Exploring the Impact of Temperature Scaling in Softmax for Classification and Adversarial Robustness
Abstract
The softmax function is a fundamental component in deep learning. This study delves into the often-overlooked parameter within the softmax function, known as "temperature," providing novel insights into the practical and theoretical aspects of temperature scaling for image classification. Our empirical studies, adopting convolutional neural networks and transformers on multiple benchmark datasets, reveal that moderate temperatures generally introduce better overall performance. Through extensive experiments and rigorous theoretical analysis, we explore the role of temperature scaling in model training and unveil that temperature not only influences learning step size but also shapes the model’s optimization direction. Moreover, for the first time, we discover a surprising benefit of elevated temperatures: enhanced model robustness against common corruption, natural perturbation, and non-targeted adversarial attacks like Projected Gradient Descent. We extend our discoveries to adversarial training, demonstrating that, compared to the standard softmax function with the default temperature value, higher temperatures have the potential to enhance adversarial training. The insights of this work open new avenues for improving model performance and security in deep learning applications.
I Introduction
Deep learning has achieved dramatic breakthroughs in recent years, excelling in tasks such as image classification [12], nature language processing (NLP) [5], and semantic segmentation [27]. A critical component of most deep learning methods is the softmax function, which normalizes a set of real values into probabilities. The generalized softmax function incorporates a parameter known as "temperature," which controls the softness of the output distribution. Despite its importance in theory, the impact of temperature scaling on classification tasks has been relatively underexplored, particularly in contrast to its use in other areas such as knowledge distillation [8], contrastive learning [24], confidence calibration [21], and natural language processing. Specifically, though the temperature scaling has occasionally been applied in prior experimentation [23, 6, 10], these studies often integrate additional complex techniques such as Gaussian noise injection in [23], adversarial training in [6, 22], and innovative quadratic activation functions in [10], making it challenging to isolate and understand the specific contribution of temperature scaling to the overall system performance. Consequently, the specific role of temperature in classification tasks remains ambiguous. Previous study by [1] has hinted at the potential benefits of temperature scaling, but a comprehensive investigation is still lacking.
This study aims to fill this gap by conducting extensive experiments to explore the practical and theoretical aspects of temperature scaling in the softmax function for image classification. We employ convolutional neural networks (CNNs) and transformers on multiple benchmark datasets, including CIFAR-10 [11], CIFAR-100 [11], and Tiny-ImageNet [16], to systematically analyze the effects of different temperature values. Our empirical results consistently show that moderate temperatures generally improve overall performance, challenging the conventional knowledge derived from contrastive learning that low temperature facilitates representation learning.
We also delve into the theoretical underpinnings of temperature scaling in model training. Our analysis reveals that temperature not only influences the learning step size but also shapes the model’s optimization direction. Specifically, lower temperatures focus the model’s learning on error-prone classes, while higher temperatures promote a more balanced learning across all classes. This insight is crucial for understanding the nuanced effects of temperature scaling on model optimization.
Furthermore, we uncover a surprising benefit of elevated temperatures: enhanced model robustness against common corruptions, natural perturbations, and non-targeted adversarial attacks, such as Projected Gradient Descent (PGD). We extend our investigation to adversarial training introduced by [18], demonstrating that higher temperatures can potentially enhance the robustness of models trained with adversarial methods compared to those using the standard softmax function with the default temperature.
In summary, this work provides new perspectives on the practical applications and theoretical implications of temperature scaling in the softmax function. Our contributions can be summarized as follows:
-
•
We conduct extensive experiments demonstrating that applying a reasonably large temperature during model training improves overall performance.
-
•
We discover that models trained with elevated temperatures exhibit enhanced robustness against gradient-based untargeted adversarial attacks.
-
•
Additionally, we show the potential of integrating temperature control into adversarial training to boost model performance and security in deep learning applications.
II Related Works
The softmax function has been a longstanding component of neural networks, usually used to normalize a vector of real values into probabilities. Modulating the temperature scaling factor within the softmax function allows for reshaping the probability distribution. This section provides a concise overview of the application of temperature scaling in various computational tasks.
Knowledge Distillation proposed by [8] is one innovative way to transfer knowledge from a teacher model to a student model. Temperature is utilized during training to control both the student and teacher model’s output. The author argues that lower temperatures make the distillation assign less weight to logits that are much smaller than the average. Conversely, employing larger temperatures softens the probability distribution and pays more attention to the unimportant part of the logit. Larger temperatures are proven to be beneficial in the distillation process since the hard-target term already ensures the dominant part of the logit (target class) is correct. By focusing on the remaining logit, the student model can capture more fine-grained information from the teacher model. Note that despite various temperatures used during training, it is set to 1 when the model is deployed.
Model Confidence Calibration usually utilizes temperature scaling to address the over-confident issue in deep learning [7, 15, 19]. It centers on estimating predictive uncertainty to match its expected accuracy [14, 13]. Despite multiple generic calibration methods being proposed, temperature scaling proposed by [7] remains a baseline method for being simple, effective and able to apply to various cases without major expense. The motivation behind temperature scaling is simple, since the goal is to control the network’s confidence to match its accuracy, applying temperature to the softmax function that can directly modify the probability distribution seems a perfect fit for the problem. During training, a validation set is needed to find the ideal temperature parameter for the network, and the same temperature is used when deployed.
Contrastive Learning is one paradigm for unsupervised learning [20, 26]. To achieve a powerful feature encoder, it utilizes contrastive loss to pull similar samples close and push negative pairs away in the latent space. Although the temperature has long existed as a hyper-parameter in contrastive loss, its actual mechanism is just understudied recently. [24] analyze the contrastive loss closely and find that as the temperature decreases, the distribution of the contrastive loss becomes sharper, which applies larger penalties to samples similar to the anchor data. Also, uniformity of feature distribution increases, indicating the embedding feature distribution aligns with a uniform distribution better [25].
Temperature Scaling in Image Classification has occasionally been utilized in the experimental sections of prior studies, yet focused investigations on this subject remain limited. For example, previous studies aiming to improve adversarial robustness have utilized temperature scaling to adjust logits within their experimentation [23, 6, 10]. However, these studies often integrate additional complex techniques such as Gaussian noise injection [23], adversarial training [6, 22], and innovative quadratic activation functions [10], making it challenging to isolate and understand the specific contribution of temperature scaling to the overall system performance. In contrast, our study narrows its focus to investigating the direct impact of temperature scaling applied through the softmax function on model optimization processes. Among the few related works, "The Temperature Check" by [1] is notably relevant to our discussion. It mainly explores the dynamics of model training by considering factors such as temperature, learning rate, and time, and presents an empirical finding that a model’s generalization performance is significantly influenced by temperature settings. While our observations align with these findings, our research approaches the issue from a different perspective of gradient analysis. Specifically, we delve into how temperature scaling impacts model optimization process. Furthermore, our study broadens the scope of inquiry by assessing the effect of temperature scaling on a model’s resilience to common corruptions and adversarial attacks, thereby adding a new dimension to the existing research.
III Preliminary
III-A Softmax Function
Given a set of real numbers, , the generalized softmax function can be used to normalize into a probability distribution.
| (1) |
where represents the softmax function and is the temperature scaling factor. The temperature controls the smoothness (softness) of the probability it produces. Specifically, when , the output tends toward a uniform distribution; while when , the softmax function assigns a probability of 1 to the element with the highest value and a probability of 0 to the rest. The standard (unit) softmax function, with , is widely used in conventional classification tasks.
III-B Problem Definition and Notation
We consider multi-category classification in this study, where paired training data are drawn from a data distribution . Here, are the dimension of a sample , is the number of categories, and is a one-hot vector indicating the class of the input . A classifier, , is a function predicting the label for a given data . That is . In the canonical classification setting, a neural network classifier, , is usually composed of a feature extractor parameterized by and a weight matrix . is a function mapping the input to a real-valued vector in the model’s penultimate layer and represents the coefficients of the last linear layer before the softmax layer. So the likelihood probability of data corresponding to the categories can be formulated as
| (2) |
Note that each vector in matrix can be considered as the prototype of class and the production in Eqn. 2 quantifies the similarity between the feature and different class-prototypes.
During training, the model is optimized to minimize a specific loss, usually a Cross-Entropy (CE) loss.
| (3) |
Though is the default setting in classification tasks, we preserve in the Eqn.s to facilitate theoretical analysis.
IV Gradient Analysis
To investigate the impact of temperature scaling factors for model optimization in classification tasks, we calculate the loss gradients with respect to the training parameters in the model. Specifically, given a data sample from the category, we refer to as the positive class prototype and the rest, for , as the negative class prototypes. Then the gradients with respect to the positive class prototype, negative class prototypes, and the encoder are:
| (4) |
| (5) |
| (6) |
Learning rate: In Eqn. 4, 5, 6, since , the actual learning rate is inversely proportional to the temperature . That is, larger temperatures lead to a reduced gradient step in model update, while smaller temperatures not only increase the gradient step. Furthermore, when the sample is misclassified, smaller temperatures give a further boost on updating and for , because smaller temperatures in softmax function lead to shaper distributions.
Optimization direction: From Eqn. 4, the positive class prototype is updated toward in the latent space. In contrast, the negative prototypes move away from the direction of according to Eqn. 5. The optimization direction of is a weighted sum of all class prototypes, as shown in Eqn. 6. The fundamental optimization policy is to update the trainable parameters of the encoder in such a way that moves closer to the positive class prototype and farther away from the negative class prototypes in the latent space. However, when we take the temperature parameter into account, we find that temperature has an impact on the update direction of . Specifically, when the temperature is low, the probability distribution produced by the softmax function is sharper, leading to significant differences in probability values among different prototypes. Consequently, the update direction of the encoder is predominantly influenced by the class prototype with the highest probability and the positive class prototype (if they are different). Fig. 1(a) visualizes the bias toward the hard class in model optimization, where is the latent code of a data sample from category 3. In contrast, when the temperature is high, the differences in probability values among different prototypes are relatively smaller, and the encoder updates with a mixture of all class prototype directions, as demonstrated in Fig. 1(b). In other words, a low temperature makes the model focus on learning hard-class pairs, while a high temperature de-biases the influence among different classes for a balanced learning.

Moreover, when considering all the samples in one batch, the compound gradient of all samples are
| (7) |
| (8) |
| (9) |
Similar to the single sample case, when optimizing in a whole batch, with small temperatures, the model focuses on learning misclassified samples (i.e. hard samples), whereas higher temperatures help de-bias the update direction and distribute similar weight to all samples.


V Empirical Analysis and Discussion
As discussed in Section 4, applying a small temperature encourages a model to learn more about hard (misclassified) samples and hard (error-prone class) classes. A low temperature, however, leads to more equitable learning across different classes and data points. Theoretically, both approaches to optimize feature distribution sound reasonable, with low temperatures focusing on weaker classes and high temperatures decreasing inequality across all negative classes. We argue that which optimization strategy is better for classification tasks remains an empirical problem.
V-A Experiment Setting
We conduct image classification on multiple benchmarks (i.e. CIFAR10, CIFAR100, and Tiny-ImageNet) and their extended Common Corruptions and Perturbations sets (i.e. CIFAR10-C, CIFAR100-C, and Tiny-ImageNet-C with corruption strentgh being 3) to investigate the impact of temperature scaling. In addition, we also evaluate the model’s robustness against adversarial attacks such as PDG20 [18] and C&W [2]. Both attacks are bounded by the box with the same maximum perturbation .
To get a comprehensive evaluation, we set . Unless stated otherwise, we takes ResNet50 and VIT-small-patch16-224 as the CNN and transformer backbones, respectively. The ResNet50 is trained from scratch, with SGD optimizer and learning rate setting to 0.1. We also utilize the Cosine Annealing scheduler to better train the model. The transformer is pretrained on ImageNet-21K and finetuned on the target dataset using Adam optimizer. All experiments run on one RTX3090.
To clarify, the temperature scaling only involves in model training in this study, but not model evaluation and attacks. All empirical evaluation and adversarial sample generation by PGD and C&W are based on the standard cross entropy, i.e. . Thus, attack gradients are not attenuated, reflecting model’s true sensitivity to data perturbation.
V-B Experiment Results
The quantitative results on CNN and Transformer are summarized in Table I and Table II, respectively. For the CNN model, ResNet50, training from scratch, the standard accuracy increases with the temperature increase. Furthermore, CNN models trained at elevated temperatures show more robustness against naturally corrected images. We believe that such improvements are majorly attributed to better model optimization with leveraged temperature. For the transformer finetuned on the target set, the standard accuracy and robustness against natural corruptions and perturbations is quite stable. We hypothesize that such stable performance is due to the fact that ViT has already been pre-trained on ImageNet and has reached a relatively high-quality state. Additionally, we observed that the model’s adversarial robustness gradually improves with increasing temperature.
Clustering is a crucial metric when measuring how an encoder performs. In classification, a good encoder should be able to gather samples from the same class while separating clusters of different classes. Fig. 2 and Fig. 3 present 2D TSNE visualization of the CIFAR10 sample distribution by ResNet50 and transformer. We observe a similar trend: low temperatures lead to more mixed clusters, while models trained with elevated temperatures have better cluster effects. These empirical observations also explain the improved classification performance on clean and non-adversarial perturbations, as well as stronger adversarial robustness, with high temperature in Table I and Table II.
| Temp. | CIFAR10 | CIFAR100 | Tiny-Imagenet | |||||||||
| Clean | -C | PGD20 | C&W | Clean | -C | PGD20 | C&W | Clean | -C | PGD20 | C&W | |
| 90.05 | 73.31 | 0 | 27.79 | 70.39 | 44.52 | 0 | 14.32 | 54.53 | 12.63 | 0 | 23.17 | |
| 94.17 | 72.51 | 0 | 16.03 | 74.79 | 45.41 | 0 | 8.44 | 61.07 | 18.55 | 0 | 19.44 | |
| 94.26 | 72.53 | 0 | 19.19 | 74.58 | 46.47 | 0 | 11.26 | 62.93 | 18.66 | 0 | 19.09 | |
| 95.41 | 73.94 | 0.56 | 39.79 | 78.21 | 50.67 | 0.29 | 15.33 | 64.70 | 21.66 | 2.59 | 23.88 | |
| 95.26 | 74.93 | 91.09 | 43.35 | 78.27 | 50.17 | 68.47 | 18.81 | 63.60 | 21.30 | 49.45 | 26.50 | |
| 94.92 | 74.44 | 93.04 | 36.13 | 77.97 | 49.87 | 72.92 | 20.50 | 62.85 | 20.40 | 54.95 | 28.68 | |
| 95.05 | 74.26 | 93.85 | 35.43 | 77.20 | 49.61 | 73.49 | 21.66 | 62.14 | 20.57 | 55.54 | 30.14 | |
| 95.05 | 73.08 | 94.29 | 37.32 | 77.14 | 49.31 | 73.65 | 22.83 | 61.46 | 18.82 | 54.60 | 32.71 | |
| Temp. | CIFAR10 | CIFAR100 | ||||||
| Clean | -C | PGD20 | C&W | Clean | -C | PGD20 | C&W | |
| 98.45 | 92.83 | 0 | 26.13 | 89.79 | 74.7 | 0 | 23.71 | |
| 98.33 | 91.60 | 0 | 26.26 | 90.53 | 74.9 | 0 | 29.25 | |
| 98.29 | 92.21 | 0 | 31.69 | 90.78 | 75.5 | 0 | 31.97 | |
| 98.06 | 92.19 | 89.07 | 31.89 | 89.94 | 75.5 | 58.71 | 34.96 | |
| 98.23 | 91.72 | 97.10 | 38.21 | 89.52 | 74.6 | 86.25 | 36.07 | |
| 98.22 | 91.43 | 97.75 | 39.52 | 89.28 | 73.8 | 87.29 | 33.64 | |
| 98.03 | 91.20 | 97.72 | 39.02 | 89.48 | 74.2 | 87.96 | 33.81 | |
| 98.07 | 91.56 | 97.87 | 38.26 | 89.13 | 73.47 | 86.99 | 31.84 | |
V-C Training Convergence
We then conduct experiments observing the training process when applying different temperatures to the model. We validate the model on the test set every epoch and record the error probability. As our results shown in Fig. 4(a), we can clearly observe that not only does the training convergence speed increase as the temperature goes up, but models trained with higher temperatures also tend to converge to lower points, leading to better final performance. In fact, when we further decrease the temperature to around 0.1, the model would have a substantial risk of not converging at all. While this might appear contrary to the common understanding that focusing on hard classes will generally benefit the model, a more nuanced explanation is provided by delving further into the gradient analysis provided in Section 4.

From Eqn. 4, 5, 6, we observe that if the logit of the target class is not the largest, its gradient will increase dramatically with low temperatures. This is potentially bad for models being known to converge inefficiently under large learning rates. One straightforward solution would be lowering the learning rate as shown in Fig. 4. While the training converging speeds are closer, the run with a higher temperature can still reach a better performance. Furthermore, regardless of the increase in overall training converging speed for and runs when lowering the learning rate, the final performances for all three runs actually get worse than runs with 0.1 learning rate. Therefore, this phenomenon cannot be attributed solely to a high learning rate. However, if we shift our perspective to the overall direction for optimization as done in Eqn. 9, it becomes clear that during the early stage of training, the encoder has not converged to an ideal point, leading to sub-optimal values produced for certain update directions. If this happens to be the direction of the target class and the error-prone class which models with small temperatures tend to focus on, the model training can be impacted harmfully. In the meantime, high temperatures equalize the weight given to all the classes and ensure the update is not terribly wrong even if a few are in the wrong direction. Upon reaching this conclusion, we are surprised to find that this reasoning and our empirical observations align perfectly with the curriculum learning philosophy, that starting from hard samples may harm model optimization and learning outcomes.

V-D Adversarial Robustness
Table I and Table II show that models trained with elevated temperatures have strong adversarial robustness. TSNE plots in Fig. 2 and Fig. 3 also support this observation. This prompts questions regarding the mechanism behind the gained robustness. In this section, our focus is on investigating the model’s behavior under adversarial attacks and understanding why the model demonstrates such robustness.
Gradient analysis for adversarial generation. In order to discern the source of model robustness, we follow the work in [9] and study the gradient of the classification loss with respect to the input to analyze the direction of the PGD attack, which can be written as
| (10) |
As illustrated above, given a well-trained model, for most inputs where , the gradient does not have a noticeable portion in target class on the early stage of the attack. This implies that rather than directly ’stepping away’ from the target class, the attack will initially focus on approaching other class prototypes. Moreover, the second term, , indicates that all the other directions are weighted by their according probabilities. Therefore, untargeted attacks are actually targeted toward the error-prone class, which most commonly is the largest probability class other than the target class. However, if a model lacks an error-prone class given an input, all will be weighted equally. Consequently, the gradient would point toward all negative class prototypes, making it exceptionally challenging to determine the optimal direction. We noticed that such a scenario occurs when a model is trained with a small . Then let’s focus on the gradient update strength. For a data sample is classified correctly, would be small when the model training temperature increases. That is, when a model is trained with high temperatures, not only the gradient direction to generate adversarial samples is not clear, but the gradient strength is also small. Both factors contribute to the robustness of the model when optimized with elevated temperatures.
Raw Logit Analysis. With the insight from the gradient analysis on adversarial attack, we then turn to observe the logit output around the adversarial attack, as shown in Fig. 5. Each bar represents the logit value for each class, blue bars stand for the logit outputs of clean samples and orange bars are the logit outputs from adversarial samples. Models share similar characteristics in low temperatures, Fig. 5(a,b), with the logit of the target class going down while the logit of the error-prone class going up. However, for models trained with large temperatures, Fig. 5(c,d), two logits are nearly identical with a minimal amount of changes. This contrasts the robustness gains during adversarial training, where the model learns the pattern of the adversarial noise.

Class Prototypes Analysis. To further analyze the model behavior, we investigate the relation between the encoded feature, , and each class prototype, . Here, we observe the Euclidean distance and cosine similarity. Fig. 6 shows Euclidean distance and cosine similarity between one sample and all class prototypes. It is evident that as the training temperature goes up, the feature tends to have an identical distance to all negative class prototypes. This indicates the model trained with high temperature is less likely to have an error-prone class, which is essential for untargeted attacks as we discuss above.
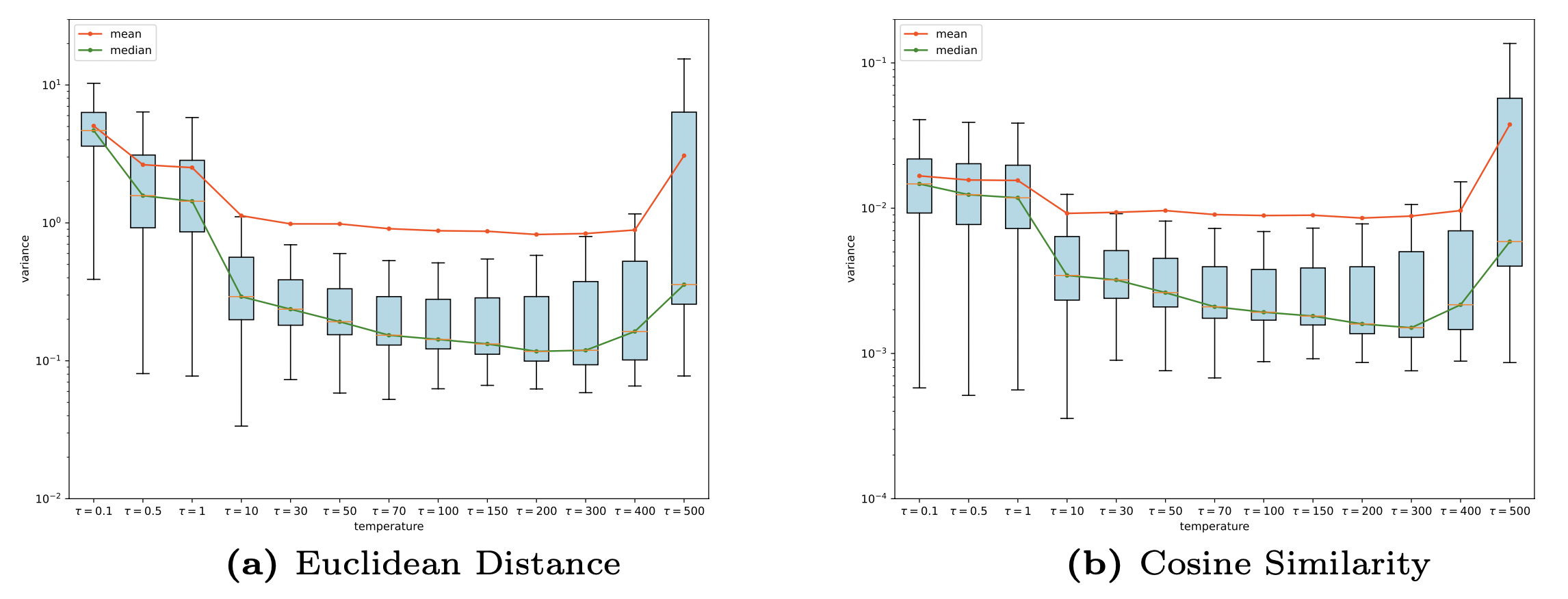
Furthermore, to illustrate that the phenomenon shown in Fig. 6 is not limited to one or a few samples, we calculate the variance of Euclidean distance and cosine similarity of all negative class prototypes across all samples in CIFAR10 test set. Note that as illustrated in Fig. 6, different models have very different ranges for Euclidean distance between encoded feature and class prototypes. Therefore, we map the value of different models into the same range to make a more direct comparison. Box plots are drawn in Fig. 7 showing the overall variance results with each box being a model trained with a different temperature. We can observe a clear trend that when the temperature rises, the variance for both Euclidean distance and cosine similarity drops indicating the encoded sample, , has a more similar distance to all negative class prototypes. One might notice an increase in variance when the temperature reaches some threshold. We label them as extreme temperatures, which are so large that they can adversely affect the model’s convergence.
V-E Further Discussion on Adversarial Robustness
Despite the model trained with high temperatures showing superb robustness against untargeted PGD attack due to its nature attribute that discovers the weakness of PGD attack, it does not hold robustness against targeted attacks. The reason behind this is straightforward. In targeted attacks, Eqn. 10 no longer holds, and the gradient is not obligated to move towards all negative class prototypes with a weighted step size. Therefore, with the only source of the model robustness gained eliminated, it is naturally vulnerable to targeted attacks.
Remark: Even though many attacks claim themselves to be untargeted attacks, they actually optimize toward one self-selected target, which we do not consider untargeted attacks under this setting. One popular example is the Difference of Logits Ratio(DLR) attack proposed by [4]. Regardless of its ability to rescale the logit,
| (11) |
shows that the DLR loss automatically selects the class holding the largest logit other than the target class as the attack target. Therefore, during optimization, it does not need to optimize toward all negative class prototypes. A similar example also includes FAB attack [3].
V-F Extended Experiment on Adversarial Training
Given that our temperature control method is used inside the Cross-Entropy Loss, it is possible to apply this method in adversarial training. Here, we do preliminary experiments on the adversarial training baseline proposed by [18] for the simplicity of its loss function. We add temperature control inside vanilla loss term forming
| (12) |
where is a combination of encoder and class prototypes.
| Temp. | |||||||
| Clean | 88.98 | 85.67 | 81.71 | 82.62 | 83.75 | 84.28 | 84.27 |
| PGD20 | 35.93 | 42.63 | 40.95 | 44.96 | 48.61 | 49.16 | 48.53 |
Our preliminary results are listed in Table III. We can clearly observe that model robustness increases as the temperature increases with a slight trade-off with clean accuracy, which confirms the possibility of combining the temperature control method with adversarial training. While further extension to other adversarial training methods is possible, it remains a complex problem for most adversarial training involves complex loss functions that may introduce terms other than the Cross-Entropy function. Also, balancing the vanilla loss term and adversarial loss term largely relies on empirical experiments. Therefore, further exploration of fitting this into other adversarial training methods falls beyond the scope of this paper.
VI Conclusion & Limitation
In this paper, we investigate the under-explored property of temperature scaling with the softmax function on image classification tasks. By performing gradient analysis with the Cross-Entropy classification loss and executing different empirical experiments, we show that temperature scaling can be a significant factor in model performance. Further experiments reveal applying high temperatures during training introduces enormous robustness against gradient-based untargeted adversarial attacks. We hope our work raises the interest of other researchers to utilize the simple temperature scaling in the common Cross-Entropy loss.
One limitation of this study was that we didn’t report an explicit algorithm to set the best temperature values. We will work on this in our future work. One takehome note, as a hyperparameter, the tuning cost of the tempeerature is low as a wide range of temperatures (30 to 70) can provide improvements to the model.
References
- [1] Agarwala, A., Pennington, J., Dauphin, Y.N., Schoenholz, S.S.: Temperature check: theory and practice for training models with softmax-cross-entropy losses. CoRR abs/2010.07344 (2020)
- [2] Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: 2017 ieee symposium on security and privacy (sp). pp. 39–57. IEEE (2017)
- [3] Croce, F., Hein, M.: Minimally distorted adversarial examples with a fast adaptive boundary attack. In: III, H.D., Singh, A. (eds.) Proceedings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 2196–2205. PMLR (13–18 Jul 2020)
- [4] Croce, F., Hein, M.: Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In: III, H.D., Singh, A. (eds.) Proceedings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 2206–2216. PMLR (13–18 Jul 2020)
- [5] Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. CoRR abs/1810.04805 (2018)
- [6] Engstrom, L., Ilyas, A., Athalye, A.: Evaluating and understanding the robustness of adversarial logit pairing. arXiv preprint arXiv:1807.10272 (2018)
- [7] Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 70, pp. 1321–1330. PMLR (06–11 Aug 2017)
- [8] Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network (2015)
- [9] Hou, P., Han, J., , Li, X.: Improving adversarial robustness with self-paced hard-class pair reweighting. In: Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence (2023)
- [10] Kanai, S., Yamada, M., Yamaguchi, S., Takahashi, H., Ida, Y.: Constraining logits by bounded function for adversarial robustness. In: 2021 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2021)
- [11] Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
- [12] Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Pereira, F., Burges, C., Bottou, L., Weinberger, K. (eds.) Advances in Neural Information Processing Systems. vol. 25. Curran Associates, Inc. (2012)
- [13] Kull, M., Perello Nieto, M., Kängsepp, M., Silva Filho, T., Song, H., Flach, P.: Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration. In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 32. Curran Associates, Inc. (2019)
- [14] Kumar, A., Sarawagi, S., Jain, U.: Trainable calibration measures for neural networks from kernel mean embeddings. In: Dy, J., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 80, pp. 2805–2814. PMLR (10–15 Jul 2018)
- [15] Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive uncertainty estimation using deep ensembles. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017)
- [16] Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N 7(7), 3 (2015)
- [17] Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research 9(11) (2008)
- [18] Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. In: International Conference on Learning Representations (2018)
- [19] Minderer, M., Djolonga, J., Romijnders, R., Hubis, F., Zhai, X., Houlsby, N., Tran, D., Lucic, M.: Revisiting the calibration of modern neural networks. In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W. (eds.) Advances in Neural Information Processing Systems. vol. 34, pp. 15682–15694. Curran Associates, Inc. (2021)
- [20] van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. CoRR abs/1807.03748 (2018)
- [21] Pereyra, G., Tucker, G., Chorowski, J., Kaiser, L., Hinton, G.: Regularizing neural networks by penalizing confident output distributions (2017), https://openreview.net/forum?id=HkCjNI5ex
- [22] Prach, B., Lampert, C.H.: Almost-orthogonal layers for efficient general-purpose lipschitz networks. In: European Conference on Computer Vision. pp. 350–365. Springer (2022)
- [23] Shafahi, A., Ghiasi, A., Huang, F., Goldstein, T.: Label smoothing and logit squeezing: A replacement for adversarial training? (2019)
- [24] Wang, F., Liu, H.: Understanding the behaviour of contrastive loss. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2495–2504 (June 2021)
- [25] Wang, T., Isola, P.: Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In: III, H.D., Singh, A. (eds.) Proceedings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 9929–9939. PMLR (13–18 Jul 2020)
- [26] Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2018)
- [27] Zhao, H., Qi, X., Shen, X., Shi, J., Jia, J.: Icnet for real-time semantic segmentation on high-resolution images. In: Proceedings of the European Conference on Computer Vision (ECCV) (September 2018)