Exploring Code Language Models for Automated HLS-based Hardware Generation: Benchmark, Infrastructure and Analysis
Abstract.
Recent advances in code generation have illuminated the potential of employing large language models (LLMs) for general-purpose programming languages such as Python and C++, opening new opportunities for automating software development and enhancing programmer productivity. The potential of LLMs in software programming has sparked significant interest in exploring automated hardware generation and automation. Although preliminary endeavors have been made to adopt LLMs in generating hardware description languages (HDLs) such as Verilog and SystemVerilog, several challenges persist in this direction. First, the volume of available HDL training data is substantially smaller compared to that for software programming languages. Second, the pre-trained LLMs, mainly tailored for software code, tend to produce HDL designs that are more error-prone. Third, the generation of HDL requires a significantly higher number of tokens compared to software programming, leading to inefficiencies in cost and energy consumption. To tackle these challenges, this paper explores leveraging LLMs to generate High-Level Synthesis (HLS)-based hardware design. Although code generation for domain-specific programming languages is not new in the literature, we aim to provide experimental results, insights, benchmarks, and evaluation infrastructure to investigate the suitability of HLS over low-level HDLs for LLM-assisted hardware design generation. To achieve this, we first finetune pre-trained models for HLS-based hardware generation, using a collected dataset with text prompts and corresponding reference HLS designs. An LLM-assisted framework is then proposed to automate end-to-end hardware code generation, which also investigates the impact of chain-of-thought and feedback loops promoting techniques on HLS- design generation. Comprehensive experiments demonstrate the effectiveness of our methods. Limited by the timeframe of this research, we plan to evaluate more advanced reasoning models in the future.
ACM Reference Format:
Jiahao Gai, Hao (Mark) Chen, Zhican Wang, Hongyu Zhou, Wanru Zhao, Nicholas Lane, Hongxiang Fan. 2025. Exploring Code Language Models for Automated HLS-based
Hardware Generation. In Proceedings of Asia and South Pacific Design Automation Conference (ASP-DAC’25). ACM, New York,
NY, USA, 8 pages. https://doi.org/10.1145/3658617.3697616
1. Introduction
In the field of Generative AI (GenAI), significant strides have been made in producing complex and creative content across various domains such as text (Brown et al., 2020), image (Avrahami et al., 2022; Saharia et al., 2022), and video (Zheng et al., 2024). Among various GenAI technologies, large language models (LLMs) have emerged as particularly influential techniques in the realm of natural language processing (Zhao et al., 2023). This great capability of LLMs also raises intensive industrial interests in leveraging these models in automated code generation, as evidenced by GitHub Copilot (Chen et al., 2021) and DeepMind’s AlphaCode (Li et al., 2022). Meanwhile, over 50 pre-trained models and more than 170 programming language datasets have been published in the past few years (Zhang et al., 2023). Although significant progress has been made in this direction, most of these works mainly focus on software code generation ***This paper mainly focuses on text-to-code generation., and the potential of LLM for hardware design generations has not been fully exploited.
The promises of LLM-assisted software programming has led to several recent attempts to explore automated code generation for hardware description languages (HDLs) such as Verilog and SystemVerilog (Li et al., 2023a; Lu et al., 2024; Liu et al., 2023a; Thakur et al., 2023). Although multiple datasets, pre-trained models, and code infrastructures have been introduced, several key challenges reamin in LLM-assisted hardware design generation:
-
•
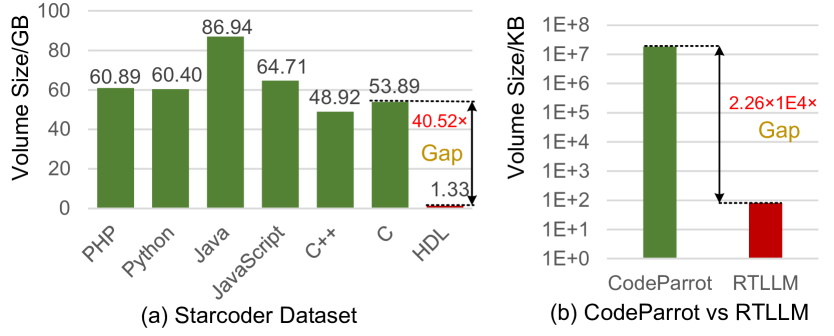
The data availability of HLD designs for LLM training and finetuning. Figure 1 compares the volume of training samples for software programming languages versus HDLs. For instance, the general-purpose code dataset StarCoder (Li et al., 2023a), as presented in Figure 1 (a), shows that the available amount of HDL designs is less than of those for C++. Similar trends can also be observed in specialized datasets, such as RTLLM (Lu et al., 2024) for Verilog and CodeParrot (Tunstall et al., 2022) for Python. Figure 1(b) indicates that the dataset size of RTLLM is less than of that for CodeParrot. Therefore, the quantity of training data available for hardware design is significantly lower than for software programming languages.
-
•
Inability of utilizing learned knowledge from pre-trained coding LLMs. Pre-trained coding LLMs are primarily trained on software programming languages, which differ significantly in semantics and syntax from HDLs. Therefore, the knowledge acquired during pre-training cannot be directly applied to hardware code generation, compounding the data scarcity issue.
-
•
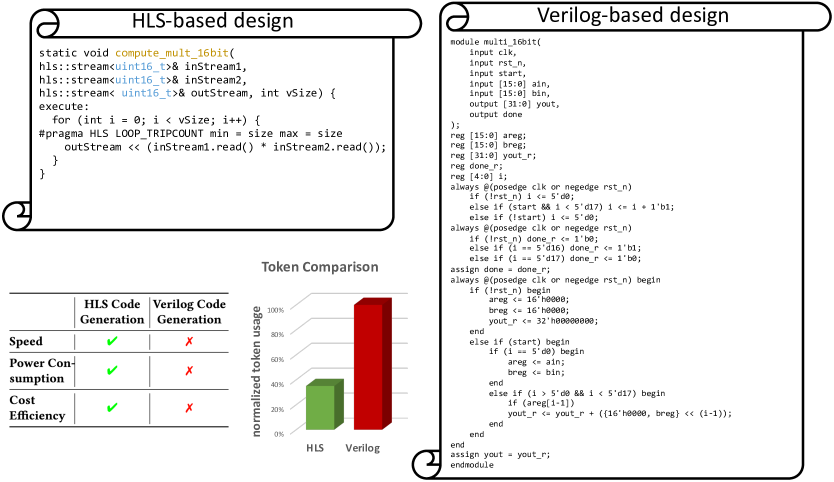
Cost of HDL generation using LLMs. Figure 2 illustrates the number of tokens required for generating identical hardware designs using High-Level Synthesis (HLS) versus HDL. It shows that HDL implementations require approximately times more tokens than HLS designs, making HLS-based design generation a more sustainable solution considering the latency, energy, and monetary costs associated with LLM inference.
To address the aforementioned issues, this paper proposes an LLM-assisted framework for generating HLS-based†††This paper focues on C-based HLS. hardware designs. By crawling HLS designs from open-source Github repositories, we collect a dataset to facilitate the fine-tuning of pre-trained LLM for the downstream HLS code generation. The benefits of generating HLS code are two folds: i) Given that HLS shares main semantics and syntax with C/C++, the coding knowledge acquired during the pre-training phase of the LLMs can be effectively utilized for hardware design. This compatibility also reduces the learning curve and dataset requirements for fine-tuning, as the additional knowledge needed for HLS is less than for traditional HDL coding. ii) The number of tokens required to generate HLS code is lower compared to HDLs, rendering our approach more cost-effective and energy-efficient than previous methodologies. To further improve the quality of the generated designs, the framework incorporates debugging feedback loops and a chain-of-thought enhancement mechanism, systematically integrating detected bugs back into the input for iterative refinement. Overall, our contributions can be summarized as follows:
-
•
Finetuning pre-trained code language models for HLS-based hardware generation, using a collected dataset with over data entries, each containing a text prompt and the corresponding HLS-based hardware design (Section 3).
-
•
Developing a framework that automatically produces HLS designs from input prompts, with an end-to-end evaluation of the syntax and functionality correctness (Section 4.1).
- •
2. Background and Related work
2.1. LLM-Assisted Software Engineering
Based on the modality of inputs and outputs, language models for software engineering can be categorized into several downstream code tasks (Zhang et al., 2023) such as text-to-code (code generation/synthesis (Ling et al., 2016)), code-to-text (code summarization (Iyer et al., 2016)), and code-to-pattern processing (defect detection (Ray et al., 2016)). This paper focuses on code generation that aims at producing code from natural language descriptions/prompts. To facilitate the development of code generation with language models, various datasets, approaches, and pre-trained models have been introduced over the past decade.
Due to the lack of model capability, the early-stage methods (Ling et al., 2016; Iyer et al., 2018) of code generation mainly focus on a few programming languages such as Python or Java. Subsequently, with the increasing computational power, larger datasets are introduced to train models for multiple general-purpose programming languages. CodeXGLUE (Lu et al., 2021) presents a comprehensive code dataset consisting of different code tasks such as clone detection and code repair. HumanEval (Chen et al., 2021) dataset together with the code model CodeX marks as a milestone by using pre-trained LLMs for code generation. The promising capability shown by CodeX sparks significant academic and industrial interests in developing LLM-assisted code generation. Larger code datasets, such as StarCoder (Li et al., 2023a) and CodeParrot (Tunstall et al., 2022), and LLMs, including Code-LLaMA (Roziere et al., 2023) and CodeFuse (Di et al., 2023), are open-sourced in this community. However, most of these recent efforts focus on software programming languages.
2.2. Automated Hardware Design Generation
Building on the success of LLM-assisted software programming, recent studies have explored using language models for automated hardware generation. Since the data is the key to training LLMs for hardware code generation, multiple HDL datasets have been introduced recently. Thakur et al. present Verigen (Thakur et al., 2023) dataset that contains hardware designs with K lines of HDL code. To increase the diversity of hardware designs for training and evaluation, Lu et al. open-source a larger benchmark consisting of designs with more than K lines. Sourced from HDLBits‡‡‡https://hdlbits.01xz.net/wiki/Main_Page, Verilogeval (Liu et al., 2023a) introduces larger datasets with problems. These open-sourced datasets provide public benchmarks for text-to-HDL generation.
The evaluation metrics of LLM-assisted hardware code generation focus on three aspects: i) syntax, ii) functionality, and iii) quality. In previous literature (Chen et al., 2021; Liu et al., 2023a), syntax correctness and functionality are measured using pass metric which represents whether any of generated code samples can pass the syntax check of synthesis tools or functional unit tests. The quality usually is defined as power, performance, and area of the generated hardware, collectively reflect the capability of the code generation methods.
Aiming at improving these metrics, existing approaches (Thakur et al., 2023; Lu et al., 2024; Liu et al., 2023a) fine-tune pre-trained LLMs on the downstream task with optimized sampling schemes. These LLMs are mainly pre-trained using software programming languages. RTLFixer (Tsai et al., 2023) introduces an automated framework that adopts retrieval-augmented generation (Lewis et al., 2020) and ReAct prompting (Yao et al., 2022) to enable LLM-assisted debugging for RTL designs. LLM-VeriPPA (Authors, 2024) enhances the code generation of RTL using a two-stage refinement process to progressively improve syntax, functionality, and hardware performance. However, these approaches focus on low-level hardware languages instead of HLS. In this work, we take the first step to investigate the HLS code generation with LLM. Since HLS shares similar semantics and syntax with programming languages commonly used during LLM pre-training, this paper explores whether HLS is better than low-level hardware languages for automated hardware design generation. Although code generation with feedback and CoT prompting is not new in the literature of coding language models, our experimental results, insights, benchmark, and evaluation infrastructure specific to LLM-assisted HLS design offer valuable contributions to the future development of automated hardware generation.
3. HLS Generation Benchmark
3.1. Format of Design Points
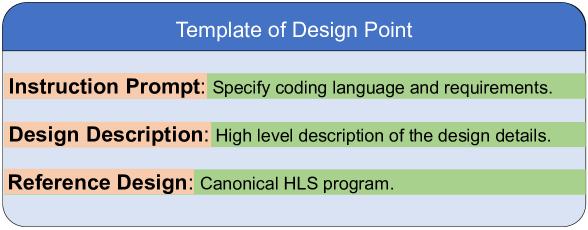
Following the practices of Python benchmark HumanEval (Chen et al., 2021) and Verilog dataset VerilogEval (Liu et al., 2023a), each design point has three components: i) user instruction prompts, ii) design descriptions and iii) reference designs. Figure 3 shows the standardized format template, with each data point stored as a JSONL following the Alpaca format. The default user instruction prompt is Generate HLS code with the following instructions:, which can be enhanced using the chain-of-thought (COT) prompting technique as detailed in Section 4.2.
3.2. Dataset Collection
We collect HLS-based designs from open-source repositories, including HLSyn (Bai et al., 2023)§§§https://github.com/UCLA-DM/HLSyn and ML4Accel¶¶¶https://github.com/UT-LCA/ML4Accel-Dataset. These designs are split into training and testing sets at a 4:1 ratio and fall into five categories:
-
•
Matrix and Linear Algebra Operations: Includes sparse matrix-vector multiplications, dense matrix-matrix multiplication, array transformation and stencil computations.
-
•
Scientific Simulations: Methods for solving physical and mathematical problems such as heat distribution and electromagnetic simulations.
-
•
Statistical Computations: Calculations of statistical metrics from datasets.
-
•
Iterative Methods: Techniques for solving equations using iterative approaches.
-
•
Other Computational Kernels: Specialized computational tasks like molecular dynamics and interactions, encryption algorithms, and optical flow.
Each of these designs is associated with different combinations of programs such as PIPELINE, PARALLEL and TILE. We filter out the HLS programs that are invalid, resulting in a collection of over HLS programs. The whole dataset is split into training and test sets for supervised fine-tuning and evaluation, respectively.
3.3. Generation of Design Description
Given that the dataset encompasses over 42,000 HLS programs, manually generating design descriptions for each program is both labor-intensive and time-consuming. Inspired by both HumanEval (Chen et al., 2021) and Verilog, we utilize ChatGPT (version and ) to automate the creation of design descriptions for the datasets. We append each HLS program with this base prompt when utilizing ChatGPT to generate the corresponding design descriptions. Both the reference design and its generated description are stored in JSON format, adhering to the structure outlined in Section 3.1. This method ensures streamlined and consistent documentation of design descriptions across the dataset. Following the practice of (Liu et al., 2023a), we provide two versions of prompts for each HLS program in the test set: MachineGen and HumanRefine. The MachineGen version comprises prompts and instructions generated by GPT-based models without human modifications. In contrast, the HumanRefine includes manually refined prompts to ensure more concise and human-like instructions.
3.4. Assessment Infrastructure
We provide evaluation infrastructure for both syntax and functionality. For syntax verification, we use the GCC compiler with the ”-fsyntax-only” option. It allows us to verify the syntax without the overhead of compiling the code, thereby enhancing time and space efficiency. Regarding functionality correctness, we design unit tests tailored for each example in the test dataset. Each test case is associated with its corresponding ‘source_file‘. To achieve this goal, we modified the original test JSONL file to add another attribute ‘source_file‘. The testing process involves executing both the generated code and the original source code to compare their outputs. For instance, if the outputs from both codes consist of matrices, we conduct a targeted comparison. This is done by selecting specific positions within the matrices from both outputs at random and verifying if they match.
4. Automated Hardware Generation
4.1. Framework Overview
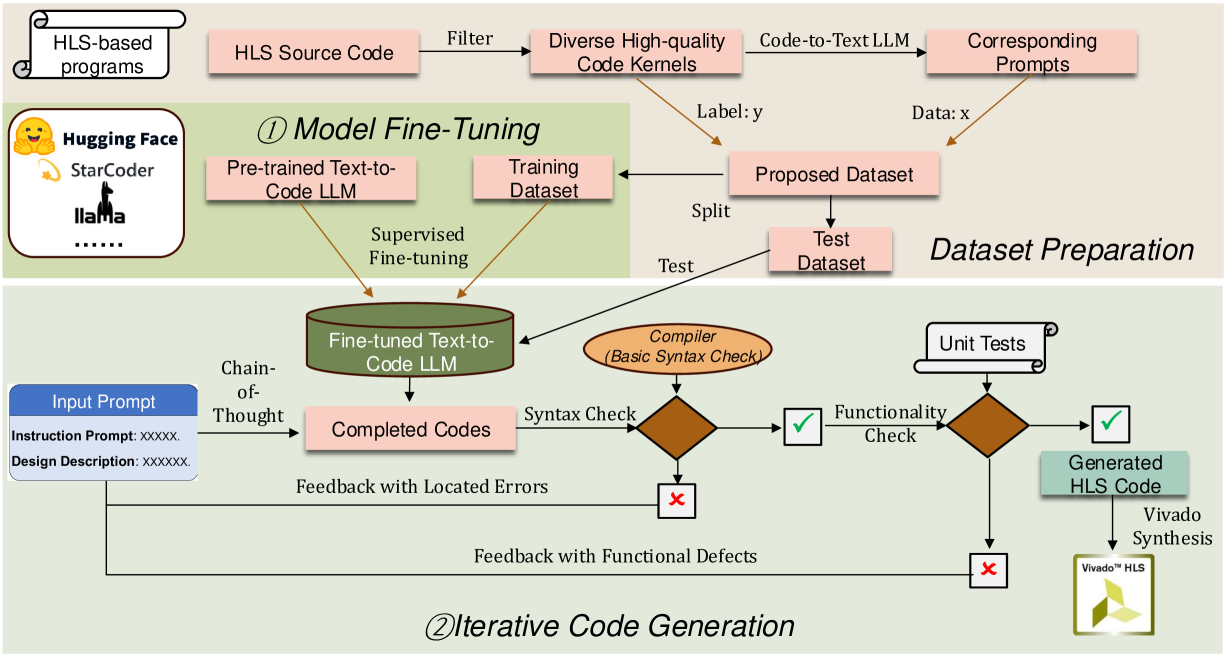
An overview of our proposed framework is depicted in Figure 4. The framework comprises two main stages: i) model fine-tuning and ii) iterative code generation. The final output is an HLS-based program that can be synthesized into the corresponding hardware design. While focused on Vivado-HLS, our framework is adaptable to any HLS language with appropriate datasets.
In the model fine-tuning stage, our framework initiates by retrieving coding LLMs from open-source repositories, such as Code-Llama∥∥∥https://huggingface.co/codellama and Start-Coder******https://huggingface.co/blog/starcoder. Then, supervised fine-tuning is conducted on these pre-trained models using the HLS training data (Section 3.2). We adopt axolotl††††††https://github.com/OpenAccess-AI-Collective/axolotl to perform the fine-tuning, allowing for customization of models and training parameters, such as learning rate, batch size, and epoch number to fit specific scenarios and available resources.
In the second stage, we employ the fine-tuned LLM for iterative code generation. The process begins with initial inputs consisting of user instruction prompts and design descriptions. To enhance the quality of the generated HLS designs, we incorporate a chain-of-thought optimization technique (Section 4.2) into the instruction prompts. The code generation then proceeds with a feedback loop (Section 4.3) that iteratively improves the correctness of the HLS designs. This iterative process continues until a refined HLS program is generated as the final output. Users can specify the number of iterations, providing the flexibility to navigate this trade-off according to their specific needs, with more iterations typically yielding higher quality at increased runtime expense.

4.2. Chain-of-Thought
Previous studies indicate that the quality of generated content is significantly influenced by the instructional prompt (Zhao et al., 2021). The Chain-of-Thought (CoT) (Wei et al., 2022) technique has proven simple and effective for enhancing the performance of LLMs across a wide range of tasks, including arithmetic, commonsense, and symbolic reasoning (Wei et al., 2022). Although initially, COT yielded a modest point increase in the pass@1 metric in code generation, this improvement was substantially augmented through structured prompting (Li et al., 2023b). In this paper, we investigate the effect of CoT in generating HLS-based hardware designs.
Figure 5 illustrates the CoT prompt structured for HLS code generation. The prompt guides a systematic approach through several targeted steps: understanding FPGA characteristics, defining program structure, developing logic, selecting data types and interfaces, before finalizing the code. This structured process ensures thorough consideration of each key aspect to optimize the HLS code generation.
4.3. Two-Step Feedback Loops
Code generation with feedback loop has shown promising results in previous literature (Liu et al., 2023b; Shojaee et al., 2023; Wang et al., 2022; Authors, 2024). This paper investigates its impact on HLS code generation using a two-step feedback loop tailored for automated hardware generation, focusing on HLS-related feedback. At each iteration, the framework evaluates the syntax and functional correctness of the generated HLS program. The located syntax error and functional defects are then fed back into the input prompts as additional information for subsequent code generation.
In the first step, syntax feedback is provided using the GCC compiler with the ‘-fsyntax-only‘ option, as specified in 3.4. It captures the syntax errors without fully compiling the code. It allows rapid identification including the types and locations, and precise error mapping for targeted corrections. If the syntax check passes, our framework proceeds to the second step by executing predefined unit tests to compare the outputs of the generated and the original source code. Functional defects are recorded and added to the prompts for the next iteration. This two-step feedback loop continues for user-specified iterations, providing flexibility to balance the trade-off between design quality and runtime cost.
5. Evaluation
5.1. Experimental Setup
In our evaluation, we adopt Code-Llama-7B as the pre-trained model for fine-tuning, employing the low-rank-adaption (QLoRA) (Hu et al., 2021; Dettmers et al., 2024) technique for faster training and lower memory consumption. Key configurations include loading the model in 8-bit, a sequence length of 4096, sample packing, and padding to sequence length. We set the warmup steps to 100, with a gradient accumulation of 4 steps, a micro-batch size of 4, and an inference batch size of 2. For both syntax and functionality checks, we measure pass@3 accuracy as metrics. In the ablation study from Section 5.2 to Section 5.6, we adopt MachineGen for evaluation.
Experiments are conducted on a server with four NVIDIA L20 GPUs (48 GB each), an 80 vCPU Intel® Xeon® Platinum 8457C, and 100GB of RAM. This setup ensures sufficient computational power and memory to handle the intensive demands of fine-tuning and inference efficiently, especially for long data sequences in the feedback loop experiment.
5.2. Effect of Supervised Finetuning
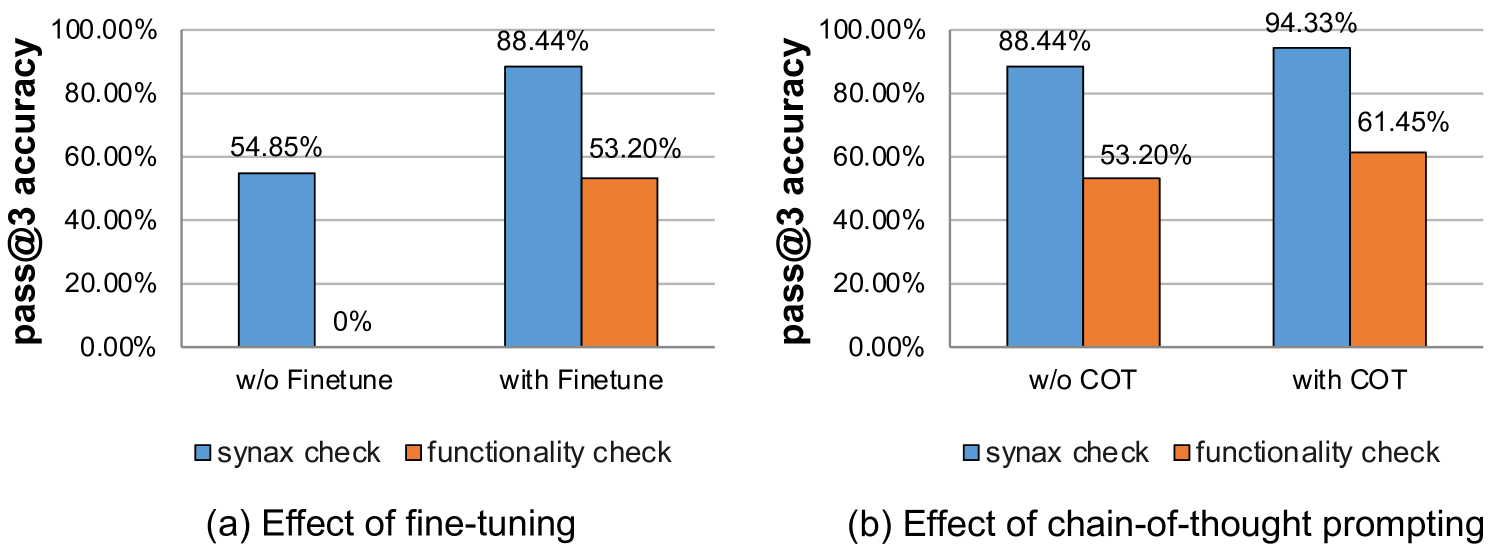
Our first ablation study investigates the effect of the model fine-tuning. We evaluated the performance based on both syntax and functionality checks. As shown in Figure 6(a), the results demonstrate that the finetuning dramatically increases syntax correctness from % to %. More importantly, the impact of finetuning is even more pronounced in the functionality evaluation, where the non-finetuned model failed to achieve any correct functionality test, but the accuracy is improved to % in the finetuned model. These enhancements highlight the critical role of finetuning in producing not only syntactically correct but also functionally viable codes, which demonstrates the benefits of finetuning LLMs for hardware design in the HLS code generation task.
5.3. Effect of Chain-of-Thought Prompting
To assess the effect of the chain-of-thought (CoT) technique, we perform both syntax and functionality evaluation on the fine-tuned model with and without the use of CoT. As indicated in Figure 6(b), incorporating CoT leads to a noticeable improvement in both metrics. Specifically, syntax correctness increases from % to %, and functionality score rises from % to %. The result demonstrates the effectiveness of CoT in enhancing the reasoning capability, thereby improving its overall performance.
5.4. Effect of Feedback Loops
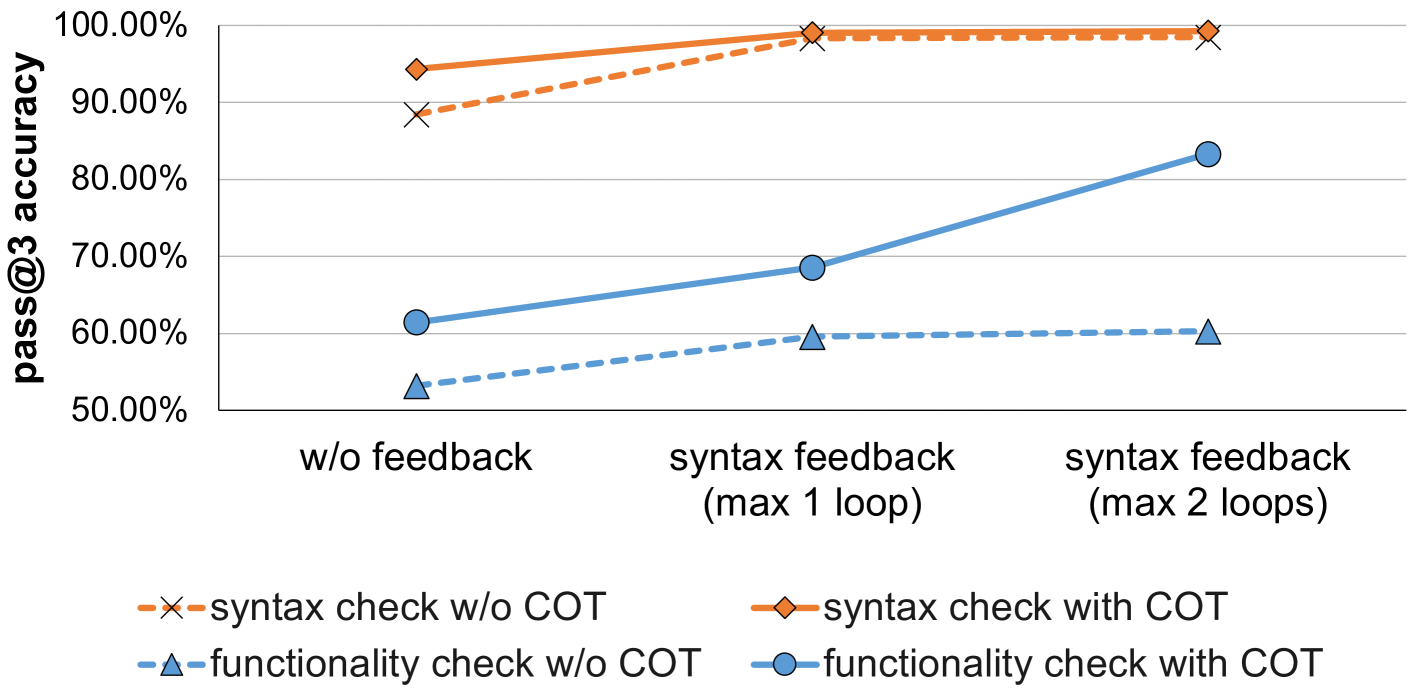
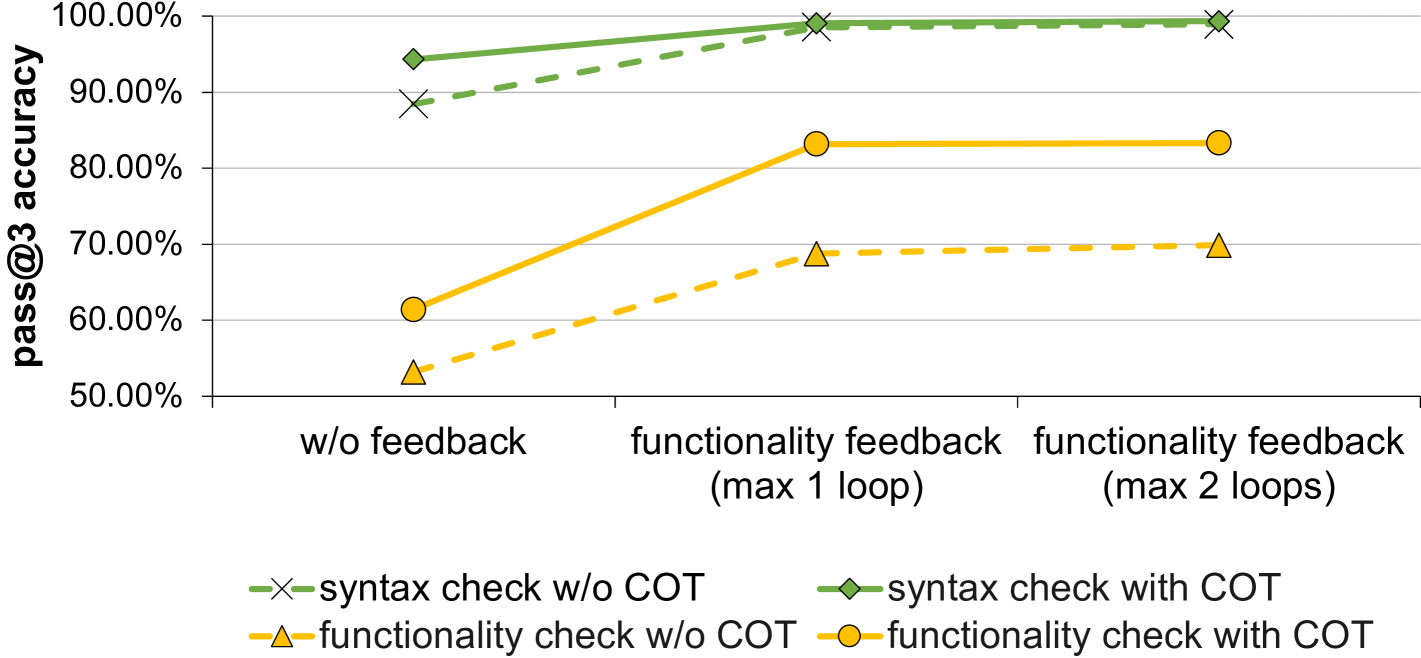
Our two-step feedback loop provides both syntax and functionality feedback. We evaluate the impact of these feedback loops with different numbers of iterations, ranging from 0 to 2.The results, shown in Figure Figure 7 and Figure 8, indicate that both syntax and functionality feedback loops significantly improve model performance, especially when combined with COT prompting. The initial feedback loop yields substantial accuracy improvements in both syntax correctness and functionality evaluation, though the second loop shows diminishing returns.Syntax feedback loops enhance both syntax correctness and functionality performance, suggesting that iterative refinement is particularly effective for complex tasks. Similarly, functionality feedback loops not only improve functionality checks but also boost syntax accuracy, indicating that enhancements in functional understanding contribute to better syntactic performance.
5.5. Time Cost and Hardware Performance
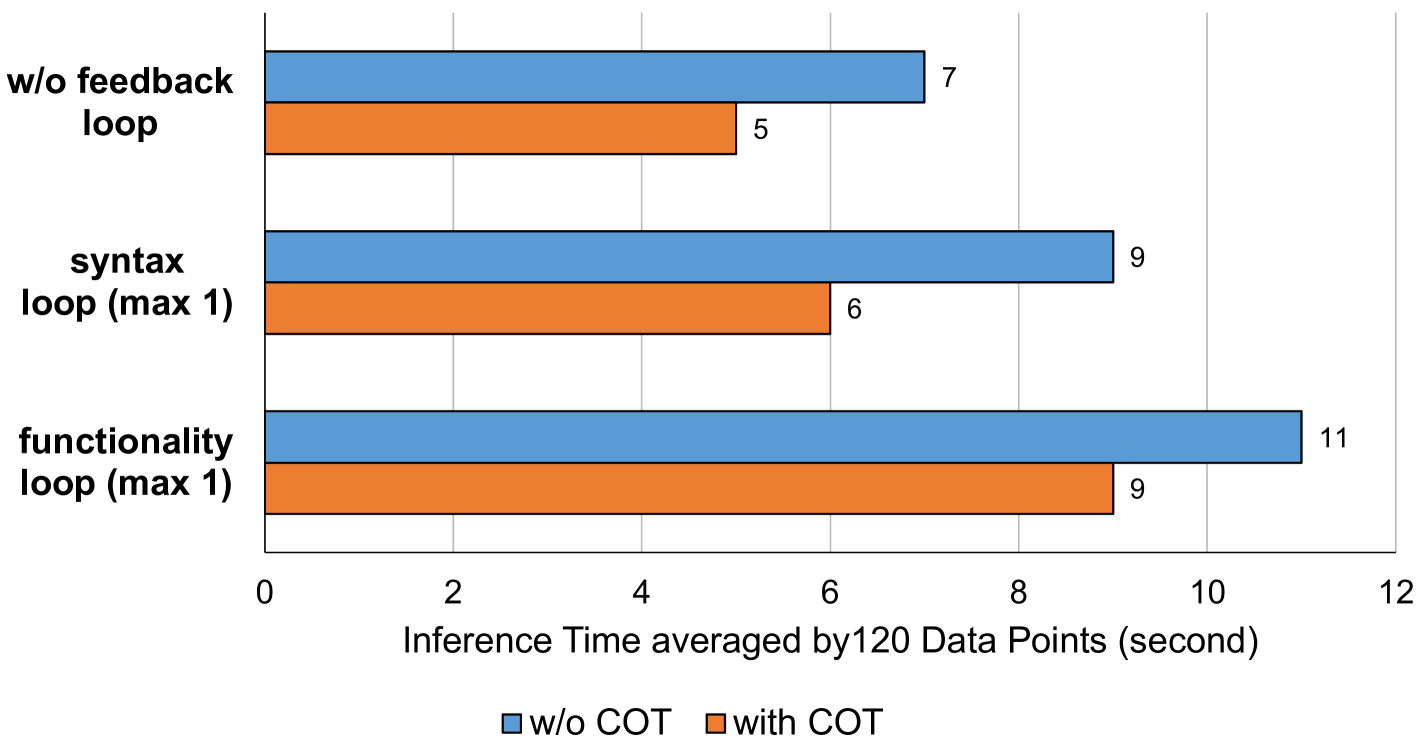
Figure 9 shows the time cost for generating 120 data entries under different conditions, measuring the impact of CoT and feedback loops. Without a feedback loop, CoT significantly reduces the time. Adding a syntax feedback loop increases the time, but CoT continues to notably decrease the duration. The functionality feedback loop is the most time-consuming, though CoT still provides a notable reduction, albeit less dramatic. This demonstrates CoT’s effectiveness in reducing operational times across varying complexities.
For the test set, we evaluate the latency and resource consumption of the generated HLS designs using a Xilinx VCU118 as our target FPGA, with a clock frequency of MHz and Xilinx Vivado 2020.1 for synthesis. As shown in Table 1, all HLS designs demonstrate reasonable performance, with BRAM usage consistently remained at zero due to the design scale.
| Latency (ms) | LUTs | Registers | DSP48s | BRAMs | |
| Available | - | 1182240 | 2364480 | 6840 | 4320 |
| ellpack | 0.304 | 1011 | 1079 | 11 | 0 |
| syrk | 21.537 | 1371 | 1621 | 19 | 0 |
| syr2k | 40.626 | 1572 | 1771 | 19 | 0 |
| stencil2d | 1.368 | 287 | 123 | 3 | 0 |
| trmm-opt | 15.889 | 1262 | 1239 | 11 | 0 |
| stencil3d | 21.537 | 1173 | 1271 | 20 | 0 |
| symm | 24.601 | 1495 | 1777 | 19 | 0 |
| symm-opt | 16.153 | 1361 | 1608 | 19 | 0 |
| symm-opt-medium | 579.0 | 2223 | 2245 | 22 | 0 |
5.6. Effect of Task Complexity
We analyze the effects of code complexity on the performance of fine-tuning our language model with CoT prompting and tested without the use of any feedback loops during inference. We categorize MachineGen into three classes according to their code complexity: easy, medium, and difficult. The results shown in the Table 2 indicates a clear trend: as the complexity of the generated code increases, both syntax and functionality correctness rates decline. This outcome could be attributed to several factors. First, more complex code inherently presents more challenges in maintaining syntactic integrity and functional accuracy. Second, the absence of feedback loops in the inference phase may have limited the model’s ability to self-correct emerging errors in more complicated code generations.
| Test Set | Syntax Check | Functionality |
|---|---|---|
| Easy | 96.67% | 63.33% |
| Medium | 96.67% | 53.33% |
| Difficult | 90% | 53.33% |
5.7. Analysis of MachineGen and HumanRefine
| Test Set | Syntax Check | Functionality Check |
|---|---|---|
| MachineGen | 93.83% | 62.24% |
| HumanRefine | 47.29% | 21.36% |
As shown in Table 3, this section compares the performance of our model on MachineGen and HumanRefine test sets. Our findings reveal that the performance on the HumanRefine is significantly lower than on the MachineGen. This disparity suggests that the model is more adept at handling machine-generated prompts. The primary reasons for this are: the model’s training data bias towards machine-generated prompts, the increased complexity and nuanced nature of human-generated prompts, and the conciseness and clarity of human-generated prompts that often omit repetitive or explicit details found in machine-generated prompts, making it harder for the model to generate syntactically and functionally correct code.
5.8. Thoughts, Insights, and Limitations
1. HLS versus HDL for AI-assisted code generation: The selection of programming language for hardware code generation should mainly depend on two factors:
-
•
Quality of Generated Hardware Design: The evaluation of hardware design’s quality includes syntax correctness, functionality, and hardware performance. Since HLS shares similar semantics and syntax with programming languages commonly used during LLM pre-training, this work demonstrates that the LLM-assisted code generation for HLS has the potential to achieve high syntax and functional correctness in hardware designs. While this work does not leverage hardware performance as feedback for design generation, it identifies this aspect as a key direction for future research and enhancements.
-
•
Runtime Cost of Hardware Generation: Although HLS-based designs typically require fewer tokens compared to HDL during the code generation phase—suggesting potentially lower costs—the overall runtime costs associated with HLS synthesis must also be considered. A more comprehensive quantitative comparison of these runtime costs is planned for our future work.
2. Input instructions and datasets are crucial: The fine-tuning of pre-trained LLMs on HLS dataset can bring a significant improvement in the design quality, echoing findings from previous studies on Verilog code generation (Thakur et al., 2023). Additionally, during our evaluation, we found that employing simple CoT prompting largely improves hardware design quality. This result contrasts with the application of CoT in general-purpose programming languages, where a specialized form of CoT is necessary (Li et al., 2023b). Therefore, future efforts for further enhancement can focus on collecting high-quality datasets and exploring better refinement of input prompts.
3. Limitations: At the time of this research, more advanced reasoning models, such as DeepSeek-R1 (Guo et al., 2025), were not available for evaluation. Additionally, test-time scaling approaches (Welleck et al., 2024) could be incorporated to further enhance performance in the future. Moreover, we observe that the diversity of hardware designs in the benchmark is limited, which may impact the generalizability of our findings. We intend to address these limitations in our future work.
6. Conclusion
This paper explores automating hardware generation with code language models and High-Level Synthesis (HLS). We aim to investigate the suitability of HLS over low-level hardware description languages for hardware design generation. To facilitate this, we propose benchmarks and code infrastructures for evaluating LLM-assisted HLS design generation. Our experimental findings reveal that, with the integration of advanced optimizations such as feedback loops and chain-of-thought techniques, LLM-assisted HLS code generation shows substantial promise in designing complex hardware with high levels of syntax and functional correctness.
References
- (1)
- Authors (2024) Anonymous Authors. 2024. LLM-VeriPPA: Power, Performance, and Area-aware Verilog Code Generation and Refinement with Large Language Models. https://openreview.net/pdf?id=nZL6S0b-HcI
- Avrahami et al. (2022) Omri Avrahami, Dani Lischinski, and Ohad Fried. 2022. Blended diffusion for text-driven editing of natural images. In IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18208–18218.
- Bai et al. (2023) Yunsheng Bai, Atefeh Sohrabizadeh, Zongyue Qin, Ziniu Hu, Yizhou Sun, and Jason Cong. 2023. Towards a Comprehensive Benchmark for High-Level Synthesis Targeted to FPGAs. Advances in Neural Information Processing Systems 36 (2023), 45288–45299.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems 33 (2020), 1877–1901.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- Dettmers et al. (2024) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2024. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems 36 (2024).
- Di et al. (2023) Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, et al. 2023. Codefuse-13b: A pretrained multi-lingual code large language model. arXiv preprint arXiv:2310.06266 (2023).
- Guo et al. (2025) Daya Guo et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025).
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- Iyer et al. (2016) Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing source code using a neural attention model. In 54th Annual Meeting of the Association for Computational Linguistics 2016. Association for Computational Linguistics, 2073–2083.
- Iyer et al. (2018) Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2018. Mapping language to code in programmatic context. arXiv preprint arXiv:1808.09588 (2018).
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459–9474.
- Li et al. (2023b) Jia Li, Ge Li, Yongmin Li, and Zhi Jin. 2023b. Structured chain-of-thought prompting for code generation. arXiv preprint arXiv:2305.06599 (2023).
- Li et al. (2023a) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023a. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161 (2023).
- Li et al. (2022) Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with alphacode. Science 378, 6624 (2022), 1092–1097.
- Ling et al. (2016) Wang Ling, Edward Grefenstette, Karl Moritz Hermann, Tomáš Kočiskỳ, Andrew Senior, Fumin Wang, and Phil Blunsom. 2016. Latent predictor networks for code generation. arXiv preprint arXiv:1603.06744 (2016).
- Liu et al. (2023b) Jiate Liu, Yiqin Zhu, Kaiwen Xiao, Qiang Fu, Xiao Han, Wei Yang, and Deheng Ye. 2023b. Rltf: Reinforcement learning from unit test feedback. arXiv preprint arXiv:2307.04349 (2023).
- Liu et al. (2023a) Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023a. Verilogeval: Evaluating large language models for verilog code generation. In 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 1–8.
- Lu et al. (2021) Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv preprint arXiv:2102.04664 (2021).
- Lu et al. (2024) Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. 2024. RTLLM: An open-source benchmark for design rtl generation with large language model. In 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 722–727.
- Ray et al. (2016) Baishakhi Ray, Vincent Hellendoorn, Saheel Godhane, Zhaopeng Tu, Alberto Bacchelli, and Premkumar Devanbu. 2016. On the” naturalness” of buggy code. In Proceedings of the 38th International Conference on Software Engineering. 428–439.
- Roziere et al. (2023) Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023).
- Saharia et al. (2022) Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J Fleet, and Mohammad Norouzi. 2022. Image super-resolution via iterative refinement. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 4 (2022), 4713–4726.
- Shojaee et al. (2023) Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K Reddy. 2023. Execution-based code generation using deep reinforcement learning. arXiv preprint arXiv:2301.13816 (2023).
- Thakur et al. (2023) Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. 2023. Verigen: A large language model for verilog code generation. ACM Transactions on Design Automation of Electronic Systems (2023).
- Tsai et al. (2023) YunDa Tsai, Mingjie Liu, and Haoxing Ren. 2023. Rtlfixer: Automatically fixing rtl syntax errors with large language models. arXiv preprint arXiv:2311.16543 (2023).
- Tunstall et al. (2022) Lewis Tunstall, Leandro Von Werra, and Thomas Wolf. 2022. Natural language processing with transformers. ” O’Reilly Media, Inc.”.
- Wang et al. (2022) Xin Wang, Yasheng Wang, Yao Wan, Fei Mi, Yitong Li, Pingyi Zhou, Jin Liu, Hao Wu, Xin Jiang, and Qun Liu. 2022. Compilable neural code generation with compiler feedback. arXiv preprint arXiv:2203.05132 (2022).
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837.
- Welleck et al. (2024) Sean Welleck et al. 2024. From decoding to meta-generation: Inference-time algorithms for large language models. arXiv preprint arXiv:2406.16838 (2024).
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022).
- Zhang et al. (2023) Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jianguo Li, and Rui Wang. 2023. Unifying the perspectives of nlp and software engineering: A survey on language models for code. arXiv preprint arXiv:2311.07989 (2023).
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223 (2023).
- Zhao et al. (2021) Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In International conference on machine learning. PMLR, 12697–12706.
- Zheng et al. (2024) Zangwei Zheng, Xiangyu Peng, and Yang You. 2024. Open-Sora: Democratizing Efficient Video Production for All. https://github.com/hpcaitech/Open-Sora