Exploring Visual Explanations for Contrastive Language-Image Pre-training
Abstract
Contrastive Language-Image Pre-training (CLIP) learns rich representations via readily available supervision of natural language. It improves the performance of downstream vision tasks, including but not limited to the zero-shot, long tail, segmentation, retrieval, caption, and video. However, the visual explainability of CLIP is rarely studied, especially for the raw feature map. To provide visual explanations of its predictions, we propose the Image-Text Similarity Map (ITSM). Based on it, we surprisingly find that CLIP prefers the background regions than the foregrounds, and shows erroneous visualization results against human understanding. This phenomenon is universal for both vision transformers and convolutional networks, which suggests this problem is unique and not owing to certain network. Experimentally, we find the devil is in the pooling part, where inappropriate pooling methods lead to a phenomenon called semantic shift. For this problem, we propose the Explainable Contrastive Language-Image Pre-training (ECLIP), which corrects the explainability via the Masked Max Pooling. Specifically, to avoid the semantic shift, we replace the original attention pooling by max pooling to focus on the confident foreground, with guidance from free attention during training. Experiments on three datasets suggest that ECLIP greatly improves the explainability of CLIP, and beyond previous explainability methods at large margins. The code will be released later.
1 Introduction
Pre-training is ubiquitously applied in many computer vision tasks such as image classification [3], object detection [24] and semantic segmentation [4]. Various weakly-supervised pre-training [29] and self-supervised pre-training[13, 21] methods have been introduced to reduce the high requirements of training labels. Recently, the Contrastive Language-Image pre-training (CLIP) [31] achieved stunning results by pre-training the model on 400 million image-text pairs and learning the representations by directly matching raw text with the corresponding image. The success of CLIP improves the model performance on various downstream tasks, such as zero-shot and long tail classification [7], domain generalization [6], segmentation [39, 38], retrieval [27] and video classification [30]. Taking inspiration from CLIP, researchers further extend the work from several perspectives, including training efficiency [42], prompt design [45] and language type [19].
GT

CLIP

ECLIP








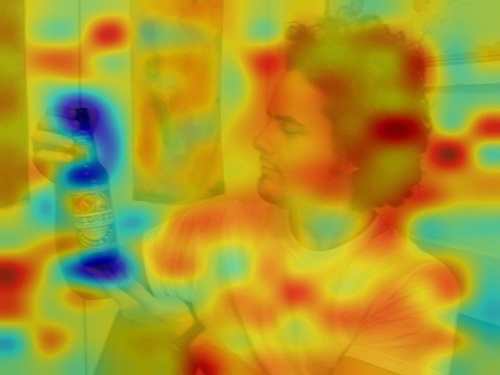
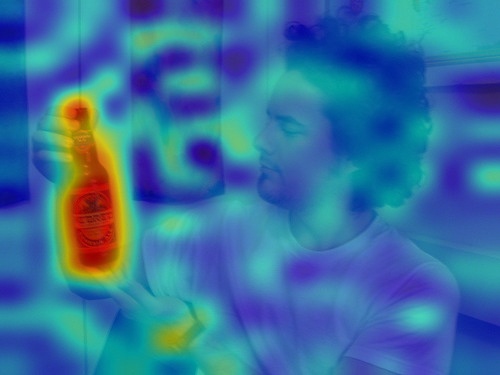
Although considerable efforts have been devoted to improving CLIP or using it to enhance various downstream tasks, the explainability of CLIP has been paid less attention. An existing explainable method [18] interprets the active neurons of CLIP via generating images related to the text. However, it doesn’t locate the discriminative regions as most common explainable methods, such as CAM [44], Grad-CAM [33], Grad-CAM++ [8], Score-CAM [36]. Another explainable method [9] treats CLIP as vision transformer [10] and relies on the self-attention of ViT [14] to explain the images, followed by rollout [1] to expand class-agnostic attention map into class-specific. However, the self-attention quality of CLIP is bad, thus leads to confused results and focuses on partial regions; see results in Fig. 4.2. Most importantly, the raw predictions of CLIP, a natural cue for the visual explanation, is ignored by above methods.
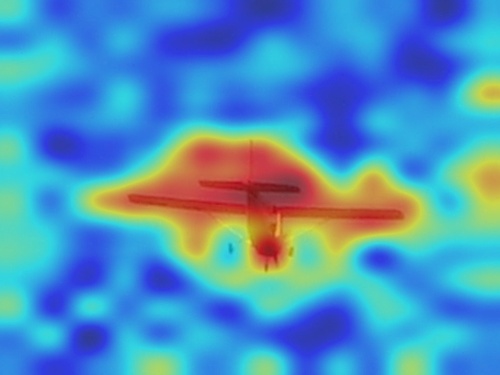
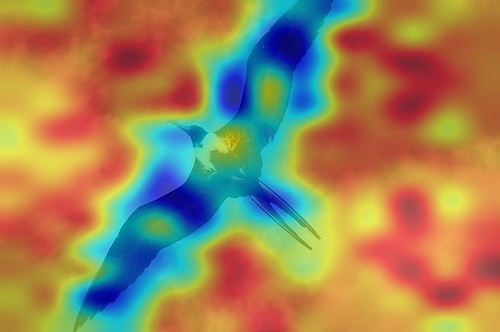
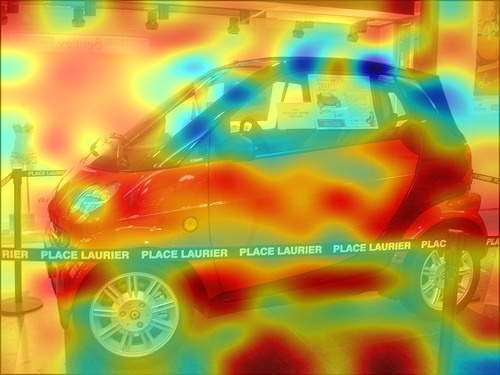
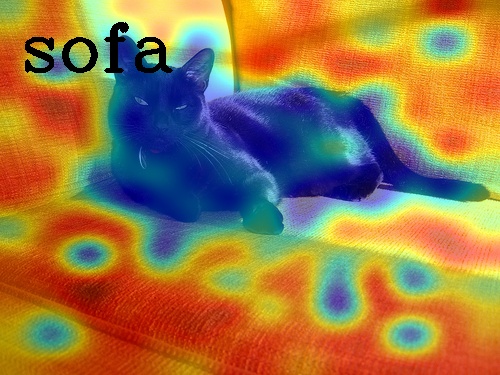
When we visually explain the raw predictions of CLIP, via the proposed Image-Text Similarity Map (ITSM), an abnormal phenomenon occurs. Specifically, we use the similarity map between text feature and image features of image tokens to visualize the prediction map. And we surprisingly find that image features from background tokens are more close to the text feature than foregrounds, as shown in Fig. 1. It means CLIP prefers the background regions more, regardless of vision transformers [14] and convolutional networks [20], which is opposite to general understanding.
For the reason of this problem, we find better representation ability with high quality self-attention cannot solve this matter. Instead, the devil is in the pooling part. Specifically, we replace the original attention pooling by global average pooling and global max pooling, respectively. This problem only disappears in max pooling. And average pooling behaves like attention pooling, since it can be regarded as a weighted average pooling. We further analyze the reason and find one factor: features are shifted from discriminative locations to opposite semantic regions, owing to average-like operations. This shift makes target text features are matched to background regions instead of foregrounds, leading to the problem of erroneous visualization.
To correct the above semantic shift, we replace the original attention pooling by max pooling to focus on the confident foreground regions. Besides, to better align the text token to foreground image tokens, we apply attention map from self-supervised model as mask to guide the training, which is freely available without manual annotation. Note, this attention mask is not applied in test phase, and all the parameters are locked except an extra pair of linear projection layers. Thus, there is no sacrifice of recognition performance, with great improvements of explainability. We call the pooling as Masked Max Pooling (MMP) and name this framework as Explainable Contrastive Language-Image Pre-training (ECLIP). Then we set rich experiments on three datasets, to measure the explainability in level of mask and score. Results suggest our ECLIP beyond original CLIP and other conventional explainability methods at large margins without any loss of recognition accuracy. Our main contributions are summarized as follows:
-
•
We apply the Image-Text Similarity Map to explain the raw predictions of CLIP, and find CLIP prefers background regions than foregrounds, showing opposite visual results against human understanding, regardless of vision transformers and convolutional networks.
-
•
We further locate the problem at the pooling module, and point out the reason is the semantic shift, which shifts discriminative features to opposite semantic regions, owing to average-like operations.
-
•
The masked max pooling is proposed to correct the visualization results, also align the text tokens towarfs discriminative image tokens without manual annotation or any sacrifice of recognition performance.
-
•
We propose ECLIP and a simple version RCLIP, which surpass the original CLIP and other methods at large margins (e.g. mean improvements of mIoU at 27.26% on three datasets for CLIP ResNet101.).
2 Related Work
2.1 Contrastive Language-Image pre-training
Extensive works have been developed on the interaction of computer vision and natural language processing, such as text-to-image retrieval [37], visual question answering [2] and referring segmentation [38]. Recently, contrastive language-image pre-training (CLIP) [31] has gained substantial attention due to its impressive performance and superior transfer ability over diverse classification datasets. The following researchers either further extend CLIP from different perspectives [45, 16, 42] or use it to enhance the performance of various downstream tasks [39, 30, 6, 7]. For example, CoOp [45] and CLIP-Adapter [16] improved the performance by fine-tuning CLIP with adapter or prompt optimization. LiT [42] designed a new pre-training strategy that only tuned the text model CLIP using image-text pairs and froze the image model. Lei et al. [22] and Luo et al. [27] showed that the CLIP model can contribute to the image retrieval task. Ma et al. [28] leveraged language modality via CLIP backbone to improve the long-tailed recognition task. Although stunning results have been achieved by CLIP, its visual explainability is still underexplored.
2.2 Dense Predictions of CLIP
Visual explainability of CLIP is related to dense prediction tasks of CLIP in some extent. For example, Rao et al. [32] extend image-text relationships to pixel-text relationships, then fine-tune the pretraining model on detection and segmentation tasks. But this work doesn’t focus on the behaviors of CLIP itself. Instead, it fine-tunes down stream tasks with fully supervision. Besides, Zhong et al. [43] match regions to text with dense predictions, but the localization ability is borrowed from a fully-supervised region proposal network, instead of explainability from the raw predictions of CLIP. Similarly, Xu et al. [40] and Li et al. [23] use manual mask to locate the foregrounds for semantic segmentation. And it utilizes the recognition ability of CLIP, instead of explainability. Besides, Xu et al. [39] use language supervision only for segmentation. However, they abandon the network architecture of the original CLIP, instead, use a grouping module to merge tokens, which is quite different from the visual explanation task.
2.3 Explainability for Deep Learning Models
Most existing methods for visual explainability are designed for convolutional networks [41, 44] or vision transformers [9, 10]. Specifically, the prior work, CAM [44], locates the discriminative regions of CNN to explain the model. Inspired by this work, some researchers explored different methods (e.g., Grad-CAM [33] and Score-CAM [36]) to more precisely and effectively generate CAM to reveal visual cues distributed on images. Compared with CNN-based methods, self-attention is an additional visualization target in visual transformers [14]. Abnar et al. [1] presented a rollout method and attention flow method to consider the path and max-flow problems along the pairwise attention graph. Then, Chefer et al. [10] expand the class-agnostic self-attention of rollout to class-specific.
As for visual explainability in CLIP, Goh et al. [18] visualizes the activated neurons of CLIP by image generation, while the location of discriminative regions are not provided. Besides, Bi-Model [9] based on [10] treats CLIP as ViT [14] and explains it with self-attention, even the quality of self-attention in CLIP is bad (see Fig. 2(b)). Specifically, it uses the similarity scores of CLIP as “logit” and interprets CLIP with gradient and self-attention. Note, this “logit” is also applicable to Grad-CAM [33]. But experiments in Fig. 4.2 suggest Grad-CAM shows opposite visualization as CLIP, and Bi-Module is confused at multiple classes, focusing on partial regions. Besides the problems of performance, the raw predictions of CLIP, a natural cue for the visual explanation, is ignored by above methods, even it’s more straight forward without backpropagation multiple times for each image as gradient-based methods.
3 Method
3.1 Image-Text Similarity Map
Foremost, we define the involved components of CLIP as below symbols: image encoder , text encoder , and corresponding pair of linear projections (learnable 2-D parameter matrix). Then we have text features from text input as:
| (1) |
and image features:
| (2) |
from image input , where is the class token for classification, and rest image tokens are the raw feature map ( and indicates number of text tokens and image tokens, respectively, C is the embedding size). In CLIP, and are both belong to the final predictions of , but unlike CLIP which skips the image features , we need it for prediction explanation.
The acquisition of Image-Text Similarity Map (ITSM) is similar to the generation of confidence score from class feature , text features and corresponding linear projections , :
| (3) |
The difference is that we replace the class feature to features of image tokens , thus we have intermediate ITSM as:
| (4) |
Then we reshape to final ITSM with resize operation and min-max normalization:
| (5) |
where H and W indicates the height and width of original image, and ( and are the resize scales).
After the generation of ITSM over varied backbones of CLIP, we find the behavior of CLIP’s ITSM is erroneous and against human understanding, as shown in Fig. 1.
3.2 The Devil Is in the Pooling Module


Truth


CLIP

DINO


with CLIP


with DINO
Representation ability is not the key factor. This first influential factor is the representation ability of the image encoder. For the image encoder, we experimentally replace it by the self-supervised image encoder, DINO [5], to introduce better localization ability. As Shown in Fig. 2(c), the attention quality is much better than that of CLIP (Fg. 2(b)), when the self-supervised image encoder is applied. However, its ITSM still focuses on background as Fig. 2(e). So, it shows the image encoder is not the key of erroneous results.
Max pooling solve the problem. As Fig. 3, we focus on the second factor: pooling methods. We lock the parameters of CLIP, and add a new pair of linear projections, with different pooling methods to pool the image features . And all the models use the same training settings. When we replace the original attention pooling layer to global average pooling, the average pooling is similar to attention pooling. While the max pooling solves the problem, which suggests the devil is in the pooling module.


Truth

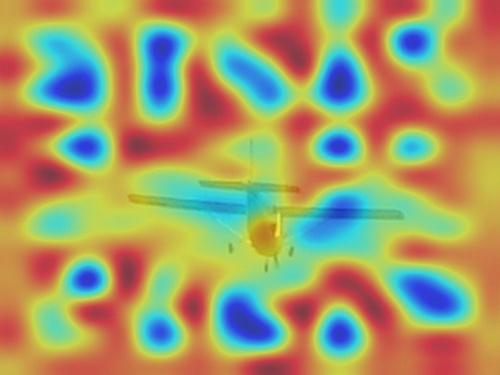
Pooling

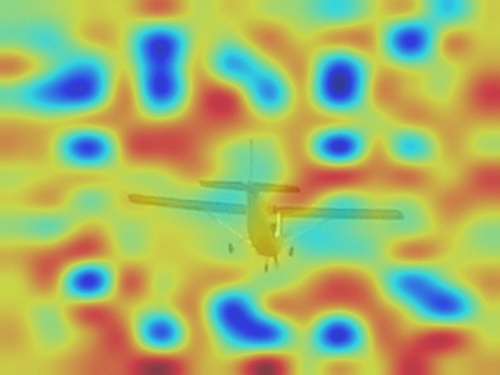
Pooling

Pooling
Reason analyze. After locating the problem at the pooling module. We analyze the reason by element-wise feature comparison among different pooling methods. Specifically, we draw a point for each channel on the image. And the location of a point is the same as the pixel on this channel map, whose score is most close to the pooled score. As the number of points are fixed, and we can see the points in Fig. 4(a) (from max pooling) is less than others, which indicates the points are highly aggregated and overlapped. Since max pooling has the best localization ability as Fig. 3, we compare it with average pooling (Fig. 4(b)) and attention pooling (Fig. 4(c)). We find average pooling and attention pooling disperse the points from overlapped status. We call this phenomenon as feature shift. And feature shift between foregrounds and backgrounds is the semantic shift as Fig. 4(d). This feature shift leads foregrounds are matched to backgrounds, and background features are turned to foreground regions. Exactly, it behaves as the problem of opposite visualization results, and explain how it happens. Besides, why CLIP is more sensitive than single modality model about pooling method is waiting to explore.








3.3 Masked Max Pooling
As analyzed above, the first principle to improve the explainability of CLIP is to avoid semantic shift owing to average-like pooling. Another motivation is to emphasize features of foregrounds to boost the alignment. As shown in Fig. 2(b), the attention map of self-supervised model is better than the original CLIP. While, this attention map is class-agnostic. We aim to correct the explainability of CLIP with it, to get high quality class-aware visualization maps. In this paper, we propose the Masked Max Pooling (MMP) to correct the semantic shift, as well as emphasize the discriminative features.
To remain original recognition ability, we lock all the parameters of CLIP, and correct the explainability with an extra pair of linear projection layers, and for image encoder and text encoder, respectively. Besides, we introduce the free available self-attention mask from another offline self-supervised model (e.g. DINO [5], MoCo [11]). Specifically, the multi-head attention mask comes from the last transformer layer, where is the number of heads and is the size of image tokens. Before deploying it, we reduce the head dimension by mean operation and expand to the shape of as image features . Here we have the expanded mean attention map :
| (6) |
Then we apply the offline mean attention map as mask to guide the alignment between text features and salient image tokens. We achieve this step by element-wise production towards image features as:
| (7) |
where indicates masked class token, pooled by global max pooling along dimension . And means the locked image encoder with masked max pooling.
Then back to Eq. 2, we update it as:
| (8) |
Where MMP is included in with new image projection layer , and MMP doesn’t influence the output image features ( is not applied to ). Specifically, this attention mask is only used to guide the training and not applied in test phase.
Then we optimize the new pair of linear projection layers by the contrastive loss as below:
| (9) |
To conclude, MMP is designed to learn and for reasonable localization results, without interference to the recognition performance.
3.4 ECLIP and RCLIP
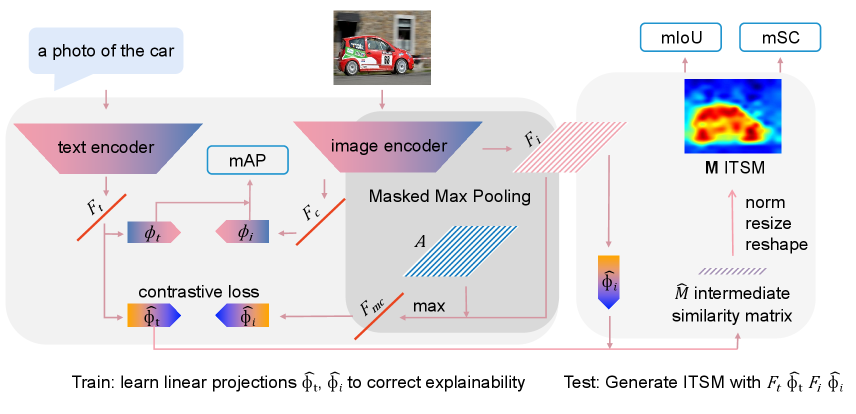
As shown in Fig. 5, Explainable CLIP (ECLIP) is consisted of three parts. The left part indicates a new pair of linear projections are used to correct the explainability, and the recognition task is evaluated with original parameters without optimization. Because of limited computational resources, we just correct its explainability with a small dataset compared to the original CLIP. This design allows the original recognition ability is not damaged under a small dataset. The middle part is the proposed masked max pooling. Specifically, max pooling locates the confident foregrounds, and offline attention mask guides the alignment during training only as Eq. 7. Besides, we draw the ITSM with and as the right part. This part is described from Eq. 1 to Eq. 5.
Besides ECLIP, we also propose a simple version, Reversed CLIP (RCLIP), to correct the explainability without training. Our motivation is to make good use of the mistake. As shown in Fig. 1, CLIP shows opposite visualization results and prefers the background more. Analyzed in Fig. 4(d), this problem is owing to semantic shift. So, one simple idea is to make the best of a mistake by reversing the ITSM to get predictions of RCLIP as:
| (10) |
where gets the absolute value for .
4 Experiments
4.1 Experimental Setup
Dataset. The original CLIP [31] uses 400 millions data. However, this dataset is not available, also too large to reproduce. Because of limited computational resources, we use the dataset of Google Conceptual Captions 3 millions (GCC3M) [34] to train the model for the moderate quantity. For the evaluation, we use three datasets with pixel-level annotations, which support the measurement of localization ability well. Specifically, we use the validation sets of Pascal VOC 2012 [15], MS COCO 2017 [25] and ImageNet-Segmentation-50 (ImageNet-S50) [17], whose quantities are 1449, 5000 and 752, respectively. Note that there are 80 foreground categories in COCO, and it’s more complex and difficult than VOC whose class number is 20. ImageNet-S50 has 50 foregrounds, while it’s single label dataset, thus it’s simpler than above two datasets.
| VOC 2012 | COCO 2017 | ImageNet-S50 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Network | mIoU | mSC | mIoU | mSC | mIoU | mSC | mIoU | mSC |
| CLIP | ResNet50 | 17.72 | -27.07 | 10.50 | -19.21 | 28.15 | -25.46 | 18.79 | -23.91 |
| ECLIP | ResNet50 | 49.30 | 29.16 | 26.98 | 22.78 | 61.07 | 28.64 | ||
| \hdashline[0.5pt/5pt] CLIP | ResNet101 | 17.99 | -23.95 | 10.63 | -18.05 | 28.10 | -23.13 | 18.91 | -21.71 |
| ECLIP | ResNet101 | 49.33 | 28.93 | 26.95 | 22.39 | 62.22 | 30.01 | ||
| \hdashline[0.5pt/5pt] CLIP | ViT-B/32 | 17.52 | -25.01 | 10.14 | -22.54 | 27.89 | -22.83 | 18.52 | -23.46 |
| ECLIP | ViT-B/32 | 48.39 | 34.74 | 25.78 | 25.00 | 62.37 | 35.94 | ||
| \hdashline[0.5pt/5pt] CLIP | ViT-B/16 | 17.46 | -18.55 | 9.80 | -22.30 | 27.94 | -16.54 | 18.40 | -19.13 |
| ECLIP | ViT-B/16 | 45.22 | 26.16 | 23.39 | 17.77 | 54.94 | 23.75 | ||
| \hdashline[0.5pt/5pt] CLIP | ViT-L/14 | 17.26 | -21.59 | 9.67 | -26.46 | 27.99 | -16.35 | 18.31 | -21.47 |
| ECLIP | ViT-L/14 | 46.11 | 26.03 | 27.20 | 22.45 | 59.69 | 27.24 | ||
Evaluation metric. As the evaluated datasets have multiple label of single image, we use mAP to measure the recognition performance, which is widely used in multi-label classification. For explainability, we evaluate it with the pixel-level annotations by mIoU (mean Intersection of Union). Since the threshold for foreground mask influences mIoU a lot, to avoid the interference of manual threshold, we apply grid search to ITSM for each image at step 0.01 to match the appropriate foreground mask. Thus, each image for all models are fairly compared without influence of thresholds. Besides, we evaluate the existed foreground categories to avoid the interference of varied classification performance. We also propose a metric mSC (mean Score Contrast, range from 100% to -100% for the ITSM) to measure the explainability in the level of score contrast. Specifically, we use the mean score of foregrounds to minus the mean score of backgrounds, then count the mean score over categories. This metric is necessary in two aspects as Shown in Fig. 6: (1) mSC can measure the phenomenon of opposite visualization, when the score is lower than 0, while mIoU cannot. (2) If the mSC is high, the color contrast between foreground and background is obvious, which presents better visualization results than low score contrast.

Settings. For the CLIP, we use the official models trained from 400 millions private data, without fine-tuning the original parameters. And our models are all trained with GCC3M to update and only. The output side of ResNet50, ResNet101, ViT-B/32 are 7 from input image size 224 without center crop. And the sizes of ViT-B/16 and ViT-L/14 are 14 and 16, respectively. The text prompt is ”a photo of the”. For the offline attention map, we try DINO [5] and MoCoV3 [11] which are pre-trained from ImageNet [12] without label. We extract the self-attention map from the last transformer layer, and select DINO (ViT-B/16) for the main experiments finally. The weights of new projections are updated by AdamW [26], at learning rate 1e-4, total batch size 1024, weight decay 0.05 for 10 epochs. Other training settings including augmentation, scheduler are followed by [35].
4.2 Results
Significant improvements compared with original CLIP. We list the results on three datasets as shown in Tab. 1. It’s clear that our ECLIP increases the explainability performances at large margins compared with the original CLIP. And these improvements are universal for all networks, regardless of vision transformer or convolutional networks. Look at the average results, our mean mIoU ranges from 41.18% to 46.17%, which beyond CLIP 27.26% at most. For the mSC, ViT-B/32 achieves the highest result at 31.89% and surpasses CLIP by 55.35%. Among these networks, ViT-B/32 shows the highest explainability performance, while ViT-B/16 performs worst. As shown in Fig. 1 higher output resolution is more detailed, but the noise is more obvious, so patch size 16 performs worse.
Compared with conventional explainability methods. We pick ViT-B/32 and ViT-B/16 as backbones, because they perform the best and worst, respectively, in Tab. 1. Then we apply the most used gradient based method, Grad-CAM [33], and the latest explainability method [9] for bi-model (based on [10] for transformer). Note, other methods for ViT (e.g. rollout [1]) are not compared, because it’s class agnostic only. Besides, we compare the ITSM of CLIP with our ECLIP and RCLIP (Eq. 10). These three methods are based on the raw feature map without backpropagation. So our methods allow batch operation for fast and straight forward visualization. As shown in Tab. 4.2, Grad-CAM shows the same behavior as CLIP, which prefers the background more measured by mSC. The latest explainability method [9] works better than Grad-CAM, but the mean mSC is still low at 6.53% for ViT-B/16. It suggests its performance on dense prediction is bad, which limits its applicability. Lock at RCLIP, it’s the simplest method without training or backpropagation, with performances obviously beyond the well-designed Bi-Model. For the ECLIP, it almost ranks first at all datasets and networks, and shows greatly improvements compared with other methods, e.g. 12.84% average improvement at mIoU of ViT-B/32 and 16.03% average improvement at mSC on ViT-B/16.
| VOC 2012 | COCO 2017 | ImageNet-S50 | Average | ||||||
| Method | BP | mIoU | mSC | mIoU | mSC | mIoU | mSC | mIoU | mSC |
| ViT-B/16 | |||||||||
| \hdashline[0.5pt/5pt] CLIP [31] | ✗ | 17.46 | -18.55 | 9.80 | -22.30 | 27.94 | -16.54 | 18.40 | -19.13 |
| Grad-CAM [33] | ✓ | 18.12 | -12.30 | 10.04 | -16.66 | 29.10 | -7.81 | 19.09 | -12.26 |
| Bi-Model[9] | ✓ | 29.32 | 6.02 | 17.42 | 7.28 | 41.85 | 6.30 | 29.53 | 6.53 |
| RCLIP (ours) | ✗ | 36.32 | 18.56 | 24.80 | 22.30 | 47.38 | 16.54 | 36.13 | 19.13 |
| ECLIP (ours) | ✗ | 45.22 | 26.16 | 23.39 | 17.77 | 54.94 | 23.75 | 41.18 | 22.56 |
| \hdashline[0.5pt/5pt] ViT-B/32 | |||||||||
| \hdashline[0.5pt/5pt] CLIP [31] | ✗ | 17.52 | -25.01 | 10.14 | -22.54 | 27.89 | -22.83 | 18.52 | -23.46 |
| Grad-CAM [33] | ✓ | 18.87 | -10.38 | 10.57 | -13.91 | 30.48 | -4.96 | 19.97 | -9.75 |
| Bi-Model[9] | ✓ | 32.61 | 16.80 | 18.72 | 15.50 | 46.67 | 16.24 | 32.67 | 16.18 |
| RCLIP (ours) | ✗ | 39.79 | 25.01 | 23.20 | 22.54 | 50.95 | 22.83 | 37.98 | 23.46 |
| ECLIP (ours) | ✗ | 48.39 | 34.74 | 25.78 | 25.00 | 62.37 | 35.94 | 45.51 | 31.89 |
4.3 Ablation Study
Effectiveness of masked max pooling. From Tab. 3, we can see that max pooling correct the opposite visualization results from the original attention pooling (baseline), with improvements by 17.55% and 30.53% at mIoU and mSC, respectively. Based on max pooling, we further add attention map to form the masked max pooling in the bottom part. The MoCoV3 [11] and DINO [5] both improves the performance, via the guidance during training to emphasize the salient region. This operation requires no annotation, and doesn’t bring cost to the inference phase.
| Pooling | Attention Mask | mIoU (%) | mSC (%) |
|---|---|---|---|
| attntion (baseline) | no | 17.90 | -13.86 |
| average | no | 19.14 | -4.11 |
| max | no | 35.45+17.55 | 16.67+30.53 |
| max | no (baseline) | 35.45 | 16.67 |
| max | MoCoV3 [11] | 44.70 | 25.03 |
| max | DINO [5] | 45.52+10.07 | 26.16+9.49 |
Necessity of new linear projections. In ECLIP, we add a new pair of linear projections to explain the model for two reasons. (1) To remain the recognition performance without interference. In Tab. 4, directly training on 3 million data from random weights leads to serious performance drop. Compared with it, ECLIP remain original performances, because original parameters are locked. And RCLIP doesn’t require training. (2) Classification and interpretability suit different pool methods. In general experience, max pooling doesn’t suit the classification task. If we use max pooling for CLIP to train from scratch, the recognition task must be sacrificed, even its interpretability is corrected. Thus, adding a new pair of linear projections is essential for both task, without interference to each other.
| Method | Data | VOC12 | COCO17 | ImageNet-S50 |
|---|---|---|---|---|
| CLIP | - | 80.31 | 53.07 | 90.54 |
| CLIP | 3M | 46.78 | 19.37 | 35.86 |
| RCLIP | - | 80.31 | 53.07 | 90.54 |
| ECLIP | 3M | 80.31 | 53.07 | 90.54 |
4.4 Visualization
As shown in Fig.7, we draw the qualitative visualization results on VOC12, COCO17 and ImageNet. From these qualitative results, we believe the proposed method is able to explain which parts influence the predictions most, and help us to understand the model for better credibility. Also, these results show the potentiality for tasks like segmentation and localization. Then we compare the conventional methods with ours as Fig. 4.2. The latest method [9] for transformer is confused at multiple objects and locate partial regions, because it uses the class agnostic self-attention in bad quality during visualization. And Grad-CAM [33], the most used gradient based method, behaves like CLIP in Fig. 1 and often focus on the backgrounds. Our RCLIP is simpler than these well-designed methods, also performs better. And ECLIP has the best explainability over others.
VOC







COCO








ImageNet








![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_004654_bicycle.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_004654_person.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_002958_car.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_002958_dog.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2007_002260_motorbike.jpg)
5 Conclusion
In summary, we visually explain the Contrastive Language-Image Pre-training (CLIP) from its raw prediction map. And we observe that CLIP is prone to focus on the background, presenting opposite visualization results. Then, the reason is located as the pooling module, where features are shifted to opposite semantic regions. To solve the problem, the masked max pooling is proposed to correct the explainability, with free attention mask. Then we propose the Explainable CLIP (ECLIP) based on this pooling, and a simple version, reversed CLIP (RCLIP). Our methods achieve nontrivial explainability improvements over original CLIP and conventional methods at large margins.
References
- [1] Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. arXiv preprint arXiv:2005.00928, 2020.
- [2] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015.
- [3] Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3478–3488, 2021.
- [4] Hangbo Bao, Li Dong, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- [5] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021.
- [6] Junbum Cha, Kyungjae Lee, Sungrae Park, and Sanghyuk Chun. Domain generalization by mutual-information regularization with pre-trained models. arXiv preprint arXiv:2203.10789, 2022.
- [7] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3558–3568, 2021.
- [8] Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE winter conference on applications of computer vision (WACV), pages 839–847. IEEE, 2018.
- [9] Hila Chefer, Shir Gur, and Lior Wolf. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 397–406, 2021.
- [10] Hila Chefer, Shir Gur, and Lior Wolf. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 782–791, 2021.
- [11] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9640–9649, 2021.
- [12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [13] Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE international conference on computer vision, pages 1422–1430, 2015.
- [14] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [15] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010.
- [16] Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters. arXiv preprint arXiv:2110.04544, 2021.
- [17] Shanghua Gao, Zhong-Yu Li, Ming-Hsuan Yang, Ming-Ming Cheng, Junwei Han, and Philip Torr. Large-scale unsupervised semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [18] Gabriel Goh, Nick Cammarata, Chelsea Voss, Shan Carter, Michael Petrov, Ludwig Schubert, Alec Radford, and Chris Olah. Multimodal neurons in artificial neural networks. Distill, 6(3):e30, 2021.
- [19] Jiaxi Gu, Xiaojun Meng, Guansong Lu, Lu Hou, Minzhe Niu, Hang Xu, Xiaodan Liang, Wei Zhang, Xin Jiang, and Chunjing Xu. Wukong: 100 million large-scale chinese cross-modal pre-training dataset and a foundation framework. arXiv preprint arXiv:2202.06767, 2022.
- [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [21] Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon. A survey on contrastive self-supervised learning. Technologies, 9(1):2, 2020.
- [22] Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7331–7341, 2021.
- [23] Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl. Language-driven semantic segmentation. arXiv preprint arXiv:2201.03546, 2022.
- [24] Hengduo Li, Bharat Singh, Mahyar Najibi, Zuxuan Wu, and Larry S Davis. An analysis of pre-training on object detection. arXiv preprint arXiv:1904.05871, 2019.
- [25] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- [26] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [27] Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval. arXiv preprint arXiv:2104.08860, 2021.
- [28] Teli Ma, Shijie Geng, Mengmeng Wang, Jing Shao, Jiasen Lu, Hongsheng Li, Peng Gao, and Yu Qiao. A simple long-tailed recognition baseline via vision-language model. arXiv preprint arXiv:2111.14745, 2021.
- [29] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens Van Der Maaten. Exploring the limits of weakly supervised pretraining. In Proceedings of the European conference on computer vision (ECCV), pages 181–196, 2018.
- [30] Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. arXiv preprint arXiv:2208.02816, 2022.
- [31] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [32] Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18082–18091, June 2022.
- [33] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017.
- [34] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018.
- [35] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021.
- [36] Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 24–25, 2020.
- [37] Zihao Wang, Xihui Liu, Hongsheng Li, Lu Sheng, Junjie Yan, Xiaogang Wang, and Jing Shao. Camp: Cross-modal adaptive message passing for text-image retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5764–5773, 2019.
- [38] Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. In CVPR, pages 11686–11695, 2022.
- [39] Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18134–18144, 2022.
- [40] Mengde Xu, Zheng Zhang, Fangyun Wei, Yutong Lin, Yue Cao, Han Hu, and Xiang Bai. A simple baseline for zero-shot semantic segmentation with pre-trained vision-language model. arXiv preprint arXiv:2112.14757, 2021.
- [41] Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision, pages 818–833. Springer, 2014.
- [42] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18123–18133, 2022.
- [43] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- [44] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2921–2929, 2016.
- [45] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, pages 1–12, 2022.
Appendix A Analyze of semantic shift.
To support semantic shift, the explanation for the problem of opposite visualization in CLIP [31], we list the details of of semantic shift in Tab. 5. For different foreground sizes, the ratio of B2F (confident features shifted from background to foreground) and F2B (foreground features shifted to background) varies. For the size (0.25,0.75), the shifted feature takes about half (248.3 out of 512 channels after linear projection), which suggests the feature shift between opposite semantic regions is universal, and takes a large ratio. Then, these features at opposite semantic regions forms an erroneous prediction map.
| Size | B2F | F2B | B2B/F2F |
|---|---|---|---|
| (0, 0.25] | 78.0 | 45.2 | 388.7 |
| (0.25, 0.75] | 111.8 | 136.5 | 263.7 |
| (0.75, 1] | 44.7 | 97.0 | 370.3 |
| (0, 1] | 78.8 | 114.7 | 318.5 |
Then, we list more examples of semantic shift with corresponding Image-Text Similarity Map (ITSM) on CLIP ViT-B/16 and ViT-L/14 as 4.2. From these images, we can see that shifted features in blue (background to foreground) and red (foreground to background) take a large promotion. Besides, we can find obvious gray points on these examples, where opposite visualization doesn’t happen on ITSM (red regions on foreground).
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2009_001991_shift.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2010_004559_shift.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_004612_chair.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2009_001991_sheep.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2010_004559_bird.jpg)
Appendix B Opposite Visualization is Universal for CLIP
Ground Truth ResNet50 ResNet101 ViT-B/32 ViT-B/16 ViT-L/14
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2007_001239_dog.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2009_003378_bird.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2007_002823_motorbike.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2007_002823_person.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2009_002990_car.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2009_001255_car.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2009_001255_bicycle.jpg)
As shown in Fig. 4.2, the opposite visualization results are universal for CLIP, regardless of convolutional networks or vision transformers. Besides, lower output size (e.g. 7 7 for ResNets [20] and ViT-B/16 [14]) show smoother results than larger output (14 14 of ViT-B/16 and 16 16 of ViT-L/14). Thus, lower output side seems better, while networks at larger output sides provide detailed results. Out of these differences, the opposite explainability of CLIP is common.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2011_000813_cat.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2011_000813_chair.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_008629_bicycle.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2011_000456_bird.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/2008_004396_horse.jpg)
As discussed above, the output side is related to the visualization result. And we find the impact of output side is much serious in Bi-Model [9]. As shown in Fig. 4.2, our ECLIP is much less influenced by the output side, and larger network (ViT-B/16) show detailed results and beyond ViT-B/32 for some cases. But Bi-Model meets serious performance damage, and shows punctate heatmap. Besides, Bi-Model is confused at multiple classes, especially for larger output side. The visualization results are almost the same for different categories, when the output side is scaled up, which shows the limitation of output side. And our method breaks this limitation.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00002690_grand_piano.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00006185_hamster.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00007684_agaric.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00012507_american_black_bear.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00019266_umbrella.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00013228_park_bench.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00017692_siamese_cat.jpg)
Besides the visual comparison on VOC [15] in the main paper, we set additional comparison between conventional methods and ours as Fig. 4.2 on ImageNetS-50 (ImageNet-Segmentation-50) [17]. These results are based on ViT-B/32 at output size , which suits Bi-Model best [9]. Even so, the latest transformer based explanation methods for CLIP, Bi-Model, performs much worse than our RCLIP and ECLIP. And the most used gradient based method, Grad-CAM [33], behaves like the original CLIP, shown opposite visualization results. Then we draw the results on ViT-B/16 in Fig. 4.2. In the condition of dense prediction, our methods outperform conventional methods with larger margins.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00002282_african_elephant.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00016899_grand_piano.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00005428_street_sign.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00015903_goldfinch.jpg)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/005cb5ed-6bdb-4e09-a40b-dd7b913288bb/ILSVRC2012_val_00010078_african_elephant.jpg)