Exploring Complicated Search Spaces with Interleaving-Free Sampling
Abstract
The existing neural architecture search algorithms are mostly working on search spaces with short-distance connections. We argue that such designs, though safe and stable, obstacles the search algorithms from exploring more complicated scenarios. In this paper, we build the search algorithm upon a complicated search space with long-distance connections, and show that existing weight-sharing search algorithms mostly fail due to the existence of interleaved connections. Based on the observation, we present a simple yet effective algorithm named IF-NAS, where we perform a periodic sampling strategy to construct different sub-networks during the search procedure, avoiding the interleaved connections to emerge in any of them. In the proposed search space, IF-NAS outperform both random sampling and previous weight-sharing search algorithms by a significant margin. IF-NAS also generalizes to the micro cell-based spaces which are much easier. Our research emphasizes the importance of macro structure and we look forward to further efforts along this direction.
1 Introduction
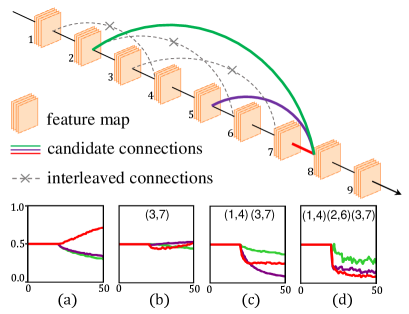
Neural architecture search (NAS) is a research field that aims to automatically design deep neural networks [27, 19, 1]. There are two important factors that define a NAS algorithm, namely, the search space that determines what kinds of architectures can appear, and the search strategy that explores the search space efficiently. Despite the rapid development of search algorithms which have become faster and more effective, the search space design is still in a preliminary status. In particular, for the most popular search spaces used in the community, either MobileNet-v3 [12] or DARTS [17], the macro structure (i.e., how the network blocks are connected) is not allowed to change. Such a conservative strategy is good for search stability (e.g., one can guarantee to achieve good performance even with methods that are slightly above random search), but it reduces the flexibility of NAS, impeding the exploration of more complicated (and possibly more effective) neural architectures.
The goal of this paper is to break through the limitation of existing search spaces. For this purpose, we first note that the MobileNet-v3 and DARTS allow a cell to be connected to 1 and 2 precursors, respectively, resulting in relatively simple macro structures. In opposite, we propose a variant that each cell is connected to precursors ( is 4, 6, or 8), and each connection can be either present or absent. We evaluate three differentiable NAS algorithms, namely DARTS [17], PC-DARTS [23], and GOLD-NAS [3] in the designed -chain search space, and all of them run into degraded results. We perform diagnosis in the failure cases and the devil turns out to be the so-called interleaved connections, which refers to a pair of connections and that satisfies . Figure 1 shows an example that how interleaved connections affects the search results. With the increasing extent of interleaving, the search results gradually deteriorate, reflecting in the reduced accuracy and the weak operator gaining heavier weights. More examples are provided in the experiment.
The above observation motivates us to maximally eliminate the emerge of interleaved connections during the search procedure. This is easily done by performing interleaving-free sampling, where we group all candidate connections into groups and there exist no interleaved connections in every single group, based on which we periodically choose one group and perform regular NAS algorithms. This schedule can optimize the weight of every connection without suffering the issue of interleaved connections. Discretization and pruning are performed afterwards to derive the final architecture. The entire algorithm is named interleaving-free NAS, or IF-NAS for short.
We conduct experiments on ImageNet, a popular benchmark of NAS. In the newly proposed -chain space, IF-NAS significantly outperforms three differentiable search baselines, DARTS, PC-DARTS and GOLD-NAS, and the advantage becomes more evident as the number of possible input blocks grows larger, i.e., heavier interleaving presents. Moreover, we evaluate IF-NAS in the existing search spaces of DARTS and GOLD-NAS, and show that it generalizes well to these easier search spaces.
In summary, the contributions of this paper are two-fold. First, we advocate for investigating the macro structure and put forward a novel search space for this purpose. The existing NAS methods cannot guarantee satisfying performance in this space. Second, we show that the major difficulty lies in dealing with the interleaved connections and hence propose an effective solution named IF-NAS. We hope that our efforts can inspire the NAS community to study the challenging new problem.
2 Related Work
Search Strategy
Early NAS methods generally rely on individually evaluating the sampled sub-architectures under heuristic strategies, including reinforcement learning [27] and the evolutionary algorithm [19], which are computationally expensive. To accelerate the search, one-shot methods [2, 4, 11] propose to represent the search space with a super-network, where the weights of all the candidate architectures are shared. Individual architecture training from scratch is avoided and the search cost is reduced by large magnitudes. Recently differentiable NAS (DNAS) has aroused great popularity in this field, which maps the discrete search space into a parameterized super network so that the search process can be executed by gradient descent. DARTS [17], as a pioneer differentiable framework, relaxes the search space by introducing updatable architecture parameters. The bi-level optimization is performed to update super-network weights and architectural parameters alternately. The target architecture is derived according to the distribution of architectural parameters. Due to its high efficiency, many works extend DNAS to more applications, including semantic segmentation [15, 25], object detection [9, 10], etc. Some DNAS works [5, 22, 8] propose to integrate co-optimization with both accuracy and hardware properties into the search phase. In this paper, we target at promoting DNAS in terms of both flexibility and robustness. With the two factors improved, the final performance of DNAS can reach a higher level.
Eliminating Collapse in DNAS
Though DNAS has achieved great success due to its high efficiency, many inherent problems exist with it and may cause collapse during search. A series of methods propose to improve DNAS from various perspectives. P-DARTS [6] bridges the gap between the super and searched network by gradually increasing the depths the networks. FairDARTS [7] improves the sampling strategy and breaks the two indispensable factors of unfair advantages and exclusive competition. [21, 3] alleviate the discretization error by pushing the weights to sharp distributions. [14, 13, 24] robustify the search process by introducing regularization techniques, including early stopping and observing eigenvalues of the validation loss Hessian, etc. We reveal the degradation phenomenon in complicated search spaces when using the conventional DNAS method, and propose to suppress the interleaved connections during search. The proposed IF-NAS eliminates collapse most DNAS methods may encounter and shows superior performance.
Search Space
Most existing NAS methods only explore in the micro search space, while the limited flexibility hinders further development of NAS. The cell-based space is firstly proposed in NASNet [27], which is widely adopted by the following works [18, 19, 26, 17]. This type of search space takes several nodes into one cell structure, which though eases the search procedure, suppresses many possible architectures with stronger feature extraction ability. [16] proposes to search architectures under a hierarchical space which introduces flexible topology structures. Auto-DeepLab [15] searches in a space with multiple paths and allows feature extraction in diverse resolutions. DenseNAS [8] introduces densely connections in the search space and improves search freedom in terms of operators, depths and widths. GOLD-NAS [3] liberates the restriction of the cell-based design and performs search in a global range. We further extends the search space complexity to explore architectures with more possibilities and potential. Though intractable is the search in such a complicated space, our proposed IF-NAS still shows evident effectiveness and advantages over other compared DNAS methods.
3 Our Approach
3.1 Preliminaries: NAS in a Super-Network
In neural architecture search (NAS), a deep neural network can be formulated into a mathematical function that receives an image as the input and produces the desired information (e.g., a class label ) as the output. We denote the function to be where the form of is determined by a set of architectural parameters, , and the learnable weights (e.g., the convolutional weights) are denoted by . The goal of NAS is to find the optimal architecture, , that leads to the best performance, i.e.,
| (1) | |||||
where denotes the ground truth label. Most often, takes discrete values, implying that solving Eqn (1) requires enumerating a large number of sampled architectures and performing individual evaluation. To accelerate, researchers propose to slack into a continuous form so that solving Eqn (1) involves optimizing a super-network, after which is discretized into the optimal architecture for other applications.
In particular, this paper is built upon the differentiable search algorithms, in which the super-network is solved by computing the gradient with respect to . We will introduce the details of optimization in the experimental part.
3.2 Exploring a Complicated Search Space

We design a search space shown in Figure 2. We define a fixed integer, , indicating that each layer can be connected to precursors. For convenience, we name this space -chain space. When , it degrades to the chain-styled network (the backbone of MobileNet-v3). On the contrary, we study the cases of , , and even , making the topology of the space much more complicated. We follow R-DARTS [24] to allow two candidate operations, i.e. the separable convolution and skip-connection. Throughout the remaining part of this paper, we use to indicate the proposed space with precursor connections. For convenience, the connection between the -th and -th layers (nodes) is named the pre- connection of the -th layer.
Before entering the algorithm part, we emphasize that we do not use additional rules to assist the architecture search, e.g., forcing all nodes to survive by preserving at least one connection. This raises new challenges to the search algorithm, because the depth of the searched architecture becomes quite indeterminate. Although some prior work has explored the option of optimizing the macro and micro architectures jointly [15] or adding mid-range connections to the backbone [8], they still rely on the cell/block unit to perform partial search. Instead, we break the limitations of the unit, and allow search in a wider and macro space.
| DARTS | GOLD-NAS | -chain | -chain | -chain |
|---|---|---|---|---|
In each edge, there are two candidate operators in our -chain space. Each node receives at most input feature maps. For the purpose of validity, each node has at least one input to be preserved. However, not every node may be used as an input node, and these nodes will be deleted, which means that the architectures are allowed to be very shallow. For a node , there are input possibilities because each of the operators can be on or off. As a result, there are combinations if there are nodes in one stage. There are 3 stages to be searched in our space, Fig. 2, with the node number of 18, 20 and 18 respectively. Therefore, if is 4, 6 and 8, there are about , and possible architectures respectively. The complexity comparison of popular spaces are shown in Tab. 1.
3.3 Failure Cases and Interleaved Connections
We first evaluate DARTS [17] and GOLD-NAS [3] in the search space of . On the ImageNet-1k dataset, trained for 250 epochs for each network, DARTS and GOLD-NAS report top-1 accuracy of and , respectively, and the FLOPs of both networks are close to (i.e., the mobile setting), Tab. 2. In comparison, the simple chain-styled architecture (each node is only connected to its direct precursor) achieves with merely FLOPs. More interestingly, if we only preserve one input for each node, DARTS and GOLD-NAS report completely failed results of and (trained for 100 epochs), which are even much worse than preserve one input randomly, Tab. 3.
We investigate the searched architectures, and find that both DARTS and GOLD-NAS tend to find long-distance connections. This decreases the depth of the searched architectures, however, empirically, deeper networks often lead to better performance. This drives us to rethink the reason that the algorithm gets confused. For this purpose, we randomly choose an intermediate layer from the super-network and the algorithm needs to determine the preference among its precursors.
We start from the simplest situation that all network connections are frozen (the architectural weights are fixed) besides the candidate connections. We show the trend of three (pre-, pre-, pre-) connections in Figure 1. One can observe that the pre- connection overwhelms other two connections, aligning with our expectation that a deeper network performs better. However, when we insert one connection that lies between these candidates, we observe that the advantage of the pre- connection largely shrinks, and a long training procedure is required for it to take the lead. The situation continues deteriorating if we insert more connections into this region. When two or more connections are added, the algorithm cannot guarantee to promote the pre- connection and, sometimes, the ranking of the three connections is totally reversed.
The above results inspire us that two connections are easily interfered by each other if the covering regions (i.e., the interval between both ends) overlap. Hereafter, we name such pair of connections interleaved connections. Mathematically, denote a connection that links the a-th and b-th nodes as , where . Overlook the candidate connections of the activated nodes, two connections, and , interleave if and only if there exists at least one integer that satisfies and . Intuitively, for a real number , if is satisfied, the interleaved connection occurs.
As a side comment, the DARTS space is also impacted by the interleaved connections, which partly cause the degradation problem observed in prior work [14, 6, 20]. However, since the search space is cell-based, the degradation does not cause dramatic accuracy drop. In the experiments, we show that our solution, elaborated in the next part, generalizes well to the DARTS space.
3.4 Interleaving-Free Sampling
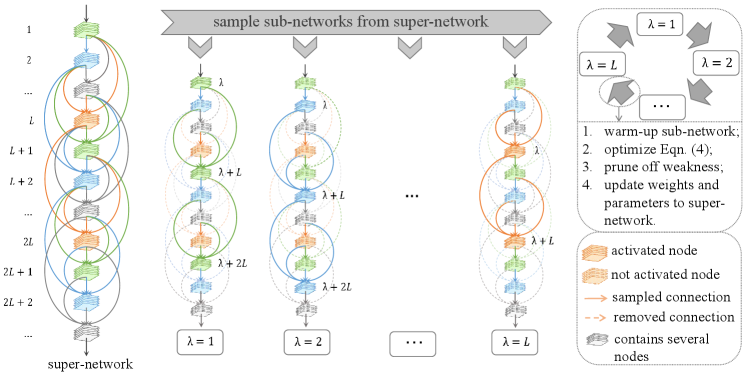
Following the above analysis, the key to design the search algorithm is to avoid interleaved connections, meanwhile ensuring that all connections can be considered. For this purpose, we propose IF-NAS, a sampling-based approach that each time optimizes a interleaving-free sub-super-network from the super-network.
This is implemented by partitioning the layers into groups, , according to their indices modulo . In other words, the distance between any consecutive layers that belong to the same group is exactly . When any group is chosen, we obtain an interleaving-free sub-super-network by preserving (i) the main backbone (all pre- connections) and (ii) all connections that end at any layer in . We denote the sub-super-network by for . Correspondingly, the optimization goal can be written as:
| (2) |
A straightforward search procedure repeats the loop of sub-super-networks, as shown in Figure 3. Training each sub-super-network is an approximation of optimizing the entire super-network, , but, since the sub-super-network are fixed, the co-occurring connections may gain unexpected advantages over other ones. To avoid it, we add a warm-up step to the beginning of each loop, in which the entire super-network is trained (all connections are activated, but the architectural parameters are not updated). Throughout the remainder of the loop, we train the sub-super-networks orderly. We set the length of each step to be iterations (i.e., mini-batches). Note that this number shall not be too large, otherwise the gap between the sampled and non-sampled connections will increase and harm the search performance.
3.5 Discretization and Pruning
The last step is to determine the final architecture. In a complicated search space, this is not simple as it seems, because many connections may have moderate weights (i.e., not close to or ). For such a connection, either pruning it or promoting it can bring significant perturbation on the super-network. Therefore, we follow the idea of prior works [7, 3, 21] to first perform a discretization procedure to push the weights towards either or , after which pruning is much safer. We introduce two kinds of architectural parameters, the connectivity of edges are determined by and operators are determined by .
The key of discretization is to add a regularization term to Eqn. (2). The term penalizes the moderate weights of edges and operators, represented by and respectively. Once these weights are less than , the corresponding edges or operators will be pruned off. The regularization term is computed by:
| (3) |
where is the number of layers, and is the activate function . means to only include operators on that have not been pruned off. is the average of . is multiplied by a factor of and added to the cross-entropy loss, so that optimizing the overall loss will not only improve the recognition accuracy of the super-network, but also push the weights of all connections towards or .
When the weight of a connection is sufficiently small, we prune it permanently from the super-network. This merely impacts the super-network itself, but the computation of changes and will push the next weak operator to . This process iterates until the complexity (e.g., FLOPs) of the super-network achieves the lower-bound.
4 Experiments
In this section, we first introduce experimental details and implementation details. Next, we introduce the results and analysis of IF-NAS and other advanced methods in our -chain space under different settings. Finally, we compare -chain spaces with 2 cell-based micro spaces using IF-NAS and other 2 search strategies.
4.1 Implementation Details
The Dataset. We use the large-scale ImageNet dataset (ILSVRC2012) to evaluate the models. ImageNet contains 1,000 object categories, which consists of 1.3M training images and 50K validation images. The images are almost equally distributed over all classes. Unless specified, we apply the mobile setting, in which the input image is set to and the number of multiply-add operations (MAdds) does not exceed 600M. We randomly sample 100 classes from the original ImageNet dataset to perform studying and analysis experiments, ImageNet-100 for short.
The Search Settings. Before searching, IF-NAS warm-ups the super-network for 20 epochs, with only the super-network weights updated and the architectural parameters frozen. Then we start to update firstly, and after 10 epochs, start to update . Super-network weights and architectural parameters are both optimized by the SGD optimizer. We gradually prune off weak edges and operators with threshold of until the MAdds of the retained architecture meets the mobile setting, i.e., 600M.
The Training Settings. We evaluate the searched architectures following the setting of PC-DARTS [23]. Each searched architecture is trained from scratch with a batch size of 1024 on 8 Tesla V100 GPUs. A SGD optimizer is used with an initial learning rate of 0.5, weight decay ratio of , and a momentum of 0.9. Other common techniques including label smoothing, auxiliary loss, and learning rate warm-up for the first 5 epochs are also applied.
4.2 Results on -chain Search Space
| Setting | Method | Test Err. (%) | Params | ||
|---|---|---|---|---|---|
| top-1 | top-5 | (M) | (M) | ||
| = 4 | DARTS [17] | 25.3 | 8.1 | 5.1 | 589 |
| PC-DARTS [23] | 24.7 | 7.5 | 5.3 | 593 | |
| GOLD-NAS [3] | 24.7 | 7.5 | 5.5 | 591 | |
| IF-NAS | 24.3 | 7.4 | 5.3 | 592 | |
| = 6 | DARTS [17] | 25.7 | 8.1 | 5.1 | 587 |
| PC-DARTS [23] | 24.9 | 7.7 | 5.2 | 586 | |
| GOLD-NAS [3] | 25.0 | 7.8 | 5.4 | 596 | |
| IF-NAS | 24.4 | 7.4 | 5.2 | 598 | |
| = 8 | DARTS [17] | 25.9 | 8.2 | 5.2 | 591 |
| PC-DARTS [23] | 25.1 | 7.9 | 5.2 | 582 | |
| GOLD-NAS [3] | 25.1 | 7.9 | 5.3 | 592 | |
| IF-NAS | 24.3 | 7.3 | 5.4 | 594 | |
We study our method IF-NAS on the proposed macro -chain search space, and compare it with three other popular DNAS frameworks, including DARTS [17], PC-DARTS [23] and GOLD-NAS [3]. For a fair comparison, the hyper-parameters are kept the same for all the studied methods. Without pruning gradually, DARTS and PC-DARTS derive the final architectures by removing weak edges and operators after searching until they meet the requirements of mobile setting. All the searched architectures are re-trained from scratch on ImageNet-1k for 250 epochs.
We perform three sets of experiments by setting , which indicates the precursors number of each layer can be connected, to 4, 6 and 8 respectively, and show the results in Tab. 2. When is 4, DARTS gets the worst performance as expected. Compared with DARTS, PC-DARTS and GOLD-NAS get better results of and with similar MAdds. Our IF-NAS gets the best result of with equivalent Params and MAdds. This proves that IF-NAS can work better in such a enlarged complicated space compared to the methods.
When is 6, DARTS achieves the result of . PC-DARTS and GOLD-NAS get results of and respectively. And our IF-NAS gets the best result of with similar Params and MAdds. Note that the results of the compared 3 frameworks get worse when increases to 6 compared to as 4. However, IF-NAS nearly maintains the performance. When increases, more interleaved connections occur, and bring more interference to the search process. The compared 3 methods, which do not suppress interleaved connections during search, are more severely effected and achieve worse results. However, IF-NAS samples interleaving-free sub-networks and updates the architectural parameters more accurately. This further confirms that our IF-NAS has great potential to handle complicated spaces.
When set to 8, IF-NAS still achieves a promising result of , which is comparable to the former two settings. The compared ones get similar or weaker results. Due to the increase in complexity, the performances of PC-DARTS and GOLD-NAS continue to decrease. But the MAdds of these architectures are close to 600M, which prevents performance from declining.
| Setting | random | DARTS | GOLD-NAS | IF-NAS |
|---|---|---|---|---|
| = 4 | 29.8 | 28.8 | 26.7 | |
| = 6 | 30.2 | 29.0 | 26.9 | |
| = 8 | 31.6 | 30.8 | 27.3 |
If we do not derive architectures with MAdds and preserve one input for each node, the results are shown in Tab. 3. Interestingly, without the protection of keeping so many MAdds, DARTS and GOLD-NAS show completely failed results. When =4, the results of DARTS and GOLD-NAS are and , which are even much worse than the randomly generated architectures. When increases to 8, the performances of DARTS and GOLD-NAS further degrade. The architectures searched without suppressing interleaved connections only preserve very few nodes, which damages the final performance dramatically. On the contrary, IF-NAS still achieves comparable results even without any MAdss restriction.
The above experiments imply interleaving connections cause non-negligible impacts to DNAS methods when the search space grows larger and more complicated. IF-NAS is able to handle this challenge by the proposed interleaving-free sampling.
| Setting | Depth | Params (M) | Err. (%) |
|---|---|---|---|
| w/o IF | |||
| w/ IF |
4.3 IF Sampling Effectiveness on -chain Space
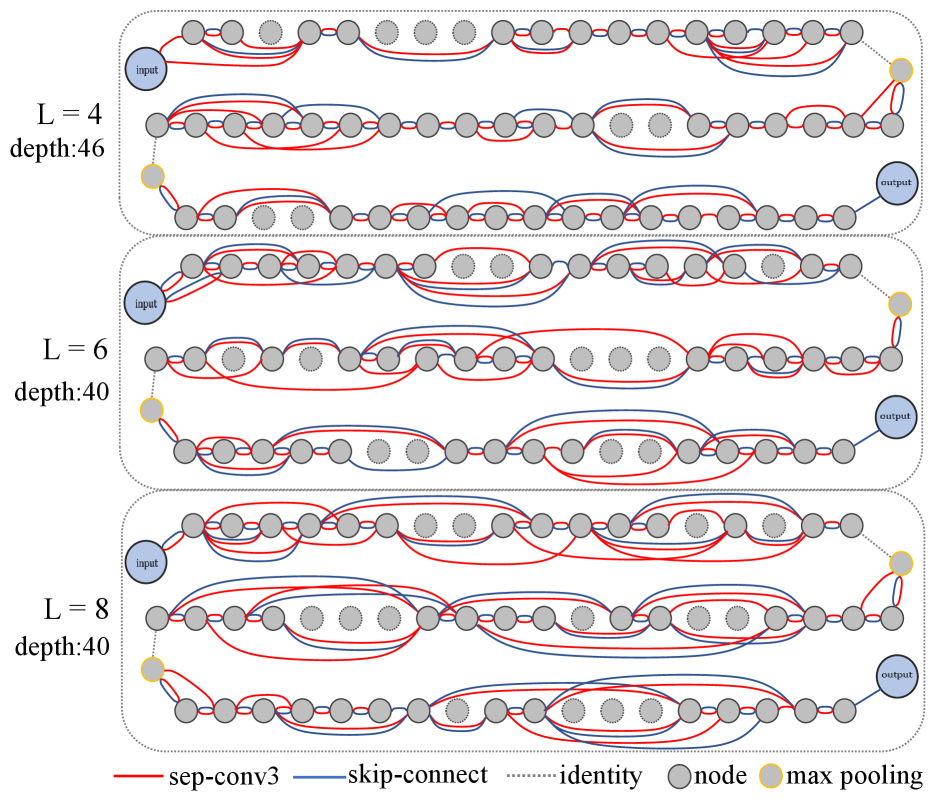
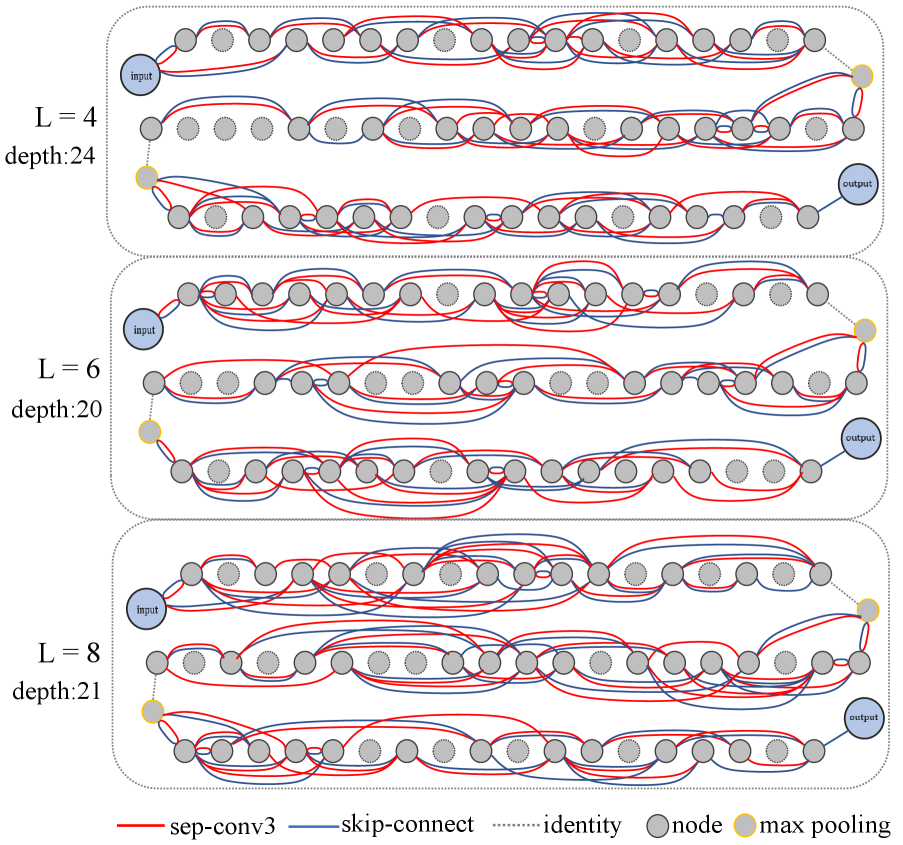
In this part, we design a comparative experiment to verify the effectiveness of IF sampling. We search for 4 times independently for each setting, and the results are shown in Tab. 4. The Depth in Tab. 4 refers to the depth summation of 3 stages, which represents the longest path length of the network. And all architectures are train on ImageNet-1k for 100 epochs.
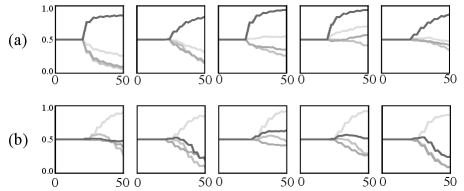
We find the accuracy of the architectures searched without IF (“w/o IF”) sampling is much worse than that with IF (“w/ IF”) sampling by a margin of with similar Params. It is worth noting that the depth of w/o IF is much smaller than w/ IF, because the interleaved connections produce serious interference to the search process. This verifies that our IF-NAS can effectively handle interleaved connections and guarantee the search performance.
The visualizations of searched architectures are shown in Fig. 4 and Fig. 5. We can find that w/ IF preserves many serial pattern connections and w/o IF mainly preserves parallel connections, as a result, the architectures of w/ IF is much deeper than w/o IF. Fig. 6 shows some weight change curves of w/ IF and w/o IF. One can see that w/ IF can select more closer inputs, which derives deeper architectures. w/o IF prefers farther nodes, which usually leads to parallel connections and discards more nodes.
4.4 Effects of Interleaved Connections
| IC Number | Depth | Params (M) | Err. (%) |
|---|---|---|---|
| 0 | |||
| 1 | |||
| 2 | |||
| 3 |
We allow various numbers (1/2/3) of interleaved connections to be sampled during search to understand the effects they may bring. The searched architectures are trained on ImageNet-100 for 100 epochs and the results are shown in Tab. 5. We find with more interleaved connections added, the performance degrades more. This shows more interleaved connections cause greater impact on the search. It implies that Interleaving-Free is necessary in such a flexible space. Interestingly, the performance drops greatly even through one interleaved connection is sampled during searching, which demonstrates that as long as the interleaved connection is involved, interference is generated.
4.5 Comparison with Cell-based Micro Spaces
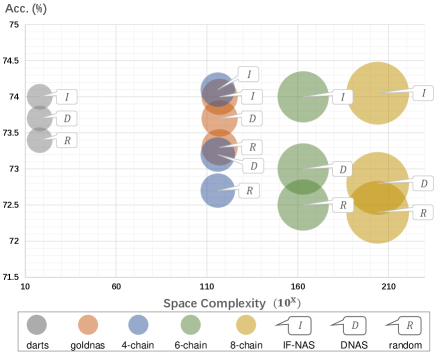
In this section, we test IF-NAS in two micro search spaces, DARTS space referred to as and GOLD-NAS space referred to as . The two spaces adopt the same separable convolution and skip-connection operators as ours, thus that the comparison is fair. The results are shown in Fig. 7. The horizontal axis denotes the space complexity (the exponential base of 10) and the vertical axis denotes the accuracy trained on ImageNet-1k for 100 epochs. The bubble sizes imply the complexity of spaces. The results on and are close among 3 strategies (even with random search), which implies the 2 spaces are inflexible and have a protection mechanism (the cell design) to help the search methods. The -chain spaces are more flexible and difficult so that the gaps between IF-NAS and others in -chain spaces are much larger. Moreover, the larger the spaces, the worse the performances of DNAS and random search. However, our IF-NAS provides all best results in the 5 spaces, which shows that IF-NAS are robust and generalize well to micro spaces.
We also test our IFNAS by training 250 epochs under the mobile setting and the results are shown in Table 6. IFNAS achieves test error in , which is same as PCDARTS (a specially designed method in this space). In , our IFNAS-G1 beats GOLD-I by with M fewer parameters and our IFNAS-G2 surpasses GOLD-X with M fewer parameters.
| arch. | para. (M) | Err. (%) | arch. | para. (M) | Err. (%) |
|---|---|---|---|---|---|
| DARTS | 4.7 | 26.7 | GOLD-I | 5.3 | 24.7 |
| PDARTS | 4.9 | 24.4 | GOLD-X | 6.4 | 24.3 |
| PCDARTS | 5.3 | 24.2 | IF-NAS-G1 | 5.1 | 24.5 |
| IF-NAS | 5.3 | 24.2 | IF-NAS-G2 | 6.0 | 24.2 |
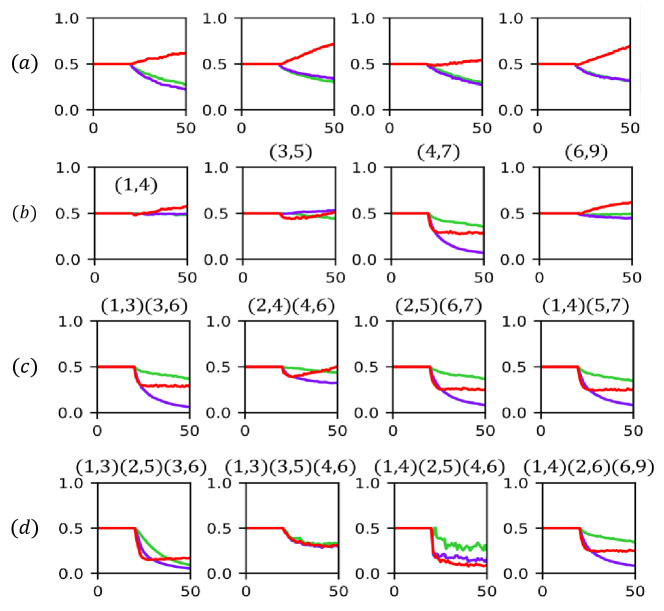
4.6 More Examples of Interleaved Connections
In Section 3.3, we show failure cases from the simplest situation. Here we perform more experiments to show the influence of interleaved connections and the weight change curves are shown in Figure 8. In Fig. 8 (a), we run 4 times independently under interleaving-free setting and the nearest candidate inputs have a dominant weight at this time. In Fig. 8 (b)-(d), We run 4 times independently and each time we add 1-3 different interference connections. One can see that the more interleaved connections are added, the harder it it the nearest candidate input is picked.
5 Conclusions
This work extends the design of search space towards higher flexibility by adding lots of long-range connections to the super-network. The long-range connections raise new challenges to the search algorithm, and we locate the problem to be the interference introduced by interleaved connections during search. We propose IF-NAS based on this observation, which makes a schedule to sample sub-networks and thus guarantees that interleaved connections do not occur.
Searching in a more complicated space has been of critical importance for NAS. Our research delivers the message that new properties/challenges of NAS emerge when the search space is augmented. We advocate for more efforts in this direction to improve the ability of the search algorithms.
Limitations of this work. First, the architectures searched in the complicated spaces do not show advantages than the existing cell-based ones, which implies that the greater flexibility we introduced does not necessarily lead to better results but greater difficulties. Second, IF-NAS needs an extra warm up process to make up for the accuracy drop of super-network caused by sampling operation.
References
- [1] Bowen Baker, Otkrist Gupta, Nikhil Naik, and Ramesh Raskar. Designing neural network architectures using reinforcement learning. In ICLR, 2017.
- [2] Gabriel Bender, Pieter-Jan Kindermans, Barret Zoph, Vijay Vasudevan, and Quoc V. Le. Understanding and simplifying one-shot architecture search. In ICML, 2018.
- [3] Kaifeng Bi, Lingxi Xie, Xin Chen, Longhui Wei, and Qi Tian. GOLD-NAS: gradual, one-level, differentiable. CoRR, abs/2007.03331, 2020.
- [4] Andrew Brock, Theodore Lim, James M Ritchie, and Nick Weston. SMASH: one-shot model architecture search through hypernetworks. In ICLR, 2018.
- [5] Han Cai, Ligeng Zhu, and Song Han. ProxylessNAS: Direct neural architecture search on target task and hardware. In ICLR, 2019.
- [6] Xin Chen, Lingxi Xie, Jun Wu, and Qi Tian. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In ICCV, 2019.
- [7] Xiangxiang Chu, Tianbao Zhou, Bo Zhang, and Jixiang Li. Fair DARTS: eliminating unfair advantages in differentiable architecture search. In ECCV, 2020.
- [8] Jiemin Fang, Yuzhu Sun, Qian Zhang, Yuan Li, Wenyu Liu, and Xinggang Wang. Densely connected search space for more flexible neural architecture search. In CVPR, 2020.
- [9] Jiemin Fang, Yuzhu Sun, Qian Zhang, Kangjian Peng, Yuan Li, Wenyu Liu, and Xinggang Wang. Fna++: Fast network adaptation via parameter remapping and architecture search. TPAMI, 2020.
- [10] Jianyuan Guo, Kai Han, Yunhe Wang, Chao Zhang, Zhaohui Yang, Han Wu, Xinghao Chen, and Chang Xu. Hit-detector: Hierarchical trinity architecture search for object detection. In CVPR, 2020.
- [11] Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun. Single path one-shot neural architecture search with uniform sampling. In ECCV, 2020.
- [12] GAndrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, and Hartwig Adam. Searching for mobilenetv3. In ICCV, 2019.
- [13] Guilin Li, Xing Zhang, Zitong Wang, Zhenguo Li, and Tong Zhang. Stacnas: Towards stable and consistent optimization for differentiable neural architecture search. CoRR, abs/1909.11926, 2019.
- [14] Hanwen Liang, Shifeng Zhang, Jiacheng Sun, Xingqiu He, Weiran Huang, Kechen Zhuang, and Zhenguo Li. DARTS+: improved differentiable architecture search with early stopping. CoRR, abs/1909.06035, 2019.
- [15] Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan L. Yuille, and Fei-Fei Li. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In CVPR, 2019.
- [16] Hanxiao Liu, Karen Simonyan, Oriol Vinyals, Chrisantha Fernando, and Koray Kavukcuoglu. Hierarchical representations for efficient architecture search. In ICLR, 2018.
- [17] Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. In ICLR, 2019.
- [18] Hieu Pham, Melody Y. Guan, Barret Zoph, Quoc V. Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. In ICML, 2018.
- [19] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V. Le. Regularized evolution for image classifier architecture search. In AAAI, 2019.
- [20] Yao Shu, Wei Wang, and Shaofeng Cai. Understanding architectures learnt by cell-based neural architecture search. In ICLR, 2020.
- [21] Yunjie Tian, Chang Liu, Lingxi Xie, Jianbin Jiao, and Qixiang Ye. Discretization-aware architecture search. CoRR, abs/2007.03154, 2020.
- [22] Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In CVPR, 2019.
- [23] Yuhui Xu, Lingxi Xie, Xiaopeng Zhang, Xin Chen, Guo-Jun Qi, Qi Tian, and Hongkai Xiong. PC-DARTS: partial channel connections for memory-efficient architecture search. In ICLR, 2020.
- [24] Arber Zela, Thomas Elsken, Tonmoy Saikia, Yassine Marrakchi, Thomas Brox, and Frank Hutter. Understanding and robustifying differentiable architecture search. In ICLR, 2020.
- [25] Yiheng Zhang, Zhaofan Qiu, Jingen Liu, Ting Yao, Dong Liu, and Tao Mei. Customizable architecture search for semantic segmentation. In CVPR, 2019.
- [26] Hongpeng Zhou, Minghao Yang, Jun Wang, and Wei Pan. Bayesnas: A bayesian approach for neural architecture search. In ICML, 2019.
- [27] Barret Zoph and Quoc V. Le. Neural architecture search with reinforcement learning. In ICLR, 2017.