Extending the Frontier of ChatGPT: Code Generation and Debugging
Abstract
Large-scale language models (LLMs) have emerged as a groundbreaking innovation in the realm of question-answering and conversational agents. These models, leveraging different deep learning architectures such as Transformers, are trained on vast corpora to predict sentences based on given queries. Among these LLMs, ChatGPT, developed by OpenAI, has ushered in a new era by utilizing artificial intelligence (AI) to tackle diverse problem domains, ranging from composing essays and biographies to solving intricate mathematical integrals. The versatile applications enabled by ChatGPT offer immense value to users. However, assessing the performance of ChatGPT’s output poses a challenge, particularly in scenarios where queries lack clear objective criteria for correctness. For instance, evaluating the quality of generated essays becomes arduous and relies heavily on manual labor, in stark contrast to evaluating solutions to well-defined, closed-ended questions such as mathematical problems. This research paper delves into the efficacy of ChatGPT in solving programming problems, examining both the correctness and the efficiency of its solution in terms of time and memory complexity. The research reveals a commendable overall success rate of 71.875%, denoting the proportion of problems for which ChatGPT was able to provide correct solutions that successfully satisfied all the test cases present in Leetcode. It exhibits strengths in structured problems and shows a linear correlation between its success rate and problem acceptance rates. However, it struggles to improve solutions based on feedback, pointing to potential shortcomings in debugging tasks. These findings provide a compact yet insightful glimpse into ChatGPT’s capabilities and areas for improvement.
Index Terms:
ChatGPT, Code Generation, Programming Problems, DebuggingI Introduction
Artificial intelligence has achieved remarkable prowess across a plethora of dimensions, encompassing code generation [23, 24, 25, 26, 27], program explanation [28, 29, 30, 31], error correction [32, 33, 34, 35], and more. Within the domain of code generation, these AI tools exhibit a remarkable capability to write programs based on natural language descriptions of a given problem. Recent years have witnessed an unprecedented surge in the development of neural network architectures, notably the transformer model[5]. This surge has started a new era of large-scale language models (LLMs), empowering users with the ability to leverage pre-trained models that have been extensively trained on vast amounts of code and natural language data.[36, 37, 38, 39, 40]
The advent of these large language models has sparked a cosmic shift in the landscape of code generation. With their immense knowledge and linguistic expertise, these LLMs have transformed the way coding problems are approached. By bridging the gap between human language and programming language, these models have opened up new horizons for programmers and researchers alike.
OpenAI’s[3] ChatGPT[19] exemplifies the epitome of AI tools, harnessing the power of large language models (LLMs) integrated within a user interface to engage in interactive, conversational exchanges and generate responses. This tool transcends boundaries, catering to an extensive array of user needs expressed in natural language. Within the domain of code generation, ChatGPT boasts exceptional features that enable it to answer queries pertaining to programming challenges while maintaining logical coherence. These distinctive attributes of ChatGPT can be listed as such:
-
•
Knowledge and Pattern Recognition: By virtue of its extensive training on a vast dataset encompassing software development and programming languages, the model has gained a deep understanding of the essence of programming problems, discerning intricate patterns within inputs, and expertly leveraging its vast knowledge to generate accurate and contextually appropriate solutions.
-
•
Natural Language Processing Capability: At the core of ChatGPT’s capabilities lies its aptitude in natural language processing (NLP), endowing it with the ability to comprehend and interpret human language. The neural network model powering ChatGPT has been meticulously trained to grasp the nuances of human expression, enabling it to generate outputs that effectively address queries posed in natural language.
-
•
Generalizing Capability: Impressively, ChatGPT possesses a remarkable generalization capability, transcending the confines of its training data. Although trained on an extensive dataset comprising a vast corpus of code, the model demonstrates exceptional performance when confronted with novel queries that lie beyond the scope of its training. This generalization capability further enhances its utility and flexibility, making it an invaluable tool for developers and programmers seeking comprehensive code generation support.
Amidst the rising popularity of ChatGPT among programmers, it is imperative to acknowledge that its responses to programming problems expressed in natural language may exhibit imperfections. Consequently, a comprehensive study is imperative to fully assess ChatGPT’s effectiveness in addressing such problems. This research endeavors to conduct a meticulous evaluation of ChatGPT’s code generation capabilities, as well as its debugging aptitude. A central focus is placed on assessing the model’s performance across a diverse spectrum of programming problems, spanning various domains and levels of complexity. To facilitate this study, a carefully curated custom dataset comprising programming problems from Leetcode[6] is employed, encompassing a rich variety of problem scenarios.
In addition to evaluating ChatGPT’s code generation, the research uniquely delves into its debugging capabilities. After ChatGPT initially fails to produce correct solutions for certain problems, Leetcode’s feedback and error messages are provided to the model in an attempt to prompt improvements in its solutions. The research meticulously analyzes ChatGPT’s response to this feedback, elucidating its capacity to learn from errors and rectify its solutions. By incorporating this evaluation of ChatGPT’s debugging aptitude, the research offers a holistic assessment of the model’s performance, addressing both its strengths and limitations in solving programming problems.
Upon concluding the study, several key findings have emerged:
-
•
ChatGPT showcased a strong overall performance, by providing correct solution to 71.875% of the problems present in the constructed dataset. Notably, it exhibited particular proficiency in structured domains such as “Tree” and “Divide and Conquer”. However, it encountered challenges when confronted with complex problems falling under “Greedy” and “Dynamic Programming (DP)” domains.
-
•
The model’s success rate displayed a linear correlation with the acceptance rates of the problems. It excelled in problems with higher acceptance rates while facing difficulties in problems with lower acceptance rates.
-
•
ChatGPT demonstrated limited adaptability in response to feedback, improving its solutions in only 36.7% of cases. This finding suggests potential weaknesses in the model’s debugging and error-learning capabilities, which refers to its ability to learn from the feedback provided, analyzing the errors in the initially generated solutions, which seems to be constrained, warranting further research and enhancement to bolster its capacity in effectively incorporating feedback for improved performance.
These findings provide valuable insights into ChatGPT’s performance in solving programming problems, allowing users to make informed decisions about utilizing the tool and emphasizing areas for future enhancement and refinement.
II Literature Review
In recent years, large language models (LLMs) have significantly influenced the field of natural language processing. These models, trained on vast text and code datasets, exhibit exceptional performance on a wide range of tasks including text generation, code generation, machine translation, question-answering, summarization, and more[11, 10, 13, 12]. Such advancements have far-reaching impacts across several domains such as education, healthcare, finance, and customer service [2, 1, 7, 8, 9].
GPT-1 [14], a pioneering LLM, was trained on the task of next-word prediction, enabling it to understand word dependencies and generate relevant, context-aware content. Its successor, GPT-2 [15], was trained on a much larger dataset and incorporated 1.5 billion parameters, significantly improving its performance in a zero-shot learning setting. GPT-3 [17] marked a considerable advancement, boasting an impressive 175 billion parameters.
ChatGPT, a conversational AI model developed by OpenAI, is currently considered one of the most advanced LLMs due to its sophisticated training techniques and large training corpus. Notably, it is powered by GPT-4 [4], the latest iteration of the model.
The concept of using these LLMs for automatic code generation has been a significant area of research, given its potential to reduce human error and boost efficiency.
For example, Dakhel et al. [16] assessed the efficacy of GitHub Copilot in generating solutions for fundamental algorithmic problems. While the model was able to provide correct solutions for several problems, it fell short of matching human programmers’ performance. Prenner et al. [18] explored Codex, a pre-trained LLM, and its ability to identify and rectify bugs in code. Their research showed that Codex is extraordinarily effective, even competitive with leading automated program repair techniques, especially in fixing Python bugs. Sobania et al.[20] evaluated ChatGPT’s capability in code repair using the QuixBugs benchmark set. By harnessing its conversational abilities, ChatGPT successfully repaired 31 out of 40 bugs, outperforming established methods. Xia et al. [21] presented the enhanced performance of conversational automated program repair (APR) over earlier LLM-based APR approaches. Chen et al. [36] developed Codet, a tool that uses a pre-trained language model to generate test cases for code samples, a feature that can significantly improve code quality and correctness.
Tian et al. [23] investigated ChatGPT’s potential as a programming assistant. Their research indicated that ChatGPT could generate correct code for a variety of problem types and difficulty levels based on the LeetCode benchmark. However, they also noted that ChatGPT struggles to generalize its code generation capabilities to unseen and novel problems.
III Research Methodology
III-A Preparation of Dataset
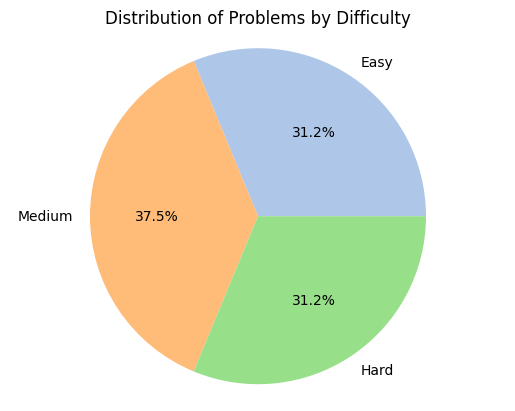
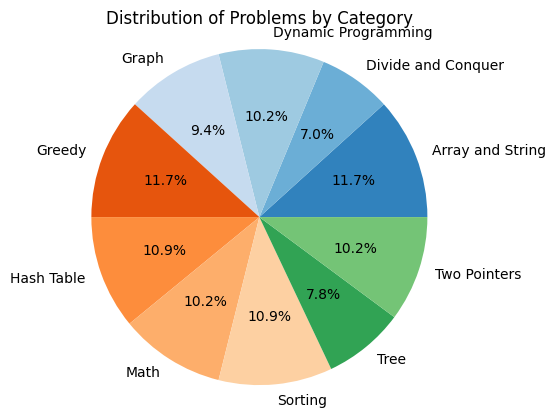
In order to ascertain the practical applicability of ChatGPT in addressing coding problems, a dataset was meticulously curated comprising coding challenges sourced from Leetcode, a renowned platform known for its extensive collection of coding problems. Leetcode provides users with a comprehensive array of coding questions, complete with visualizations and an integrated development environment (IDE) that facilitates coding solutions. The dataset construction process commenced with the extraction of coding questions from diverse domains that represent the most prominent areas of coding expertise, including but not limited to Hash-tables, Divide and Conquer, Greedy approach, and Graph. To ensure a comprehensive evaluation, the incorporation of coding challenges of varying difficulty levels, ranging from rudimentary problems to advanced and intricate ones was ensured. Figures 1 and 2 provide a visual depiction of the domains of problems covered in the dataset along with the difficulty variation. It is imperative to acknowledge that the data collection occurred prior to May 2023, and the outcomes presented in this study are contingent upon the specific dataset utilized. It is essential to recognize that these results may be subject to modifications if more recent data is gathered.
III-B Analysis of Dataset
| Difficulty | Acceptance | Number of Problems in each category | |||||||||
| Level | Rate | Array & String | DP | Divide & Conquer | Graph | Greedy | Hash Table | Math | Sorting | Tree | Two Pointers |
| 2 | 0 | 0 | 0 | 2 | 2 | 2 | 0 | 0 | 0 | ||
| Easy | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 2 | 1 | 3 | |
| 2 | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | ||
| 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 0 | 2 | ||
| Medium | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | ||
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 2 | ||
| Hard | 1 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 2 | 1 | |
| 2 | 2 | 0 | 0 | 2 | 0 | 0 | 2 | 1 | 0 | ||
| Total Number of Problems | 15 | 13 | 9 | 12 | 15 | 14 | 13 | 14 | 10 | 13 | |
The dataset construction process meticulously considered the need for diversity across various problem domains, while also accounting for the difficulty levels of the challenges and their solution acceptance rates on the Leetcode platform. The resulting dataset comprises carefully chosen problems that reflect a wide range of genres, ensuring comprehensive coverage of the coding landscape. Table I presents a detailed overview of the dataset, presenting the genres of problems alongside the number of problems from each difficulty level and their respective solution acceptance rates. The dataset was thoughtfully crafted to include precisely 15 problems from each problem category. Within each difficulty level (Easy, Medium, and Hard), we ensured the inclusion of five problems, following a specific acceptance rate criterion. Two problems were selected with an acceptance rate below 30%, one problem with an acceptance rate between 30% and 70%, and the remaining two problems with an acceptance rate exceeding 70%. It is essential to acknowledge that due to the scarcity of problems meeting these specified criteria in certain categories, the total number of problems in the dataset amounts to 128. Nevertheless, the careful selection process and adherence to acceptance rate distributions ensure a balanced representation of difficulty levels and problem acceptance rates within the dataset which can be noticed in the figures 1 and 2.
III-C Approaching each problem
After constructing the dataset, each individual problem, along with its corresponding code structure available in Leetcode, was presented as input to the ChatGPT model. The objective was to leverage the power of the large language model (LLM) to generate code solutions based on the provided code structure. The ChatGPT model, prompted with the problem description and code structure, responded by generating a code solution, which was then utilized as the suggested solution within Leetcode’s integrated development environment (IDE).
The generated solution provided by ChatGPT after running in the IDE of Leetcode is submitted for evaluation which results in one of the following:
-
1.
Upon successful execution of the generated code solution, the Leetcode platform displays vital performance metrics and the solution’s comparative efficiency in terms of outperforming other submitted solutions. In that case, the following steps are taken:
-
a.
The solution provided by ChatGPT is listed as a “Passed Instance”.
-
b.
The runtime of the generated solution in millisecond (ms) and the memory consumption of the executed solution in megabytes (MB) is noted.
-
c.
The percentage of other submitted solutions for that problem in Leetcode that this solution beats in runtime is noted.
-
d.
The percentage of other submitted solutions for that problem in Leetcode that this solution beats in memory consumption is noted.
-
a.
-
2.
In the event that the generated solution is not accepted by the Leetcode platform, it can be attributed to one of the following scenarios:
-
a.
The occurrence of a runtime error (RTE), indicating that the program encountered an error during the execution of the provided test cases.
-
b.
A time limit exceeded error (TLE), signifying that the program surpassed the allotted execution time designated by Leetcode.
-
c.
A memory limit exceed error (MLE), denoting that the program surpassed the allocated memory usage threshold specified by Leetcode.
-
d.
Failure to pass all the test cases provided by Leetcode, indicating that the solution does not attain complete correctness and accuracy.
-
a.
-
3.
In the event of a failed solution, the error messages generated by the Leetcode platform or the failed test cases are utilized as feedback to the ChatGPT model. The model is then prompted to rectify and enhance the provided solution, effectively evaluating the model’s debugging capabilities. The resulting modified solution is subsequently re-submitted to the Leetcode IDE for evaluation.
-
a.
If the modified solution successfully passes all the test cases, the process proceeds to Step 1 for further analysis and assessment.
-
b.
Conversely, if the modified solution fails to meet the desired requirements and triggers any of the error messages encountered in Step 2, the corresponding problem is deemed as a failed attempt by ChatGPT.
-
a.
IV Analysis of ChatGPT’s Performance
Following the construction of the comprehensive dataset, comprising a total of 128 problems from various categories of problems mentioned earlier, we proceed to evaluate the performance of ChatGPT in generating the solutions to the programming challenges from natural language problem descriptions. The results obtained provided valuable statistical insights into the model’s capabilities.
Overall Performance
ChatGPT exhibited an overall success rate of 71.875% across the entire dataset. This indicates that out of 128 problems, ChatGPT successfully generated solutions for 92 of them. Notably, among these successful cases, 84 problems were solved in the initial attempt, rest 8 were solved after prompting the ChatGPT to debug the previously provided solution with the feedback received from Leetcode.
There were 36 problems within the dataset for which ChatGPT did not produce satisfactory solutions, even after revisiting the problems with feedback from Leetcode.
Feedback and Debugging
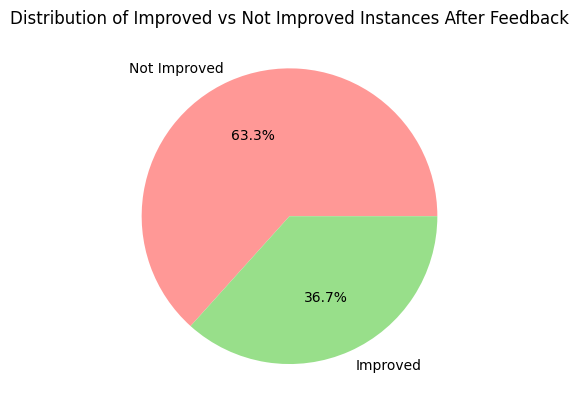
Out of the 36 problems for which ChatGPT initially failed to produce any correct solution, the Leetcode platform provided error messages and feedback as guidance for improvement. This feedback, accompanied by a few of the test cases that the solution failed to pass, was utilized to prompt ChatGPT to rectify its errors and generate corrected solutions. Surprisingly, despite the availability of this feedback, ChatGPT failed to produce correct solutions in the majority of cases.
In fact, when ChatGPT attempted to fix its errors using the provided feedback, the new solutions exhibited a downgrade in performance. It can be seen from Figure 3 that approximately 63% of the time, these revised solutions failed to pass test cases that were previously passed, indicating a decrease in solution correctness. Only around 36% of the instances did the new solutions perform better, passing more test cases than before but yet not completely accurate.
The inability of ChatGPT to generate correct solutions even after receiving feedback highlights its limitations in effectively incorporating debugging information from Leetcode. This indicates a weakness in ChatGPT’s current debugging capabilities, impeding its ability to learn from and rectify errors based on provided feedback. Consequently, the model’s performance in improving solution correctness falls short, as demonstrated by the downgrade in performance observed in the revised solutions.
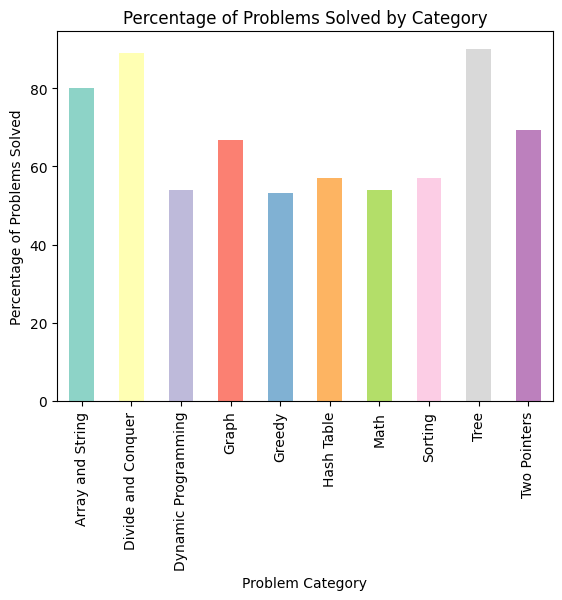
Across Different Domains
Analyzing the success rate of ChatGPT at solving problems across different domains reveals intriguing findings, as depicted in Figure 4. The model showcases the highest success rates on problems stemming from “Tree” and “Divide and Conquer” domains. On the contrary, the model showed subpar performance while solving problems from “Greedy” and “Dynamic Programming (DP)” domains.
This observation suggests that ChatGPT has a higher success rate at solving problems that adhere to well-defined rules and structured patterns as they are easier for the model to understand and generate solutions for. Therefore, intuitively, the model finds it more challenging to solve problems that require deeper analyses and do not conform to specific rules for generating solutions that eventually lead to lower success rates. For instance, in a tree problem, it is possible for the model to easily identify the root node and then recursively solve the problem for each child node. Similarly, in a divide and conquer problem, the model can easily divide the problem into smaller subproblems, solve each subproblem, and then combine the solutions to solve the original problem.
In contrast, the fundamental nature of Greedy and Dynamic Programming is much different. Greedy problems start with local optimal decisions with the goal to reach an optimal global decision via the steps it takes. Similarly, in a Dynamic Programming problem, the solution comprises a sequence of decisions where it breaks the original problem into overlapping subproblems and then reuses the subproblems’ solutions to solve the original problem. Such categories of problems require advanced reasoning and exploration of a wide-ranging set of possibilities that are difficult for ChatGPT to accommodate during the generation of solutions, eventually resulting in a lower comparative success rate.
These findings suggest that ChatGPT excels in generating solutions for problems that follow a well-structured methodology or adhere to established patterns. However, the model faces challenges in generating solutions for problems that require more complex decision-making processes and the analysis of various test cases. In such cases, ChatGPT’s performance falls short, indicating the limitations of the model in handling problems that demand nuanced reasoning and consideration of diverse scenarios.
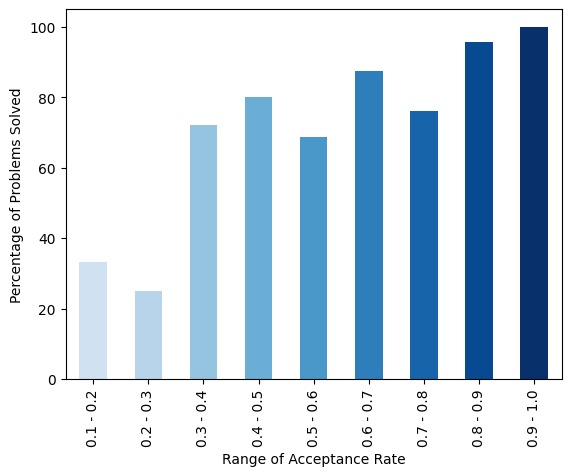
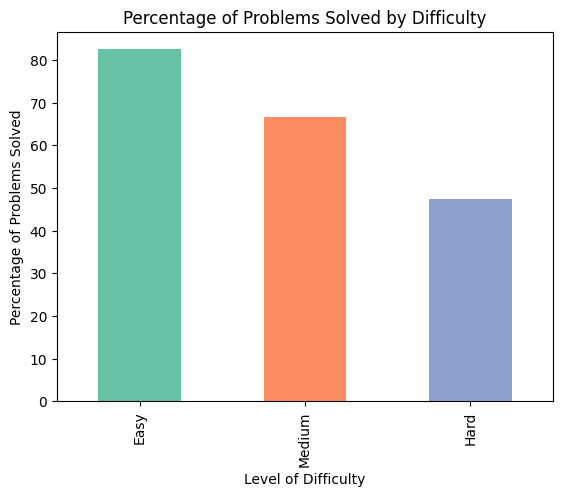
Across Different Difficulty levels and Acceptance Rates
A similar problem trend can be observed from Figure 6 and Figure 5, which provide insights into ChatGPT’s success rate in solving problems of varying difficulties and acceptance rates. Notably, the model encountered challenges when tackling problems labeled as “Hard”, achieving a success rate of 55% in generating accurate solutions. Conversely, when confronted with problems labeled as “Easy”, ChatGPT demonstrated a notably high success rate of 90%. This observation reveals a downward trend in the percentage of successfully solved problems as the difficulty level increases. This phenomenon can be attributed to the fact that “Easy” problems often involve well-established techniques and require less analytical prowess, while more challenging problems necessitate deeper analysis and novel problem-solving approaches, which may exceed ChatGPT’s current capabilities.
Additionally, ChatGPT’s performance is influenced by the acceptance rate of the problems. The acceptance rate reflects the success rate of all submitted solutions for a particular problem on the Leetcode platform. It is noteworthy that the dataset used in this study does not encompass problems with acceptance rates below 10% or above 90%. When analyzing problems with lower acceptance rates, particularly below 30%, ChatGPT struggled to produce accurate solutions, resulting in success rates ranging from 30% to 40%. Conversely, as the acceptance rate increased, ChatGPT exhibited higher success rates, achieving an impressive 95.65% success rate when the acceptance rate exceeded 80%.
These observations that have been made from our experiments indicate that ChatGPT thrives in generating solutions for problems that conform to well-structured methodologies or established patterns, like Tree and Divide and Conquer problems. However, when confronted with challenges on domains whose solutions are not structured or do not have a blatant pattern for approaching the problem and require intricate test case analysis and consideration of input correlations, such as Dynamic Programming and Greedy problems, the model encounters difficulties in generating successful solutions.
Run-time and Memory Efficiency
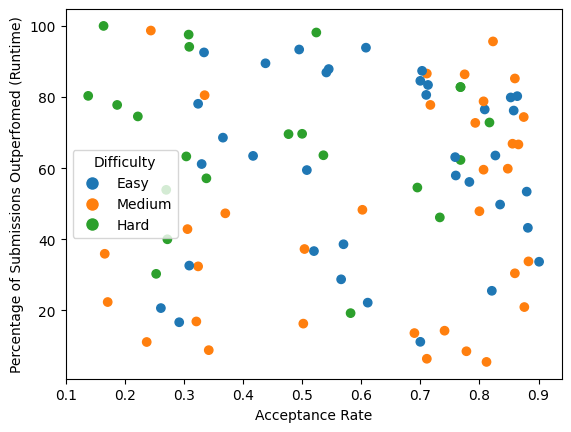
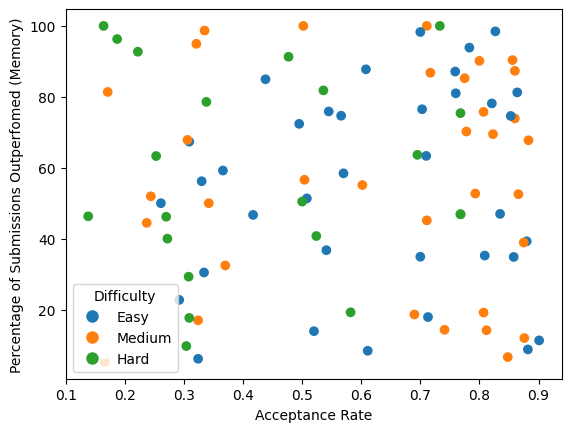
Let us shift our focus from the broader dataset to a more specific subset comprising instances where ChatGPT successfully solved problems. Figure 7 provides a visual representation of the runtime distribution of these successful instances, categorized by the difficulty level of the problems and the acceptance rate of the solutions. The runtime ranking metric indicates the percentage of submitted solutions on Leetcode that ChatGPT outperformed in terms of runtime efficiency. Similarly, Figure 8 illustrates the percentage of submitted solutions on Leetcode that ChatGPT’s solution surpassed in terms of memory efficiency. These analyses offer valuable insights into ChatGPT’s ability to optimize runtime and memory utilization while generating solutions for the presented problems.
Upon analyzing Figure 7 and 8, several notable trends emerge, providing insightful observations regarding the efficiency of ChatGPT in terms of solution run-time and memory efficiency. Firstly, there is a discernible correlation between the difficulty level of “Easy” problems and their higher acceptance rates, resulting in higher efficiency in terms of run-time and memory usage. This means that ChatGPT was able to develop solutions that are efficient in terms of running time and memory utilization for these problems.
However, no distinct trend is apparent when examining problems classified as “Medium” difficulty level. This suggests that the relationship between problem difficulty and run-time or memory efficiency may not be as straightforward in this situation.
Remarkably, an intriguing phenomenon is observed among problems categorized as “Hard” with lower acceptance rates. Contrary to initial expectations, these problems exhibit higher efficiency in terms of run-time as well as memory consumption for ChatGPT’s solutions. These findings run counter to intuition, as problems marked as “Hard” with lower acceptance rates are anticipated to pose greater challenges for the model.
The efficiency patterns of ChatGPT in terms of run-time and memory usage reveal complex relationships between problem difficulty, acceptance rate, and the model’s performance.
V Conclusion and Future Direction
ChatGPT represents a groundbreaking leap in the realm of AI-driven code generation, showcasing a remarkable success rate across a diverse array of coding problems. Its proficiency in effectively tackling structured problem domains and the linear correlation between its success rate and problem acceptance rates underscore its capabilities. However, it is important to acknowledge that while ChatGPT excels in generating solutions, it does not consistently produce the most efficient solutions in terms of runtime or memory usage. Additionally, approximately 30% of the time, it generates inaccurate solutions that cannot be rectified even with feedback provided by Leetcode. This highlights the limitations of the model in certain problem scenarios.
Nevertheless, this exploration into the capabilities of ChatGPT underscores its potential to revolutionize code generation and assist programmers in their tasks. It serves as a testament to the power of AI-driven tools in augmenting coding workflows. Furthermore, it emphasizes the necessity for continuous refinement and evolution to enhance the capabilities of LLMs like ChatGPT, paving the way for more efficient, intuitive, and powerful coding assistance in the future.
References
- [1] Gu, Y., Tinn, R., Cheng, H., Lucas, M., Usuyama, N., Liu, X., Naumann, T., Gao, J., & Poon, H. (2021). Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3(1), 1-23.
- [2] Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., … & Kasneci, G. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, 102274.
- [3] OpenAI, Available: https://openai.com/
- [4] GPT-4, Available: https://openai.com/gpt-4
- [5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- [6] Leetcode, Available: https://leetcode.com/
- [7] Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., & others. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- [8] Chen, Z., Chen, W., Smiley, C., Shah, S., Borova, I., Langdon, D., … & Wang, W. Y. (2021). Finqa: A dataset of numerical reasoning over financial data. arXiv preprint arXiv:2109.00122.
- [9] Syeed, M. M. A., Farzana, M., Namir, I., Ishrar, I., Nushra, M. H., & Rahman, T. (2022, June). Flood Prediction Using Machine Learning Models. In 2022 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA) (pp. 1-6). IEEE.
- [10] Abacha, A. B., & Zweigenbaum, P. (2015). MEANS: A medical question-answering system combining NLP techniques and semantic Web technologies. Information processing & management, 51(5), 570-594.
- [11] Dabre, R., Chu, C., & Kunchukuttan, A. (2020). A survey of multilingual neural machine translation. ACM Computing Surveys (CSUR), 53(5), 1-38.
- [12] Abualigah, L., Bashabsheh, M. Q., Alabool, H., & Shehab, M. (2020). Text summarization: a brief review. Recent Advances in NLP: the case of Arabic language, 1-15.
- [13] Chen, B., Zhang, F., Nguyen, A., Zan, D., Lin, Z., Lou, J. G., & Chen, W. (2022). Codet: Code generation with generated tests. arXiv preprint arXiv:2207.10397.
- [14] Radford, A., Narasimhan, K., Salimans, T. & Sutskever, I. (2018). Improving language understanding by generative pre-training.
- [15] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
- [16] Dakhel, A. M., Majdinasab, V., Nikanjam, A., Khomh, F., Desmarais, M. C., & Jiang, Z. M. J. (2023). Github copilot ai pair programmer: Asset or liability?. Journal of Systems and Software, 203, 111734.
- [17] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. & others (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165, .
- [18] Prenner, J. A., & Robbes, R. (2021). Automatic Program Repair with OpenAI’s Codex: Evaluating QuixBugs. arXiv preprint arXiv:2111.03922.
- [19] OpenAI. 2022. ChatGPT: Optimizing language models for dialogue. https://openai.com
- [20] Sobania, D., Briesch, M., Hanna, C., & Petke, J. (2023). An analysis of the automatic bug fixing performance of chatgpt. arXiv preprint arXiv:2301.08653.
- [21] Xia, C. S., & Zhang, L. (2023). Conversational automated program repair. arXiv preprint arXiv:2301.13246.
- [22] Chen, B., Zhang, F., Nguyen, A., Zan, D., Lin, Z., Lou, J. G., & Chen, W. (2022). Codet: Code generation with generated tests. arXiv preprint arXiv:2207.10397.
- [23] Tian, H., Lu, W., Li, T. O., Tang, X., Cheung, S. C., Klein, J., & Bissyandé, T. F. (2023). Is ChatGPT the Ultimate Programming Assistant–How far is it?. arXiv preprint arXiv:2304.11938.
- [24] Bavishi, R., Lemieux, C., Fox, R., Sen, K., & Stoica, I. (2019). AutoPandas: neural-backed generators for program synthesis. Proceedings of the ACM on Programming Languages, 3(OOPSLA), 1-27.
- [25] Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., … & Vinyals, O. (2022). Competition-level code generation with alphacode. Science, 378(6624), 1092-1097.
- [26] Siddiq, M. L., Majumder, S. H., Mim, M. R., Jajodia, S., & Santos, J. C. (2022, October). An Empirical Study of Code Smells in Transformer-based Code Generation Techniques. In 2022 IEEE 22nd International Working Conference on Source Code Analysis and Manipulation (SCAM) (pp. 71-82). IEEE.
- [27] Svyatkovskiy, A., Deng, S. K., Fu, S., & Sundaresan, N. (2020, November). Intellicode compose: Code generation using transformer. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (pp. 1433-1443).
- [28] Hu, X., Li, G., Xia, X., Lo, D., & Jin, Z. (2018, May). Deep code comment generation. In Proceedings of the 26th conference on program comprehension (pp. 200-210).
- [29] Li, B., Yan, M., Xia, X., Hu, X., Li, G., & Lo, D. (2020, November). DeepCommenter: a deep code comment generation tool with hybrid lexical and syntactical information. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (pp. 1571-1575).
- [30] Stapleton, S., Gambhir, Y., LeClair, A., Eberhart, Z., Weimer, W., Leach, K., & Huang, Y. (2020, July). A human study of comprehension and code summarization. In Proceedings of the 28th International Conference on Program Comprehension (pp. 2-13).
- [31] Wang, W., Zhang, Y., Sui, Y., Wan, Y., Zhao, Z., Wu, J., … & Xu, G. (2020). Reinforcement-learning-guided source code summarization using hierarchical attention. IEEE Transactions on software Engineering, 48(1), 102-119.
- [32] Gupta, R., Pal, S., Kanade, A., & Shevade, S. (2017, February). Deepfix: Fixing common c language errors by deep learning. In Proceedings of the aaai conference on artificial intelligence (Vol. 31, No. 1).
- [33] Jiang, N., Lutellier, T., Lou, Y., Tan, L., Goldwasser, D., & Zhang, X. (2023). Knod: Domain knowledge distilled tree decoder for automated program repair. arXiv preprint arXiv:2302.01857.
- [34] Li, Y., Wang, S., & Nguyen, T. N. (2022, May). Dear: A novel deep learning-based approach for automated program repair. In Proceedings of the 44th International Conference on Software Engineering (pp. 511-523).
- [35] Ye, H., Martinez, M., & Monperrus, M. (2022, May). Neural program repair with execution-based backpropagation. In Proceedings of the 44th International Conference on Software Engineering (pp. 1506-1518).
- [36] Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., … & Zaremba, W. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- [37] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- [38] Tian, H., Liu, K., Kaboré, A. K., Koyuncu, A., Li, L., Klein, J., & Bissyandé, T. F. (2020, December). Evaluating representation learning of code changes for predicting patch correctness in program repair. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering (pp. 981-992).
- [39] Zhang, T., Xu, B., Thung, F., Haryono, S. A., Lo, D.,& Jiang, L. (2020, September). Sentiment analysis for software engineering: How far can pre-trained transformer models go?. In 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME) (pp. 70-80). IEEE.
- [40] Lertbanjongngam, S., Chinthanet, B., Ishio, T., Kula, R. G., Leelaprute, P., Manaskasemsak, B., … & Matsumoto, K. (2022, October). An Empirical Evaluation of Competitive Programming AI: A Case Study of AlphaCode. In 2022 IEEE 16th International Workshop on Software Clones (IWSC) (pp. 10-15). IEEE.