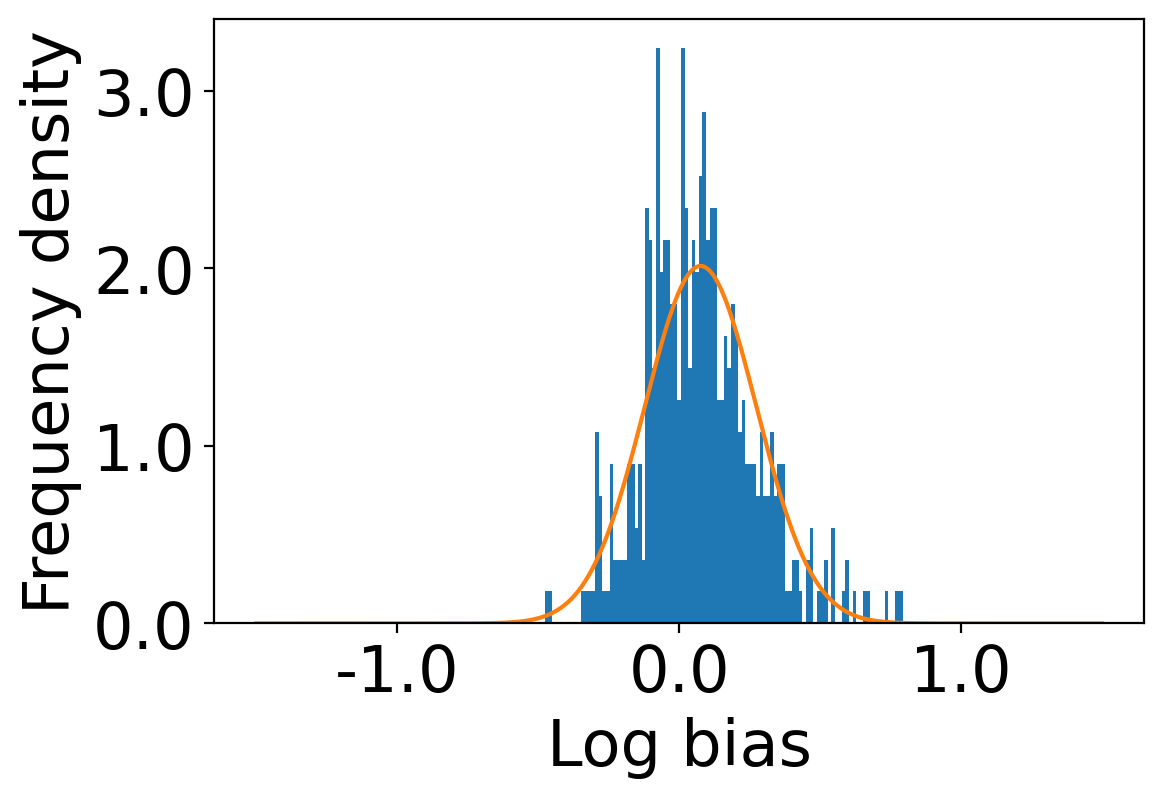
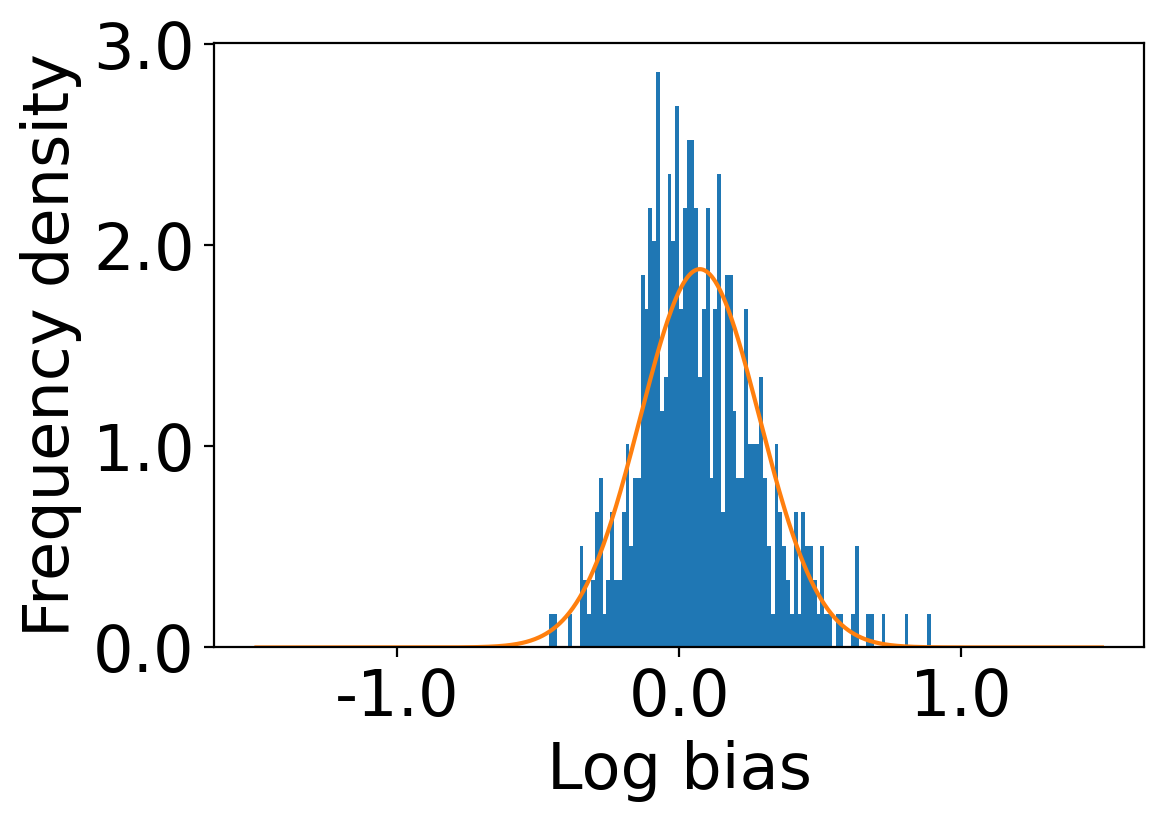
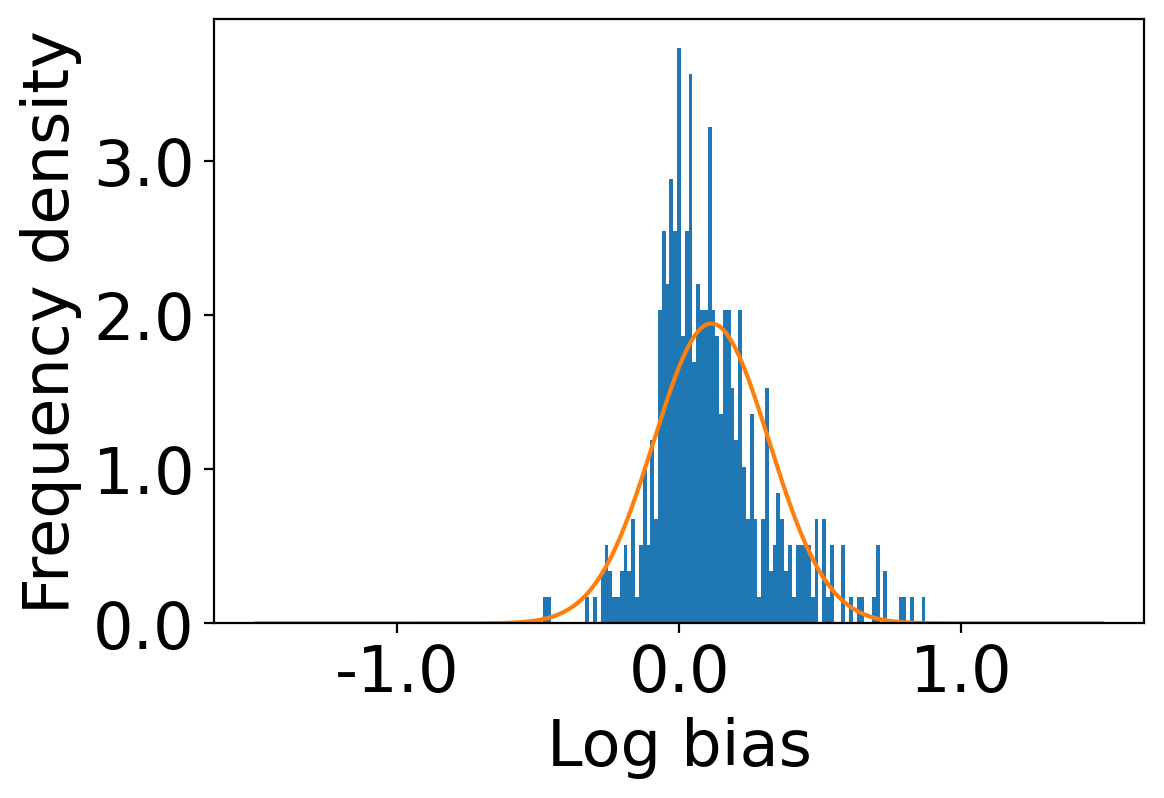
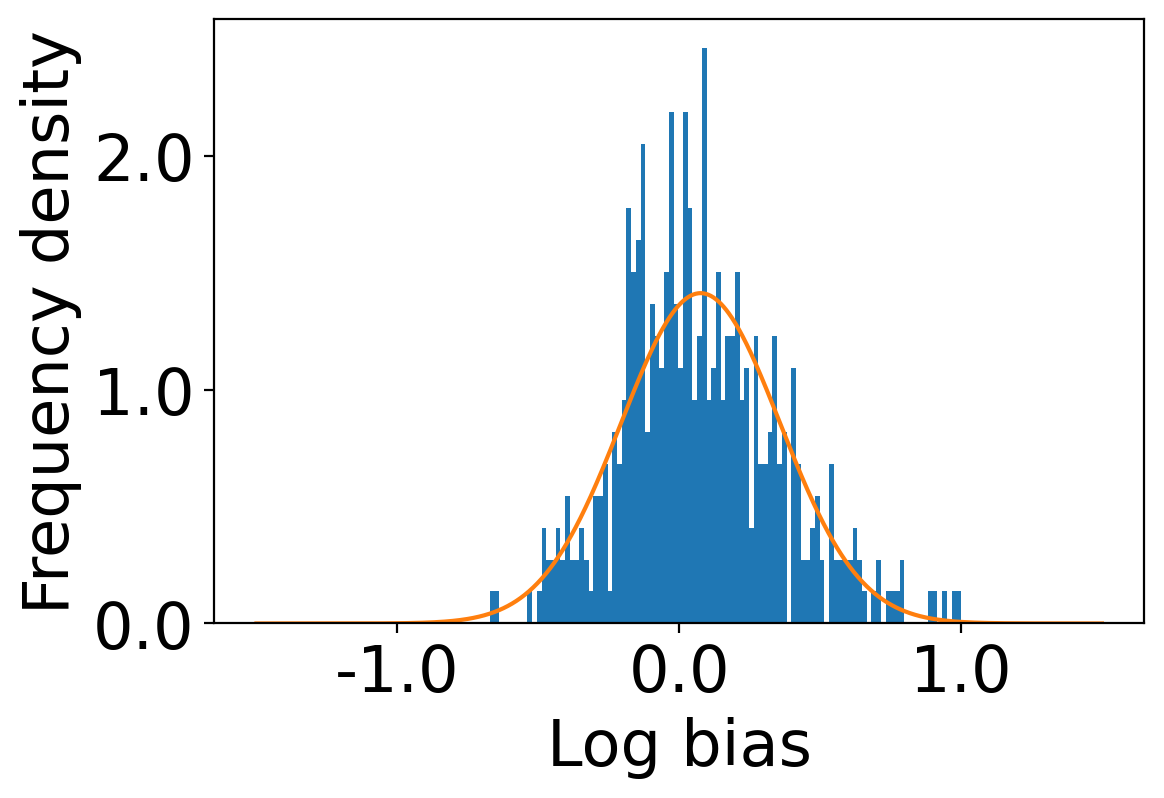
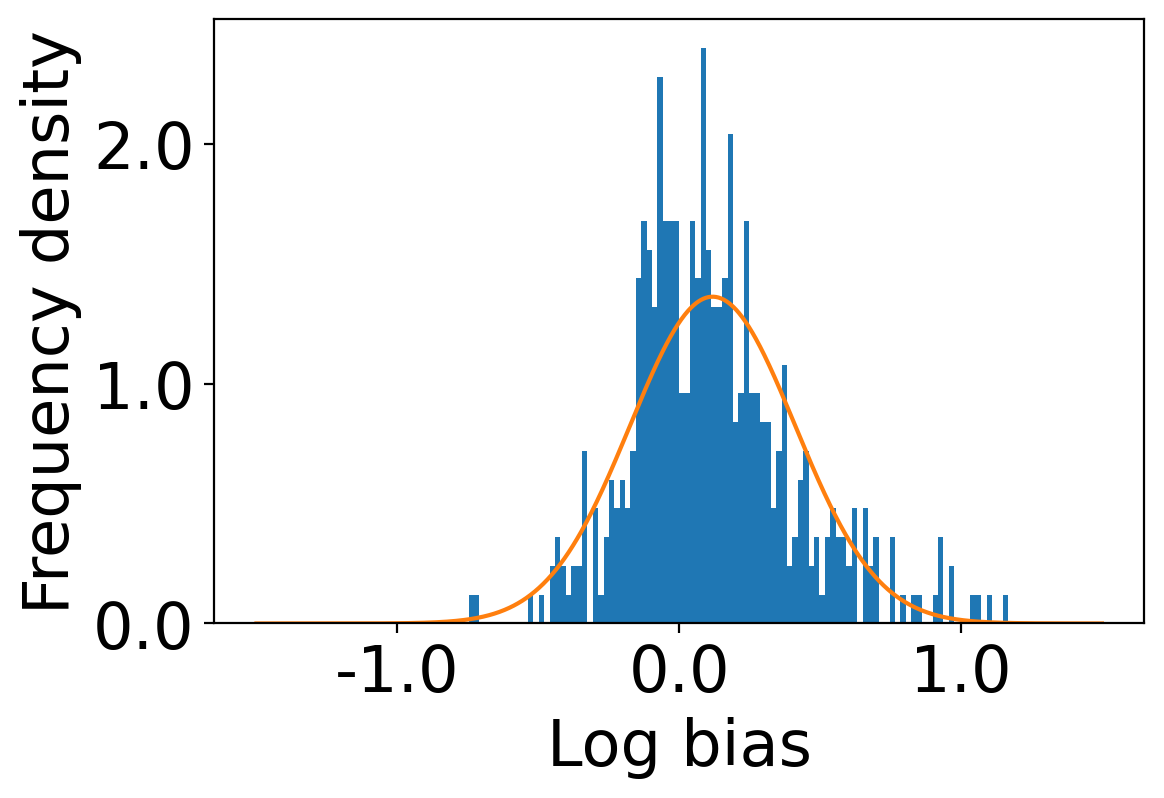
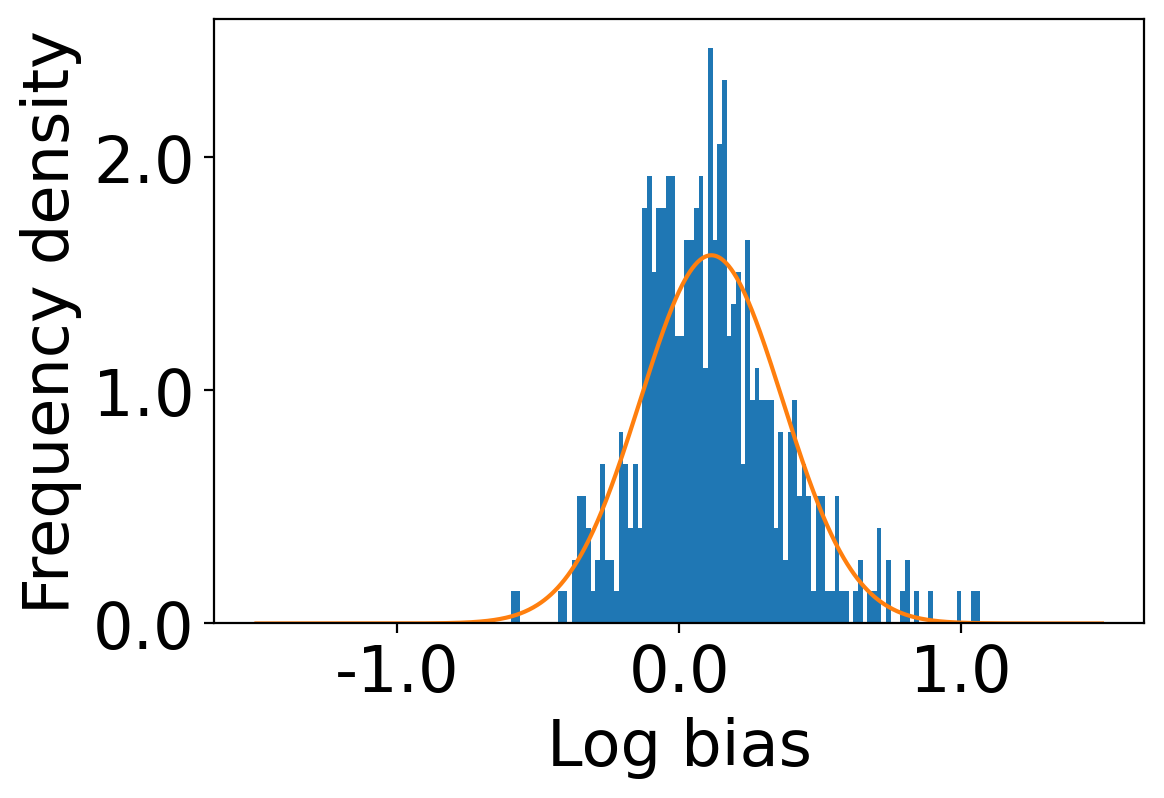
We first begin plotting the log-bias () distribution for the recommendations produced by the algorithms without employing our debiased model in Figures 3 and 6 for Amazon and Book-Crossing datasets respectively. We compute the log-bias by feeding biased ratings to the four algorithms. Table 2 shows the exact values for comparison with other cases. We next deploy our model partially. We leave out the preference correction phase and produce the recommendations using the algorithms mentioned before by feeding the debiased ratings to these algorithms. We estimate the mean log-bias tendency in the recommendations using debiased ratings produced by the algorithms . The log-bias () distribution for the recommendations produced by the algorithms for the Amazon as well as Book-Crossing dataset after partial deployment of the model is depicted in the Figure 4 and Figure 7 with the exact values provided in the Table 2. As can be seen, there is a significant reduction in log-bias tendency () in the Amazon dataset and () in Book-Crossing dataset for the UserKNN algorithm. However, we also see an increase in error rates on both datasets. This is because the test data itself contains biases.
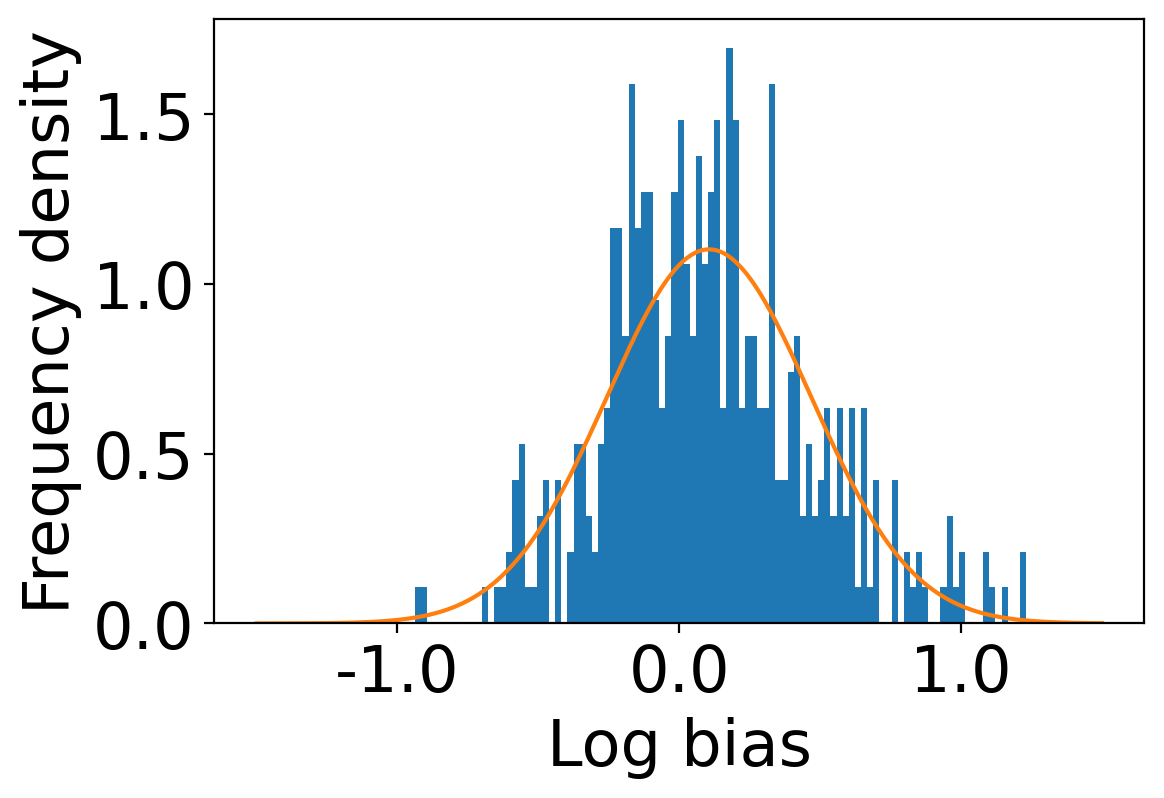
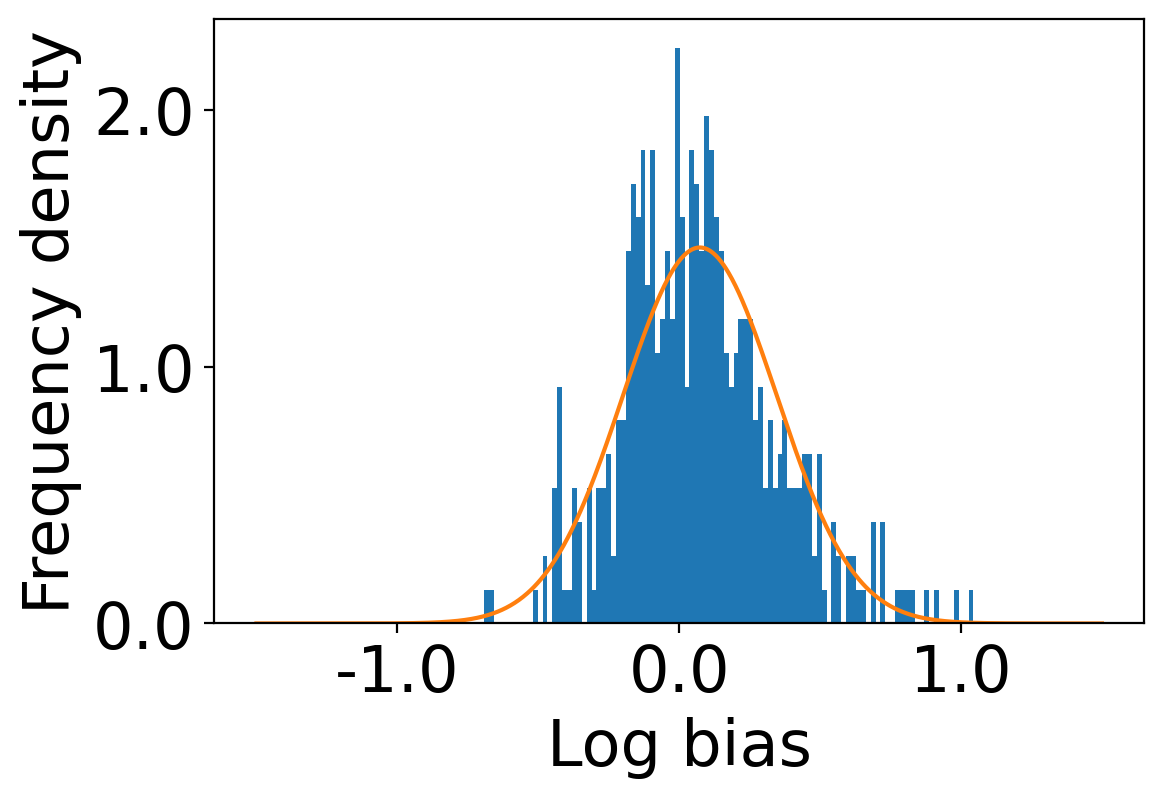
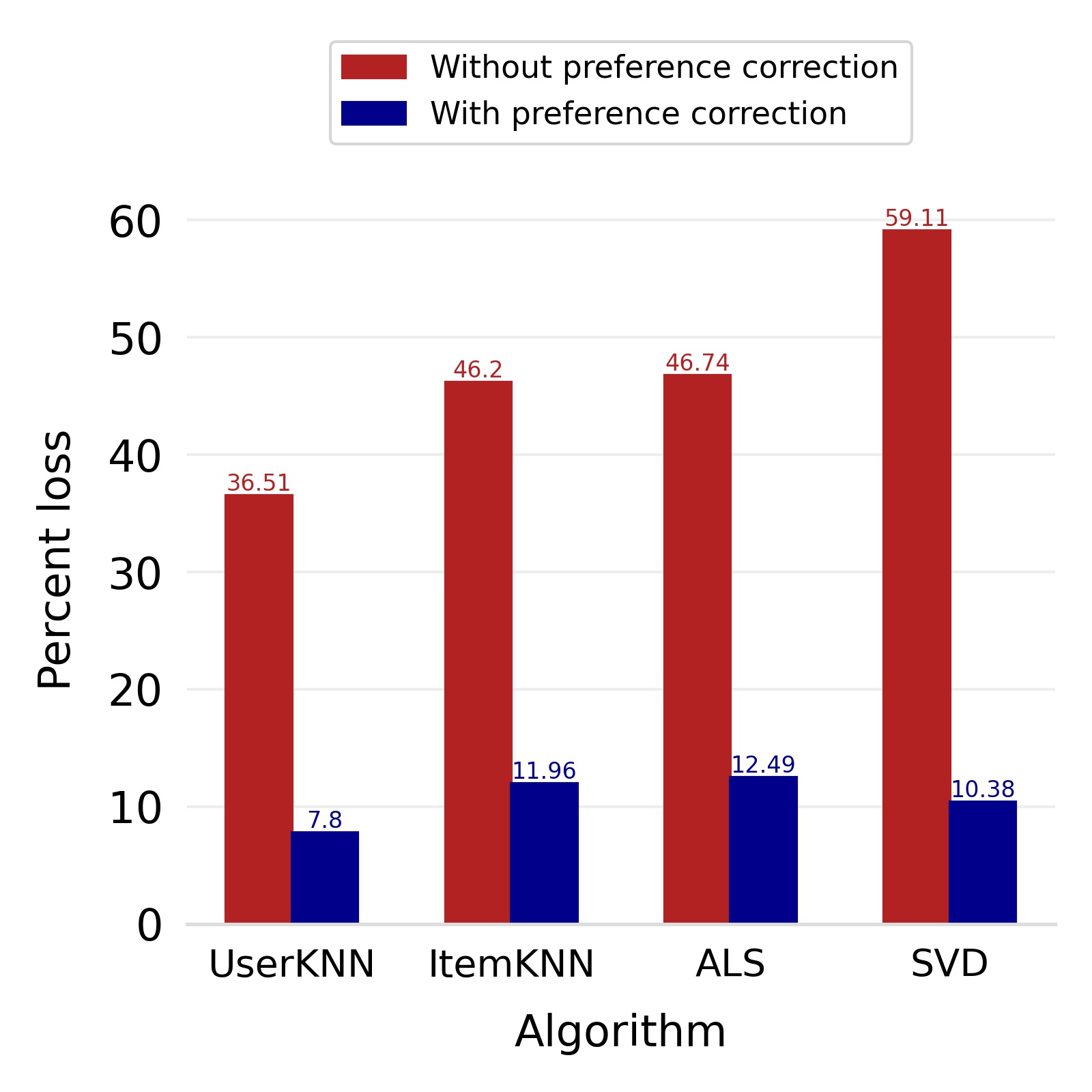
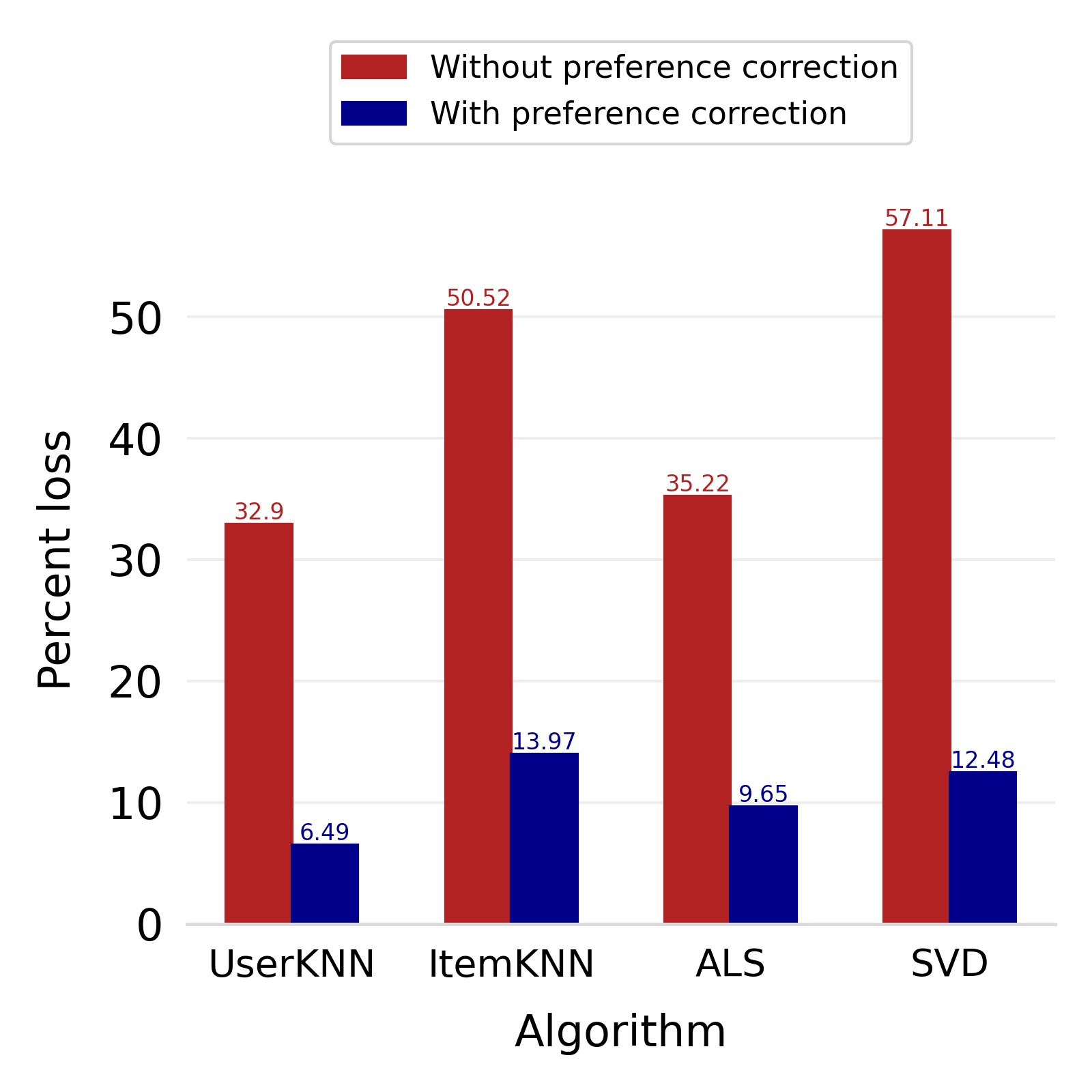
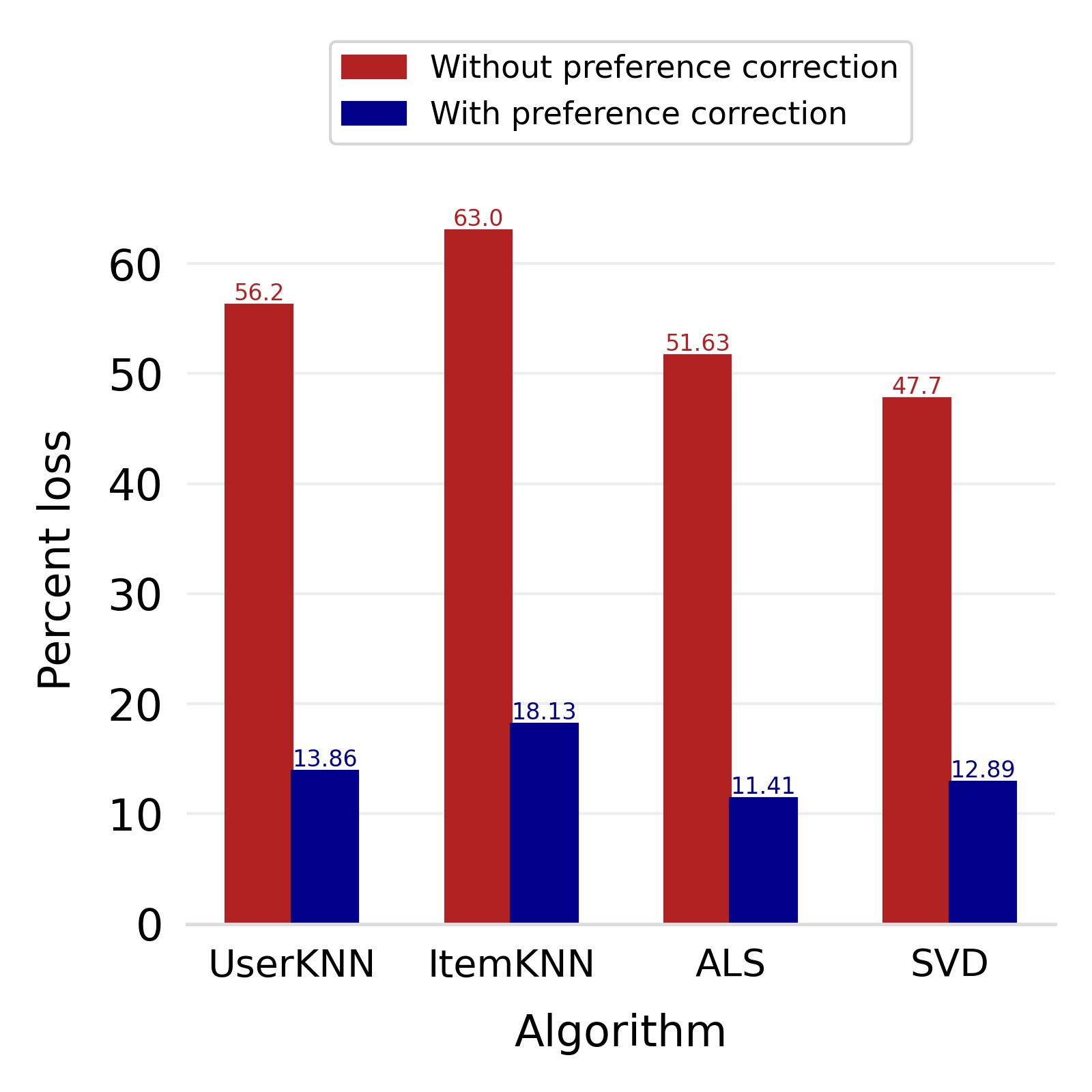
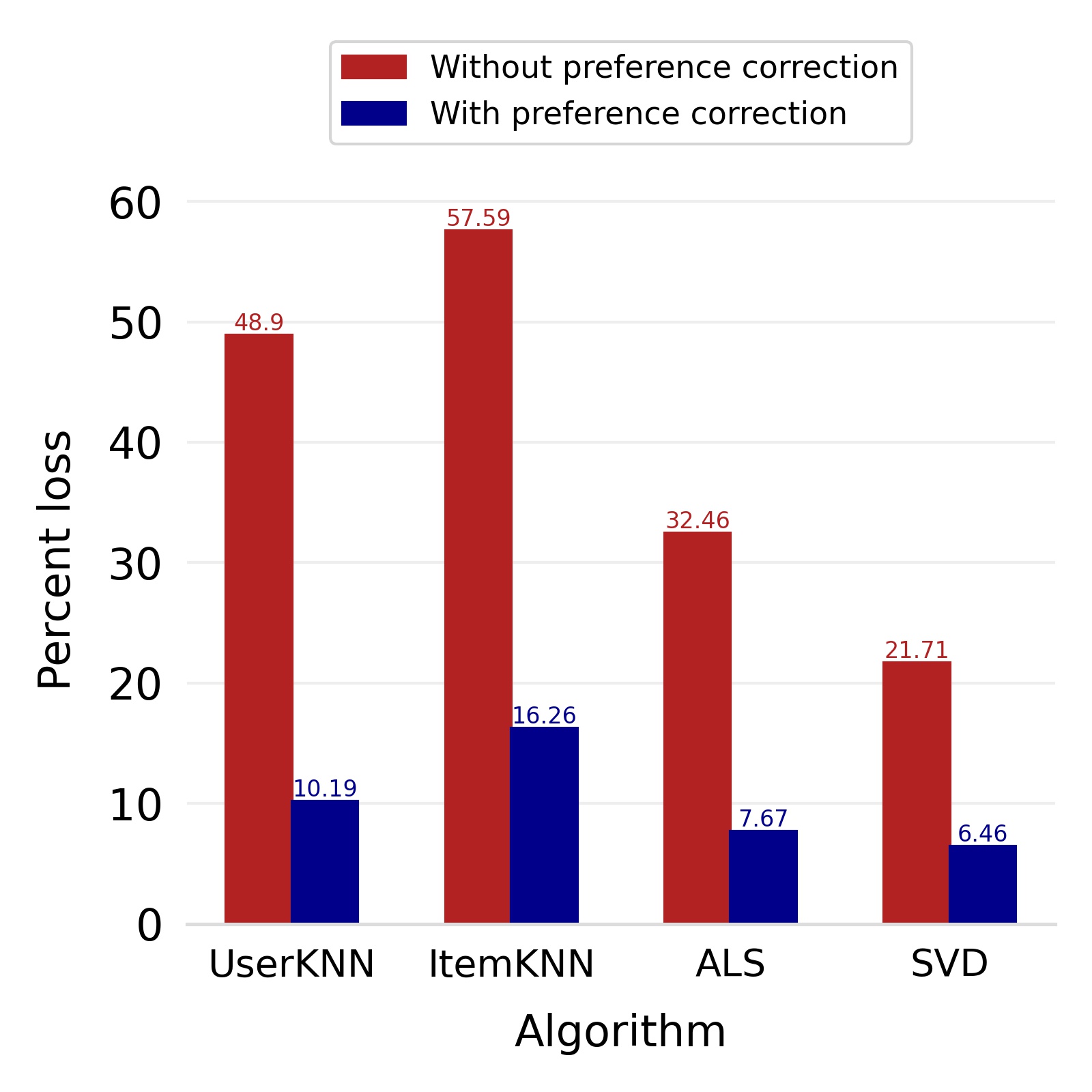
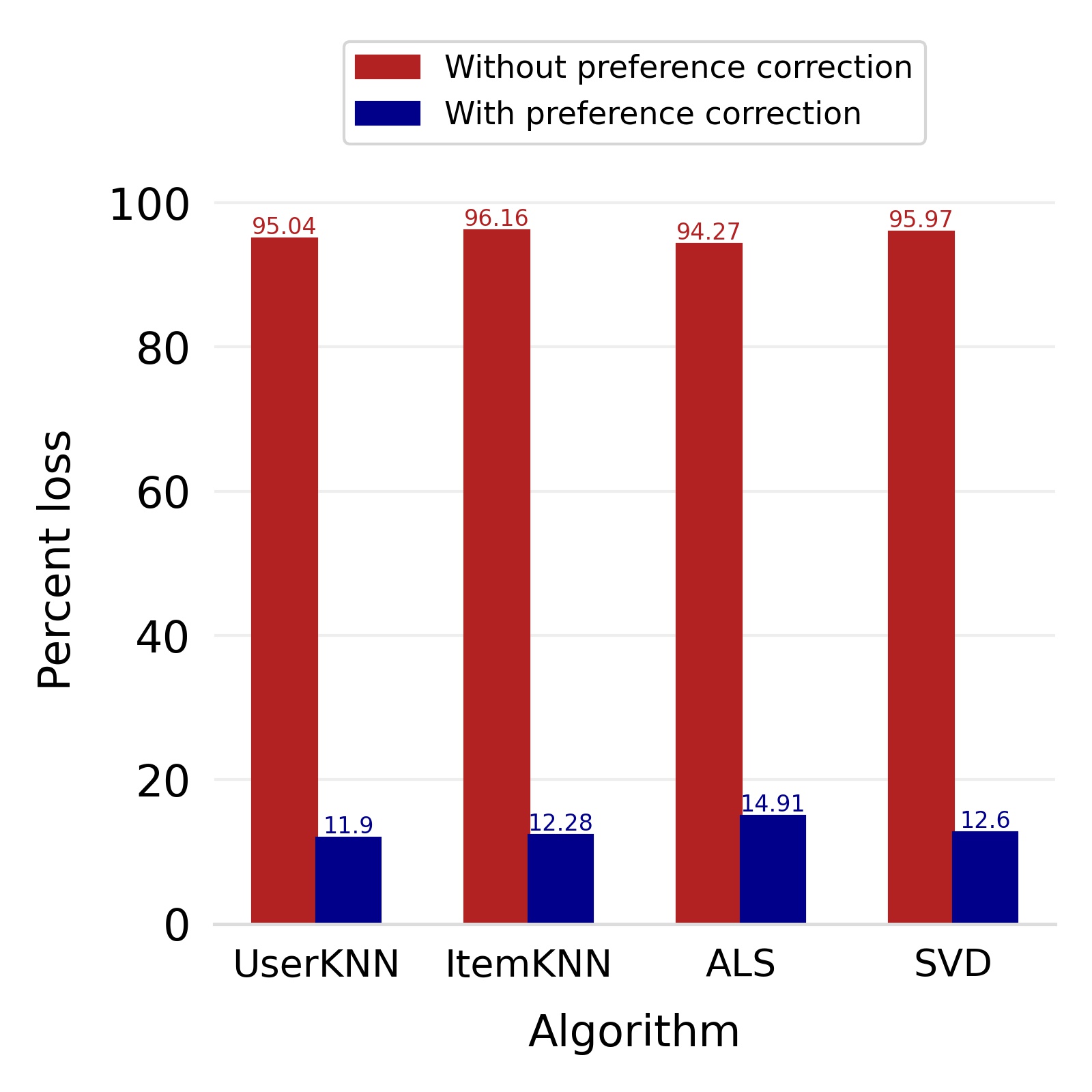
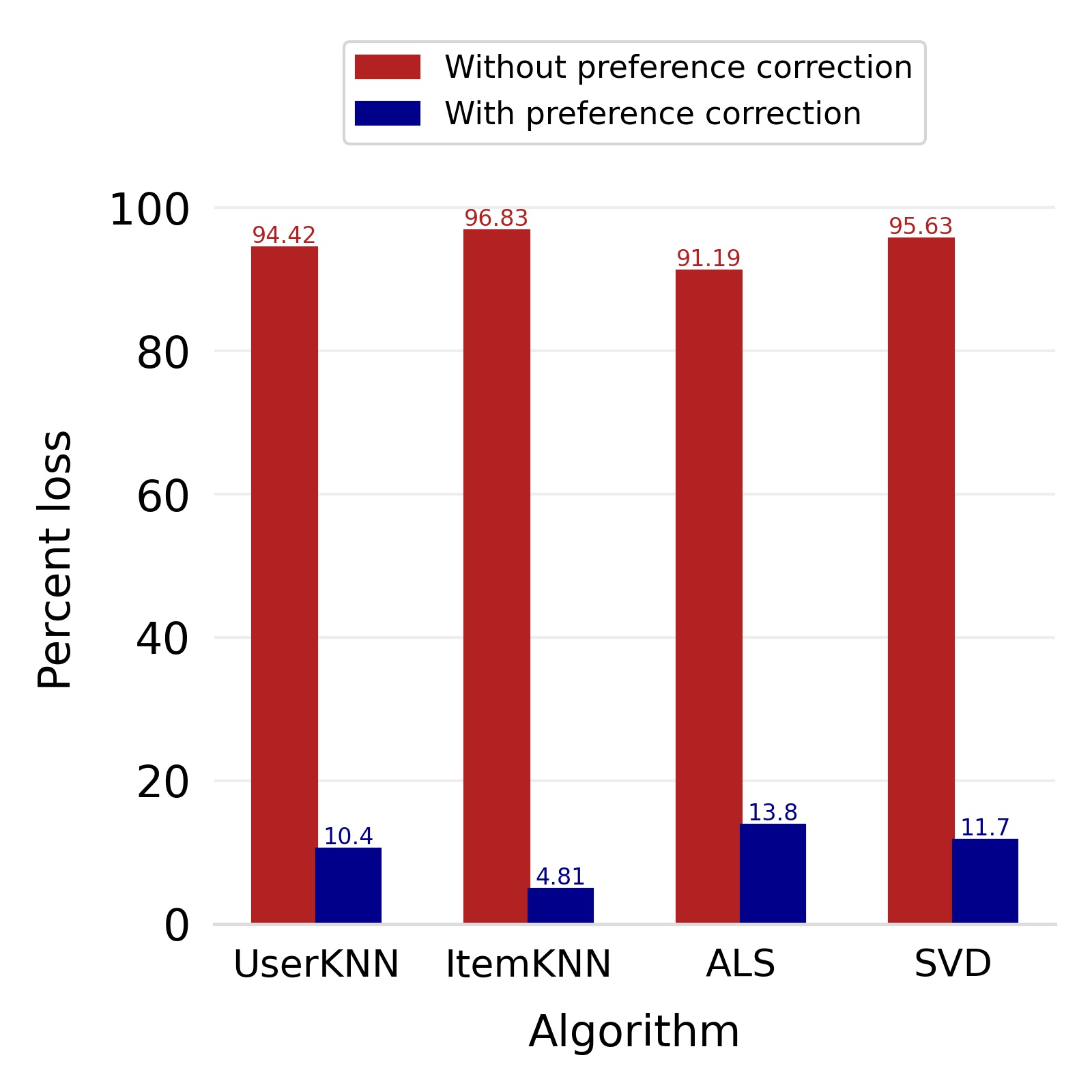
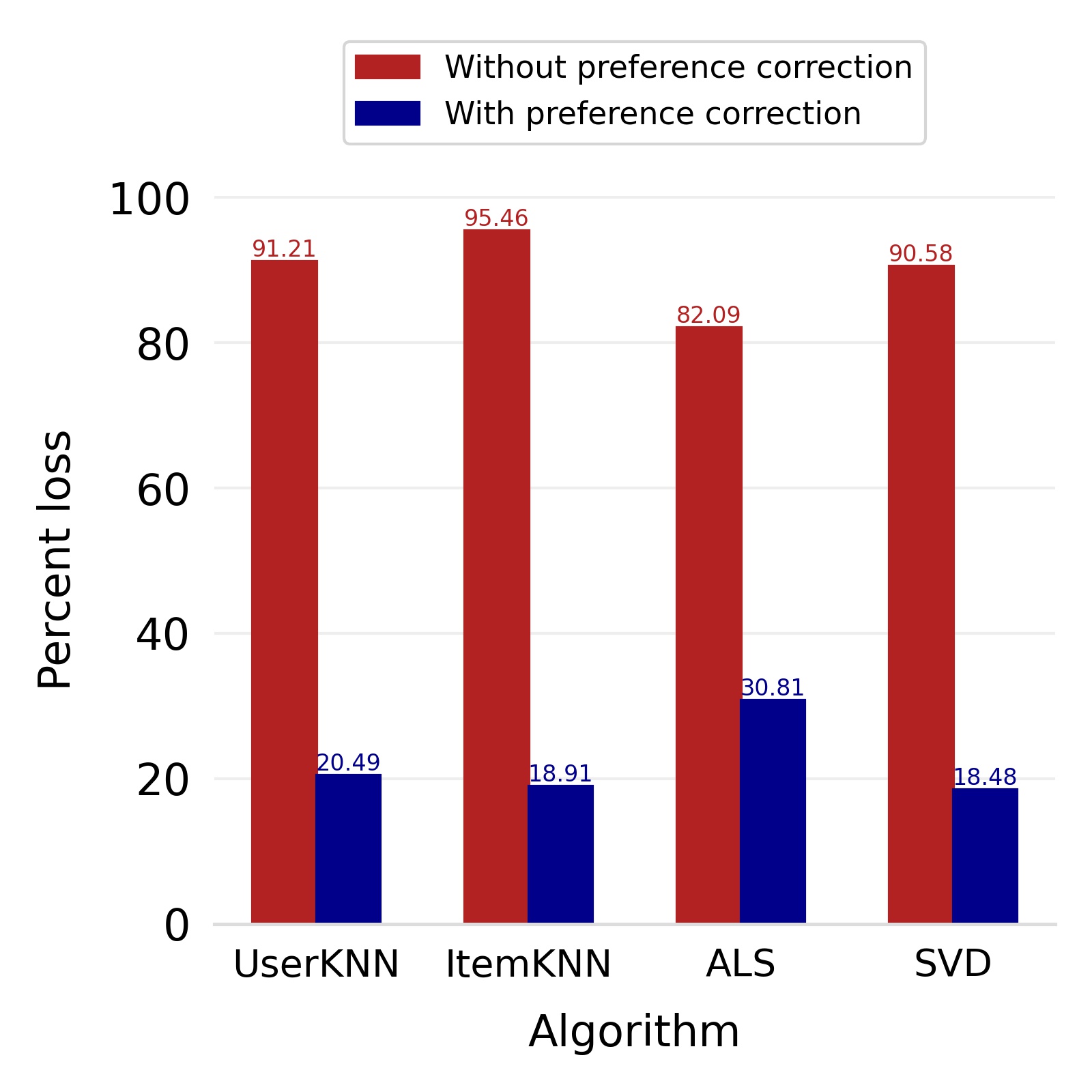
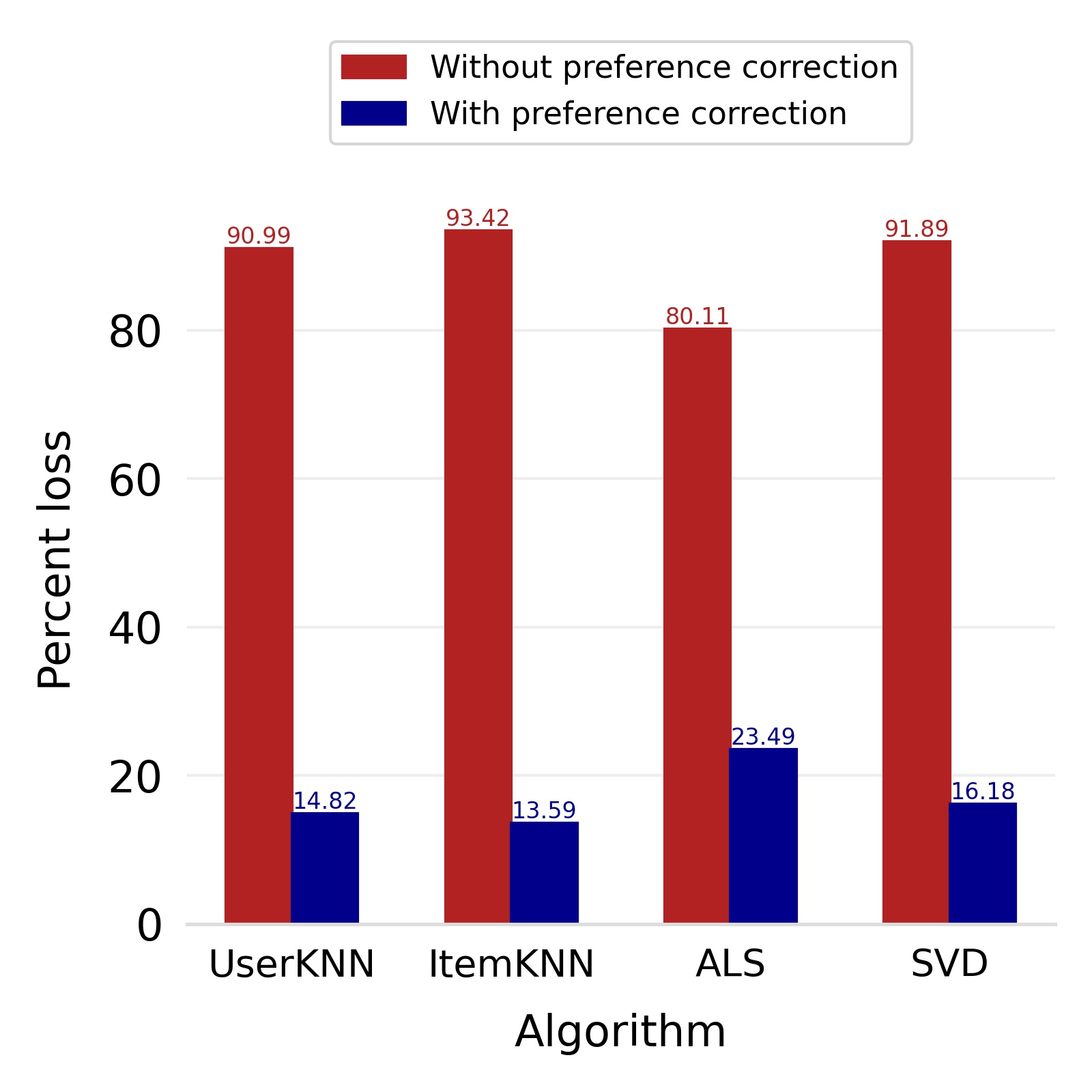
Finally, we deploy our complete model and repeat the experiment. The log-bias () distribution for the recommendations produced by the algorithms after deployment of the complete model is depicted in Figures 5 and 8 with the values in the Table 2. As can be seen, there is still a significant reduction in mean log-bias tendency, which reduces by in the Amazon dataset and by in the case of the Book-Crossing dataset for UserKNN algorithm. The accuracy loss, however, is insignificant, making this trade-off advantageous. Figure 9 presents the percentage gain in bias reduction for both the dataset. The percentage loss in accuracy is depicted in figures 10 and 11 for Amazon and Book-Crossing datasets respectively. The percentage loss in ranking relevancy metrics are depicted in figures 12 and 13 respectively.
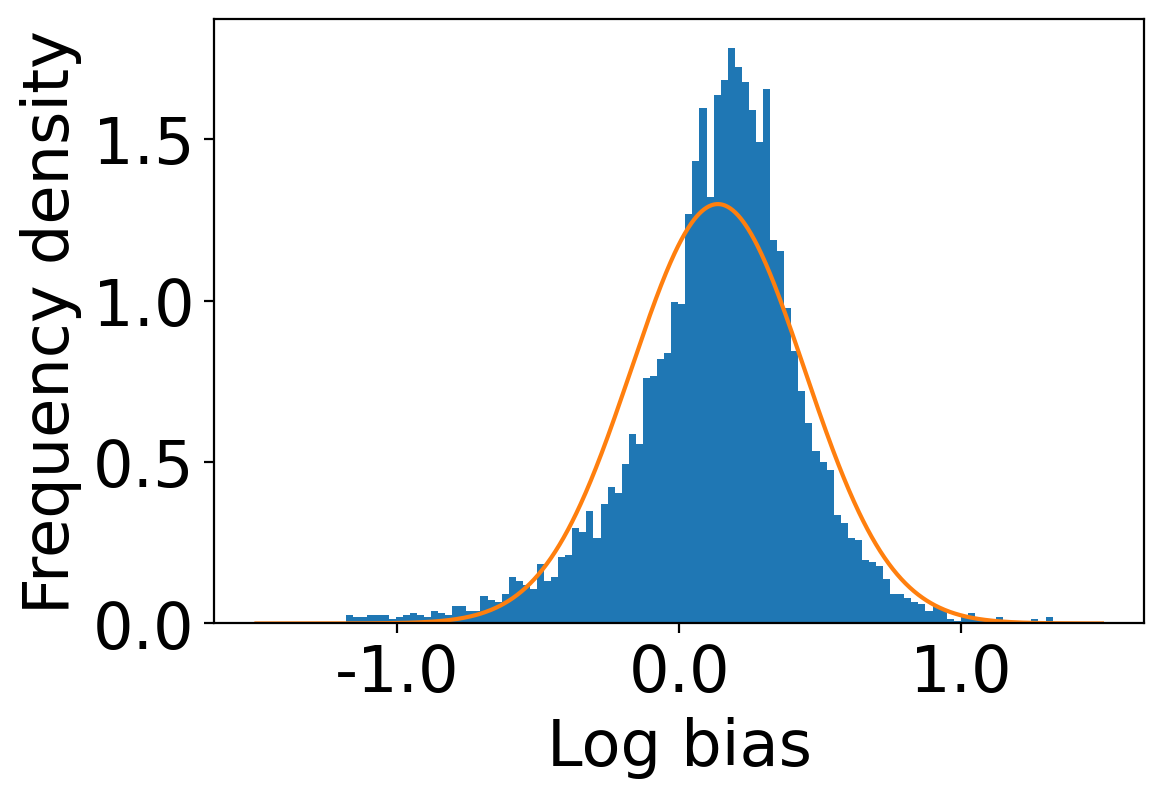
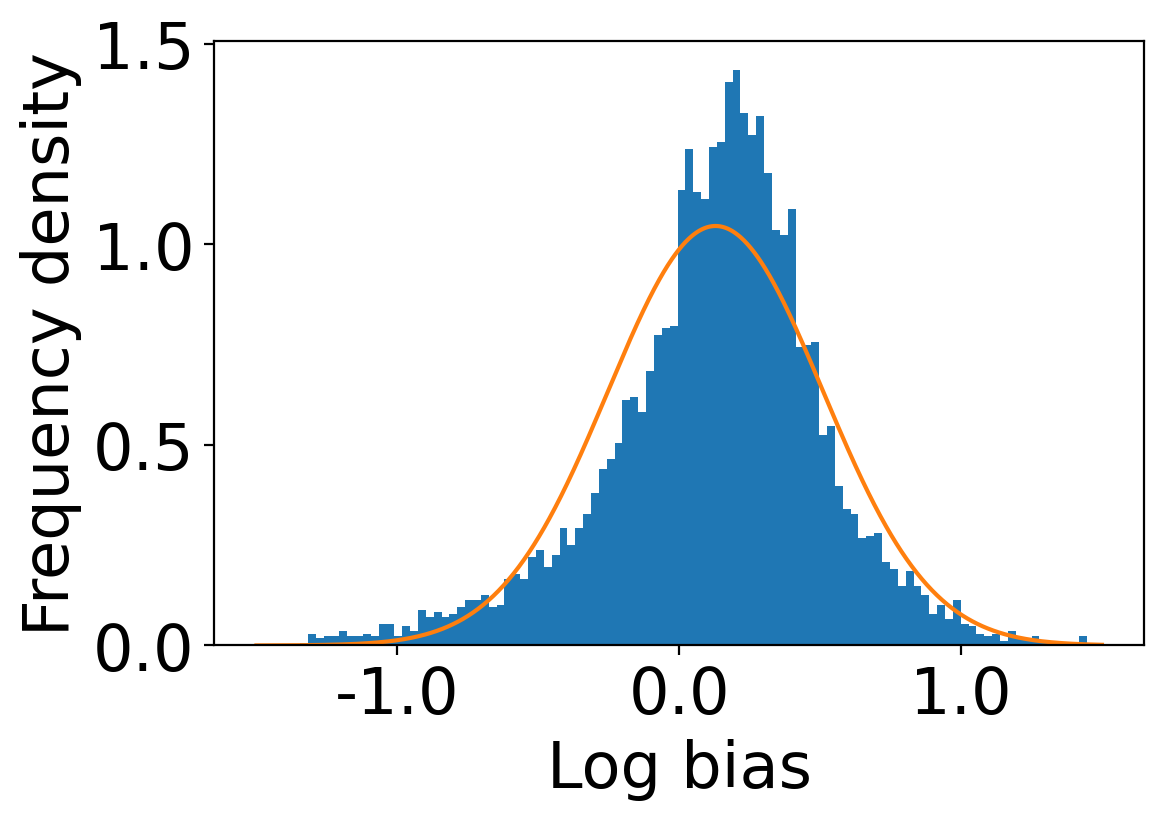
| AZ | BX | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case | Algorithm |
|
RMSE | MAE | NDCG |
|
|
RMSE | MAE | NDCG |
|
||||||||
| Recommendations without model | UserKNN | 0.137 | 0.808 | 0.693 | 0.452 | 0.498 | 0.122 | 1.580 | 1.178 | 0.264 | 0.272 | ||||||||
| ItemKNN | 0.129 | 0.736 | 0.580 | 0.597 | 0.643 | 0.106 | 1.511 | 1.304 | 0.313 | 0.412 | |||||||||
| ALS | 0.164 | 0.873 | 0.829 | 0.281 | 0.447 | 0.158 | 1.815 | 1.642 | 0.235 | 0.370 | |||||||||
| SVD | 0.175 | 0.790 | 0.753 | 0.342 | 0.471 | 0.169 | 1.761 | 1.626 | 0.277 | 0.296 | |||||||||
| Recommendations without preference correction phase | UserKNN | 0.049 | 1.103 | 0.921 | 0.0224 | 0.0278 | 0.057 | 2.468 | 1.754 | 0.0232 | 0.0245 | ||||||||
| ItemKNN | 0.063 | 1.076 | 0.873 | 0.0229 | 0.0204 | 0.054 | 2.463 | 2.055 | 0.0142 | 0.0271 | |||||||||
| ALS | 0.093 | 1.281 | 1.1211 | 0.0161 | 0.0394 | 0.087 | 2.752 | 2.175 | 0.0421 | 0.0736 | |||||||||
| SVD | 0.071 | 1.257 | 1.183 | 0.0138 | 0.0206 | 0.072 | 2.601 | 1.979 | 0.0261 | 0.0240 | |||||||||
| Recommendations with preference correction phase | UserKNN | 0.079 | 0.871 | 0.738 | 0.3982 | 0.4462 | 0.076 | 1.799 | 1.298 | 0.2099 | 0.2317 | ||||||||
| ItemKNN | 0.080 | 0.824 | 0.661 | 0.5236 | 0.6121 | 0.073 | 1.785 | 1.516 | 0.2538 | 0.3560 | |||||||||
| ALS | 0.121 | 0.982 | 0.903 | 0.2391 | 0.3853 | 0.119 | 2.022 | 1.768 | 0.1626 | 0.2831 | |||||||||
| SVD | 0.103 | 0.872 | 0.847 | 0.2989 | 0.4159 | 0.114 | 1.988 | 1.731 | 0.2258 | 0.2481 | |||||||||
We next conduct significance testing to validate the log-bias reduction. Table 3 shows the p-values obtained from left-tail significance tests on the log-bias of the recommendations made for the users in the sample. We can see from the p-value for the Amazon datasets that the bias reduction is significant. For the Book-Crossing dataset, the significance of the bias reduction is less pronounced. One of the prominent reasons for this is that the test sample size for the Book-Crossing dataset was relatively small due to the small number of users in the dataset. In essence, the utility of the recommender system is maintained while reducing the log-bias tendency in the recommendations.
| AZ | BX | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | ||||||||||
| UserKNN | 0.079 | 0.137 | 0.307 | -17.90 | 0.076 | 0.122 | 0.343 | -1.164 | 0.122 | |
| ItemKNN | 0.080 | 0.129 | 0.381 | -12.06 | 0.073 | 0.106 | 0.362 | -0.780 | 0.218 | |
| ALS | 0.121 | 0.164 | 0.394 | -10.46 | 0.119 | 0.158 | 0.464 | -0.738 | 0.230 | |
| SVD | 0.103 | 0.175 | 0.354 | -19.27 | 0.114 | 0.169 | 0.335 | -1.413 | 0.079 | |
We further observe that the bias reduction is more in the case of UserKNN based recommendations than the ItemKNN based recommendations. This observation can be attributed to the fact that our model addresses the bias originating from the distortion in ratings from the users’ side. It compares the ratings of an item given by a particular user with the appropriately scaled average of ratings given by other users to that item in the dataset. It, therefore, resonates with the UserKNN algorithm, which predicts the ratings of an item for a particular user based on the ratings of that item for his or her peers. The ItemKNN algorithm, on the other hand, predicts the ratings of an item for a particular user based on the ratings given to similar items by that user. The model does not sit squarely with ItemKNN. Thus the bias reduction in UserKNN is more as compared to that in the case of ItemKNN. We further observe that the bias reduction is more in the case of the AZ dataset as compared to the BX dataset. This observation can be attributed to the AZ dataset having a higher input mean log-bias tendency. Further, the AZ dataset has a significantly larger number of users and items which leads to a more accurate estimation of user bias scores and, therefore, more effective bias mitigation.
We observe that accuracy and ranking relevancy loss is, in general, higher for ItemKNN as compared to UserKNN. This is due to the fact that the model quantifies the bias of users by comparing the ratings given by them to particular items with a scaled average of ratings given by their peers to those items. This resonates with the UserKNN algorithm, which predicts user ratings for particular items based on the ratings of similar users. Thus the model is better oriented towards the UserKNN algorithm, giving better accuracy and bias reduction in its case. In the case of matrix factorization algorithms, the accuracy and ranking relevancy losses are relatively comparable. It is not clear which one of the two algorithms is more coherent with the model.
We further observe that accuracy loss on BX dataset is higher than that of AZ dataset. This observation can be attributed to the fact that the user and item base of the AZ dataset is higher as compared to the BX dataset. Thus, the bias score estimates are more accurate, which provides more accurate predictions of the item scores for the users when reinserted into the recommendations.
6 Conclusion and Future Work
We proposed a model to quantify and mitigate the bias in the explicit feedback given by the users to different items. We theoretically showed that the debiased ratings produced by our model are unbiased estimators of the true preference of the users for the books. With the help of comprehensive experiments on two publically available book datasets, we show a significant reduction in the bias (almost 40%) with just 10% decrease in accuracy using the UserKNN algorithm. Similar trends were observed for other algorithms such as ItemKNN, ALS, and SVD. Our model is independent of these algorithms’ choices and can be applied with any recommendation algorithm. We used book recommender system because we were able to generate the gender information from publicly available APIs. Our model is not restricted to book recommender system as long as protected attribute information about the items is known. We leave extension of the model to missing protected attribute as an interesting future work. It will be an interesting direction to see if the ideas from fair classification literature with missing protected attributes Coston et al. (2019) can be leveraged. We further did not address the bias originating from fewer ratings for a female-authored book than a male-authored one. We leave extending the model to the bias originating from lesser number of ratings and extensively studying the model for other recommender systems as the future directions.
References
- (1)
- Amatriain et al. (2011) Xavier Amatriain, Alejandro Jaimes, Nuria Oliver, and Josep Pujol. 2011. Data Mining Methods for Recommender Systems. 39–71. https://doi.org/10.1007/978-0-387-85820-3_2
- APIs (2 24) Google Books APIs. Accessed: 2021-02-24. https://developers.google.com/books
- Boratto et al. (2019) Ludovico Boratto, Gianni Fenu, and Mirko Marras. 2019. The Effect of Algorithmic Bias on Recommender Systems for Massive Open Online Courses. 457–472. https://doi.org/10.1007/978-3-030-15712-8_30
- Burke (2017) Robin Burke. 2017. Multisided Fairness for Recommendation. (07 2017).
- Coston et al. (2019) Amanda Coston, Karthikeyan Natesan Ramamurthy, Dennis Wei, Kush R Varshney, Skyler Speakman, Zairah Mustahsan, and Supriyo Chakraborty. 2019. Fair transfer learning with missing protected attributes. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. 91–98.
- Dwork et al. (2011) Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Rich Zemel. 2011. Fairness Through Awareness. CoRR abs/1104.3913 (04 2011). https://doi.org/10.1145/2090236.2090255
- Ekstrand et al. (2018) Michael Ekstrand, Mucun Tian, Mohammed Kazi, Hoda Mehrpouyan, and Daniel Kluver. 2018. Exploring Author Gender in Book Rating and Recommendation. (08 2018). https://doi.org/10.1145/3240323.3240373
- Hajian et al. (2016) Sara Hajian, Francesco Bonchi, and Carlos Castillo. 2016. Algorithmic Bias: From Discrimination Discovery to Fairness-aware Data Mining. 2125–2126. https://doi.org/10.1145/2939672.2945386
- Hajian and Domingo-Ferrer (2013) Sara Hajian and Josep Domingo-Ferrer. 2013. A Methodology for Direct and Indirect Discrimination Prevention in Data Mining. IEEE Transactions on Knowledge and Data Engineering (07 2013). https://doi.org/10.1109/TKDE.2012.72
- Hajian et al. (2014a) Sara Hajian, Josep Domingo-Ferrer, and Oriol Farràs. 2014a. Generalization-based privacy preservation and discrimination prevention in data publishing and mining. Data Mining and Knowledge Discovery (09 2014). https://doi.org/10.1007/s10618-014-0346-1
- Hajian et al. (2014b) Sara Hajian, Josep Domingo-Ferrer, Anna Monreale, Dino Pedreschi, and Fosca Giannotti. 2014b. Discrimination- and privacy-aware patterns. Data Mining and Knowledge Discovery 29 (11 2014). https://doi.org/10.1007/s10618-014-0393-7
- Herlocker et al. (2004) Jonathan L. Herlocker, Joseph A. Konstan, Loren G. Terveen, and John T. Riedl. 2004. Evaluating Collaborative Filtering Recommender Systems. ACM Trans. Inf. Syst. 22, 1 (Jan. 2004), 5–53. https://doi.org/10.1145/963770.963772
- Hurley and Zhang (2011) Neil Hurley and Mi Zhang. 2011. Novelty and Diversity in Top-N Recommendation – Analysis and Evaluation. ACM Trans. Internet Technol. 10, 4, Article 14 (March 2011), 30 pages. https://doi.org/10.1145/1944339.1944341
- ISBNDB (2 27) ISBN Database | ISBNDB. Accessed: 2021-02-27. https://isbndb.com/isbn-database
- Kamiran et al. (2010) Faisal Kamiran, Toon Calders, and Mykola Pechenizkiy. 2010. Discrimination Aware Decision Tree Learning. 869–874. https://doi.org/10.1109/ICDM.2010.50
- Kamiran et al. (2012) Faisal Kamiran, Asim Karim, and Xiangliang Zhang. 2012. Decision Theory for Discrimination-Aware Classification. Proceedings - IEEE International Conference on Data Mining, ICDM, 924–929. https://doi.org/10.1109/ICDM.2012.45
- Knijnenburg et al. (2012) Bart Knijnenburg, Martijn Willemsen, soncu gantner, and newell. 2012. Explaining the user experience of recommender systems. User Modeling and User-Adapted Interaction 22 (10 2012), 441–504. https://doi.org/10.1007/s11257-011-9118-4
- Leavy et al. (2020) Susan Leavy, Gerardine Meaney, Karen Wade, and Derek Greene. 2020. Mitigating Gender Bias in Machine Learning Data Sets. (05 2020).
- Mancuhan and Clifton (2014) Koray Mancuhan and Chris Clifton. 2014. Combating discrimination using Bayesian networks. Artificial Intelligence and Law 22 (06 2014). https://doi.org/10.1007/s10506-014-9156-4
- Mansoury et al. (2020) Masoud Mansoury, Himan Abdollahpouri, Jessie Smith, Arman Dehpanah, Mykola Pechenizkiy, and Bamshad Mobasher. 2020. Investigating Potential Factors Associated with Gender Discrimination in Collaborative Recommender Systems. (02 2020).
- Neve and Palomares (2019) James Neve and Ivan Palomares. 2019. Latent factor models and aggregation operators for collaborative filtering in reciprocal recommender systems. In Proceedings of the 13th ACM Conference on Recommender Systems. 219–227.
- Ni et al. (2019) Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. 188–197. https://doi.org/10.18653/v1/D19-1018
- OpenLibrary (3 02) Developers API | OpenLibrary. Accessed: 2021-03-02. https://openlibrary.org/developers/api
- Pedreschi et al. (2008) Dino Pedreschi, Salvatore Ruggieri, and Franco Turini. 2008. Discrimination-aware data mining. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 560–568. https://doi.org/10.1145/1401890.1401959
- Pedreschi et al. (2009) Dino Pedreschi, Salvatore Ruggieri, and Franco Turini. 2009. Measuring Discrimination in Socially-Sensitive Decision Records. 581–592. https://doi.org/10.1137/1.9781611972795.50
- Ruggieri et al. (2014) Salvatore Ruggieri, Sara Hajian, Faisal Kamiran, and Xiangliang Zhang. 2014. Anti-discrimination Analysis Using Privacy Attack Strategies. https://doi.org/10.1007/978-3-662-44851-9_44
- Ruggieri et al. (2010) Salvatore Ruggieri, Dino Pedreschi, and Franco Turini. 2010. Data Mining for Discrimination Discovery. TKDD 4 (05 2010). https://doi.org/10.1145/1754428.1754432
- Shakespeare et al. (2020) Dougal Shakespeare, Lorenzo Porcaro, Emilia Gómez, and Carlos Castillo. 2020. Exploring Artist Gender Bias in Music Recommendation. (09 2020).
- Shani and Gunawardana (2011) Guy Shani and Asela Gunawardana. 2011. Evaluating Recommendation Systems. Vol. 12. 257–297. https://doi.org/10.1007/978-0-387-85820-3_8
- Thanh et al. (2011) Binh Thanh, Salvatore Ruggieri, and Franco Turini. 2011. k-NN as an Implementation of Situation Testing for Discrimination Discovery and Prevention. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 502–510. https://doi.org/10.1145/2020408.2020488
- the gender of a name (03 5) Genderize.io | Deteremine the gender of a name. Accessed: 2021-03-5. https://genderize.io/
- Tsintzou et al. (2018) Virginia Tsintzou, Evaggelia Pitoura, and Panayiotis Tsaparas. 2018. Bias Disparity in Recommendation Systems. (11 2018).
- Valcarce et al. (2020) Daniel Valcarce, Alejandro Bellogín, Javier Parapar, and Pablo Castells. 2020. Assessing ranking metrics in top-N recommendation. Information Retrieval Journal 23 (2020), 411–448.
- Zemel et al. (2013) R. Zemel, Y. Wu, K. Swersky, T. Pitassi, and C. Dwork. 2013. Learning fair representations. 30th International Conference on Machine Learning, ICML 2013 (01 2013), 1362–1370.
- Ziegler et al. (2005a) Cai-Nicolas Ziegler, Sean M. McNee, Joseph A. Konstan, and Georg Lausen. 2005a. Improving Recommendation Lists through Topic Diversification (WWW ’05). Association for Computing Machinery, New York, NY, USA, 22–32. https://doi.org/10.1145/1060745.1060754
- Ziegler et al. (2005b) Cai-Nicolas Ziegler, Sean M. McNee, Joseph A. Konstan, and Georg Lausen. 2005b. Improving Recommendation Lists through Topic Diversification. In Proceedings of the 14th International Conference on World Wide Web (Chiba, Japan) (WWW ’05). Association for Computing Machinery, New York, NY, USA, 22–32. https://doi.org/10.1145/1060745.1060754