Exploring Linkablility of Community Reviewing
Abstract
Large numbers of people all over the world read and contribute to various review sites. Many contributors are understandably concerned about privacy in general and, specifically, about linkability of their reviews (and accounts) across multiple review sites. In this paper, we study linkability of community-based reviewing and try to answer the question: to what extent are ”anonymous” reviews linkable, i.e., highly likely authored by the same contributor? Based on a very large set of reviews from one very popular site (Yelp), we show that a high percentage of ostensibly anonymous reviews can be linked with very high confidence. This is despite the fact that we use very simple models and equally simple features set. Our study suggests that contributors reliably expose their identities in reviews. This has important implications for cross-referencing accounts between different review sites. Also, techniques used in our study could be adopted by review sites to give contributors feedback about privacy of their reviews.
1 Introduction
In recent years, popularity of various types of review and community-knowledge sites has substantially increased. Prominent examples include Yelp, Tripadvisor, Epinions, Wikipedia, Expedia and Netflix. They attract multitudes of readers and contributors. While the former usually greatly outnumber the latter, contributors can still number in hundreds of thousands for large sites, such as Yelp or Wikipedia. For example, Yelp had more than million visitors and reached million reviews in late 2010 yelpstat . To motivate contributors to provide more (and more useful/informative) reviews, certain sites even offer rewards yelpeliete .
Some review sites are generic (e.g., Epinions) while others are domain-oriented, e.g., Tripadvisor. Large-scale reviewing is not limited to review-oriented sites; in fact, many retail sites encourage customers to review their products. e.g., Amazon and Netflix.
With the surge in popularity of community- and peer-based reviewing, more and more people contribute to review sites. At the same time, there has been an increased awareness with regard to personal privacy. Internet and Web privacy is a broad notion with numerous aspects, many of which have been explored by the research community. However, privacy in the context of review sites has not been adequately studied. Although there has been a lot of recent research related to reviewing, its focus has been mainly on extracting and summarizing opinions from reviews mine-peanut ; mine-summarize-rev ; thumbsup as well as determining authenticity of reviews opinion-spam-analysis ; opinion-spam-analysis-2 ; opinion-spam-analysis-3 .
In the context of community-based reviewing, contributor privacy has several aspects: (1) some review sites do not require accounts (i.e., allow ad hoc reviews) and contributors might be concerned about linkability of their reviews, and (2) many active contributors have accounts on multiple review sites and prefer these accounts not be linkable. The flip side of the privacy problem is faced by review sites themselves: how to address spam-reviews and sybil-accounts?
The goal of this paper is to explore linkability of reviews by investigating how close and related are a person’s reviews. That is, how accurately we can link a set of anonymous reviews to their original author. Our study is based on over reviews and contributors from Yelp. The results clearly illustrate that most (up to 99% in some cases) reviews by relatively active/frequent contributors are highly linkable. This is despite the fact that our approach is based on simple models and simple feature sets. For example, using only alphabetical letter distributions, we can link up to 83% of anonymous reviews. We anticipate two contributions of this work: (1) extensive assessment of reviews’ linkability, and (2) several models that quite accurately link “anonymous” reviews.
Our results have several implications. One of them is the ability to cross-reference contributor accounts between multiple review sites. If a person regularly contributes to two review sites under different accounts, anyone can easily link them, since most people tend to consistently maintain their traits in writing reviews. This is possibly quite detrimental to personal privacy. Another implication is the ability to correlate reviews ostensibly emanating from different accounts that are produced by the same author. Our approach can thus be very useful in detecting self-reviewing and, more generally, review spam opinion-spam-analysis whereby one person contributes from multiple accounts to artificially promote or criticize products or services.
One envisaged application of our technique is to have it integrated into review site software. This way, review authors could obtain feedback indicating the degree of linkability of their reviews. It would then be up to each author to adjust (or not) the writing style and other characteristics.
Organization: Section 2 provides background information about techniques used in our experiments. The sample dataset is described in Section 3 and study settings are addressed in Section 4. Next, our analysis methodology is presented in Section 5. Section 5.4 discusses issues stemming from this work and Section 6 sketches out some directions for the future. Then, Section 7 overviews related work and Section8 concludes the paper.
2 Background
This section provides some background about statistical tools used in our study. We use two well-known approaches based on: (1) Naïve Bayes Model nbayes , (2) Kullback-Leibler Divergence Metric bishopbook . We briefly describe them below.
2.1 Naïve Bayes Model
Naïve Bayes Model (NB) is a probabilistic model based on the eponymous assumption stating that all features/tokens are conditionally independent given the class. Given tokens: in document , we compute conditional probability of a document class as follows:
According to the Naïve Bayes assumption,
Therefore,
To use NB for classification, we return the class value with maximum probability:
| (1) |
Since is the same for all values, and assuming is the same for all class values, the above equation is reduced to:
Probabilities are estimated using the Maximum-Likelihood estimator bishopbook as follows:
We smooth the probabilities with Laplace smoothing mlearn1 as follows:
2.2 Kullback-Leibler Divergence Metric
Kullback-Leibler Divergence (KLD) metric measures the distance between two distributions. For any two distributions and , it is defined as:
KLD is always positive: the closer to zero, the closer is to . It is an asymmetrical metric, i.e., . To transform it into a symmetrical metric, we use the following formula (that has been used in mal-domains-detect ):
| (2) |
Basically, is a symmetrical version of that measures the distance between two distributions. As discussed below, it is used heavily in our study. In the rest of the paper, the term ”KLD” stands for 111Note that, under certain conditions, NB and asymmetrical KLD models could be equivalent. That is, is equivalent to , where are the tokens of a document and is their derived distribution. The proof for this equivalency is in mal-domains-detect . However, this equivalence does not hold when we use the symmetrical version ..
3 Data Set
Clearly, a very large set of reviews authored by a large number of contributors is necessary in order to perform a meaningful study. To this end, we collected reviews for contributors from yelp.com, a very popular site with many prolific contributors. As shown in Figure 1, the minimum number of reviews per contributor is , the maximum – and the average – reviews, with a standard deviation of . For the purpose of this study, we limited authorship to prolific contributors, since this provides more useful information for the purpose of review linkage.
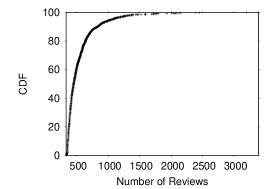
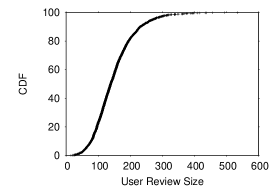
Figure 1 shows the Cumulative Distribution Function (CDF) of the number of reviews per contributor. 50% of the contributors authored fewer than reviews and 76% authored fewer than . Only 6% of the contributors exceed reviews.
Figure 1 shows the CDF for average review size (number of words) per contributor. It shows that 50% of the contributors write reviews shorter than words (on average) and 75% – have average review size smaller than . Also, 97% of contributors write reviews shorter than words. The overall average review size is relatively small – words.
4 Study Setting
As mentioned earlier, our central goal is to study linkability of relatively prolific reviewers. Specifically, we want to understand – for a given prolific author – to what extent some of his/her reviews relate to, or resemble, others. To achieve that, we first randomly order the reviews of each contributor. Then, for each contributor with reviews, we split the randomly ordered reviews into two sets:
-
1.
First reviews: We refer to this as the identified record (IR) of .
-
2.
Last reviews: These reviews represent the full set of anonymous reviews of from which we derive several subsets of various sizes. We refer to each of these subset as an anonymous record (AR) of . An AR of size consists of the first reviews of the full set of anonymous reviews of . We vary the AR size for the purpose of studying the user reviews linkability under different numbers of anonymous reviews.
Since we want to restrict the AR size to a small portion of the complete user reviews set, we restrict to 60 as this represents less than 20% of the minimum number of reviews for authors in our set (330 total). We use the identified records (IRs) of all contributors as the training set upon which we build models for linking anonymous reviews. (Note that the IR size is not the same for all contributors, while the AR size is uniform.) Thus, our problem is reduced to matching an anonymous record to its corresponding IR. Specifically, one anonymous record serves as input to a matching/linking model and the output is a sorted list of all possible account-ids (i.e., IR sets) listed in a descending order of probability, i.e., the top-ranked account-id corresponds to the contributor whose IR represents the most probable match for the input anonymous record. Then, if the correct account-id of the actual author is among top entries, the matching/linking model has a hit; otherwise, it is a miss. Consequently, our study boils down to exploring matching/linking models that maximize the hit ratio of the anonymous records for varying values of both and AR sizes. We consider three values of : 1 (perfect hit), 10 (near-hit) and 50 (near-miss). Whereas, for the AR size, we experiment with a wider range of values: 1, 5, 10, 20, 30, 40, 50 and 60.
Even though our focus is on the linkability of prolific users, we also attempt to assess performance of our models for non-prolific users. For that, we slightly change the problem setting by making the IR size smaller; this is discussed in Section 5.3.4.
5 Analysis
As mentioned in Section 2, we use Naïve Bayes (NB) and Kullback-Leibler Divergence (KLD) models. Before analyzing the collected data, we tokenize all reviews and extract four types of tokens:
-
1.
Unigrams: set of all single letters. We discard all non-alphabetical characters.
-
2.
Digrams: set of all consecutive letter-pairs. We discard all non-alphabetical characters.
-
3.
Rating: rating associated with the review. (In Yelp, this ranges between 1 and 5).
-
4.
Category: category associated with the place/service being reviewed. There are 28 categories in our dataset,
Why such simple tokens? Our choice of these four primitive token types might seem trivial or even naïve. In fact, initial goals of this study included more “sophisticated” types of tokens, such as: (1) distribution of word usage, (2) sentence length in words, and (3) punctuation usage. We originally planned to use unigrams and digrams as a baseline, imagining that (as long as all reviews are written in the same language – English, in our case) single and double-letter distributions would remain more-or-less constant across contributors. However, as our results clearly indicate, our hypothesis was wrong.
In the rest of this section, we analyze results produced by NB and KLD models. Before proceeding, we re-cap abbreviations and notation in Table 1.
| NB | Naïve Bayes Model |
|---|---|
| KLD | Symmetrical Kullback-Leibler Divergence Model |
| R | Token Type: rating, unigram or digram |
| LR | Linkability Ratio |
| AR | Anonymous Record |
| IR | Identified Record (corresponding to a certain reviewer) |
| symmetric KLD distance between and | |
| symmetric KLD of rating tokens | |
| symmetric KLD of category tokens | |
| symmetric KLD of lexical(unigram or digram) tokens | |
| symmetric KLD of rating and category tokens | |
| symmetric KLD of lexical, rating and category tokens |
5.1 Methodology
We begin with the brief description of the methodology for the two models.
5.1.1 Naïve Bayes (NB) Model
For each account , we built an NB model, , from its identified record. Probabilities are computed using the Maximum-Likelihood estimator bishopbook and Laplace smoothing mlearn1 as shown in 2. We then construct four models corresponding to the four aforementioned token types. That is, for each , we have , , and .
To link an anonymous record to an account with respect to token type , we first extract all -type tokens from , (Where is the -th token in ). Then, for each , we compute the probability . Finally, we return a list of accounts sorted in decreasing order of probabilities. The top entry represents the most probable match.
5.1.2 Kullback-Leibler Divergence (KLD) Model
We use symmetric KLD (see Section 2) to compute the distance between anonymous and identified records. To do so, we first compute distributions of all records, as follows:
To avoid division by 0, we smooth distributions via Laplace smoothing mlearn1 , as follows:
As before, we compute four distributions. To link with respect to token type , we compute between the distribution of for and the distribution of for each . Then, we return a list sorted in ascending order of values. The first entry represents the account with the most likely match.
5.2 Study Results
We now present the results corresponding to our four tokens. Then, in the next section, we experiment with some combinations thereof.
5.2.1 Non-Lexical: Rating and Category
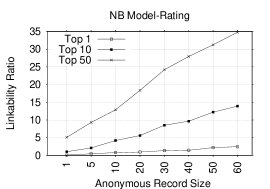
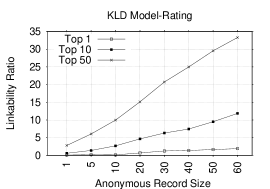
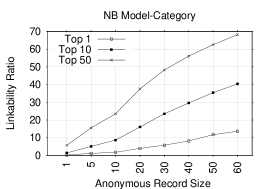
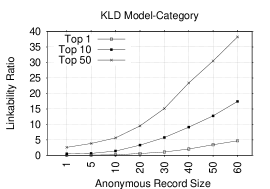
Figure 2 shows Top-1, Top-10, and Top-50 plots of the linkability ratios (LRs) for NB and KLD models for several anonymous record sizes when either rating or category is used as the token. Not surprisingly, an increase in the anonymous record size causes an increase in the LR. Figures 2 and 2 show LRs when rating token alone is used. In the Top-1 plot, LRs are low and the highest ratio is 2.5%/1.9% in NB/KLD for an anonymous record size of 60. However, in Top-10 and Top-50 plots, LRs become higher and reach 13.9%(11.9%) and 34.8%(33.3%) in Top-10 and Top-50 plots, respectively, in NB(KLD) for the same anonymous record size. Figures 2 and 2 show LRs for the category token. In Top-1, the highest LR is 13.6%/4.7% in NB/KLD for anonymous record size of 60. A significant increase occurs in LRs in Top-10 and Top-50 plots: 40.4%(17.4%) and 68.2%(38.3%), respectively, in NB(KLD) model. The category is clearly more effective than the rating token. Additionally, we observe that NB performs better than KLD model, especially, for the category token.
We conclude that rating- and category-based models are only somewhat helpful, yet insufficient to link accounts for many anonymous records. However, it turns out that they are quite useful when combined with other lexical tokens, as discussed in Section 5.3 below.
5.2.2 Lexical: Unigram and Digram
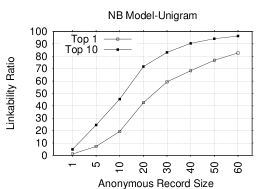
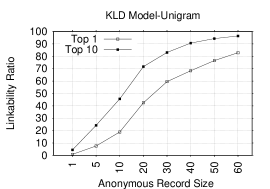
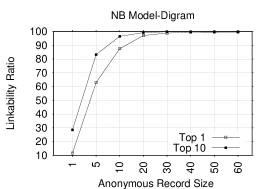
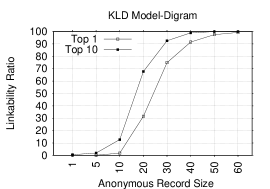
Figures 3 and 3 depict LRs (Top-1 and Top-10) for NB and KLD with the unigram token. As expected, with the increase in the anonymous record size, the LR grows: it is high in both Top-1 and Top-10 plots. For example, in Top-1 of both figures, the LRs are around: 19%, 59% and 83% for anonymous record sizes of 10, 30 and 60, respectively. Whereas, in Top-10 of both figures, the LRs are around: 45.5%, 83% and 96% for same record sizes. This suggests that reviews are highly linkable based on trivial single-letter distributions. Note that the two models exhibit similar performance.
Figures 3 and 3 consider the digram token. In both models, the LR is impressively high: it gets as high as 99.6%/99.2% in Top-1 for NB/KLD for an AR size of 60. For example, the Top-1 LRs in NB are: 11.7%, 62.9%, 87.5% and 97.1%, for respective AR sizes of 1, 5, 10 and 20. Whereas, in KLD, the Top-1 LRs for record sizes of 10, 30 and 60 are: 1.9%,74.9% and 99.2%, respectively.
Unlike unigrams – where LRs in both models are comparable – KLD in digram starts with LRs considerably lower than those of NB. However, the situation changes when the record size reaches 50, with KLD performing comparable to NB. One reason for that could be that KLD improves when the distribution of ARs is more similar to that of corresponding identified records; this usually occurs for large record sizes, as there are more tokens.
Not surprisingly, in both lexical and non-lexical models, larger AR sizes entail higher LRs. With NB, a larger record size implies that, a given AR has more tokens in common with the corresponding IR. Thus, an increase in the prediction probability . For KLD, a larger record size causes the distribution derived from the AR to be more similar to the one derived from the corresponding IR.
5.3 Improvement I: Combining Lexical with non-lexical Tokens
In an attempt to improve the LR, we now combine the non-lexical token with its lexical counterparts.
5.3.1 Combining Tokens Methodology
This is straightforward in the NB. We simply increase the list of tokens in the unigram- or digram-based NB by adding the non-lexical tokens. Thus, for every AR, we have , and .
Combining non-lexical with lexical tokens in KLD is less clear. One way is to simply average values for both token types. However, this might degrade the performance, since lexical distributions convey much more information than their non-lexical counterparts. Thus, giving them the same weight would not yield better results. Instead, we combine them using a weighted average. First, we compute the weighted average of rating and category :
Then, we combine the above with of the lexical tokens to compute the final weighted average:
Thus, our goal is to get the right and values. Intuitively, should have more weight as it carries more information. Since there is no clear way of assigning weight values, we experiment with several choices and pick the one with the best performance; we discuss the selection process below. We experiment only within the IR set and then verify the results generalizes to the AR. This is done as follows:
First, for every IR, we allocate the last 30 reviews as a testing record and the remainder – as a training record. Then, we experiment with using several values and set to the value that yields the highest LR based on the tested records. Then, we experiment with using several values and, similarly, pick the one with the highest LR.
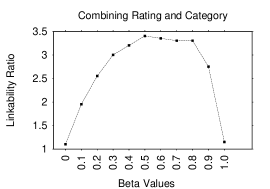
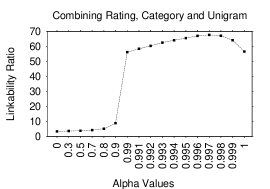
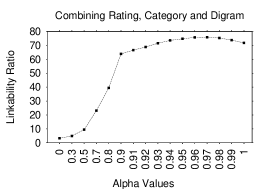
Since or could assume any values, we need to restrict their choices. For , we postulate that its optimal value is close to since LRs for rating and category are comparable. Thus, we experiment with a range of values, from to in increments. For , we expect the optimal value to exceed , since the LR for lexical tokens is significantly higher than for non-lexical ones. Therefore, we experiment with the weighted average by varying between and in increments.
If the values exhibit an increasing trend (i.e., at of 0.99 is the largest in this range) we continue experimenting in the range in increments. Otherwise, we stop. For further verification, we also experiment with smaller values: , all of which yield LRs significantly lower than 0.9 for both the unigram and digram. We acknowledge that we may be missing or values that could further optimize . However, results in sections 5.3.2 and 5.3.3, show that our selection yields good results.
Figure 4 shows LRs (Top-1) for values. The LR gradually increases until it tops off at with and then it gradually decreases. Figure 4 shows LRs (Top-1) for values in the unigram case. The LR has an increasing trend until it reaches with and then it decreases. Figure 4 shows LRs (Top-1) for values in the diagram case where it tops off at with . Thus, the final values are for and / for in the unigram/digram case. Even though we extract and values by testing on a record size of 30, the results in following sections show that the derived weights are effective when tested on ARs of other sizes.
5.3.2 Combining Rating and Category - Results
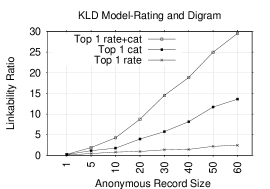
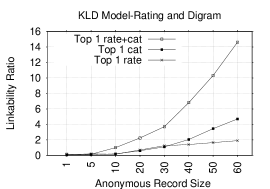
Figures 5 and 5 show Top-1 plots for NB and KLD models when rating and category tokens are combined or used separately. Clearly, combining the tokens significantly improves LRs in several record sizes. In NB, the gain in Top-1 LRs ranges from 2.5-15.9%/3.5-27.1% over the category/rating based model for most record sizes. For example, LRs increase from 5.8(1.4)% and 13.6(2.5)% in category(rating) based model to 14.5% and 29.5% in NB combined model for record sizes of 30 and 60, respectively. In Top-50, the LR could reach as high as 87.7%, versus 68.2(34.8)% in the category (rating) based model for a record size of 60.
In KLD, the gain in Top-1 LRs ranges from 1.7-9.9%/1.6-12.7% over category/rating based model for most record sizes. For example, it leaps from 1.1(1.3)% and 4.7(1.9)% in category (rating) based model to 3.7% and 14.6% in KLD combined model for record sizes of 30 and 60, respectively. The gain is even higher in Top-50 where it reaches 69.1%, versus 38.3(33.3)% in the category (rating) based model for a record size of 60. These results show that combining rating and category tokens is very effective in increasing LRs in both NB and KLD models.
5.3.3 Combining Lexical with Non-Lexical Tokens
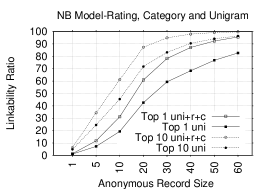
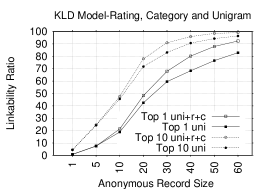
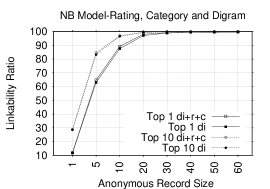
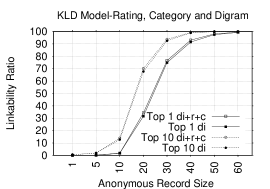
Figures 6 and 6 show Top-1 and Top-10 plots in NB and KLD models of unigram tokens before and after combining them with rating and category tokens. Adding non-lexical tokens to unigrams substantially increases LRs in several record sizes. In NB, the gain in Top-1 LRs ranges from 0.25-18.9% (1.4 - 15.7% for Top-10 LRs). In KLD, the gain in Top-1 LRs ranges from 2.5-11.9 (2-7.8% in Top-10 LRs) for most record sizes. These findings shows how effective is combining the non-lexical tokens with the unigrams. In fact, we can accurately identify almost all ARs.
5.3.4 Restricting Identified Record Size
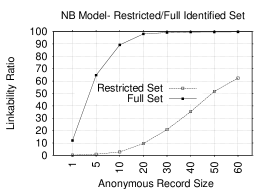
In previous sections, our analysis was based on using the full data set. That is, except for the anonymous part of the data set, we use all of the user reviews as part of our identified set. Although the LR is high in many cases, it is not clear how the models will perform when we restrict the IR size. To this end, we re-evaluate the models with the same problem settings, however, with a restricted IR size. We restrict the IR size to the AR size; both randomly selected without replacement.
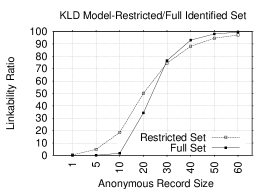
Figures 7 and 7 show two Top-1 plots in NB and KLD models: one plot corresponds to the restricted identified set and the other – to the full set. Tokens used in the models consist of digrams, ratings and categories (since this combination gives the highest LR). Unlike the previous sections, where NB and KLD behaved similarly, the two models now behave differently when restricting the identified set. While NB performs better than KLD on the full set, the latter performs much better than NB when the identified set is restricted. In fact, in some cases, KLD performs better when the set is restricted.
The reason for this improved KLD performance might be the following: in the symmetric KLD distance function, the distributions of both the IR and AR have to be very close in order to match regardless of the size of the IR; unlike the NB, where larger training sets would lead to better estimates of the token probabilities and thus more accurate predictions.
In KLD, we achieve high LRs for many record sizes. For example, Top-1 LRs in the restricted set are 74.5%, 88% and 97.1% when the anonymous (and identified) record sizes are 30, 40 and 60, respectively. Whereas, the LRs in the full set for the same AR sizes are: 76.5% , 93% and 99.4%. When the record size is less than 30, KLD performs better in the restricted set than the full one. For example, when the AR size is 20, the LR in the restricted set is 50.1% and 34.3% in the full set. In NB, Top-1 LR in the restricted set is lower than the full set. For instance, it is 20.8%, 35.3% and 62.4% for AR sizes of: 30, 40 and 60, respectively. Whereas, for the same sizes, the LR is more than 99% in the full set.
This result has one very important implication: even with very small IR sizes, many anonymous users can be identified. For example, with only IR and AR sizes of only 30, most users can be accurately linked (75% in Top-1 and 90% in Top-10). This situation is very common since many real-world users generate 30 or more reviews over multiple sites. Therefore, even reviews from less prolific accounts can be accurately linked.
5.3.5 Improvement II: Matching all ARs at Once
We now experiment with another natural strategy of attempting to match all ARs at once.
5.3.6 Methodology
| Algorithm : Pseudo Code | |
|---|---|
| Input: | (1) Set of ARs: |
| (2) Set of reviewer-ids / identified records: | |
| (3) Set of matching lists for each AR: | |
| Output: | Matching list: |
| 1: | set |
| 2: | While : |
| 3: | Find with smallest in all lists in |
| 4: | Get corresponding reviewer-id |
| 5: | Add to |
| 6: | Delete from |
| 7: | Delete from |
| 8: | For each in , |
| 9: | Delete tuple containing from |
| 10: | End For |
| 11: | End While |
NOTE 1: in is a list of pairs where , for all
NOTE 2: is sorted in increasing order of , i.e., with lowest at the top.
In the previous section, we focused on linking one AR at a time. That is, ARs were independently and incrementally linked to IRs (accounts/reviewer-ids). One natural direction for potential improvements is to attempt to link all ARs at the same time. To this end, we construct algorithm in Figure 8 as an add-on to the KLD models suggested in previous sections.
symmetrically measures the distance between their (’s and ’s) distributions. Since every maps to a distinct ( maps to ), it would seem that lower would lead to a better match. We use this intuition to design . As shown in the figure, picks the smallest as the map between and and then deletes the pair from all remaining lists in . The process continues until we compute all matches. Note that, for any , is deleted from the list only when there is another pair in , such that , and has been selected as the match for .The output of the algorithm is a match-list: .
We now consider how could improve the LR. Suppose that we have two ARs: and along with corresponding sorted lists and and assume that is at the top of each list. Using only KLD, we would return for both ARs and thus miss one of the two. Whereas, , would assign to only one AR – the one with the smaller value. We would intuitively suspect that since is the right match for and thus their distributions would probably be very close. If this is the case, would delete (erroneous match) from the top of which could help clearing up the way for (correct match) to the top of .
We note that there is no guarantee that will always work: one mistake in early rounds would lead to others in later rounds. We believe that works better if () holds most of the time.
In the next section, we show the results of when we experiment with the KLD model with digram, rating and category tokens.222We also tried with the NB model and it did not improve the LR..
5.3.7 Results
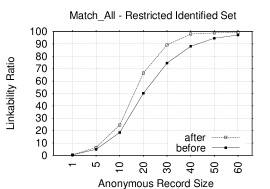
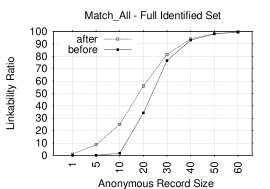
Figures 9 and 9 show the effect of on Top-1 LRs in both the restricted identified set and the full identified set, respectively. The combination of diagram, rating and category tokens are used. Each figure shows two Top-1 plots: one for the LR after using and the other – for the LR before using it. Clearly, is effective in improving the LR for almost all record sizes. For the restricted set, the gain in the LR ranges from 1.6-16.4% for nearly all AR sizes. A Similar increase is observed in the full set that ranges from 1-23.4% for most record sizes. This shows that the is very effective when used with diagram, rating and category tokens. The privacy implication of is important as it significantly increases the LR for small ARs in the restricted set. This shows that privacy of less prolific users is exposed even more with .
5.4 Study Summary
We now summarize the main findings and conclusions of our study.
-
1.
The LR becomes very high – reaching up to 99.5% in both KLD and NB when using only digram tokens. (See Section 5.2.2).
-
2.
Surprisingly, using only unigrams, we can link up to 83% in both NB and KLD models, with 96% in Top-10. (See Section 5.2.2). This suggests that reviewers expose a great deal merely from their single letter distributions.
-
3.
Even with small record sizes, we accurately link a significant ratio of ARs. Specifically, for AR sizes of 5 and 10 (using NB with diagrams), we can accurately link 63% and 88% ARs, respectively. (See Section 5.2.2).
-
4.
Rating and category tokens are more useful if combined where 88%/69% of ARs (size 60) fall into Top-50 in NB/KLD. (See Section 5.3.2).
-
5.
Non-lexical tokens are very useful in tandem with lexical tokens, especially, the unigram: we observe a 19%/12% Top-1 LR increase in NB/KLD for some cases. (See Section 5.3.3).
-
6.
Relying only on unigram, rating and category tokens, we can accurately link 96%/92% of the ARs (size 60) in NB/KLD. (See Section 5.3.3).
-
7.
Restricting the IR size does not always degrade linkability. In KLD, we can link as many as 97% ARs when the IR size is small. (See Section 5.3.4).
-
8.
Linking all ARs at once (instead of each independently) helps improve accuracy. The gain is up to 16/23% in restricted/full set. (See Section 5.3.7).
-
9.
Generally, NB performs better than KLD when we use the full identified set and KLD performs better when we use the restricted identified set.
sectionDiscussion Implications: We believe that the results of, and techniques used in, this study have several implications. First, we demonstrated the practicality of cross-referencing accounts (and reviews) among multiple review sites. If a person contributes to two sites under two identities, it is highly likely that sets of reviews from these sites can be linked. This could be quite detrimental to contributors’ privacy.
The second implication is the ability to correlate – on the same review site – multiple accounts that are in fact manipulated by the same person. This could make our techniques very useful in detecting review spam opinion-spam-analysis , whereby a contributor authors reviews under different accounts to tout (also self-promote) or criticize a product or a service.
Prolific Users: While there are clearly many more occasional (non-prolific) reviewers than prolific ones, we believe that our study of prolific reviewers is important, for two reasons. First, the number of prolific contributors is still quite large. For example, from only one review site – Yelp – we identified such reviewers. Second, given the spike of popularity of review sites yelpstat , we believe that, in the near future, the number of such prolific contributors will grow substantially. Also, even many occasional reviewers, with the passage of time, will enter the ranks of “prolific” ones, i.e., by slowly accumulating a sufficient corpus of reviews over the years. Nevertheless, our study suggests that privacy is not high even for non-prolific users, as discussed in Section 5.3.5. For example, when both IR and AR sizes are only 20 (i.e., total per user contribution is 40 reviews), we can accurately link half of anonymous records to their reviewers.
Anonymous Record Size: Our models perform best when the AR size is 60. However, for every reviewer in our dataset, 60 represents less than 20% of that person’s total number of reviews. Also, using NB coupled with digram, rating and category tokens, we can accurately link most anonymous records when the AR size is only 10. Interestingly, the AR size of 10 represents only 3% of the minimum user contribution.
Unigram Tokens: While our best-performing models are based on digram tokens, we also obtain high linkability results from unigram tokens that reach up to 83% (96% in the Top 10) in NB or KLD. The results improve to 96/92% when we combine unigrams with rating and category tokens. Note that the number of tokens in unigram-based models is 59 (26) tokens with (without) combining them with rating and category tokens. Whereas, the number of tokens in diagram-based models is 676 (709 when combined with rating and category tokens). This makes linkability accuracy based on unigram models very comparable to its diagram counterpart, while the number of tokens is significantly fewer. This implies a substantial reduction in resources and processing power in unigram-based models which would make them scale better. For example, if we assume that the attacker wants to link a set of anonymous reviews to many large review datasets, unigram-based models would scale better, while maintaining the same level of accuracy.
Potential Countermeasures: One concrete application of our techniques is via integration with the review site’s front-end software in order to provide feedback to authors indicating the degree of linkability of their reviews. For example, when the reviewer logs in, a linkability nominal/categorical value (e.g. high, medium, and low) could be shown indicating how his/her last reviews (where is small, e.g., 5 or 10) are linkable to the rest. It would then be up to to the individual to maintain or modify their reviewing patterns to be less linkable. Another way of countering linkability is for the front-end software to automatically suggest a different choice of words that are less revealing (less personal) and more common among many users. We suspect that, with the use of such words, reviews would be less linkable and lexical distributions for different users would be more similar.
6 Future Work
Although our results point at high linkability of reviews, there remain many open questions. First, the anonymous records are not highly linkable when their sizes are very small, e.g., 1 or 5. As part of future work, we plan to improve linkability on very small anonymous records. In addition, although we take advantage of ratings and categories to boost LRs, we need to further explore usage of other non-textual features, such as sub-categories of places, products and services reviewed as well as the length of reviews. In fact, it would be interesting to see how the LR can be improved without resorting to lexical features, since they generally entail heavy processing. We also plan to implement countermeasures techniques described in Section 5.4 and examine their efficacy.
Moreover, we plan to investigate LRs in other preference databases, such as music/song ratings, and check whether contributors inadvertently link their reviews through preferences. It would be interesting to see how to leverage techniques used in recommender systems (for future rating prediction) to increase LRs.
In Section 5.3.5, we showed how to improve LRs by linking all anonymous records at once. We intend to further investigate the effect on the LR of the number anonymous records when each record belongs to a different reviewer.
7 Related Work
Many authorship analysis studies have appeared in the literature. Among the most prominent recent studies are: unified-data-mine ; author-ident-framework-rong ; writeprints-abbasi . The study in unified-data-mine proposed techniques that extract frequent pattern write-prints that characterized one (or a group of) authors. The best achieved accuracy was 88% when identifying an author, from a single anonymous message, from a small set of four and with training set size of forty messages per author. In author-ident-framework-rong , a framework for author identification for on-line messages was introduced where four types of features are extracted: lexical, syntactic, structural and content-specific. Three types of classifiers were used for author identification: Decision Trees, Back Propagation Neural Networks and Support Vector machines. The last one outperformed the others, achieving 97% in a set of authors less than 20. The work in writeprints-abbasi also considered author identification and similarity detection by incorporating a rich set of stylistic features along with a novel technique(based on Karhunen-Loeve-transforms) to extract write-prints. These techniques performed well, reaching as high as 91% in identifying the author of anonymous text from a set of 100. The same approach was tested on a large set of Buyer/Seller Ebay feedback comments collected from Ebay. Such comments typically reflect one’s experience when dealing with a buyer or a seller. Unlike our general-purpose reviews, these comments do not review products, services or places of different categories. Additionally, the scale of the problem was different and the analysis was performed for 100 authors, whereas, our analysis involved reviewers.
A problem very similar to ours was explored in herbert-deanonymizer . It focused on identifying authors based on reviews in both single- and double-blinded peer-reviewing processes. Naïve Bayes classifier was used – along with unigrams, bigrams and trigrams – to identify authors and the best result was around 90%. In blind-review , citations of a given paper were used to identify its authors. The data set was a very large archive of physics research papers (KDDCUP 2003 physics-paper archive). Authors were identified 40-45% of the times. In ngram-bayes-topic-fixed , authorship analysis was performed on a set of candidate authors who wrote on the same topics. Specifically, analysis was done on movie reviews of five reviewers on the same five movies. Although reviews similar to ours were used, there were significant differences. We use over reviews by authors, whereas, only 25 reviews by 5 authors were used in ngram-bayes-topic-fixed . A related result gender-movie studied the problem of inferring the gender of a movie reviewer from his/her review. Using logistic regression log-regress along with features derived from the writing style, content, and meta-data of the review, accuracy of up to 73.7% was achieved in determining the correct gender. The goal of this study was clearly quite different from ours. For a comprehensive overview of authorship analysis studies, we refer to author-survey .
While all aforementioned results are somewhat similar to our present work, there are some notable differences. First, we perform authorship identification analysis in a context that has not been extensively explored – user reviews. User reviews are generally written differently from other types of writing, such as email and research papers. In a review, the author generally assesses something and thus the text conveys some evaluation and personal opinions. A review usually conveys information about personal taste, since most people tend to review things of interest to them. In addition, reviews contain other non-textual information, such as the ratings and categories of things being reviewed. These types of extra information provide added leverage; recall that, as discussed earlier, ratings and categories are particularly helpful in increasing the overall linkability ratio. Second, our problem formulation is different. We study linkability of reviews (and user-ids of their authors) in the presence of a large number of prolific contributors where the number of anonymous reviews could be more than one (up to 60 reviews). Whereas, most prior work attempts to identify authors from a small set of authors, each with small sets of texts where the number of anonymous documents/messages is one.
Some work has been done in recovering authors based on their ratings, using external knowledge. In particular, you-what-u-say studied author linkability with two different databases; one public and the other – private. Several techniques were used to link authors in public forums (public) who state their opinions and rating about movies to reviewers who contribute to a sparse database (private) of movie ratings. A related result deanonymize-netflix considered anonymity in high-dimensional and sparse data sets of anonymized users. First, it presented a general definition and model of privacy breaches in such sets.Second, a statistical de-anonymization attack was presented that was resilient to perturbation. Third, this attack was used to de-anonymize the Netflix netflix data set. Note that the problem formulation of these two results differs from ours. They studied anonymity in the presence of an external source of public information. Whereas, our work does not rely on any external sources.
Last but not least, other related research effort assessed authenticity of reviews opinion-spam-analysis . It explored the problem of identifying spam. Results demonstrated that spam reviews were prevalent and a counter-measure based on logistic regression was proposed.
8 Conclusion
Large numbers of Internet users are becoming frequent visitors and contributors to various review sites. At the same time, they are concerned about their privacy. In this paper, we study linkability of reviews. Based on a large set of reviews, we show that a high percentage (99% in some cases) are linkable, even though we use very simple models and very simple features set. Our study suggests that users reliably expose their identities in reviews. This has certain important implications for cross-referencing accounts among different review sites and detecting people who write reviews under different identities. Additionally, techniques used in this study could be adopted by review sites to give contributors feedback about linkability of their reviews.
References
- [1] Netflix. http://www.netflix.com.
- [2] Yelp By The Numbers. http://officialblog.yelp.com/2010/12/2010-yelp-by-the-numbers.html.
- [3] Yelp Elite Squad. http://www.yelp.com/faq#what_is_elite_squad.
- [4] A. Abbasi and H. Chen. Writeprints: A Stylometric Approach to Identity-Level Identification and Similarity Detection in Cyberspace. In ACM Transactions on Information Systems, 2008.
- [5] C. M. Bishop. Pattern Recognition and Machine Learning. Springer, 2006.
- [6] K. Dave, S. Lawrence, and D. M. Pennock. Mining the Peanut Gallery: Opinion Extraction and Semantic Classification of Product Reviews. In international conference on World Wide Web, 2003.
- [7] D. Frankowski, D. Cosley, S. Sen, L. Terveen, and J. Riedl. You Are What You Say: Privacy Risks of Public Mentions. In International ACM SIGIR Conference on Research and Development in Information Retrieval, 2006.
- [8] S. Hill and F. Provost. The Myth of the Double-Blind Review?: Author Identification Using Only Citations. In SIGKDD Explorations Newsletter, 2003.
- [9] M. Hu and B. Liu. Mining and Summarizing Customer Reviews. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2004.
- [10] F. Iqbal, H. Binsalleeh, B. Fung, and M. Debbabi. A unified data mining solution for authorship analysis in anonymous textual communications. In Information Sciences (INS): Special Issue on Data Mining for Information Security, 2011.
- [11] N. Jindal and B. Liu. Opinion Spam and Analysis. In ACM International Conference on Web Search and Data Mining, 2008.
- [12] N. Jindal, B. Liu, and E.-P. Lim. Finding Unusual Review Patterns Using Unexpected Rules. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, 2010.
- [13] D. Lewis. Naive(bayes) at forty:the independence assumption in information retrieval. In Proceedings of the 10th European Conference on Machine Learning, 1998.
- [14] E.-P. Lim, V.-A. Nguyen, N. Jindal, B. Liu, and H. Lauw. Detecting Product Review Spammers using Rating Behaviors. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, 2010.
- [15] S. Menard. Applied Logistic Regression Analysis. In Sage University Press, 2002.
- [16] T. Mitchell. Machine Learning. McGraw Hill, 1997.
- [17] M. Nanavati, N. Taylor, W. Aiello, and A. Warfield. Herbert West – Deanonymizer. In 6th USENIX Workshop on Hot Topics in Security, 2011.
- [18] A. Narayanan and V. Shmatikov. Robust De-anonymization of Large Sparse Datasets. In IEEE Symposium on Security and Privacy, 2009.
- [19] J. Otterbacher. Inferring Gender of Movie Reviewers: Exploiting Writing Style, Content and Metadata. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, 2010.
- [20] B. Pang, L. Lee, and S. Vaithyanathan. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Empirical Methods on Natural Language Processing Conference, 2002.
- [21] D. S. Ross Clement. Ngram and Bayesian Classification of Documents for Topic and Authorship. In Literary and Linguistic Computing, 2003.
- [22] E. Stamatatos. A Survey of Modern Authorship Attribution Methods. In Journal of the American Society for Information Science and Technology, 2009.
- [23] S. Yadav, A. K. Reddy, A. N. Reddy, and S. Ranjan. Detecting Algorithmically Generated Malicious Domain Names. In Internet Measurement Conference, 2010.
- [24] R. Zheng, J. Li, H. Chen, and Z. Huang. A Framework for Authorship Identification of Online Messages: Writing Style Features and Classification Techniques. In Journal of the American Society for Information Science and Technology, 2006.